
Некоторые из них напрямую или косвенно связаны с когнитивными искажениями человеческого сознания – в этих случаях я даю ссылки на соответствующие вики-статьи. Также интересен список известных когнитивных искажений.
1 Преждевременная оптимизация
В 97% случаев надо забыть об эффективности малых частей программы: преждевременная оптимизация – корень всех зол. Но в 3% случаев об оптимизации забывать не нужно.
Дональд Кнут
Хотя никогда зачастую лучше, чем прямо сейчас
Тим Питерс, Зен языка Python
Что это
Оптимизация, проводимая до того, как у вас есть вся информация, необходимая для принятия взвешенных решений по поводу того, где и как нужно её проводить.
Почему плохо
На практике сложно предсказать, где встретится узкое место. Попытки навести оптимизацию до получения эмпирических результатов приведут к усложнению кода и появлению ошибок, а пользы не принесут.
Как избежать
Сначала пишите чистый, читаемый, работающий код, используя известные и проверенные алгоритмы и инструменты. При необходимости используйте инструменты для профилирования для поиска узких мест. Полагайтесь на измерения, а не на догадки и предположения.
Примеры и признаки
Кэширование до того, как провели профилирование. Использование сложных и недоказанных эвристических правил вместо математически верных алгоритмов. Выбор новых, непротестированных фреймворков, которые могут повести себя плохо под нагрузкой.
В чём сложность
Сложность в том, чтобы знать, когда оптимизация будет преждевременной. Важно заранее оставлять место для роста. Нужно выбирать решения и платформы, которые позволят легко оптимизировать и расти. Также иногда можно использовать преждевременную оптимизацию в качестве оправдания за плохой код. Например, использование алгоритма O(n2) просто потому, что алгоритм O(n) сложнее.
Слишком длинно, не читал
Сначала профилирование, потом оптимизация. Не меняйте простоту на эффективность, пока об этом не заявят эмпирически полученные данные.
2 Байкшеддинг
(прим.перев. – англосаксы любят придумывать глаголы. Этот термин также называется «Закон тривиальности Паркинсона», и появился после того, как этот Паркинсон обратил внимание, как люди любят тратить время на совещаниях на всякую ерунду, вместо того, чтобы обсуждать насущные проблемы. Конкретно, проектировщики атомной электростанции очень долго спорили, какой материал должен пойти на навес для велосипедов – bike-shed).
Периодически мы прерывали разговор, чтобы обсудить типографику и цвет страницы. После каждого обсуждения мы голосовали. Я думал, что эффективнее всего будет проголосовать за тот же цвет, который мы выбрали на предыдущей встрече, но я всегда оказывался в меньшинстве. Наконец, мы выбрали красный (а в итоге получился синий).
Ричард Фейнман, «Почему вас заботит, что о вас думают другие?»

Что это
Склонность тратить время на обсуждение тривиальных и субъективных вещей.
Почему это плохо
Трата времени. Подробное письмо от Пола-Хенинга Кэмпа по этому поводу.
Как избежать
Напоминайте другим членам команды об этой склонности, и о том, что в этих случаях главное – быстрее принять решение (бросить монетку, проголосовать, и т.п.). Если речь идёт о вещах вроде пользовательского интерфейса, обратитесь к A/B тестированию, вместо того, чтобы обсуждать это в команде.
Примеры и признаки
Часы или дни проводятся в обсуждениях цвета фона или расположения кнопки в интерфейсе, или использования табуляции вместо пробелов в коде.
В чём сложность
Байкшеддинг легче заметить и предотвратить, чем преждевременную оптимизацию. Замечайте время, требуемое для принятия решений и сопоставляйте его со сложностью задачи.
Слишком длинно, не читал
Не тратьте много времени на простейшие решения.
3 Аналитический паралич
Желание предсказать что-либо, нежелание действовать, когда это было бы просто и эффективно, недостаток ясности мысли… Всё это свойства, заставляющие бесконечно повторять историю.
Уинстон Черчилль, Дебаты в парламенте
Сейчас лучше, чем никогда
Тим Питерс, Зен языка Python
Что это
Переизбыток анализа до такой степени, что прогресс и действия останавливаются.
Почему плохо
Переизбыток анализа может замедлить или остановить прогресс. В тяжёлых случаях, результаты анализа становятся не нужны к тому моменту, когда они готовы, или даже проект вообще не покидает фазу анализа. Часто кажется, что чем больше у вас информации, тем больше это поможет принятию тяжёлого решения. См. информативное искажение и иллюзию допустимости.
Как избежать
Наблюдайте за итерациями и улучшениями. Каждая итерация даёт обратную связь и информацию, которую можно использовать для более осмысленного анализа. Без этой информации анализ будет лишь спекулятивным.
Примеры и признаки
Месяцы и годы, проведённые в анализе требований проекта, интерфейса или структуры БД.
В чём сложность
Бывает сложно понять, когда пора переходить от планирования, анализа требований и дизайна к реализации и тестированию.
Слишком длинно, не читал
Вместо чрезмерного анализа и спекуляций используйте пошаговое развитие.
4 Класс Бога
Простое лучше сложного
Тим Питерс, Зен языка Python
Что это
Классы, контролирующие множество других классов, имеющие много зависимостей и много ответственности.
Почему плохо
Классы Бога разрастаются до тех пор, пока не превращаются в кошмар поддержки. Они нарушают принцип одной ответственности, с ними тяжело проводить юнит-тесты, отлаживать и документировать.
Как избежать
Разбивайте ответственность по мелким классам, с единственной ответственностью, которая чётко определена, юнит-тестируется и задокументирована.
Примеры и признаки
Ищите классы с именами «manager», «controller», «driver», «system» или «engine». Подозрительно смотрите на классы, импортирующие или зависящие от других, контролирующие слишком много других классов или имеющие много методов, занимающихся чем-то, не связанным с основной деятельностью.
В чем сложность
Проекты, запросы и количество программистов растет, и маленькие специализированные классы медленно превращаются в классы Бога. Рефакторинг таких классов может занять впоследствии много времени.
Слишком длинно, не читал
Избегайте больших классов со слишком большими ответственностями и зависимостями
5 Страх перед добавлением классов
Разреженное лучше, чем плотное
Тим Питерс, Зен языка Python
Что это
Вера в то, что увеличение количества классов усложняет дизайн, приводит к страху перед добавлением новых классов или разбитием больших классов на мелкие.
Почему это плохо
Добавление классов уменьшает сложность. Распутать несколько мелких клубков пряжи проще, чем один крупный. Несколько простых в поддержке и документировании классов предпочтительнее одного большого и сложного класса со множеством зависимостей (класс Бога).

Как избежать
Замечайте те места, в которых добавление классов может упростить дизайн и разрубайте ненужные связи между частями кода
Примеры и признаки
class Shape:
def __init__(self, shape_type, *args):
self.shape_type = shape_type
self.args = args
def draw(self):
if self.shape_type == "круг":
center = self.args[0]
radius = self.args[1]
# Draw a circle...
elif self.shape_type == "квадрат":
pos = self.args[0]
width = self.args[1]
height = self.args[2]
# Draw rectangle...
А теперь сравните со следующим:
class Shape:
def draw(self):
raise NotImplemented("Подклассам Shape необходимо определить метод 'draw'.")
class Circle(Shape):
def __init__(self, center, radius):
self.center = center
self.radius = radius
def draw(self):
# Нарисовать круг...
class Rectangle(Shape):
def __init__(self, pos, width, height):
self.pos = pos
self.width = width
self.height = height
def draw(self):
# Нарисовать квадрат...
Пример достаточно очевидный, но он демонстрирует, что большие классы с условной или сложной логикой обычно стоит разбивать на более простые. В итоговом коде будет больше классов, но они будут проще.
В чем сложность
Добавление классов – не панацея. Упрощение дизайна разбиванием больших классов требует глубокого анализа областей ответственности и требований.
Слишком длинно, не читал
Большое число классов – не признак плохого дизайна
6 Эффект внутренней платформы
Те, кто не понимает Unix, обречены на переизобретение его плохих копий
Генри Спенсер
Любая достаточно сложная программа на Си или Фортране содержит заново написанную, неспецифицированную, глючную и медленную реализацию половины языка Common Lisp.
Десятое правило Гринспена
Что это
Тенденция сложных программных систем изобретать заново возможности платформы, на которой они работают, или языка, на котором они написаны.
Почему это плохо
Задачи уровня платформы – планировка задач, дисковый буфер и т.д. непросто реализовать правильно. В плохих решениях часто встречаются узкие места и ошибки, особенно с ростом системы. Воссоздание альтернативных конструкций для того, что уже возможно сделать при помощи языка, приводит к усложнению кода и к подъёму кривой обучения для новичков. Также это ограничивает пользу от рефакторинга и инструментов для анализа кода.
Как избежать
Используйте имеющиеся возможности и свойства платформы или операционки. Не создавайте языковые конструкции, конкурирующие с существующими (особенно, если вы не привыкли к новому языку и скучаете по старому).
Примеры и признаки
Использование базы данных как очереди задач. Переизобретение дискового буфера вместо использования возможностей операционки. Написание менеджера задач для веб-сервера на PHP. Определение макроса в С для поддержки конструкций, напоминающих Python.
В чём сложность
В очень редких случаях всё-таки может потребоваться воссоздание имеющихся у платформы возможностей (JVM, Firefox, Chrome и т.д.).
Слишком длинно, не читал
Избегайте переизобретения тех возможностей, которые уже есть в операционке или платформе.
7 Магические числа и строчки
Явное лучше, чем неявное
Тим Питерс, Зен языка Python
Что это
Использование безымянных чисел или строковых констант вместо именованных констант в коде.
Почему это плохо
Без поясняющего имени семантика числа или строки скрыта от нас. Это усложняет понимание кода, а необходимость поменять константу может привести к ошибкам. Рассмотрим следующий код:
def create_main_window():
window = Window(600, 600)
# и т.д....
Что это за числа? Допустим, первое – ширина, второе – высота. Если в дальнейшем придётся поменять ширину на 800, то поиском и заменой можно будет зацепить случайно и такую же высоту.
Использование неименованных строковых констант не так подвержено ошибкам, но затрудняет возможную локализацию, и также может привести к ошибкам из-за использования одинаковых строк в разных смыслах. Слово «точка» может обозначать пиксель, знак препинания или окончание рассуждений – в результате, поиск и замена слова приведут к ошибкам. Этого можно избежать, заменяя строки механизмом получения строк извне.
Как избежать
Используйте именованные константы, средства для получения ресурсов извне
Примеры и признаки
Даны выше. Такой анти-паттерн легко распознать.
В чем сложность
Иногда сложно сказать, будет ли используемое число магическим. 0 в языках, в которых индексирование начинается с нуля. 100 для подсчёта процентов, 2 для проверки чётности и т.д.
Слишком длинно, не читал
Избегайте использования чисел или строковых констант без имён и пояснений.
8 Управление через количество
Измерение прогресса программиста по количеству строк кода – то же самое, что измерение прогресса строительства самолёта по весу.
Билл Гейтс
Что это
Принятие решений на основании одних лишь чисел.
Почему это плохо
Числа – это хорошо. Первые два анти-паттерна, преждевременную оптимизацию и байкшеддинг, надо избегать при помощи A/B-тестирования и получения неких количественных результатов. Но основываться только на числах опасно. К примеру, числа переживают те модели, в которых они имели смысл, или же модели устаревают и перестают корректно отражать реальность. Это приводит к плохим решениям, в особенности, когда они принимаются автоматически (искажение автоматизации).

