

Что вас ждет в статье:
Описание подхода, который мы применили для исследования фильтров на сайте одного из наших клиентов, а также детальное описание технологий.
На кого рассчитана статья:
Статья будет интересна веб-аналитикам и всем, кто сталкивается с задачами исследования пользовательского опыта на основе количественных данных.
Дисклеймер:
Все описанное в статье является лишь мнением автора (Артем Кулбасов, веб-аналитик AGIMA) и не является единственно верным решением задачи. Многие описанные в статье технологии могут быть заменены аналогами.

1. Описание задачи
Задача от клиента звучала так: провести всесторонний анализ пользовательского поведения и на основании анализа полученных данных сформировать задание на проектирование нового сайта. Что важно, сделать это нужно с учетом всей философии User Experience и в блаженном чувстве, что ты помогаешь пользователю, ты обязан сделать ему хорошо!
Одной из работ был анализ использования пользователями фильтров на сайте в разделе акций, который потенциально подходил бы под пользовательскую модель (ментальную) и служил бы фундаментом обоснования разработки и внедрения фильтров на основе поведенческих паттернов пользователей.
В сборе и анализе данных мы использовали следующие технологии:
Экосистема №1
- jQuery (для быстрой разметки)
- GTM (как часть изолированного и удобного иерархического древа фронтенда, который работает атомарно и независимо от морды сайта)
- Google Universal Analytics Enhanced Ecommerce Abstraction (эта схема данных применима в ecommerce, но никто не запрещает использовать здесь абстрактный подход и имплементировать ее на контентные сайты, которые не продают в онлайне)
Экосистема №2
- Pandas (для анализа данных)
- Seaborn (для визуализации данных)
- PGA (библиотека собственной разработки для выгрузки данных из GUA, подробное описание библиотеки)
2. Сбор необходимых данных
Не будем расписывать базовые задачи и возможности GTM, сразу перейдем к сути.
При разметке раздела акций с фильтрами мы использовали абстракцию расширенной электронной торговли GUA. Поскольку фактически сайт не является интернет-магазином, то для страницы со списком магазинов в качестве товара выбрали карточку магазина. За добавление товара в корзину — клик по карточке магазина, просмотром карточки товара — переход на страницу магазина.
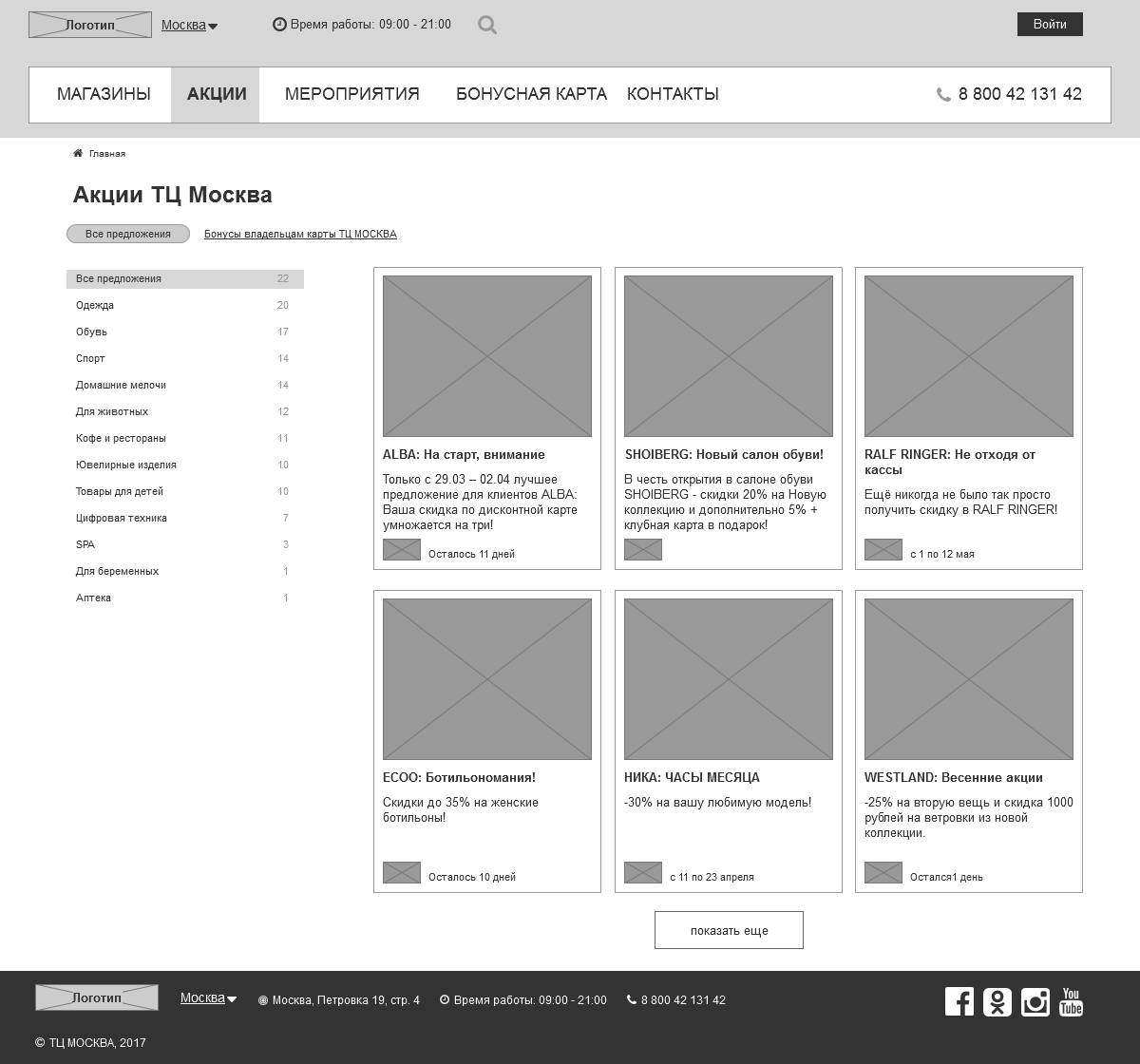

