
EF наикрутейшая ORM от MS. habrahabr.ru/post/157267 это действительно круто. Разработать такую систему очень затратно по всем направлениям. CodeFirs вещь, знания проектирования БД, да какой там! Не нужны сами знания SQL – и это круто. Но так ли все радужно?
Julie Lerman может много рассказать msdn.microsoft.com/en-us/magazine/ff898427.aspx
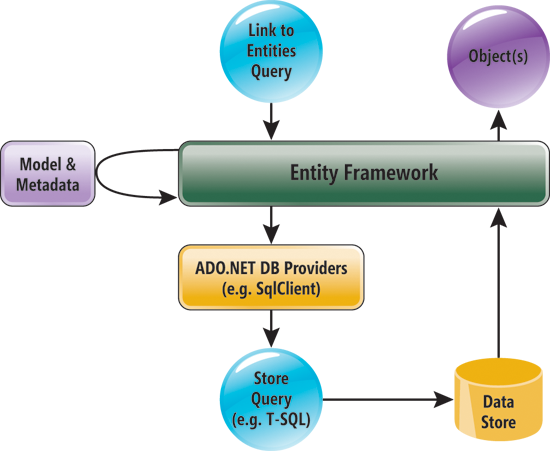
Ничего не напоминает?
Это реализация Repository + UoW. Так значит, при использовании EF делать всевозможные обертки бесполезно?
EF безумно популярная технология, не найти нужного провайдера под свое хранилище затруднительно.
Основная идея EF ( как и любого Repository ) – отделение предметного слоя от слоя хранения. Но зачем?
Все просто – что бы без болезненно изменять хранилище и предметку не зависимо.
Когда нужно менять хранилище?
Хотелось бы что бы никогда, но как говориться «никогда не говори..». Я работаю над проектом, в котором два боевых слоя хранилища и еще одно демонстрационное. Клиент сам выбирает, как он будет хранить свои данные.
Нужно ли строить абстракцию поверх абстракции и делать то, что уже и так реализовано?
Ответ лежит в совместимости конкретных провайдеров. Вот что о совместимости говорит один из разработчиков таких провайдеров Yevhen Shchyholyev www.infoq.com/articles/multiple-databases. Проблемы которые были понятны на интуитивном уровне укрепляются самими разработчиками.
Вот некоторые из них
Типы данных
Entity Framework поддерживает ограниченный набор .NET типов (signed integers, Single, Double, Decimal, String, Byte[], TimeSpan, DateTime, DateTimeOffset, Boolean, Guid). Однако не все.NET типы из этого списка поддерживаются базами данных.
Типы – вечная проблема. То есть один сценарий, выполненный на одном провайдере ( именно на провайдере ) может не дать тех же результатов на другом.
Поддержка DateTimeOffset
DataTimeOffset — самый проблематичный тип.NET. Он поддерживается в SQL Server MS 2008, Oracle и SQLite, но не в SQL Server MS 2005, MySQL или PostgreSQL, так как в этих базах данных отсутствует DateTime, который может сохранить смещение часового пояса.
Проблема возникшая у нас, дата храниться в UTC, но EF под SQLight упорно возвращал в Local. Проблема легко была решена, тк мы используем Mapping.
Производительность
Если специфические особенности определенной базы данных не приняты во внимание, возможно, что LINQ-запрос может быть обработан быстрее в одной базе данных и медленнее в другой.
Разбивка на страницы данных, выполненная LINQ-методы .Skip ()/.Take(), может быть одной из самых затратных операций. В отличие от в SQL Server, Skip /Take, Oracle, генерирует два подзапроса с сортировкой во внутреннем подзапросе, который может негативно повлиять на производительность. Нужно отметить, что разбивка на страницы может быть довольно неэффективной в других базах данных, особенно если сортировка выполнена по неиндексируемыми столбцами.
Вот тут самое интересное, под разные провайдеры нужно писать свои запросы на LINQ. Еще интересный сценарий: написали некоторый функционал с кучей запросов к контексту и все прекрасно работает. Но приложение cross и нужно проверить, как это все будет работать на другом провайдере. Было обнаружено, что часть запросов стали не эффективные. Не беда – оптимизация. Все хорошо. Вопрос как оптимизация отразилась на работе при исходном провайдере?
Ограничения запроса
В EF разработчик может сформировать запросы, используя или LINQ to Entities, или Entity SQL или их комбинацию. В любом случае такой запрос преобразовывается механизмом EF в промежуточное представление как expression tree и отправляется в EF-провайдер, чтобы он сгенерировал SQL запрос. Так как EF была первоначально разработана для SQL Server, то иногда EF-провайдеры должны значительно преобразовать первоначальное expression tree, чтобы сгенерировать корректный SQL для определенной базы данных. Однако это не всегда возможно.
Здесь ясно сказано mission impossible. SQL SQLю рознь, провайдер провайдеру. Тут даже речь не о том, что запрос будет не эффективен, а о том, что он может покрошить выполнение приложения.
Соответствующий раздел MSDN говорит, что все эти функции поддерживаются всеми EF-провайдерами:
«В этом разделе рассматриваются канонические функции, которые поддерживаются всеми провайдерами данных и могут использоваться всеми технологиями запросов».
Этот раздел, кажется, сверхоптимистичен, поскольку различные DBMS обладают различной функциональностью, и иногда невозможно реализовать все возможности для совместимости.
Вот ссылка. Но не абы кто, а ведущий разработчик набора сторонних провайдеров говорит mission impossible.
Заключение
В этой статье я попытался предоставить краткое описание наиболее распространенных проблем в процессе разработки EF-приложений для не Microsoft SQL Server баз данных. Несомненно, много других аспектов не получили внимания в этой статье...
То есть это не все проблемы какие могут возникнуть по мимо описанных, и о каких можно узнать только встав на грабли.
Подводя итоги.
EF это хорошая абстракция, и как любая абстракция, она не лишена главного недостатка – ее реализации. Проблемы описанные в этой статье взяты не из головы и не из уст скептиков, а из первых рук – разработчика провайдеров.
Провайдеры разрабатываются разными фирмами и я уверен, что если в одном проекте использовать провайдеры от разных производителей проблем с совместимостью будет гораздо больше. forums.mysql.com/read.php?174,614148,614148
Я ни в коем случае не говорю НЕТ EF, я говорю да Repository, ведь все описанные проблемы легко обойти с помощью этой абстракции которая обернет EF и поглотит проблемы совместимости.
P. S.
Рассмотрен лишь технологический пример для чего может понадобиться реализовывать «Велосипед», причин по которым можно и нужно использовать репозиторий и примочки гораздо больше.
Комментарии (269)

SVVer
28.06.2015 10:45inwake, спасибо за статью! На мой взгляд, эту тему нужно периодически поднимать, чтобы те, кто рассматривает возможность использования EF или других ORM в первый раз, понимали, с какими ограничениями они столкнутся в будущем, и учитывали это в своих проектных решениях. Как говорит Мартин Фаулер:
Часто мне кажется, что в большой степени разочарование ORM связано с раздутыми ожиданиями
Хотелось бы добавить к сказанному еще несколько моментов.
- Почти все сказанное в статье, по-моему, можно отнести ко всем ORM, поскольку все занимаются связыванием двух разных моделей представлений: объектно-ориентированной и реляционной, т.е. как-то решают вопрос с уже набившим оскомину object-relational impedance mismatch.
- Проблемы с производительностью могут возникать не только при выполнении одного LINQ-запроса на разных провайдерах, но и при попытке выполнить сложные запросы на одном провайдере. Например, я имел опыт написания LINQ-запроса с группировкой данных, в качестве СУБД выступал SQL Server. Я понимал, что EF построит мой запрос не оптимально, но на первых порах я не хотел заниматься оптимизацией. В итоге, проблема проявилась гораздо раньше, чем я ее ждал: получилось что при наличии 800 записей в основной таблице с данными запрос выполнялся 8 секунд, а на следующий день, когда записей в таблице стало 1200 — 14 секунд. Как выяснилось, запрос, который строил EF, содержал 8 вложенных select-выражений! В итоге тот же запрос был написан на чистом SQL с использованием только двух вложенных select-ов и все стало выполняться в пределах одной секунды.
- EF предоставляет нам репозиторий с максимально универсальным поисковым интерфейсом — IQueryable. И именно потому, что количество запросов, построенных с его помощью, безгранично, то разработчики конкретных LINQ-провайдеров вынуждены как-то ограничивать это множество. В итоге, мы действительно получаем то, что при работе с конкретным провайдером нужно понимать, что он поддерживает, а что нет. Т.е. особенности реализации провайдера «протекают» через абстракцию IQueryable. У Mark Seemann есть хорошая статья о том, что не нужно использовать IQueryable в интерфейсах репозитория. Хоть она и несколько категорична, почитать ее стоит.
Разрабатывая собственный репозиторий со специализированным интерфейсом, мы в силах ограничить число возможных запросов к нему и, соответственно, обеспечить более полную реализацию.Но проблема может возникнуть тогда, когда мы должны создать достаточно универсальный репозиторий, который может хранить различные классы объектов и допускать достаточно сложные запросы. И тут нам все-равно придется либо вводить свой универсальный запросный язык, либо использовать IQueryable, ограничив набор поддерживаемых запросов и доведя это до тех, кто будет наш репозиторий использовать.

gandjustas
28.06.2015 14:44Как выяснилось, запрос, который строил EF, содержал 8 вложенных select-выражений!
Во-первых сам EF ничего не строит сам, он только интерпретирует ваш запрос.
Во-вторых сами по себе 8 вложенных select никакого влияния на быстродействие не оказывают.
Вообще вложенный select в запросе может быть как correlated subquery, так и derived table. Derived table вообще никак не влияет на быстродействие, в плане все проекции будут спущены на самый нижний уровень. Correlated subquery может приводить к проблемам быстродействия. НО EF сам нигде correlated subquery не генерирует. Надо постараться, чтобы так случилось.
То есть проблема не в том, что EF плохой, а в том, что вы не смогли родить на нем нормальный запрос.
Кстати вы могли еще нарваться на баг с Navigation Properties, его просто надо знать и обходить.SVVer
28.06.2015 15:19+1Во-первых сам EF ничего не строит сам, он только интерпретирует ваш запрос
Конечно. Но только интерпретировать он его может по-разному. И получается, что помимо LINQ я должен понимать особенности интерпретации expression tree с запросом каждым конкретным провайдером. Т.е. абстракция уже не скрывает от меня детали реализации, а значит она «течет».
То есть проблема не в том, что EF плохой
Я не говорил, что EF плохой! EF отличный, просто нужно понимать, что он не избавляет от необходимости хорошо понимать его работу с СУБД. Вы, кстати, наглядно аргументировали это в своем комментарии.gandjustas
28.06.2015 16:21И получается, что помимо LINQ я должен понимать особенности интерпретации expression tree с запросом каждым конкретным провайдером.
Конечно. Для оптимизации быстродействия всегда надо знать что происходит на два уровня ниже твоего уровня абстракции. А еще и на один выше.
абстракция уже не скрывает от меня детали реализации, а значит она «течет»
Любая нетривиальная абстракция течет. Это нормально.SVVer
28.06.2015 16:25Отлично! Я ведь с этого и начал:
… чтобы те, кто рассматривает возможность использования EF или других ORM в первый раз, понимали, с какими ограничениями они столкнутся в будущем, и учитывали это в своих проектных решениях
gandjustas
28.06.2015 16:31-1И? Я же писал о том, что проблемы с производительностью это не проблемы EF. Он ничего не делает чтобы ухудшить производительность. Все делают программисты. И репозиторий тут не поможет, а скорее хуже сделает.
SVVer
28.06.2015 16:38Как-то Вы мой пример, который приведен лишь для того, чтобы обратить внимание на возможные последствия (чаще всего, по незнанию того, «что происходит на два уровня ниже твоего уровня абстракции»), вырвали из контекста и за него меня «хлещете». Он не направлен на то, чтобы как-то упрекнуть EF. Это как раз пример того, как непонимание механизмов внутренней работы (в данном случае мое) может привести к проблеме.
gandjustas
28.06.2015 16:45А чем тогда репозиторий поможет если вы механизмов работы не понимаете?
SVVer
29.06.2015 20:59А где я сказал, что репозиторий поможет решить эти проблемы?
Похоже я в своем первом посте выразил слишком общее одобрение всему сказанному в статье. Моя вина, каюсь! Но попробую пояснить: подавляющая часть статьи содержит описание проблем, с которыми можно столкнуться при, скажем так, использовании EF «в лоб», без должного понимания. Именно к этому описанию я и попытался добавить некоторое дополнение.
А вот это высказывание я поддержать не готов:я говорю да Repository, ведь все описанные проблемы легко обойти с помощью этой абстракции которая обернет EF и поглотит проблемы совместимости
Оно вообще похоже на то, что найдена «серебряная пуля». Но мне кажется, что здесь свое дело сделали эмоции автора, ведь и стиль изложения материала в статье несколько «импульсивный», имхо. Насчет Repository над EF не хочу писать обрывками: думаю, идея полезная и может решить часть проблем, но каких и как — нужно пояснить. Попробую сформулировать это чуть позже.
lair
29.06.2015 21:02А ведь именно это высказывание является обобщением статьи и месседжем автора.
SVVer
29.06.2015 21:10Пришлось перечитать несколько раз. Автору стоило бы как-то выделить, на мой взгляд. Просто человеку ведь свойственно выделять из множества информации ту, которая его беспокоит больше. Вот так же вышло и со мной.

InWake Автор
29.06.2015 23:03Да, и я не отказываюсь, от своих слов. Описанные проблемы он решит, добавит новых? может и такое быть
gandjustas
29.06.2015 23:04Описанные проблемы можно решить и без добавления новых. Так что полезность repository сильно преувеличена.
