

Будет много текста и картинок. Вкратце, вот что мы добавили:
Дерево базы данных
— Новое управление схемами
— Привязка файлов к источникам данных
— Интерфейс для создания баз и схем
— Настройки цветов для редактора и результатов запроса
Импорт и экспорт данных
— Экспорт таблиц из одной базы в другую
— Сопоставление столбцов файла и таблицы
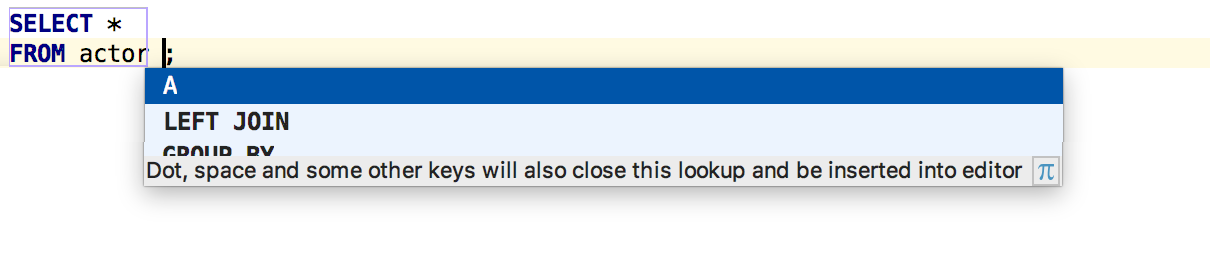
Консоль запросов
— Сохранение пути поиска по умолчанию в PostgreSQL
— Шаблон для генерации триггеров
— Настройки для отключения автоматической конкатенации многострочных литералов и для автоматической квалификации объектов
Остальное
— Время выполнения запроса и номера столбца и строки выделенного поля в панели статуса
— Поиск имени таблиц и остальных объектов в комментариях и строках
— Windows-аутентификация в SQL Server для jTDS-драйвера
— Предупреждение об изменении исходного кода представления, процедуры и т.д.
Дерево баз данных
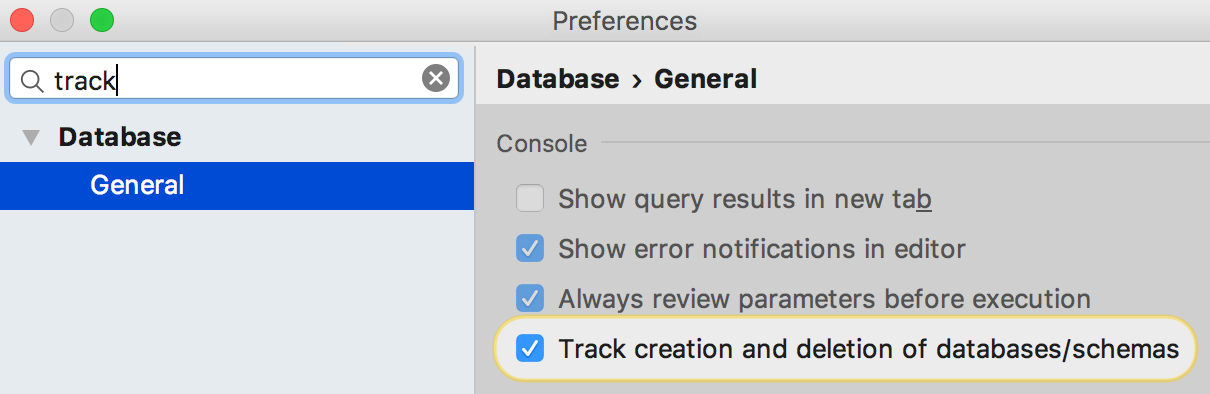
Управление схемами
Мы ещё раз переработали интерфейс для выбора схем в дереве баз данных. Надеемся, теперь это надолго :)
Дерево выбора открывается по двойному щелчку на Schemas…. Выбирайте сразу все схемы, текущую или только те, что вы хотите видеть.
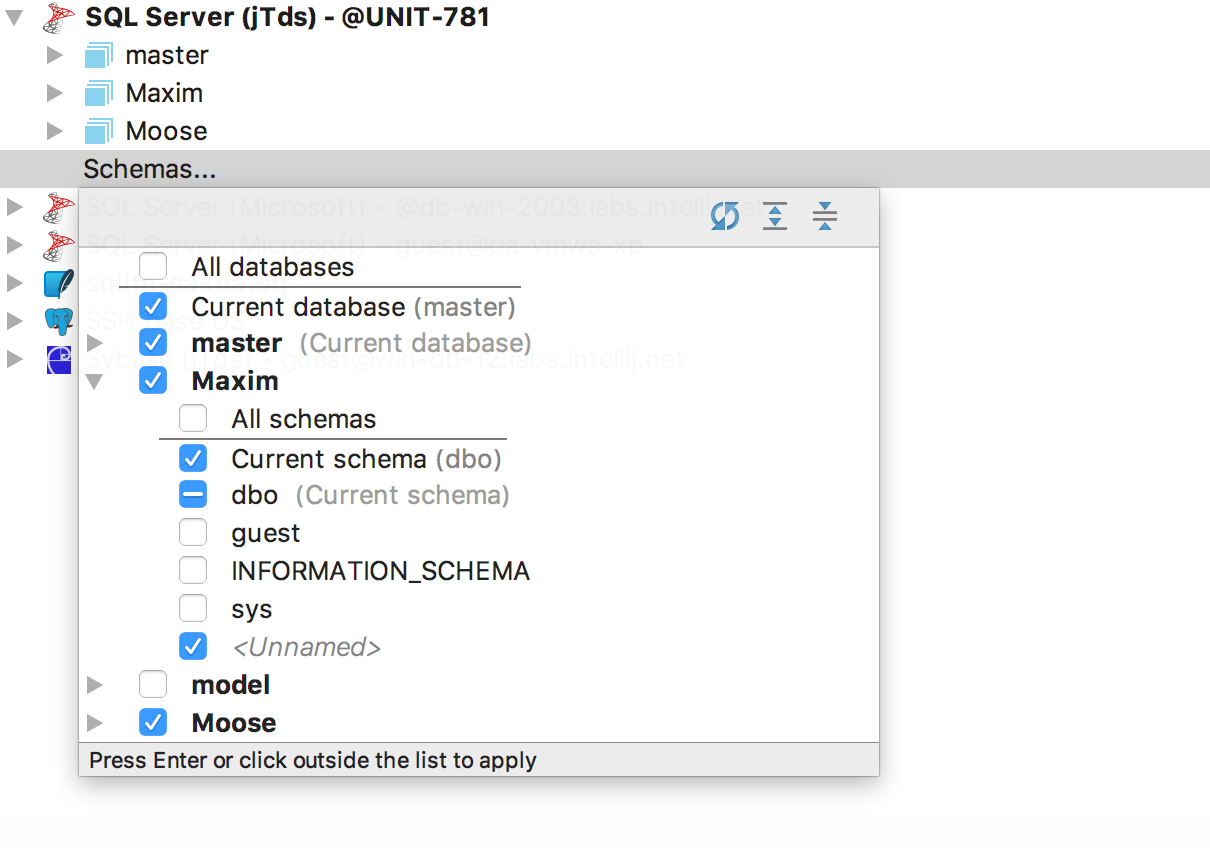
Вкладку Schemas мы вернули в свойства источника данных — там теперь такое же дерево выбора. Можно указать отображаемые схемы в текстовом шаблоне, язык которого описан в окне информации (Ctrl+Q или F1 для OSX).
Соответствия файлов и источников данных
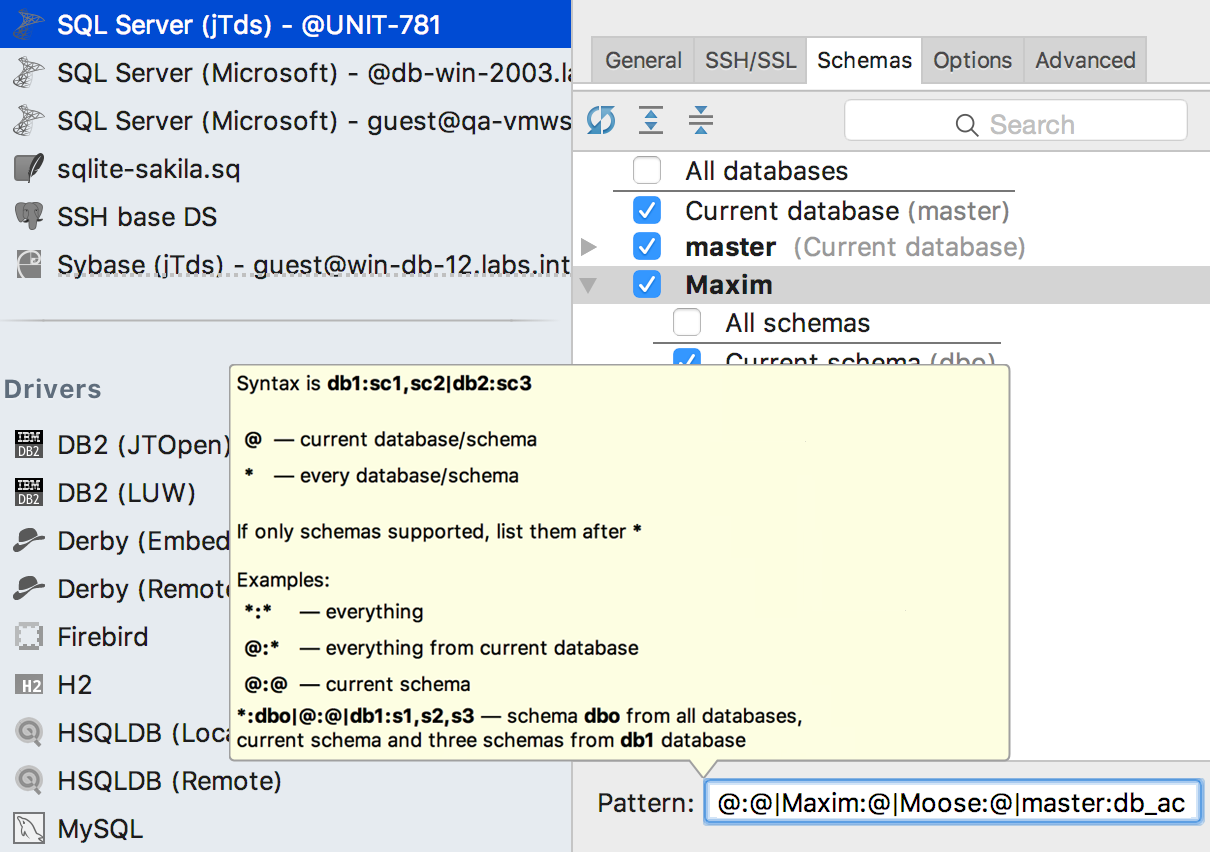
