

Петр Зайцев показывает разницу между MySQL и MongoDB. Это — расшифровка доклада с Highload++ 2016.
Если посмотреть такой известный DB-Engines Ranking, то можно увидеть, что в течении многих лет популярность open source баз данных растет, а коммерческих — постепенно снижается.
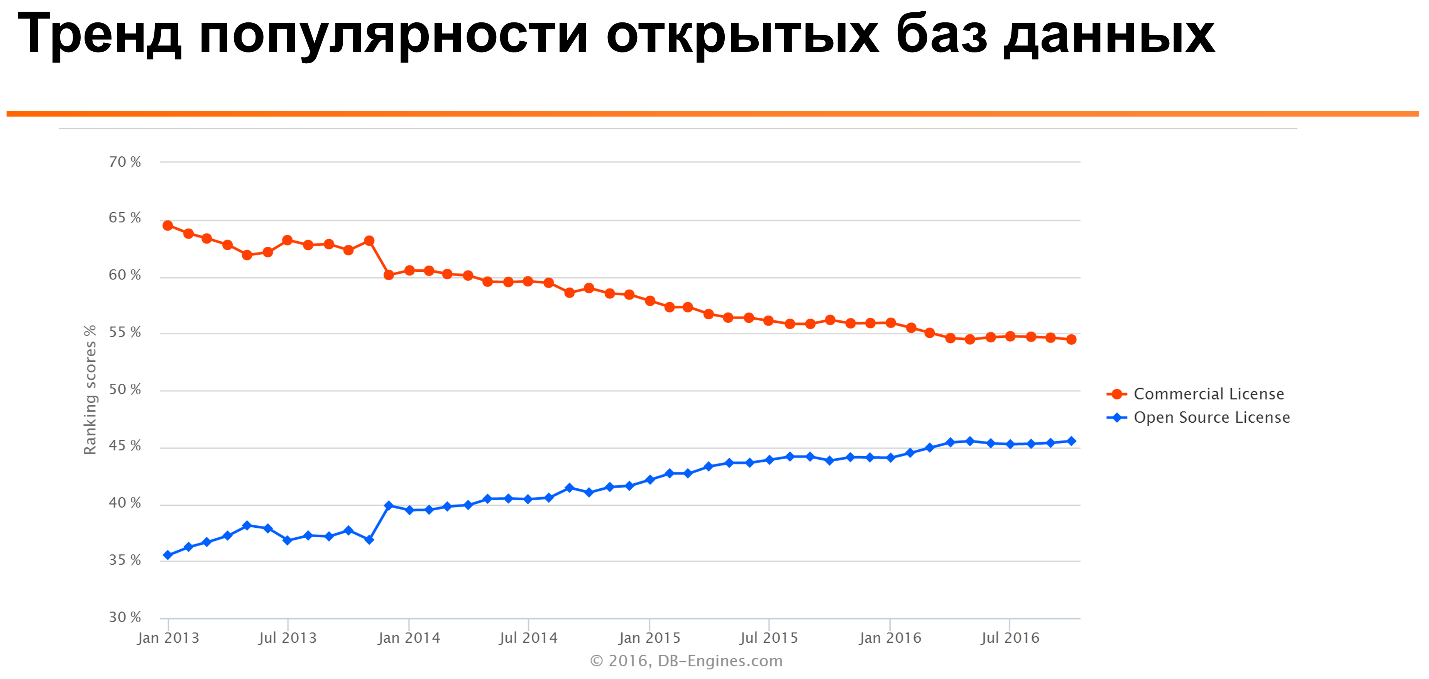
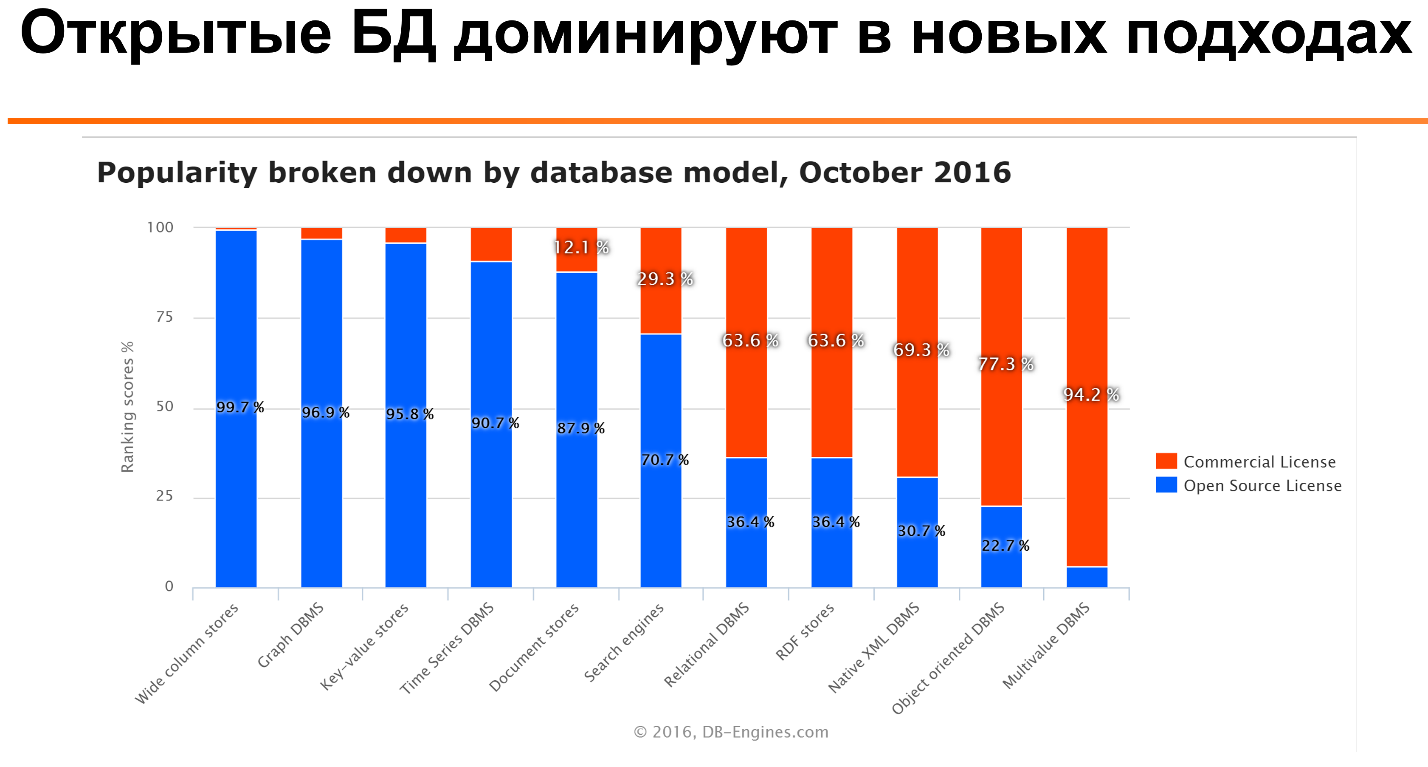
Что еще более интересно: если посмотреть на вот это отношение для разных типов баз данных, то видно, что для многих типов — таких, как колунарные базы данных, time series, document stories — open source базы данных наиболее популярны. Только для более старых технологий, таких как реляционные базы данных, или еще более древних, как multivalue база данных, коммерческие лицензии значительно популярнее.
Мы видим, что для многих приложений используют несколько баз данных для того, чтобы задействовать их сильные стороны. Ни одна база данных не оптимизирована для всех всевозможных юзкейсов. Даже если это PostgreSQL [смех на сцене и в зале].
С одной стороны, это хороший выбор, с другой — нужно пытаться найти баланс, так как чем у нас больше разных технологий, тем сложнее их поддерживать, особенно, если компания не очень большая.
Часто что видим, что люди приходят на такие конференции, слушают Facebook или «Яндекс» и говорят: «Ух ты! Сколько вот люди делают интересного. У них технологий разных используется штук 20, и еще штук 10 они написали сами». А потом они тот же самый подход пытаются использовать в своем стартапе из 10 человек, что работает, разумеется, не очень хорошо. Это как раз тот случай, где размер имеет значение.
Подходы к архитектуре
Очень часто мы видим, что используется основное операционное хранилище и какие-то дополнительные сервисы. Например, для кэширования или полнотекстового поиска.
Другой подход к архитектуре с использованием разных баз данных — это микросервисы, у каждого из которых может быть своя база данных, которая лучше оптимизирована для задач именно этого сервиса. Как пример: основное хранилище может быть на MySQL, Redis и Memcache — для кэширования, Elastic Search или родной Sphinx — для поиска. И что-то вроде Kafka — чтобы передавать данные в систему аналитики, которая часто делалась на чём-то вроде Hadoop.
Если мы говорим про основное операционное хранилище, наверное, у нас есть два выбора. С одной стороны, мы можем выбрать реляционные базы данных, с языком SQL. С другой стороны — что-то нереляционное, а дальше уже смотреть на подвиды, которые доступы в данном случае.
Если говорить про NoSQL-модели данных, то их тоже достаточно много. Наиболее типичные — это либо key value, либо document, либо wide column базы данных. Примеры: Memcache, MongoDB, Cassandra, соответственно.
Почему в данном случае мы сравниваем именно MySQL и MongoDB? На самом деле причин несколько. Если посмотреть на Ranking баз данных, то мы видим, что MySQL, согласно этому рейтингу, — наиболее популярная реляционная база данных, а MongoDB — наиболее популярная нереляционная база данных. Поэтому их разумно сравнивать.
А ещё у меня есть наибольший опыт в использовании этих двух баз данных. Мы в Percona занимаемся плотно именно с ними, работаем с многими клиентами, помогаем им сделать такой выбор. Еще одна причина: обе технологии изначально ориентированы на разработчиков простых приложений. Для тех людей, для которых PostgreSQL — это слишком сложно.
Компания MongoDB изначально очень активно фокусировалась на пользователях MySQL. Поэтому очень часто у людей есть опыт использования и выбор между этими двумя технологиями.
В Percona кроме того, что мы занимаемся поддержкой, консалтингом для этих технологий, у нас есть достаточно много написанного open source софта для обеих технологий. На слайде можно посмотреть. Подробно я рассказывать об этом не буду.

