
 Привет, Хабр! Не первый раз я пытаюсь написать эту статью, но давно уже есть желание поделиться опытом и люди просят.
Привет, Хабр! Не первый раз я пытаюсь написать эту статью, но давно уже есть желание поделиться опытом и люди просят.На Хабре много статей о различных технологиях, языках, api и т.д., но часто программисты в пылу разработки забывают для чего все это, ниже я постараюсь описать, как не забыть о самом главном при разработке.
Статья будет о том как мы организовали работу с бизнес логикой в PHP, совмещающую разные подходы.
Тут будет изложено как уйти от проблем PHP фреймворков, связанных с размазыванием предметной логики по слою контроллеров.
Не буду гарантировать что изложенные решения это какая-то серебряная пуля, все нижеследующее всего лишь один из вариантов подхода к решению общих проблем. В нем есть и плюсы и минусы и со своей основной задачей этот подход справляется.
Немного о том как работать с бизнес логикой в популярных PHP фреймворках
Обычная ситуация
Если мы смотрим на самые популярные фреймворки то за основу в них взят архитектурный паттерн MVC. Инструментов по организации бизнес логики как таковых нет, а вот для создания простых crud все есть.
Стандартная ситуация которую мы видим в большинстве случаев это анемичная модель, когда например класс UserModel является просто набором атрибутов и не содержит никакой логики. Бизнес логика же содержится в слое контроллеров.
Контроллеры превращаются в что-то среднее между Transaction Script и Service Layer в Domain Model. Они валидируют входные данные, получают из базы модельные сущности и реализуют бизнес логику этих сущностей.
Я не говорю, что это неправильно, в некоторых случаях это оправдывающий себя подход. Когда стоит разрабатывать без какой-то сложной архитектуры для бизнес логики:
- При простой бизнес логике
- Для создания mvp
- При создании прототипов
Если у вас не такая ситуация то стоит задуматься об архитектуре и о месте бизнес логики в этой архитектуре.
Сложная бизнес логика
Если бизнес логика достаточно сложна то есть два стандартных варианта решения:
Transaction Script
Чтобы отделить бизнес логику от фреймворка стоит выделать ее в отдельные сущности. Используя Transaction Script мы можем создать большой набор сценариев, обрабатывающих конкретные запросы пользователей.
Например если нужно загрузить фото то можно создать сценарий загрузки фото. Программно он может быть выделен в отдельный класс:
{
public function run()
{
/*реализация сценария загрузки фото*/
}
}
Подробнее советую почитать об этом подходе в книге «Архитектура корпоративных программных приложений», там описаны все его плюсы и минусы.
Domain Model
При реализации Domain Model все становится значительно сложнее. Надо продумать бизнес логику и выделить сущности с четко разделенной ответственностью. Тут много подводных камней, это и как организовать фасад для предметной области и как избежать создания приложения с клубком связей между бизнес сущностями и т.д.
В книге «Архитектура корпоративных программных приложений» предлагается ввести слой Service Layer который послужит интерфейсом бизнес логики и будет состоять из нескольких сервисов сгруппированных по общему функционалу(например UserService, OrderService и т.д.).
Более подробной этот подход рассмотрен в книгах «Архитектура корпоративных программных приложений» и также ему посвящена целая книга «Предметно-ориентированное проектирование (DDD)», которую я лично очень рекомендую к прочтению.
Наша история
Как все начиналось
В 2014 году было решено начать свой проект и встал вопрос выбором языка, технологий, библиотек и т.д.
Выбор пал на PHP, а вот от использования существующих фреймворков было решено отказаться. За основу была взята старая наработка и принято решение дать ей новую жизнь в новом обличии.
В нашей организации мы понимаем важность таких вещей как тестирование, бизнес-логика, шаблоны проектирования и т.д., как раз поэтому было принято решение написать инструмент подконтрольный нам и позволяющий в PHP работать с бизнес-логикой.
Архитектура, словарь
За основу была взята многослойная архитектура. Если рассматривать очень общую и укрупненную схемы то можно выделть 3 слоя:

Что-то бралось из “Большой синей книги” по DDD, что-то из книги «Архитектура корпоративных программных приложений» и все это перерабатывались, если это было необходимо, под наши нужды.
Interface
Interface это в нашем случае слой отвечающий за доступ к предметной области из внешнего мира.
У нас на данный момент есть 2 вида интерфейса:
API — это RESTful api состоящий из View и Controller.
CLI — интерфейс вызова бизнес логики из командной строки(например крон задачи, воркеры для очередей, и т.д.).
View
Данная часть слоя Interface очень проста, так как наши проекты на PHP это исключительно API и не имеют пользовательского интерфейса.
Соответственно не было необходимости включать работу с шаблонизаторами, мы просто отдаем view в виде json.
При необходимости этот функционал можно расширить, добавить поддержку шаблонизаторов, ввести разные форматы отдачи ответа (например xml ), но у нас таких потребностей пока нет. Данное упрощение позволило больше времени уделять более важным частям архитектуры.
Controller
Контроллеры не должны содержать никакой логики предметной области. Контроллер просто получает запрос от роутера и вызывает соответствующий интерфейс модели с параметрами запроса. Он может делать какое-то небольшое преобразование для связи с моделью но никакой бизнес логики в нем нет.
Model
В слое модели был выделен базовый набор сущностей на котором можно развернуть практически любую предметную область, не нарушая ее изоляции от других частей архитектуры.
Было выделено 3 основных обобщенных элемента модели:
Entity — это сущность с набором характеристик в виде списка параметров и с поведением в виде функций.
Context — это сценарий в рамках которого взаимодействуют сущности.
Repository — это абстракция для хранения Entity.