Раньше, особенно в других IDE со встроенной поддержкой баз, возникала путаница с тем, к какому источнику данных привязан файл. Если запросы, скажем, из java-класса использовали неквалифицированные объекты, IntelliJ IDEA сама пыталась догадаться, в какой базе они выполняются. Среде можно было помочь во вкладке Resolve Unqualified References. Но если в источнике данных были объекты с одинаковыми именами в разных схемах, эту проблему решить было нельзя.
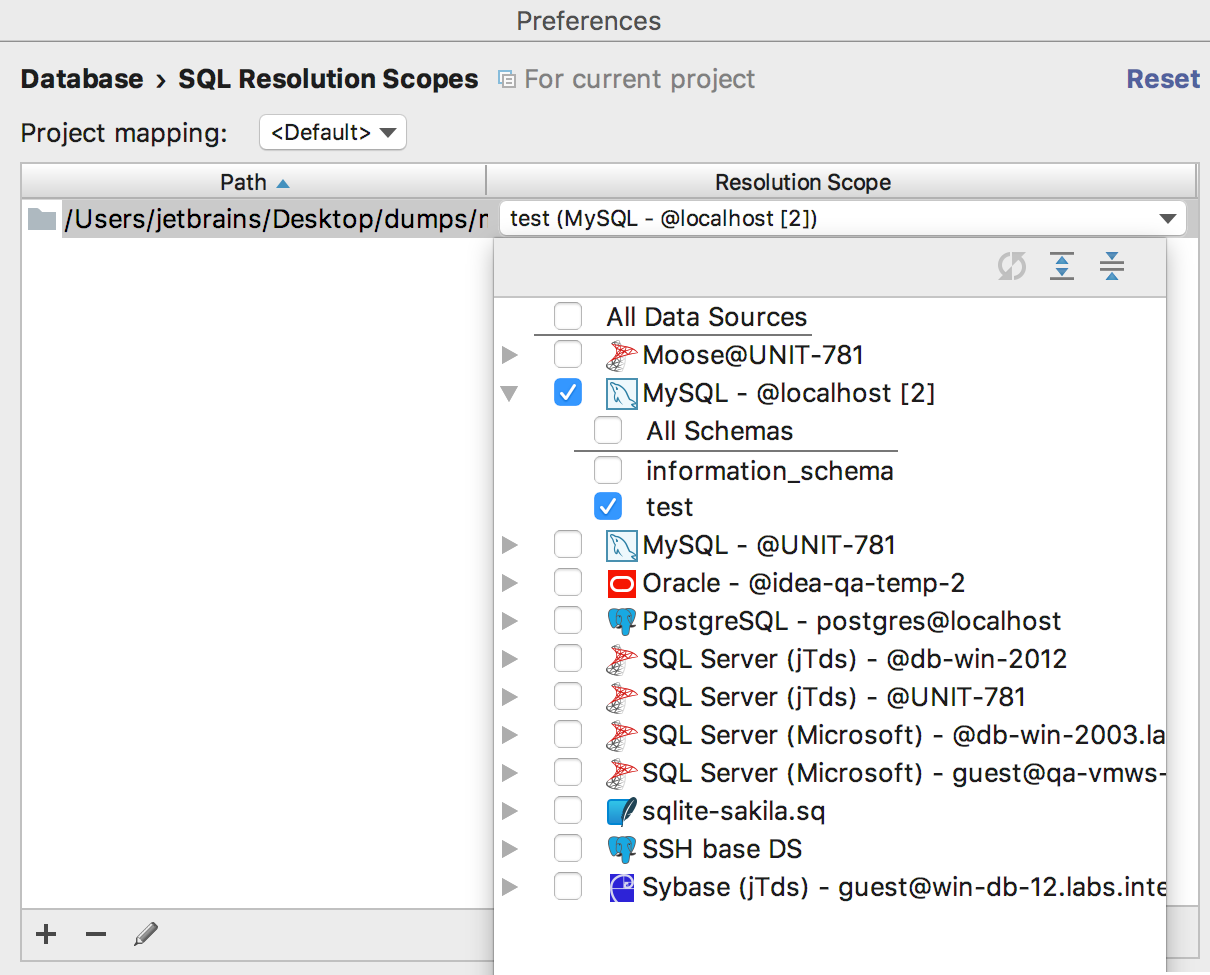
Стало проще: любой файл или папку можно явно привязать к одному или нескольким источникам данных или даже к отдельным схемам. Делается это в Settings > Database > SQL resolution scopes. В результате, неквалифицированные объекты базы данных из ваших запросов будут восприниматься как объекты из указанного источника. То есть будут работать автодополнение и навигация.
UI для создания баз и схем
В прошлый раз нас просили это сделать — готово! В новом окне генерируется простой SQL.
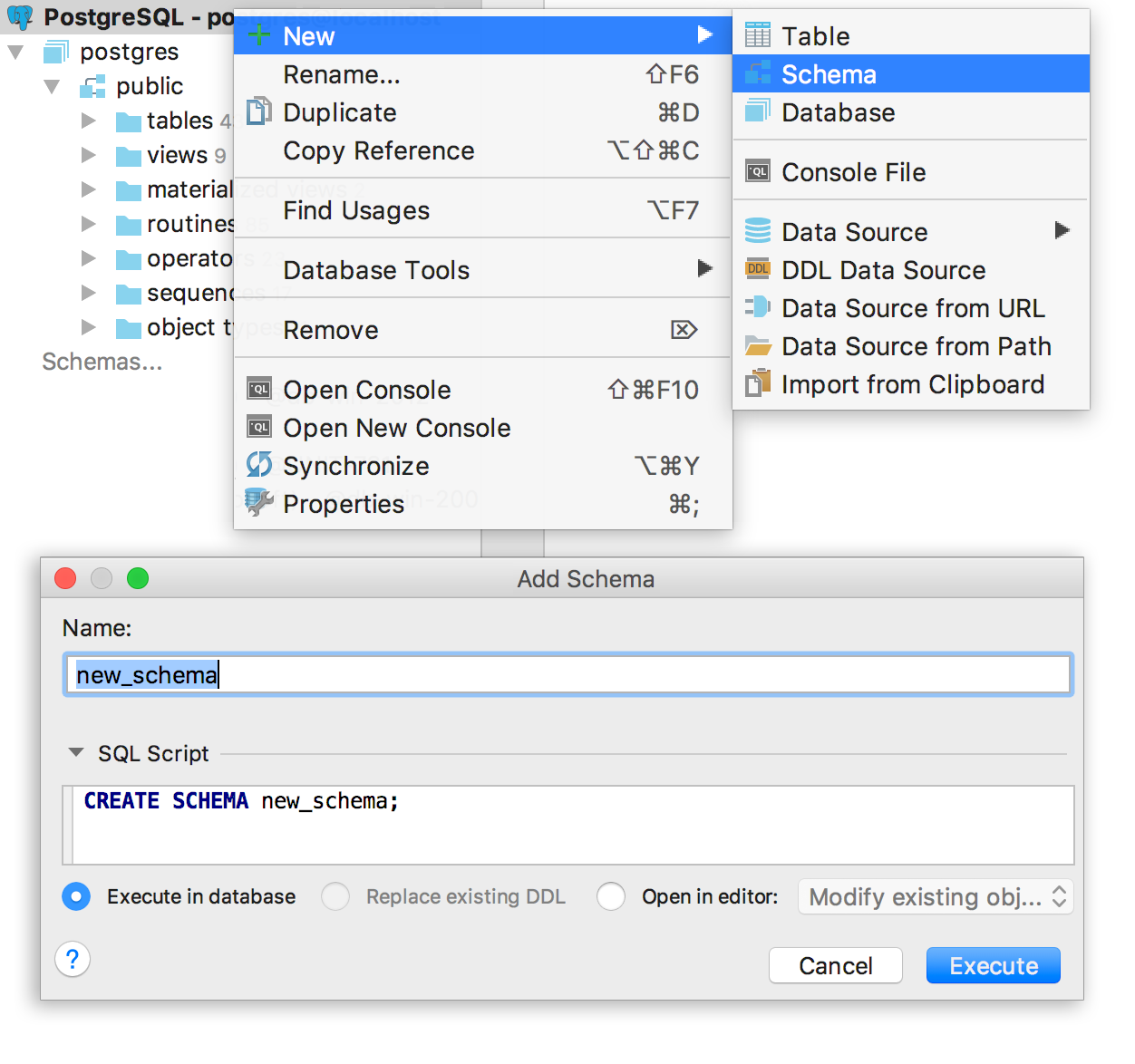
Укажите, хотите ли вы видеть созданные схемы и базы в дереве немедленно. Эта опция также работает для создания схем и баз прямо из консоли.
NB! DataGrip до сих пор не поддерживает нескольких баз в PostgreSQL для одного источника данных. Поэтому созданные новые базы в дереве не появятся — для работы с ними создайте отдельный источник данных. Но мы начали работу над этим.
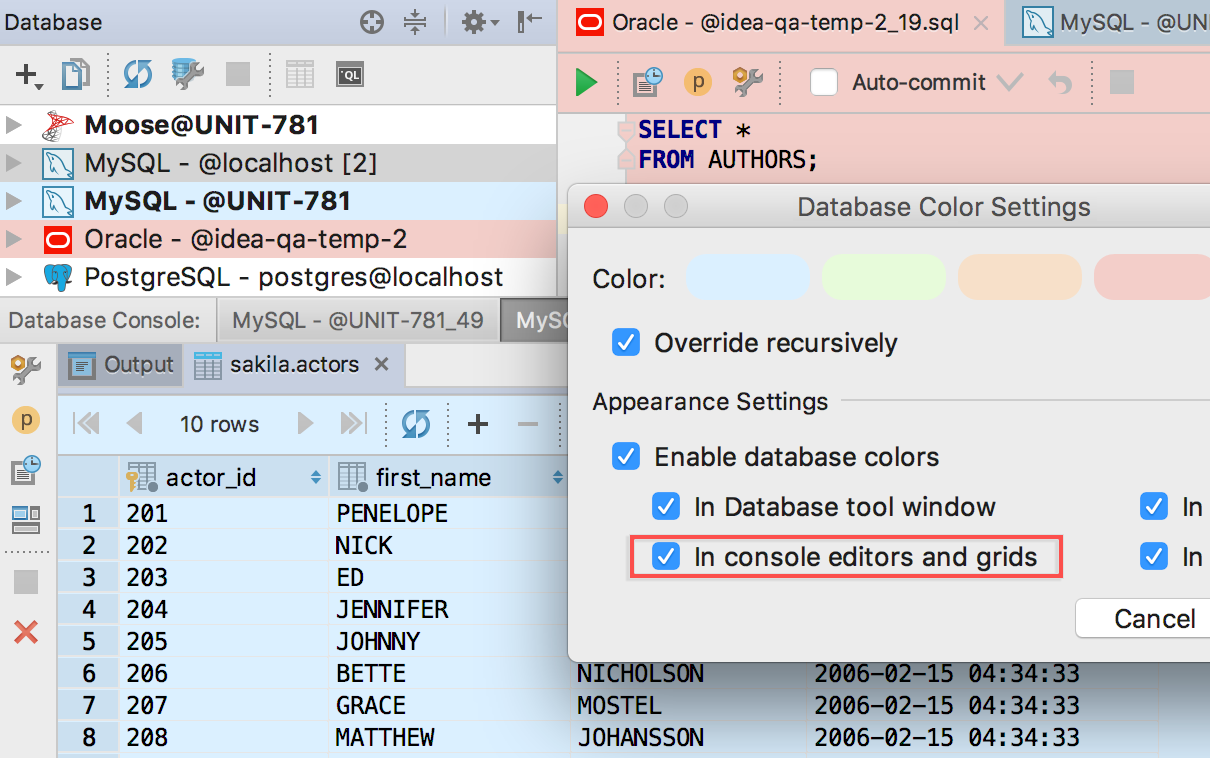
Настройки цвета
Color settings в контекстном меню источника данных были и раньше (знали о них? :), но теперь цвет можно применить и к фону консоли, и к таблице результатов запроса. Надеемся, это поможет не запускать тестовые скрипты на живой базе.
