
Не так давно мы решали задачу оптимизации потребления ресурсов нашего кластера elasticsearch. Неосилив настроить сам эластик, мы сделали что-то типа кэша результатов поиска, использовав при этом подход называемый "обратным" поиском или перколятором. Под катом рассказ про то, как мы работаем с метаданными метрик и собственно перколятор.
Цель сервиса мониторинга, который мы разрабытываем — показывать причины проблем, для этого мы снимаем очень много подробных метрик про разные подсистемы инфраструктуры клиентов.
С одной стороны мы решаем задачу записи большого количества метрик с тысяч хостов, с другой стороны метрики не лежат мертвым грузом в нашем хранилище, а постоянно читаются:
- клиенты смотрят графики, при отрисовке которых может вычитываться несколько тысяч метрик
- у нас много преднастроенных триггеров для обнаружения типичных проблем, и каждых из них может постоянно вычитывать очень много метрик
Что такое метрика
Когда мы начинали разработку okmeter (в тот момент еще не было публичных версий influxdb, prometheus), нам было сразу понятно, что метрики не должны быть "плоскими". В нашем случае идентификатор метрики это словарь ключ-значение (у нас он исторически называется label_set):
{
"name": "nginx.requests.rate",
"status": "403",
"source_hostname": "front3",
"file": "/var/log/access.log",
"cache_status": "MISS",
"url": "/order"
}Для каждой такой метрики у нас есть значения, привязанные к определенным моментам времени (временной ряд).
Как мы храним метрики
На основе хэша от label_set для каждой метрики рассчитывается строковый ключ, по которому мы идентифицируем метрики в хранилище. И тут мы разделяем задачу хранения значений метрик по ключу от задачи хранения и обработки метаинформации о метриках:

Хранилище значений метрик мы в этой статье рассматривать не будем, а о метаданных поговорим более детально.
Метаинформация метрики это собственно ключ, label_set, время создания, время обновления и еще несколько служебных полей.
Эту информацию мы храним в кассандре и можем ее получать по ключу метрики. В дополнении к основному хранилищу метаданных у нас есть индекс в elasticsearch, который по некоторому поисковому запросу пользователя возвращает набор ключей метрик.
Запись метрик
Когда от агента, установленного на сервере клиента, приходит пачка метрик, на сервере для каждой метрики происходит примерно следующее:
Вычисляем metric_key, проверяем, есть ли эта метрика в хранилище метаинформации (C*)
Регистрируем новую, если нужно (записали в C* и ES)
Поднимаем updated_ts и вычисляем, пора ли его обновить (обновляется раз в 12 часов, ради снижения нагрузки на индексацию в ES)
Если пора – обновляем updated_ts в C* и ES
- Пишем значение в metric_storage
Чтение метрик
У нас есть 2 основных источника запросов на чтение метрик: запросы пользователей на отрисовку графиков и система проверки триггеров. Такие запросы представляют собой некие выражения на нашем dsl:
top(5, sum_by(url, metric(name=“nginx.requests.rate”, status=“5*”)))Это выражение содержит:
"Селектор" метрик (аргументы функции metric()), который является поисковым запросом для выбора всех метрик, интересных пользователю. В данном случае мы выбираем все метрики с именем "nginx.requests.rate" и меткой status, имеющей префикс на "5" (хотим посчитать все http-5xx ошибки)
- Функции преобразования метрик. В данном случае все выбранные метрики мы сгруппируем (суммой) по метке url (например значения с разных серверов или файлов просумируются), а потом возьмем только 5 наибольших по сумме урлов, а хвост сложим в значение с меткой "~other"
При этом всегда наш запрос работает в каком-то интервале времени: [since_ts=X, to_ts=Y]
Селектор метрик преобразуется в примерно такой запрос к elasticsearch (валидный json запроса сильно многословнее):
{"name": “nginx.requests.rate”, "status_prefix": "5", "created_lt": "Y", "updated_gt": "X+12h"}
Получили N (часто тысячи) ключей
Идем в C* получать label_sets по ключам
Идем в metric_storage получать данные по ключам
- Вычисляем выражение top(5, sum_by(…))
Нагрузка и размер данных
В данный момент наше облако обрабатывает чуть больше 100 тысяч метрик в секунду на запись. Посковых запросов в среднем около 350 rps (90% из них от триггеров). Каждый поисковый запрос идет по 1-3 индексам ES, каждый индекс ~100млн документов (~30GB).
