
Итак, после постановки требований описанной в части 1 можно перейти к проектированию системы.
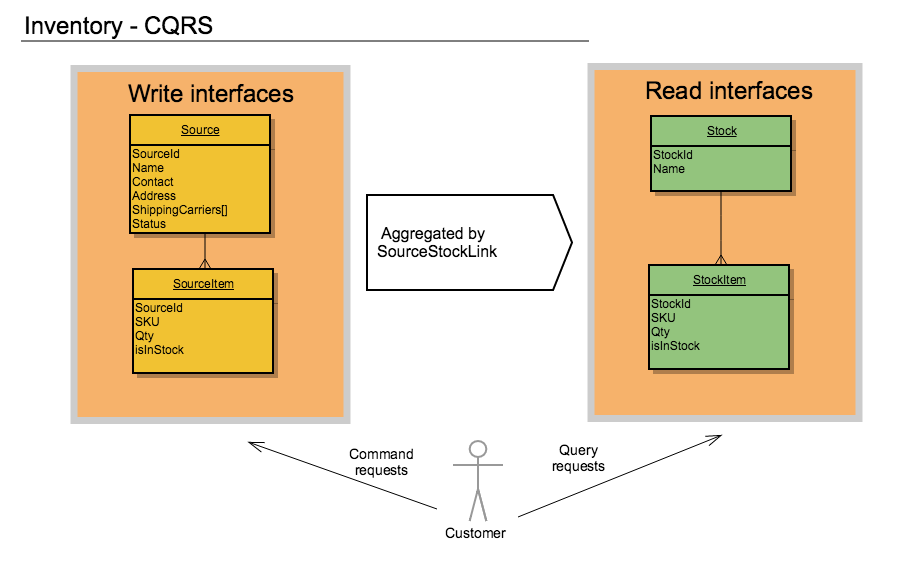
Основная наша задача в проектировании, как это понятно из названия статьи, добиться разделения интерфейсов на Query и Command, чтобы впоследствии разделить бизнес сценарии на те, которые будут читать данные (Query интерфейсы) и на те, которые будут изменять данные (Command интерфейсы). А также обеспечить минимальное время ожидание (latency) на обновление данных, доступных через Query, после того как мы изменили данные через Command.
Почему CQRS?
В последнее время разделение методов интерфейса (CQS), а впоследствии и самих интерфейсов на Query/Command стало популярным веянием в разработке архитектуры приложений. Но в Magento CQRS применяют не из-за популярности, а из-за того, что для нас иногда это единственный способ построить гибкое расширяемое (адаптирование к специфическим потребностям) решение с возможностью независимо масштабировать операции Чтения и Записи.
Фактически мы пришли к CQRS в результате осмысления и повсеместного применения SOLID в написании кода. CQRS это реализация принципа единой ответственности (The Single Responsibility Principle) и принципа разделения интерфейсов (The Interface Segregation Principle) и уход от классического CRUD.
Элементы CQRS у нас появились достаточно давно, когда мы задавались вопросом как масштабировать модель данных EAV (entity-attribute-value) для операций чтения и вводили индексные агрегационные таблицы для этого.
Более подробно про CQRS, и что он для нас значит можно послушать в презентации, которую я делал на MageCONF 2016 (видео, слайды).