Storage
В слое Storage у нас просто набор мапперов которые знают как какую сущность из модели сохранять в базу, либо загружать из базы.
Подробно теория
View-Controller
Эта часть платформы организует API интерфейс для бизнес логики из вне. Она состоит из множества элементов, но для понимания можно описать несколько:
Router — маршрутизатор http запросов в соответствующий метод контроллера (все стандартно).
View — это по сути преобразователь ответов от модели передаваемых как ValueObjet ( тут мы тоже, не даем view много знаний о бизнес логики) в json. Хотя в классическом MVC view получает обновления от model напрямую, у нас это делается через Controller.
Controller это прослойка скрывающая интерфейсы модели. Controller преобразует http запрос в входные параметры для модели, вызывает сценарий модели, получает результат выполнения и возвращает его View для отображения.
Это часть не содержит никакой бизнес логики и в течении проекта не меняется если только не нужно создать новые API интерфейсы. Мы не раздуваем слой контроллеров, оставляем их компактными и простыми.
Модель
А теперь поговорим о самом главном и ценном элементе, заключающем в себя бизнес логику.
Рассмотрим подробнее основные элементы модели: Entity, Context и Repository.
Entity
abstract class Entity
{
protected $_privateGetList = [];
protected $_privateSetList = [ 'ctime', 'utime'];
protected $id = 0;
protected $ctime;
protected $utime;
public function getId()
{
return $this->id;
}
public function setId( $id)
{
$this->id = $this->id == 0? $id: $this->id;
}
public function getCtime()
{
return $this->ctime;
}
public function getUtime()
{
return $this->utime;
}
public function __call( $name, $arguments)
{
if( strpos( $name, "get" ) === 0)
{
$attrName = substr( $name, 3);
$attrName = preg_replace_callback( "/(^[A-Z])/", create_function( '$matches', 'return strtolower($matches[0]);'), $attrName);
$attrName = preg_replace_callback( "/([A-Z])/", create_function( '$matches', 'return \'_\'.strtolower($matches[0]);'), $attrName);
if( !in_array( $attrName, $this->_privateGetList))
return $this->$attrName;
}
if( strpos( $name, "set" ) === 0)
{
$attrName = substr( $name, 3);
$attrName = preg_replace_callback( "/(^[A-Z])/", create_function( '$matches', 'return strtolower($matches[0]);'), $attrName);
$attrName = preg_replace_callback( "/([A-Z])/", create_function( '$matches', 'return \'_\'.strtolower($matches[0]);'), $attrName);
if( !in_array( $attrName, $this->_privateSetList))
$this->$attrName = $arguments[0];
}
}
public function get( $name)
{
if( !in_array( $name, $this->_privateGetList))
return $this->$name;
}
public function set( $name, $value)
{
if( !in_array( $name, $this->_privateSetList))
$this->$name = $value;
}
static public function name()
{
return get_called_class();
}
} Entity это сущности предметной области, например пользователь, заказ, автомобиль и т.д. Все подобные сущности могут иметь параметры: идентификатор, время регистрации, цена, скорость. Работу с параметрами мы обеспечиваем в базовом классе Entity, а поведение уже определяет разработчик в классах наследниках.
Список параметров так же нужен для сохранения Entity в базу данных, но модель ничего об этом сохранении не знает. В инфраструктурном уровне есть мапперы которые знают как сохранять сущности модели в базу.
Идентификатор у Entity в нашей платформе это базовый параметр, он позволяет однозначно идентифицировать разные сущности внутри одно класса объектов.
Подробнее можно сказать что наш Entity очень похож на Entity, который описан в книге Эрика Эванса.
Как говорится у Эванса, идентификация объекта а программных системах это одна из важнейших задач. Так же Эванс уточняет что идентификация достигается не только за счет одних атрибутов объектов.
Что же можно считать характеристиками которые могут идентифицировать объект в программной системе: атрибуты, класс объекта, поведение. При разработке нашего Entity мы как раз отталкивались от этих характеристик.
Атрибуты могут быть разные в зависимости от сущности, но идентификатор мы выделили в базой как присущий практически всем. Класс объекта мы задаем благодаря ООП и наследованию предоставляемому нам языком разработки. Поведение задается методами для каждого класса.
Context
abstract class Context
{
protected $_property_list = null;
function __construct( \foci\utils\PropertyList $property_list)
{
$this->_property_list = $property_list;
}
abstract public function execute();
static public function name()
{
return get_called_class();
}
}
Context это сценарий в рамках которого взаимодействуют Entity. Например «Регистрация пользователя» у нас отдельный контекст, и работа этого контекста выглядит примерно так:
- Запускаем контекст и передаем ему параметры для регистрации. На вход контекст получает список простых параметров (int, string, text и т.д.).
- Проходит валидация корректности параметров. Валидация тут именно для предметной области, мы не проверяем тут запросы http.
- Создание пользователя.
- Сохранение пользователя. Это тоже часть предметной области, главное, что она абстрагирована от того куда и как мы этого пользователя сохраняем. Тут для абстракции сохранения мы используем Репозитории.
- Отправка на почту уведомления.
- Возврат результатов выполнения контекста. Для возврата результата есть специальный класс ContextResult который содержит признак успешности выполнения контекста и либо данные с результатами, либо список ошибок. (на уровне view-controller модельные ошибки переводятся в ошибки http)
Context практически в чистом виде Transaction Script, но с некоторыми исключениями. Фаулер приводит пример реализации бизнес логики через Transaction Script либо Domain Model. При использовании Domain Model он рекомендует использовать Service Layer в котором сервисы создаются на основе общности функционала (например UserService, MoneyService, и т.д.). В нашем случае Transaction Script может выступать тем же Service Layer если не делать модельные сущности анемичными.