В качестве значений полей Product List Name и Product Variant мы отправляем данные в формате сериализованного объекта, в котором значениями являются:
В первом варианте — информация по текущим настройкам фильтров.
Во втором варианте — дополнительная информация по акции, например время, когда акция завершится. В дальнейшем сериализованный объект мы будем парсить с помощью Pandas.
По сути данную задачу можно решить и проще, используя пользовательские параметры GA. Но, как известно, на один ресурс в стандартном GA их всего 20, и этого числа не хватит. В GAP с 200 пользовательскими параметрами ту же задачу можно решить значительно проще.
Пример того, в каком виде передается структура Enhanced Ecommerce:
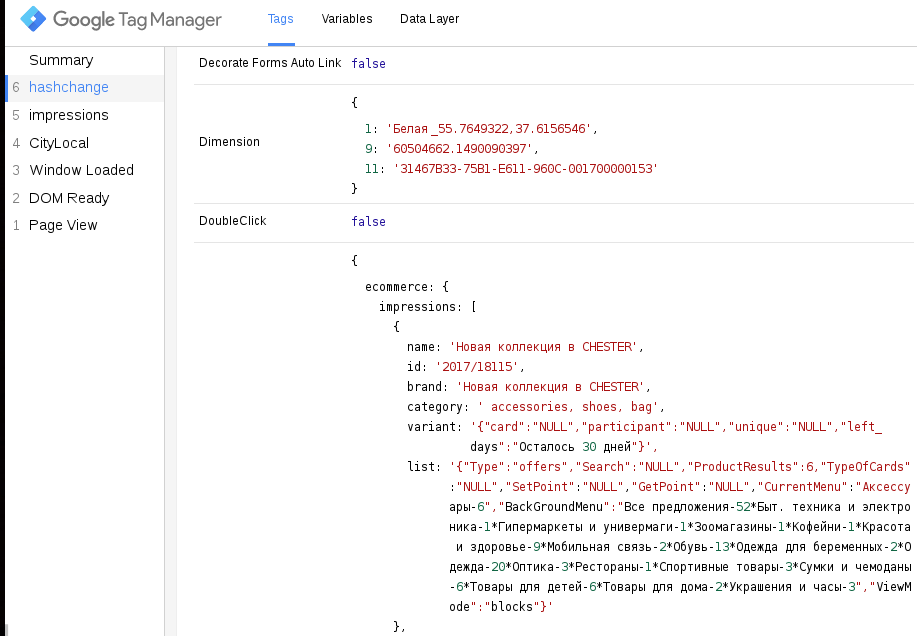
Рассмотрим куски кода реализации разметки:
На весь код у нас существует два главных селектора mainItemSelectorForClick и mainItemSelectorForView, к которому цепляются JS события, в этом куске кода — это скролл.
При скролле мы единожды отправляем только те акции, которые попадают в данный момент в область видимости экрана по селектору “:in-viewport:visible”. В глобальный объект window.ec_ попадает структура данных Enhanced Ecommerce. Это позволяет в дальнейшем подставлять значения в теги по хитам. Далее, мы пушим ‘event’:’scroll’, для того, чтобы привязать другой тег к этому событию со значением window.ec_
В самом конце алгоритм подставляет к каждой акции класс, который говорит о том, что акция уже просмотрена ‘impressionSent’ и в дальнейшем ее не нужно добавлять в массив Enhanced Ecommerce. Это сделано для того, чтобы избежать перенасыщения данных и не сильно превышать ограничения на хиты в день.

