
1. Пролог
Несколько лет назад разработал внутренний язык для расчета отчетов, который используется в нашей фирме. Язык получился странным, в нем нет ни циклов, ни стандартных условных операторов (if), динамическая типизация, но со своими функциями он справлялся. Идея языка была реализовать простой expression evaluator. Со временем требований становилось все больше, как следствие язык стал расширяться, пришлось разработать простой сценарий добавления новых функций.
На сегодняшний момент внутренний язык предназначенный для расчета отчетов превратился в монстра, не поворотливого мутанта. Это творение породили на свет отсутствие документации, простота расширения и лень разработчиков (проще написать, что то новое, чем разобраться в том что есть и найти нужное). Язык стал уметь много, слишком много того, для чего он не предназначался (разве что блинчики его печь не научили, а жаль).
2. Переосмысление
Отдел начал расширяться, появились новички, которых нужно обучать этому языку, а это не просто. Было принято решение о переводе отчетов на новую систему, лишенную недостатков текущей, задачу осложняет появившийся отдел аналитики. Взаимодействие примерно такое аналитика -> расчеты -> разработка -> скрипт -> аналитика. Задача усложняется тем, что код внутреннего языка должны читать аналитики (не программисты) и отправить на доработку, если будут выявлены ошибки. Звучит потрясно – делай! Это был вердикт, задача досталась мне, за искупление предыдущих грехов. Когда задача была озвучена и поставлена голоса критиков куда то подевались “Где циклы? Разработчик видимо о них не знал”, “А не проще ли это все писать на c#? C = a + b”. Языковые конструкции шарпа очень уместны будут в отделе аналитики (где такие слова как функционал, тернарный оператор звучат как мат).
3. Поиск решения
Текущая версия языка была разработана на коленках ни знаний, ни опыта на тот момент не было, нужно было что то разработать быстро, что удовлетворяло бы текущие потребности. На данный момент есть опыт, который говорит «Нет, садиться делать это бред! Нет знаний! Нужно использовать чужой опыт и знания.”. Первое, что приходит на ум – это разработка компилятора (вполне себе идея). Нашел. После просмотра понял, что очень интересно, очень сложно и походу слишком я замахнулся на компилятор. Иногда в проекте мы использовали файлы конфигурации различных сервисов (обычно это xml ), гордо называя это DSL! Я решил более подробно ознакомиться с аббревиатурой – походу это то, что надо. С этим дядькой я уже знаком, он имеет не хилый вес в области проектирования – надо ознакомить с его трудами. В этой книге он постоянно упоминает ANTLR.
4. Установка ANTLR4 в VS
Не нашел адекватных статей по использованию ANTLR в VS, это заставило написать данную статью (на самом деле все просто, когда знаешь, когда знаешь – все просто). Здесь в принципе описан пример (с ручной правкой файла проекта). Не катит. Всё, что нужно, можно найти в расширениях и nuget самой студии.
ANTLR Language Support:

Что это дает:
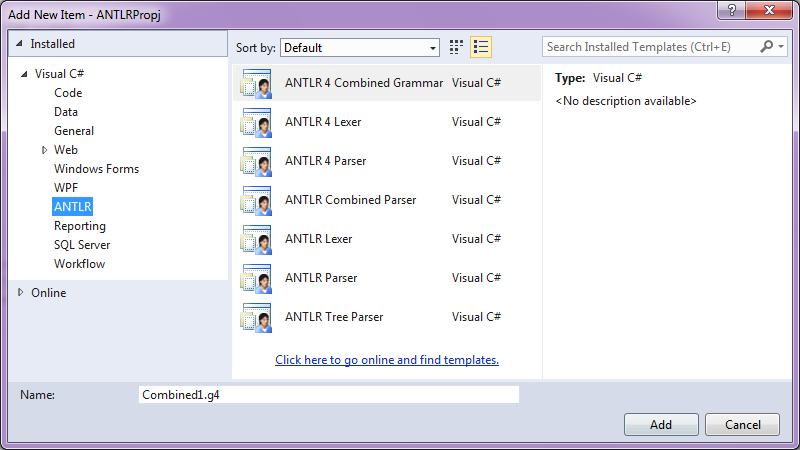
Далее две библиотеки с nuget:
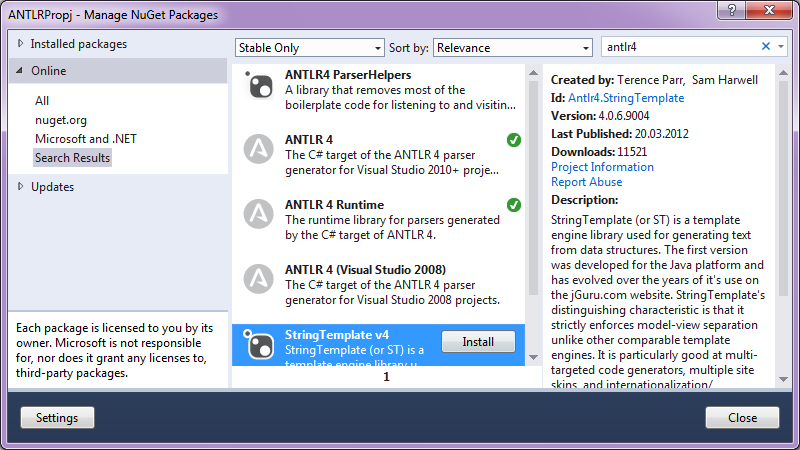
Дале создание грамматики, добавление в проект antlr4 Combined Grammar файла Calculator.g4. С примерно таким содержимым:
grammar Calculator;
@parser::members
{
protected const int EOF = Eof;
}
@lexer::members
{
protected const int EOF = Eof;
protected const int HIDDEN = Hidden;
}
/*
* Parser Rules
*/
prog: expr+ ;
expr : left = expr op=('*'|'/') right = expr # MulDiv
| left = expr op=('+'|'-') right = expr # AddSub
| INT # int
| '(' expr ')' # parens
;
/*
* Lexer Rules
*/
INT : [0-9]+;
MUL : '*';
DIV : '/';
ADD : '+';
SUB : '-';
EQU : '=';
WS
: (' ' | '\r' | '\n') -> channel(HIDDEN)
;
Взятого почти без изменений с сайта указанного выше. В свойствах файла нужно выставить:
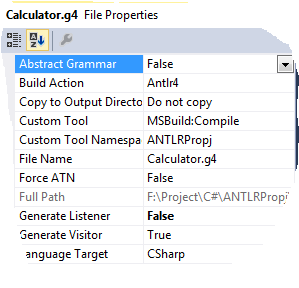
Далее F5… И ничего, ни ошибок, ни обещанного CalculatorBaseVisitor.cs. Ах, да, как же я мог забыть, у меня же не стоит окружения для выполнения программ на JAVA (эпично, что для разработки на C# нужна JAVA).
Повторная попытка запустить проект выдала:
Error 5 '@' came as a complete surprise to me
Error 2 '¬' came as a complete surprise to me
Error 3 missing SEMI at '¬grammar'
И тому подобное. Нет отчаяния в наших сердцах или Google в помощь, в общем, дело в кодировке: utf8(BOM) должна быть utf8 (без BOM).
MS Word в шоке при открытии файла:

Я преобразовал в windows – 1251 и сразу видны кривые символы в начале файла (забавно, но на другой машине таких проблем не было).
Проект собрался, но (что-то последнее время всегда есть но) обещанного CalculatorBaseVisitor.cs в проекте так и не обнаружил. Yandex раскрыл все карты (и не важно, какая поисковая система) …\obj\Debug — здесь живут сгенерированные файлы анализатора, возможно, это правильно сгенерированные файлы, не подлежат модификации, wpf в эту же папку скидывает .g файлы, но сброс туда посетителя мне доставило неудобства, когда Parser и Lexer были добавлены в проект, а посетитель нет.
Дальше можно воспользоваться ссылкой, откуда я брал пример грамматики для завершения урока.
Далее
P. S.
Возможно, все проблемы из-за того, что родной язык ANTLR — это JAVA, и генератор не так популярен на C#, но после преодоления всех проблем по подключению (а это не 1 час) система оказалась довольно хорошей, хоть и примеров для C# очень мало.
P. P. S.
Основано на реальных событиях. Некоторые имена и события были искажены в целях соблюдения авторских прав и безопасности.
Комментарии (12)

