

Привет всем, кто проходит курс машинного обучения на Хабре!
В первых двух частях (1, 2) мы попрактиковались в первичном анализе данных с Pandas и в построении картинок, позволяющих делать выводы по данным. Сегодня наконец перейдем к машинному обучению. Поговорим о задачах машинного обучения и рассмотрим 2 простых подхода – деревья решений и метод ближайших соседей. Также обсудим, как с помощью кросс-валидации выбирать модель для конкретных данных.
Напомним, что к курсу еще можно подключиться, дедлайн по 2 домашнему заданию – 13 марта 23:59.
- Первичный анализ данных с Pandas
- Визуальный анализ данных c Python
- Классификация, деревья решений и метод ближайших соседей
- Линейные модели классификации и регрессии. Кросс-валидация и оценка модели
- Композиции: бэггинг, случайный лес. Кривые валидации и обучения
- Обучение без учителя: PCA, кластеризация, поиск аномалий
- Искусство построения и отбора признаков. Приложения в задачах обработки текста, изображений и гео-данных
План этой статьи:
- Введение
- Дерево решений
- Как строится дерево решений
- Как дерево решений работает с количественными признаками
- Основные параметры дерева
- Дерево решений в задаче регрессии
- Метод ближайших соседей
- Метод ближайших соседей в реальных задачах
- Класс KNeighborsClassifier в Scikit-learn
- Выбор параметров модели и кросс-валидация
- Примеры применения
- Деревья решений и метод ближайших соседей в задаче прогнозирования оттока клиентов телеком-оператора
- Сложный случай для деревьев решений
- Деревья решений и метод ближайших соседей в задаче распознавания рукописных цифр MNIST
- Сложный случай для метода ближайших соседей
- Плюсы и минусы деревьев решений и метода ближайших соседей
- Домашнее задание №3
- Обзор ресурсов
Введение
Наверное, хочется сразу рвануть в бой, но сначала поговорим про то, какую именно задачу будем решать и каково ее место в области машинного обучения.
Классическое, общее (и не больно-то строгое) определение машинного обучения звучит так (T. Mitchell "Machine learning", 1997):
говорят, что компьютерная программа обучается при решении какой-то задачи из класса T, если ее производительность, согласно метрике P, улучшается при накоплении опыта E.
Далее в разных сценариях под T, P, и E подразумеваются совершенно разные вещи. Среди самых популярных задач T в машинном обучении:
- классификация – отнесение объекта к одной из категорий на основании его признаков
- регрессия – прогнозирование количественного признака объекта на основании прочих его признаков
- кластеризация – разбиение множества объектов на группы на основании признаков этих объектов так, чтобы внутри групп объекты были похожи между собой, а вне одной группы – менее похожи
- детекция аномалий – поиск объектов, "сильно непохожих" на все остальные в выборке либо на какую-то группу объектов
- и много других, более специфичных. Хороший обзор дан в главе "Machine Learning basics" книги "Deep Learning" (Ian Goodfellow, Yoshua Bengio, Aaron Courville, 2016)
Под опытом E понимаются данные (без них никуда), и в зависимости от этого алгоритмы машинного обучения могут быть поделены на те, что обучаются с учителем и без учителя (supervised & unsupervised learning). В задачах обучения без учителя имеется выборка, состоящая из объектов, описываемых набором признаков. В задачах обучения с учителем вдобавок к этому для каждого объекта некоторой выборки, называемой обучающей, известен целевой признак – по сути это то, что хотелось бы прогнозировать для прочих объектов, не из обучающей выборки.
Пример
Задачи классификации и регрессии – это задачи обучения с учителем. В качестве примера будем представлять задачу кредитного скоринга: на основе накопленных кредитной организацией данных о своих клиентах хочется прогнозировать невозврат кредита. Здесь для алгоритма опыт E – это имеющаяся обучающая выборка: набор объектов (людей), каждый из которых характеризуется набором признаков (таких как возраст, зарплата, тип кредита, невозвраты в прошлом и т.д.), а также целевым признаком. Если этот целевой признак – просто факт невозврата кредита (1 или 0, т.е. банк знает о своих клиентах, кто вернул кредит, а кто – нет), то это задача (бинарной) классификации. Если известно, на сколько по времени клиент затянул с возвратом кредита и хочется то же самое прогнозировать для новых клиентов, то это будет задачей регрессии.
Наконец, третья абстракция в определении машинного обучения – это метрика оценки производительности алгоритма P. Такие метрики различаются для разных задач и алгоритмов, и про них мы будим говорить по мере изучения алгоритмов. Пока скажем, что самая простая метрика качества алгоритма, решающего задачу классификации – это доля правильных ответов (accuracy, не называйте ее точностью, этот перевод зарезервирован под другую метрику, precision) – то есть попросту доля верных прогнозов алгоритма на тестовой выборке.
Далее будем говорить о двух задачах обучения с учителем: о классификации и регресcии.
Дерево решений
Начнем обзор методов классификации и регрессии с одного из самых популярных – с дерева решений. Деревья решений используются в повседневной жизни в самых разных областях человеческой деятельности, порой и очень далеких от машинного обучения. Деревом решений можно назвать наглядную инструкцию, что делать в какой ситуации. Приведем пример из области консультирования научных сотрудников института. Высшая Школа Экономики выпускает инфо-схемы, облегчающие жизнь своим сотрудникам. Вот фрагмент инструкции по публикации научной статьи на портале института.

В терминах машинного обучения можно сказать, что это элементарный классификатор, который определяет форму публикации на портале (книга, статья, глава книги, препринт, публикация в "НИУ ВШЭ и СМИ") по нескольким признакам: типу публикации (монография, брошюра, статья и т.д.), типу издания, где опубликована статья (научный журнал, сборник трудов и т.д.) и остальным.
Зачастую дерево решений служит обобщением опыта экспертов, средством передачи знаний будущим сотрудникам или моделью бизнес-процесса компании. Например, до внедрения масштабируемых алгоритмов машинного обучения в банковской сфере задача кредитного скоринга решалась экспертами. Решение о выдаче кредита заемщику принималось на основе некоторых интуитивно (или по опыту) выведенных правил, которые можно представить в виде дерева решений.
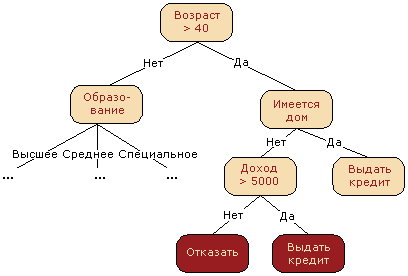
В этом случае можно сказать, что решается задача бинарной классификации (целевой класс имеет два значения: "Выдать кредит" и "Отказать") по признакам "Возраст", "Наличие дома", "Доход" и "Образование".
Дерево решений как алгоритм машинного обучения – по сути то же самое: объединение логических правил вида "Значение признака меньше И Значение признака меньше … => Класс 1" в структуру данных "Дерево". Огромное преимущество деревьев решений в том, что они легко интерпретируемы, понятны человеку. Например, по схеме на рисунке выше можно объяснить заемщику, почему ему было отказано в кредите. Скажем, потому, что у него нет дома и доход меньше 5000. Как мы увидим дальше, многие другие, хоть и более точные, модели не обладают этим свойством и могут рассматриваться скорее как "черный ящик", в который загрузили данные и получили ответ. В связи с этой "понятностью" деревьев решений и их сходством с моделью принятия решений человеком (можно легко объяснять боссу свою модель), деревья решений получили огромную популярность, а один из представителей этой группы методов классификации, С4.5, рассматривается первым в списке 10 лучших алгоритмов интеллектуального анализа данных ("Top 10 algorithms in data mining", Knowledge and Information Systems, 2008. PDF).
Как строится дерево решений
В примере с кредитным скорингом мы видели, что решение о выдаче кредита принималось на основе возраста, наличия недвижимости, дохода и других. Но какой признак выбрать первым? Для этого рассмотрим пример попроще, где все признаки бинарные.
Здесь можно вспомнить игру "20 вопросов", которая часто упоминается во введении в деревья решений. Наверняка каждый в нее играл. Один человек загадывает знаменитость, а второй пытается отгадать, задавая только вопросы, на которые можно ответить "Да" или "Нет" (опустим варианты "не знаю" и "не могу сказать"). Какой вопрос отгадывающий задаст первым делом? Конечно, такой, который сильнее всего уменьшит количество оставшихся вариантов. К примеру, вопрос "Это Анджелина Джоли?" в случае отрицательного ответа оставит более 7 миллиардов вариантов для дальнейшего перебора (конечно, поменьше, не каждый человек – знаменитость, но все равно немало), а вот вопрос "Это женщина?" отсечет уже около половины знаменитостей. То есть, признак "пол" намного лучше разделяет выборку людей, чем признак "это Анджелина Джоли", "национальность-испанец" или "любит футбол". Это интуитивно соответствует понятию прироста информации, основанного на энтропии.
Энтропия
Энтропия Шеннона определяется для системы с возможными состояниями следующим образом:
где – вероятности нахождения системы в -ом состоянии. Это очень важное понятие, используемое в физике, теории информации и других областях. Опуская предпосылки введения (комбинаторные и теоретико-информационные) этого понятия, отметим, что, интуитивно, энтропия соответствует степени хаоса в системе. Чем выше энтропия, тем менее упорядочена система и наоборот. Это поможет нам формализовать "эффективное разделение выборки", про которое мы говорили в контексте игры "20 вопросов".
Пример
Для иллюстрации того, как энтропия поможет определить хорошие признаки для построения дерева, приведем тот же игрушечный пример, что в статье "Энтропия и деревья принятия решений". Будем предсказывать цвет шарика по его координате. Конечно, ничего общего с жизнью это не имеет, но позволяет показать, как энтропия используется для построения дерева решений.

Здесь 9 синих шариков и 11 желтых. Если мы наудачу вытащили шарик, то он с вероятностью будет синим и с вероятностью – желтым. Значит, энтропия состояния . Само это значение пока ни о чем нам не говорит. Теперь посмотрим, как изменится энтропия, если разбить шарики на две группы – с координатой меньше либо равной 12 и больше 12.
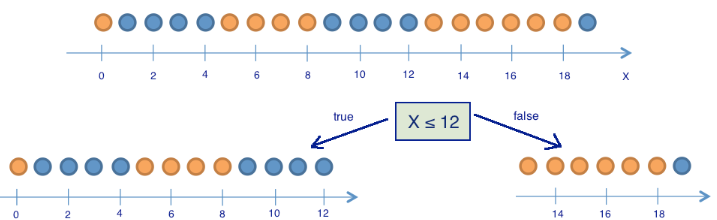
В левой группе оказалось 13 шаров, из которых 8 синих и 5 желтых. Энтропия этой группы равна . В правой группе оказалось 7 шаров, из которых 1 синий и 6 желтых. Энтропия правой группы равна . Как видим, энтропия уменьшилась в обеих группах по сравнению с начальным состоянием, хоть в левой и не сильно. Поскольку энтропия – по сути степень хаоса (или неопределенности) в системе, уменьшение энтропии называют приростом информации. Формально прирост информации (information gain, IG) при разбиении выборки по признаку (в нашем примере это признак "") определяется как
где – число групп после разбиения, – число элементов выборки, у которых признак имеет -ое значение. В нашем случае после разделения получилось две группы () – одна из 13 элементов (), вторая – из 7 (). Прирост информации получился
Получается, разделив шарики на две группы по признаку "координата меньше либо равна 12", мы уже получили более упорядоченную систему, чем в начале. Продолжим деление шариков на группы до тех пор, пока в каждой группе шарики не будут одного цвета.