Что следует обо мне лично: я занимаюсь MySQL значительно больше, чем MongoDB. Несмотря на то, что я постараюсь предоставить сбалансированный обзор с моей стороны, у меня могут быть какие-то предрасположенности к MySQL, так как его тараканы я знаю лучше.
Выбор MySQL и MongoDB

Вот список разных вопросов, которые на мой взгляд имеет смысл рассматривать. Сейчас из них рассмотрим каждый более детально.
Что наиболее важно на мой взгляд — это учитывать, какие есть опыт и предпочтения команды. Для многих задач подходят оба решения. Их можно сделать и так, и так, может быть несколько сложнее, может быть несколько проще. Но если у вас команда, которая долго работала с SQL-базами данных и понимает реляционную алгебру и прочее, может быть сложно перетягивать и заставлять их использовать нереляционные базы данных, такие как MongoDB, где нет даже полноценной транзакции.
И наоборот: если есть какая-то команда, которая использует и хорошо знает MongoDB, SQL-язык может быть для неё сложен. Также имеет смысл рассматривать как оригинальную разработку, так и дальнейшее сопровождение и администрирование, поскольку всё это в итоге важно в цикле приложения.
Какие есть преимущества у данных систем?
Если говорить про MySQL — это проверенная технология. Понятно, что MySQL используется крупными компаниями более 15 лет. Так как он использует стандарт SQL, есть возможность достаточно простой миграции на другие SQL-базы данных, если захочется. Есть возможность транзакций. Поддерживаются сложные запросы, включая аналитику. И так далее.
С точки зрения MongoDB, здесь преимущество то, что у нас гибкий JSON-формат документов. Для некоторых задач и каким-то разработчикам это удобнее, чем мучиться с добавлением колонок в SQL-базах данных. Не нужно учить SQL — для некоторых это сложно. Простые запросы реже создают проблемы. Если посмотреть на проблемы производительности, в основном они возникают, когда люди пишут сложные запросы с
JOIN в кучу таблиц и GROUP BY. Если такой функциональности в системе нет, то создать сложный запрос получается сложнее.В MongoDB встроена достаточно простая масштабируемость с использованием технологии шардинга. Сложные запросы если возникают, мы их обычно решаем на стороне приложения. То есть, если нам нужно сделать что-то вроде
JOIN, мы можем сходить выбрать данные, потом сходить выбрать данные по ссылкам и затем их обработать на стороне приложения. Для людей, которые знают язык SQL, это выглядит как-то убого и ненатурально. Но на самом деле для многих разработка application-серверов такое куда проще, чем разбираться с JOIN.Подход к разработке и жизненный цикл приложений
Если говорить про приложения, где используется MongoDB, и на чём они фокусируются — это очень быстрая разработка. Потому что всё можно постоянно менять, не нужно постоянно заботиться о строгом формате документа.
Второй момент — это схема данных. Здесь нужно понимать, что у данных всегда есть схема, вопрос лишь в том, где она реализуется. Вы можете реализовывать схему данных у себя в приложении, потому что каким-то же образом вы эти данные используете. Либо эта схема реализуется на уровне базы данных.
Очень часто если у вас есть какое-то приложение, с данными в базе данных работает только это приложение. Например, мы сохраняем данные из этого приложения в эту базу данных. Схема на уровне приложения работает хорошо. Если у нас одни и те же данные используются многими приложениями, то это очень неудобно, сложно контролировать.
Здесь возникает также вопрос времени жизни приложения. С MongoDB хорошо делать приложения, у которых очень ограниченный цикл жизни. То есть если мы делаем приложение, которое живёт недолго, например, сайт для запуска фильма или олимпиады. Мы пожили несколько месяцев после этого, и это приложение практически не используется. Если приложение живёт дольше, то тут уже другой вопрос.
Если говорить про распределение преимуществ и недостатков MySQL и MongoDB с точки зрения цикла разработки приложения, то их можно представить так:
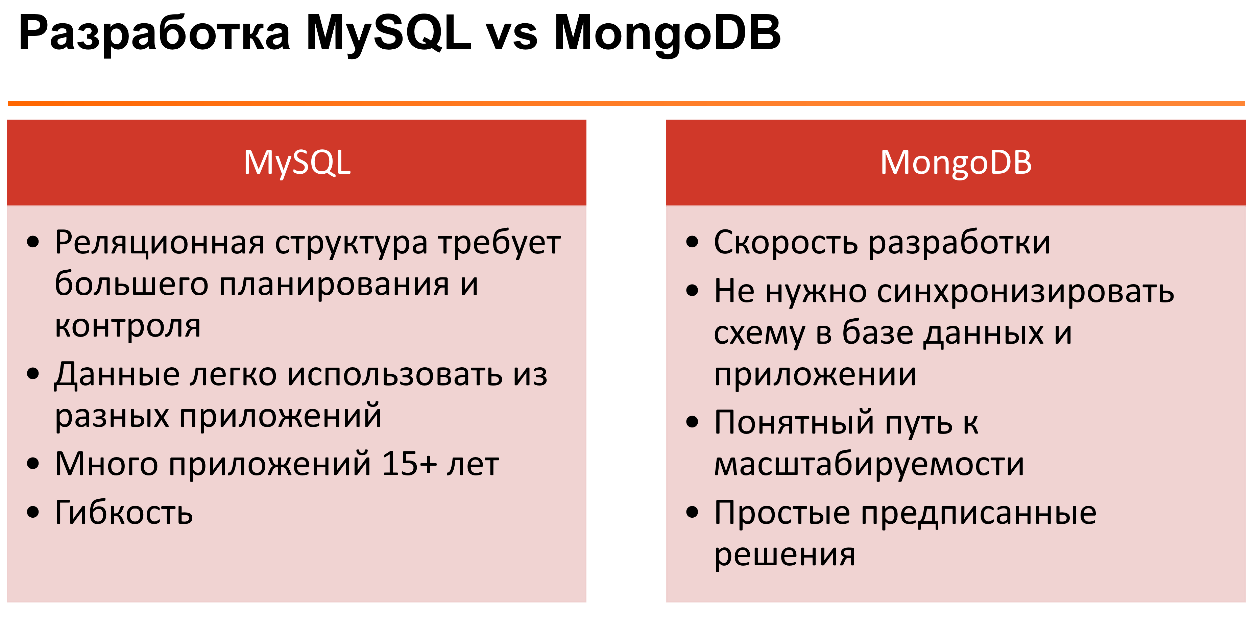
Модель данных очень сильно зависит от приложения и опыта команды. Было бы странным сказать, что у нас реляционный или нереляционный подход к базам данных лучше и лучше всегда.
Если сравнивать их между собой, то понятно, что у нас есть. В MySQL — реляционная база данных. Мы можем с помощью реляционной базы данных легко отображать связи между таблицами. Нормализуя данные, мы можем заставлять изменения данных происходить атомарно в одном месте. Когда данные у нас денормализованы, нам не нужно при каких-то изменениях бежать и модифицировать кучу документов.
Хорошо это или плохо? Результат — всегда таблица. С одной стороны, это просто, с другой — некоторые структуры данных не всегда хорошо ложатся на таблицу, нам может быть неудобно с этим работать.
Это всё в теории. Если говорить о практическом использовании MySQL, мы знаем, что часто денормализуем данные, иногда для некоторых приложений мы используем что-то подобное: храним JSON, XML или другую структуру в колонках приложения.
У MongoDB структура данных основана на документах. Данные многих веб-приложений отображать очень просто. Потому что если храним структуру — что-то вроде ассоциированного массива приложения, то это очень просто и понятно для разработчика сериализуется в JSON-документ. Раскладывать такое в реляционной базе данных по разным табличкам — задача более нетривиальная.
Результаты как список документов, у которых может быть совершенно разная структура — более гибкое решение.
Пример. Мы хотим сохранить контакт-лист с телефона. Понятно, что есть данные, которые хорошо кладутся в одну реляционную табличку: Фамилия, Имя и т.д. Но если посмотреть на телефоны или email-адреса, то у одного человека их может быть несколько. Если подобное хранить в хорошем реляционном виде, то нам неплохо бы это хранить в отдельных таблицах, потом это всё собирать
JOIN, что менее удобно, чем хранить это всё в одной коллекции, где находятся иерархические документы.