Описание доменных сущностей
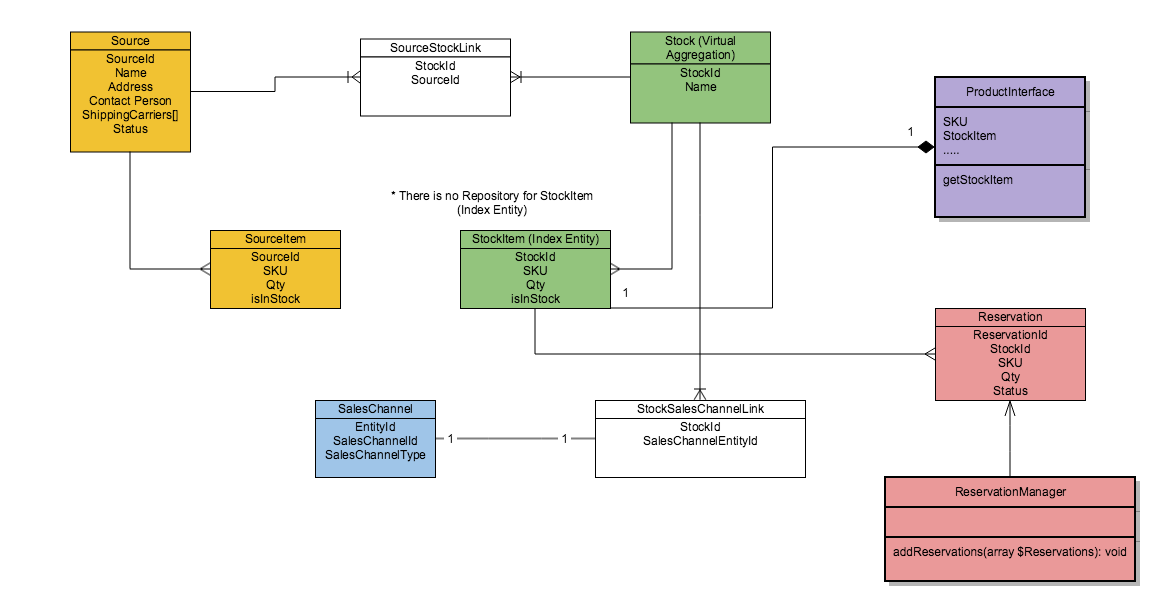
В предметной области Inventory у нас есть шесть основных доменных моделей:
- Source — сущность ответственная за представление любого физического склада где может находиться товар (магазин, склад).
- Source Item — сущность-связка, представляет собой количество определенного продукта (SKU) на конкретном физическом хранилище. А также хранит статус доступен ли продукт для продажи в данный момент.
- Stock — виртуальная сущность ответственная за представление запасов на нескольких физических складах (Source) одновременно. Представляет собой аргрегацию по физическим складам. Связь между складами и Stock (какие именно склады входят в агрегацию) задается администратором в админ панеле либо через вызов API.
- Stock Item — индексная сущность, строится на основании связей между Source и Stock, и представляет собой количество определенного продукта (SKU) доступное на конкретном Stock, т.е. виртуальной агрегации.
- Sales Channel — канал продаж через который осуществляется продажа конечному покупателю. В случае Magento это может быть (Website, Store, Store View), но канал продаж может определяться продавцом самостоятельно, поэтому для некоторых продавцов это может быть Страна (Country), или большой Оптовый клиент (Wholesale) может выступать самостоятельным каналом продаж. Фактически канал продаж это контекст (scope) в рамках которого происходит продажа, который помогает нам четко определить Stock который должен быть использован во время выполнения бизнес операции.
- Reservation — объект резервации, создается для того, чтобы иметь актуальный уровень товаров, которыми мы располагаем для продажи между событиями создания заказа и уменьшением количества товаров на конкретных физических складах. Фактически объект резервации помогает нам избавиться от надобности выполнения проверок, блокировок и списывания товаров из инвентаря физических складов (Source Item) во время операции размещения заказа, при этом значение товаров доступных для продажи в рамках определенного Stock меняется сразу же.
Данная диаграмма представляет собой взаимодействие описанных выше сущностей:
Таким образом мы получаем разделение интерфейсов на Query и Command:
Theory of operation
Одна из наших основных задач — это максимально разгрузить процесс размещения заказа. И идеально сделать эту операцию такой, которая не будет изменять состояние системы (State Modification). Это избавит от лишних блокировок и улучшит масштабирование чекаута.
По диаграммам выше видно, что такие операции как рендеринг страницы категории будет выполнен используя только Query API (StockItem), где нам нужно отобразить количество товаров, которые мы можем продать в определенном контексте (SalesChannel).
Операция синхронизации с внешней ERP или PIM системой будет использовать Command API (SourceItem) и обновлять количество товаров на конкретных складах, после чего реиндексация, которая пересоберет StockItem позволит этим обновлениям быть видимыми на фронте.
