
Не так давно пришлось разрабатывать функциональность для которой нужно быстро и часто сбрасывать большие объемы данных на диск, а время от времени их оттуда читать. Нужно было найти где, как и с помощью чего хранить эти данные. В статье короткий разбор задачи, исследование и сравнение решений.

Контекст задачи
Я работаю в команде, которая занимается разработкой средств разработки для разработчиков реляционных баз данных (SqlServer, MySql, Oracle), среди них как отдельные приложения, так и те, что встраиваются в такой 32 битный “дредноут” как Microsoft Management Studio.
Задача
Восстановить документы открытые в IDE на момент закрытия при следующем запуске.
Usecase
Быстро закрыть IDE перед уходом домой, не думая о том, какие документы сохранены, а какие нет. При следующем запуске среды получить тоже окружение, что было на момент закрытии и продолжить работу.
Сохранить все результаты работы разработчика на момент аварийного завершения работы: падение программы или операционной системы, отключение питания.
Разбор задачи
Похожая функция есть в браузерах. Там им, с технической точки зрения, живется куда проще: нужно всего-то сохранить пачку URL адресов, а даже у меня редко бывает более сотни вкладок, сам URL это в среднем всего две сотни символов. Таким образом мы хотим получить поведение подобное тому, что есть в браузере, но хранить нам нужно содержимое документа целиком. Получается, что нам нужно куда-то часто и быстро сохранять все документы пользователя. Усложнял задачу и тот факт, что люди иногда работают с SQL не так как с другими языками. Если я, как разработчик на С#, напишу класс более чем на тысячу строк кода, то
Требования к хранилищу
Проанализировав задачу сформулировали следующие требования к хранилищу:
- Это должно быть встраиваемое легковесное решение.
- Скорость записи.
- Возможность многопроцессорного доступа. Требование не критичное, так как мы могли бы и сами обеспечить его с помощью объектов синхронизации, но иметь это из коробки было бы чертовски приятно.
Претенденты на роль
Первый лобовой и топорный вариант: хранить все в папке, где-нибудь в AppData.
Очевидный вариант это SQLite. Стандарт в области встраиваемых баз данных. Очень обстоятельный и популярный проект.
Третьим стала база LiteDB. Первый ответ гугла на вопрос: “embedded database for .net”
Первый взгляд
Файловая система — файлы есть файлы. За ними придется следить, им придется придумывать имена. Помимо содержимого файла нужно хранить и небольшой набор свойств(оригинальный путь на диске, строка соединения, версия IDE в которой он был открыт), а значит придется или создавать по два файла на один документ или придумывать формат, дабы отделить свойства от содержимого.
SQLite — классическая реляционная база данных. База представлена одним файлом на диске. На этот файл накатывается схема данных, после чего с ней придется взаимодействовать средствами SQL. Можно будет создать две таблицы: одну для свойств, другую для контента, на случай если будут задачи где понадобится одно без другого.
LiteDB — нереляционная база. Как и в SQLite база представлена одним файлом. Полностью написана на С#. Подкупающая простота использования: всего лишь нужно отдать библиотеке объект, а сериализацию она уже берет на себя.
Performance тест
Перед тем как привести код, я лучше поясню общую концепцию и приведу результаты сравнения.
Общая идея была следующая: сравнить как долго будет записываться в базу много маленьких файлов, среднее количество средних по размеру файлов и немного очень больших файлов. Вариант со средними файлами наиболее близкий к реальному, а маленькие и большие файлы это пограничные случаи, которые тоже нужно учитывать.
В файлы писал через FileStream со стандартным размером буфера.
