

Буквально месяц назад в Яндекс.Деньгах завершился переезд сервиса профилей пользователей с Oracle на PostgreSQL. Так что теперь у нас есть опробованное решение по миграции больших объемов данных без потерь и остановки использующего их сервиса.
Под катом я расскажу подробнее о том, как все происходило, зачем мы выбрали для миграции SymmetricDS и почему без «ручных» усилий все равно не обошлось. Поделюсь также некоторыми наработками по вспомогательному коду для миграции.
Для первой миграции и обкатки решения выбрали сервис, обслуживающий пользовательские профили. К профилю относится история платежей, избранное, напоминалки и прочие подобные вещи — все важное, но для работы системы не критичное. База данных у нас без встроенной логики, поэтому перевезти на новую платформу нужно было только сами данные и секвенции.
Итак, через 3 месяца профили пользователей должны работать без Oracle
В связи с надвигающимися релизами по другим проектам решили завершить перенос за три месяца. Команда миграции состояла из 4 человек, зато это были разработчики уровня Senior и специалисты DBA. Чтобы небольшая команда смогла справиться в сжатый срок, под проект искали максимально автоматизированное решение: без написания кода миграции данных, ручной сборки схемы БД и т.п. База содержит около 50 таблиц, поэтому вероятность человеческой ошибки особенно высока при ручных преобразованиях.
Обычно такие миграции выполняются с остановкой сервиса — в нерабочее время. Но в Яндекс.Деньгах платежи проходят круглосуточно, поэтому останавливать систему ради внутренних «оптимизаций» было нельзя. Фактически для этого компонента бизнес согласовал нам приостановку на одну-две минуты, без потери данных.
В поисках идеального инструмента
Квартальный срок проекта не оставлял простора для изобретения собственных квазивелосипедов. Поэтому путем мозгового штурма мы собрали и отсеяли список подходящих продуктов для миграции:
Oracle GoldenGate — может показаться, что это та самая серебряная пуля. По крайней мере, до момента ознакомления с ценой.
SymmetricDS — есть миграция схемы, она будет создана или обновлена при регистрации узла PostgreSQL в мастер-узле Oracle. Есть возможность трансформировать данные при выгрузке или загрузке, используя BASH, Java или SQL.
Full Convert — умеет мигрировать схему и данные, но ограничены возможности кастомизации, нет изменяемых трансформеров (код для изменения данных при миграции).
Oracle to PostgreSQL Migration — переносит схему, данные, внешние ключи, индексы. Полуавтоматическая репликация, трансформации нет, но можно задать соответствие типов в разных БД.
ESF Database Migration Toolkit — переносит все то же, что и Oracle to PostgreSQL Migration. Данные передаются в пакетном режиме, возможность миграции в несколько потоков отсутствует.
Ora2Pg — переносит схему, данные, внешние ключи, индексы, возможна миграция в несколько потоков. Из минусов: медленный перенос таблиц с типами blob/clob (около 200 записей/сек), нет трансформатора.
- SQLData Tool — мигрирует только схему, ограничены возможности кастомизации.
Остальные представленные на рынке продукты или уже заброшены разработчиками, или не имеют развитой поддержки в сообществе.
В результате выбрали Ora2Pg для переноса схемы БД и SymmetricDS для миграции данных. Вообще, последний предназначен больше для синхронизации разных СУБД, чем для переноса данных. Но в нашем случае он позволил обеспечить миграцию без остановки сервисов.
Тысяча и одна мелочь для миграции
Когда обкатывали миграцию на копии продакшн-базы, то нашли целый набор «особенностей» и странностей в миграционном решении. PostgreSQL не корректно отрабатывал некоторые запросы, которые без проблем проходили в Oracle. Например, SELECT * вызывал ошибку и остановку работы всего зависящего от БД сервиса. Вообще, такие запросы — дурной тон, на самом деле они были другие, а эти я привел просто как дозволенный пример. Оказалось, что это скорее проблема Java-драйвера, поэтому на момент реализации проекта было проще не использовать проблемные запросы. Позже этот баг исправили.
