

Привет, Хабр! Под катом пойдёт речь о реализации свёрточной нейронной сети архитектуры InceptionV3 с использованием фреймворка Keras. Статью я решил написать после ознакомления с туториалом "Построение мощных моделей классификации с использованием небольшого количества данных". С одобрения автора туториала я немного изменил содержание своей статьи. В отличие от предложенной автором нейронной сети VGG16, мы будем обучать гугловскую глубокую нейронную сеть Inception V3, которая уже предустановлена в Keras.
Вы научитесь:
- Импортировать нейронную сеть Inception V3 из библиотеки Keras;
- Настраивать сеть: загружать веса, изменять верхнюю часть модели (fc-layers), таким образом, приспосабливая модель под бинарную классификацию;
- Проводить тонкую настройку нижнего свёрточного слоя нейронной сети;
- Применять аугментацию данных при помощи ImageDataGenerator;
- Обучать сеть по частям для экономии ресурсов и времени;
- Оценивать работу модели.
При написании статьи я ставил перед собой задачу представить максимально практичный материал, который раскроет некоторые интересные возможности фреймворка Keras.
В последнее время всё чаще появляются туториалы, посвящённые созданию и применению нейронных сетей. С большим удовольствием наблюдаю за интересной тенденцией: новые посты становятся всё более и более понятными для неспециалистов в области программирования. Некоторые авторы и вовсе делают попытки введения читателей в эту тему, применяя максимально естественный язык. Есть также отличные статьи (напр. 1, 2, 3), которые сочетают разумное количество теории и практики, что позволяет как можно быстрее понять необходимый минимум и начать создавать что-то своё.
Итак, за дело!
1. Данные:
В нашем примере мы будем использовать изображения с соревнования по машинному обучению под названием "Dogs vs Cats" на kaggle.com. Данные будут доступны после регистрации. Набор включает в себя 25000 изображений: 12500 кошек и 12500 собак. Класс 1 соответствует собакам, класс 0- кошкам. После загрузки архивов, разместите по 1000 изображений каждого класса в директориях следующим образом:
data/
train/
dogs/
dog001.jpg
dog002.jpg
...
cats/
cat001.jpg
cat002.jpg
...
validation/
dogs/
dog001.jpg
dog002.jpg
...
cats/
cat001.jpg
cat002.jpg
...
Вам ничего не мешает пользоваться всем набором данных. Я, также как и автор оригинальной статьи, решил использовать ограниченную выборку, чтобы проверить эффективность работы сети с малым набором изображений.
У нас есть три проблемы:
- Ограниченный объём данных;
- Ограниченные системные ресурсы (у меня, к примеру, Intel Core i5-4440 3.10GHz, 8 Гб оперативной памяти, NVIDIA GeForce GTX 745);
- Ограниченное время: мы хотим обучать модель меньше суток.
При ограниченном объёме изображения высока вероятность переобучения. Для борьбы с этим нужно:
- Установить большой Dropout. В нашем случае он будет 0.5;
- Будем использовать аугментацию данных. Этот приём позволит нам увеличить количество изображений путём различных трансформаций (в нашем случае будут изменения масштаба, сдвиги, горизонтальное отражение).
- Для нашего эксперимента мы возьмём глубокую сеть.
Последний пункт должен нас настораживать, потому что глубокая нейронная сеть требовательна к ресурсам. Я на своей видеокарте не смог обучить даже VGG16, не говоря уж о таком гигантище, как Inception. Тем не менее, решение есть:
- Изначально мы используем модель, обученную на большом количестве изображений из базы imagenet. Благо, что набор изображений включал кошек и собак;
- Будем обучать модель по частям:
- Сначала прогоним аугментированные изображения через нижнюю часть сети (только через Inception) и сохраним их в виде numpy массивов;
- Обучим с помощью полученных numpy массивов верхний полносвязный слой;
- Затем, мы объединим верхний и нижний слои модели и проведём тонкую настройку новой модели, но при этом мы заблокируем от обучения у Inception все слои, кроме последнего.
Единственным решением проблемы со временем я пока что вижу применение параллельных вычислений. Вам для этого нужна видеокарта с поддержкой CUDA. Я надеюсь, что установка CUDA для Python не вызовет у вас сильных затруднений.