Для правой группы потребовалось всего одно дополнительное разбиение по признаку "координата меньше либо равна 18", для левой – еще три. Очевидно, энтропия группы с шариками одного цвета равна 0 (), что соответствует представлению, что группа шариков одного цвета – упорядоченная.
В итоге мы построили дерево решений, предсказывающее цвет шарика по его координате. Отметим, что такое дерево решений может плохо работать для новых объектов (определения цвета новых шариков), поскольку оно идеально подстроилось под обучающую выборку (изначальные 20 шариков). Для классификации новых шариков лучше подойдет дерево с меньшим числом "вопросов", или разделений, пусть даже оно и не идеально разбивает по цветам обучающую выборку. Эту проблему, переобучение, мы еще рассмотрим далее.
Алгоритм построения дерева
Можно убедиться в том, что построенное в предыдущем примере дерево является в некотором смысле оптимальным – потребовалось только 5 "вопросов" (условий на признак ), чтобы "подогнать" дерево решений под обучающую выборку, то есть чтобы дерево правильно классифицировало любой обучающий объект. При других условиях разделения выборки дерево получится глубже.
В основе популярных алгоритмов построения дерева решений, таких как ID3 и C4.5, лежит принцип жадной максимизации прироста информации – на каждом шаге выбирается тот признак, при разделении по которому прирост информации оказывается наибольшим. Дальше процедура повторяется рекурсивно, пока энтропия не окажется равной нулю или какой-то малой величине (если дерево не подгоняется идеально под обучающую выборку во избежание переобучения).
В разных алгоритмах применяются разные эвристики для "ранней остановки" или "отсечения", чтобы избежать построения переобученного дерева.
def build(L):
create node t
if the stopping criterion is True:
assign a predictive model to t
else:
Find the best binary split L = L_left + L_right
t.left = build(L_left)
t.right = build(L_right)
return t Другие критерии качества разбиения в задаче классификации
Мы разобрались в том, как понятие энтропии позволяет формализовать представление о качестве разбиения в дереве. Но это всего лишь эвристика, существуют и другие:
- Неопределенность Джини (Gini impurity): . Максимизацию этого критерия можно интерпретировать как максимизацию числа пар объектов одного класса, оказавшихся в одном поддереве. Подробнее об этом (как и обо многом другом) можно узнать из репозитория Евгения Соколова. Не путать с индексом Джини! Подробнее об этой путанице – в блогпосте Александра Дьяконова
- Ошибка классификации (misclassification error):
На практике ошибка классификации почти не используется, а неопределенность Джини и прирост информации работают почти одинаково.
В случае задачи бинарной классификации ( – вероятность объекта иметь метку +) энтропия и неопределенность Джини примут следующий вид:
Когда мы построим графики этух двух функций от аргумента , то увидим, что график энтропии очень близок к графику удвоенной неопределенности Джини, и поэтому на практике эти два критерия "работают" почти одинаково.
from __future__ import division, print_function
# отключим всякие предупреждения Anaconda
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import pylab as plt
%matplotlib inline
import seaborn as sns
from matplotlib import pyplot as pltplt.rcParams['figure.figsize'] = (6,4)
xx = np.linspace(0,1,50)
plt.plot(xx, [2 * x * (1-x) for x in xx], label='gini')
plt.plot(xx, [4 * x * (1-x) for x in xx], label='2*gini')
plt.plot(xx, [-x * np.log2(x) - (1-x) * np.log2(1 - x) for x in xx], label='entropy')
plt.plot(xx, [1 - max(x, 1-x) for x in xx], label='missclass')
plt.plot(xx, [2 - 2 * max(x, 1-x) for x in xx], label='2*missclass')
plt.xlabel('p+')
plt.ylabel('criterion')
plt.title('Критерии качества как функции от p+ (бинарная классификация)')
plt.legend();
Пример
Рассмотрим пример применения дерева решений из библиотеки Scikit-learn для синтетических данных. Два класса будут сгенерированы из двух нормальных распределений с разными средними.
# первый класс
np.seed = 7
train_data = np.random.normal(size=(100, 2))
train_labels = np.zeros(100)
# добавляем второй класс
train_data = np.r_[train_data, np.random.normal(size=(100, 2), loc=2)]
train_labels = np.r_[train_labels, np.ones(100)]Отобразим данные. Неформально, задача классификации в этом случае – построить какую-то "хорошую" границу, разделяющую 2 класса (красные точки от желтых). Если утрировать, то машинное обучение в этом случае сводится к тому, как выбрать хорошую разделяющую границу. Возможно, прямая будет слишком простой границей, а какая-то сложная кривая, огибающая каждую красную точку – будет слишком сложной и будем много ошибаться на новых примерах из того же распределения, из которого пришла обучающая выборка. Интуиция подсказывает, что хорошо на новых данных будет работать какая-то гладкая граница, разделяющая 2 класса, или хотя бы просто прямая (в -мерном случае – гиперплоскость).
plt.rcParams['figure.figsize'] = (10,8)
plt.scatter(train_data[:, 0], train_data[:, 1], c=train_labels, s=100,
cmap='autumn', edgecolors='black', linewidth=1.5);
plt.plot(range(-2,5), range(4,-3,-1));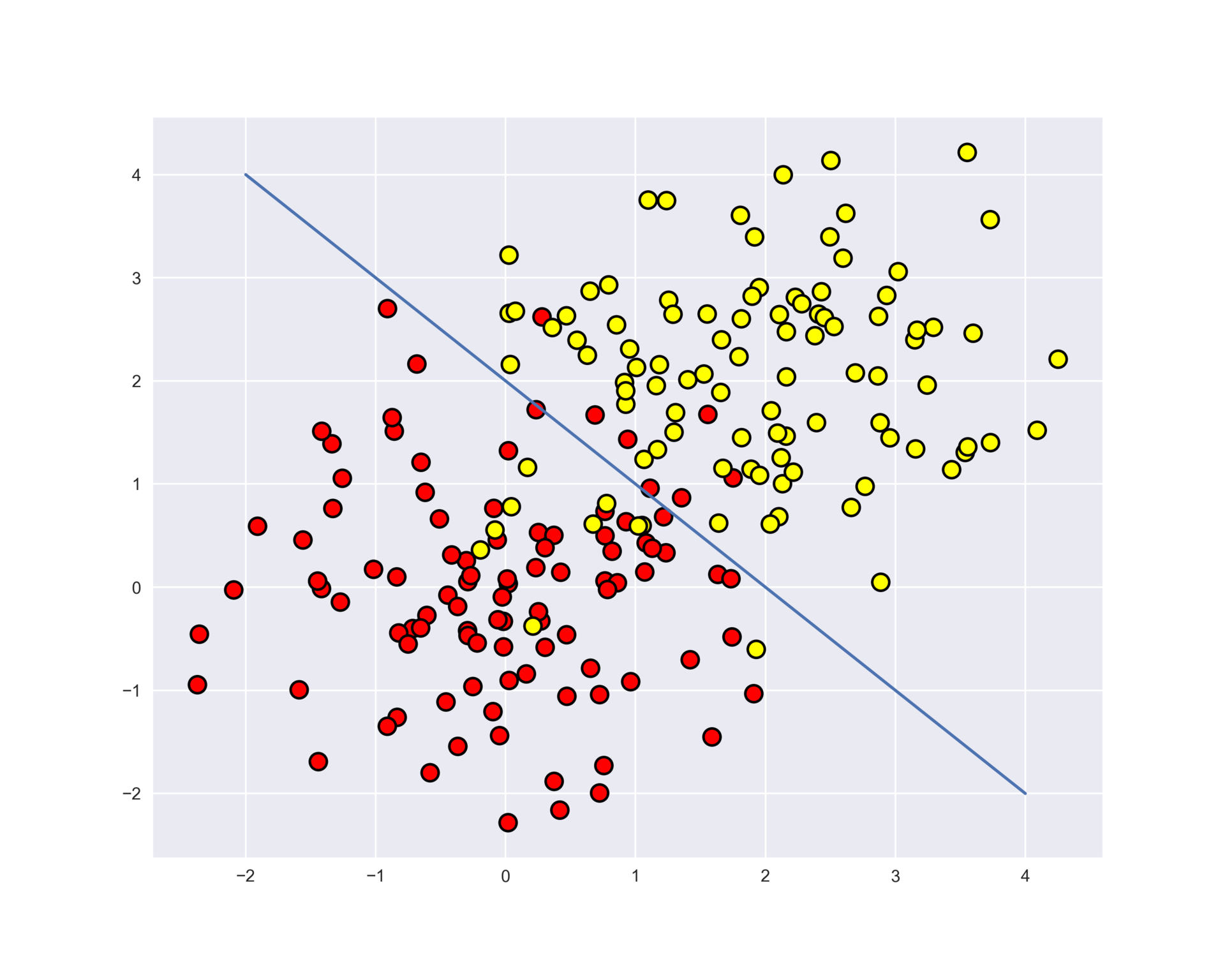
Попробуем разделить эти два класса, обучив дерево решений. В дереве будем использовать параметр max_depth, ограничивающий глубину дерева. Визуализируем полученную границу разделения классов.
from sklearn.tree import DecisionTreeClassifier
# Напишем вспомогательную функцию, которая будет возвращать решетку для дальнейшей визуализации.
def get_grid(data):
x_min, x_max = data[:, 0].min() - 1, data[:, 0].max() + 1
y_min, y_max = data[:, 1].min() - 1, data[:, 1].max() + 1
return np.meshgrid(np.arange(x_min, x_max, 0.01), np.arange(y_min, y_max, 0.01))
# параметр min_samples_leaf указывает, при каком минимальном количестве
# элементов в узле он будет дальше разделяться
clf_tree = DecisionTreeClassifier(criterion='entropy', max_depth=3, random_state=17)
# обучаем дерево
clf_tree.fit(train_data, train_labels)
# немного кода для отображения разделяющей поверхности
xx, yy = get_grid(train_data)
predicted = clf_tree.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
plt.pcolormesh(xx, yy, predicted, cmap='autumn')
plt.scatter(train_data[:, 0], train_data[:, 1], c=train_labels, s=100,
cmap='autumn', edgecolors='black', linewidth=1.5);
А как выглядит само построенное дерево? Видим, что дерево "нарезает" пространство на 7 прямоугольников (в дереве 7 листьев). В каждом таком прямоугольнике прогноз дерева будет константным, по превалированию объектов того или иного класса.
# используем .dot формат для визуализации дерева
from sklearn.tree import export_graphviz
export_graphviz(clf_tree, feature_names=['x1', 'x2'],
out_file='../../img/small_tree.dot', filled=True)
# для этого понадобится библиотека pydot (pip install pydot)
!dot -Tpng '../../img/small_tree.dot' -o '../../img/small_tree.png'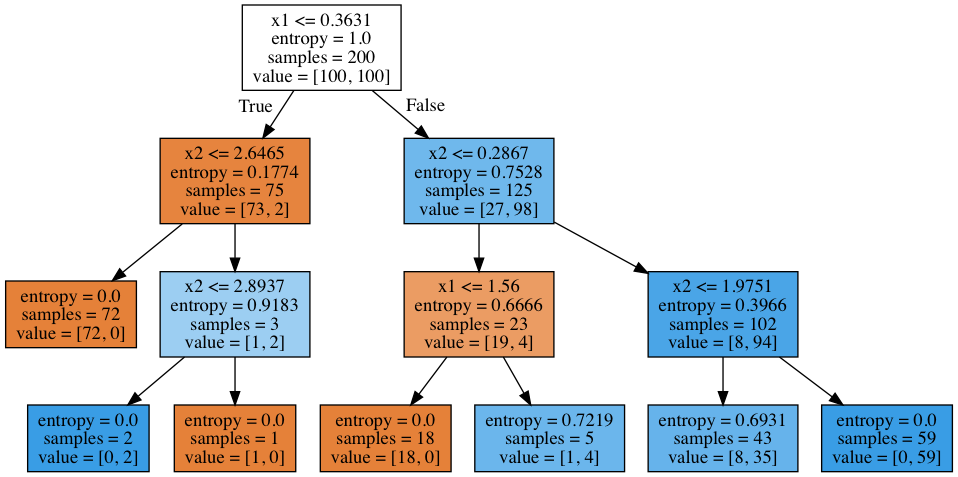
Как "читается" такое дерево?
В начале было 200 объектов, 100 — одного класса и 100 – другого. Энтропия начального состояния была максимальной – 1. Затем было сделано разбиение объектов на 2 группы в зависимости от сравнения признака со значением (найдите этот участок границы на рисунке выше, до дерева). При этом энтропия и в левой, и в правой группе объектов уменьшилась. И так далее, дерево строится до глубины 3. При такой визуализации чем больше объектов одного класса, тем цвет вершины ближе к темно-оранжевому и, наоборот, чем больше объектов второго класса, тем ближе цвет к темно-синему. В начале объектов одного класса поровну, поэтому корневая вершина дерева – белого цвета.
Как дерево решений работает с количественными признаками
Допустим, в выборке имеется количественный признак "Возраст", имеющий много уникальных значений. Дерево решений будет искать лучшее (по критерию типа прироста информации) разбиение выборки, проверяя бинарные признаки типа "Возраст < 17", "Возраст < 22.87" и т.д. Но что если таких "нарезаний" возраста слишком много? А что если есть еще количественный признак "Зарплата", и зарплату тоже можно "нарезать" большим числом способов? Получается слишком много бинарных признаков для выбора лучшего на каждом шаге построения дерева. Для решения этой проблемы применяют эвристики для ограничения числа порогов, с которыми мы сравниваем количественный признак.
Рассмотрим это на игрушечном примере. Пусть имеется следующая выборка:
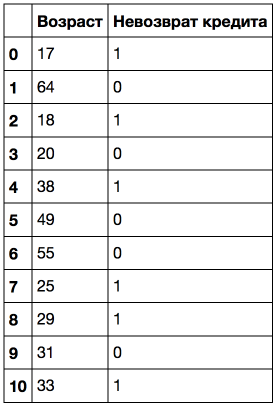
Отсортируем ее по возрастанию возраста.