Например набор контекстов связанных с пользователем (UserRegContext, UserGetContext, UserChangePasswordContext, и т.д.) при не аннемичном пользователе практически равноценен UserService (Service Layer). У нас есть контексты которые берут на себя очень много бизнес логики и их можно считать Transaction Script, но есть и контексты которые просто вызывают какой-то функционал Entity а дальше уже вся бизнес логика скрыта от контекста и тут они уже ближе к Service Layer.
Отсюда в случаях со сложной бизнес логикой можно либо в чистом виде сделать DDD архитектуру системы, либо можно организовать логику через Transaction Script если бизнес логика не так сложна и состоит из стандартных сценариев создать, запросить, обновить и т.д.
Repository
class Repository
{
function add( \foci\model\Entity &$entity)
{
$result = $this->_mapper->insert( $entity);
return $result;
}
function update( \foci\model\Entity &$entity)
{
$result = $this->_mapper->update( $entity);
return $result;
}
function delete( \foci\model\Entity &$entity)
{
$result = $this->_mapper->deleteById( $entity->getId());
return $result;
}
}Репозитории это абстракиция бизнес логики для организация сохранения/удаления/обновления/поиска сущностей в базе. Конкретные репозитории работают с конкретными сущностями, например UserRepository работает с User.
Хранение данных
Хранение данных сделано с использованием мапперов. Есть обобщенный класс Mapper который содержит базовый функционал для работы с Entity.
{
protected $_connection;
protected $_table;
function __construct( Connection $connection)
{
$this->_connection = $connection;
}
abstract protected function _createEntityFromRow( $row);
abstract public function insert( \foci\model\Entity &$entity);
abstract public function update( \foci\model\Entity &$entity);
abstract public function delete( \foci\model\Entity &$entity);
public function getTableName()
{
return $this->_table;
}
}
Для конкретных сущностей создаются свои конкретные мапперы которые знают как данную сущность сохранять в базу, как ее загружать из базы, как удалять(хотя на самом деле удалять из базы что-то это плохая практика, поэтому в большинстве случаев мы просто помечаем удаленным) и как изменять.
Таким образом если у нас в модели есть класс User то ему в соответствие создается класс UserMapper. Логика работы с БД вынесена в отдельны слой и может быть легко заменена при необходимости.
Модельные сущности ничего не знаю о мапперах, мапперы же наоборот все знают о своих модельных сущностях.
Обобщенная схема
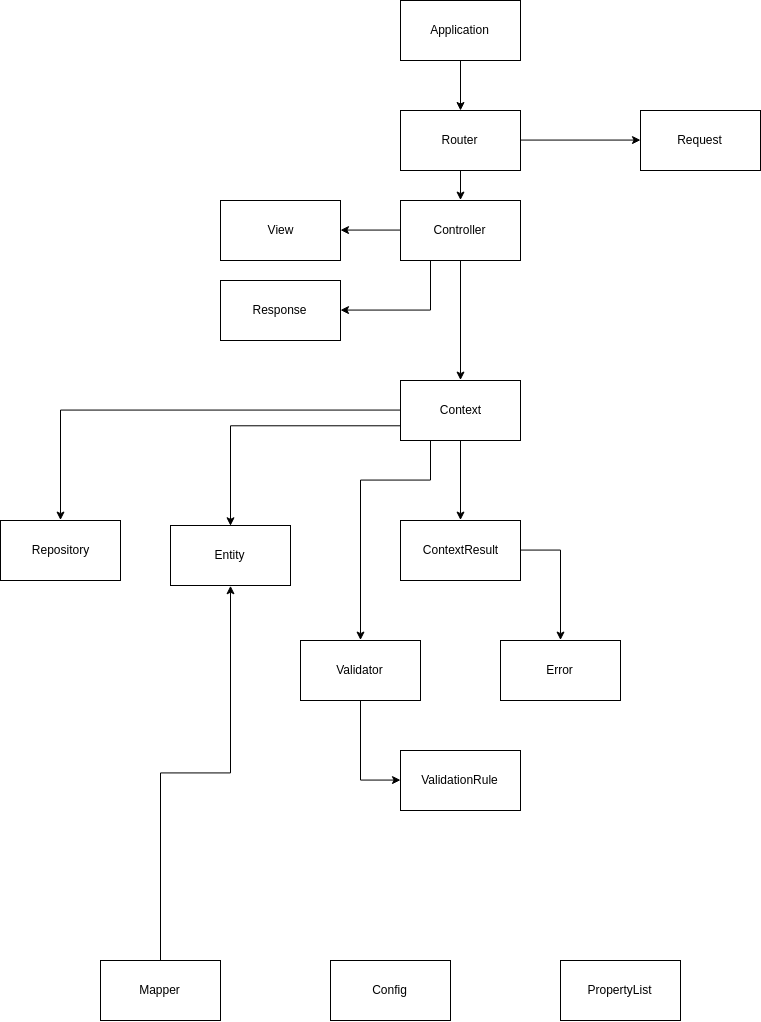
Тут расписана очень общая структура классов нашей платформы, многие мелкие менее важные классы опущены.
Как видно уже только эта базовая структура содержит достаточно много элементов. В конкретном проекте ко всему этому добавиться множество классов контекстов, сущностей, репозиториев, мапперов реализующих конкретные бизнес задачи.
Config и PropertyList на схеме это утилитарные сущности которые используются всеми.
Немного практики (совсем чуть чуть)
Теория это хорошо, но давайте рассмотрим, как все это применить на практике. Допустим у нас есть задача сделать приложение для персонального учета финансов. Примерный словарь терминов (расписывать определения не буду, тут пока все просто): Деньги, Бюджет, Пользователь, Товар, Услуга, Календарь
Далее составим пару сценариев пользователя, возьмем что-то нестандартное, для большей наглядности. Покупка товара — будем считать что покупка для нас это просто факт однократного списания денег. Установка оплаты услуги по календарю — это будет регулярное списания денег с описанием.
