
За это время много чего произошло, и я хочу поделиться с вами новостями. Три месяца назад GVFS был только мечтой. Не в том смысле, что его не существовало — у нас была готовая реализация — но в том, что он еще не показал себя в деле. Мы опробовали его на больших репозиториях, но не успели внедрить в рабочий процесс для сколько-нибудь значимого количества разработчиков. Поэтому у нас было только умозрительное убеждение, что все будет работать. Теперь же у нас есть подтверждение этому.

Сегодня я хотел быть представить результаты. Кроме того, мы озвучим для пользователей следующие шаги, которые планируем предпринять в целях развития GVFS: в частности, добавление возможности вносить свой вклад в открытый код и улучшение функционала в соответствии с потребностями нашей компании, партнеров и клиентов.
Windows на Git: прямая трансляция
За эти три месяца мы практически завершили процесс внедрения Git/GVFS для команды, работающей с Windows в Microsoft.
Если в двух словах: кодовая база Windows состоит из 3.5 миллионов файлов; когда заливаешь ее на Git, получается репозиторий размером где-то в 300 гигабайт. Более того, в компании работает около 4000 инженеров; инженерная система ежедневно производит 1,760 сборок по 440 веткам, вдобавок к pull-запросам на валидацию билдов. Все эти три обстоятельства (количество файлов, размер репозитория, темп работы) сильно усложняют дело даже по отдельности, а взятые вместе делают обеспечение позитивного опыта невероятно сложной задачей. До перехода на Git мы пользовались Source Depot и код был распределен по 40 с лишним репозиториям, у нас даже был специальный инструмент, чтобы управлять операциями.
На момент выхода моей первой статьи три месяца назад весь наш код хранился в одном Git репозитории, которым пользовались несколько сотен программистов для обработки очень скромного процента билдов (менее 10%). С тех пор мы в несколько этапов выкатили проект для всего инженерного состава.
Первый, и самый массовый, скачок произошел 22 марта, когда мы перевели на новую систему всю команду Windows OneCore целиком — а это около 2000 человек. Эти 2000 инженеров еще в пятницу работали с Source Depot, а вернувшись в офис после выходных, обнаружили, что их ждет радикально новый опыт с Git. Все выходные моя команда просидела скрестив пальцы и молясь, чтобы в понедельник нас не разорвала разъяренная толпа инженеров, у которых застопорилась вся работа. На самом деле, команда Windows очень хорошо продумала запасные планы на случай, если что-то пойдет не так; к счастью, нам не пришлось к ним прибегнуть.
Но все прошло неожиданно гладко и разработчики с первого же дня сумели приспособиться к новым условиям без ущерба продуктивности — честно говоря, я даже удивился. Несомненно, возникали и сложности. К примеру, команде Windows из-за ее огромных размеров и специфики работы, часто приходилось производить слияние ОЧЕНЬ крупных ветвей (речь идет о десятках тысяч изменений и тысячах конфликтов). Уже в первую неделю стало ясно, что наш интерфейс для pull-запросов и разрешения конфликтов слияния просто не приспособлен для таких масштабных изменений. Пришлось в срочном порядке виртуализировать списки и получать данные командой fetch поэтапно, чтобы интерфейс не подвисал. Через пару дней мы с этим справились и, в целом, неделя прошла на более позитивной ноте, чем мы рассчитывали.
Один из способов, которые мы использовали, чтобы оценить успешность всего мероприятия — это опрос инженеров. Главный вопрос, который мы им задали — это «Довольны ли вы?», хотя, конечно, не забыли расспросить и о подробностях. Первый опрос состоялся через недели после запуска проекта и показал следующие результаты:

(Полностью довольны: 54;
Скорее довольны: 126;
Скорее недовольны: 54;
Крайне недовольны: 17)
Показатели не такие, чтобы запрыгать от радости, но учитывая, что у команды только что, можно сказать, мир перевернулся, им пришлось учиться работать по новой схеме и они все еще находились в процессе перехода — результаты показались мне вполне приличными. Да, из 2000 сотрудников откликнулись только 251, но добро пожаловать в мир тех, кто пытается заставить людей участвовать в опросах.
Другой способ, который мы применяли для оценки успешности, — отслеживание деятельность инженеров, чтобы проверить, выполняется ли необходимый объем работы. Например, мы фиксировали количество залитых фрагментов кода для всех официальных подразделений. Разумеется, половина компании все еще оставалась на Source Depot, в то время как вторая половина уже перешла на Git, поэтому наши замеры отражали некую смесь из их результатов. На графике, приведенном ниже, вы можете заметить ощутимый спад в числе залитых файлов на Source Depot и ощутимый подъем в pull-запросах на Git, но суммарное количество остается примерно одинаковым на всем отрезке. Мы решили, что на основании этих данных можно сделать вывод: система работает и существенных препятствий к использованию не содержит.

