
Введение
Недавно заглянув на КиноПоиск, я обнаружила, что за долгие годы успела оставить более 1000 оценок и подумала, что было бы интересно поисследовать эти данные подробнее: менялись ли мои вкусы в кино с течением времени? есть ли годовая/недельная сезонность в активности? коррелируют ли мои оценки с рейтингом КиноПоиска, IMDb или кинокритиков?
Но прежде чем анализировать и строить красивые графики, нужно получить данные. К сожалению, многие сервисы (и КиноПоиск не исключение) не имеют публичного API, так что, приходится засучить рукава и парсить html-страницы. Именно о том, как скачать и распарсить web-cайт, я и хочу рассказать в этой статье.
В первую очередь статья предназначена для тех, кто всегда хотел разобраться с Web Scrapping, но не доходили руки или не знал с чего начать.
Off-topic: к слову, Новый Кинопоиск под капотом использует запросы, которые возвращают данные об оценках в виде JSON, так что, задача могла быть решена и другим путем.
Задача
Задача будет состоять в том, чтобы выгрузить данные о просмотренных фильмах на КиноПоиске: название фильма (русское, английское), дату и время просмотра, оценку пользователя.
На самом деле, можно разбить работу на 2 этапа:
- Этап 1: выгрузить и сохранить html-страницы
- Этап 2: распарсить html в удобный для дальнейшего анализа формат (csv, json, pandas dataframe etc.)
Инструменты
Для отправки http-запросов есть немало python-библиотек, наиболее известные urllib/urllib2 и Requests. На мой вкус Requests удобнее и лаконичнее, так что, буду использовать ее.
Также необходимо выбрать библиотеку для парсинга html, небольшой research дает следующие варианты:
- re
Регулярные выражения, конечно, нам пригодятся, но использовать только их, на мой взгляд, слишком хардкорный путь, и они немного не для этого. Были придуманы более удобные инструменты для разбора html, так что перейдем к ним. - BeatifulSoup, lxml
Это две наиболее популярные библиотеки для парсинга html и выбор одной из них, скорее, обусловлен личными предпочтениями. Более того, эти библиотеки тесно переплелись: BeautifulSoup стал использовать lxml в качестве внутреннего парсера для ускорения, а в lxml был добавлен модуль soupparser. Подробнее про плюсы и минусы этих библиотек можно почитать в обсуждении. Для сравнения подходов я буду парсить данные с помощью BeautifulSoup и используя XPath селекторы в модуле lxml.html. - scrapy
Это уже не просто библиотека, а целый open-source framework для получения данных с веб-страниц. В нем есть множество полезных функций: асинхронные запросы, возможность использовать XPath и CSS селекторы для обработки данных, удобная работа с кодировками и многое другое (подробнее можно почитать тут). Если бы моя задача была не разовой выгрузкой, а production процессом, то я бы выбрала его. В текущей постановке это overkill.
Загрузка данных
Первая попытка
Приступим к выгрузке данных. Для начала, попробуем просто получить страницу по url и сохранить в локальный файл.
import requests
user_id = 12345
url = 'http://www.kinopoisk.ru/user/%d/votes/list/ord/date/page/2/#list' % (user_id) # url для второй страницы
r = requests.get(url)
with open('test.html', 'w') as output_file:
output_file.write(r.text.encode('cp1251'))Открываем полученный файл и видим, что все не так просто: сайт распознал в нас робота и не спешит показывать данные.

Разберемся, как работает браузер
Однако, у браузера отлично получается получать информацию с сайта. Посмотрим, как именно он отправляет запрос. Для этого воспользуемся панелью "Сеть" в "Инструментах разработчика" в браузере (я использую для этого Firebug), обычно нужный нам запрос — самый продолжительный.