Обучим на этих данных дерево решений (без ограничения глубины) и посмотрим на него.
age_tree = DecisionTreeClassifier(random_state=17)
age_tree.fit(data['Возраст'].values.reshape(-1, 1), data['Невозврат кредита'].values)
export_graphviz(age_tree, feature_names=['Возраст'],
out_file='../../img/age_tree.dot', filled=True)
!dot -Tpng '../../img/age_tree.dot' -o '../../img/age_tree.png'Видим, что дерево задействовало 5 значений, с которыми сравнивается возраст: 43.5, 19, 22.5, 30 и 32 года. Если приглядеться, то это аккурат средние значения между возрастами, при которых целевой класс "меняется" с 1 на 0 или наоборот. Сложная фраза, поэтому пример: 43.5 – это среднее между 38 и 49 годами, клиент, которому 38 лет не вернул кредит, а тот, которому 49 – вернул. Аналогично, 19 лет – среднее между 18 и 20 годами. То есть в качестве порогов для "нарезания" количественного признака, дерево "смотрит" на те значения, при которых целевой класс меняет свое значение.
Подумайте, почему не имеет смысла в данном случае рассматривать признак "Возраст < 17.5".

Рассмотрим пример посложнее: добавим признак "Зарплата" (тыс. рублей/месяц).
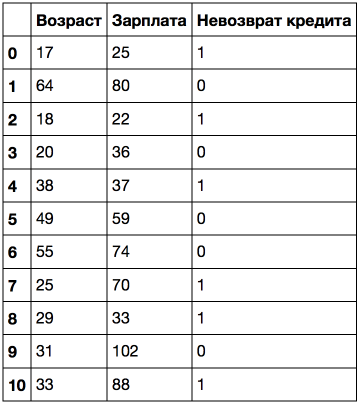
Если отсортировать по возрасту, то целевой класс ("Невозврат кредита") меняется (с 1 на 0 или наоборот) 5 раз. А если отсортировать по зарплате – то 7 раз. Как теперь дерево будет выбирать признаки? Посмотрим.
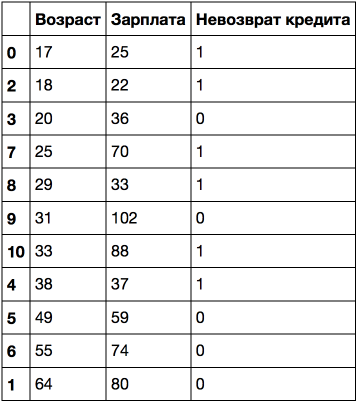

age_sal_tree = DecisionTreeClassifier(random_state=17)
age_sal_tree.fit(data2[['Возраст', 'Зарплата']].values, data2['Невозврат кредита'].values);
export_graphviz(age_sal_tree, feature_names=['Возраст', 'Зарплата'],
out_file='../../img/age_sal_tree.dot', filled=True)
!dot -Tpng '../../img/age_sal_tree.dot' -o '../../img/age_sal_tree.png'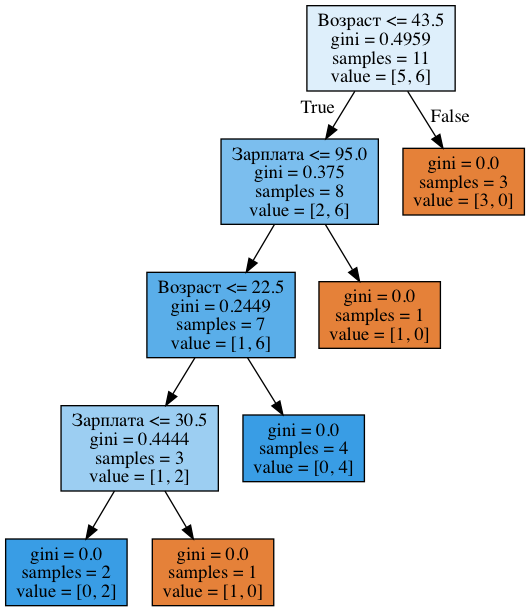
Видим, что в дереве задействованы как разбиения по возрасту, так и по зарплате. Причем пороги, с которыми сравниваются признаки: 43.5 и 22.5 года – для возраста и 95 и 30.5 тыс. руб/мес – для зарплаты. И опять можно заметить, что 95 тыс. – это среднее между 88 и 102, при этом человек с зарплатой 88 оказался "плохим", а с 102 – "хорошим". То же самое для 30.5 тыс. То есть перебирались сравнения зарплаты и возраста не со всеми возможными значениями, а только с несколькими. А почему в дереве оказались именно эти признаки? Потому что по ним разбиения оказались лучше (по критерию неопределенности Джини).
Вывод: самая простая эвристика для обработки количественных признаков в дереве решений: количественный признак сортируется по возрастанию, и в дереве проверяются только те пороги, при которых целевой признак меняет значение. Звучит не очень строго, но надеюсь, я донес смысл с помощью игрушечных примеров.
Дополнительно, когда в данных много количественных признаков, и у каждого много уникальных значений, могут отбираться не все пороги, описанные выше, а только топ-N, дающих максимальный прирост все того же критерия. То есть, по сути, для каждого порога строится дерево глубины 1, считается насколько снизилась энтропия (или неопределенность Джини) и выбираются только лучшие пороги, с которыми стоит сравнивать количественный признак.
Для иллюстрации: при разбиении по признаку "Зарплата 34.5" в левой подгруппе энтропия 0 (все клиенты "плохие"), а в правой – 0.954 (3 "плохих" и 5 "хороших", можете проверить, 1 часть домашнего задания будет как раз на то, чтоб разобраться досконально с построением деревьев). Прирост информации получается примерно 0.3.
А при разбиении по признаку "Зарплата 95" в левой подгруппе энтропия 0.97 (6 "плохих" и 4 "хороших"), а в правой – 0 (всего один объект). Прирост информации получается примерно 0.11.
Посчитав таким образом прирост информации для каждого разбиения, можно предварительно, до построения большого дерева (по всем признакам) отобрать пороги, с которыми будет сравниваться каждый количественный признак.
Еще примеры дискретизации количественных признаков можно посмотреть в постах, подобных этому или этому. Одна из самых известных научных статей на эту тему – "On the handling of continuous-valued attributes in decision tree generation" (U.M. Fayyad. K.B. Irani, "Machine Learning", 1992).
Основные параметры дерева
В принципе дерево решений можно построить до такой глубины, чтоб в каждом листе был ровно один объект. Но на практике это не делается (если строится только одно дерево) из-за того, что такое дерево будет переобученным – оно слишком настроится на обучающую выборку и будет плохо работать на прогноз на новых данных. Где-то внизу дерева, на большой глубине будут появляться разбиения по менее важным признакам (например, приехал ли клиент из Саратова или Костромы). Если утрировать, может оказаться так, что из всех 4 клиентов, пришедших в банк за кредитом в зеленых штанах, никто не вернул кредит. Но мы не хотим, чтобы наша модель классификации порождала такие специфичные правила.
Есть два исключения, ситуации, когда деревья строятся до максимальной глубины:
- Случайный лес (композиция многих деревьев) усредняет ответы деревьев, построенных до максимальной глубины (почему стоит делать именно так, разберемся позже)
- Стрижка дерева (pruning). При таком подходе дерево сначала строится до максимальной глубины, потом постепенно, снизу вверх, некоторые вершины дерева убираются за счет сравнения по качеству дерева с данным разбиением и без него (сравнение проводится с помощью кросс-валидации, о которой чуть ниже). Подробнее можно почитать в материалах репозитория Евгения Соколова.
Картинка ниже – пример разделяющей границы, построенной переобученным деревом.

Основные способы борьбы с переобучением в случае деревьев решений:
- искусственное ограничение глубины или минимального числа объектов в листе: построение дерева просто в какой-то момент прекращается;
- стрижка дерева
Класс DecisionTreeClassifier в Scikit-learn
Основные параметры класса sklearn.tree.DecisionTreeClassifier:
max_depth– максимальная глубина дереваmax_features— максимальное число признаков, по которым ищется лучшее разбиение в дереве (это нужно потому, что при большом количестве признаков будет "дорого" искать лучшее (по критерию типа прироста информации) разбиение среди всех признаков)min_samples_leaf– минимальное число объектов в листе. У этого параметра есть понятная интерпретация: скажем, если он равен 5, то дерево будет порождать только те классифицирующие правила, которые верны как минимум для 5 объектов
Параметры дерева надо настраивать в зависимости от входных данных, и делается это обычно с помощью кросс-валидации, про нее чуть ниже.
Дерево решений в задаче регрессии
При прогнозировании количественного признака идея построения дерева остается та же, но меняется критерий качества:
- Дисперсия вокруг среднего:
где – число объектов в листе, – значения целевого признака. Попросту говоря, минимизируя дисперсию вокруг среднего, мы ищем признаки, разбивающие выборку таким образом, что значения целевого признака в каждом листе примерно равны.
Пример
Сгенерируем данные, распределенные вокруг функции c некоторым шумом, обучим на них дерево решений и изобразим, какие прогнозы делает дерево.
n_train = 150
n_test = 1000
noise = 0.1
def f(x):
x = x.ravel()
return np.exp(-x ** 2) + 1.5 * np.exp(-(x - 2) ** 2)
def generate(n_samples, noise):
X = np.random.rand(n_samples) * 10 - 5
X = np.sort(X).ravel()
y = np.exp(-X ** 2) + 1.5 * np.exp(-(X - 2) ** 2) + np.random.normal(0.0, noise, n_samples)
X = X.reshape((n_samples, 1))
return X, y
X_train, y_train = generate(n_samples=n_train, noise=noise)
X_test, y_test = generate(n_samples=n_test, noise=noise)
from sklearn.tree import DecisionTreeRegressor
reg_tree = DecisionTreeRegressor(max_depth=5, random_state=17)
reg_tree.fit(X_train, y_train)
reg_tree_pred = reg_tree.predict(X_test)
plt.figure(figsize=(10, 6))
plt.plot(X_test, f(X_test), "b")
plt.scatter(X_train, y_train, c="b", s=20)
plt.plot(X_test, reg_tree_pred, "g", lw=2)
plt.xlim([-5, 5])
plt.title("Decision tree regressor, MSE = %.2f" % np.sum((y_test - reg_tree_pred) ** 2))
plt.show()
Видим, что дерево решений аппроксимирует зависимость в данных кусочно-постоянной функцией.
Метод ближайших соседей
Метод ближайших соседей (k Nearest Neighbors, или kNN) — тоже очень популярный метод классификации, также иногда используемый в задачах регрессии. Это, наравне с деревом решений, один из самых понятных подходов к классификации. На уровне интуиции суть метода такова: посмотри на соседей, какие преобладают, таков и ты. Формально основой метода является гипотеза компактности: если метрика расстояния между примерами введена достаточно удачно, то схожие примеры гораздо чаще лежат в одном классе, чем в разных.
Согласно методу ближайших соседей, тестовый пример (зеленый шарик) будет отнесен к классу "синие", а не "красные".

