

Доброго времени суток! Apache Kafka – очень быстрый распределенный брокер сообщений, и сегодня я расскажу как его “готовить” и реализовать с его помощью простую микросервисную архитектуру из консольных приложений. Итак, всем, кто хочет познакомиться с Apache Kafka и опробовать ее в деле, добро пожаловать под кат.
Обзорная часть
Введение
Данный материал ни в коем случае не претендует ни на доскональное описание Apache Kafka, ни на тонкие вопросы построения микросервисной архитектуры. Единственное, что надо знать — это как строить приложения на платформе .NET. Мы будем использовать .Net Core 2.0
Итак, что мы в итоге создадим? Приложение, которое подскажет, как назвать своего ребенка. Для простоты, оно будет выдавать случайные мужские и женские имена из заранее составленного списка. Система будет состоять из двух консольных приложений и одной библиотеки.
Идея в том, чтобы построить не “монолитное”, а распределенное приложение. Тем самым, мы обеспечим себе задел для будущего масштабирования и множество других преимуществ, описанных, например, здесь.
Вот какая структура будет у нашей системы:
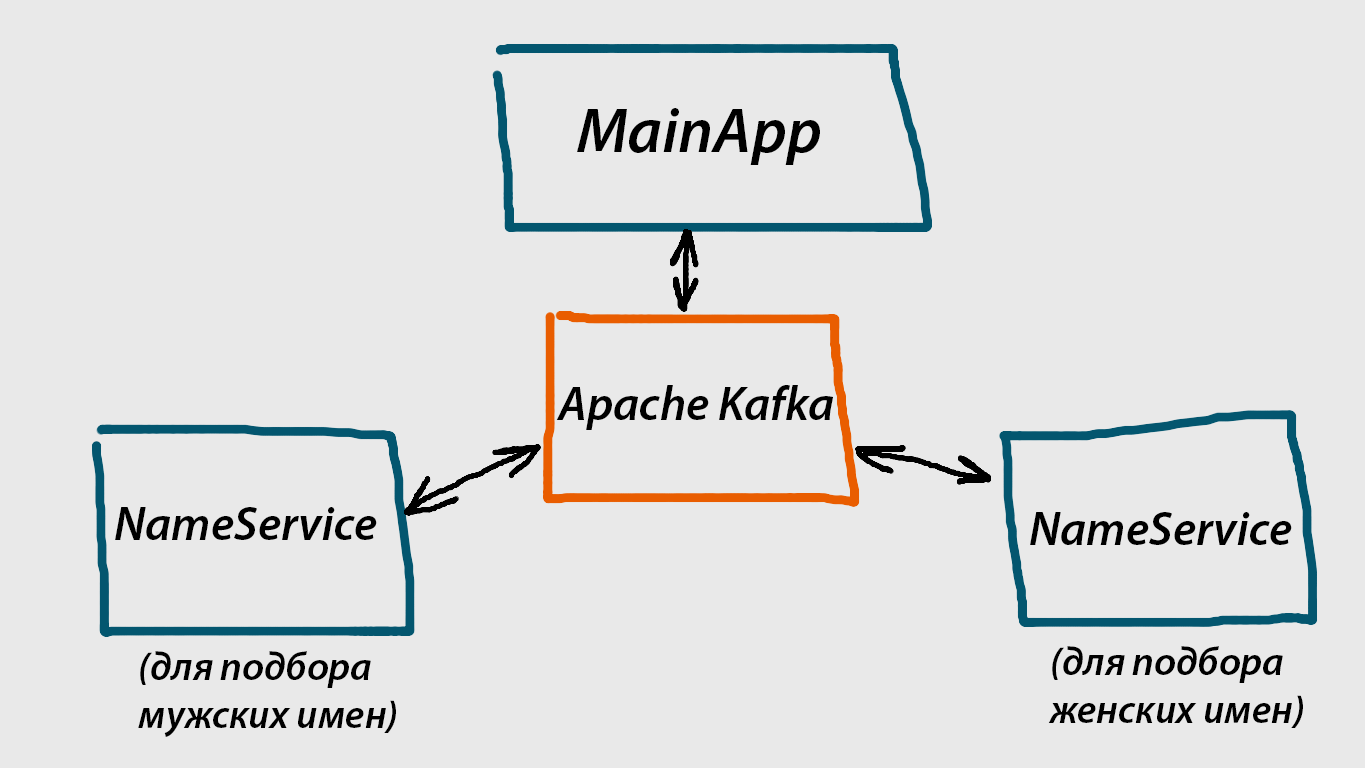 3 синих “прямоугольника” по сторонам – это консольные приложения. По сути, те два, что внизу, это микросервисы, а MainApp – пользовательское приложение, через него мы будем запрашивать имена. NameService у нас будет универсальным сервисом, способным генерировать либо мужские, либо женские имена.
