
Одним из самых популярных докладов конференции PG Day в 2015 году стал рассказ Владимира Бородина и Ильдуса Курбангалиева о ситуациях, когда посгресовым базам становится плохо, надо их диагностировать и искать узкие места. Все примеры в докладе взяты из реальной практики Яндекса, сопровождаются иллюстрациями и подробным рассказом о поиске «боттлнека». Не смотря на то, что проблемы рассматривались в разрезе 9.4 и 9.5 версий базы данных, общая ценность и практическая применимость советов Владимира и Ильдуса остается неизменной. Рады предложить вам транскрипцию этого доклада.
Вступление Ильи Космодемьянского: сейчас у нас будет рассказ о том, как жить, если очень хочется иметь Oracle, а его нет. На самом деле, это полезный доклад, потому что одна из проблем, которую мы сейчас имеем – это проблема средств диагностики. Средства диагностики местами не достают, местами, вместо привычных средств диагностики нужно использовать довольно сложные тулзы, которые вообще предназначены для разработчиков Linux, а не для DBA. У DBA зубы начинают болеть, когда они смотрят на эти скрипты. И вот ребята из Яндекса и PG Pro расскажут о методах диагностики Postgres, которые они применяют, как ими пользоваться и немного расскажут о том, как они собираются улучшить этот мир.

Владимир Бородин: Всем привет. Меня Вова зовут, и я админ Яндекс почты. Доклад совместный с Ильдусом, он занимается разработкой PostgreSQL в компании Postgres Pro.
Доклад про диагностику Postgres и важный в нем момент — это картинки. Первая часть доклада посвящена тому, что делать тому, что делать, если у вас сорвался мониторинг.

Куда в этом случае бежать? Взорвался мониторинг – это такая абстрактная штука, имеется ввиду, что взорвался мониторинг, связанный с базой данных.

Мы считаем Postgres хорошей базой данных. А хорошая база данных, когда у нее все плохо, то она во что-то упирается, как правило. В большинстве случаев — это какой-то системный ресурс. Ей не хватает процессора. Ей не хватает дисков или даже сети. Она вполне может упираться в heavy-weight локи, блокировки на строчки, таблички, еще чего-нибудь. Но бывают случаи, когда база упирается во что-то другое.
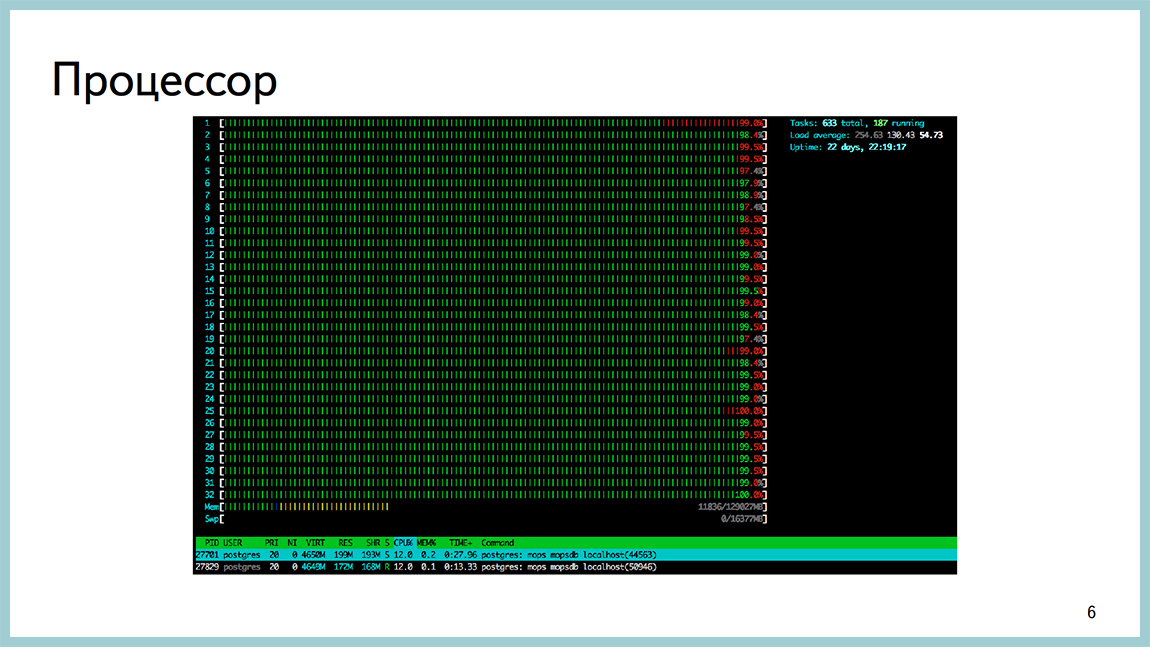
Немного картинок из того самого продакшена. Вот, например, htop с одной Postgres базы, которая уперлась в процессор. Load Average 200, куча сессий и весть процессор в userspace, такое бывает.
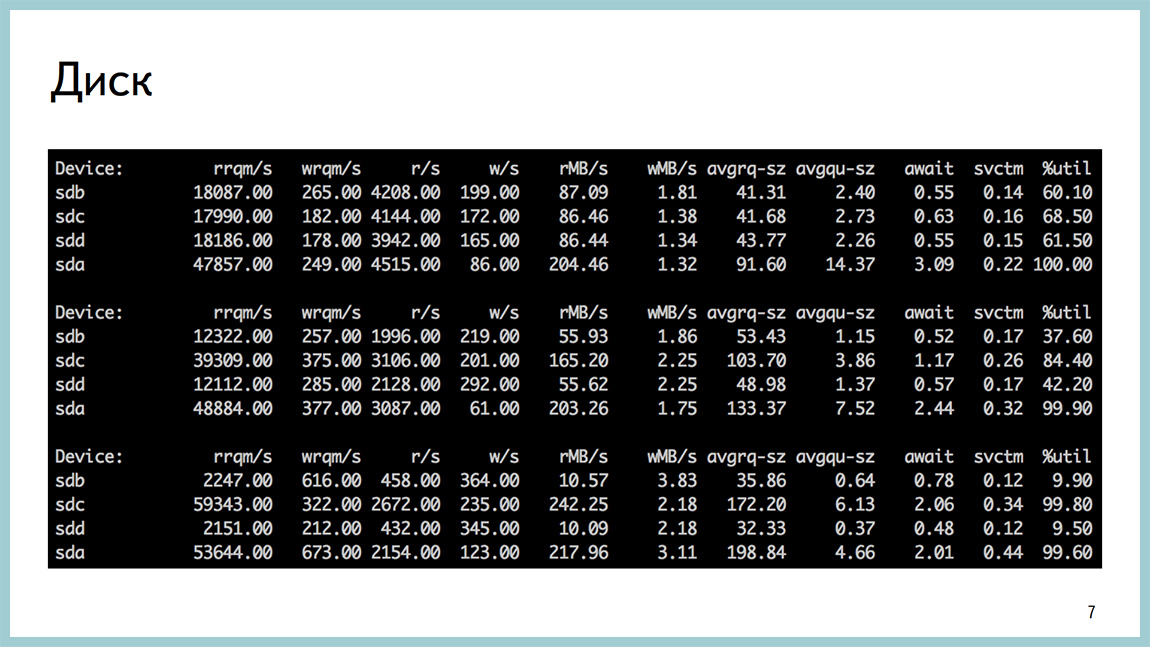
Базу также можно упереть в диски. С посгресом достаточно популярная штука. Утилизация на паре дисков близка к 100%. await огромное количество чтений с диска.
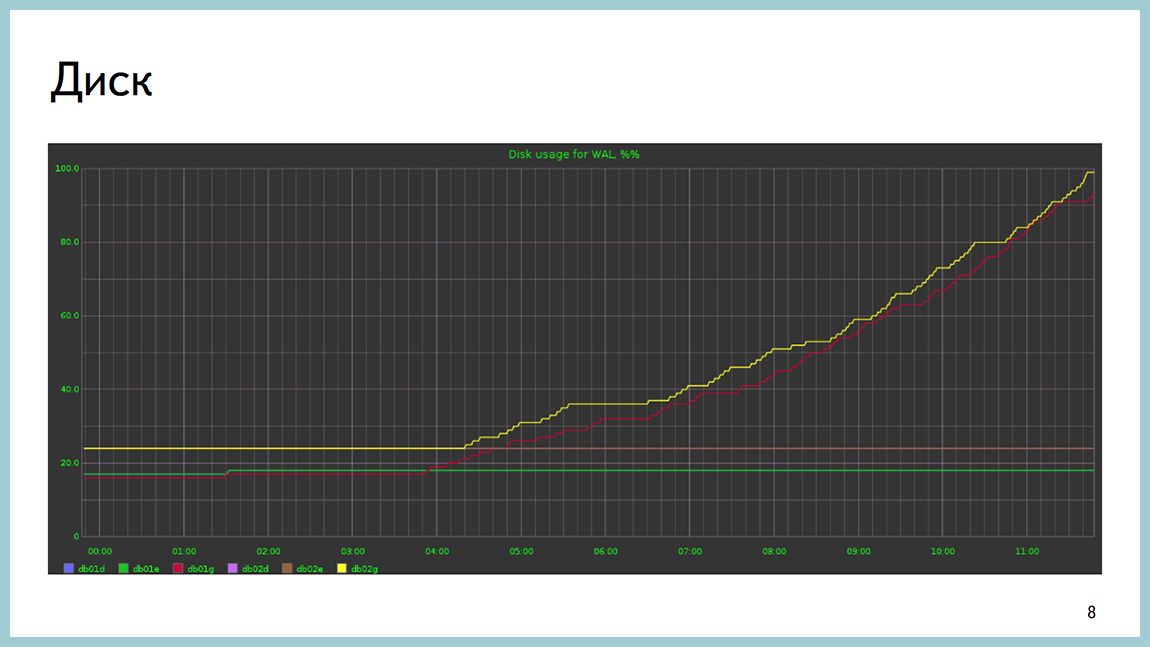
Диск умеет кончаться не только по iops или по пропускной способности, он может кончаться и по месту, к сожалению. Это картинка с базой, где кончился на разделе с xlog.

У нас бывают ситуации, когда база упирается в сеть на передаче икслогов на реплики, в архив или еще куда-нибудь на “толстые” ответы клиентам.

В случае с памятью все сложнее. Как правило, вы не увидите, что у вас проблемы именно с памятью. В зависимости от того как настроена ваша операционная система, либо вы начнете залезать в SWAP и увидите это как проблемы с дисковой активностью, либо придет OOM, убьет бекэнд, и в результате этого сложится весь Postgres.
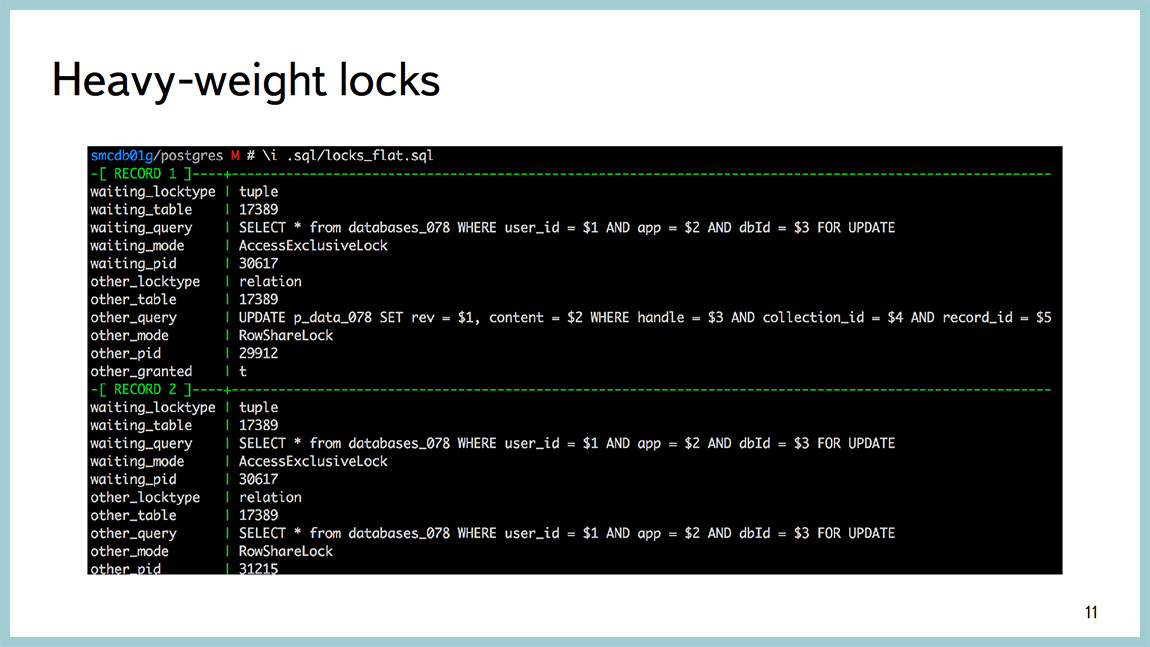

