

Как мы запускаем наш веб-сервер
Веб-сервер Instagram работает на Django в мультипроцессном режиме, где мастер-процесс копирует сам себя, создавая десятки рабочих процессов, принимающих запросы от пользователей. В качестве сервера приложений мы используем uWSGI в режиме prefork, чтобы регулировать распределение памяти между мастер-процессом и рабочими процессами.
Чтобы у Django не закончилась память, мастер-процесс uWSGI предоставляет возможность перезапустить рабочий процесс, когда его резидентная память (RSS) превышает заранее установленный предел.
Как работает память
Сперва мы решили выяснить, почему RSS рабочих процессов начинает так быстро расти сразу после того, как их порождает мастер. Мы заметили, что, хотя RSS начинается с 250 МБ, размер используемой разделяемой памяти за несколько секунд сокращается с 250 МБ до почти 140 МБ (размер разделяемой памяти можно посмотреть в
/proc/PID/smaps). Числа здесь не слишком интересны, так как они постоянно меняются, но то, насколько быстро освобождается распределяемая память (почти на 1/3 от общего объема памяти), представляет интерес. Затем мы решили выяснить, почему эта разделяемая память становится частной памятью каждого процесса в начале его жизни.Наше предположение: Copy-on-Read
В ядре Linux существует механизм копирования при записи (Copy-on-Write, CoW), который служит для оптимизации работы дочерних процессов. Дочерний процесс в начале своего существования делит каждую страницу памяти со своим родителем. Страница копируется в собственную память процесса только при записи.
Но в мире Python из-за подсчета ссылок происходят интересные вещи. Каждый раз при чтении Python-объекта интерпретатор увеличит его счетчик ссылок, что в сущности является операцией записи в его внутреннюю структуру данных. Это вызывает CoW. Получается, что с Python мы на самом деле используем Copy-on-Read (CoR)!
#define PyObject_HEAD _PyObject_HEAD_EXTRA Py_ssize_t ob_refcnt; struct _typeobject *ob_type;
...
typedef struct _object {
PyObject_HEAD
} PyObject;Назревает вопрос: выполняем ли мы копирование при записи для immutable объектов, таких, как объекты кода? Так как
PyCodeObject на самом деле “подкласс” PyObject, очевидно, да. Нашей первой идеей было отключить подсчет ссылок для PyCodeObject.Попытка номер 1: отключить подсчет ссылок для объектов кода
Мы в Instagram начинаем с простого. В качестве эксперимента мы добавили небольшой хак в интерпретатор CPython, убедились, что счетчик ссылок не меняется для объектов кода, а затем установили этот CPython на один из рабочих серверов.
Результат нас разочаровал: в использовании разделяемой памяти ничего не изменилось. Когда мы попытались выяснить, почему так происходит, мы поняли, что не можем найти каких-либо надежных метрик, чтобы доказать, что наш хак сработал, а также не можем доказать связь между общей памятью и копией объекта кода. Очевидно, мы что-то упустили из вида. Вывод: прежде, чем следовать вашей теории, докажите ее.
Анализ страничных прерываний
Немного погуглив на тему Copy-on-Write, мы выяснили, что Copy-on-Write связан с ошибками отсутствия страниц в памяти (page faults, или страничными прерываниями). Каждая операция CoW вызывает страничное прерывание в работе процесса. Инструменты для мониторинга производительности, встроенные в Linux, позволяют записывать системные события, включая страничные прерывания, и, когда это возможно, даже выводят стек-трейс!
Мы снова отправились на продакшн-сервер, перезагрузили его, подождали, пока мастер-процесс породит дочерние процессы, узнали PID рабочего процесса, а потом выполнили следующую команду:
perf record -e page-faults -g -p <PID>С помощью стек-трейса мы получили представление о том, когда в процессе случаются страничные прерывания.