Ещё одна проблема в использовании чисел для принятия решений (а не для простого информирования) – процессами измерения можно манипулировать для достижения желаемой цели (эффект наблюдателя и ожиданий). В сериале The Wire красочно показано, как полицейское управление и система образования перешли от осмысленных целей к игре с числами. Следующий график иллюстрирует этот вопрос. На нём изображено распределение оценок по тесту, в котором минимальная оценка для прохождения теста – 30.
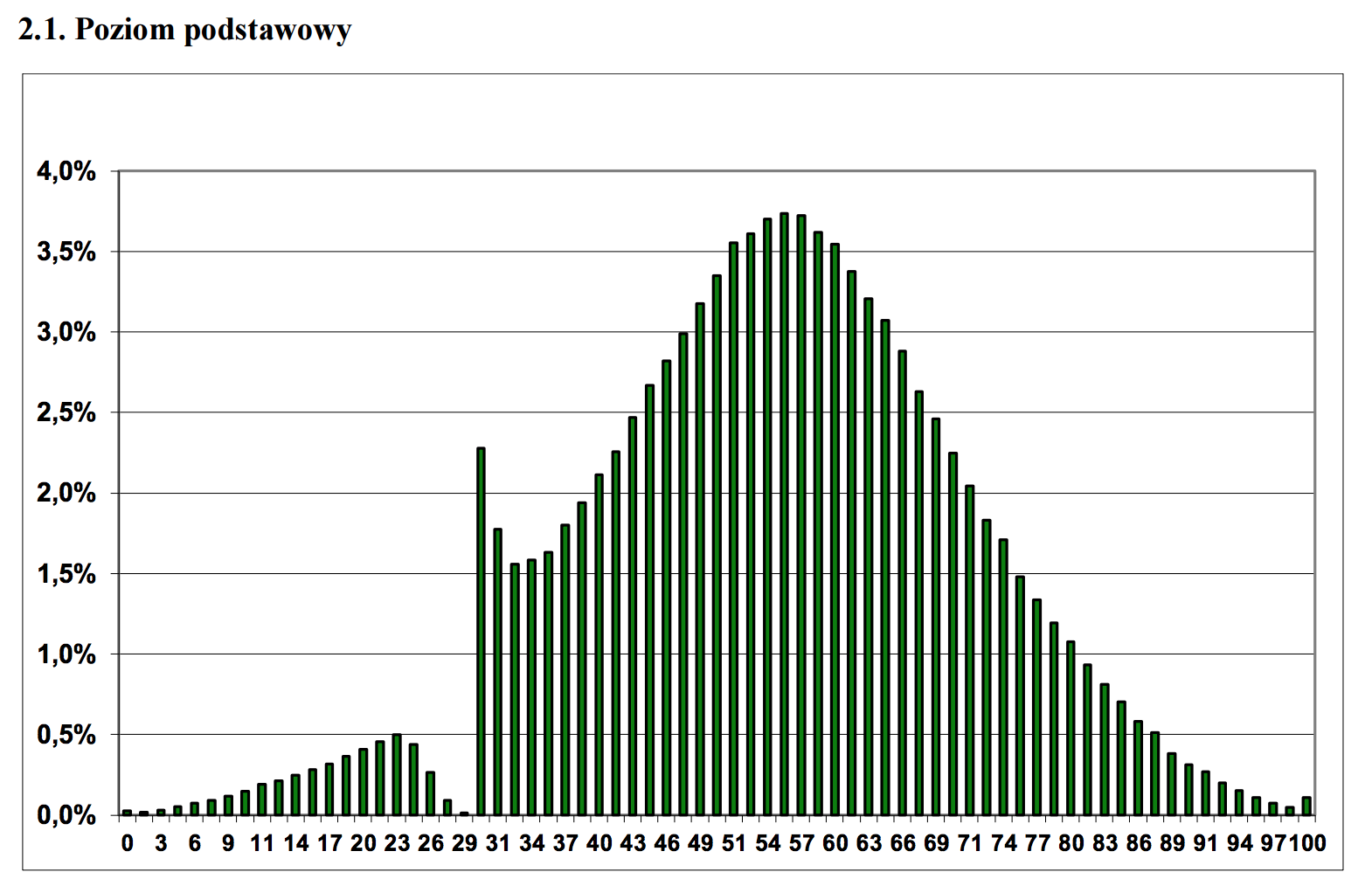
Как избежать
Используйте измерение и числа мудро, не слепо.
Примеры и признаки
Использование количества строк, количества коммитов и т.д. для оценки эффективности программистов. Измерение эффективности сотрудника по количеству часов, проведённых в офисе.
В чём сложность
Чем больше фирма, тем больше требуется принимать решений, тем сильнее их автоматизация и вера в слепые цифры начинает проникать в процесс их принятия.
Слишком длинно, не читал
Используйте числа для информирования, а не как основу для принятия решений
9 Бесполезные (полтергейстные) классы
По-видимому, совершенства достигают не тогда, когда нечего добавить, а тогда, когда нечего отнять.
Антуан де Сент-Экзюпери
Что это
Бесполезные классы без зависимостей, используются для вызова методов другого класса или просто добавляют ненужный слой абстракции.
Почему плохо
Полтергейстные классы добавляют сложность, код для поддержки и тестирования, и делают код менее читаемым. Надо определить, что делает полтергейст (а обычно – почти ничего), и натренироваться мысленно заменять его использование тем классом, который реально работает.
Как избежать
Не пишите бесполезные классы и избавляйтесь от них при возможности.
Примеры и признаки
Несколько лет назад при работе над дипломом я обучал первокурсников программированию на Java. Для одной из лабораторных работ мне дали материал по теме стэка и использования связанных списков. И мне дали «решение». Вот такое это было решение, почти дословно:
import java.util.EmptyStackException;
import java.util.LinkedList;
public class LabStack<T> {
private LinkedList<T> list;
public LabStack() {
list = new LinkedList<T>();
}
public boolean empty() {
return list.isEmpty();
}
public T peek() throws EmptyStackException {
if (list.isEmpty()) {
throw new EmptyStackException();
}
return list.peek();
}
public T pop() throws EmptyStackException {
if (list.isEmpty()) {
throw new EmptyStackException();
}
return list.pop();
}
public void push(T element) {
list.push(element);
}
public int size() {
return list.size();
}
public void makeEmpty() {
list.clear();
}
public String toString() {
return list.toString();
}
}
Представьте моё замешательство, когда я его читал, пытался понять, зачем нужен класс LabStack и что студенты поймут из такого бесполезного упражнения. Если это ещё непонятно, этот класс не делает вообще ничего. Он просто передаёт вызовы в объект LinkedList. Также он меняет имена нескольких методов (makeEmpty вместо clear), что ещё больше запутывает. Логика проверки ошибок не нужна, поскольку методы в LinkedList делают то же самое (просто через другое исключение, NoSuchElementException). По сию пору не могу понять, что было в голове у авторов этого материала.
В чём сложность
На первый взгляд, совет будет противоположен совету в разделе «Страх перед добавлением классов». Важно понимать, когда класс выполняет ценную роль и упрощает дизайн, а когда он бесполезным образом увеличивает сложность.
Слишком длинно, не читал
Избегайте классов без реальной ответственности.
Комментарии (123)

neolink
13.06.2015 23:45+3> Использование базы данных как очереди задач.
а что в этом плохого? в конечном итоге standalone решение тоже должно использовать БД для хранения задач иначе они могут потеряться
> Переизобретение дискового буфера вместо использования возможностей операционки.
посмотреть в памяти процесса или shared-memory группы процессов много быстрее, чем запрашивать теже данные у операционки даже если они лежат в буферах

defuz
13.06.2015 23:54+40Проблема таких правил в том, что тем, кто осознает эти правила, они ни к чему, а тем, кто их не прочувствовал на себе они все равно не помогут, ведь они настолько общие, что способны оправдать любую глупость.
Так что думаю, любой список подобных правил должен начинаться Правилом 0 с наивысшим приоритетом: «Если возможно, воспользуйтесь здравым смыслом».
denver
14.06.2015 01:40+1False. Тому кто еще не прочувствовал эти правила может показаться что вот именно в его случае можно чем-то пренебречь. С точки зрения его «здравого» смысла конечно.

