

Мы в компании любим и уважаем Apache Kafka, и в ознаменование выхода ее недавнего обновления я решил подготовить статью про ее производительность. А еще рассказать немного про то, как выжать из нее максимум.
Зачем нам это?
Дело в том, что нам повезло иногда заниматься высоконагруженными внутренними системами, автоматизирующими набор в нашу компанию. Например, одна из них собирает все отклики с большинства самых известных работных сайтов страны, обрабатывает и отправляет это все рекрутерам. А это довольно большие потоки данных.
Чтобы все работало, нам необходимо осуществлять обмен данными между разными приложениями. Причем обмен должен происходить достаточно быстро и без потерь, ведь, в конечном счете, это выливается в эффективность подбора персонала.
Для решения этой задачи нам предстояло выбрать среди нескольких доступных на рынке брокеров сообщений, и мы остановились на Apache Kafka. Почему? Потому что она быстрая и поддерживает семантику гарантированно единственной доставки сообщения (exactly-once semantic). В нашей системе важно, чтобы в случае отказа сообщения все равно доставлялись, и при этом не дублировали бы друг друга.
Как все устроено
Все в Apache Kafka построено вокруг концепции логов. Не тех логов, что вы выводите куда-либо для чтения человеком, а других, абстрактных логов. Логи, если взглянуть шире, это наиболее простая абстракция для хранения информации. Это очередь данных, которая отсортирована по времени, и куда данные можно только добавлять.
Для Apache Kafka все сообщения – это логи. Они передаются от производителей (producer) к потребителям (consumer) через кластер Apache Kafka. Вы можете адаптировать кластер Apache Kafka под свои задачи для повышения производительности. Помимо изменения настроек брокеров (машин в кластере), настройки можно менять у производителей и потребителей. В статье пойдет речь об оптимизации только производителей.
Есть несколько важных концепций, которые нужно понять, чтобы знать, что и зачем “тюнить”:
Нет потребителей — скорость падает
Если новые сообщения тут же никто не забирает, они сохраняются на диск. А это очень дорогая операция. Поэтому если потребители внезапно отключились или “залагали”, пропускная скорость упадет.
Чем больше размер сообщения, тем выше пропускная способность
Факт, что гораздо “легче” записать на диск 1 файл размером в 100 байт, чем 100 файлов в 1 байт. А ведь Apache Kafka при необходимости скидывает сообщения на диск. Интересный график с сайта Linkedin:
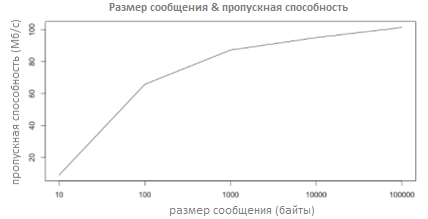
Новые производители/потребители почти линейно увеличивают производительность
Но не забываем о пункте №1.
Асинхронное реплицирование может потерять ваши данные
В отличие от синхронного механизма реплицирования, при асинхронном главная нода Apache Kafka не дожидается подтверждения получения сообщения от дочерних нод. И при сбое мастер-ноды данные могут быть утеряны. Так что надо решать – или скорость, или живучесть.
Про параметры производителей
Вот основные параметры конфигурации производителей, которые влияют на их работу:
- Batch.size
Размер пакета сообщений, который отправляется от производителя к брокеру. Производители умеют собирать эти “паки“, чтобы не отправлять сообщения по одному, т.к. они могут быть достаточно маленькими. В общем случае, чем больше этот параметр, тем:
- (Плюс) Больше степень сжатия, а значит выше пропускная способность.
- (Минус) Больше задержка в общем случае.
- Linger.ms
По умолчанию равно 0. Обычно продюсер начинает собирать следующий пакет сообщений сразу после того, как отправляет предыдущий. Параметр linger.ms говорит продюсеру, сколько нужно подождать времени, начиная с предыдущей отправки пакета и до следующего момента комплектации нового пакета (batch) сообщений.
- Compression.type
Алгоритм для сжатия сообщений (lzip, gzip, и т.д). Этот параметр сильно влияет на задержку.
