

О JHiccup
JHiccup это простая программа, которая позволяет измерить задержки операционной системы с точки зрения конечного приложения. Она была написана CTO компании Azul?—? Гилом Тени для измерения задержек ОС.
Почему задержки так важны
Мы в живем во времена сетевых приложений. Большинство программ запущенных на нашем компьютере регулярно ходят в интернет. Если мы запустим браузер и откроем google.com, то произойдет 50–60 запросов.
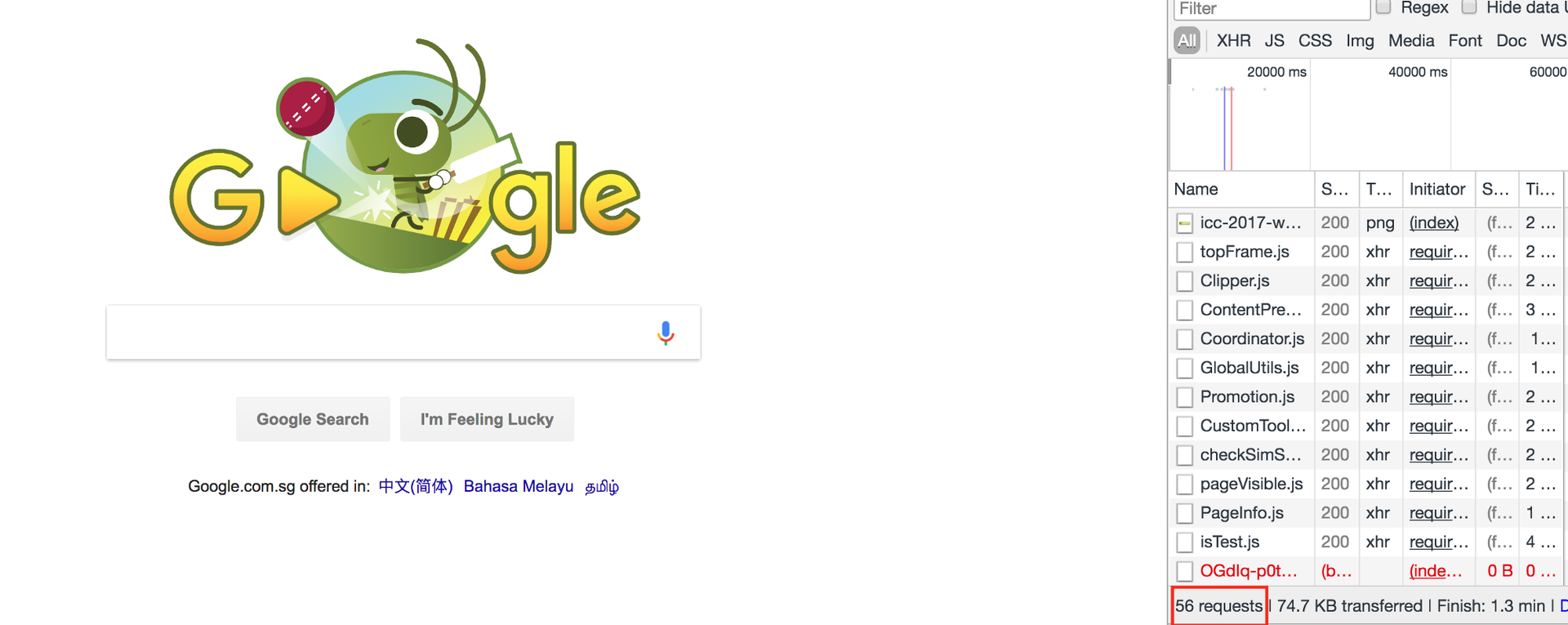
Для открытия google.com произошло 56 запросов
Если мы говорим о более сложных сайтах, то количество запросов будет исчисляться сотнями. И задержка любого из этого запросов может задержать отрисовку всего сайта.
Рассмотрев пример с сайтами, мы можем легко провести аналогию с клиент-серверным приложение или популярными микро-сервисами. Если в цепочке вызова микро-сервисом один из микро-сервисов вернет ответ позже обычного, то это может затормозить всю логику. Например, медленный ответ о цене продукта из БД может замедлить весь процесс покупки в интернет магазине.
Поэтому когда мы говорим о производительности и задержках программы, важен не только лучший и средний результат, но и худшие результаты.
