
Я люблю истории про апокалипсис, про то, как нашу планету порабощают пришельцы, обезьяны или терминаторы, и с детства мечтал приблизить последний день человечества.
Однако, я не умею строить летающие тарелки или синтезировать вирусы, а потому речь пойдет про терминаторов, а точнее о том как этим трудягам помочь отыскать Джона Коннора.
Мой рукодельный терминатор будет несколько упрощён — он не сможет ходить, стрелять, говорить "I'll be back". Единственное на что он будет способен — распознать голос Коннора, ежели он его услышит (ну или, например, Черчилля, если его тоже надо будет найти).
Общая схема
Любая система распознавания работает в двух режимах: в режиме регистрации и режиме идентификации. Другими словами, необходимо иметь пример голоса.
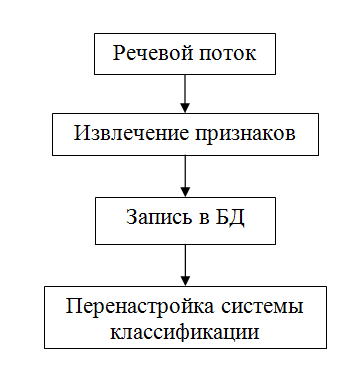
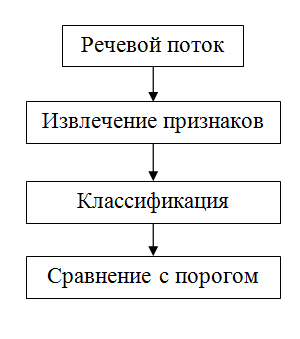
На картинках выше представлена общая схема работы системы в каждом из режимов. Как можно заметить, эти режимы весьма похожи. Обоим для работы необходимо захватить речевой аудио поток и вычислить его основные признаки. Отличие же состоит в том, что же делать с этими признаками. При регистрации их так или иначе необходимо как-то запомнить для использования в будущем. Ведь гораздо эффективнее работать с основными признаками, чем с исходными сырыми данными. При идентификации ничего сохранять нельзя, так как система на данном этапе не имеет обратной связи и не может достоверно знать принадлежность голоса.
Классификаторы
Что представляют собой "признаки"? На самом деле это всего лишь набор чисел, характеризующих оратора — вектор в многомерном пространстве. А задача классификатора заключается в том, чтобы построить функцию отображения этого многомерного пространство в пространство действительных чисел. Другими словами, его задача состоит в получении числа, которое бы характеризовало меру схожести.
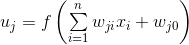 Сеть нелинейных функций
Сеть нелинейных функций Эксперименты
Бинарная классификация
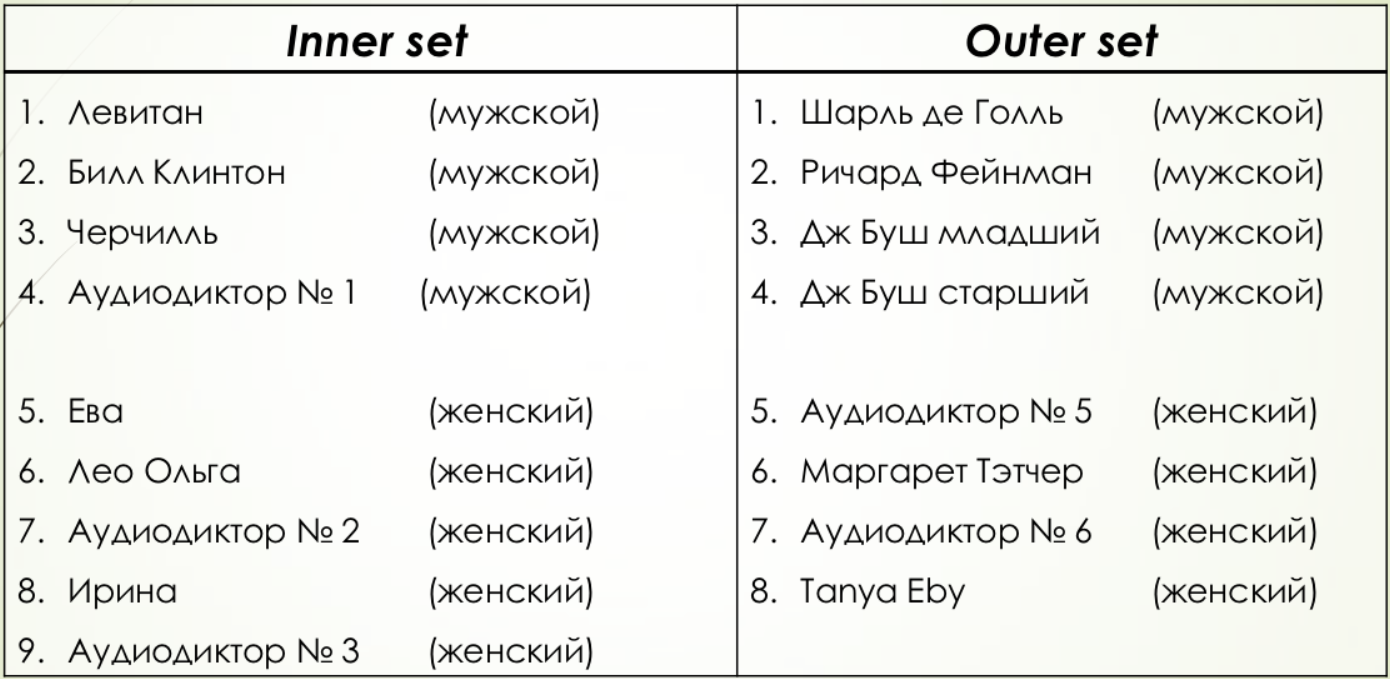
Для бинарной классификации была выбрана задача распознавания пола оратора. Таким образом, существует всего 3 четко определенных возможных результата: мужской голос, женский голос, неизвестно.
Было проведены две серии экспериментов. В первом случае проверка проводилась на тех же данных, на которых и настраивалась система. Во втором случае тестирования проводилось на аудиозаписях людей, данных о которых система не имеет, и проверялось способность метода на обобщение.
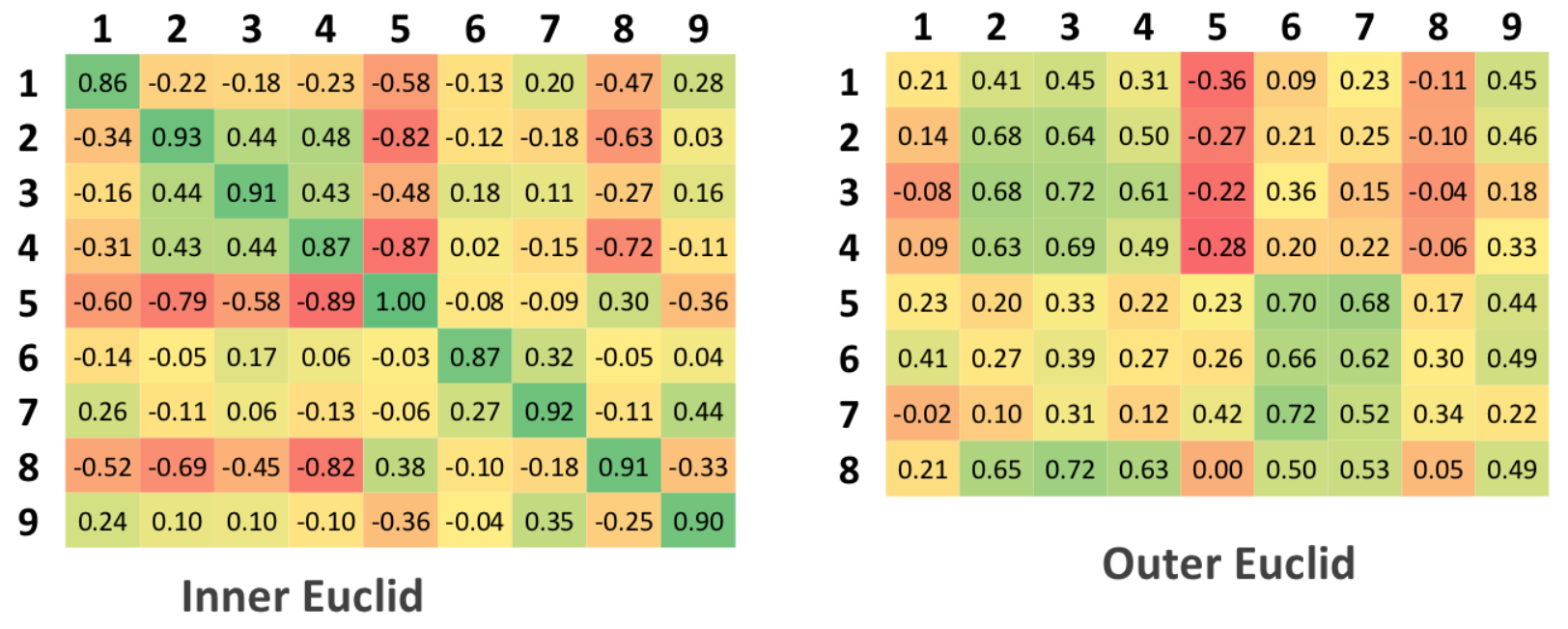
Euclid
В данном случае высчитывалось среднее значение векторов признаков для мужского и женского голосов, после чего находилось евклидово расстояние тестируемого голоса с каждым из средних, на результате которого делался выбор.
Для вычисления порогового значения находилось среднее значение расстояния внутри группы и между группами, после чего происходила нормировка до единицы.

