

Привет всем, кто начал проходить курс! Новые участники, добро пожаловать! Второе занятие посвящено визуализации данных в Python. Сначала мы посмотрим на основные методы библиотек Seaborn и Plotly, затем поанализируем знакомый нам по первой статье набор данных по оттоку клиентов телеком-оператора и подглядим в n-мерное пространство с помощью алгоритма t-SNE.
Напомним, что к курсу еще можно подключиться, дедлайн по 1 домашнему заданию – 6 марта 23:59.
Сейчас статья уже будет существенно длиннее. Готовы? Поехали!
- Первичный анализ данных с Pandas
- Визуальный анализ данных c Python
- Классификация, деревья решений и метод ближайших соседей
- Линейные модели классификации и регрессии. Кросс-валидация и оценка модели
- Композиции: бэггинг, случайный лес. Кривые валидации и обучения
- Обучение без учителя: PCA, кластеризация, поиск аномалий
- Искусство построения и отбора признаков. Приложения в задачах обработки текста, изображений и гео-данных
План этой статьи
- Демонстрация основных методов Seaborn и Plotly
- Пример визуального анализа данных
- Подглядывание в n-мерное пространство с t-SNE
- Домашнее задание №2
- Обзор полезных ресурсов
Демонстрация основных методов Seaborn и Plotly
В начале как всегда настроим окружение: импортируем все необходимые библиотеки и немного настроим дефолтное отображение картинок.
# Python 2 and 3 compatibility
# pip install future
from __future__ import (absolute_import, division,
print_function, unicode_literals)
# отключим предупреждения Anaconda
import warnings
warnings.simplefilter('ignore')
# будем отображать графики прямо в jupyter'e
%pylab inline
#увеличим дефолтный размер графиков
from pylab import rcParams
rcParams['figure.figsize'] = 8, 5
import pandas as pd
import seaborn as snsПосле этого загрузим в dataframe данные, с которыми будем работать. Для примеров я выбрала данные о продажах и оценках видео-игр из Kaggle Datasets.
df = pd.read_csv('../../data/video_games_sales.csv')
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 16719 entries, 0 to 16718
Data columns (total 16 columns):
Name 16717 non-null object
Platform 16719 non-null object
Year_of_Release 16450 non-null float64
Genre 16717 non-null object
Publisher 16665 non-null object
NA_Sales 16719 non-null float64
EU_Sales 16719 non-null float64
JP_Sales 16719 non-null float64
Other_Sales 16719 non-null float64
Global_Sales 16719 non-null float64
Critic_Score 8137 non-null float64
Critic_Count 8137 non-null float64
User_Score 10015 non-null object
User_Count 7590 non-null float64
Developer 10096 non-null object
Rating 9950 non-null object
dtypes: float64(9), object(7)
memory usage: 2.0+ MBДанные об оценках есть не для всех фильмов, поэтому давайте оставим только те записи, в которых нет пропусков с помощью метода dropna.
df = df.dropna()
print(df.shape)(6825, 16)Всего в таблице 6825 объектов и 16 признаков для них. Посмотрим на несколько первых записей c помощью метода head, чтобы убедиться, что все распарсилось правильно. Для удобства я оставила только те признаки, которые мы будем в дальнейшем использовать.
useful_cols = ['Name', 'Platform', 'Year_of_Release', 'Genre',
'Global_Sales', 'Critic_Score', 'Critic_Count',
'User_Score', 'User_Count', 'Rating'
]
df[useful_cols].head()
Прежде чем мы перейдем к рассмотрению методов библиотек seaborn и plotly, обсудим самый простой и зачастую удобный способ визуализировать данные из pandas dataframe — это воспользоваться функцией plot.
Для примера построим график продаж видео игр в различных странах в зависимости от года. Для начала отфильтруем только нужные нам столбцы, затем посчитаем суммарные продажи по годам и у получившегося dataframe вызовем функцию plot без параметров.
sales_df = df[[x for x in df.columns if 'Sales' in x] + ['Year_of_Release']]
sales_df.groupby('Year_of_Release').sum().plot()Реализация функции plot в pandas основана на библиотеке matplotlib.
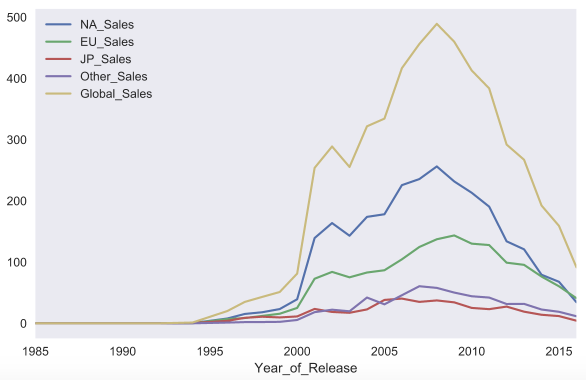
C помощью параметра kind можно изменить тип графика, например, на bar chart. Matplotlib позволяет очень гибко настраивать графики. На графике можно изменить почти все, что угодно, но потребуется порыться в документации и найти нужные параметры. Например, параметра rot отвечает за угол наклона подписей к оси x.
sales_df.groupby('Year_of_Release').sum().plot(kind='bar', rot=45)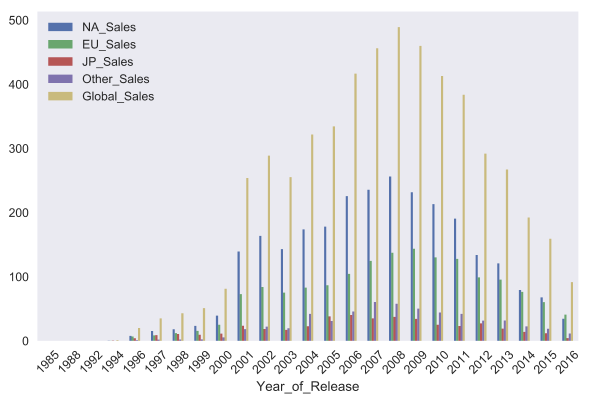
Seaborn
Теперь давайте перейдем к библиотеке seaborn. Seaborn — это по сути более высокоуровневое API на базе библиотеки matplotlib. Seaborn содержит более адекватные дефолтные настройки оформления графиков. Если просто добавить в код import seaborn, то картинки станут гораздо симпатичнее. Также в библиотеке есть достаточно сложные типы визуализации, которые в matplotlib потребовали бы большого количество кода.