3 синих “прямоугольника” по сторонам – это консольные приложения. По сути, те два, что внизу, это микросервисы, а MainApp – пользовательское приложение, через него мы будем запрашивать имена. NameService у нас будет универсальным сервисом, способным генерировать либо мужские, либо женские имена.Оранжевый “прямоугольник” посередине – брокер сообщений Apache Kafka. Брокер сообщений это то, что связывает все части нашей системы воедино. В нашем случае мы будем использовать Apache Kafka, но с таким же успехом могли бы воспользоваться RabbitMQ, ActiveMQ, или каким-нибудь еще.
А вот так происходит взаимодействие MainApp c Apache Kafka:
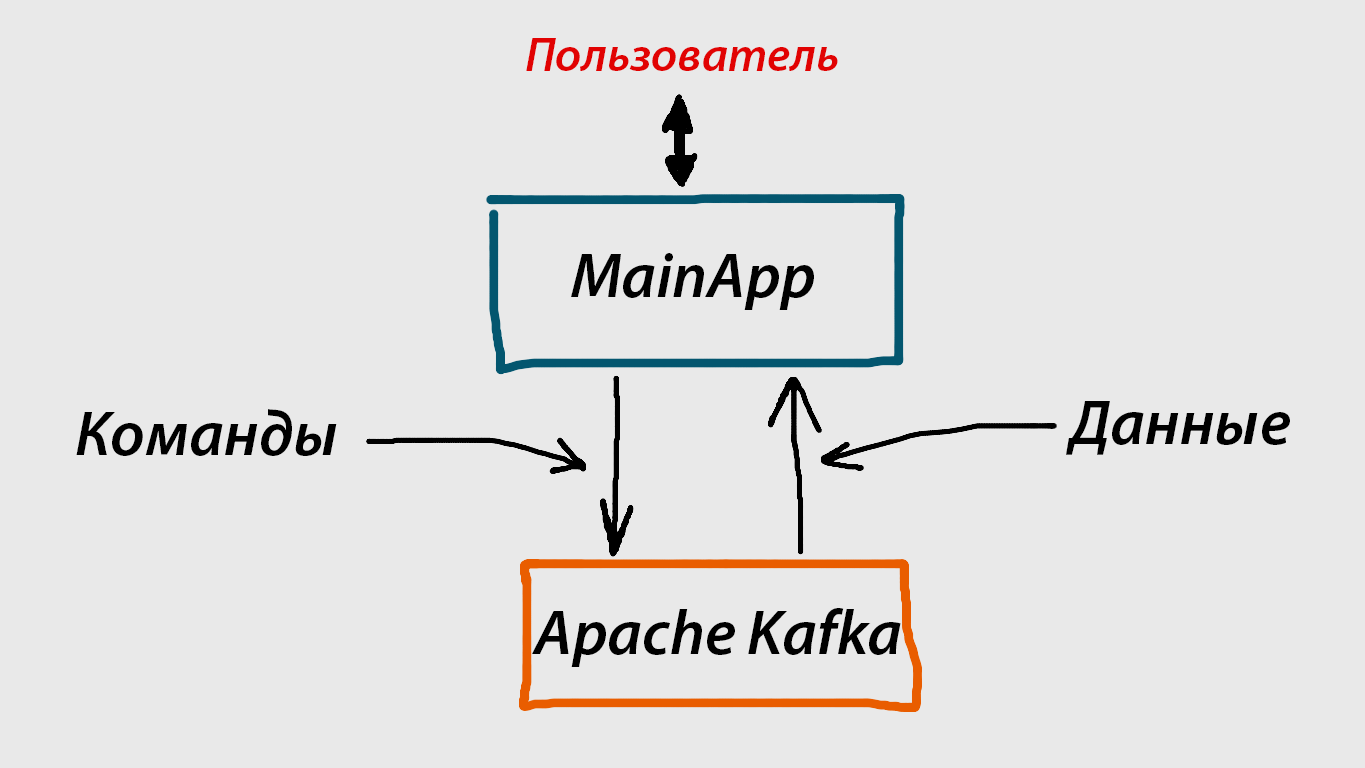
Работает это по следующей схеме:
- Пользователь запрашивает какие-то данные (в нашем случае, мужское или женское имя).
