
В принципе она была тестовой, пока в один прекрасный день не стала боевой. Мы знать не знали проблем, с которыми столкнулись потом. Начальство, радостно потирая руки, решило обновить парк систем. В том числе и тестовую платформу OpenStack.
Решили разворачивать вручную, поскольку в тот момент не было fuel решений под версию Mitaka. Поэтому развернули всё по рецептам c официального сайта. Конечно, немного добавили и от себя, например, заменили Memcached на Couchbase, а в качестве базы данных взяли percona в кластерном режиме. И всё шло хорошо. До определённого момента.
Cтали у нас пропадать пакеты. Сначала мы думали, что виноват коммутатор. На нём была Junos довольно старой версии — 11, которая имеет известные баги. И на консоли у неё действительно были сообщения, подтверждающие нашу догадку. Мы заменили это железо на другое, с новой, 15-й прошивкой Junos.
Между тем проблема не исчезла, а только стала потихоньку расширяться. Общий симптом выглядит так — пинги внезапно теряются. Постоянно обрывается связь.
Удручающе для нас и клиентов.
Есть у нас один клиент, много трафика потребляет. И генерирует в ответ тоже много. У него трансляции с веб-камер идут. Стал он жаловаться: пропадает связь и всё тут.
Вот что мы увидели на мониторинге:
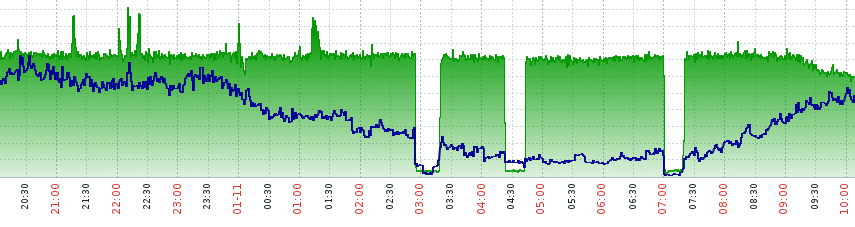
Действительно — клиент прав, что-то не так. Но где??? В один из таких моментов мы нашли причину — не тот ARP светился в сети. Где же виновник? Виновный адрес был найден на выпускающем файрволе. Там стояла строчка, по-ошибке вписанная админом:
set security nat proxy-arp interface xxxx address yy.zz.tt.cc/32Слава богу, нашли — была первая мысль. Но не тут-то было. Пропадание пакетов, не важно каких tcp, icmp, udp — продолжалось.
Мы продолжали искать, и стало ясно, что проблема где-то внутри OpenStack. Когда я стал пинговать тестовую виртуальную машину — чуть не упал со стула:

Это значило, что по какой-то причине часть пакетов не транслировалась, и вывалилась наружу с серыми адресами! Естественно, эти пакеты ни до кого не дошли.
Мы поделимся тем, что смогли раскопать, но позже. Хотелось бы увидеть мнение уважаемой публики, что мы делали не так и где надо было искать
Комментарии (7)


xcore78
08.02.2017 17:41Если на правах «поязвить», то трогать коммутатор было не самым взвешенным решением (хотя, догадываюсь, что самым простым).
Из того, что вы написали, можно пока что принять точку зрения divanikus
Мало информации. В частности, непонятно, откуда пинговали.
Проблемы с хост-машинами были, или только с гостями? Если эта гипотеза проверена, как проведена изоляция проблемы?

Shaz
08.02.2017 23:39ИМХО — не так вы делали то, что выпустили в продакшн систему без тестирования, судя по тексту основываясь на том, что предыдущая сборка была без проблем.
И кстати, раз вы говорите что проблема проявлялась в виде обрыва пингов, то интересно какие у тех пингов были значения, и если также по 1.5-3 секунды то почему не обратили внимания на это. И ещеКонечно, немного добавили и от себя, например, заменили Memcached на Couchbase, а в качестве базы данных взяли percona в кластерном режиме. И всё шло хорошо. До определённого момента.
— в части виртуализации сети тоже наверно добавили отсебятины?

Konkase
09.02.2017 08:28А вы точно проблему решили? Или решили так оригинально задать вопрос на хабре, а не на тостере?
Shaz
09.02.2017 14:01Судя по пингам в 17 или 38 мс (в зависимости от площадки) таки починили.
Надеюсь что сервисы МинФина не на этой платформе лежат?

Smile42RU
http://serverfault.com