Это все вполне хорошо диагностируется внешними по отношению к Postgres инструментами. То есть любимая top-like утилита, dstat, iostat и т.д. Я говорю, преимущественно, о Linux. В случае, если база упирается в тяжеловесные блокировки, эту информацию вполне можно посмотреть через PG locks, и есть какое-то количество запросов, которые облегчают парсинг вывода оттуда глазами. Но они собраны на Postgres-ной wiki. Собственно, пример выше показывает все красиво.
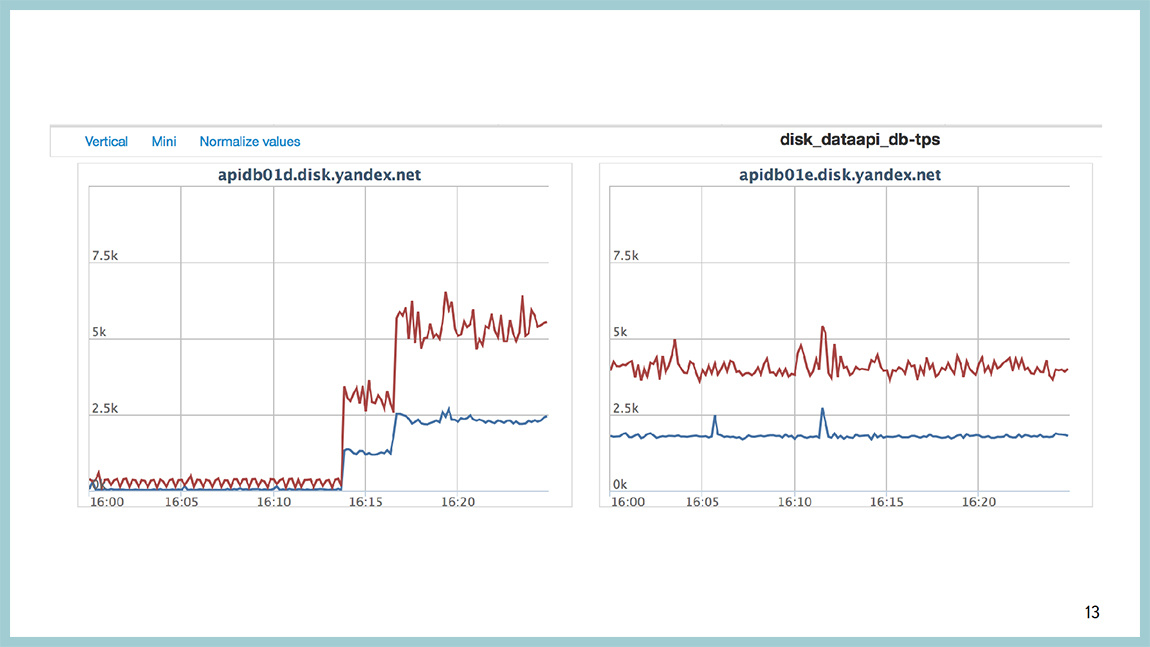
Взрыв произошел, вы во что-то уперлись. Из-за чего уперлись, черт его знает. В большинстве случаев что-то изменилось, что-нибудь выкатили, у вас увеличилась нагрузка на базу, как на этой картинке, или поехал план какого-нибудь запроса и он стал работать не так, как ожидалось.
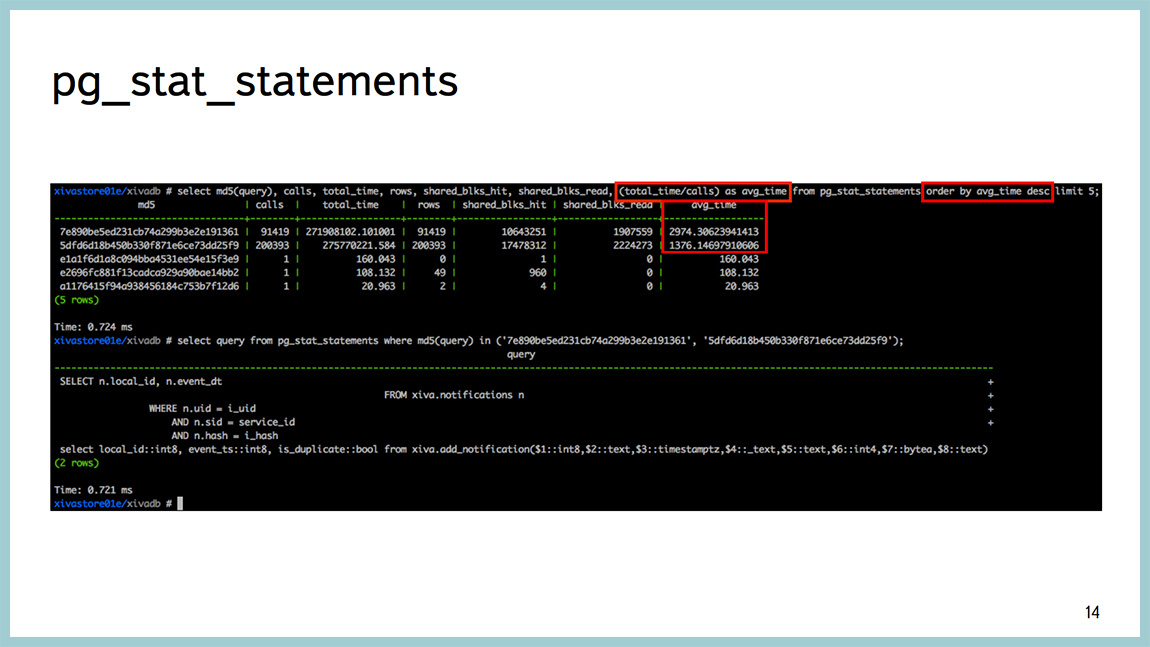
До версии 9.4 существовал хороший инструмент pg_stat_statements. Можно посмотреть с точностью до запроса, какой из них потребляет больше всего времени. То есть, на какие запросы база тратит больше всего времени. Ну а дальше уже стандартно, explain analyze смотреть, где они это время тратят, что делают и так далее. Но время, которое база тратит на выполнение запросов, это не самый лучший показатель. Это время можно тратить на самых разных ресурсах. Можно читать с диска, можно «насиловать» процессор, можно сортировать что-то, можно ожидать какой-либо блокировки и так далее.
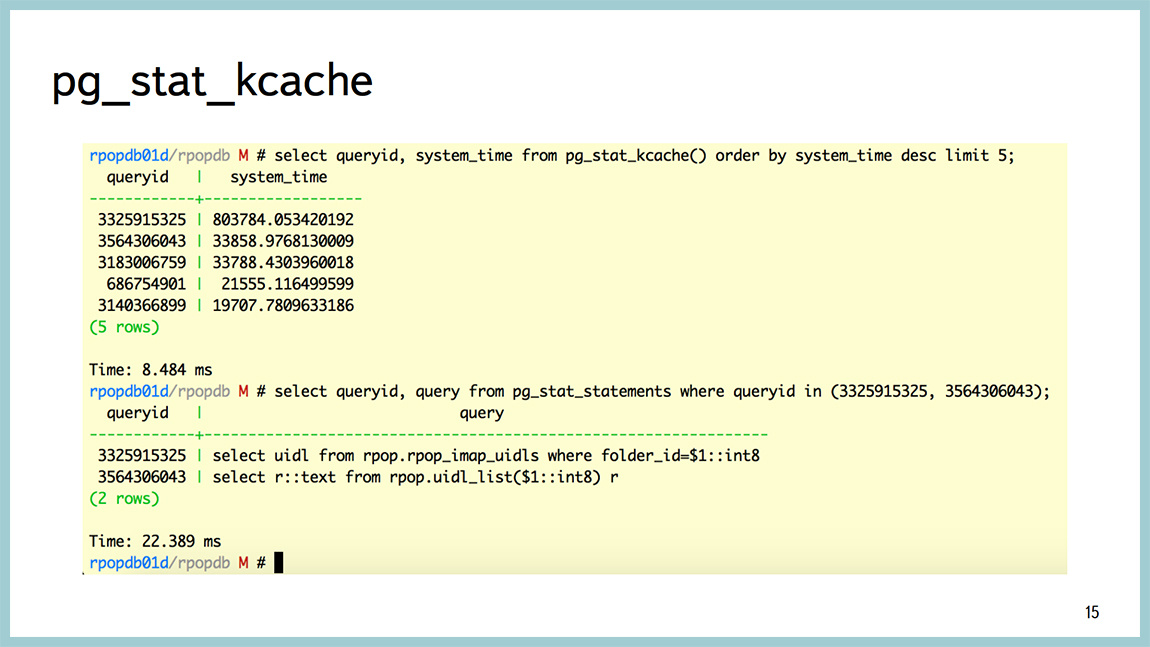
Начиная с 9.4, появилась отличная штука, которая называется pg_stat_kcache, которая позволяет посмотреть с точностью до запроса, в том числе потребление процессора в юзертайме, потребление процессора в системтайме. И очень крутая штука, которую она умеет – это разделение физических чтений с диска и получение данных page cache из операционной системы.

Несколько примеров. Например, запрос, который точно также выводит информацию по топовым запросам. Опять же, отсортированный по времени. Но в том числе показывает, сколько они съели процессора в системтайме, юзертайме, сколько они писали/читали с диска, сколько получили из памяти и так далее. Можно посмотреть тексты этих запросов.
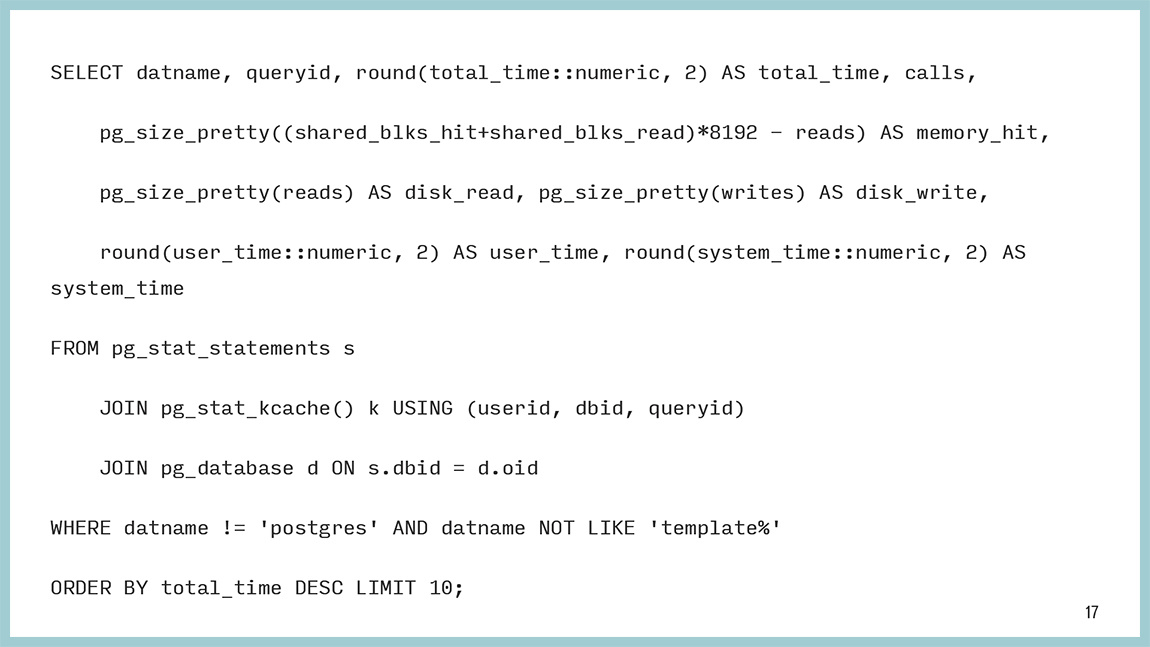

Сам запрос выглядит так. Этот текст можно скопировать. Он на самом деле не такой сложный. Тут все просто. Мы забираем данные из pg_stat_statements, pg_stat_kcache и сортируем, в данном конкретном случае тоже по времени, которое база потратила на этот запрос.

Но это не самое большое преимущество pg_stat_kcache. Можно сортировать по чтениям с диска, по записи на диск, и т.д. Например, тот же самый pg_stat_statements умеет разделять shared_hit и shared_read. Это значит чтение из разделяемой памяти (shared buffers) и все остальное. И это все остальное может быть из page cache операционной системы, а может быть физически с диска. pg_stat_kcache их умеет разделять. Делает он это с помощью системного вызова getrusage(), который дёргается после каждого запроса.
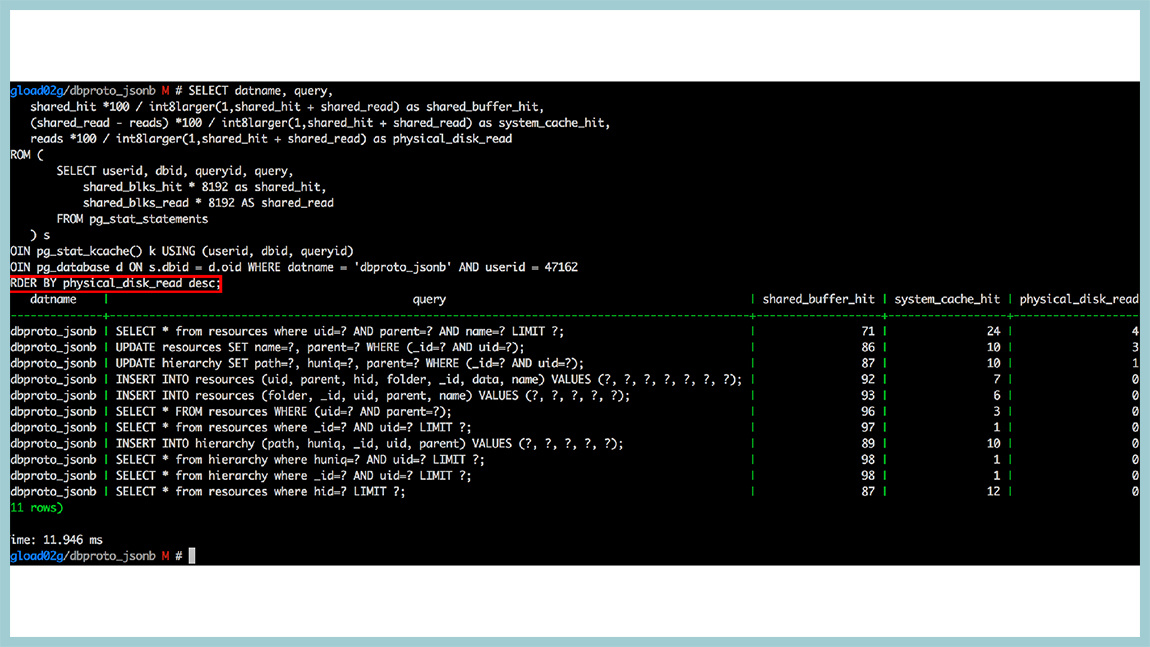
Например, у нас была база, которая упиралась в диск чтениями, и мы построили такую штуку: запрос, который сортирует по физическому чтению с диска. И это уже относительные величины. Тут видно, что у нас запросы, которые в топе. У них единицы процентов доходят до диска и что-то с диска читают. Все остальное отдается либо из разделяемой памяти, либо из кеша операционной системы. То есть кеширование в этой базе работало вполне эффективно. Если вы используете 9.4, обязательно используйте pg_stat_kcache, отличная штука.
Бывают проблемы сложнее, которые вообще не детерминируются на конкретные запросы. Например, такая проблема. Берем и по первой стрелочке увеличиваем дисковое ИО. Описание полей в середине картинки. Эти два столбца, это иопсы. Увеличиваем иопсы с 10 тысяч до 100 тысяч. И через какое-то время у нас база начинает весь процессор убивать в системтайме. В этот момент времени все становится плохо и вообще непонятно, чем она занимается. И если мы посмотрим в pg_stat_statements или pg_stats_kcache, мы увидим, что в системтайме система проводит, без малого, все запросы. Это не проблема какого-то конкретного запроса.