Например, если не знаешь, какой тип товара указать в объявлении для Bluetooth-гарнитуры, можешь найти 5 похожих гарнитур, и если 4 из них отнесены к категории "Аксессуары", и только один — к категории "Техника", то здравый смысл подскажет для своего объявления тоже указать категорию "Аксессуары".
Для классификации каждого из объектов тестовой выборки необходимо последовательно выполнить следующие операции:
- Вычислить расстояние до каждого из объектов обучающей выборки
- Отобрать объектов обучающей выборки, расстояние до которых минимально
- Класс классифицируемого объекта — это класс, наиболее часто встречающийся среди ближайших соседей
Под задачу регрессии метод адаптируется довольно легко – на 3 шаге возвращается не метка, а число – среднее (или медианное) значение целевого признака среди соседей.
Примечательное свойство такого подхода – его ленивость. Это значит, что вычисления начинаются только в момент классификации тестового примера, а заранее, только при наличии обучающих примеров, никакая модель не строится. В этом отличие, например, от ранее рассмотренного дерева решений, где сначала на основе обучающей выборки строится дерево, а потом относительно быстро происходит классификация тестовых примеров.
Стоит отметить, что метод ближайших соседей – хорошо изученный подход (в машинном обучении, эконометрике и статистике больше известно, наверное, только про линейную регрессию). Для метода ближайших соседей существует немало важных теорем, утверждающих, что на "бесконечных" выборках это оптимальный метод классификации. Авторы классической книги "The Elements of Statistical Learning" считают kNN теоретически идеальным алгоритмом, применимость которого просто ограничена вычислительными возможностями и проклятием размерностей.
Метод ближайших соседей в реальных задачах
- В чистом виде kNN может послужить хорошим стартом (baseline) в решении какой-либо задачи;
- В соревнованиях Kaggle kNN часто используется для построения мета-признаков (прогноз kNN подается на вход прочим моделям) или в стекинге/блендинге;
- Идея ближайшего соседа расширяется и на другие задачи, например, в рекомендательных системах простым начальным решением может быть рекомендация какого-то товара (или услуги), популярного среди ближайших соседей человека, которому хотим сделать рекомендацию;
- На практике для больших выборок часто пользуются приближенными методами поиска ближайших соседей. Вот лекция Артема Бабенко про эффективные алгоритмы поиска ближайших соседей среди миллиардов объектов в пространствах высокой размерности (поиск по картинкам). Также известны открытые библиотеки, в которых реализованы такие алгоритмы, спасибо компании Spotify за ее библиотеку Annoy.
Качество классификации/регрессии методом ближайших соседей зависит от нескольких параметров:
- число соседей
- метрика расстояния между объектами (часто используются метрика Хэмминга, евклидово расстояние, косинусное расстояние и расстояние Минковского). Отметим, что при использовании большинства метрик значения признаков надо масштабировать. Условно говоря, чтобы признак "Зарплата" с диапазоном значений до 100 тысяч не вносил больший вклад в расстояние, чем "Возраст" со значениями до 100.
- веса соседей (соседи тестового примера могут входить с разными весами, например, чем дальше пример, тем с меньшим коэффициентом учитывается его "голос")
Класс KNeighborsClassifier в Scikit-learn
Основные параметры класса sklearn.neighbors.KNeighborsClassifier:
- weights: "uniform" (все веса равны), "distance" (вес обратно пропорционален расстоянию до тестового примера) или другая определенная пользователем функция
- algorithm (опционально): "brute", "ball_tree", "KD_tree", или "auto". В первом случае ближайшие соседи для каждого тестового примера считаются перебором обучающей выборки. Во втором и третьем — расстояние между примерами хранятся в дереве, что ускоряет нахождение ближайших соседей. В случае указания параметра "auto" подходящий способ нахождения соседей будет выбран автоматически на основе обучающей выборки.
- leaf_size (опционально): порог переключения на полный перебор в случае выбора BallTree или KDTree для нахождения соседей
- metric: "minkowski", "manhattan", "euclidean", "chebyshev" и другие
Выбор параметров модели и кросс-валидация
Главная задача обучаемых алгоритмов – их способность обобщаться, то есть хорошо работать на новых данных. Поскольку на новых данных мы сразу не можем проверить качество построенной модели (нам ведь надо для них сделать прогноз, то есть истинных значений целевого признака мы для них не знаем), то надо пожертвовать небольшой порцией данных, чтоб на ней проверить качество модели.
Чаще всего это делается одним из 2 способов:
- отложенная выборка (held-out/hold-out set). При таком подходе мы оставляем какую-то долю обучающей выборки (как правило от 20% до 40%), обучаем модель на остальных данных (60-80% исходной выборки) и считаем некоторую метрику качества модели (например, самое простое – долю правильных ответов в задаче классификации) на отложенной выборке.
- кросс-валидация (cross-validation, на русский еще переводят как скользящий или перекрестный контроль). Тут самый частый случай – K-fold кросс-валидация