Были сложности и с транзакциями при установленном флаге AutoCommit-OFF. В PostgreSQL код падал, если при его выполнении предварительно не была открыта транзакция. Oracle вел себя иначе: транзакция откатывалась или завершалась кодом, который пришёл в этот же поток выполнения. Решение для PostgreSQL — написать код, который бы проверял наличие явно открытой транзакции для всех запросов на изменение данных.
При выполнении запросов сервис пользовательских профилей не указывал порядок сортировки выводимых значений (ORDER BY), так как в Oracle отсутствие признака означает вывод в хронологическом порядке. И на этом мы поскользнулись в PostgreSQL, который выводил результаты запроса вразнобой — причесали код так, чтобы ORDER BY был везде.

Интересный нюанс был и с композитными транзакциями, которые изменяли данные как в исходной БД Oracle, так и в перенесенном на PostgreSQL экземпляре. Чтобы в обеих базах были одинаковые значения, наша команда разработала специальный менеджер транзакций. Он синхронно открывал и закрывал транзакции в обеих СУБД. Если в таких транзакциях возникали ошибки, то их уже приходилось решать вручную.
И понеслось
Миграция данных была поэтапной — по заранее утвержденному списку из 50 таблиц. Переключение решили сделать на уровне каждой таблицы в базе, что позволило достичь высокой гибкости и декомпозиции процесса. То есть в определенный момент, после переноса данных, для таблицы выставлялся специальный флаг, по которому сервис Я.Денег переключался на экземпляр данных в PostgreSQL.
Для удачной миграции Oracle-PostgreSQL важно заранее составить план, чтобы никакая досадная мелочь не забылась. Такой план был и у нас, вот он под спойлером:
Что нужно сделать разработчику:
получить DDL таблицы на PostgreSQL;
выделить интерфейс для DAO-класса;
создать DAO-класс для работы с PostgreSQL;
создать флаг для переключения работы с Oracle DAO на PostgreSQL DAO;
написать тесты на новое DAO с покрытием от 80% (очень помогает избежать ошибок в синтаксисе SQL запросов использование механизма jOOQ). Больше — лучше;
обкатать миграцию на тестовом стенде;
выполнить миграции на приемочном стенде, убедиться в прохождении приемочных тестов;
- Релиз изменений на боевую среду.
Методичка для DBA:
получить от разработчика DDL мигрируемой таблицы в БД PostgreSQL, создать таблицу и все связанные с ней сущности;
уточнить у разработчика способ миграции — нужна ли первичная прогрузка старых данных и синхронизация новых записей?
Если данных много, то по каким критериям можно ограничить объем первичной загрузки;
настроить SymmetricDS на синхронизацию таблицы;
в одной транзакции запустить первичную загрузку (если требуется) и синхронизацию новых записей;
периодически проверять статус загрузки и синхронизации;
- непосредственно перед переключением сервисов на PostgreSQL передвинуть секвенции в таблице назначения для запаса по первичным ключам.
Что нужно не забыть ответственному за процесс:
убедиться, что на продакшене поддерживается работа с PostgreSQL для конкретной таблицы;
проверить, что на продакшене успешно выполнена первичная загрузка данных и включена синхронизация новых записей;
попросить DBA передвинуть секвенции в PostgreSQL;
переключить один экземпляр сервиса на работу с PostgreSQL, убедиться, что нет ошибок в логах и логике работы сервиса;
переключить оставшиеся экземпляры сервиса;
- после полного переключения попросить DBA переименовать мигрированные таблицы в Oracle. Внимательно следить за ошибками в системе — какая-то «забытая» логика сервиса может пытаться по-прежнему работать с Oracle.