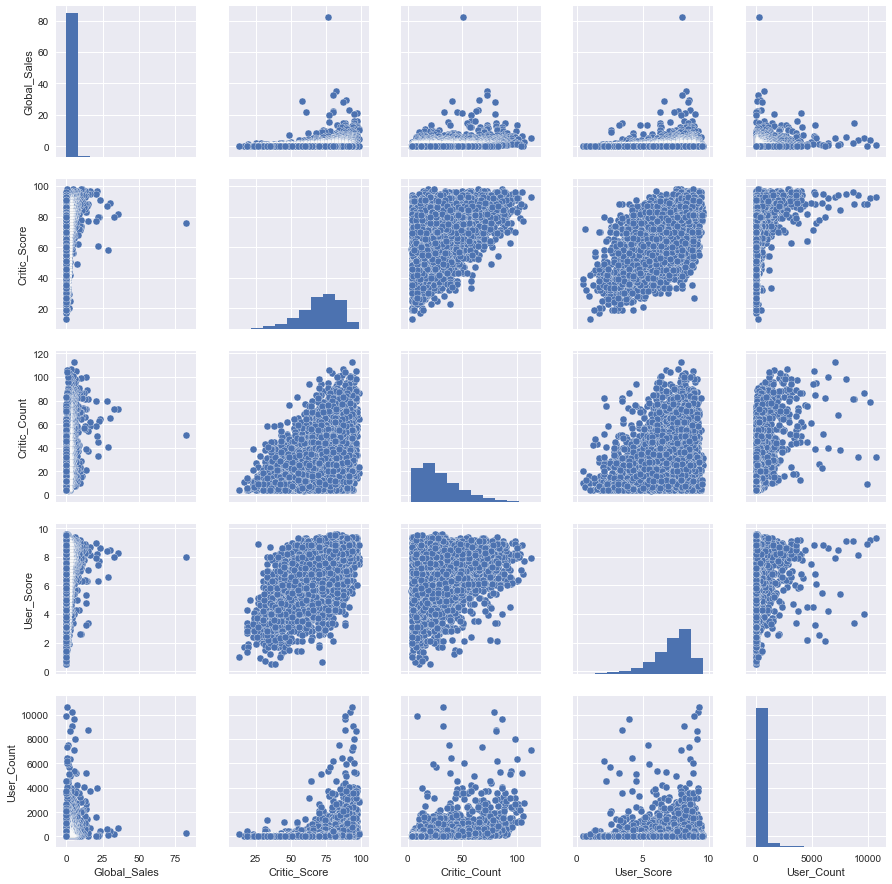
Познакомимся с первым таким "сложным" типом графиков pair plot (scatter plot matrix). Эта визуализация поможет нам посмотреть на одной картинке, как связаны между собой различные признаки.
cols = ['Global_Sales', 'Critic_Score', 'Critic_Count', 'User_Score', 'User_Count']
sns_plot = sns.pairplot(df[cols])
sns_plot.savefig('pairplot.png')Как можно видеть, на диагонали матрицы графиков расположены гистограммы распределений признака. Остальные же графики — это обычные scatter plots для соответствующих пар признаков.
Для сохранения графиков в файлы стоит использовать метод savefig.
С помощью seaborn можно построить и распределение dist plot. Для примера посмотрим на распределение оценок критиков Critic_Score. По default'у на графике отображается гистограмма и kernel density estimation.
sns.distplot(df.Critic_Score)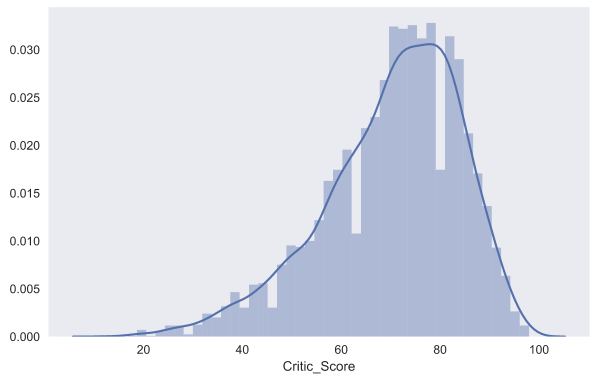
Для того, чтобы подробнее посмотреть на взаимосвязь двух численных признаков, есть еще и joint plot — это гибрид scatter plot и histogram. Посмотрим на то, как связаны между собой оценка критиков Critic_Score и оценка пользователя User_Score.
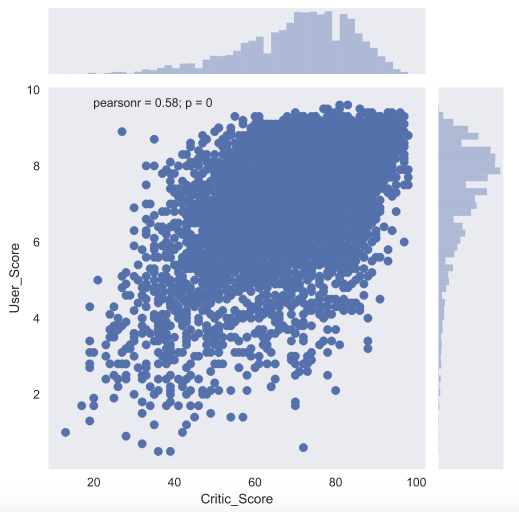
Еще один полезный тип графиков — это box plot. Давайте сравним оценки игр от критиков для топ-5 крупнейших игровых платформ.