- MainApp посылает сообщение (на схеме это «Команды») в Apache Kafka, которое автоматически получают все необходимые нам сервисы.
- Эти сервисы отвечают тем, что также посылают другое сообщение (на схеме – данные) в Apache Kafka. MainApp принимает это сообщение из Apache Kafka (на схеме это «Данные»), заключающее в себе нужную нам информацию, и предоставляет ее пользователю.
Взаимодействие каждого сервиса с Apache Kafka происходит по аналогичной “двухсторонней” схеме.
Обратите внимание, MainApp ничего не знает о NameService, и наоборот. Все взаимодействие происходит через Apache Kafka. Но и MainApp, и NameService должны использовать одни и те же «каналы связи». На практике это означает, что, например, название топика, куда посылает сообщения MainApp, должно полностью совпадать с названием топика, из которого «слушает» сообщения NameService.
Как видите, работа Apache Kafka в нашем примере заключается в передаче сообщений между разными элементами системы. Именно этим, исключительно быстро и надежно, она и занимается. Конечно, у нее есть другие возможности, почитать о них можно на официальном сайте здесь
Что такое Apache Kafka
Apache Kafka – распределенный брокер сообщений. По сути, это система, которая может очень быстро и эффективно передавать ваши сообщения. В качестве сообщений могут выступать любые типы данных, поскольку для Kafka это всего лишь последовательность байтов. Apache Kafka может работать как на одной машине, так и на нескольких, которые вместе образуют кластер и повышают эффективность всей системы. В нашем случае мы запустим Apache Kafka локально, и для взаимодействия с ней будем использовать библиотеку от Confluent.
Важно понять то, как работает Apache Kafka. Мы можем писать в нее сообщения, и можем читать из нее. Все сообщения в Kafka принадлежат к тому или иному топику (topic). Топик – это как заглавие, и он должен быть определен для каждого сообщения, которое мы хотим передать в Apache Kafka. Точно также, если мы собираемся читать из Kafka сообщения, мы должны указать, с каким топиком будут эти сообщения.
Топик поделен на разделы, и их количество мы указываем, как правило, самостоятельно. Количество разделов в топике имеет большое значение для производительности, почитать об этом можно тут
Практическая часть
Скачиваем и запускаем Apache Kafka 0.11
На данный момент последней версией является версия 0.11. Скачайте архив с официального сайта (https://kafka.apache.org/downloads) и распакуйте в любую папку. Дальше из консоли надо запустить 2 файла (zookeeper-server.start и kafka-server-start) следующим образом.
Открываем первую консоль (если распаковали на диск С, открываем от имени Администратора, на всякий случай), переходим туда, где мы распаковали наш архив с Kafka, и вводим команду:
bin\windows\zookeeper-server-start.bat config\zookeeper.properties
После этого, если все хорошо и этот процесс не прекратился вскоре после старта, открываем так же вторую консоль, и запускаем уже саму Apache Kafka
bin\windows\kafka-server-start.bat config\server.properties
Только что мы запустили Zookeeper и Apache Kafka со стандартными настройками, указанными в zookeeper.properties и server.properties соответственно. Zookeeper – необходимый элемент, без него Apache Kafka не работает.
Полную информацию о запуске и конфигурировании Kafka можно посмотреть на официальном сайте
Начинаем кодить
Итак, Kafka запущена, теперь создадим наше “распределенное“ приложение. Оно будет состоять из 2 консольных приложений и одной библиотеки. В результате получим решение из 3 проектов, которое будет выглядеть примерно вот так:
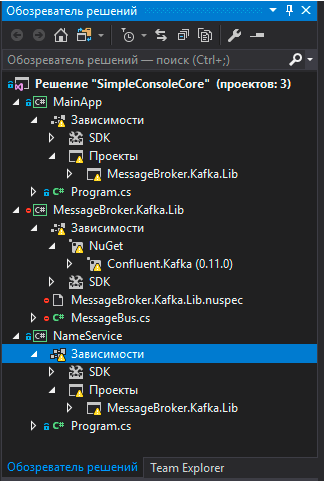
Наша библиотека — это “обертка” вокруг библиотеки Confluent.Kafka, она нам нужна для взаимодействия с Apache Kafka. Кроме этого, она будет использоваться каждым из наших консольных приложений.