veloriba
14.06.2015 10:21Похоже на то. Но, возможно, источник проблемы лежит глубже. Это психологические страхи, так же как и в оффлайн. Страх что твой код кому то не понравится, страх что будет ошибка и посыпятся шишки, перфекционизм. Или как в торговле на бирже — есть стратегия, но не можешь ее реализовать когда смотришь на прыгающий график. Сам стараюсь отключать психологию, но это как раз и есть самое трудное, т.к. не поддается программированию.

vintage
14.06.2015 00:15+89. Что тут не понятного? Это реализация адаптера. С практической точки зрения, удобно прятать все внешние зависимости за адаптерами — так мы не зависим от внешнего api и можем легко и просто менять реализации.

bromzh
14.06.2015 01:59+2Ещё такая ситуация может возникнуть, если класс реализует несколько интерфейсов, один из которых какой-нибудь стандартный контейнер (типа Map, List, etc). Самому реализовывать такие интерфейсы в продакшене вредно.
Например, вот класс Document из дравера для 3-й монги.
И это явно не бесполезный класс.
kstep
14.06.2015 02:06Плохой пример, так как этот класс не просто создаёт обёртку методов вокруг LinkedHashMap, но и определяет некоторую дополнительную логику по конструированию объекта, доступа к полям разных типов и т.п. Это немного сложнее, чем пример из статьи.
denis_g
15.06.2015 08:50Но, тем не менее, можно ж было использовать обычный LinkedHashMap, а логику вынести в какой-нибудь DocumentManager. Но это было бы достаточно костыльным решением — как раз для того, чтобы этого избежать, и был сделан класс-обертка с дополнительной логикой.
kstep
15.06.2015 11:56Какая там такая особенная логика? Проброс исключения другого типа? Было бы о чем говорить.
denis_g
15.06.2015 12:08Вы же сами про нее написали ;)
Плохой пример, так как этот класс не просто создаёт обёртку методов вокруг LinkedHashMap, но и определяет некоторую дополнительную логику по конструированию объекта, доступа к полям разных типов и т.п. Это немного сложнее, чем пример из статьи.
А вообще да, особенной логики там нет, поэтому этот класс как раз хорошо подходит в качестве примера.
vintage
14.06.2015 00:25+121. Архитектурную оптимизацию нужно проводить как можно раньше, иначе после «получения эмпирических данных» весь написанный код придётся выбрасывать, ибо смена архитектуры — это с высокой вероятностью переписывание всего кода.

lair
14.06.2015 00:56+4«Как известно», правильно выбранная архитектура — это та, в которой все решения с наибольшим влиянием приняты в начале, так что стоимость внесения всех прочих изменений сравнительно невысока.
(типичный идеальный мир, впрочем)
A_Kochurov
14.06.2015 09:18+7Не могу не согласиться.
Самый банальный пример такой архитектурной оптимизации — это выбор между поэлементной обработкой и обработкой пачками (batch-processing).
Как правило, batch-processing обладает большей эффективностью, но при этом код гораздо более запутан. А поэлементная обработка даёт возможность продемонстрировать все красоты ООП. Желательно на самом начальном этапе сделать выбор между этими двумя подходами, даже если это и кажется преждевременной оптимизаций (мол, потом переделаю) — ведь batch-processing может сильно отличаться от обычной поэлементной обработки. К примеру, переписать процессинг логов с использованием map-reduce может потребовать выкинуть весь красивый ООП-код поэлементной обработки, и написать его заново.
Сколько раз я слышал от борцов с преждевременной оптимизаций, что писать надо красиво, а потом профилировать! И сколько раз потом наблюдал, как они выкидывают свой код в помойное ведро, потому что поддались соблазну написать красиво, и не оценили, сколько ресурсов потребует обработка 20+ гигабайт логов :-)
akhmelev
14.06.2015 14:46Лучше вообще все делать параллельно: проектирование, код, тесты, профилирование, рефакторинг и т.д. Это даст и скорость, и качество.
Но проблема в том, что это — самый дорогой способ разработки. Да и годится лишь для прожжёных профи-единомышленников. И милионных проектов.
А если в проекте сидят аутсорсеры или квалификации хотя бы у кого-то из команды пока недостаточно, то step-by-step — неизбежный, но довольно эффективный путь. Результат может и не быстр, кода лишнего может и много, но в головах у народа порядок и все УЧАТСЯ его поддерживать.
Высоконагруженных проектов не так уж и много, а вот порядок в коде — редкость. И это наверное самая главная проблема для крупных решений, где люди много читают чужого. Все не перепишешь в asm-style. И всё своё так не напишешь тоже. Поэтому всё-таки выделить конкретно тяжелое на оптимизацию (вплоть до переписывания всего куска) эффективнее, чем абсолютно все писать с расчетом на дикие нагрузки.A_Kochurov
14.06.2015 21:57+1Поэтому всё-таки выделить конкретно тяжелое на оптимизацию (вплоть до переписывания всего куска) эффективнее, чем абсолютно все писать с расчетом на дикие нагрузки.
Ну а кто предлагает переписать все-все? Просто надо знать, где сразу надо писать эффективно, а где можно и через годик вернуться, да переделать, если припрет.
Все твердят, мол, начинай писать неэффективно, потом перепишешь. Будто бы «эффективно» и «красиво/понятно» — это какие-то две крайности, разные полюса.
Во-первых, если чуть-чуть подумать, то часто можно сделать и эффективно, и красиво. Как в оригинальной статье — за «красотой» часто на самом деле кроется банальная неэффективность, сортировка пузырьком, вместо которой можно было воспользоваться чем-то более приличествующим.
Но программист, одурманенный страхом преждевременных оптимизаций уже боится думать о производительности («а вдруг это преждевременно? вдруг старшие товарищи ругаться станут? в прошлом месяце премии лишили за это!»), пишет пузырек и радуется, что не попал в ловушку.
А во-вторых, есть места, где требования к эффективности изначально выше, чем в другом коде, например во фреймворках и библиотеках, обработке логов, нераспараллеливаемых сервисах внутри распределенных систем. Но только об этом никто не говорит — все внушают программисту простую мысль «пиши красиво, эффективно сделаешь после». Вот и получается, что о них перестают думать, «после» не наступает.
А ведь что такое фреймворк? Это сотня тысяч строк чужого кода, в котором подчас разобраться затруднительно. Если автор фреймворка при его написании тестировал его на простеньких примерах, и не профилировал на большом объеме данных — то это каюк, переписать его невозможно (это может стоить дороже, чем все приложение). А ведь можно даже и попрофилировать на терабайте данных, да не том, и все проскочит как по маслу — никогда не знаешь, для чего фреймворк решат применить!
<Лирическое отступление>
Мне довелось поработать в компании, которая сделала свой фреймворк. Нет, даже Фреймворк, с большой буквы. Решал он очень специфический задачи логистики и планирования и был, надо думать, один такой в своём роде.
С точки зрения ООП он был совершенен. Да, не без сотни слоёв абстракции внутри. Но кто сам без этого греха написал свой Фреймворк — пусть первый бросит в меня камень.
С точки зрения прикладного программиста — весьма красив, джавадоки повсюду, функциональность — загляденье, тырк-тырк — и вот сложнючая функция работает, тырк-тырк — и вот результаты разжеваны и доступны пользователю.
С точки зрения менеджера — прекрасен, им можно было замечательно пудрить мозги клиентам, предъявляя как своё ноу-хау.
И все было ничего, пока объем данных был невелик. Но вот приходит клиент побольше, лакомый кусочек… И бамц — все еле движется… Начинается профайлинг… День, два, три — круг поиска сужается… Четыре, пять, неделя — все ниточки тянутся во Фреймворк…
И вот тут начинается Пичаль, тоже с большой буквы. Из песни слова не выкинешь, слой абстракции из Фреймворка не уберешь — где-то в другом проекте на него кто-то завязался… LinkedList на ArrayList не заменишь — кто-то ведь и к его поведению мог привязаться, применений-то у Фреймворка не счесть…
Идешь к авторам Фреймворка на поклон — «ребята, выручайте, тормозит безбожно, причем по всей площади Фреймворка сразу — нету батлнеков, все сплошняком адовое!» — а они тебе: «да мы с зимы ковыряемся с этим, в проекте ХХХ такая же шляпа, но у нас тут 44 слоя абстракции, 12 делегатов, 7 прокси, куда теперь это уберешь :-( Ну погоди, в версии 11.4 станет полегче».
</Лирическое отступление>
mird
15.06.2015 11:23И вот тут начинается Пичаль, тоже с большой буквы. Из песни слова не выкинешь, слой абстракции из Фреймворка не уберешь — где-то в другом проекте на него кто-то завязался… LinkedList на ArrayList не заменишь — кто-то ведь и к его поведению мог привязаться, применений-то у Фреймворка не счесть…
Простите, но либо у вас уровни абстракции либо возможность для потребителя завязаться на конкретную реализацию коллекции. Вы уж определитесь. А то похоже, что Фреймворк хреново спроектирован с точки зрения ООП.A_Kochurov
15.06.2015 11:34Простите, но либо у вас уровни абстракции либо возможность для потребителя завязаться на конкретную реализацию коллекции. Вы уж определитесь. А то похоже, что Фреймворк хреново спроектирован с точки зрения ООП.
Беда в том, что даже в правильно спроектированном фреймворке пользователи найдут способ привязаться к конкретным особенностям работы.
Даже если они не смогут залезть внутрь и получить сам LinkedList, все равно эта особенность ведет к примеру к быстрой вставке в начало списка и медленному доступу к элементам в середине.
MacIn
14.06.2015 01:38+16как люди любят тратить время на совещаниях на всякую ерунду, вместо того, чтобы обсуждать насущные проблемы. Конкретно, проектировщики атомной электростанции очень долго спорили, какой материал должен пойти на навес для велосипедов – bike-shed
Этот эпизод из «Закона Паркинсона» — он чуть о другом.
Там было заседание в мэрии, на котором обсуждались два вопроса — смета на постройку АЭС и смета на постройку сарая для велосипедов служащих мэрии. Обсуждение сметы АЭС прошло в стиле «По смете стоит X долларов. Принимаем? Да, я слышал, что строительство другой АЭС стоило больше. Принимаем». Приняли минут за пять. А вот навес для велосипедов обсуждали очень долго и в итоге вроде решили вообще не строить, точно не помню.
Суть тут не в том, что «много тратят времени на ерунду», это вообще не об этом. Суть в том, что у людей есть определенный уровень компетенции, и что такое АЭС, они не представляют, не представляют масштаб цен и поэтому их легко ввести в заблуждение и они даже ничего не поймут, т.к. некомпетентны. А вот что такое «сарай», сколько стоят жесть и гвозди, представляет всякий, поэтому готов это обусждать, и обсуждать очень долго.
Т.е. оно, конечно, выходит, что о ерунде спорят дольше, но это следствие, суть — в разном уровне компетенции. И, как следствие, то, о чем люди не имеют представления, пройдет легче, а о чем имеют — может вообще не пройти.
Это как с выборами — проголосовать за людей, о которых и о работе и компетентности которых представления мы не имеем, мы можем быстро и гладко, а вот обсуждать смету ТСЖ на ремонт подъезда будут месяцами и в итоге, может, к согласию и не придут.
kstep
14.06.2015 01:39+24Зен языка Python
Дзен же, дзен. Дзен, Карл!
mktums
14.06.2015 01:52Выдержки из оного также переведены неверно.
Однако статью этот факт, в принципе, не очень портит :)kstep
14.06.2015 02:07+4Просто на этом месте меня аж передёрнуло. Переводить Zen как непонятное нерусское «Зен» — это какой-то ужас-ужас, за гранью. Остальные неточности я ещё могу простить, но изобретать новые слова, когда есть существующие канонические… Лень посмотреть в словарь?
MacIn
14.06.2015 01:55+3Добавление классов уменьшает сложность.
Очень смелое заявление. Это далеко не всегда так, здесь придется положиться на «здравый смысл», определяя, где он — предел разбиения.
Встречал такие ситуации, когда новичок, находясь в эйфории от «паттернов, ООП, вот этого всего» делал разбиения там, где это совершенно не нужно. Например, есть некий метод, который на основании одного флага (т.е. вариантов работы данного метода только два и всегда будет два, больше физически невозможно сделать). Вместо того, чтобы написать код вида:
… какие-то действия…
if () {
вариант 1
} else {
вариант 2
}
… еще какие-то действия
составляющий в сумме строчек 15, он создавал два разных класса с перегрузкой методов, скрывающих действия вариант1, вариант2. В итоге, когда потребовалось изменить поведение, пришлось ломать всю структуру классов и переделывать с нуля, причем в других местах потребовалась перегрузка, которая очень просто реализовалась, а в этом конкретном месте — вариант с if'ом. Ощущение было, что человек не решал проблему, а писал курсовую на тему «как написать простейший код так, чтобы он использовал все самые хитрые заморочки ООП». Разве только интерфейсов не хватало.
Или, например, работа с каким-либо файлом, например, log'ом. Реализована в виде простого метода: открыть файл, отформатировать строку, записать ее в файл, закрыть его. Вернуть признак ошибки.
Вместо этого был создан класс, в конструкторе которого файл открывался, потом отдельный метод для форматирования строки, причем с разными параметрами вместо стандартного sprintf'а (язык другой, не Си, суть та же). Закрытие в деструкторе, отдельное поле ошибки. В итоге вместо if(!DoLog(...)) do something; необходимо создать экземпляр класса, инициализировать его, вызвать запись, сохранить код ошибки, вызвать деструктор, проанализировать код ошибки.
Или когда создается отдельный класс для очень узкой, специализированной задачи, которая вызывается ровно один раз ровно в одном месте. Реализуется простой процедурой, класс не нужен вообще, но он создается. Со всеми прелестями конструирования его и деинициализации.kstep
14.06.2015 02:15+3Подход с классом-логгером может быть оправдан. Например, что если понадобиться логировать не только в файл, но и в память, в стандартный вывод, по сети на сервер логов, в syslog? В таком случае просто нужно будет переопределить метод записи в классе логгере. А если нужно ещё различать классы сообщений (ошибка, информационное, дебаг, предупреждение…), логировать разные классы в разные места, конфигурировать это всё с помощью файлов конфигурации, плюс в зависимости от источника лог-сообщения… Тут уж без целой иерархии классов не обойтись, иначе будет просто god-class какой-то.
MacIn
14.06.2015 04:30Может, но там не тот случай, это был именно «лог в файл», который не перенаправлялся бы ни в какой другой носитель, да и сама реализация класса не позволяла переопределеить носитель, это была по сути обертка, в которой процедуру log разодрали на части, неудачно смешав с инициализацией самого класса. Просто класс ради класса. Если у нас есть процедурка, которая работает с типом данных А, и выдает типы Б, В, вовсе необязательно создавать специальный класс-обертку из одного метода просто «чтобы было ООП».
A_Kochurov
14.06.2015 09:31-1Например, что если понадобиться логировать не только в файл, но и в память, в стандартный вывод, по сети на сервер логов, в syslog
Справедливости ради, если появились такие потребности, то не стоит изобретать велосипед, даже если это красивый абстрактный велосипед, лучше поискать готовую альтернативу. Так что в любом случае разработчик был не прав :-)
velvetcat
14.06.2015 09:45Как раз прав. Если его реализация инджектится в виде интерфейса, то поменять ее на готовую либу становится делом десяти секунд.
lair
14.06.2015 09:49+3… после чего реализация станет просто оберткой вокруг готовой библиотеки, а это не всегда осмысленный код.
velvetcat
14.06.2015 10:18Нет-нет, я имею ввиду, что вся эта самописная либа логгирования инджектится в класс-потребитель за каким-нибудь общепринятым интерфейсом.
lair
14.06.2015 15:42+1Это если вам повезло, и у вас был общепринятый интерфейс. А то — в случае с тем же логированием — каждая библиотека зачастую объявляет свой.