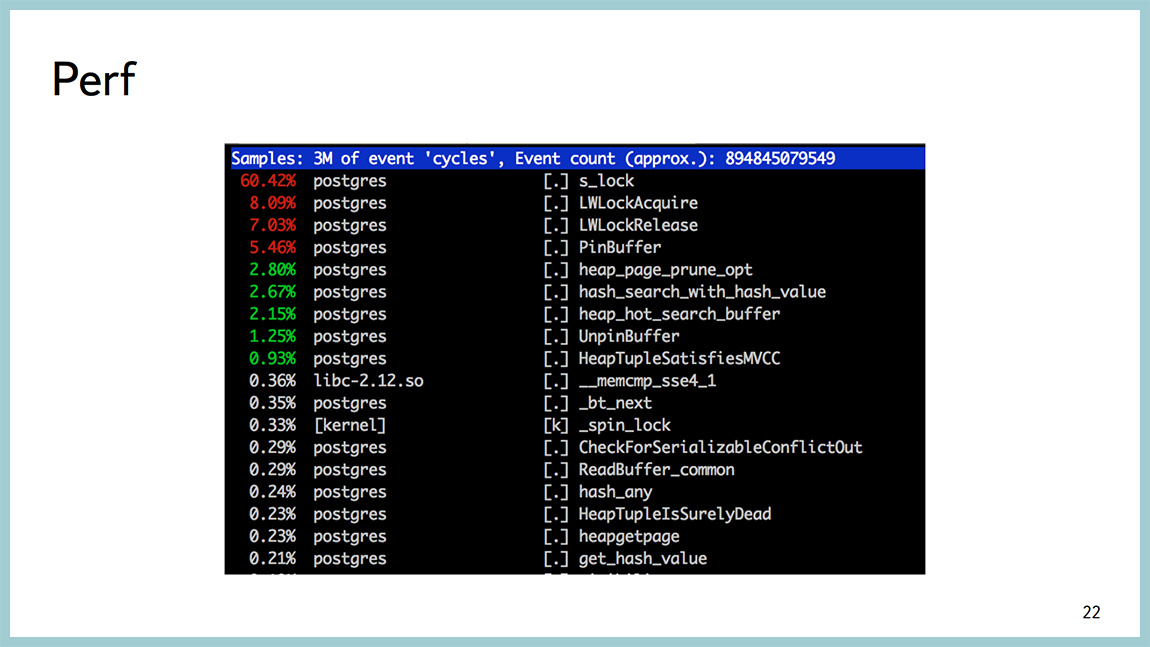
Для диагностики того, на что тратится процессор, есть замечательная утилита perf, она полезна не для DBA и больше для разработчиков ядра, но она работает за счет семплинга, не задевает боевые процессы. Вообще не «насилует» систему. И тут видно, что большая часть времени процессора тратится в спинлоке. При этом видно, что, скорее всего, мы спинлочимся на получении легковесных блокировок. И, скорее всего, в районе работы буферного кеша. Вызвали PinBuffer, UnpinBuffer, ReadBuffer и так далее. Глядя в такой вывод perf top, можно понять, где тратится процесс в системтайме или предположить, где именно внутри базы он тратится.
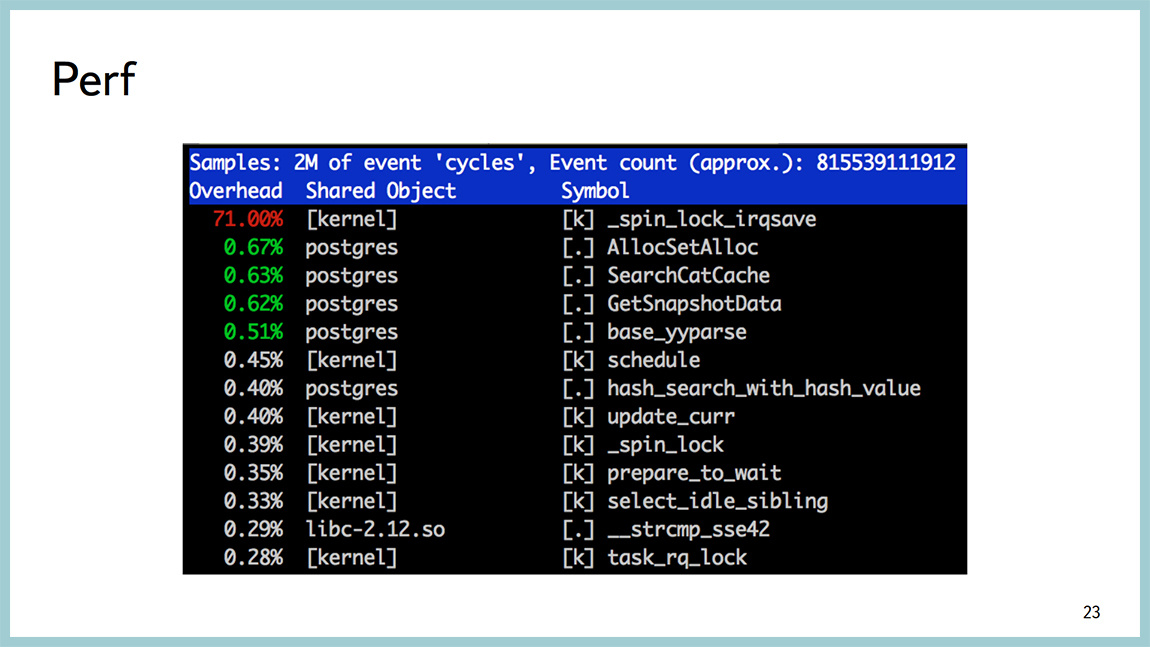
Бывают ситуации хуже, когда мы видим тот же самый спинлок, но при этом вообще ничего непонятно, откуда у нас этот спинлок и что с ним дальше делать.
Тут должна быть мем-картинка. Нам можно залезать глубже, смотреть, что там происходит и во что мы уперлись.

Есть некое количество инструментов для этого. Один из них — это dtrace и systemtap (в случае линукса). Его преимущество в том, что посмотреть им можно буквально все. Но для этого нужно немного кода написать. Это первое. Второе, нужно пересобирать Postgres для того, чтобы systemtap мог в него залазить. И самая большая проблема – это то, что systemtap неприменим при любых условиях. Его можно использовать на стендах для нагрузочного тестирования. Потому что работает он не всегда стабильно и может вам сложить “продакшен”. У нас такое несколько раз происходило. На правах рекламы, в “бложике” я писал про дебаг ситуации с помощью systemtap.
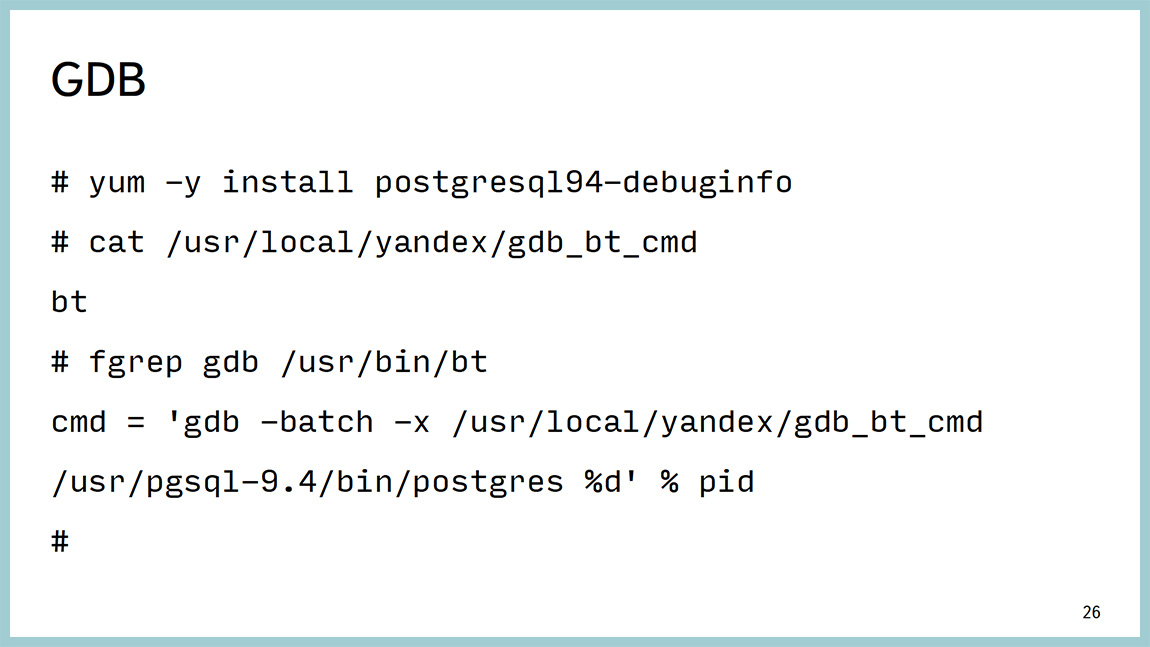
Другой инструмент — это классический отладчик GDB, и его мы используем. Очень просто он цепляется к процессу, снимает бэктрейс с потоков, в случае Postgres — один процесс, один поток. Поэтому просто снимаем бектрейс. И отцепляется от процессора.

Вывод выглядит следующим образом. Из него видно, что мы висим на ожидании легковесной блокировки (light-weight lock) в районе работы с буферным кешом и непросто где-то там, а вот на конкретной строчке исходников. Мы можем пойти в исходники на 591 строку bufmgr.c и посмотреть, что там происходит. Даже, если вы не знаете С, там вполне хорошие комментарии и можно понять, где и что происходит.

Единственное, что у GDB есть неприятный недостаток. Если вы прицепитесь к процессу и скажите ctrl+C, то до процесса долетит не SIGTERM или SIGQUIT, а долетит SIGKILL, и вам это Postgres сложит. Поэтому мы написали совсем тупую обвязку. Она просто все те сигналы, которые вы посылаете этой обвязке, до GDB не досылает. Соответственно, до посгресных бекендов оно тоже не долетает.
Обвязка позволяет нам снимать стектрейсы с посгресного бекенда, и дальше в них глазами пялиться и понимать, что там происходит. Из плюсов то, что она стабильно работает и не задевает “бой”. Для того, чтобы это работало, вам не надо ничего пересобирать. Вам просто нужно поставить пакеты debuginfo: postgresql-debuginfo, libc-debuginfo, kernel-debuginfo, и будет вам счастье. Важно, оно дает с точностью до строчки кода понимание, где именно бекэнды проводят время.

Вторая часть презентации посвящена тому, что делать, когда вы не наступили какую-то проблему производительности, она у вас уверенно воспроизводится. Вы не знаете, как ее дальше лечить. И вам подсказывают, что надо было бы написать в рассылку и спросить, что делать. Но перед тем, как писать в рассылку, можно насобирать побольше диагностики.
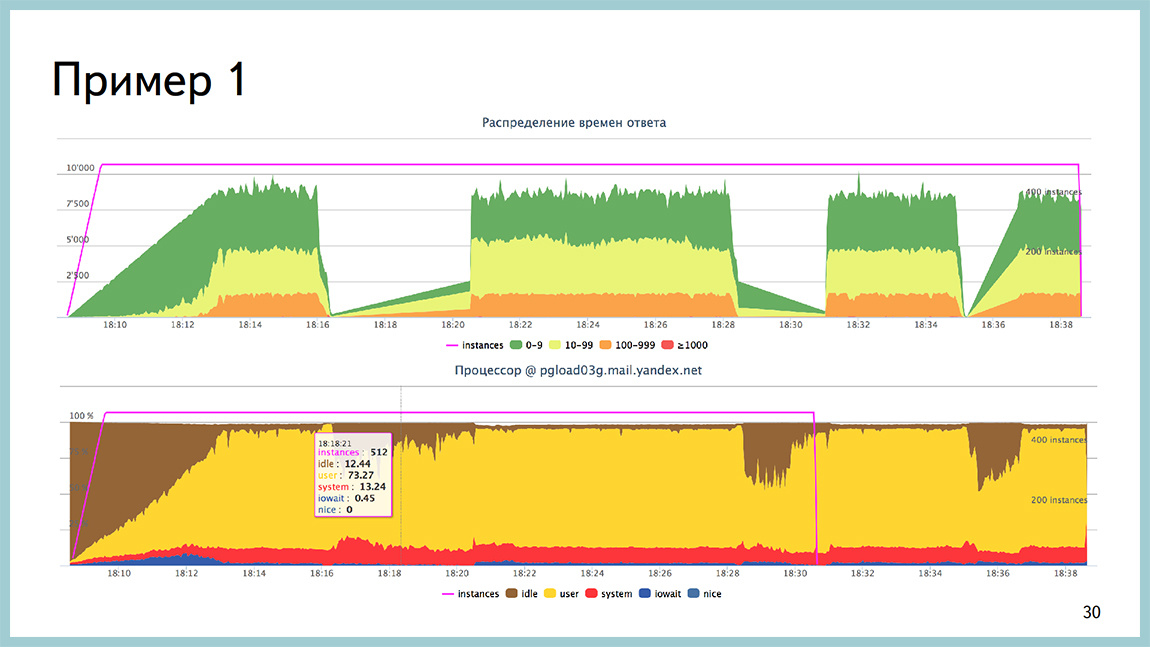
Несколько примеров. Например, у нас была такая ситуация. Мы стреляли в базу, которая упиралась в процессор. Тут на второй картинке видно, что жёлтенькое — это процессор в userspace, он весь, без малого, съеден. При этом, на такой профильной нагрузке у нас возникали интервалы времени до двух минут, когда база вообще не обрабатывала нагрузку. Все стояло колом. Всплесков со стороны операционной системы видно не было.
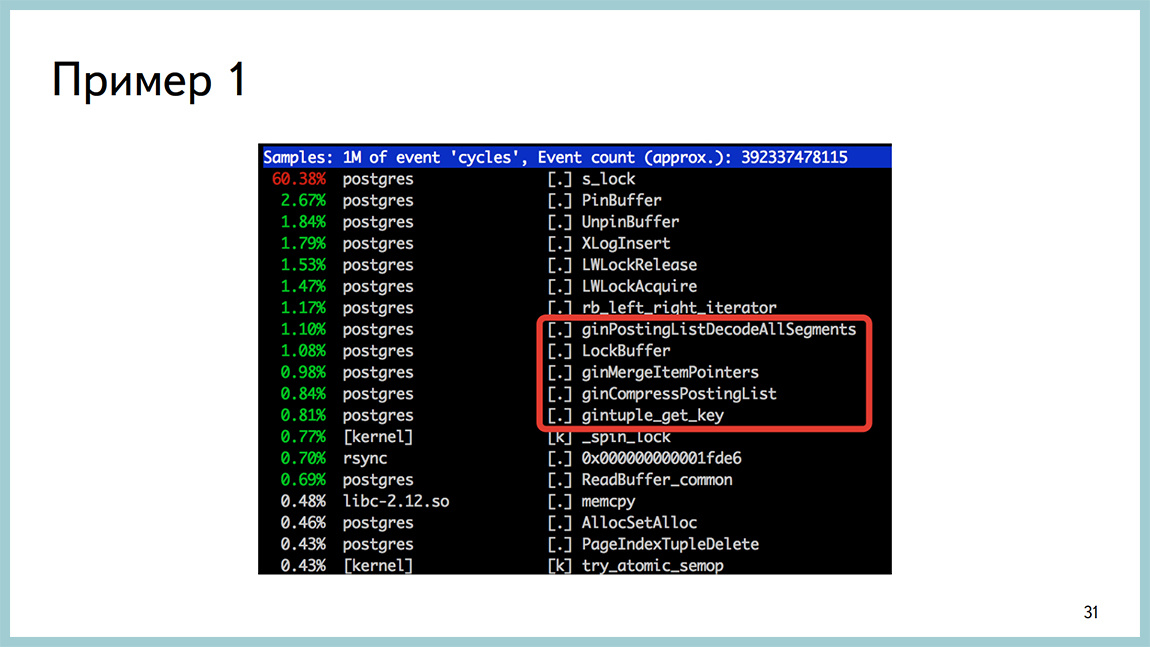
На выводе perftop тоже ничего такого, что бросалось бы в глаза тоже не было. Единственное, на что мы обратили внимание на тот момент времени, что, когда появляется этот провал в выводе, то появляются вызовы работы с gin. При том, что там совсем небольшие объемы времени на это тратятся. Но вот как только провал, они появляются. Как только все становится хорошо, они исчезают. У нас был в этой базе один gin-индекс. В первую очередь мы его выключили и выключили запрос, который этот gin-индекс использовал, и увидели, что все стало хорошо.
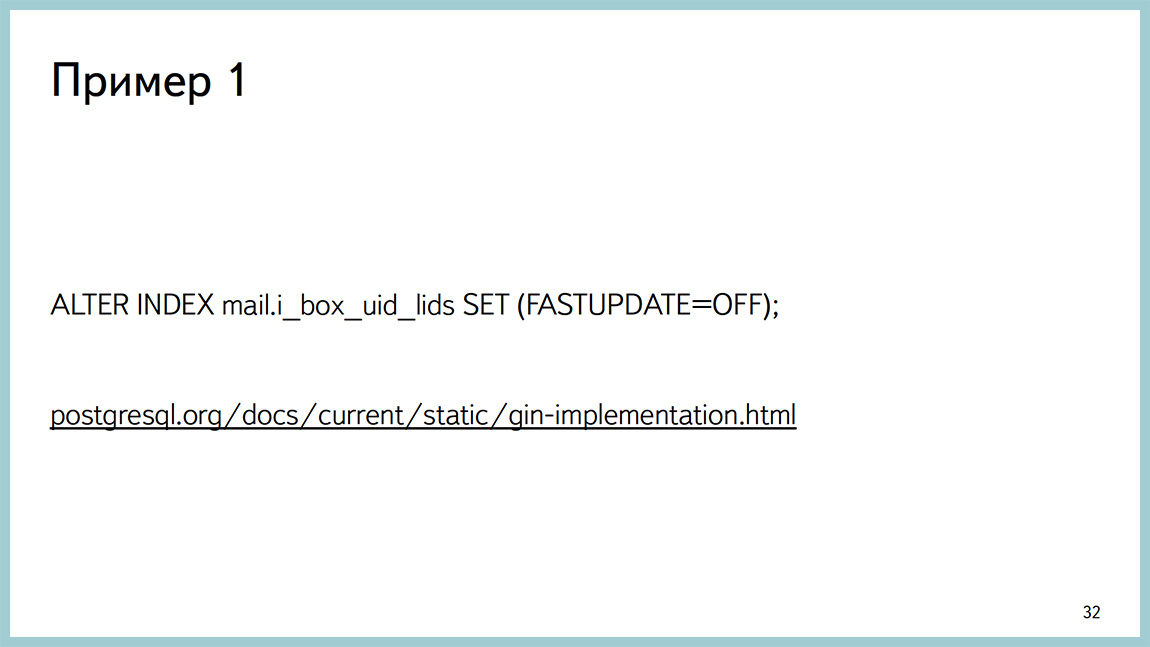
Дальше стали разбираться. Оказалось, что мы не дочитали документацию, как обычно. В 9.4 появился fastupdate для gin. Он в большинстве случаев ускоряет время вставки, но временами может приводить к недетерминированному времени самой вставки. Для нас стабильность времени важнее, чем интервал этого самого времени, условно говоря. Мы выключили fastupdate, все стало хорошо. Поэтому первая рекомендация – перед тем как писать на какую то рассылку, надо почитать документацию. Скорее всего, ответ там найдёте.