22 апреля мы выкатили продукт еще для 1000 инженеров; чуть позже, 12 мая — для следующих 300-400. Адаптация каждой следующей волны происходила по тем же паттернам, что и у предыдущих, и в данный момент 3500 из 4000 инженеров Windows перешли на Git. Оставшиеся команды в данный момент доводят свои проекты до завершения и пытаются определиться с оптимальным временем для перехода, но, думаю, к концу месяца будут охвачены все сотрудники.
Количество данных, с которыми работает система, потрясает воображение. Давайте посмотрим на конкретные цифры:
- В общей сложности за 4 месяца существования репозитория было совершено более 250,000 Git коммитов;
- 8,421 пушей в среднем за день;
- 2,500 pull-запросов и 6,600 инспекций кода в среднем за рабочий день;
- 4,352 активных ответвлений;
- 1,760 официальных сборок в день.
Как вы сами видите, это огромное количество операций на очень обширной кодовой базе.
Производительность GVFS при работе на масштабных проектах
По результатам опроса видно, что существующим положением вещей довольны не все. Мы собрали много данных на этот счет, и причины самые разные — от того факта, что не все инструменты поддерживают Git, до досады, что приходится осваивать что-то новое. Но основная проблема — производительность, и ее-то я и хочу разобрать досконально. Выкатывая Git, мы знали, что с точки зрения производительности он еще недоработан, да и в процессе внедрения многому научились. Мы отслеживаем производительность для ряда ключевых операций. Вот данные, которые собрали телеметрические системы, по работе 3500 инженеров, использующих GVFS.
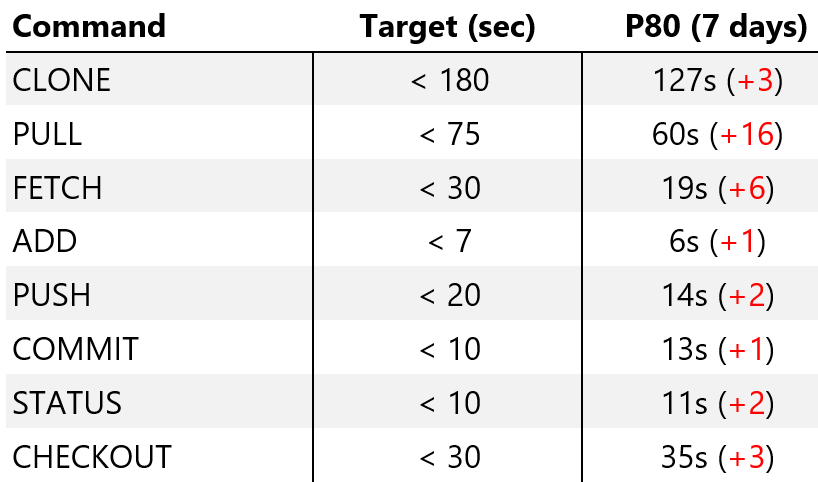
Здесь вы видите «цель» (мы рассчитывали ее как худшее из допустимых значений — не то, к чему мы стремимся, а порог, ниже которого нельзя опускаться, чтобы система вообще работала). Также приведены результаты по 80му перцентилю за последние семь дней и разница с результатами предыдущей недели. (Как можете заметить, все замедляется — мы поговорим об этом подробнее чуть позже).
Чтобы вам было с чем сравнивать, скажу так: если бы мы попытались проделать что-то подобное на «классическом Git», прежде чем начали работу над ним, многие из команд выполнялись бы от тридцати минут до нескольких часов, а некоторые вообще никогда бы не дошли до завершения. То, что большинство сейчас обрабатывается за 20 секунд и меньше — это огромный шаг вперед, хотя в постоянных 10-15 секундных интервалах ожидания тоже, конечно, ничего хорошего.