В процессе миграции часть из 50 таблиц работала на Oracle, другая — на PostgreSQL. Здесь и пригодился SymmetricDS, который мигрировал данные из Oracle в PostgreSQL и тем самым обеспечивал консистентность как для логики с перенесенными таблицами, так и для тех, что еще работали по старой схеме.
После переноса данных в сервисе устанавливался флажок «работай с PostgreSQL» для каждой конкретной таблицы, и запросы переходили к новой СУБД. Сначала переключение проверялось на dev-стенде, потом на приемочном. Если ОК — переключение на продакшн и переименование таблицы в Oracle (чтобы понять, не используется ли еще где старая таблица).
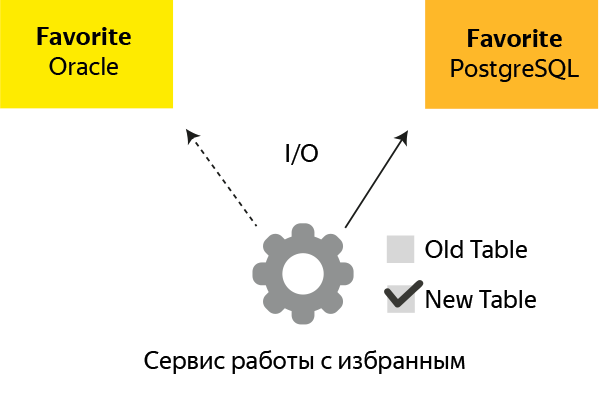
На схеме суть идеи: после создания дубликата базы на PostgreSQL в сервисе устанавливается флаг new db, после чего все обращения идут к новой базе.
Но самым сложным было правильно подобрать момент переключения. Фактически у нас было 3 варианта миграции, в зависимости от критичности и сложности таблицы:
Перенос таблицы целиком с последующим переключением. Вариант подходил в тех случаях, когда часть запросов можно было потерять (пользователя можно попросить нажать кнопку еще раз, или сработает автоматическое продолжение операции).
На уровне дата центра (ДЦ, всего их 2). Способ для переноса критичных таблиц, при котором сначала переводим на PostgreSQL первый ЦОД, а в процессе его включения отключаем второй (с Oracle). На время старта — остановки Oracle и PostgreSQL могли работать параллельно, поэтому тут и пригодились механизмы синхронизации и переключения данных. Простоя в работе сервисов при этом не было.
- По методике «остаточного дожатия». Оставляем 2 экземпляра: Oracle для обработки опоздавших к переключению запросов и новый PostgreSQL. Новые задачи обрабатывались в новой базе, а старые удалялись после выполнения в оставшемся Oracle. Так переезжали очереди базы — автоплатежи, напоминалки и т.п.
Не обошлось и без сложностей. При первичном формировании схемы БД под PostgreSQL конвертер выдал не на 100% готовый вариант, что и ожидалось, в общем-то. Пришлось вручную менять некоторые типы колонок, исправлять секвенции и разбивать схему по таблицам и индексам. Впрочем, последнее — это уже для порядка и общей эстетики.
Чуть позже оказалось, что SymmetricDS не синхронизирует таблицы объемом более 150 ГБ. Поэтому пришлось засесть за код и создать обходной вариант переноса на такие случаи.
Впрочем, серебряной пули и тут не получилось. SymmetricDS не переносил поля CLOB\BLOB, если из-за них был превышен суммарный объем таблицы, поэтому пришлось писать ручные очереди миграции. Столкнулись и с совсем экзотическими случаями, когда миграция с Oracle на PostgreSQL приводила к резкому проседанию производительности. Ничего не оставалось, кроме как вручную разбирать каждый отдельный случай. Например, для одной таблицы пришлось выделить поле CLOB в отдельную таблицу, перенести ее на SSD-диск и читать это поле только при необходимости.
Так как нужно было поддерживать одновременно активными старые и новые экземпляры БД, для новых мы сделали запас по секвенциям, чтобы не происходило наслоения и попыток переноса в PostgreSQL дублирующихся ключей.