Выделим сущности: Money, Budget, User, Product, Service, Calendar.
Выделим 3 контекста по пользовательским сценариям:
Первый контекст это просто покупка товара.
BuyOrderContex
- Получаем User из базы по входным данным(например по токену)
- Получаем или создаем новый Product
- Говорим Budget установить покупку Product за указанную сумму Money
Дальше все сложнее, второй пользовательский сценарий разделился на 2 контекста, в первом мы устанавливаем когда списывать деньги, а во втором делаем само списание.
SetSchedulePayForServiceContext
- Получаем User из базы по входным данным(например по токену)
- Получаем или создаем новый Service
- Устанавливаем в Calendar списание денег на услугу Service по заданной дате
SchedulePayForServiceContext
- Смотрим в Calendar есть ли на текущее время списание за Service
- Загружаем Service за которой надо списать деньги
- Списываем деньги за Service
Уже в этом небольшом примере видны и какие-то плюсы данного подхода и минусы(например дублирование логики в разных контекстах, об этом хорошо написано в книге «Архитектура корпоративных программных приложений»).
Заключение
Наши практики
Разделение функционала
Разбиение всего приложения на контексты позволяет легко разносить его на разные сервера.
Например у нас есть контексты связанные с регистрацией пользователей, легко можно взять всю эту группу и перенести на другой сервер не нарушая работы остальных частей приложения.
Контекст вызывает контекст
Контекст может вызывать контекст, и так можно выстраивать сложные цепочки. Такой прием используется очень редко. Так же такой подход кроет в себе много подводных камней поэтому у есть планы запретить такое использование.
Крон задачи
Контекст как единица выполнения позволяет вызывать его откуда угодно. На этом основана логика запуска контекстов как крон задач.
SPA
Один из наших проектов это сайт в котором клиентская часть полностью написана на JavaScript и через RESTfull api взаимодействует с серверной часть на PHP. Мы такое даже не планировали когда начинали разработку, но эта возможность строить SPA приложения с нашей платформой в качестве сервера оказалась очень удобной.
Тестирование
Весь код покрывается тестами. Мы используем 2 вида тестов:
- Unit тесты, например для таких классов как Config
- Acceptnce тесты, для запросов к нашему api.
Планы
- Нам очень сильно не хватает более широко распространения нашей разработки. Все написано исключительно для внутреннего использования и это накладывает свои минусы.
- Не хватает обкатки в высоконагруженных проектах. У нас уже несколько работающих коммерческих проектов, но высоконагруженными их назвать нельзя.
- Логика работы с транзакция пока что у нас сильно не продуманна. В этом месте у нас на данный момент есть небольшое нарушение инкапсуляции модели. В будущем планируется ввести Unit Of Work для абстрагирования от транзакций баз данных
- Тестирование главным образом покрывает api, в планах сделать тестирование контекстов. Так появится возможность изолированно тестировать предметную область.
Что мы получили в итоге
- Гибкую платформу для создания приложения с четким отделением бизнес логики от инфраструктуры.
- Полностью подконтрольную нам разработку и это дает много плюсов в решении технических задач спорных моментов.
- Архитектуру основанную на всем известных шаблонах проектирования, позволяющую новым разработчикам быстро включаться в проект.
- Огромный опыт применения зарекомендовавших себя подходов в проектировании, про которые часто забывают в новых проектах и не стремятся их использовать в уже существующих.
Выводы
В общем результатом проделанной работы мы довольны. Написанная платформа решает наши задачи. Она позволяет гибко реализовывать бизнес логику, что значительно упрощает разработку. Есть множество планов по улучшению и расширению.
PS: Если такой подход к решению проблемы с предметной областью в PHP фреймворках будет интересен сообществу то мы вполне можем поднатужиться и подготовить open source.
PSS: Сразу предвижу фразы на счет того зачем вам велосипед, если все уже есть. Не вижу смысла спорить по этому поводу, это наш подход и он сработал.
PSS: Так же предвижу вопросы, зачем делать кровосмешение Transaction Script и Domain Model, а почему бы не сделать и не получить гибкий инструмент для решения бизнес задач.
Комментарии (67)

Fantyk
01.06.2017 09:56+1Спасибо за статью, у вас грамотно описана теория (кто за что отвечает)
В вашей общей схеме Applicatioin->router->controller->domain->response вы оригинально подошли только к реализации domain. Эту схему можно организовать на любом современном php фреймворке (symfony, slim ,laravel...), поэтому не стоило акцентировать внимание на вашей реализации («велосипеде»).
Сама же реализация доменных команд через контексты вполне интересна, видел не много примеров, поэтому прочел бы о вашей реализации.
И да, «Обычная ситуация» в современных php фреймворках с бизнес логикой в контроллере — встречается только у новичков и в документации(откуда они это и берут). А в документации просто нет смысла создавать сервисный слой, чтобы показать как отрендерить страницу списка пользователей.
xanm
01.06.2017 10:11Согласен с тем что данную схему можно организовать на любом современном фреймворке, но также придется повозиться, а акцентировал внимание я в связи с тем что мы старались сделать какуюто платформу именно для бизнес логики в то время как все современные фрейворки предоставляют инструменты для создани одной инфраструктуры.