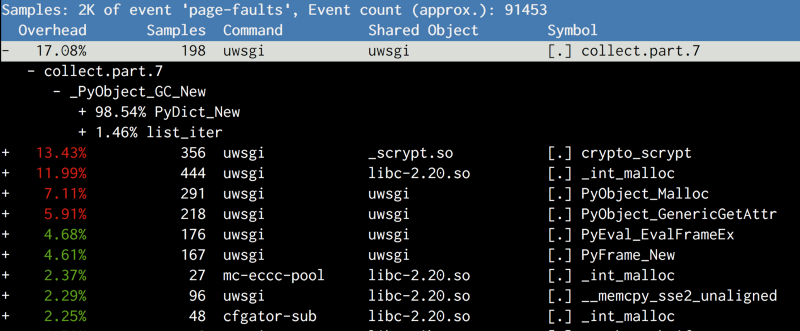
Результаты отличались от того, что мы ожидали. Главным подозреваемым оказалось не копирование объектов кода, а метод
collect, принадлежащий gcmodule.c, и вызываемый при запуске сборщика мусора. Почитав, как работает GC в CPython, мы разработали следующую теорию:Сборщик мусора в CPython вызывается детерминировано на основании порогового значения. Пороговое значение по умолчанию очень низкое, поэтому сборщик мусора запускается на очень ранних стадиях. Он обслуживает связные списки, содержащие информацию о создании объектов, и во время сборки мусора связные списки перемешиваются. Так как структура связного списка существует вместе с самим объектом (совсем как
ob_refcount), перемешивание этих объектов в связных списках вызовет CoW соответствующих страниц, что является досадным побочным эффектом./* GC information is stored BEFORE the object structure. */
typedef union _gc_head {
struct {
union _gc_head *gc_next;
union _gc_head *gc_prev;
Py_ssize_t gc_refs;
} gc;
long double dummy; /* force worst-case alignment */
} PyGC_Head;Попытка номер 2: Попробуем отключить сборщик мусора
Ну что ж, раз сборщик мусора вероломно предал нас, давайте отключим его!
Мы добавили вызов
gc.disable() в наш скрипт загрузки. Перезагрузили сервер – и снова неудача! Если снова взглянуть на perf, мы увидим, что gc.collect все еще вызывается, и копирование в память все еще выполняется. После небольшой отладки в GDB, мы обнаружили, что одна из используемых нами внешних библиотек (msgpack) вызывает gc.enable(), чтобы оживить сборщик мусора, так что gc.disable() в загрузочном скрипте был бесполезен.Патчить msgpack для нас было недопустимо, так как это открывало другим библиотекам возможность сделать то же самое, не ставя нас в известность. Во-первых, необходимо доказать, что отключение сборщика мусора действительно помогает. Ответ снова лежит в
gcmodule.c. В качестве альтернативы gc.disable мы выполнили gc.set_threshold(0), и на этот раз ни одна библиотека не вернула это значение на место.Таким образом мы успешно увеличили объем разделяемой памяти для каждого рабочего процесса с 140 МБ до 225 МБ, и общий объем используемой памяти на хосте упал до 8 ГБ на каждой машине. Это позволило сэкономить 25% ОЗУ на всех серверах Django. С таким запасом свободного пространства мы можем как запустить намного больше процессов, так и повысить порог для резидентной памяти. В результате это увеличивает пропускную способность слоя Django на более чем 10%.
Попытка номер 3: Полностью отключаем сборщик мусора
После экспериментов со множеством настроек, мы решили проверить нашу теорию в более широком контексте: на кластере. Результаты не заставили себя ждать, и наш процесс непрерывного развертывания развалился, так как с выключенным сборщиком мусора веб-сервер стал перезагружаться намного медленнее. Обычно на перезапуск уходило менее 10 секунд, но когда сборщик мусора отключили, он занимал иногда до 60 секунд.
2016-05-02_21:46:05.57499 WSGI app 0 (mountpoint='') ready in 115 seconds on interpreter 0x92f480 pid: 4024654 (default app)Этот баг был с трудом воспроизводим, так как поведение не было детерминированным. После множества экспериментов удалось определить точные шаги воспроизведения. Когда такое происходило, свободная память на этом хосте падала почти до нуля и прыгала обратно, заполняя весь кэш. Тогда наступал момент, когда весь код или данные приходилось читать с диска (DSK 100%), и все работало медленно.
Это могло сигнализировать о том, что Python выполняет окончательный сбор мусора во время остановки интерпретатора, что может вызывать гигантский скачок количества используемой памяти за очень короткий период времени. И опять я решил сперва доказать это, а потом уже решить, как это исправить. Итак, я закомментировал вызов
Py_Finalize в плагине uWSGI для Python, и проблема исчезла.Очевидно, что мы не могли просто выключить
Py_Finalize. Многие важные процедуры, связанные с очисткой, зависели от этого метода. В конце концов мы добавили в CPython динамический флаг, который полностью отключал сборку мусора.Наконец, нам было необходимо применить наше решение в более крупных масштабах. Мы попробовали применить его на всех серверах, но это снова сломало процесс непрерывного развертывания. Тем не менее, на этот раз пострадали только машины со старыми моделями процессоров (Sandy Bridge), и воспроизвести это было еще сложнее. Вывод: всегда тестируйте старых клиентов/оборудование, так как они легче всего ломаются.
