

На календаре май, а значит – «серая зона» праздников. Каждый, у кого выходил из строя сервис в праздники, знает, что такое две недели, в которых выходных больше, чем рабочих дней. По такому случаю рассказываем, как устроена наша техподдержка и что происходит с заявками, пришедшими в ночь с субботы на воскресенье. В конце статьи – небольшой чек-лист по составлению запроса в техподдержку. Чтобы на том конце провода вас правильно поняли и быстро смогли помочь.
Структура нашей техподдержки
Все клиентские обращения сначала поступают операторам по телефону или почте. Они в круглосуточном режиме обрабатывают и регистрируют их. Оператор – своего рода “нулевой километр”, откуда заявка в зависимости от профиля, сложности и критичности попадает на нужный уровень техподдержки. Всего таких уровней три.
Первая линия поддержки
Дежурные инженеры. Монтируют и демонтируют оборудование, прокладывают СКС, сопровождают клиентов в дата-центре, следят за системой мониторинга. Работают в режиме 24x7.
Дежурные администраторы. Разбираются в поддержке физической, виртуальной, сетевой инфраструктуры, ОС и ПО, но могут решать только типовые задачи по инструкции. Работают в режиме 24х7.
Инженеры профильных групп: виртуализация, сеть, hardware, эксплуатация инженерной инфраструктуры ЦОД, информационная безопасность, СУБД, Microsoft, Linux/Unix, AIX, SAP-базис, мониторинг. Решают задачи по системам, за которые они отвечают, в режиме 8х5. Ежедневно в каждом отделе назначается дежурный. Инженер профильной группы подключается, если задача нетривиальная, и знаний дежурного администратора не хватает. В критичных ситуациях его могут привлечь к решению задачи ночью и в выходные.
Дежурные по инженерной инфраструктуре. Отвечают на запросы, связанные с основными инженерными системами (энергоснабжение, холодоснабжение, мониторинг и пр.), в нерабочее время. На каждой площадке вахту круглосуточно несет один дежурный. При возникновении сложных инцидентов привлекают дежурного из отдела эксплуатации инженерной инфраструктуры ЦОД.
Вторая линия поддержки
Старшие инженеры профильных групп. Более опытные инженеры. Решают задачи, которые невозможно выполнить по инструкции.
Третья линия поддержки
Ведущие инженеры профильной группы. Отвечает за наиболее сложные задачи.
Руководитель группы. Контролирует критичные обращения (потеря сетевой связности, выход оборудования из строя или отказ сервисов) и аварии на уровне всей инфраструктуры.
Получается вот такая схема:

Путь обращения в техподдержке
Источника запросов два – клиенты и информация о сбоях из системы мониторинга. Все клиентские обращения делятся на штатные запросы и инциденты – заявки, связанные с недоступностью сервиса. Вот какой путь проходит заявка от клиента:
Регистрация обращения. При регистрации обращения в тикетной системе оператор делает следующее:
- описывает суть обращения;
- определяет тип – запрос или инцидент;
- устанавливает приоритет и срок выполнения;
- назначает профильную группу или конкретного исполнителя;
- записывает контактные данные заказчика;
- сообщает аккаунт-менеджеру клиента о заведенном обращении.
На регистрацию обращения оператору отводится 5-15 минут в зависимости от приоритета обращения. Обращению присваивается уникальный шестизначный идентификатор, по которому клиент сможет отслеживать статус своей заявки.
Назначение исполнителя. Если обращение приходит в рабочее время, оператор передает его дежурному инженеру или инженеру профильной группы. В нерабочее время заявкой занимается дежурный инженер или дежурный администратор.