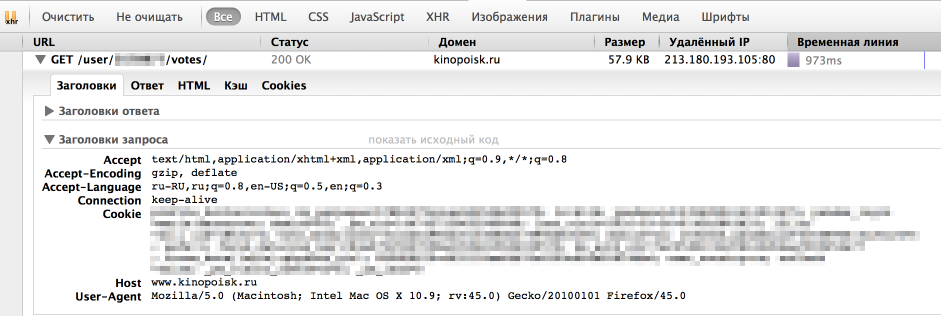
Как мы видим, браузер также передает в headers UserAgent, cookie и еще ряд параметров. Для начала попробуем просто передать в header корректный UserAgent.
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0'
}
r = requests.get(url, headers = headers)На этот раз все получилось, теперь нам отдаются нужные данные. Стоит отметить, что иногда сайт также проверяет корректность cookie, в таком случае помогут sessions в библиотеке Requests.
Скачаем все оценки
Теперь мы умеем сохранять одну страницу с оценками. Но обычно у пользователя достаточно много оценок и нужно проитерироваться по всем страницам. Интересующий нас номер страницы легко передать непосредственно в url. Остается только вопрос: "Как понять сколько всего страниц с оценками?" Я решила эту проблему следующим образом: если указать слишком большой номер страницы, то нам вернется вот такая страница без таблицы с фильмами. Таким образом мы можем итерироваться по страницам до тех, пор пока находится блок с оценками фильмов (
<div class = "profileFilmsList">).
import requests
# establishing session
s = requests.Session()
s.headers.update({
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0'
})
def load_user_data(user_id, page, session):
url = 'http://www.kinopoisk.ru/user/%d/votes/list/ord/date/page/%d/#list' % (user_id, page)
request = session.get(url)
return request.text
def contain_movies_data(text):
soup = BeautifulSoup(text)
film_list = soup.find('div', {'class': 'profileFilmsList'})
return film_list is not None
# loading files
page = 1
while True:
data = load_user_data(user_id, page, s)
if contain_movies_data(data):
with open('./page_%d.html' % (page), 'w') as output_file:
output_file.write(data.encode('cp1251'))
page += 1
else:
breakПарсинг
Немного про XPath
XPath — это язык запросов к xml и xhtml документов. Мы будем использовать XPath селекторы при работе с библиотекой lxml (документация). Рассмотрим небольшой пример работы с XPath
from lxml import html
test = '''
<html>
<body>
<div class="first_level">
<h2 align='center'>one</h2>
<h2 align='left'>two</h2>
</div>
<h2>another tag</h2>
</body>
</html>
'''
tree = html.fromstring(test)
tree.xpath('//h2') # все h2 теги
tree.xpath('//h2[@align]') # h2 теги с атрибутом align
tree.xpath('//h2[@align="center"]') # h2 теги с атрибутом align равным "center"
div_node = tree.xpath('//div')[0] # div тег
div_node.xpath('.//h2') # все h2 теги, которые являются дочерними div ноде
Подробнее про синтаксис XPath также можно почитать на W3Schools.