Второй пример. Снова во время стрельб мы наблюдали сканы всплески ответов до безумных значений единиц секунд. И они не коррелировали по времени ни с какими-нибудь автовакуумами, ни с чекпойнтами, ни еще с какими-либо системными процессами.
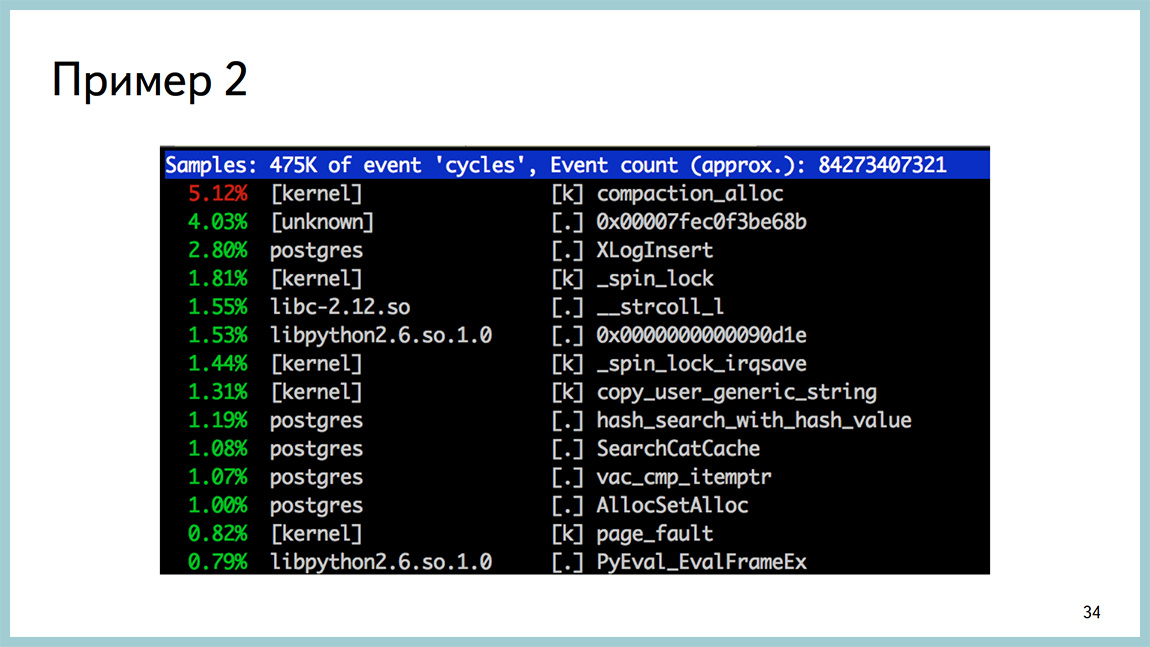
Со стороны перфа это выглядело вот так. Вверху compaction_alloc, а дальше вполне ничего необычного не было. Классическая картина потребления процессором.
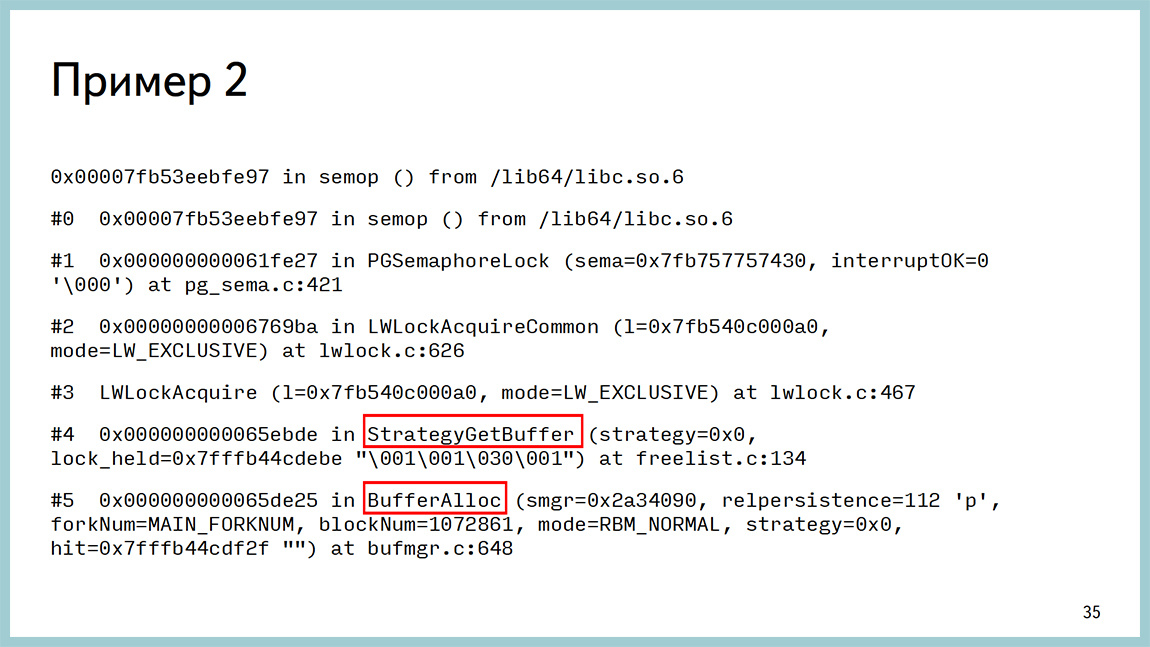
В GDB это выглядело как проблема с разделяемой памятью, но опять же, в районе буферного кеша. Важно, это стало вылазить после обновления на 9.4. В 9.3 такого не было. Стали такое ловить, потому что в 9.4 появилась поддержка huge pages, и в red hat-based операционных системах по умолчанию включены transparent huge pages и работают они отвратительно. Собственно, мы далеко не первые, кто с этой проблемой столкнулись.
Вот ссылка на “тред” с обсуждением этой проблемы. Выключили transparent huge pages, все стало лететь. Это вторая рекомендация, поле того, как чтение документации не помогло. Хотя в 95% случаев поможет. Имеет смысл поискать в интернете, скорее всего, с этой проблемой кроме вас уже кто-нибудь столкнулся.
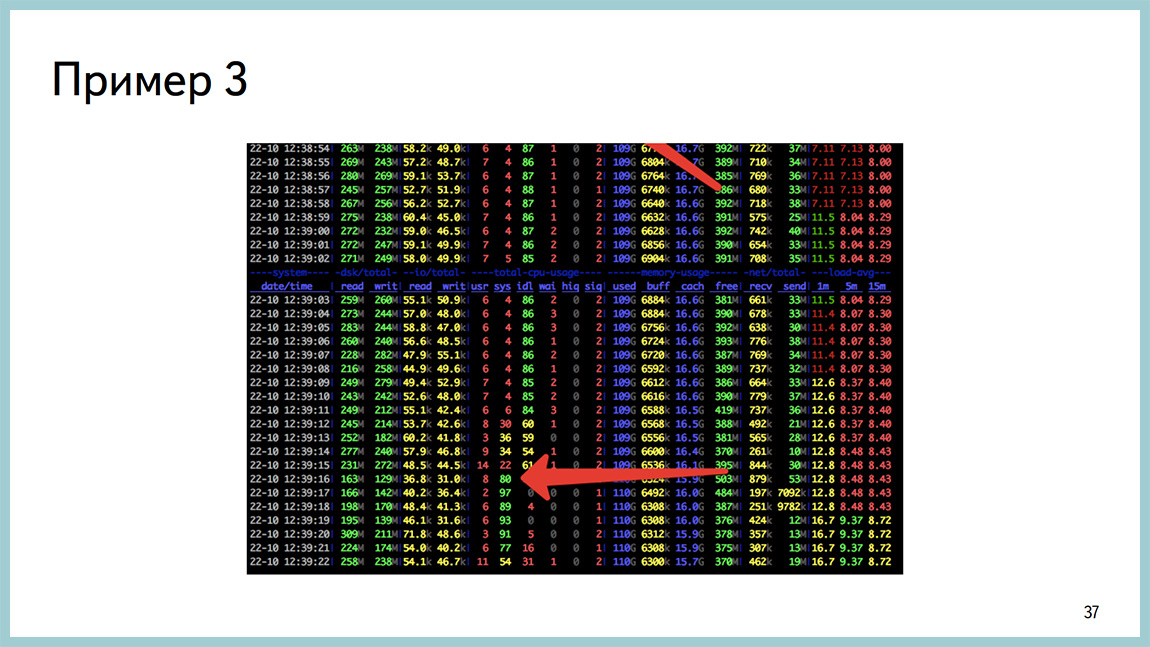
Третий пример. Та самая проблема, когда через какое-то время после увеличения дискового IO база начинает все время тратить в system. Весь процессор.
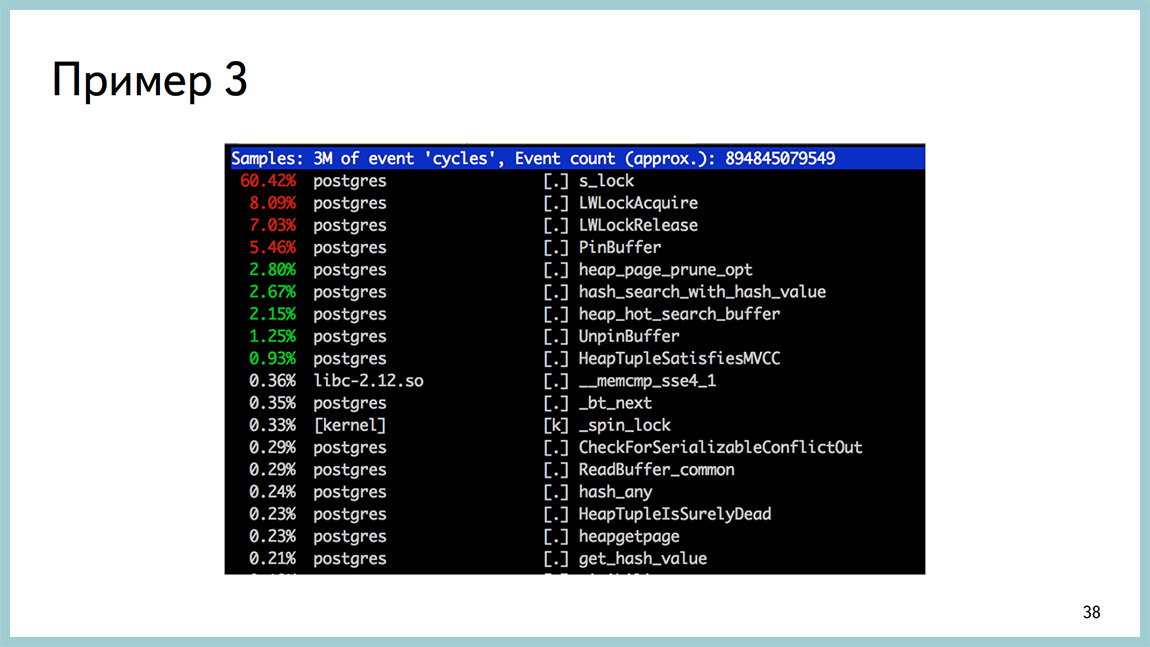
И в выводе perf это выглядит как spinlock.
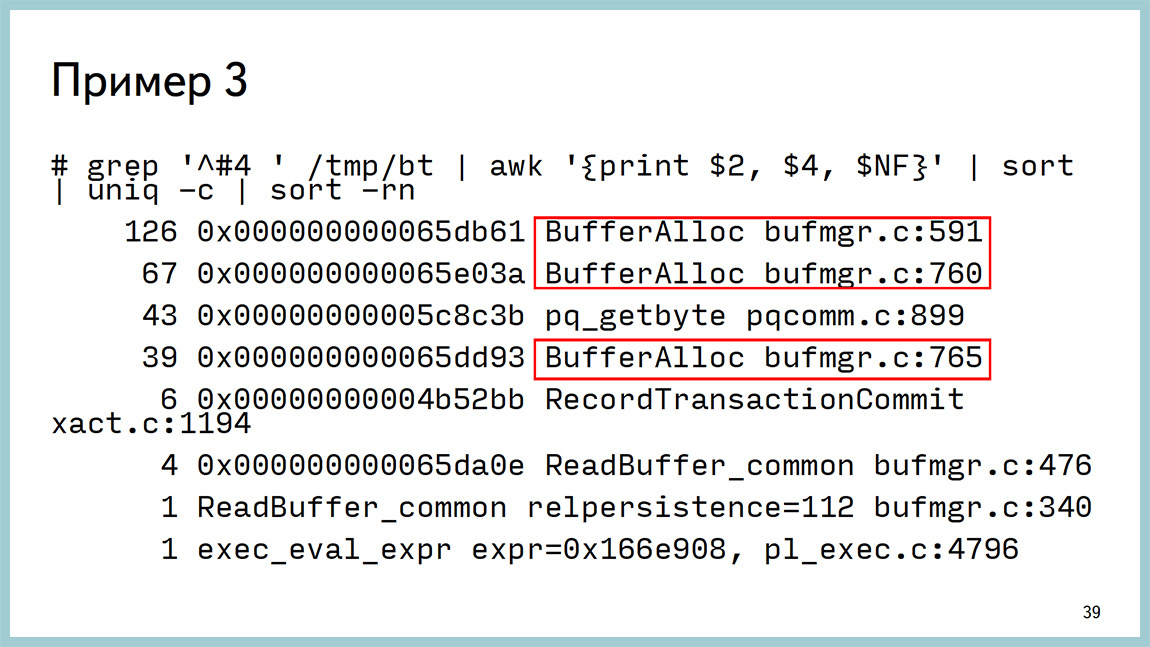
Мы наснимали некое количество backtrace’ов и дальше их проанализировали и выявили, что практически все вокруг работы с буферным кешом. Даже в исходники ходить не надо.