В SQLite был один нюанс на котором считаю нужным заострить внимание. Мы не могли складывать всё содержимое документа(выше писал, что они могут быть действительно большими) в одну ячейку базы данных. Дело в том, что в целях оптимизации мы храним текст документа построчно, а это значит, что для того чтобы сложить текст в одну ячейку нам нужно было бы слить весь текст в одну строку, чем удвоить, количество используемой оперативной памяти. Другую сторону той же проблемы получили бы и на чтении данных из базы. Поэтому в SQLite была отдельная табличка, где данные хранились построчно и были связаны по внешнему ключу с таблицей, где лежали лишь свойства документов. Кроме того, получилось немного ускорить базу, вставляя данные пачками по несколько тысяч строк в режиме синхронизации OFF, без журналирования и в рамках одной транзакции(этот трюк я подсмотрел здесь и здесь).
В LiteDB просто отдавался объект, у которого одним из свойств был List<string> и библиотека сама это сохраняла на диск.
Еще во время разработки тестового приложения я понял, что мне больше нравится LiteDB, дело в том, что тестовый код для SQLite занимал более 120 строк, а код решающий ту же задачу для LiteDB менее 20.
internal class FileStrings {
private static readonly Random random = new Random();
public List<string> Strings {
get;
set;
} = new List<string>();
public int SomeInfo {
get;
set;
}
public FileStrings() {
}
public FileStrings(int id, int minLines, decimal lineIncrement) {
SomeInfo = id;
int lines = minLines + (int)(id * lineIncrement);
for (int i = 0; i < lines; i++) {
Strings.Add(GetString());
}
}
private string GetString() {
int length = 250;
StringBuilder builder = new StringBuilder(length);
for (int i = 0; i < length; i++) {
builder.Append(random.Next((int)'a', (int)'z'));
}
return builder.ToString();
}
}
Program.cs
List<FileStrings> files = Enumerable.Range(1, NUM_FILES + 1)
.Select(f => new FileStrings(f, MIN_NUM_LINES, (MAX_NUM_LINES - MIN_NUM_LINES) / (decimal)NUM_FILES))
.ToList();
private static void SaveToDb(List<FileStrings> files) {
using (var connection = new SQLiteConnection()) {
connection.ConnectionString = @"Data Source=data\database.db;FailIfMissing=False;";
connection.Open();
var command = connection.CreateCommand();
command.CommandText = @"CREATE TABLE files
(
id INTEGER PRIMARY KEY,
file_name TEXT
);
CREATE TABLE strings
(
id INTEGER PRIMARY KEY,
string TEXT,
file_id INTEGER,
line_number INTEGER
);
CREATE UNIQUE INDEX strings_file_id_line_number_uindex ON strings(file_id,line_number);
PRAGMA synchronous = OFF;
PRAGMA journal_mode = OFF";
command.ExecuteNonQuery();
var insertFilecommand = connection.CreateCommand();
insertFilecommand.CommandText = "INSERT INTO files(file_name) VALUES(?); SELECT last_insert_rowid();";
insertFilecommand.Parameters.Add(insertFilecommand.CreateParameter());
insertFilecommand.Prepare();
var insertLineCommand = connection.CreateCommand();
insertLineCommand.CommandText = "INSERT INTO strings(string, file_id, line_number) VALUES(?, ?, ?);";
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Prepare();
foreach (var item in files) {
using (var tr = connection.BeginTransaction()) {
SaveToDb(item, insertFilecommand, insertLineCommand);
tr.Commit();
}
}
}
}
private static void SaveToDb(FileStrings item, SQLiteCommand insertFileCommand, SQLiteCommand insertLinesCommand) {
string fileName = Path.Combine("data", item.SomeInfo + ".sql");
insertFileCommand.Parameters[0].Value = fileName;
var fileId = insertFileCommand.ExecuteScalar();
int lineIndex = 0;
foreach (var line in item.Strings) {
insertLinesCommand.Parameters[0].Value = line;
insertLinesCommand.Parameters[1].Value = fileId;
insertLinesCommand.Parameters[2].Value = lineIndex++;
insertLinesCommand.ExecuteNonQuery();
}
}
private static void SaveToNoSql(List<FileStrings> item) {
using (var db = new LiteDatabase("data\\litedb.db")) {
var data = db.GetCollection<FileStrings>("files");
data.EnsureIndex(f => f.SomeInfo);
data.Insert(item);
}
}
В таблице приведены средние результаты нескольких прогонов тестового кода. При измерении статистическое отклонение было незначительным.