Импорт и экспорт данных
Экспорт таблиц и результатов
Теперь можно перетащить таблицу из одной базы в другую. Причём, даже если это базы от разных СУБД. Скопируются структура таблицы и сами данные.
Создать новую таблицу в другой базе можно и из результатов запроса: добавили кнопку Export to database.
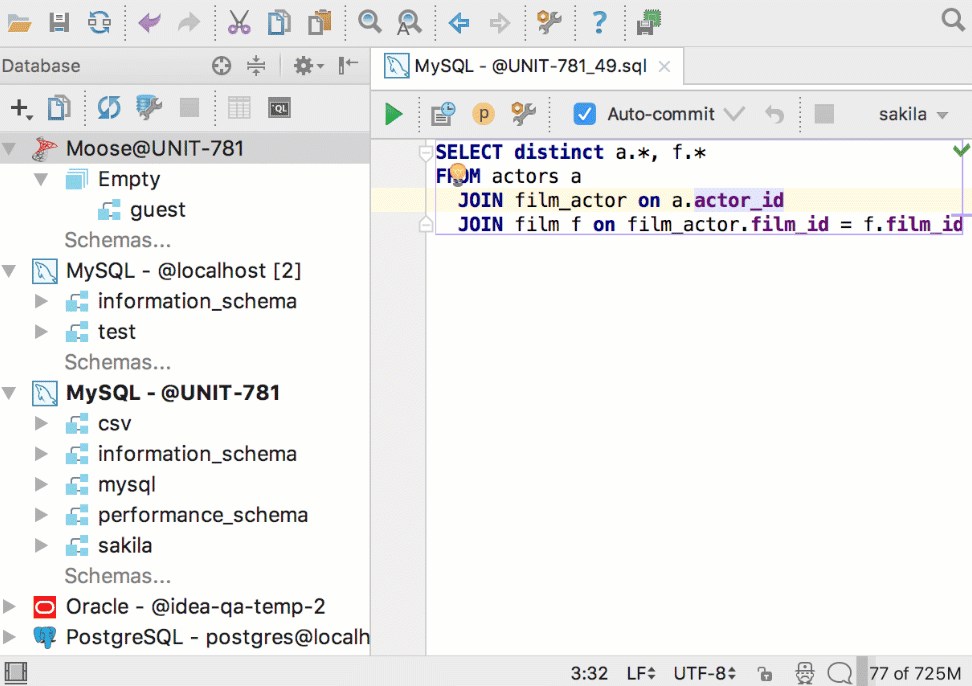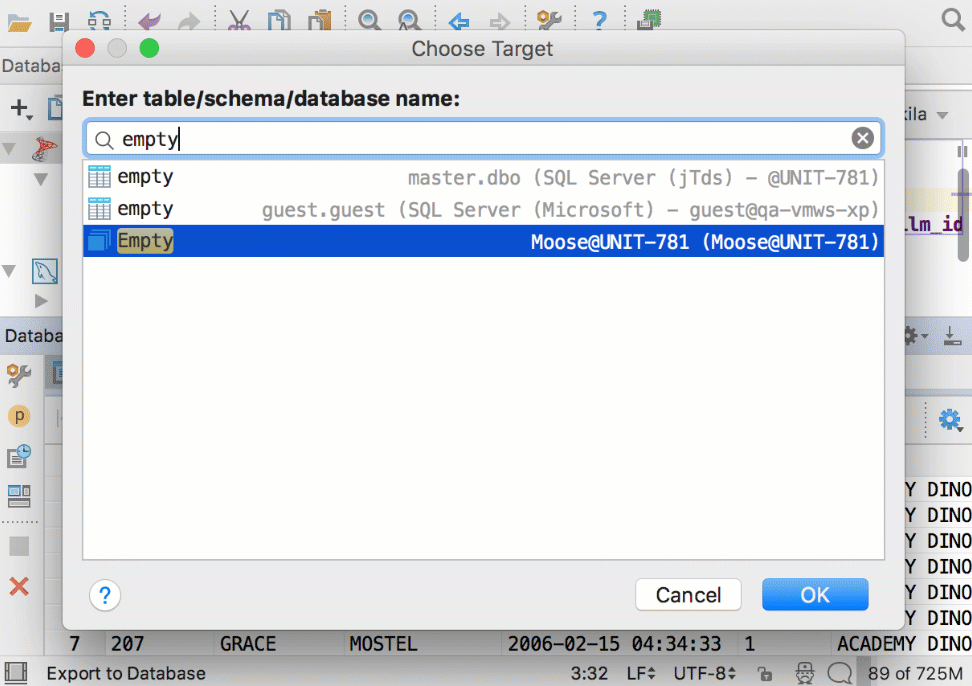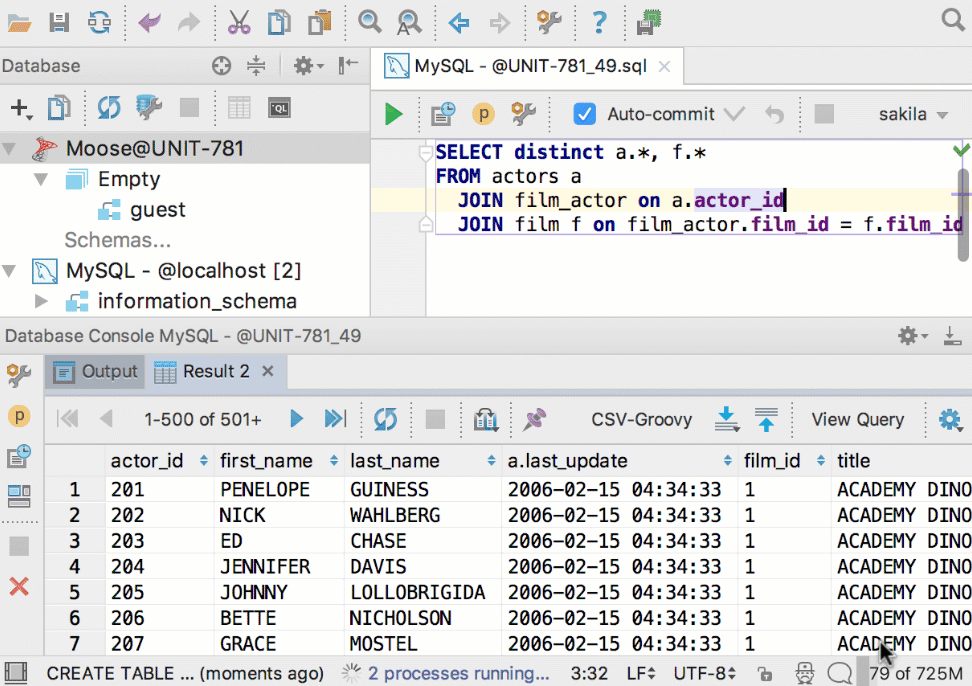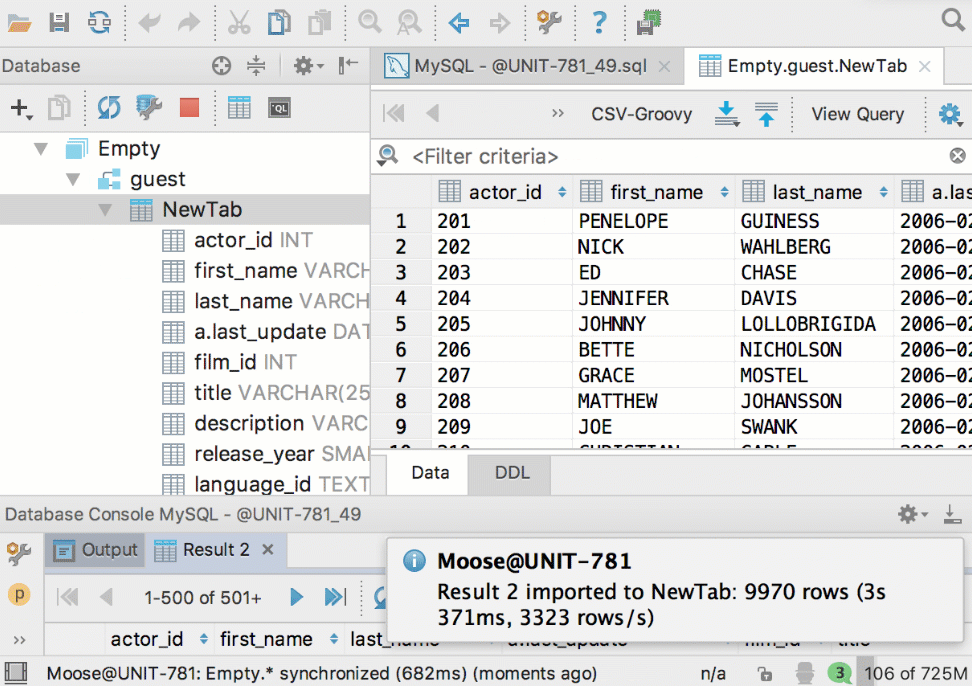
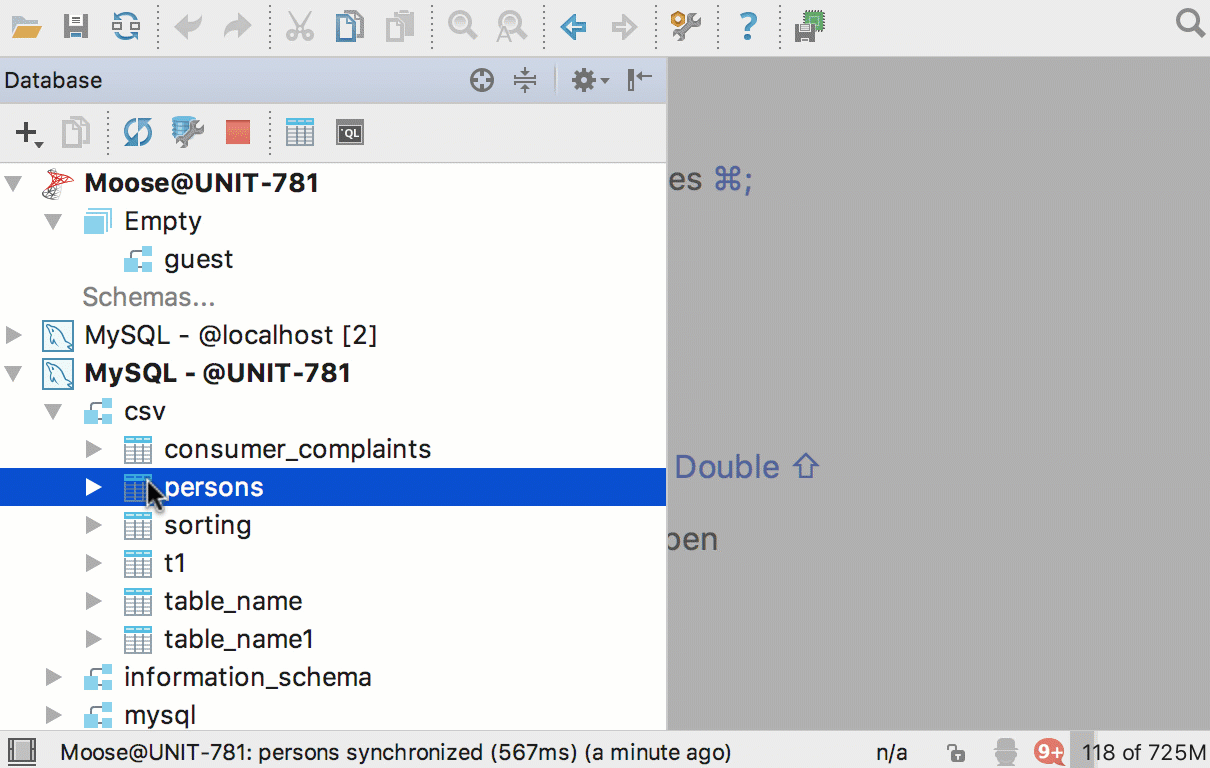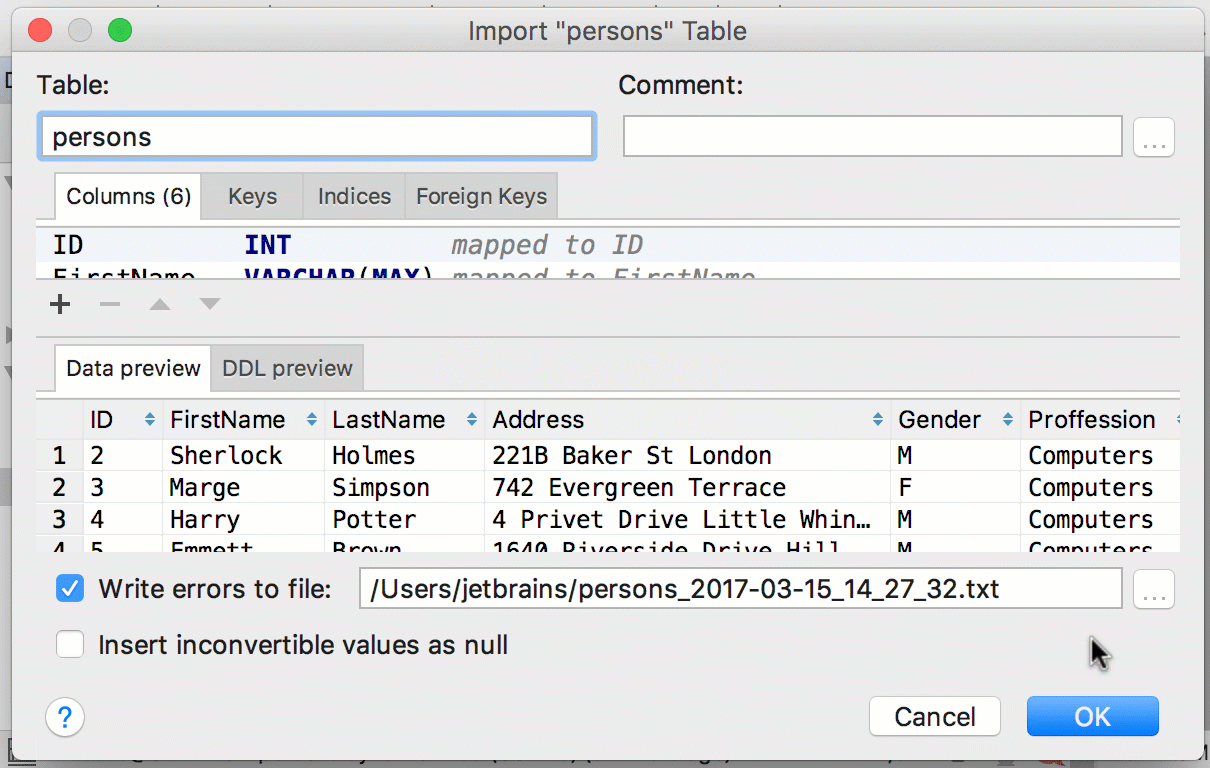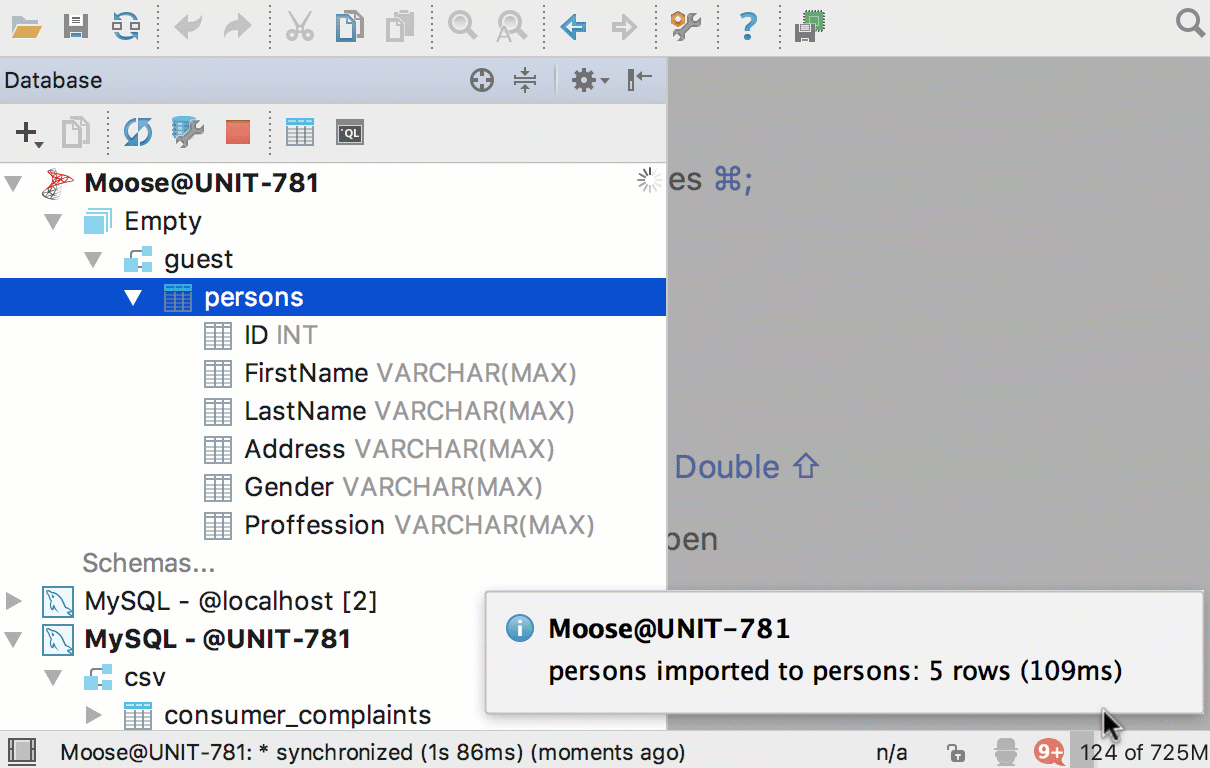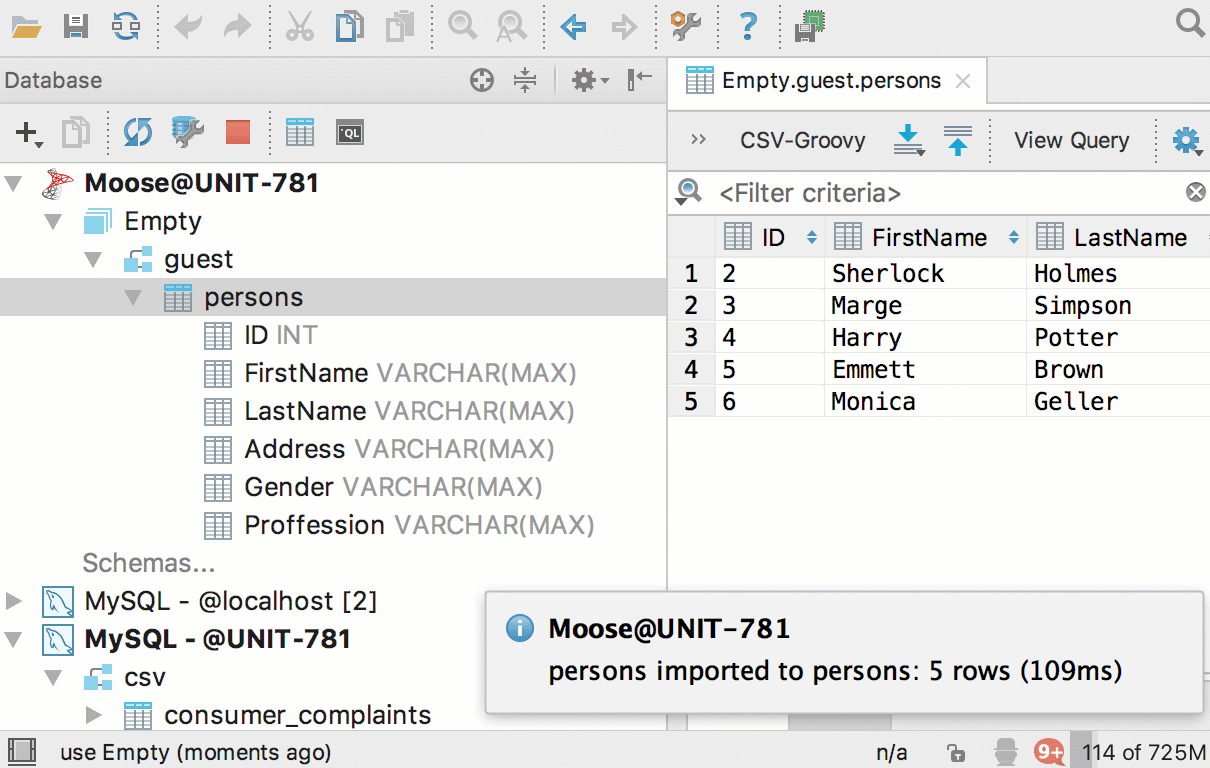
Улучшения в диалоге импорта
Было много предложений по тому, как сделать импорт более гибким.
Укажите, в какую таблицу импортируете данные, и отредактируйте скрипт её создания. Сопоставление столбцов поможет понять, какие данные куда попадут. Для имён столбцов работает автодополнение.
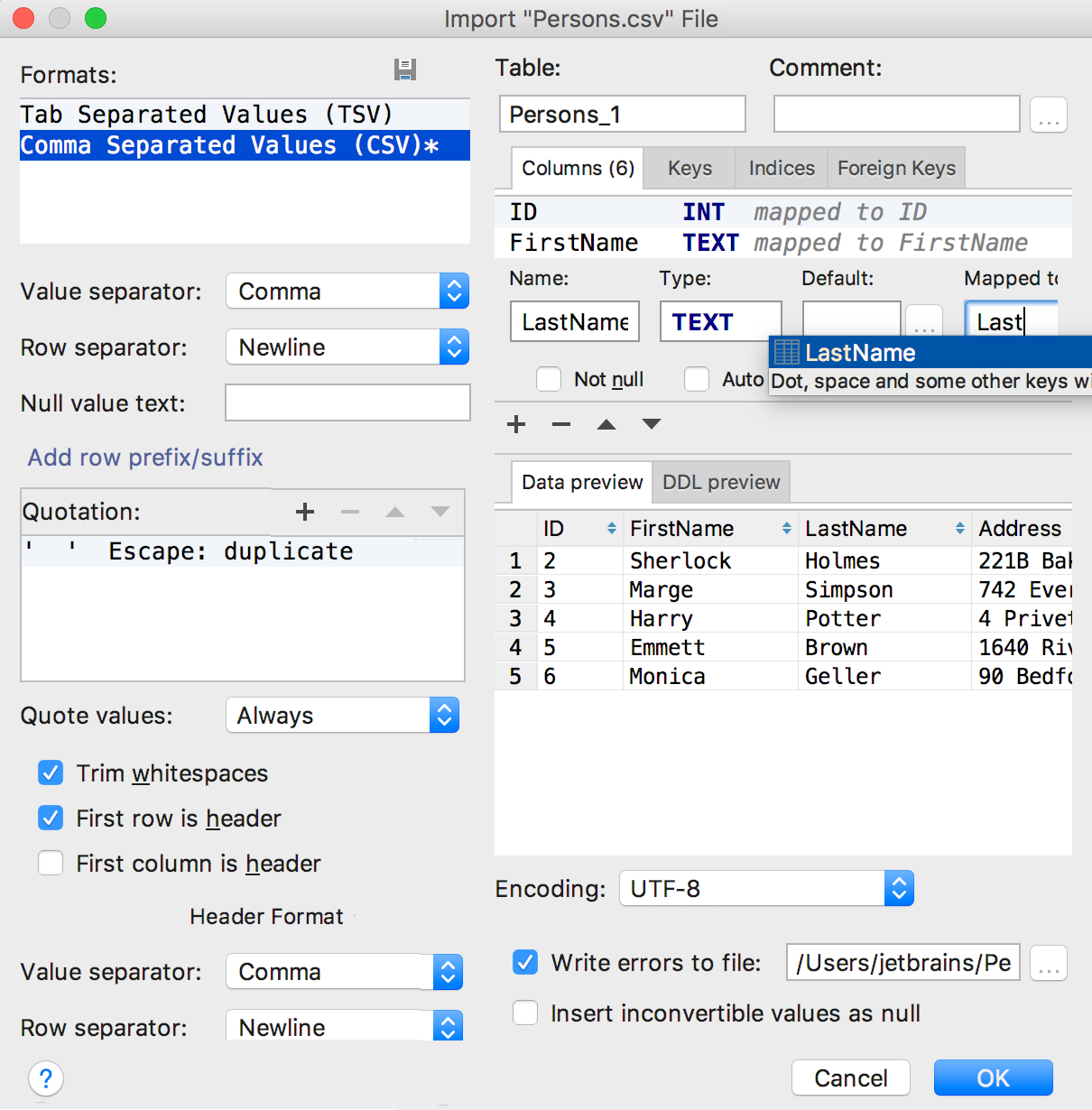
Консоль запросов
Путь поиска в PostgreSQL
Самое важное для пользователей PostgreSQL: теперь мы не забываем о пути поиска по умолчанию. Как и раньше, он настраивается в верхнем правом углу.
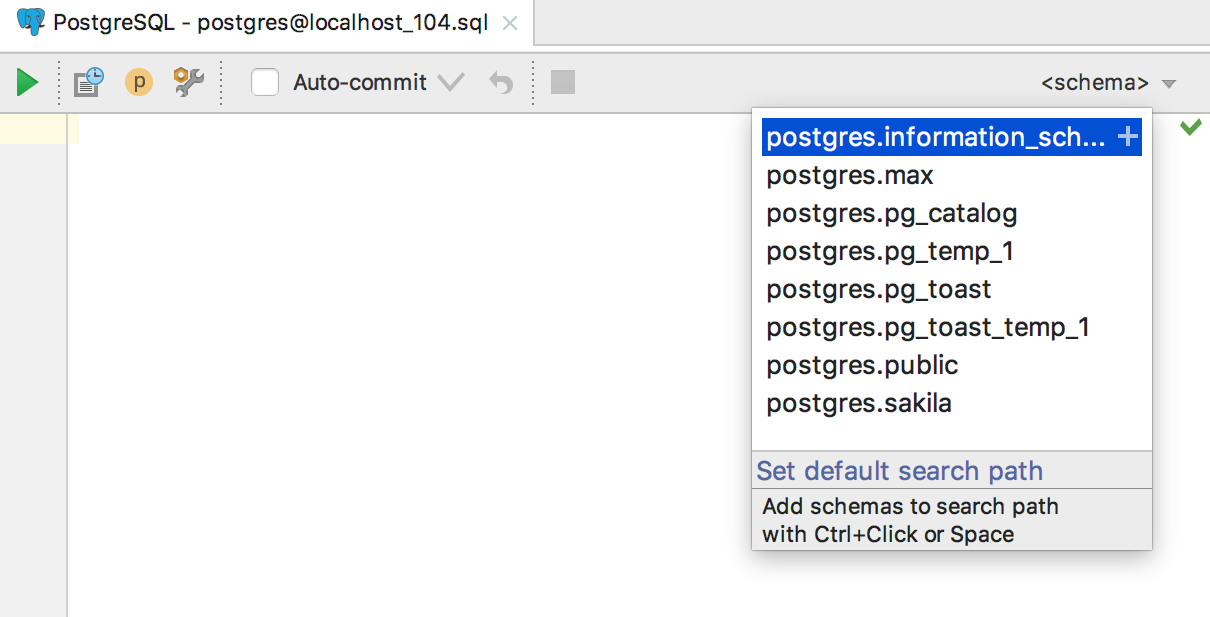
Триггеры
Добавили шаблон для генерации триггеров по Ctrl+N (Cmd+O для OSX).
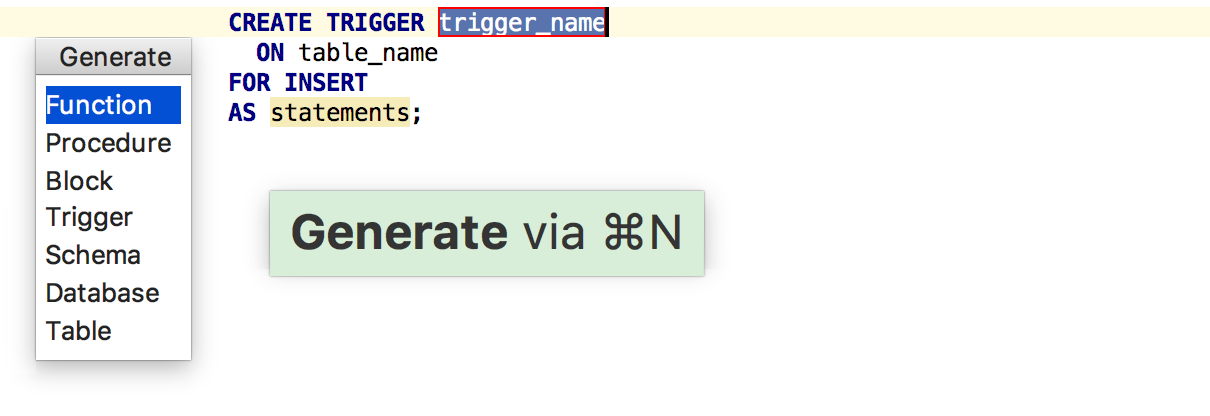
Поддержали NEW/OLD и INSERTED/UPDATED для исходников триггеров.
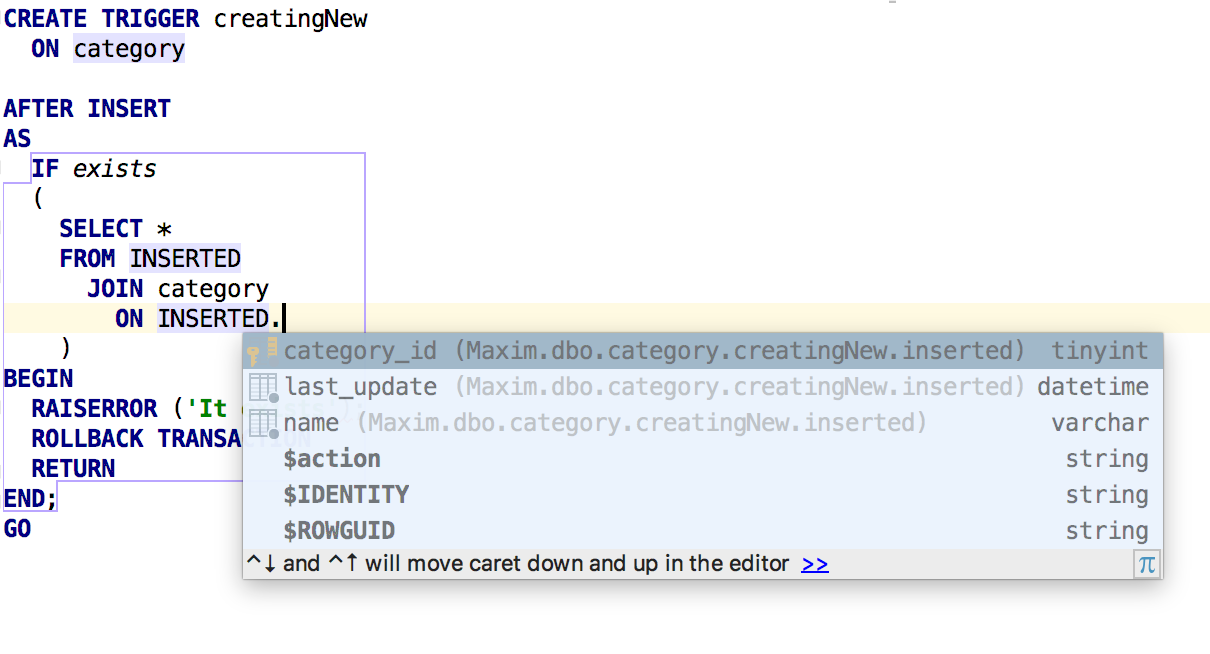
Написание кода
Знакомая по другим IDE опция Settings > Editor > Appearance > Show parameter name hints работает и в DataGrip: показывает имена столбцов для предложений INSERT.