Когда мы только-только выкатили проект, результаты были куда лучше. Это стало для нас одним из главных открытий. Если вы прочитаете вводный пост, где я даю общее представление о GFVS, там говорится о том, как мы работали над Git и GVFS, чтобы сделать ряд операций пропорциональными не общему числу файлов в репозитории, но числу «прочитанных» файлов. Как выясняется, со временем инженеры расползаются по кодовой базе и прикасаются к все большему числу файлов, что приводит к проблеме, которую мы называем «over hydration» (перенасыщение). В итоге мы имеем кучу файлов, которых кто-то когда-то касался, но после этого не использовал и определенно не вносил никаких изменений. Как следствие, производительность падает. Люди могут «подчищать» свои списки заходов, но это лишняя морока и никто этого не делает, а работа системы все замедляется и замедляется.
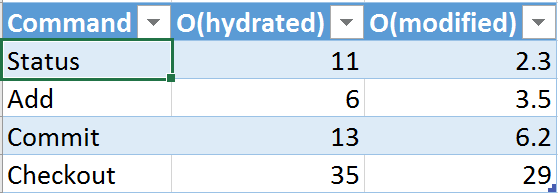
Это вынудило нас запустить очередную серию модификаций для улучшения производительности под названием «O(modified)», которые меняют многие ключевые команды, делая их пропорциональными количеству измененных файлов (в смысле, что имеются изменения, для которых коммит еще не был сделан). Мы добавим эти изменения в основную версию на той неделе, так что у меня еще нет статических данных, но тестирование пилотной версии показало неплохие результаты.
У меня пока что нет всех значений, но я отобрал для примера несколько полей из таблицы выше и вставил соответствующие цифры в колонку O(hydrated). В добавленной колонке O(modified) я привел результаты, которые мы получили по тем же командам с применением оптимизированной версии, которую собираемся выкатить на следующей неделе. Единица измерения там и там — секунды. Как видите, в целом и общем наблюдается заметный прогресс: где-то скорость возросла незначительно, где-то — в два раза, а где-то — в пять. Мы возлагаем большие надежды на эти улучшения и рассчитываем, что они качественно изменят пользовательский опыт. Я не совсем доволен (не успокоюсь, пока Status не станет занимать меньше секунды), но все-таки мы здорово продвинулись.
Другая немаловажная область производительности, которой я не коснулся в предыдущем посте — это географическое распределение команд. Инженеры Windows разбросаны по всему земному шару — США, Европа, Средняя Азия, Индия, Китай и так далее. Pulling больших объемов данных на большие расстояния, зачастую с далекой от идеала пропускной способностью — серьезная проблема. Чтобы с ней справиться, мы создали прокси-решение на Git для GVFS, которое позволяет кэшировать данные с Git на выходе. Также мы использовали прокси, чтобы разгружать очень большие объемы траффика (скажем, серверы билдов) из главного сервиса Visual Studio Team Services, чтобы пользовательский опыт не страдал даже в часы, когда нагрузка максимальная. В общей сложности у нас 20 прокси для Git (которые, кстати, мы просто инкорпорировали в уже существующий Team Foundation Server Proxy) по всему свету.
Чтобы вы лучше представляли, какой это дало эффект, позвольте привести пример. Аккаунт Windows Team Services находится в дата-центре Azure, на западном побережье США. Выше я указывал, что для инженера Windows операция клонирования по 80му перцентилю занимает 127 секунд. Так как большая часть инженеров работает из Редмонда, это значение актуально в первую очередь для них. Мы провели тест в отделении в Северной Каролине, которое и более удалено от центра, и располагает меньшей пропускной способностью. Без применения прокси на ту же операцию потребовалось около 25 минут. С настроенным и обновленным прокси время сократилось до 70 секунд (то есть быстрее, чем в отделении Редмонда — там команда не пользуется прокси и от Azure их отделяют сотни миль интернет-кабелей). 70 секунд против 25 минут — это улучшение почти на 95%.
В целом, Git с GVFS абсолютно готов к употреблению и может применяться к проектам невероятного масштаба. Результаты показывают, что продуктивность наших инженеров при этом не страдает. Однако нам предстоит еще много работы, прежде чем система будет усовершенствована настолько, чтобы сотрудники были ей довольны. Работа, проделанная в O(modified), которую мы выкатим на следующей неделе, станет большим шагом в этом направлении, но потребуется несколько месяцев дополнительных доработок, чтобы с чистой совестью сказать, что все, что нужно, сделано.
Если хотите подробнее узнать о тех технических сложностях, с которыми мы столкнулись в процессе масштабирования Git и обеспечения хорошего уровня производительности, рекомендую цикл статей о масштабировании Git и GVFS от Saeed Noursalehi. Очень увлекательное чтение.