grossws
15.06.2015 20:37+3Поэтому у каждой третьей java-библиотеки своё логгирование, которое, в хорошем случае, рано или поздно становится обёрткой над slf4j, log4j, jcl, jul или osgi logging. Вместо того, чтобы сразу использовать slf4j/jcl/log4j

Yan169
14.06.2015 10:45+2/Проектируя газонокосилку/ — А что, если данный узел будет использоваться не только в газонокосилках, но и в городских автомобилях, танках, машинах формулы-1, или марсоходе? Надо учесть все варианты…
Например, что если понадобиться ...
А если не понадобится? Тогда весь труд по написанию и поддержке превентивной архитектурной гибкости окажется напрасным. В конечном итоге выбор, где расположить ползунок на шкале «KISS <-> заложенная гибкость», всегда субъективен, объективные критерии априорно определить целесообразность такого выбора не существуют. На практике есть только некоторая корреляция, что с опытом удачно сделать выбор получается чаще.velvetcat
14.06.2015 11:10А если не понадобится?
А просто надо перед тем, как браться за работу, уточнить, пишем ли мы одноразовый скрипт, или что-то другое. Если что-то другое — то надо сразу делать нормально. Здесь, коли речь вообще зашла о сохраняемом логе, видно, что речь идет о продукте. Тем более, что выше автор говорит "… когда пришлось менять поведение".
И вообще KISS и заложенная гибкость являются противоположностями только для очень, очень простых программ. Вот скажите, нафига мне в коде перевода денег со счета на счет открывать файловый дескриптор, проверять результат, форматировать строку, делать запись, проверять результат, закрывать дескриптор?
А еще такой псевдо-KISS приводит к тому, что в одном блоке у нас оказывается бизнес-логика, работа с ФС, работа с БД, работа с UI. А что, там же все просто, пара строк всего.
Субъективность — это для говнокода. Чистый код тем и хорош, что маскимально объективен, ибо в каждом отдельно взятом модуле делается что-то одно и спорить там не о чем.
fetis26
14.06.2015 12:25Такое уточнение почти всегда неизвестно. Иначе задача бы звучала «реализовать логинг в файл и ХХХ»
Yan169
14.06.2015 15:05Здесь напрашиваются определения, что такое «нормально» и «чистый код», потому как на практике почему-то оказывается, что разработчики эти определения могут понимать по-разному. Никто не ставит перед собой цель написать говно, однако иногда с одной стороны получаем «псевдо-KISS», а с другой — «астронавтов архитектуры» и истории про то, как сложный многотысячный код удалось заменить одним скриптом на пару сотен строк. А определившись с определениями, какими бы они ни были, потребуется объективное доказательство, что такой «нормальный чистый код» есть единственно верное во всех случаях решение. Доказательство по сути невозможное, потому как программирование — лишь инструмент решения класса задач, а применять любой иструмент надо с оглядкой на цели и окружающие условия (с чем очевидно, Вы тоже согласны, приводя в пример одноразовый скрипт).
С моей точки зрения, хороший код — это:
— код, в котором есть необходимость; если задачу эффективнее решить без программирования, например организационно, такой вариант определенно стоит рассмотреть;
— код, который работает;
— код, который написан быстро (дешево);
— код, который дешево поддерживать и дополнять (если есть такая задача);
Исходя из этих тезисов хороший программист постарается подобрать соответствующую задаче методику разработки, руководствуясь вполне объективными аргументами, например «IoC облегчает тестирование, а тестирование повышает качество и снижает затраты на поддержку», но все равно будет принимать решения в контексте субъективного мнения о целях и перспективах разрабатываемого ПО.
Поэтому, к слову, когда видишь нечто, напоминающее говнокод, порой стоит задуматься, в каких условиях он был написан (дедлайны, наличие других задач с высшим приоритетом?), и какие задачи он должен был решить, и лишь потом хаять программиста. Вполне возможно на момент написания это был действительно хороший код, просто со временем условия и требования к нему изменились.
MacIn
14.06.2015 18:42Тем более, что выше автор говорит "… когда пришлось менять поведение".
Это о другом случае, там ряд примеров.
ибо в каждом отдельно взятом модуле делается что-то одно и спорить там не о чем.
Так то модуль, а то — класс, я о другом говорил.
kstep
15.06.2015 21:04Да вы идеалист, батенька. Обычно ответ на такие уточнения: «надо как получится, только быстрее-быстрее-быстрее и вчера», а потом выясняется, что нужно это расширять, хотят такую же штуку ещё где-то, и т.п.
velvetcat
14.06.2015 09:42Или когда создается отдельный класс для очень узкой, специализированной задачи, которая вызывается ровно один раз ровно в одном месте. Реализуется простой процедурой, класс не нужен вообще, но он создается. Со всеми прелестями конструирования его и деинициализации.
Как раз специализированная задача и должна быть вынесена в отдельный класс. С единственной целью избавить класс-потребитель от знания деталей этой специализации.
Отдельным бонусом идет возможность протестировать специализированный класс отдельно, а его потребитель — отдельно.
Особенно это важно, когда эти два класса работают на разных уровнях абстракции, например один класс чисто логический, а другой — инфраструктурный, или один является жизненно важным, а другой — второстепенным. Как например, упомянутый Вами лог, попадающий под оба критерия.
вызывается ровно один раз ровно в одном месте
Уже много лет дубликация не является единственным, и даже основным, поводом выделения юнита. Гуглите SRP, и заодно IoC.
P.S. Сорри за резкость, но лог джуниор сделал правильно (включая выделение отдельного метода для форматирования), а Вы — нет. Логгирование, реализованное отдельным классом — это стандарт, даже если это просто обертка над записью в файл. Если хотите, могу подробно расписать, почему это так, без упоминания абрревиатур и ссылок на Гугл.
vintage
14.06.2015 13:13+2Мне вот интересно как вы видите идеальное логирование. Желательно с примерами :-)
velvetcat
14.06.2015 23:26В идеале хочу указывать, что надо залоггировать, в аннотации к методу :) Чтобы в коде не было ни одной строки, без которой он не мог бы обойтись, чтобы сделать свою главную (и единственную задачу).
Ну а в неидеальном мире мне хватает инъекции через конструктор интерфейса с методами info, warning и error. В продакшене этот интерфейс реализовывается логгером в GrayLog, в CI — записью в файл, а во время юнит-теста в IDE — заглушкой с выводом в никуда, если все ок, или на экран, если что-то не хочет заводится и мне нужен этот лог. Конкретная реализация выбирается бутстрапом приложения на основе переменной окружения, при этом бизнес-код не меняется, не ломается и вообще ничего не знает о логгере, кроме того, что он есть.
Все просто и комфортно :)
MacIn
14.06.2015 18:18+3Как раз специализированная задача и должна быть вынесена в отдельный класс. С единственной целью избавить класс-потребитель от знания деталей этой специализации.
Зачем? «чтобы был класс»? Это ООП ради ООП.
Такую задачу можно вынести в отдельную процедуру в отдельном модуле. Которая будет тестироваться отдельно и далее по тексту.
Просто создавать класс-обертку с 1 статическим методом или пустыми конструктором-деструктором + необходимость объект конструировать там, где нам просто надо 1 раз вызвать процедуру — бессмыслица. Это бездумное следование мантрам.
Уже много лет дубликация не является единственным, и даже основным, поводом выделения юнита.
Я разве спорю? Вот есть отдельная процедура (пусть даже разбитая еще на части) в отдельном модуле.
Класс зачем?
Если хотите, могу подробно расписать, почему это так, без упоминания абрревиатур и ссылок на Гугл.
Вы не знаете исходных данных задачи, поэтому не можете полностью судить о правоте. Я лишь привел пример, на самом деле, там была работа с файлом, но это был не лог. Я просто упростил для изложения здесь.velvetcat
14.06.2015 23:08-1Класс — чтобы объявить его реализующим интерфейс, и в потребитель передать именно этот интерфейс. Думаю, не надо перечислять преимущества зависимости от инъектируемого интерфейса перед зависимостью.
velvetcat
14.06.2015 23:27-1… (сорри) перед зависимостью от жестко прописанной процедурой в другом модуле.
MacIn
14.06.2015 23:38Даже и в этом случае, с другим модулем: в чем разница между зависимостью от интерфейса класса, прописанном в модуле X и зависимостью от реализации в виде процедуры в классе Y? Учитывая, что процедура перегружаема в зависимости от типа данных, с которыми она работает и то, что она может быть просто однострочной оберткой (тот же интерфейс по сути)?
lair
14.06.2015 23:55+2В том, что вбрасывание зависимостей, выраженных в процедурах, несколько сложнее, нежели вбрасывание зависимостей, выраженных в интерфейсах. А это, в свою очередь, затрудняет тестирование.
MacIn
15.06.2015 00:05-1Без конкретных случаев говорить не о чем, слишком общая фраза. Да и как писал выше: если процедура — обертка, то это тот же интерфейс по сути.
lair
15.06.2015 00:19Хотите конкретный случай? Легко. Вот у вас есть простенький C#-ный «модуль» (не важно, класс ли, метод ли). Внутри него делается два логирования — одно с уровнем Info, другое с уровнем Error. Каждый уровень логирования — отдельный метод.
Теперь мы хотим это протестировать (т.е., удостовериться, что логи пишутся в нужных случаях). Можете показать пример кода для такого случая?MacIn
15.06.2015 00:30Нет, на шарпе не пишу, к сожалению. Ваша задача сводится к тому, чтобы зафиксировать факт вызова этих двух процедур, выполняюших логирование. Например, вы можете использовать conditionals для перехвата. Или компиляции другого, отладочного модуля-заглушки с теми де процедурами. Или библиотеку, перехватывающую вызов любой процедуры, втч встроенной в язык (у нас в проекте используется такая).
Но это все не важно, потому что я говорил о другом, тривиальном использовании (см. пример кода, пусть утрированный, но все же, ниже).lair
15.06.2015 00:37-1… а в случае с классами и интерфейсами я просто задам нужный мне мок, и сделаю все проверки на нем.