Функция list_set_data() подставляет data-* атрибуты к $(document), другими словами, мы сохраняем текущее значение фильтров в один глобальный объект — document.
На выходе мы имеем сохраненную структуру данных, к которой можно обращаться уже из других тегов или кусков кода.
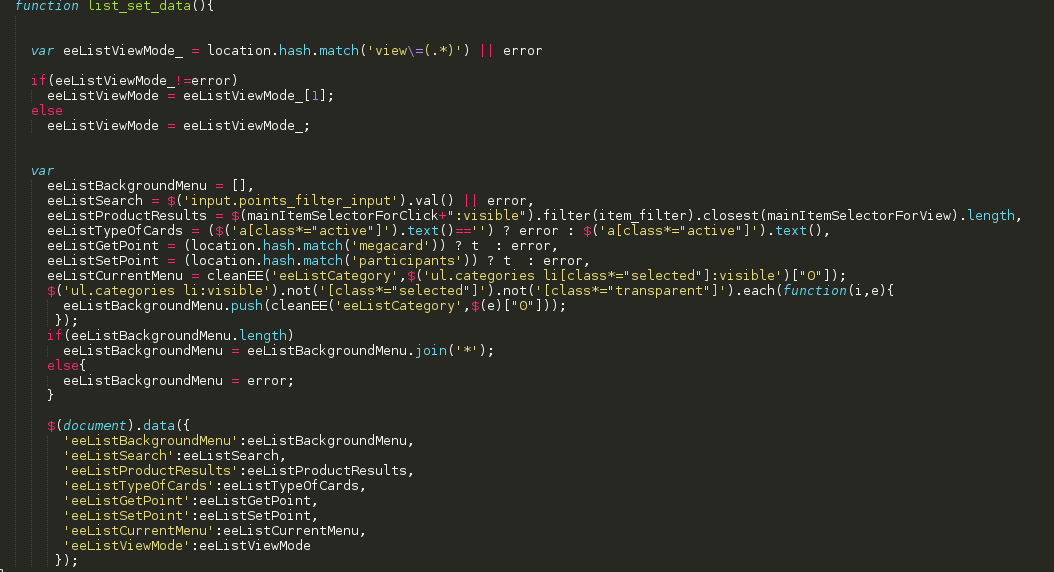
Остановимся подробнее на функции item_generate_json.
Функция отвечает за создания объекта product с сериализированными полями с помощью функции JSON.stringify({}), которая преобразует объект в строку. Часть значений полей объекта инициализируются с помощью data — * атрибутов jQuery, которые заблаговременно были созданы в других кусках кода.