Импортируем библиотеки:
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential, Model
from keras.applications.inception_v3 import InceptionV3
from keras.callbacks import ModelCheckpoint
from keras.optimizers import SGD
from keras import backend as K
K.set_image_dim_ordering('th')
import numpy as np
import pandas as pd
import h5py
import matplotlib.pyplot as plt2. Создадим модель InceptionV3, загрузим в неё изображения, сохраним их:
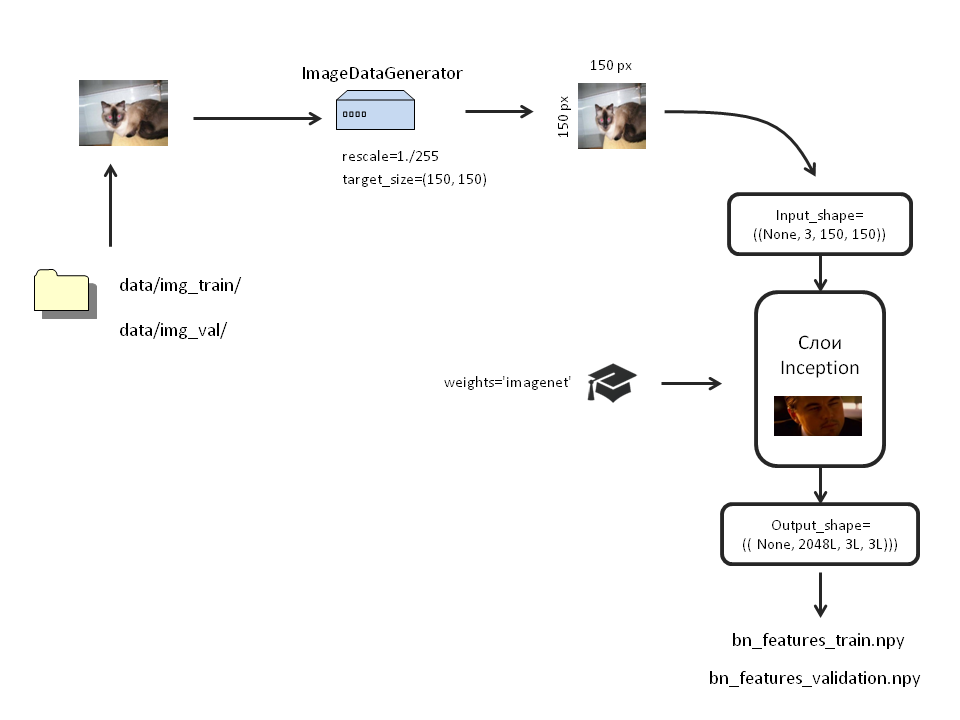
В библиотеке Keras находится несколько подготовленных нейронных сетей.
Нам он без надобности, поэтому ставим: include_top=False;
weights: загружать/не загружать обученные веса. Если None, веса инициализируются случайно. Если «imagenet», будут загружены веса, тренированные на данных ImageNet.
В нашей модели веса нужны, поэтому weights=«imagenet»;
input_tensor: данный аргумент удобен, если мы используем слой Input для нашей модели.
Мы его не будем трогать.
input_shape : в этом аргументе мы задаём размер нашего изображения. Его указывают, если отсоединяется верхний слой (include_top=False). Если мы загрузили модель с верхним слоем, сто размер изображения должен быть только (3, 299, 299).
Мы убрали верхний слой и хотим анализировать изображения меньшего размера (3, 150, 150). Поэтому кажем: input_shape=()
Создаём нашу модель:
inc_model=InceptionV3(include_top=False,
weights='imagenet',
input_shape=((3, 150, 150)))Теперь сделаем аугментацию данных. Для этого в Keras предусмотрены так называемые ImageDataGenerator. Они будут брать изображения прямо из папок и проводить над ними все необходимые трансформации.
Картинки каждого класса должны быть в отдельных папках. Для того, чтобы нам не загружать оперативную память изображениями, мы их трансформируем прямо перед загрузкой в сеть. Для этого используем метод .flow_from_directory. Создадим отдельные генераторы для тренировочных и тестовых изображений:
bottleneck_datagen = ImageDataGenerator(rescale=1./255) #собственно, генератор
train_generator = bottleneck_datagen.flow_from_directory('data/img_train/',
target_size=(150, 150),
batch_size=32,
class_mode=None,
shuffle=False)
validation_generator = bottleneck_datagen.flow_from_directory('data/img_val/',
target_size=(150, 150),
batch_size=32,
class_mode=None,
shuffle=False)Хочу выделить важный момент. Мы указали shuffle=False. То есть, изображения из разных классов не будут перемешиваться. Сначала будут поступать изображения из первой папки, а когда они все закончатся, из второй. Зачем это нужно, увидите позже.