«Обычная ситуация» действительно встречается у новичков и в документации, но она есть и в больших коммерческих проектах часто просто потому что это были изначально так написано и менять никто ничего не планирует.Fantyk
01.06.2017 10:38Фреймворки предоставляют инструменты лишь для инфраструктуры, чтобы вы могли реализовать свою бизнес логику как вашей душе угодно(у вас это Transaction Script, у вторых Service Layer, у третьих CommandBus\CQRS). Вы же говорите, что создали платформу для написания бизнес логики — она тем более должна быть «framework agnostic». В любом случае увидеть еще один способ полезно.
mistergonza
01.06.2017 13:41Если я всё правильно понял, то мне кажется вы немного ошибаетесь, что фреймворки предоставляют инструменты для создания только одной инфраструктуры, это верно не для всех фреймворков (Из php тут же в голову пришел Zend Framework), не говоря уже о микрофреймворках, которые дают базовые вещи, на основе которых можно построить любую структуру которую можно пожелать (правда и писать кода придется побольше).
P.S. Статья очень хорошая, но было бы классно в дальнейшем увидеть продолжение с более подробными примерами различных архитектурных слоев.xanm
01.06.2017 13:48Не спорю, что есть очень гибкие фрейфорки, в которых можно развернуть любую архитектуру, но для организации бизнес логики придется написать много своего кода.
Впринципе нашу реализацию при желании можно встроить в любой фрейворк, как раз за счет того что есть какаято стурктура для бизнес логики.
alexhott
01.06.2017 21:02есть у меня в сопровождении личный кабинет созданный семь лет назад.
Интерфейс на PHP+Smarty шаблонизатор.
А все сущности и логика в хранимых процедурах MS SQL.
Для этой цели архитектура оказалось вполне удачной, а по производительности — быстрее я не видел.
Но новый проект так бы уже делать не стал — сопровождается тяжело.

AmdY
02.06.2017 03:53+1У вас всё плохо, очень плохо.
DDD вы не понимаете.
Enity — хрень с защищёнными свойствами в массиве, магическим __call и даже сеттер для айди работает с неявным поведением $this->id = $this->id == 0? $id: $this->id;
Репозиторий который не репозиторий, в котором мэппер, который почему-то не мэпит, а персистит данные.
Контекст непонятная штука, чей контракт зафиксирован в виде абстрактноо класса и не предполагает нормальную инъекцию зависимостей.
Ну и это первая половина проблемы. Вы не знаете синтаксиса php и работаете с отключёнными ошибками вроде E_NOTICE, E_DEPRECATED, потому принимаете объекты по ссылке. Даже оформление кода не по PSR и вооще пахнет временами php 4.
И ещё куча ног торчит из стога.xanm
02.06.2017 07:05Ваш комментарий лучше всех показывает что статья удалась! А-то я уже сомневаться начал :)
Loki3000
02.06.2017 11:03Честно говоря, я тоже мало что понял:
чем вообще занимается репозиторий, если он не работает с хранилищем? Зачем он тогда нужен?xanm
02.06.2017 11:29Репозиторий это абстракция в бизнес-логике которая позволяет не зная ничего о инфраструктурном уровне работы с базой данных получать оттуда сущности, сохранять их туда.
Этот подход описан в DDD как альтернатива ActiveRecord который встречается во многих php фреймворках.
Плюс этого подхода в том что мы сущности предметной области отделяем от логики и персистентного хранения в отличии от ActiveRecord, где все свалено в суперкласс который умеет все.michael_vostrikov
02.06.2017 12:04Ну не все, а только сохранение/загрузка сущности)
А подскажите, в чем плюс того, что мы сущности отделяем от логики?xanm
02.06.2017 12:17Сущности это часть бизнес-логики, они от нее никак не отделяются.
michael_vostrikov
02.06.2017 13:21Плюс этого подхода в том что мы сущности предметной области отделяем от логики
Или я не так понял?
xanm
02.06.2017 13:58это там опечатка «отделяем от логики персистентного хранения»

aprusov
05.06.2017 13:42Оба паттерна (AR, DM) имеют свои плюсы и минусы. Отделение логики персистентного хранения может быть реализовано и в нормальном AR.
AR вполне решает многие задачи и отлично тестируется (не верьте мифам о том что это не так). Далеко не всегда нужен DM с IdentityMap и UnitOfWork.
Хватит уже смотреть на них как на черное и белое.
Fesor
05.06.2017 19:29Отделение логики персистентного хранения может быть реализовано и в нормальном AR.
вот только называется это уже не AR а Row Data Gateway. Суть AR как раз в отсутствии разделения. В этом есть свои преимущества в определенном спектре задач.
AR вполне решает многие задачи и отлично тестируется
А вот тут поподробнее. Либо вы имеете ввиду обычные интеграционные тесты где надо поднимать реальную базу (выходить за пределы процесса в котором выполняются тесты), либо у вас есть чем поделиться с народом по этому вопросу.
Хватит уже смотреть на них как на черное и белое.
Мне в последнее время нравится идея использования DM с IM и UoW для операций записи и бизнес логики, и AR для операций чтения где надо просто в базу сходить да достать данные. Эдакое тупое DTO между базой и view частью приложения. Для этого AR идеально.
Loki3000
02.06.2017 12:07Но в вашем примере он не несет никакой полезной нагрузки. В качестве репозитория на самом деле вы используете маппер. Похоже что на него возложены задачи и репозитория и маппера.
В приведенном фрагменте, если в качестве зависимости передать не Repository а Mapper не поменяется вообще ничего.xanm
02.06.2017 12:23В примере у меня показан самая общая релизация.
Полезная нагрузка мапперов например получать сущности по какимто специфическим условиям.
Пример: из предметной области можно просто сказать репозиторию, дай мне пользователя с id = 4 и статусом = 10 и не заблокированного.
И в данном случае предментая область не нуждается в знаниях как это делается, Репозиторий преобразует этот запрос мапперу.