Если проходиться конкретно по сериализованным объектам, то тут следующие параметры:
Type — тип листа (в нашем примере, это акции). В статье мы рассматриваем анализ раздела акций, но это не единственный раздел сайта.
Search — в данное поле попадает текущий ключевой запрос по данной акции, либо NULL, в зависимости от существования / отсутствия поиска.
ProductResults — просчитывает количество сущностей на странице, в нашем случае количество акций.
TypeOfCards — тип карты, в данном случае у бизнеса был депозитный вариант карты, либо кредитный
CurrentMenu — текущее зажатый фильтр категории в данном хите
BackGroundMenu — текущее остаточное меню фильтра категории в данном хите(которое осталось)
ViewMode — тип сортировки акций (блочная или списком)
….
Кроме того SetPoint — начисление баллов, GetPoint — зачисление баллов…
Следующее мы получаем в интерфейсе Google Universal Analytics:
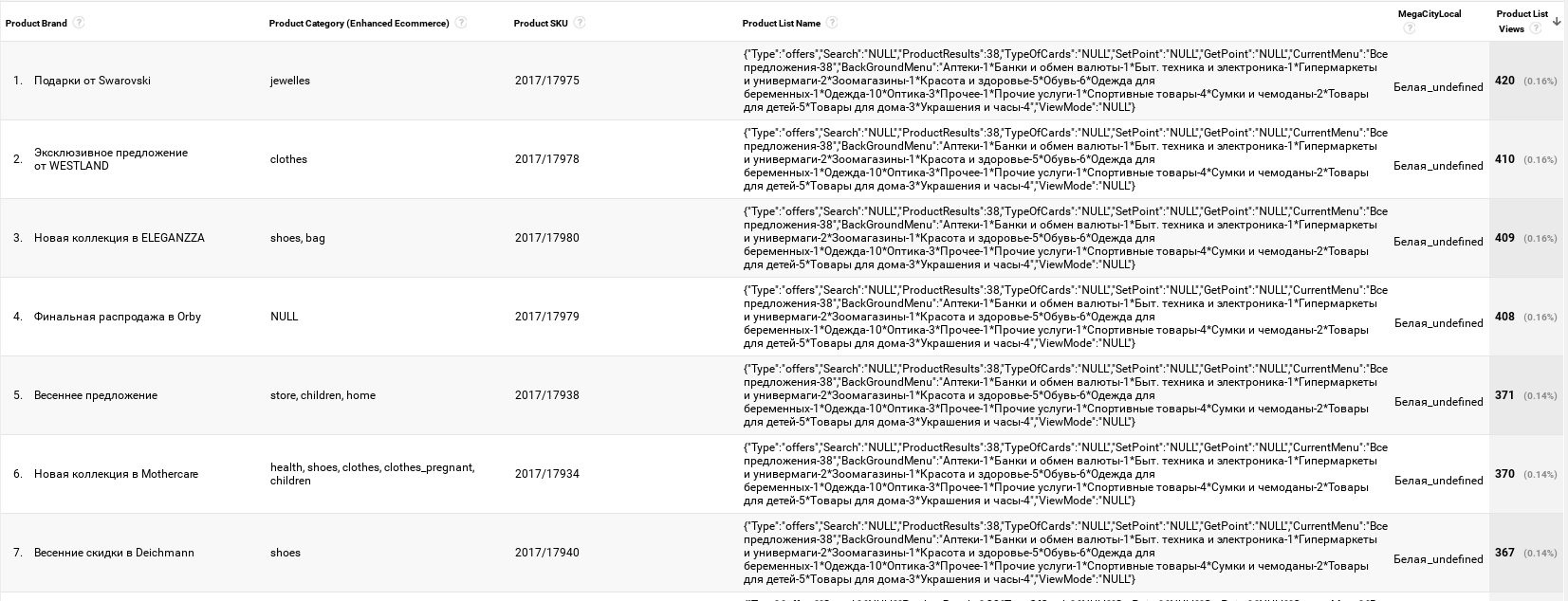
Также не стоит забывать, что в случае стриминга или батчинга данных в собственную БД сериализованные объекты на первый взгляд будут не к месту и не отвечают всем стандартам БД. Однако могу заверить, что используя, например, ClickHouse, данный функционал можно реализовать через функции для работы с JSON.
3. После того, как собралось достаточно данных, мы переходим к их анализу.

