
Данная статья является первой частью текстовой версии одноименного доклада с февральской конференции C++ CoreHard Winter 2017. Так уж получилось, что вот уже 15 лет я отвечаю за разработку фреймворка SObjectizer. Это один из тех немногих все еще живых и все еще развивающихся OpenSource фреймворков для C++, которые позволяют использовать Модель Акторов. Соответственно, за это время неоднократно доводилось попробовать Модель Акторов в деле, в результате чего накопился некоторый опыт. В основном это был положительный опыт, но есть и некоторые неочевидные моменты, про которые было бы хорошо узнать заранее. О том, на какие грабли довелось наступить, какие шишки были набиты, как можно упростить себе жизнь и как это сказалось на развитии SObjectizer-а и пойдет речь далее.
Подозреваю, что многое из того, о чем я буду говорить, хорошо известно в Erlang-сообществе. Но Erlang-сообщество слабо пересекается с C++ сообществом. Кроме того, есть разница между тем, что доступно Erlang-разработчику и тем, что доступно C++ разработчику. Поэтому надеюсь, что данная статья окажется интересной и полезной C++никам.
Сам SObjectizer появился весной 2002-го года в компании «Интервэйл». SObjectizer создавался исключительно как рабочий инструмент. Поэтому он сразу же пошел «в дело» и использовался внутри нескольких продуктов как внутри компании, так и за ее пределами:
- электронная и мобильная коммерция;
- мобильный банкинг;
- агрегация SMS/USSD-трафика;
- имитационное моделирование;
- тестовые стенды для проверки ПО АСУ ж/д транспорта;
- прототипирование распределенной системы сбора измерительной информации.
Часть из этих продуктов находится в эксплуатации до сих пор.
Пара слов об актуальности Модели Акторов
Коротко освежим в памяти основные моменты Модели Акторов:
- актор – это сущность, обладающая поведением;
- акторы реагируют на входящие сообщения;
- получив сообщение, актор может:
- отослать некоторое (конечное) количество сообщений другим акторам;
- создать некоторое (конечное) количество новых акторов;
- определить для себя новое поведение для обработки последующих сообщений.
Модель Акторов подразумевает, что прикладная работа в приложении выполняется отдельными сущностями, акторами, которые взаимодействуют друг с другом только посредством асинхронных сообщений.
Актор спит в ожидании входящего сообщения, затем, когда входящее сообщение появляется, он просыпается и выполняет обработку сообщения, после чего снова засыпает до получения следующего сообщения.
По историческим причинам у нас в SObjectizer используется термин агент, а не актор, поэтому далее в тексте будут употребляться оба термина, обозначать они будут одно и то же.
И еще пара слов о применимости Модели Акторов в С++
По моему личному мнению, использование Модели Акторов в C++ дает нам целый ряд бонусов:
- каждый актор обладает собственным состоянием, которое доступно только ему одному. Это очень сильно упрощает жизнь в многопоточном программировании;
- передача информации посредством асинхронных сообщений является удобным и естественным способом решения некоторых типов задач. И Модель Акторов в таких задачах снижает семантический разрыв между предметной областью и реализацией;
- при использовании Модели Акторов связность компонентов оказывается очень слабой, что упрощает их композицию и тестирование;
- механизм взаимодействия на основе асинхронных сообщений очень хорошо дружит с таймерами. Использовать таймеры в виде отложенных или периодических сообщений в Модели Акторов — это одно удовольствие;
- C++ники-новички входят в тему многопоточного программирования на базе Модели Акторов на удивление быстро. Вчерашние студенты за короткое время начинают писать надежный многопоточный код.
Грабли и набитые шишки
Описанные выше бонусы мы получаем только если задача хорошо ложится на Модель Акторов. А хорошо ложится далеко не всегда. Так что нужно проявлять осмотрительность: если мы возьмемся за Модель Акторов, например, в тяжелых вычислительных задачах, то можем получить больше боли, чем удовольствия.
Если же Модель Акторов хорошо подходит под какую-то предметную область, то за счет использования правильного инструментария можно очень сильно упростить себе жизнь.
Но и в этом случае крайне желательно иметь представление о некоторых вещах, которые можно отнести к категории «граблей» или «подводных камней». Далее я буду рассказывать о некоторых граблях, по которым довелось потоптаться лично. Надеюсь это поможет кому-то набить меньше шишек, чем довелось мне.
Перегрузка агентов
Один из самых страшных подводных камней — это проблема перегрузки акторов.
Перегрузка возникает тогда, когда агент не успевает обрабатывать свои сообщения.
Например, кто-то нагружает агента с темпом 3 сообщения в секунду, а агент может обработать только 2 сообщения в секунду. Получается, что в очереди агента на каждом такте оказывается еще одно необработанное сообщение.
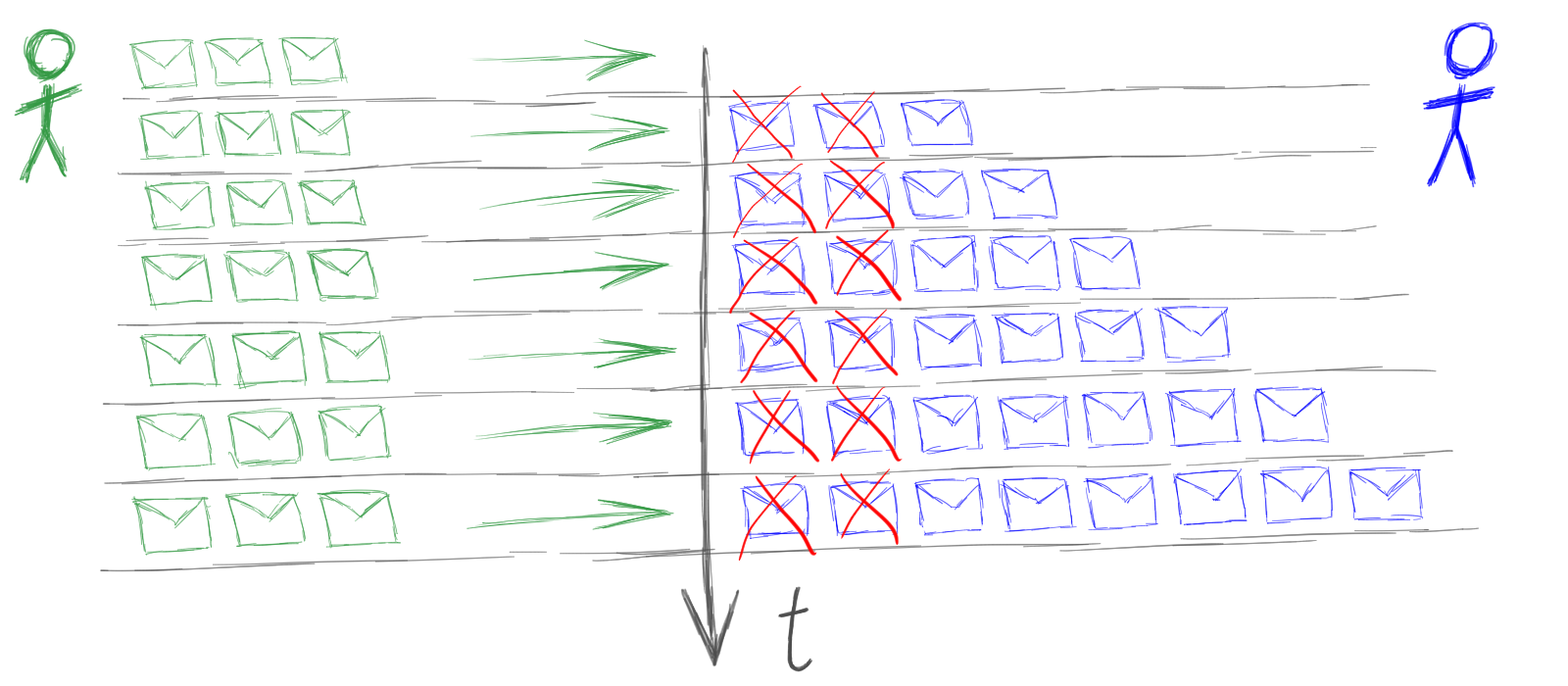
Если агент никак не защищен от перегрузок, то последствия будут печальными: очередь входящих сообщений будет распухать, память будет отжираться, расход памяти будет приводить к замедлению скорости работы, что будет приводить еще к более быстрому росту очередей и т.д. В итоге приложение деградирует до полной потери работоспособности.
Почему перегрузка так страшна в Модели Акторов?
При асинхронном взаимодействии на базе отсылки сообщений нет простой возможности реализовать обратную связь (она же back pressure). Т.е. агент-отправитель просто не знает, насколько заполнена очередь агента-получателя и не может просто так приостановиться до тех пор, пока агент-получатель разгребет свою очередь. В частности, и агент-отправитель, и агент-получатель, могут работать на одной и той же рабочей нити, поэтому если агент-отправитель «уснет», то заблокирует общую рабочую нить вместе с агентом-получателем.