MacIn
15.06.2015 03:16+1Кому что удобнее. Все равно вам придется создавать класс-заглушку и подставлять либо его, либо рабочий класс через интерфейс учитывая вариант сборки.
Да и это не тот случай, как я уже написал. Я же не говорю «нет таких ситуаций, когда использование ООП оправдано», я говорю, что есть случаи, когда не оправдано.lair
15.06.2015 10:59-1Не «учитывая вариант сборки», а через DI. Это фундаментальная разница.
kstep
15.06.2015 13:32+1А DI надо конфигурировать… разными конфигами в зависимости от варианта сборки!
lair
15.06.2015 13:42-1Мне кажется, тут где-то терминологическая путаница. Варианты сборки для меня — это всяческая условная компиляция, что приводит к тому, что тестируемая сборка бинарно отличается от выкатываемой. Все, что настраивается в рантайме (в том числе — конфигурация) — это не варианты сборки.
kstep
15.06.2015 15:26В общем и целом, похоже на то. А в принципе всё зависит от реализации DI, коих вагон и маленькая тележка. Взять тот же Cake Pattern в Скале.
lair
15.06.2015 16:18Насколько я успел понять из беглого прочтения, этот паттерн тоже рекомпиляции не требует. Это в моем понимании критичное отличие.
kstep
15.06.2015 19:32+1Как это не требует? Чтобы изменить конкретную используемую реализацию, нужно изменить объявление класса. Как следствие, нужна пересборка. См. например www.cakesolutions.net/teamblogs/2011/12/19/cake-pattern-in-depth
lair
15.06.2015 21:56Прочитал повнимательнее.
С одной стороны, я бы очень аккуратно подумал прежде, чем относить Cake Pattern к DI, особенно после вот этой фразы:
In plain dependency injection, we create components and we assemble these components together to form an application. Using the Cake Pattern, we create pieces of functionality and we assemble the functionality to form the application.
С другой стороны, то, как выглядит тест — это типичный DI, просто не через конструктор, а через миксины/дженерики (первыми из которых трейты и являются):
class CakeTestSpecification extends Specification with Mockito { trait MockEntitManager { val em = mock[EntityManager] def expect(f: (EntityManager) => Any) { f(em) } } "findAll should use the EntityManager's typed queries" in { val query = mock[TypedQuery[User]] val users: java.util.List[User] = new ArrayList[User]() val userService = new DefaultUserServiceComponent with UserRepositoryJPAComponent with MockEntitManager userService.expect { em => em.createQuery("from User", classOf[User]) returns query query.getResultList returns users } userService.userService.findAll must_== users } }
И здесь, кстати, хорошо видно, что рекомпиляции тестируемого кода для замены зависимостей не нужно: зависимости определяются в тесте.kstep
15.06.2015 22:33Да, но нужна будет перекомпиляция теста. То есть по любому придётся что-то перекомпилировать, не сами базовые классы, так место их использования. Про то и говорю.
lair
15.06.2015 22:34Перекомпиляция теста никого не пугает. Важно, что не будет перекомпиляции тестируемого кода, т.е. тот же код, который тестировался, уйдет в продакшн.
kstep
15.06.2015 22:38+1Я про это место писал если что:
val userService = new DefaultUserServiceComponent with UserRepositoryJPAComponent with MockEntitManager
Вот именно про перекомпиляцию этого используемого анонимного класса я писал:
Чтобы изменить конкретную используемую реализацию, нужно изменить объявление класса.
Так что похоже мы просто не до конца поняли друг друга.
.
MacIn
17.06.2015 01:12Естественно, и это — нормально, обычная практика.
Если вы хотите сказать, мол, мы тестируем не то — так я не понимаю — какая разница — вы через ООП подставляете заглушку-отладочный логер, который фиксирует вызов метода, или через условнуб компиляцию — другу процедуру-заглушку-отладочный логгер?
Говорить про различные бинарные сборки ни к чему — вы тестируете «черными ящиками». Вот тестируете процедуру, как описали, которая вызывает логер. Значит, считаем логгер рабочим черным ящиком и сейчас конкреткно «зажимаем в тиски» юнит-теста то, что логгер вызывает, а не его самого. Так что без разницы, та же самая сборка, или нет. Все равно сделать т.н. полный тест невозможно из-за обилия сочетаний.lair
17.06.2015 11:29+1Смотрите, тут есть один очень критичный — для меня — пойнт. Если бинарник, который я тестирую, не совпадает с тем, который в продуктиве, то я не могу быть уверенным, что тот, который в продуктиве — протестирован. Откуда я знаю, что еще подменила условная компиляция?
(заметим, этот пойнт критичен не только для меня, Хамбл и Фарли в Continuous Delivery говорят о том же, причем вплоть до расчета хэшей файлов)MacIn
17.06.2015 14:07то я не могу быть уверенным, что тот, который в продуктиве — протестирован
Это неважно. Ваш бинарник, условно, состоит из двух блоков: один вызывает логгер, другой — сам логгер. Вы тестируете их по отдельности, каждый раз эмулируя поведение другого. Вы все равно не можете провести полное тестирование целой программы, это невозможно, понимаете? Поэтому приходится полагаться на ряд тестов, которые, как мы считаем, обеспечивают приемлемое покрытие. Это допущение, на которое приходится идти, и это абсолютно нормально.
Более того, вашим продуктом может быть не программа, а программный комплекс. Который полагается на другие части — например, базу данных.
Вот вы протестировали у себя свою программу с СУБД, например, MySQL 5.1.44, в требованиях у вас указано, что ПО работает с версией не ниже 5.1.44.
А у клиента — 5.1.45 и в ней, например, исправлен какой-то баг, который не вылазил у вас в предыдущей версии. И так можно продолжать долго — вплоть до ОС и самого железа. Вы не можете быть уверены, что ваш продукт будет работать у клиента так же, если только вы не отдадите ему компьютер тестировщика со всеми настройками. Это все — допущения — о том, что сторонние части будут работать так же. В ситуации с блоками программы та же логика, можно рассматривать те два блока из примера как два компонента программного комплекса.
Откуда я знаю, что еще подменила условная компиляция?
Это только вариант. Система тестирования может подменять весь модуль, например, просто редирект на другую директорию, где хранится модуль с тестовыми заглушками.
Ведь так или иначе — будь то ООП или голый машинный код без всякой парадигмы вообще — для перехвата вызовов (в логгер) вам придется подменять его заглушками (неважно как технически — будь то танцы с условной компиляцией или подстановка другого класса через интерфейс/наследование) для компиляции тестовой сборки.lair
17.06.2015 14:24Это только вариант. Система тестирования может подменять весь модуль, например, просто редирект на другую директорию, где хранится модуль с тестовыми заглушками.
Вот я предпочитаю «варианты», где модель-под-тестированием бинарно идентичен тому, который пойдет в продуктив.
Да, я понимаю, что есть допущения. Но все допущения, которые под моим контролем, я постараюсь минимизировать.MacIn
17.06.2015 15:46Мы, наверно, о разном говорим.
где модель-под-тестированием бинарно идентичен тому
потому что мне непонятно, как модель под тестированием может быть идентична релизной, если нам нужен не логгер, а заглушка, фиксирующая вызовы. Как вы тестируете, если у вас вызывающий блок слинкован с логгером, а не с заглушкой?lair
17.06.2015 15:53Да легко же.
public class ClassUnderTest { private readonly ILogger _logger; public ModuleUnderTest(ILogger logger) { _logger = logger; } public void MethodUnderTest() { _logger.Info("abc"); ... _logger.Error("def"); } }
Что бы я ни делал, какая бы зависимость не вбрасывалась, код под тестированием будет бинарно идентичен продуктивному.
В этом, собственно, вся идея Dependency Inversion: вызывающий код зависит от абстракции, а не от реализации.MacIn
17.06.2015 16:25Да это ясно, вы не поняли вопроса: в чем разница-то? Тестируемый блок зависит от интерфейса ILogger, но что подставляется — логгер или заглушка — определяется на этапе линковки, верно? Это просто точка стыковки двух блоков, но сама комбинация определяется при сборке, верно? В релиз версии через ModuleUnderTest будет задан реальный логгер, в тестовой сборке — тестовая заглушка. Бинарно идентичными сборки «модуль+логгер» и «модуль+заглушка» не могут быть. А то, что сам «модуль» бинарно идентичен — так он и в процедурной реализации бинарно идентичен. Различается второй блок (логгер vs заглушка), а он и у вас отличается.
lair
17.06.2015 16:30Тестируемый блок зависит от интерфейса ILogger, но что подставляется — логгер или заглушка — определяется на этапе линковки, верно?
Нет, неверно. На этапе рантайма.MacIn
17.06.2015 16:50В таком случае имеет смысл говорить об идентичном поведении, а не бинарно идентичных модулях. Потому что все равно есть код, который решает в зависимости от каких-то условий подставить заглушку или логгер. Здесь мы должны быть уверены не в бинарной идентичности, а в верности подстановки. Ведь суть принципа «идентичности» в том, чтобы получить некоторый блок, который будет при одинаковых воздействиях выдавать одинаковый результат, а у вас есть некоторая внутренняя закрытая логика, которая меняет поведение блока.
И даже это реализуемо в рамках процедурной парадигмы, например при помощи процедурного типа. Или просто прямого перенаправления в другую функцию в случае тестирования — ведь все равно у нас есть код, определяющий, что подставить в ILogger.lair
17.06.2015 17:00В таком случае имеет смысл говорить об идентичном поведении, а не бинарно идентичных модулях
Отнюдь. В моем случае модуль в тесте и в продуктиве бинарно идентичен, это уменьшает степень неуверенности.
Потому что все равно есть код, который решает в зависимости от каких-то условий подставить заглушку или логгер.
Нет такого кода. Просто нет.
Composition root, вызываемый в продуктиве, всегда подставляет продуктивную реализацию логгера (мы сейчас, естественно, не рассматриваем ситуации, когда в продуктиве логгеров больше одного и они определяются конфигом, это тема другого разговора).