Тут модель обучается раз на разных () подвыборках исходной выборки (белый цвет), а проверяется на одной подвыборке (каждый раз на разной, оранжевый цвет).
Получаются оценок качества модели, которые обычно усредняются, выдавая среднюю оценку качества классификации/регрессии на кросс-валидации.
Кросс-валидация дает лучшую по сравнению с отложенной выборкой оценку качества модели на новых данных. Но кросс-валидация вычислительно дорогостоящая, если данных много.
Кросс-валидация – очень важная техника в машинном обучении (применяемая также в статистике и эконометрике), с ее помощью выбираются гиперпараметры моделей, сравниваются модели между собой, оценивается полезность новых признаков в задаче и т.д. Более подробно можно почитать, например, тут у Sebastian Raschka или в любом классическом учебнике по машинному (статистическому) обучению
Примеры применения
Деревья решений и метод ближайших соседей в задаче прогнозирования оттока клиентов телеком-оператора
Считаем данные в DataFrame и проведем предобработку. Штаты пока сохраним в отдельный объект Series, но удалим из датафрейма. Первую модель будем обучать без штатов, потом посмотрим, помогают ли они.
df = pd.read_csv('../../data/telecom_churn.csv')
df['International plan'] = pd.factorize(df['International plan'])[0]
df['Voice mail plan'] = pd.factorize(df['Voice mail plan'])[0]
df['Churn'] = df['Churn'].astype('int')
states = df['State']
y = df['Churn']
df.drop(['State', 'Churn'], axis=1, inplace=True)
Выделим 70% выборки (X_train, y_train) под обучение и 30% будут отложенной выборкой (X_holdout, y_holdout). отложенная выборка никак не будет участвовать в настройке параметров моделей, на ней мы в конце, после этой настройки, оценим качество полученной модели. Обучим 2 модели – дерево решений и kNN, пока не знаем, какие параметры хороши, поэтому наугад: глубину дерева берем 5, число ближайших соседей – 10.
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.neighbors import KNeighborsClassifier
X_train, X_holdout, y_train, y_holdout = train_test_split(df.values, y, test_size=0.3,
random_state=17)
tree = DecisionTreeClassifier(max_depth=5, random_state=17)
knn = KNeighborsClassifier(n_neighbors=10)
tree.fit(X_train, y_train)
knn.fit(X_train, y_train)Качество прогнозов будем проверять с помощью простой метрики – доли правильных ответов. Сделаем прогнозы для отложенной выборки. Дерево решений справилось лучше: доля правильных ответов около 94% против 88% у kNN. Но это мы пока выбирали параметры наугад.
from sklearn.metrics import accuracy_score
tree_pred = tree.predict(X_holdout)
accuracy_score(y_holdout, tree_pred) # 0.94knn_pred = knn.predict(X_holdout)
accuracy_score(y_holdout, knn_pred) # 0.88Теперь настроим параметры дерева на кросс-валидации. Настраивать будем максимальную глубину и максимальное используемое на каждом разбиении число признаков. Суть того, как работает GridSearchCV: для каждой уникальной пары значений параметров max_depth и max_features будет проведена 5-кратная кросс-валидация и выберется лучшее сочетание параметров.
from sklearn.model_selection import GridSearchCV, cross_val_scoretree_params = {'max_depth': range(1,11),
'max_features': range(4,19)}tree_grid = GridSearchCV(tree, tree_params,
cv=5, n_jobs=-1,
verbose=True)tree_grid.fit(X_train, y_train)Лучшее сочетание параметров и соответствующая средняя доля правильных ответов на кросс-валидации:
tree_grid.best_params_{'max_depth': 6, 'max_features': 17}
tree_grid.best_score_0.94256322331761677
accuracy_score(y_holdout, tree_grid.predict(X_holdout))0.94599999999999995
Теперь попробуем настроить число соседей в алгоритме kNN.
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScalerknn_pipe = Pipeline([('scaler', StandardScaler()), ('knn', KNeighborsClassifier(n_jobs=-1))])knn_params = {'knn__n_neighbors': range(1, 10)}knn_grid = GridSearchCV(knn_pipe, knn_params,
cv=5, n_jobs=-1,
verbose=True)knn_grid.fit(X_train, y_train)knn_grid.best_params_, knn_grid.best_score_({'knn__n_neighbors': 7}, 0.88598371195885128)
accuracy_score(y_holdout, knn_grid.predict(X_holdout))0.89000000000000001
В этом примере дерево показало себя лучше, чем метод ближайших соседей: 94.2% правильных ответов на кросс-валидации и 94.6% на отложенной выборке против 88.6% / 89% для kNN. Более того, в данной задаче дерево проявляет себя очень хорошо, и даже случайный лес (который пока представляем просто как кучу деревьев, которые вместе работают почему-то намного лучше, чем одно дерево) в этом примере показывает долю правильных ответов не намного выше (95.1% на кросс-валидации и 95.3% –на отложенной выборке), а обучается намного дольше.
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators=100, n_jobs=-1, random_state=17)
print(np.mean(cross_val_score(forest, X_train, y_train, cv=5))) # 0.949forest_params = {'max_depth': range(1,11),
'max_features': range(4,19)}forest_grid = GridSearchCV(forest, forest_params,
cv=5, n_jobs=-1,
verbose=True)forest_grid.fit(X_train, y_train)forest_grid.best_params_, forest_grid.best_score_ # ({'max_depth': 9, 'max_features': 6}, 0.951)accuracy_score(y_holdout, forest_grid.predict(X_holdout)) # 0.953Нарисуем получившееся дерево. Из-за того, что оно не совсем игрушечное (максимальная глубина – 6), картинка получается уже не маленькой, но по дереву можно "прогуляться", если отдельно открыть рисунок.
export_graphviz(tree_grid.best_estimator_, feature_names=df.columns,
out_file='../../img/churn_tree.dot', filled=True)
!dot -Tpng '../../img/churn_tree.dot' -o '../../img/churn_tree.png'
Сложный случай для деревьев решений
В продолжение обсуждения плюсов и минусов обсуждаемых методов приведем очень простой пример задачи классификации, с которым дерево справляется, но делает все как-то "сложнее", чем хотелось бы. Создадим множество точек на плоскости (2 признака), каждая точка будет относиться к одному из классов (+1, красные, или -1 – желтые). Если смотреть на это как на задачу классификации, то вроде все очень просто – классы разделяются прямой.
def form_linearly_separable_data(n=500, x1_min=0, x1_max=30, x2_min=0, x2_max=30):
data, target = [], []
for i in range(n):
x1, x2 = np.random.randint(x1_min, x1_max), np.random.randint(x2_min, x2_max)
if np.abs(x1 - x2) > 0.5:
data.append([x1, x2])
target.append(np.sign(x1 - x2))
return np.array(data), np.array(target)
X, y = form_linearly_separable_data()
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='autumn', edgecolors='black');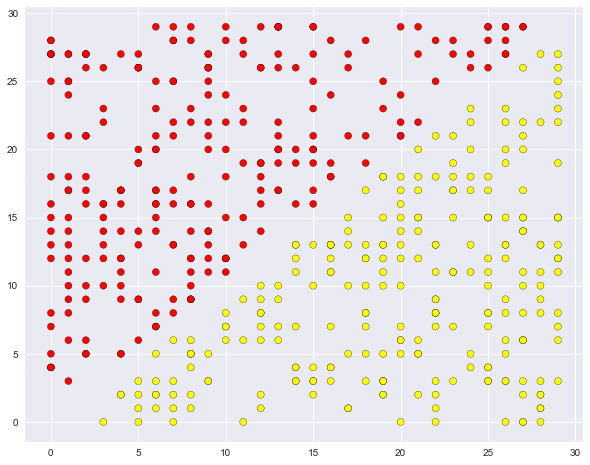
Однако дерево решений строит уж больно сложную границу и само по себе оказывается глубоким. Кроме того, представьте, как плохо дерево будет обобщаться на пространство вне представленного квадрата , обрамляющего обучающую выборку.
tree = DecisionTreeClassifier(random_state=17).fit(X, y)
xx, yy = get_grid(X, eps=.05)
predicted = tree.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
plt.pcolormesh(xx, yy, predicted, cmap='autumn')
plt.scatter(X[:, 0], X[:, 1], c=y, s=100,
cmap='autumn', edgecolors='black', linewidth=1.5)
plt.title('Easy task. Decision tree compexifies everything');
Вот такая сложная конструкция, хотя решение (хорошая разделяющая поверхность) – это всего лишь прямая .
export_graphviz(tree, feature_names=['x1', 'x2'],
out_file='../../img/deep_toy_tree.dot', filled=True)
!dot -Tpng '../../img/deep_toy_tree.dot' -o '../../img/deep_toy_tree.png'
Метод одного ближайшего соседа здесь справляется вроде лучше дерева, но все же не так хорошо, как линейный классификатор (наша следующая тема).
knn = KNeighborsClassifier(n_neighbors=1).fit(X, y)
xx, yy = get_grid(X, eps=.05)
predicted = knn.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
plt.pcolormesh(xx, yy, predicted, cmap='autumn')
plt.scatter(X[:, 0], X[:, 1], c=y, s=100,
cmap='autumn', edgecolors='black', linewidth=1.5);
plt.title('Easy task, kNN. Not bad');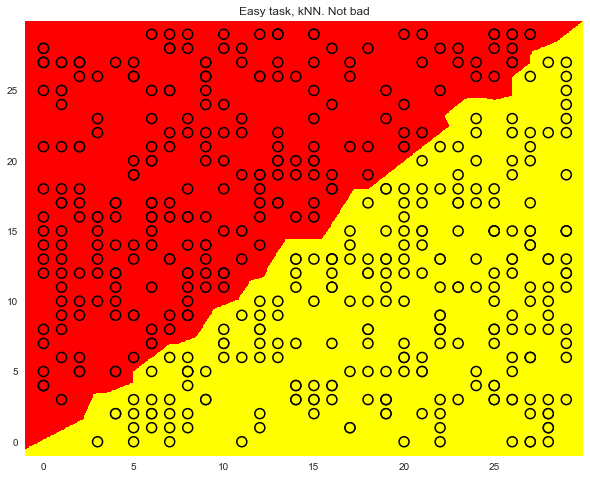
Деревья решений и метод ближайших соседей в задаче распознавания рукописных цифр MNIST
Теперь посмотрим на описанные 2 алгоритма в реальной задаче. Используем "встроенные" в sklearn данные по рукописным цифрам. Эта задача будет примером, когда метод ближайших соседей работает на удивление хорошо.
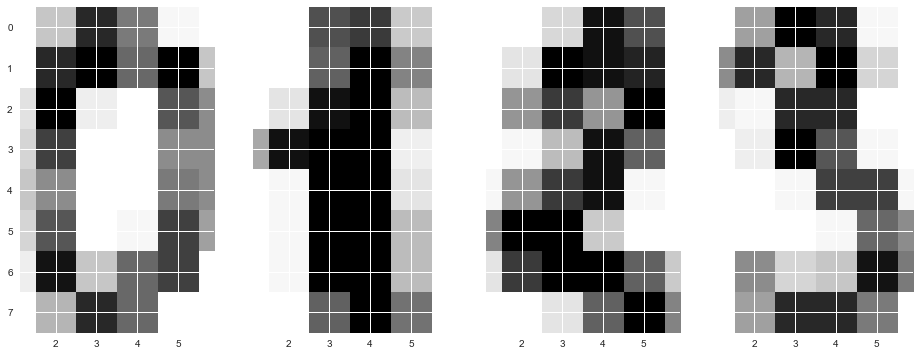
Картинки здесь представляются матрицей 8 x 8 (интенсивности белого цвета для каждого пикселя). Далее эта матрица "разворачивается" в вектор длины 64, получается признаковое описание объекта.
Нарисуем несколько рукописных цифр, видим, что они угадываются.
from sklearn.datasets import load_digits
data = load_digits()
X, y = data.data, data.target
X[0,:].reshape([8,8])array([[ 0., 0., 5., 13., 9., 1., 0., 0.],
[ 0., 0., 13., 15., 10., 15., 5., 0.],
[ 0., 3., 15., 2., 0., 11., 8., 0.],
[ 0., 4., 12., 0., 0., 8., 8., 0.],
[ 0., 5., 8., 0., 0., 9., 8., 0.],
[ 0., 4., 11., 0., 1., 12., 7., 0.],
[ 0., 2., 14., 5., 10., 12., 0., 0.],
[ 0., 0., 6., 13., 10., 0., 0., 0.]])
f, axes = plt.subplots(1, 4, sharey=True, figsize=(16,6))
for i in range(4):
axes[i].imshow(X[i,:].reshape([8,8]));
Далее проведем ровно такой же эксперимент, как и в прошлой задаче, только диапазоны изменения настраиваемых параметров будут немного другие.
Выделим 70% выборки (X_train, y_train) под обучение и 30% будут отложенной выборкой (X_holdout, y_holdout). отложенная выборка никак не будет участвовать в настройке параметров моделей, на ней мы в конце, после этой настройки, оценим качество полученной модели.
X_train, X_holdout, y_train, y_holdout = train_test_split(X, y, test_size=0.3,
random_state=17)Обучим дерево решений и kNN, опять параметры пока наугад берем.
tree = DecisionTreeClassifier(max_depth=5, random_state=17)
knn = KNeighborsClassifier(n_neighbors=10)
tree.fit(X_train, y_train)
knn.fit(X_train, y_train)Сделаем прогнозы для отложенной выборки. Видим, что метод ближайших соседей справился намного лучше. Но это мы пока выбирали параметры наугад.
tree_pred = tree.predict(X_holdout)
knn_pred = knn.predict(X_holdout)
accuracy_score(y_holdout, knn_pred), accuracy_score(y_holdout, tree_pred) # (0.97, 0.666)Теперь так же, как раньше настроим параметры моделей на кросс-валидации, только учтем, что признаков сейчас больше, чем в прошлой задаче — 64.
tree_params = {'max_depth': [1, 2, 3, 5, 10, 20, 25, 30, 40, 50, 64],
'max_features': [1, 2, 3, 5, 10, 20 ,30, 50, 64]}
tree_grid = GridSearchCV(tree, tree_params,
cv=5, n_jobs=-1,
verbose=True)
tree_grid.fit(X_train, y_train)Лучшее сочетание параметров и соответствующая средняя доля правильных ответов на кросс-валидации:
tree_grid.best_params_, tree_grid.best_score_ # ({'max_depth': 20, 'max_features': 64}, 0.844)Это уже не 66%, но и не 97%. Метод ближайших соседей на этом наборе данных работает лучше. В случае одного ближайшего соседа на кросс-валидации достигается почти 99% угадываний.
np.mean(cross_val_score(KNeighborsClassifier(n_neighbors=1), X_train, y_train, cv=5)) # 0.987Обучим на этих же данных случайный лес, он на большинстве выборок работает лучше, чем метод ближайших соседей. Но сейчас у нас исключение.
np.mean(cross_val_score(RandomForestClassifier(random_state=17), X_train, y_train, cv=5)) # 0.935Вы будете правы, если возразите, что мы тут не настраивали параметры RandomForestClassifier, но даже с настройкой доля правильных ответов не достигает 98%, как для у метода одного ближайшего соседа.
Результаты эксперимента
(Обозначения: CV и Holdout– средние доли правильных ответов модели на кросс-валидации и отложенной выборке соот-но. DT – дерево решений, kNN – метод ближайших соседей, RF – случайный лес)
| CV | Holdout | |
|---|---|---|
| DT | 0.844 | 0.838 |
| kNN | 0.987 | 0.983 |
| RF | 0.935 | 0.941 |
Вывод по этому эксперименту (и общий совет): вначале проверяйте на своих данных простые модели – дерево решений и метод ближайших соседей (а в следующий раз сюда добавится логистическая регрессия), может оказаться, что уже они работают достаточно хорошо.
Сложный случай для метода ближайших соседей
Теперь рассмотрим еще один простой пример. В задаче классификации один из признаков будет просто пропорционален вектору ответов, но методу ближайших соседей это не поможет.
def form_noisy_data(n_obj=1000, n_feat=100, random_seed=17):
np.seed = random_seed
y = np.random.choice([-1, 1], size=n_obj)
# первый признак пропорционален целевому
x1 = 0.3 * y
# остальные признаки – шум
x_other = np.random.random(size=[n_obj, n_feat - 1])
return np.hstack([x1.reshape([n_obj, 1]), x_other]), y
X, y = form_noisy_data()Как обычно, будем смотреть на долю правильных ответов на кросс-валидации и на отложенной выборке. Построим кривые, отражающие зависимость этих величин от параметра n_neighbors в методе ближайших соседей. Такие кривые называются кривыми валидации.
Видим, что метод ближайших соседей с евклидовой метрикой не справляется с задачей, даже если варьировать число ближайших соседей в широком диапазоне. Напротив, дерево решений легко "обнаруживает" скрытую зависимость в данных при любом ограничении на максимальную глубину.
X_train, X_holdout, y_train, y_holdout = train_test_split(X, y, test_size=0.3,
random_state=17)
from sklearn.model_selection import cross_val_score
cv_scores, holdout_scores = [], []
n_neighb = [1, 2, 3, 5] + list(range(50, 550, 50))
for k in n_neighb:
knn = KNeighborsClassifier(n_neighbors=k)
cv_scores.append(np.mean(cross_val_score(knn, X_train, y_train, cv=5)))
knn.fit(X_train, y_train)
holdout_scores.append(accuracy_score(y_holdout, knn.predict(X_holdout)))
plt.plot(n_neighb, cv_scores, label='CV')
plt.plot(n_neighb, holdout_scores, label='holdout')
plt.title('Easy task. kNN fails')
plt.legend();
tree = DecisionTreeClassifier(random_state=17, max_depth=1)
tree_cv_score = np.mean(cross_val_score(tree, X_train, y_train, cv=5))
tree.fit(X_train, y_train)
tree_holdout_score = accuracy_score(y_holdout, tree.predict(X_holdout))
print('Decision tree. CV: {}, holdout: {}'.format(tree_cv_score, tree_holdout_score))Decision tree. CV: 1.0, holdout: 1.0
Итак, во втором примере дерево справилось с задачей идеально, а метод ближайших соседей испытал трудности. Впрочем, это минус скорее не метода, а используемой евклидовой метрики: в данном случае она не позволила выявить, что один признак намного лучше остальных.
Плюсы и минусы деревьев решений и метода ближайших соседей
Плюсы и минусы деревьев решений
Плюсы:
- Порождение четких правил классификации, понятных человеку, например, "если возраст < 25 и интерес к мотоциклам, то отказать в кредите". Это свойство называют интерпретируемостью модели;
- Деревья решений могут легко визуализироваться, то есть может "интерпретироваться" (строгого определения я не видел) как сама модель (дерево), так и прогноз для отдельного взятого тестового объекта (путь в дереве);
- Быстрые процессы обучения и прогнозирования;
- Малое число параметров модели;
- Поддержка и числовых, и категориальных признаков.
Минусы:
- У порождения четких правил классификации есть и другая сторона: деревья очень чувствительны к шумам во входных данных, вся модель может кардинально измениться, если немного изменится обучающая выборка (например, если убрать один из признаков или добавить несколько объектов), поэтому и правила классификации могут сильно изменяться, что ухудшает интерпретируемость модели;
- Разделяющая граница, построенная деревом решений, имеет свои ограничения (состоит из гиперплоскостей, перпендикулярных какой-то из координатной оси), и на практике дерево решений по качеству классификации уступает некоторым другим методам;
- Необходимость отсекать ветви дерева (pruning) или устанавливать минимальное число элементов в листьях дерева или максимальную глубину дерева для борьбы с переобучением. Впрочем, переобучение — проблема всех методов машинного обучения;
- Нестабильность. Небольшие изменения в данных могут существенно изменять построенное дерево решений. С этой проблемой борются с помощью ансамблей деревьев решений (рассмотрим далее);
- Проблема поиска оптимального дерева решений (минимального по размеру и способного без ошибок классифицировать выборку) NP-полна, поэтому на практике используются эвристики типа жадного поиска признака с максимальным приростом информации, которые не гарантируют нахождения глобально оптимального дерева;
- Сложно поддерживаются пропуски в данных. Friedman оценил, что на поддержку пропусков в данных ушло около 50% кода CART (классический алгоритм построения деревьев классификации и регрессии – Classification And Regression Trees, в
sklearnреализована улучшенная версия именно этого алгоритма); - Модель умеет только интерполировать, но не экстраполировать (это же верно и для леса и бустинга на деревьях). То есть дерево решений делает константный прогноз для объектов, находящихся в признаковом пространстве вне параллелепипеда, охватывающего все объекты обучающей выборки. В нашем примере с желтыми и синими шариками это значит, что модель дает одинаковый прогноз для всех шариков с координатой > 19 или < 0.
Плюсы и минусы метода ближайших соседей
Плюсы:
- Простая реализация;
- Неплохо изучен теоретически;
- Как правило, метод хорош для первого решения задачи, причем не только классификации или регрессии, но и, например, рекомендации;
- Можно адаптировать под нужную задачу выбором метрики или ядра (в двух словах: ядро может задавать операцию сходства для сложных объектов типа графов, а сам подход kNN остается тем же). Кстати, профессор ВМК МГУ и опытный участник соревнований по анализу данных Александр Дьяконов любит самый простой kNN, но с настроенной метрикой сходства объектов. Можно почитать про некоторые его решения (в частности, "VideoLectures.Net Recommender System Challenge") на персональном сайте;
- Неплохая интерпретация, можно объяснить, почему тестовый пример был классифицирован именно так. Хотя этот аргумент можно атаковать: если число соседей большое, то интерпретация ухудшается (условно: "мы не дали ему кредит, потому что он похож на 350 клиентов, из которых 70 – плохие, что на 12% больше, чем в среднем по выборке").
Минусы:
- Метод считается быстрым в сравнении, например, с композициями алгоритмов, но в реальных задачах, как правило, число соседей, используемых для классификации, будет большим (100-150), и в таком случае алгоритм будет работать не так быстро, как дерево решений;
- Если в наборе данных много признаков, то трудно подобрать подходящие веса и определить, какие признаки не важны для классификации/регрессии;
- Зависимость от выбранной метрики расстояния между примерами. Выбор по умолчанию евклидового расстояния чаще всего ничем не обоснован. Можно отыскать хорошее решение перебором параметров, но для большого набора данных это отнимает много времени;
- Нет теоретических оснований выбора определенного числа соседей — только перебор (впрочем, чаще всего это верно для всех гиперпараметров всех моделей). В случае малого числа соседей метод чувствителен к выбросам, то есть склонен переобучаться;
- Как правило, плохо работает, когда признаков много, из-за "прояклятия размерности". Про это хорошо рассказывает известный в ML-сообществе профессор Pedro Domingos – тут в популярной статье "A Few Useful Things to Know about Machine Learning", также "the curse of dimensionality" описывается в книге Deep Learning в главе "Machine Learning basics".
На этом мы подходим к концу, надеемся, этой статьи Вам хватит надолго. К тому же, есть еще и домашнее задание.
Домашнее задание № 3
В третьем домашнем задании Вам предлагается сначала разобраться с тем, как работают деревья решений, построив игрушечное дерево для маленького веселого примера задачи классификации, а затем – настроить дерево решений для задачи классификации на данных из первого задания – Adult из репозитория UCI.
Ссылка на форму для ответов (она же – в тетрадке). Ответы в форме можно менять после отправки, но не после дедлайна.
Дедлайн: 20 марта 23:59 (жесткий).
Полезные ресурсы
- Реализация многих алгоритмов машинного обучения с нуля – репозиторий rushter. Полезно, например, посмотреть, как реализованы деревья решений и метод ближайших соседей;
- Курс Евгения Соколова по машинному обучению (материалы на GitHub). Хорошая теория, нужна неплохая математическая подготовка;
- Курс Дмитрия Ефимова на GitHub (англ.). Тоже очень качественные материалы;
- Статья "Энтропия и деревья принятия решений" на Хабре;
- Статья "Машинное обучение и анализ данных. Лекция для Малого ШАДа Яндекса" на Хабре.
Благодарю Maaariii за помощь с домашним заданием и сообщество OpenDataScience – за идеи по улучшению материала.
Комментарии (38)