Классическая рекомендация в этом случае – уменьшение shared buffers. Обычно те, кто начинают работать с Postgres, отрезают под shared buffers весь доступный объем оперативной памяти. Как правило, это заканчивается плохо. Классическая рекомендация – 25% от всей памяти, но не больше 8 Гб. Собственно уменьшение до 8 Гб у вас эту проблему снимет. Но нам очень хотелось под shared buffers отрезать много, в силу каких-то причин.
Мы пошли в исходники и посмотрели, где эти строчки происходят. Увидели, что они вокруг блокировок на партиции буферного кеша. В 9.5 значение 128 будет по-умолчанию. В 9.4 все еще 16. Мы взяли и увеличили. Это уменьшило количество блокировок. Кроме того, есть в 9.5 пару патчей, о которых уже говорили. Это улучшенная производительность на многих типах нагрузки. Единственное, что эти патчи, в основном, про читающую нагрузку. Если у вас там база данных, в которой много чтений, вы может отрезать почти всю память под shared buffers и проблем, скорее всего, испытывать не будете.
Если у вас туда много записей, то вы рано или поздно с этой проблемой все равно столкнетесь. На wiki “посгресной” собираются идеи, как эту ситуацию в будущем улучшать. Собственно говоря, если внезапно чтение документации и поиск в интернете не дали вам ответ на решение вашей проблемы, имеет смысл покурить исходники и, возможно, подкрутить одну переменную, и она решит вашу проблему. Но, кажется, что это весьма в редких случаях.
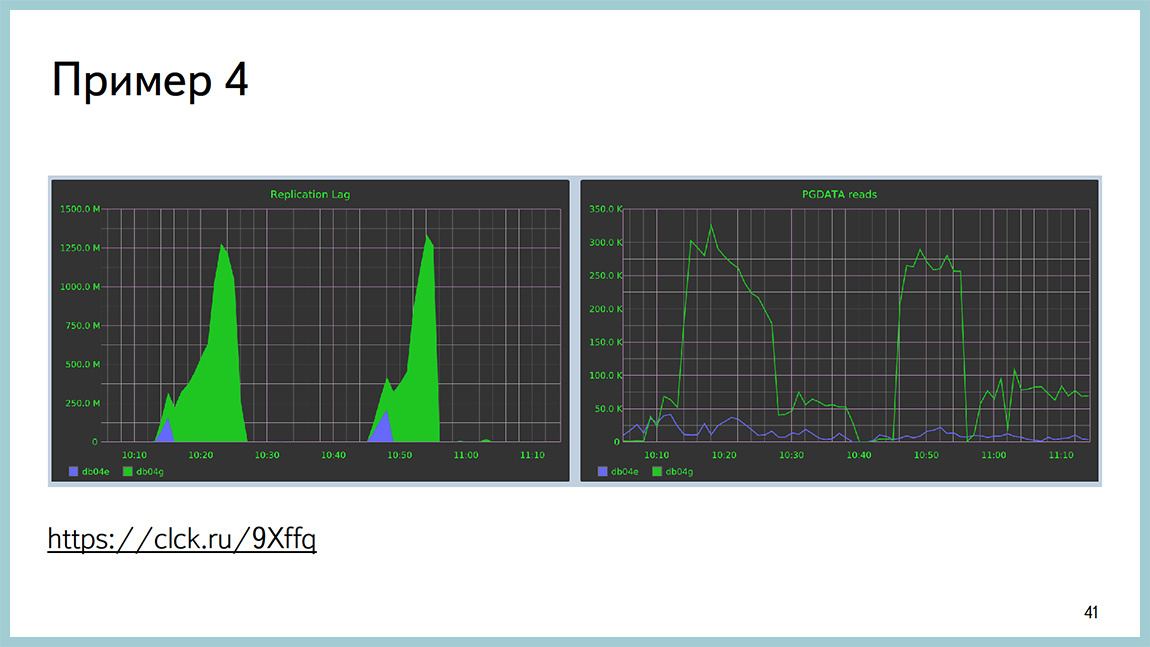
Четвёртый пример. Описание проблемы доступно по ссылке. Суть примерно следующая: большая табличка размером около миллиарда строк, большой B-tree индекс (размером 200 Гб). Вы говорите VACUUM на эту табличку, и у вас в течение 15 минут накат изменений на репликах останавливается. Речь про поточную репликацию.
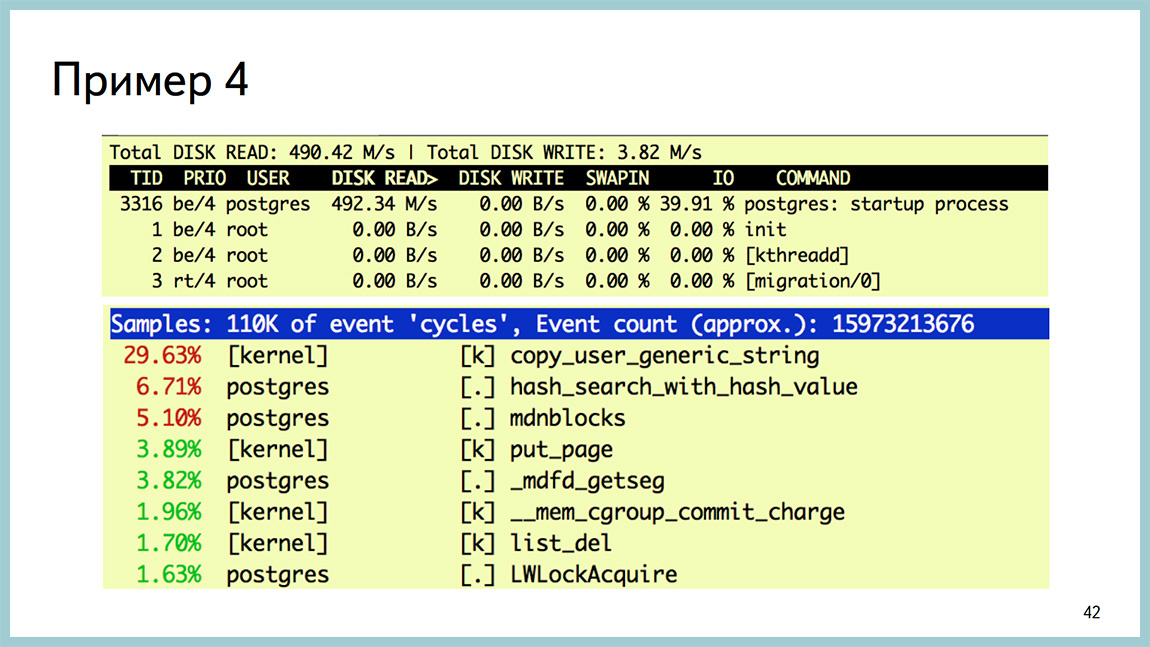
И при этом видно, что реплики начинают много читать с диска, с того раздела, где лежат сами данные. Видно, что startup процесс тот самый, который накатывает xlog’и, кушает очень много дискочтения.

Вывод перф топа в этом случае смотреть бесполезно, раз мы все проводим в ИО, а не в процессоре. В GDB это видно, что мы действительно висим на чтении с диска. Это libc’шный вызов. И с точностью до строчки кода видно, где мы это проводим. Если пойти в исходники и посмотреть, что там происходит, там прямо нерусским по белому написано, что здесь сделано не оптимально. Можно улучшить.

Ссылка на обсуждение этой проблемы, про способы ее решения. Закончилось все это патчем к Postgres’у, который позволяет отставание реплик сократить. Не убрать вообще, а сократить. Вот тут на картинке как раз две реплики. Та, что зеленая, это реплика без патча. Та, что синяя, это реплика с патчем. На графике видно отставание. А это на графике чтения с диска [прим. ред.: справа]. Объем чтения не увеличивается. Это я к тому, что если чтение документации, поиск в интернете и тупое созерцание исходников не дало вам ответ на ваш вопрос, то хорошо бы их поправить. Но, если вы не знаете C, как например, я, то для этой конкретной ситуации, когда у нас большая табличка, большой B-Tree индекс и при этом у вас там изменений мало, в основном insert-only нагрузка, ее имеет смысл секционировать и такой проблемы у вас не будет.

К этому моменту времени у вас должна возникнуть в голове следующая мысль: да они упоролись, GDB в бою, патчить исходники Постгреса, ни один нормальный DBA этим заниматься не будет. И эта мысль правильная. Мы тоже так подумали. Потому, я приглашаю сюда Ильдуса, который расскажет нам про светлое будущее, которое нас ждет.

Ильдус Курбангалиев: Всем привет. Меня зовут Ильдус. Я работаю в Postgres Professional разработчиком. На данный момент я делаю мониторинг. То есть, делаю патч для мониторинга, который позволит мониторить вот эти ожидания в Postgres. Ожидание — это как раз то, на чем упирается Postgres. Это, например, диск, сеть, “латчи”, легковесные “локи”, которые внутри происходят, или сами heavy-weight “локи”. Эти ожидания подразделяются на много подтипов. Легковесных локов может быть штук 50. Локов 9 штук. Network – может быть чтение или запись. Storage — то же самое.

Зачем нужен отдельный инструмент для мониторинга? Часто как раз, второй пункт на самом деле первый. Потому что их очень много, и с каждым отдельно надо разбираться. Желательно иметь инструмент, который их объединяет. У меня как раз такая задача стояла. Например, systemtap — хороший инструмент, но его нельзя использовать в продакшене.

Поэтому я разработал pg_stat_wait, который умеет делать профайлинг, трассировку в файл и историю ожидания. Есть специальный параметр, их можно писать и сохранять, потом отдельно читать. Профайлинг читает количество и время ожиданий по каждому ожиданию. Для отдельных процессов можно включить трассировку. Там оказывается PID процесса, имя файла, и туда пишутся все ожидания по этому процессу. Минус трассировки в том, что получается большой overhead и его нельзя использовать в онлайн режиме. Как раз профайлинг я делал так, чтобы можно было использовать в продакшене.

Здесь я написал требования, которые ставились. То есть патч должен работать в онлайн. Не сильно нагружать саму базу данных. По всем ожиданиям желательно получать точные данные. А именно, время в миллисекундах, количество и основная цель, что мы объединяем кучу инструментов в один. Во так это выглядит.
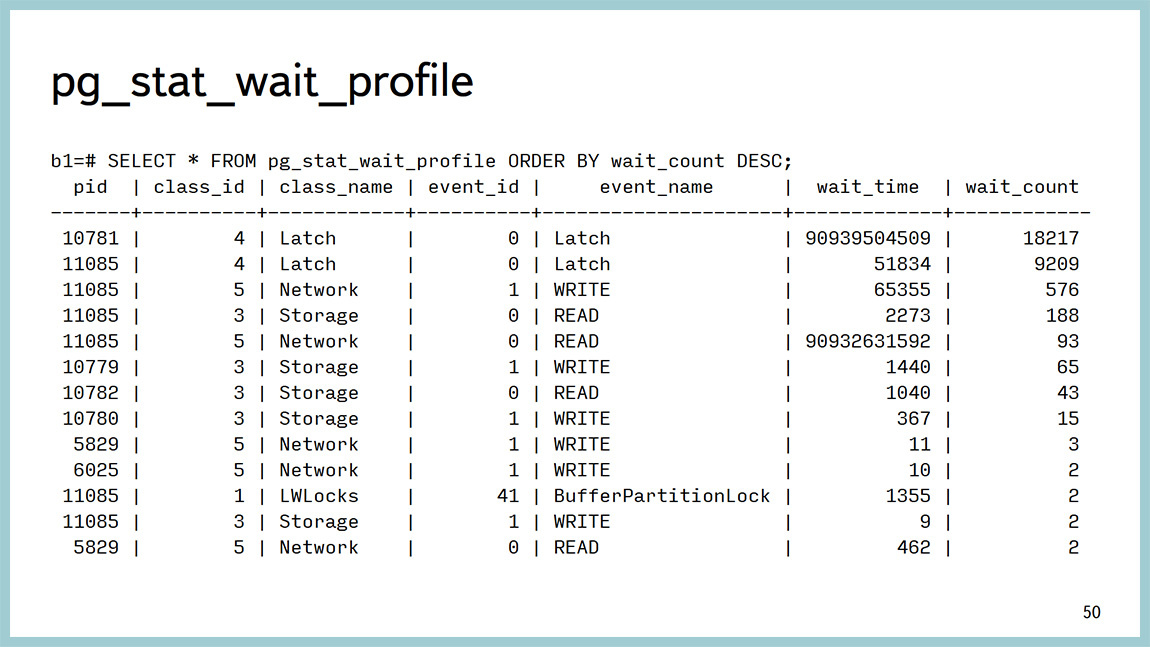
Для профайлера есть такая фишка, которая вызывает отдельную функцию, которая как раз возвращает эти данные. То есть, по каждому ожиданию как раз можно увидеть, сколько времени это заняло, количество. Можно, например, делать какие-то красивые графики, можно делать резерв, запрашивать еще раз и строить график, на котором все будет видно. Здесь видно, что основное количество времени здесь как раз на “латчах” тратится и на работу с сетью. И здесь попал один LWLock.

История выглядит таким образом. Если стоит параметр 5 тысяч, мы получаем последние 5 тысяч ожиданий, их тоже надо быстро запрашивать, потому что они быстро стираются. И мы видим как раз параметры каждого ожидания. На storage можно увидеть, какой конкретно блок пишется. И вычислить саму таблицу, которую мы выгружаем.