Положительное значение относительно порога – классификация женского голоса. Отрицательное – мужского.
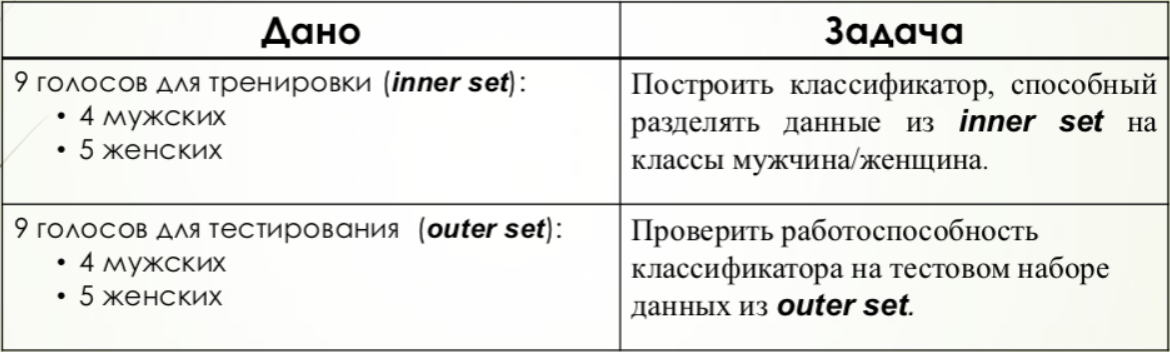
SVM
Для данного метода создавался массив, содержащий бинарное значение, положительное значение которого соответствовало женскому голосу. Данный бинарный массив вместе с матрицей обучающих признаков подавался на вход алгоритма, после чего происходило тестирование.
В данном случае порогом является число 0, так как все положительные результаты должны соответствовать одному классу, отрицательные — другому. Однако для улучшения сравнения с другими методами результаты были сжаты в 2 раза и смещены на 0,5.
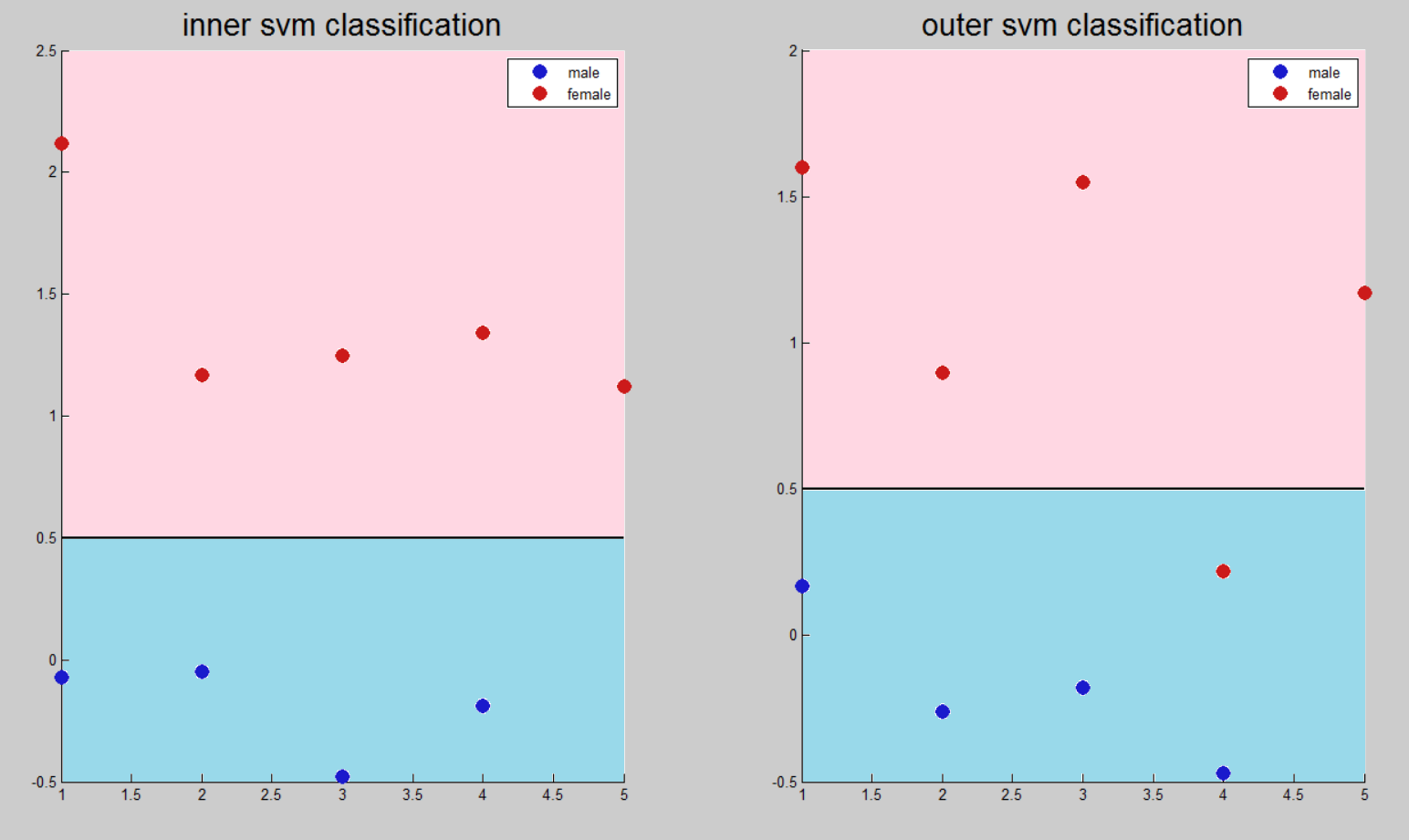
MLP
Задача многослойного персептрона заключается в аппроксимации функций, а не бинарная классификация. В связи с этим не существует разделяющего порога, а есть интервал возле идеального значения, в котором нейронная сеть выдает результат.
При настройке векторам признаков женских голосов ставилось в соответствие значение 1, для мужских – 0.
Задача аутентификации
Для проверки возможности обобщения алгоритма дополнительно проводилось тестирование на множестве, не соответствующем исходному.
В исходной таблице 9 столбцов и 9 строк, так как проверка проводилась по принципу каждый с каждым, а всего 9 образцов людей в исходном множестве. В обобщенной таблице 9 столбцов и 8 строк, так как в тестируемом множестве всего 8 человек, отличающихся от исходного множества
Euclid
Классификация по «обучаемому» множеству. Хотя для данного алгоритма понятие «обучаемое множество» неприменимо, так как самого обучения не происходит. Вычисляются средние значения расстояний внутри класса и между классами и нормализация: первому случаю ставится в соответствие значение 1, в противном случае – 0.
В результате матрица аутентификации в идеальном должна содержать единицы на главной диагонали и нули во всех остальных ячейках.
Для тестируемой матрицы, в идеале, не должно быть значений больше тех, которые стояли на главной диагонали матрицы аутентификации, что соответствует тому, что алгоритм сумел обнаружить несоответствие между исходными и тестируемыми данными
SVM
Так как машины опорных векторов решают задача бинарной, а не многоклассовой классификации, то для задачи аутентификации было составлено 9 различных SVM, каждая из которых настроена на конкретного человека, а остальные рассматриваются, как негативный
пример классификации.
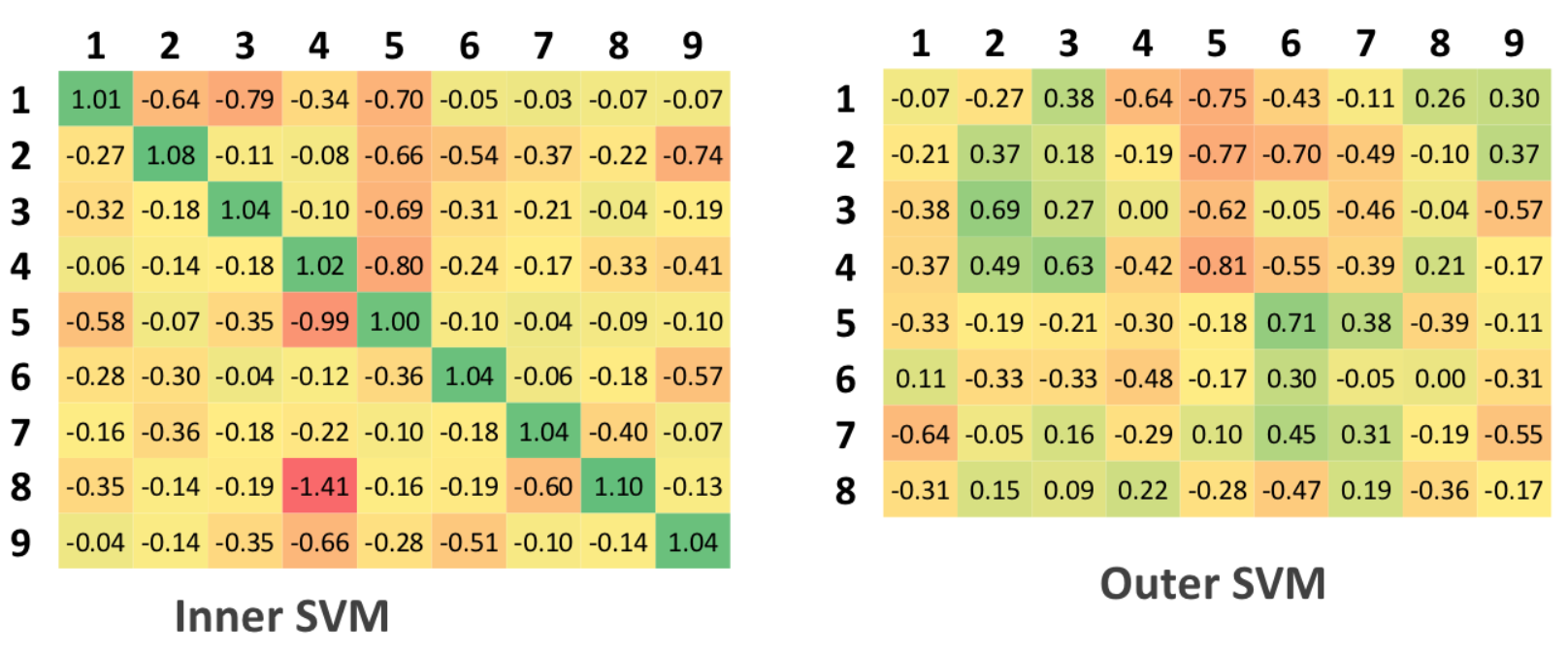
Интерпретация данных таблиц для SVM аналогична таблицам для алгоритма Евклида, т.е. 0.5 является пороговым значением.