top_platforms = df.Platform.value_counts().sort_values(ascending = False).head(5).index.values
sns.boxplot(y="Platform", x="Critic_Score", data=df[df.Platform.isin(top_platforms)], orient="h")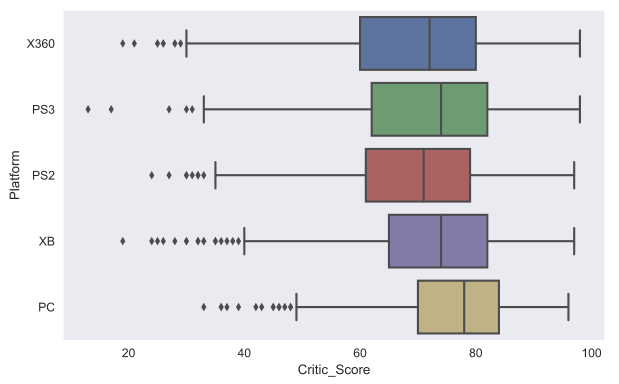
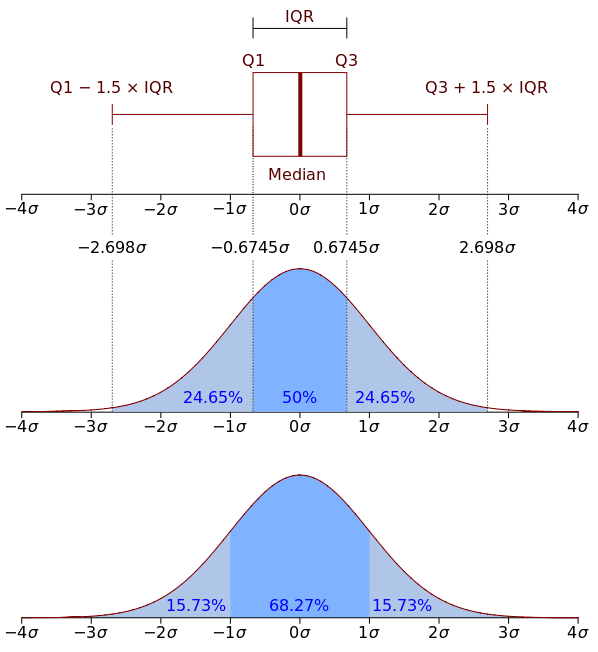
Думаю, стоит обсудить немного подробнее, как же понимать box plot. Box plot состоит из коробки (поэтому он и называется box plot), усиков и точек. Коробка показывает интерквартильный размах распределения, то есть соответственно 25% (Q1) и 75% (Q3) перцентили. Черта внутри коробки обозначает медиану распределения.
С коробкой разобрались, перейдем к усам. Усы отображают весь разброс точек кроме выбросов, то есть минимальные и максимальные значения, которые попадают в промежуток (Q1 - 1.5*IQR, Q3 + 1.5*IQR), где IQR = Q3 - Q1 — интерквартильный размах. Точками на графике обозначаются выбросы (outliers) — те значения, которые не вписываются в промежуток значений, заданный усами графика.
Для понимания лучше один раз увидеть, поэтому вот еще и картинка с wikipedia:
И еще один тип графиков (последний из тех, которые мы рассмотрим в этой статье) — это heat map. Heat map позволяет посмотреть на распределение какого-то численного признака по двум категориальным. Визуализируем суммарные продажи игр по жанрам и игровым платформам.
platform_genre_sales = df.pivot_table(
index='Platform',
columns='Genre',
values='Global_Sales',
aggfunc=sum).fillna(0).applymap(float)
sns.heatmap(platform_genre_sales, annot=True, fmt=".1f", linewidths=.5)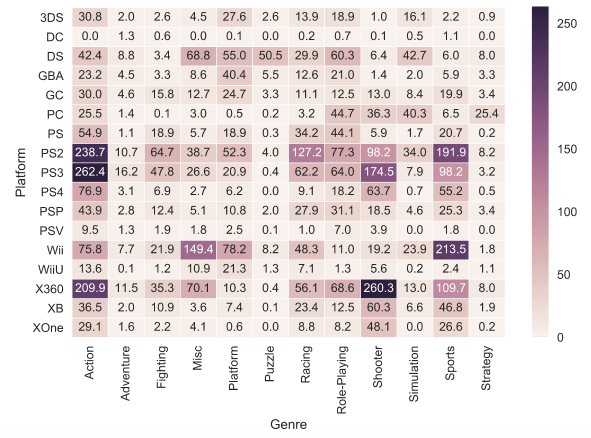
Plotly
Мы рассмотрели визуализации на базе библиотеки matplotlib. Однако это не единственная опция для построения графиков на языке python. Познакомимся также с библиотекой plotly. Plotly — это open-source библиотека, которая позволяет строить интерактивные графики в jupyter.notebook'e без необходимости зарываться в javascript код.
Прелесть интерактивных графиков заключается в том, что можно посмотреть точное численное значение при наведении мыши, скрыть неинтересные ряды в визуализации, приблизить определенный участок графика и т.д.
Перед началом работы импортируем все необходимые модули и инициализируем plotly с помощью команды init_notebook_mode.
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
import plotly
import plotly.graph_objs as go
init_notebook_mode(connected=True)Для начала построим line plot с динамикой числа вышедших игр и их продаж по годам.
# посчитаем число вышедших игр и проданных копий по годам
years_df = df.groupby('Year_of_Release')[['Global_Sales']].sum().join(
df.groupby('Year_of_Release')[['Name']].count()
)
years_df.columns = ['Global_Sales', 'Number_of_Games']
# создаем линию для числа проданных копий
trace0 = go.Scatter(
x=years_df.index,
y=years_df.Global_Sales,
name='Global Sales'
)
# создаем линию для числа вышедших игр
trace1 = go.Scatter(
x=years_df.index,
y=years_df.Number_of_Games,
name='Number of games released'
)
# определяем массив данных и задаем title графика в layout
data = [trace0, trace1]
layout = {'title': 'Statistics of video games'}
# cоздаем объект Figure и визуализируем его
fig = go.Figure(data=data, layout=layout)
iplot(fig, show_link=False)В plotly строится визуализация объекта Figure, который состоит из данных (массив линий, которые в библиотеке называются traces) и оформления/стиля, за который отвечает объект layout. В простых случаях можно вызывать функцию iplot и просто от массива traces.
Параметр show_link отвечает за ссылки на online-платформу plot.ly на графиках. Поскольку обычно это функциональность не нужна, то я предпочитаю скрывать ее для предотвращения случайных нажатий.
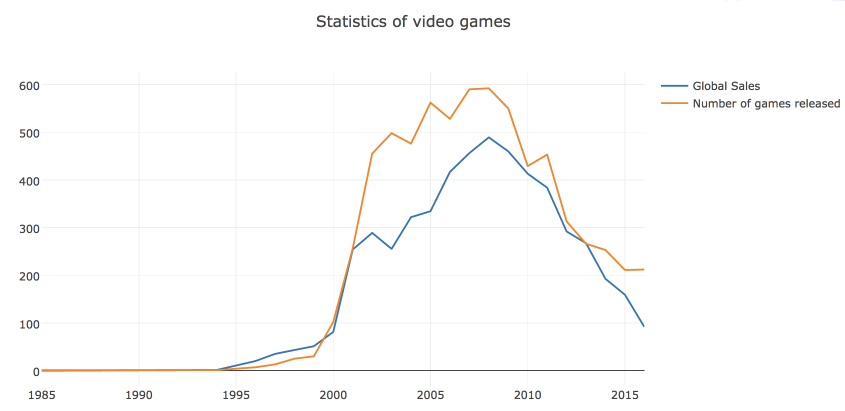
Можно сразу сохранить график в виде html-файла.
plotly.offline.plot(fig, filename='years_stats.html', show_link=False)Посмотрим также на рыночную долю игровых платформ, рассчитанную по количеству выпущенных игр и по суммарной выручке. Для этого построим bar chart.