Зачем нужен мониторинг ОС
Часто разработчикам поступают жалобы от клиентов или других систем о том, что приложение обрабатывало запрос слишком долго. К сожалению, такую проблему бывает трудно воспроизвести локально или даже заметить в реальном окружении.
Многие разработчики в этом случае сразу начинают искать проблемы в коде. Для этого используется например логи, метрики и профайлер. Но правильный анализ производительности должен начинаться снизу-вверх, начиная с уровня железа и ос и заканчивая программой.
Большинство ос не являются операционными системами реального времени. А значит они не могут давать гарантии на определенное время выполнение операций. Значит производительность программ, запущенный на таких ос, может сильно отличаться в течение времени работы программы. Попросту говоря, программа может даже не получать процессорное время в какой-то момент. И тогда абсолютно не важно какой код выполняется в программе.
Вот несколько причин почему программа может “спать” не имея возможности выполнять полезные действия:
- ОС может выполнять внутреннюю сборку мусора;
- Другое ресурсоемкое приложение может использовать CPU или другие ресурсы;
- ОС может выполняться поверх гипервизора и не зная об этом быть не единственной ос запущенной на этом железе.
Почему jHiccup?
Существует множество утилит и метрик, позволяющих увидеть загруженность разных компонентов системы с разной степенью детализации. Проблема в том, что таких метрик очень много и для каждой программисту нужно ответить на два вопроса:
- Может ли эта метрика быть причиной задержки?
- Является ли конкретное значение этой метрики аномальным?
jHiccup позволяет посмотреть на систему с точки зрения приложения. jHiccup это маленькое приложение с простой функцией : бесконечный поток засыпает и просит ос разбудить его через определенный период, например 1 секунду. Если ос была занят через 1 секунду и не смогла разбудить поток, то приложение это увидит сравнив время пробуждения с расчетным временем пробуждения (время засыпания + 1 сек). Мы можем построить график, где мы увидем задержки системы в течение выполнения программы.
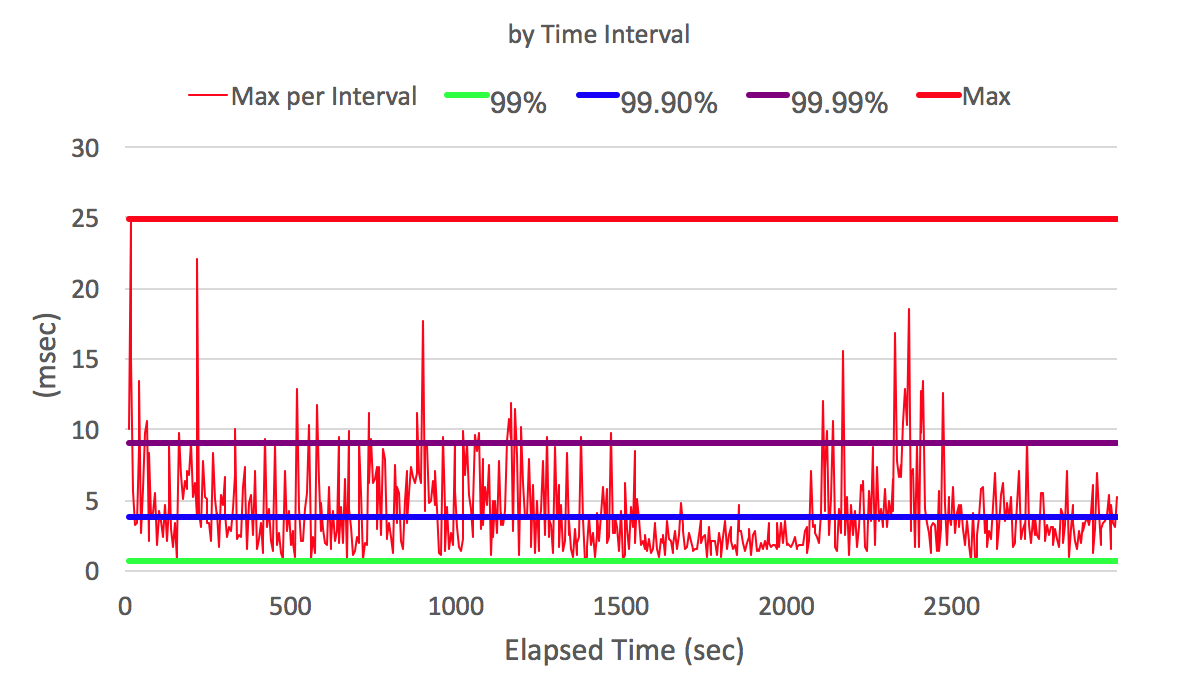
На оси X время выполнения программы в секундах. На оси Y задержка пробуждения в миллисекундах (то сколько программа ждала, когда ОС даст ей возможность выполняться)
Зная время жалобы на медленный ответ нашей системы клиенту и видя график задержек пробуждения нашей программы, мы можем сказать, была ли ос причиной задержки или нет.