Прогоним аугментированные изображения через обученную Inception и сохраним вывод в виде numpy массивов:
bottleneck_features_train = inc_model.predict_generator(train_generator, 2000)
np.save(open('bottleneck_features/bn_features_train.npy', 'wb'), bottleneck_features_train)
bottleneck_features_validation = inc_model.predict_generator(validation_generator, 2000)
np.save(open('bottleneck_features/bn_features_validation.npy', 'wb'), bottleneck_features_validation)Процесс займёт некоторое время.
3. Создадим верхнюю часть модели, загрузим в неё данные, сохраним их:
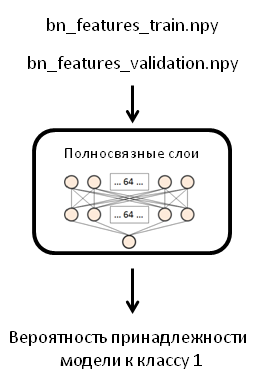
В оригинальном посте автор использовал один слой сети с 256 нейронами, однако я буду использовать два слоя по 64 нейрона в каждом и Dropout слой со значением 0.5. Это изменение я был вынужден внести из-за того, когда я обучал готовую модель (которую мы сделаем в следующем шаге), мой компьютер зависал и перезагружался.
Загрузим массивы:
train_data = np.load(open('bottleneck_features_and_weights/bn_features_train.npy', 'rb'))
train_labels = np.array([0] * 1000 + [1] * 1000)
validation_data = np.load(open('bottleneck_features_and_weights/bn_features_validation.npy', 'rb'))
validation_labels = np.array([0] * 1000 + [1] * 1000)Обратите внимание, ранее мы указывали shuffle=False. А теперь мы легко укажем labels. Поскольку в каждом классе у нас 2000 изображений и все изображения поступали по очереди, у нас будет по 1000 нулей и 1000 единиц для тренировочной и для тестовой выборок.
Создадим модель FFN сети, скомпилируем её:
fc_model = Sequential()
fc_model.add(Flatten(input_shape=train_data.shape[1:]))
fc_model.add(Dense(64, activation='relu', name='dense_one'))
fc_model.add(Dropout(0.5, name='dropout_one'))
fc_model.add(Dense(64, activation='relu', name='dense_two'))
fc_model.add(Dropout(0.5, name='dropout_two'))
fc_model.add(Dense(1, activation='sigmoid', name='output'))
fc_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])Загрузим в неё наши массивы:
fc_model.fit(train_data, train_labels,
nb_epoch=50, batch_size=32,
validation_data=(validation_data, validation_labels))
fc_model.save_weights('bottleneck_features_and_weights/fc_inception_cats_dogs_250.hdf5') # сохраняем весаТеперь мы загружаем данные не из папок, поэтому используем обычный метод fit.
Train on 2000 samples, validate on 2000 samples
Epoch 1/50
2000/2000 [==============================] - 1s - loss: 2.4588 - acc: 0.8025 - val_loss: 0.7950 - val_acc: 0.9375
Epoch 2/50
2000/2000 [==============================] - 1s - loss: 1.3332 - acc: 0.8870 - val_loss: 0.9330 - val_acc: 0.9160
…
Epoch 48/50
2000/2000 [==============================] - 1s - loss: 0.1096 - acc: 0.9880 - val_loss: 0.5496 - val_acc: 0.9595
Epoch 49/50
2000/2000 [==============================] - 1s - loss: 0.1100 - acc: 0.9875 - val_loss: 0.5600 - val_acc: 0.9560
Epoch 50/50
2000/2000 [==============================] - 1s - loss: 0.0850 - acc: 0.9895 - val_loss: 0.5674 - val_acc: 0.9565Оценим точность модели:
fc_model.evaluate(validation_data, validation_labels)[0.56735104312408047, 0.95650000000000002]
Наша модель удовлетворительно справляется со своей задачей. Но принимает она только numpy массивы. Это нас не устраивает. Для того, чтобы получить полноценную модель, которая принимает на вход изображения, мы соединим две наши модели и обучим их ещё раз.