Следует сказать, что это всё в строго реляционной теории — некоторые базы данных поддерживают массивы. В MySQL поддерживается формат JSON, в который можно засунуть такие вещи, как несколько email-адресов. Или многие годы люди серилизовали это ручками: надо нам сохранить несколько email-адресов, то давайте запишем их через запятую, и дальше приложение разберётся. Но как-то это не очень кошерно.
Термины
Интересно, что между MySQL и MongoDB — вообще, между реляционными и нереляционными СУБД — что-то совпадает, что-то различается. Например, в обоих случаях мы говорим о базах данных, но то, что мы называем таблицей в реляционной базе данных, часто в нереляционной называется коллекцией. То, что в MySQL — колонка, в MongoDB — поле. И так далее.
С точки зрения использования
JOIN, в MongoDB нет такого понятия — это вообще понятие из реляционной структуры. Там мы либо делаем встроенный документ, что близко к концепту денормализации, либо мы просто сохраняем идентификатор документа в каком-то поле, называем это ссылкой и дальше ручками выбираем данные, которые нам нужны.Что касается доступа: там, где мы к реляционным данным используем язык SQL, в MongoDB и многих других NoSQL-базах данных используется такой стандарт, как CRUD. Этот стандарт говорит, что есть операции для создания, чтения, удаления и обновления документов.
Несколько примеров.
Как у нас могут выглядеть наиболее типичные задачи по работе с документами в MySQL и MongoDB:
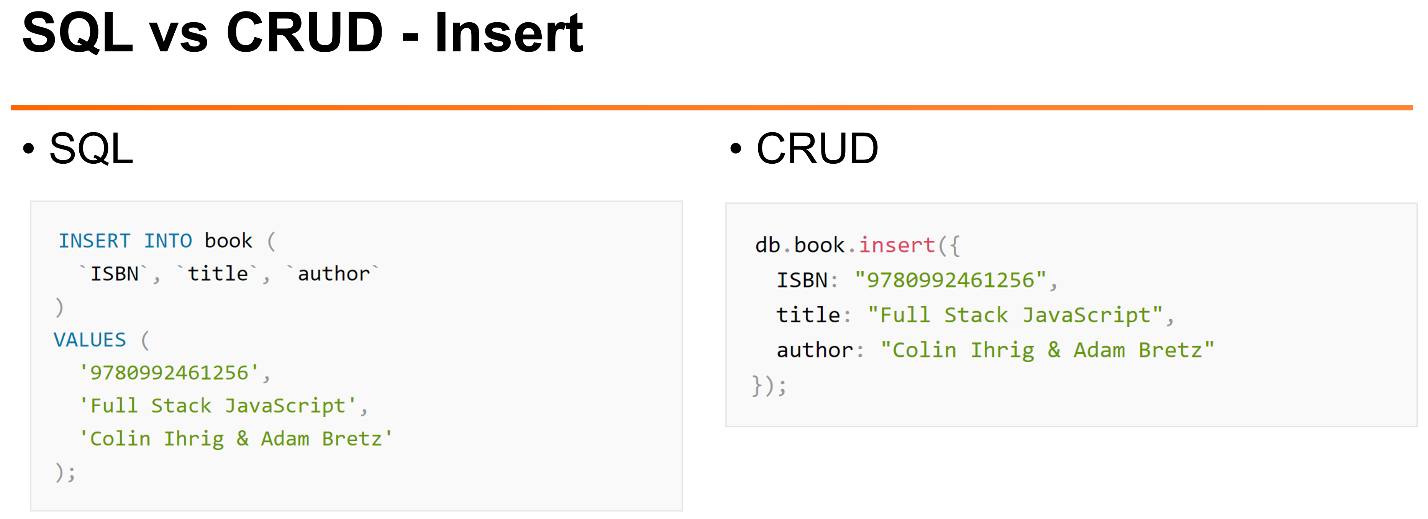
Вот пример вставки.
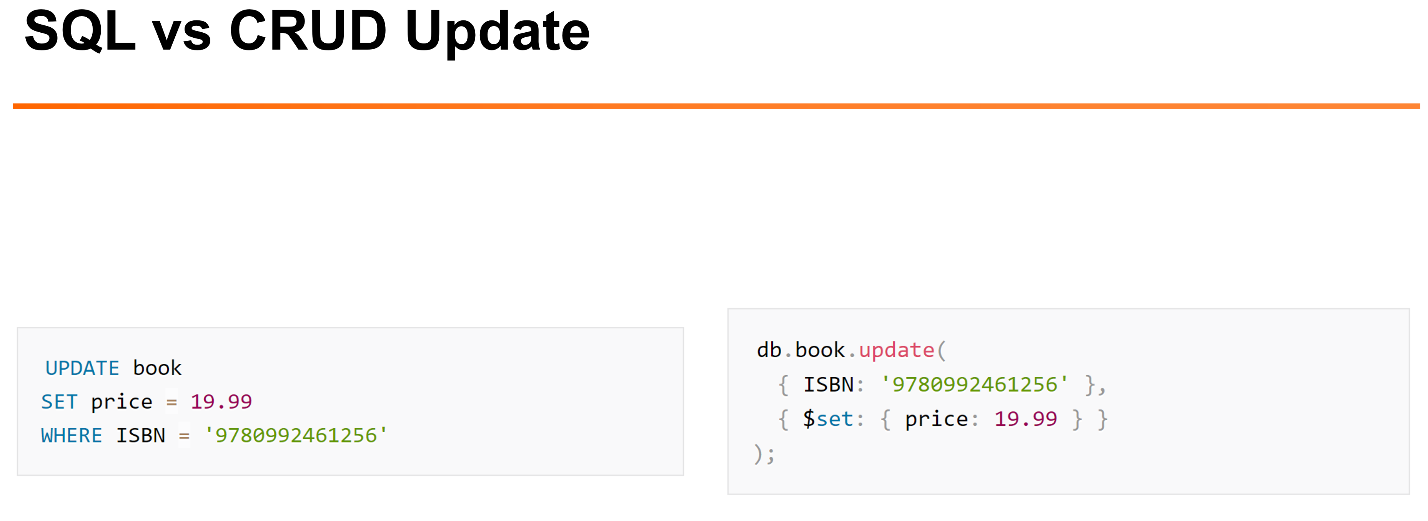
Пример обновления.
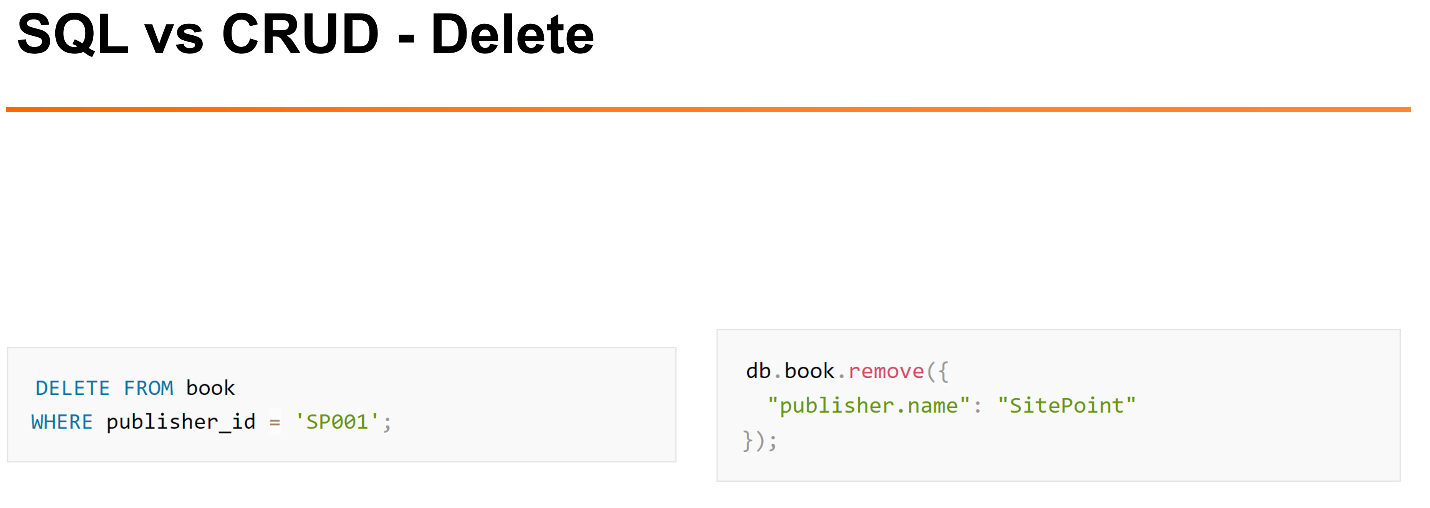
Пример удаления.
Если вы разработчик, который знаком с языком JavaScript, то такой синтаксис, который предоставляет CRUD (MongoDB), для вас будет более естественным, чем синтаксис SQL.
На мой взгляд, когда у нас есть простейшие операции: поиск, вставка, они все работают достаточно хорошо. Когда речь идёт о более интересных операциях выборки, на мой взгляд, язык SQL куда более читаемый.
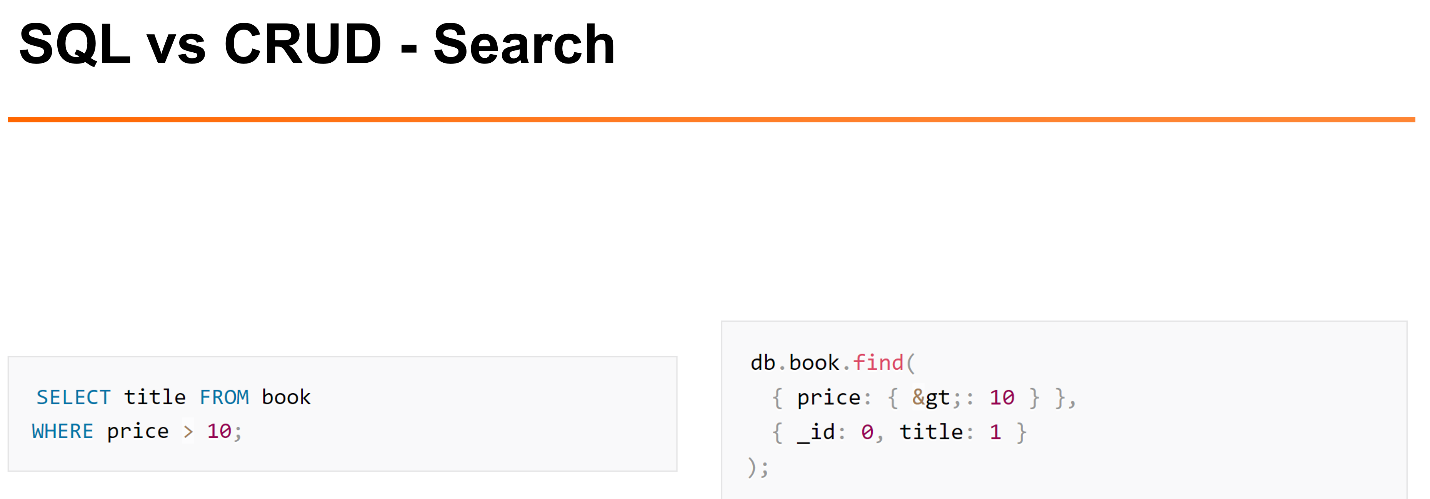
> вместо простого знака «>». Не очень читаемо, на мой взгляд.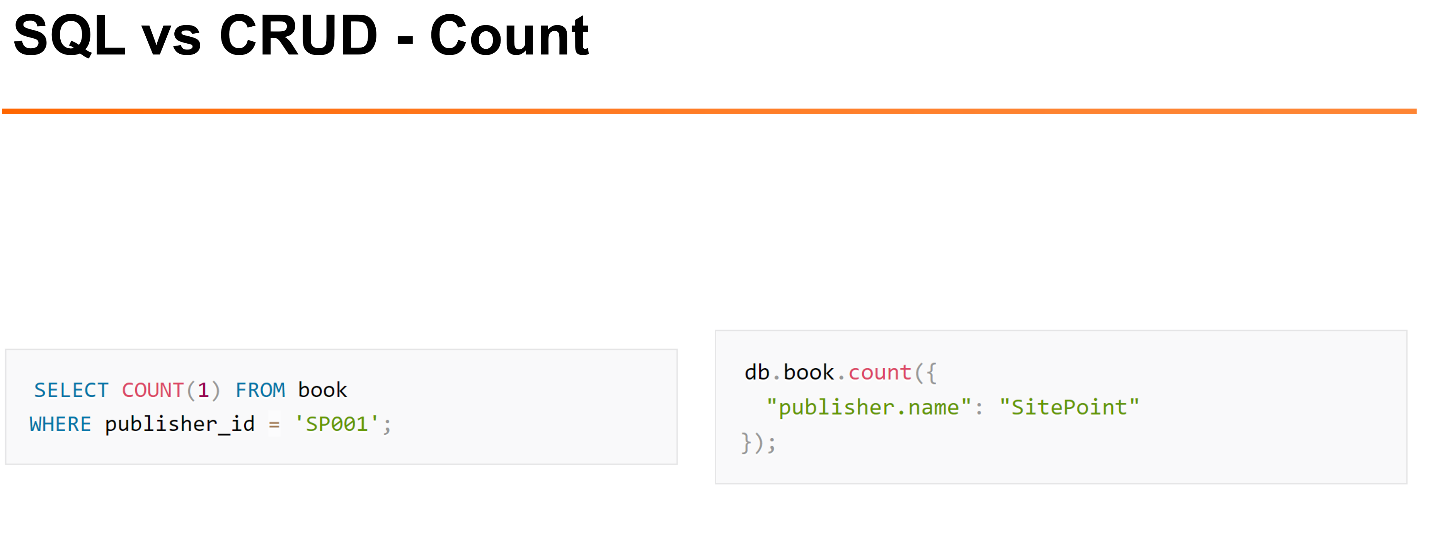
Достаточно легко с помощью интерфейса делать такие вещи, как подсчёт числа строк в таблице или коллекции.
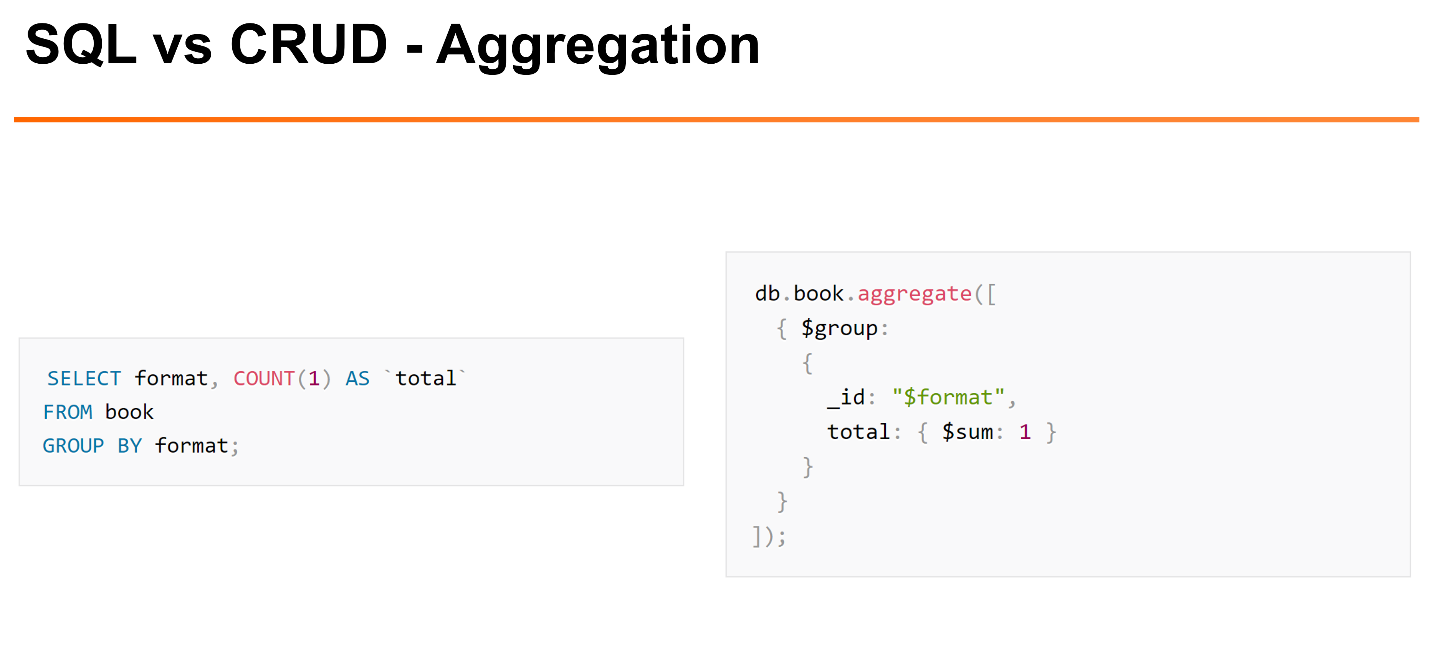
Но если мы делаем более сложные вещи, например,
GROUP BY, в MongoDB для этого требуется использовать Aggregation Framework. Это несколько более сложный интерфейс, который показывает, как мы хотим отфильтровать, как мы хотим группировать и т.д. Aggregation Framework уже поддерживает что-то вроде операций JOIN.Следующий момент — это транзакции и консистентность (ACID). Если пойти и почитать документацию MongoDB, там будет: «Мы поддерживаем ACID-транзакции, но с ограничением». На мой взгляд, стоит сказать: «ACID мы не поддерживаем, но поддерживаем другие минимальные нетранзакционные гарантии».
Какая у нас между ними разница?
Если говорить про MySQL, он поддерживает ACID-транзакции произвольного размера. У нас есть атомарность этих транзакций, у нас есть мультиверсионность, можно выбирать уровень изоляции транзакций, который может начинаться с
READ UNCOMMITED и заканчиваться SERIALIZABLE. На уровне узла и репликаций мы можем конфигурировать, как данные хранятся. Мы можем сконфигурировать у InnoDB, как работать с лог-файлом: сохранять его на диск при коммите транзакции или же делать это периодически. Мы можем сконфигурировать репликацию, включить, например, Semisynchronous Replication, когда у нас данные будут считаться сохранёнными только тогда, когда их копия будет принята на одном из slave’ов.
MongoDB не поддерживает транзакции, но он поддерживает атомарные операции над документом. Это значит, что с точки зрения одного документа операция у нас будет атомарна. Если у нас операция изменяет несколько документов, и во время этой операции произойдет какой-то сбой внутри, то какие-то из этих документов могут быть изменены, а какие-то — не изменены.
Консистентность тоже делается на уровне документов. В кластере мы можем выбирать гибкую консистентность. Мы можем указать, какие мы хотим гарантии — гарантии, что у нас данные были записаны только на один узел, или они были реплицированы на все узлы кластеров. Чтение консистентности тоже происходит на уровне документа.
Есть такой вариант обновления isolated, который позволяет выполнить обновление изолированно от других транзакций, но он очень неэффективен — он переключает базы данных в монопольный режим доступа, поэтому он используется достаточно редко. На мой взгляд, если говорить про транзакции и консистентность, то MongoDB достаточна убогая.
Производительность
Производительность очень сложно сравнивать напрямую, потому что мы часто делаем разные схемы баз данных, дизайн приложения. Но если говорить в целом, MongoDB изначально была сделана, чтобы хорошо масштабироваться на много узлов через шардинг, поэтому эффективности было уделено меньше внимания.
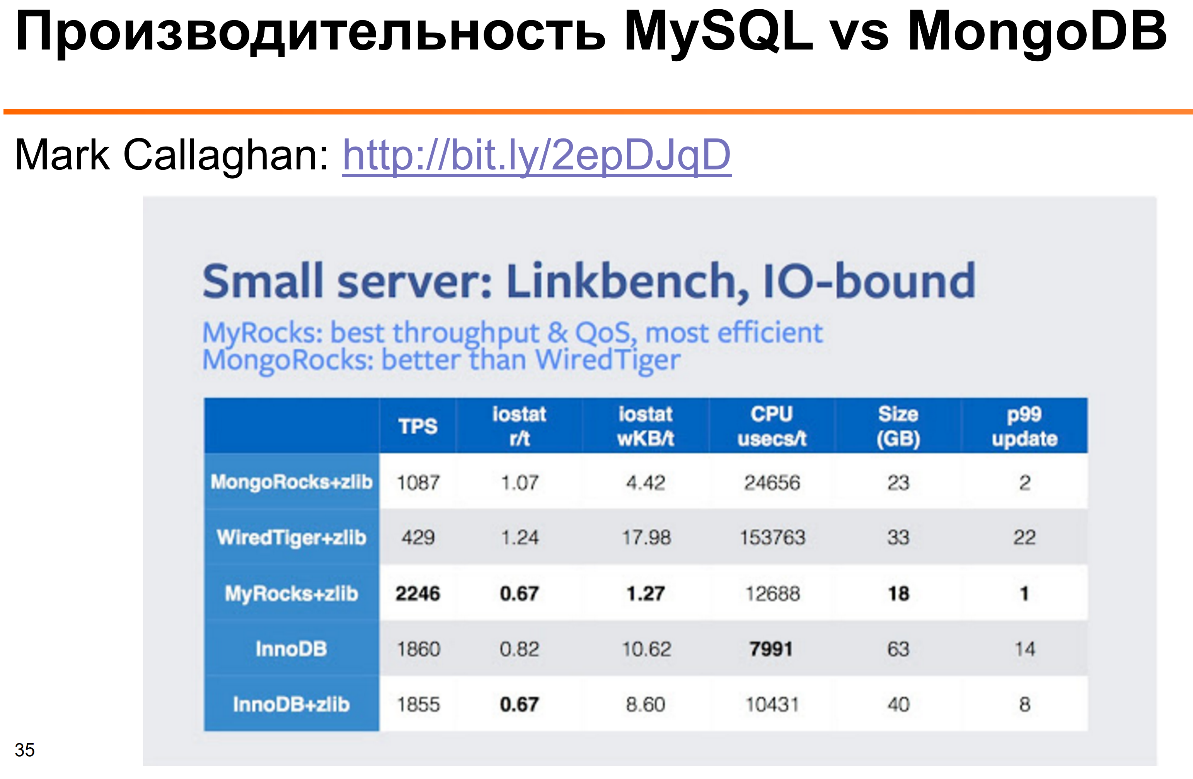
Это результаты бенчмарка, который делал Марк Каллаган. Здесь видно, что с точки зрения использования процессора, ввода/вывода MySQL — как InnoDB, так и MyRocks — использует значительно меньше процессора и дискового ввода/вывода на операции бенчмарка Linkbench от Facebook.
Масштабируемость.
Что такое масштабируемость в данном контексте? То, насколько легко нам взять наше маленькое приложение и масштабировать его на многие миллионы, может быть, даже на миллиарды пользователей.
Масштабируемость бывает разная. Она бывает средняя, в рамках одной машины, когда мы хотим поддерживать приложения среднего размера, либо масштабируемость на кластере, когда у нас приложения уже очень большие, когда понятно, что даже одна самая мощная машина не справится.
Также имеет смысл говорить о том, масштабируем ли мы чтение, запись или объем данных. В разных приложениях их приоритеты могут различаться, но в целом, если приложение очень большое, обычно им приходится работать со всеми из этих вещей.