Библиотека предназначена для целевой платформы .NET Core 2.0 (Хотя, с таким же успехом могла бы быть создана для платформы .NET Standard) Ее код представлен ниже. Обратите внимание, для нее необходимо скачать nuget пакет Confluent.Kafka.
using System;
using System.Collections.Generic;
using System.Text;
using System.Threading;
using Confluent.Kafka;
using Confluent.Kafka.Serialization;
namespace MessageBroker.Kafka.Lib
{
public sealed class MessageBus : IDisposable
{
private readonly Producer<Null, string> _producer;
private Consumer<Null, string> _consumer;
private readonly IDictionary<string, object> _producerConfig;
private readonly IDictionary<string, object> _consumerConfig;
public MessageBus() : this("localhost") { }
public MessageBus(string host)
{
_producerConfig = new Dictionary<string, object> { { "bootstrap.servers", host } };
_consumerConfig = new Dictionary<string, object>
{
{ "group.id", "custom-group"},
{ "bootstrap.servers", host }
};
_producer = new Producer<Null, string>(_producerConfig, null, new StringSerializer(Encoding.UTF8));
}
public void SendMessage(string topic, string message)
{
_producer.ProduceAsync(topic, null, message);
}
public void SubscribeOnTopic<T>(string topic, Action<T> action, CancellationToken cancellationToken) where T: class
{
var msgBus = new MessageBus();
using (msgBus._consumer = new Consumer<Null, string>(_consumerConfig, null, new StringDeserializer(Encoding.UTF8)))
{
msgBus._consumer.Assign(new List<TopicPartitionOffset> { new TopicPartitionOffset(topic, 0, -1) });
while (true)
{
if (cancellationToken.IsCancellationRequested)
break;
Message<Null, string> msg;
if (msgBus._consumer.Consume(out msg, TimeSpan.FromMilliseconds(10)))
{
action(msg.Value as T);
}
}
}
}
public void Dispose()
{
_producer?.Dispose();
_consumer?.Dispose();
}
}
}
Далее мы построим “главное” приложение MainApp, а потом наш “микросервис” NameService, который запустим после в двух экземплярах. Каждый из них будет отвечать за генерацию либо мужских, либо женских имен.
Код простого консольного приложения MainApp для целевой платформы .NET Core 2.0 приведен ниже. Обратите внимание, в нем необходимо добавить ссылку на библиотеку, которую мы только что построили и которая находится в пространстве имен MessageBroker.Kafka.Lib.
using System;
using System.Threading;
using MessageBroker.Kafka.Lib;
using System.Threading.Tasks;
namespace MainApp
{
class Program
{
private static readonly string bTopicNameCmd= "b_name_command";
private static readonly string gTopicNameCmd = "g_name_command";
private static readonly string bMessageReq = "get_boy_name";
private static readonly string gMessageReq= "get_girl_name";
private static readonly string bTopicNameResp = "b_name_response";
private static readonly string gTopicNameResp= "g_name_response";
private static readonly string userHelpMsg = "MainApp: Enter 'b' for a boy or 'g' for a girl, 'q' to exit";
static void Main(string[] args)
{
using (var msgBus = new MessageBus())
{
Task.Run(() => msgBus.SubscribeOnTopic<string>(bTopicNameResp, msg => GetBoyNameHandler(msg), CancellationToken.None));
Task.Run(() => msgBus.SubscribeOnTopic<string>(gTopicNameResp, msg => GetGirlNameHandler(msg), CancellationToken.None));
string userInput;
do
{
Console.WriteLine(userHelpMsg);
userInput = Console.ReadLine();
switch (userInput)
{
case "b":
msgBus.SendMessage(topic: bTopicNameCmd, message: bMessageReq);
break;
case "g":
msgBus.SendMessage(topic: gTopicNameCmd, message: gMessageReq);
break;
case "q":
break;
default:
Console.WriteLine($"Unknown command. {userHelpMsg}");
break;
}
} while (userInput != "q");
}
}
public static void GetBoyNameHandler(string msg)
{
Console.WriteLine($"Boy name {msg} is recommended");
}
public static void GetGirlNameHandler(string msg)
{
Console.WriteLine($"Girl name {msg} is recommended");
}
}
}
Точно также, наш MainApp подписан на топики, в которые передают полезную информацию наши сервисы NameService. Например, переменная bTopicNameResp — это название топика, который предусмотрен для готовых мужских имен, которые сгенерировал NameService. Сервис посылает имя в этот топик, а MainApp их оттуда получает.