Так как наш процесс непрерывного развертывания достаточно быстр, чтобы понять, что происходит, я добавил отдельную утилиту
atop в наш установочный скрипт. Теперь мы могли поймать момент, когда кэш почти полностью заполнялся, и все uWSGI процессы выбрасывали множество MINFLT (минорных ошибок отсутствия страниц в памяти).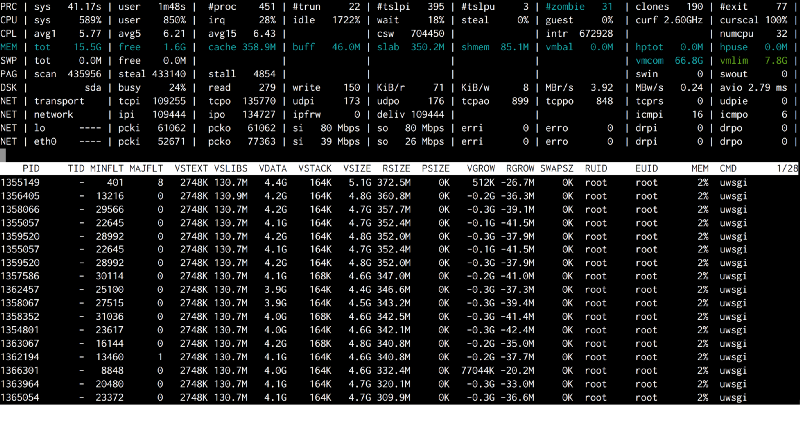
И снова, выполняя профилирование производительности, мы встречаем
Py_Finalize. При выключении, кроме сборки мусора, Python выполняет несколько операций, связанных с очисткой: таких, как уничтожение объектов типов или выгрузка модулей. И это снова нанесло вред общей памяти.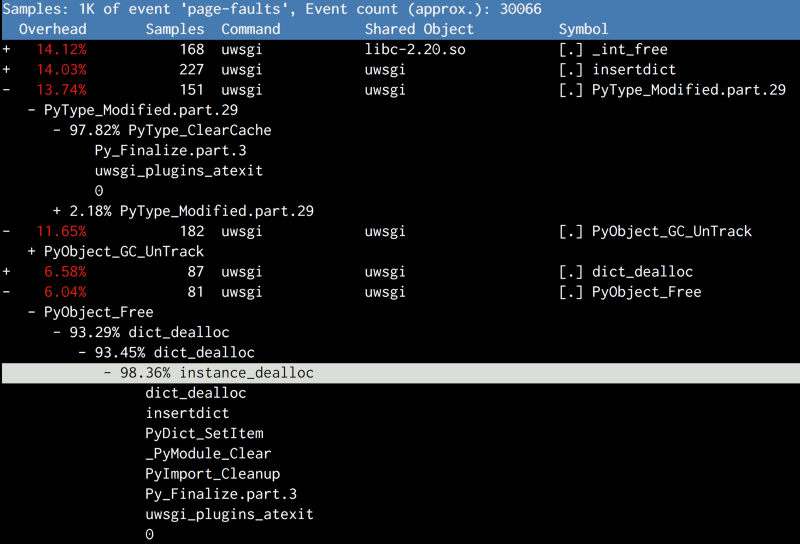
Попытка номер 4: Последний шаг к выключению сборщика мусора: никакой очистки
А зачем вообще что-то очищать? Процесс умрет, и мы получим замену для него. О чем нам стоит беспокоиться, так это об обработчиках функции atexit, которые подчищают за нашими приложениями. А вот об очистках Python беспокоиться не стоит. Вот как мы в конце концов изменили наш загрузочный скрипт:
# gc.disable() doesn't work, because some random 3rd-party library will
# enable it back implicitly.
gc.set_threshold(0)
# Suicide immediately after other atexit functions finishes.
# CPython will do a bunch of cleanups in Py_Finalize which
# will again cause Copy-on-Write, including a final GC
atexit.register(os._exit, 0)Решение основано на том факте, что функции atexit запускаются из регистра в обратном порядке. Функция atexit завершает остальные очистки, а затем вызывает
os._exit(0), чтобы завершить текущий процесс. Изменив всего две строчки, мы наконец выкатили решение на все наши сервера. Тщательно настроив пороговые значения для памяти, мы получили общий прирост производительности 10%!