# считаем число проданных и вышедших игр по платформам
platforms_df = df.groupby('Platform')[['Global_Sales']].sum().join(
df.groupby('Platform')[['Name']].count()
)
platforms_df.columns = ['Global_Sales', 'Number_of_Games']
platforms_df.sort_values('Global_Sales', ascending=False, inplace=True)
# создаем traces для визуализации
trace0 = go.Bar(
x=platforms_df.index,
y=platforms_df.Global_Sales,
name='Global Sales'
)
trace1 = go.Bar(
x=platforms_df.index,
y=platforms_df.Number_of_Games,
name='Number of games released'
)
# создаем массив с данными и задаем title для графика и оси x в layout
data = [trace0, trace1]
layout = {'title': 'Share of platforms', 'xaxis': {'title': 'platform'}}
# создаем объект Figure и визуализируем его
fig = go.Figure(data=data, layout=layout)
iplot(fig, show_link=False)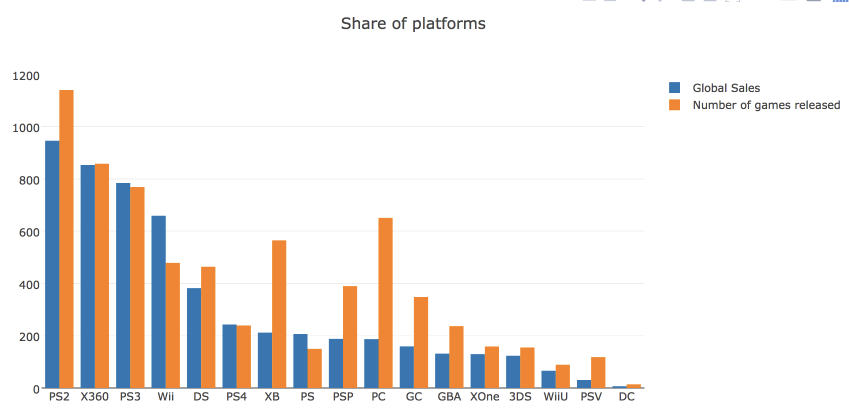
В plotly можно построить и box plot. Рассмотрим распределения оценок критиков в зависимости от жанра игры.
# создаем Box trace для каждого жанра из наших данных
data = []
for genre in df.Genre.unique():
data.append(
go.Box(y=df[df.Genre==genre].Critic_Score, name=genre)
)
# визуализируем данные
iplot(data, show_link = False)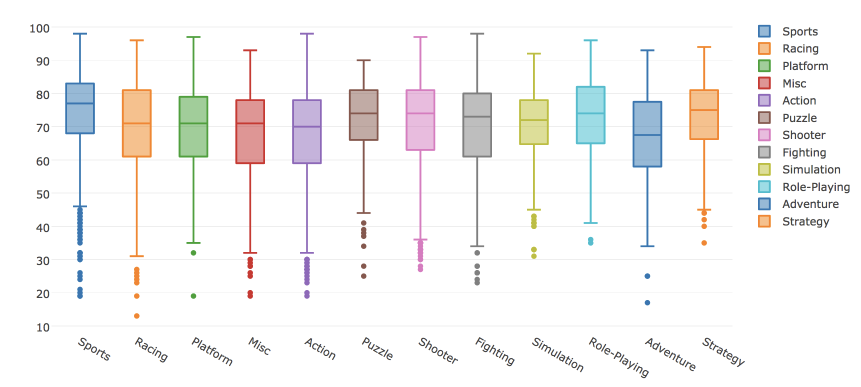
С помощью plotly можно построить и другие типы визуализаций. Графики получаются достаточно симпатичными с дефолтными настройками. Однако библиотека позволяет и гибко настраивать различные параметры визуализации: цвета, шрифты, подписи, аннотации и многое другое.
Пример визуального анализа данных
Считываем в DataFrame знакомые нам по первой статье данные по оттоку клиентов телеком-оператора.
df = pd.read_csv('../../data/telecom_churn.csv')Проверим, все ли нормально считалось – посмотрим на первые 5 строк (метод head).
df.head()
Число строк (клиентов) и столбцов (признаков):
df.shape(3333, 20)Посмотрим на признаки и убедимся, что пропусков ни в одном из них нет – везде по 3333 записи.
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3333 entries, 0 to 3332
Data columns (total 20 columns):
State 3333 non-null object
Account length 3333 non-null int64
Area code 3333 non-null int64
International plan 3333 non-null object
Voice mail plan 3333 non-null object
Number vmail messages 3333 non-null int64
Total day minutes 3333 non-null float64
Total day calls 3333 non-null int64
Total day charge 3333 non-null float64
Total eve minutes 3333 non-null float64
Total eve calls 3333 non-null int64
Total eve charge 3333 non-null float64
Total night minutes 3333 non-null float64
Total night calls 3333 non-null int64
Total night charge 3333 non-null float64
Total intl minutes 3333 non-null float64
Total intl calls 3333 non-null int64
Total intl charge 3333 non-null float64
Customer service calls 3333 non-null int64
Churn 3333 non-null bool
dtypes: bool(1), float64(8), int64(8), object(3)
memory usage: 498.1+ KB| Название | Описание | Тип |
|---|---|---|
| State | Буквенный код штата | номинальный |
| Account length | Как долго клиент обслуживается компанией | количественный |
| Area code | Префикс номера телефона | количественный |
| International plan | Международный роуминг (подключен/не подключен) | бинарный |
| Voice mail plan | Голосовая почта (подключена/не подключена) | бинарный |
| Number vmail messages | Количество голосовых сообщений | количественный |
| Total day minutes | Общая длительность разговоров днем | количественный |
| Total day calls | Общее количество звонков днем | количественный |
| Total day charge | Общая сумма оплаты за услуги днем | количественный |
| Total eve minutes | Общая длительность разговоров вечером | количественный |
| Total eve calls | Общее количество звонков вечером | количественный |
| Total eve charge | Общая сумма оплаты за услуги вечером | количественный |
| Total night minutes | Общая длительность разговоров ночью | количественный |
| Total night calls | Общее количество звонков ночью | количественный |
| Total night charge | Общая сумма оплаты за услуги ночью | количественный |
| Total intl minutes | Общая длительность международных разговоров | количественный |
| Total intl calls | Общее количество международных разговоров | количественный |
| Total intl charge | Общая сумма оплаты за международные разговоры | количественный |
| Customer service calls | Число обращений в сервисный центр | количественный |
Целевая переменная: Churn – Признак оттока, бинарный (1 – потеря клиента, то есть отток). Потом мы будем строить модели, прогнозирующие этот признак по остальным, поэтому мы и назвали его целевым.