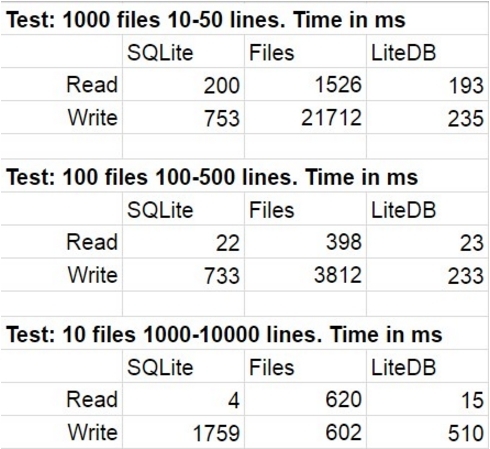
Нас не удивила победа LiteDB над SQLite, хоть и удивил порядок этой победы. В полный шок меня повергла победа LiteDB над файлами. Немного исследовав репозиторий библиотеки я, например, нашел очень грамотно реализованную постраничную запись на диск, на этом и успокоился, хоть и уверен это лишь один из многих performance-tricks, которые там используются. Еще хочу обратить внимание на то, как быстро деградирует скорость доступа к файловой системе, когда файлов в папке становится действительно много.
Для разработки это feature была выбрана LiteDB, о чем в дальнейшем мы жалели довольно редко. Спасало, что библиотека написана на родном для всех c# и если что-то было не до конца ясно, то всегда можно было почитать в исходниках.
Недостатки
Помимо выше приведенных преимуществ LiteDB над конкурентами по мере разработки стали всплывать и недостатки, большинство из которых можно списать на молодость библиотеки. Начав использовать библиотеку слегка за рамками “обычного” сценария нашли несколько проблем(#419, #420, #483, #496) Автор библиотеки всегда очень быстро отвечал на вопросы, большинство проблем очень быстро исправлялись. Сейчас осталась только одна(и пусть статус closed вас не смущает). Это проблема конкурентного доступа. По всей видимости где-то в глубине библиотеки спрятался очень противный race-condition. Для себя мы этот баг обошли довольно интересным способом, о чем я планирую написать отдельно.
Еще стоит упомянуть об отсутствии удобного редактора и просмотрщика. Есть LiteDBShell, но это для фанатов консоли.
UPD: недавно нашелся инструмент
Резюме
Мы построили большую и важную функциональность поверх LiteDB, а сейчас ведется разработка еще одной крупной feature где тоже будем использовать эту библиотеку. Для тех, кто сейчас ищет in-process базу для своих нужд предлагаю посмотреть в сторону LiteDB и того как она ляжет на ваши задачи, ведь нет никакой гарантии, что то, что сработало для одного, так же хорошо сработает для чего-то совершенно другого.
Комментарии (22)

apro
25.04.2017 12:47+1Странное сравнение:
Если уж сравнивать sqlite и nosql, то логично (по-моему) в случае с sqlite
использовать sqlite json extension,
или в C# обертку для sqlite json еще "не завезли"?
- По поводу времени "write" для sqlite, хотелось бы увидеть какой journal mode sqlite
использовался, какой его аналог в LiteDB, сколько транзакций во время записи было
в случае sqlite и LiteDB

podkolzzzin
25.04.2017 13:30Не очень пойму как мог бы помочь sqlite json extension. Это ведь набор функций для работы с json или я не прав?
Если это действительно всего лишь набор функций, то думаю еще бы потерял в скорости, генерируя для вставки в базу из текста json, а потом разбирая его, пусть даже последним бы и занималась SQLite. SQLite реляционная база и я ожидал от нее наибольшей производительности именно если складывать в нее реляционные данные.
Режим журналирования SQLite: PRAGMA journal_mode = OFF
Использовал по транзакции на файл.