- Max.in.flight.requests.per.connection
Если этот параметр больше 1, то мы находимся в так называемом режиме “трубы” (“pipeline”). Вот к чему это ведет в общем случае
- (Плюс) Более хорошую пропускную способность.
- (Минус) Возможность нарушения порядка сообщений в случае отказа.
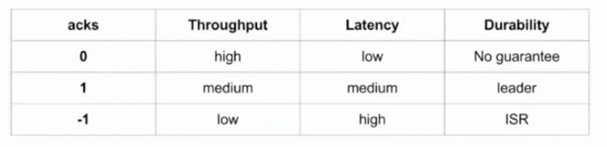
- Acks
Влияет на “живучесть” сообщений в случае отказа чего-либо. Может принимать четыре параметра: -1, 0, 1, all (то же самое, что -1). В таблице ниже сведения о том, как и на что он влияет:
Как выжать максимум
Итак, вы хотите подкрутить параметры производителя и тем самым ускорить систему. Под ускорением понимается увеличение пропускной способности и уменьшение задержки. При этом должна сохраниться “живучесть” и порядок сообщений в случае отказа.
Возьмем за данность то, что у вас уже определен тип сообщений, которые вы отправляете от производителя к потребителю. А значит, примерно известен его размер. Мы в качестве примера возьмем сообщения размером в 100 байт.
Понять в чем “затык” можно с помощью файла bin\windows\kafka-producer-perf-test.bat. Это достаточно гибкий инструмент для профилирования Apache Kafka, и для построения графиков я использовал именно его. А если его пропатчить (git pull github.com/becketqin/kafka KAFKA-3554), в нем можно выставлять два дополнительных параметра: --num-threads (кол-во потоков производителей) и --value-bound (диапазон случайных чисел для нагрузки компрессора).
Есть два варианта того, что можно изменить в производителях, чтобы все ускорить:
- Найти оптимальный размер пакета (batch.size).
- Увеличить кол-во производителей и кол-во разделов в топике (partitions).
Мы воспроизвели это все у себя. И вот что получилось:
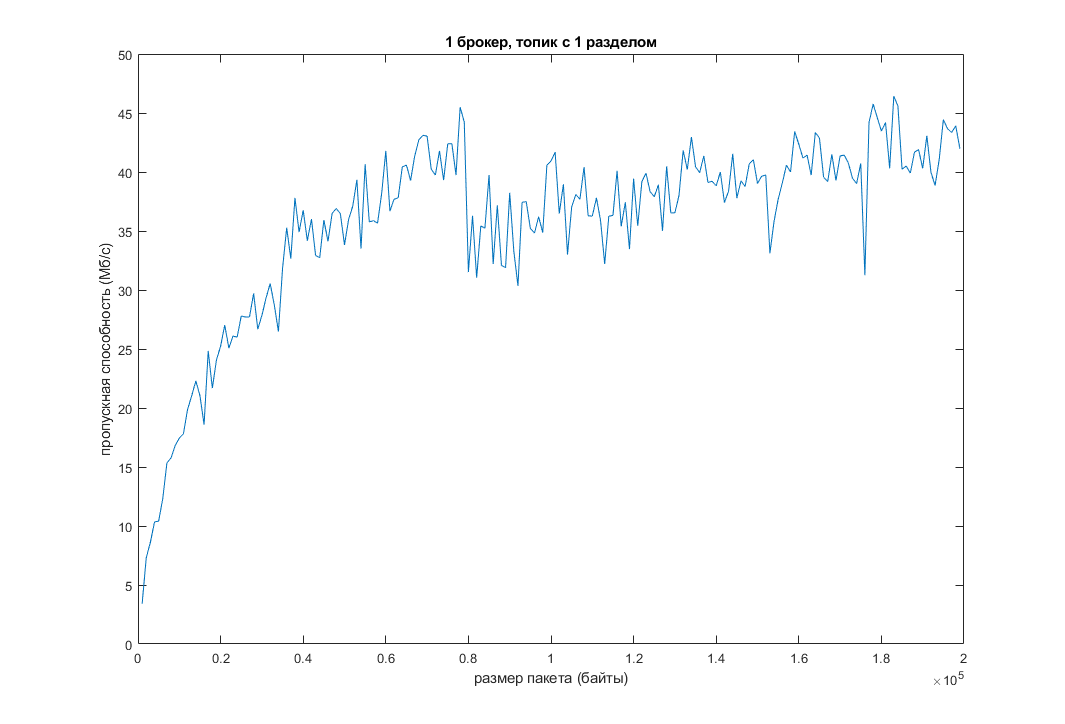

Как видно, при увеличении дефолтного размера пакета сообщений, увеличивается пропускная способность и уменьшается задержка. Но всему есть предел. В моем случае, когда размер пакета перевалил за 200 КБ, функция почти “легла”:


Другим вариантом является увеличение количества разделов в топике при одновременном увеличении количества потоков. Проведем те же тесты, но с уже 16 разделами в топике и 3-мя разными величинами –num-threads (теоретически это должно повысить эффективность):


Пропускную способность это немного подняло, а задержку немного уменьшило. Видно, что при дальнейшем увеличении количества потоков производительность падает из-за издержек на время переключения контекста между потоками. На другой машине график, естественно, будет немного иным, но общая картина скорее всего не изменится.
Заключение