Далее представлен код “микросервиса” NameService. Обратите, внимание, здесь тоже надо добавить ссылку на уже созданную нами библиотеку в пространстве имен MessageBroker.Kafka.Lib
using System;
using System.Threading;
using System.Threading.Tasks;
using MessageBroker.Kafka.Lib;
namespace NameService
{
class Program
{
private static MessageBus msgBus;
private static readonly string userHelpMsg = "NameService.\nEnter 'b' or 'g' to process boy or girl names respectively";
private static readonly string bTopicNameCmd = "b_name_command";
private static readonly string gTopicNameCmd = "g_name_command";
private static readonly string bTopicNameResp = "b_name_response";
private static readonly string gTopicNameResp = "g_name_response";
private static readonly string[] _boyNames =
{
"Arsenii",
"Igor",
"Kostya",
"Ivan",
"Dmitrii",
};
private static readonly string[] _girlNames =
{
"Nastya",
"Lena",
"Ksusha",
"Katya",
"Olga"
};
static void Main(string[] args)
{
bool canceled = false;
Console.CancelKeyPress += (_, e) =>
{
e.Cancel = true;
canceled = true;
};
using (msgBus = new MessageBus())
{
Console.WriteLine(userHelpMsg);
HandleUserInput(Console.ReadLine());
while (!canceled) { }
}
}
private static void HandleUserInput(string userInput)
{
switch (userInput)
{
case "b":
Task.Run(() => msgBus.SubscribeOnTopic<string>(bTopicNameCmd, (msg) => BoyNameCommandListener(msg), CancellationToken.None));
Console.WriteLine("Processing boy names");
break;
case "g":
Task gTask = Task.Run(() => msgBus.SubscribeOnTopic<string>(gTopicNameCmd, (msg) => GirlNameCommandListener(msg), CancellationToken.None));
Console.WriteLine("Processing girl names");
break;
default:
Console.WriteLine($"Unknown command. {userHelpMsg}");
HandleUserInput(Console.ReadLine());
break;
}
}
private static void BoyNameCommandListener(string msg)
{
var r = new Random().Next(0, 5);
var randName = _boyNames[r];
msgBus.SendMessage(bTopicNameResp, randName);
Console.WriteLine($"Sending {randName}");
}
private static void GirlNameCommandListener(string msg)
{
var r = new Random().Next(0, 5);
var randName = _girlNames[r];
msgBus.SendMessage(gTopicNameResp, randName);
Console.WriteLine($"Sending {randName}");
}
}
}
- Сначала определяемся, мужские или женские имена данные сервис будет генерировать (т.е. просто выбирать случайное имя из подготовленного списка, в нашем случае)
- Подписываемся на соответствующий топик
В теле метода обработчика события мы посылаем сообщение с готовым именем в топик, на который MainApp уже подписан. А это событие наступает каждый раз, как MainApp посылает сообщение о том, что нужно получить какое-то имя.
Запускаем
На этом этапе у вас, по идее, уже должно быть готовое решение со всем необходимым кодом. Далее можно поступить следующим образом: настроить решение так, чтобы запускались сразу 2 приложения (MainApp и NameService), и запустить их (Только проверьте, что у вас уже запущена Apache Kafka). В NameService вводим 'b', или 'g', чтобы настроить сервис для генерирования мужских или женских имен, после чего, точно также, вводим в MainApp 'b' или 'g', но уже для получения этих самых имен. После чего в MainApp вы должны получить какое-то имя.
На данном этапе мы получаем имена только одного пола. Допустим, только мужского. Теперь мы захотели получать имена женского пола. Идем в папку, куда собрался наш проект NameService, и запускаем в консоли еще один сервис с помощью команды "dotnet NameService.dll".