4. Создадим итоговую модель, загрузим в неё аугментированные данные, сохраним веса:
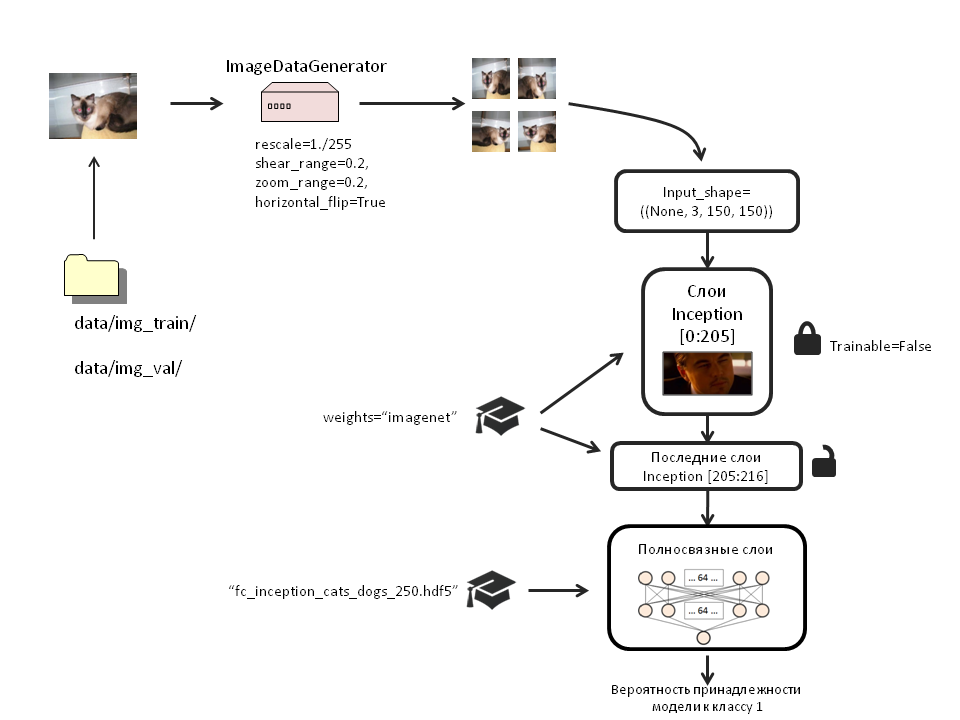
weights_filename='bottleneck_features_and_weights/fc_inception_cats_dogs_250.hdf5'
x = Flatten()(inc_model.output)
x = Dense(64, activation='relu', name='dense_one')(x)
x = Dropout(0.5, name='dropout_one')(x)
x = Dense(64, activation='relu', name='dense_two')(x)
x = Dropout(0.5, name='dropout_two')(x)
top_model=Dense(1, activation='sigmoid', name='output')(x)
model = Model(input=inc_model.input, output=top_model)Загрузим в неё веса:
weights_filename='bottleneck_features_and_weights/fc_inception_cats_dogs_250.hdf5'
model.load_weights(weights_filename, by_name=True)Скажу честно, я не заметил никакой разницы между эффективностью обучения модели с загрузкой весов или без неё. Но оставил этот раздел, потому что он описывает, как загрузить веса в определённые слои по имени (by_name=True).
Заблокируем с 1 по 205 слои Inception:
for layer in inc_model.layers[:205]:
layer.trainable = FalseСкомпилируем модель:
model.compile(loss='binary_crossentropy',
optimizer=SGD(lr=1e-4, momentum=0.9),
#optimizer='rmsprop',
metrics=['accuracy'])Обратите внимание, когда мы в первый раз обучали полносвязные слои из .npy массивов, мы использовали оптимизатор RMSprop. Теперь, для тонкой настройки модели мы используем Стохастический градиентный спуск. Сделано это для того, чтобы предотвратить слишком выраженные обновления уже обученных весов.
Сделаем так, чтобы в процессе обучения сохранялись только веса с наибольшей точностью на тестовой выборке:
filepath="new_model_weights/weights-improvement-{epoch:02d}-{val_acc:.2f}.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='val_acc', verbose=1, save_best_only=True, mode='max')
callbacks_list = [checkpoint]Создадим новые генераторы изображений для обучения полной модели. Мы будем трансформировать только учебную выборку. Тестовую трогать не будем.
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
'data/img_train/',
target_size=(150, 150),
batch_size=32,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
'data/img_val/',
target_size=(150, 150),
batch_size=32,
class_mode='binary')
pred_generator=test_datagen.flow_from_directory('data/img_val/',
target_size=(150,150),
batch_size=100,
class_mode='binary')pred_generator мы используем позже для демонстрации работы модели.