vsns
13.03.2017 15:58-2про минимальность глубины дерева для шариков не верно. например, на втором уровне вместо 8 можно было взять 4 и на следующем уровне уже закончить. для одномерного множества количество условий очевидно считается и минимальная глубина достигается, в том числе, на максимально сбалансированном дереве. но так как важна целая часть логарифма, а общее число разбиений далеко не степень двойки, то и другие деревья могут быть «оптимальны» с точки зрения глубины. Дерево из статьи оптимально в том плане, что мы «отщипили» самую большую группу наиболее быстро

yorko
13.03.2017 16:25+3а где что-либо говорится про "минимальность глубины дерева для шариков"?
vsns
13.03.2017 16:39-2уже частично поправили:
Можно убедиться в том, что построенное в предыдущем примере дерево является в некотором смысле оптимальным – потребовалось только 5 «вопросов» (условий на признак x), чтобы «подогнать» дерево решений под обучающую выборку, то есть чтобы дерево правильно классифицировало любой обучающий объект. При других условиях разделения выборки дерево получится глубже.
здесь раньше были не 5 вопросов, а глубина. поэтому и последнее процитированное предложение про глубину теперь выглядит вырванным из контекста. Спасибо, что поправили. Обидно, что сделали это тихо, отчего появились вопросы ;)yorko
13.03.2017 16:48+3я ничего не правил. Если что-то серьезное правлю, ставлю UPD
В репозитории в ipynb-файле та же фраза, что и сейчас.vsns
13.03.2017 17:59ок. видимо сложилось вкупе со фразой
При других условиях разделения выборки дерево получится глубже.
как я написал выше, может получится и менее глубоким.
В любом случае, хорошо что пишите, а то народ играет в «кубики», меняя параметры, а что за этим стоит не всегда понимают
Dark_kot
13.03.2017 21:21Зануда-mod on
Если вы по какой-то причине набираете ручками всё вышеизложенное, да ещё и на производной от ubuntu16(не знаю как там на других дистрах), то с удивлением можете обнаружить, что графы нифига не рисуются. И дело тут вовсе не в вашей криворукости или криворукости авторов, а в неустановленном по умолчанию graphviz. И это не тот graphviz, который можно поставить через pip, а пакет утилит, для установки которого надо юзать apt
Зануда-mod offyorko
13.03.2017 21:23+3graphviz не обязателен. Достаточно создать dot-файл методом export_graphviz из sklearn.tree и дальше отрендерить этот dot-файл либо c помощью pydot (pip install pydot) либо онлайн-ковертером.
Dark_kot
14.03.2017 03:43+1Конечно можно. Но это никак не поможет запуститься
!dot -Tpng '../../img/age_sal_tree.dot' -o '../../img/age_sal_tree.png'
А комментарий был именно про это.yorko
14.03.2017 08:32+1Именно поэтому первый раз, когда в коде появляется вызов dot (в спойлере "Код для отображения дерева"), я пишу
# для этого понадобится библиотека pydot (pip install pydot)
!dot -Tpng '../../img/small_tree.dot' -o '../../img/small_tree.png'Очевидно, если не установить pydot, не выполнится и команда.

qlmv
17.03.2017 16:53Установка pydot не помогла. Нашел другой вариант для Windows: и посмотреть и сохранить дерево:
from sklearn.tree import DecisionTreeClassifier
clf_tree = DecisionTreeClassifier(criterion='entropy', max_depth=10, random_state=17)
clf_tree.fit(df_train, y)
from sklearn import tree
from IPython.display import Image
import pydotplus
dot_data = tree.export_graphviz(clf_tree, feature_names=df_train.columns, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf('df_train.pdf')
graph.write_png('df_train.png')
Image(graph.create_png())
firexonix
14.03.2017 08:24+1Как вариант для пользующихся docker
- Устанавливаем пакет в запущенный контейнер
sudo docker exec -u 0 -i -t mlcourse_open /usr/bin/apt install graphviz - Конвертируем командой в jupyter-notebook
!dot -Tpng '../../img/small_tree.dot' -o 'small_tree.png' - Отрисовываем в Markdown-ячейке jupyter-notebook

yorko
14.03.2017 08:34+2В файле настроек (Dockerfile) предлагаемого в курсе докер-контейнера уже прописана установка pydot. Graphviz не обязательно ставить, тут это будет из пушки по воробьям.
Dark_kot
14.03.2017 09:27+2Мне кажется, вы заблуждаетесь. Выполняя !dot получаем вывод:
/bin/sh: 1: dot: not found
И и при этом
pip show pydot Name: pydot Version: 1.2.3 Summary: Python interface to Graphviz's Dot Home-page: https://github.com/erocarrera/pydot Author: Ioannis Filippidis Author-email: jfilippidis@gmail.com License: MIT Location: /usr/local/lib/python3.5/dist-packages Requires: pyparsing
Установка через pip лично мне никакого исполняемого файла не добавила. Если я заблуждаюсь, то буду рад, если вы покажете мне где.yorko
14.03.2017 11:05+1Согласен, GraphViz указан как dependency в репозитории pydot. Значит, он у меня уже был установлен, а я не заметил.
С путем к pydot тоже приходилось повозиться, в случае Windows вообще не берусь комментировать, в случае *nix помогает StackOverflow, хотя если вдруг установлены 2 версии питона (2.x и 3.x), тоже могут быть осложнения.
Пути решения:
- проверить установку pydot в докер-контейнере festline/mlcourse_open – инструкции в репозитории нашего курса
- установить pydot самостоятельно, StackOverflow в помощь :)
- накрайняк, использовать онлайн-конвертер из dot в png
А в целом, да, за отрисовку деревьев, sklearn-у незачет.