Сам маппер это уже отдельная сущность которая в отличии от репозитория знает как сохранять в базу, как загружать из нее, знает про sql и прочие инфраструктурные нюансы.Loki3000
02.06.2017 12:31Мне непонятно почему репозиторий этого не знает? У него же из названия следует что он должен этим заниматься.
xanm
02.06.2017 14:00Он не знает как делать сохранение, он знает только что ему надо делегировать сохранение в слой мапперов
Loki3000
02.06.2017 14:13Так а для чего он тогда нужен? почему сразу не передавать данные в маппер?
xanm
02.06.2017 14:18Он нужен для того чтоб убрать зависимость бизнес логики от работы с базой данных.
Loki3000
02.06.2017 14:34Дайте угадаю, а при смене хранилища вы подменяете маппер?
Тогда что мешает подменять целиком репозиторий?
В чем зависимость-то?xanm
02.06.2017 14:37Репозиторий менять как раз таки не надо потомучто от него зависит бизне логика, сам репозиторий использует интерфейс мапперов так что подставлять туда можно хоть маппр сохраняющий на диск и бизне логики это без разницы.
Loki3000
02.06.2017 14:46… а сделать это можно потому что мапперы реализуют одинаковый интерфес. Так что мешает разным репозиториям реализовывать одинаковый интерфейс? Как от этого пострадает бизнес-логика?
xanm
02.06.2017 14:57Репозитории реализуют один интерфейс и каждый конкретный может содержать свою специфическую логику.
Fesor
05.06.2017 19:36updateнамекает что бизнес логике все еще приходится париться с обновлением данных в базе. А это ломает всю идею.xanm
06.06.2017 00:21ну к сожалению ничего идеального нет и бизнес логике приходится переодически сохранять свое состояние в базу
Fesor
06.06.2017 00:33Для этого придумали unit of work, дабы ваш слой персистентности декларировал объекты бизнес транзакции как некий юнит, который можно было бы красиво "флашнуть".
Да, это сложно, но мне интересно было бы глянуть как вы "сохраняете" большой граф объектов. Просто интересно ибо "изолированно" я этого ниукого не видал. Как-то две крайности — либо размазано либо строгий unit of work.
Fesor
05.06.2017 19:35Репозиторий это абстракция в бизнес-логике которая позволяет не зная ничего о инфраструктурном уровне работы с базой данных получать оттуда сущности, сохранять их туда.
save your repository from save. Когда в вашем репозитории появляется метод
saveилиupdateто он перестает быть репозиторием и становится TableGateway который "вытек" из слоя персистентности в бизнес логику.
Более того, не очень понятно к чему приведет пример. Привели бы реальный пример репозитория для агрегата сущности. Что мол "нам теперь на каждый агрегат придется писать мэппер".
xanm
06.06.2017 00:22Не буду говорить что данная реализация репозитория удалась, но она решает поставленные задача. Следующий этап сделать ее ближе к эталону
Fesor
06.06.2017 00:33Следующий этап сделать ее ближе к эталону
Опять же, зачем? Это как-то поможет бизнесу? Если да то как?
p.s. есть неплохой докладик на эту тему: Greg Young — Stop Over Engineering
xanm
06.06.2017 00:37Тут палка о двух концах, в целях бизнеса вообще могут быть не нужны все эти архитектурные плюшки, есть проекты в которых жуткий га*нокод и они приносят бизнесу доход.
С другой стороны инженер должен исследовать.
Здесь уже надо балансировать между этим двумя крайностями)
AmdY
02.06.2017 12:55Почему удалась? Статья ужасная и вредная для прочтения. Не дай о кто-то прочтёт, не дойдёт до комментариев и будет это воспринимать как райт вэй. Автору надо подучить сам php, а затем перечитать книги на который он ссылался и почитать какого-нибудь Нильссона, чтобы увидеть практическую реализацию.
xanm
02.06.2017 14:02Жду вашей статьи на хабре про «райт вэй»!
AmdY
02.06.2017 14:09Зачем писать? Есть книги Эвайнса и Фаулера и куча статей от этих же авторов — это райт вэй. Надо их внимательной читать, а не набравшись по вершка и статьям лепить свои велосипеды.
xanm
02.06.2017 14:16Ну во первых книги это только теория которая нуждается в шлефовке на практике что и было сделано.
Во вторых нет такого понятия как райт вэй, любая практика берется и адаптируется под конкретные нужды.
От вас к сожалению кроме голой и агрессивной критики я не получил ни одного примера реализации бизнес-логики ни по книге Эванся ни по книгам Фаулера.
Вам я советую почитать книги Карнеги, например «Как завоёвывать друзей и оказывать влияние на людей» и для начала научиться общаться с людьми.AmdY
02.06.2017 14:50+1Да почитайте вы их, там есть реализации с кодом, плюс в посте выше я писал о Нильссоне, у него практики ещё больше. Но вы даже с терминами не разобрались, а пытаетесь делиться «опытом».
Карнеги хорош, кода хочешь навешать лапши на уши. Здесь же профессиональный ресурс, где люди обмениваются знаниями и опытом, а не заводят новых друзей. В отношении вас я умышленно применил агрессию и троллинг, дабы заставить вас усомниться и освежить знания.xanm
02.06.2017 14:55И опять пустой ответ, если вам есть что-то сказать по существу с примерами, говрите.
А просто тыкать в умные книжки не надо.
Жду аргументированных комментариев с примервами, с обоснованиями, если таковых нет то удачных вам споров в следущем посте на хабре.
aprusov
05.06.2017 14:02Здесь же профессиональный ресурс, где люди обмениваются знаниями и опытом, а не заводят новых друзей.
А может вы поделитесь опытом на серьезном ресурсе? Автор поделился своей практикой и он молодец.