Попробуйте GVFS сами
GVFS — это проект с открытым кодом, и мы приглашаем всех желающих попробовать с ним поработать. Все, что от вас требуется — скачать и установить его, завести аккаунт в Visual Studio Team Services с репозиторием Git, и можно приступать. С первой публикации GVFS мы основательно продвинулись. Среди самых существенных изменений можно назвать:
1. Мы стали регулярно обновлять кодовую базу, постепенно переходя на «открытую» модель разработки. На данный момент все последние изменения (включая все, что было сделано для O(modified)) опубликованы, и мы планируем периодически загружать обновления и в дальнейшем.
2. На момент первой публикации мы были не готовы принимать вклад от сторонних разработчиков. Сегодня мы дошли до того этапа, когда можем официально заявить, что открыты для этой практики. Нам представляется, что базовая инфраструктура уже в достаточной степени заложена, чтобы дать людям возможность брать и развивать ее вместе с нами. Если кто-то хочет подключиться и помочь — мы будем только рады.
3. GVFS опирается на файловую систему Windows, которую мы называем GVFlt. До сих пор драйвер, доступ к которому мы обеспечили, был неподписанным (так как над ним еще активно велась работа). Очевидно, это значительно усложняло жизнь тем, кто хотел его опробовать. Теперь же мы выпустили подписанную версию GVFlt, в которой устранены все шероховатости (так, вам больше не придется отключать BitLocker для установки). Но хотя у нас появился подписанный GVFlt драйвер, это только временное решение. Мы планируем внедрить соответствующие функции в будущую версию Windows и в данный момент прорабатываем детали.
4. После выступления на конференции Git Merge мы стали активнее обсуждать нюансы масштабирования Git и, в частности, GVFS с широким кругом специалистов, заинтересованных в этой теме. Мы очень продуктивно пообщались с другими крупными компаниями (Google, Facebook), которые сталкиваются с такими же сложностями, и стали делиться своим опытом и подходом. Также мы провели работу с несколькими популярными Git-клиентами, чтобы убедиться, что они совместимы с GVFS. В их число вошли:
- Atlassian SourceTree — SourceTree стал первым инструментом, который прошел валидацию на совместимость с GVFS; уже вышло обновление, в котором были введены некоторые изменения для более гладкого рабочего процесса.
- Tower — команда Tower рада сообщить, что они работают над добавлением поддержки GVFS в версию приложения для Windows. В ближайшем будущем соответствующий функционал будет доступен в бесплатном обновлении.
- Visual Studio — само собой, неплохо бы и нашему собственному Visual Studio Git нормально работать с GVFS. Мы внедрим поддержку GVFS в версию 2017.3, первое превью которой (со всем необходимым для поддержки) выйдет в начале июня.
- Git на Windows — в рамках своей инициативы по масштабированию Git мы внесли ряд изменений под Git в Windows (к примеру, командная строка Git), включая поддержку GVFS. Сейчас у нас на Git создано особое ответвление для Windows, но со временем мы хотим все перенести в основную версию кода.
Обобщая сказанное
Мы будем и дальше упорно работать над масштабированием Git, чтобы приспособить его для крупных команд и массивных кодовых баз в Microsoft. С тех пор, как мы впервые заговорили об этом проекте три месяца назад, много чего произошло. В частности, мы:
- успешно внедрили проект для 3500 инженеров;
- подключили прокси и доработали продуктивность;
- обновили открытый код и дали другим пользователям возможность вносить правки/вклады;
- обеспечили signed GVFlt драйвер, чтобы проще было воспользоваться сервисом;
- стали сотрудничать с другими командами, чтобы внедрить поддержку в популярные инструменты — SourceTree, Tower, Visual Studio и так далее;
- опубликовали несколько статей, где с технической точки зрения подробно рассматривается наш подход к масштабированию Git и GVFS.
Это был захватывающий опыт для Microsoft и серьезный вызов для моей команды и команды Windows. Я в восторге от того, чего мы уже добились, но не склонен недооценивать объем работы, который еще остается. Если вы тоже часто оказываетесь в ситуациях, когда приходится работать с кодовыми базами очень больших размеров, но при этом всей душой хотите перейти на Git, призываю вас попробовать GVFS. В данный момент Visual Studio — это единственное бэкенд-решение, которое поддерживает GVFS протокол со всеми нововведениями. В дальнейшем, если проект окажется востребован, мы добавим поддержку GVFS также в Team Foundation Server; также мы провели переговоры с другими сервисами Git, создатели которых рассматривают возможность обеспечить совместимость в будущем.