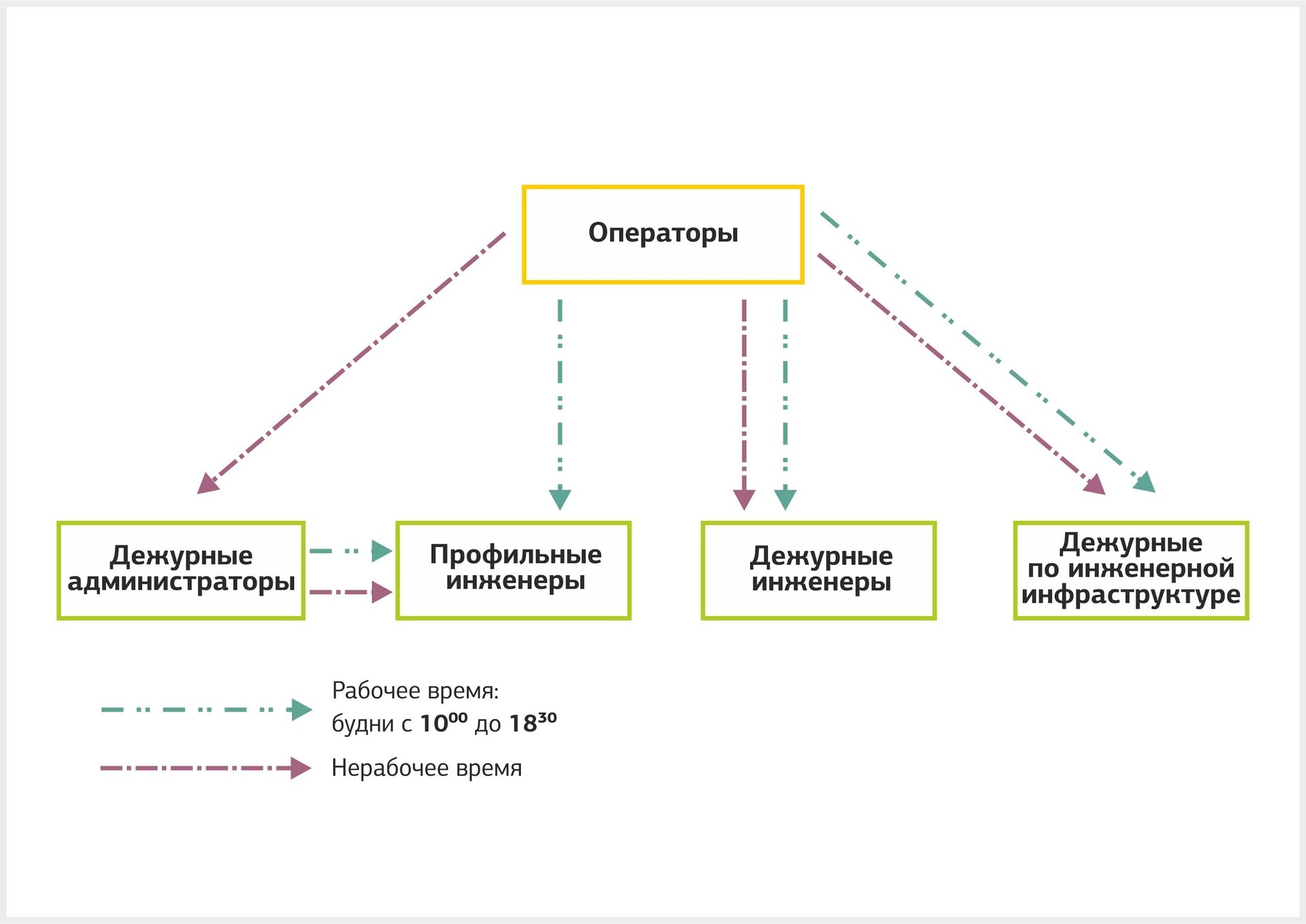
Схема назначения исполнителя в зависимости от того, когда поступило обращение.
Разрешение обращения. Дежурные администраторы обрабатывают клиентское обращение по инструкции. Если оно не имеет типового решения, администратор передает его на вторую линию поддержки. Бывают ситуации, когда обращение назначается на одну профильную группу, но для решения необходимо привлечь инженеров, отвечающих за другие системы. Информация об этом направляется оператору и аккаунт-менеджеру, а заявка переводится на соответствующую группу.
Если инцидент невозможно закрыть за время, установленное по SLA, он эскалируется на вторую и третью линии поддержки. В случае аварии подключается дирекция для анализа инцидента. Когда невозможно самостоятельно устранить проблему, мы привлекаем подрядчиков.