Вернемся к нашей задаче
Теперь перейдем непосредственно к получению данных из html. Проще всего понять как устроена html-страница используя функцию "Инспектировать элемент" в браузере. В данном случае все довольно просто: вся таблица с оценками заключена в теге
<div class = "profileFilmsList">. Выделим эту ноду:from bs4 import BeautifulSoup
from lxml import html
# Beautiful Soup
soup = BeautifulSoup(text)
film_list = soup.find('div', {'class': 'profileFilmsList'})
# lxml
tree = html.fromstring(text)
film_list_lxml = tree.xpath('//div[@class = "profileFilmsList"]')[0]Каждый фильм представлен как
<div class = "item"> или <div class = "item even">. Рассмотрим, как вытащить русское название фильма и ссылку на страницу фильма (также узнаем, как получить текст и значение атрибута).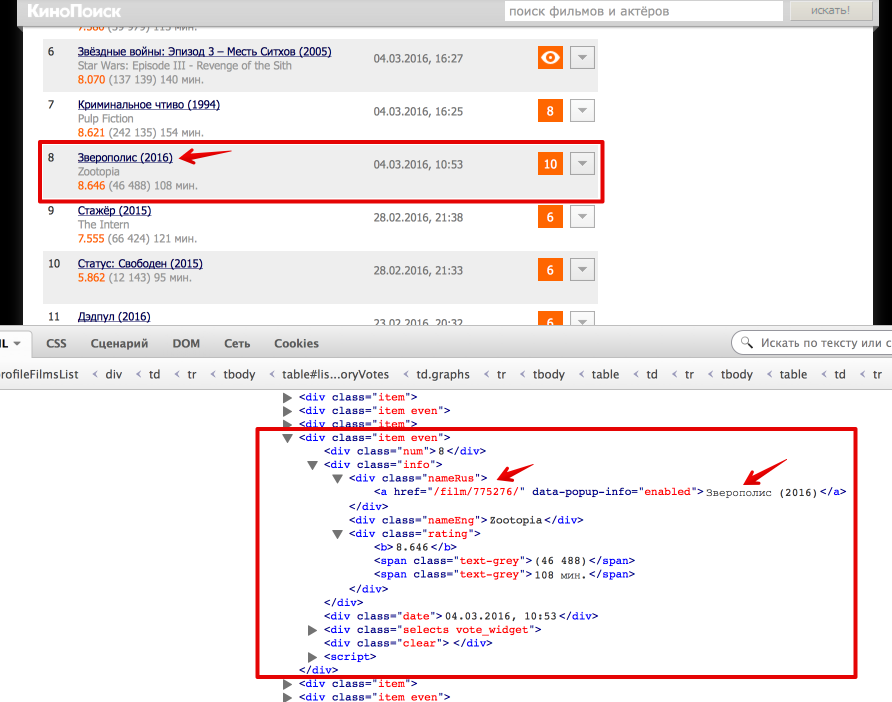
# Beatiful Soup
movie_link = item.find('div', {'class': 'nameRus'}).find('a').get('href')
movie_desc = item.find('div', {'class': 'nameRus'}).find('a').text
# lxml
movie_link = item_lxml.xpath('.//div[@class = "nameRus"]/a/@href')[0]
movie_desc = item_lxml.xpath('.//div[@class = "nameRus"]/a/text()')[0]Еще небольшой хинт для debug'a: для того, чтобы посмотреть, что внутри выбранной ноды в BeautifulSoup можно просто распечатать ее, а в lxml воспользоваться функцией
tostring() модуля etree.# BeatifulSoup
print item
#lxml
from lxml import etree
print etree.tostring(item_lxml)def read_file(filename):
with open(filename) as input_file:
text = input_file.read()
return text
def parse_user_datafile_bs(filename):
results = []
text = read_file(filename)
soup = BeautifulSoup(text)
film_list = film_list = soup.find('div', {'class': 'profileFilmsList'})
items = film_list.find_all('div', {'class': ['item', 'item even']})
for item in items:
# getting movie_id
movie_link = item.find('div', {'class': 'nameRus'}).find('a').get('href')
movie_desc = item.find('div', {'class': 'nameRus'}).find('a').text
movie_id = re.findall('\d+', movie_link)[0]
# getting english name
name_eng = item.find('div', {'class': 'nameEng'}).text
#getting watch time
watch_datetime = item.find('div', {'class': 'date'}).text
date_watched, time_watched = re.match('(\d{2}\.\d{2}\.\d{4}), (\d{2}:\d{2})', watch_datetime).groups()
# getting user rating
user_rating = item.find('div', {'class': 'vote'}).text
if user_rating:
user_rating = int(user_rating)
results.append({
'movie_id': movie_id,
'name_eng': name_eng,
'date_watched': date_watched,
'time_watched': time_watched,
'user_rating': user_rating,
'movie_desc': movie_desc
})
return results
def parse_user_datafile_lxml(filename):
results = []
text = read_file(filename)
tree = html.fromstring(text)
film_list_lxml = tree.xpath('//div[@class = "profileFilmsList"]')[0]
items_lxml = film_list_lxml.xpath('//div[@class = "item even" or @class = "item"]')
for item_lxml in items_lxml:
# getting movie id
movie_link = item_lxml.xpath('.//div[@class = "nameRus"]/a/@href')[0]
movie_desc = item_lxml.xpath('.//div[@class = "nameRus"]/a/text()')[0]
movie_id = re.findall('\d+', movie_link)[0]
# getting english name
name_eng = item_lxml.xpath('.//div[@class = "nameEng"]/text()')[0]