При этом потребление CPU эластиком не оставит равнодушным любого, кто считает деньги, потраченные на хостинг :)
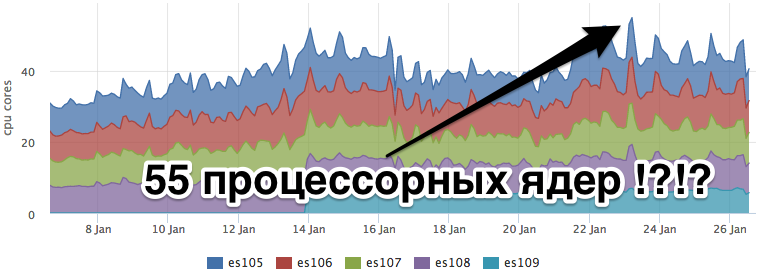
Elasticsearch
Мы пытались крутить настроки elasticsearch, ожидая, что встроенный query cache как раз создан для нашего случая повторяющихся запросов. Была попытка смоделировать индекс, в который для некоторых запросов не приходят никакие обновления, чтобы исключить инвалидацию кэша для этих запросов.
Но к сожалению все наши упражнения не дали ни снижения потребляемых ресурсов, ни снижения времени ответа эластика.
Внешний кэш
Мы решили сделать внешний по отношению к ES кэш результатов поиска и сформулировали к нему такие требования:
Поиск всегда идет по интервалу времени
Метрики, которые перестали приходить, должны уходить из кэша
- Новые метрики должны попадать в результаты поиска в течении 1 минуты
При таких требованиях просто кэшировать ответ ES можно лишь на 1 минуту, при этом понятно, что hit rate будет никакой. В итоге мы пришли к тому, что будем делать не совсем кэш, а что-то вроде материлизованного представления с результатами поиска по каждому известному нам поисковому запросу.
Перколятор
Идея заключалась в том, что при каждой записи метрики мы будем проверять, какому известному поисковому запросу она соответствует. В случае совпадения, метрика записывается в наш кэш.
Такой подход называется "перспективным поиском", он же "обратный поиск", он же "перколятор".
Насколько я понял, термин "перколяция" здесь употребляется из-за схожести процесса, мы как-бы проверяем "протекание" документа через множество поисковых запросов.
В задаче обычного поиска у нас есть документы, мы строим из них индекс, в котором (сильно упрощенно) каждому "слову" соответствует список документов, в котором это слово встречается.

В случае перколяции у нас есть заранее известные поисковые запросы, а каждый документ является поисковым запросом:
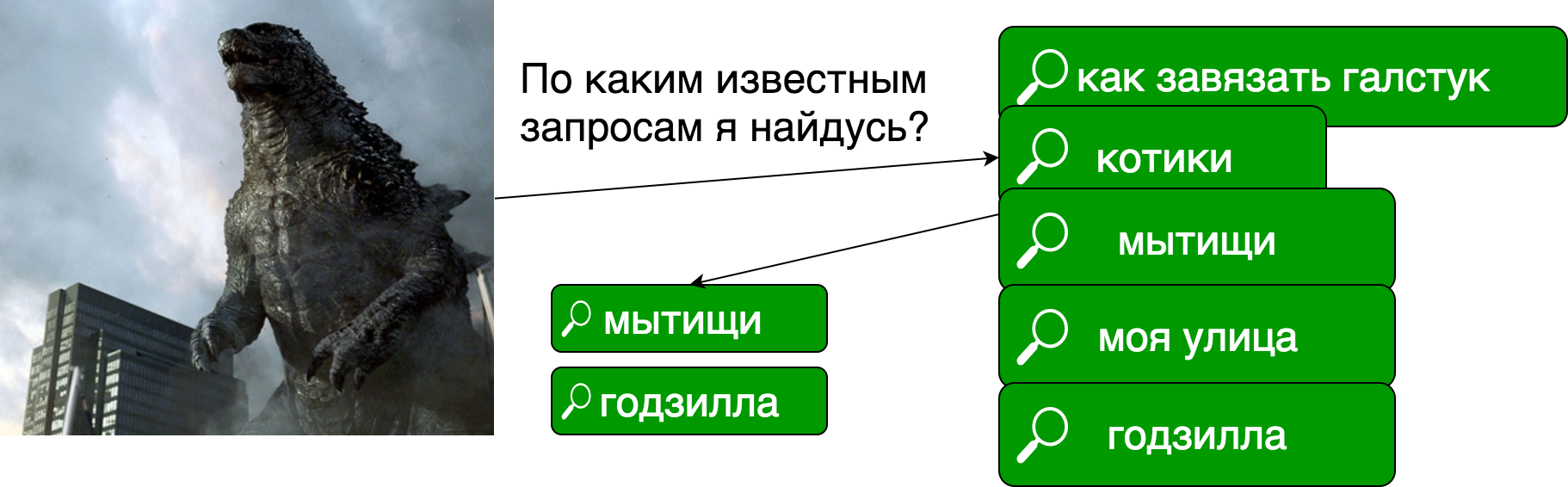
Реализации перколятора:
- В elasticsearch есть percolate query
- В solr есть открытый тикет, может когда-нибудь доделают
- Luwak — библиотека для java на базе Lucene
- Google App Engine Prospective Search API — сервис для GAE, но он уже deprecated
Мы рассматривали только elasticsearch, там перколятор представляет из себя специальный тип индекса, в котором мы описываем структуру наших будущих документов: какие будут поля у документа и их типы (mapping). Дальше в этот индекс мы сохраняем наши запросы, после чего ищем, подавая на вход документы.