Выгрузили данные с помощью PGA скрипта. Скрипт позволяет выгрузить данные посуточно, что позволило на большом объеме данных исключить семплирование данных и получить точные цифры по поведению пользователей.
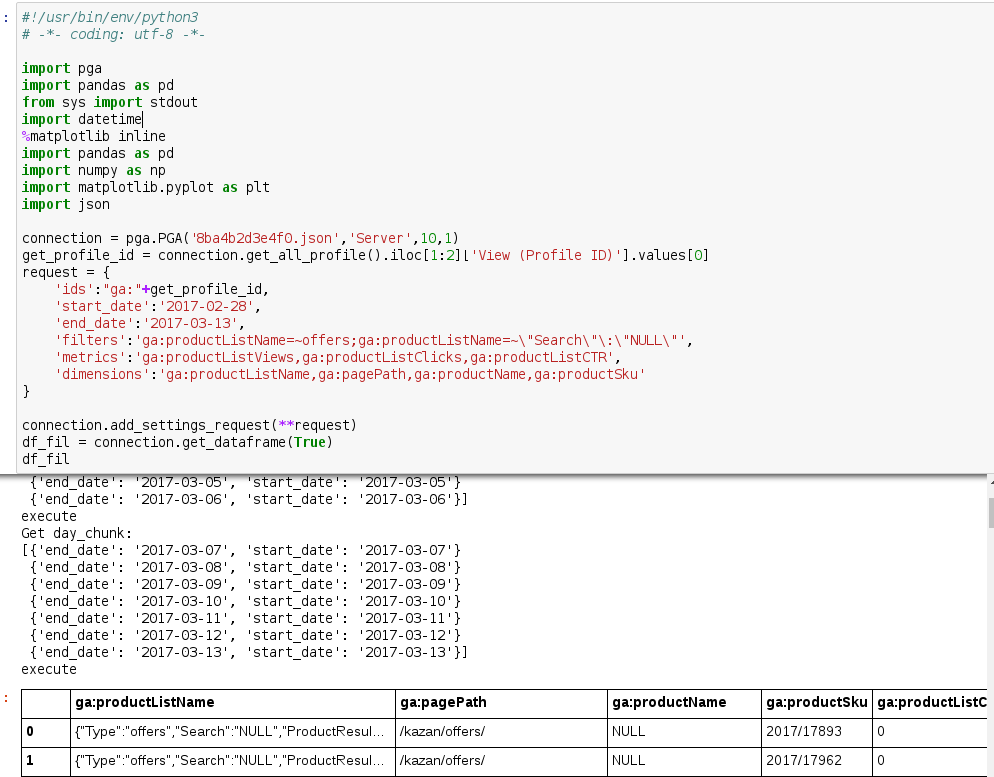
Разберем по частям алгоритм кода:
Подключаем библиотеки. Здесь импортируются все перечисленные выше библиотеки в данной статье.

2. Генерируем запрос Core Reporting V3 к Google Analytics c настройками подключения сервера, (поскольку Jupyter тетрадка запускался из под сервачка). Не забываем указывать, чтобы сырые данные по каждому дню группировались автоматически.

3. Код, что ниже создает новый DataFrame и джойнит в него Series со значениями из заранее раскодированого по json.loads колонке ga:productListName из исходного DataFrame.
Другими словами, мы взяли функцию, которая дает «право» или «разрешение» использовать формат текущего значения как JSON по столбцу ‘ga:productListName’ из Google Universal Analytics и из него получили новый DataFrame по уже новым колонкам.