Закрытие обращения. После выполнения запроса или устранения инцидента исполнитель готовит отчет и передает обращение аккаунт-менеджеру. Он получает подтверждение со стороны клиента о разрешении заявки, обращение закрывается и переводится в статус “Решено”.
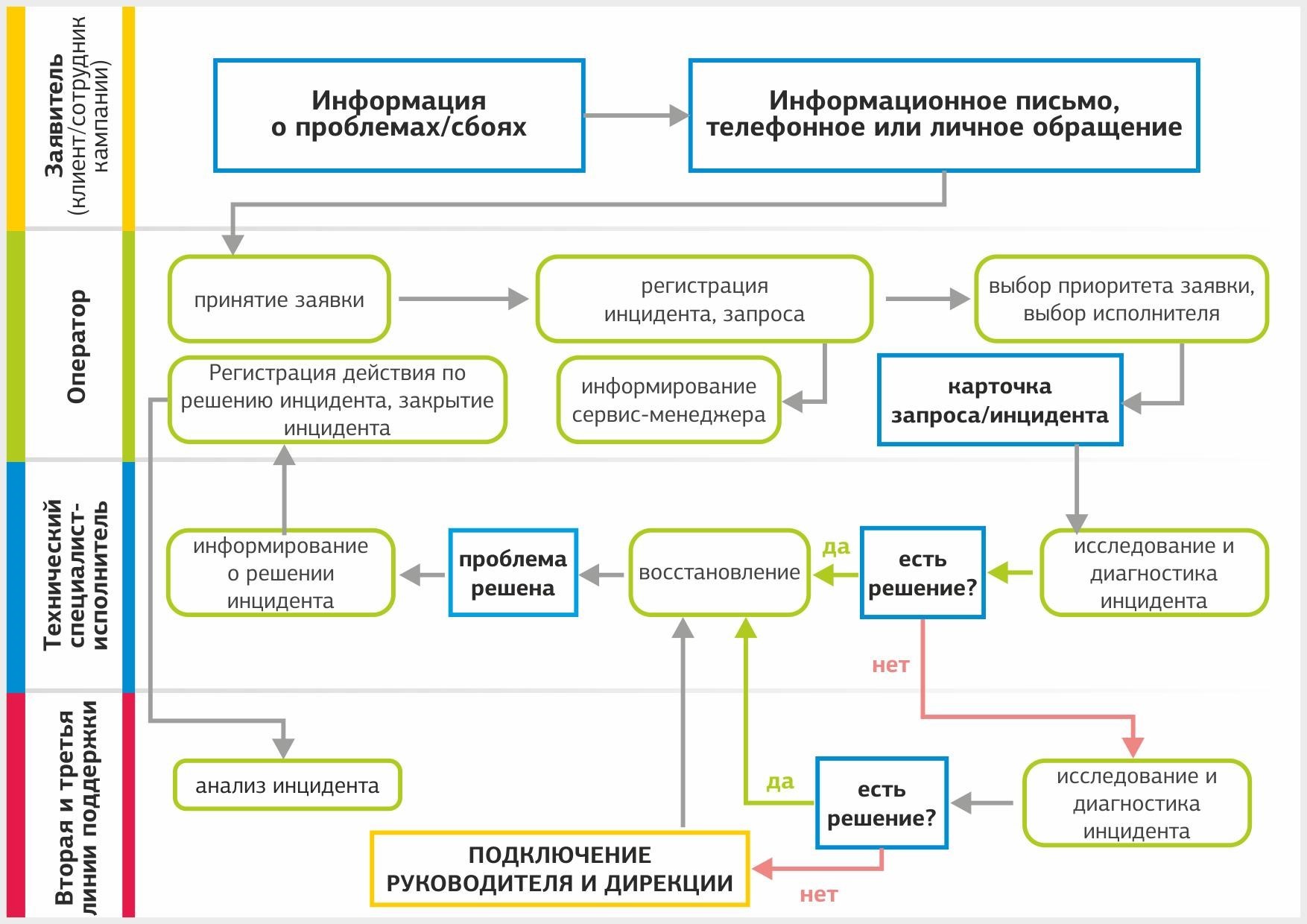
Процесс управления инцидентами выглядит так.