Новые настройки появились в Settings > Editor > General > Smart Keys.
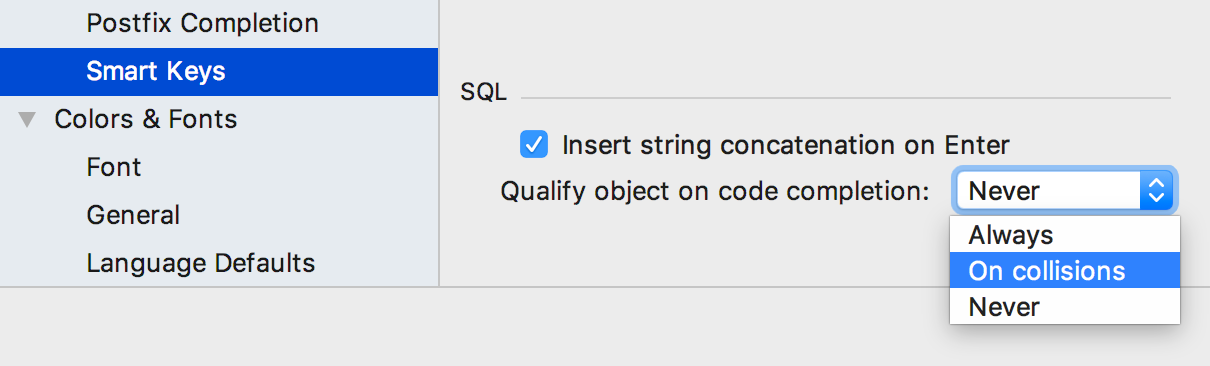
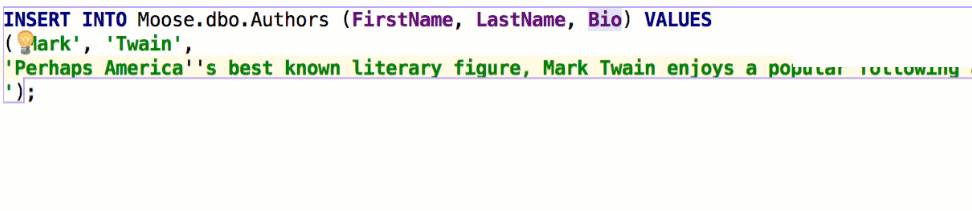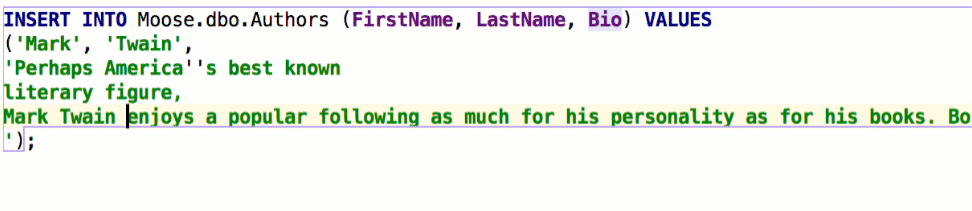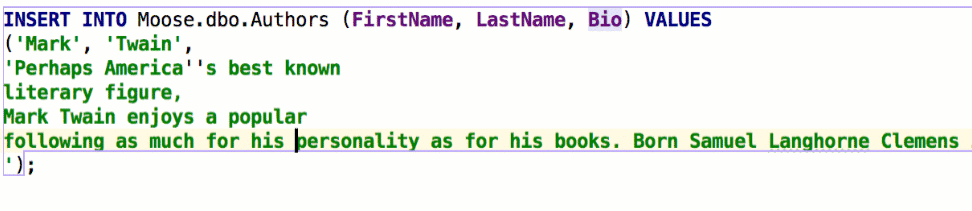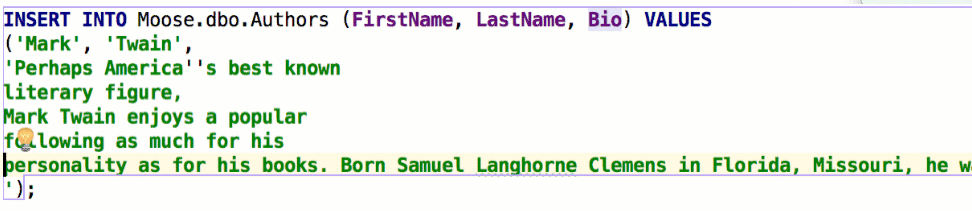
Insert string concatenation on Enter отвечает за то, будут ли строки при переносе автоматически конкатенироваться. Раньше это работало по умолчанию и выглядело так:
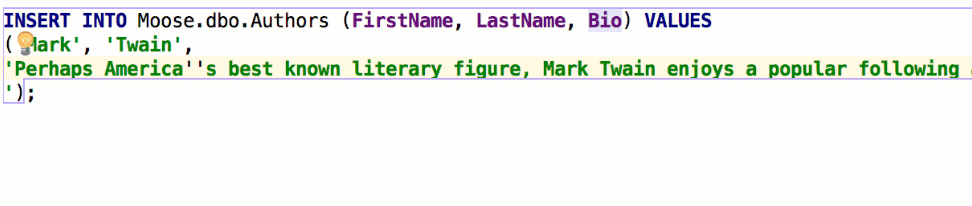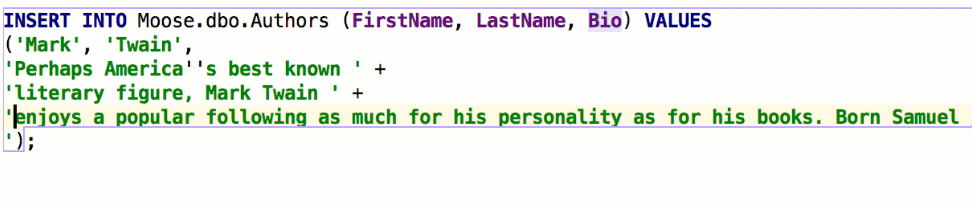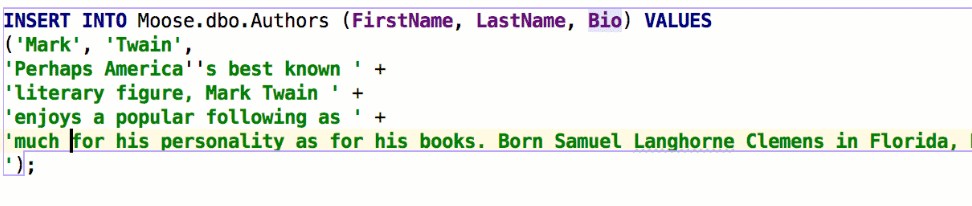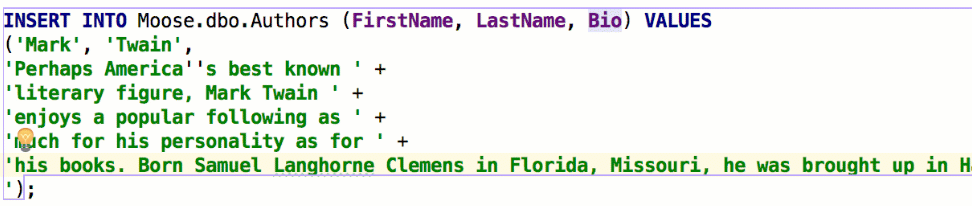
В некоторых базах используются многострочные литералы, и такое поведение было неудобным. Если снять галочку, перенос строк не будет ничего вставлять:
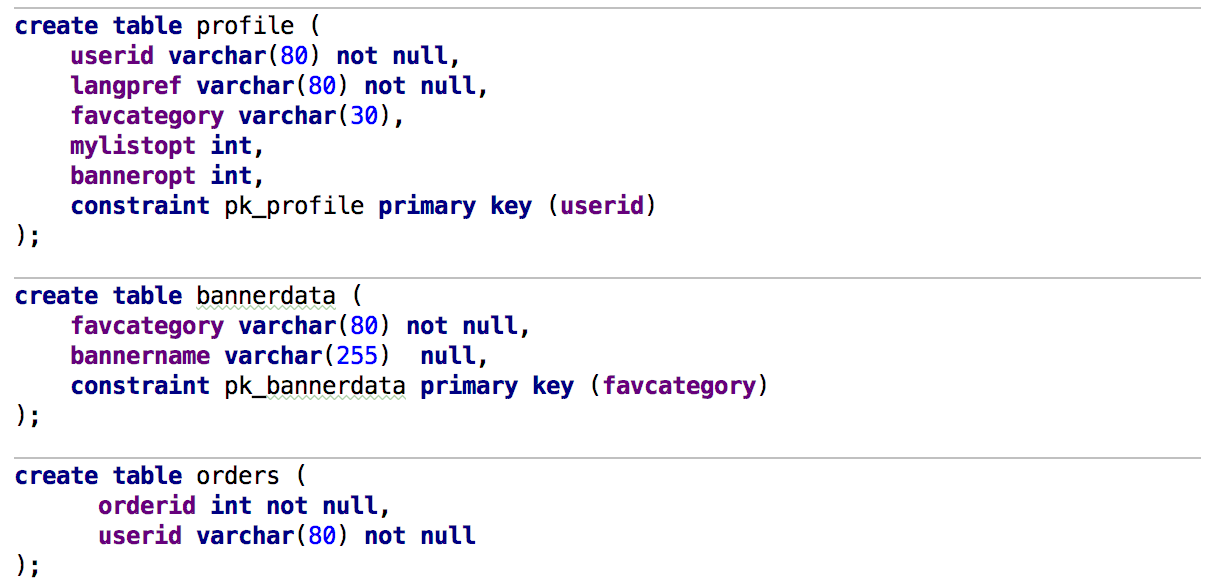
Опцию Qualify object in completion тоже просили. Кому-то удобно, чтобы объекты квалифицировались всегда, кого-то это раздражает даже при коллизиях — одни и те же скрипты будут запущены на разных базах, и люди не хотят в них ничего менять. Скажем, у нас есть две схемы — max и public, с такими таблицами:

Вот как будет вести себя IDE при параметре Qualify on collisions:

Именованные параметры дополняются по второму нажатию Ctrl+Space. Вообще, во всех наших IDE это приводит к интересным результатам, попробуйте.
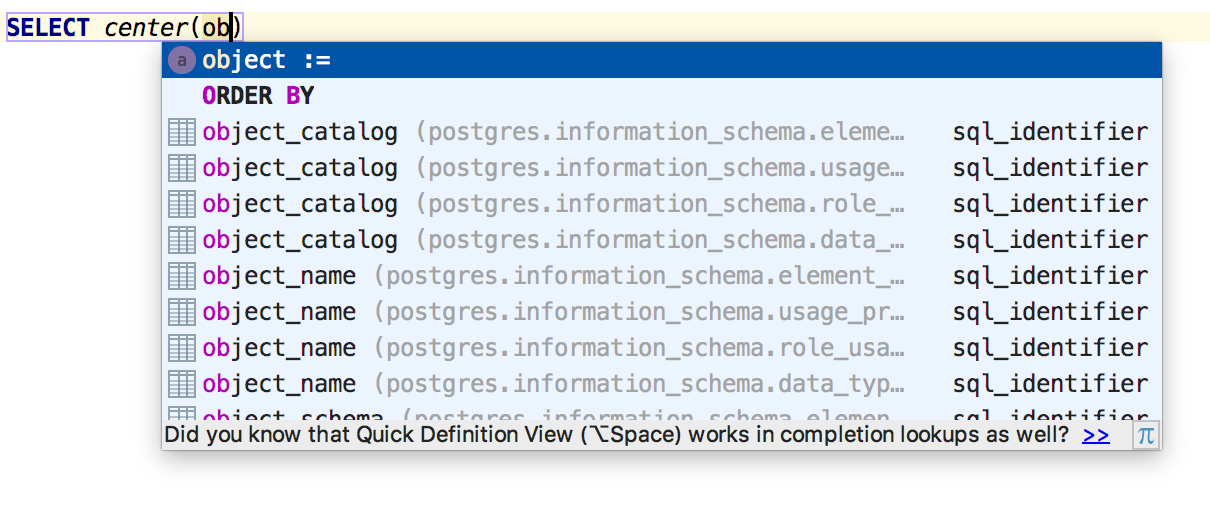
Дополнение по Ctrl+Space после простого SELECT вставляет алиас. В Settings > Editor > Code style > SQL теперь можно настроить — использовать для него прописные или строчные буквы.
Ещё одна настройка из платформы работает для DataGrip. Settings > Editor > Appearance > Show method separator будет рисовать линии между запросами.
В MySQL есть баги в грамматике при использовании UNION. Мы добавили забавную инспекцию, которая об этом предупредит.

