
В одном из прежних постов я рассказывал, как реализовать «простейшую в мире lock-free хеш-таблицу» на C++. Она была настолько проста, что было невозможно удалять из нее записи или менять ее размерность. С тех пор прошло несколько лет, и не так давно я написал несколько многопоточных ассоциативных массивов без таких ограничений. Их можно найти в моем проекте Junction на GitHub.
Junction содержит несколько многопоточных реализаций интерфейса map – даже «самая простая в мире» среди них, под названием
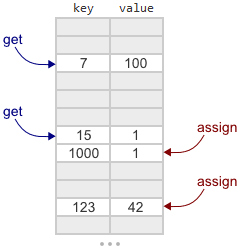
Можете ознакомиться с объяснением того, как работает Crude map, в первоначальном посте. Если коротко, то она основана на открытой адресации и линейном пробировании. Это значит, что она по сути является большим массивом ключей и значений, использующим линейный поиск. Во время добавления или поиска заданного ключа мы вычисляем хеш от ключа, чтобы определить, с какого места начать поиск. Добавление и поиск данных возможны в многопоточном режиме.
Linear map в Junction основана на том же принципе, за следующим исключением: когда массив переполняется, все его содержимое переносится в новый массив большей размерности. Когда перенос данных заканчивается, старая таблица заменяется новой. Но как же нам удается все еще поддерживать многопоточные операции? Подход Linear map основан на неблокирующем Hash Map Клифа Клика на Java, за исключением нескольких отличий.
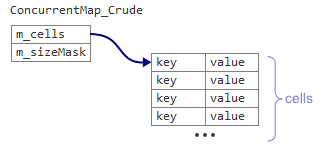
Для начала нам придется немного изменить структуру данных. В Crude map изначально было два элемента данных: указатель
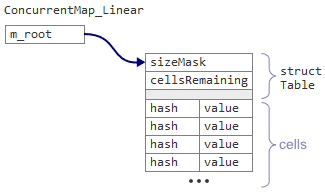
В Linear map — единственный элемент данных
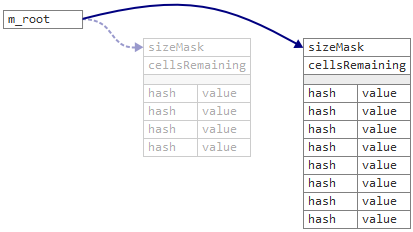
В структуре
С такой структурой данных мы можем одновременно заменить таблицу,
Другое отличие между двумя мапами состоит в том, что Linear map хранит захешированные ключи вместо оригинальных. Это позволяет ускорить миграцию, так как в этом случае нам не приходится заново вычислять хеш-функцию. Хеш-функция, используемая в Junction’, также обратима, так что исходный ключ всегда можно восстановить из захешированного.
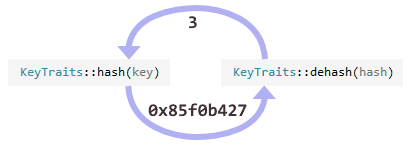
Так как хеш-функция обратима, задача нахождения существующего ключа так же проста, как вычисление его хеша. Поэтому Junction пока поддерживает только целочисленные ключи и ключи-указатели. (По моему мнению, лучше всего обеспечить поддержку более сложных ключей могла бы реализация многопоточного множества (set) вместо map).
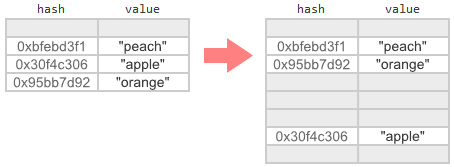
Теперь, когда ты знаем, когда начинать перенос данных, давайте рассмотрим саму задачу миграции. По сути мы должны найти каждую используемую ячейку в старой таблице и добавить ее копию в новую таблицу. Некоторые записи окажутся на прежних местах в массиве, некоторые будут иметь более высокие индексы, and некоторые сместятся ближе к их идеальному индексу.