InWake Автор
29.06.2015 23:53я пока не увидел ни 1 нормального решения, кроме «Репозиторий это плохо, нужно писать, расходы, автор врет»
gandjustas
29.06.2015 23:57Решения чего? Я уже объяснил, что нет смысла городить репозитории, берите ваши QueryBulder_ы и инжектите их в БЛ. Все, репозитории не нужны.
InWake Автор
30.06.2015 00:03а много раз говорил, что выставление наружу контекста это плохо. описанве здемь проблемы
gandjustas
30.06.2015 00:08Почему плохо?
InWake Автор
30.06.2015 15:50IQuariable — не контролируемые запросы
gandjustas
30.06.2015 21:24Не контролируемые кем?
InWake Автор
30.06.2015 21:47ни кем, синтаксически можна написать сколь угодно сложные выражения, которые не возможно перевести в sql, и об этом узнается только при исполнении.
gandjustas
30.06.2015 21:561) А кто помешает программисту сделать тоже самое внутри репозитария?
2) Кто помешает написать запрос любой степени сложности для IEnumerable, который отдается из репозитария и получить тормоза?
3) Что лучше — программа которая работает, но дико тормозит, или программа, которая падает при тестировании?
Обычно один и тот же программист пишет всю логику. Поэтому ему в любом случае надо уметь писать запросы к EF.
lair
30.06.2015 00:07Мы уже обсудили, что репозиторий не решает описанные проблемы сам по себе, он просто их переносит в другие части системы.
InWake Автор
30.06.2015 15:53Repository — это фасад, фасад ничего никогда не решает
Repository also supports the objective of achieving a clean separation and one-way dependency between the domain and data mapping layers.
lair
30.06.2015 16:01Правда? Так зачем же вы пишете «ведь все описанные проблемы легко обойти с помощью этой абстракции которая обернет EF и поглотит проблемы совместимости»?

VolCh
30.06.2015 07:02Репозиторий поможет обойти непонятные механизмы чтобы получить тот SQL-запрос, который хочется в данном конкретном случае. Или поможет обойти механизмы, которые понятно что такой запрос сгенерировать не могут.
gandjustas
30.06.2015 21:27Каким образом? Если репозиторий вызывает тот же EF, то другой запрос вы не получите. Если вы рассматриваете репозиторий вместо EF, то сразу бросьте это занятие.
InWake Автор
28.06.2015 16:16Спасибо за поддержку, похоже эта идея не популярна.
lair
28.06.2015 16:23Просто это немного другая идея. Это идея о том, что вообще парадигма ORM (лежащая в основе EF и любого другого решения, хранящего объектные данные в реляционной структуре) обладает внутренними противоречиями, которые не снимаются ни репозиторием, ни чем-либо еще. Фаулер, на самом деле, просто предлагает рассматривать и нереляционные хранилища, поскольку зачастую они оказываются выигрышнее.
gandjustas
28.06.2015 16:43Никаких внутренних противоречий у ORM нет (если понимать его именно как маппер данных на языковые конструкции). Есть внешние противоречия. ОО-программисты хотят работать с данными как с графом объектов, а поднимать из базы этот граф, отслеживать изменения и сохранять — очень накладно. В нереляционных хранилищах каждый граф объектов и есть сущность, которая поднимается из базы и сохраняется целиком. Вот только нереляционные хранилища гораздо менее приспособлены для хранения данных, чем реляционные субд.
lair
28.06.2015 16:45Вот собственно сама идея «мы хотим работать с данными как с графом объектов, но хранить их в реляционной БД» — а именно она лежит в основе ORM — и содержит внутренние противоречия, которые вы же прекрасно и описали.
gandjustas
28.06.2015 16:48Так ORM тут не при чем. Мапинг данных на объекты на основе метаданных вовсе не требует сводить всю логику к операциям на графе объектов (domain model).
lair
28.06.2015 16:51+1Бррр, а какое отношение имеет сведение логики к операциям к обсуждаемому вопросу? Проблемы ORM как подхода именно в том, что он пытается сделать взаимное преобразование двух плохо сочетающихся парадигм, причем в идеале сделать это преобразование максимально незаметно для потребителя — и на этом и гибнет.
Это, однако, не означает, что ORM лишен смысла, или что этот недостаток фатален — просто надо осознавать эту особенность (O-R impedance mismatch) при выборе технологий и подходов.gandjustas
28.06.2015 17:07Проблемы создает именно попытка бизнес-логику описать в терминах операций с графом объектов (классов с методами), а не сам мэпинг.
сделать это преобразование максимально незаметно для потребителя
Если отказаться от этой идеи, то ORM начинает прекрасно работать.
lair
28.06.2015 16:35+1Кстати, обратите внимание, что в статье, на которую вы ссылаетесь, Симан пишет весьма занятную вещь, несколько, скажем так… подрывающую идею поста:
If you have a specific ORM in mind, then be explicit about it. Don't hide it behind an interface. It creates the illusion that you can replace one implementation with another. In practice, that's impossible.
Ведь идея поста сформулирована вот так:
я говорю да Repository, ведь все описанные проблемы легко обойти с помощью этой абстракции которая обернет EF и поглотит проблемы совместимости.
InWake Автор
28.06.2015 19:36Вы увидели свет в конце тоннеля, луч надежды, но не заметили что он не для вас, тк читаете между строк.
If you have a specific ORM in mind
да это так, меня очень волнует как конкретная ОРМ обрабатывает мои запросы.Don't hide it behind an interface. It creates the illusion that you can replace one implementation with another. In practice, that's impossible.
«Не скрывайте ее за интерфейсом», да это то о чем пишу я, общий IQuariable это большая проблема. «Это создает иллюзию, что можно заменить одну реализацию другой» именно об этом я и пишу, нельзя один провайдер заменить другим и думать что это прокатит. Заметьте у меня в голове Repository который знает о проблемах конкретных провайдеров и борется только с ними а не с общими проблемами ОРМ.lair
28.06.2015 19:41Тогда зачем вы скрываете конкретную ORM (EF) за интерфейcом (репозиторием)?
InWake Автор
28.06.2015 21:44да интерфейс общий, но используется ограниченный набор запросов, отражающий запросы предметной области, и для меня важно что изменения в запросах к одной бд не поломают запросы к другим, тк переводом запросы предметной области переводятся в запросы к конкретной ОРМ, конкретной реализацией репозитория.
lair
28.06.2015 21:58используется ограниченный набор запросов
То есть вы не используете expression trees от LINQ, а сделали свой интерфейс запросов?InWake Автор
28.06.2015 22:32expression trees ведет к описанной проблеме
lair
28.06.2015 22:55Ага, то есть вы используете свой интерфейс запросов. Собственно, это и есть то следствие выбранного вами подхода о котором вы умалчиваете в вашем посте: теперь вам либо придется реализовать развитый собственный язык запросов (и тогда еще не факт, что вы не столкнетесь с теми же проблемами, что и выше), либо вы радикально урежете доступную коду-потребителю функциональность. Потому-то репозиторий и не решает проблемы, которую создает LINQ — он делает вид, что ее не существует, потому что он просто не дает пользователю таких возможностей.
InWake Автор
28.06.2015 23:03Доступно все, что описано в предметной области, это ограждает от невалидных и неэффективных запросов, дублирования и головной боли по совместимости при нескольких бд.
lair
28.06.2015 23:07Доступно все, что описано в предметной области, это ограждает от невалидных и неэффективных запросов
Вы серьезно? Вот у вас есть предметная область с типом «документ», у которого есть заголовок и тело, и то, и другое — строка. Чем определяется, в каком из двух полей можно делать полнотекстовый поиск, а в каком — нет?InWake Автор
28.06.2015 23:31предметной областью, то что в предметке есть такой документ, ничего не говорит о том как можно с ним взаимодействовать, исходя из описания поиск можно вести по любому из полей, а почему нет?
lair
28.06.2015 23:37Конечно, можно. Только поиск по заголовку можно делать стандартным для реляционных БД способом, а по телу — нет (потому что оно слишком большое, и поиск перебором становится вечным). Предметной области на это наплевать, поэтому от неэффективных запросов она вас не защитит.
InWake Автор
29.06.2015 00:07да ладно, если это документы справки и текста в них не более 150 символов, почему нет? это конкретная предметная область.
lair
29.06.2015 00:12Вот я вам и даю конкретную предметную область, где документы — это архив на 6+ Tb, а тело каждого документа превышает десятки тысяч символов. При этом, что характерно, пользователю нужен поиск по телу.
InWake Автор
29.06.2015 15:17изначально вы об этом не упомянули, что вы подразумеваете под
можно делать стандартным для реляционных БД способом
lair
29.06.2015 15:20что вы подразумеваете под «можно делать стандартным для реляционных БД способом»
LIKE '%term%'InWake Автор
29.06.2015 23:06а какой способ вы предлагаете для оьхода данной проблемы?
lair
30.06.2015 00:08А это, очевидно, зависит от доступного инструментария. В данном случае я просто хотел вам продемонстрировать, что подход «доступно все, что есть в предметной области» не «ограждает от неэффективных запросов».
InWake Автор
30.06.2015 15:56как раз наоборот, если для предметной области нужен поиск по строке, то лучше всего подойдет хранить тела документов в файлах, отфильтровать документы из бд, получить расположение файлов, провести поиск в них, эт овсе можно скрыть все тем же репозиторием
lair
30.06.2015 16:02Вы, похоже, вообще не следите за тем, что вам показывают. Жаль.
InWake Автор
30.06.2015 21:49расшифруйте.
lair
30.06.2015 22:16Вы написали:
Доступно все, что описано в предметной области, это ограждает от невалидных и неэффективных запросов,
Я вам продемонстрировал, как подход «доступно все, что описано в предметной области» не ограждает от неэффективных запросов.
VolCh
30.06.2015 07:11Совсем необязательно урезать доступную коду-потребителю функциональность. Просто в интерфейсе репозитория можно оставить (унаследовать или проксировать) стандартный интерфейс, а для критичных запросов иметь отдельные. Или реализовать оптимизацию запросов под конкретного провайдера как декоратор — перед выполнением запроса проверять его на принадлежность к некоему множеству и выполнять «нативный» код, если принадлежит к нему, а если нет, то передавать стандартному.
InWake Автор
30.06.2015 15:59Совсем необязательно урезать доступную коду-потребителю функциональность
я согласен
а для критичных запросов иметь отдельные
а как узнать какой запрос критический если у нас «доступную коду-потребителю функциональность» есть доступ и тут можно пилить что угодно и как угодно.
lair
28.06.2015 12:17Ничего не напоминает? Это реализация Repository + UoW. [...] Основная идея EF ( как и любого Repository )...
EF — это не репозиторий. В терминах Фаулера (PoEAA), EntityFramework — это Data Mapper. Репозиторий — это следующий уровень (в сторону домена), и его задачи отличаются от задач data mapper.
я говорю да Repository, ведь все описанные проблемы легко обойти с помощью этой абстракции
Посмотрим внимательнее на некоторые описанные вами проблемы.
Вот тут самое интересное, под разные провайдеры нужно писать свои запросы на LINQ. Еще интересный сценарий: написали некоторый функционал с кучей запросов к контексту и все прекрасно работает. Но приложение cross и нужно проверить, как это все будет работать на другом провайдере. Было обнаружено, что часть запросов стали не эффективные. Не беда – оптимизация. Все хорошо. Вопрос как оптимизация отразилась на работе при исходном провайдере?
И как же репозиторий позволяет обойти эти проблемы? Вероятно, вы имеете в виду, что вы напишете две разных реализации репозитория для двух разных провайдеров. Это здорово, но вы помните, что вы только что увеличили свои затраты вдвое?
Ограничения запроса
В EF разработчик может сформировать запросы, используя или LINQ to Entities, или Entity SQL или их комбинацию. В любом случае такой запрос преобразовывается механизмом EF в промежуточное представление как expression tree и отправляется в EF-провайдер, чтобы он сгенерировал SQL запрос. Так как EF была первоначально разработана для SQL Server, то иногда EF-провайдеры должны значительно преобразовать первоначальное expression tree, чтобы сгенерировать корректный SQL для определенной базы данных. Однако это не всегда возможно.
Здесь ясно сказано mission impossible. SQL SQLю рознь, провайдер провайдеру. Тут даже речь не о том, что запрос будет не эффективен, а о том, что он может покрошить выполнение приложения.
Во-первых, вы передергиваете: нигде не сказано, что эта задача не имеет решения; сказано лишь что не всегда возможно сгенерировать корректный SQL для всех БД для любого AST. Но предположим на минуту, что вы правы, и эта задача действительно не имеет решения. Как же репозиторий ее решает в таком случае?
Nagg
28.06.2015 12:26+1>>EF — это не репозиторий.
Ну чем же DbContext не репозиторий? Классик, который наружу выставляет коллекции _доменных_ объектов с которыми можно работать как с обычнми коллекциями + немного UoW.lair
28.06.2015 13:46Repository replaces specialized finder methods on Data Mapper classes with a specification-based approach to object selection. Compare that with the direct use of Query Object, in which client code may construct a criteria object (a simple example of the specification pattern),
add()that directly to the Query Object, and execute the query. With a Repository, client code constructs the criteria and then passes them to the Repository, asking it to select those of its object that match. From client code's perspective, there's no notion of query «execution»; rather there's the selection of appropriate objects through the «satisfaction» of the query's specification. This may seem an academic distinction, but it illustrates the declarative flavor of object interaction with Repository, which is a large part of its conceptual power. [PoEAA, 2003, pp. 323-324]SVVer
28.06.2015 14:10+1С другой стороны там же написано [PoEAA, 2003]:
A Repository mediates between the domain and data mapping layers, acting like an in-memory domain object collection. Client objects construct query specifications declaratively and submit them to Repository for satisfaction. Objects can be added to and removed from the Repository, as they can from a simple collection of objects, and the mapping code encapsulated by the Repository will carry out the appropriate operations behind the scenes. Conceptually, a Repository encapsulates the set of objects persisted in a data store and the operations performed over them, providing a more object-oriented view of the persistence layer.