# getting watch time
watch_datetime = item_lxml.xpath('.//div[@class = "date"]/text()')[0]
date_watched, time_watched = re.match('(\d{2}\.\d{2}\.\d{4}), (\d{2}:\d{2})', watch_datetime).groups()
# getting user rating
user_rating = item_lxml.xpath('.//div[@class = "vote"]/text()')
if user_rating:
user_rating = int(user_rating[0])
results.append({
'movie_id': movie_id,
'name_eng': name_eng,
'date_watched': date_watched,
'time_watched': time_watched,
'user_rating': user_rating,
'movie_desc': movie_desc
})
return resultsРезюме
В результате, мы научились парсить web-сайты, познакомились с библиотеками Requests, BeautifulSoup и lxml, а также получили пригодные для дальнейшего анализа данные о просмотренных фильмах на КиноПоиске.

Полный код проекта можно найти на github'e.
UPD
Как отметили в комментариях, в контексте Web Scrapping'a могут оказаться полезны следующие темы:
- Аутентификация: зачастую для того, чтобы получить данные с сайта нужно пройти аутентификацию, в простейшем случае это просто HTTP Basic Auth: логин и пароль. Тут нам снова поможет библиотека Requests. Кроме того, широко распространена oauth2: как использовать oauth2 в python можно почитать на stackoverflow. Также в комментариях есть пример от Terras того, как пройти аутентификацию в web-форме.
- Контролы: На сайте также могут быть дополнительные web-формы (выпадающие списки, check box'ы итд). Алгоритм работы с ними примерно тот же: смотрим, что посылает браузер и отправляем эти же параметры как data в POST-запрос (Requests, stackoverflow). Также могу порекомендовать посмотреть 2й урок курса "Data Wrangling" на Udacity, где подробно рассмотрен пример scrapping сайта US Department of Transportation и посылка данных web-форм.
Комментарии (48)

EvilsInterrupt
27.03.2016 10:07+1Не осветили двух важных вопросов:
- Авторизация на сайте. Популярные по логину и паролю, и oauth2
- Не осветили вопроса вбивания данных в контролы на странице, к примеру на странице может быть Combobox для выбора города. Или Edit для ввода возраста. Тажке часто встречается снять\выделить галочку и т.д. и т.п.

Odeann
27.03.2016 10:53+1Отвечу на второй вопрос. Такие контролы либо перезагружают страницу и тогда мы можем получить адрес, либо грузят дополнительные данные по Ajax, тогда нам совсем просто.

Terras
27.03.2016 15:52+2USERNAME = input('Введите вашу почту: ') PASSWORD = input('Введите ваш пароль: ') LOGIN_URL = "***" # Страница Логина URL = "***" # Страница самого контента для парсинга session_requests = requests.session() def parse_one(): # Create payload payload = { "email": USERNAME, "password": PASSWORD } # Perform login result = session_requests.post(LOGIN_URL, data = payload, headers = dict(referer = LOGIN_URL)) # Scrape journal_url result = session_requests.get(URL, headers = dict(referer = URL)) soup = BeautifulSoup(result.content)
вот так можно пройти логин, сохранить данные в сессию, перейти к странице контента, используя данные сессии.EvilsInterrupt
27.03.2016 16:14+1Я не про то что я не знаю. Я бы поленился подобный вопрос задавать, а просто и тупо вбил в гугл "python authentication to website", что привело бы меня к страничке на SO.