В данной статье были рассмотрены основные настройки производителей, изменив которые можно добиться увеличения производительности. Также было продемонстрировано, как изменение этих параметров влияет на пропускную способность и задержку. Надеюсь, мои небольшие изыскания в этом вопросе вам помогут и спасибо за внимание.
Список использованной литературы
Комментарии (23)

andyrootman
22.11.2017 16:01А чем вы мониторите кластер?

musinit Автор
22.11.2017 16:07Вообще пока ничем, хотим в ближайшее время рассмотреть несколько вариантов, например kafka-monitor от Linkedin. А для тестов, как я и написал, мы создавали определенную нагрузку и смотрели что получается.

Alex_Crack
22.11.2017 16:13Читаю уже не первую статью про Kafka. Хотелось бы узнать, есть ли у нее какие-то киллер-фичи относительно того же RabbitMQ?
musinit Автор
22.11.2017 16:14Насколько я знаю, rabbit mq не может гарантировать exactly-once семантику доставки сообщений, которая хорошо описана, например, здесь habrahabr.ru/company/badoo/blog/333046

sshikov
22.11.2017 21:14Насколько я помню, семантика доставки в кафке во-первых, зависит от настроек. А во-вторых, по-идее должна (возможно сильно), влиять на производительность. Вы это учитывали в своих тестах?
И второе:
Например, одна из них собирает все отклики с большинства самых известных работных сайтов страны, обрабатывает и отправляет это все рекрутерам. А это довольно большие потоки данных.
Отклики — это люди? Или вы о чем-то другом? Если люди, то верится с трудом — люди не могут генерировать реально большие потоки данных. По сравнению с роботами это всегда мало. Да как правило еще и сильно варьируется в течение суток, потому что к утру Москвы активность Владивостока уже спала.
blind_oracle
22.11.2017 18:26Главная киллер фича — это скорость и масштабируемость. Кролик, по факту, очень трудно масштабируем. Ну и указанная exatly-once тоже хороша, но появилась там совсем недавно.
Alex_Crack
23.11.2017 13:50+1Просто мы используем RabbitMQ в продакшене. Кластер из двух нод прекрасно работает. При этом и продьюсеры и консьюмеры могут быть подключены к разным нодам. Т.е. масштабируется довольно хорошо.
Нагрузка пока не очень большая — около 1000 сообщений/сек. И Rabbit прекрасно справляется.
Но, тем не менее, знание других брокеров сообщений очень полезно. Особенно их плюсов, минусов и различий. Это вполне может пригодиться в будущем.blind_oracle
23.11.2017 14:42Просто мы используем RabbitMQ в продакшене. Кластер из двух нод прекрасно работает. При этом и продьюсеры и консьюмеры могут быть подключены к разным нодам. Т.е. масштабируется довольно хорошо.