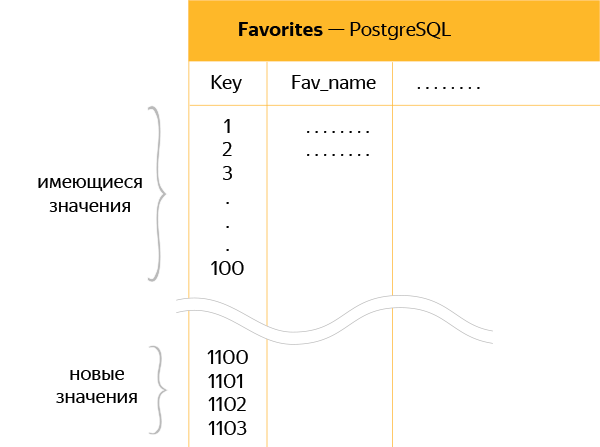
На схеме — схематичное изображение новой таблицы в PostgreSQL с «отступом» между старыми и новыми данными в 1000 ключей.
То есть если в таблице последний ключ был 100, то при переносе к этому значению добавлялась еще 1000, чтобы SymmetricDS мог свободно синхронизировать ключи 101, 102 и все остальные без перезаписи новых данных.
Финишная ленточка
За плановый квартал наша маленькая команда перенесла 80% таблиц на PostgreSQL. Оставшиеся 20% — это большие таблицы (в среднем более 150 ГБ), включая сборную таблицу с объемными полями CLOB\BLOB. Все это пришлось доделывать вручную следующие 1,5 месяца. Тем не менее связка SymmetricDS и Ora2Pg сделала большую часть рутинной работы, что и требовалось по условиям задачи. Наша команда разработки изрядно пополнила за этот проект внутреннюю копилку «грабель», часть из которых на момент выхода статьи наверняка осталась за кадром.
Но от Яндекс.Денег уже готовится десант на грядущую конференцию PG Day'17, которая пройдет в Санкт-Петербурге. Приходите на расширенный доклад и готовьте каверзные вопросы.
Впрочем, самые животрепещущие темы предлагаю поднять прямо тут, в комментариях. Очень любопытно почитать о вашем опыте миграции и, может быть, о том, что мы упустили из виду.
В репозитории Яндекс.Денег вы найдете немного кода описанных в статье решений:
Исходники Transaction Manager
- Код класса проверки наличия транзакции.
Комментарии (52)

amakarov
20.04.2017 17:28А для каких данных использовали blob'ы, да еще и в таком количестве?

Silron
20.04.2017 19:53Все неструктурированные данные, которые нельзя красиво уместить в реляционную модель:
— входные параметры платежа
— описание состояния платежа (контексты операций)
— результат платежа
— кастомные параметры профиля пользователя
Размер LOB у нас обычно варьируется от 1 до 8 Кб на одну строку.VolCh
21.04.2017 14:52Не лучше ли подобные данные хранить в json(b) или xml? Или они настолько неструктурированы, что овчинка выделки не стоит?
wadeg
21.04.2017 16:53-1Да вы почитайте внимательнее. Они переносили таблицы по одной. Понимаете? Т.е. у них даже джойны из разных таблиц в приложении. Из разных таблиц РСУБД! Из Оракла, карл! Ну как так-то? Это же настолько наколеночная поделка, что тут даже «разработчики», уверенные, что из каких-то там запросов данные поступают в некоем порядке, уже абсолютно естественны.
Меня больше удивляет вот что. Если их купил СБ, то почему не послал людей из СБТ посмотреть, на чем крутится купленная поделка? В СБТ уйма грамотного народа. После заключения СБТ этих самодельщиков просто бы по-тихому разогнали и переписали бы все по-человечески, все-таки деньги. Где внутренний аудит СБ?Silron
21.04.2017 19:38+1Как уже отмечалось в комментариях, разные сценарии миграции требуют разных подходов. В статье описана конкретная методика на примере одного типа таблиц, для которого целесообразен был именно описанный вариант.