Загрузим изображения в модель:
model.fit_generator(
train_generator,
samples_per_epoch=2000,
nb_epoch=200,
validation_data=validation_generator,
nb_val_samples=2000,
callbacks=callbacks_list)Epoch 1/200
1984/2000 [============================>.] - ETA: 0s - loss: 1.0814 - acc: 0.5640Epoch 00000: val_acc improved from -inf to 0.71750, saving model to new_model_weights/weights-improvement-00-0.72.hdf5
2000/2000 [==============================] - 224s - loss: 1.0814 - acc: 0.5640 - val_loss: 0.6016 - val_acc: 0.7175
Epoch 2/200
1984/2000 [============================>.] - ETA: 0s - loss: 0.8523 - acc: 0.6240Epoch 00001: val_acc improved from 0.71750 to 0.77200, saving model to new_model_weights/weights-improvement-01-0.77.hdf5
2000/2000 [==============================] - 215s - loss: 0.8511 - acc: 0.6240 - val_loss: 0.5403 - val_acc: 0.7720
…
Epoch 199/200
1968/2000 [============================>.] - ETA: 1s - loss: 0.1439 - acc: 0.9385Epoch 00008: val_acc improved from 0.90650 to 0.91500, saving model to new_model_weights/weights-improvement-08-0.92.hdf5
2000/2000 [==============================] - 207s - loss: 0.1438 - acc: 0.9385 - val_loss: 0.2786 - val_acc: 0.9150
Epoch 200/200
1968/2000 [============================>.] - ETA: 1s - loss: 0.1444 - acc: 0.9350Epoch 00009: val_acc did not improve
2000/2000 [==============================] - 206s - loss: 0.1438 - acc: 0.9355 - val_loss: 0.3898 - val_acc: 0.8940У меня на каждую эпоху уходило по 210-220 секунд. 200 эпох обучения заняли около 12 часов.
5. Оценим точность модели
model.evaluate_generator(pred_generator, val_samples=100)[0.2364250123500824, 0.9100000262260437]
Вот нам и пригодился pred_generator. Обратите внимание, val_samples должны соответствовать величине batch_size в генераторе!
Точность 91,7%. Учитывая ограниченность выборки, возьму на себя смелость сказать, что это неплохая точность.
Проиллюстрируем работу модели
Просто смотреть на % правильных ответов и величину ошибки нам не интересно. Давайте посмотрим, сколько правильных и неправильных ответов дала модель для каждого класса:
imgs,labels=pred_generator.next()
array_imgs=np.transpose(np.asarray([img_to_array(img) for img in imgs]),(0,2,1,3))
predictions=model.predict(imgs)
rounded_pred=np.asarray([round(i) for i in predictions])pred_generator.next() удобная штука. Она загружает изображения в переменную и присваивает лейблы.
Количество изображений каждого класса будет различным при каждой генерации:
pd.value_counts(labels)
0.0 51
1.0 49
dtype: int64Сколько изображений каждого класса модель предсказала правильно?
pd.crosstab(labels,rounded_pred)
| Col_0 | 0.0 | 1.0 |
|---|---|---|
| Row_0 | ||
| 0.0 | 47 | 4 |
| 1.0 | 8 | 41 |
Для модели было загружено 100 случайных изображений: 51 изображение кошек и 49 собак. Из 51 кошки модель правильно распознала 47. Из 50 собак правильно были распознаны 41. Общая точность модели на этой узкой выборке составила 88%.
Посмотрим, какие фотографии были распознаны неправильно:
wrong=[im for im in zip(array_imgs, rounded_pred, labels, predictions) if im[1]!=im[2]]
plt.figure(figsize=(12,12))
for ind, val in enumerate(wrong[:100]):
plt.subplots_adjust(left=0, right=1, bottom=0, top=1, wspace = 0.2, hspace = 0.2)
plt.subplot(5,5,ind+1)
im=val[0]
plt.axis('off')
plt.text(120, 0, round(val[3], 2), fontsize=11, color='red')
plt.text(0, 0, val[2], fontsize=11, color='blue')
plt.imshow(np.transpose(im,(2,1,0)))
Синие числа-истинный класс изображений. Красные числа- предсказанные моделью (если красное число меньше 0.5, модель считает, что на фото кот, если больше 0.5, то собака). Чем больше число приближается к нулю, тем сеть больше уверена, что перед ней кот. Интересно, что много ошибок с изображениями собак содержат породы небольшого размера или щенков.