MLP
Для использования многослойного персептрона на этапе настройки подавались 9-мерные вектора в качестве выходных значений системы. В этом случае для каждого входного вектора признаков на выходе MLP аппроксимировал значения 9 функций, отвечающих за задачу классификации.
Как и для случая бинарной классификации, не существует порогового значения, который бы однозначно классифицировал класс входного вектора, а есть некоторый интервал около идеальных значений. Любой выход из интервала свидетельствует о неспособности сети с данным уровнем доверительного интервала выдать однозначного ответа.
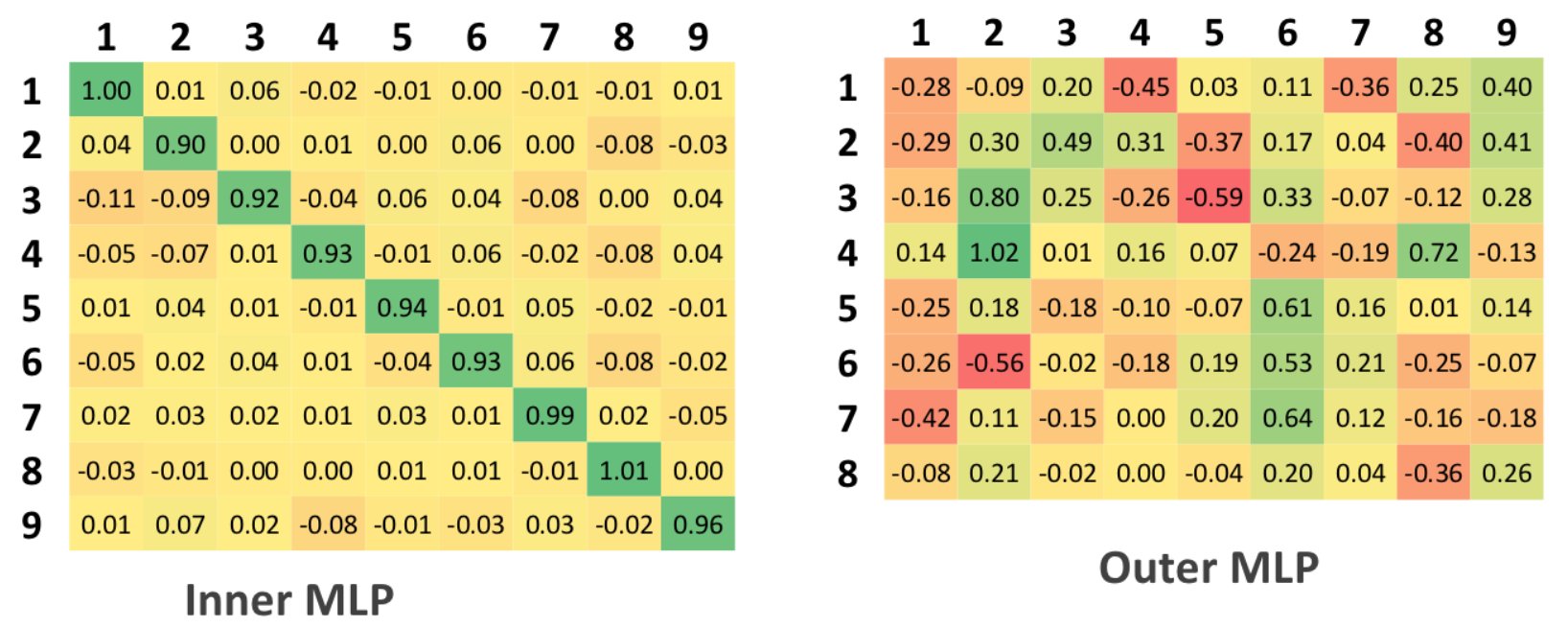
Дополнительно необходимо заметить, что доверительный интервал не может быть больше 0.5, так как именно такое значение равняется половинному значению между идеальными значениями классификации.
Сравнение методов классификации
Наиболее заметными результатами, полученными в ходе экспериментов являются низкий уровень точности методом Евклида и очень высокие вычислительные затраты на настройку многослойного персептрона: длительность настройки MLP превышала длительность настройки SVM в несколько сотен раз на одном и том же наборе данных.
Результаты бинарной классификации говорят о том, что все три метода качественно справились на всем тестовом множестве, кроме голоса Tanya Eby, который был ошибочно классифицирован всеми методами. Данный результат можно объяснить грубостью голоса данной женщины.
Решение задачи многоклассовой классификации для нейросетевых систем, как оказалось, разительно отличается для случаев «внутренней» и «внешней» аутентификации. Если в первом случае с задачей справились оба нейросетевых метода, то во втором случае оба допустили ряд ошибочных классификаций.
В качестве двух основных характеристик любой системы идентификации можно принять ошибки первого и второго рода. В теории радиолокации их обычно называют «ложная тревога» или «пропуск цели», а в системах идентификации наиболее устоявшиеся понятия — FAR (False Acceptance Rate) и FRR(False Rejection Rate). Первое число характеризует вероятность ложного совпадения биометрических характеристик двух людей. Второе – вероятность отказа доступа человеку, имеющего допуск. Система тем лучше, чем меньше значение FRR при одинаковых значениях FAR.
Ниже представлены FAR/FRR графики созданных мной систем для задачи аутентификации.
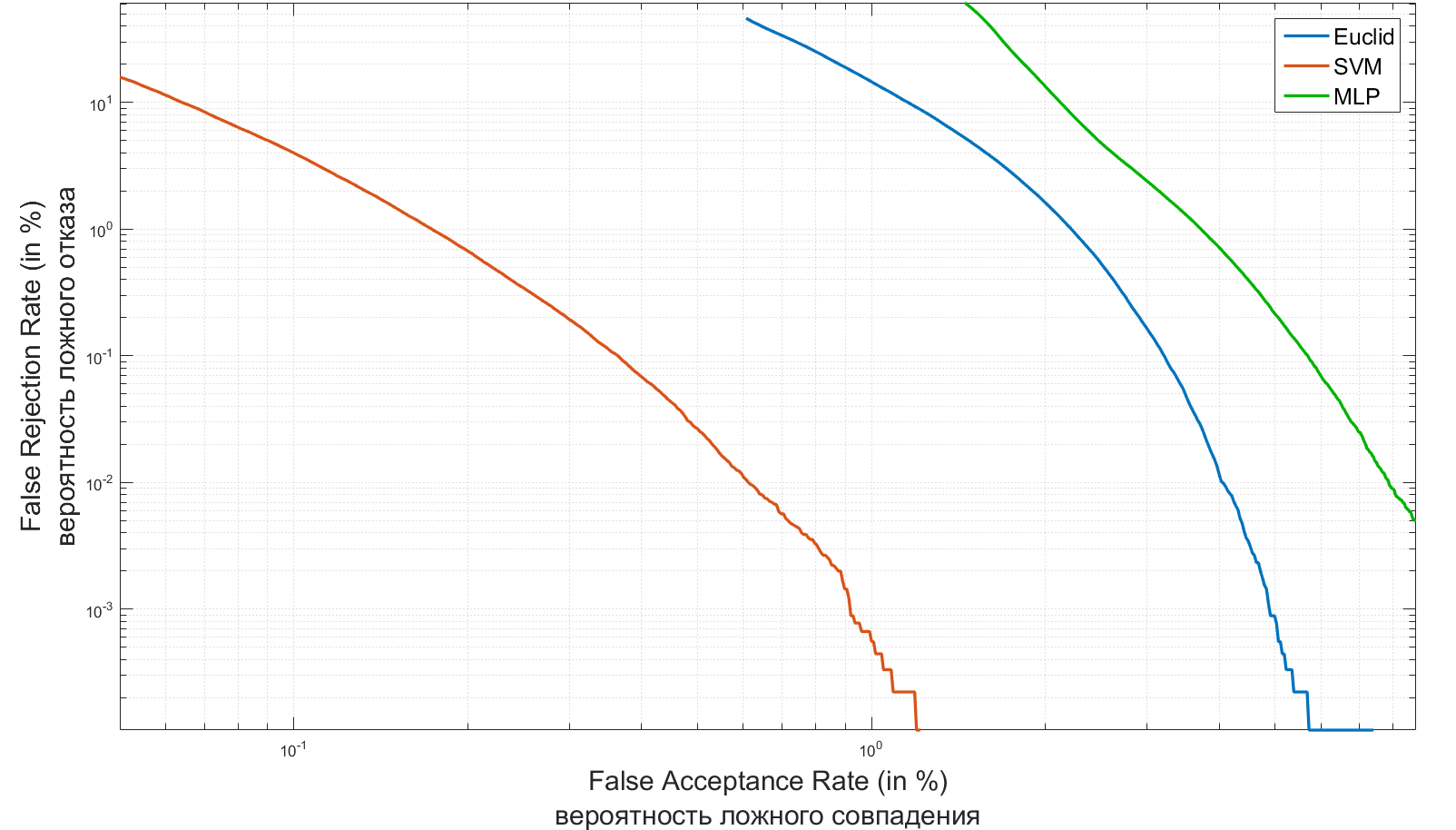
Хороший обзор биометрических систем идентификации и оценка значений их FAR/FRR можно найти тут.