Так же и litedb все льется одним insert'ом, что, пусть и с натяжкой, с натяжкой можно считать одной транзакцией.
verysimplenick
25.04.2017 17:14+1Сферические цифры по сохранению несложных POCO объектов (диск hdd):
[Serializable] public class MscEvent { public Int64 msisdn; public DateTime chargingdatetime; public Int64 chargeableduration; public Int64 bnumber; public Int16 typeofrecord; public Int16 sourceId; }
Testing on 1 000 000 events [Sqlite Journal Mode=Off] write/read 89462/287835 op/s] time elapsed write/read 11,1778348 / 3,4742009 s] [LevelDbBatch MsgPackSerializer NoCompression] write/read 178024/501050 op/s] time elapsed write/read 5,6172074 / 1,995808 s] [LiteDb] write/read 82346/218760 op/s] time elapsed write/read 12,1438787 / 4,5712058 s] [CsvBench] write/read 749532/392383 op/s] time elapsed write/read 1,3341648 / 2,5485245 s] [SerializedFile MsgPackSerializer] write/read 2193977/675174 op/s] time elapsed write/read 0,4557931 / 1,4810979 s] [SerializedFile JsonSerializer] write/read 301375/317855 op/s] time elapsed write/read 3,3181228 / 3,1460794 s] [SerializedFile WireSerializer] write/read 2214939/2129023 op/s] time elapsed write/read 0,4514795 / 0,4696988 s] Testing on 10 000 000 events [Sqlite Journal Mode=Off] write/read 89674/285626 op/s] time elapsed write/read 111,514258 / 35,0107894 s] [LevelDbBatch MsgPackSerializer NoCompression] write/read 136594/488647 op/s] time elapsed write/read 73,2091265 / 20,4646613 s] [LiteDb] write/read 75120/196484 op/s] time elapsed write/read 133,1192939 / 50,8947216 s] [CsvBench] write/read 709238/398380 op/s] time elapsed write/read 14,099631 / 25,10166 s] [SerializedFile MsgPackSerializer] write/read 1533240/673520 op/s] time elapsed write/read 6,5221352 / 14,8473537 s] [SerializedFile JsonSerializer] Необработанное исключение: OutOfMemoryException. [SerializedFile WireSerializer] write/read 1567601/2205764 op/s] time elapsed write/read 6,3791707 / 4,5335747 s]
C leveldb пробовал разные параметры компрессии, буферов и т.д. (например
new Options() {Compression = CompressionType.SnappyCompression, WriteBufferSize = 128*1024*1024})
Вообщем вот. Выводы делайте сами
podkolzzzin
26.04.2017 08:10Мой тест имел кое-какую специфику, о которой я писал:
Мы храним текст построчно, а значит хотим и сохранять и вычитывать тоже построчно. К тому же при вычитке одним куском рискуем нарваться на огромный memory allocation, и нарваться на него же при сохранении, если для этого нужно склеить все строки вместе. В LiteDB есть возможность скормить IEnumerable и он отлично сохранится, и отлично вычитается. В SQLite строка в документе представляла собой строку в базе. Получается для документа в 100 строк, выполнялось 100 инсертов, что было дольше чем выполнить 1 в LiteDB.

werwolflg
25.04.2017 17:14+2А в сторону ESENT не смотрели? По скорости быстрее, чем SQLite.
podkolzzzin
26.04.2017 08:14Как-то в Сети не почти ничего про эту технологию. Можете рассказать или навести на правильные ссылки?

Siemargl
26.04.2017 10:57+1https://en.wikipedia.org/wiki/Extensible_Storage_Engine
https://blogs.msdn.microsoft.com/windowssdk/2008/10/22/esent-extensible-storage-engine-api-in-the-windows-sdk/
для c#
https://www.nuget.org/packages/ManagedEsent/
werwolflg
26.04.2017 11:19+2Это низкоуровневый ISAM движок, который раньше
ESENT очень широко используется внутри самой Windows, это нативное win32 API со всеми последствиями, но есть обёртка под .NET и работает это решение даже на WindowsPhone и в UWP приложениях (Даже в плеере Zune в качестве БД использовался ESENT). Потребляет больше памяти чем SQLite, но и больше функционал (снапшот изоляция транзакций, полное журналирование, и т.д.). Из минусов пишут такое: «своеобразные требования к thread-ингу. Приложение может открыть сколько угодно параллельных сессий. Но одна сессия должна жить в рамках одного треда.»