Посмотрим первые 20 изображений, которые модель предсказала правильно:
right=[im for im in zip(array_imgs, rounded_pred, labels, predictions) if im[1]==im[2]]
plt.figure(figsize=(12,12))
for ind, val in enumerate(right[:20]):
plt.subplots_adjust(left=0, right=1, bottom=0, top=1, wspace = 0.2, hspace = 0.2)
plt.subplot(5,5,ind+1)
im=val[0]
plt.axis('off')
plt.text(120, 0, round(val[3], 2), fontsize=11, color='red')
plt.text(0, 0, val[2], fontsize=11, color='blue')
plt.imshow(np.transpose(im,(2,1,0)))
Видно, что модель прилично справляется с задачей распознавания изображений на сравнительно небольших выборках.
Я надеюсь, что пост был вам полезен. С удовольствием выслушаю ваши вопросы или пожелания.
Проект на Гитхабе
Комментарии (20)

IliaSafonov
14.02.2017 18:40+1Спасибо! Всё очень чётко и подробно.
Я бы хотел только подчеркнуть границы применимости данного подхода.
Взята обученная сеть на ImageNet, в которой всего 14,197,122 изображений, причем изображений животных 2,799,000 (больше чем в любой другой категории). Собаки и кошки в ImageNet также есть. Потом взято 2000 изображений кошек и собак (то есть изображений концептуально похожих на огромную часть исходной обучающей выборки) и кусок сети переобучен/перенастроен на них. Получен неплохой результат.
Но если мы возьмём 2000 изображений, например, документов на русском и английском языке и попробуем использовать подобный подход, то, вероятно, он «не взлетит». А если изображений специфического типа для обучения ещё меньше, например, несколько десятков или пара сотен, то это наверняка тупиковый путь.
Судя по профилю, автор к.м.н. Есть ли мнение о применимости данного подхода для медицинских изображений?
bak
14.02.2017 19:34+2Transfer learning рабочий подход. К сожалению данная статья не иллюстрирует основной смысл transfer learning-а а и не объясняет ключевую концепцию. Архитектура deeplearning (а точнее сверточных нейросетей, в частности inception) похожа на работу зрительной коры мозга. Она состоит из нескольких уровней, каждый из которых определяет всё более сложные формы. На нижнем (ближайшем к глазу / входному изображению) сеть распознаёт различные ключевые точки, на следующем — выстраивает из них линии, затем более сложные фигуры, и так далее. И лишь на последних уровнях по целой кучи характерных паттернов происходит определение объекта. Чтобы обучить нейростеть такой сложности необходимо гигантское количество примеров (порядок — от десятков тысяч до миллионов). Transfer learning вместо обучения всей сети целиком предлагает дообучить лишь верхние слои, по которым происходит непосредственно определение объектов. Это работает, так как у большинство объектов похоже на уровне основных визуальных паттернов — почти везде будут различные линии (разной степени изогнутости), градиенты, выпуклости, острые части, сочетания цветов и прочие. Для transfer-learning-а достаточно коллекции из сотен / тысяч элементов.
IliaSafonov
14.02.2017 20:35OK, получается, что все проблемы распознавания изображений уже решены. Достаточно взять Inception V3, несколько сотен примеров, transfer learning и все проблемы решены. Так?
Здравый смысл должен подсказать, что в жизни всё гораздо сложнее.
Архитектура deeplearning (а точнее сверточных нейросетей, в частности inception) похожа на работу зрительной коры мозга.
Ваше мнение основано на вере, что NN похожа на то, как человек видит или мыслит. На самом деле, наука пока не знает, как в точности у человека работает «зрительная кора мозга». Есть некоторые эксперименты, есть некоторые теории, общего знания нет. Автор поста врач, пусть он меня поправит, если я не прав.
Моё мнение основано на опыте коллег. Transfer learning в примере, который похож на приведённый выше не работает. Веса сети, настроенные на фотографиях животных, скамеек, самолётов и т.д. не помогают понять особенности сканированного документа в случае разных шрифтов, цветов, фонов и прочее.
К сожалению данная статья не иллюстрирует основной смысл transfer learning-а а и не объясняет ключевую концепцию.
Тут одно «не», кажется, лишнее.
Я считаю, что автор прекрасно демонстрирует, что иногда transfer learning работает. Мой комментарий относится к тому, что стоит добавить слово «иногда».bak
14.02.2017 21:42OK, получается, что все проблемы распознавания изображений уже решены.
Интересно, откуда у вас такой вывод?
Ваше мнение основано на вере, что NN похожа на то, как человек видит или мыслит.