В MySQL в новых версиях весьма хорошая масштабируемость в рамках одного узла для LTP-нагрузок. Если у нас маленькие транзакции, есть какое-нибудь железо, в котором 64 процессора, то масштабируется достаточно хорошо. Аналитика или сложные запросы масштабируются плохо, потому что MySQL может использовать для одного запроса только один поток, что плохо.
Традиционно чтение в MySQL масштабируется с репликацией, запись и размер данных — через шардинг. Если смотреть на все большие компании — Facebook, Twitter — они все используют шардинг. Традиционно шардинг в MySQL используется вручную. Есть некоторые фреймворки для этого. Например, Vitess — это фреймворк, который Google использует для scaling сервиса YouTube, они его выпустили в open source. До этого был framework Jetpants. Стандартного решения для шардинга MySQL не предлагает, часто переход на шардинг требует внимания от разработчиков.
В MongoDB фокус изначально был в масштабируемости на многих узлах. Даже в случаях с маленьким приложением многим рекомендуется использовать шардинг с самого начала. Может, всего пару replica set, потом вы будете расти вместе со своим приложением.
В шардинге MongoDB есть некоторые ограничения: не все операторы с ним работают, например, есть isolated-вариант для обеспечения консистентности. Она не работает если использовать шардинг. Но при этом многие основные операции хорошо работают в шардингом, поэтому людям позволяется scale’ить приложения значительно лучше. На мой взгляд, шардинг и вообще репликация в MongoDB сделаны куда лучше, чем MySQL, значительно проще в использовании для пользователя.
Администрирование
Администрирование – это все те вещи, о которых не думают разработчики. По крайней мере в первую очередь. Администрирование — это то, что нам приложение придётся бэкапить, обновлять версии, мониторить, восстановливать при сбоях и так далее.
MySQL достаточно гибок, у него есть много разных подходов. Есть хорошие open source реализации всего, но это множество вариантов порождает сложность. Я часто общаюсь с пользователями, которые только начинают изучать MySQL. Они говорят: «Ёлки-палки, сколько же у вас всего вариантов. Вот только репликация — какую мне использовать: statement-репликацию, raw-репликацию, или mix? А еще есть gtid и стандартная репликация. Почему нельзя сказать „просто работай“?»
В MongoDB всё больше ориентированно на то, что оно работает каким-то одним стандартным образом — есть минимизация администрирования. Но понятно, что это происходит при потере гибкости. Коммьюнити open source решений для MongoDB значительно меньше. Многие вещи в MongoDB с точки зрения рекомендаций достаточно жестко привязаны к Ops Manager — коммерческой разработке MongoDB.
Мифы
Как в MongoDB, так и в MySQL есть мифы, которые были в прошлом, которые были исправлены, но у людей хорошая память, особенно если что-то не работает. Помню, в MySQL после того как появились транзакции с InnoDB, люди мне лет десять говорили: «А в MySQL нет же транзакций?»
В MongoDB было много разных проблем с производительностью MMAP storage engine: гигантские блокировки, неэффективное использование дискового пространства. Сейчас в стандартном движке WiredTiger уже нет многих из этих проблем. Есть другие проблемы, но не эти.
«Нет контроля схемы» — ещё такой миф. В новых версиях MongoDB можно для каждой коллекции определить на JSON структуру, где данные будут валидироваться. Данные, которые мы пытаемся вставить, и они не соответствуют какому-то формату, можно выкидывать.
«Нет аналога
JOIN» — то же самое. В MongoDB это появилось, но нескольких ограниченных вещах. Только на уровне одного шарда и только если мы используем Aggregation Framework, а не в стандартных запросах.Какие у нас есть мифы в MySQL? Здесь я буду говорить больше о поддержке NoMySQL решений в MySQL, об этом я буду говорить завтра. Следует сказать, что MySQL сейчас тоже можно использовать через интерфейс CRUD’a, использовать в NoSQL режиме примерно как MongoDB.
Типичный пример, где используется MySQL-решение — это сайт электронной коммерции. Когда у нас идёт вопрос о деньгах, часто мы хотим полноценные транзакции и консистентность. Для таких вещей хорошо подходит реляционная структура, которая была проработана, и commerce на реляционных базах данных уже делается многие десятилетия. Так что можно взять один из готовых подходов к структуре данных и использовать его.
Обычно с точки зрения e-commerce объем данных у нас не такой большой, так что даже достаточно большие магазины могут долго работать без шардинга. Приложения у нас постоянно разрабатываются и усовершенствуется на протяжении многих лет. И у этого приложения много компонент, которые работают с одними и теми же данными: кто-то рассчитывает, где цены поменять, кто-то ещё что-то делает.
MongoDB часто задействуется как бэкенд больших онлайн-игр. Electronic Arts для очень многих игр использует MongoDB. Почему? Потому что масштабируемость важна. Если какая-то игра хорошо выстрелит, её приходится масштабировать значительно больше, чем предполагалось.
С другой стороны, если не выстрелит, нам хотелось бы, чтобы инфраструктуру можно было бы уменьшить. Во многих играх это идет так: мы запустили игру, у нее есть какой-то пик, приходится делать большой кластер. Потом игра уже выходит из популярности, для неё бэкенд нужно сжимать, сохранять и использовать. В данном случае есть одно приложение (игра), база данных, с одной стороны, несложная, с другой — сильно привязанная к приложению, в котором хранятся все важные для игры параметры.
Часто консистентность базы данных на уровне объектов здесь достаточна, потому что многие вопросы консистентости решаются на уровне приложения. Например, данные одного игрока сохраняет только один application service.
Дополнительная информация
Всем рекомендую это старое, древнее, но очень смешное видео http://www.mongodb-is-web-scale.com/ [YouTube]. На этом мы закончим.
MySQL и MongoDB — когда что лучше использовать?
Комментарии (86)