Взгляд назад
При осмыслении улучшения производительности у нас возникла пара вопросов:
Во-первых, не должна ли память Python переполниться без сборки мусора, так как она больше не очищается? (Вспомните, что в памяти Python нет настоящего стека, так как все объекты хранятся в куче)
К счастью, это не так. Основной механизм освобождения объектов в Python – это подсчет ссылок. Когда ссылка на объект удаляется (при вызове
Py_DECREF), Python всегда проверяет, не достиг ли счетчик ссылок на этот объект нуля. В этом случае будет вызван деаллокатор данного объекта. Главная задача сборки мусора – разрушать циклические зависимости, когда механизм подсчета ссылок не работает.
#define Py_DECREF(op) do { if (_Py_DEC_REFTOTAL _Py_REF_DEBUG_COMMA --((PyObject*)(op))->ob_refcnt != 0) _Py_CHECK_REFCNT(op) else _Py_Dealloc((PyObject *)(op)); } while (0)Разберем, откуда выигрыш
Второй вопрос: откуда берется прирост производительности?
Выключение сборщика мусора дает двойной выигрыш:
- Мы освободили почти 8 ГБ оперативной памяти на каждом сервере и смогли использовать их для создания большего количества рабочих процессов на серверах с ограниченной пропускной способностью памяти, или сократить количество перезапусков процессов на серверах с ограничением по мощности ЦП;
- Пропускная способность ЦП также увеличилась, так как количество инструкций, выполняемых за один такт (IPC) возрастает почти на 10%.
# perf stat -a -e cache-misses,cache-references -- sleep 10
Performance counter stats for 'system wide':
268,195,790 cache-misses # 12.240 % of all cache refs [100.00%]
2,191,115,722 cache-references
10.019172636 seconds time elapsedС отключенным сборщиком мусора количество неудачных обращений к кэш-памяти (cache-miss rate) падает на 2–3%, что и является главной причиной 10%-ного улучшения IPC. Кэш-промахи дороги, так как они тормозят вычислительный конвейер процессора. Небольшое увеличение рейтинга попаданий в кэш ЦП может значительно улучшить IPC. Чем меньше выполняется операций копирования при записи (CoW), тем больше кэш-линий с различными виртуальными адресами (в разных рабочих процессах) указывают на один и тот же адрес в физической памяти, что приводит к увеличению рейтинга попаданий в кэш.
Как видим, не каждый компонент работает так, как мы думаем, и результаты иногда могут быть неожиданными. Потому продолжайте исследования и удивляйтесь тому, как все устроено на самом деле!
О, а приходите к нам работать? :)wunderfund.io — молодой фонд, который занимается высокочастотной алготорговлей. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Присоединяйтесь к нашей команде: wunderfund.io
Комментарии (29)
vesper-bot
15.05.2017 15:42+2Неясна реальная логика вызова GC в finalize(). Зачем собирать мусор, если все равно всю память при выходе отдавать? Молодцы, что поймали.
Интересно, правда, а чем было в итоге вызвано то, что «пострадали только машины со старыми моделями процессоров (Sandy Bridge)» во время одного из экспериментов? Это же нелогично, когда абстракция минимум третьего уровня является процессорно-зависимой.
veveve
15.05.2017 22:35+5Неясна реальная логика вызова GC в finalize(). Зачем собирать мусор, если все равно всю память при выходе отдавать?
Какая-нибудь очистка ресурсов может быть завязана на уничтожении объекта сборщиком.
arheops
15.05.2017 22:40+2Обьект может иметь деструктор, выполняющий нетривиальные действия. Например, сохранения статистики о использовании обьекта. Уборщик мусора вызывается, чтоб не пропустить такие деструкторы.
DistortNeo
16.05.2017 12:18+1А разве в языках со сборкой мусора не предписывается в таких случаях вызывать функцию уничтожения объекта явно? Финализаторы нужны на крайний случай, когда программист забыл освободить ресурсы явно.
khim
16.05.2017 13:30+1Python — это не «язык со сборкой мусора». Это «язык со сборкой мусора сбоку».