В случае операции размещения заказа все становится интересней.
Размещение Заказа по Шагам
Операция размещения заказа разделяется на две операции: непосредственно размещение заказа, в которой принимает участие покупатель и которая заканчивается оплатой и подтверждением принятия заказа на выполнение; и обработка заказа, которая происходит постфактум (с определенной задержкой от нескольких миллисекунд до минут и часов) основная задача которой определить из какого именно склада (или складов) мы должны выполнить доставку нашему покупателю и произвести калибровку количества товаров на этих складах после выполнения заказа.
Собственно, рассмотрим эти операции на примере подробней.
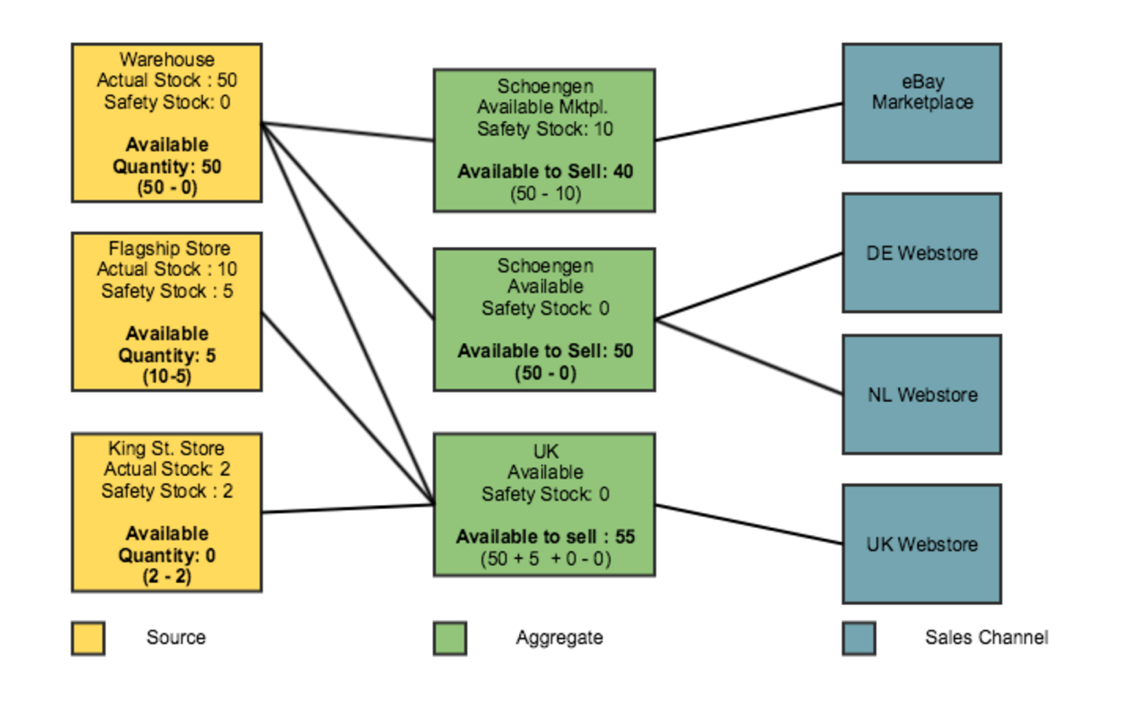
Пусть мы имеем 3 физических склада: Source A, Source B, Source C. На которых хранится товар SKU-1 в таком количестве:
- SourceItem A — 20
- SourceItem B — 25
- SourceItem C — 10
Для этого канала продаж у нас есть созданная виртуальная агрегация Stock A, с которой связаны все текущие физические склады (Source A, Source B, Source C). Получаем StockItem A для SKU-1 имеет количество 20+25+10 = 55
Соответственно, когда покупатель заходит на Website, система точно определяет Stock, который должен быть применен для определения количества товаров, и использует Stock Item-ы в рамках этого стока для всех продуктов (SKU) в категории, в нашем случае SKU-1.
Размещение заказа
Пусть покупатель решил купить 30 единиц товара SKU-1.