FeNUMe
24.02.2017 23:07+2Спасибо за статью, достаточно интересно. Но к сожалению она не отвечает на вопрос из заголовка, скорее это просто обзорное сравнение двух типов бд. Очень бы хотелось увидеть набор критериев по которым стоит оценивать какую бд выбирать для приложения(помимо масштабируемости) и возможно конкретные примеры.
Лично передо мной сейчас дилемма: есть приложение использующее реляционную базу и она отлично подходит для текущего функционала, но в планах добавить новые фичи, которые без костылей не реализовать в *SQL, а в монго они «взлетят с пол пинка».
akzhan
25.02.2017 01:04+2Кроме легкого шардинга, что?
Естественно, если сравнивать с Postgres, а не с MySQL.
P.S.: Я вообще предпочитаю связку Postgres + Redis для OLTP+, хотя последний не нравится многим (ну так путают области применения).
FeNUMe
25.02.2017 01:26Сейчас я тоже использую постгрес, но новые фичи предполагают использование разного количества полей у хранимых объектов, то есть придется хранить json в уже существующих таблицах и городить дополнительную логику в приложении для его разбора поверх ORM. Плюс мне очень желателен быстрый UPSERT. Плюс простое версионирование некоторых свойств объектов. Пока я в процессе поиска решения в рамках постгреса, потому что не хочется терять полноценные транзакции для финансовой части приложения. Но пока результата нет, вот и думаю собрать тестовую версию с монгой и проверить скорость основных операций — возможно в итоге буду использовать 2 базы под разные части.
akzhan
25.02.2017 08:02+1Мы используем JSONB-поля, всё хорошо. Индексы на них строятся, что радует безмерно.
Рекомендую не городить логику в приложении, а форкнуть ваш ORM и влить функционал JSON туда. И отдать в upstream обратно.
Польза всем, и приложение будет проще.
P.S.: да, мы тоже просто расширили ORM.
P.P.S.: Postgres для биллинга и что-то иное для контента — имеет право на жизнь, все зависит от потребностей.
VolCh
25.02.2017 11:10Поддержка schemaless в библиотеках/фреймворках, ориентированных на Mongo. Постгресс базу тоже можно свести к schemaless, оставив в каждой таблице два поля: id и jsonb data (попутно выкинув кучу таблиц часто), но вот поддержка таких SQL типов в различных ORM оставляет желать лучшего.

