

Не так давно я писал о C++ библиотеках для микробенчмаркинга. Я рассказал о трех библиотеках: Nonius, Hayai и Celero. Но в действительности я хотел поговорить о четвертой. Мой Windows тогда не поддерживал Google Benchmark library, так что я не мог ее протестировать. К счастью, из комментариев к прошлому посту я узнал, что теперь библиотека доступна в Visual Studio!
Давайте посмотрим, как можно ее использовать.
Библиотека
> Основной github репозиторий
> Обсуждение
Благодаря коммиту KindDragon: Support MSVC on appveyor, мы можем собрать библиотеку в Visual Studio. Я без затруднений скачал последний код из репозитория, сгенерировал solution-файлы с помощью CMake и собрал нужную версию. Чтобы использовать библиотеку в вашем проекте, остается только подключить саму библиотеку и один заголовочный файл.
Простой пример
В исходной статье я проводил два эксперимента:
IntToStringConversionTest(count)— конвертирует целые числа из диапазона 0…count-1 в строки и возвращает вектор этих строк.DoubleToStringConversionTest(count)— конвертирует 0.12345… count-1+0.12345 в строки и возвращает вектор строк.
Пример бенчмарков целиком:
#include "benchmark/benchmark_api.h"
#include "../commonTest.h"
void IntToString(benchmark::State& state) {
while (state.KeepRunning()) {
benchmark::DoNotOptimize(
IntToStringConversionTest(state.range_x())
);
}
}
BENCHMARK(IntToString)->Arg(TEST_NUM_COUNT1000);
void DoubleToString(benchmark::State& state) {
while (state.KeepRunning()) {
benchmark::DoNotOptimize(
DoubleToStringConversionTest(state.range_x())
);
}
}
BENCHMARK(DoubleToString)->Arg(TEST_NUM_COUNT1000);
BENCHMARK_MAIN()Красиво и просто! Макрос
BENCHMARK используется для определения бенчмарка, затем можно добавить параметры вызова. В примере выше я использовал метод Arg. Параметр в этом методе передается в объект state, доступный функции бенчмарка. В нашем примере мы получаем это значение с помощью state.range_x(). Затем оно используется как размер выходного вектора строк.Внутри функции бенчмарка в while-цикле выполняется основной код. Количество итераций библиотека выберет автоматически.
Обычно приложение выполняется в консоли и выводит следующий результат:

Вывод очень прост: название бенчмарка, время в наносекундах (можно изменить с помощью метода
Unit()), время CPU, количество выполненных итераций.Чем же так хороша эта библиотека?
- Можно легко изменять параметры: Arg, ArgPair, Range, RangePair, Apply.
- Значения можно получить с помощью
state.get_x(),state.get_y() - Так что можно создавать бенчмарки для задач в одно- и двухмерном пространстве.
- Значения можно получить с помощью
- Fixture
- Измерения в несколько потоков
- Ручное управление временем: полезно, когда код выполняется на графическом процессоре или другом устройстве, где стандартное время CPU не применимо.
- Форматы вывода: в виде таблицы, CSV, Json
- Возможность добавлять свои метки с помощью
state.SetLabel() - Метки для обработанных объектов и обработанных байтов, благодаря
state.SetItemsProcessed()иstate.SetBytesProcessed()
Вот так выглядит вывод бенчмарка с байтами в секунду, объектами в секунду, метками и измененными единицами времени.