Такой путь проходят обращения и уведомления из системы мониторинга. Теперь посмотрим, как разрешаются штатный запрос и инцидент на примерах.
Отработка штатного запроса
Предположим, клиент в субботу хочет развернуть виртуальную инфраструктуру с двумя серверами MS SQL.
13:00. Клиент отправляет запрос в службу поддержки и уже через 4 часа планирует начать работу с новыми серверами.
13:05. Оператор регистрирует запрос в системе и передает на первую линию поддержки — профильному инженеру группы виртуализации.
13:30. Для клиента выделены виртуальные ресурсы, и он уже может работать с ними. Для создания SQL-серверов инженер виртуализации переводит запрос дальше на группу Microsoft.
15:30. Инженер группы Microsoft развернул виртуальные машины с MS SQL и подготовил серверы к работе: обновил версии ПО, расширил диски и протестировал службы. Создание и настройка ВМ заняла около 2 часов.
15:35. Аккаунт-менеджер подтвердил выполнение запроса у клиента.
Клиент может начинать работать на новых виртуальных серверах.
Так выполняются штатные запросы. Здесь нет спешки, хотя тоже есть норматив по времени. Но что делать, если происходит отказ сервиса и счет идет на минуты. На эту тему у нас есть реальная история, которая произошла не так давно.
Отработка инцидента
У нас есть собственная оптоволоконная магистраль в Москве, соединяющая наши дата-центры и клиентские площадки. В середине марта случилась авария на участке между дата-центрами OST и NORD. Вот хронология событий и действия нашей технической поддержки.
15 марта 2017
02:00. Система мониторинга зафиксировала потерю связности OST – NORD. Дежурный администратор зарегистрировал инцидент и назначил его на сетевую группу. Так как обрыв связи затронул наши и клиентские трассы, инцидент был сразу эскалирован на ведущего инженера ВОЛС и руководителя сетевой группы.
02:15. Дежурный инженер сетевой группы связался с подрядчиком, обслуживающим ВОЛС.
04:00. Ведущий инженер сетевого отдела определил предполагаемое место обрыва со стороны дата-центра OST. Дежурный обслуживающей компании выехал на место для осмотра.
Также инженеры установили, что в результате аварии пострадали клиенты, арендующие темную оптику. Списки пострадавших клиентов передали аккаунт-менеджерам, чтобы они оповестили клиентов об аварии и собрали информацию об обрывах связи.
04:35. Сетевые инженеры совместно с дежурным инженером подрядчика установили, что обрыв произошел на участке Красносельского коллектора, и связались с ГУП “Москоллектор”. Диспетчер сообщил о возгорании на ПК-42 Красносельского коллектора и принял заявку на допуск ремонтной бригады, но предупредил, что доступ на коллектор закрыт до выяснения обстоятельств.
08:00. Отправлена телефонограмма в ГУП “Москоллектор” с повторной заявкой на аварийный допуск ремонтной бригады подрядчика на территорию коллектора.
08:15. ГУП «Москоллектор» сообщил об отключении силовых кабелей и локализации пожара. Но доступ в коллектор для операторов связи был по-прежнему закрыт до 16.03.2017 г., до восстановления общегородских коммуникаций, инженерных сетей и выявления причин аварии от СК РФ и сотрудников ГУП “Москоллектор”.
09:00. Инженеры начали переключать пострадавших клиентов на резервные маршруты. У некоторых клиентов были свои резервные оптические трассы, и их удалось переключить быстро. Клиентов, не имеющих резерва, переключали на свои собственные резервные трассы.
15:00. Все пострадавшие клиенты переведены на резервные маршруты.
16 марта 2017
09:00. Ремонтная бригада подрядчика наконец-то смогла попасть в коллектор и определить объем работ по восстановлению.

10:30. Установили, что в результате пожара повреждено 144 волокна. Было принято решение об организации кабельной вставки.

11:00. Приступили к прокладке кабеля в коллекторе.
16:00. Восстановили рабочие волокна на магистрали.
20:40. Монтажные работы завершены, магистральный кабель полностью восстановлен. Все клиенты переведены на основные трассы.
В итоге устранение аварии заняло 40 часов.