На предыдущем графике мы рассмотрели задержки относительно времени выполнения программы. Кроме этого бывает удобно взять все задержки и отсортировать по возрастанию. Это даст нам представление о распределении задержек и их вероятности.

Задержка в миллисекундах на оси y и ее вероятность на оси x
Некоторые особенности JHiccup:
- не страдает проблемой Coordinate Omission хорошо описанной Гилом Тене в его видео
Внутри jHiccup использует гистограмму как структуру данных. Обычная гистограмма разбивает весь интервал задержек (например от 1мс до 1 сек) на отрезки и подсчитывает сколько задержек попало в определенный интервал. Это позволяет представить данные о задержках в более компактном виде, чем просто список наблюдаемых значений (1.55мс, 2.6мс и тд).
На самом деле в jHicuup используется специальная имплементация гистограммы?—?HDR-Histogram, которая обладает следующими свойствами:
- Гистограммы имеют высокое разрешение. Мы можем видеть не только 95% и 99% худших результатов, но и намного более подробные данные ( 99.999%).
- Хранит данные в компактном виде, что позволяет измерять производительность в течение долгого времени. Для этого размер сегмента гистограммы увеличивается экспоненциально. Благодаря этому получается более компактно хранить аномальные значения.
Библиотека HDR-Histogram получило широкое распространение. Можно найти имплементации на разных языках. Разные системы для сбора метрик стали поддерживать hdr-historgram как один из внутренних форматов, благодаря ее компактности и точности.
Зачем такая точность?
На графиках выше мы видели данные о 99.9999% случае. У многих возникает вопрос, нужна ли такая точность и надо ли рассматривать данные дальше 95% или 99% персентиля. Давайте рассмотрим два примера. В обоих примерах мы возьмем вероятность аномальной задержки P(A) как 5% и 1% соответственно. Нам надо ответь на вопрос, какова вероятность того, что пользователь увидит аномальный запрос P(B):
- Мы видели что google.com делает около 60 запросов. Для примера рассмотрим сайт онлайн-магазина где для покупки необходимо выполнить 200 запросов. В случае P(A)=5%, P(B)=1–(0.95 в степени 200)=99.997%. В случае P(A)=1%, P(B)=1-(0.99 в степени 200)=86.6%
- Пусть у нас есть 10 микро-сервисов. И каждый вызывается дважды во время выполнения определенного сценария, то есть происходит 20 вызовов. В случае P(A)=5%, P(B)=1–(0.95 в степени 20)=64.15%. В случае P(A)=1%, P(B)=1-(0.99 в степени 20)=18.2%.
Как мы видим, рассматривать данные только до 95-ого или 99-ого персентеля недостаточно.
Пример использования jHiccup
Скачать jhiccup можно с http://www.azul.com/downloads/jhiccup/ или https://github.com/giltene/jHiccup.
./jHiccup -d 4000 /usr/bin/java org.jhiccup.Idle -t 300000
# первые 4 секунды старта не буду записаны, всего будет записано 300 секунд. По умолчанию поток будет просыпаться каждые 5 секунд (настраивается с помощью параметра -i).
# создан hiccup.170617.1120.3461.hlog
./jHiccupLogProcessor -i hiccup.170617.1120.3461.hlog -o hiccup.170617.1120.3461
# создан hiccup.170617.1120.3461 и hiccup.170617.1120.3461.hgrmФайл hiccup.170617.1120.3461 можно просмотреть с помощью excel-файла jHiccupPlotter.xls.
Для просмотра hiccup.170617.1120.3461.hgrm можно воспользоваться онлайн приложением https://hdrhistogram.github.io/HdrHistogram/plotFiles.html. Оно также удобно для сравнения нескольких hdrm файлов (например, во время разной загрузки системы или с разных серверов).