Сложность борьбы с перегрузками в том, что хороший механизм защиты от перегрузки должен быть заточен под конкретную задачу. Где-то при возникновении перегрузки можно выбрасывать самые свежие сообщения. Где-то нужно выбрасывать самые старые. Где-то для старых сообщений нужно выбирать другую стратегию обработки.
Где выход?
Мы на своем опыте убедились, что довольно хорошо зарекомендовал себя поход на базе двух агентов: collector-а и performer-а, каждый из которых работает на разных рабочих нитях. Агент-collector накапливает сообщения и обеспечивает защиту от перегрузки. Агент-perfomer периодически запрашивает очередную порцию сообщений у агента-collector-а. Когда очередная порция обработана, агент-performer вновь запрашивает следующую порцию и т.д.
Но плохо здесь то, что это все нужно делать прикладному программисту. Было бы лучше иметь набор готовых инструментов для этих целей. Поэтому мы встроили в SObjectizer специальный механизм под названием "лимиты для сообщений" который позволяет программисту использовать несколько готовых простых политик для защиты своих агентов от перегрузки.
Выглядеть в коде это может вот так:
class collector : public so_5::agent_t {
public :
collector(context_t ctx, so_5::mbox_t quick_n_dirty)
: so_5::agent_t(ctx
// Запроса get_status достаточно всего одного.
+ limit_then_drop<get_status>(1)
// Лишние запросы будут передаваться другому агенту,
// который работает более грубо, но быстро.
+ limit_then_redirect<request>(50, [quick_n_dirty]{ return quick_n_dirty; } )
// Если же не успеваем отдавать накопленное, то работать
// дальше не имеет смысла.
+ limit_then_abort<get_messages>(1))
...
};Небольшие пояснения
Посредством «лимитов для сообщений» можно указать, например, что в очереди сообщений агента достаточно иметь только одно сообщение типа get_status, а остальные сообщения этого типа можно просто и безболезненно выбрасывать:
limit_then_drop<get_status>(1)Можно указать, что в очереди должно быть не более 50 сообщений типа request, а остальные сообщения этого типа нужно отсылать другому агенту, который выполнит обработку каким-то другим способом (скажем, если это запрос на ресайз картинки, то сделать ресайз можно более грубо, но значительно быстрее):
limit_then_redirect<request>(50, [quick_n_dirty]{ return quick_n_dirty; } )В некоторых случаях превышение допустимого количества сообщений в очереди является свидетельством того, что все совсем плохо и лучше прервать работу всего приложения. Например, если в очереди появляется второе сообщение типа get_messages, пока еще не было обработано первое,
то явно что-то идет совсем не так, поэтому нужно вызвать std::abort, рестартовать и начать все заново:
limit_then_abort<get_messages>(1)Добавленные в SObjectizer лимиты для сообщений не являются полноценным механизмом защиты от перегрузки (поскольку такие механизмы должны затачиваться под конкретную задачу), но в простых случаях и при быстром прототипировании лимиты для сообщений зарекомендовали себя вполне успешно.
Доставка сообщений ненадежна
Для кого-то это может стать сюрпризом, но доставка отосланного сообщения получателю не гарантируется. Т.е. сообщение может быть просто потеряно где-то по дороге. Есть несколько основных причин, по которым отосланное сообщение может не дойти до агента-получателя:
- получателя уже просто нет. Т.е. он существовал на момент отправки, но затем успел исчезнуть;
- получатель есть, сообщение до него дошло, но получатель просто проигнорировал сообщение в своем текущем состоянии;
- сообщение до получателя не доходит, например, из-за механизма «лимитов для сообщений».
Иными словами, когда вы асинхронно отсылаете кому-то сообщение, у вас нет никакой уверенности в том, что сообщение до получателя дойдет.
Давайте представим себе, что агент A отсылает сообщение x агенту B и ожидает получить в ответ сообщение y. Когда сообщение y к агенту A доходит, агент A счастлив и продолжает свою работу.
Однако, если сообщение x до агента B не дошло, а потерялось где-то по дороге, то агент A будет напрасно ждать ответного сообщения y.

Если забыть про ненадежность сообщений, то легко можно оказаться в ситуации, когда приложение просто перестало работать после потери нескольких сообщений. Как в данном примере: агент A не сможет продолжать работу, пока не получит сообщение y.
Соответственно, возникает вопрос: «Если сообщения ненадежны, то как с этим жить?»
Что делать?
Нужно проектировать работу агентов так, чтобы потеря сообщений не сказывалась на работоспособности. Есть два простых способа для этого:
- Перепосылка сообщения после тайм-аута. Так, если агент A не получил от агента B сообщение y в течении 10 секунд, то агент A может заново перепослать сообщение x. Но! Здесь нужно понимать, что перепосылки сообщений — это прямой путь к перегрузке агентов. Поэтому агент B должен быть защищен от перегрузки сообщениями x.
- Откат операции, если ее результат не был получен в течении разумного времени. Так, если агент A не получает от агента B сообщение у в течении 10 секунд, агент A может отменить ранее выполненые действия на своей стороне. Ну или выставить для своей текущей операции статус «результат неизвестен» и перейти к обработке следующей операции.
На первый взгляд может показаться, что если взаимодействие посредством асинхронных сообщений ненадежно, то ненадежным будет и само приложение, которое разрабатывается на базе Модели Акторов. На практике же оказывается интереснее: надежность приложения как раз таки повышается (на мой взгляд, по крайней мере). Объясняется это тем, что разработчик сразу вынужден закладывать в своих агентов какие-то механизмы преодоления нештатных ситуаций. И эти механизмы срабатывают, когда нештатные ситуации все-таки возникают.
Коды ошибок vs Исключения
На эти грабли мы наступили именно как разработчики SObjectizer-а. Хотя последствия сказываются на пользователях. Дело в том, что когда мы сделали первую версию SObjectizer в 2002-ом году, мы не стали использовать исключения для информирования об ошибках. Вместо этого использовались коды возврата.
Со временем выяснилось, что коды ошибок не есть надежно. Тут сработало правило: если что-то может быть забыто, оно будет забыто. Достаточно где-то прозевать обработку ошибок или же свести обработку ошибки только к ее логированию, то это обязательно со временем вылезет боком. Например, приложение перестанет обрабатывать какие-то запросы пользователя. Следы проблемы затем можно будет отыскать где-то в логе. Но это уже постфактум, когда проблема уже проявилась на пользователях.
Поэтому когда в 2010-ом мы начали делать новую версию SObjectizer, сломав совместимость с предыдущей, мы перешли на использование исключений для информирования о возникающих ошибках.
На мой взгляд, это положительным образом сказалось и на надежности и на качестве приложений. Проблемы теперь не «проглатываются» и любое отклонение от нормы сразу становится заметно.
Вопрос почти на миллион
Давайте представим себе ситуацию, когда агент B обрабатывает сообщение от агента A. И в процессе обработки этого сообщения возникает ошибка, агент B выбрасывает из своего обработчика исключение. Что с этим делать?
У этой проблемы есть две составляющие:
- Агент B работает на контексте, которым владеет SObjectizer. И SObjectizer понятия не имеет, что делать с исключением, которое вылетело из агента B. Может это исключение говорит о том, что все совсем плохо и продолжать работу дальше нет смысла. А может это какая-то ерунда, на которую можно не обращать внимания.
- Даже если перехватить исключение, которое вылетело из агента B, и попытаться доставить его агенту A, то может оказаться, что:
- Агента A уже попросту нет, он уже прекратил свое существование.
- Даже если агент A есть, ему может быть просто не интересно получать информацию о проблемах агента B.
- Даже если агент A есть и даже если ему интересно получить информацию о проблемах агента B, то мы можем просто не доставить эту информацию до агента A по каким-то причинам (например, из-за защиты агента A от перегрузок).
Что же с этим сделать?
В SObjectizer мы сделали специальный флаг, который определяет, что нужно делать, если из агента вылетает исключение. Например, убить все приложение сразу, дерегистрировать проблемного агента или проигнорировать исключение.
То, что агент дерегистрируется при выпуске наружу исключения, позволяет организовать механизмы супервизоров, как в Erlang-е. Т.е., если какой-то агент «падает» из-за исключения, то агент-супервизор сможет на такое падение среагировать и рестартовать «упавшего» агента.
Здесь вам не Erlang, здесь климат иной
Только вот наша практика показывает, что в случае C++ это все не так радужно, как в Erlang-е или каком-то другом безопасном языке. В Erlang-е принцип let it crash возведен в абсолют. Там, грубо говоря, даже на деление на ноль обращать внимание не принято. Ну попробует Erlang-овый процесс поделить на ноль, ну упадет, Erlang-овая виртуальная машина почистит мусор, супервизор создаст упавший процесс заново и все. А вот в C++ попытка деления на ноль, скорее всего, убьет все приложение, а не только того агента, в котором ошибка произошла.
Еще один важный момент: агент — это C++ный объект. Если мы принимаем решение его изъять из приложения, то мы все равно должны его аккуратно удалить, как любой другой объект, время жизни которого истекло. Т.е. для объекта-агента будет вызван деструктор, и этот деструктор должен нормально отработать.