Он на счётчиках ссылок построен — до весии 2.0 в нём вообще ничего другого не было, но и сейчас — они используются тоже. GC — это, так сказать, «вторая линия обороны».
Поскольку финализаторы вызываются, в большинстве случаев, известно где — то многие на них полагаются (хотя, теоретичнски и не должны, так как существуют всякие Jython'ы — но кто их реально использует-то?).DistortNeo
16.05.2017 19:24-3Я даже при программировании на C++ не полагаюсь на деструкторы, да и вообще, не сторонник RAII-идиомы, т.к. считаю, что деструктор должен быть простым и иметь минимум побочных эффектов.
Если программист не освободил ресурс явно, значит, в программе имеется ошибка, требующая исправлений. В этом плане подход Java/C# с паттерном IDisposable мне более приятен.
khim
16.05.2017 20:44+3Я даже при программировании на C++ не полагаюсь на деструкторы, да и вообще, не сторонник RAII-идиомы, т.к. считаю, что деструктор должен быть простым и иметь минимум побочных эффектов.
К сожалению или к счастью, но вы не пишите все компоненты, которые использует инстаграмм. RAII — это весьма распростанённый паттерн в С++ (по большому счёту без него написать сколько-нибудь надёжную программу с использованием исключений просто не получится, замучаятесь ловить и пробрасывать исключения) и многие используют его и в Python'е (хотя там есть и более надёжная альтернатива).
Если программист не освободил ресурс явно, значит, в программе имеется ошибка, требующая исправлений.
С чего вдруг? При использовании счётчиков ссылов (Python, Objective C, Swift) или вещей типа unique_ptr (в C++) выход переменной из области видимости гарантирует освобождение ресурса именно в этой точке.
То что вам этот подход не нравится по непонятной причине — не значит, что другие его не будут использовать.
Подход, который вы проповедуете (нет исходного кода == нет сгенерённого кода) это — скорее C, не C++ или Python.DistortNeo
16.05.2017 21:23-3К сожалению или к счастью, но вы не пишите все компоненты, которые использует инстаграмм. RAII — это весьма распростанённый паттерн в С++ (по большому счёту без него написать сколько-нибудь надёжную программу с использованием исключений просто не получится, замучаятесь ловить и пробрасывать исключения)
Спасибо, я намучился отлаживать многопоточный код, когда из деструкторов бросались исключения, случайсь двойные исключения и дедлоки — больше не хочу.
Проблема C++ в том, что в нём нет
finally. Приходится пихать в деструктор то, что можно было бы поместить вfinally. Но коварство деструкторов заключается в том, что с исключениями они дружат очень плохо. Если коротко: не пишите код, который может в деструкторе бросить исключение.
С чего вдруг? При использовании счётчиков ссылов (Python, Objective C, Swift) или вещей типа unique_ptr (в C++) выход переменной из области видимости гарантирует освобождение ресурса именно в этой точке.
Да я не против
unique_ptr, я против того, чтобы в деструкторе содержалась навороченная логика.
arheops
16.05.2017 14:01Нет, конкретно в питоне деструкторы автоматические. Хотя вы можете их вызывать явно, если хотите.

mikhanoid
16.05.2017 08:07Неясна реальная логика вызова GC в finalize(). Зачем собирать мусор, если все равно всю память при выходе отдавать? Молодцы, что поймали.
Python же рассчитан на работу не только в операционках с поддержкой виртуальной памяти. Его ещё и просто встраивать можно.
Idot
15.05.2017 16:54+5Наконец-то до многих начало доходить очевидная вещь, что когда важна скорость работы, то сборкой мусора лучше не пользоваться.

Razaz
16.05.2017 00:57+5Очень спорно. Важно просто контролировать GC pressure и не выделять память направо и налево. Даже с GC есть языки и платформы дающие возможность детерминированного контроля памяти в некоторых случаях.
mikhanoid
16.05.2017 08:09Дело не в самой сборке мусора, а в том, насколько она эффективна. В Python за эффективностью никто никогда не гонялся. Ну и, обычно, когда действительно важна скорость, то, скорее всего, Вы просто непишете некий custom-вариант сборки мусора. Размазывать malloc/free по коду тоже не самая лучшая практика для повышения произвоидтельности.

turbo_exe
16.05.2017 00:05+11если честно, для меня выглядит как «мы потратили вагон человеко-часов и поставили под угрозу стабильность системы для того чтобы платить на 10% меньше за сервера».