Конечно, если во время миграции другие потоки все еще смогут менять данные в старой таблице, все несколько усложняется. Используя наивный подход, мы рискуем потерять изменения. Предположим, например, что наш map почти полон, а в это время два потока выполняют следующее:
В этот момент мы ждем, что
Чтобы избежать вышеописанной проблемы, мы можем заблокировать многопоточные изменения с помощью readers-writer lock, хотя в этом случае больше подошло бы определение «совместно-исключительная блокировка (shared-exclusive lock)». При таком подходе любая функция, изменяющая содержание таблицы, поставит совместную блокировку. Поток, занимающийся переносом данных между таблицами, поставит исключительную блокировку. И благодаря QSBR, для
Но Linear map этого не делает. Она на шаг впереди — в ней даже не требуется совместной блокировки для изменения данных. Суть метода в следующем: в процессе переноса данных из старой таблицы поле

Это изменение затрагивает все операции map. В частности, функция
Теперь, если мы разрешим многопоточные операции во время переноса данных, тогда, очевидно, необходимо следить за тем, чтобы каждому ключу в обеих таблицах соответствовали одинаковые значения. К сожалению, способа автоматически выставлять

В этом цикле конкурирующие потоки все еще могут изменить исходное
В текущей версии Linear map даже вызовы
В структуре

Что если сразу несколько потоков попытаются начать миграцию? В случае такого состояния гонки, Linear map использует блокировку с двойной проверкой (double-checked locking), чтобы предотвратить появление дубликата объекта
В этом посте я не уделил достаточно внимания функции
Вот так в общих чертах выглядит Linear map! Leapfrog map и Grampa map в Junction основаны на той же идее, но по-разному ее расширяют.
Параллельное программирование — сложное занятие, но я думаю, что стоит развивать его понимание, так как многоядерные процессоры не уходят из употребления. Поэтому я и решил поделиться опытом реализации Linear map. Примеры — это хороший способ чему-то научиться или хотя бы ознакомиться с новой областью.
Junction содержит несколько многопоточных реализаций интерфейса map – даже «самая простая в мире» среди них, под названием
ConcurrentMap_Crude. Для краткости будем называть ее Crude map. В этом посте я объясню разницу между Crude map и Linear map из библиотеки Junction. Linear — самый простой map в Junction, поддерживающий и изменение размера, и удаление.Можете ознакомиться с объяснением того, как работает Crude map, в первоначальном посте. Если коротко, то она основана на открытой адресации и линейном пробировании. Это значит, что она по сути является большим массивом ключей и значений, использующим линейный поиск. Во время добавления или поиска заданного ключа мы вычисляем хеш от ключа, чтобы определить, с какого места начать поиск. Добавление и поиск данных возможны в многопоточном режиме.
Linear map в Junction основана на том же принципе, за следующим исключением: когда массив переполняется, все его содержимое переносится в новый массив большей размерности. Когда перенос данных заканчивается, старая таблица заменяется новой. Но как же нам удается все еще поддерживать многопоточные операции? Подход Linear map основан на неблокирующем Hash Map Клифа Клика на Java, за исключением нескольких отличий.
Структура данных
Для начала нам придется немного изменить структуру данных. В Crude map изначально было два элемента данных: указатель
m_cells и целое число m_sizeMask.В Linear map — единственный элемент данных
m_root, который указывает на структуру Table, за которой следуют сами ячейки в виде единого непрерывного блока памяти.В структуре
Table хранится новый разделяемый счетчик cellsRemaining, с начальным значением, равным 75% размера таблицы. Каждый раз, когда поток пытается добавить новый ключ, он первым делом уменьшает cellsRemaining. Если cellsRemaining становится меньше нуля, значит таблица переполнена и пора переносить данные в новую.С такой структурой данных мы можем одновременно заменить таблицу,
sizeMask и cellsRemaining за один атомарный шаг, просто перенаправив указатель m_root.Другое отличие между двумя мапами состоит в том, что Linear map хранит захешированные ключи вместо оригинальных. Это позволяет ускорить миграцию, так как в этом случае нам не приходится заново вычислять хеш-функцию. Хеш-функция, используемая в Junction’, также обратима, так что исходный ключ всегда можно восстановить из захешированного.