Напишите, пожалуйста, чем конкретно он не прав и где ошибся в терминологии, а так же приведя примеры из своей практики, как вы сделали «по книжке» и это принесло профит проекту — в этом и ценность ресурса, не так ли?AmdY
05.06.2017 16:03Я в начальном комментарии указал пару проблем, но вся статья хреновая, а главное вредная.
Именно потому, я не хочу делиться опытом, потому что мои советы тоже могут быть вредными за пределами контекста. Надо опираться на серьёзную литературу, где рассмотрена куча разных кейсов, она не раз уже упоминалась.
К тому же в php есть готовые решения вроде doctrine-propel, которые значительно лучше поделки автора, который даже php знает с оговорками.
Fesor
05.06.2017 21:35Ну во первых книги это только теория
а вы их читали? У Эванса практически все примеры рассматриваются в контексте его проектов. У Фаулера если читать книжки вроде "Рефакторинг" тоже все хорошо.
Тут просто загвоздка какая, с такими концепциями как DDD это возможность "неверно понять" и потом закрепить это неверное понимание на практике. Так что по сути не стоит "сразу делать по DDD" а просто продолжаем делать как делаем и пытаемся осмыслить "чем отличается".
С другой стороны ваша статья просто про ваш вариант архитектуры приложения, в котором не сказать что есть что-то новое.
По своему опыту могу сказать что то что у вас описано как
Context(тут к слову может возникать конфликт с термином bounded context) далеко не самый удобный вариант. Это получше конечно чем "классы менеджеры", но в целом одно и то же (упор на transaction script). У Роберта Мартина в его "чистой архитектуре" скажем похожий концепт назывался Interactor, реализация юзкейса. Но это просто эдакое место в котором декларируется порядок действий в отвязке от UI. Никакой логики там быть не должно, вся логика делегируется сервисам, сущностям и объектам значениям. И вот это вполне удобно, хотя и требует весьма много дисциплины.xanm
06.06.2017 00:32Книги читали регулярно возвращаюсь к конкретным главам, но даже приведенные примеры достаточно ограничены и указывают только на какие-то базовые аспекты. Для полноты без практики не обойтись.
Fesor
06.06.2017 00:41Для полноты без практики не обойтись.
практика будет приносить пользу только с постоянным анализом всех принятых решений. Большинство как-то этот момент упускают.
Скажем из описания в вашей статье я так и не услышал зачем вы сделали что-то свое. У меня к примеру есть на этот счет теория почему толковых дата мэпперов мало а реализаций недо-orm пруд пруди. Всем хочется что-то свое что они знают (NiH синдром или просто скучно), но делать что-то по настоящему полезное лень. В итоге мы имеем сотни тысяч строк никому ненужного кода.
Просто скажите сколько человекочасов ушло на реализацию вашей инфраструктуры? При том что все компоненты необходимые для этого уже давно есть. Я понимаю если бы вы инвестировали время в то что бы допилить какой-нибудь интересный компонент который несправедливо забыт, но я этого не увидел.
Ну и все же — хотелось бы примерчики увидеть что бы вышла более конструктивная критика. Ибо я так понял планов выпуска в opensource нет. В частности меня интересует как вы покрываете код тестами. Есть ли логика в сущностях, насколько грамотно вы дробите систему на модули… А то что у вас там есть объект контроллер (не тот который с http работает а тот который декларирует control-flow — context в вашем случае) — это у всех есть так или иначе.
xanm
08.06.2017 12:07Ну я бы сказал что все есть с точки поддрежки технологий, баз данных, апи, библиотек и т.д…
В этом плане у нас все работа с финраструктурными частями основана на готовых решениях, тут и работа с базой и роутинг и всевозможные апи.
На себя было взята только организация каркаса, бизнес-логики и верхней части хранения.
На каркас ушло гдето 1-2 месяца 1 человека, дальше мелкие доработки.
В наше время вообще использование громостких фреймворков часто стрельба по воробьям из пушки, легко можно собрать свое приложение хранящее бизнес логику и окружить его готовыми библиотеками работающими с инфраструктырными частями.
На счет мапперов и хранения мне странно что всех это так волнует, самая важная частьб всетаки юизнес логика а как сохранять ее состояния уже не важно, важно ее отделить от сохранения, об этом говорять все подходы начеленные на работу с бизнес-логикой.
Платформа написана и не стоит на месте, есть планы после анализа развивать ее дальше, написанная статья тоже говорит о том что мы будем учитывать критику :)
Тесты у нас приемочные, есть план перейти на тестирование базнес логики по контекстам.
Логика есть как в контекстах так и в сущностях.
Модулей как таковых нет есть наборы контекстов.
Ну контроллер и TransactionScript конечно похожи но это разные концепции, не стоит их путать. Как вы говорите control-flow инфраструктуры и control-flow бизнес логики это 2 разные вещи, хотя часто их сваливают в одно и это как раз Controller слой в MVC подобных фрейворках.
voidshah
02.06.2017 06:29хорошая статья. С удовольствием бы прочел следующую, где было бы больше практики и примеров кода.
xanm
02.06.2017 07:02На данный момент я думаю над следующей. Жаль только что на хабре такие статьи не почете.

samizdam
02.06.2017 10:58+1Ну почему же… Держите плюсик)
А если серьёзно, то конечно спрос ниже, чем на всякие общие хау ту по технологиям и новости с жёлтыми заголовоками. Но это нормально, т.к. целевая аудитория небольшая. Она ограничена как языком, так и уровнем, необходимым для восприятия. Большинство начинающих и средних разработчиков этой темой не интересуются, поскольку проектирование такого уровня выполняет кто-то за них. А многие мыслящие на нужном уровне этот этап прошли, и всё уже для себя решили.