конечно, в случае инстаграмма 10% экономии на серверах может стоить десятки/сотни тысяч долларов в месяц, но сколько капитализации они потеряют если их сервис упадёт на пару часиков потому что какая-нибудь dependency будет делать неочевидные вещи в деструкторе своих классов? как отмечается выше, своими действиями они выпилили защиту от такого рода проблем убрав вызов GC в finalize().mikhanoid
16.05.2017 08:10+1Ну, наверное, они достаточно хорошо знают о своих зависимостях, чтобы не рисковать.
turbo_exe
16.05.2017 10:43+7сдаётся мне, они этим шагом ещё и повысили минимальную квалификацию программиста, работающего с их code base до уровня «выше некуда». просто senior уже не канает. ибо имея такие хаки в коде не наступить на грабли становится всё труднее. так что потенциальных рисков они себе добавили ого-го, дело не только в зависимостях.
khim
16.05.2017 13:26Госсподя! Вы, я надеюсь, понимаете, что GC в Python — это необязательный компонент? До версии 2.0 его там вообще не было, а обязательным он стал только с версии 2.3!
Так что они, фактически, просто вернули режим в котором Python существовал много лет…
homm
16.05.2017 17:26-1И много вы знаете успешных проектов написанных на Python за те «много лет», что в нем не было сборки мусора?
khim
16.05.2017 20:50А много вы знаете вообще успешных проектов тех лет? Все управляющие скрипты RedHat'а и SuSE, Gentoo и Debian'а, всякие Bittorrent'ы и SCons — всё это и многое другое было написано именно «на той» версии Python'а.
turbo_exe
17.05.2017 19:12нет, не понимаю. спасибо, что объяснили. но судя по release history, версия 2.0 вышла в 2000 году, а версия 2.3 вышла в 2003. с тех пор прошло больше лет, чем питон существовал без GC.
ещё стоит учесть что с годами софта пишется всё больше, так что импакт доGCшного питона на инстаграм в той части, которую затрагивают эти хаки ничтожен. сомневаюсь, что какой-то используемый ими код дожил с 2003 до 2017 без изменений.
khim
16.05.2017 12:00+1конечно, в случае инстаграмма 10% экономии на серверах может стоить десятки/сотни тысяч долларов в месяц
Вы потеряли пару, а то и тройку нуликов в своих оценках.
но сколько капитализации они потеряют если их сервис упадёт на пару часиков потому что какая-нибудь dependency будет делать неочевидные вещи в деструкторе своих классов?
Как показывает опыт — почти нисколько.
Да, в момент, когда оно всё упадёт — капитализация может скакнуть вниз довольно серьёзно, но если потери данных не будет, то уже через неделю-другую об этом все забудут.turbo_exe
17.05.2017 19:23+1если честно, я совсем профан в оценках трат на сервера. но учитывая, что экономия на серверах складывается из:
— экономии на электричестве
— экономии на рабочих часах обслуживающего персонала (что скорее всего влияет слабо, ибо всё делается автоматически и не зависит от количества серверов)
— единоразовой экономии на средствах на закупку железа (что тоже ничтожно в контексте хотя бы года работы сервиса)
, то сомневаюсь, что они на электричестве сэкономили 1-100 миллионов долларов.khim
17.05.2017 20:56единоразовой экономии на средствах на закупку железа (что тоже ничтожно в контексте хотя бы года работы сервиса)
Конечно Instagram (как и сам Facebook, как и Google и как все другие «большие» компании) покупают железо со скидкой, но она всёж-таки не настолько велика.
, то сомневаюсь, что они на электричестве сэкономили 1-100 миллионов долларов.
Могли и больше экономию получить. Вы вообще учитываете, что речь идёт о сервисе с почти миллиардом пользователей? Сколько, по вашему, потребуется ресурсов чтобы хранить 200 миллиардов фоток?
Вас не удивляет тот факт, что Google входит в пятёрку крупнейших производителей серверов в мире — где-то сразу после HP, Dell'а и IBM? Притом что Google, в общем-то, серверами не торгует?
Понятно что Instagram и Facebook «поменьше будут» — но они тоже тратят на железо суммы, измеряемые в миллиардах. Так что 10% легко могу дать экономию не в один миллион.




Barafu
Instagram использует на сервере CPython? Чего-то я не понимаю в змеях...