Вера тут не при чем. Есть научные работы в которых рассматривается устройство зрительной части мозга, к примеру в этом paper-е. Архитектура сверточных нейросетей (как вообщем то и сами нейросети) была позаимствована из биологии.
Transfer learning в примере, который похож на приведённый выше не работает.
Вы утверждаете что я не смогу дообучить inception определить язык документа по 1000 сканам русских и английских документов, я вас правильно понимаю?IliaSafonov
14.02.2017 22:23OK, получается, что все проблемы распознавания изображений уже решены.
Из Ваших слов: «Transfer learning вместо обучения всей сети целиком предлагает дообучить лишь верхние слои… Это работает, так как у большинство объектов похоже… Для transfer-learning-а достаточно коллекции из сотен / тысяч элементов. » Для любой задачи берем Inception и так далее -> задача решена.
Интересно, откуда у вас такой вывод?
Вы утверждаете что я не смогу дообучить inception определить язык документа по 1000 сканам русских и английских документов, я вас правильно понимаю?
Дообучить сможете. Но, если всё делать как написано в статье без дополнительных трюков, то работать будет плохо. По крайней мере, значительно хуже альтернативных подходов. Проверено.
Есть научные работы
Пусть своё мнение об устройстве мозга и биологии скажут врачи и биологи. Научных работ есть много. Периодически одни опровергают другие. В любом случае, все модели зрения/мышления очень условны.

bredd_owen
14.02.2017 22:42+2По Transfer learning есть хороший пост, правда, он без кода. Единственное, при этом методе мы НЕ корректируем верхние слои, которые различают контуры предметов, потому что контуры, как раз, универсальны.
Действительно, работа таких сетей похожа на работу центрального отдела зрительного анализатора, о работе которого мы можем cудить прямыми измерениями у животных: в данном эксперименте был выявлен интересный феномен, говорящий о том, что отдельные зоны затылочной коры могут возбуждаться в зависимости от угла источника света. О работе зрительного анализатора у человека можно судить, например, при травматическом или ишемическом поражении различных отделов зрительной коры, а также при раздражении этой области, к примеру, опухолью или при ауре эпилепрического припадка. При этом человек видит различные феномены: искры, пятна и.т.д. (при повреждении медиальных отделов). Это позволяет нам в какой-то мере говорить, о том, что расположение образов в зрительной коре может быть топическим. Но, вот, точно сказать, как происходит идентификация предметов человеком пока что нельзя. Свёрточные НС — это, в какой-то степени, математическое представление (я бы сказал, чертёж) работы зрительного анализатора. Пока что трудно проводить между ними параллели.
bredd_owen
14.02.2017 21:43+3Спасибо за вопрос!
Я начал изучать свёрточные нейронные сети, чтобы применять их для классификации медицинских изображений, но в процессе построения таких сетей столкнулся с проблемой ресурсов компьютера. В данном посте я по большей части описал некоторые полезные приёмы работы со свёрточными сетями: как создавать модели, делать из нескольких моделей одну, изменять верхнюю часть модели, загружать веса на нужные нам слои, сохранять веса с наилучшими результатами, делать аугментацию данных и.т.д. Собственно, я решил, что данные моменты будут полезны для начинающих изучать эту тему.
Сейчас я веду работу с этой базой данных. Как только получу результаты, обязательно сделаю на эту тему пост.IliaSafonov
14.02.2017 22:42+1Сейчас я веду работу с этой базой данных. Как только получу результаты, обязательно сделаю на эту тему пост.
Желаю удачи! Интересно будет узнать результаты!
Tremere
15.02.2017 13:43+1Я понимаю как с Keras работать и собрал бы вашу модель как надо, но можно попросить ссылку на исходный код?
bredd_owen
15.02.2017 13:44+1К концу недели времени выложу на Гитхабе и размещу ссылку в конце статьи
Sorokinv
20.02.2017 12:41А каким образом магические цифры размеров слоев: 32-64-128-256-… и тд, связаны с размером исходных изображений для обучения (traning) и предсказаний (predict)? Откуда они такие берутся? Понятно, что их делить на два удобно, как опускать, так и поднимать, но как они связаны с размерами изображений используемых в обучении? Насколько их можно задирать вверх и вниз? Существует ли практическая эмпирика?
bredd_owen
20.02.2017 13:36Тут смотря, с какой стороны посмотреть на вопрос:
1) Для корректной загрузки данных в сеть (например, изображений), нужно, чтобы размеру этих данных соответствовал ВХОДНОЙ слой сети. В моём случае, размер входного слоя пришлось указывать дважды: при создании Inception (там есть параметр: input_shape=((3, 150, 150))) и при создании FFN модели (input_shape=train_data.shape[1:])). Параметр input_shape говорит, что «нужно сделать слой Input, который будет содержать в первом случае 3*150*150 нейронов». Дальше, размер изображений ни с какими слоями модели не связан.