Вводим в нем команду 'g', и теперь, при запросе женского имени в MainApp, мы его получаем.
Кстати, таким образом можно запустить сколько угодно сущностей NameService, и в этом заключается одно из достоинств микросервисной архитектуры. Например, если один из сервисов «упадет», вся система не рухнет, т.к. у нас есть другие сервисы, которые делают точно такую же работу.
Одно но: cейчас если мы, например, запустим 5 штук NameService, то в MainApp придет 5 имен, а не одно. Это из-за настроек Apache Kafka, прописанных в файле server.properties. В рамках туториала я этого намеренно не касаюсь, чтобы не усложнять материал.
Заключение
В данной статье я хотел как можно проще и доступнее описать принцип построения микросервисной архитектуры и познакомить читателя с распределенным брокером сообщений Apache Kafka на живом примере. Надеюсь, получилось, и спасибо за внимание:)
Ссылки на использованные в статье материалы
Комментарии (28)
mayorovp
21.08.2017 14:16Да,
while (!canceled) { }— тоже чудесный цикл...
Вы вообще осознаете, что с таким подходом ваши распределенные микросервисные приложения будут всухую проигрывать классическим монолитам по производительности и требованиям к железу? Добавить еще пару десятков микросервисов, как того учит микросервисная архитектура — и вот уже для их запуска требуется кластер из десятка серверов даже при отсутствии нагрузки?

musinit Автор
21.08.2017 15:43-1Упор был сделан на максимальное упрощение системы для знакомства с концепцией микросервисной архитектуры. Никто и не говорит о промышленной реализации кода со всевозможными проверками и оптимизациями.
mayorovp
21.08.2017 15:50+6А я и не говорю про оптимизации. Я говорю о том, что проект уровня "Hello, world!" не должен подвешивать систему.
Для знакомства с концепцией это особенно важно.
ik62
21.08.2017 14:21Два вопроса:
Сколько времени реально уходит на цикл запрос-ответ?
Почему kafka женского рода?musinit Автор
21.08.2017 15:29Хороший вопрос, если честно, в разговоре я просто привык употреблять Apache Kafka в женском роде. Но, можно было бы ответить, что на официальном сайте написано, что Apache Kafka™ is a distributed streaming platform. А слово «платформа» — женского рода:)
musinit Автор
21.08.2017 15:39И да, на одну итерацию у меня уходило довольно много времени, что-то порядка 300-500 миллисекунд. Связано, по всей видимости, как с реализацией библиотеки, так и с настройками Apache Kafka
mayorovp
21.08.2017 15:54+1На самом деле, это связано с тем, что у вас шесть потоков висят в активном ожидании, не давая происходить никакой полезной работе.
alexkov87
22.08.2017 08:58+3Почему kafka женского рода?
— А вы Кафку любите?
— Да, особенно грефневую!
:)

Dobby007
21.08.2017 21:21+2Одно но: cейчас если мы, например, запустим 5 штук NameService, то в MainApp придет 5 имен, а не одно. Это из-за настроек Apache Kafka, прописанных в файле server.properties. В рамках туториала я этого намеренно не касаюсь, чтобы не усложнять материал.
У вас получается по коду, что делая запрос из клиента MainApp, мы сразу выходим из цикла и пишем ответ уже в другом потоке. При этом получается, что будь это веб-приложение, нам бы пришлось поддерживать на стороне бэкенда свою очередь тоже (т.е. пользователь нажимает на кнопку "Сгенерировать имя", мы сопоставляем этому запросу некий идентификатор, сохраняем его, а потом клиент через какое-то время достает ответ отдельным запросом к бэкенду, имея на руках этот идентификатор). Это, как известно, имеет свои последствия (в частности, возникает вопрос о масштабируемости такого решения). Но я всегда считал, что Message Broker должен позволять это сделать без всяких самописных очередей. Разве протокол Kafka не позволяет сделать нечто подобное?
var response = await msgBus.SendMessage(topic: gTopicNameCmd, message: gMessage); Console.WriteLine(response);
Здесь подразумевается, что запрос и ответ имеют одинаковый topic gTopicNameCmd. Следовательно, Kafka сама разруливает кому какой ответ отдать, а мы ждем от нее ответ и никуда не уходим, пока он не прилетит.