И если рассматривать в качестве реализации data-mapper только часть EF, то я не вижу каких-то особенных противоречий в утверждении, что EF реализует в том числе и шаблон Repository. Ведь и в приведенной Вами цитате сказано, что:
...This may seem an academic distinction, but it illustrates the declarative flavor of object interaction with Repository, which is a large part of its conceptual power.
Т.е. концептуально EF конечно не репозиторий, поскольку репозиторий более окрашен в «тона предметной области». Так же, как и Specification по сравнению с Query Object, как мне кажется. С другой стороны, формально фасад EF очень похож на описание фасада репозитория.
Некоторые интересные мысли по поводу EF и Repository можно найти в этой дискуссии на stackexchange.com.lair
28.06.2015 14:14Т.е. концептуально EF конечно не репозиторий, поскольку репозиторий более окрашен в «тона предметной области». Так же, как и Specification по сравнению с Query Object, как мне кажется.
Именно так. Я считаю это разделение очень важным, поскольку оно позволяет точнее определять ответственности в сложной системе.
С другой стороны, формально фасад EF очень похож на описание фасада репозитория.
Что именно вы считаете фасадом EF?SVVer
28.06.2015 14:26Что именно вы считаете фасадом EF?
В данном случае я имею ввиду DbSet<T>, который, реализуя IQueryable<T> и добавляя Add и Remove, фактически и действует как
… in-memory domain object collection
lair
28.06.2015 14:29Проблема в том, что там еще есть
SaveChanges. И вот тут вся эта конструкция превращается в UoW, и начинается путаница, которой лучше бы избегать.SVVer
28.06.2015 15:22В общем да. Но только как в случае с созданным поверх EF репозиторием реализовать тот же UoW, не внося путаницы уже в наш репозиторий?
lair
28.06.2015 15:23А это вопрос на пять, который как раз и является иллюстрацией того, почему репозиторий поверх EF строить не всегда удобно.
InWake Автор
28.06.2015 16:13Создать транзакцию и раздать ее репозиториям. Конкретная реализация UOWScope, будет подтверждать или отменять.
lair
28.06.2015 16:15Свою транзакцию или из
System.Transactions?InWake Автор
28.06.2015 16:52Мы используем BuisnessTransaction (посути обертка для наших нужд над системной)
lair
28.06.2015 16:53То есть внутри у вас системная? А как вы гарантируете поддержку всеми репозиториями этой системной транзакции (учитывая, что даже у EF с этим есть… некоторые проблемы, скажем так)?
InWake Автор
28.06.2015 17:15А как вы гарантируете поддержку всеми репозиториями этой системной транзакции
вы наверное ошиблись, скорее всего речь о провайдере?lair
28.06.2015 18:05Я вряд ли ошибся, скорее, кто-то из нас кого-то неправильно понял. Кто определяет границы транзакции — репозиторий или использующий его код?
InWake Автор
28.06.2015 19:28Границы транзакции определяет UoW только он, и не кто больше.
lair
28.06.2015 19:28UoW находится снаружи репозитория?
InWake Автор
28.06.2015 19:38да
lair
28.06.2015 19:42В таком случае он ничего не знает о деталях репозиториев (и о наличии внутри них каких-либо провайдеров). Как следствие, с его точки зрения, все репозитории должны поддерживать транзакции из
System.Transactions(ну или вашу транзакцию, что, в принципе, одинаково). Как вы это гарантируете?InWake Автор
28.06.2015 21:52Гарантировать это ни как нельзя, поэтому мы и используем обертки для контроля, закрепление данных происходит только при сохранении, идет отслеживание UoWscope, по сотоянию которых ясно, нужно ли сохранять изменения или нет.
lair
28.06.2015 21:59А как обертка может отследить, что происходит внутри репозитория? Или вы выставляете статус изменений наружу?
InWake Автор
28.06.2015 22:37наружу, это один из вариантов, но это захламляет объекты, для простых свойст при сохранении в маппинге происходит обновление всех полей, тут нужно отдать должное ChangeTracker отметить измененными только те свойства, которые были изменены.
SVVer
29.06.2015 21:44Тогда все же хочется понять Ваш подход.
Пусть мы имеем РСУБД, даже конкретно SQL Server, и храним в ней данные модели предметной области. Для точности пусть это будут DDD-агрегаты типа Foo с какой-то внутренней структурой. Для маппинга используем EF и получаем объекты Foo через DbSet<Foo>.
В то же время обобщенный интерфейс DBSet-ов нас не устраивает в том плане, что в разных местах системы, где он используется будет «зверинец» LINQ-запросов, в том числе и повторяющихся. Логично, вроде бы, в этом случае ввести над DbSet<Foo> какой-то репозиторий FooRepo, в интерфейсе которого будет ограниченное число методов доступа к данным, которых достаточно для работы всего вышестоящего кода в системе. Но в то же время нам нужен UoW, чтобы мы могли модифицировать объекты группам и рамках одной транзакции. Как добавить этот UoW?
Как бы Вы подошли к решению такой задачи?lair
29.06.2015 22:00Решение, которое я реально использовал в практике — это выставить все необходимые методы прямо на DbContext, и сделать из них интерфейс (тем самым ограничив доступ). UoW в таком случае проще всего реализовать, просто выставив
SaveChangesв публичном интерфейсе.
В этом сценарии, правда, надо очень четко следить за жизненным циклом контекста, чтобы в нем не было «лишних» изменений, которые провалятся в БД незаметно для программиста. Идеальный вариант — открыть контекст по месту использования, внести нужные изменения, сохранить, закрыть.SVVer
29.06.2015 22:37Т.е. получается что-то вроде:
public class FooRepo { private FooDbContext _dbContext; public FooRepo() { _dbContext = new FooDbContext(); } public GetFooByParamSet1(paramSet1) { ... } public GetFooByParamSet2(paramSet2) { ... } ... public AddFoo() {} public RemoveFoo() {} ... public SaveChanges() {} }
Если я правильно понимаю, получается обертка над DbContext-ом, которая одновременно и UoW и Репозиторий?lair
30.06.2015 00:06Намного проще.
public interface IFooDbContext { GetFooByParamSet1(paramSet1); GetFooByParamSet2(paramSet2); AddFoo(); RemoveFoo(); SaveChanges(); } class FooDbContext: DbContext, IFooDbContext { public GetFooByParamSet1(paramSet1) { ... } public GetFooByParamSet2(paramSet2) { ... } ... public AddFoo() {} public RemoveFoo() {} ... public SaveChanges() {} }SVVer
30.06.2015 20:08+1Мне почему-то кажется, что это не намного проще. Если я правильно понимаю, это замена композиции наследованием? И здесь меня смущают следующие моменты.
- Ограничение доступа к DbContext-у очень условное: т.е. можно конечно коду-потребителю передавать IFooDbContext и там будет только то, что мы туда внесли. Но ведь пытливый разработчик может всегда привести его к типу FooDbContext и получить тот же DbSet и снова начать плодить «зверинец» разнообразных запросов. Конечно, в случае замены наследования композицией можно тоже взять Reflection и сделать все, что хочется, но это уже явный «хак», на который просто так никто не решится.
- Что если мы захотим написать unit tests к методам GetFooByParamSet1 и т.д.? Как мы заменим сам DbContext каким-нибудь mock-объектом?
lair
30.06.2015 22:13Нет, это не замена композиции наследованием. Это сохранение функциональности в изначально ответственной за нее сущности. Я напомню, что использование наследника DbContext — это стандартный шаблон в EF. Путь развития приблизительно такой:
1. Сначала делаем «как в книжке», выставляя сеты на каждую сущность:
class FooDbContext: DbContext { public DbSet<A> A {get;} public DbSet<B> B {get;} }
2. Затем извлекаем интерфейс, чтобы можно было спокойно тестировать зависимые объекты:
interface IFooDbContext { DbSet<A> A {get;} DbSet<B> B {get;} }
3. Понимаем, что интерфейс отдает слишком конкретные реализации, которые неудобно тестировать, и которые при этом никому не нужны:
interface IFooDbContext { IQueryable<A> A {get;} IQueryable<B> B {get;} }
4. В качестве бесплатного бонуса получаем возможность внутри подменитьIQueryableна что угодно. При этом важно то, что для потребителей это как был интерфейс контекста данных, так и остался, просто он стал чуть более обобщенным. Мы не порождаем никаких новых сущностей и новых слоев.
Ограничение доступа к DbContext-у очень условное: т.е. можно конечно коду-потребителю передавать IFooDbContext и там будет только то, что мы туда внесли. Но ведь пытливый разработчик может всегда привести его к типу FooDbContext и получить тот же DbSet и снова начать плодить «зверинец» разнообразных запросов. Конечно, в случае замены наследования композицией можно тоже взять Reflection и сделать все, что хочется, но это уже явный «хак», на который просто так никто не решится.
Вы-первых, вы совершенно зря думаете, что если человек решился на обратное приведение, то он не решится на reflection. От злонамеренного программиста вы не защититесь все равно, наша задача состоит в том, чтобы упростить работу нормальному.
Во-вторых, обратное приведение не проходит unit-тесты.
Наконец, в-третьих, я обычно выношу весь DAL в отдельную сборку, где интерфейс публичный, а контекст — internal.
Что если мы захотим написать unit tests к методам GetFooByParamSet1 и т.д.? Как мы заменим сам DbContext каким-нибудь mock-объектом?
Точно так же, как если вы захотите написать тесты наSetв DbContext — никак. Какой-то из уровней абстракции тестировать уже не нужно. Если вы хотите написать тесты на этот уровень, и при этом это реально оправданно, а не блажь, значит, у вас ошибка в разделении обязанностей.
SVVer
01.07.2015 08:02Я правильно понимаю, что через интерфейс IFooDbContext вы отдаете потребителям IQueryable<A> и IQueryable<B>?
Если так, то как мы решаем проблему «зверинца» запросов от потребителей? Хочется ведь их свести вместе и ограничить-таки интерфейс DbContext-а.interface IFooDbContext { IQueryable<A> A {get;} IQueryable<B> B {get;} }lair
01.07.2015 10:04Интерфейс мы уже ограничили — наружу выставлено только то, что нам надо. А унификация запросов, если это необходимо, делается либо через методы-расширения на IQueryable, либо через построители для expression.
SVVer
01.07.2015 13:00+1Выставить наружу IQueryable это довольно слабое ограничение. Множество всевозможных запросов, построенных с его помощью, со временем может очень вырасти. Унификация с помощью методов-расширений к IQueryable, как я понимаю, не ограничит разнообразие запросов: ведь я по-прежнему могу писать запросы на «чистом» LINQ. А насчет «построителя для expression» что имеется ввиду? И главное, как это ограничит для потребителей возможность писать чистые LINQ-запросы?
lair
01.07.2015 14:10А меня не пугает множество запросов. До тех пор, пока они покрывают бизнес-требования, по большому счету, все равно, как они написаны. Как следствие, у меня нет задачи отобрать у пользователя возможность работать с LINQ (более того, у меня как раз есть задача ее сохранить, потому что тогда я упрощу интеграцию с кучей полезных вещей), у меня есть задача упростить его работу в типовых сценариях.
SVVer
01.07.2015 15:42Тогда получается, что если мы используем EF в качестве ORM (или, кстати говоря, C# LINQ driver над MongoDb), то репозиторий и не нужен? Или есть все-таки какие-то условия, при которых нам стоит ввести репозиторий и скрыть ORM и в том числе IQueryable?
lair
01.07.2015 15:47Да, именно так и получается. Именно об этом пишет, например, Симан в статье, на которую вы же и ссылаетесь: если вы используете конкретный ORM, и не планируете использовать их несколько (а это, будем честными, очень редкая ситуация) — не надо пытаться этот ORM скрыть за другим паттерном.
SVVer
01.07.2015 16:18+1Понятно. Но насчет Симана я не соглашусь: по-моему Вы отделяете приведенное Вами ранее высказывание от контекста.
If you have a specific ORM in mind, then be explicit about it. Don't hide it behind an interface. It creates the illusion that you can replace one implementation with another. In practice, that's impossible. Imagine attempting to provide an implementation over an Event Store.
Во-первых, статья называется «IQueryable is Tight Coupling» и весь ее посыл в том, чтобы не использовать этот интерфейс в своем API. Мне даже кажется, что Симан считает, что IQueryable вообще не стоило разрабатывать, поскольку абстракция «дырявая» до неприличия. Хотя непонятно, как тогда стоило бы поступить.
Во-вторых, в приведенной цитате я бы выделил фразу «It creates the illusion that you can replace one implementation with another». Возникает вопрос: implementation of what? Мне кажется, что речь об интерфейсе IQueryable.
В-третьих, в подтверждение этого есть комментарий к статье с просьбой к Марку оценить интерфейс репозитория над NHibernate:
What do you think about the API outlined in this post: http://stackoverflow.com/a/9943907/572644
И вот ответ Марка:
Looks good, Daniel. I'd love to hear your experience with this once you've tried it on for some time
По ссылке на StackOverflow есть пример кода, где IQueriable скрыт за своим интерфейсом, который уже не предоставляет IQueryable.
Только это уже какая-то герменевтика пошла…lair
01.07.2015 16:30Во-первых, статья называется «IQueryable is Tight Coupling» и весь ее посыл в том, чтобы не использовать этот интерфейс в своем API.
Нет, ее посыл в том, чтоIQueryable— это текущая абстракция, которая не предоставляет изоляции. Если это осознавать, равно как и осознавать ограничения этого — все будет хорошо.
Возникает вопрос: implementation of what? Мне кажется, что речь об интерфейсе IQueryable.