Комментарии (42)

MzMz
31.05.2017 15:50+3До перехода на Git мы пользовались Source Depot и код был распределен по 40 с лишним репозиториям
Не очень понятно почему бы не продолжать делать также — разбить на изолированные независимые модули и работать с ними также независимо. Зачем хранить исходники всей системы (видимо даже солитер там) в одном репозитории?
mwizard
31.05.2017 15:54-1Похоже, ребята из Microsoft не до конца разобрались с тем, как этим пользоваться. Или, возможно, их код страдает от сильной связности, поэтому нельзя сделать какие-то изменения только в одном компоненте — нужно делать pull request в сотне репозиториев одновременно, а это неудобно и приводит к ошибкам.

FractalizeR
31.05.2017 17:17+6Microsoft не единственные перешли на монорепозитарий. Facebook и Google тоже это сделали. Видимо, тоже не разобрались… :)
mwizard
31.05.2017 17:39+9Ну я не претендую на то, чтобы быть истиной в последней инстанции. Мне казалось, что разбиение на множество мелких репозиториев имеет те же преимущества, что и микросервисная архитектура — между микропроектами получаются жесткие контракты, и говнокод каждого микропроекта изолирован, что позволяет заменять реализации чуть ли не на ходу, до тех пор, пока контракт выполняется.
Если хранить все в одном гигантском репозитории… я не знаю, я не могу придумать плюсов такому решению. То, что предлагается как плюсы в гугловском документе, мне кажется достаточно надуманным:
Unified versioning, one source of truth;
Зачем? Какой профит в "единой версии всего", особенно когда поменялась, грубо говоря, версия солитера, но это вынуждает глобальную систему бампнуть версию? Как отслеживать версию такого проекта согласно семантическому версионированию, когда у меня произошел breaking change в солитере, но это никак не влияет на другие части системы?
Extensive code sharing and reuse;
Что мешает реюзать код в распределенном окружении? Если какой-то код используется в двух проектах, то он должен быть вынесен в библиотеку, а не скопирован. У этой библиотеки свой репозиторий, своя версия, свои зависимости.
Simplified dependency management;
Я понимаю, к чему это — вместо того, чтобы перечислять зависимости явно, там, скорее всего, здоровенный список "давайте любой код будет зависеть от libcommon, в которую включено все, что у нас только есть". Хороший ли это подход? Я думаю, это омерзительный подход, так как в libcommon вносятся несовместимые изменения, то как узнать, что именно нужно чинить?
Atomic changes;
Единственное "достоинство". В распределенных системах надо сначала поменять базовую зависимость, протестировать ее, затем поменять тех, кто зависит от базовой зависимости, и т.д. Впрочем, минусы этого решения покрывают возможный плюс, как мне кажется.
Large-scale refactoring;
Для этого и существуют контракты между разными компонентами. Если есть контракт, возможно автоматически или полуавтоматически определить, где проходит общая граница ответственности — т.е. какие именно компоненты можно буквально слить воедино, а потом переразбить иначе, с другой реализацией, так, чтобы для "внешнего мира" их зависимости все еще были валидны.
Collaboration across teams;
Flexible team boundaries and code ownership;Это не является достоинством монорепозитория. Отдельными репозиториями легче управлять, в том числе разделяя права доступа, и легче определить, кто что сломал. Не говоря уже о том, что список веток в микрорепозитории может быть небольшим и управляемым, а вот что делать с миллиардом веток в монорепозитории, в котором любой Джон Иванов, начиная работу над своей фичей, создаст себе ветку? Не пушить их? Пушить их в отдельный origin, в котором есть не все ветки?
Code visibility and clear tree structure providing implicit team namespacing.
Тут мне на ум приходит только цитата Гвидо ван Россума, одного из сотрудников Гугл — Explicit is better than implicit. Simple is better than complex. Flat is better than nested. Sparse is better than dense.. Если деление на команды все равно происходит неявно на уровне структуры репозитория, зачем делать это одним репозиторием, когда это УЖЕ логически разделяет репозиторий на подрепозитории?
Так много вопросов, так мало ответов.
FractalizeR
31.05.2017 17:44-2Я бы не стал просто потому, что мало ответов, считать себя умным, а Google, Facebook и Microsoft идиотами, не понимающими, что они делают. У вас есть личный опыт работы с действительно большими репозитариями, чтобы вы могли судить, что работает на таких объемах, а что нет?
mwizard
31.05.2017 17:48+2Понимаю, "сперва добейся". Нет, очевидно, у меня нет опыта работы с репозиториями размера кодобазы Microsoft, поэтому это автоматически лишает меня права задавать вопросы и высказывать мнение. Извините, пожалуйста, я больше так не буду.