Euclid:
- Наиболее быстрый и простой алгоритм
- Ухудшение характеристик при масштабировании
- Низкое качество классификации
SVM:
- Наилучшая обобщающая способность
- Требует малые вычислительные ресурсы на этапе обучения
- Необходимость создавать N различных SVM
MLP:
- Наименьшая ошибка обучения
- Отсутствие понятия классификации
- Требователен к вычислительным ресурсам на этапе обучения
- Необходимость переобучения всей системы при регистрации нового диктора
Звукоуловители
Вся аудиоинформацию система получает в виде массива аудиопотока и значения частоты квантования.
Массив формируется путем считывания из файлов mp3, flac, wav или любого другого формата, вырезается нужный фрагмент, усредняется в одну дорожку и вычитается постоянная составляющая:
filename = 'sample/Irina.mp3';
[x, fs] = audioread(filename);
% x - массив аудио-потока
% fs - частота дискретизации
%% установка параметров
sec_start = 0.5;
sec_stop = 10;
frame_start = max(sec_start*fs, 1);
frame_stop = min(length(x), sec_stop*fs);
sec_start = (frame_start / fs) - fs;
sec_stop = frame_stop / fs;
%% обрезка
x = x(frame_start : frame_stop, :);
x = mean(x, 2);
x = x - mean(x);Извлечение признаков
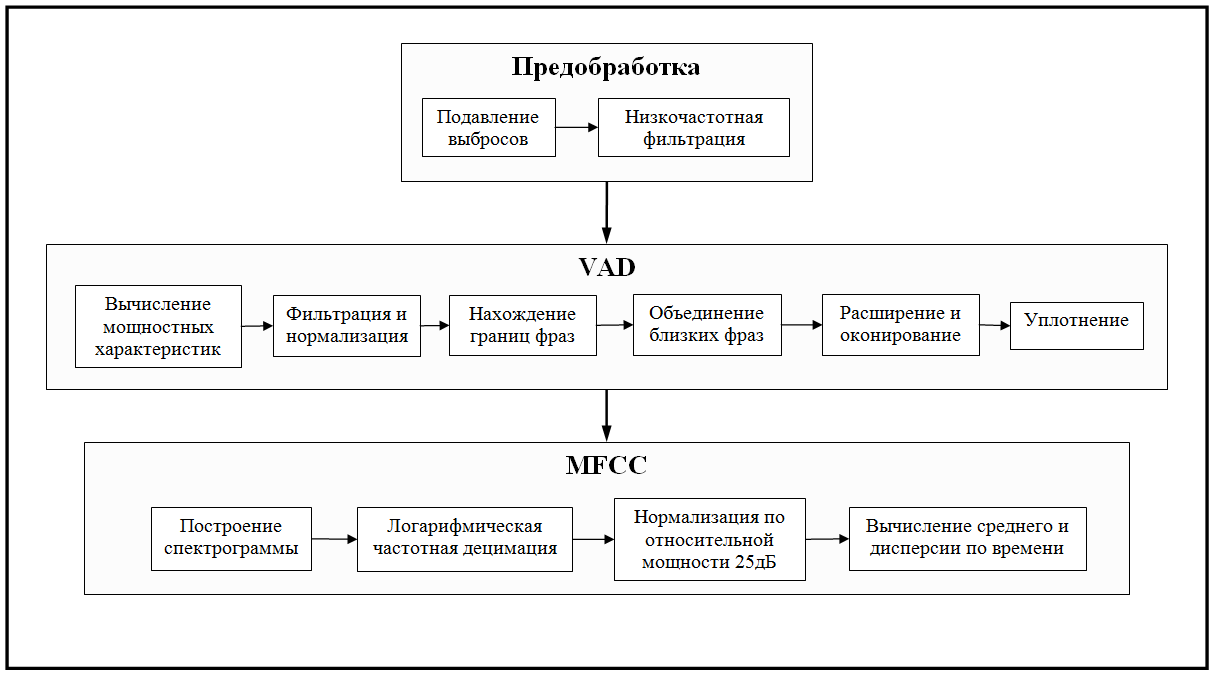
Предобработка
Наш терминатор хоть и бюджетный, но даже и ему не обойтись без цифровой обработки. Задачей предварительной фильтрации была в избавлении от шумовых характеристик аудиозаписей, наиболее влияющих на алгоритм дальнейшей обработки. Такими характеристиками были выбраны «выбросы» и «низкочастотный» шум.
Выбросы
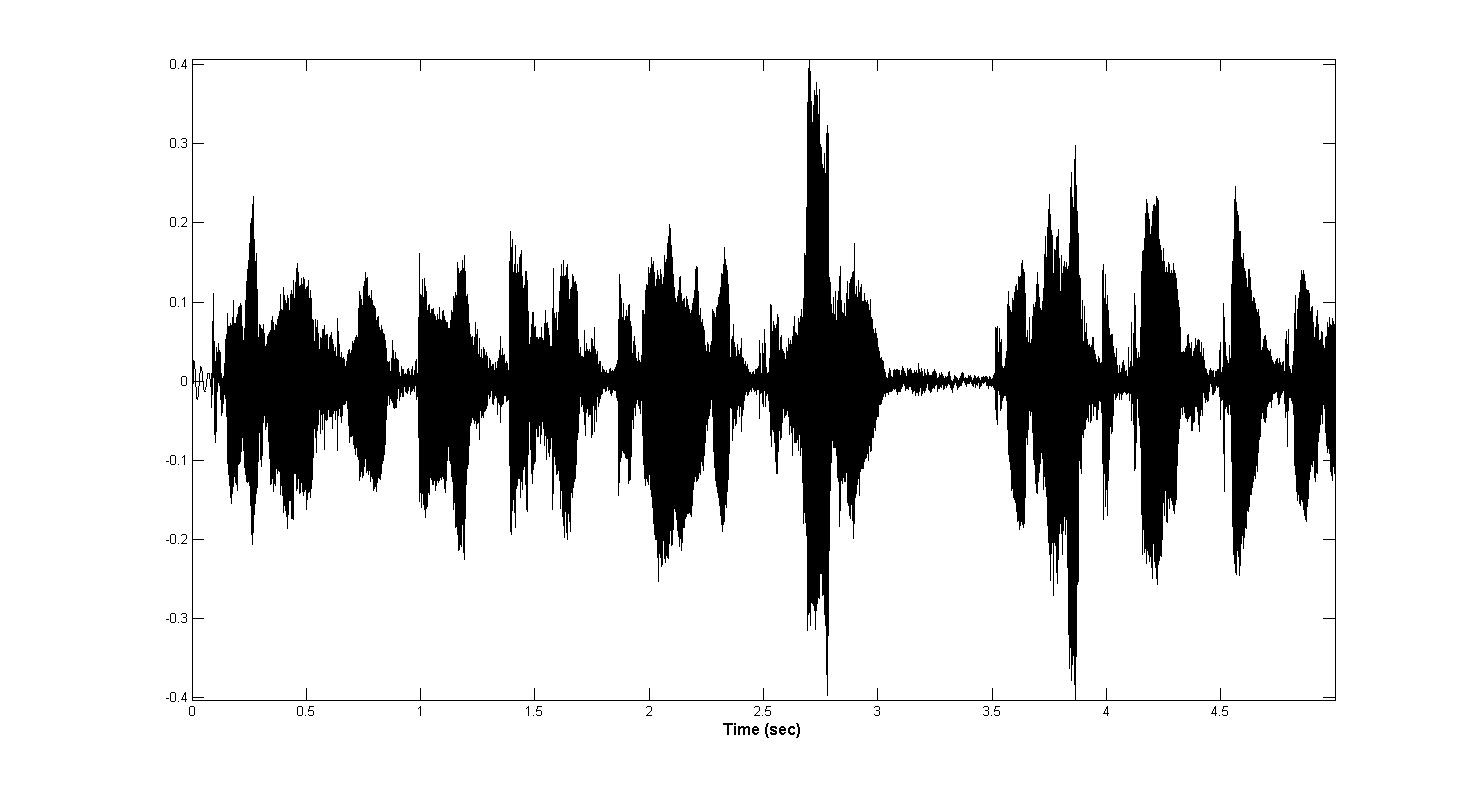
Микрофоны, с помощью которых я записывал голоса оказались весьма различны по качеству. Некачественная аппаратура записи звука приводила к кратковременным мощностным выбросам. Данные шумовые явления могут предоставить большие трудности для алгоритма нахождения активности голоса. Пример подобных «выбросов» представлен на рисунке ниже.