Вам кажется. На самом деле, речь идет о замене ORM за абстрактным интерфейсом (это, на самом деле, приведет и к замене реализацииIQueryable, но это побочный эффект).
В-третьих, в подтверждение этого есть комментарий к статье с просьбой к Марку оценить интерфейс репозитория над NHibernate:
Важный пойнт оттуда: «The nice thing about this is that the business layer is completely free of querying logic and thus the data store can be switched easily.»
Если вы предполагаете заменять хранилище — тогда зависимость отIQueryableплоха (потому что его реализации не взаимозаменяемы). Если нет — то нет.
В каком-то смысле, на эту проблему можно смотреть так: представьте себе, что у вас нетIQueryable, а естьIQueryableEF,IQueryableL2S,IQueryableNHи так далее. Когда вы принимаете решение выставить такой интерфейс — вы принимаете решение «я не буду заменять EF на NH». Если это решение вас устраивает, то ничего плохого в этом интерфейсе нет.
(Ну и у меня есть отдельные замечания к описанному на SO, но они во многом уже озвучены здесь в посте: как только мы отбираемIQueryable, мы берем на себя обязанность предоставить замену. Банальный пример: как в предложенном DSL выразить запрос на (а) начатые и незавершенные (б) начатые или незавершенные? А проекции? А джойны? Ну и понеслась. А интеграция с UI и сервисной моделью навроде OData?)SVVer
01.07.2015 17:06Нет, ее посыл в том, что IQueryable — это текущая абстракция, которая не предоставляет изоляции. Если это осознавать, равно как и осознавать ограничения этого — все будет хорошо.
А эти слова разве я написал в начале статьи?
From time to time I encounter people who attempt to express an API in terms of IQueryable. That's almost always a bad idea. In this post, I'll explain why
На всякий случай напомню, что я написал почти то же самое:
весь ее посыл в том, чтобы не использовать этот интерфейс в своем API
Вам кажется. На самом деле, речь идет о замене ORM за абстрактным интерфейсом
Когда мне говорят, что мне кажется, а собеседник знает, как «на самом деле», я очень настораживаюсь: возможно у человека сверхспособности. Боюсь что в данном случае у нас с Вами просто разный прошлый опыт и набор тех проблем, с которыми мы сталкивались. Поэтому Вы смотрите на это в своем контексте, а я в своем. А кто из нас «на самом деле» прав, может сказать только Марк Симан.
Если вы предполагаете заменять хранилище — тогда зависимость от IQueryable плоха (потому что его реализации не взаимозаменяемы). Если нет — то нет.
Но заметьте, что автор ответа на SO (он же и автор вопроса) нигде не говорит о том, что собирается заменять NHibernate. И тем не менее, он зачем-то инкапсулирует IQueryable внутри репозитория.
как только мы отбираем IQueryable, мы берем на себя обязанность предоставить замену. Банальный пример: как в предложенном DSL выразить запрос на (а) начатые и незавершенные (б) начатые или незавершенные? А проекции? А джойны? Ну и понеслась. А интеграция с UI и сервисной моделью навроде OData?
А вот тут я с Вами полностью согласен. Как только у нас появляется разнообразие запросов, мы будем изобретать велосипед, создавая нечто такое же гибкое, как IQueryable, с теми же проблемами. Вопрос только в том, всегда ли нужно такое разнообразие и те возможности, о которых Вы написали.lair
01.07.2015 17:13На всякий случай напомню, что я написал почти то же самое:
Для меня важное отличие в слове «почти».
Но заметьте, что автор ответа на SO (он же и автор вопроса) нигде не говорит о том, что собирается заменять NHibernate.
Я процитировал место, где этот посыл возникает.
Вопрос только в том, всегда ли нужно такое разнообразие и те возможности, о которых Вы написали.
В моем опыте ситуации делятся ровно на две категории: те, где возникает, и те, где не возникает. Любой UI, с которым мне приходилось иметь дело, равно или поздно оказывался в первой категории.
… что, кстати, мило приводит нас к забавному паттерну, где собственно бизнес-логика и отображение в UI работают через разные слои: привет, CQRS (я знаю, что он не вполне об этом, но на его основе это делать удобнее).
InWake Автор
01.07.2015 20:49.
Как только у нас появляется разнообразие запросов, мы будем изобретать велосипед,
если запросов очень много, то лучше всего использховать habrahabr.ru/post/125720
InWake Автор
01.07.2015 20:17Я работаю над проектом, в котором два боевых слоя хранилища и еще одно демонстрационное.
lair
01.07.2015 21:35И сколько из них не на EF (если не считать то, которое в памяти)?
InWake Автор
02.07.2015 19:52Linq2Sql и EF, 2Sql издревна пошел, проект изначально на нем писался, к стати использовалось расширение контекста как хранилище набора скомпилированных запросов, вы приводили этот прием, только работа шла на прямую с контекстом.
lair
02.07.2015 21:30Ну вот и ответ, зачем вам репозиторий поверх EF — чтобы иметь возможность не использовать EF. Good luck with that.
InWake Автор
02.07.2015 21:34у нас было несколько экспериментов по EF, разные комбинации, если использовать провайдеры от разного производителя, то результат не очень, с одним производителем дела на много лучше, но проблемы с запросами есть.
mird
03.07.2015 20:23В моей практике ORM скрывался за репозиторием когда источником данных выступала как реляционная бд, так и Key-Value хранилище. И подмена эта происходила в рантайме в зависимости от неких параметров.
SVVer
03.07.2015 21:22А каким был интерфейс репозитория? Универсальным, т.е. выставлялся IQueryable или его аналог, или просто содержал конечный набор методов, который и определял набор возможных запросов?
И еще интересно было бы узнать Ваше мнение. Допустим в некой задаче нет необходимости поддерживать разные хранилища/ORM, есть только EF и, к примеру, SQL Server. Но в то же время набор возможных запросов к БД сильно ограничен и расширяется очень предсказуемо. Стали бы Вы оборачивать EF в репозиторий с простым интерфейсом, или же просто использовали бы DbContext?lair
03.07.2015 22:01Допустим в некой задаче нет необходимости поддерживать разные хранилища/ORM, есть только EF и, к примеру, SQL Server. Но в то же время набор возможных запросов к БД сильно ограничен и расширяется очень предсказуемо. Стали бы Вы оборачивать EF в репозиторий с простым интерфейсом, или же просто использовали бы DbContext?
Я в описанной ситуации — только доведенной до экстремума, там все взаимодействие с БД сводилось к 5-8 методам — построил отдельный DAL-интерфейс, из банальной мотивации: его было намного легче подменять в моке. Но это именно потому, что операций было очень мало.
mird
03.07.2015 22:52А каким был интерфейс репозитория? Универсальным, т.е. выставлялся IQueryable или его аналог, или просто содержал конечный набор методов, который и определял набор возможных запросов?
Конечный набор методов. То есть там был набор CRUD для корней агрегатов и дополнительные методы для работы с объектами и коллекциями вложенных в агрегат сущностей. Но надо понимать, что это была конкретная часть хранилища с такой спецификой, по ней не предполагалось поисковых и фильтрующих запросов, нужен был только CRUD.
И еще интересно было бы узнать Ваше мнение. Допустим в некой задаче нет необходимости поддерживать разные хранилища/ORM, есть только EF и, к примеру, SQL Server. Но в то же время набор возможных запросов к БД сильно ограничен и расширяется очень предсказуемо. Стали бы Вы оборачивать EF в репозиторий с простым интерфейсом, или же просто использовали бы DbContext?
Я не вижу смысла городить тут репозиторий, хотя, возможно, выставил бы интерфейс с ограниченным набором методов вместо Generic интерфейса с Set (этот ограниченный набор методов реализовал бы прямо на DbContext)
Но, такие интерфейсы очень быстро разрастаются до нескольких десятков методов и тут важно быстро это прекратить и свести к Set.
InWake Автор
30.06.2015 22:00
а что, не плохо. мы только что ограничили запросы, а вот теперь нам нужно получить элементы по paramSet2 и paramSet3, и вотGetFooByParamSet2(paramSet2); GetFooByParamSet3(paramSet3); //-------- GetFooByParamSetN(paramSetN);
100% рабочий вариант, спору нет, но чем он лучше? проще — да, но попытка комбинирования запросов приводит к разрастанию интерфейса — это нормально?GetFooByParamSetN+1(paramSetN+1);SVVer
01.07.2015 08:05Вы имеете ввиду, что набор возможных запросов к репозиторию со временем разрастается так, что лучше иметь IQueryable или его аналог?
InWake Автор
28.06.2015 12:33И как же репозиторий позволяет обойти эти проблемы? Вероятно, вы имеете в виду, что вы напишете две разных реализации репозитория для двух разных провайдеров. Это здорово, но вы помните, что вы только что увеличили свои затраты вдвое?
В двое? Я реализую абстракцию, которая позволит переопределить обработку запросов отдельно, и в каждой реализации переопределю только не эффективные.
Как же репозиторий ее решает в таком случае?
написано причем не мнойОднако это не всегда возможно.
на это я ответил выше.lair
28.06.2015 13:48В двое? Я реализую абстракцию, которая позволит переопределить обработку запросов отдельно, и в каждой реализации переопределю только не эффективные.
А где реализованы те, которые вы переопределяете.
Как же репозиторий ее решает в таком случае?
написано причем не мной
Так как же? Написанное всегда можно процитировать.
Однако это не всегда возможно.
на это я ответил выше.
Можете повторить? Я не очень понимаю ни на что вы ответили, ни что вы ответили.InWake Автор
28.06.2015 14:00А где реализованы те, которые вы переопределяете.
в базовом репозитории.
Во-первых, вы передергиваете: нигде не сказано, что эта задача не имеет решения; сказано лишь что не всегда возможно сгенерировать корректный SQL для всех БД для любого AST. Но предположим на минуту, что вы правы, и эта задача действительно не имеет решения. Как же репозиторий ее решает в таком случае?
Задача не имеет решения. я это комментирую
написано причем не мной
Однако это не всегда возможно.
наи эта задача действительно не имеет решения. Как же репозиторий ее решает в таком случае?
на это ответ выше, можно выполнить другой эквивалентный запрос внутри репозитория.lair
28.06.2015 14:07А где реализованы те, которые вы переопределяете.
в базовом репозитории.
Наверное, вами же реализованы? Вот и увеличение ресурсных затрат.
можно выполнить другой эквивалентный запрос внутри репозитория
Ох. Давайте пойдем сначала. Вот есть проблема: не всякий запрос, переданный в DAL снаружи (и, как следствие, сформулированный в терминах объектов), можно преобразовать в запрос в терминах хранилища. Я правильно вас понял, или вы что-то другое имеете в виду?InWake Автор
28.06.2015 14:12Наверное, вами же реализованы? Вот и увеличение ресурсных затрат.
хорошую архитектуру бесплатно не получить.
Ох. Давайте пойдем сначала. Вот есть проблема: не всякий запрос, переданный в DAL снаружи (и, как следствие, сформулированный в терминах объектов), можно преобразовать в запрос в терминах хранилища. Я правильно вас понял, или вы что-то другое имеете в виду?
все что можно написать в LINQ запросах не всегда можно отразить в SQL запросе.lair
28.06.2015 14:17хорошую архитектуру бесплатно не получить.
Конечно. За то, что вы называете хорошей архитектурой, вы чем-то платите. Возможно, для всех остальных эти расходы не являются настолько оправданными по сравнению с предлагаемым выигрышем. Из вашей статьи создается ложное ощущение, что преимущества Repository бесплатны. Это не так.
все что можно написать в LINQ запросах не всегда можно отразить в SQL запросе.
И как репозиторий решает эту проблему?InWake Автор
28.06.2015 15:07преимущества Repository бесплатны
я ни где об этом не пишу, я пишу что это способ решить проблему совместимости
И как репозиторий решает эту проблему?
передав информацию о том что нужно, репозиторий переведет ее в как получить.lair
28.06.2015 15:10я ни где об этом не пишу, я пишу что это способ решить проблему совместимости
Вы пишете, что все описанные проблемы можно легко решить с помощью repository.
передав информацию о том что нужно, репозиторий переведет ее в как получить.
А разве (любой LINQ-based DAL) делает не то же самое? В чем преимущества репозитория в решении этой проблемы?InWake Автор
28.06.2015 16:56Вы пишете, что все описанные проблемы можно легко решить с помощью repository.
легко не не бесплатно.
А разве (любой LINQ-based DAL) делает не то же самое? В чем преимущества репозитория в решении этой проблемы?
то же самое, но один и тот же LINQ запрос может по разному обрабатываться разными провайдерами, а именно построенный запрос для конкретной базы мб не эффективным или даже покрашить систему.
В репозитории можно это все компенсировать.lair
28.06.2015 18:06Как именно можно все это компенсировать в репозитории?
InWake Автор
28.06.2015 19:39по разному формировать запросы, которые формируются в конкретном репозитории
lair
28.06.2015 19:44То есть запросы формирует репозиторий, а не код-потребитель? Тогда вы не решаете проблему, вы ее избегаете. Теперь давайте выясним, за счет чего: как же именно код-потребитель объясняет репозиторию, какие объекты ему нужны?
VolCh
28.06.2015 14:32Вот и увеличение ресурсных затрат.
Вероятно имеется в виду, что при необходимости поддерживать эффективно две SQL-базы данных можно вынести общие и(или) некритичные части в родителя (или ещё как сделать совместно используемыми), пользоваться дефолтными реализациями, а затачивать под конкретную СУБД только ту часть запросов, что критична, причём именно в данном приложении. При такой организации оценка «в 2 раза больше ресурсов» будет пессимистичной, если каждый запрос будет не будет критичным, подлежащим оптимизации под конкретную СУБД.lair
28.06.2015 14:44Да я понимаю, что имеется в виду, только вот к чему это в реальности приводит:
- нам нужен общий интерфейс для провайдеров к разным БД
- этот интерфейс мы запихиваем в базовый класс репозитория
- нам нужны провайдеры, удовлетворяющие этому интерфейсу
- поверх этого интерфейса мы пишем расширения в каждой реализации репозитория для конкретного провайдера БД
- в написании этих расширений мы ограничены возможностями провайдеров из поза-предыдущего пункта
Проще говоря, мы имеем два слоя абстракции вместо одного, что увеличивает наши накладные расходы на поддержание и понимание всего этого цирка.