Прочитайте внимательно формулировку предложений! Она звучит не "А не подскажите как сделать авторизацию?", нет, она звучит по-другому: "не раскрыты важные вопросы.
По опыту могу сказать, что очень много людей ищущих ответы на вопросы в гугле не читаю больше чем 2-3 комментариев к статье, если вообще читают. Поэтому подобные вопросы должны освещаться непосредствено в самой статье!
Мне показалось, что автор хочет передать знания, значит нужно осветить как можно больше важных вопросов, которые очень часто встают перед новичком. Если же автор ленится, то это уже не желание научить, а попытка сказать "смотрите какой я крутой".
miptgirl
27.03.2016 18:52+1Спасибо, действительно эти темы могут пригодиться при решении задач Web Scrapping'a — добавила в статью.
quarckster
27.03.2016 10:27+5Для парсинга веб-страниц есть отличный фреймворк Grab. На Хабре были статьи о нём от автора.
Odeann
27.03.2016 10:51+1Если скрэппинг нужен не на регулярной основе (например когда сервер постоянно откачивает чужой контент), а для разовой или периодических задач, когда можно запустить скрипт вручную, то мне гораздо быстрее и проще написать JS скрипт с использованием jQuery и запустить его прямо из командной строки инспектора. Тогда уже будет и правильный юзер агент и решена проблема с авторизацией и вообще проблем будет меньше.
alexkuku
27.03.2016 11:49Lxml получается быстрее? А если использовать beautifulsiup с бекэндом lxml разница остаётся ?
miptgirl
27.03.2016 17:30+2Стоит отметить, что BeautifulSoup выбирает оптимальный парсер из установленных:
If you don’t specify anything, you’ll get the best HTML parser that’s installed. Beautiful Soup ranks lxml’s parser as being the best, then html5lib’s, then Python’s built-in parser
(источник)
Я измерила время работы на своих данных и в среднем получила такие цифры
bs_html_parser: 0.43 секунды
bs_lxml_parser: 0.43 секунды (значимой разницы между lxml и python's default html-parser в BS на своих данных я не вижу)
lxml: 0.05 секунд (lxml явно выигрывает)


sledopit
27.03.2016 12:35+2В целом тема интересная, но конкретно вашу задачу можно решить чуть проще.
По ссылке httр://www.kinopoisk.ru/user/<user_id>/votes/list/export/xls/vs/vote/ оно вернёт вам xls файл со всей необходимой информацией (и даже больше чем нужно).
Правда, в новом кинопоиске такую замечательную возможность выпилили. Там нужно либо извращаться, либо не пользоваться.
У меня даже где-то shell скрипт закронен, чтобы скачивать его раз в неделю (после осенних событий я им больше так не доверяю, как это было раньше).
and7ey
27.03.2016 13:24+1Вот это действительно полезно. Как вы об этой ссылке узнали? Что-то еще подобное-полезное есть?
(ps. кажется, у вас в ссылке p в http русская, вот корректная ссылка — http://www.kinopoisk.ru/user/<user_id>/votes/list/export/xls/vs/vote/)sledopit
27.03.2016 13:27+1Эта ссылка доступна всем желающим авторизованным пользователям на странице собственного профиля :)
http://www.kinopoisk.ru/user/<user_id>/votes/ > прямо под ником там есть ссылка "экспорт в MS Excel".