Как правильно писать в техподдержку
От скорости реакции и компетентности технической поддержки зависит многое. Но тот, кто пишет, тоже влияет на скорость решения запроса. Помните: точно описанный запрос полезен для здоровья администраторов и помогает решить проблему быстрее.
Мы составили предпраздничную памятку о том, как писать в техподдержку:
- Старайтесь однозначно идентифицировать объект обслуживания. Укажите номер стойки-юнита, название ВМ, систему или приложение, к которому относится запрос.
- Укажите, что именно не работает или какие именно работы по администрированию требуются.
- Если выполнялись какие-то действия перед появлением ошибки, сообщите о них. Менялись ли настройки системы, были ли внешние сбои (отключение Интернет-соединения или электропитания).
- Не было ли непредвиденной высокой нагрузки на систему?
- Выполнялась ли диагностика системы, какие инструменты диагностики использовались и какие результаты показала диагностика.
- Проверялись ли смежные системы?
- Что еще было проверено?
На сегодня это всё, ждем ваши вопросы в комментариях.
Комментарии (11)

KorP
04.05.2017 19:46+1В конце так и ждал список вакансий :)
А если не секрет — какое кол-во инженеров в профильных группах всего у вас трудится?
dataline
05.05.2017 10:51Так вот же он :)
В каждом отделе от 5 до 15 человек. Самые большие — это отделы сети и виртуализации.KorP
05.05.2017 10:54Просто меня удивляет такое малое кол-во требующихся сотрудников :) Видимо у вас хорошо обстоят дела с подготовкой кадров.
dataline
05.05.2017 11:15+1Да, часть сотрудников растим из дежурных инженеров, об этом рассказывали здесь.
Ну а вообще, хорошим людям мы всегда рады, даже если в данный момент на сайте не висит соответствующей вакансии. Так что можно смело отправлять резюме на job@dtln.ru в любое время :)KorP
05.05.2017 11:17Ну растят в общем то многие, но судя по всему — не у всех это хорошо получается :)
Буду иметь ввиду.

l1tero
10.05.2017 16:2404:35. Сетевые инженеры совместно с дежурным инженером подрядчика установили, что обрыв произошел на участке Красносельского коллектора, и связались с ГУП “Москоллектор”. Диспетчер сообщил о возгорании на ПК-42 Красносельского коллектора и принял заявку на допуск ремонтной бригады, но предупредил, что доступ на коллектор закрыт до выяснения обстоятельств.
Почему клиентов не начали переключать в 4:35, а только лишь в 9:00? Это же потери для клиентов в т.ч. и финансовые возможно.dataline
10.05.2017 16:25Переключение на резервные маршруты в случае с темной оптикой – по сути организация новой кроссировки. Организация новой кроссировки занимает до 8 часов и требует следующих работ:
- анализ существующей схемы включения клиента
- внесение изменения через другую магистраль
- создание задания на новую кроссировку
- выписывание оптических патчкордов
- прокладка
- тестирование
- переключение старой трассы на новую
Данные работы выполняются инженерами профильных групп, а не дежурной группой. К тому же не у всех клиентов имелись резервные маршруты, требовалось согласование с клиентами по построению новых маршрутов
varnav
Создание и настройка ВМ заняла около 2 часов.
Ой. По часу на сервер с MS SQL? На дворе 2017-й!
msolovyev
Можно развернуть продукт по шаблону — это можно сделать быстро. Можно развернуть по требованиям клиента — в частности, сделать служебных пользователей, разложить разные файлы по типам информации на них по разным томам, настроить политики, проверить.
И конечно мы используем ansible — но в типовых системах ;)
navion
Вы лучше объясните какую роль тут играет инженер группы виртуализации, если инженер группы Microsoft сам всё делает?
msolovyev
Мы предоставляем не просто отдельные ВМ, а услугу «виртуальный датацентр». В рамках нее для клиента выделяются ресурсы в купленном им объеме, организуются необходимые сети и связанность этих сетей — в том числе L2 до офиса\ЦОД заказчика, VPNы и тп, настраивается граничный маршрутизатор (файрвол, NAT) под нужды клиента, раздаются права. В общем случае, если запрос клиента стандартный, все это выполняется по шаблону.