Но это еще полбеды. Вот вам вторая занимательная половина: репозиторий обычно специфичен для сущности (или агрегата, если у нас DDD). Иными словами, код-потребитель использует неrepository.Get<Product>, аproductRepository.Get. И это даже имеет смысл, потому что для каждой конкретной сущности наиболее эффективный способ получения/фильтрации/отображения может отличаться. И обычно эти классы все наследуются от базового репозитория, чтобы переиспользовать базовые операции. И вот тут-то и возникает занимательный конфликт (ну, занимательный он для языков без множественного наследования) — у нас есть общий код для (а) всех репозиториев (б) репозиториев под MS SQL (в) репозиториев продуктов — как бы нам теперь весь его переиспользовать в конкретном репозитории продуктов в MS SQL?InWake Автор
28.06.2015 15:18нам нужен общий интерфейс для провайдеров к разным БД
да
этот интерфейс мы запихиваем в базовый класс репозитория
да
нам нужны провайдеры, удовлетворяющие этому интерфейсу
не понял юмора, зачем провайдер?
поверх этого интерфейса мы пишем расширения в каждой реализации репозитория для конкретного провайдера БД
только необходимые
в написании этих расширений мы ограничены возможностями провайдеров из поза-предыдущего пункта
только из за не совместимости провайдеров это нужно
как бы нам теперь весь его переиспользовать в конкретном репозитории продуктов в MS SQL?
единственное что нужно будет модифицировать это некоторые преобразователи запроса в завпросы к хранилищу (для EF это будут специфичные LINQ запросы)lair
28.06.2015 15:22Иэх. Похоже, без примеров кода не обойтись. Давайте начнем с простого: вот у вас есть репозиторий чего-нибудь, нам надо сделать в нем «получить постраничный список» (на входе — номер страницы и размер страницы), как вы это будете реализовывать?
InWake Автор
28.06.2015 15:28если в основе репозитория лежит реализация использующая EF, то на IQuariable Order/Skip/Take.
lair
28.06.2015 15:33Можете привести короткий пример кода?
InWake Автор
28.06.2015 15:43Только из за интереса.
set.DefaultOrder().Skip(skipCount).Take(takeCount).Map()
можно и такой записью
Map(DefaultOrder(set).Skip(skipCount).Take(takeCount))
правда вторая запись хуже читаемаяlair
28.06.2015 15:52Очень хорошо. А теперь давайте возьмем провайдер БД A и провайдер БД B, из которых один поддерживает
Skip/Take, а второй — нет. Как паттерн Repository поможет вам решить эту проблему?
PS Обратите внимание, что абстракция skipCount/takeCount отличается от постраничного списка, описанного мной выше. Это для данного примера не очень критично, но вообще показательно.InWake Автор
28.06.2015 16:04Очень просто, я написал общий вариант, оборачивается все в функции типа Shift и TakeEntity
что то типа того
set.DefaultOrder().Shift (skipCount).TakeEntity(takeCount).Map()
и там где нужно можно переопределить DefaultOrder Shift TakeEntity
правда мы используем построитель запросов.lair
28.06.2015 16:06Где именно реализуются методы
ShiftиTakeEntity? Можете привести пример кода одного (любого) из них?InWake Автор
28.06.2015 16:21Самый простой и самый не хороший метод это функции самого репозитория
virtual IQuariable<T> Shift (IQuariable<T> set, long conut) { return set.Skip(count); }
если реализация по каким то причинам не подходит, ее можно переопределить.
правда мы используем построитель запросов.
lair
28.06.2015 16:29Правильно ли я понимаю, что вы предлагаете завести три репозитория (типизация по сущности опущена специально)?
class GenericRepository { public IEnumerable GetPaged(int skip, int take) { return set.DefaultOrder().Shift(skip).TakeEntity(take).Map(); } protected virtual IQueryable Shift(IQueryable source, long count) { return source.Skip(count); } } class DbProviderARepository: GenericRepository { //не оверрайдим ничего, все работает "из коробки } class DbProviderBRepository: GenericRepository { protected virtual IQueryable Shift(IQueryable source, long count) { //например, так, детали не очень важны return source.AsEnumerable().Skip(count).AsQueryable(); } }InWake Автор
28.06.2015 17:02Нет!
public IEnumerable GetPaged(int skip, int take)
это будет работать нормально только если запросов очень ограниченное количество, я не на столько болен что бы такое предлагать, хотя…
public IEnumerable Get(Query)
это выставляется во вне, все остальное скрыто за фасадом, причем запросы для каждого репозитория свои, например всегда ли нужен постраничный вывод?lair
28.06.2015 18:07Вот именно поэтому я и просил вас привести код, чтобы не играть тут в угадайку.
Пожалуйста, покажите, как в вашем случае реализуется описанный мной сценарий (необходимость постраничного вывода, две СУБД, одна поддерживаетSkip, другая — нет). Меня интересует структура задействованных классов и конкретные точки расширения, которые вы используете, чтобы обойти проблему.InWake Автор
28.06.2015 22:181. Формируется запрос в терминах предметной области
var query = new Query(); query.PagingOptions.SkipCount = 10; query.PagingOptions.TakeCount = 10; repository.Get(query);
2. Базовый Rep обрабатывает этот запрос
public virtual IEnumerable<Entity> Get( Query query ) { IQueryable<Entity> filtrate = _table; //обработка запроса //----------- ... filtrate = Build( filtrate, query.PagingOptions ); return Map(filtrate); }
3. Магический метод построения запроса
private IQueryable<Entity> Build<Q>( IQueryable<Entity> filtrate, Q query ) where Q : struct { if ( !_builders.ContainsKey( typeof( Q ) ) ) return filtrate; var builder = (IQueryBuilder<Entity, Q>)_builders[typeof( Q )]; return builder.Build( filtrate, query ); }
4. Конкретный строитель запроса
public class PagingQueryBuilder<T> : IQueryBuilder<T, PagingOptions> { public IQueryable<T> Build( IQueryable<T> queriable, PagingOptions query ) { var buildQuery = queriable; if ( query.SkipCount > 0 ) buildQuery = buildQuery.Skip( query.SkipCount ); if ( query.TakeCount > 0 ) buildQuery = buildQuery.Take(query.TakeCount); return buildQuery; } }
он является универсальным, можно заморочиться и распилить на 2 (но я не уверен что это нужно, хотя я могу ошибаться)
5. Конфигурация строителей
protected Dictionary<Type, object> _builders;
в базовом репозитории для типа сущности идет общая конфигурация, конкретная реализация может управлять регистрацией и чем меньши блоки запросов, тем гибче ( минус только в том что таких запросов может быть много )
Вы писали про 18 критериев фильтрации (правда походу не в этой теме, но отвечу тут, подходящие место), вам всеравно нужно будет их анализировать при построение Linq запроса, так почему же их не сгрупировать на критерии подзапросов, оформить в запрос и передать репозиторию. Или вы предпочитаете эти 18 параметров засунуть в 1 LINQ запрос? или еще хуже передать эти 18 параметров в функцию?lair
28.06.2015 22:52Так в каком же конкретно месте происходит выбор специфичного для конкретной БД способа пейджинга? Если в QueryBuilder, то, удивительным образом, репозиторий для этого не нужен.
Вы писали про 18 критериев фильтрации (правда походу не в этой теме, но отвечу тут, подходящие место), вам всеравно нужно будет их анализировать при построение Linq запроса, так почему же их не сгрупировать на критерии подзапросов, оформить в запрос и передать репозиторию. Или вы предпочитаете эти 18 параметров засунуть в 1 LINQ запрос? или еще хуже передать эти 18 параметров в функцию?
Я предпочитаю взять 18 критериев фильтрации, пришедших с клиента в виде одного AST, сконвертировать их в другой AST и скормить в DAL. Просто и прямолинейно.InWake Автор
28.06.2015 23:44Так в каком же конкретно месте происходит выбор специфичного для конкретной БД способа пейджинга? Если в QueryBuilder, то, удивительным образом, репозиторий для этого не нужен.
Нужен, конфигурация билдера происходит в нем, да это можно сделать и в других местах, репозиторий — фасад, скрывающий создание/удаление/запросы/маппинг и конкретную технологию доступа к данным. Я считаю что очень важно запрещать прямой доступ к контексту данных, тк мы получим описанные здесь проблемы.lair
28.06.2015 23:48конфигурация билдера
Что именно вы под этим подразумеваете?
Я считаю что очень важно запрещать прямой доступ к контексту данных
Для этого достаточно — всего лишь — убрать контекст за интерфейс. Не создать новую прослойку, а просто выделить интерфейс с нужными методами.
Чем больше вы прячете, тем меньше возможностей вы оставляете пользовательскому коду, тем беднее он становится (если, конечно, вы не тратите неимоверные ресуры на написание полного DSL).InWake Автор
28.06.2015 23:59Что именно вы под этим подразумеваете?
связь реализации построителя с параметром запроса.Для этого достаточно — всего лишь — убрать контекст за интерфейс. Не создать новую прослойку, а просто выделить интерфейс с нужными методами.
сделаем Create Save Delete Query и получим тот же репозиторий.Чем больше вы прячете, тем меньше возможностей вы оставляете пользовательскому коду, тем беднее он становится (если, конечно, вы не тратите неимоверные ресуры на написание полного DSL).
Меньше возможностей пользовательскому коду — меньше ошибок, да это может доставить некоторые неудобства, но не зря появляется куча DSL, например XAML.lair
29.06.2015 00:13сделаем Create Save Delete Query и получим тот же репозиторий.
Не, не получите — потому что у него будет другая семантика. EF за интерфейсом — все тот же EF.
Меньше возможностей пользовательскому коду — меньше ошибок
Ну, если вы считаете себя заведомо умнее разработчика, который пользуется вашим кодом, то тут мне помочь нечем.
InWake Автор
28.06.2015 23:51Я предпочитаю взять 18 критериев фильтрации, пришедших с клиента в виде одного AST, сконвертировать их в другой AST и скормить в DAL. Просто и прямолинейно.
да все этого хотят, но на практике приходиться плясать, и не только с бубном, что бы желания вписывались в реалии.
gandjustas
29.06.2015 02:16Или вы предпочитаете эти 18 параметров засунуть в 1 LINQ запрос? или еще хуже передать эти 18 параметров в функцию?
У linq запросов есть потрясающее свойство — композируемость. Тебе не надо 18 параметров передавать в функции. Ты можешь 18 раз применить функции (комбинаторы), при этом каждая функция будет тривиальной (IQueryable, param) => IQueryable.
Если же тебе надо будет в каждом вызове передавать 18 параметров, да еще и править каждый раз код при добавлении нового, то ты быстро забьешь на это дело и будешь просто тянуть всю простыню данных на клиент, а потом фильтровать уже объекты. И под любой серьезной нагрузкой это ляжет.InWake Автор
29.06.2015 15:22У linq запросов есть потрясающее свойство — композируемость. Тебе не надо 18 параметров передавать в функции. Ты можешь 18 раз применить функции (комбинаторы), при этом каждая функция будет тривиальной (IQueryable, param) => IQueryable.
именно по этой схеме и работает QueryBuilder о котором я пишу, и нам все равно нужно анализировать каждый из параметров отдельно.
Если же тебе надо будет в каждом вызове передавать 18 параметров, да еще и править каждый раз код при добавлении нового, то ты быстро забьешь на это дело и будешь просто тянуть всю простыню данных на клиент, а потом фильтровать уже объекты. И под любой серьезной нагрузкой это ляжет.
кто ж спорит.lair
29.06.2015 15:28именно по этой схеме и работает QueryBuilder о котором я пишу, и нам все равно нужно анализировать каждый из параметров отдельно.
Вам — возможно. А во всех адекватных реализациях LINQ-провайдеров для этого написана обобщенная функция.InWake Автор
29.06.2015 20:30я про построение запроса, такие условия как больше, меньше, равно, есть параметр нет… это все равно где то придется анализировать, и очень будет плохо, если подобных запросов по коду будет много и что то придется менять.
lair
29.06.2015 21:02В описанном выше сценарии (про 18 параметров) они все прилетают из UI, они не могут измениться. А бизнес-правила (навроде «активные заказы») прекрасно выпинываются в list comprehensions. Правда, если нужна их композиция по «или», то ситуация сложнее, но и тут можно сделать нормальный AST builder.
gandjustas
29.06.2015 22:02именно по этой схеме и работает QueryBuilder о котором я пишу, и нам все равно нужно анализировать каждый из параметров отдельно.
При изменении набора параметров надо лезть и править query builder? Такое решение нежизнеспособно даже при небольшом количестве параметров.
gandjustas
29.06.2015 22:31public virtual IEnumerable<Entity> Get( Query query ) { IQueryable<Entity> filtrate = _table; //обработка запроса //----------- ... filtrate = Build( filtrate, query.PagingOptions ); return Map(filtrate); //Ахтунг }
Прочитал ваш код, у вас нет проекций, вы всегда тянете полные сущности. Это тормозит.
Но это еще пол-беды. Самое интересное, что метод Get у вас принимает один Query, то есть никакой декомпозиции, все параметры запроса надо выписать по месту вызова. И разные Query вы не сделаете, надо будет много копипастить. У каждой сущности будет постраничная разбивка, у половины фильтры активных, еще у части фильтры доступа.
То есть у вас в Query должны быть все возможные параметры для всех возможных запросов. На практике нежизнеспособное решение.