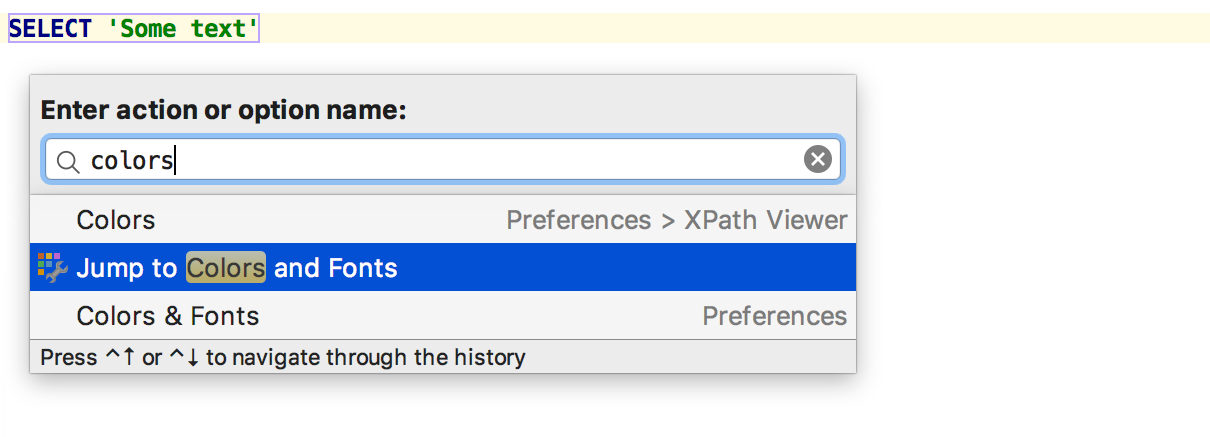
Навигация к настройкам цветов и шрифтов
А это понадобится пользователям любой IDE на платформе IntelliJ — не ищите, где в дебрях настроек изменить цвет или шрифт. Команда Jump to colors and fonts в вездесущем меню по Ctrl+Shift+A (Cmd+Shift+A для OSX) отправит вас в настройку цвета того контекста, в котором стоит курсор.
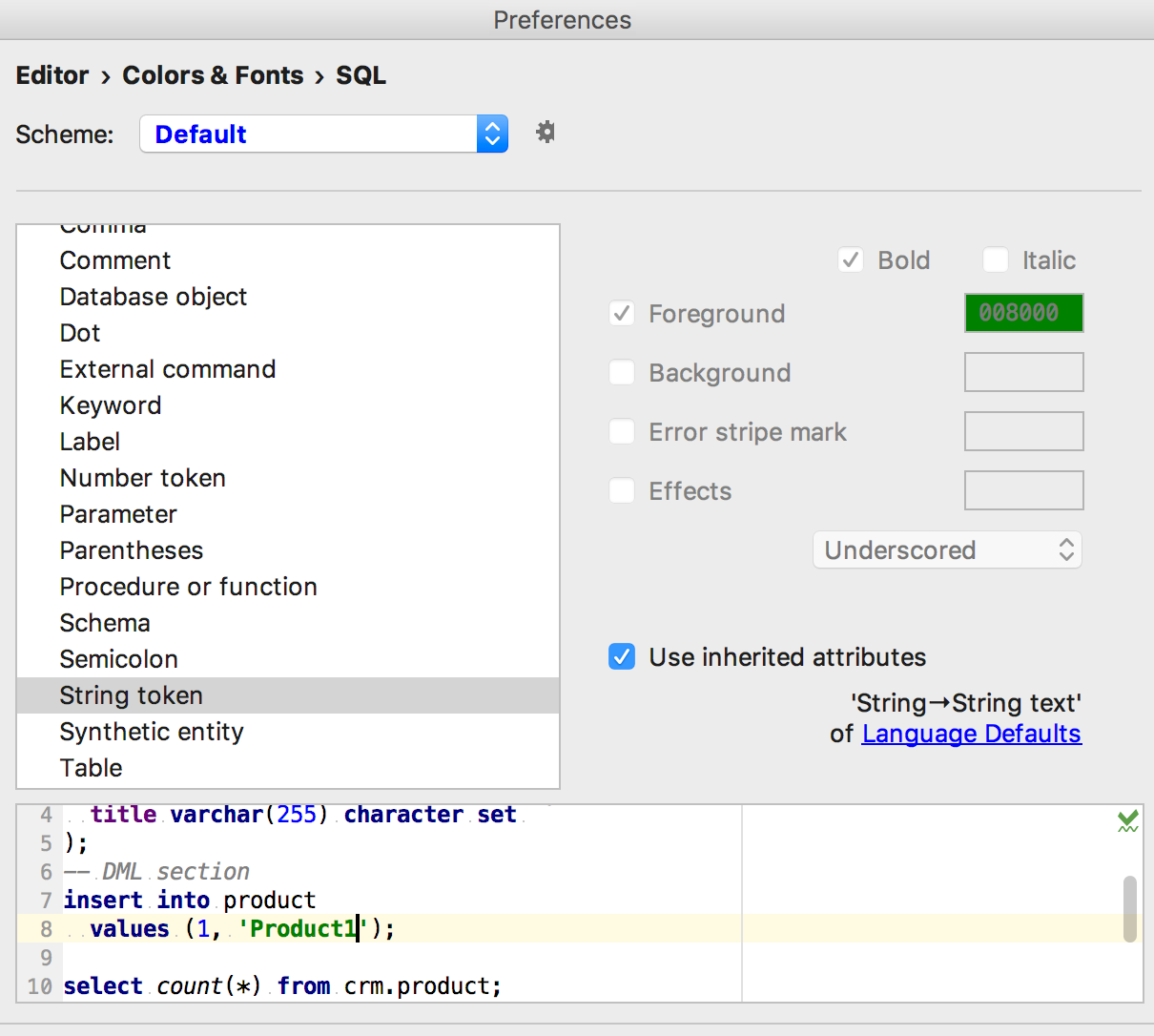
Если контекстов несколько, выберите нужный. Здесь предлагается настроить цвет и отображение для запускаемого запроса (фиолетовая рамка) и цвет строчного литерала (зелёный). Предположим, нас волнует строчный литерал.