Подключены могут быть, да. Но владельцем очереди всё равно будет одна нода — другие будут просто пересылать ей\от неё сообщения используя встроенную эрланговскую механику. Плюс, если используется HA-политика, будет N нод-реплик, которые имеют зеркало очереди.
Так что нет, не масштабируется — в рамках отдельной очереди всегда будет упор в одну ноду, плюс, чтобы не нагружать еще и соседей, нужно знать к какой именно подключаться. Если просто сделать TCP-балансёр перед кроликами то получим доп. нагрузку на межкластерных линках и процессоре.
Некое масштабирование получить можно, но для этого нужно реализовывать его в приложении — распределять нагрузку на кластер из него по большому количеству очередей. Но по сути это костыль.
Нагрузка пока не очень большая — около 1000 сообщений/сек. И Rabbit прекрасно справляется.
1к сообщений это вообще ни о чём для брокера. Когда я его последний раз мучал, кластер из 3 нод умирал примерно на 20к msg/sec в режиме с 1 репликой (могу ошибаться).
Кафка же не особо напрягаясь прожует и 200-300к и даже больше.
В общем, если нужна сложная логика обработки сообщений:
exchange -> exchange -> queue
роутинг по header
разные хитрые TTL
плагины
и прочее
то без кролика не обойтись.
Если нужно просто и быстро — кафка. Плюс есть всякие менее распространённые штуки типа NSQ, но там другая парадигма немного.
Optik
22.11.2017 17:47Какой у вас реальный объем сообщений в топиках?
musinit Автор
22.11.2017 17:55Прогоняли тесты на 200-стах итерациях по 500К сообщений в каждой. Настройки кафки и потребителя дефолтные. Ресурсы: 16G ОЗУ, Core i7 x2, SSD
Optik
22.11.2017 17:57Я не про тесты, а про промышленную эксплуатацию. Короткая синтетика совсем не то же самое, что постоянная работа.
musinit Автор
22.11.2017 18:26Чаще всего она «размазана» по времени и колеблется в районе 250к в секунду на 6-ти нодовом кластере
Optik
23.11.2017 11:38Это «отклики с большинства самых известных работных сайтов страны»? Выглядит крайне сомнительно что там такой трафик даже на серверах статики. Эти сайты продают вам трафик?
Зачем в этом кейсе exactly once? Как вы проектировали свое приложение для работы с exactly once?
Какие настройки пришлось менять? Как выбирали репликацию, ретеншн? Как настраивали размер сообщений (то о чем у вас указано в статье)? Какие проблемы были? Были ли проблемы с ребалансом?musinit Автор
23.11.2017 13:25Как вы справедливо заметили, в наших hr-системах нагрузка сейчас существенно ниже, а приведенные значения — это максимальные цифры, с которыми приходилось сталкиваться коллегам в работе.
В приведенных кейсах не используется exaclty once. Упоминание об excaclty once связано с тем, что это фича привлекла внимание к использованию Apache Kafka. Остальные вопросы требуют подготовки отдельной, более глубокой статьи.
le1ic
22.11.2017 19:54По-моему там exactly-once гарантрируется только для случая взяли из одной очереди, обработали идемпотентной функцией, положили в другую очередь кафка. Если у вас внешние системы (а брокер как раз и работает с внешними системами), то at least once
Hixon10
22.11.2017 21:23Вот-вот, ни о какой exactly once semantic ( www.confluent.io/blog/exactly-once-semantics-are-possible-heres-how-apache-kafka-does-it ) в вакуме и речи нет. Только есть все такие из себя идемпотентные и правильные.
mosinnik
23.11.2017 13:48Куча вопросов к статье:
1. Желтушный заголовок, и где ваш миллион сообщений, по графикам вижу максимум 500к
2. Где конфиги обеспечивающие ваши требования? Почему только один брокер, где реплика?
2. Сколько времени гонялись тесты. Успевал ли за это время время заполняться хип и в какой момент бралось время для графика
3. Почему взята мифическая цифра в 100 байт не объяснено, а каков средний размер ваших сообщений?