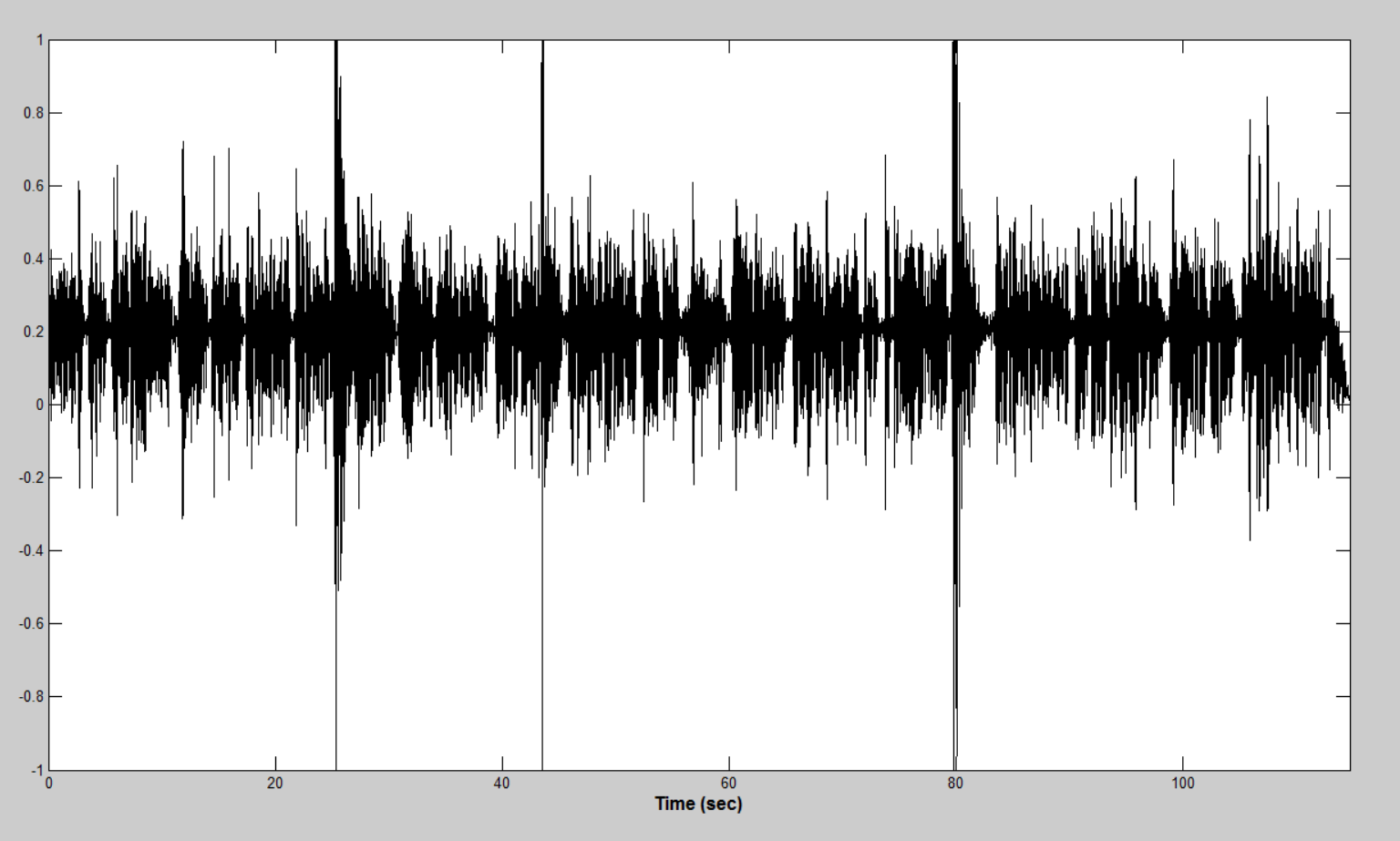
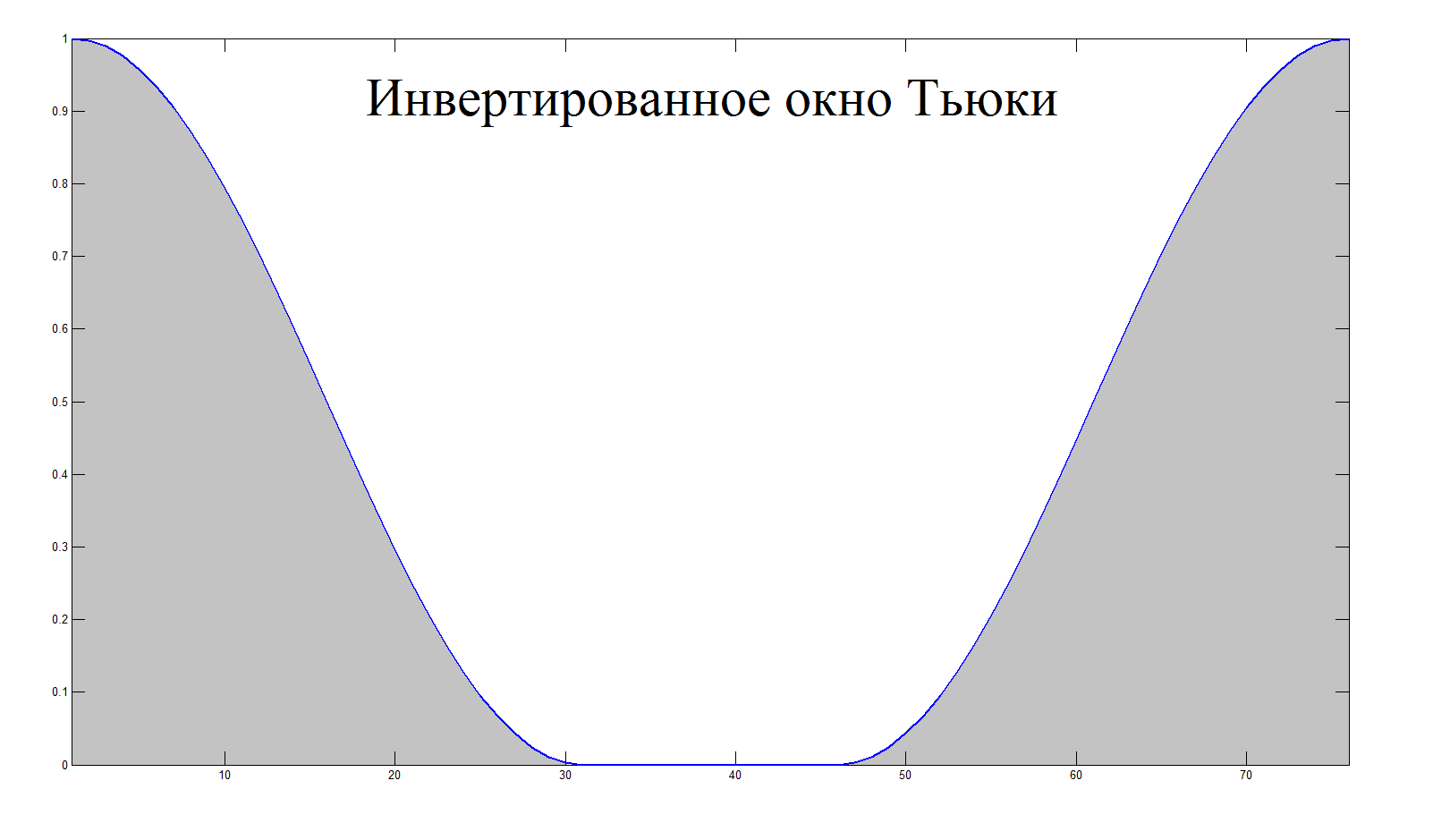
Идея алгоритма заключается в последовательном вычислении энергии коротких участков, сравнении со средним значением энергии и подавлении с помощью перемножении с инвертированным окном Тьюки в случае превышения энергии участка среднего значения на
некоторый порог. Для более гладкой фильтрации и точного детектирования промежуточные участки аудиофайла выбирались с перекрытием.