musinit Автор
22.08.2017 09:33-1Вы правы, некоторая неоднозначность с отправкой/приемом сообщения имеет место быть. Но вот с очередями на стороне сервера — не уверен что правильно вас понял. Apache Kafka — это такой большой черный ящик, и всю механику того, кем и в какой последовательности было отправлено сообщение контролирует тоже Kafka. Нашими идентификаторами принадлежности сообщений в данном случае являются названия топиков.
var response = await msgBus.SendMessage(topic: gTopicNameCmd, message: gMessage);
Console.WriteLine(response);
Я очень хотел реализовать также, когда это все задумывал, потому что это было бы намного проще и понятнее, но не нашел подходящих вариантов реализации клиента для общения с Kafka.Dobby007
23.08.2017 22:34Да, Вы меня не поняли немного. Переформулирую: как вы отдадите случайное имя JS-скрипту, который обратился к вашему бэкенду? Вы либо будете писать в тело каждого сообщения для Kafka какой-то идентификатор, а потом этот идентификатор отдавать клиенту (то что я описал выше). Вариант второй: Вы поставите в паузу текущий поток общения клиента с сервером и будете ждать, пока другой поток не запишет результат в Ваше хранилище (при этом потребность в идентификаторах никуда не уходит, потому что вам нужно как-то различать одинаковые топики). В первом варианте клиент может оставить в покое сокет и сделать еще несколько запросов, дожидаясь результата на своей стороне. Во втором варианте сокет между браузером и приложением же будет висеть, поток для обработки тоже будет в повисшем состоянии, и вскоре сервер поднимет лапки (если мы говорим о более менее нагруженном сайте). Прибавьте к этому горизонтальное расширение бэкенд-серверов и распределение нагрузки между ними, и вы получите какую-то кашу.
musinit Автор
24.08.2017 10:15-1Переформулирую: как вы отдадите случайное имя JS-скрипту, который обратился к вашему бэкенду?
В таком случае у нас есть 2 варианта того, как его отдать(оба кстати хорошо описаны здесь): либо мы делаем запросы к каждому из наших NameService, у которых должно быть WebApi, либо обращаемся к некому GatewayApi, который аккумулирует информацию со всех NameService.
Запросы JS скрипта происходят синхронно по HTTP.
Обмен сообщениями между сервисами NameService и GatewayApi происходит асинхронно с помощью Kafka, что также позволяет не привязываться к конкретным сущностям NameService за счет того, что все они подписываются/отправляют сообщения по заранее установленной схеме.
Когда мы делаем синхронный запрос, например, к GatewayApi, то GatewayApi посылает сообщение в Kafka о том, что нужно новое имя. Это сообщение видят все (или некоторые, в зависимости от кол-ва разделов в топике, но не суть) сущности NameService, для которых оно предназначалось, и генерируют имя, которое в конце концов получает GatewayApi. Можно безболезненно ввести сколько угодно таких сущностей NameService для распределения нагрузки, и это будет легко сделать.mayorovp
24.08.2017 10:34Вас спрашивают о деталях реализации GatewayApi — а вы зачем-то начинаете про масштабируемость NameService рассказывать. Вы вообще читать умеете?!
Вы так и не объяснили, каким образом информация дойдет до точки назначения — скрипта на фронтенде.
GatewayApi получил HTTP-запрос и отправил сообщение в кафку. Через какое-то время из кафки пришел ответ. Как связать запрос от клиента с ответом-то?
musinit Автор
24.08.2017 10:45Я ответил развернуто по нескольким ключевым моментам, о которых был вопрос. О GatewayApi вообще-то изначально в вопросе ни слова, это уже я предложил вариант реализации той задачи, о которой говорит Dobby007, прочитайте его комментарий внимательнее.
Видимо, написал недостаточно ясно: мы делаем синхронный HTTP запрос к GatewayApi и ждем, пока он нам не отдаст имя, которое получит из Kafka.mayorovp
24.08.2017 10:56Видимо, написал недостаточно ясно: мы делаем синхронный HTTP запрос к GatewayApi и ждем, пока он нам не отдаст имя, которое получит из Kafka.
Как он поймет, кому из клиентов его отдавать?
musinit Автор
24.08.2017 11:06По сессии. Делаются обычные запросы, и в простейшем случае у GatewayApi есть 2 поля для мужского и женского имени, которые обновляются при получении сообщений из кафки. Они же и и отдаются при запросе клиентов
mayorovp
24.08.2017 11:08То есть вы в принципе не рассматриваете задачу отдавать разным клиентам — разные имена?