Разумеется, переключение связанных таблиц происходило одновременно, с учетом явной связи в БД — join и неявной — по коду.
Что касается логики в БД, то мы принципиально против такого подхода в своей системе.
Oracle хороший мощный инструмент. Особенности нашей работы не позволяют использовать все его возможности. Нам важны производительность сервиса, утилизация железа, возможность дешевого масштабирования и применение автоматического тестирования.
Все это зачастую закрывает для нас такие теоретические подходы как нормальная форма, логические связи в бд и даже внешние ключи.

chemtech
20.04.2017 18:14Кроме бага pgjdbc и выкладывания oracle-to-postgres-migration-utils улучшали какие -либо opensource решения? (отправляли ли патчи, заводили ли баги)
Silron
20.04.2017 20:07С точки зрения Postgres хватило текущей функциональности и документации.
А вот по SymmetricDS потребовалась помощь их саппорта.

GlukKazan
20.04.2017 22:00так как в Oracle отсутствие признака означает вывод в хронологическом порядке.
Об этом как-то упомянуто в документации? Насколько мне известно, отсутствие order by означает только одно — то что сервер имеет право вывести данные в любом порядке. Один раз я даже на это крупно напоролся. На Oracle.Silron
20.04.2017 22:34+3В тексте статьи проблема описана неточно.
Суть проблемы — если запросе есть limit, то планировщик Postgres решает, что ему дешевле искать полным перебором.
В итоге получаем full scan, несмотря на наличие индекса.
Oracle в запросах с limit корректно использует индекс.
Лечится проблема в Postgres:
• либо оборачиванием запроса в set enable_seqscan to off; set enable_seqscan to on;
• либо сортировкой (order by) по полю, для которого есть индекс.
Ссылки по теме:
1) https://www.postgresql.org
2) stackoverflowGlukKazan
21.04.2017 08:56+4Не сочтите меня занудой, но в Oracle нет фразы "limit" (есть rownum, но он с причудами).
Суть моего комментария не в том, что в PostgreSQL нельзя рассчитывать на порядок выборки без order by, а в том, что и в Oracle этого нельзя делать! Никогда! Даже если, по каким-то причинам (например из за наличия в запросе группировки), оптимизатор выбирает план, приводящий к выводу строк в требуемом (например «хронологическом») порядке, никак нельзя рассчитывать на то, что он будет использовать этот план всегда. В какой-то момент план изменится и вся логика, завязанная на порядок выборки строк сломается! И невозможно сказать, в какой момент это произойдёт! Если вам требуется порядок выборки — используйте order by.Silron
21.04.2017 20:45+1Поясню с чем мы столкнулись на примере.
На Oracle запрос выглядел вот так:
SELECT EVENT_ID, EVENT_TYPE FROM EVENT WHERE EVENT_DATE < :eventDate AND ROWNUM = 1 FOR UPDATE SKIP LOCKED
Для Postgres мы переписали его вот так:
SELECT EVENT_ID, EVENT_TYPE FROM EVENT WHERE EVENT_DATE < :eventDate FOR UPDATE SKIP LOCKED LIMIT 1
И поняли, что получили нереально большую просадку по производительности.
При этом количество записей, которые попадали под условие EVENT_DATE < :eventDate было небольшим — десятки.
Посмотрели план запроса:
postgres@demo:5432 (demo-service) # explain (analyze,buffers) SELECT EVENT_ID, EVENT_TYPE FROM EVENT WHERE EVENT_DATE < now() + '30 day' limit 100; QUERY PLAN ----------------------------------------------------------------------------------------------- Limit (cost=0.00..59.53 rows=100 width=18) (actual time=0.022..0.817 rows=100 loops=1) Buffers: shared hit=20 -> Seq Scan on event (cost=0.00..154329.33 rows=559239 width=18) (actual time=0.022..0.807 rows=100 loops=1)
Индекс по EVENT_DATE есть, но видно, что Postgres его не использует и выполняется Seq Scan.