FractalizeR
31.05.2017 17:58+6Не "сперва добейся", а "сперва разберись".
Здесь ведь Хабр, а не лавочка у дома. Вы не работали с большими репозитариями, не знаете, какие проблемы могут возникнуть в процессе, но уже обвинили людей, которые работали и решали соответствующие проблемы в том, что они "не разобрались". Я бы сказал, что для этого нужно основание. Причем факт, что таких людей (читай, компаний) не одна, а несколько, вашу критику никак не остановил. Как и тот факт, что это крупнейшие ИТ-компании в мире с умнейшими людьми в штате и менеджменте.
mwizard
31.05.2017 17:59-4Я согласен — раз уж умнейшие люди из крупнейших IT-компаний приняли такое решение, то мои вопросы автоматически стали глупыми и непрофессиональными. Наверняка ответ есть, дорасту — узнаю.
FractalizeR
31.05.2017 18:04+7Я полагаю, что вопросы — весьма уместны. У меня тоже найдется достаточно.
А вот высказывания в духе "ребята из Microsoft не до конца разобрались с тем, как этим пользоваться", на мой взгляд, — нет.
vics001
31.05.2017 19:44-2Не надо ставить Google, Facebook вместе с Microsoft в одну цепочку. Одни делают web, грубо говоря, у них всегда есть одна версия происходящего прямо сейчас: все сервисы и т.п. Microsoft делает ПО релизное.
Грубо говоря выгода от одного репозитория уже менее очевидна, так как может быть куча разных версий и они могут быть друг с другом не связаны. Можно сказать это выглядит как разработка абсолютно разных приложений и не всегда имеет смысл запихивать в один репозиторий, как раз из-за проблем описанных в статье.

kafeman
31.05.2017 20:10+2Есть опыт KDE. От монолитного репозитория (с условным «солитером»), по совету Линуса, они ушли ко множеству маленьких, выделив все зависимости в отдельные библиотеки.
khim
31.05.2017 20:44То же самое было проделано с X'ами.
kafeman
31.05.2017 20:49Мне кажется, в KDE все-таки по-больше кода будет. И монолитный репозиторий у них также жутко тормозил, как и у Microsoft (до этого использовался SVN, откуда данные можно выкачивать частями). Тем более, что значительная часть Иксов сейчас перенесена в ядро.
khim
31.05.2017 20:43+4Мне казалось, что разбиение на множество мелких репозиториев имеет те же преимущества, что и микросервисная архитектура — между микропроектами получаются жесткие контракты, и говнокод каждого микропроекта изолирован, что позволяет заменять реализации чуть ли не на ходу, до тех пор, пока контракт выполняется.
Вы абсолютно правы — но смотрите на медаль только с одной стороны.
Вот собственно в этом «пока контракт выполняется» — и есть главная проблема. В случае с монорепозиторием вы можете поменять в любой момент всё, что угодно — в том числе и контракт между компонентами. Собственно это не изобретение Microsoft'а, Facebook'а или Google'а. Классическое Stable API nonsense всё описывает…
Как отслеживать версию такого проекта согласно семантическому версионированию, когда у меня произошел breaking change в солитере, но это никак не влияет на другие части системы?
А зачем? Если вы код никому не поставляете и не релизите? Сделаете релиз — увеличите счётчик…
Я понимаю, к чему это — вместо того, чтобы перечислять зависимости явно, там, скорее всего, здоровенный список «давайте любой код будет зависеть от libcommon, в которую включено все, что у нас только есть».
Ровно наоборот. Если вы обнаружили, что у вас вдруг завелась библиотека, которая и стрижёт кошечек и запускает ракеты в космос, то вы её можете извести, условно говоря, в два commit'а: первый выносит функциональность по стрижке кошечек в libcathaircut и одновременно изменяет всех клиентов, второй — делает то же с библиотекой libspacelaunch. Всё. После двух коммитов у вас библиотеки libcommon больше нету.
На практике, конечно, стараются коммиты делать меняющими не сто тысяч файлов за раз, а несколько меньшее число, так что совсем уж мастабный рефакторинг в два коммита не уложится — но идея понятна, я думаю.
libbase, конечно, тоже есть — но там живут вещи, которые реально нужны всем (система выдачи сообщений об ошибках, к примеру).
В распределенных системах надо сначала поменять базовую зависимость, протестировать ее, затем поменять тех, кто зависит от базовой зависимости, и т.д. Впрочем, минусы этого решения покрывают возможный плюс, как мне кажется.