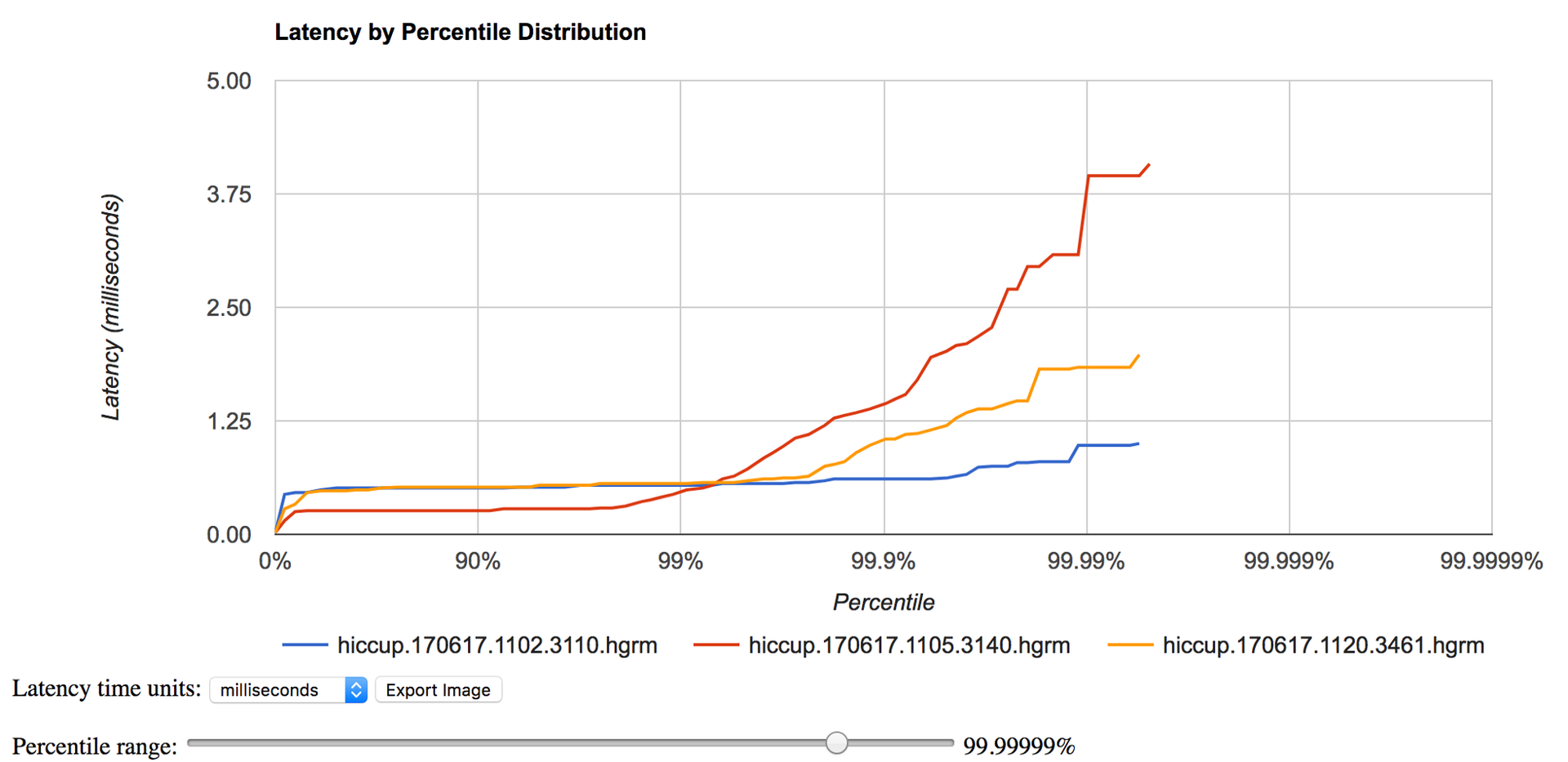
Сравнивая график производительности нашей программы (например, задержки http-ответов) с полученной hdr-диаграммой, мы можем понять работала ли вся система медленно в определенный период или только наша программа.
Мы запускали jhiccup как отдельный процесс. Другой способ это запуск javaagent-а вместе с нашей программой.
java -javaagent:jHiccup.jar="-d 0 -i 1000 -l hiccuplog -c" MyProgram.jar -a -b -cВ этом случае jhiccup будет просыпаться и сохранять информацию о задержках в течении всего времени выполнения программы.