Это надо было написать сразу же.

aosja
21.08.2017 22:18+2А в чем в данном случае преимущество общения микросервисов через Kafka (messaging) по сравнению с обычным синхронным request/response + load balancer?
musinit Автор
22.08.2017 09:11Преимущество заключается, например, в том, что в последней версии Kafka 0.11 появилась новая фича, благодаря которой теперь можно реализовать «exactly-once» семантику доставки сообщений. Но, возвращаясь к вопросу, в конкретно «данном» случае, если говорить о сравнении с синхронным запросом к балансировщику, то у нас синхронным является только отправка сообщения о том, что мы хотим получить имя в Kafka. А ответ мы ждем в отдельном потоке.
mayorovp
22.08.2017 09:19Но является ли ожидание ответа в отдельном потоке преимуществом?
musinit Автор
22.08.2017 09:36Нет, это просто особенность
aosja
22.08.2017 09:54+1Так я про преимущества спрашивал, не про особенности. Мне вот интересно, чем в данном случае оправдано применение сложной распределенной системы и почему это лучше простого LB?
musinit Автор
22.08.2017 10:15-3Ну смотрите: это обучающий материал, призванный, с одной стороны, познакомить с микросервисами и Apache Kafka, а в другой — сделать это максимально понятно и просто. Потенциальные преимущества такого подхода — exactly once семантика, гарантируемая Apache Kafka, о которой я уже написал, возможность повторить сообщения «из прошлого», их параллельная обработка за счет разбиения топика на разделы, и др.
Но в статье о этих преимуществах почти ничего нет(разве что ссылка на них на офф. сайте), и я сделал это намеренно, чтобы не усложнять, потому что сразу все охватить не получится. Вот и написал вводную, чтобы читатель, если захочет, пойдет изучать Apache Kafka уже дальше самостоятельно.
mayorovp
Ну зачем же вот так-то писать?
Почему нельзя проверку в условие цикла вынести?
Зачем создается новый экземпляр MessageBus в методе SubscribeOnTopic и почему ему никто не делает Dispose?
Почему _consumer разрушается как в методе Dispose, так и в методе SubscribeOnTopic?
Зачем SubscribeOnTopic принимает параметр CancellationToken, если вы туда передаете None?
Что такое TimeSpan.FromMilliseconds(10) в методе SubscribeOnTopic, и, если это тайм-аут операции чтения, зачем он вообще нужен? Вы же все равно после истечения тайм-аута сразу же делаете повторную попытку.
musinit Автор
Спасибо за конструктивную критику реализации библиотеки, многие моменты не помешало бы исправить.
1) Проверку внести в условие цикла — не помешает, но не критично.
2) Насчет MessageBus — решил сделать так из-за метода, которым мы подписываемся на сообщения и внутри которого у нас цикл. И потом выполнять метод этого обьекта в отдельном потоке.
3) В методе Dispose он может и не разрушится, т.к. там он обозначен как тип Nullable. Но согласен, избыточность.
4) SubscribeOnTopic может принимать CancellationToken по известным причинам, но я просто решил не использовать этот функционал. Еще там есть перегруженный конструктор, через аргумент которого мы можем указать хост, где у нас выполняется Apache Kafka, но его я тоже не использовал
5) Этот параметр в библиотеке Confluent.Kafka отвечает, как вы правильно заметили, за тайм-аут операции чтения из топика, и здесь указано просто дефолтное значение, на котором я не заострял внимание.
mayorovp
Но зачем создавать новый объект только ради одного его поля? Код был бы намного менее индусским если бы _consumer был не полем, а локальной переменной.
Этого тайм-аута вообще не должно быть! Вы, фактически, выделили отдельный поток для потребителя — а значит, можете позволить себе ожидание до победного.
musinit Автор
Так и есть, для каждого потребителя я создаю отдельных поток, и этот параметр необходим для того, чтобы определить, как часто мы будем обращаться к Apache Kafka и получать оттуда сообщения. Кроме того, такой вариант с потоками для каждого топика мне показался наиболее удачным в плане понимания того, как взаимодействовать с Apache Kafka
mayorovp
Нет, этот параметр определяет как часто поток будет переставать получать сообщения от брокера.