Так как хеш-функция обратима, задача нахождения существующего ключа так же проста, как вычисление его хеша. Поэтому Junction пока поддерживает только целочисленные ключи и ключи-указатели. (По моему мнению, лучше всего обеспечить поддержку более сложных ключей могла бы реализация многопоточного множества (set) вместо map).
Перенос данных в новую таблицу — неправильный способ
Теперь, когда ты знаем, когда начинать перенос данных, давайте рассмотрим саму задачу миграции. По сути мы должны найти каждую используемую ячейку в старой таблице и добавить ее копию в новую таблицу. Некоторые записи окажутся на прежних местах в массиве, некоторые будут иметь более высокие индексы, and некоторые сместятся ближе к их идеальному индексу.
Конечно, если во время миграции другие потоки все еще смогут менять данные в старой таблице, все несколько усложняется. Используя наивный подход, мы рискуем потерять изменения. Предположим, например, что наш map почти полон, а в это время два потока выполняют следующее:
- Поток 1 вызывает
assign(2, "apple"), уменьшаетcellsRemainingдо 0. - Поток 2 выполняет
assign(14, "peach")и уменьшаетcellsRemainingto -1. Необходима миграция. - Поток 2 переносит содержание старой таблицы в новую, но еще не открывает доступ в новой таблице.
- Поток 1 вызывает
assign(2, "banana")на старой таблице. Так как для этого ключа ячейка уже существует, функция не уменьшаетcellsRemaining. Она просто заменят “apple” на “banana” в старой ячейке. - Поток 2 связывает новую таблицу с указателем
m_root, тем самым перетирая изменения потока 1. - Поток 1 вызывает
get(2)на новой таблице.
В этот момент мы ждем, что
get(2) вернет “banana”, потому что ключ был изменен только одним потоком, и это было последним записанным значением. К сожалению, get(2) вернет старое значение “apple”, что неправильно. Значит, нам нужна другая стратегия.Безопасный перенос данных
Чтобы избежать вышеописанной проблемы, мы можем заблокировать многопоточные изменения с помощью readers-writer lock, хотя в этом случае больше подошло бы определение «совместно-исключительная блокировка (shared-exclusive lock)». При таком подходе любая функция, изменяющая содержание таблицы, поставит совместную блокировку. Поток, занимающийся переносом данных между таблицами, поставит исключительную блокировку. И благодаря QSBR, для
get блокировок вообще не понадобится.Но Linear map этого не делает. Она на шаг впереди — в ней даже не требуется совместной блокировки для изменения данных. Суть метода в следующем: в процессе переноса данных из старой таблицы поле
value каждой ячейки заменяется на специальный маркер Redirect.Это изменение затрагивает все операции map. В частности, функция
assign больше не может вслепую изменять поле value ячейки. Вместо этого она должны выполнить над value операцию чтения-изменения-записи (read-modify-write), чтобы избежать переписывания маркера Redirect, если он был установлен. Если функция находит маркер Redirect, соответствующий value, значит новая таблица уже существует и операция должна выполняться уже над ней.Теперь, если мы разрешим многопоточные операции во время переноса данных, тогда, очевидно, необходимо следить за тем, чтобы каждому ключу в обеих таблицах соответствовали одинаковые значения. К сожалению, способа автоматически выставлять
Redirect для старой ячейки и одновременно копировать ее старое значение в новую ячейку не существует. Тем не менее, мы можем обеспечить целостность данных, перенося каждое значение в цикле. Linear map использует следующий цикл:В этом цикле конкурирующие потоки все еще могут изменить исходное