Внутри ES при каждом запросе перколяции создается временный индекс в памяти, состоящий только из одного документа, который мы подали на вход. Из всех сохраненных запросов отбрасываются те, которые заведомо не подходят документу по набору полей. После чего для каждого оставшегося запроса-кандидата выполняется поиск по нашему временному индексу.
На нашем простеньком бенчмарке мы получили 2-10ms на проверке 1 документа на соответствие 1 запросу в перколяторе. При нашем потоке документов, это будет очень накладно. К тому же мы так и не научились "готовить" elasticsearch:)
Наивный самодельный перколятор
Вернемся к нашим метрикам. Как я говорил выше, наш документ — это словарь ключ-значение. Наш поисковый запрос — поиск по точному или префиксному совпадению полей. То есть как таковой полнотекстовый поиск нам не требуется.
Мы решили попробовать сделать "наивную" реализацию перколятора, то есть в лоб проверять соответствие каждой метрики всем известным запросам. У нас есть поток записи ~100 тысяч метрик в секунду, каждую метрику нужно проверить на соответствие ~100 запросам.
Бенчмарк одной проверки (данный кусок нашего кода работает на golang, на нем и писали прототип) показал ~300ns. Так как это полностью cpu bound задача, имеем право суммировать время, получаем:
100k * 100 = 10M проверок в секунду
10M * 300ns = 3 секунды в секуду = 3 процессорных ядра
Логика работы нашего кэша получилась примерно такой:

В процесс записи метрик добавились дополнительные этапы:
- Поднимаем все сохраненные запросы для данного клиента из С*
- Проверяем каждую пришедшую метрику на совпадение по каждому запросу
- В случае совпадения записываем метаинформацию о метрике в кэш, одна и та же метрика может быть много раз записана в кэш (дубликаты уберет кассандра)
Стоит отметить, что после того, как мы регистрируем новый запрос, кэш для него валиден не сразу. Мы должны дождаться окончания запросов на запись, которые уже начались и не видели новый запрос в списке известных. Поэтому мы отодвигаем время инициализации кэша на величину таймаута запроса на запись метрик.
Как устроен кэш
Кэш мы храним в кассандре, результаты для каждого запроса побиты на куски по времени (каждый кусок 24 часа). Это сделано для того, чтобы обеспечить вымывание из результатов метрики, которые перестали приходить.