Посмотрим на распределение целевого класса – оттока клиентов.
df['Churn'].value_counts()False 2850
True 483
Name: Churn, dtype: int64df['Churn'].value_counts().plot(kind='bar', label='Churn')
plt.legend()
plt.title('Распределение оттока клиентов');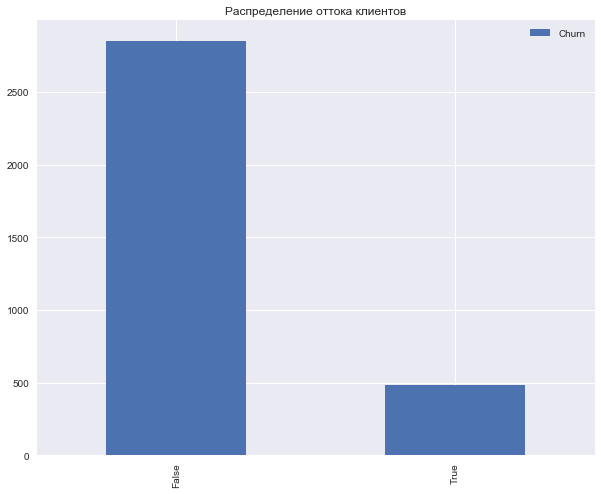
Выделим следующие группы признаков (среди всех кроме Churn ):
- бинарные: International plan, Voice mail plan
- категориальные: State
- порядковые: Customer service calls
- количественные: все остальные
Посмотрим на корреляции количественных признаков. По раскрашенной матрице корреляций видно, что такие признаки как Total day charge считаются по проговоренным минутам (Total day minutes). То есть 4 признака можно выкинуть, они не несут полезной информации.
corr_matrix = df.drop(['State', 'International plan', 'Voice mail plan',
'Area code'], axis=1).corr()sns.heatmap(corr_matrix);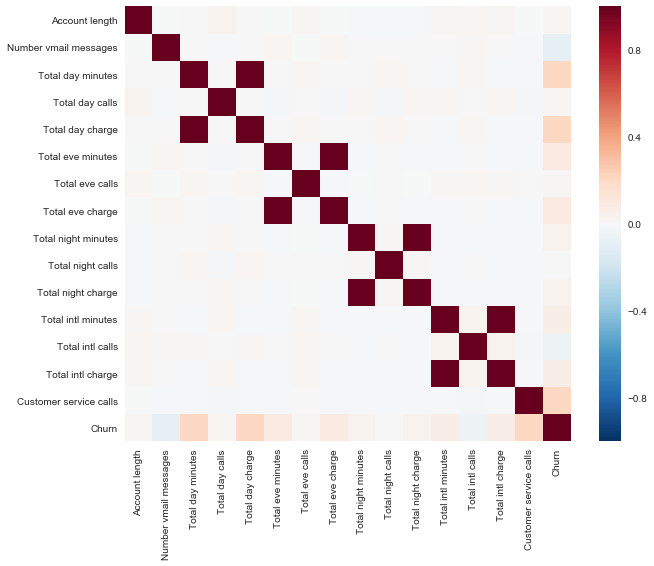
Теперь посмотрим на распределения всех интересующих нас количественных признаков. На бинарные/категориальные/порядковые признакие будем смотреть отдельно.
features = list(set(df.columns) - set(['State', 'International plan', 'Voice mail plan', 'Area code',
'Total day charge', 'Total eve charge', 'Total night charge',
'Total intl charge', 'Churn']))
df[features].hist(figsize=(20,12));
Видим, что большинство признаков распределены нормально. Исключения – число звонков в сервисный центр (Customer service calls) (тут больше подходит пуассоновское распределение) и число голосовых сообщений (Number vmail messages, пик в нуле, т.е. это те, у кого голосовая почта не подключена). Также смещено распределение числа международных звонков (Total intl calls).
Еще полезно строить вот такие картинки, где на главной диагонали рисуются распредления признаков, а вне главной диагонали – диаграммы рассеяния для пар признаков. Бывает, что это приводит к каким-то выводам, но в данном случае все примерно понятно, без сюрпризов.
sns.pairplot(df[features + ['Churn']], hue='Churn');
Дальше посмотрим, как признаки связаны с целевым – с оттоком.
Построим boxplot-ы, описывающее статистики распределения количественных признаков в двух группах: среди лояльных и ушедших клиентов.
fig, axes = plt.subplots(nrows=3, ncols=4, figsize=(16, 10))
for idx, feat in enumerate(features):
sns.boxplot(x='Churn', y=feat, data=df, ax=axes[idx / 4, idx % 4])
axes[idx / 4, idx % 4].legend()
axes[idx / 4, idx % 4].set_xlabel('Churn')
axes[idx / 4, idx % 4].set_ylabel(feat);
На глаз наибольшее отличие мы видим для признаков Total day minutes, Customer service calls и Number vmail messages. Впоследствии мы научимся определять важность признаков в задаче классификации с помощью случайного леса (или градиентного бустинга), и окажется, что первые два – действительно очень важные признаки для прогнозирования оттока.
Посмотрим отдельно на картинки с распределением кол-ва проговоренных днем минут среди лояльных/ушедших. Слева — знакомые нам боксплоты, справа – сглаженные гистограммы распределения числового признака в двух группах (скорее просто красивая картинка, все и так понятно по боксплоту).
Интересное наблюдение: в среднем ушедшие клиенты больше пользуются связью. Возможно, они недовольны тарифами, и одной из мер борьбы с оттоком будет понижение тарифных ставок (стоимости мобильной связи). Но это уже компании надо будет проводить дополнительный экономический анализ, действительно ли такие меры будут оправданы.