А это означает, что объект-агент должен обеспечивать хотя бы базовую гарантию безопасности исключений. Т.е., если объект-агент выпустил наружу исключение, то никаких утечек ресурсов или порчи чего-либо в программе возникнуть не должно.
Что автоматически ведет к тому, что в C++ принцип «let it crash» выглядит сильно иначе, чем в Erlang-е. И если мы уж начинаем заботиться о том, чтобы агент обеспечивал какие-то вменяемые гарантии по отношению к исключениям, то быстро выясняется, что нам незачем перекладывать заботы о преодолении последствий ошибок на фреймворк. Это может сделать сам агент.
Что ведет к тому, что агенты естественным образом начинают поддерживать nothrow гарантию. Т.е. не выпускают наружу исключений вообще. Грубо говоря, обработчики сообщений в агентах, в которых делается что-то серьезное, содержат внутри блоки try-catch. А уж если при этом из агента исключение вылетает наружу (что означает что-то непредвиденное в блоке catch), то значит что-то не так со всем приложением. И в этом случае убивать нужно не одного проблемного агента, а все приложение. Поскольку мы не можем гарантировать его дальнейшей корректной работы.
Отсюда мораль: С++ — не Erlang и не стоит в C++ переносить подходы для обработки ошибок, подходящие для Erlang-а или какого-то другого языка программирования.
На этом для первой части все, продолжение здесь.
Комментарии (70)

eao197
22.03.2017 12:55Пока, у меня возник, только, один вопрос: а почему агенты обязаны быть объектами — экземплярами классов C++?
Ну тут, скорее, смешение деталей реализации и опыта использования. В агенте должны быть какие-то атрибуты, которые нужны самому фреймворку для обслуживания агента. Удобно это оформлять в виде агента. Кроме того, практика показала, что в реальной жизни агенты очень быстро перерастают маленькие однострочники и могут достигать размеров в сотни, а то и в тысячи строк. Плюс временами активно используется наследование. Т.е. какой-то базовый класс агента вбирает в себя основной функционал, а другие классы-наследники только уточняют его работу. Так что использование здесь объектов и принципов ООП себя, на мой взгляд, оправдывает.
Кроме того, у нас есть такое понятие, как ad-hoc агент, когда агент просто конструируется из лямбда-функций без необходимости определять класс агента и создавать его экземпляр. Вот простой пример. А вот еще один — тут агент ponger реализуется в виде ad-hoc агента с лямбдой-однострочником.
OlegZH
22.03.2017 13:34А как-то опробовать в деле это всё можно?
eao197
22.03.2017 13:56Конечно. Берете SObjectizer с SourceForge или с github-а и пробуете сколько угодно :)
С SourceForge можно сразу бинарники для MSVC++ загрузить.
AlexTheLost
22.03.2017 12:58+1Использовал Akka+Scala. Был в начале воодушевлен идей акторов. Попробовал Akka, был несколько разочарован. В итоге для классического подхода считаю нужно выбирать Future, далее объясню что имею ввиду.
Почему? Мы работаем c актором просто как с ActorRef без типа, соответственно нет гарантий на стадии компиляции что сообщение передается конкретному актору(типу акторов) и актор может его обработать в принципе, нужно писать тесты. Нет гарантий на стадии компиляции что актор инициализируется корректно, из-за отсутствия типа, например передаются не корректные параметры как аргументы конструктора.
По итогу мы получаем такую цепочку боли:
1) Нет гарантии что все акторы инициализировались правильно при старте приложения.
2) Нет гарантий что все акторы передают сообщения тем акторам которым должны и принимаю сообщения от тех от которых должны.
3) Нет гарантии что актор сможет обработать пришедшее сообщение. Вы добавляете передачу сообщения в один актор но можете пропустить добавление его обработчика в один из акторов который потенциально его может принимать, и это из-за отсутствия типизации.
Т.е. нужно писать очень много тестов.
В целом хорошо описано тут: http://stew.vireo.org/posts/I-hate-akka/
Сейчас вижу только одно применение акторам, но сильное (по сути это и есть их суть, замысел) — построение stateful вместо stateless приложений когда на каждую сущность в системе ровно один актор и даже если это распределенная система(через akka claster). Если строить систему таким образом то получается очень много преимуществ — отсутствие необходимости кэша между backend'ом и хранилищем данных и состояния гонок, потому что за каждую сущность отвечает ровно один актор хранящий свое состояние и он обрабатывает все приходящие к нему данные последовательно. В случае распределенной системы akka cluster — это секционирование(partitioning) из коробки. Но остается все же вопрос как выполнить транзакцию которая захватывает больше одного актора(т.е. сущности).
eao197
22.03.2017 13:09В итоге для классического подхода считаю нужно выбирать Future, далее объясню что имею ввиду.
Для классического подхода к чему?
Нет гарантии что все акторы инициализировались правильно при старте приложения.
С Akka не работал, поэтому не сильно понимаю, как такое возможно.
Нет гарантий что все акторы передают сообщения тем акторам которым должны и принимаю сообщения от тех от которых должны.
Ну вот это как сильная, так и слабая сторона. Сильная сторона в том, что позволяет писать в стиле fire-and-forget, а так же позволяет легко подменять отправителей/получателей. С другой стороны, все проверки только в run-time. Но, опять же, за счет легкой подмены отправителей/получателей тестировать легко, а ведь тестировать саму обработку сообщения все равно нужно, даже если правильность подписки по типам гарантируется в compile-time.
Кроме того, это не столько проблема самой Actor Model, скорее отдельных ее реализаций. В CAF, например, делают каких-то типизированных акторов, у которых соответствие типов сигнала/слота проверяется в compile-time. Я, правда, не сильно понимаю, насколько это полезно на практике, мы как-то с подобными проблемами не сильно сталкивались. Да и с расширяемостью не очень понятно.
Плюс очень сильно жизнь упрощается, когда у фреймворка есть средства трассировки процесса доставки сообщений.
построение stateful вместо stateless приложений когда на каждую сущность в системе ровно один актор
Об этом речь пойдет во второй части статьи.

solver
22.03.2017 13:58+2А как вы планируете типами гарантировать, что актор послал сообщения тем кому «должен» послать и от кого «должен» принять? Может все таки не «должен», а «может»? )
Суть акторов, что любой актор может послать любое сообщение любому актору и только актор сам решает, может он обработать это сообщение или нет. Это позволяет строить очень гибкие решения.
Иначе у вас получится обычный ООП с дерганьем методов и сильной связанностью. Поэтому вам и Future больше подходит для задач чем акторы.
Собственно никто и никогда не обещал, что акторы везде хорошо подходят.
Писал несколько проектов на Akka, вообще ни разу не сталкивался с неправильной инициализацией акторв и всеми теми проблемами что вы описали. Даже новички так не ошибались в коде.
Все эти проблемы выглядят теоретиконадуманными или притянутыми за уши. И на практике возможны только у совсем пофигистов новичков, которые копипастят код со SO не понимаю что и как они делают…
Потому что ровно все те же проблемы есть у всех языков и всех фреймворков:
1. Более менее еще в тему, хотя проблема правильно иницализации пристутствует во многих фреймворках.
2. Таких гарантий нет ни в одном приложении. Это все зависит только от разработчика. Он может забыть что угодно. В одном месте добавил метод, в другом забыл его «дернуть».
3. Таких гарантий тоже нет ни в одном приложении, см п 2.
И да, на такие вещи помогут только тесты, нет других вариантов пока.eao197
22.03.2017 14:06А как вы планируете типами гарантировать, что актор послал сообщения тем кому «должен» послать и от кого «должен» принять?
Объективно, бывают случаи, когда хорошо было бы заранее знать, что отсылать сообщение типа x агенту А бесполезно, он такие сообщения в принципе не обрабатывает. Обычно такое бывает в результате разделения большого старого актора на несколько новых, поменьше. Раньше актор А обрабатывал x, теперь это делает актор B.
Но, опять же, это палка о двух концах. Т.к. со временем актор A вновь может начать обрабатывать x, только уже совсем по-другому.
Так что тут, имхо, нет однозначных преимуществ у проверок в compile-time и в run-time, у обоих подходов сильные стороны превращаются в недостатки и наоборот.
PHmaster
22.03.2017 15:55+1А как вы планируете типами гарантировать, что актор послал сообщения тем кому «должен» послать и от кого «должен» принять? Может все таки не «должен», а «может»? )
…
- Таких гарантий нет ни в одном приложении. Это все зависит только от разработчика. Он может забыть что угодно. В одном месте добавил метод, в другом забыл его «дернуть».
- Таких гарантий тоже нет ни в одном приложении, см п 2.