snakers4
14.03.2017 14:22+1Код, который работал в jp notebook для меня после установки библиотек:
# используем .dot формат для визуализации дерева from sklearn.tree import export_graphviz export_graphviz( clf_tree, feature_names=['x1', 'x2'], out_file='/small_tree.dot', filled=True) # для этого понадобится библиотека pydot (pip install pydot) import pydot (graph,) = pydot.graph_from_dot_file('/small_tree.dot') graph.write_png('/small_tree.png') from IPython.core.display import Image, display display(Image('/small_tree.png', unconfined=True))
- Устанавливаем пакет в запущенный контейнер
yorko
14.03.2017 11:36+2Немного картинок по результатам 2 домашек:
2 домашка оказалась сложнее (да, формулировки менее четкие, но тут уже исправленные результаты, где за 2 вопрос – всем 2 балла выставлено)
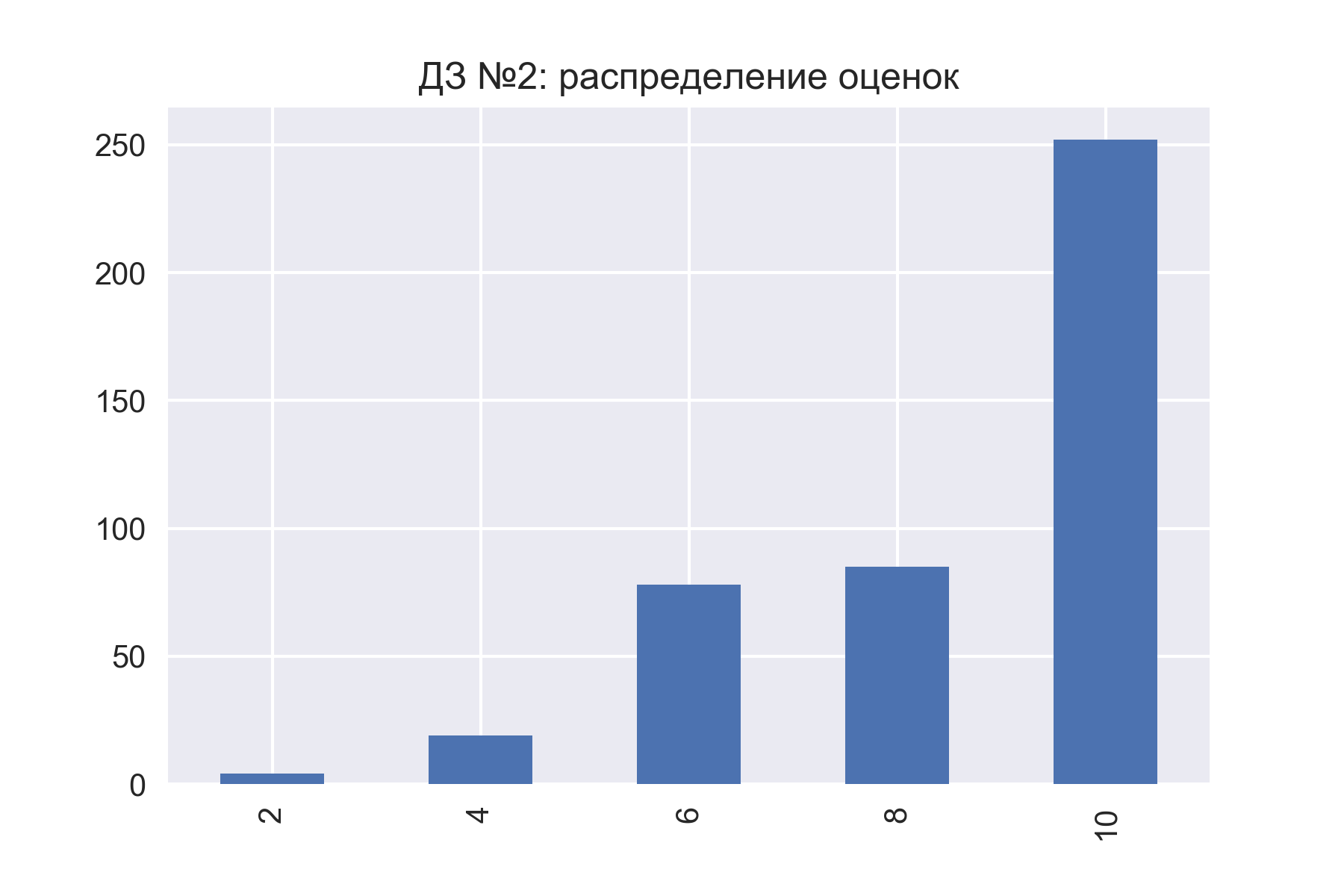

Стали больше откладывать на последний момент :) может быть связано с тем, что задание сложнее и вызвало большее оживление на форуме.
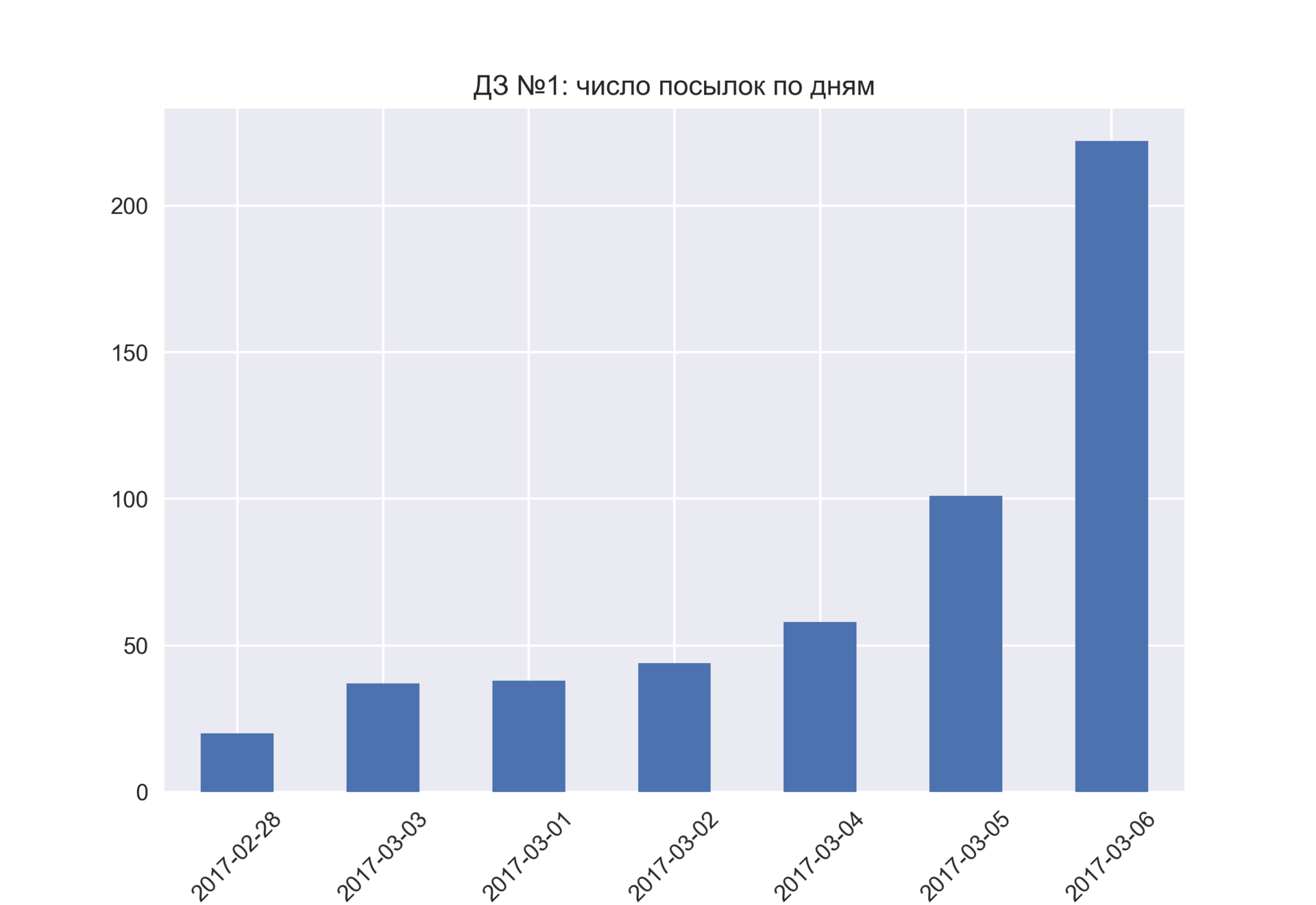
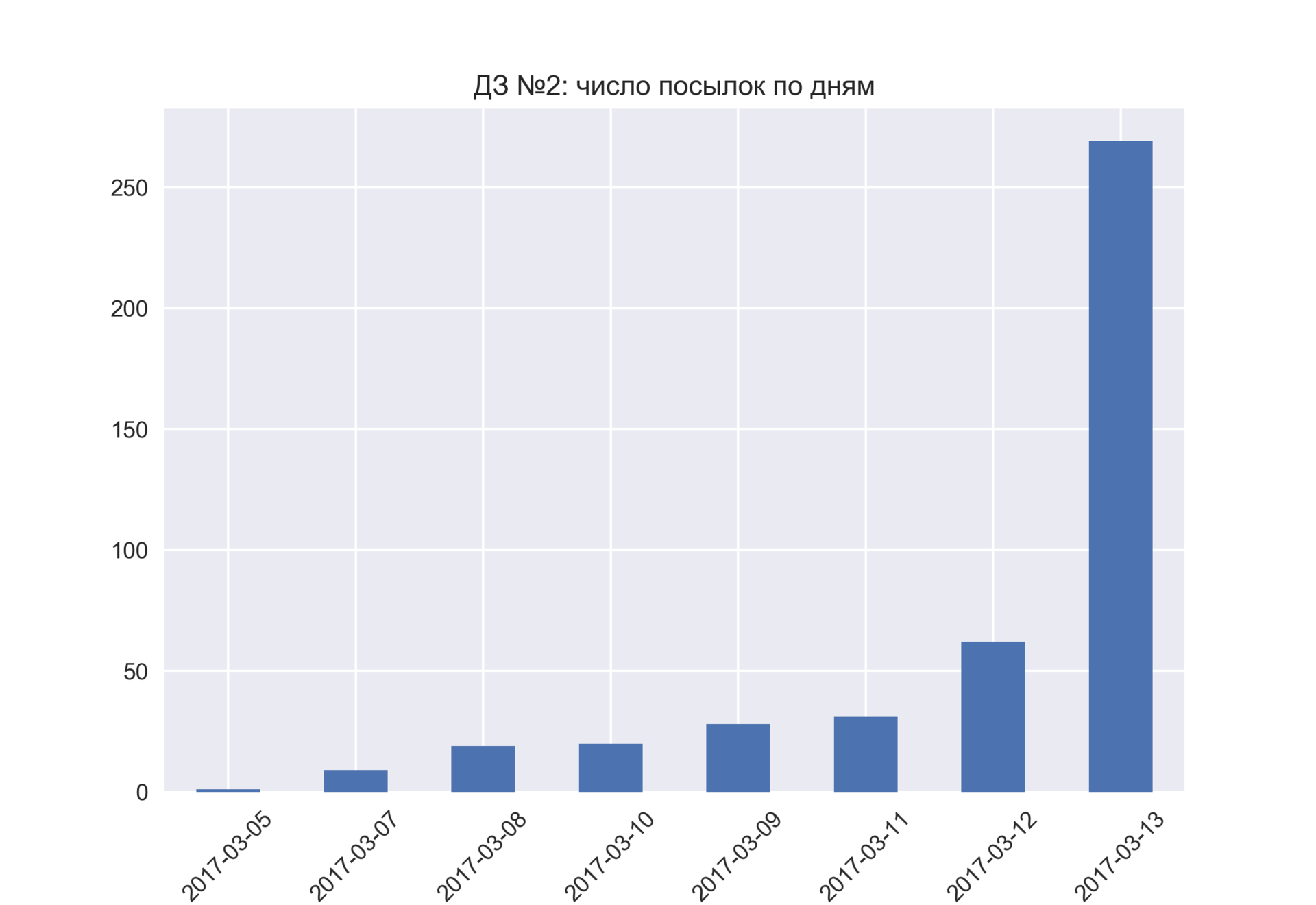
Ко второй домашке присоединились 26 новых участников, 107 "старых" – забили (из начальных 519 участников)



Gewissta
14.03.2017 23:55+1Остается добавить, все вышеописанное по деревьям относилось к CRT, соответственно информация о недостатках и преимуществах относится к нему. На практике CRT используется крайне мало, в Штатах скормодель на базе CRT регулятор сразу завернет, потому что метод не стабилен. Основное применение — разведочный анализ и выделить полезные сложные взаимодействия признаков, которые логрегрессия и CHAID не смогут определить, а лес определит, но не даст увидеть, поскольку «черный ящик». Интересно было бы прочитать статьи по реализации CHAID в Питоне, преимущество CHAID — используем для формирования категорий и разбиения узлов жесткий статкритерий (хи-квадрат или F-тест), который работает как препрунинг. Собственно CHAID для скормоделей на втором месте идет после логрегрессии, либо сначала CHAID'ом делаем сегменты, а потом внутри них запускаем скормодели на базе логрегрессии, либо строим сразу скормодели на базе CHAID.
yorko
15.03.2017 00:03+1Вы все же имели в виду CART – Classification And Regression Trees. Реализация деревьев в Sklearn – это оптимизированная версия CART. Случайный лес в Sklearn опять же построен на деревьях CART, только усредняются не ответы, как в оригинале, а вероятности.
В документации Xgboost Вы опять же встретите CART.
Так что, мягко говоря, Вы поспешили заявить, что «На практике CRT используется крайне мало», а если не мягко, то надо порой отвлечься от того, что в твоей задаче происходит, и посмотреть немного вокруг.

cotique
15.03.2017 00:05+1Интересно было бы прочитать статьи по реализации CHAID в Питоне
А написать про CHAID, случаем, вам не было бы интересно? :)
yorko
15.03.2017 00:06Кстати, интересно будет, если расскажете, как в деревьях с проверкой гипотез в узлах делается поправка на множественную проверку.