Tomio
27.03.2016 13:56+4Еще есть в открытом доступе ссылка, для получения рейтинга фильма или сериала:
http://rating.kinopoisk.ru/{{kinopoisk_id}}.xml
Вместо {{kinopoisk_id}} просто подставьте нужный ID. Например, для Зверополиса — http://www.kinopoisk.ru/film/775276/ — вам нужно подставить в ссылку id 775276
Еще есть вот такой сервис с API для Кинопоиска — http://kinopoisk.cf/, узнал про него в свое время с Тостера
EvilsInterrupt
27.03.2016 19:29-1with open('test.html', 'w') as output_file: output_file.write(r.text.encode('cp1251'))
А почему вы явно указываете кодировку?miptgirl
27.03.2016 20:01+1Requests возвращает ответ в виде Unicode
isinstance(r.text, unicode) # True
При попытке записать unicode строку в файл по умолчанию будет использована кодировка ASCII и ничего не получится (ASCII не может закодировать символы >128):
UnicodeEncodeError: 'ascii' codec can't encode characters in position 23-31: ordinal not in range(128).
Вот поэтому я явным образом указываю кодировку cp1251.
Если интересно, подробнее про кодировки в Python есть хорошая статья на Хабре.EvilsInterrupt
27.03.2016 20:17Я про хардкод. Ведь можно же спросить про кодировку у пришедшего ответа. Если использовать urllib, то это как-то так:
>>> from urllib.request import urlopen >>> URL = 'http://habrahabr.ru' >>> page = urlopen(URL) >>> page.info().get_content_charset() 'utf-8' >>> charset = page.info().get_content_charset() >>> document = page.read().decode(charset)EvilsInterrupt
27.03.2016 20:24Снят Вопрос.
Не внимательно читаю код, в упор не видел вызова "save".
Вы же пишите, тогда все логично ;)))
mizhgun
27.03.2016 20:50-1Вот такая конструкция
tree.xpath('//div[@class = "profileFilmsList"]')[0]
поломает Ваш скрапер не только на первой 4xx/5xx странице, но и просто на той, на которой элемент по какой-либо причине отсутствует — например, как это часто бывает, элементы с отсутствующими данными просто не рендерятся в HTML. При парсинге файлов оно, может быть, и не суть важно, но когда данные парсятся без сохранения в кэш это существенно.miptgirl
28.03.2016 01:01+1Да, верно: в полноценной production версии пришлось бы обвешать код дополнительными проверками на наличие тегов/атрибутов и обрабатывать exceptional cases

stagnantice
27.03.2016 22:47-1Если честно не понятно о чем статья. О том, что такое xpath и как парсить html есть целая куча статей. О том же scrapy и grab есть статьи на хабре.
Вот если бы в статье рассматривались какие-то хитрые обходы блокировок сайтов от роботов, ну или хотя бы была раскрыта тема подмены прокси, куков, referrer. А тут извините очень банально все.
spitty
28.03.2016 00:56+3Если ограничивать авторов в темах требованием писать всё более и более хардкорные вещи, пишущих авторов будет становится всё меньше и меньше.
Данная статья имеет свою целевую аудиторию — тех людей, кто не является профи в разборе страниц сайтов и хочет с чего-то начать. То, что вы не относитесь к этой категории, делает статью "банальной" лишь для вас.
tessio
28.03.2016 16:14+1Возможно, стоило делать запросы к Kinopoisk в несколько потоков? Однопоточная версия скрипта не самая быстрая.
miptgirl
28.03.2016 16:21Да, Вы правы, это могло бы ускорить время выгрузки данных, но тут нужно пробовать: сайт может забанить за слишком частые запросы с одного IP.
tessio
28.03.2016 17:55Сайту ничего не мешает вас забанить и при запросах в один поток. Всё упирается в разумную паузу между отправкой запросов или пачками запросов (скажем, отправляем N запросов, засыпаем на M секунд, снова отправляем и т.д.).