- Мы принимаем решение о том можем ли мы выполнить продажу (хватает ли у нас товара для продажи), количество StockItem A для SKU-1 = 55 минус количество всех резерваций для продукта SKU-1 на Stock A, в нашем случае 0 (так как пока ни одна резервация не создана), 55 — 0 > 30, то мы принимаем решение, что продать 30 единиц товара SKU-1 можем.
- Во время размещения заказа мы агностичны к тому с каких именно физических складов произойдет в итоге списание, поэтому мы не работаем с Source Item сущностями. *Данная тема будет рассмотрена в отдельной статье, которая будет полностью посвящена алгоритму выбора складов для доставки в рамках выполнения заказа.
- При этом мы не можем уменьшить кол-во SKU-1 на StockItem, так как это Read проекция, созданная только для чтения. Поэтому мы создаем резервацию (Reservation) для SKU-1 на Stock A в количестве 30 единиц. Создание резервации это Append Only операция, которая добавляется без каких либо проверок.
- Сама команда заказа может при этом класться в очередь на последующую обработку.
Состояние системы, которое мы имеем на текущий момент:
Количество товара SKU-1 на складах:
- SourceItem A — 20
- SourceItem B — 25
- SourceItem C — 10
Reservation для SKU-1 на Stock A в количестве 30.
Пока мы не успели обработать данный заказ, например из-за большой latency, к нам на сайт приходит другой покупатель, который также хочет приобрести товар SKU-1 в количестве 10 единиц.
Система начинает выполнять те же шаги, что описаны выше.
Проверяем можем ли мы продать 10 единиц SKU-1. Проверка осуществляется таким образом: количество StockItem A для SKU-1 = 55 минус количество всех резерваций для продукта SKU-1 на Stock A, в нашем случае 30, 55 — 30 = 25 > 10 принимаем решение, что продать 10 единиц товара SKU-1 можем.
По факту состояние в Event Sourcing определяется как проекция агрегированных данных (в нашем случае StockItem), с добавлением всех событий, которые были получены за дельту времени с момента формирования данной проекции (в нашем случае это Reservation).
Обработка заказа
На данном этапе мы должны определить какие именно физические склады будут принимать участие в доставке, и для этих складов уменьшить значение количества отгруженных товаров.
За эту часть ответсвенный алгоритм, который приймет решение о выборе складов (будет описан в следующей статье). Например, алгоритм принял решение, что делевле всего для продавца будет отправить 30 товаров со складов Source С и Source B.
Соответсвенно количество товара SKU-1 на складах должно измениться:
- SourceItem A: 20
- SourceItem B: 25 — 20 = 5
- SourceItem C: 10 — 10 = 0
А открытая резервация для SKU-1 на Stock A удалена (либо изменить статус этой резервации на Complete), чтобы она больше не участвовала в вычислениях. После этого должна создастся команда на обновление индекса Stock Item, которая также может быть асинхронной.
Magento MSI (Multi Source Inventory)
Данная статья является второй статьей в цикле «Система управления складом с использованием CQRS и Event Sourcing» в рамках которого будет рассмотрен сбор требований, проектирование и разработка системы управления складом на примере Magento 2.
Открытый проект, где ведется разработка, и куда привлекаются инженеры из сообщества, а также где можно ознакомиться с текущим состоянием проекта и документацией, доступен по ссылке.
Комментарии (11)

flancer
20.07.2017 12:30+1Возник небольшой диссонанс по схеме данных. SourceItem — это запись кол-ва доступного продукта в каком-то реальном хранилище Source. Множество Source'ов (в общем случае) могут быть объединены в одно виртуальное хранилище Stock. Каждое виртуальное хранилище Stock содержит StockItem — аггрегацию записей кол-ва продукта SourceItems по всем Source'ам, входящим в данный Stock. До сих пор все понятно, если я понял все правильно.
Вопрос возникает по поводу связки StockItem <-> ProductInterface. Я понимаю, что каждому StockItem соответствует некий продукт (это прослеживается хотя бы по SKU), но почему ProductInterface связан с одним единственным StockItem? На это указывает связь 1-в-1 и имя метода "getStockItem" (не ...Items).