Лечение заключается в прямом указании Postgres на использование нужного индекса путем добавления сортировки, которая не требуется с точки зрения бизнес-логики клиента:
SELECT EVENT_ID, EVENT_TYPE FROM EVENT WHERE EVENT_DATE < $1 order by EVENT_DATE FOR UPDATE SKIP LOCKED limit 1
В итоге получаем Index Scan:
postgres@demo:5432 (demo-service) # explain (analyze,buffers) SELECT EVENT_ID, EVENT_TYPE FROM EVENT WHERE EVENT_DATE < now() + '30 day' order by EVENT_DATE limit 100; QUERY PLAN ----------------------------------------------------------------------------------------------- Limit (cost=0.44..87.03 rows=100 width=26) (actual time=0.061..183.099 rows=100 loops=1) Buffers: shared hit=28 read=89 I/O Timings: read=182.489 -> Index Scan using event_idx1 on event (cost=0.44..205111.55 rows=559239 width=26) (actual time=0.060..183.057 rows=100 loops=1) Index Cond: (event_date < (now() + '30 days'::interval)) Buffers: shared hit=28 read=89 I/O Timings: read=182.489 Planning time: 0.301 ms Execution time: 183.175 msGlukKazan
21.04.2017 21:32А, магия skip locked и волшебные индексы Oracle.
Это конечно немного другая история, согласен.

pavel_pimenov
21.04.2017 22:09+1а LIMIT 1 с order by в PG точно работает аналогично по
приоритетам как и в Oracle ROWNUM = 1 c order by?
странный способ стабилизации плана выполнения — уж лучше запрещенные хины в Oracle

aynur_safin
24.04.2017 11:03Лечение заключается в прямом указании Postgres на использование нужного индекса путем добавления сортировки, которая не требуется с точки зрения бизнес-логики клиента:
Silron, т.е. вам нужны случайные записи?
zhekappp
23.04.2017 14:02-1Я бы еще добавил, что дело может быть даже не в плане, а в версии oracle.
недавно столкнулись, что выборка
select * from ( select * from ... order by ... ) where rownum<10;
на 12.1 стала иногда выдавать результаты не в порядку внутреннего order by, хотя план запроса не не изменился.
Пришлось добавлять внешний order by.wadeg
25.04.2017 23:25-1Господь/ЛММ/провидение, храни и размножай дальше таких работничков, как эти топикстартеры, ибо пока они каким-то образом пробираются на продакшн и показывают себя, на нас всегда будут молиться работодатели как на последнюю надежду, данную свыше.



TimoshkinVlad
21.04.2017 08:52А как вы сейчас считаете, стоило делать такую сложную схему или все же можно было остановить сервис на некоторое время и перенести часть таблиц? Например сделать несколько таких итераций, поделив их по времени. Т.е. например перенести справочники целиком. А операции по частям, например по годам или кварталам?
Если НСИ потребуют остановки, то наверное, большую часть операций, можно перегрузить «в фоне».
dimskiy
21.04.2017 11:34+2Яндекс.Деньги — финансовый сервис, и минута простоя стоит достаточно, чтобы избегать простоев :) Например, переводили как-то сервис работы с магазинами. И там был нюанс в том, что БД маленькая и владельцы магазинов обычно спят по ночам. Поэтому ту миграцию выполняли ночью с простоем 25 минут — сценарий миграции может отличаться в зависимости от условий.
Что касается описанной в статье ситуации, то мы и перегружали данные в фоне, а потом делали обновления в обе БД. И только после этого выполняли переключениеTimoshkinVlad
21.04.2017 15:21Спасибо. Очень бы потом хотелось бы увидеть к-либо данные по фактической производительности. Как по факту выросли или упали требования к производительности.