Из-за этого код Build непонятно зачем нужен, у вас же всегда один тип QueryBuilder будет, который фактически разбирает Query со всеми параметрами.
Кстати вы применил зачем-то словарь, вместо полиморфизма. Почему Query не может накладывать фильтры на IQueryable сам?
И в итоге все это делалось, чтобы вызвать разные методы Build для разных провайдеров. Только я так и не понял, почему нельзя нужный QueryBuilder заинжектить в БЛ и не использовать репозитории вообще? И проблем с проекциями не будет.InWake Автор
29.06.2015 23:29Прочитал ваш код, у вас нет проекций, вы всегда тянете полные сущности. Это тормозит.
это простейший пример, для оптимизации используются параметры прогрузки сущностный (аля Include ), так же в терминах предметной области.Самое интересное, что метод Get у вас принимает один Query, то есть никакой декомпозиции, все параметры запроса надо выписать по месту вызова.
декомпозиция — если не заполнено, значит нет,У каждой сущности будет постраничная разбивка, у половины фильтры активных, еще у части фильтры доступа.
плохо написано, возможно не разобрал, но для каждого репозитория свой queryТо есть у вас в Query должны быть все возможные параметры для всех возможных запросов. На практике нежизнеспособное решение.
правильно определив корни агрегации и хорошо зная предметную область разбив все крупные запросы на простые как правило получается что и вариантов та таких подзапросов на конкретную предметку не много.Кстати вы применил зачем-то словарь, вместо полиморфизма. Почему Query не может накладывать фильтры на IQueryable сам?
для того что бы решить проблему совместимости, переопределив нужные билдеры запросовИ в итоге все это делалось, чтобы вызвать разные методы Build для разных провайдеров. Только я так и не понял, почему нельзя нужный QueryBuilder заинжектить в БЛ и не использовать репозитории вообще? И проблем с проекциями не будет.
потому что реп это не просто построитель запросов — он умеет создавать сохранять удалять еще и маппинг,gandjustas
29.06.2015 23:56это простейший пример, для оптимизации используются параметры прогрузки сущностный (аля Include ), так же в терминах предметной области.
Это еще хуже. Чтобы работало с приемлемой скоростью нужны проекции. Иначе простейший список документов с фильтром по автору будет тормозить уже на паре тысяч записей.
декомпозиция — если не заполнено, значит нет
Это не декомпозиция, плохая шутка.
для каждого репозитория свой query
Я про это и говорю. У каждого Query будут возможности постраничной разбивки, фильтры для разграничений доступа итп. То есть будет много копипасты. При этом разные сущности могут поддерживать разные возможности. Например у некоторых есть флаги неактивности, а у других нет. У некоторых есть фильтры с учетом ролей пользователя, а у других нет итд. Причем копипаста в итоге будет как в самом классе query, так и в QueryBuilder.
как правило получается что и вариантов та таких подзапросов на конкретную предметку не много.
Вариантов запросов может быть сколько угодно. Можно вообще всегда один запрос иметь и вытягивать таблицу целиком. Но чтобы работало быстро — надо иметь много запросов, под каждый сценарий нужен свой специализированный запрос. У меня примитивное приложение с 5 таблицами генерирует 150 разных запросов. Там и проекции, и джоины, и фильтры. А если добавить разграничение доступа и нетривиальную логику, то запросов станет сотни три.
правильно определив корни агрегации и хорошо зная предметную область
Берем простой интернет-магазин. Товары-Клиенты-Заказы-Позиции. 4 сущности всего.
Функции: каталог товаров, создание заказа, список заказов для менеджера, статистика продаж товаров, список заказов клиента (для расчета скидки в онлайн).
Что будет корнями агрегации?
потому что реп это не просто построитель запросов — он умеет создавать сохранять удалять еще и маппинг
То же самое делает EF. То есть вы в репозитории объединили функции построения запросов и исполнения запросов, что нарушает SRP, да еще и пессимизироали программу.
Где же польза?InWake Автор
30.06.2015 00:33Причем копипаста в итоге будет как в самом классе query, так и в QueryBuilder.
о каком копипасте идет речь в билдере?Но чтобы работало быстро — надо иметь много запросов, под каждый сценарий нужен свой специализированный запрос.
поэтому и описние идет в терминах предметной области, а там где запрос выполняется идет анализ как лучше обработать данный запрос.У меня примитивное приложение с 5 таблицами генерирует 150 разных запросов.
на сколько элементарных подзапросов можно их разбить? или они все уникальны?Берем простой интернет-магазин. Товары-Клиенты-Заказы-Позиции. 4 сущности всего.
а для магеров таблички нет? все сущности являются корнями..
Функции: каталог товаров, создание заказа, список заказов для менеджера,То же самое делает EF. То есть вы в репозитории объединили функции построения запросов и исполнения запросов,
умеет ли он строить идентичные запросы которые будут одинаково адекватно выполняться на разных БД — нет. Безопасно ли заменять один провайдер другим — нет. Умеет ли EF адекватно сохранять корни агрегации — нет, умеет ли он правильно сохранять корни — нет.что нарушает SRP
Secure Remote Password?да еще и пессимизироали программу
пессимизироали это противоположенное оптимизировали?gandjustas
30.06.2015 00:45о каком копипасте идет речь в билдере?
У вас свой Query на каждый репозиторий, так? И почти в каждом Query есть paging, так? И для каждого Query есть свой Bulder. И в каждом builder есть обработка paging. Не копипаста?
поэтому и описние идет в терминах предметной области, а там где запрос выполняется идет анализ как лучше обработать данный запрос.
Лучше — сделать проекцию, но вы не можете так сделать, потому что хотите тянуть целые объекты. Все остальное быстродействию не поможет. Самый лучший запрос можно составить точно зная как его результаты будут обрабатываться. Увы ваш репозиторий лишает такой возможности.
на сколько элементарных подзапросов можно их разбить? или они все уникальны?
Каких «элементарных подзапросов»? С точки зрения SQL Server все запросы уникальны. У меня в коде от силы 10 местах происходит обращение к IQueryable. А дальше эти обращения комбинируются в итоговый запрос и накладывается проекция. На выходе получается порядка 150 разных запросов.
а для магеров таблички нет? все сущности являются корнями..
То есть запросов получится много даже для такой примитивнй модели. Что уж говорить о сложных моделях…
умеет ли он строить идентичные запросы которые будут одинаково адекватно выполняться на разных БД — нет.
EF запросы не строит, их строит программист.
Безопасно ли заменять один провайдер другим — нет.
Прости, но никто не умеет. Если у тебя в модели DateTimeOffset, то половина провайдеров тебя пошлют нафиг. Если у тебя нет DateTimeOffset в модели, то все провайдеры для EF спокойно прожуют твою модель. Лишние прослойки тут не помогут.
Умеет ли EF адекватно сохранять корни агрегации — нет, умеет ли он правильно сохранять корни — нет.
Мы выше рассмотрели простой пример модели, где каждая сущность является корнем и EF с ними нормально работает. Это при том, что в 90% статей про aggregation root ты увидишь пример агрегата Заказ-ПозицияЗаказа ;)
Есть подозрение что агрегаты существуют только в таких статьях.
что нарушает SRP
Secure Remote Password?
Single Responsibility Principle
пессимизироали это противоположенное оптимизировали?
Да, сделали заведомо медленнее, чем она могла бы быть.InWake Автор
30.06.2015 16:11У вас свой Query на каждый репозиторий, так?
Build(filtrate,query.Paging) — много копи паста.
Лучше — сделать проекцию, но вы не можете так сделать, потому что хотите тянуть целые объекты. Все остальное быстродействию не поможет. Самый лучший запрос можно составить точно зная как его результаты будут обрабатываться. Увы ваш репозиторий лишает такой возможности.
я привел самый простой случай, ни кто не мешает передать в билдер context и там вывернуть его на изнанку.
То есть запросов получится много даже для такой примитивнй модели. Что уж говорить о сложных моделях…
да ладно, можно группировать запросы, например запрос зака, передовать с запросом пользователя в репозитория пользователей, обернуть билдеры в фабрику, а в нутри репозитория можно это все дело совместить и скомбинировать, сделать проекции и тд, не проблема
EF запросы не строит, их строит программист
вот именно, это на его совести, к сожалению совесть вещь не предсказуемая.
Прости, но никто не умеет. Если у тебя в модели DateTimeOffset, то половина провайдеров тебя пошлют нафиг. Если у тебя нет DateTimeOffset в модели, то все провайдеры для EF спокойно прожуют твою модель. Лишние прослойки тут не помогут.
речь не только о типах, но и о самих провайдерах, как они отработают на одних и тех же запросах заранее сказат ьне возможноgandjustas
30.06.2015 21:33Build(filtrate,query.Paging) — много копи паста.
Не у каждого query будет Paging.
я привел самый простой случай, ни кто не мешает передать в билдер context и там вывернуть его на изнанку.
Вот именно, самый простой случай работает сильно медленнее, чем мог бы. Боюсь представить что в сложном будет.
да ладно, можно группировать запросы, например запрос зака, передовать с запросом пользователя в репозитория пользователей, обернуть билдеры в фабрику, а в нутри репозитория можно это все дело совместить и скомбинировать, сделать проекции и тд, не проблема
Тогда репозиторий превратится в бизнес-логику.
вот именно, это на его совести, к сожалению совесть вещь не предсказуемая.
Весь код на совести программиста. Думаешь у программистов, которые пишут репозитории другая совесть?
речь не только о типах, но и о самих провайдерах, как они отработают на одних и тех же запросах заранее сказат ьне возможно
Вот именно, поэтому совершенно неясно как поможет репозиторий. Все равно надо будет написать-протестировать-поправить. Репозиторий для этого категорически не нужен.InWake Автор
30.06.2015 22:21Не у каждого query будет Paging.
вот именно! каждый из репозиториев будет принимать свой тип запроса.случай работает сильно медленнее
а вы можите написать выражение которое будет делать скип и тэйк быстрее?Тогда репозиторий превратится в бизнес-логику.
то есть если query является составным query.UserOptions и query.OrderOptions то обработка этого запроса это бизнес уровень, а написать LINQ запрос который будет получать пользователей по определенному критерию заказов — это нет. А в чем разница?Думаешь у программистов, которые пишут репозитории другая совесть?
таже, но ограничив запросы предметной области идет естественное ограничение совести, тк нет универсального построителя в котором безсовестно можно писать все что угодно.gandjustas
30.06.2015 22:33вот именно! каждый из репозиториев будет принимать свой тип запроса.
То есть Build(filtrate,query.Paging) надо будет скопипастить как минимум в половине билдеров. Это и есть копипаста.
а вы можите написать выражение которое будет делать скип и тэйк быстрее?
Конечно, нужно сделать проекцию (select).
А в чем разница?
Разница в том, что бизнес-логика, то есть та логика, которая непосредственно относится к решению бизнес-задачи очень часто подвергается изменениям. А твой подход рождает изрядное количество копипасты. БЛ с таким подходом писать нельзя в принципе.
но ограничив запросы предметной области идет естественное ограничение совести, тк нет универсального построителя в котором безсовестно можно писать все что угодно.
А кто помешает программисту написать любой запрос внутри репозитария? Это вообще глупая идея, что программиста можно в чем-то ограничить. Ограничить может компилятор или тест, но тест тоже пишет программист, поэтому кроме компилятора рассчитывать не на что.InWake Автор
01.07.2015 00:23Build(filtrate,query.Paging) надо будет скопипастить как минимум в половине билдеров.
тоже самое что и рассматривать за копипаст Skip(n).Take(k), для особого извращения это все можно сделать с помощью рефлексии ( крайне не рекомендую ) универсально.А твой подход рождает изрядное количество копипасты.
запросы изменяются для каждого репозитория отдельно, причем эти запросы специфический, такие запросф как Paging с точки зрения предметной области меняться не будут, может меняться только их построение.А кто помешает программисту написать любой запрос внутри репозитария?
ни кто, но так он будет находиться в конкретном месте.кроме компилятора рассчитывать не на что.
к сожалению компилятор не в силах распознать LINQ запросы которые приведут к краху, тк с точки зрения статического анализа они верны, но перевести их в SQL imposible.gandjustas
01.07.2015 01:00тоже самое что и рассматривать за копипаст Skip(n).Take(k)
Не то же самое. Считаем для пейджинга со Skip(n).Take(k) нужно написать только эти вызовы и больше ничего.
Для твоего варианта с Query надо:
1) Написать код объекта Query со свойством Paging
2) Написать инициализацию ствойства
3) Создать объект в месте вызова
4) Заполнить свойство Paging
5) Написать билдер
Все кроме п4 — водопровдный код, а по твоей логике он будет копипаститься для каждого класса Query. И самое смешное что 99,99% случаев он сведется к тем же Skip\Take.
А кто помешает программисту написать любой запрос внутри репозитария?
ни кто, но так он будет находиться в конкретном месте.
Не будет. У тебя формирование запроса будет размазано по десятку билдеров, каждый еще и со своей нетривиальной логикой. Кто помешает там написать плохой запрос?InWake Автор
01.07.2015 20:215) Написать билдер
это делается 1 раз,
Кто помешает там написать плохой запрос?
ни кто, но это будет не в 10 местах по коду, а в одном, и так же легко поправитьсяgandjustas
01.07.2015 20:39это делается 1 раз,
Один раз на каждый тип запросов.
ни кто, но это будет не в 10 местах по коду, а в одном, и так же легко поправиться
Ты сам выше сказал, что у тебя будут методы Build, которые обрабатывают свои части запросов, потому что формирование запроса уже размазано по куче методов Build.InWake Автор
01.07.2015 20:48смысл в дефрагментации крупного запроса на простые.
gandjustas
01.07.2015 21:59Правильно, поэтому у тебя никогда не будет весь запрос в одном месте и контролировать запросы будет сложно. Поэтому и нет смысла запросы прятать в репозитарии, кроме снижения быстродействия это ничего не даст.