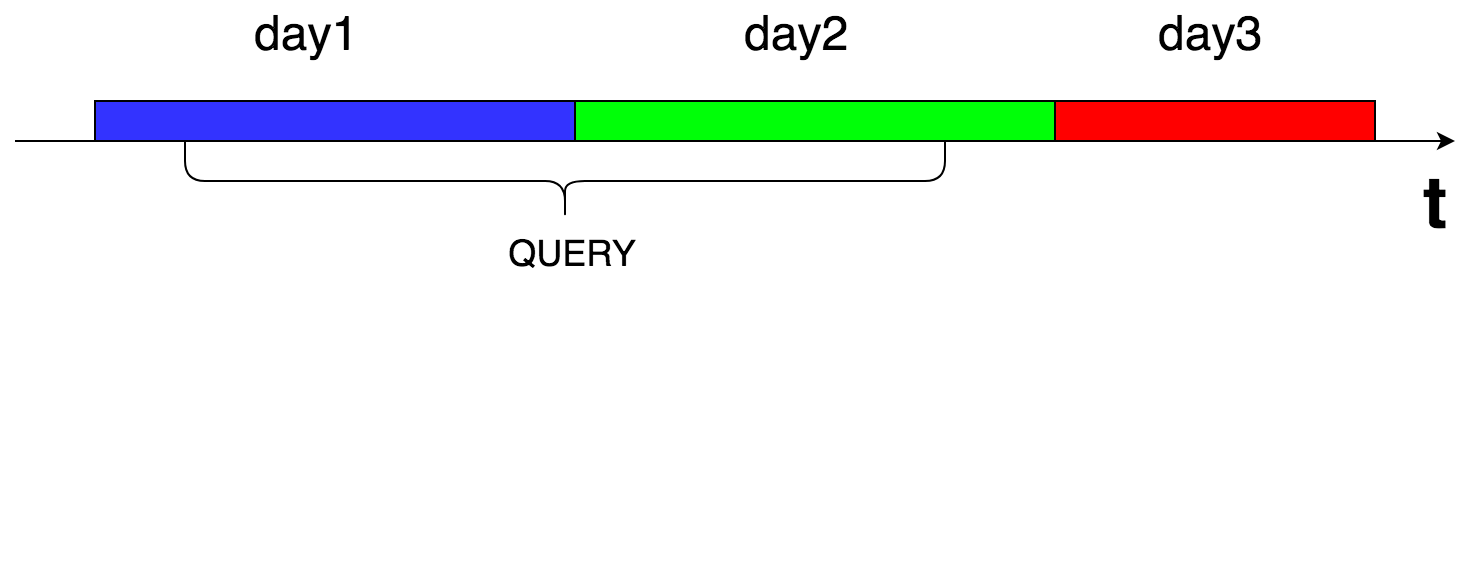
При запросе мы вычитываем все суточные куски, попадающие в интересующий нас интервал времени и объединяем результаты в памяти.
Значением является словарь ключ метрик и json представление label_set. Таким образом, если мы используем результаты из кэша, нам не нужно дополнительно идти в кассандру еще и за метаданными метрики по ключу, как мы делали это после получения результатов из ES.
Выкатили в production
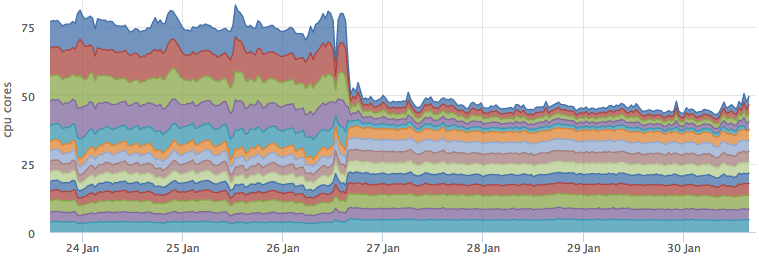
После того, как мы выкатили кэш в бой и он стал валиден для большинства запросов, нагрузка на ES сильно упала:
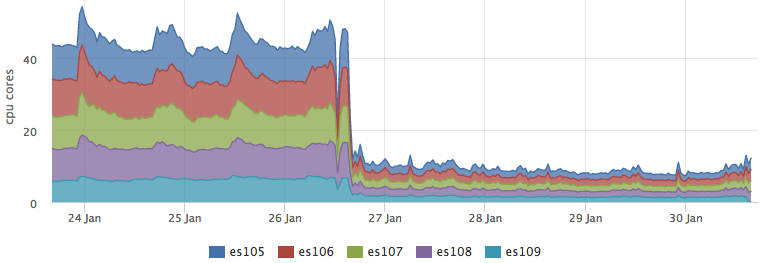
При этом потребление ресурсов кассандрой никак не изменилось:
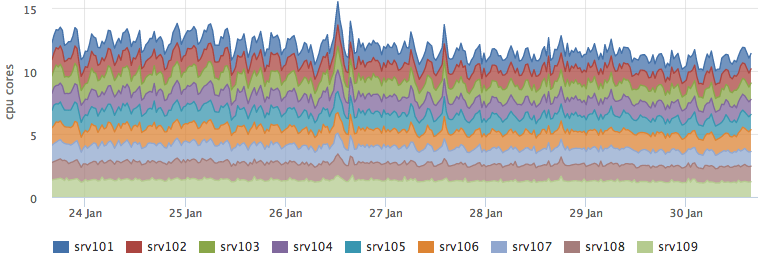
А бэкенд, который выполняет перколяцию вырос как раз на прогнозируемые ~3 ядра:
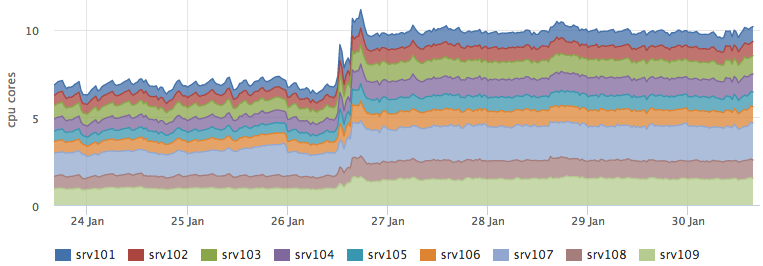
Как бонус мы получили хорошую оптимизацию по latency, взять из кэша результаты оказалось в ~5 раз быстрее, чем сходить в ES и потом достать метаинформацию из C*:
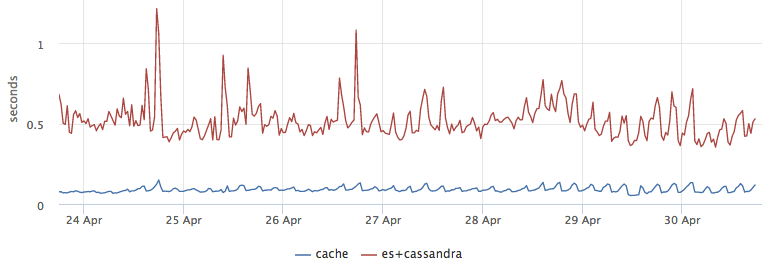
Проверка консистентности
Чтобы убедиться, что мы нигде не накосячили с логикой работы кэша, первые несколько дней поиск шел одновременно и по ES и по кэшу, при этом мы сравнивали результаты и писали соответствующую метрику. После переключения нагрузки на кэш, мы не стали выпиливать логику валидации кэша и делаем спекулятивные запросы в ES для 1% запросов. Эти же запросы являюся ещё и "грелкой" для ES, в противном случае без нагрузки индексы могут не попасть в page cache и запросы пользователей будут тупить.