Про интерфейсы в ООП не слышали? А про статическую типизацию? То и другое вместе дает целый ряд определенных гарантий. Модель акторов просто лишает разработчика всего вот этого. В
Akka, например, для решения этой проблемы существуютTyped Actors(которые сейчас в процессе замещения проектомTyped Akka). По сути, из актора получается все тот же объект из ООП, со строго типизированным интерфейсом, дающим определенные гарантии, но с асинхронным вызовом методов (с пересылкой сообщений, асинхронными ответами, тайм-аутами и прочими акторскими плюшками "под капотом"). И это гарантирует на этапе компиляции, что сообщение будет отправлено нужному агенту, а не кому попало. Иначе приложение просто не скомпилируется. А если агент на каком-то этапе разработки приложения перестанет обрабатывать сообщения какого-то типа — то из его интерфейса пропадет соответствующий метод, и компилятор об это сообщит, и покажет все места, в которых кто-то все еще пытается этот метод дергать.eao197
22.03.2017 16:01И это гарантирует на этапе компиляции, что сообщение будет отправлено нужному агенту, а не кому попало.
Все не так однозначно.
Во-первых, кому попало все равно можно отправить. Если вы отсылаете сообщения акторам A и B, и по ошибке отсылаете сообщение актору A вместо актора B, то вы все равно ошибаетесь с адресатом.
Во-вторых, как сказано в статье, даже если вы отсылаете сообщение правильного типа правильному агенту, вам все равно никто в compile-time не гарантирует ни доставку сообщения, ни его корректной обработки.
Так что в теории выгода от проверок в compile-time есть и она выглядит существенной. На практике все равно без тестирования прогона всех нужных сообщений не обойтись. Что уменьшает стоимость этого аргумента.PHmaster
22.03.2017 19:41+1Во-первых, кому попало все равно можно отправить.
Ну, с типизацией совсем уж кому попало отправить уже не получится, как минимум принимающий интерфейс должен будет соответствовать отправляемому сообщению. Что уже отсекает довольно много возможных неприятностей. А если спрятать актора за фасадом какого-ниубдь интерфейса в духе Active Object, то добавятся еще названия методов, и возможность сделать что-то не так сводится к минимуму.
В общем, типизированные акторы не на ровном месте появились, и развитие в этом направлении продолжается.
eao197
22.03.2017 19:50На эту тему можно бесконечно спорить, но меня вот что интересует: вы на своем опыте поимели много неприятностей из-за нетипизированности акторов? Может какие-то примеры сможете вспомнить?
А то на моем опыте это совершенно не проблема. Гораздо больше неприятностей доставляют такие ошибки, когда подписку на сообщение вообще забывают сделать или же забывают ее сделать в нужном состоянии.
Но вот случаи, когда агенту отсылается какое-то не то сообщение — это какая-то экзотика.PHmaster
23.03.2017 02:04+1вы на своем опыте поимели много неприятностей из-за нетипизированности акторов?
Да, иначе бы я об этом не писал. Статья же о шишках — вот я своих еще в копилку подбросил. Могу вспомнить пару-тройку неудобств из-за отсутсвия типизированного интерфейса у акторов:
- Отсутствие подсказок в IDE. Что приводит к частой необходимости лезть либо в исходный код актора, либо в документацию (если это сторонняя библиотека, и/или поведение в исходном коде не очевидно). Это ощутимо замедляет процесс разработки.
- Дополнительные тесты на то, что актор не отправляет ничего "левого" другому актору. С типизированными интерфейсами это невозможно "by design". Опять разработка замедляется: часть работы компилятора перекладывается на программиста.
- С эволюцией приложения какой-то компонент обновляется, какие-то эти обновления подхватывают, а какие-то обновить забыли — и они продолжают использовать старый "интерфейс". Компилятор это не отлавливает, приходится сталкиваться с последствиями в рантайме и долго и нудно разгребать логи, чтобы понять, где причина. А ошибки рантайма, как известно, гораздо более дорого обходятся в конечном счете. С типизированными интерфейсами вероятность такой ситуации — минимальная. Разве что если в методе два однотипных аргумента зачем-то местами поменять.
Больше так не вспомню, это пару лет назад было, и с тех пор я весь проект перевел таки на фьючерсы, а от акторов совсем отказался (несмотря на ряд их неоспоримых достоинств). А вообще, в интернетах много холиваров на тему "статическая типизация vs динамическая", почитайте как-то на досуге — там можно встретить много интересного и полезного. По обе стороны баррикад.
eao197
23.03.2017 08:09Понятно, спасибо за подробности.
Правильно ли я понимаю, что этот опыт был получен на основе использования Akka в Scala/Java?PHmaster
23.03.2017 10:21Да, Akka+Scala.
eao197
23.03.2017 10:54Я тут пытался понять, почему мы у себя с такими проблемами не сталкивались. Есть подозрение, что на то есть две причины.
У нас зачастую типы сообщений были вложенными типами для агентов. Т.е., у нас было что-то вроде (пример грубый, просто для иллюстрации):
Соответственно, все взаимодействие шло через имена вида file_agent::write_data и file_agent::loaded_data.class file_agent { public : // Сообщения, которыми оперирует агент. struct write_data {...}; struct loaded_data {...}; ... };
Основное взаимодействие у нас происходило между агентами, которые входили в одну группу (у нас это называется кооперацией). Создание таких агентов выполняется в одном месте, все взаимосвязи устанавливаются там же, поэтому шансов допустить ошибку меньше.
Тем не менее, если у пользователей акторных фремворков есть желание работать с типизированными интерфейсами и иметь контроль типов в compile time, то об этом нужно задуматься. Вот, например, что-то подобное вас бы устроило? Или этого недостаточно и хочется чего-то еще более строгого?PHmaster
23.03.2017 13:02Дело в том, что это не совсем даже и проблема, это скорее просто неудобство. И только для тех, кто привык к строгой типизации и проектированию через интерфейсы. Может быть, это вообще попытка натянуть ужа на ежа, и акторы по природе своей должны быть нетипизированными. В Akka до сих пор ищут элегантное решение этого вопроса: текущая реализация, экспериментальная новая версия. Ведь помимо типизированных ящиков для сообщений там всплавает еще ряд тонкостей и нюансов: смена поведения, типизированный отправитель обрабатываемого сообщения, и т.п. И сам язык должен быть достаточно гибким, чтобы все эти нюансы учесть.
eao197
23.03.2017 13:07смена поведения, типизированный отправитель обрабатываемого сообщения
А в чем суть этих нюансов? Хотя бы в двух словах? Ну или ссылку на какое-то описание. Реально поможет лучше разобраться.PHmaster
23.03.2017 14:48Ну так я же привел выше 2 ссылки, там даже с примерами кода на Scala. Там же и для Java, думаю, можно найти аналогичные разделы в доках, если есть необходимость. А в двух словах: если поведение актора меняется (в ответ на сообщение) — то в типизированном интерфейсе это должно как-то отражаться. А типизированный sender: актору должен быть известен тип отправителя, когда он получает от кого-то сообщение. Для ответа, например.
eao197
23.03.2017 14:53Я прочел. Но думал, может у вас дополнительная информация есть.
На счет поведения: походу, во втором документе они сами пришли к выводу, что это статически непроверяемо. Да и вообще вряд ли нужно. Особенно, если на актора смотреть как на конечный автомат: внешний наблюдатель знает только общий список входящих сообщений для КА, но не должен иметь представления о том, какие сообщения актуальны для КА в его текущем состоянии. Тем более, если брать в рассмотрение иерархические КА, в которых реакция на входящее сообщение может наследоваться из родительского состояния.
По поводу ответов тут вроде как все тривиально: типизированные почтовые ящики/каналы в качестве получателя ответа успешно закрывают эту тему.PHmaster
24.03.2017 02:55Насчет поведения: все еще усложняется тем, что одному актору-конечному автомату могут слать сообщения несколько других, и у них между собой будет рассинхронизация, так как нет никаких гарантий, что между двумя сообщениями от одного актора не прилетело что-то от другого и не изменило состояние конечного автомата. На этапе компиляции я не вижу возможности эту проблему как-то решить.
По поводу ответов — мне это таким уж тривиальным не кажется. Есть актор A, он получил сообщение M. От кого он его получил? Какой тип имеет отправитель этого сообщения? Какие сообщения он может принимать в ответ? Гарантировать тип отправителя можно, например, в том случае, если "зашить" его в протокол, то есть ограничить интерфейс с двух сторон: что вот это сообщение может приходить только от такого типа акторов, и только такому типу акторов. В Akka этот механизм тоже претерпевает эволюционные изменения, и об этом по приведенным ссылкам тоже упоминается.
eao197
24.03.2017 08:58На этапе компиляции я не вижу возможности эту проблему как-то решить.
А зачем ее решать на этапе компиляции?
Тут скорее вопрос владения ссылкой на актора-получателя. Если ссылкой владеет только один отправитель, то никаких сложностей нет, идет обычное взаимодействие 1:1. Если ссылкой владеет N отправителей, то ничто не препятствует взаимодействию N:1. Если конкретного программиста N:1 для конкретного актора-получателя не устраивает то… То такому программисту нужно выдумывать для своей задачи какой-то аналог Rust-овских «заимствований» для actor_reference. Чтобы добиться гарантий того, что в конкретный момент времени actor_reference доступен только одному отправителю.
Только есть большие сомнения в том, что многим потребуется что-то подобное.
Гарантировать тип отправителя можно, например, в том случае, если «зашить» его в протокол, то есть ограничить интерфейс с двух сторон: что вот это сообщение может приходить только от такого типа акторов, и только такому типу акторов.