Усложненный пример
В другом посте о библиотеках для микробенчмаркинга я тестировал библиотеки на немного более сложном примере. Это мой обычный бенчмарк — вектор указателей против вектора объектов. Посмотрим, сможем ли реализовать этот пример с помощью Google Benchmark.
Настройка
Вот, что мы собираемся протестировать:
- Класс Particle (частица) — содержит 18 атрибутов типа float: 4 для обозначения перемещения (pos), 4 для обозначения скорости (vel), 4 для ускорения (acceleration), 4 для цвета (color), 1 для времени (time), 1 для поворота (rotation). Еще у нас будет буфер, также типа float, с переменным количеством элементов в нем.
- Стандартная частица составляет 76 байт
- Увеличенная частица — 160 байт
- Хотим измерить скорость работы метода Update на векторе частиц.
- Будем использовать пять видов контейнеров:
-
vector<Particle> -
vector<shared_ptr<Particle>>— с рандомизацией размещения в памяти -
vector<shared_ptr<Particle>>— без рандомизации размещения в памяти -
vector<unique_ptr<Particle>>— с рандомизацией размещения в памяти -
vector<unique_ptr<Particle>>— без рандомизации размещения в памяти
-
Немного кода
Пример кода для
vector<Particle>:template <class Part>
class ParticlesObjVectorFixture : public ::benchmark::Fixture {
public:
void SetUp(const ::benchmark::State& st) {
particles = std::vector<Part>(st.range_x());
for (auto &p : particles)
p.generate();
}
void TearDown(const ::benchmark::State&) {
particles.clear();
}
std::vector<Part> particles;
};А вот бенчмарк:
using P76Fix = ParticlesObjVectorFixture<Particle>;
BENCHMARK_DEFINE_F(P76Fix, Obj)(benchmark::State& state) {
while (state.KeepRunning()) {
UpdateParticlesObj(particles);
}
}
BENCHMARK_REGISTER_F(P76Fix, Obj)->Apply(CustomArguments);
using P160Fix = ParticlesObjVectorFixture<Particle160>;
BENCHMARK_DEFINE_F(P160Fix, Obj)(benchmark::State& state) {
while (state.KeepRunning()) {
UpdateParticlesObj(particles);
}
}
BENCHMARK_REGISTER_F(P160Fix, Obj)->Apply(CustomArguments);С помощью этого кода мы протестируем два вида частиц: маленькие — 76 байт и побольше — 160 байт. Метод CustomArguments генерирует количество частиц для каждой итерации бенчмарка: 1k, 3k, 5k, 7k, 9k, 11k.
Результаты
В этом посте мы уделили основное внимание самой библиотеке, но я хотел бы ответить на вопрос, который мне задавали раньше — вопрос о различных размерах частиц. Пока я использовал только два типа: 76-байтные и 160-байтные.
Результаты для 76 байт:

Рандомизированные указатели почти на 76% медленнее, чем векторы объектов.
Результаты для 160 байт:
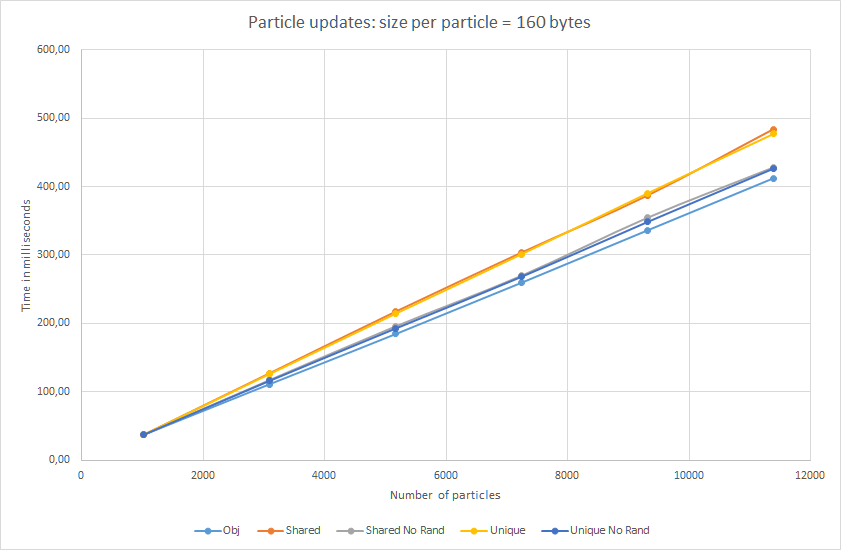
Почти прямые линии в случае больших частиц! Рандомизированные указатели медленнее только на 17%…. Ну хорошо, пускай не совсем прямые :)
Кроме того, мы протестировали и
unique_ptr. Как видите, с точки зрения update (доступа к данным), скорость почти такая же, как и у shared_ptr. Таким образом, косвенное обращение — это проблема умного указателя, а не неизбежные накладные расходы.Итог
Репозиторий с примерами кода
У меня не было трудностей с использованием Google Benchmark library. Вы сможете освоить основные принципы написания бенчмарков за несколько минут. Многопоточные бенчмарки, fixture, автоматический подбор количества итераций, вывод в формате CSV или Json — вот и все базовые функции. Лично мне больше всего нравится гибкость передачи параметров в код бенчмарка. У остальных проверенных мной библиотек имелись проблемы с тем, чтобы передать бенчмарку параметры проблемной области. Самой простой с этой точки зрения была Celero.
Не хватает, пожалуй, только расширенного отображения результатов. Библиотека показывает нам только среднее время выполнения итераций. Хотя в большинстве случаев этого достаточно.
С точки зрения эксперимента, я получил интересные результаты для частиц разного размера. Это может стать основой для будущего финального теста. Я попробую переписать мои примеры с большим разнообразием размеров объектов. Ожидаю увидеть огромную разницу в результатах для маленьких объектов и незначительную — для больших.
О, а приходите к нам работать? :)wunderfund.io — молодой фонд, который занимается высокочастотной алготорговлей. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Присоединяйтесь к нашей команде: wunderfund.io
Поделиться с друзьями