InWake Автор
02.07.2015 19:55при появлении новых запросов строиться новый билдер только для него, тестируется как запрос отрабатывает на разных репах, если на кком то что то плохо, то правки только для этой реализации. удобно кстате
gandjustas
02.07.2015 20:11Верю, только для этого репозитарий вовсе не нужен. Ранее я приводил пример кода, который точно также подменяется и тестируется при необходмости.
lair
30.06.2015 00:10для оптимизации используются параметры прогрузки сущностный (аля Include ), так же в терминах предметной области.
Я и говорю — по факту, вы написали свой аналог LINQ, только попроще. Вы вынуждены были повторить половину имеющихся там фич.InWake Автор
30.06.2015 00:36нет не аналог, при работе с LINQ вы не множите управлять построением запросов при смене провайдера
lair
30.06.2015 00:38А что мне мешает-то? Вообще-то, поправить AST на лету — не запредельной сложности задача.
InWake Автор
30.06.2015 16:04context.Where(e=>e.Value == true). простой пример, я в коде на прямую обратился к контексту, сменил провайдер и запрос неэффективен, как мне выйти из этой ситуации с гарантией, что никто никогда это не сможет повторить.
lair
30.06.2015 16:06Скрыть запрос за интерфейсом, который будет отдавать ваш собственный
IQueryable.InWake Автор
30.06.2015 16:16то есть это IQuariable не из Context?
lair
30.06.2015 16:18Если у меня есть потребность контролировать запросы, передаваемые внешним кодом, то да.
InWake Автор
30.06.2015 22:03и вы будите анализировать epression tree и на его осннове формировать новый AST (как вы любите писать)?
lair
30.06.2015 22:17Во-первых, да.
Во-вторых, я могу врезаться еще в этап построения дерева, это в большинстве случаев упростит мне анализ.InWake Автор
30.06.2015 22:26Ух, это жесть. Плохо, что она не лишена обсуждаемой сдесь проблемы, вам все равно нужно будет любой запрос перевести в дерево и передать его провайдеру, слабое звено в пищевой цепочки скармливания деревьев — провайдер, он просто может не переварить приготовленную кухню.
lair
30.06.2015 22:27У вас под вашим репозиторием тот же самый провайдер, так что это слабоватый аргумент, вы не находите?
(Я бы понял, если бы речь шла про EF vs Repository over any-other-DAL)InWake Автор
01.07.2015 00:25Тот же самый, но меньше возможностей у клиента покрошить выполнение, тк он ограничен запросом синтаксически.
lair
01.07.2015 00:28Что возвращает нас к уже описанному выше тезису: вы даете потребителю вашего кода ограниченное (причем сильно) подмножество возможностей. Это та цена, которую ваш потребитель платит за ваше решение использовать репозиторий.
Кстати, а что вы будете делать в следующем сценарии: вы дали потребителю некий запрос, а потом вам понадобилось добавить поддержку еще одной БД. А в ней, вот незадача, этот запрос невыполним. Ваши действия?
lair
28.06.2015 14:08Ответ лежит в совместимости конкретных провайдеров. Вот что о совместимости говорит один из разработчиков таких провайдеров Yevhen Shchyholyev www.infoq.com/articles/multiple-databases.
Кстати, вы на дату смотрели?InWake Автор
28.06.2015 14:13и что? Проблема лежит в попытке универсализации доступа к совершенно разным системам, что на практике не получается.
lair
28.06.2015 14:17+1Проблема лежит в попытке универсализации доступа к совершенно разным системам, что на практике не получается.
Бинго. У EF не получается, но, по вашим утверждениям, получается у паттерна репозиторий. Как?InWake Автор
28.06.2015 15:20Каждый репозиторий знает для чего он нужен, а значит ему не нужна универсализация, он работает с тем о чем знает вся логика по обработке запросов находиться именно в нем.
lair
28.06.2015 15:24Так каждый конкретный db-провайдер тоже знает, для чего он нужен, далее все аналогично. Видимо, разница не в этом.
InWake Автор
28.06.2015 15:30В том что разные провайдеры по разному переводят одни и те же LINQ запросы, я об этом, и это надо учитывать.
lair
28.06.2015 15:33А разные репозитории по-разному переводят одни и те же запросы предметной области — это не надо учитывать?
InWake Автор
28.06.2015 15:36Для того и делается репозиторий что бы это учесть и там где это действительно нужно иметь возможность переопределить.
lair
28.06.2015 15:39Какая разница потребляющему коду, кто по разному трактует его запросы — репозиторий или LINQ-провайдер? Результат-то один и тот же: один и тот же с точки зрения клиента код может иметь неожиданно разное поведение на разных БД.
InWake Автор
28.06.2015 17:21код может иметь неожиданно разное поведение на разных БД.
если один и тот же LINQ на одном провайдере выполняется нормально, а на другом крашит приложение, то нам нужно переписать запрос под второй провайдер и только под него.
gandjustas
28.06.2015 14:57Прочитал статью дважды очень внимательно, но не понял зачем нужен Repository/
Типы данных
Логично что надо использовать только то подмножество типов, которое понимается всеми базами. Иначе затраты на мапинг превысят все разумные пределы.
Поддержка DateTimeOffset
См выше, про поддерживаемое подмножество.
Производительность
Ограничения запроса
Решается тем, что делаются разные генераторы запросов под разные базы, то есть разные наборы функций DbContext => IQueryable. Причем не для всех запросов, а только для тех где имеются значимые различия (обычно не более 5%).
В итоге я так и не понял зачем городить Repository. И это как-бы самый сложны случай, когда надо поддерживать несколько СУБД. По факту же 99% и более приложений работают с одной базой и у них вообще таких проблем нет.InWake Автор
28.06.2015 15:25Решается тем, что делаются разные генераторы запросов под разные базы, то есть разные наборы функций DbContext => IQueryable. Причем не для всех запросов, а только для тех где имеются значимые различия (обычно не более 5%).
как мы в коде будем определять какие можно запросы использовать а какие нет?
В итоге я так и не понял зачем городить Repository. И это как-бы самый сложны случай, когда надо поддерживать несколько СУБД. По факту же 99% и более приложений работают с одной базой и у них вообще таких проблем нет.
так и есть, но если бы вы действительно внимательно читали статьюЯ работаю над проектом, в котором два боевых слоя хранилища и еще одно демонстрационное.
gandjustas
28.06.2015 16:27как мы в коде будем определять какие можно запросы использовать а какие нет?
А зачем это определять?InWake Автор
28.06.2015 17:24А зачем это определять?
как зачем? если система работает с несколькими провайдерами, и мы выяснили что нет возможности написать общий LINQ запрос что бы он был приемлемый для этих провайдеров.gandjustas
28.06.2015 18:06И? Зачем определять?
Чтобы узнать что запрос не подходит — надо его написать или детально знать особенности каждого провайдера (в том числе будущего). Второе на практике невозможно, поэтому единственный вариант — написали-протестировали-поправили.InWake Автор
28.06.2015 22:211 программа, 2 бд как вы себе представляете править это независимо используя обращения к контексту?
gandjustas
29.06.2015 01:21нормально представляю. А вот как репозиторий поможет — не понимаю.
Можете пример привести?InWake Автор
29.06.2015 15:22я приводил пример, свой пожалуйста
gandjustas
29.06.2015 22:04Какой пример? Вы покажите код, в котором для разных баз генерируются разные запросы. И посмотрим что там дает репозиторий и какие есть альтернативы.

chumakov-ilya
28.06.2015 20:11+3Если я правильно понял, топистартер пишет разные запросы для различных провайдеров, при этом необходимо менять провайдеров незаметно для бизнес-логики — вот он и выделил под каждый провайдер свои «репозитории». А как бы Вы решали подобную задачу?
InWake Автор
28.06.2015 22:23+1именно, мы это и делаем, и причем успешно, да на старте были затыки с архитектурными решениями, но они окупились.
gandjustas
29.06.2015 01:24Взял бы ef и общее подмножество типов. А там где запросы кардинально отличаются подсовывал бы разные функции, возвращающие IQueryable. Собственно как выше и написал.
chumakov-ilya
29.06.2015 10:18+2Да, реализация будет попроще, но вам все равно нужен слой между EF и BL, определяющий, какую конкретную функцию использовать?
gandjustas
29.06.2015 22:12+1Это не слой, а обычный сервис, который через IoC попадает в BL.
Напрмиер:
class SomeBL { SomeBL(private IPlatformSpecificQuery queryService, MyDbContext context) {....} IQueryable<Entity> GetEntites() { // some code return queryService.PlatfomSpecificQuery1(context, ...); } }
Вообще плодить много слоев — вредно. Сильно растут затраты на поддержку, когда надо добавлять параметры и расширять схему.InWake Автор
29.06.2015 23:35-1SomeBL(private IPlatformSpecificQuery queryService, MyDbContext context)
то есть вы не управляете жизнью контекста? Предоставляя открытый доступ к MyDbContext, печально,IQueryable GetEntites() а дальше мы выставляем общий интерфейс с проблемами о которых описано. Круто, чего сказать.
gandjustas
30.06.2015 00:01IoC управляет. PerRequestInstance.
Про какие проблемы вы говорите я так и не понял.
Проблема это когда есть задача и её решение ведет к ухудшению характеристик приложения. То есть ваш репозиторий это проблема, потому что тормозит.
А в чем проблема IQueryable? В том, что его неправильно могут использовать? Это проблема в обучении, а не в коде.
Тем более вы же отдаете IEnumerable из репозитария, как вы заставите писать фильтры в базе (Query) вместо применения Where для IEnumerable?InWake Автор
30.06.2015 16:18Это проблема в обучении, а не в коде.
нет, это проблема MS которые решили, что можно спрятаться за правайдером с передачей любого выражения.
InWake Автор
30.06.2015 16:19-1кстате а как ваш класс будет справляться с 18 параметрами, которые где то тут гуляют. Передадим это в функцию? (о да класс) а она передаст это в query? замечательно
lair
30.06.2015 16:22+1Никак. Он уже отдал
IQueryable, все критерии фильтрации применяются туда. Магия компонующихся функций.InWake Автор
01.07.2015 00:29ну и опять мы вернулись IQuariable, вы же сами указывали
If you have a specific ORM in mind, then be explicit about it. Don't hide it behind an interface. It creates the illusion that you can replace one implementation with another. In practice, that's impossible.
lair
01.07.2015 00:30А никто ничего и не прячет. Мы честно говорим: вот EF, вот его интерфейс — именно его, а не абстрактный «репозиторий» — работайте.
InWake Автор
01.07.2015 20:23Don't hide it behind an interface.
речь про IQuariable, за которым прячется конкретная орм,lair
01.07.2015 21:37И еще раз повторю: нет. Я уже выше приводил пример — проблема
IQueryableв том, что между разными ORM его поведение отличается (может отличаться). Но если мы знаем, что с той стороны EF, то мы, по факту, имеем дело с одним и тем жеIQueryable. До тех пор, пока мы не говорим «нет, у нас тут не EF, тут может быть любой QueryProvider» — мы ничего не прячем.InWake Автор
02.07.2015 19:59Согласен что AST (я походу подхватил, писать действительно проще чем expression tree) будет одно и то же, но вот провайдер может не суметь его обработать
lair
02.07.2015 21:30Вот чтобы их переписать, там и стоит адаптер.
InWake Автор
04.07.2015 15:41Я конечно может быть и загоняюсь, но есть Область задания функции, вы же согласны, что у разных провайдеров она разная, то есть мы может сформировать выражение так, что один провайдер сможет его обработать, а другой нет, более того можно нагородить такое, что не одному провайдеру не обработать. Я сторонник жестких ограничений, в том числе и синтаксических ( хотя это не всегда хороший подход, тк на его содержание может уйти много ресурсов ) и я плохо перевираю, когда ограничения нужно держать в голове ( других ограничителей просто нет ), а работая в команде приходиться это все держать не только в свой голове. О чем то можно забыть упустить и потом долго разбираться почему программа работает не так.
lair
04.07.2015 15:45+1Любое наложенное ограничение упрощает вашу жизнь, как разработчика DAL, и усложняет жизнь программиста, которому с этим DAL интегрироваться. Вот и весь компромис.
InWake Автор
04.07.2015 17:24Любое наложенное ограничение упрощает вашу жизнь, как разработчика DAL
да, а еще тестировщика, заказчика и начальства.и усложняет жизнь программиста
да, но меньше вариантов получить по шее, за то что он по ( не знанию, лени и тд ) накосячил, за ним не до проверил тестировщик, из за этого заказчик пожаловался руководству.Вот и весь компромис.
какой там. жесткая диктатура. Но пусть она остается в коде.lair
04.07.2015 17:39-1да, а еще тестировщика, заказчика и начальства.
А вот это иллюзия.
да, но меньше вариантов получить по шее, за то что он по ( не знанию, лени и тд ) накосячил, за ним не до проверил тестировщик, из за этого заказчик пожаловался руководству.
Это только в том случае, если вы уверены, что вы знаете бизнес лучше, чем этот разработчик.
mird
06.07.2015 10:33+1Как результат — при необходимости выйти за рамки очерченные вашим репозиторием, привлекается сразу 2 программиста, прикладной и программист DAL.
InWake Автор
06.07.2015 12:44Возможно, но я не думаю, что нужно иметь универсальных солдат, он и UI и DAL и еще много чего делаем, что касается доступ к разным БД, то этим явно должен заниматься человек, который в это погружен и знает ( или хотя бы догадывается ) где может возникнуть проблема.
mird
06.07.2015 18:27Есть разница между прикладной программист сделал запросы сам (через IQueryable) и с каждым 10-м нужно разбираться потому что он тормозит и разбираться с каждым запросом прикладного программиста. Это банально удорожает и усложняет процесс разработки.