ZOXEXIVO
25.02.2017 12:39+1Допустим, но как будем делать update одного поля в большом json документе ?
VolCh
25.02.2017 12:52Обновлением документа в целом. А там база разбирается как она это будет делать.
ZOXEXIVO
25.02.2017 14:18Ну вы шутите чтоли? При значительном объеме документа, ваш сервер сразу же захлебнется по CPU на сериализации-десериализации.

Fortop
25.02.2017 16:53+1Справедливости ради, даже при 1000-2000 входящих ежедневно (а это достаточно крупная компания) для современного сервера это не нагрузка
The535
25.02.2017 00:44Хм… Всерьез задумался. В статье нет ответа на вопрос.
Помню, как-то давно, из-за сложности данных пришлось прописывать на sql базовые CRUD операции, а логику писать уже на java. В принципе, такой подход мне понравился. Вообще, очень странно, я конечно понимаю, что sql это не так сложно, но не люблю его юзать. Хотя, какая мне разница, сейчас этим вопросом занимаются архитекторы баз данных и sql программисты, так что в итоге я получаю готовый апи. И мне, как программисту, вообще никакой разницы, где там хранятся мои данные.
Хотелось бы увидеть второй день презентации, может там хоть будет ответ на поставленные в названии статьи вопросы.tangro
25.02.2017 01:48+5Я как-то было дело одновременно наблюдал как мои коллеги из одной команды переписывали логику с SQL на Java (потому, что нужна была правильная архитектура, модульность, тесты, всякое такое), а во второй команде переписывали тоже логику с Java на SQL (потому что архитектура — это хорошо, но SQL работает быстрее)
:)The535
25.02.2017 13:59-7Даа) Быстрее. Но если бы я стал писать эти ужасные запросы на sql, наверное ушло бы пару недель. Я и до сих пор никак не заставлю себя добраться до вопроса с sql и понять, как все таки писать эти запросы. Структура данных что-то вроде:
Статья {
Текст статьи, автор, список комментарев {текст комментария, автор, ответы на комментарий { текст, автор, ответы} } } и т.д.)) Поэтому было решено писать на привычной джаве)

batment
25.02.2017 03:15У меня опыта с MongoDB нет, но насколько я понял из статьи — его имеет смысл использовать для простых CRUD-приложений с перспективой быстрого роста, когда при этом не очень страшно, что часть данных будет неконсистентной. То есть действительно информация по онлайн-играм, сообщениям и прочей пользовательской активности.
С другой стороны, если у меня точные данные или нужна сложная аналитика, то тут уже придется брать *SQL базу на одной машине с репликами, и надеятся, что до шардинга дело дойдет нескоро.VolCh
25.02.2017 12:25+1его имеет смысл использовать для простых CRUD-приложений
Очень сильное упрощение. Плюсы SQL заключаются прежде всего в транзакционности, в возможности атомарно для всех остальных менять одновременно несколько сущностей либо не менять ни одной, если что-то пошло не так. В случае если архитектура микросервисная, где каждый микросервис отвечает за одну сущность/агрегат (в терминах DDD), необходимость что-то атомарно менять в нескольких местах одного приложения (микросервиса) часто не возникает и выбор SQL/NoSQL часто сводится к оценке направления развития конкретного приложения (микросервиса) — будем масштабироваться в будущем горизонтально или будем усложнять логику хранения.

jehy
25.02.2017 14:18-4В 2017 году вы уже не пишете на SQL, вы используете ORM для 90% операций. И логика оказывается в коде, где ей и место.
jehy
26.02.2017 01:48-3Видимо, минуснули люди, гордые тем, что умеют написать SQL запрос. Ну молодцы, да.
А я пишу на SQL больше 10 лет, преподаю его, и в том числе мне пришлось писать всякий ад на PL/SQL. И после этого использовать ORM это счастье. Логика остаётся в коде, снижается порог входа для разработчиков, и в любой момент можно перейти на любую другую РСУБД щелчком пальцев.
lovermann
27.02.2017 11:06+1В смысле «снижается порог входа для разработчиков»? Тут уже кто-то писал, что, если SQL сам по себе — это барьер, то разработкой, наверное, не стоит заниматься вообще.
jehy
27.02.2017 11:29Скорее всего, вы не в курсе, но существует много диалектов SQL. И обычно разработчик знает один из них. И заставлять его думать над тем, как в очередной СУБД реализованы простейшие вещи вроде лимитов выборки, строковых функций, автоинкрементных полей и так далее — просто глупая потеря времени. Хватает прописать всё в ORM, а потом проследить, что была создана адекватная струтура и сгенерированы оптимальные запросы. SQL при этом в любом случае must have — но для проверки, не для написания кода.
Но гордые знатоки однострочных запросов MySQL минуснут и этот комментарий.lovermann
27.02.2017 23:16Вы так активно пропагандируете ORM, что мне даже стало интересно. Может, напишете статейку? Видите, народ (и я в том числе), не знает все мега-плюсов этой панацеи. Не поленитесь, просветите народ, вам спасибо скажут.
jehy
28.02.2017 03:42+1Статьи писать люблю по темам, на которые до меня не писали. А про ORM всё было сказано уже тысячу раз. Как пример, можете почитать про query builder в yii2 в php или про knex в node.js. На том же хабре про всё это писали много раз.
Если вкратце, то никакой серебряной пули, конечно, нет, и в случае сильно сложной СУБД лучше писать запрос руками — но по факту большинство проектов укладываются в рамки использования ORM.
Fortop
28.02.2017 00:11а потом проследить, что была создана адекватная струтура и сгенерированы оптимальные запросы.
Это как бы не сложнее чем знать все диалекты.
А уж степень глупости потерянного времени прямо таки безразмерная. Ибо сначала создаем себе трудности, а потом героически их преодолеваем.
ORM снижает требования к качеству среднестатистического разработчика — это его основной плюс и выгода для бизнеса.jehy
28.02.2017 03:53Это как бы не сложнее чем знать все диалекты.
Тут на самом деле много вариантов.
Самый популярный — забить и считать, что ORM всё знает лучше.
СпойлерНа самом деле нет!Fortop
28.02.2017 17:17Если бы технология была выгодна только для бизнеса, бизнес бы о ней никогда не узнал (кто б ему рассказал)
какая наивность…
DjOnline
03.03.2017 21:56+11. ORM и Highload несовместимы
2. Так как существует как ты говоришь десятки диалектов SQL, существует десятки разных ORM.
3. Бывают заковыристые запросы, которые никак не написать на ORM, и нужно опять писать на SQL.VolCh
04.03.2017 13:41Вы хотите, скзать, что в хайлоаде нельзя даже пытаться маппить объекты на базу?

Elsedar
25.02.2017 10:15+3С точки зрения MongoDB, здесь преимущество то, что у нас гибкий JSON-формат документов. Для некоторых задач и каким-то разработчикам это удобнее, чем мучиться с добавлением колонок в SQL-базах данных. Не нужно учить SQL — для некоторых это сложно. Простые запросы реже создают проблемы. Если посмотреть на проблемы производительности, в основном они возникают, когда люди пишут сложные запросы с JOIN в кучу таблиц и GROUP BY. Если такой функциональности в системе нет, то создать сложный запрос получается сложнее.
Это уже через чур. Ощущение, что тебя разводят.
Если по теме, то считаю, что отсутствие схемы очень редко, когда действительно нужно. Чаще всего данные можно формализовать, а если так, то явная структура таблицы(документа) обязана быть. А если у нас множество таблиц со связями между ними, то реляционные БД дают слишком сильные преимущества.VolCh
25.02.2017 10:55+1А если у нас множество таблиц со связями между ними
Часто встречаюсь, что SQL и ко настолько проникли в мозги разработчиков, что таблицы и связи городят даже там, где их быть не должно в принципе, не говоря о том, где можно решить задачу другими способами не менее эффективно. Вот на днях проблемка возникла у бизнеса — есть некий документ, который оформляет пользователь системы, на печатной форме документа его ФИО стоит. Разработчики, создавшие систему изначально, не мудрствуя лукаво сделали в таблице документа поле user_id, ведь ФИО есть в таблице пользователей. Нормализация наше всё и т. п. Но не учли, что людям, особенно девушкам, свойственно иногда менять ФИО, а на печатных формах ФИО пользователя должно быть на момент, грубо говоря, создания документа.
отсутствие схемы очень редко, когда действительно нужно
Полное отсутствие, да. Но очень часто нужно либо часто менять схему, либо часто добавлять новую, но очень близкую к имеющейся. Часто это вырождается либо в одну таблицу с кучей (реально куча, даж не десятки) nullable полей, либо в сложные схемы типа одна главная талица, десяток связанных 1:0..1 и имя таблицы с которой связь в поле главной, что приводит к чему-то типа:
SELECT * FROM main_table LEFT JOIN table_1 ON main_table.id = table_1.id AND main_table.type = 'table_1' -- ... LEFT JOIN table_10 ON main_table.id = table_10.id AND main_table.type = 'table_10';Elsedar
25.02.2017 11:03Это больше похоже на недоработку в проектировании БД. А не в выборе типа БД.
А почему просто не мигрировать на новую схему?VolCh
25.02.2017 11:14+1Новая схема для какой-то сущности добавляется, то есть одновременно надо работать с несколькими. Да и сама миграция может быть очень длительной, что недопустимо в системах непрерывной операционной деятельности.
Fortop
25.02.2017 13:33+2Но не учли, что людям, особенно девушкам, свойственно иногда менять ФИО, а на печатных формах ФИО пользователя должно быть на момент, грубо говоря, создания документа.
К реляционным базам это имеет никакое отношение.
В вашем конкретном случае документы должны были иметь два поля user_id, user_fullname, например.
Это если нигде более смена фамилии не является критичной.
В противном случае вам придётся вынести список фамилий и имён пользователя выносить в отдельную сущность и хранить в отдельной таблице user_id, firstname, lastname, date_create…
Но интересен другой вопрос.
MongoDB и прочие schema-less решения каким образом внезапно спасли бы вас в описанном вами случае?VolCh
25.02.2017 14:01Имеет, такие схемы сейчас по умолчанию делают очень многие, впитав шесть (или сколько их там) форм нормализации реляционных баз данных чуть ли не с молоком матери, не вникая ни то, что в бизнес-процессы, но и игнорируя свои обычные бытовые знания, о том, что ФИО может меняться, паспорта теряться и т. п. В терминах теории "лучшие практики" их приучили любой домен объявлять отдельным отношением, "заставляя" не делать его набором атрибутов других отношений, а использовать соединения между отношениями.
Внезапно, да. По умолчанию в них бы внесли значение user_fullname, если необходимость какой-то нормализации и дедупликации явно не задана в ТЗ, просто чтобы не париться. "Реляционщики" чтобы не париться нормализуют по умолчанию, где надо и где не надо, чтобы обеспечить дедупликацию ценой использования JOIN-ов, а "документщики" чтобы не париться денормализуют где надо и где не надо, чтобы избежать запросов подобных JOIN-ам.
Fortop
25.02.2017 14:09+1Внезапно, да. По умолчанию в них бы внесли значение user_fullname
Ну таки в ловушку попались.
Ведь для случаев, когда критична смена фамилии вам же нужно знать не только фамилию подписавшего, но и однозначно идентифицировать его по этой фамилии.
А из вашего рассказа получается что после смены фамилии документы теряют связь с пользователем, но продолжают хранить информацию о его бывшей фамилии…
То есть в документе зафиксирован Вася Пупкин, а вот самих Пупкиных в вашей БД при этом может не быть вовсе теперь.
Так что, как вы справедливо указали, проблема именно в
не вникая ни то, что в бизнес-процессы
И schema-less в данном случае просто создают другой тип ошибки неконсистентности данныхVolCh
25.02.2017 14:38Естественно имелось в виду наряду с user_id.
В чём разница межды мышлением «реляционщиков» и «документальщиков». Первые по умолчанию стараются оставить только id, вынеся всё остальное в отдельные таблицы, рассчитывая на джойны, а вторые стараются кроме id внести всё, что может понадобиться чтобы избежать джойнов.
Но вообще, для документарных баз вполне нормальна ситуация, когда наличие ссылки в одних документах на другой не препятствует удалению последнего. Проще говоря, даже если удалим пользователя из коллекции, то не будет ошибкой пустой результат при поиске в коллекции пользователей, ведь все нужные для заказа данные пользователя у нас сохранены непосредственно в документе заказа. Собственно user_id там на всякий случай обычно. Реляционные же «заставляют» нас делать либо каскадное удаление, либо вводить какой-то атрибут «уволен» и учитывать его в одних процессах, типа на кого назначить заказ и не учитывать в других типа печати документов.