В тестировании composition root находится прямо внутри теста (иногда — внутри тест-сетапа), и там задаются нужные тестовые зависимости, опять-таки, напрямую.MacIn
17.06.2015 17:29Не работаю ни с Net, ни с Java платформами, поэтому наберитесь терпения.
Отнюдь. В моем случае модуль в тесте и в продуктиве бинарно идентичен, это уменьшает степень неуверенности.
Вы говорите про тестируемый модуль, или про всю программу? Тестируемый модуль и в процедурной парадигме бинарно идентичен.
Нет такого кода. Просто нет.
Тем не менее — через один и тот же интерфейс мы контактируем либо с логгером, либо с заглушкой. Чем это определяется, если, как вы утверждаете, не линкером и не динамически(рантайм)?
Composition root, вызываемый в продуктиве, всегда подставляет продуктивную реализацию логгера… В тестировании composition root находится прямо внутри теста
Т.е. все-таки есть внешний модуль/сущность, которая определяет связь между тестируемым модулем и логгером либо заглушкой. Причем эта связь различна в тестовой версии и в релизе?
У вас есть модуль А, который вызывает Б или В:
А-(1)>Б
А-(2)>В
если вы говорите, что связи (1) и (2) не устанавливаются во время рантайма, значит они установлены статически при сборке, соответственно, комплексы различны — либо А+Б в релизе, либо А+В в тестовой среде.
В чем тогда разница по сравнению с ситуацией, когда связь А-> прописана в виде прототипа, объектный файл модуля А бинарно идентичен в тесте и в релизе, но при сборке мы используем объектный модуль либо Б, либо В, причем это задано make файлом?lair
17.06.2015 17:38Вы говорите про тестируемый модуль, или про всю программу? Тестируемый модуль и в процедурной парадигме бинарно идентичен.
Я говорю про сборку (assembly), как единицу развертывания. Это (условно) независимый бинарный файл.
Чем это определяется, если, как вы утверждаете, не линкером и не динамически(рантайм)?
Composition root.
В чем тогда разница по сравнению с ситуацией, когда связь А-> прописана в виде прототипа, объектный файл модуля А бинарно идентичен в тесте и в релизе, но при сборке мы используем объектный модуль либо Б, либо В, причем это задано make файлом?
Если язык/платформа позволяет одновременно иметь статически верифицируемую связь с используемым компонентом, и при этом заменять реализацию этого компонента при сборке, сохраняя компонент-пользователь бинарно неизменным, то ничем.
Но дальше вопрос в том, какой гранулярности объектные модули вы можете использовать, потому что описываемый мной подход вообще не требует разбиения на отдельные единицы сборки (у вас хоть вся система может быть в одном модуле, на тестирование это не повлияет).MacIn
17.06.2015 17:52Это (условно) независимый бинарный файл.
Но вы же говорите, что composite root в тестовой среде определен статически. Пара «модуль+composite root(тест)» и «модуль+composite root(релиз)» бинарно различны, нет?
и при этом заменять реализацию этого компонента при сборке, сохраняя компонент-пользователь бинарно неизменным, то ничем.
Так и получается — в процедурной парадигме реализация — это отдельный объектный файл, а «интерфейс» — заголовок, прототип процедуры.
у вас хоть вся система может быть в одном модуле, на тестирование это не повлияет
В приципе, если добавить один кросс-модуль с глобальными переменными процедурного типа, которые будут инициализироваться по-разному в разных сборках — это будет то же самое, что у вас composite root.lair
17.06.2015 17:55Так и получается — в процедурной парадигме реализация — это отдельный объектный файл, а «интерфейс» — заголовок, прототип процедуры.
Не в «процедурной парадигме», а в конкретных языках/платформах, которые это позволяют. Например, .net такого не позволяет.
lair
17.06.2015 17:07На самом деле, я был не прав, фраза «на этапе рантайма» неточна. На этапе рантайма происходит определение, какую продуктивную зависимость использовать, если их несколько или если используется DI-контейнер. В противном случае зависимость прописывается статически прямо в composition root, и никакого выбора не происходит вовсе.
lair
17.06.2015 16:47А, да. Если у меня нет возможности сделать нормальный рантайм-DI, я всегда могу вынести composition root в отдельный модуль, зависящий от всех остальных. Тогда этот модуль будет единственным, отличающимся между тестом и продуктивом, но это уже никого не волнует, потому что composition root все равно не тестируется юнит-тестами.
MacIn
14.06.2015 23:30+1Класс — чтобы объявить его реализующим интерфейс, и в потребитель передать именно этот интерфейс.
Абстракция уровня интерфейса абсолютно не нужна в рамках некоторых задач. Более того, если вы хотите реализовать интерфейс в рамках процедурной парадигмы, вам никто не запрещает превратить в дальнейшем исходно процедурную реализацию в обертку-интерфейс для других процедур и даже классов — интерфейс, насколько можно говорить об интерфейсе в рамках ПП — останется тем же.
Простой пример: у вас функция, реализующая некоторый алгоритм. Совершенно неважно, это функция-член класса, или отдельно стоящая функция. Часть ее, являющуюся логически законченным блоком, выделяется в отдельную функцию для повышения читаемости. Данная функция работает с одним и тем же типом данных, ее функционал никогда не будет использован повторно, более того она не вызывается не только из других модулей, но даже из других процедур. Она решает одну конкретную задачу. Попробуйте, покажите, зачем здесь нужен абстрактный интерфейс.
Упрощенно: у вас есть кусок кода (простой тип данных использую условно, just to make a point):
bool func1(){
…
if(a > 0) {
действие1
}
…
}
он преобразован в функции:
bool positive(int b){
return (b > 0);
}
bool func1(){
…
if(positive(a)){
действие1
}
…
}
Покажите, почему функцию positive следует реализовать в парадигме ООП «чтобы передать потребителю — функции func1 — интерфейс». Без додумывания вида «а что если потом нам потребуется работать не только с int, мы тогда сможем перегрузить». Постановка задачи именно такова — тип данных — int — зависит от внутренней реализации функции func1 и меняться не будет. Даже если и будет — positive тоже перегружаема, без ООП.velvetcat
15.06.2015 23:02-1Хм. Потому что я не хочу перегружать. Я хочу прямо в конструкторе видеть все зависимости класса-потребителя (вы же знаете, чем плохи глобальные переменные? в том числе неявным контрактом того куска кода, где они используются. А если у меня нет доступа к исходникам?); я хочу в рантайме эти зависимости устанавливать на то, что мне нужно в данный момент, включая то, что в один экземпляр класса я передам одну реализацию, а в другой — другую (я не про абстрактное «вдруг мне понадобиться заменить...», а про запуск на проде и в IDE в изоляции, например); я хочу нормальное переиспользование кода за счет SRP; за счет SRP же я хочу простую поддерживаемость в дальнейшем; наконец, я не хочу хитровывертов с перегрузкой, даже если я могу их сделать.
Слушайте, ну поищите уже в интернете, зачем нужны интерфейсы… Пожалуста, не обижайтесь за такой совет, но это азы и об этом написаны просто кучи материалов и книг.
P.S. Было бы интересно узнать, для чего по Вашему мнению нужны классы/объекты (или ООП).kstep
16.06.2015 05:49Какие глобальные переменные, если функция чистая? Вот о чём речь.
velvetcat
16.06.2015 21:37-1Глобальные переменные — это пример неявного контракта. Прямая зависомость кода от юзер-функции в другом модуле — это тоже неявный контракт. Так же плохо, как глобальная переменная.
P.S. Чистая функция, пишущая в файл (в вашем исходном примере, с которого все началось)? Вы издеваетесь? :)MacIn
17.06.2015 01:14P.S. Чистая функция, пишущая в файл (в вашем исходном примере, с которого все началось)? Вы издеваетесь? :)
Э, нет, началось не с записи в файл. Там было 3 разных случая, только в одном шла работа с файлом. И пример, приведенный выше — просто ящик: data in — data out.
Прямая зависомость кода от юзер-функции в другом модуле — это тоже неявный контракт.
Так разница-то — вы зависите от интерфейса в другом модуле, или от процедуры-обертки?
MacIn
17.06.2015 01:28+1Хм. Потому что я не хочу перегружать
Вам придется, если надо работать с другим типом данных.
Я хочу прямо в конструкторе видеть все зависимости класса-потребителя
В примере выше потребитель у функции только один — func1. Входные и выходные параметры известны, вот все ваши зависимости. В рамках этого примера покажите, пожалуйста, почему функционал positive надо реализовывать при помощи класса.
я хочу нормальное переиспользование кода за счет SRP
Так не используется positive нигде более. SRP соблюден.
Слушайте, ну поищите уже в интернете, зачем нужны интерфейсы… Пожалуста, не обижайтесь за такой совет, но это азы и об этом написаны просто кучи материалов и книг.
Не в интерфейсах дело. Вы доказываете примерно такую точку зрения: «Существуют ситуации, когда нам требуется сделать X, Y и Z, наиболее просто и полно это реализуется в рамках ООП парадигмы».
Тогда как я говорил «Существуют ситуации, когда нам не треубется делать X, Y и Z, наиболее просто это реализуется в рамках процедурной парадигмы, ООП же излишне». Вы воююте с ветряной мельницей — так, будто я утверждал никчемность ООП, тогда как моя позиция была «создавать класс каждый раз не всегда нужно и полезно».
MacIn
17.06.2015 01:39+1P.S. Было бы интересно узнать, для чего по Вашему мнению нужны классы/объекты (или ООП).
Говорить об объектах можно тогда, когда у нас есть некоторое внутреннее состояние, которое изменяется в течение времени жизни объекта.
в том числе неявным контрактом того куска кода, где они используются. А если у меня нет доступа к исходникам?
Не люблю глобальные переменные, но, справедливости ради, если переменная глобальна в рамках модуля (область видимости — данный модуль), то это терпимо. Потому что если какой-то модуль реализует какой-либо класс, доступ к полю данных класса по сути то же самое (с точки зрения кода, не рантайма, конечно — объектов может быть много, в отличие от г.п., но доступ к этой г.п. можно получить так же только в рамках модуля).