_, axes = plt.subplots(1, 2, sharey=True, figsize=(16,6))
sns.boxplot(x='Churn', y='Total day minutes', data=df, ax=axes[0]);
sns.violinplot(x='Churn', y='Total day minutes', data=df, ax=axes[1]);
Теперь изобразим распределение числа обращений в сервисный центр (такую картинку мы строили в первой статье). Тут уникальных значений признака не много (признак можно считать как количественным целочисленным, так и порядковым), и наглядней изобразить распределение с помощью countplot. Наблюдение: доля оттока сильно возрастает начиная с 4 звонков в сервисный центр.
sns.countplot(x='Customer service calls', hue='Churn', data=df);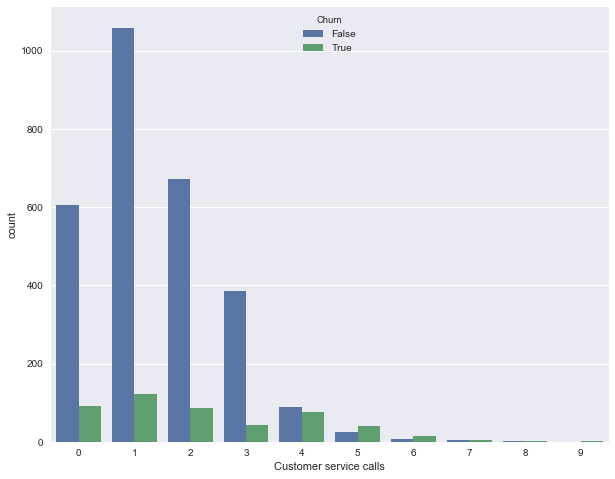
Теперь посмотрим на связь бинарных признаков International plan и Voice mail plan с оттоком. Наблюдение: когда роуминг подключен, доля оттока намного выше, т.е. наличие международного роуминга – сильный признак. Про голосовую почту такого нельзя сказать.
_, axes = plt.subplots(1, 2, sharey=True, figsize=(16,6))
sns.countplot(x='International plan', hue='Churn', data=df, ax=axes[0]);
sns.countplot(x='Voice mail plan', hue='Churn', data=df, ax=axes[1]);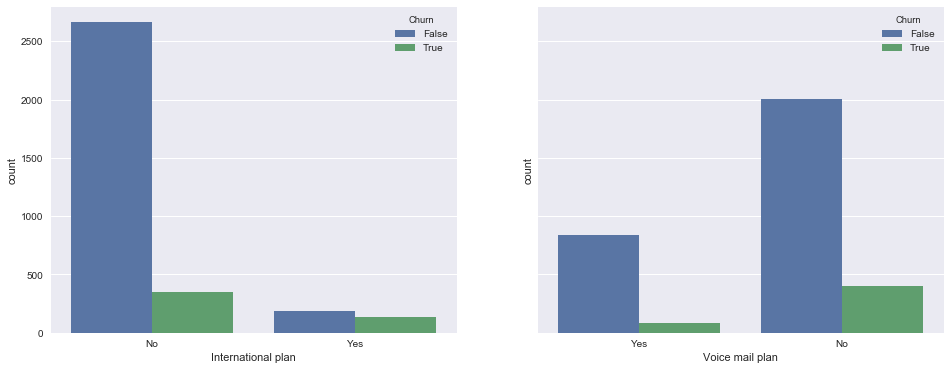
Наконец, посмотрим, как с оттоком связан категориальный признак State. С ним уже не так приятно работать, поскольку число уникальных штатов довольно велико – 51. Можно в начале построить сводную табличку или посчитать процент оттока для каждого штата. Но данных по каждом штату по отдельности маловато (ушедших клиентов всего от 3 до 17 в каждом штате), поэтому, возможно, признак State впоследствии не стоит добавлять в модели классификации из-за риска переобучения (но мы это будем проверять на кросс-валидации, stay tuned!).
Доли оттока для каждого штата:
df.groupby(['State'])['Churn'].agg([np.mean]).sort_values(by='mean', ascending=False).T

Видно, что в Нью-Джерси и Калифорнии доля оттока выше 25%, а на Гавайях и в Аляске меньше 5%. Но эти выводы построены на слишком скромной статистике и возможно, это просто особенности имеющихся данных (тут можно и гипотезы попроверять про корреляции Мэтьюса и Крамера, но это уже за рамками данной статьи).
Подглядывание в n-мерное пространство с t-SNE
Построим t-SNE представление все тех же данных по оттоку. Название метода сложное – t-distributed Stohastic Neighbor Embedding, математика тоже крутая (и вникать в нее не будем, но для желающих – вот оригинальная статья Д. Хинтона и его аспиранта в JMLR), но основная идея проста, как дверь: найдем такое отображение из многомерного признакового пространства на плоскость (или в 3D, но почти всегда выбирают 2D), чтоб точки, которые были далеко друг от друга, на плоскости тоже оказались удаленными, а близкие точки – также отобразились на близкие. То есть neighbor embedding – это своего рода поиск нового представления данных, при котором сохраняется соседство.
Немного деталей: выкинем штаты и признак оттока, бинарные Yes/No-признаки переведем в числа (pd.factorize). Также нужно масштабировать выборку – из каждого признака вычесть его среднее и поделить на стандартное отклонение, это делает StandardScaler.
from sklearn.manifold import TSNE
from sklearn.preprocessing import StandardScaler# преобразуем все признаки в числовые, выкинув штаты
X = df.drop(['Churn', 'State'], axis=1)
X['International plan'] = pd.factorize(X['International plan'])[0]
X['Voice mail plan'] = pd.factorize(X['Voice mail plan'])[0]
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)%%time
tsne = TSNE(random_state=17)
tsne_representation = tsne.fit_transform(X_scaled)CPU times: user 20 s, sys: 2.41 s, total: 22.4 s
Wall time: 21.9 splt.scatter(tsne_representation[:, 0], tsne_representation[:, 1]);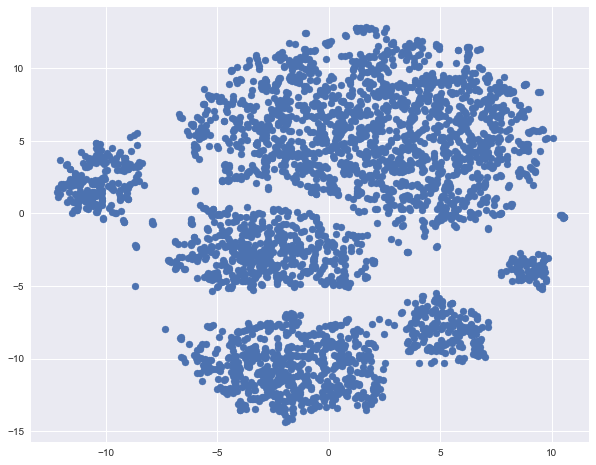
Раскрасим полученное t-SNE представление данных по оттоку (зеленые – лояльные, красные – ушедшие клиенты).