function [ y ] = outlier_suppression( x, fs )
buffer_duration = 0.1; % in seconds
accumulation_time = 3; % in seconds
overlap = 50; % in percent
outlier_threshold = 7;
buffer_size = round( ((1 + 2*(overlap / 100))*buffer_duration) * fs);
sample_size = round(buffer_duration * fs);
y = x;
cumm_power = 0;
amount_iteration = floor(length(y) / sample_size);
for iter = 1 : amount_iteration
start_index = (iter - 1) * sample_size;
start_index = max(round(start_index - (overlap / 100)*sample_size), 1);
end_index = min(start_index + buffer_size, length(x));
buffer = y(start_index : end_index);
power = norm(buffer);
if ((accumulation_time/buffer_duration < iter)
&& ((outlier_threshold*cumm_power/iter) < power))
buffer = buffer .* (1 - tukeywin(end_index - start_index + 1, 0.8));
y(start_index : end_index) = buffer;
cumm_power = cumm_power + (cumm_power/iter);
continue
end
cumm_power = cumm_power + power;
end
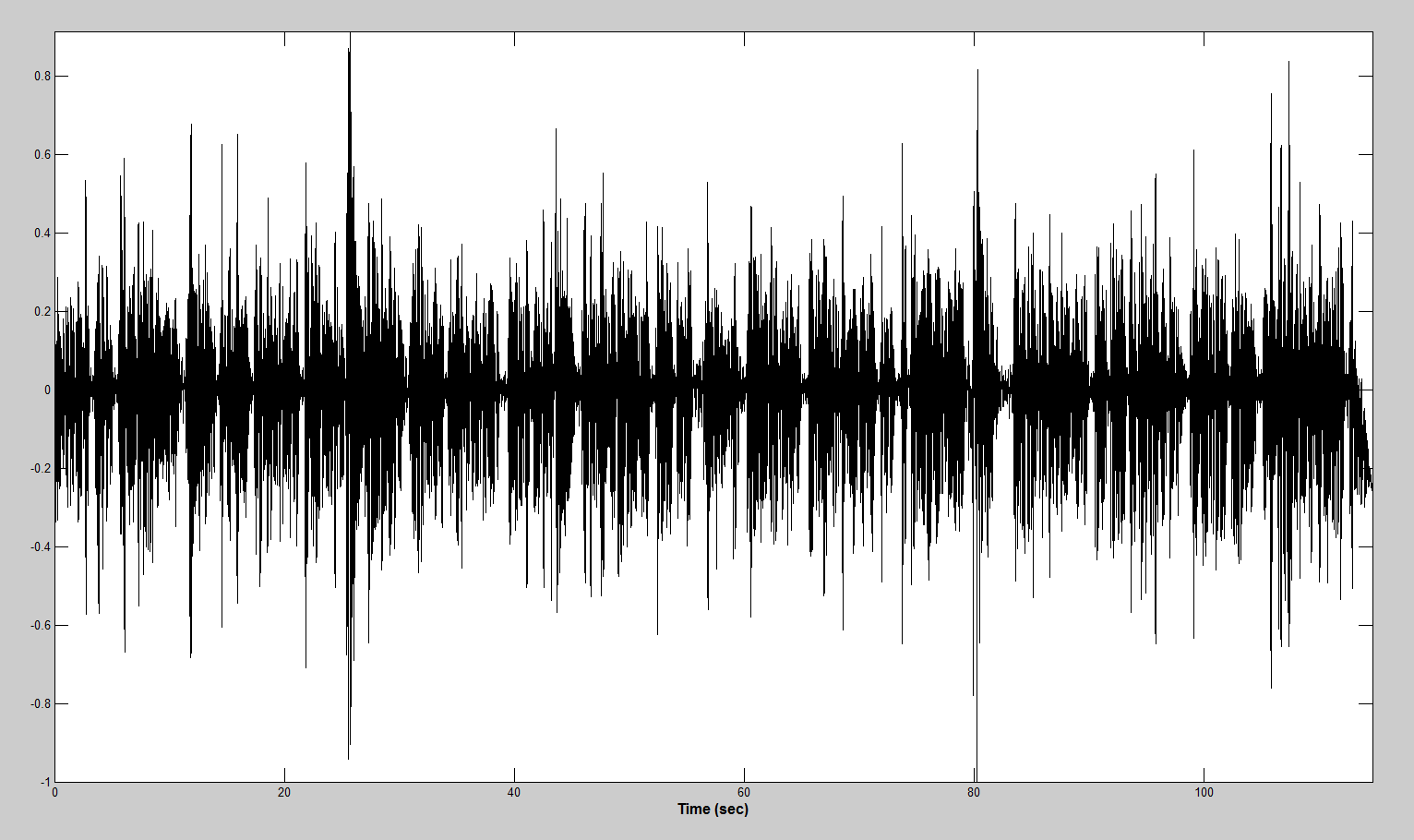
endПосле обработки представленный выше сэмпл выглядит вот так:
Низкочастотный шум
Низкочастотные гармоники опасны тем, что создают постоянную энергетическую составляющую на коротком промежутке времени, которая может ошибочна быть признана как активность голоса, если не предпринять необходимые меры.
Для избавления от подобных составляющих был выбран эллиптический ФВЧ 3-го порядка с частотой среза, равной 30Гц, и обеспечивающий подавление 20 дБ в полосе задержания. Выбор эллиптического фильтра был сделан из-за того, что эллиптические фильтры обеспечивают более крутой (по сравнению с фильтрами Баттерворта и Чебышева) спад АЧХ в переходной зоне между полосами пропускания и задерживания. Платой за это является наличие равномерных пульсаций АЧХ как в полосе пропускания, так и в полосе задерживания.
Ниже представлены сигнал до и после фильтрации соответственно:

Voice Activity Detection
Построенная мной система выделения временных участков активности голоса основывается исключительно на мощностных характеристиках сигнала и шума. В некотором роде это стало компромиссом между простым вычислением нормы и сложной обработкой спектровременной матрицы. Бонусом шло резкое уменьшение размерности массивов (в несколько тысяч раз), что оказалось весьма кстати, учитывая интенсивность обращения к данным.
Вычисление мощностных характеристик
В качестве мощностных характеристик сигнала и шума использовались следующие формулы:

function [ signal_power_array, noise_power_array ] = compute_power_arrays(x,fs)
buffer_duration = 10 * 10^(-3); % in seconds
overlap = 50; % in percent
sample_size = round(buffer_duration * fs);
buffer_size = round( ((1 + 2*(overlap / 100))*buffer_duration) * fs);
signal_power_array = zeros(floor(length(x) / sample_size), 1);
noise_power_array = zeros(length(signal_power_array), 1);
for iter = 1 : length(signal_power_array)
start_index = (iter - 1) * sample_size;
start_index = max(round(start_index - (overlap / 100)*sample_size), 1);
end_index = min(start_index + buffer_size, length(x));
buffer = x(start_index : end_index);
signal_power_array(iter) = norm(buffer);
noise_power_array(iter) = norm(abs(diff(sign(buffer))));
end
endПолученные массивы мощностей фильтруются и нормируются от 0 до 1
%% filtering
gw = gausswin(8);
signal_power_array = filter(gw, 1, signal_power_array);
signal_power_array = signal_power_array - base_value(signal_power_array);
signal_power_array = max(signal_power_array, 0);
signal_power_array = signal_power_array ./ max(signal_power_array);
gw = gausswin(16);
noise_power_array = filter(gw, 1, noise_power_array);
noise_power_array = noise_power_array - base_value(noise_power_array);
noise_power_array = max(noise_power_array, 0);
noise_power_array = -noise_power_array + max(noise_power_array);
noise_power_array = noise_power_array ./ max(noise_power_array);
noise_power_array = (1 - noise_power_array);Так как значения мощности сигнала может быть смещено из-за постоянного значения энергии аддитивного шума, то необходимо вычислить и вычесть постоянную составляющую. Это производиться в функции base_value().
function [ value ] = base_value( array )
[nelem, centres] = hist(array, 100);
[~, index_max] = max(nelem);
value = centres(index_max);
endНахождение границ фраз
Для нахождения границ фраз массив мощностей сигнала проходится в обоих направлениях. В каждом случае ищется спад энергии, а так как массив проходится в двух направлениях, то находятся как начало, так и конец фраз.
%% find the end of phrases
phrase_detection = zeros(size(signal_power_array));
max_magn = 0;
for iter = 1 : length(signal_power_array)
max_magn = max(max_magn, signal_power_array(iter));
if (signal_power_array(iter) < 2*threshold*max_magn)
phrase_detection(iter) = 1;
max_magn = 0;
end
end
%% find the start of phrases
max_magn = 0;
for iter = length(signal_power_array) : -1 : 1
max_magn = max(max_magn, signal_power_array(iter));
if (signal_power_array(iter) < 2*threshold*max_magn)
phrase_detection(iter) = 1;
max_magn = 0;
end
end
%% post processing of phrase detection array
phrase_detection = not(phrase_detection);
phrase_detection(1) = 0;
phrase_detection(end) = 0;
edge_phrase = diff(phrase_detection);
%% create phrase array
phrase_counter = 0;
for iter = 1 : length(edge_phrase)
if (0 < edge_phrase(iter))
phrase_counter = phrase_counter + 1;
phrase(phrase_counter).start = iter;
elseif (edge_phrase(iter) < 0)
start = phrase(phrase_counter).start;
phrase(phrase_counter).end = iter;
phrase(phrase_counter).power = mean(signal_power_array(start : iter));
phrase(phrase_counter).noise_power = mean(noise_power_array(start : iter));
end
endОбъединение фраз
Зачастую длительность вычисленных фраз оказывается менее 100мс. В связи с этим, разработан алгоритм, объединяющий короткие близко расположенные фразы в одну. Для этого сравниваются энергии соседних участков, и если они отличаются менее чем на установленный порог, то данные участки объединяются. При этом происходил перерасчет энергии объединенных фраз соразмерно длительности и мощности каждого.
%% union small phrases
length_threshold = 16;
iter = 1;
while (iter < length(phrase))
phrase_length = phrase(iter).end - phrase(iter).start;
if ((phrase_length<length_threshold) && (iter<length(phrase)) && (iter~=1))
lookup_power = phrase(iter+1).power;
behind_power = phrase(iter-1).power;
if (abs(lookup_power-phrase(iter).power) < abs(behind_power-phrase(iter).power))
next_iter = iter + 1;
else
next_iter = iter - 1;
end
power_ratio = phrase(next_iter).power / phrase(iter).power;
power_ratio = min(power_ratio, 1 / power_ratio);
if ( power_ratio < threshold )
iter = iter + 1;
continue;
end
min_index = min(phrase(iter).start, phrase(next_iter).start);
max_index = max(phrase(iter).end, phrase(next_iter).end);
phrase_next_length = (phrase(next_iter).end - phrase(next_iter).start);
phrase(next_iter).power = ...
((phrase(iter).power*phrase_length)+(phrase(next_iter).power*phrase_next_length)) / (phrase_length + phrase_next_length);
phrase(next_iter).noise_power = ...
((phrase(iter).noise_power*phrase_length)+phrase(next_iter).noise_power*phrase_next_length)) / (phrase_length + phrase_next_length);
phrase_detection((min_index+1) : (max_index-1)) = phrase_detection(phrase(next_iter).start+1);
phrase(next_iter).start = min_index;
phrase(next_iter).end = max_index;
phrase(iter) = [];
else
iter = iter + 1;
end
end%% union neibours phrases
threshold = 0.1;
iter = 1;
while (iter <= length(phrase))
if (phrase_power_threshold < phrase(iter).power)
phrase(iter).voice = 1;
elseif ((phrase_power_threshold < 5*phrase(iter).power) ...