А зачем это нужно? В каких практических задачах это может потребоваться?
Я еще могу понять, когда на уровне контракта пытаются описать, что в ответ на сообщение X может быть получено Y или Z. Но чтобы при этом требовалось, что ответ на X должен получить только актор типа N, это уже что-то противоречащее здравому смыслу. Ибо такая типизация мешает переиспользованию акторов.
Какой-нибудь актор connection_pool сегодня используется в одном проекте, где он общается с акторами temperature_sensors, а завтра будет использоваться в другом проекте, где он общается с акторами risk_managers. Введение требований к типам агентов-consumer-ов приведет к тому, что эти требования придется удовлетворять и для temperature_sensors, и для risk_managers. Ну и зачем это нужно, если temperature_sensors и risk_managers и так будут вынуждены приспосабливаться к интерфейсу connection_pool-а на уровне сообщений acquire, release, take и failure?PHmaster
24.03.2017 13:16А зачем ее решать на этапе компиляции?
А зачем это нужно? В каких практических задачах это может потребоваться?Все это нужно для обеспечения типобезопасности. Все эти вопросы Akka пытается решить. Раз пытается — значит, видит необходимость.
Введение требований к типам агентов-consumer-ов приведет к тому...
Это ведь не совсем ограничение на тип, это ограничение на реализуемый ими интерфейс. В Akka приводится пример реализации протокола, когда в ответ на вот такое сообщение актор может отправить вот такое сообщение, а следом за этим сообщением "тип" (интерфейс) актора меняется на вот такой (то есть он уже может получать-отправлять другие сообщения). Протокол ограничен типами с двух сторон, то есть, актор A1, получая сообщение типа M1, уверен на этапе компиляции, что его ему отправил актор A2, которому можно ответить сообщением M2. Как-то так.
Добавлено: отправка сообщения типизированному актору — это же ведь только половина задачи типизации. Актор же должен иметь возможноть точно так же типобезопасным способом на это сообщение ответить.
PHmaster
24.03.2017 13:25В данном случае, A1 и A2 — это всего лишь интерфейсы, которые говорят о том, что эти акторы могут принимать сообщения M1 и M2 соответсвтенно. То есть, если завтра вашему connection_pool-у захочет отправлять сообщения другой актор — он просто реализует необходимый интерфейс для получения типизированных ответов от connection_pool-а. При этом, в самом connection_pool ничего не нужно менять, так как сообщения-ответы не меняются и интерфейс любого получателя ему известен заранее.
eao197
24.03.2017 13:27В данном случае, A1 и A2 — это всего лишь интерфейсы, которые говорят о том, что эти акторы могут принимать сообщения M1 и M2 соответсвтенно.
Ну так в Модели Акторов M1 и M2 и есть те самые интерфейсы A1 и A2. Просто в статически типизированных ОО языках мы привыкли, что интерфейсы выражаются через перечисление методов. А в Модели Акторов интерфейсы выражаются через перечисление сообщений.PHmaster
24.03.2017 13:53А в Модели Акторов интерфейсы выражаются через перечисление сообщений.
Именно! Только в модели акторов нет интерфейсов, и сообщения нигде не перечислены. Ну, кроме как в исходном коде самого актора.
eao197
24.03.2017 13:25Все это нужно для обеспечения типобезопасности.
Типобезопасность не является самоцелью, как я надеюсь. Akka, как и SObjectizer, — это инструмент для решения практических задач. Если типобезопасность в каких-то задачах становится настолько важной, что этому уделяется внимание, то должны быть какие-то примеры.
Пока же разговор идет о том, что раз мы находимся в рамках статической типизации, то хотим иметь ее везде. В том числе и при взаимодействии акторов посредством асинхронных сообщений. Только вот проблема в том, что преимущества статической типизации для синхронных вызовов — они понятны и очевидны. А вот типизация асинхронного обмена сообщениями… Не понятно, и не очевидно.
Протокол ограничен типами с двух сторон, то есть, актор A1, получая сообщение типа M1, уверен на этапе компиляции, что его ему отправил актор A2, которому можно ответить сообщением M2.
Но зачем это? Это все может решаться и без попыток подружить Модель Акторов со статической типизацией.PHmaster
24.03.2017 14:02Типобезопасность не является самоцелью, как я надеюсь.
Да. Как и молоток. Это лишь удобный инструмент, который помогает решить некоторые задачи. Я привык к этому инструменту, он очень плотно вписан в мой рабочий процесс. И его потеря для меня очень ощутима.
Но зачем это? Это все может решаться и без попыток подружить Модель Акторов со статической типизацией.
Мы топчемся по кругу, вы не находите? Можете прочитать всю ветку комментариев еще раз, все мои доводы там перечислены. На всякий случай обобщу: просто потому что некоторые люди предпочитают типобезопасность другим решениям. Просто потому, что некоторые люди считают, что типобезопасноть решает многие проблемы эффективнее других подходов. Просто потому, что каждый выбирает для себя инструмент, которым лично ему удобнее работать.
solver
24.03.2017 14:22+1> Мы топчемся по кругу, вы не находите?
Потому собственно и топчемся, что нет внятного ответа на вопрос, зачем нужна такая навороченная типизация обмена сообщениями. Есть только очень абстрактное «потому что с типами лучше чем без них». Но речь ведь идет не о сферическом коне «статика vs динамика», а конкретно об интерфейсе для сообщений в акторах. И вот тут нет внятного объяснения что вылечит весь этот геморрой с такой жесткой типизацией интерфейсов.
Потому что на практике все описываемые проблемы вообще никак не ощущаются. Все примеры проблем, здесь в каментах, очень абстрактные и ничего толком не объясняют.
Все что я пока вижу, это попытку сделать из акторов обычный ООП с интерфейсами. И я не понимаю зачем это? ООП уже есть, зачем из акторов делать ООП мне не понятно…PHmaster
24.03.2017 16:27+1Я привел несколько вполне конкретных доводов из моей личной практики в пользу статической типизации акторов. Их дополнил eao197 еще парой примеров. Если вам все еще мало конкретики — то в тех же сферических холиварах "статика vs динамика" их есть еще, и к акторам это тоже вполне применимо.
Более того, есть мнение, что изначальная задумка ООП-подхода основывалась как раз на агентах, которые посылают сообщения друг другу. Но потом что-то пошло не так, и сейчас мы имеем ООП с синхронным дерганьем методов вместо пересылки сообщений. Хотя, попытки реализации объектов на сообщениях были (Objective-C, например).
eao197
24.03.2017 14:24Можете прочитать всю ветку комментариев еще раз, все мои доводы там перечислены.
Уверяю вас, все доводы прочитаны и осмыслены. Более того, я сам сторонник статической типизации и для проектов свыше 5KLOC вряд ли выберу динамически-типизированный язык.
Я продолжаю выпытывать у вас подробность из-за того, что отвечаю за разработку акторного фреймворка и пытаюсь понять, можно или из того, что вы рассказываете получить аргументы «за» для добавления в фреймворк дополнительной функциональности.
Поэтому и интересны примеры из жизни, дабы идею поддержки более строгой статической типизации было проще «продать» остальной команде.PHmaster
24.03.2017 16:51Если я единственный человек, который в принципе заговорил о типизации акторов (безотносительно вашего фреймворка, замечу, так как мой опыт основывается исключительно на Akka+Scala) — то ваше желание сразу же внедрить подобную функциональность в ваш фреймворк лично мне кажется несколько поспешным. Если ваши пользователи им и без того довольны — то оно им может быть и не нужно.
Если же были запросы от ваших пользователей — то вам лучше поспрашивать у них, зачем им это может быть нужно. Потому что Akka — это другой фреймворк, а Scala — другой язык и другой подход к программированию. Может быть, то, что применимо и удобно на Scala и Akka — совсем ненужно, неудобно или неприменимо к вашему фреймворку и C++.eao197
24.03.2017 17:02Ну мы же делать еще ничего не побежали. А вот в перспективный wish list почему бы и не добавить. Тем более, что наш опыт ограничен и SObjectizer, насколько мне известно, не использовался в проектах размером более 1MLOC. Так что может на других масштабах эта фича будет более востребованной.
Тем не менее, про примеры. Примеры с рефакторингом хороши, даже не смотря на то, что мы сами по каким-то причинам с подобными проблемами не сталкивались, представить себе их актуальность несложно.
А вот за примерам того, что агент-обработчик заинтересован в знании типа агента-отправителя, приходится идти куда-то далеко… :(
PHmaster
24.03.2017 13:35Ну и зачем это нужно, если temperature_sensors и risk_managers и так будут вынуждены приспосабливаться к интерфейсу connection_pool-а на уровне сообщений acquire, release, take и failure?
Ровно затем же, зачем нужна типобезопасность и интерфейсы в классическом ООП: там ведь тоже объекты вынуждены приспосабливаться к интерфейсам других объектов, посредством вызова методов друг друга. Так зачем интерфейсы, если и без них объект A может вызвать метод acquire у объекта B? Сообщения — это по сути те же методы. Только в интерфейсе они нигде не прописаны. В общем, эти все вопросы из разряда PHP vs Java. В PHP можно сделать $anyVar->anyMethod(), и получить ошибку на этапе исполнения, а Java этого не пропустит еще на этапе компиляции.