Все же такой опыт поможет сломать недоверие некоторых заказчиков к опен-сорс ПО.

Germanets
21.04.2017 15:49В любом случае результат будет у каждого свой, так как во-первых у Яндекса могут оказаться какие-то специфичные требования к БД, которых не будет в другом проекте, и наоборот. Так что основной вопрос так и останется к применимости того или иного инструмента(в данном случае СУБД) под использование в конкретной задаче.
TimoshkinVlad
21.04.2017 16:28Это понятно. Но тут речь о другом. О самой возможности заменить в очень крупной компании, Оракл, который работает в 24*7 с критическими финансовыми данными, на Постгрес.
Т.е. это определенное доверие опен-сорс продукту.
Мне вот сложно обосновать, почему заказчик может использовать Постгрес, а не, например, mssql. Точнее обосновать то я могу. Но доверие берется как раз на примере таких переходов.
VolCh
21.04.2017 15:33По сути вы использовали обычные техники zero downtime deployment для деплоев с изменением схем баз данных, с тем лишь нюансом, что новая и старая схема оказались на разных СУБД?
Silron
21.04.2017 20:16Важно, что меняется не только БД, но и её тип. А значит нужен код, который может одновременно работать с двумя типами БД.
Учитывая что код разрабатывался годами и разными людьми, такая миграция представляет ещё большой риск.
И наша статья про то, как давно живущее приложение аккуратно перенести в сжатый срок на новое окружение с полной миграцией всех данных без прерывания процесса.VolCh
22.04.2017 10:34Понятно, что нужна дополнительная обвязка в коде, но логически, по-моему, код, который работает одновременно с двумя БД одного типа не сильно отличается от кода, который работает с двумя БД разного (но идеологически схожего) типа. Задача переноса без даунтайма с БД одного типа на БД другого типа, конечно, сложнее, но пока не доходит до специфических команд, то концептуально она не сильно отличается от переноса между двумя БД одного типа, если не пользоваться встроенными инструментами СУБД для этого. Те же принципы, основной из которых, то, что код клиента при переходе модифицируется поэтапно:
- читаем из старой, пишем в старую (исходная точка)
- читаем из старой, пишем в обе
- читаем из новой, пишем в обе (необязательный в целом шаг, но уменьшает риски)
- читаем из новой, пишем в новую (конечная точка)
Silron
24.04.2017 16:08Для основной массы таблиц использовался более простой, надежный и дешевый способ миграции через SymmetricDS. В конце проекта «легкие» таблицы кончились и последние 1.5 месяца мы потратили на ручную миграцию через специально написанные очереди миграции данных. Такой подход требует больше ресурсов на разработку и внимательного тестирования.
По аналогии с SymmetricDS, очередь выполняла не только синхронизацию новых и измененных данных, но и начальную массовую загрузку исторических данных в батч режиме.
Особенно важно при работе с критичными таблицами для нас было иметь возможность отката на Oracle без потери данных после переключения на Postgres. Несколько раз мы воспользовались этой функциональностью, когда Postgres не вытянул нагрузку и пришлось переключаться обратно, до решения проблемы.
VolCh
21.04.2017 14:55SymmetricDS мощная штука. Мы на нём ДВХ начали делать.
Вы опенсорс версией пользовались или покупали полный комплект инструментария и поддержки? Там, помнится, тысячи долларов за год.
semI-PACK
21.04.2017 15:00Интересный опыт. Тоже планируем переход на постгрес (только с MS SQL). И спасибо за подборку инструментов миграции.