Metus
25.02.2017 14:57А обнулить user_id реляционные БД не дают возможности?
VolCh
27.02.2017 10:33Дают, но зачем его обнулять? Главное, что РСУБД обычно дают не делать ограничения на значения типа reference, хотя их практически все по умолчанию делают, даже если в ТЗ отсутствует требование на соблюдение ссылочной целостности в базе и вообще база не упоминается.
Вообще есть две красные тряпки для "реляционщиков":
- нарушение ссылочной целостности
- дупликация данных
Они, грубо говоря, приходят в двойное бешенство если видят в таблице order 1000 записей user_id=1, user_name = "Иванов Иван Иванович" и при этом в таблице user нет записи c id =1 и вообще в таблице order нет ссылочных ограничений на поле user_id. Разработчика такой схемы они автоматически объявляют бэдлокодером, раз он дублирует данные и не поставил ограничение. Даже не поинтересуются были ли в постановке задачи соответствующие требования.
Metus
27.02.2017 12:48Вы уверены, что эти красные тряпки существуют не только у "реляционщиков" у Вас в голове? Как и сами "реляционщики"?
VolCh
27.02.2017 13:13Я уверен, что они существуют у "реляционщиков", как и в том, что они сами существуют. Прежде всего это те, кто нереляционные базы не использовал ("нет джойнов и ссылочной целостности? даже время на посмотреть тратить нет смысла"), а при знакомстве с проектом в первую очередь лезут в базу данных, а потом долго возмущаются, что референсы там не прописаны, и вообще таблицы не маппятся на объектную модель 1:1, а то есть таблицы которые в объектной модели не представлены, а то есть объекты которые в базе хранятся, но таблицы для них нет.
Fortop
25.02.2017 18:40Реляционные же «заставляют» нас делать либо каскадное удаление, либо вводить какой-то атрибут «уволен»
Считаете неправильным хранить значимую историю изменений?VolCh
27.02.2017 10:22Считаю правильным хранить значимую историю изменений. Так же считаю, что реляционная модель для этого подходит плохо, поскольку не оперирует упорядоченными множествами. Главное преимущество реляционного моделирования — не дублируем данные, потом мучаясь с их синхронизацией, а изменяем в одном месте и это изменение распространяется на все выборки. Для фиксации же исторических значений это не походит, суть такой фиксации — зафиксировать значение на какой-то момент времени и держать его в независимости от следующих изменений.
Правильное моделирование сущностей типа заказа заключается в копировании всех значимых для заказа данных из текущего состояния сущностей типа клиент и товар, собственно даже идентификатор этих сущностей в заказе особо не нужен, кроме как для аналитических целей типа посчитать сколько заказов сделал конкретный клиент или сколько конкретного товара заказано. Но "лучшие практики" реляционного моделирования "заставляют" нас из заказа только на сущности ссылаться, дублируя только те данные из сущностей, которые явно в ТЗ указаны как подлежащие дублированию. Либо вводить дополнительные сущности типа "состояние сущности такой-то на такой-то момент" и ссылаться на них явно через идентификатор, либо через составной ключ (часто неявный, без ограничений reference) типа ссылки на основную сущность и дату на которую нужно фиксировать изменение.
Fortop
27.02.2017 20:13Эм, у вас какой-то свой взгляд на реляционную модель.
Базой ее является то, что данные представляются в формате связей.
Вас кто-то знатно потроллил на тему нормальных моделей.
Так вот — нормальные формы как и любые другие абстракции следует применять там, где это уместно. Непосрественно же реляционная модель на это не накладывает ограничений.
Правильное моделирование сущностей типа заказа заключается
Неа, не заключается.
Ибо зависит от анализа предметной области. Вы же не тупо 1 в 1 копируете бизнеспроцессы, которые родились еще во времена бумажного документооборота и никакой другой формы кроме «копирования значимых данных» не предусматривали.VolCh
27.02.2017 20:38+1Если кто и троллил, то код, с которым сталкиваюсь ежедневно, в котором связи (причем с контролем ссылочной целостности) лепятся просто по умолчанию.
Именно, что тупо копирую. Моя задача как разработчика автоматизировать имеющиеся бизнес-процессы, зачастую заданные даже не бизнесом, а государством.
Fortop
28.02.2017 16:21Именно, что тупо копирую. Моя задача как разработчика автоматизировать имеющиеся бизнес-процессы, зачастую заданные даже не бизнесом, а государством.
Фиговые у вас аналитики, раз ставят именно такие задачи.
Например, тот же НБУ еще в 1999 году издавал соответствующие постановления об электронном документообороте. И там была формализация результатов, а не процесса.
2.1.1. Вимоги до первинних облікових документів
Підставою для бухгалтерського обліку операцій банку є
первинні документи, які фіксують факти здійснення цих операцій.
Первинні документи повинні бути складені під час здійснення
операції, а якщо це неможливо — безпосередньо після її закінчення
та можуть складатися у паперовій формі та/або у вигляді
електронних записів (у формі, яка доступна для читання та виключає
можливість внесення будь-яких змін). У разі складання їх у вигляді
електронних записів при потребі повинно бути забезпечене отримання
інформації на паперовому носії.
Первинні документи як у паперовій формі, так і у вигляді
електронних записів (непаперовій формі) повинні мати такі
обов'язкові реквізити:
— назву документа (форми);
— дату складання документа; { Абзац п'ятий підпункту 2.1.1
пункту 2.1 із змінами, внесеними згідно з Постановою Національного
банку N 283 ( z0675-01 ) від 18.07.2001 }
— назву підприємства (банку), від імені якого складений
документ;
— місце складання документа;
— назву отримувача коштів;
— зміст операції (підстави для її здійснення) та одиницю її
виміру; { Абзац дев'ятий підпункту 2.1.1 пункту 2.1 із змінами,
внесеними згідно з Постановою Національного банку N 203
( z0926-12 ) від 23.05.2012 }
и т.д. и т.п.
Fortop
28.02.2017 16:27Если кто и троллил, то код, с которым сталкиваюсь ежедневно, в котором связи (причем с контролем ссылочной целостности) лепятся просто по умолчанию.
А это скорее от тяги попробовать все новое. И раз есть — надо применять…
Я в одном месте встретил каскадное удаление первичных документов после удаления акции по которой они могли создаваться.
В результате посетитель приходил, ему приходила смс, а вот заявки о нем в БД не было от слова вовсе…VolCh
28.02.2017 17:29Скорее именно "раз есть — надо применять". Причём часто инструментарий разработки лепит ограничения, если его специально не проиформировать, что не надо.
michael_vostrikov
25.02.2017 17:08+1Кмк, здесь проблема сложнее, чем кажется на первый взгляд.
При нормализации избыточные данные обычно заменяются на связи между сущностями. Под сущностью, как правило, подразумевается первичный ключ плюс текущее состояние. Здесь имеет значение не текущее состояние, а состояние на определенный момент времени. Это не денормализация, это связь с конкретным состоянием сущности.
То есть технически нормализация была сделана не совсем правильно, не были учтены некоторые связи, из-за чего произошла потеря информации.
Надо различать изменение текущего состояния и создание нового. Изменение распространяется по всем связям и влияет на все время занесения данных, создание влияет только на будущие данные.
В общем случае надо делать ссылки на состояние объекта. То есть объект это просто primary key + state id. А state хранится отдельно. Там, где всегда требуется текущее состояние, используется object_id, там где конкретное object_state_id.
Это конечно теоретические рассуждения.
VolCh
25.02.2017 18:06Суть проблемы в том, что, говоря языком DDD, в сущности заказа используется не сущность пользователя, а объект-значение пользователя, а они традиционно плохо ложатся на реляционную модель, так как не имеют идентичности, первичного ключа.
michael_vostrikov
25.02.2017 19:17А, ну вот, как раз все сходится. Сущность это primary_key + state_id, значит state_id это объект-значение. Объекты-значения составляют множество, элементам одного множества можно сопоставить элементы другого множества. Например целые числа. То есть идентификатор состояния это не первичный ключ, а просто короткое обозначение значения.
VolCh
26.02.2017 11:45+1state_id является значением — ссылкой на сущность state. Я же говорю, что объекты-значения плохо ложатся на реляционную модель, по крайней мере на классический SQL. Для их эмуляции нам приходится вводить новые сущности. Причём часто забывают о нормализации — для двух Ивановых Иванов Ивановичей скорее всего будет две записи значений, а не одна. Таблица с ФИО скорее всего будет таблицей истории ФИО конкретного лица, а не множеством всех ФИО без повторений.