P.S. Прошу прощения за раздробленный ответ.
eao197
24.03.2017 14:20там ведь тоже объекты вынуждены приспосабливаться к интерфейсам других объектов, посредством вызова методов друг друга
Не совсем так. Если есть что-то вроде:
то нам не нужно заботиться о том, какой интерфейс имеет объект, который дергает connection_pool::acquire. Аналогичная ситуация и с акторами: есть сообщение acquire и есть ответное сообщение take. С ними все понятно. Легко придумать пример, который демонстрирует их надобность.class connection_pool { public: optional<connection> acquire(); ... };
А вот когда заходит речь о том, что для отсылки ответного сообщения take нужно, чтобы отправитель имел какой-то специальный тип take_acceptor, то здесь уже возникают проблемы с придумыванием конкретных примеров из практики, которые могли бы это все оправдать.
В общем, эти все вопросы из разряда PHP vs Java. В PHP можно сделать $anyVar->anyMethod(), и получить ошибку на этапе исполнения
Не совсем так. Принципиальная разница в том, что если в динамически-типизированном языке вы вызываете у объекта метод, которого у объекта нет, то вы гарантированно получите ошибку в run-time. В случае же с акторами, если вы отправляете актору сообщение, которое актор не поддерживает, вы об этом не узнаете. Более того, если вы отсылаете актору сообщение, которое он поддерживает, но сообщение до получателя не доходит, то вы имеете точно такой же эффект. Т.е. вы якобы получаете гарантии в компайл-тайм, которые ничего не стоят в ран-тайм.
И еще один момент. Если нетипизированные actor_reference настолько мешают жить, то ведь очень легко они превращаются в типизированных. Достаточно сделать что-то вроде:
И дальше у вас будет типизированная ссылка на актора, по которой вы легко определите, какой интерфейс есть у этого актора.namespace connection_pool { struct acquire { ... }; struct release { ... }; ... class actor_ref : protected actor_reference { ... }; ... }; connection_pool::actor_ref pool = make_actor<connection_pool::pool_actor>(...);PHmaster
24.03.2017 16:39нам не нужно заботиться о том, какой интерфейс имеет объект, который дергает connection_pool::acquire
Верно, потому что при этом мы имеем тип возвращаемого значения, которое получим, вызвав метод aquire(). А чтобы узнать, можно ли вообще отправить актору сообщение aquire, что он на него ответит, и должен ли вообще отвечать — нужно лезть либо в документацию к нему, либо в исходный код, что не всегда практически осуществимо. И это сильно понижает производительность труда программиста. Мою, по крайней мере.

Bronx
26.03.2017 05:47Похоже, вам нужно чтобы все акторы реализовали общий интерфейс типа IUnknown, с методом/сообщением QueryInterface, возвращающим информацию о поддержке того или иного интерфейса и дающий гарантию, что этот интерфейс будет поддерживаться пока жива ссылка на актора.
solver
22.03.2017 16:19+1Еще раз повторю вопрос.
Как вы, с помощью статической типизации, интерфейсов и прочего сможете гарантировать, что актор послал сообщение тем, кому должен?
Вот по пунктам распишие.
Если конкретизировать, то выражение «Гарнтия того что актор послал сообщение тому кому должен», означает, что вы в компайл тайме проверили, что какое-то сообщение актор отправил и какое-то сообщение актор получил. Для этого компилятору необходимо знание о том, что вообще должно происходить.
Другими словами, компилятор должен знать, что если мы создали метод, то кто-то где-то должен его обязательно его «дернуть». Как вы себе представляете это решение использую статическую типизацию?
Статическая типизация поможет только провериь, что мы передаем конкретный тип сообщения, и этот тип может обработаться актором. Но никак не может гарантировать что мы вообще посылаем такое сообщение и уж тем более не может гарантировать доставку сообщений.
У вас все смешалось в кучу.
Если говорить про акторы в целом, то т.к. под акторам подразумевается распределенная система, говорят что нет гарантий доставки. Но не потому что это акторы, а потому что система распределенная. Это обычная для новичков подмена понятий. На классическом ООП с Future то же нет гарантий доставки.
В общем случае вообще нет гарантии доставки сообщений в распределенной среде. Это в принципе не решаемая сейчас проблема. Ее только можно минимизировать разными способами. Гуглите «Задача двух генералов».
В рамках же одного приложения, гарантия доставки сообщения ровно такая же как и при вызове обычного метода.
Т.е. единственная проблема акторов в Акка, это не забыть сделать обработку сообщения в акторе.
Но эту ошибку точно так же легко допустить в любом коде и без акторов, забыв дернуть нужный метод.
P.S. Интерфейс с типами, в который обернут актор не гарантирует, что сообщение именно будет отправлено. А только то, что оно может быть отправлено именно с таким типом.
Программист легко может забыть его отправить при рефакторинге)PHmaster
22.03.2017 18:30Это вы вообще все в кучу смешали. Если уж вашими категориями рассуждать — то где вообще гарантия, что программист Василий написал программу, а не ушел пить кофе и играться в приставку?
Гарантия доставки сообщений — это отдельная история. Причем тут она к статической типизации?
Я говорю о том, что есть конкретные гарантии, которые предоставляет статическая типизация и статически типизированные интерфейсы. Я говорю о том, что я, выбрав для себя статически типизированный язык, привык к этим гарантиям, привык работать именно в этой парадигме, и вижу в ней лично для себя целую кучу удобств и бонусов. Я говорю о том, что нетипизированные акторы в статически типизированном языке лишают меня тех гарантий, которые дает мне этот язык. И заставляют меня работать так, как будто я перешел на какой-нибудь скриптовый язык с динамической типизацией. И мне это не нравится.
Это как если бы вам по почте прислали гаечный ключ, а на посылке написали, что это отвертка. А вы бы по внешнему виду не смогли бы понять, что это, попробовали этим открутить шуруп — но у вас не получилось, и только тогда вы поняли, что это не отвертка. Или может отвертка, а вы просто не так крутите? Или это не шуруп у вас вовсе? Вот в статически типизированном языке если вы имеете шуруп — то вы имеете шуруп, и его интерфейс это гарантирует. И если вы ждете отвертку — то вы получите отвертку, потому что ключ на ее место физически в посылку не влезет, и вам не смогут его отправить. А вот соизволил ли отправитель явиться на почту, не вскрыли ли посылку по пути, не сошел ли с рельс грузовой поезд — это уже к вопросам типизации не относится, это все из совершенно другой плоскости, не нужно мух с котлетами мешать.
eao197
22.03.2017 18:45Я говорю о том, что нетипизированные акторы в статически типизированном языке лишают меня тех гарантий, которые дает мне этот язык.
Статическая типизация никуда не девается. Вы вешаете обработчик на сообщение типа Msg1 и в этот обработчик приходит только сообщение типа Msg1. Сообщения других типов в ваш обработчик не попадут.
А вот как раз гарантии доставки и отсылка сообщения по другому адресу отношения к типизации не имеет. И из-за этих гарантий работа с Моделью Акторов имеет свои специфические особенности.PHmaster
22.03.2017 19:08+1Статическая типизация никуда не девается.
Внутри самого актора — да. Но сам по себе актор — вещь абсолютно бесполезная. Для того, чтобы он работал и приносил пользу — он должен взаимодействовать с внешним миром. Вот для формализации этого взаимодействия в ООП и существуют интерфейсы. А нетипизрованные акторы их начисто лишены. Кто-то может от этого испытывает какое-то особое наслаждение, кто-то выбирает своим рабочим инструменом языки с динамической типизацией, — это их неотъемлемое право. Но лично для меня, отсутствие типизированных интерфейсов — это большое неудобство.
eao197
22.03.2017 19:12Но лично для меня, отсутствие типизированных интерфейсов — это большое неудобство.
Тут выше уже говорили про такой аспект, как распределенность. Жизнь показала, что жестко специфицированные интерфейсы в распределенных системах (те же самые CORBA и DCOM) отнюдь не так хороши, как жесткотипизированное взаимодействие в рамках одного процесса. Например, сложности с расширением интерфейсов со временем. Тогда как взаимодействие систем на основе обмена сообщениями (причем с поддержкой разных версий) оказывается удобнее и гибче.PHmaster
22.03.2017 20:03Не вижу, как типизация может помешать системе обмениваться сообщениями. Типизированный актор просто добавляет удобный "фасад" для программиста в виде интерфейса взаимодействия, который уже является подсказкой, что из себя представляет этот актор, в отличие от безмолвного и безликого ActorRef. И ограничивает возможные способы неправильного применения. Упрощает поддержку в будущем, читабельность кода, время вхождения в проект для новичков. В общем, одни бонусы. А под капотом всего этого — все тот же актор, все та же пересылка сообщений, все та же асинхронщина.
eao197
22.03.2017 20:07А кто гарантирует, что реальный актор, который стоит за «фасадом», действительно поддерживает интерфейс «фасада»?