plt.scatter(tsne_representation[:, 0], tsne_representation[:, 1],
c=df['Churn'].map({0: 'green', 1: 'red'}));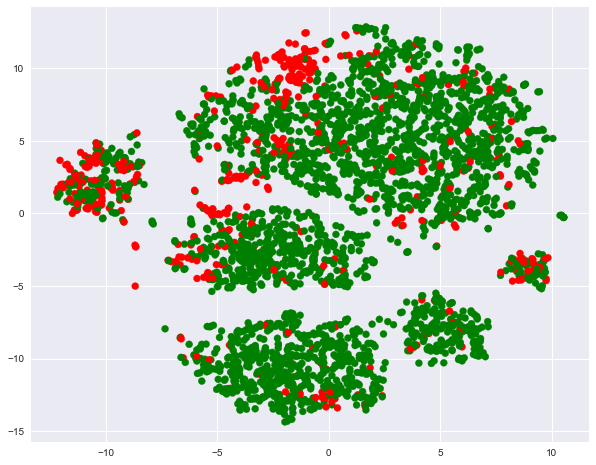
Видим, что ушедшие клиенты преимущественно "кучкуются" в некоторых областях признакового пространства.
Чтоб лучше понять картинку, можно также раскрасить ее по остальным бинарным признакам – по роумингу и голосовой почте. Зеленые участки соответствуют объектам, обладающим этим бинарным признаком.
_, axes = plt.subplots(1, 2, sharey=True, figsize=(16,6))
axes[0].scatter(tsne_representation[:, 0], tsne_representation[:, 1],
c=df['International plan'].map({'Yes': 'green', 'No': 'red'}));
axes[1].scatter(tsne_representation[:, 0], tsne_representation[:, 1],
c=df['Voice mail plan'].map({'Yes': 'green', 'No': 'red'}));
axes[0].set_title('International plan');
axes[1].set_title('Voice mail plan');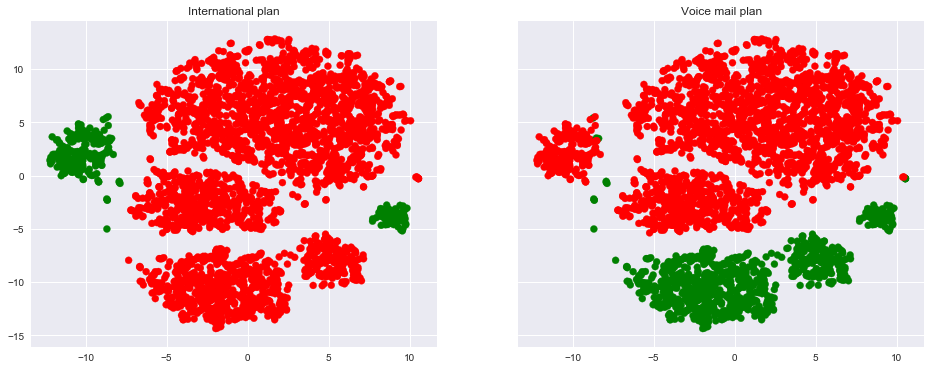
Теперь понятно, что, например, много ушедших клиентов кучкуется в левом кластере людей с поключенным роумингом, но без голосовой почты.
Напоследок отметим минусы t-SNE (да, по нему тоже лучше писать отдельную статью):
- большая вычислительная сложность. Вот эта реализация
sklearnскорее всего не поможет в Вашей реальной задаче, на больших выборках стоит посмотреть в сторону Multicore-TSNE; - картинка может сильно поменяться при изменении random seed, это усложняет интерпретацию. Вот хороший тьюториал по t-SNE. Но в целом по таким картинкам не стоит делать далеко идущих выводов – не стоит гадать по кофейной гуще. Иногда что-то бросается в глаза и подтверждается при изучении, но это не часто происходит.
И еще пара картинок. С помощью t-SNE можно действительно получить хорошее представление о данных (как в случае с рукописными цифрами, вот хорошая статья), а можно просто нарисовать елочную игрушку.


Домашнее задание № 2
Второе домашнее задание посвящено анализу набора данных по популярности статей на Хабрахабре.
Мы предлагаем выполнить это задание и затем ответить на несколько вопросов. Ссылка на форму для ответов (она же – в тетрадке). Ответы в форме можно менять после отправки, но не после дедлайна.
Дедлайн: 13 марта 23:59 (жесткий).
Полезные ресурсы
- Прежде всего, официальная документация и галерея примеров различных графиков для
seaborn - При работе с
plotlyтакже поможет официальный сайт: полная документация, большое количество разобранных примеров - Кроме того, примеры анализа данных и визуализаций на
plotlyможно посмотреть в моей статье на Хабрахабре Немного про кино или как делать интерактивные визуализации в python. Из не расcмотренного здесь, но иногда полезного, в статье можно найти пример графика с drop-down menu.
Статья написана в соавторстве с yorko при поддержке комьюнити Open Data Science. Автор домашнего задания – cotique
Комментарии (36)

Meklon
06.03.2017 16:45+5Спасибо за публикацию) seaborn очень зацепил в свое время. Все же приятно, когда иллюстрации в научные журналы не только информативные, но и выглядят хорошо.

yorko
07.03.2017 00:55+3Рейтинг участников. Будет считаться по домашним заданиям, соревнованиям и, возможно, дополнительным бонусам, оговариваемым заранее и публично.

abliznyuk
07.03.2017 10:44+2Можно ли подключится к курсу со второго домашнего задания?
yorko
07.03.2017 13:23+1Да, конечно! Правда, и оценки пойдут со второй домашки.
Tsimur_S
07.03.2017 14:37+1Может есть смысл сделать что-бы у разных заданий был разный вес(например рассчитывался динамически исходя из количества справившихся с заданием)? Иначе у стартующих после 2 лекции нету никаких шансов догнать, ведь по 1 заданию практически у всех 10.