Razaz
04.06.2015 09:53То же намаялся с ANTLR. Хотел прикрутить его для парсинга фильтров в WebApi. В результате портировал кусок из ApacheDS Escimo и допилил его)
Жаль что поддержка на C# слабая, так как в целом — классная штука.
InWake Автор
04.06.2015 19:55Примеров на c# не достать, правда их можно транслировать с JAVA примеров

LightSUN
04.06.2015 20:58Ещё можно использовать gplex / gppg. Это аналог yacc/lex но для C#. Пробовал для небольшого приложения — вполне нормально работает.
InWake Автор
04.06.2015 21:18в документации пример 7.3 Tree-Building Calculator
калькуляторы, куда ж без них. Нужно будет посмотреть спасибо!LightSUN
04.06.2015 21:26Вот ещё работающий пример калькулятора :).
InWake Автор
05.06.2015 16:05что то мне не нравиться сгенерированный парсер, понятно что он авто, но вот поиск ошибок будет затруднен
states[0] = new State(new int[]{28,27,8,31,9,35,10,39,11,43,12,47,13,51,14,55,15,59,16,63,17,67,18,71,19,75,20,79,21,83,22,87,23,91,24,95,25,99,26,103,3,108,4,109,5,110,6,112,7,113,39,114,32,116,31,118},new int[]{-1,1,-3,3,-4,30,-5,107,-6,111}); states[1] = new State(new int[]{2,2}); states[2] = new State(-1);
и так 150 строк не перевариваемого кода. можно захлебнуться
Mingun
06.06.2015 19:44Если хочется иметь читаемый парсер, я бы порекомендовал посмотреть в сторону PEG-парсеров, для C#, например, на Pegasus.

xGromMx
06.06.2015 22:10Тогда уж лучше Nemerle rsdn.ru/article/nemerle/PegGrammar.xml он для этого предназначен
InWake Автор
07.06.2015 10:44Левая рекурсия
PEG фактически описывает нисходящий рекурсивный парсер с откатами. Этот тип парсеров имеет одно ограничение. Без специальной доработки (негативно влияющей на производительность и сильно усложняющей парсер) парсеры этого типа не могут разбирать леворекурсивные грамматики.
Леворекурсивной грамматикой называют грамматику, которая имеет леворекурсивные правила (прямые или нет). Например, следующая грамматика имеет левую рекурсию:
X = X '+' 1 / 1
…
Научно доказано, что любое леворекурсивное правило можно переписать без левой рекурсии. Например, приведенное выше правило можно переписать так:
X = 1 ('+' 1)*
я не очень знаком с грамматиками
expr : expr ('*'|'/') expr # MulDiv | expr ('+'|'-') expr # AddSub | INT # int | '(' expr ')' # parens ;
очевидно левая рекурсия, но как от нее избавиться?
InWake Автор
06.06.2015 22:14что то очень не привычная грамматика (да же смешивание грамматики с парсером, хотя и более читаемая чем массивы)
@namespace MyProject @classname ExpressionParser additive <decimal> -memoize = left:additive "+" right:multiplicative { left + right } / left:additive "-" right:multiplicative { left - right } / multiplicative multiplicative <decimal> -memoize = left:multiplicative "*" right:primary { left * right } / left:multiplicative "/" right:primary { left / right } / primary primary <decimal> = decimal / "(" additive:additive ")" { additive } decimal <decimal> = value:([0-9]+ ("." [0-9]+)?) { decimal.Parse(value) }
когда примерно то же самое в antlr
grammar Calculator; /* * Parser Rules */ prog: expr+ ; expr : left = expr op=('*'|'/') right = expr # MulDiv | left = expr op=('+'|'-') right = expr # AddSub | INT # int | '(' expr ')' # parens ; /* * Lexer Rules */ INT : [0-9]+; ADD : '+'; MUL : '*'; WS : (' ' | '\r' | '\n') -> channel(HIDDEN) ;
а если убрать весь шум (помогающий обходить дерево)
grammar Calculator; prog: expr+ ; expr : expr ('*'|'/') expr # MulDiv | expr ('+'|'-') expr # AddSub | INT # int | '(' expr ')' # parens ; INT : [0-9]+; WS : (' ' | '\r' | '\n') -> channel(HIDDEN) ;
хотя обход нужно писать отдельно (но за разделение ответственности нужно платить)
xGromMx
А что по поводу этого? www.jetbrains.com/mps
InWake Автор
Мощно! Правда JAVA