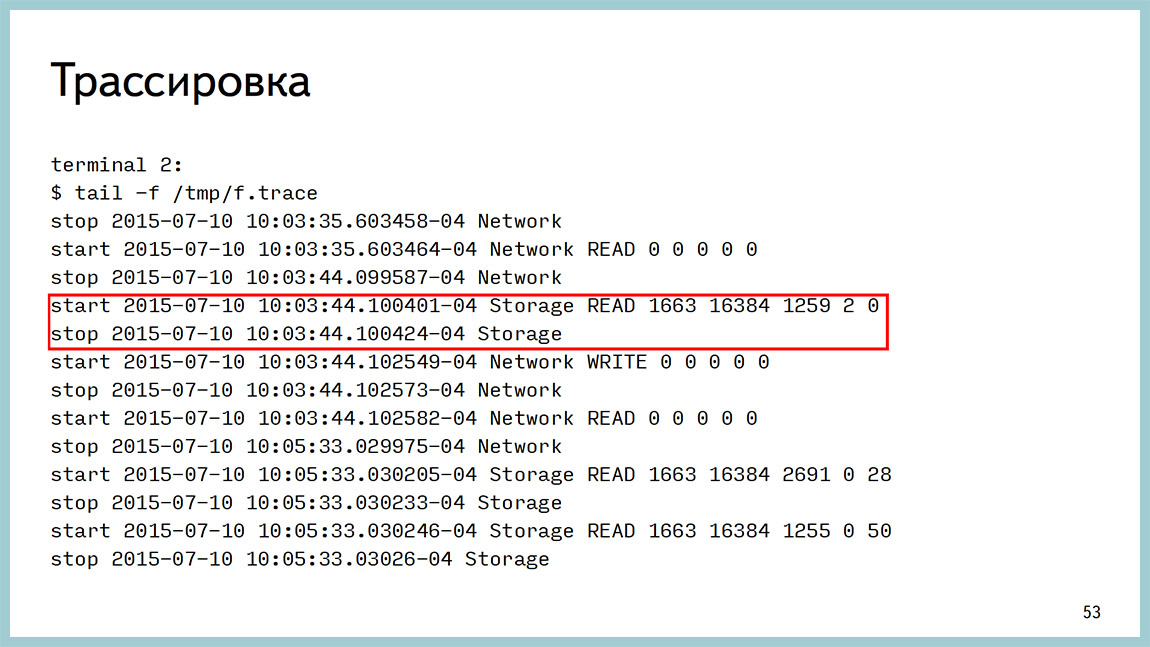
Здесь запуск трассировки: вызываем функцию (pid, file) и видим такой результат. Здесь написано, когда был старт, и когда все закончится, можно посчитать время и посмотреть куда эта запись делается.
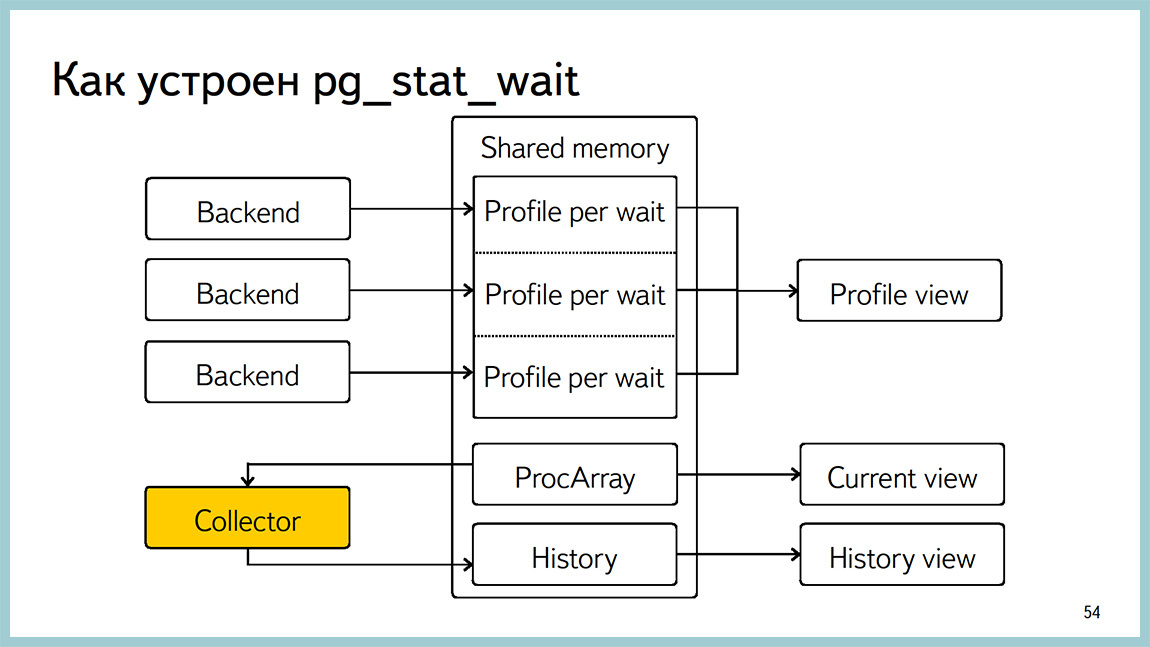
Немного о реализации. Изначально в мониторинге был только один параметр. Вот эти пять типов, и они собирались сэмплингом, и профайл делался по ним. Это оказалось не очень полезно, потому что сэмплинг, во-первых, ставит блок на список процессов. И, во-вторых, когда перебор идет, другие процессы могут ставить локи, и они пропускаются. Сейчас сделано немного по-другому. То есть каждый бекэнд собирает внутри себя агрегацию и время от времени скидывает это в shared memoery. Оттуда как раз профайл и отдается.
История собирается желтым коллектором: оно перебирает ProcArray и записывает то, что сейчас там происходит. Есть current view отдельный, которым можно увидеть, на чем висит конкретный процесс в данный момент. Все реализовано на block free алгоритмах, чтобы попытаться избежать оверхэда.
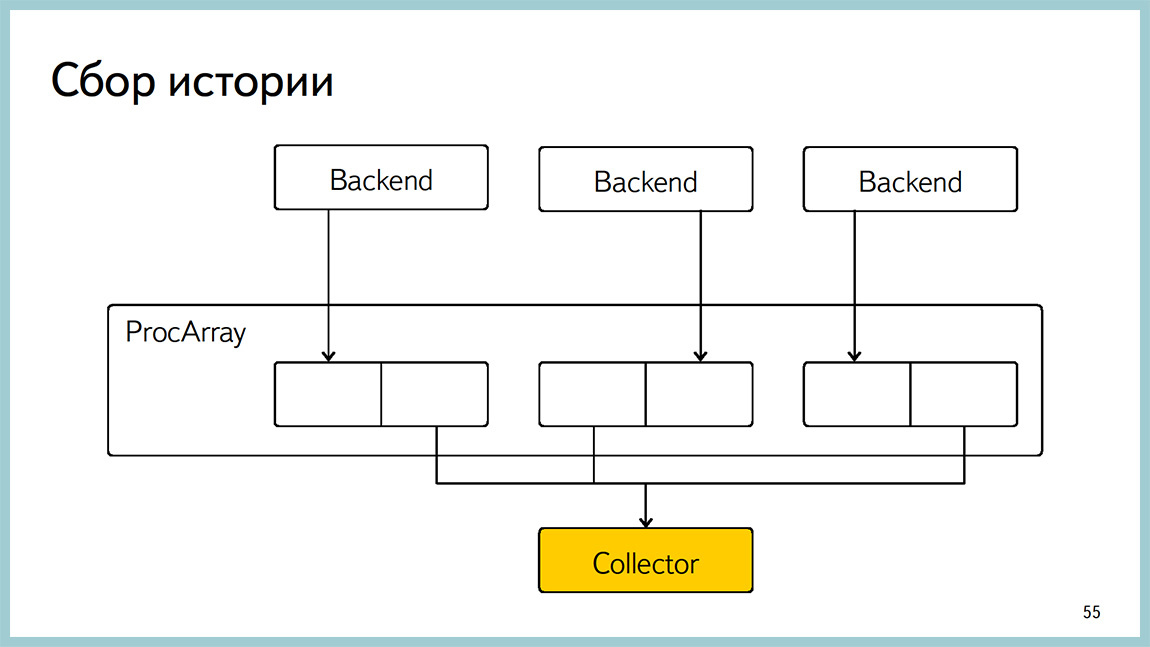
Здесь пример, как сделан такой block free алгоритм на истории. Мы держим два блока для каждого ожидания. И когда бекэнд пишет в один, мы читаем другой. И, таким образом избегаем блокировки.


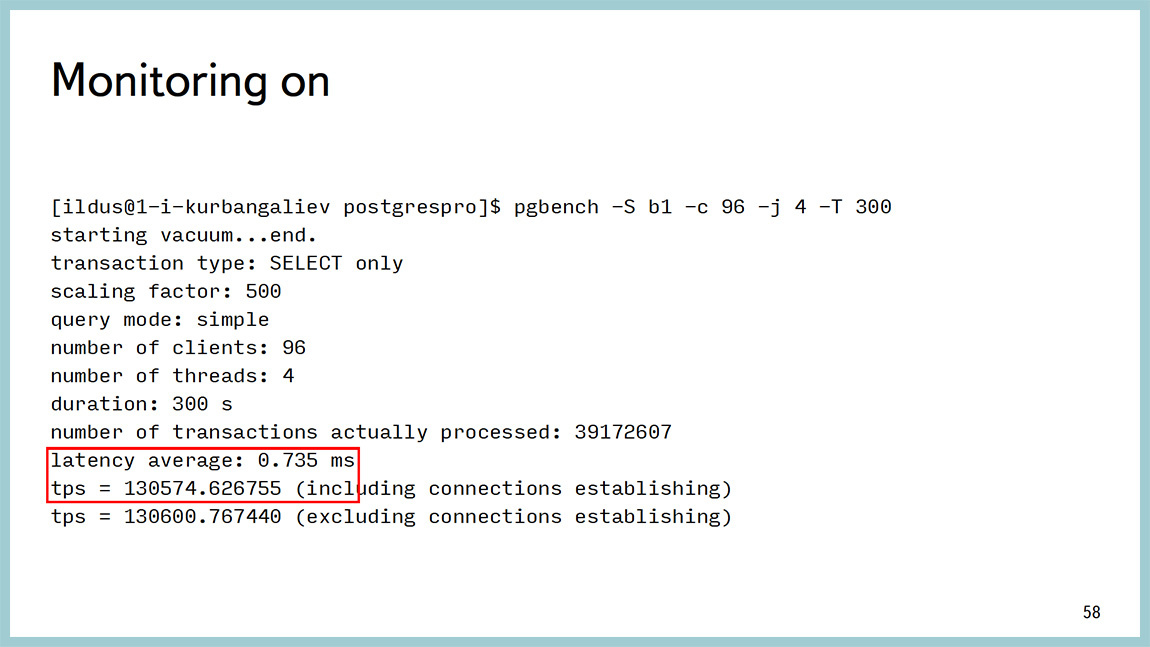
И я делал много замеров оверхеда. Эти тесты показали, что у нас оверхед получается меньше, чем, в данном случае, 0,5%. Но уточню, что тестировал это на SELECT запросах, и поэтому получается разброс результатов pg_bench. Там даже с мониторингом и без невозможно оценить оверхед. И если кто-то придумает как это сделать, буду очень благодарен. Потому что стабильный результат при записи получить очень тяжело.
Здесь код у нас открыт в open source, в gitgub есть этот проект, там можно создать issue, если вам чего-то не хватает, потестить мониторинг, у себя в базе проверить, и баги поискать тоже. Это очень полезно. Есть еще две ссылки, где можно увидеть переписку по этим вопросам, там тоже поучаствовать.

Есть примеры использования этого мониторинга. Про это расскажет Вова.
Владимир Бородин: Немного про примеры. Ильдус сказал, что можно скачать, попробовать, протестировать, поискать баги. Мы скачали, попробовали, поискали, протестировали. У нас уже в продакшен стоит на всех машинах 9.4. Патч есть для 9.4 и есть патч для текущего мастера, который сейчас толкается в upstream.