Мне кажется, тут закладывается "мина" — какой из всех доступных StockItem'ов я получу, если у конкретного продукта дерну метод "$product->getStockItem()"? Есть ощущение, что программные объекты не совсем корретно отображают отношения соответствующих сущностей в структурах данных (таблицах). IMHO, было бы корректно убрать метод getStockItem (или заменить на getStockItems) и ввести дополнительный объект типа StockManager (Helper) с методом getProductOnStock($prodId, $stockId).

maghamed
20.07.2017 13:29Отличный вопрос!
Есть ощущение, что программные объекты не совсем корретно отображают отношения соответствующих сущностей в структурах данных (таблицах).
Да, именно так. В струтурах данных связь один (Product) ко многим (StockItems) колличество продуктов в разных виртуальных агрегациях.
Но в программных интерфейсах связь 1-к-1 как вы правильно заметили.
Дело в том, что у нас Stock всегда определяется в рамках определенного контекста (Sales Channel), т.е. для текущего контекста, например Store View = default у нас есть только одно представление Stock. А если Stock определен, то мы можем получить только один StockItem для определенного SKU.
Здесь есть и определенные ограничения, так как контекст Stock должен быть точно такой же как и контекст Product.
Сейчас продукт извлекается в таком контексте.
http://<magento_host>/rest/<store_code>/schema&services=<serviceName1,serviceName2,..> rest/<store_code>/V1/products The value of `store_code` can be one of the following: default The assigned store code all. This value only applies to the CMS and Product modules. If this value is specified, the API call affects all the merchant's stores. GEToperations cannot be performed when you specify all.
http://devdocs.magento.com/guides/v2.0/rest/rest_endpoints.html
Так как мы делаем Coarse-grained API для продукта, т.е. через вызов API продукта мы должны получить StockItem для этого продукта в том же контексте в котором запрашивается сам продукт.
Т.е. мы уходим от один-к-многим за счет определения контекста, в рамках которого был выполнен вызов API получения продукта.
flancer
20.07.2017 12:46+1Ну и вдогонку, пока писал первый коммент, подумалось, а в чем задумка связывания Source и Stock в отношении многие-ко-многим? Если мы хотим продавать продукт с конкретного физического склада, то у нас есть SalesChannel для этого. SalesChannel связан со Stock'ом один-ко-многим. Я могу понять, когда несколько физических складов (Source'ов), собираются в один виртуальный (Stock, отношение многие-к-одному). Но плюсов от привязки многих физических складов ко многим вирутальным пока что не вижу (в свете наличия тех же каналов продаж). А вот минусы видны сразу — если один физический склад (Ф) завязан на несколько виртуальных (А, Б, В), то изменение кол-ва продукта в StockItem (продукт на виртуальном складе А) мы не только должны отразить на SourceItem (физическом складе Ф), но и обратно на все связанные с Ф виртуальные склады (Б и В).
Какие плюсы от многие-ко-многим в SourceStockLink компенсируют такой пинг-понг?
maghamed
20.07.2017 14:19Еще один очень праильный вопрос.
Да, Вы правы, когда физический склад (Ф) завязан на несколько виртуальных (А, Б, В), то даже механизм резерваций (Reservation) нам не поможет гарантировать на 100%, что мы продали по факту больше чем у нас есть на складе.
Так как в этом случае оформив заказ через сток А и создав резервацию по продукту SKU-1 для Stock A, мы не знаем по факту с какого Source она спишется (т.е. какой физический склад выполнит доставку). Поэтому не совсем корректно уменьшать количество товара SKU-1 для Stock Б, используя резервацию на стоке А.
Из-за этого пока первый заказ не обработан и находится, скажем в очереди, когда второй покупатель выполняет покупку через Stock Б, он будет видеть первоначальное число товаров (без учета продажи через Stock А).
Система выполнит при этом продажу, и спишет деньги у покупателя, но на момент обработки второго заказа — первый будет уже обработан и система будет знать точные данные по товарам на физических складах. Поэтому выбросит ошибку, что не может обработать второй заказ, если товара на складе Ф будет не достаточно, и его также не будет на других складах.