PHmaster
23.03.2017 00:46+1Язык, фреймворк и психическая адекватность программиста. А так-то да, кошмар сплошной кругом. Бывает, булочку в магазин выйдешь купить — а где гарантия, что то вообще булочка, а не рогалик, а за прилавком не марсианин переодетый, а человек?
eao197
23.03.2017 08:13Язык, фреймворк и психическая адекватность программиста.
Когда речь заходит о гарантиях во время компиляции, все, что касается самого программиста, учитывать не стоит. Единственная гарантия, которую может дать фреймворк — это выброс исключения при попытке приведения нетипизированной ссылки на удаленного актора (грубо говоря actor_reference<>) к типизированной (грубо говоря, к actor_reference<Mgs1, Msg2, Msg3>). Вас устраивает, если на этом этапа в run-time вы получаете исключение (ведь нет никаких гарантий в compile-time, что каст всегда пройдет успешно)?PHmaster
23.03.2017 10:47Само собой, у компилятора есть свои границы. Дальше — вопросы грамотного проектирования и конфигурирования системы. Но то, что он не может гарантировать вам вообще всего на свете, написать за вас программу и сварить вам кофе — не повод обесценить все то, что он может сделать, и от этого всего отказаться. Это как заявить: ай, бывают случаи, когда подушки безопасности не помогают, так зачем их вообще в автомобили ставить, давайте не будем.
eao197
23.03.2017 10:49Это понятно. Вопрос скорее был вызван тем, чтобы понять, что может устроить пользователя акторного фреймворка, а что нет.
solver
23.03.2017 11:17Я смотрю с чисто практической стороны.
Хорошо когда компилятор может проверить, что в акторе сть обработчик нужного типа сообщения и соответсвенно дать гарантию, что именно этот тип может обработаться актором. Соответсвенно при рефакторинге он может указать на ошибку этого типа.
Другой вопрос, что на практике я даже теоретически не вижу, где это мне поможет. По одной простой причине. На обработку сообщений всегда пишется тест. Не для проверки типа, а для того что бы быть уверенным — актор корректно обработает сообщение. На этом этапе сразу отсекаются ошибки типов сообщений. При чем AkkaTest позволяет как раз описать поведение акторов, т.е. например актор обязан получить сообщение обработать его.
Не просто может, а именно обязан получить.
Но если не писать тестов вообще, то конечно типы помогут в таких случаях.
Опять же, я не могу представить себе ситуацию, что программист берет, выпиливает часть акторов, меняет сообщения и даже не проверят то что он сделал. Таких надо ссаными тряпками гнать из професии.
Умолчу уже о том, что писать систему (на важно на чем) без тестов это жесть и само по себе существенно снижает ценность типизации вызовов. Т.к. типизация сообщений (применительно именно к Акка конечно же) сама по себе может проверить лишь малую часть кода.
И она не стоит того, чтобы городить огород.
P.S. Прошу обратить внимание, что речь не про сферического коня «статика vs динамика». А конкретно про типизацию акторов в Акка. Потому что во всех других частях Акка с типами все отлично.eao197
23.03.2017 11:24+1Опять же, я не могу представить себе ситуацию, что программист берет, выпиливает часть акторов, меняет сообщения и даже не проверят то что он сделал.
Я так понимаю, что речь идет про то, что когда приходится делать такой суровый рефакторинг, компилятор бы взял на себя часть работы — например, отказался бы компилировать места, где акторам отсылаются сообщения, в которых акторы больше не заинтересованы. Соответственно, при этом объем тестирования уменьшается.
Не думаю, что речь идет о том, чтобы вообще от тестирования отказаться.solver
23.03.2017 11:48Да, безусловно компилятор на себя возмет часть работы. Но эта часть в общем-то небольшая.
И фишка в том, что объем тестирования это не уменьшит, т.к. все равно надо написать тесты на все сообщения получаемые актором. И в процессе этого дела я не представляю как можно пропустить что актор не обрабатывает нужное сообщение…eao197
23.03.2017 11:56+1И в процессе этого дела я не представляю как можно пропустить что актор не обрабатывает нужное сообщение…
Думаю, что основная проблема не в этом. Допустим, у нас есть актор A, который обрабатывал сообщения x, y и z. После рефакторинга он стал обрабатывать сообщения x, v и w. Соответственно, тестами мы проверим, что актор A эти сообщения обрабатываются. Ну и кроме как тестами мы это никак не проверим.
Но, в большой программе с актором A могут взаимодействовать акторы B, C и D. Полагаю, проблема, с которой столкнулся PHmaster в том, что нужно вручную проверять, отсылают ли B, C и D сообщения y и z. Если отсылают, то нужно править код. И тут вопрос упирается в количество и качество интеграционных тестов.
Еще хуже ситуация может быть, если какой-то актор N в run-time получает ссылку на актора, которому можно отослать сообщение y. И заранее нельзя сказать, будет ли это актор A или актор AA. После рефакторинга актора A актор N продолжит успешно взаимодействовать с актором AA, но у него возникнет облом с новым актором A. Но это может выясниться спустя несколько месяцев после рефакторинга.
Т.е. теоритически понятно, про какие преимущества говорит PHmaster, но интересно, почему в нашей практике это не было проблемой. При том, что приложения жили и развивались по десятку лет и рефакторились неоднократно.PHmaster
23.03.2017 13:48Да, все так. Юнит-тесты проверяют работоспособность одного отдельно взятого актора, интеграционные тесты покрывают некоторые варианты взаимодействия нескольких акторов, но тестами нельзя покрыть все возможное варианты взаимодействий в настоящей и будущих версиях активно развивающегося приложения. Помимо того, что один разработчик не способен постоянно держать в голове всю структуру достаточно маштабной системы, — таких разработчиков в проекте может быть много, они могут неоднократно меняться, их уровен знаний и осведомленности может сильно различаться. Тесты, документация — все это хорошо и полезно, но почему к этим инструментам не добавить еще и строгую типизацию? Да, она одна не решает сразу всех проблем, она лишь помогает решить некоторые из них более эффективно и менее затратно. Добавляет больше контроля над процессом разработки, и уменьшают количество способов выстрелить себе в ногу.
eao197
23.03.2017 13:58Видимо, у нас с этим не было проблем как раз потому, что сообщения у нас, обычно принадлежат актору-получателю (как показано здесь, вроде file_agent::write_data). И когда происходит рефакторинг актора, то меняется список его вложенных типов (вроде того, что из класса file_agent уходит тип write_data). Посему при перекомпиляции мы сразу получаем от компилятора все места, где использовалось старое имя.
PHmaster
24.03.2017 03:15Да, у меня все так и начиналось: стройно и элегантно. Но потом один актор разбивается на несколько подакторов, сообщения транслируются по цепочке и обрабатываются уже не тем актором, кому изначально отосланы. И кому они теперь "принадлежат" — становится не совсем понятно. В общем, может мне просто не хватило времени, чтобы упорядочить и наладить свой рабочий процесс разработки в этой парадигме.
eao197
24.03.2017 08:47Тут я чего-то не понимаю. Есть некий service (например, пул коннекшенов к БД), есть service consumer (тот, кому нужен коннекшен из пула) и есть service producer (тот, кто владеет пулом и выдает коннекшены consumer-ам по запросу). Типизация интерфейса взаимодействия между service consumer-ом и service producer-ом нужна для того, чтобы producer был уверен, что к нему обращаются только с сообщениями acquire и release, а consumer был уверен, что в ответ он получает take или failure.
Если с течением времени происходит изменение логики работы producer-а (он разбивается на группу акторов), то тогда есть два варианта:
1. Это сказывается на интерфейсе взаимодействия. Т.е. вместо acquire и release появляются другие запросы. Это элементарная ситуация, она отлавливается самим компилятором.
2. Интерфейс взаимодействия не меняется (т.е. остаются acquire и release), но теперь consumer-у нужно взаимодействовать с одним актором для выполнения acquire и с другим актором для выполнения release.
Мне не кажется, что проблемы второго случая имеют отношение к достоинствам или недостаткам модели акторов. И что преодоление таких проблем должно контролироваться системой типов и проверяться в compile-time. Ибо здесь, по сути, мы имеем проблемы с владением actor_reference, а не проблемы типов сообщений.
AlexTheLost
22.03.2017 15:55Суть акторов, что любой актор может послать любое сообщение любому актору и только актор сам решает, может он обработать это сообщение или нет. Это позволяет строить очень гибкие решения.
Я с вами полностью согласен, но они одновременно и гибкие и не безопасные. Актор это скажем человек, вы можете пасти его на поле и кормить сеном, хотя он будет отказываться), но я думаю вам все же нужно знать что это человек и как с ним взаимодействовать — т.е. его тип и связанный с типом интерфейс.
Иначе у вас получится обычный ООП с дерганьем методов и сильной связанностью. Поэтому вам и Future больше подходит для задач чем акторы.
ООП и акторы это концепции очень схожие и да я хочу что бы у меня была сущность ведущая себя как актор но предоставляющая такие же гарантии как интерфейсы в ООП(дерганье методов).
Писал несколько проектов на Akka, вообще ни разу не сталкивался с неправильной инициализацией акторов и всеми теми проблемами что вы описали. Даже новички так не ошибались в коде.