Готово! Можно менять цвет.
Разное
В панель статуса результатов запросы мы добавили время выполнения запроса и номера столбца и строки выделенной записи.
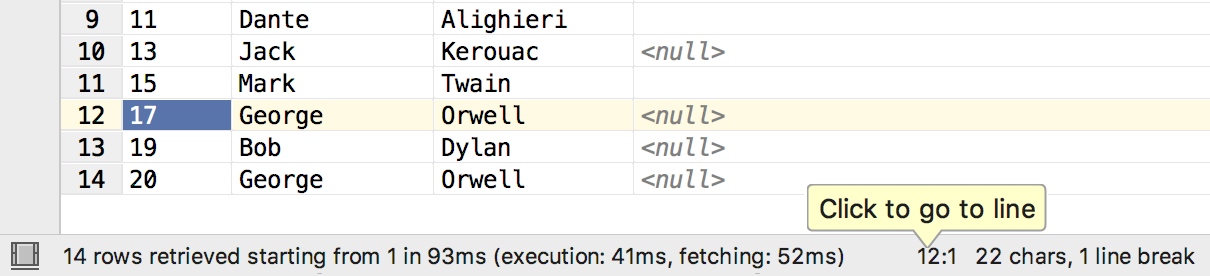
В окне Modify table детали столбца открываются по двойному клику, а не по одинарному.
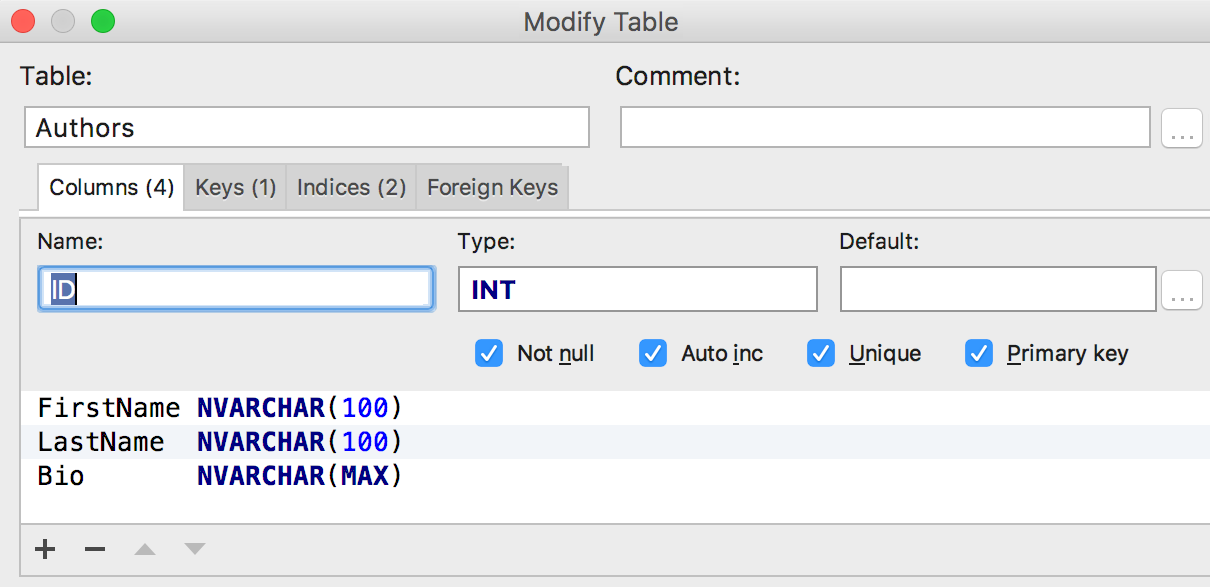
Редактор исходников отлавливает, что объект изменился из DataGrip, и предупреждает об этом.
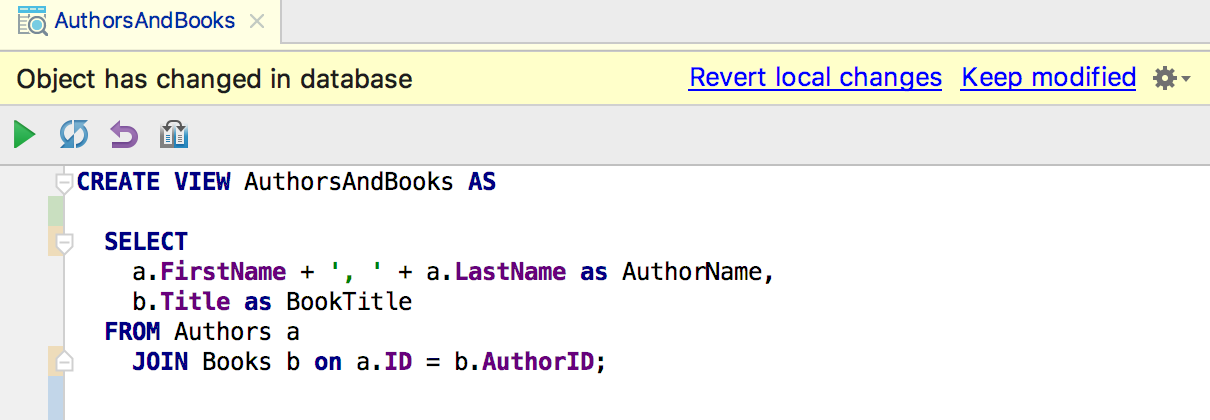
В окно информации для системных таблиц в PostgreSQL добавлена ссылка на документацию.
В поиске использований объектов можно исключить текстовые вхождения — комментарии, динамический SQL.
А ещё в новой версии:
— Предпросмотр для больших файлов в режиме «только для чтения».
— Windows-аутентификация в SQL Server для jTDS-драйвера.
— Поддержка запроса CREATE/ALTER в SQL Server 2016.
— TNS-имена корректно считываются из файла tnsnames.ora в Oracle.
— Коммит запускает синхронизацию в PostgreSQL.
— Интроспектируется больше объектов в SQLite.
— Предупреждения появляются во вкладке Output сразу.
— Zero-latency typing (набор без задержки) включен по умолчанию.
— Настройки цвета для регулярных выражений.
Вероятно, вы про это всё знаете, но тем не менее:
— Скачать бесплатную пробную версию здесь.
— У нас есть Твиттер и форум.
— О багах сообщайте в трекер.
Вот и всё. Как всегда, продолжим в комментариях.
Комментарии (26)

and_rew
28.03.2017 21:54Спасибо ребят, столько офигенных фич. Отдельное спасибо за датагрип — от pgAdmin глаза болят )) Осталось запилить нормальный рестор кастомных бекапов для постгреса, и про pgAdmin можно забыть. Может не я один такой, вдруг кому еще надо, vote pls https://youtrack.jetbrains.com/issue/DBE-4293?