Это зависит от того, что вы, собственно, пытаетесть сделать. Минус — более-менее один, но он существенен: «подход с поменять базовую зависимость, протестировать ее, затем поменять тех, кто зависит от базовой зависимости, и т.д.» занимает на два порядка больше времени. То есть какое-нибудь простое измнение (типа переименования поля в структуре с «childs» на «children») занимает годы, а не часы.
Если есть контракт, возможно автоматически или полуавтоматически определить, где проходит общая граница ответственности — т.е. какие именно компоненты можно буквально слить воедино, а потом переразбить иначе, с другой реализацией, так, чтобы для «внешнего мира» их зависимости все еще были валидны.
А что происходт в случае изменения контракта?
Не говоря уже о том, что список веток в микрорепозитории может быть небольшим и управляемым, а вот что делать с миллиардом веток в монорепозитории, в котором любой Джон Иванов, начиная работу над своей фичей, создаст себе ветку?
Откуда там миллиарды веток? Любой Джон Иванов может насоздавать себе локально сколько угодно веток, но когда он свои изменения зальёт — он будет их заливать в те ветки, которые соответствуют «мастеру» и, возможно, их «заберут» в старые релизы, если нужно.

roman_kashitsyn
01.06.2017 12:59+2Единственное "достоинство"
Это большое достоинство, очень хорошее. Приходилось работать с системой, которая состояла из десятков пакетов, которые нужно собирать и релизить независимо. Каждый раз, когда нужно протащить что-то через 2-3 компонента, разработка превращается в головную боль, протестировать всё вместе очень сложно.
С монорепозиторием жизнь несравнимо легче. Все обладатели нетривиальной кодовой базы, которая быстро развивается, рано или поздно приходят к монорепозиторию.
Large-scale refactoring
Для этого и существуют контракты между разными компонентамиТут не только контрактах речь. Допустим, вы решили заменить во всей кодовой базе NULL на nullptr. С кучей мелких репозиториев это настолько большая морока, что никто просто не будет этим заниматься. С монорепозиторием это тривиально.
Далее, если вдруг хочется избавиться от какого-то компонента, всех его пользователей найти тривиально, можно использовать привычные инструменты, при этом исправление будет атомарным. Если этот компонент лежит в отдельном репозитории, найти (и поправить) всех его пользователей гораздо сложнее.
Simplified dependency management;
Я понимаю, к чему это
вместо того, чтобы перечислять зависимости явноНаоборот, с монорепозиторием гораздо проще делать явные списки зависимостей. Хочешь сделать либу: положи код в каталог, создай зависимость в билд-системе. Любой сможет её найти. Настройка отдельного репозитория и настройка интеграции с ним сложнее. Опять же, нужно сделать что-то, чтобы другие разработчики смогли найти и использовать ваш код.
Когда репозиториев много, соблазн просто скопировать нужный код к себе гораздо сильнее.
Посмотрите хотя бы на vendoring в Go-community.
Гвидо ван Россума, одного из сотрудников Гугл
Он давно уже в Dropbox работает

niya3
31.05.2017 17:19+2Зачем хранить исходники всей системы (видимо даже солитер там) в одном репозитории?
Масштабирование Git (и кое-какая предыстория)
Когда-нибудь работали с огромной кодовой базой в течение 20 лет? Когда-нибудь пробовали впоследствии вернуться назад и разбить её на маленькие репозитории? Можете догадаться, к какому ответу мы пришли. Этот код очень сложно разобрать на части. Цена будет слишком велика. Риски от такого уровня смешения станут чудовищными.
tijs
31.05.2017 20:32Вот здесь хорошо объясняются преимущества монолитного репозитория (на примере Google):
Google PiperNakosika
31.05.2017 22:01Грубо говоря, что если солитеру нужно использовать 10 фич новой сетевой библиотеки которая находится на этапе написания и разработка должна идти параллельно чтобы успеть к релизу? А сетевая библиотека требует 10 других зависимостей которые также находятся в процессе.
kafeman
31.05.2017 22:20если солитеру нужно использовать 10 фич новой сетевой библиотеки
Солитер с мультиплеером? Прошу прощения, что придираюсь, мысль ваша, конечно, понятна.EvilPartisan
31.05.2017 23:02В последней винде солитер включен в комплект карточных игр, среди которых есть и сетевые, и там еще и ачивки, рейтинговые доски, и прочие современные игровые фичи. А сапёра превратили в Rogue-like RPG.