По большому счету такое поведение может быть приемлемым, например, тот же Amazon делает похожим способом. Используя Eventual Consistency для обновления товаров на складе. И если происходит такая «накладка» — возвращает деньги покупателю и отменяет заказ.
Мы используем много-много между Складами (Source) и Вирутальным агрегациями (Stock) по двум причинам:
1. Мы строим фреймворк и не должны искусственно ограничивать мерчатнов в построении их бизнес модели. Т.е. если для вашего бизнеса это абсолютно неприемлемо продать больше чем есть на складе — просто не мапте один сорс на несколько виртуальных агрегаций и используйте связь как один-ко-многим.
2. КДПВ в посте (первая диаграмма) это фактически бизнес требования для нас, которые основаны на том, какие есть сейчас клиенты у нашего Magento Commerce Order Management. И сейчас они сталкиваются с тем, что один физический склад присвоен нескольким виртуальным Stock.
Здесь на видео, кстати, можете послушать нашего VP технологий и продукта, который рассказывает об Omni Channel на примере Франкфуртского аэропорта.
Так вот там Stock динамический и всегда определяется под клиента, например, если вы летите только через один терминал аэропорта, то ваш сток это сумма товаров только в этом терминале. Если вы находитесь в двух терминалах, например летите транзитом, то сток — это сумма по двум терминалам. В этом случае если у вас склад (Source) в каждом из терминалов, то этот склад Source будет использоваться в разных виртуальных агрегациях Stock
https://www.youtube.com/watch?v=MlDWsJugF78&feature=youtu.be&t=1m5s
Кстати, на проекте MCOM они решают описанную выше проблему тем, что используюь threthhold пороги продаж по Source и Stock. На первой диаграмме это хорошо видно. За это отвечает поле Safety Stock, если оно например равно 10, то система не будет продавать дальше товары если их количество в StockItem достигнет или опустится ниже 10. Safety Stock выставляется на каждый Stock и Source, т.е. вы можете поставить не нулевое значение для тех Stock-ов которые переиспользуют один и тот же Source.
flancer
20.07.2017 14:42Спасибо за ответ. Я понял, что основная причина наличия связки "многие-ко-многим" между Source & Stock:
Мы строим фреймворк и не должны искусственно ограничивать мерчатнов в построении их бизнес модели.
Пример с терминалами, к сожалению, не дошел — мозг сломался на "если вы летите только через один терминал аэропорта, то ваш сток это сумма товаров только в этом терминале" :) Но, в принципе, достаточно приведенного аргумента.
flancer
20.07.2017 13:23Соответственно, когда покупатель заходит на Website, система точно определяет Stock, который должен быть применен для определения количества товаров, и использует Stock Item-ы в рамках этого стока для всех продуктов (SKU) в категории, в нашем случае SKU-1.
А что делать, если Website (SaleChannel) связан со многими Стоками? Покупатель выбирает отдельный Сток в рамках Канала? Да, получается так.
В случае Magento это может быть (Website, Store, Store View), но канал продаж может определяться продавцом самостоятельно, поэтому для некоторых продавцов это может быть Страна (Country)
Т.е. где-то в недрах приложения есть данные о привязке Website/Store/StoreView/Country/… к КаналамПродаж. Некий helper/manager анализирует текущую сессию клиента и на основании данных о привязках определяет, какой Канал предоставить клиенту. После чего клиент выбирает из доступных Стоков тот, с которого он хочет приобрести продукт?
Все-таки мне кажется, что концепция Канала здесь лишняя. IMHO.
Фактически канал продаж это контекст (scope) в рамках которого происходит продажа, который помогает нам четко определить Stock который должен быть использован во время выполнения бизнес операции.
В том-то и дело, что нет. Канал помогает определить группу Стоков, а дальше — сама-сама-сама, как говаривал персонаж Никиты Михалкова.
maghamed
20.07.2017 14:26А что делать, если Website (SaleChannel) связан со многими Стоками? Покупатель выбирает отдельный Сток в рамках Канала? Да, получается так.