arturgspb
28.03.2017 22:06+1@and_rew, а вы используйте Navicat. Очень дельная программа, уже лет 5-6 пользуюсь. Вместе с pgAdmin-ом правда.

lui
29.03.2017 01:25Уже не представляю себе, как можно работать без DataGrip'а :)
Из желаемого: очень хотелось бы в дереве базы данных видеть ещё и активные триггеры этой базы.
Папочка routines — это здорово, но в ней не видно к какой таблице и к какому событию триггер привязан.
Приходится то и дело писать использовать эти два запроса:
SELECT * FROM pg_catalog.pg_trigger WHERE tgisinternal = FALSE;
SELECT * FROM information_schema.triggers;

moscas
29.03.2017 19:24+1Да, спасибо — всё по делу. Обсудили сегодня, как лучше это реализовать — будем делать.

darthunix
29.03.2017 04:10+2Хотелось бы для PostgreSQL больше поддержки нативных объектов. Сейчас нет ни оберток над внешними данными (внешние таблицы, схемы и сервера), ни типов, ни расширений, ни объектов полнотекстового поиска (словари, парсеры, шаблоны), ни правил. К сожалению, как бы я ни желал перейти с PgAdmin на DataGrip, пока функционал последнего не позволяет это сделать…
moscas
29.03.2017 20:26А вы какой версией пользовались в последний раз? Типы и правила есть.
Остального нет, вот тикеты:
Обёркти: https://youtrack.jetbrains.com/issue/DBE-1865
Расширения: https://youtrack.jetbrains.com/issue/DBE-4366
Текстовый поиск: https://youtrack.jetbrains.com/issue/DBE-4367

Banan
29.03.2017 12:39Планируется поддержка диалекта для Vertica?
moscas
29.03.2017 14:12Следующая база, поддержку которой мы добавим, почти точно будет Redshift. Хотя мы точно не знаем, когда. Но на Вертику есть ишью, пожалуйста поделитесь своими мыслями там: https://youtrack.jetbrains.com/issue/DBE-1190

Vicking
29.03.2017 14:10Спасибо за очередной релиз удобного и полезного инструмента.
Из того, что хотелось бы видеть в будущих релизах:
- аналог регионов из Visual Studio, чтобы на панели Structure можно было переключится на отображение данных названий, а то не всегда удобно искать нужный запрос среди списка SELECT foo… FROM bar ...
- backup/restore для MS SQL Server
- Для MS SQL Server отключенные триггеры в дереве объектов может цветом выделять
Спасибоmoscas
29.03.2017 19:231. Это уже есть — оберниет нужные куски кода в тэги вида
-- <editor-fold desc="Description"> -- </editor-fold>
2. Об этом своими мыслями поделитесь, пожалйуста зедсь: https://youtrack.jetbrains.com/issue/DBE-220
3. На это тоже есть тикет https://youtrack.jetbrains.com/issue/DBE-3444
Спасибо!
grossws
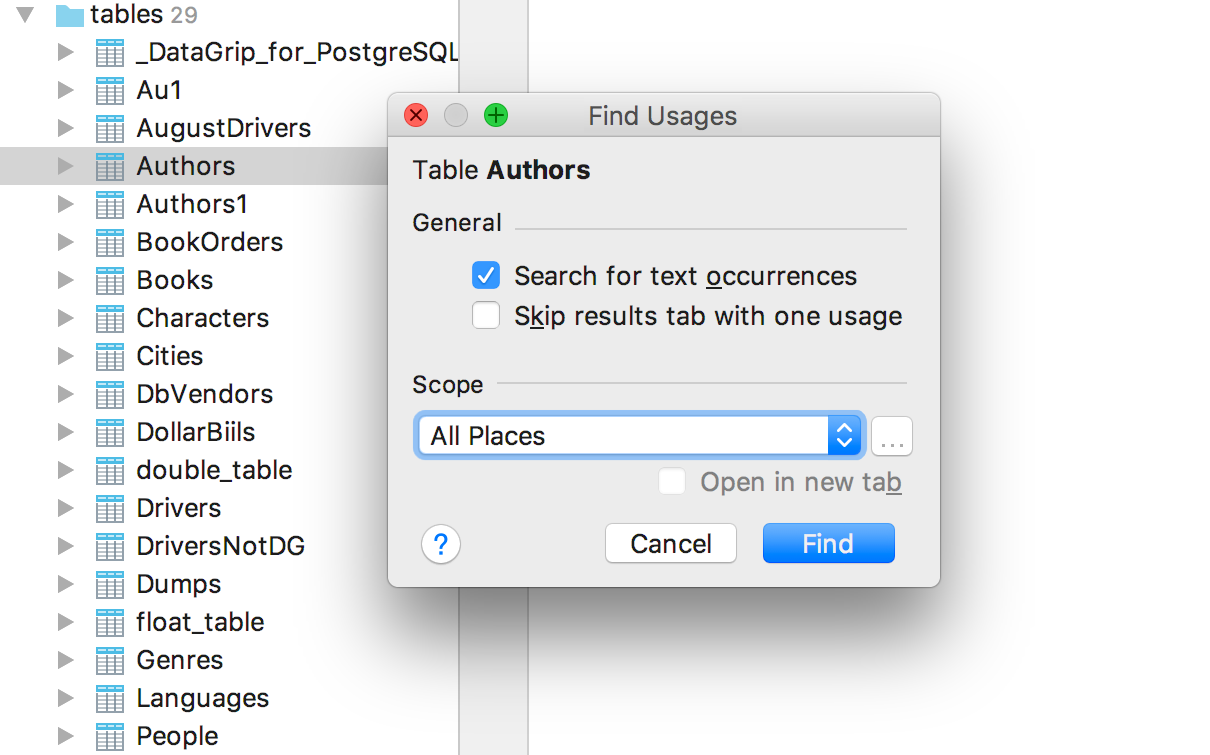
30.03.2017 02:24А с чем связано использование
editor-fold, а неregion .../endregionкак в идее? Или оно тоже поддерживается?
valery1707
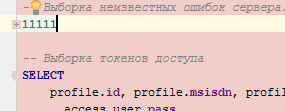
30.03.2017 17:38Так вроде регионы работают:
- свёрнуто:
- развёрнуто:
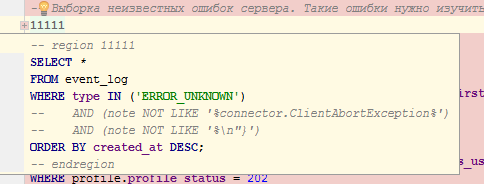
Или это работает только в IDEA?
- свёрнуто:


erlioniel
29.03.2017 14:17Хорошее и перспективное начинание. Я попросил наших базистов (которые используют PL/SQL Developer) потестировать и им не понравилось. Главным образом потому что поддержка Oracle фич недостаточна и IDE показывает ошибки там где их нет.
moscas
29.03.2017 16:47А можно вас попросить, чтобы ваши базисты прислали примеры неверно подсвечиваемого кода? Тогда мы поправим эти ошибки.
erlioniel
03.04.2017 10:11Можно конечно :)
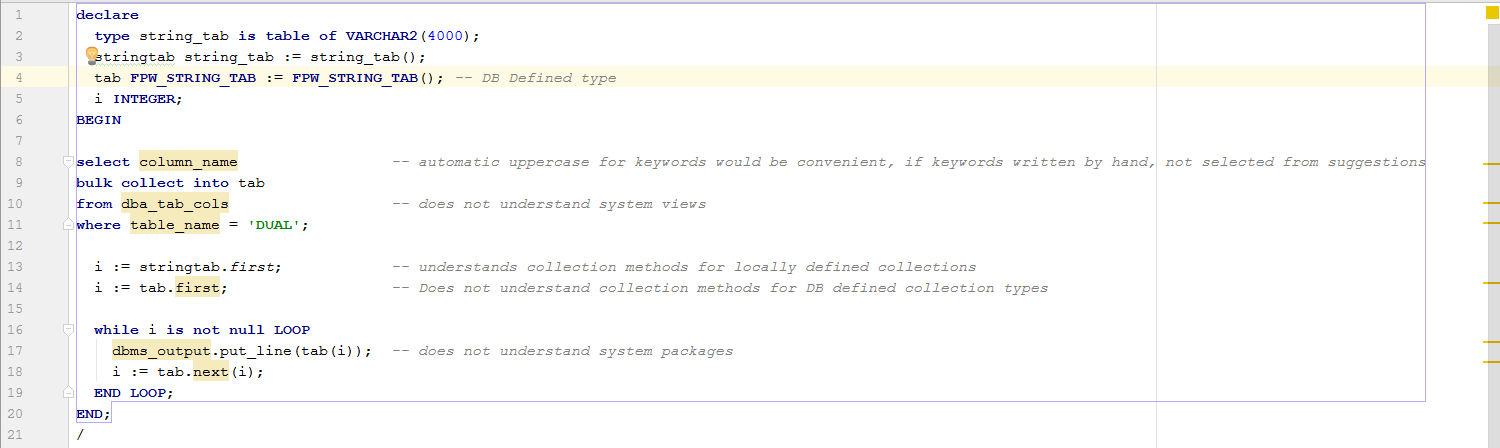
+ would be nice to have UI for DB session management
would be nice to have Oracle built in java objects recognized by ide
Would be nice to have scheduler jobs recognized as objects by ide
+ ide does not understand reference to constants defined in external package — a package that is not the same as the one where the reference is used, for example. use of fpw_global_pkg.c_env in package import_case
Same applies to types defined in external packages, for example type format.format_array that's used in import_file package
if global variable is defined in package header and used in the package body, it's highlighted as not resolvable


FractalizeR
31.03.2017 19:16Было бы неплохо увидеть наконец комментарии к столбцам таблиц в виде всплывающих подсказок на их заголовках.

robert_ayrapetyan
>Insert string concatenation on Enter
Спасибо что наконец-то пофиксили!
Подскажите где можно найти эту же настройку в IntelliJ IDEA Ultimate?
moscas
Так там же: Settings > Editor > General > Smart Keys > SQL
Но, вообще, в настройках же работает поиск. Набериет в нём «Smart Keys» и все подобные вопросы отпадут сами собой :)