2) Второй момент связан уже с качеством вашей модели. Чем больше свёрточных слоёв и чем больше в них фильтров, тем лучше модель различает изображения, тем меньше величина ошибок и выше точность. Если, к примеру, вы возьмёте зашумлённые изображения сетчатки глаза (для классификации диабетической ретинопатии) размерами 3Х299Х299 и попытаетесь обучить ими VGG16, точность модели вам не понравится. Тут нужно либо с нуля учить более глубокую сеть (с бОльшим количеством слоёв), либо как-то подготавливать сами изображения.
3) Если мы решаем проблему muticlass классификации, то размер выходного слоя должен содержать столько же нейронов, сколько у нас классов. В случае бинарной классификации (как у нас) или регрессии, размер выхода будет один.
Пока что ни в какой работе я не увидел, чтобы размер слоя имел какое-либо значение. То есть размеры можно сделать и 30, 56, 110, 200.Sorokinv
20.02.2017 14:54Спасибо за ответ. Я вообщем-то может быть не совсем точно выразился. Я имел ввиду не степень двойки, а размер, например, почему не поставить 1024, 4096, 9132, в свертке и в Dense. Кроме как, увеличения объемов вычислений, для изображений с размерами 200*200, особого эффекта я не заметил в обработке. Даже в чем-то хуже. Такое впечатление, что количество слоев имеет влияние в районе значения стороны грани изображения. То есть для изображений 200*200 увеличивать его выше 128-256 смысла нет. Результативность останавливается, но это мое личное наблюдение, хотя может я и ошибаюсь.
bredd_owen
21.02.2017 12:41Количество слоёв сети и размер свёрток зависит от данных. Для простых чб изображений типа MNIST достаточно небольшого размера сети, потому что в рукописных символах не так много признаков. Для набора изображений типа CIFAR требуется больше слоёв и больше свёрток. Также и с размером изображений: больший размер- большее количество признаков, значит и параметров требуется больше.
Для наглядности: простые изображения, сложные изображения.
Если даже при большом количестве слоёв и свёрток результат плохой, следует поиграться с гиперпараметрами (в первую очередь с методами оптимизации) и инициализацией весов.

JDTamerlan
22.02.2017 10:53Скажите пожалуйста, а сколько времени ушло на проделывание вот этой всей реальной работы без учета написания самой статьи?
bredd_owen
22.02.2017 11:16Сухой работы было немного (около 3-х часов), поскольку мне не нужно было предобрабатывать изображения. Много времени ушло на тренировку модели, потому что я экспериментировал с гиперпараметрами. Суммарно было 3-4 тренировки по 12 часов (ставил на ночь). Ну, а делал я это всё недели три, так как приходилось отвлекаться на работу с пациентами и дежурства :)
erwins22
немного в сторону.
Есть фотография на которой изображена полка с продукцией в том числе и нашей фирмы, насколько сложно идентифицировать ее на фотографии.
rPman
В теории все можно.
Но если ваш логотип будет нанесен на мятую/неровную поверхность с перекрытиями (видно только часть), и фотография будет качественная, а не сделанная дрожащей рукой смартфоном — то в общем случае нет либо затраты ресурсов на создание такой сети будут несоизмеримо велики.
p.s. помним, что для обучения сети с нуля потребуются не только данные но и мощные вычислительные ресурсы, и не один компьютер а кластер… амазон конечно вам все предоставит, за деньги!
не нужно нейронной сети, опишите каждый элемент вашего логотипа в виде функций (векторные рисунки) и запрограммируйте их поиск теми же алгоритмамми, которыми идет распознавание тех же qr-кодов
bredd_owen
Если Вам необходимо идентифицировать лишь определённые логотипы продукции на полке, можете попробовать библиотеку opencv, вот пример. Вы можете использовать её для получения изображений продукции для обучающей выборки, затем как-либо разметить полученные изображения (напримет, бутылки, пакеты сока, и.т.д.), предобработать и обучить ими сеть. Я бы рекомендовал первые эксперименты проводить на неглубоких сетях. Если вы увидите, что на каком-то наборе гиперпараметров происходит снижение ошибки и повышение точности модели, тогда уже применяйте сеть глубже.