Tomio
28.03.2016 21:04+1Я, кстати, когда парсил кинопоиск, тоже был забанен за частые запросы =) Но голь на выдумку хитра. Чтобы это обойти, банально нужно авторизоваться на нем, плюс сохранить куки. В итоге в один поток парсил лимитировано по 150 сериалов за запрос, включая всю информацию по сезонам и эпизодам. Ничего, живем :)
Вот с afisha.mail.ru такое не прокатило(( Пришлось купить 3 персональных анонимных проксика, и уже с ними, рандомно выбирая при каждом запросе один из них, маилру тоже поддался и пропали баны за многократное обращение =)

lotint
30.03.2016 16:00+1Все отлично, хорошая статья для начинающих.
Только название можно было изменить: Web scraping
en.wikipedia.org/wiki/Web_scrapingspitty
31.03.2016 00:01+1Спасибо, lotint.
Поймал себя на мысли, что никогда бы не заметил эту опечатку.
Как выясняется, написание с 'pp' довольно популярно.
www.google.ru/search?q=web+scraping
About 557,000 results
www.google.ru/search?q=web+scrapping
About 460,000 results
Terras
Вопрос.
Допустим у нас ряд ссылок динамически формируются с помощью JS, т.е. мы их не можем получить во время парсинга. А они нам нужны для перехода парсера по страничкам. Что делать?
rSedoy
Рендерить с помощью selenium, phantomjs и т.п. или разбираться как js их формирует (допустим выяснили что ссылки получают ajax запросом, делаем подобный запрос и парсим его). У каждого метода свои плюсы и минусы, какой использовать зависит уже от конкретного задания.
EvilsInterrupt
Не вариант. Мелькание браузера и непонятно что происходящего с ним может очень здорово испугать пользователя. Я как-то автоматизировал одному человеку с помощью Selenium и ChromeDriver-а. Так меня потом человек раз 5 спрашивал, а его браузер не испорится ли случайно? ;)))
rSedoy
а причем тут пользователи?
phantomit
Как уже было написано ниже, в большинстве случае если смысл посмотреть какие запросы делает браузер, и понять, каким образом JS заполняет сайт. Второй вариант — Selenium. Его совсем необязательно использовать в оконном режиме, к примеру: headless firefox
EvilsInterrupt
Спасибо. Посмотрю!
BSoD
Отлично работает связка из Selenium + PhantomJS. Ничего не мелькает и при этом всё делает.
P.S. Долго читал, медленно отвечал.
fox_12
Использовать Phantomjs либо Selenium webdriver
karb0f0s
использовать Selenium. позволяет подключать драйвер как реального (Chrome, Firefox, IE) так и виртуального (Phantom JS) браузера и через этот «браузер» получать динамически формируемые данные.
mixaly4
Эмулятор браузера вам нужен — Selenium, например. Но скорость парсинга, конечно, упадет — сами понимаете.
mixaly4
Да, с R&C аккаунтом чувствуешь себя идиотом: после одобрения комментария оказывается, что точно такой же ответ дали еще трое человек до тебя и столько же — после, а опубликовалось все это оптом.
lostpassword
Так напишите статейку, избавьтесь от проблем.)
drupa
И использовать selenium вместе с phantomjs. Пример
quarckster
Можно использовать Selenium или phantom.js для исполнения скриптов.
mizhgun
Использовать splash от kmike сотоварищи из Scrapinghub. Selenium вообще для других задач, Splash — специально заточенный под скрапинг JS-рендер на PhantomJS.
excentro
Для Scrapy можно попробовать scrapyjs. Чем и займусь в ближайшее время…
mizhgun
ScrapyJS это middleware для работы со Splash.
hudson
Из опыта могу сказать что в каждом случае подход индивидуальный. Зависит от сайта — иногда ссылка есть, но не прямо в href/src. Иногда можно понять правило ее формирования, иногда можно запросить API сайта и получить ссылку там. Иногда комбинируется несколько вариантов. Т.е. производится своеобразный реверс-инжиниринг сайта.
В особо тяжелых случаях придется использовать (как писали выше) реальный браузер или же эмулятор, но такие на моей практике встречались нечасто.