Я, когда активно интересовался подобными материалами, как раз столкнулся с дефицитом публикаций, особенно на русском, и уж совсем в контексте php.
Так что пишите обязательно ещё, потомки будут в долгу)xanm
02.06.2017 11:32За плюс спасибо. Информации на этот счет действительно мало, поэтому в свое время я и занялся практическим применением этих подходов. Буду очень рад видеть что программисты начнут использують хотябы TransactionScript как стандарт в своих проектах.
voidshah
02.06.2017 12:19вот и я столкнулся с дефицитом. Теории много, а вот чтоб с практикой — совсем мало.

dmitriylanets
02.06.2017 14:19очень хочется увидеть инструмент по работе с БД на основе DataMapper, выложите пожалуйста на github
dmitriylanets
02.06.2017 17:35конкретно Маппинг связанных сущностей интересует, транзакционность, валидация
xanm
02.06.2017 17:57Могу четсно сказать что с этим мы не придумывали ничего сложного и нового у нас простая раздельная работа со связанными сущностями. В мапперах нет хранения связей между таблицами, все связи прописаны в бизнес логике и за ее пределы не выходят.

sspat
03.06.2017 13:32По мэпперам так и не понял, зачем вы выбрали такое решение, свалив в один класс и мэппинг и сохранение в базу. Это как минимум нарушает SRP и класс очень сильно раздуется если ему придется сохранять какой-то сложный агрегат со множеством внутренних связей, ValueObjects хранящихся по разным таблицам и т.д.
Второй момент, зачем передавать обьект по ссылке вот так? У вас же судя по тайп-хинтингу явно не php4.
function delete(\foci\model\Entity &$entity)
А за статью спасибо, чужой велосипед всегда интересно посмотреть, когда это не просто копирование уже существующего решения а что-то оригинальное.xanm
08.06.2017 11:53Я бы сказал так что маппер делает только меппинг, а сохранение как финальная чать мепинга.
Сама логика разрабатывается так чтоб в мепперах не надо было работать со сложными связями объектов, каждый меппер знает только свой один объект с которым он работает.
SRP очень важен, но в реальности к нему надо стремится как к идеалу но достигнуть его бывает достаточно сложно или в некоторых случаях нецелесообразно.
Ссылка это как бы показатель того что первый код тут был написан уже давно :)
hanovruslan
Кажется, ни один из известных, по крайней мере из популярных, подходов проектирования не рассматривает задачу избежание сегментации бизнес-логики. Причем это про разные стэки верно.
xanm
Тут я соглашусь, все подходы дают часто только теоретическую базу, а все важные нюансы появляются как раз на практике. Если я правилньо понял про сегментирование бизнес-логики, то мы в одном проекте использовали подход разделение бизнес-логики на под бизнес домены. Сценарии пользователя строили по взаимодействию этих доменов.
Fesor
Можете чуть больше раскрыть проблему?
hanovruslan
Я имею в виду ситуацию, когда у нас есть, например, шина событий и, как это часто бывает, задачи, которые надо сделать вчера.
Но начать лучше с начала:
Разберу пример с обновлением какой-то сущности, потому что чтение не так наглядно, хотя и там бывают приколюхи.
Потом приходят требования, которые можно быстро внедрить, например, прям на уровне (де)сериализации. В моей практике это было требование воспринимать строки true\false\0\1 как bool. Это часть бизнес-логики, потому что отправляющая сторона уже написана и формирует запросы именно так. Другой пример, после сохранения новой сущности нужно тригерить обновление чего-то другого в системе. это очень просто делается добавлением еще одного события и эксклюзивного подписчика оного.
В этих двух простых примерах бизнес-логика после внесения изменений теперь находится в двух частях и сходу не видно как без серьезного переписывания не сегментировать (логику). Вероятно, нужно держать разный набор схемы данных для разных слоёв — (де)сериализация, контроллер, дополнительные обработчики — и получится что-то типа middleware, но, кажется, что 1) код распухает и 2) система становится переусложненной со всеми вытекающими последствиями
P.S.: прошу прощения за не очень спешный ответ.
P.S.: Опыт проектирования у меня чуть более чем нулевой, поэтому я не стал приводить несколько разных примеров архитектуры, но, кажется, одного будет достаточно
Fesor
Скорее логики представления. Вы же конвертируете там представление данных а не бизнес логикой занимаетесь. Или там не тупо
0вtrueскастить?То есть под сегментированием логики вы подразумеваете случаи когда логика вытекает наружу? Ну мол нарушение инкапсуляции, закона Деметры, open/close и srp?
в чем это выражается?
Опять же, мне сложно представить себе подобное разделение ответственности усложняет код. Было бы все же интересно хотя бы приблизительно разобрать ваш случай.
hanovruslan
Логика представления специфична для клиента, который присылает данные, а не для протокола, которым клиент пользуется. Причем это один из с пару десятков вариантов специфичности десериализации. Этот код нельзя будет применить для другого клиента. Так что я думаю, что это именно бизнес-логика. Возможно я не прав.
Если говорить известными терминами, то да. Оно самое.
Это когда ты смотришь на исходники и понимаешь, можно бы было обойтись меньшим количеством байт ))
Наверное, лучше привести в пример то, как обычно проходит code review. Обычно приходит набор файлов с диффом, из которого довольно сложно понять как точечные изменения позволяют решить поставленную задачу. Конечно, бывают и другие, где понятно, что и почему изменено и почему этот дифф оптимально решает задачу. Но таких PR мало. Увы.
Поэтому мне лично очень интересно как нужно проектировать систему, которая на достаточно большой перспективе позволяет хорошо организовывать бизнес-логику. И было бы очень круто, если подход не будет требовать писать тонны бойлерплейта.