Итого
Мы пытались не делать внешний кэш, а заставить ES использовать внутренний. Но пришлось заниматься велосипедостроением. Но есть и плюс: мы будем навешивать дополнительную логику на перколятор.
По результатам мы неплохо ужались по железкам, при этом наш самодельный перколятор достаточно хорошо масштабируется. Это для нас достаточно важно, так как мы быстро растем как по количеству клиентов, так и по количеству метрик с каждого клиентского сервера.
Комментарии (4)
gtbear
11.08.2017 12:40а ковыряли clickhouse от яндекса? он по идее для метрик самое то

NikolaySivko Автор
11.08.2017 12:56+1Clickhouse хорошо подходит для хранения сырых событий. На мой взгляд для задачи хранения timeseries колоночная БД не дает какого-то выигрыша по производительности или удобству относительно стандартных подходов.
elephantum
Кстати, интересно было бы подумать, обобщается ли это решение до уровня write-through materialized views поверх эластика. Наверняка ведь это типовая задача.
NikolaySivko Автор
Эластик не очень дружелюбный в плане диагностики, профилирования, так что навешивать на него больше логики я бы не рикнул. А вот иметь event bus например на kafka и нужными сервисами фигачить свои представления, подписавшись на события — это достаточно неплохо работает. Плюс если говорить про оптимизацию производительности, это же процесс обратный к обобщению логики как правило =)