freeart
21.04.2017 15:45А если не секрет в чем причина переезда? У нас наоборот произошло с постгреса на azure sql. Цена конечно дикая, но производительность на первый взгляд выше
TimoshkinVlad
21.04.2017 16:34Лет 10 назад пришлось столкнутся с оракл грид. Там была просто дикая производительность на обычном железе. Правда на продакшн не взлетело, но это по причине желаний заказчика.
freeart
21.04.2017 17:19С azure сервисами такая же штука, все очень быстро из «коробки», но надо быть gold партнером чтобы пользоваться этими благами по причине диких цен. Я вообще непредставляю заказчика, который согласился бы добровольно за это платить.

Yerumaku
21.04.2017 17:01С чем связан отказ от MS SQL, если лицензия уже есть? Только не говорите «импортозамещение».
P.S. Чувствую в РФ скоро будет больше запросов о миграции, чем когда-либо, так что статья в тему сегодняшнего дня.
Pusk1
21.04.2017 18:00Какие альтернативные сценарии переноса данных рассматривали? Для меня перенос по таблицам большая экзотика. Предпочитаю перенос всех ретро данных, а топом горячих. Например, за последний час. При этом остановка длится 1-2 минуты, что не критично для большинства сервисов.
maxitop
зарплату DBA Oracle после этого урезали или нет? Плюшки какие от этого переезда вам?
Dimmentio
Зарплату, конечно, не урезали. В этом нет смысла, наши DBA активно участвуют в миграции и осваивают PSQL. А вот про плюшки можно долго говорить. Их много. Во-первых, это банальная экономия. Oracle очень дорогой и в стоимости лицензий, и в поддержке. Тарифицируется в долларах, скидки дает в единицах процентов. Во-вторых, для нас крайне актуально легкость в поднятии новых баз с учетом микро-сервисной модели, обилия тестовых стендов и необходимости, порой, иметь локальную БД на разработческом ноутбуке. Тут с PSQL все сильно проще. В-третьих, за счет лицензии open source и сообщества к PSQL достаточно быстро делают необходимый в администрировании и эксплуатации инструментарий. И он так же бесплатный.
pavel_pimenov
А почему раньше был выбран oracle (и при этом не использовался хранимый PL/SQL код)?
dimskiy
Oracle был выбран исторически — системе 15 лет и речь идет о сервисе, который был с самого появления системы. Что тогда было критерием выбора — уже сложно точно узнать :)
dimskiy
Хранение логики в БД противоречит нашим принципам поддержки масштабирования и тестирования кода. Базам отводится только роль простых хранилищ с легкими операциями чтений, записи и обновлений. Максимум логики на клиенте.
pavel_pimenov
А после миграции легкость операций на ваших объемах и операциях в какую сторону изменилась?
Dimmentio
Тут я могу сказать, что без оптимизаций выдачи в профиле истории операций, мы получили заметную деградацию. Но после нескольких быстрых доработок окончательная производительность просела относительно Oracle примерно на 10-15%. Сейчас смотрим что можно сделать в плане следующей волны оптимизации, которая должна дать прирост порядка 30%. При этом, за счет отказа от переноса старых таблиц, дефрагментации и сжатия BLOB, мы в PostrgreSQL получили экономию дискового пространства порядка 40% относительно Oracle.
pavel_pimenov
«старые таблицы» это как… они нигде уже не используются и в оракле им забыли сказать drop?
Silron
Все верно — сервис очень живой: постоянно добавляется и удаляется логика, связанная с профилем.
Что-то взлетает и остается навсегда, а что-то отмирает со временем и остается как рудимент.
При миграции смотрели на нагрузку на таблицу в БД и на использование в коде.
К слову, на старте было 70, а не 50 таблиц.
Но, к сожалению разработчиков самые сложные таблицы для миграции в этот список не попали :)
AK74U
А как вы примерно 30% рассчитали?
wadeg
В принципе, эта статья и комментарии к ней — это все, что нужно знать о квалификации как старой, так и новой команды яндекс-денег.
easty
Согласен насчет мобильности psql, помню когда плотно работал с оракл, немного страдал от того, что было проблематично взять работу с собой