&& (phrase(iter).noise_power < 0.5*phrase(iter).power))
phrase(iter).voice = 1;
else
phrase(iter).voice = 0;
end
if (iter ~= 1)
if (phrase(iter-1).voice == phrase(iter).voice)
phrase(iter-1).end = phrase(iter).end;
phrase_detection(phrase(iter-1).start+1 : phrase(iter-1).end-1) = phrase(iter-1).voice;
phrase(iter) = [];
continue;
end
end
iter = iter + 1;
endДля плавного перехода между периодами активности и затишья массивы фраз расширяются на 50мс в каждую сторону (если это возможно). Перед этим, для сопоставления индексов временным интервалам, происходит перерасчет индексов мощностных массивов в индексы аудиопотока.
%% compute real sample indexes
for iter = 1 : length(phrase)
start_index = (phrase(iter).start - 1) * sample_size + 1;
end_index = phrase(iter).end * sample_size;
phrase(iter).start = start_index;
phrase(iter).end = end_index;
end
phrase(1).start = 1;
phrase(end).end = length(x);
%% spread voice in time
spread_voice = round(50 * 10^(-3) * fs);
iter = 2;
while (iter < length(phrase))
if (phrase(iter).voice)
phrase(iter).start = phrase(iter).start - spread_voice;
phrase(iter).end = phrase(iter).end + spread_voice;
else
phrase(iter).start = phrase(iter - 1).end + 1;
phrase(iter).end = phrase(iter + 1).start - 1 - spread_voice;
end
phrase(iter).start = max(phrase(iter).start, 1);
phrase(iter).end = min(phrase(iter).end, length(x));
if (phrase(iter).start < phrase(iter).end)
iter = iter + 1;
else
phrase(iter-1).end = phrase(iter).end;
phrase(iter) = [];
end
end
phrase(1).start = 1;
phrase(1).end = phrase(2).start - 1;
phrase(end).start = phrase(end - 1).end + 1;
phrase(end).end = length(x);После того, как найдены все участки активности голоса и посчитаны начальные и конечный индексы каждой из фраз, создаётся массив, который будет содержать полный аудиосигнал участков активности. Данные участки умножаются на оконную функцию Кайзера для уменьшения растекания спектра. Окно Кайзера выбрано из-за малых значений перегиба.
%% create output sample array
y = zeros(size(x));
phrase_space = zeros(size(x));
betta = 3;
for iter = 1 : length(phrase)
phrase_length = phrase(iter).start : phrase(iter).end;
if (phrase(iter).voice)
y(phrase_length) = x(phrase_length) .* kaiser(length(phrase_length), betta);
phrase_space(phrase_length) = -1;
else
y(phrase_length) = zeros(size(phrase_length));
end
if (0 < phrase(iter).end)
phrase_space(phrase(iter).end) = 0;
end
end
%% delete zero data
for iter = length(phrase) : -1 : 1
phrase_length = phrase(iter).start : phrase(iter).end;
if (~phrase(iter).voice)
y(phrase_length) = [];
end
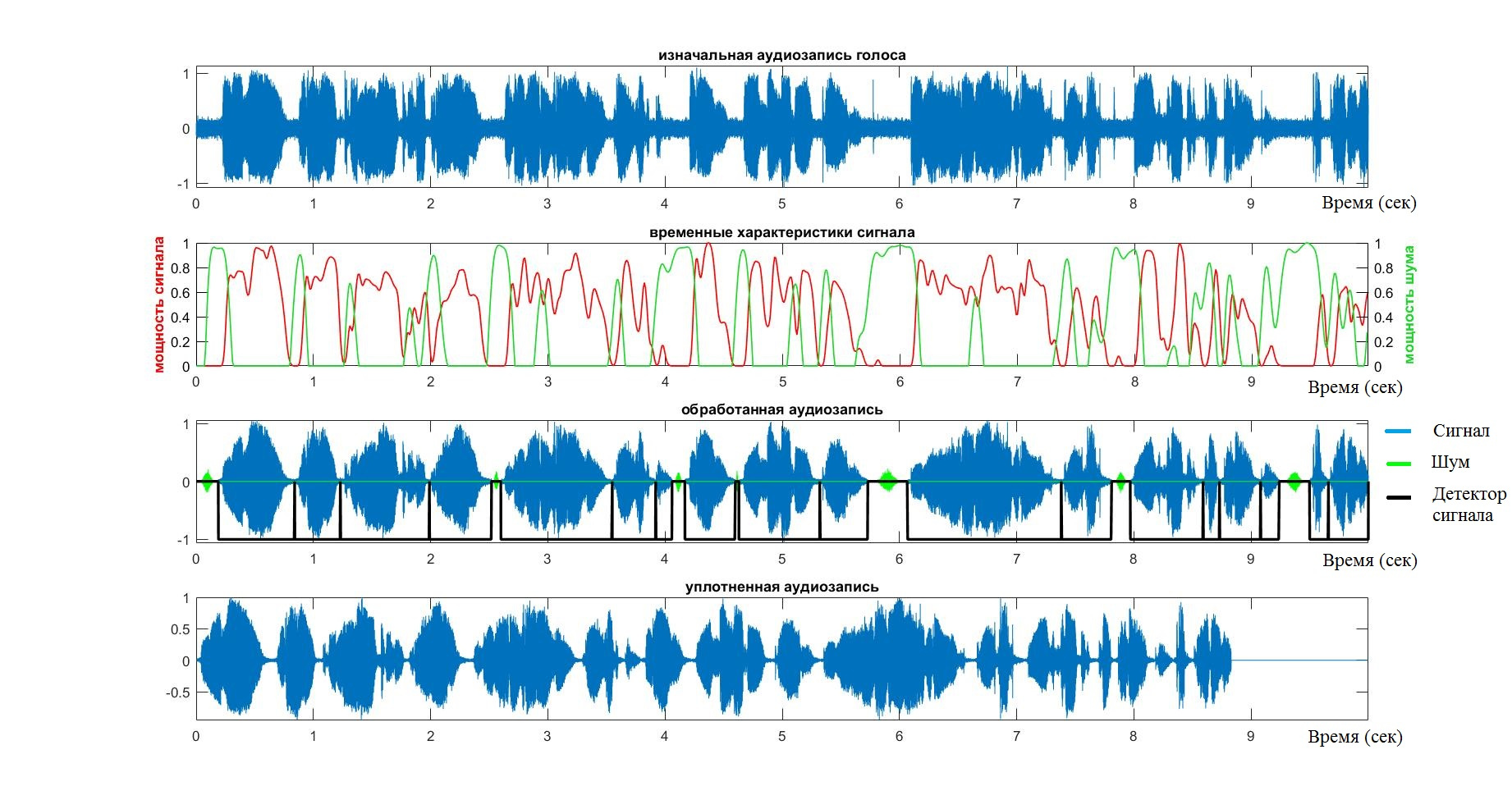
endНа этом работа системы VAD можно считать оконченной. На выходе имеем массив, содержащий исключительно голосовой сигнал. Для того, чтобы ещё раз пробежаться по стадиям работы алгоритма, а также, чтобы удостовериться в адекватности его работы, стоит обратить внимание на нижеследующий график.
- Голубым цветом отмечен аудиопоток.
- Красным цветом — мощность речевого сигнала
- Зеленым цветом — всё, что связано с шумом
Тестирование
Для того, чтобы проверить валидность, точность и устойчивость работы системы VAD, система была протестирована примерно на 20 аудиозаписей различных людей. Во всех случаях тестирование происходило на глаз и "ухо" — смотрел график и слушал уплотненный сигнал. Ошибкой считались пропуск слов или, наоборот, принятие периодов затишья.
После того, как я убедился, что алгоритм справляется со своей задачей для простых случаев, я начал добавлять различный шум в фон.