Femistoklov
09.03.2017 11:31+1Можно глупый вопрос, а зачем это? В смысле, почему именно курс с оценками и рейтингами, а не просто серия статей с заданиями для самопроверки?
yorko
09.03.2017 11:48+2Дальше планируется ряд ништяков, главный из которых – серия лекций (вживую) про state-of-the-art машинного обучения. Темы сложные, требуют некоторого базового уровня. Если приглашать лучших по рейтингу, то почти наверное это обеспечит минимальный уровень слушателей, а также будет служить дополнительной мотивацией участников. Если не хотите участвовать в гонке – без проблем, можно проходить в своем темпе, польза всяко будет.
grubberr
07.03.2017 09:55+1не могу скачать https://www.kaggle.com/rush4ratio/video-game-sales-with-ratings
есть идеи где можно еще взять этот dataset?
mephistopheies
07.03.2017 10:05у вас есть акк на кегле? если не залогиниться, то у меня тоже не качается
DEM_dwg
07.03.2017 10:44Собсно вопрос возможно не по теме…
А можно ли изолинии сохранять в dxf формате, с помощью данных библиотек.
Или хотя бы получать координаты изолиний, чтобы потом сохранить в dxf.

tatakezic
10.03.2017 00:18+1Юрий, добрый вечер.
Подскажите, пожалуйста, а нужно ли куда-то отправлять тетрадки с кодами по 2ДЗ?miptgirl
10.03.2017 00:21+2Добрый вечер! Я не Юрий, но отвечу :)
Тетрадки с решениями никуда отправлять не нужно, достаточно ответить на вопросы в google-форме.
BloodyMere
10.03.2017 00:18+2В части, касающейся tsne, в коде:
X['International plan'] = pd.factorize(X['International plan'])[0] X['Voice mail plan'] = pd.factorize(X['Voice mail plan'])[0]
необходимо добавить
чтобы факторизация признаков прошла одинаково.sort = True
Т.е. должно быть:
X['International plan'] = pd.factorize(X['International plan'], sort = True)[0] X['Voice mail plan'] = pd.factorize(X['Voice mail plan'], sort = True)[0]
Иначе Yes и No в разных колонках будут факторизованы как (1,0) и (0,1) соответственно, что приведет к невозможности в дальнейшем использовать их для обработки.

justm57
10.03.2017 00:18+1«Еще полезно строить вот такие картинки, где на главной диагонали рисуются распредления признаков, а вне главной диагонали – диаграммы рассеяния для пар признаков. Бывает, что это приводит к каким-то выводам»
А что может быть особенного в них? Откуда берутся выводы?miptgirl
10.03.2017 00:33+1Рекомендую посмотреть на примеры на странице с документацией по функции
pairplotв библиотекеseaborn.
По гистограммам можно понять распределение признаков (нормальное оно или нет, сбалансированы ли классы и т.д.)
По scatter plots будет видна, например, линейная зависимость между признаками.
Если же отображать также классы разными цветами, то можно выявить в каком пространстве (паре признаков) классы будут хорошо отделяться друг от друга. Рассмотрим, pairplot для сортов ирисов: видно, классы сливаются в пространстве признаков
(sepal_length, sepal_width), а в пространстве(petal_length, petal_width)достаточно легко провести разделяющие гиперплоскости.

Dark_kot
10.03.2017 00:19+3При работе с seaborn -ом вылетает в TypeError, что в целом и не удивительно, так как
User_Score 10015 non-null object
Нужно вспомнить первую лекцию и изменить тип колонки, что в целом, даже полезно.

atepeq
11.03.2017 18:03Вопрос по домашке:
3. Когда лучше всего публиковать статью?
…
На хабре дневные статьи комментируют чаще, чем вечерние
А что есть дневная, а что вечерняя статья? С какого по какое время?yorko
11.03.2017 18:56Да, стоило это четче в задании указывать. Но на самом деле нет необходимости: по графикам сразу понятно будет, без двояких трактовок.
Bombus
12.03.2017 10:25Правильно ли я понимаю, что только второй вопрос в домашнем задании опирается на результат первого вопроса — необходимо исследовать конкретный месяц, остальные вопросы уже относятся ко всему периоду наблюдений?
grubberr
12.03.2017 12:30у меня тоже вопрос по 2-ой домашке, второй вопрос
2. Проанализируйте публикации в этом месяце ( из вопроса 1 )
имеется ввиду df.month = M или df.month = M & df.year = Y
где M, Y ответы из первого вопросаmiptgirl
12.03.2017 20:17Имеется в виду конкретный месяц конкретного года:
(df.month = M) & (df.year = Y)
miptgirl
12.03.2017 20:15Да, все последующие вопросы относятся ко всем данным.
Bombus
12.03.2017 20:27+1Благодарю.
Прошу разрешить вопрос Шреденгера. Во втором задании второй вопрос. По ощущениям утверждения «На графике не заметны какие-либо выбросы или аномалии» и «Один или несколько дней сильно выделяются из общей картины» затрагивают один и тот же момент — есть ли особые дни. Кажется что различие в вопросах определяются точкой взгляда, т.е. субъективно. Т.е. если день вполне укладывается границы, но при этом не стандартный относительно циклов, то считать ли это аномалией или выбивается ли он в этом случае из общей картины?
yorko
15.03.2017 16:55+1Комментарий будет интересен только тем, кто делает домашки, участвует в осуждениях в #mlcourse_open в слэке и следит за рейтингом
Выложил результаты 1 опроса (который был перед стартом курса) – в репозитории data/mlcourse_open_first_survey_data.csv (учел согласие на обработку, убрал е-мейлы)
Объявляется мини-конкурс по визуализации данных. Берете данные опроса, крутите их, вертите, ищите крутые закономерности, рисуете картинку. Кидаете в слэке в #mlcourse_open (обязательно с тегом #vis_contest), чья картинка набирает больше всего плюсов – тому респект и
1 место (по плюсам) – 5 баллов в рейтинг
2 место – 3 балла
3 место – 2 балла
Подсчет баллов будет 28 марта в 00:00, т.е. вместе с результатами 4 домашки.
couatl
А планируется статья про bokeh, folium и другие? Или они уже не торт по сравнению с seaborn и plotly и не стоит про них упоминать?
cotique
А чём именно не торт?
couatl
Так я спрашиваю, а не утверждаю =)
Я до plotly offline пользовался bokeh, чтоб графики были динамичными и с функциями наведения.
Но качество его в сравнении с plotly offline — ужасное. Постоянно моргает, долго грузит.
Вот интересно мнение автора.