И до 7ки он вроде как был жестко прибит гвоздями к NTFS и зависел от размера кластера, но потом отвязали от NTFS.
https://www.codeproject.com/articles/52715/extensible-storage-engine
https://msdn.microsoft.com/en-us/library/gg269259(v=exchg.10).aspx
https://managedesent.codeplex.com/
https://en.wikipedia.org/wiki/Extensible_Storage_Engine
pansa
26.04.2017 01:15+1В винде же есть shadow copy — реализующий CoW механизмы. Да, вроде как ограничение — снимки распространяются на целый раздел, но выделить отдельный раздел под хранение рабочих файлов, получив взамен все плюшки мгновенных снапшотов состояния и эффективного их хранения, по-моему, должны всё покрывать. И самое главное — это уже есть в самой ОС.
podkolzzzin
26.04.2017 08:22Почитал про эту функцию. Насколько я понимаю, для того чтобы ею воспользоваться файл должен сперва оказаться на диске, верно? Если это так, то нам это не подходит, по причине, что интерес этой фичи представляется именно для несохраненных/измененных файлов. Или я где-то не прав?
pansa
28.04.2017 01:34+1Да, конечно, файл должен быть на диске.
Но вы хотите сказать, что у вас даже временных файлов нет? Т.е всё всегда в памяти? Задача у вас описана очень туманно. Но обычно IDE всё таки хранят «несохраненные» файлы, чтобы иметь возможность восстановить хотя бы часть работы при падении приложения/ОС.podkolzzzin
28.04.2017 10:22Так это как раз и есть та функция, которая позволит сохранить работу пользователя.
Кто-то это реализует через временные файлы, мы решили делать это через встраиваемую базу.
AigizK
26.04.2017 10:27+1Еще как вариант LMDB. По максимуму использует оперативку, очень хороши флашит данные на диск. В базе размером 25гб и с количеством записей 300млн поиск выполняется за 1-3мс при условии что SSD на вирт машине.
Единственный минус — должен быть один писатель. Но кроссплатформенныйpodkolzzzin
27.04.2017 12:27Спасибо за наводку.
Если по максимуму использует оперативную память, то это может для нас быть проблемой.
В 2017 году MS VS и MS SMS это 32 битные приложение, а значит мы делим с ними жалкие 3.25(по факту меньше) оперативной памяти.

mindtester
27.04.2017 11:15+1brightstardb не пробовали? было бы интересно сравнение
podkolzzzin
27.04.2017 12:25Не случилось, но спасибо за наводку. Глану в этом направлении
mindtester
28.04.2017 20:36если доберетесь раньше — было бы интересно узнать мнение о бенчмарках и размерах кода в сравнении с LiteDB…
функциональность у b* предлагает больше возможностей на первый взгляд
еще в разное время попадали в поле зрения:
https://ndatabase.codeplex.com/
https://github.com/Wintellect/SterlingDB
оба проекта в затишье похоже
но последний зацепился из за того что был дополнен драйвером к azure tables, а это дешевое хранилище… если актуально конечно
а ndatabase показался довольно проработанным в плане примеров, даже linqpad поддержан. но мне показалось что он не претендент по скоростным возможностям ;((
S0krat
А что сохраняется — тупо текущее состояние? История правок (с возможностью undo) не сохраняется? Что происходит при крэше приложения/ОСи?
Я как бы намекаю на одно типовое решение…
podkolzzzin
Сохраняется текущее состояние без возможности undo.
Намек, что-то не очень понял. Вы про VCS?
При крэше/блэкауте сохранится весь текст, за исключением, возможно сделанных в последние 2-3 секунды.