В этих двух способах запуска есть одно важное различие. В первом случае jHiccup запускается на отдельной JVM в другом на той же JVM. То есть во втором случае мы увидим задержки связанные с работой JVM (например паузы GC), на которой запущено основное приложение.
В файле jHiccupPlotter.xls есть возможность добавить линии SLA на график.
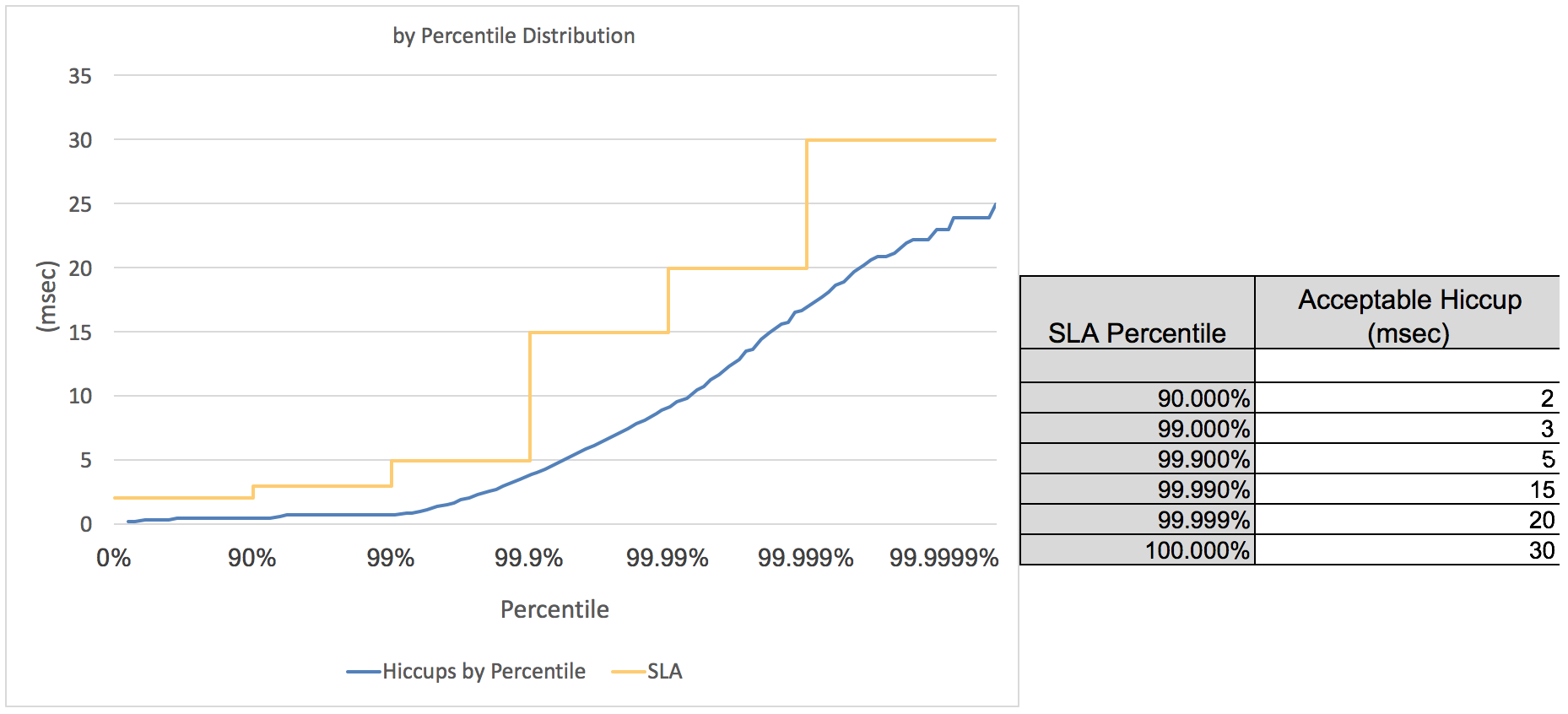
Я вижу два удобных применения для SLA:
jHiccup удобная утилита для мониторинга задержек системы. В отличии от системных метрик, jHiccup позволяет взглянуть на загрузку системы с точки зрения приложения.