4. Фильтруем колонки, удаляя лишнее и выбираем из них относящиеся к акциям

5. В нашем случае, меню категории состоит из текста, например, ’Одежда — 1’, (где число указывает количество акций в данной категории), поэтому мы должны разделить данную сущность на две: Категория, Количество акций в данной категории. Так как нас не интересует количество акций, мы можем уже в новый столбец Pandas записать список/массив, используя сплит строки Series

6. Создаем новые столбцы со значениями “Названия текущей категории” как строку и количеством акций по данной категории как число с типом ‘int’

7. После, мы делаем groupby по текущей категории (‘Current Category Name’). После, в зависимости от типа, усредняем или суммируем сгруппированные столбцы метрик Google Analytics (product list click, ctr и count).
Также мы отбираем исключительно те списки, которые собрали достаточное количество данных, применив фильтр df_fil_ac_g['ga:productListViews']>1000] и сортируем список.
В итоге получаем список столбцов с метриками и категориями фильтров.

Поскольку категории написаны на Русском языке, а некоторые библиотеки ругаются на кодировки мы транслитерелизируем их английским написанием:

8. Полученный результат визуализировали хитмэпом с помощью Seaborn, в результате получили следующее:
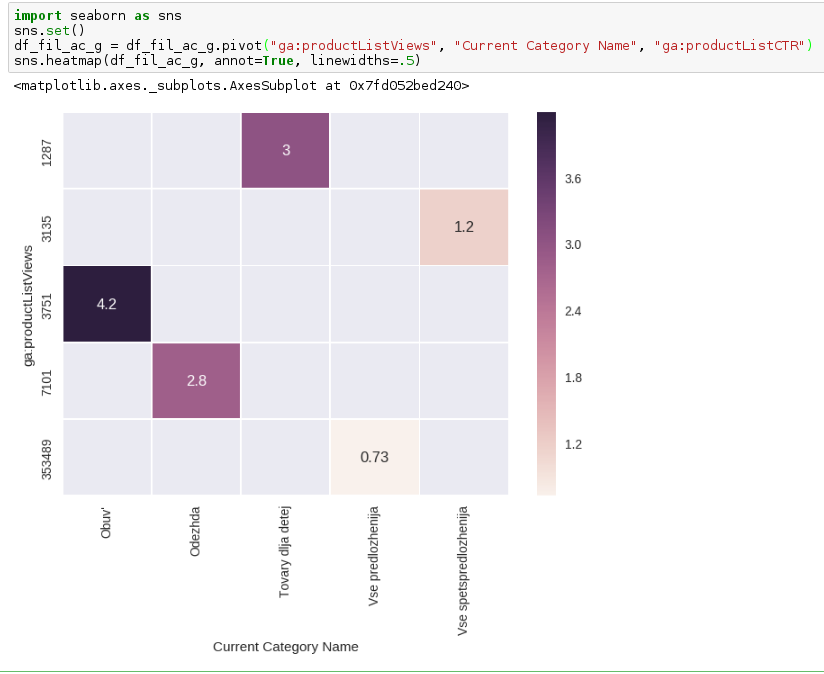
По оси x — категории фильтра
По оси y — количество просмотров карточек с фильтрами
Цифры в квадратах — CTR по карточкам с фильтрами
Полученный результат можно интерпретировать так:
Практически каждый четвертый человек, меняет фильтр со стандартного ‘Все предложения’ на какой-либо другой.
Подавляющее большинство акций с фильтром «Все предложения» или «Все спецпредложения» (и да, они отличаются акциями) в сравнении с остальными фильтрами имеют низкий CTR. Возможно, людям свойственна другая модель поведения. Есть вероятность, что при зажатых значениях, например Обуви, Одежды или объединения этих категорий в одну будет лучше отвечать ментальной модели человека, который привык видеть при первом взаимодействии с бизнесом уникальные акции по вполне логичным группам товаров, а не по всем, которые есть в базе.
Однако, данное утверждение всего лишь гипотеза и ее необходимо проверять. В контексте нашей задачи, подготовили предложение по проведению сплит теста на бою, где по дефолту в каждом варианте чередуются зажатые акции.
Поделиться с друзьями