JDay
25.02.2017 13:34А что мешает создать таблицу history для фио?
VolCh
25.02.2017 14:19Как минимум сложность выборки из неё. Не каждый оптимизатор хорошо выполнит запрос типа
SELECT order.*, ( SELECT full_name FROM history WHERE history.user_id = order.user_id AND history.date <= order.date ORDER BY history.date DESC LIMIT 1 ) FROM order
или ещё какую его вариацию, пускай
SELECT order.*, history.full_name FROM order INNER JOIN history ON history.user_id = order.user_id AND order.date BETWEEN history.valid_from AND CASE WHEN history.valid_to IS NOT NULL THEN history.valid_to ELSE current_timestamp END
Не говоря о том, насколько если усложнит логику приложения, если задачи отслеживания истории как таковой не стоит.iig
25.02.2017 17:12+1Все это решаемо, и не обязательно сложно. В основной таблице продолжаем хранить актуальную фамилию, к history обращаемся только при необходимости.
VolCh
25.02.2017 18:02Никто же не говорит, что не решаемо. Но такие модели в принципе не очень хорошо ложатся на реляционную модель. Она хорошо решает задачи как раз где нужна только актуальная информация.
iig
25.02.2017 19:43Любая модель не гарантирует полного соответствия реальности.
VolCh
26.02.2017 11:59Реальность нам не нужна обычно. Нам нужна модель, используемая в бизнес-процессах. История значений каких-то атрибутов частый элемент таких моделей, но на реляционную модель она ложится плохо, в частности потому что реляционная модель оперирует неупорядоченными множествами, а история обычно нужна упорядоченная. Приходится в реляционную модель вводить дополнительные атрибуты типа «период актуальности», чтобы получить нужный результат. Или получать его вовне реляционной модели, используя сортировки и лимиты, оконные функции и т. п. от реляционной получая объединение SELECT * FROM person p LEFT JOIN person_name_history pnh ON p.id = pnh.person_id, и обрабатывая его либо на стороне SQL (ORDER BY, last_value() OVER и т. п. — это не реляционные операции), либо вообще приложения

TheDeadOne
25.02.2017 12:13Так как он использует стандарт SQL, есть возможность достаточно простой миграции на другие SQL-базы данных, если захочется.
Ага, стандарт SQL-92 не в полном объёме. Очень даже захочется!VolCh
25.02.2017 12:28"достаточно простой" — это правда, если не вешать на сторону СУБД кучу логики в хранимках и т. п. Простая такая миграция прежде всего в смысле того, что не придётся кардинально менять принципы хранения данных.
TheDeadOne
25.02.2017 12:33Я к тому, что категорически не понимаю, зачем выбирать MySQL изначально. Чтобы программист БД страдал? Или по принципу «мы ничего сложнее левого джоина делать не будем»?
VolCh
25.02.2017 12:51Как минимум, чтобы не страдали админы. :) По крайней мере очень широко распространено мнение, что мускуль проще в администрировании, чем постгри, админам с ним меньше возиться, не нужно перезагружать на каждый чих и вообще, с чем я субъективно после 15+ лет работы с мускулем и года с постгри согласен — писать почти без разницы под что, у каждой из систем есть свои нюансы, а вот админить постгри сложнее. А программиста БД чаще всего на проекте и нет, его роль выполняют в лучшем случае обычные программисты, а то и вообще ORM.
TheDeadOne
26.02.2017 09:40-1Тоже субъективно, но разницы не заметил. Более того, у меня есть сервер, на котором всё моё админство постгреса ограничилось командой apt-get install postgresql, и который при этом достаточно резво обрабатывает базу в пару десяток гигов и прожёвывает запросы с несколькими джоинами и подзапросами по таблицам содержащим несколько миллиардов записей. За последние 4 года ребутил я его только для того, чтобы обновить.
Carburn
25.02.2017 14:25Для использования с ORM возможностей достаточно.
TheDeadOne
26.02.2017 09:31Я уже ни раз видел, как проект за несколько лет разрастался, нагрузка многократно возрастала, данных накапливалось внушительное количество и ORM начинал буксовать. После этого либо создаётся отдельный слой для сложный запросов в обход ORM, либо часть логики выносится в хранимые процедуры. И однажды разработчики сталкиваются с тем, что мигрировать на другую СУБД сложно, но работать без тех же оконных функций ещё сложнее.
Carburn
26.02.2017 10:12-1От количества записей в таблице ORM не зависит.
TheDeadOne
26.02.2017 10:35Я не только про количество записей. В процессе развития проекта может существенно увеличится количество отношений и усложниться логика работы с данными.
VolCh
26.02.2017 12:11На моей практике ORM буксуют обычно в двух случаях:
- через операционную модель пытаются получать аналитику
- грубое моделирование предметной области в ФП стиле, типа "все исходные данные есть, формулы есть, остальное посчитаем", забывая, например, что результат расчёта сегодня — это исходные данные для завтрашнего расчёта, причём они не должны измениться, даже если исходные данные изменились.
sad0vnikov
25.02.2017 13:09я для себя ответ на вопрос из заголовка сформулировал так:
- если отношения между объектами представляют собой дерево, то документно-ориентированные БД — отличный выбор. Например, мы пишем "Кинопоиск", где нам нужно хранить всякую разную информацию о фильмах:
{ "title": "The Matrix", "year": 1999, "cast": [ {"name": "Keanu Reeves", ... } ] }
или сериалах:
{ "title" : "Big Bang Theory", "series" : [ { "number" : 1, "actors" : [ { "name" : "Kelly Cuoco" } ] } ] }
здесь каждый объекты однозначно связаны отношениями "родитель-потомок", и большую часть информации (список актеров сериала, список серий, в которых снимался актер), в MongoDB можно легко получить одним запросом с помощью aggregation framework.
- но если в графе отношений между сущностями есть циклы, т.е. один объект может быть одновременно связан с несколькими, реляционные БД — более мудрый выбор.
Например, мы пишем Хабрахабр, где у нас есть посты и комментарии. У постов есть авторы, у комментариев так же есть авторы, то есть авторы относятся одновременно и к комментариям, и к постам.
Если мы используем MongoDB, придётся делать или так:
Пост:
{ "title": "Заголовок Поста", "author": { "name": "username", } }
или пойти на ухищрения со ссылками, о которых упоминал в своём докладе Пётр:
{ "title": "Заголовок Поста", "author_id": ObjectId("58b1422426353d52d75f5cc9") }
Оба варианта заставят нас реализовывать логику с удалением, сохранением консистетности ключей на уровне приложения. Зачем это делать, когда реляционные БД умеют это делать за нас, и такая структура данных для них более естественна — непонятно. Мне кажется, что в этом случае выбирая документноориентированную БД, мы гораздо больше проигрываем, чем выигрываем
lovermann
25.02.2017 13:39+2Вы сделали абсолютно неверный вывод. То, как вы описали, — так не выбирают БД. Структура данных — это лишь часть вопроса (в приведённом вами примере можно всё отлично организовать и в мускуле). Надо смотреть количество запросов к базе, как часто база апдейтится, как и кем пополняется, насколько критичен поиск… — вот эти аргументы, но никак не древовидность структуры данных.

bosha
27.02.2017 16:38+1Что простите? Если важна консистентность данных, то тут только реляционные БД. sad0vnikov верно написал. То, о чём вы говорите — это уже вторично. Не надо выдвигать производительность на передний план, когда важна сама информация и связи.

Xu4
25.02.2017 14:05+2> вместо простого знака «>». Не очень читаемо, на мой взгляд.
Странно, что вы пишете амперсанд — и в коде и в тексте. В монго операторы со знака доллара начинаются.
А так, логика формата операторов вполне понятна. Чтобы не спутать оператор с названием поля, он начинается со специального знака. Символ>, кстати, вполне может быть названием поля (так что его нельзя использовать в качестве оператора) — в названии поля можно использовать любые символы из UTF-8 (кроме точки в любой части строки или знака доллара в начале строки). И это вполне читаемо, потому что все операторы созданы по одному и тому же принципу: знак доллара + текст, по которому часто (не всегда, но часто) и без документации понятно, что происходит.
zoonman
26.02.2017 03:24Там опечатка в статье. Для такого условия используется оператор $gt.
Xu4
27.02.2017 06:11+1Интересная опечатка получается. Дело в том, что если написать > в тексте, то он превращается в символ > средствами HTML. И чтобы реально написать >, нужно вводить такой код:
&gt. Этот код на автопилоте обычно не вводится, потому что он требует дополнительных осмысленных телодвижений. То есть, в этот момент нужно реально верить, что команды в mongo начинаются с амперсанда, чтобы осознанно это вставлять в текст. :)
Carburn
25.02.2017 14:17+2MongoDB позволяет попробовать иерархическую БД, ведь активно их использовали в 60-х.
Busla
25.02.2017 15:59+9если для человека изучить SQL слишком сложно, то, пожалуй, ему не стоит заниматься разработкой вообще
Некорректно противопоставлять SQL и CRUD: CRUD — это парадигма, а не конкретный красивенький синтаксис

onyxmaster
25.02.2017 16:42Предпочту MongoDB Postgres-у any day с административной и интеграционной точки зрения.
Postgres шагает в нужную сторону, но пока там не будет автоматического надёжного failover и поддержки streaming replication хотя бы с меньшей версии к большей, я так и буду плакать, когда нужно обновить версию или перезагрузить подлежащую железку. Существующие же решения для организации кластера требуют тонкой настройки, иногда разваливаются и не совсем прозрачны для приложения.
Разумеется это всё про [near] zero-downtime, если этого не требуется, то как БД Postgres лучше почти со всех сторон.
А, ну и .NET-драйвер для Postgres просто ужасен (в плане производительности и дизайна обработки ошибок), правда.
onyxmaster
25.02.2017 16:51Заодно напишу про денормализацию в рамках MongoDB. Большинство примеров и туториалов фокусируются на неизменяемых данных относительно небольшого размера. В реальности, если поместить даже несколько сотен комментариев к посту в один документ, "денормализовав" туда никнеймы пользователей и прочие элементы, то вас ждёт жестокое разочарование, потому что под нагрузкой это будет безбожно тормозить при материализации изменений, потому что MongoDB оперирует документами, а не полями (особенно грустно с массивами).
Основой же бонус, который я вижу, это отказ от join и логики на стороне БД. Есть исключения, конечно, но разделение read models и write model обычно полезнее, чем попытка сделать вид, что одни и те же данные используются всеми клиентами одинаково. В некоторых БД есть materialized views, но и это может быть не самым оптимальным решением при нетривиальной фильтрации.
grossws
26.02.2017 01:33Ещё легко упереться в ограничение в 16M, что тоже больно. Причём в некоторых драйверах в это ограничение вполне можно упереться имея не столь большие документы, но большой bulk update.
lovermann
Я не специалист (хотя я работал и с мускулем и с пакетом Elastic (кибана, битс, логстэш) + апачевский кафка), и мне кажется, что сравнивать SQL и NoSQL базы без привязки к области применения, не совсем корректно. Где-то «тащат» нереляционные БД, а где-то — реляционные.
Вообще, статья интересная, но заголовку соответствует только полтора абзаца, и то, очень и очень сдержанно и неполно.