VolCh
22.06.2015 11:14Попробуйте, покажите, зачем здесь нужен абстрактный интерфейс.
Тут многое зависит от платформы. Он может оказаться необходим хотя бы для целей тестирования: пишем отдельные тесты на positive, а в тестах основной функции подставляем стаб. Не на каждой платформе можно легко подставить стаб без использования абстракций типа интерфейса.

deniskreshikhin
14.06.2015 08:11Вся эта идея об «анти-паттернах» в действительности и яйца выеденного не стоит.
На мой взгляд, такие неприятности возникают обычно из-за автократичного управления командой, особенно при наличии всяких номенклатурных «системных архитекторов» или «сеньоров» т.к. они обычно и бывают авторами т.н. «божественных объектов». А потом охрняют свои детища годами.
В нормальной горизонтальной команде эти все вещи просто не могут возникнуть, т.к. это всё требует жутких усилий для развития и поддержки. А ведь никто не хочет тратить свои силы напрасно, верно?
Т.е. нет причин что бы «божественный объект» не разбился на несколько объектов, при очередном рефакторинге. Поэтому для этого нужен этакий «кощей над златом» который будет жёстко навязывать другим использование этого объекта и обеспечивать его непрекосновенность.
В общем всё по Conway's Law
organizations which design systems… are constrained to produce designs which are copies of the communication structures of these organizations
Поэтому, нет смысла учить эти антипаттерны — в нормальной команде лучше сосредоточиться на рефакторинге и практике использования конкретных ООП методологий SOLID/GRASP и архитектур MVC/MVVM и т.д.
Наоборот, в порочной же команде борьба с «божественными объектами» будет всегда упираться в борьбу с их авторами, так что если вы и отобъёте какой-то участок кода, то потратите гораздо больше усилий в сравнении с тем, когда бы просто смирились с наличием быдлокода в проекте.lair
14.06.2015 09:37В нормальной горизонтальной команде эти все вещи просто не могут возникнуть, т.к. это всё требует жутких усилий для развития и поддержки.
Зато это не требует усилий для написания. Поэтому если конкретный автор (вне зависимости от того, в какой он команде), думает о «сейчас», а не о «потом» — будут и god classes, и все остальное.
Т.е. нет причин что бы «божественный объект» не разбился на несколько объектов, при очередном рефакторинге.
Есть: отсутствие рефакторинга.deniskreshikhin
14.06.2015 20:54Зато это не требует усилий для написания. Поэтому если конкретный автор (вне зависимости от того, в какой он команде), думает о «сейчас», а не о «потом» — будут и god classes, и все остальное.
Согласен, но если в команде больше 2х человек, то то что кто-то думает о «сейчас», а кто-то о «потом» вполне нормально. В том и мощь команд, если кто-то поступает неправильно его исправять, главное это движение.
Есть: отсутствие рефакторинга.
Обычно это следствие автократичности руководства которое ставит жёсткие требования типа — у нас нет времени на рефакторинг, или рефакторинг это плохо. Вообще горизонтальная команда не может обойтись без рефакторинга, это по сути основной инструмент взаимодействия разработчиков.lair
14.06.2015 22:00Согласен, но если в команде больше 2х человек, то то что кто-то думает о «сейчас», а кто-то о «потом» вполне нормально.
Ну вот чтобы из первых получались вторые, и нужны подобные статьи.
Вообще горизонтальная команда не может обойтись без рефакторинга, это по сути основной инструмент взаимодействия разработчиков.
Я всегда думал, что основной инструмент взаимодействия разработчиков — это код и речь. А рефакторинг — всего лишь инструмент.deniskreshikhin
14.06.2015 22:55Ну вот чтобы из первых получались вторые, и нужны подобные статьи.
А зачем из одни делать вторых? Люди разные у всех разные стили разработки. Для этого и создают команды — что бы сильные стороны разных людей аккумулировались, а слабые нивелировались. Если зажимать разработчиков по каким-то критериям кроме способности выполнять свои задачи — то команда довольно быстро либо стухнет, либо развалится.
Я всегда думал, что основной инструмент взаимодействия разработчиков — это код и речь. А рефакторинг — всего лишь инструмент.
Проблема в том что и речь, и код это всё субъективные вещи. Никто не знает наперёд как писать идеальный код, нельзя на словах выяснить как решить ту или иную задачу, если это что-то не тривиальное. (А деньги обычно платят за нетривиальные вещи)
Рефакторинг позволяет же привлекать объективные критерии, вроде соответствия SOLID. Не нравится чьё-то решение? Сделай и рефакторинг и представь правильное. Нормальная команда всегда оценит вычищенный и понятный класс.MacIn
14.06.2015 23:10+2Рефакторинг позволяет же привлекать объективные критерии, вроде соответствия SOLID.
Ни на секунду не отвергая и не критикуя SOLID, хочу лишь заметить, что соответствие той или иной концепции может быть объективным критерием только если верность концепции объективна (доказуема).
lair
14.06.2015 23:37А зачем из одни делать вторых?
Потому что код должен быть хорошим, вы не поверите.
Если зажимать разработчиков по каким-то критериям кроме способности выполнять свои задачи
Согласитесь, что важно не только, что задача выполнена, но и как она выполнена, нет?
Проблема в том что и речь, и код это всё субъективные вещи.
Если код субъективен, то и SOLID, на который вы ссылаетесь далее, субъективен. Но на самом деле, не забывайте, что речь — это первичный способ взаимодействия людей. Если вы отказываете ему в эффективности, то вы никуда не придете.
Рефакторинг позволяет же привлекать объективные критерии, вроде соответствия SOLID.
А вы считаете, что SOLID — безусловное объективное благо? И вы можете уверенно и объективно доказать уровень соответствия того или иного решения SOLID?
Сделай и рефакторинг и представь правильное.
В свободное от работы время, я надеюсь?
Нормальная команда всегда оценит вычищенный и понятный класс.
… а если команда не оценила — то она не нормальная. Это все субъективно.
symbix
15.06.2015 00:40+1SOLID — штука многогранная. Есть как формально валидируемые вещи (связность классов, объем классов и методов, цикломатическая сложность), так и чисто инженерные, субъективные понятия.
Однако на практике в хорошей опытной команде даже субъективные вещи все понимают примерно одинаково.