4. Если уже заупстили кафку в экплуатацию или собираетесь, то расскажите как вы добиваетесь exactly-once, на какой версии, с какими конфигами на кафке/продюсерах/консумерах, как организовали отсутвие дубликатов при краше читальщика и при этом обеспечили миллионы сообщений в секунду при постоянной нагрузке.musinit Автор
23.11.2017 13:501) 500К это количество сообщений для тестирования пропускной способности на конкретном значении batch.size. А таких различных значений приведено 200 штук, и они были проведены одна за другой. А что касается заголовка, отчасти, конечно, соглашусь.
2) Я написал, что конфиги брокера и потребителя дефолтные, чтобы протестировать кафку в общем случае, поскольку разные задачи требуют разных подходов оптимизации. Действительно, в приведенных тестах фигурирует только один брокер, без репликации, поскольку большая часть материалиа построена на оптимизации настроек producer'a
3) Цифра взята в качестве примера. У всех разный размер сообщений. В статье мы лишь должны были от чего-то отталкиваться.
4) Сейчас на практике exactly-once мы не используем, используется at-least-once. Но в перспективе мы хотели бы exaclty once, т.к. на некоторые кейсы, она удачно ложится.mosinnik
23.11.2017 17:02Просто получается введение в заблуждение, т.к. вы заявили большой спектр функционала кафки, который кардинальным образом снижает производительность, но все тестируете на инсталляции из одного брокера без этих фич, причем без явного указания, что используется SSD и практически отсутвует стоимость сохранения лога (на обычных hdd скорость диска становится крайне важным фактором при исчерпании хипа на брокере и все эти «миллионы рпс» просто падают на порядки)
Еще есть претензия к графику с 16 партициями — почему только 4,8,16, а где данные для одного продюсера? Из-за этого ваш вывод о повышении пропускной способности невозможно правильно толковать — это улчшение из-за увеличения партиций или количества продьюсеров? Т.е. создается ощущение, что нужно и то и то увеличивать, однако на практике количество партиций не ускоряют продьюсеров. А вот пара дополнительных продьюсеров положительно сказывается на утилизации ресурсов, главное не перебарщивать, а то до деградации недалеко.
Вот из-за этих всех мелких моментов статья выглядит как маркетинговый булшит, хотя в ней есть полезные моменты, но чтобы понять, что именно там полезного нужно иметь опыт в сопровождении кафки. А полезного — комментарии к статье и графики, на которые по хорошему нужно наложить линию тренда, а еще лучше — сопроводить версией с логарифмической осью Х, а то невозможно оценить разницу для 100 и 200 байт.
Kaydannik
23.11.2017 16:28>Нет потребителей — скорость падает
Что? Данные в любом случае записываются на диск согласно retention.ms/compact.policy конфигурации. Не важно прочитали их или нет.
Единственное отличие — если consumer получает самые последние данные возможно они все еще в файловом кеше, и тогда bottleneck будет не диск а сеть.
Asks не влияет на живучесть, он определяет минимальное количество подтверждений от in-sync replicas. И используется в паре с min.insync.replicas
Нарушение очередности с Max.in.flight.requests.per.connection было полностью решено в Apache Kafka 1.0 (KAFKA-5494)
linger.ms используется для уменьшения числа запросов при малой нагрузке на продюсер. Иными словами что бы плотнее набивать batch.size. Имеет смысл если у вас сотни/тысячи продюсеров и маленький кафка кластер.
Описание batch.size так же не отражает реальности.
>Асинхронное реплицирование может потерять данные
Что вы этим хотели сказать? Что при acks=0 у продюсера при падении лидера реплики данные могут быть потеряны?
>Новые производители почти линейно увеличивают производительность
Почти нет. Есть network threads на стороне брокера и это первое во что вы упретесь. Потом в random writes при записи в десятки/сотни/тысячи разных партиций одного брокера.
tru_pablo
24.11.2017 08:28Потом в random writes при записи в десятки/сотни/тысячи разных партиций одного брокера.
Кто сказал про тысячи партий брокера?В остальном ваш коммент — огонь, полностью согласен.
siffash
musinit Автор
Думали сначала взять RabbitMQ.