InWake Автор
07.07.2015 14:06Прикладной программист сделал запросы сам (расширение реализации Repository) и с каждым 10-м нужно разбираться потому что он тормозит.
Я не много переписал, получил не большой прирост в цене (относительного написанного вами). С другой стороны у прикладного программиста меньше возможностей продублировать уже существующий запрос, за счет этого идет выигрыш.gandjustas
07.07.2015 14:28+1А можно поподробнее, в чем выйгрыш то?
1) Запросы становится проще писать с репозитарием, по сравнению с IQueryable? Как то незаметно, скорее наоборот — формировать Query для репозитория гораздо более многословно, чем написать IQueryable запрос.
2) Декомпозиция запросов будет в обоих случаях.
3) Быстродействия репозиторий не прибавит, а скорее наоборот.
4) Количество изменений с репозиторием будет больше, так как репозиторий должен знать о прикладной логике приложения, чтобы хоть сколько нибудть быстро работать (нарушается принцип расслоения), а к IQueryable дописать предикат\пейджинг\сортировку\проекцию можно прямо по месту использования, не влезая в другие слои.
Эта тема больше недели существует, но ни одного явного преимущества репозитория не было показано (с примерами кода), а недостатки прут из всех щелей.InWake Автор
08.07.2015 09:591) Запросы становится проще писать с репозитарием, по сравнению с IQueryable? Как то незаметно, скорее наоборот — формировать Query для репозитория гораздо более многословно, чем написать IQueryable запрос.
всегда можно использовать запись в виде Query.With(q=>q.Param = value).With…
3) Быстродействия репозиторий не прибавит, а скорее наоборот.
любая обертка ведет к потери производительности, это согласен, касательно производительности выполнения запросов, это будет зависеть только от того что написать в конкретной реализации
4) Количество изменений с репозиторием будет больше, так как репозиторий должен знать о прикладной логике приложения, чтобы хоть сколько нибудть быстро работать (нарушается принцип расслоения),
это ему знать не нужно, он должен знать о запросе в терминах предметной области и о построителе который умеет перегонять запрос в запрос к хранилищу, тк это фасад и он ничего сам не делает, только делегирует и объединяет. Вот ваше расслоение и единственность ответственности. Что касается количества изменений, да их будет больше, но любая попытка пере использования к этому ведет.
а к IQueryable дописать предикат\пейджинг\сортировку\проекцию можно прямо по месту использования, не влезая в другие слои.
да, быстро удобно, но только если у нас в приложении работа с 1 бд и только с ней, но если даже при наличии 1 бд нет ни какой гарантии что прикладной программист напишет адекватный запрос или хуже того начнет дублировать распространяя по коду (почему это плохо наверное понятно).
Эта тема больше недели существует
мне то же уже надоело,lair
08.07.2015 11:08всегда можно использовать запись в виде Query.With(q=>q.Param = value).With…
А кто-то рассказывал про вред свободных запросов, да. В итоге, как и говорилось, вы были вынуждены ввести ту же функциональность, что и в избегаемом вами LINQ. Или вы хотите сказать, что такие конструкции не дублируются по всему коду?InWake Автор
08.07.2015 11:42А кто-то рассказывал про вред свободных запросов,
это не свободный запрос, посмотрите внимательно, это всего лишь запись
query.Param = value; query.Param1 = value1;
запрос так и остался в терминах предметной областичто такие конструкции не дублируются по всему коду?
query.Paging.Skip = 10; query.Paging.Take = 10;
формирование запроса в терминах предметной области, не нужно делать универсальных запросов, их нужно избегать, иначе мы получим собственный IQuariable.lair
08.07.2015 11:44запрос так и остался в терминах предметной области
В LINQ запрос тоже в терминах предметной области — если, конечно, у вас хранилище снаружи представляет объекты предметной области.InWake Автор
08.07.2015 14:10нет, я могу писать
что в терминах хранилища на том же LINQ будетQuery.ActiveUsers
Where(user=>user.isBanned == false && user.LastLogining < now.AddYear(-1) && user.isDeleted == false)lair
08.07.2015 14:17А вы считаете, что запрос «пользователь не забанен, и пользователь логинился не далее года назад, и пользователь не удален» — не в терминах предметной области? Термины «забанен» и «удален» — не из предметной области внезапно?
InWake Автор
08.07.2015 22:38Предметно, но вот я хочу получить всех активных пользователей, я так и пишу, и ни где снаружи нет как их получить, я пишу не «как» а «что». Плюс со временем то «как» формировать запрос может измениться, добавиться свойства, удалиться, поменяться во вне изменений не будет.
lair
08.07.2015 23:04Но что помешает вашему прикладному программисту написать
Query.With().With().With()для достижения тех же целей?
gandjustas
08.07.2015 20:43А кто мешает сделать extension метод для IQueryablr, который делает такой же запрос? Зачем городить репозитории?
InWake Автор
08.07.2015 22:38-1Ничего, но вы напрочь игнорите тему, а тема у нас «Жизнь приложения при встрече нескольких бд». static очевидно просто подменить во время выполнения…
lair
08.07.2015 23:06static очевидно просто подменить во время выполнения…
Вообще — просто. Service Locator прекрасно справляется.
(хотя на самом деле можно и QueryProvider от нижележащего запроса анализировать)
gandjustas
09.07.2015 02:42Я уже больше одного раза писал что надо сделать если хочется подменять. И репозитории для этого не нужны.
InWake Автор
10.07.2015 15:04По мимо запросов еще есть
1. Создание объекта
2. Сохранение
3. Объекты бизнеса могут отличаться от хранимых — это маппинг
Где все это делать?gandjustas
10.07.2015 16:031. Создание объекта
В бизнес логике вызывать new и add или что ты имеешь ввиду?
2. Сохранение
Вызывать SaveChanges в бизнес-логике.
3. Объекты бизнеса могут отличаться от хранимых — это маппинг
EF делает маппинг. Если тебе нужна принципиально другая структура для расчетов — например граф — то это тоже часть бизнес-логики.
В принципе вопрос не понятен. Все что написал выше все равно придется делать. Даже если ты завернешь эти функции в репозитарий, то БЛ будет вызывать репозитаий чтобы создавать объекты, сохранять в базу итп. Так что какой профит от репозитария непонятно совершенно.
gandjustas
08.07.2015 12:10всегда можно использовать запись в виде Query.With(q=>q.Param = value).With…
Тогда у вас получится тот же IQueryable.
4) Количество изменений с репозиторием будет больше, так как репозиторий должен знать о прикладной логике приложения, чтобы хоть сколько нибудть быстро работать (нарушается принцип расслоения),
это ему знать не нужно, он должен знать о запросе в терминах предметной области и о построителе который умеет перегонять запрос в запрос к хранилищу, тк это фасад и он ничего сам не делает, только делегирует и объединяет.
Проблема в том, что «предметная область» в вакууме не существует. Она всегда зависит от прикладной логики. И любой компонент программы, который работает с предметной областью неявно зависит от прикладной логики.
В вашем случае это выражается в разных классах Query для разных запросов и разных обработках этого Query внутри репозитория. Простой пример — был у вас Query без пейджинга, а вы захотели добавить — вам надо поправить и Query и билдер (как часть репозитория). А с IQueryable можно прямо в контроллере сделать пейджинг.
Что касается количества изменений, да их будет больше, но любая попытка пере использования к этому ведет.
Не любая. IQueryable+методы-комбинаторы+generics не приводят к увеличению площади изменений.
нет ни какой гарантии что прикладной программист напишет адекватный запрос
Репозиторий такую гарантию не дает. тем боле ты сам предлагаешь Linq-подобный интерфейс. Более того, отдавая IEnumerable ты никак не мешаешь разработчику написать любой linq запрос к данным в памяти, что менее эффективно любого неадекватного запроса.
хуже того начнет дублировать распространяя по коду
Репозиторий также не страхует от копипасты.
Все преимущества исключительно надуманные или требуют высокой дисциплины разработчиков, но при высокой дисциплине и с IQueryable проблем нет.InWake Автор
08.07.2015 14:10Тогда у вас получится тот же IQueryable.
это не IQuariable а Linq подобный, передавать в реп все равно QueryObject
Не любая. IQueryable+методы-комбинаторы+generics не приводят к увеличению площади изменений.
методы-комбинаторы+generics ну да, они бесплатны, и мы не как не можем оградитьмя от дублирования путем не использования всего это го
Репозиторий такую гарантию не дает. тем боле ты сам предлагаешь Linq-подобный интерфейс.
QueryObject является ограничителем
Все преимущества исключительно надуманные или требуют высокой дисциплины разработчиков, но при высокой дисциплине и с IQueryable проблем нет.
как раз на оборот, из за того что за всеми не уследишь, репозиторий повышает контроль, правда за счет ограниченностиgandjustas
08.07.2015 20:48это не IQuariable а Linq подобный, передавать в реп все равно QueryObject
Если вы позволяете передавать Expression Tree в вашем Query, то у вас появляются те же «проблемы», которые есть у IQueryable.
QueryObject является ограничителем
Не является, у вас репозитарий отдает IEnumerable. Кто помешает те же Linq методы вызвать для него?
как раз на оборот, из за того что за всеми не уследишь, репозиторий повышает контроль, правда за счет ограниченности
Ничего не повышает, а делает только хуже, так как отдает IEnumerable.InWake Автор
08.07.2015 22:38Если вы позволяете передавать Expression Tree в вашем Query, то у вас появляются те же «проблемы», которые есть у IQueryable.
это не дерево, а форма записи, простейший вариант
public static T With<T>( T target, Action<T> action ) { action( target ); return target; }
Не является, у вас репозитарий отдает IEnumerable. Кто помешает те же Linq методы вызвать для него?
ни кто, действительно ни кто, но вот нет запроса GetAll, есть один плюс IEnumerable будет одинаково фигово отрабатывать на больших выборках на всех бд, что сразу всплывет, если же выборка не большая, то этого ни кто не заметит, если такой запрос единичный, то наверное это не страшно ( хотя я не приветствую ). Другой сценарий при использовании paging, это как надо задать сколько элементов нужно пропустить и сколько взять, что бы после фильтрации IEnumerable осталось нужное количество объектов, ну наверное пропустить 0 взять 1000000 ( за такой запрос медаль только за храбрость и дадут ), но это случай с большими выборками ( разобрали ).lair
08.07.2015 23:12вот нет запроса GetAll
А как же решается простейший сценарий использования «хочу посмотреть все что-нибудь в табличном отображении»?
gandjustas
09.07.2015 02:50-1это не дерево, а форма записи, простейший вариант
Это никак не уменьшает объем писанины по сравнению с IQueryable. В совокупности с билдерами даже увеличивает.
но вот нет запроса GetAll
Ну это банальное вранье или самообман.
Во-первых можно передать пустой запрос и в этом случае ни один из билдеров не сработает и будет втянута вся таблица.
Во-вторых почти всегда есть кейс — показать все записи в UI в виде таблицы или четь в этом роде
Во-третьих, даже если вы требуете передавать параметры пейджинга, то никто не помешает передать размер страницы равный int.MaxValue.
Сколько я не видел репозиториев — почти все позволяли втянуть всю таблицу, а разработчики этим активно пользовались.InWake Автор
10.07.2015 15:04-1Это никак не уменьшает объем писанины по сравнению с IQueryable. В совокупности с билдерами даже увеличивает.
я не разу ни где не писал, что объем уменьшиться
Во-первых можно передать пустой запрос и в этом случае ни один из билдеров не сработает и будет втянута вся таблица.
пустые запросы можно отслеживать
Во-вторых почти всегда есть кейс — показать все записи в UI в виде таблицы или четь в этом роде
если записей не много то да. Вы реально хотите увидеть таблицу в UI из 999999 ( да же не миллион ) записей?
Во-третьих, даже если вы требуете передавать параметры пейджинга, то никто не помешает передать размер страницы равный int.MaxValue.
вы вообще читаете то что я вам пишу?
ну наверное пропустить 0 взять 1000000 ( за такой запрос медаль только за храбрость и дадут ),
Сколько я не видел репозиториев — почти все позволяли втянуть всю таблицу, а разработчики этим активно пользовались.
а вот это вообще шикарно, в итоге мы получаем неизвестность в плене выполнения запросов, и как результат дубляж запросов по коду, при частых изменениях в бизнесе, модификации объектов — смерть.gandjustas
10.07.2015 16:07Ты не понял вопроса. Как репозитарий помешает сделать плохой запрос то в итоге?
Мы только на пейджинг посмотрели, оказывается при всей невероятной обороне легко сделать запрос на миллион строк, а если там еще и джоины, то система уйдет в глубокий даун.
Я не увидел как можно отсечь плохие запросы с помощью репозитория для любых нетривиальных случаев.
И это при том что кода больше и оно уже тормознее работает из-за отсутствия проекций.
RPG18
Не понял про DateTimeOffset, в PostgreSQL. PostgreSQL хранит временную зону.
gurinderu
По дефолту вроде нет. И timestamp и date хранят в localdatetime. В оракле кстати тоже самое.
Вообще если есть проблемы с временем, то можно всегда сохранить epoch time как long, т.к он везде одинаковый)
RPG18
Мы используем тип timestamp with time zone. Postgres хранит в UTC, а перед выдачу клиенту преобразует в локальное.
JeStoneDev
в MySQL также в timestamp хранится время по Гринвичу и преобразуется перед выдачей клиенту.
InWake Автор
в SQLite та же беда, кто просит преобразовывать?
VolCh
Администратор, настраивая часовую зону.
InWake Автор
Не у всех есть администратор
Если нам нужны одни даты в UTC а другие в Local, БД должна возвращать ту дату, которая в ней храниться, а не преобразовывать
VolCh
Человек, выполняющий его функцию, есть всегда. Кто-то устанавливает, кто-то настраивает.
Кому БД должна? БД должна хранить и возвращать так, как указано в её документации.