Собственно в этом и задумка, что для определенного контекста у вас должен быть всего один Stock.
Т.е. в вашем случае, насколько я понимаю, хочется чтобы Store View определяло Stock, а не Website.
Это не проблема, как я описывал выше сейчас все наши API работают в контексте store_code, т.е. Store View
Т.е. где-то в недрах приложения есть данные о привязке Website/Store/StoreView/Country/… к КаналамПродаж. Некий helper/manager анализирует текущую сессию клиента и на основании данных о привязках определяет, какой Канал предоставить клиенту.
да, так и есть.
После чего клиент выбирает из доступных Стоков тот, с которого он хочет приобрести продукт?
это делает все тот же резолвер, так как для определенного контекста у нас есть всего один Stockflancer
20.07.2017 14:47Т.е., вы подтвердили мою мысль, что SaleChannel к выбору Стока имеет слабое отношение. В лучшем случае, как промежуточная шестеренка в передаточном механизме.
maghamed
20.07.2017 15:56используюя SalesChannel некий резолвер (то что вы выше назвали helper/manager) определяет Stock, и для этого стока уже берутся StockItems
Фактически да, шестеренка в передаточном механизме.
OlegZH
Всё очень интересно. Но! Ужасно хочется попробовать сделать что-нибудь такое самому.
Не можете пояснить что это такое?P.S. Очень приятно, что мои подозрения оправдываются. Например, Вы пишете:
Что означает «масшатбирование операции»? И, если это — единственный способ «построить гибкое расширяемое решение», то не должен ли этот способ стать повсеместно используемым? И почему этот способ не использовали раньше (если не использовали)?Это нужно для очень много чего, включая и обработку медицинских данных.
P.P.S. Я давно хотел сделать складскую программу (в качестве виртуального «задания на собеседованиях»), а тут ещё и в комментариях к статье на Хабре про ERP-системы речь зашла о складских системах. А тут Ваша статья! Будет крайне любопытно обогатиться полезным опытом. Спасибо.
maghamed
Вы можете послушать мою презентацию на эту тему.
Представим простой пример с базой данных СУРБД.
Какую бы вы предметную область не выбрали у вас всегда будут сценарии чтения и сценарии записи.
Если взять все тот же каталог товаров, то операциями чтения у вас будут — рендеринг страницы категорий, рендеринг страницы продуктов, рендеринг шопинг карты. В этих сценариях мы не изменяем данные, а просто читаем их из базы. Очень сильно упрощая и утрируя можно сказать, что выполняются SELECT запросы
Когда у вас совершаются покупки, или администратор добавляет новый продукт в админ панеле. Совершается операция записи. Опять же утрируя можно сказать, что в данных случая выполняются INSERT/UPDATE запросы.
Обычно соотношение запросов чтения/записи сильно в пользу чтения. Скажем, 80% на 20% как закон Парето.
Поэтому с увеличением нагрузки на сайт в какой-то момент вам нужно масштабировать ваши операции чтения.
Например, в СУРБД для этого используют механизм репликации, когда у одного мастера есть несколько слейвов, с которых данные читаются.
Когда же bottleneck выступает операции записи становится сложней, так как масштабировать запись в СУРБД всегда сложней чем чтение. До какого-то момента можно использовать все ту же мастер-мастер репликацию, но в принципе запись масштабируется хуже.
А когда код приложения написан таким образом, что одна модель (класс модели) объединяет в себе и операции чтения и записи, то на уровне кода удобно такое разделение не сделаешь.
Поэтому основная идея заключается в разделение интерфейсов по ответственностям на чтение и запись.
И такое разделение приводит к тому, что запись у нас может происходить в инфраструктуре оптимизированной под быструю запись включая сам адаптер для хранения, а чтение будет выполняться из адаптера оптимизированного под быстрое чтение, например Elasticsearch.
И если вам понадобиться оптимизировать/масштабировать отдельно чтение — вы сможете этого добиться не меняя код, ответственный за операции записи.
Выполнение такой сегрегации на уровне интерфейсов в коде всегда трудозатратно и требует тщательного проектирования.