Правда, на данный момент это отдельные приложения устанавливаемые через Microsoft Store, и я не понял, такие приложения тоже в общем большом репозитории или всё-таки отдельно?kafeman
31.05.2017 23:11Не в курсе про игры из Microsoft Store, но одному моему знакомому снилось, что в слитых исходниках Windows таки лежат «по соседству» и солитер, и Internet Explorer, и ядро, и все на свете. В одном большом репозитории, естественно.
mbait
01.06.2017 04:09Взгляд инсайдера (моего друга, которы работал на Марсе в компании Deep Startup Mining Inc.): монолитный репозиторий ужасно неудобно использовать. Тормозит любая комманда, кроме
git commitи ещё парочки ничего толком нельзя использовать. Вся работа с репозиторием, в основном, происходит через внутренние веб-инструменты. Понимают ли люди, отвечающие за VCS, что они делают? Абсолютно. Просто их задача не сделать работу программистов комфортнее, а снизить число факапов. Один из примеров использования монолитного репозитория — если случился факап, репозиторий быстро откатывается на последнюю стабильную версию. И нет проблем с зависимостями или ещё чем-то. А программистов никто не спрашивает "а не хотите ли заиметь один репозиторий, чтобы править ими всеми, судари?", их просто ставят перед фактом.
igordata
02.06.2017 00:25А как реализуется распределение доступа к коду различных разработчиков?
Или все разрабы, даже самые мелкие, имеют доступ ко всему коду всех остальных разработчиков?mbait
02.06.2017 04:18Все имеют доступ ко всему репозиторию. Для Deep Startup Mining Inc. данные пользователей гораздо важнее кода, к тому же, многие его части есть в открытом доступе.
beduin01
01.06.2017 09:35+1Очень советую всем попробовать http://pijul.com/
Куда проще и логичнее чем GIT который у меня ничего кроме неприязни не вызывает.RevenantX
01.06.2017 12:47Так-то и Mercurial местами более проще и логичнее (и даже более известен чем pijul).
Xandrmoro
01.06.2017 11:44-1Интересно, почему MS не использует TFS. Не знаю, как там на 300гб кодярника, но когда мы два года назад перевезли свои 30гб из гита в тфс жить стало радикально лучше и вселее.

domix32
01.06.2017 14:05Так они и рассказывали, что GVFS и есть смесь TFS и Git. Почитайте первую статью

Karl_Marx
03.06.2017 14:54Они писали в предыдущих постах, что Git был политическим решением. Менеджмент объявил о том, что они должны оптимизировать издержки и для этого унифицировать рабочую среду. Большинство на тот момент пользовалось TFS, но исходники винды по историческим причинам были в SourceDepot. Разработчики попытались объяснить менеджерам, что никакого смысла менять шило на мыло нет, а времени это займет много, плюс возникают дополнительные риски. В итоге конфликта менеджеры приняли решение проигнорировать вообще все мнения и заставить разработчиков перейти на Git. Видимо, они там сильно поссорились, раз не смогли донести до менеджмента, что распределенная система + 300Гб исходников = геморрой. Для того, чтобы можно было хотя бы как-то работать, они стали дописывать и переписывать Git и GVFS.


mwizard
Не увидел в статье ссылки на репозиторий.
alexkunin
Самый низ предпоследнего раздела: «особое ответвление для Windows».
mwizard
Это репозиторий с git. Хотелось бы видеть https://github.com/Microsoft/Windows/, о котором шла речь в статье.
sumanai
Все хотят, но вряд ли мы этого дождёмся.
sevikl
увидите, когда устроитесь в майкрософт. ну или когда начнете различать git и github — вопрос может и отпасть.
berezuev
> увидите, когда устроитесь в майкрософт.
Сомневаюсь, что разработчикам доверяют весь репо винды)
alemiks
C:\Users\SatyaNadella\Documents\Repos\Windows\
sumanai
Судя по путям в ASSERT в отладочных сборках, или к примеру путям к объектным файлам в отладочных символах, код Windows обычно располагается в каталогах типа d:\nt\, d:\wbrtm\, d:\th\, d:\w7rtm\, d:\rs1\, d:\longhorn\ и прочее. Почти всегда на диске D.
Исключение составляет разве что код исследовательского ядра WRK версии 1.2, который располагался в каталоге C:\PROBERT\WORK\WRK-2.0\test-build\BUILDForDrop01\.
Извиняюсь за занудство.
kafeman
Диск D:\ — это, скорее всего, где-то на build-сервере. Не занимаются же они сборкой релизов на машине разработчика?