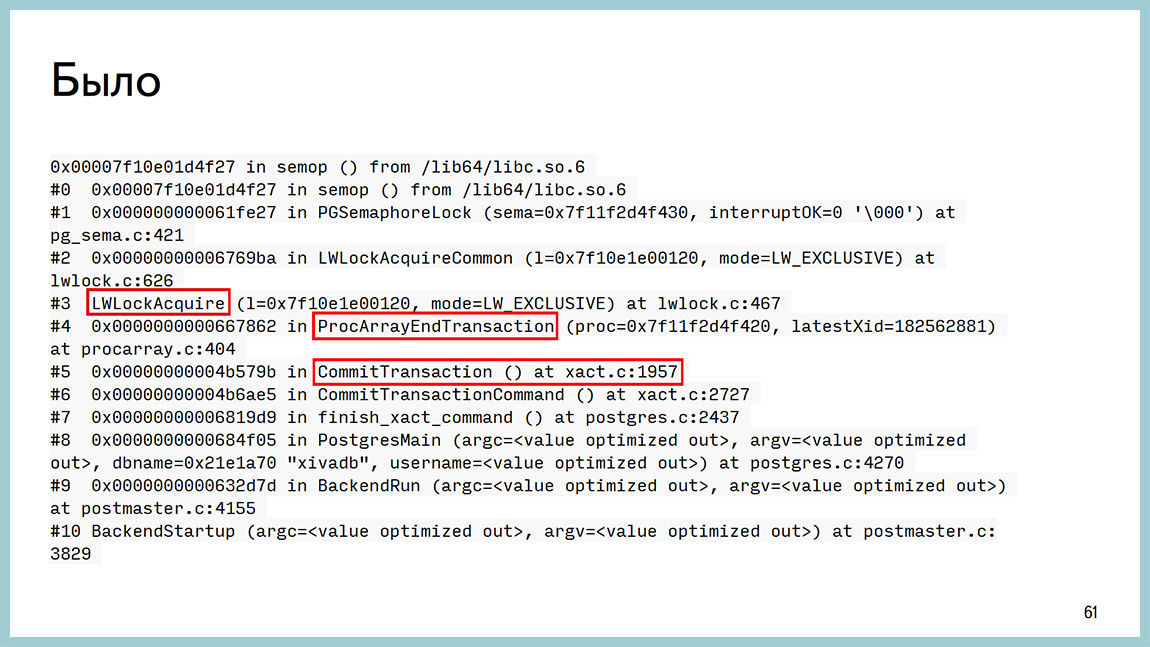
Как это было раньше? У нас есть база, которая вроде бы ни во что не упирается, но дальше больше не выдает. 20 тысяч транзакций в секунду и точка. Больше не получается. В GDB мы видели, что висит она у нас вот здесь: ProcArrayEndTransaction и получение легковесного лока. Опять же, с точностью до строчки кода, мы могли узнать, что это висит на ProcArrayLock’е. Это GDB’ой можно подключиться, поймать на конкретном бекенде и увидеть это.
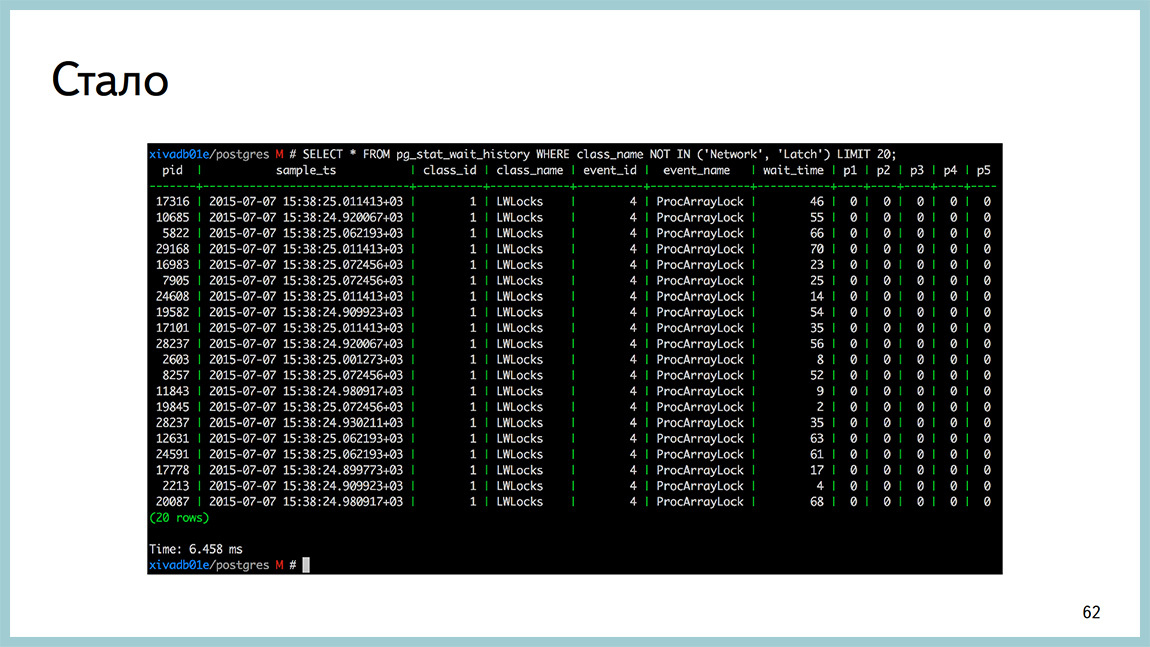
А сейчас это один SELECT запрос в pg_stat_wait_current или в pg_stat_wait_history, в зависимости от того, вы смотрите ситуацию сейчас или историю того, что было когда-то. И тут видно, что все они висят на ProcArrayLock и сколько времени они потратили в ожидании этого самого ProcArrayLock.
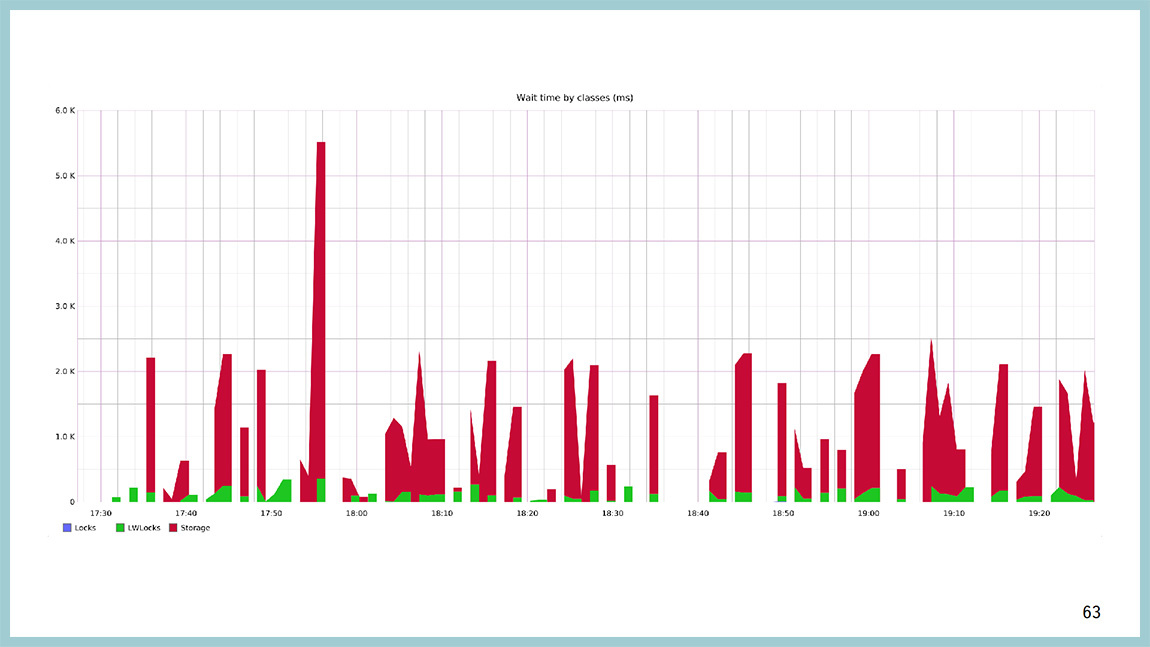
Это можно визуализировать. Это график того, сколько времени база тратит в каждом классе ожидания. Красный – это диск, зеленый – легковесные локи, синие – heavy-wait локи. Сеть и “латчи” тут выключены, потому что они, как правило, занимают очень много времени. Пока у вас бэкенд висит и ничего не делает, у него класс ожидания network, там время ожидания очень большое. Когда какой-либо чекпоинтер висит и ничего не делает, у него класс ожидания latch, и время ожидания бесконечно. Ну, не бесконечно, но очень большое. И тут очевидно, что большую часть времени база, когда чего-то ждет, она ждет дискового IO, но временами висит и на light-weight локах. По оси Y — время, которое мы ждём, а по оси Х — время календарное.
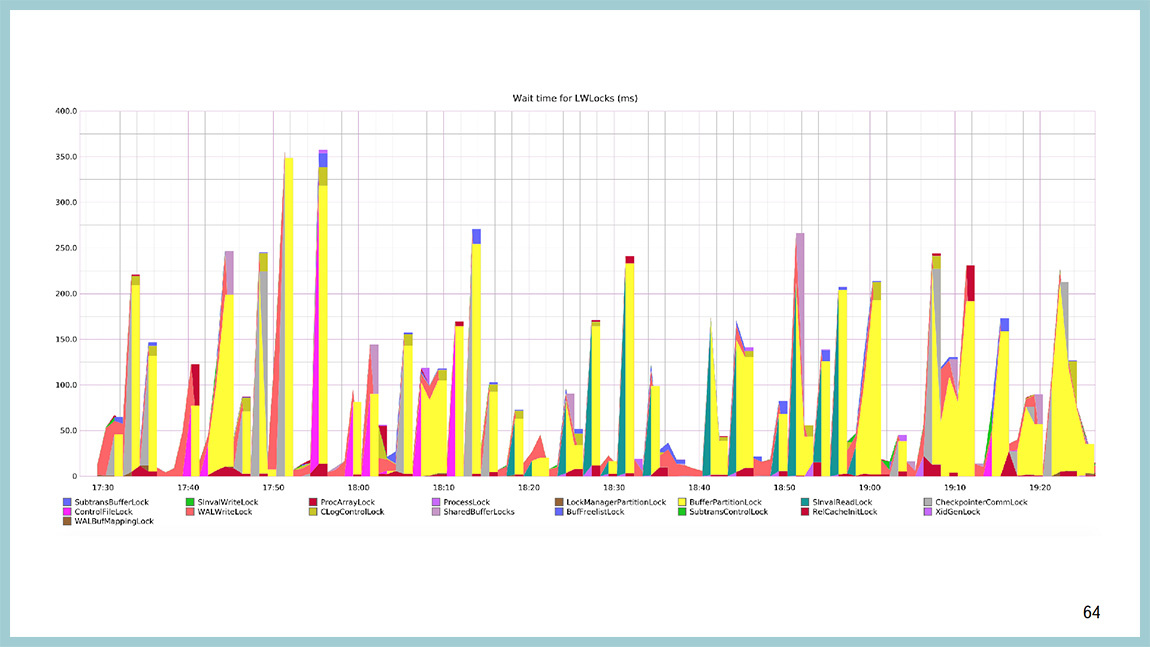
Можно такой же график построить относительно того, что происходит внутри light-weight лока. Вы увидите, что тут больше всего желтого цвета и желтый цвет – это BufferPartitionLock. Те самые блокировки и партиции буферного кеша, и не просто так мы их увеличивали с 16 до 128. Не просто так в 9.5 их сильно оптимизировали.
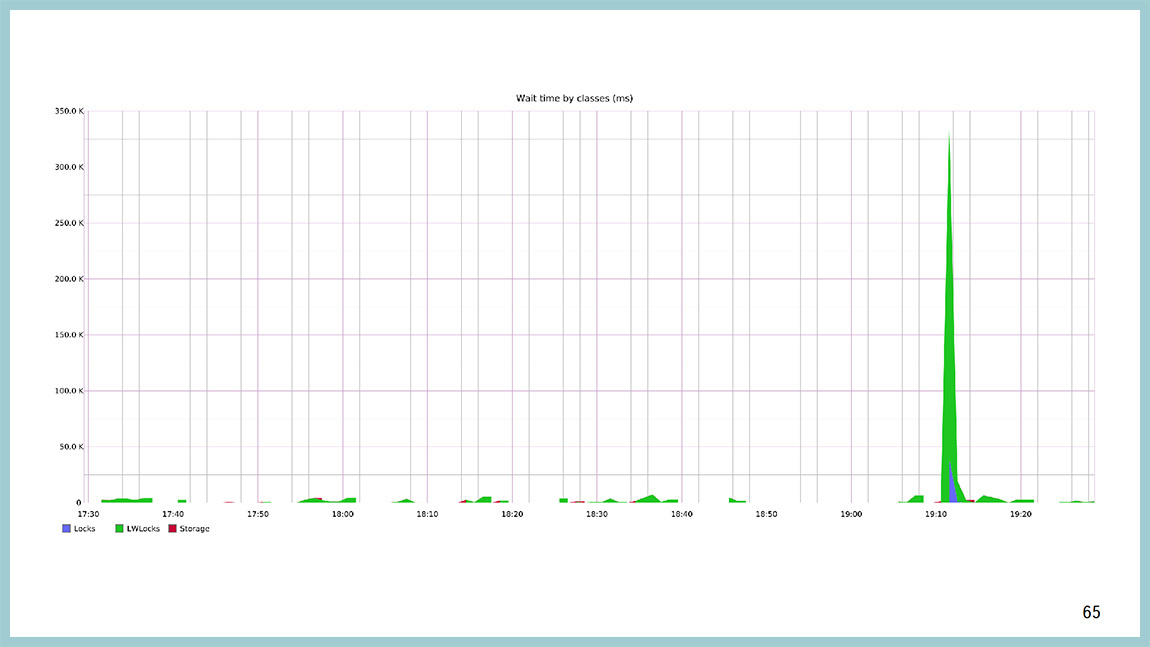
Например, вот так вот выглядит картинка классов ожидания в момент, когда в базе все стало плохо. Видно, что сначала взорвались, и мы повисли в ожидании на легковесных блокировках, а через какое-то время залочились уже на уровне строчек табличек, на heavy-weight локах.