value сразу после того, как поток, отвечающий за миграцию, прочтет его, так как маркер Redirect еще не был поставлен. В этом случае, когда поток, переносящий данные, попытается выставить маркер Redirect с помощью CAS, CAS вернет ошибку, и поток попытается выполнить операцию еще раз, уже с новым значением. Пока value в исходной таблице будет меняться, переносящий данные поток будет продолжать попытки, но рано или поздно перенос пройдет успешно. Такой подход позволяет многопоточным вызовам get безопасно находить значения в новой таблице, при этом параллельные вызовы assign не смогут модифицировать новую таблицу, пока миграция не закончена (У hash map Клиффа Клика такого ограничения нет, так что в его цикле миграции шагов немного больше).В текущей версии Linear map даже вызовы
get не читают из новой таблицы, пока все данные не будут перенесены. Поэтому в последней версии в цикле нет необходимости; миграцию можно было реализовать, выполнив атомарный обмен value в исходной таблице и затем просто сохранив value в новой таблице (Я понял это, когда уже писал этот пост). Сейчас, если вызов get наткнется на Redirect, это поможет завершить миграцию. Возможно, если бы он вместо этого сразу читал значение из новой таблицы, наше решение было бы более масштабируемым. Это тема для дальнейшего исследования.Многопоточный перенос данных
В структуре
Table есть и другие элементы данных, о которых я еще не упоминал. Один из них — jobCoordinator. Во время переноса данных jobCoordinator указывает на объект TableMigration, который отражает процесс миграции. В нем хранится новая таблица до тех пор, пока она не окажется в общем доступе в m_root. Не буду вдаваться в детали, но jobCoordinator позволяет участвовать в процессе миграции нескольким потокам.Что если сразу несколько потоков попытаются начать миграцию? В случае такого состояния гонки, Linear map использует блокировку с двойной проверкой (double-checked locking), чтобы предотвратить появление дубликата объекта
TableMigration. Именно поэтому у каждого объекта Table есть мьютекс (Hash map Клиффа Клика здесь также отличается. Он оптимистично позволяет гонку потоков за создание новых таблиц).В этом посте я не уделил достаточно внимания функции
erase, потому что она незатейлива: она просто заменяет value ячейки на специальное значение NullValue, которое мы уже использовали, чтобы ее проинициализировать. Поле hash, тем не менее, остается неизменным. Это значит, что рано или поздно таблица может оказаться переполнена удаленными ячейками, но во время переезда в новую таблицу они будут очищены. Есть также несколько тонкостей, касающихся выбора размерности новой таблицы, но эти детали я пока опущу.Вот так в общих чертах выглядит Linear map! Leapfrog map и Grampa map в Junction основаны на той же идее, но по-разному ее расширяют.
Параллельное программирование — сложное занятие, но я думаю, что стоит развивать его понимание, так как многоядерные процессоры не уходят из употребления. Поэтому я и решил поделиться опытом реализации Linear map. Примеры — это хороший способ чему-то научиться или хотя бы ознакомиться с новой областью.
О, а приходите к нам работать? :)wunderfund.io — молодой фонд, который занимается высокочастотной алготорговлей. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Присоединяйтесь к нашей команде: wunderfund.io
Поделиться с друзьями
Комментарии (4)

datacompboy
18.03.2017 04:42Я правильно понял, что она лок-фри только вне ресайза или при чтении, а при ресайзе вообще на мьютексы наступаем?
Я понимаю, что это, вероятно, не продакшен и промежуточные объяснения, но учитывая дорогую операцию копирования, итоговый результат далек от скорости и эффективности, как минимум на выставках.
Замены, вроде, стабильны...
datacompboy
(оффтоп)
"Приятный офис в центре" — по борьбе с алкоголизмом? Вселенной? Круга? ;)
dshap
Надеюсь, с офисом у них лучше, чем с тестовыми задачами :)
dshap
Их иногда надо проверять, а то молодняк не набежит ;)