Ну что ж тут я с вами спорить не буду, спасибо за "апелляцию к авторитету".)
2) Таких гарантий нет ни в одном приложении. Это все зависит только от разработчика. Он может забыть что угодно. В одном месте добавил метод, в другом забыл его «дернуть».
Не совсем об этом, речь о том что вы передали сообщение а оно не дошло, т.е. по аналогии вызвали метод а он не был вызван, причем по какой то внешней причине. Скажем вы в реализации без актора вызвали метод который проверяет является ли данный запрос мошенническим и вы будете уверены что он будет вызван, т.к. вы можете исходя из кода(т.к. это цепочка вызовов) быть уверены что на проде будет вызываться конкретная последовательность методов. Если у вас этот процесс реализован как передача сообщений от актора к актору таких гарантий нет, понятно — у вас могут быть и тесты и хорошие разработчики и тестировщики, но это дополнительная сложность, которая может привести к ошибке, и я уверен такие ошибки периодически будут встречаться вне зависимости от вашего уровня организации работы.
3) Таких гарантий тоже нет ни в одном приложении, см п 2.
Есть гарантия что если вы вызвали метод то он выполнится и есть гарантия какой будет конкретно вызван метод, понятно что только если ваш язык имеет достаточный уровень проверки типов, как в Scala.
eao197
22.03.2017 14:09В целом хорошо описано тут: http://stew.vireo.org/posts/I-hate-akka/
Почитал. Первые две проблемы (с отсылкой Foo вместо Foo() и с подпиской актора на eventStream без его ведома) — это какая-то специфика Scala и Akka. Не стоит распространять эти аргументы на Модель Акторов вообще. В частности, у нас в SObjectizer и C++ подобные фокусы крайне сложно будет повторить.AlexTheLost
22.03.2017 15:01Возможно я не везде ясно выражался, но в начале уточнил что у меня перечисленные вопросы возникли именно с Akka. В общем то это проблема не то что бы Akka+Scala а отсутствия проверки типа отправляемого сообщения. Отличие Scala лишь в том что одно имя означает близкие по сути но разные сущности. В самом простом виде эта проблема заключается в том что вы посылаете другому актору тип A но тот не имеет обработчика для этого типа(т.е. данное сообщение вообще не должно посылаться данному актору).
eao197
22.03.2017 15:05Да вроде вы высказались достаточно определенно. Просто если у вас опыт с Akka, то вот этот итог: "Сейчас вижу только одно применение акторам", он же не объективен. У людей, которые работали с другими реализациями Модели Акторов, итоговые впечатления могут сильно отличаться.
По поводу контроля типов: ведь проблема того, что актор не обрабатывает сообщения типа A ничем не отличается от той проблемы, что актор-получатель по каким-то причинам решил не обрабатывать конкретное сообщение типа A. Т.е. пульнули сообщения актору, а дошло оно или нет, будет ли обработано, если дошло или не будет — вот это вот все фундаментальная особенность акторов. Понятно, что не везде это подходит. Но там другие подходы к concurrency просто используются.AlexTheLost
22.03.2017 15:32Согласен нужно было уточнить что я говорю все же о Akka.
Касаемо:
По поводу контроля типов: ведь проблема того, что актор не обрабатывает сообщения типа A ничем не отличается от той проблемы, что актор-получатель по каким-то причинам решил не обрабатывать конкретное сообщение типа A...
Все таки я вижу отличие в одном случае это часть логики — т.е. мы так задумали что сообщение не обрабатывается, в другом это не ожидаемо(не корректное поведение).
eao197
22.03.2017 15:36Все таки я вижу отличие в одном случае это часть логики — т.е. мы так задумали что сообщение не обрабатывается, в другом это не ожидаемо(не корректное поведение).
Тут мне лично не понятно, чьи именно это проблемы: отправителя или получателя.
Вряд ли получателя, поскольку если ему отсылает кто-то сообщение, в котором он не заинтересован, то сообщение просто теряется.
Ну а отправителю, повторюсь, не важно из-за чего именно его сообщение потеряно: не тот агент или где-то защита от перегрузки сработала.

Juster
22.03.2017 13:34Можете привести несколько реальных примеров использования actor системы?
eao197
22.03.2017 14:00Не уверен, что понял ваш вопрос. Вы хотите видеть примеры прикладных систем, которые разработаны с использованием Модели Акторов?
eao197
22.03.2017 19:58В принципе, множество примеров можно найти в Google поискав по «Erlang success stories» или «Akka success stories». На сайте продавцов Akka даже целый раздел есть (правда там в основном околомаркетинговый булшит).
Из чего-то более толкового можно посмотреть вот это: How To Make An Infinitely Scalable Relational Database Management System (RDBMS)
Или вот это: REST Commander: Scalable Web Server Management and Monitoring.
С проектами, в которых наш SObjectizer использовался сложнее: это все были закрытые коммерческие разработку и я не уверен, что могу какие-то подробности озвучивать.
0serg
29.03.2017 11:24+1У нас 3D сканер построен на модели акторов. Пришлось переписывать изрядную часть приложения, но результат того стоил, приложение очень классно и надежно работает, обрабатывая в реальном времени весьма «тяжелый» поток данных. Раньше была «традиционная» многопоточная реализация так что есть с чем сравнивать, ситуация стала намного лучше.
tangro
23.03.2017 13:16Ну попробует Erlang-овый процесс поделить на ноль, ну упадет, Erlang-овая виртуальная машина почистит мусор, супервизор создаст упавший процесс заново и все. А вот в C++ попытка деления на ноль, скорее всего, убьет все приложение, а не только того агента, в котором ошибка произошла.
Я вот тут подумал, а почему бы не построить модель акторов на базе родительского процесса + по процессу на каждого актора? Это даёт нам возможность применять подход «let it crash» — супервизор точно так же сможет детектить погибших акторов и перезапускать их. Более того, мы получаем более защищённую модель поведения — акторы уже не смогут «ненароком» что-то писать\читать из общей памяти — им придётся использовать исключительно протокольный обмен сообщениями.
Да, будут определённые накладные расходы на запуск процессов и память под них, но в ряде случаев они не столь критичны. Если количество акторов будет в пределах пары десятков — эта модель вполне может жить.eao197
23.03.2017 13:19Мысль совершенно правильная, если целью является достижение высокой отказоустойчивости. Только вот в этом случае Модель Акторов как бы и не нужна :) Подобные подходы используются давным давно, наверное еще и до появления Модели Акторов. Все, что здесь нужно — это удобные и эффективные механизмы IPC. Плюс супервизор вроде runit-а.
eao197
23.03.2017 13:55Боюсь, в предыдущем ответе я не очень понятно пошутил.
Речь вот о чем: вы можете сделать сложное приложение с использованием Модели Акторов, которое будет состоять из нескольких самостоятельных процессов, взаимодействующих через IPC. Каждый процесс будет, фактически, представлять из себя актора.
По сути, это будет то же самое, что происходит сейчас в Erlang-е. Только в Erlang-е независимые процессы работают в рамках VM (если речь про одну VM на одной ноде). А тут независимые процессы будут работать в рамках ОС.
Я же хотел подчеркнуть, что для такого подхода, наверное, не потребуется чего-то специализированного. Только какой-то IPC, который будет выполнять роль «почтовых ящиков». Ну а супервизоры делаются внешними средствами (как это и происходит с использованием того же runit-а в Unix-а).
OlegZH
Попытка сделать на C++ нечто, приближённое к Erlang, очень любопытна сама по себе и побуждает подробнее узнать про Erlang. Если есть хороший подход, то почему бы не использовать именно его?! Конечно, крайне интересно было бы узнать, что по поводу всего этого говорит богатая теория и практика разработки систем, основанных на асинхронном взаимодействии. Помнится, когда-то давно была написана книга «Взаимодействующие последовательные процессы» (Хоар Ч., 1989)…
Пока, у меня возник, только, один вопрос: а почему агенты обязаны быть объектами — экземплярами классов C++? Что мешает основную инфраструктуру разрабатывать с применением классов, но сами агенты реализовывать как структуры, которые управляются ядром определённым образом?
И, конечно, это немного SmallTalk-подобная архитектура заставляет задуматься об упорядочивании агентов по типам (по типам сообщений, по задачам, по особенностям данных), и это упорядочивание (типа декомпозиции системы) само по себе способно разрешить проблему перегрузки агентов.
С другой стороны, мне очень нравится идея с удалением агентов. Я представил себе, как бы упросилась жизнь разработчика, если бы каждый объект должен был бы постоянно уничтожаться и воссоздаваться заново. Это обеспечило бы стабильность работы (объект почти всегда в корректном состоянии), надёжность доставки сообщений (необработанные сообщения можно всегда доставить новой версии объекта; а, если, осуществлять скрещивание или расщепление объектов с элементами генной инженерии?), при этом, сами сообщения тоже могут быть объектами-агентами особого сорта (могут приниматься другими объектами, но сами могут обрабатывать сообщения).
eao197
Упс, ошибся с веткой для ответа. Ответил вам здесь.