Если посмотреть, какой light-weight локов виноват, то по идее, тут должны быть ProcArrayLock и BuffFreelistLock. Повесили на BuffFreelistLock’е, а на ProcArrayLock’и было много, потому что в момент времени создалось большое количество бекендов, новых соединений открылось, и это — нагрузка на ProcArray.
Основной источник проблемы — BuffFreelistLock, которого в 9.5 уже нет, его распилили в одной из оптимизаций.
Пора подводить итоги. Кажется, что это долгожданная фича, которая есть во многих других базах данных и значительно облегчает жизнь DBA.

Предстоящим летом на PG Day'17 специалисты из Яндекса готовят для вас сразу несколько классных докладов. Владимир Красильщик побеседует с аудиторией о Big Data, Василий Созыкин поведает эпическую историю миграции на PostgreSQL в Яндекс.Деньгах, а ведущий разработчик популярной аналитической СУБД ClickHouse Алексей Миловидов расскажет о внутреннем устройстве своего изобретения. Присоединяйтесь!
Вступление Ильи Космодемьянского: сейчас у нас будет рассказ о том, как жить, если очень хочется иметь Oracle, а его нет. На самом деле, это полезный доклад, потому что одна из проблем, которую мы сейчас имеем – это проблема средств диагностики. Средства диагностики местами не достают, местами, вместо привычных средств диагностики нужно использовать довольно сложные тулзы, которые вообще предназначены для разработчиков Linux, а не для DBA. У DBA зубы начинают болеть, когда они смотрят на эти скрипты. И вот ребята из Яндекса и PG Pro расскажут о методах диагностики Postgres, которые они применяют, как ими пользоваться и немного расскажут о том, как они собираются улучшить этот мир.
Владимир Бородин: Всем привет. Меня Вова зовут, и я админ Яндекс почты. Доклад совместный с Ильдусом, он занимается разработкой PostgreSQL в компании Postgres Pro.
Доклад про диагностику Postgres и важный в нем момент — это картинки. Первая часть доклада посвящена тому, что делать тому, что делать, если у вас сорвался мониторинг.
Куда в этом случае бежать? Взорвался мониторинг – это такая абстрактная штука, имеется ввиду, что взорвался мониторинг, связанный с базой данных.
Мы считаем Postgres хорошей базой данных. А хорошая база данных, когда у нее все плохо, то она во что-то упирается, как правило. В большинстве случаев — это какой-то системный ресурс. Ей не хватает процессора. Ей не хватает дисков или даже сети. Она вполне может упираться в heavy-weight локи, блокировки на строчки, таблички, еще чего-нибудь. Но бывают случаи, когда база упирается во что-то другое.
Немного картинок из того самого продакшена. Вот, например, htop с одной Postgres базы, которая уперлась в процессор. Load Average 200, куча сессий и весть процессор в userspace, такое бывает.
Базу также можно упереть в диски. С посгресом достаточно популярная штука. Утилизация на паре дисков близка к 100%. await огромное количество чтений с диска.
Диск умеет кончаться не только по iops или по пропускной способности, он может кончаться и по месту, к сожалению. Это картинка с базой, где кончился на разделе с xlog.
У нас бывают ситуации, когда база упирается в сеть на передаче икслогов на реплики, в архив или еще куда-нибудь на “толстые” ответы клиентам.
В случае с памятью все сложнее. Как правило, вы не увидите, что у вас проблемы именно с памятью. В зависимости от того как настроена ваша операционная система, либо вы начнете залезать в SWAP и увидите это как проблемы с дисковой активностью, либо придет OOM, убьет бекэнд, и в результате этого сложится весь Postgres.
Это все вполне хорошо диагностируется внешними по отношению к Postgres инструментами. То есть любимая top-like утилита, dstat, iostat и т.д. Я говорю, преимущественно, о Linux. В случае, если база упирается в тяжеловесные блокировки, эту информацию вполне можно посмотреть через PG locks, и есть какое-то количество запросов, которые облегчают парсинг вывода оттуда глазами. Но они собраны на Postgres-ной wiki. Собственно, пример выше показывает все красиво.
Взрыв произошел, вы во что-то уперлись. Из-за чего уперлись, черт его знает. В большинстве случаев что-то изменилось, что-нибудь выкатили, у вас увеличилась нагрузка на базу, как на этой картинке, или поехал план какого-нибудь запроса и он стал работать не так, как ожидалось.
До версии 9.4 существовал хороший инструмент pg_stat_statements. Можно посмотреть с точностью до запроса, какой из них потребляет больше всего времени. То есть, на какие запросы база тратит больше всего времени. Ну а дальше уже стандартно, explain analyze смотреть, где они это время тратят, что делают и так далее. Но время, которое база тратит на выполнение запросов, это не самый лучший показатель. Это время можно тратить на самых разных ресурсах. Можно читать с диска, можно «насиловать» процессор, можно сортировать что-то, можно ожидать какой-либо блокировки и так далее.
Начиная с 9.4, появилась отличная штука, которая называется pg_stat_kcache, которая позволяет посмотреть с точностью до запроса, в том числе потребление процессора в юзертайме, потребление процессора в системтайме. И очень крутая штука, которую она умеет – это разделение физических чтений с диска и получение данных page cache из операционной системы.
Несколько примеров. Например, запрос, который точно также выводит информацию по топовым запросам. Опять же, отсортированный по времени. Но в том числе показывает, сколько они съели процессора в системтайме, юзертайме, сколько они писали/читали с диска, сколько получили из памяти и так далее. Можно посмотреть тексты этих запросов.
Сам запрос выглядит так. Этот текст можно скопировать. Он на самом деле не такой сложный. Тут все просто. Мы забираем данные из pg_stat_statements, pg_stat_kcache и сортируем, в данном конкретном случае тоже по времени, которое база потратила на этот запрос.
Но это не самое большое преимущество pg_stat_kcache. Можно сортировать по чтениям с диска, по записи на диск, и т.д. Например, тот же самый pg_stat_statements умеет разделять shared_hit и shared_read. Это значит чтение из разделяемой памяти (shared buffers) и все остальное. И это все остальное может быть из page cache операционной системы, а может быть физически с диска. pg_stat_kcache их умеет разделять. Делает он это с помощью системного вызова getrusage(), который дёргается после каждого запроса.
Например, у нас была база, которая упиралась в диск чтениями, и мы построили такую штуку: запрос, который сортирует по физическому чтению с диска. И это уже относительные величины. Тут видно, что у нас запросы, которые в топе. У них единицы процентов доходят до диска и что-то с диска читают. Все остальное отдается либо из разделяемой памяти, либо из кеша операционной системы. То есть кеширование в этой базе работало вполне эффективно. Если вы используете 9.4, обязательно используйте pg_stat_kcache, отличная штука.
Бывают проблемы сложнее, которые вообще не детерминируются на конкретные запросы. Например, такая проблема. Берем и по первой стрелочке увеличиваем дисковое ИО. Описание полей в середине картинки. Эти два столбца, это иопсы. Увеличиваем иопсы с 10 тысяч до 100 тысяч. И через какое-то время у нас база начинает весь процессор убивать в системтайме. В этот момент времени все становится плохо и вообще непонятно, чем она занимается. И если мы посмотрим в pg_stat_statements или pg_stats_kcache, мы увидим, что в системтайме система проводит, без малого, все запросы. Это не проблема какого-то конкретного запроса.
Для диагностики того, на что тратится процессор, есть замечательная утилита perf, она полезна не для DBA и больше для разработчиков ядра, но она работает за счет семплинга, не задевает боевые процессы. Вообще не «насилует» систему. И тут видно, что большая часть времени процессора тратится в спинлоке. При этом видно, что, скорее всего, мы спинлочимся на получении легковесных блокировок. И, скорее всего, в районе работы буферного кеша. Вызвали PinBuffer, UnpinBuffer, ReadBuffer и так далее. Глядя в такой вывод perf top, можно понять, где тратится процесс в системтайме или предположить, где именно внутри базы он тратится.
Бывают ситуации хуже, когда мы видим тот же самый спинлок, но при этом вообще ничего непонятно, откуда у нас этот спинлок и что с ним дальше делать.
Тут должна быть мем-картинка. Нам можно залезать глубже, смотреть, что там происходит и во что мы уперлись.
Есть некое количество инструментов для этого. Один из них — это dtrace и systemtap (в случае линукса). Его преимущество в том, что посмотреть им можно буквально все. Но для этого нужно немного кода написать. Это первое. Второе, нужно пересобирать Postgres для того, чтобы systemtap мог в него залазить. И самая большая проблема – это то, что systemtap неприменим при любых условиях. Его можно использовать на стендах для нагрузочного тестирования. Потому что работает он не всегда стабильно и может вам сложить “продакшен”. У нас такое несколько раз происходило. На правах рекламы, в “бложике” я писал про дебаг ситуации с помощью systemtap.
Другой инструмент — это классический отладчик GDB, и его мы используем. Очень просто он цепляется к процессу, снимает бэктрейс с потоков, в случае Postgres — один процесс, один поток. Поэтому просто снимаем бектрейс. И отцепляется от процессора.
Вывод выглядит следующим образом. Из него видно, что мы висим на ожидании легковесной блокировки (light-weight lock) в районе работы с буферным кешом и непросто где-то там, а вот на конкретной строчке исходников. Мы можем пойти в исходники на 591 строку bufmgr.c и посмотреть, что там происходит. Даже, если вы не знаете С, там вполне хорошие комментарии и можно понять, где и что происходит.
Единственное, что у GDB есть неприятный недостаток. Если вы прицепитесь к процессу и скажите ctrl+C, то до процесса долетит не SIGTERM или SIGQUIT, а долетит SIGKILL, и вам это Postgres сложит. Поэтому мы написали совсем тупую обвязку. Она просто все те сигналы, которые вы посылаете этой обвязке, до GDB не досылает. Соответственно, до посгресных бекендов оно тоже не долетает.
Обвязка позволяет нам снимать стектрейсы с посгресного бекенда, и дальше в них глазами пялиться и понимать, что там происходит. Из плюсов то, что она стабильно работает и не задевает “бой”. Для того, чтобы это работало, вам не надо ничего пересобирать. Вам просто нужно поставить пакеты debuginfo: postgresql-debuginfo, libc-debuginfo, kernel-debuginfo, и будет вам счастье. Важно, оно дает с точностью до строчки кода понимание, где именно бекэнды проводят время.
Вторая часть презентации посвящена тому, что делать, когда вы не наступили какую-то проблему производительности, она у вас уверенно воспроизводится. Вы не знаете, как ее дальше лечить. И вам подсказывают, что надо было бы написать в рассылку и спросить, что делать. Но перед тем, как писать в рассылку, можно насобирать побольше диагностики.
Несколько примеров. Например, у нас была такая ситуация. Мы стреляли в базу, которая упиралась в процессор. Тут на второй картинке видно, что жёлтенькое — это процессор в userspace, он весь, без малого, съеден. При этом, на такой профильной нагрузке у нас возникали интервалы времени до двух минут, когда база вообще не обрабатывала нагрузку. Все стояло колом. Всплесков со стороны операционной системы видно не было.
На выводе perftop тоже ничего такого, что бросалось бы в глаза тоже не было. Единственное, на что мы обратили внимание на тот момент времени, что, когда появляется этот провал в выводе, то появляются вызовы работы с gin. При том, что там совсем небольшие объемы времени на это тратятся. Но вот как только провал, они появляются. Как только все становится хорошо, они исчезают. У нас был в этой базе один gin-индекс. В первую очередь мы его выключили и выключили запрос, который этот gin-индекс использовал, и увидели, что все стало хорошо.
Дальше стали разбираться. Оказалось, что мы не дочитали документацию, как обычно. В 9.4 появился fastupdate для gin. Он в большинстве случаев ускоряет время вставки, но временами может приводить к недетерминированному времени самой вставки. Для нас стабильность времени важнее, чем интервал этого самого времени, условно говоря. Мы выключили fastupdate, все стало хорошо. Поэтому первая рекомендация – перед тем как писать на какую то рассылку, надо почитать документацию. Скорее всего, ответ там найдёте.
Второй пример. Снова во время стрельб мы наблюдали сканы всплески ответов до безумных значений единиц секунд. И они не коррелировали по времени ни с какими-нибудь автовакуумами, ни с чекпойнтами, ни еще с какими-либо системными процессами.
Со стороны перфа это выглядело вот так. Вверху compaction_alloc, а дальше вполне ничего необычного не было. Классическая картина потребления процессором.
В GDB это выглядело как проблема с разделяемой памятью, но опять же, в районе буферного кеша. Важно, это стало вылазить после обновления на 9.4. В 9.3 такого не было. Стали такое ловить, потому что в 9.4 появилась поддержка huge pages, и в red hat-based операционных системах по умолчанию включены transparent huge pages и работают они отвратительно. Собственно, мы далеко не первые, кто с этой проблемой столкнулись.
Вот ссылка на “тред” с обсуждением этой проблемы. Выключили transparent huge pages, все стало лететь. Это вторая рекомендация, поле того, как чтение документации не помогло. Хотя в 95% случаев поможет. Имеет смысл поискать в интернете, скорее всего, с этой проблемой кроме вас уже кто-нибудь столкнулся.
Третий пример. Та самая проблема, когда через какое-то время после увеличения дискового IO база начинает все время тратить в system. Весь процессор.
И в выводе perf это выглядит как spinlock.
Мы наснимали некое количество backtrace’ов и дальше их проанализировали и выявили, что практически все вокруг работы с буферным кешом. Даже в исходники ходить не надо.
Классическая рекомендация в этом случае – уменьшение shared buffers. Обычно те, кто начинают работать с Postgres, отрезают под shared buffers весь доступный объем оперативной памяти. Как правило, это заканчивается плохо. Классическая рекомендация – 25% от всей памяти, но не больше 8 Гб. Собственно уменьшение до 8 Гб у вас эту проблему снимет. Но нам очень хотелось под shared buffers отрезать много, в силу каких-то причин.
Мы пошли в исходники и посмотрели, где эти строчки происходят. Увидели, что они вокруг блокировок на партиции буферного кеша. В 9.5 значение 128 будет по-умолчанию. В 9.4 все еще 16. Мы взяли и увеличили. Это уменьшило количество блокировок. Кроме того, есть в 9.5 пару патчей, о которых уже говорили. Это улучшенная производительность на многих типах нагрузки. Единственное, что эти патчи, в основном, про читающую нагрузку. Если у вас там база данных, в которой много чтений, вы может отрезать почти всю память под shared buffers и проблем, скорее всего, испытывать не будете.
Если у вас туда много записей, то вы рано или поздно с этой проблемой все равно столкнетесь. На wiki “посгресной” собираются идеи, как эту ситуацию в будущем улучшать. Собственно говоря, если внезапно чтение документации и поиск в интернете не дали вам ответ на решение вашей проблемы, имеет смысл покурить исходники и, возможно, подкрутить одну переменную, и она решит вашу проблему. Но, кажется, что это весьма в редких случаях.
Четвёртый пример. Описание проблемы доступно по ссылке. Суть примерно следующая: большая табличка размером около миллиарда строк, большой B-tree индекс (размером 200 Гб). Вы говорите VACUUM на эту табличку, и у вас в течение 15 минут накат изменений на репликах останавливается. Речь про поточную репликацию.
И при этом видно, что реплики начинают много читать с диска, с того раздела, где лежат сами данные. Видно, что startup процесс тот самый, который накатывает xlog’и, кушает очень много дискочтения.
Вывод перф топа в этом случае смотреть бесполезно, раз мы все проводим в ИО, а не в процессоре. В GDB это видно, что мы действительно висим на чтении с диска. Это libc’шный вызов. И с точностью до строчки кода видно, где мы это проводим. Если пойти в исходники и посмотреть, что там происходит, там прямо нерусским по белому написано, что здесь сделано не оптимально. Можно улучшить.
Ссылка на обсуждение этой проблемы, про способы ее решения. Закончилось все это патчем к Postgres’у, который позволяет отставание реплик сократить. Не убрать вообще, а сократить. Вот тут на картинке как раз две реплики. Та, что зеленая, это реплика без патча. Та, что синяя, это реплика с патчем. На графике видно отставание. А это на графике чтения с диска [прим. ред.: справа]. Объем чтения не увеличивается. Это я к тому, что если чтение документации, поиск в интернете и тупое созерцание исходников не дало вам ответ на ваш вопрос, то хорошо бы их поправить. Но, если вы не знаете C, как например, я, то для этой конкретной ситуации, когда у нас большая табличка, большой B-Tree индекс и при этом у вас там изменений мало, в основном insert-only нагрузка, ее имеет смысл секционировать и такой проблемы у вас не будет.
К этому моменту времени у вас должна возникнуть в голове следующая мысль: да они упоролись, GDB в бою, патчить исходники Постгреса, ни один нормальный DBA этим заниматься не будет. И эта мысль правильная. Мы тоже так подумали. Потому, я приглашаю сюда Ильдуса, который расскажет нам про светлое будущее, которое нас ждет.
Ильдус Курбангалиев: Всем привет. Меня зовут Ильдус. Я работаю в Postgres Professional разработчиком. На данный момент я делаю мониторинг. То есть, делаю патч для мониторинга, который позволит мониторить вот эти ожидания в Postgres. Ожидание — это как раз то, на чем упирается Postgres. Это, например, диск, сеть, “латчи”, легковесные “локи”, которые внутри происходят, или сами heavy-weight “локи”. Эти ожидания подразделяются на много подтипов. Легковесных локов может быть штук 50. Локов 9 штук. Network – может быть чтение или запись. Storage — то же самое.
Зачем нужен отдельный инструмент для мониторинга? Часто как раз, второй пункт на самом деле первый. Потому что их очень много, и с каждым отдельно надо разбираться. Желательно иметь инструмент, который их объединяет. У меня как раз такая задача стояла. Например, systemtap — хороший инструмент, но его нельзя использовать в продакшене.
Поэтому я разработал pg_stat_wait, который умеет делать профайлинг, трассировку в файл и историю ожидания. Есть специальный параметр, их можно писать и сохранять, потом отдельно читать. Профайлинг читает количество и время ожиданий по каждому ожиданию. Для отдельных процессов можно включить трассировку. Там оказывается PID процесса, имя файла, и туда пишутся все ожидания по этому процессу. Минус трассировки в том, что получается большой overhead и его нельзя использовать в онлайн режиме. Как раз профайлинг я делал так, чтобы можно было использовать в продакшене.
Здесь я написал требования, которые ставились. То есть патч должен работать в онлайн. Не сильно нагружать саму базу данных. По всем ожиданиям желательно получать точные данные. А именно, время в миллисекундах, количество и основная цель, что мы объединяем кучу инструментов в один. Во так это выглядит.
Для профайлера есть такая фишка, которая вызывает отдельную функцию, которая как раз возвращает эти данные. То есть, по каждому ожиданию как раз можно увидеть, сколько времени это заняло, количество. Можно, например, делать какие-то красивые графики, можно делать резерв, запрашивать еще раз и строить график, на котором все будет видно. Здесь видно, что основное количество времени здесь как раз на “латчах” тратится и на работу с сетью. И здесь попал один LWLock.
История выглядит таким образом. Если стоит параметр 5 тысяч, мы получаем последние 5 тысяч ожиданий, их тоже надо быстро запрашивать, потому что они быстро стираются. И мы видим как раз параметры каждого ожидания. На storage можно увидеть, какой конкретно блок пишется. И вычислить саму таблицу, которую мы выгружаем.
Здесь запуск трассировки: вызываем функцию (pid, file) и видим такой результат. Здесь написано, когда был старт, и когда все закончится, можно посчитать время и посмотреть куда эта запись делается.
Немного о реализации. Изначально в мониторинге был только один параметр. Вот эти пять типов, и они собирались сэмплингом, и профайл делался по ним. Это оказалось не очень полезно, потому что сэмплинг, во-первых, ставит блок на список процессов. И, во-вторых, когда перебор идет, другие процессы могут ставить локи, и они пропускаются. Сейчас сделано немного по-другому. То есть каждый бекэнд собирает внутри себя агрегацию и время от времени скидывает это в shared memoery. Оттуда как раз профайл и отдается.
История собирается желтым коллектором: оно перебирает ProcArray и записывает то, что сейчас там происходит. Есть current view отдельный, которым можно увидеть, на чем висит конкретный процесс в данный момент. Все реализовано на block free алгоритмах, чтобы попытаться избежать оверхэда.
Здесь пример, как сделан такой block free алгоритм на истории. Мы держим два блока для каждого ожидания. И когда бекэнд пишет в один, мы читаем другой. И, таким образом избегаем блокировки.
И я делал много замеров оверхеда. Эти тесты показали, что у нас оверхед получается меньше, чем, в данном случае, 0,5%. Но уточню, что тестировал это на SELECT запросах, и поэтому получается разброс результатов pg_bench. Там даже с мониторингом и без невозможно оценить оверхед. И если кто-то придумает как это сделать, буду очень благодарен. Потому что стабильный результат при записи получить очень тяжело.
Здесь код у нас открыт в open source, в gitgub есть этот проект, там можно создать issue, если вам чего-то не хватает, потестить мониторинг, у себя в базе проверить, и баги поискать тоже. Это очень полезно. Есть еще две ссылки, где можно увидеть переписку по этим вопросам, там тоже поучаствовать.
Есть примеры использования этого мониторинга. Про это расскажет Вова.
Владимир Бородин: Немного про примеры. Ильдус сказал, что можно скачать, попробовать, протестировать, поискать баги. Мы скачали, попробовали, поискали, протестировали. У нас уже в продакшен стоит на всех машинах 9.4. Патч есть для 9.4 и есть патч для текущего мастера, который сейчас толкается в upstream.
Как это было раньше? У нас есть база, которая вроде бы ни во что не упирается, но дальше больше не выдает. 20 тысяч транзакций в секунду и точка. Больше не получается. В GDB мы видели, что висит она у нас вот здесь: ProcArrayEndTransaction и получение легковесного лока. Опять же, с точностью до строчки кода, мы могли узнать, что это висит на ProcArrayLock’е. Это GDB’ой можно подключиться, поймать на конкретном бекенде и увидеть это.
А сейчас это один SELECT запрос в pg_stat_wait_current или в pg_stat_wait_history, в зависимости от того, вы смотрите ситуацию сейчас или историю того, что было когда-то. И тут видно, что все они висят на ProcArrayLock и сколько времени они потратили в ожидании этого самого ProcArrayLock.
Это можно визуализировать. Это график того, сколько времени база тратит в каждом классе ожидания. Красный – это диск, зеленый – легковесные локи, синие – heavy-wait локи. Сеть и “латчи” тут выключены, потому что они, как правило, занимают очень много времени. Пока у вас бэкенд висит и ничего не делает, у него класс ожидания network, там время ожидания очень большое. Когда какой-либо чекпоинтер висит и ничего не делает, у него класс ожидания latch, и время ожидания бесконечно. Ну, не бесконечно, но очень большое. И тут очевидно, что большую часть времени база, когда чего-то ждет, она ждет дискового IO, но временами висит и на light-weight локах. По оси Y — время, которое мы ждём, а по оси Х — время календарное.
Можно такой же график построить относительно того, что происходит внутри light-weight лока. Вы увидите, что тут больше всего желтого цвета и желтый цвет – это BufferPartitionLock. Те самые блокировки и партиции буферного кеша, и не просто так мы их увеличивали с 16 до 128. Не просто так в 9.5 их сильно оптимизировали.
Например, вот так вот выглядит картинка классов ожидания в момент, когда в базе все стало плохо. Видно, что сначала взорвались, и мы повисли в ожидании на легковесных блокировках, а через какое-то время залочились уже на уровне строчек табличек, на heavy-weight локах.
Если посмотреть, какой light-weight локов виноват, то по идее, тут должны быть ProcArrayLock и BuffFreelistLock. Повесили на BuffFreelistLock’е, а на ProcArrayLock’и было много, потому что в момент времени создалось большое количество бекендов, новых соединений открылось, и это — нагрузка на ProcArray.
Основной источник проблемы — BuffFreelistLock, которого в 9.5 уже нет, его распилили в одной из оптимизаций.
Пора подводить итоги. Кажется, что это долгожданная фича, которая есть во многих других базах данных и значительно облегчает жизнь DBA.
Предстоящим летом на PG Day'17 специалисты из Яндекса готовят для вас сразу несколько классных докладов. Владимир Красильщик побеседует с аудиторией о Big Data, Василий Созыкин поведает эпическую историю миграции на PostgreSQL в Яндекс.Деньгах, а ведущий разработчик популярной аналитической СУБД ClickHouse Алексей Миловидов расскажет о внутреннем устройстве своего изобретения. Присоединяйтесь!
Поделиться с друзьями
Комментарии (8)

Andronas
01.06.2017 11:20Интересная тема, особенно про патч pg_stat_wait, но автор так и не ответил на вопрос про включение патча в PostgreSQL :(
cleaner_it
Большое спасибо вам за транскрипцию доклада!