Gewissta
15.03.2017 11:26+3По поправкам…
Для контроля вероятности ошибки I рода p-значения, вычисленные для объединенных категорий (я про CHAID сейчас), умножаются на поправку Бонферрони, получаем так называемые скорректированные p-значения. Но необязательно Бонферрони использовать, можно и другие критерии. А вот в QUEST там двойная поправка применяется. Тоже интереснейший метод, я на его базе лес часто делаю и он часто превосходит по качеству лес на базе CRT. Например, QUEST провайдер Verizon использует в своих моделях оттока.
1. Для отбора переменных алгоритм исследует все предикторы с помощью статистических тестов значимости. Для каждого количественного или порядкового предиктора QUEST выполняет дисперсионный анализ (тестируется гипотеза о том, что различные категории зависимой переменной имеют одинаковое среднее значение предиктора), а затем предикторы упорядочиваются по значимости (p-значению) F-критерия для них. Для номинальных предикторов применяется критерий хи-квадрат и полученные в результате p-значения сохраняются.
2. Затем алгоритм выбирает предиктор с наименьшим p-значением, которое сравнивается с заданным уровнем значимости. При этом обратим внимание, что перед сравнением p-значения корректируются с помощью поправки Бонферрони: p-значение умножается на общее количество предикторов. Если нескорректированное p-значение равно 0,04, то после корректировки Бонферрони оно станет равным 0,40 = 0,04 x 10.
3. Если наименьшее p-значение (скорректированное по Бонферрони для теста на значимость) меньше заданного уровня значимости, алгоритм выбирает предиктор для разбиения данного узла. Если нет, происходит переход к шагу 4.
4. Для каждого порядкового или непрерывного предиктора алгоритм выполняет тест Ливиня на однородность дисперсии (т.е. тест на однородность дисперсии предиктора по категориям зависимой переменной). Это делается по причине того, что полезная для классификации информация может содержаться в переменной, которая для разных групп имеет одинаковые средние, но сильно отличающиеся дисперсии.
5. Алгоритм находит предиктор с наименьшим p-значением, которое сравнивается с заданным уровнем значимости. Перед сравнением p-значения корректируются с помощью новой поправки Бонферрони: теперь p-значение умножается на сумму общего числа предикторов и числа порядковых и количественных предикторов, используемых в анализе неоднородности. Если имеется 10 предикторов, 5 из которых являются количественными или порядковыми, то скорректированное p-значение для количественного или порядкового предиктора станет равным 0,6 = 0,04 x 15 (если нескорректированное p-значение было равно 0,04). Поскольку вероятности не могут превосходить 1, то скорректированные p-значения, превосходящие 1, полагаются равными 1.
Если наименьшее p-значение (скорректированное по Бонферрони для теста на однородность) меньше заданного уровня значимости, то соответствующий ему предиктор используется для разбиения узла. Если нет, то для этого используется наиболее значимый предиктор, полученный на предыдущем шаге (F-тест и критерий хи-квадрат).
Таким образом, чтобы отобрать предиктор для разбиения узла, используется последовательность статистических тестов.
Но тут я сбивчиво пишу, лучше всего я об этом в своей книге изложил, ссылку на которую дал вам в личке. Там и про недостатки CRT, техники прунинга, CHAID и прочее.IliaSafonov
15.03.2017 12:18+1лучше всего я об этом в своей книге изложил, ссылку на которую дал вам в личке.
Про книгу многим может быть интересно. «Прогнозное моделирование в IBM SPSS Statistics и R. Метод деревьев решений» имеется в виду?Gewissta
15.03.2017 14:33+3Да, она. Но лучше подождать «Прогнозное моделирование в IBM SPSS Statistics, R и Python. Деревья решений и случайный лес», там добавлено построение леса в SPSS, R и Python, а также деревья в Python. Тут с Юрием как раз обсуждали, что прунинг наиболее удачно реализован в rpart. Там используется метод отсечения ветвей, основанный на мере стоимости-сложности с перекрестной проверкой (кросс-валидацией) в том виде, как это задумывалось четырьмя авторами CART.
На каждом шаге построения дерева рассчитываются стоимости-сложности и кросс-валидационные ошибки, помогающие определить, когда достигнуто максимальное качество модели и дерево можно остановить в росте. Для дерева классификации считаем ошибку классификации на объектах, не входивших в обучении, для регрессии – сумму квадратов остатков, не входивших в обучение. Затем строится удобный график зависимости кросс-валидационных ошибок (xerror) от числа расщеплений (nsplit) и сложности модели (cp). Таким образом, общая логика прунинга в rpart состоит в том, чтобы построить полное дерево с максимальным количеством расщеплений (т.е. переобученное), а затем обрезать его до нужного размера, выбрав с помощью удобного графика оптимальное сочетание значений кросс-валидационной ошибки и стоимости-сложности.
К слову, в SPSS дерево обрезается с учетом ошибки классификации (или суммы квадратов остатков) на… обучающей выборке.
jzha
15.03.2017 18:27+1Очень интересная книга у вас (сужу по оглавлению).
По CHAID'у в открытом доступе есть хорошая обзорная статья — CHAID and Earlier Supervised Tree Methods.
Gewissta
15.03.2017 21:36Да, использовал ее для книги, еще рекомендую книгу Андреаса Мюллера и Сары Гвидо по ML в Python. Андреасу удалось то, чего не удается многим авторам (я тут, наверно, не исключение) — снизить цену «входа» в ML, не просто доступное, а еще и увлекательное изложение методов ML в Python. И хоть «Вильямс» не удалось полностью передать дух книги (книга черно-белая, по тетрадкам не смогли договориться и код не очень хорошо сверстан), она будет существенной помощью в освоении Питон для самой широкой аудитории. Если нужны русифицированные тетрадки, они лежат здесь https://drive.google.com/open?id=0B6cpSQ5uHrxMbW93eXR3UmRBbjg
yorko
16.03.2017 17:20Правильно я понимаю, что если признаков (предикторов) много, скажем, 10 тыс, то такой подход не сработает?
Все p-value умножатся на 10 тыс., и тогда из п. 3 мы всегда переходим в п. 4. Там в п. 4 тоже поправка Бонферрони?
В-общем, как мы выберем первый признак, если таковых очень много, и все поправки Бонферрони привели к p-value 1 (после округления вниз). Другие поправки используются? Может, какие-то эвристики, чтоб не проверять все исходные признаки?
Или просто такой подход используется, когда признаков до нескольких сотен, не больше?Gewissta
16.03.2017 21:29Спасибо, Юрий, а я перечитываю, понять не могу)) конечно же делим, а не умножаем, спутал с модифицированной реализацией для леса
в классическом QUEST
первая поправка Бонферрони — делим на общее количество предикторов, альфа/M
вторая поправка Бонферрони — делим на количество предикторов + количество порядковых, альфа/M+M1
https://www.google.ru/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&ved=0ahUKEwirzfG_ztvSAhXBhiwKHa76C8YQFggaMAA&url=http%3A%2F%2Fwww.springer.com%2Fcda%2Fcontent%2Fdocument%2Fcda_downloaddocument%2F9783319009599-c2.pdf%3FSGWID%3D0-0-45-1431236-p175268307&usg=AFQjCNFSczJLyOv4Dc4Fd2j6n6DhhPxs8g&sig2=NpzY-WC_isLK97wzv20wQQ&bvm=bv.149760088,d.bGg
стр. 27
Gewissta
15.03.2017 14:45+1В Python тоже удобной техники прунинга нет, но все равно поудобнее, чем в SPSS, регулируем сначала max_depth, а затем подбираем min_samples_split и min_samples_leaf (последние два значения подбираем так, чтоб min_samples_leaf был где-то в половину меньше чем min_samples_split, но если шумовых объектов может и не прокатить). Вот из реальной практики пример для Питон, на днях его крутил:
ln[1]:
tree = DecisionTreeClassifier(random_state=152)
tree.fit(X_train, y_train)
print(«Правильность на обучающей выборке: {:.3f}».format(tree.score(X_train, y_train)))
print(«Правильность на контрольной выборке: {:.3f}».format(tree.score(X_control, y_control)))
Out[1]:
Правильность на обучающей выборке: 0.992
Правильность на контрольной выборке: 0.897
Поскольку правильность – точечная оценка дискриминирующей способности, для более объективной оценки берем AUC
ln[2]:
tree = DecisionTreeClassifier(random_state=152)
tree.fit(X_train, y_train)
print(«AUC на обучающей выборке: {:.3f}».
format(roc_auc_score(y_train, tree.predict_proba(X_train)[:, 1])))
print(«AUC на контрольной выборке: {:.3f}».
format(roc_auc_score(y_control, tree.predict_proba(X_control)[:, 1])))
Out[2]:
AUC на обучающей выборке: 1.000
AUC на контрольной выборке: 0.793
Делаем прунинг
ln[3]:
tree2 = DecisionTreeClassifier(max_depth=15, min_samples_leaf=15,
min_samples_split=30, random_state=152)
tree2.fit(X_train, y_train)
print(«AUC на обучающей выборке: {:.3f}».
format(roc_auc_score(y_train, tree2.predict_proba(X_train)[:, 1])))
print(«AUC на контрольной выборке: {:.3f}».
format(roc_auc_score(y_control, tree2.predict_proba(X_control)[:, 1])))
Out[3]:
AUC на обучающей выборке: 0.940
AUC на контрольной выборке: 0.881
Но меня результат все равно не устроил, я сгенерировал дополнительные признаки (а еще лучше признаки с весами сделать) и потом снова обрезал, чтоб AUC повыше получить. Для более надежной оценки подрезанных моделей (обычно на практике берут каскад из 3-4 моделей) в Python рекомендую использовать решетчатый поиск с комбинированной проверкой (класс GridSearchCV), в R для этих целей можно пакет caret использоватьyorko
16.03.2017 17:34К.В. Воронцов описывает стрижку cost-compexity prunning (изложена вкратце у Е. Соколова тут), при которой дерево строится до макс. глубины, а затем последовательно, снизу вверх, на основе кросс-валидации удаляются лишние узлы (на CV сравнивается дерево с этим узлом и без него). Утверждают, что это работает лучше, чем подбор параметров. Но вычислительная сложность высокая. Не видел, где бы на Python было реализовано. И Conditional Inference Trees в питоне не хватает, хотя видел обсуждение, что кто-то собирался реализовать в sklearn.
В целом да, в реализации деревьев R обгоняет питон. То же можно сказать и про визуализацию и линейные модели.

Dsvolkov
18.03.2017 19:05+2Мне кажется там небольшая путиница в использовании терминов в начале. «Энтропия состояния», которая несколько раз встречается — это не совсем правильно, состояний там два исходя из исходного определения — «вытащили желтый» и «вытащили синий», а энтропия — одно единственное число. Лучше набором или группой везде называть. Ну и если уж совсем придраться — энтропия не группы шариков, а энтропия вытаскивания одного шарика из этой группы. Потому что если бы мы вытаскивали 2 шарика, то состояния, вероятности и в конечном итоге энтропия были бы уже другими. Может это буквоедство, но честно сказать сбило поначалу.
Meklon
Изумительно, спасибо за хороший материал.
З.Ы. Maaariii — лови инвайт)