TheDeadOne
14.06.2015 09:43+12На страшилке про преждевременную оптимизацию воспитано поколение кретинов и вредителей.
Во-первых, всегда есть возможность даже примитивные действия написать оптимально и не оптимально. Надо выработать в себе рефлекс в каждой строке кода выбирать более оптимальный вариант. А не наращивать строку в цикле с мыслью «И так пойдёт для начала!»
Во-вторых, производительность системы очень зависима от изначально выбранной архитектуры. Которую поменять после разработки уже не получится, без переписывания всей системы или значительной её части с нуля.
Во-третьих, кэшируйте обращения к базе всегда. Особенно, если используете ORM. Особенно, если есть хоть мизерный шанс, что ваш бэкенд будут DoS'ить. Промах добавит к вызову мизерное время на проверку наличия данных в кеше и их запись, на порядок меньшее, чем время извлечения этих данных из базы. Зато хит сделает вызов на порядок же быстрее.lair
14.06.2015 09:50+10Во-третьих, кэшируйте обращения к базе всегда.
А что после этого делать с консистентностью данных?
(вот как раз кэш — в правильно спроектированной системе — можно добавить почти в любой момент)
symbix
14.06.2015 11:07+2Wrong.
Думать надо не об оптимизация, а об архитектуре. Конечно, ни в коем случае не стоит вместо O(N)-алгоритма пихать О(N^3), но архитектура и следование SOLID важнее микрооптимизаций, а это частая ошибка, часто встречается вместе с «сараем» — от неспособности спроектировать в целом. Скажем, вместо того, чтобы спроектировать такую архитектуру, когда кэширование можно при необходимости подключить где угодно, пишут его вручную. Или вот (пример из мира PHP) Smarty и Twig. Пока первые занимались ужасно важными вопросами типа «что быстрее, strlen($a) > 200 или isset($s[200])», гоняли искусственные бенчмарки сферических коней в вакууме, вторые занимались архитектурой проекта и целостностью его модели, в итоге получив гораздо более целостную библиотеку, которой приятно пользоваться и которую легко расширять и поддериживать, а проблемы с действительно узким местом решили написанным на С php-расширением.
VolCh
14.06.2015 13:09+4В программировании есть две сложных вещи: инвалидация кэша и выбор, как правильно что-нибудь назвать.
Преждевременное создание системы кэширования «на всякий случай» может сильно задержать старт проекта как на этапе постановки и проектирования (не зная реальных узких мест можно очень много времени потратить на обсуждения выборов стратегий инвалидации и их параметров там, где кэширование вовсе не требуется), так и на этапе непосредственно реализации и поддержки.

AllexIn
14.06.2015 10:43+8С наездом на код из 9 вообще не согласен.
1) Это следование правилу номер 6. Студент не стал изобретать велосипед и использовал уже существующее решение.
2) Это инкапсуляция. Просто list использоваться для стэка нельзя, потому что он позволяет работать с любым элементом и не ограничен доступом только к верхнему.
Студент взял уже существующий механизм и ограничил его работу так, как требовалось в исходной задаче.
По-моему все ОК.

andrewnester
14.06.2015 11:30Есть еще проблема #10 — Overcomplcated code
С этой проблемой сталкиваюсь все чаще и чаще, да и сам ей грешу
Особенно часто эта проблема возникает среди программистов с не очень большим опытом, скажем до 3 лет. Это выражается в необоснованном уровне абстракций, желании написать общий код там, где хватило бы конкретного и многое другое
Как упоминалось в Совершенном коде — код и ПО должно быть максимально простым, но на практике это выражается в борьбе KISS и SOLID, DRY и тд :)
WhiteAngel
14.06.2015 11:47По поводу правил 4 и 5 — наглядный пример — Django. Со своими views, forms, ..., которые разростаются до размеров в десятки тысяч строк и потом попробуй найди то, что тебе нужно. До сих пор не могу понять эту особенность Django.
andrewnester
14.06.2015 14:40В Django можно разделять их, к примеру, вьюхи у меня разделены и лежат в папке views
WhiteAngel
14.06.2015 17:58При желании — можно все сделать, но фреймворк изначалано подразумевает плоскую структуру. Ну и если все переносить в папки, то нужно редактировать urlconf или же все включать в __init__.py
Например, в ASP.NET MVC изначально придумали папочки отдельные для этого
fetis26
14.06.2015 12:31+3Мне кажется «божественный объект» более устоявшийся термин, чем «класс бога»
AtomKrieg
14.06.2015 15:09+1По анти-паттернам довольно много статей на хабре, по этой причине предпочел бы увидеть такое оформление статьи:
5 Страх перед добавлением классов
Редкое лучше, чем густое
Тим Питерс, Зен языка Python
Слишком длинно, не читал
Большое число классов – не признак плохого дизайна
Все остальные пунктыЧто это
…
В чём сложность

Albom
15.06.2015 12:28Чем объясняется искажения нормального закона распределения оценок в примере с тестом?
kstep
15.06.2015 13:33Читерством же объясняется, очень много людей, которые едва не проходили тест, читерили, стараясь попасть на хотя бы минимальную оченку. По сути этот пик — «сдвинутые» случаи из левой части.
vintage
15.06.2015 16:28+4Добротой экзаменатора, очевидно :-)
Albom
16.06.2015 15:14Рассматривал и эту версию, и ту, которая указана выше. И честно говоря, сам склонялся именно к этой. Плюсы за Ваш ответ могут косвенно свидетельствовать, что так и было — преподаватель набрасывал пару баллов для того, чтобы испытуемые всё-таки набрали минимум баллов и прошли тест.


scrutari
Хорошая статья и отличный подбор цитат.
Не подскажите, как можно найти эти цитаты на оригинальном языке? Слова Генри Спенсера, например, так просто не гугляться.
HeadFore
Это же перевод, ссылка на оригинальную статью в блоке с голосованием: sahandsaba.com/nine-anti-patterns-every-programmer-should-be-aware-of-with-examples.html
scrutari
Спасибо!
У меня не отображается никакой блок с голосованием, видимо, поэтому не увидел ссылки.
HeadFore
Если это режет блокиратор рекламы, то что-то не так:
scrutari
Теперь увидел. Спасибо!