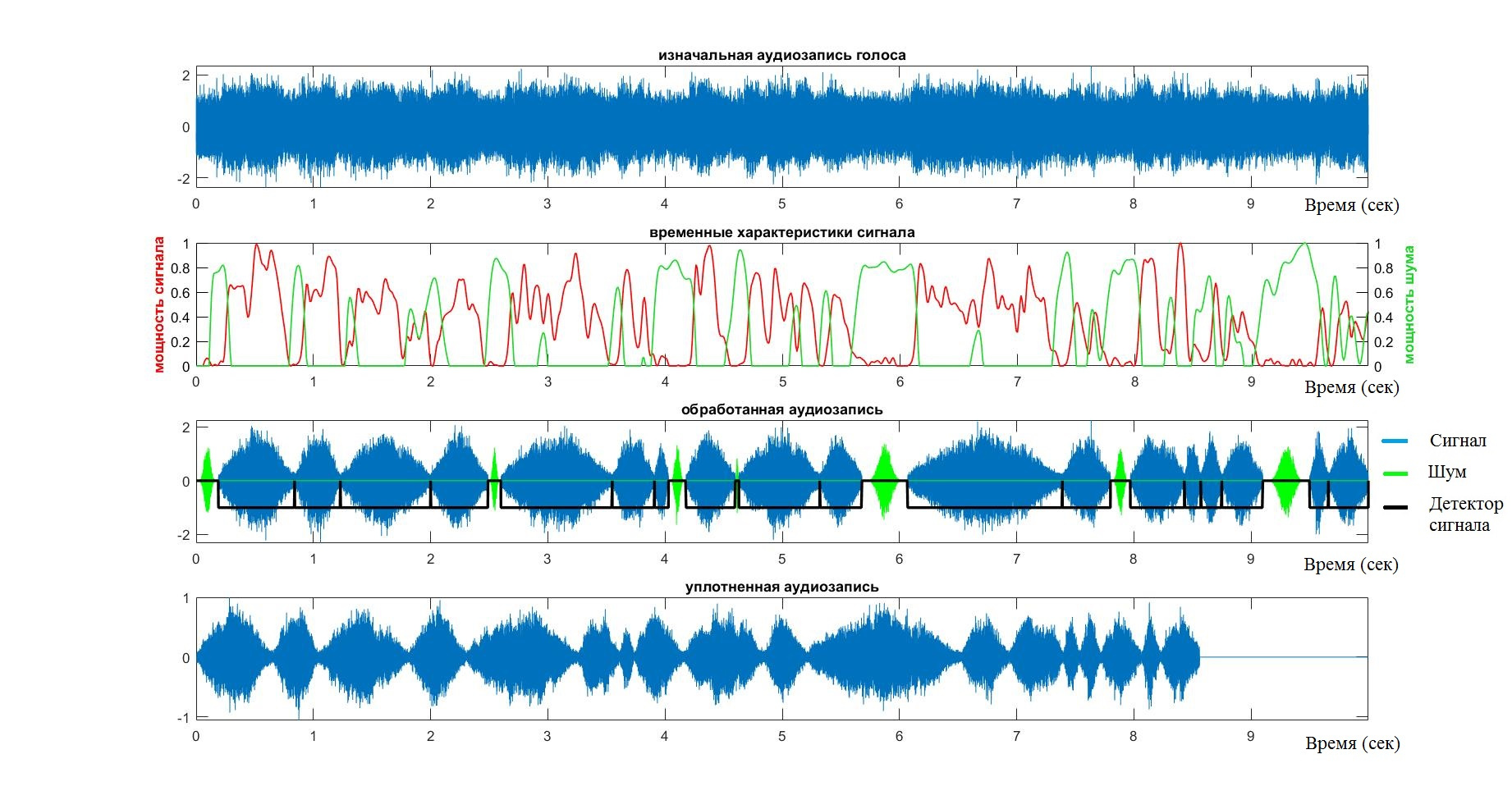
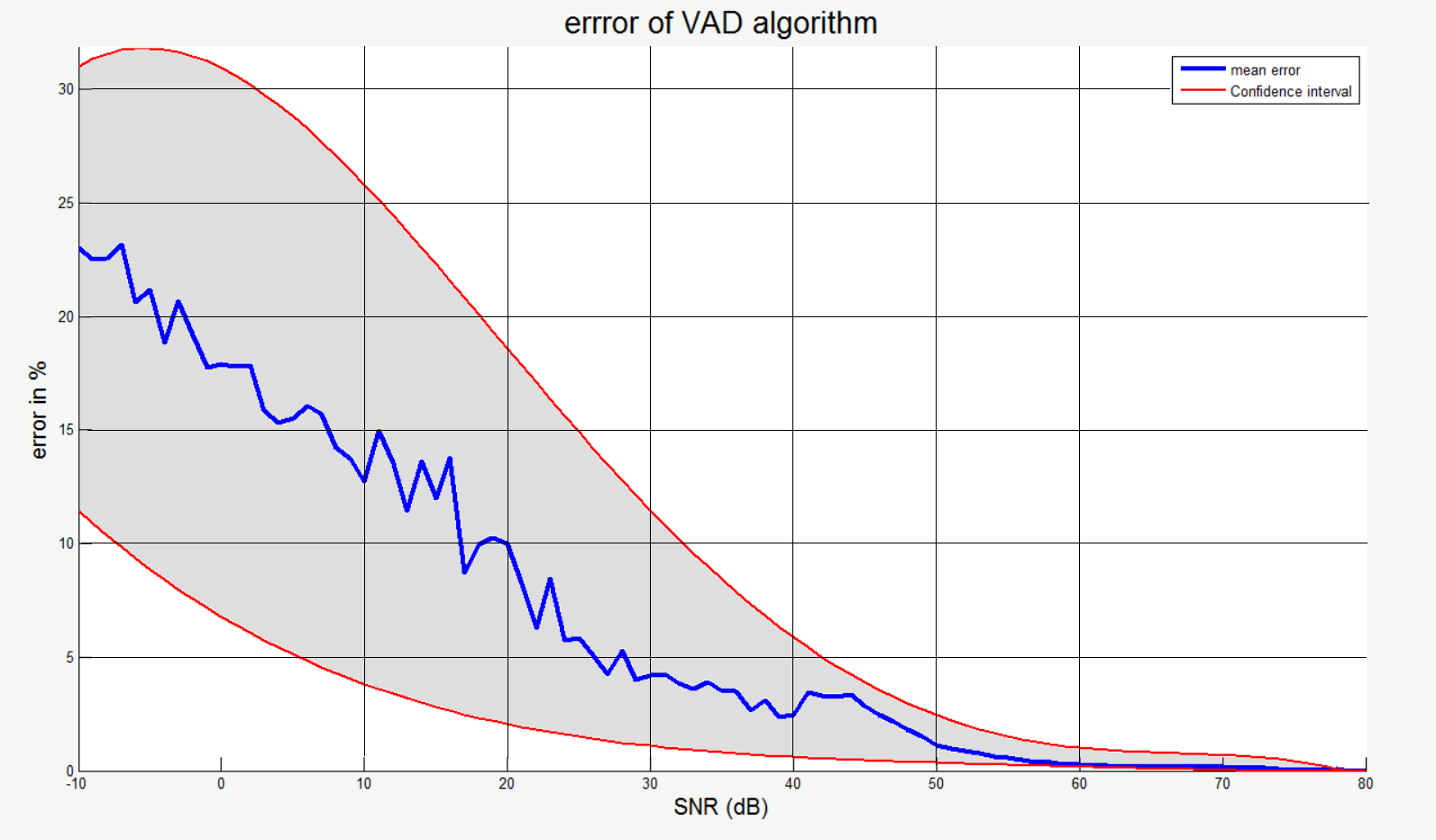
В этом случае, будучи уверенным, что в бесшумном случае алгоритм работает, я брал его за эталон и находил хеммингово расстояние между индексами эталонов и тестовым множеством. Таким образом, получив большие эталонные и тестовые множества, я составил статистический график ошибки алгоритма (по Хеммингу) в зависимости от SNR. Здесь синей линией отмечен среднее значение, а красными — границы доверительного интервала.
MFCC
Если быть честным, то никакого MFCC здесь нет. Этот термин я использую так как цели и средства MFCC совпадают с моими. В дополнение к тому, этот термин устоялся и его сокращение занимает всего 4 буквы. Отличие от основного метода MFCC в том, что в данном случае не использовалось обратное преобразование во временную область по соображениям вычислительной эффективности, а также вместо мел-свертки используется логарифмическая децимация.
Про MFCC можно прочитать здесь, здесь, здесь или здесь.
Логарифмическая децимация спектра
Для задачи логарифмической децимации создавался массив из меньшего количество точек, первый и последний элемент которого равен 1 и максимальной частоте, однако все внутренние точки являются результатом экспоненциальной функции. Таким образом, выбирая точки для выборки из созданного массива и усредняя значения исходной функции между точками выделялся массив значительно меньшей размерности.
Идея состоит в том, чтобы создать массив индексов, значение которого логарифмически распределено по всему пространству индексов исходного спектра.
function [ index_space ] = log_index_space( amount_point, input_length, decimation_speed )
index_space = exp(((0:(amount_point-1))./(amount_point-1)).*decimation_speed);
index_space = index_space - index_space(1);
index_space = index_space ./ index_space(end);
index_space = round((input_length - 1) .* index_space + 1);
endПосле составления массива индексов, единственное, что остается, это выбрать нужные точки исходного спектра и аккумулировать среднюю энергию между точками.
function [ y ] = decimation_spectrum( freq_signal, index_space )
y = zeros(size(index_space));
min_value = min(freq_signal);
freq_local = freq_signal - min_value;
for iter = 2 : (length(index_space)-1)
index_frame = index_space(iter - 1) : index_space(iter + 1);
frame = freq_local(index_frame);
if (4 < length(index_frame))
gw = gausswin(round(length(index_frame) / 2));
frame = filter(gw, 1, frame) ./ (round(length(index_frame)) / 4);
end
y(iter) = median(frame);
end
y(1) = mean(y);
y(end) = y(end-1);
y = y + min_value;
end
function [sample_spectr,log_space]=eject_spectr(sample_length,sample,fs,band_pass)
%% set parameters
band_start = band_pass(1);
band_stop = band_pass(2);
decimation_speed = 2.9;
amount_point = 800;
%% create spaces
spectrum_space = 0 : fs/length(sample) : (fs/2) - (1/length(sample));
spectrum_space = spectrum_space(spectrum_space <= band_stop);
sample_index_space = ...
log_index_space(amount_point, length(spectrum_space), decimation_speed);
%% create spectral density
sample_spectr = 10*log10(abs(fft(sample,length(sample))) ./ (length(sample)*sample_length));
sample_spectr = sample_spectr(1 : length(spectrum_space));
sample_spectr = decimation_spectrum( sample_spectr, sample_index_space );
endПример логарифмической децимации представлен ниже, где верхний график является логарифмическим спектром от 0 до 5000Гц содержащий более 16000 точек, а нижний – выделенный массив основных компонент размерностью 800 точек.
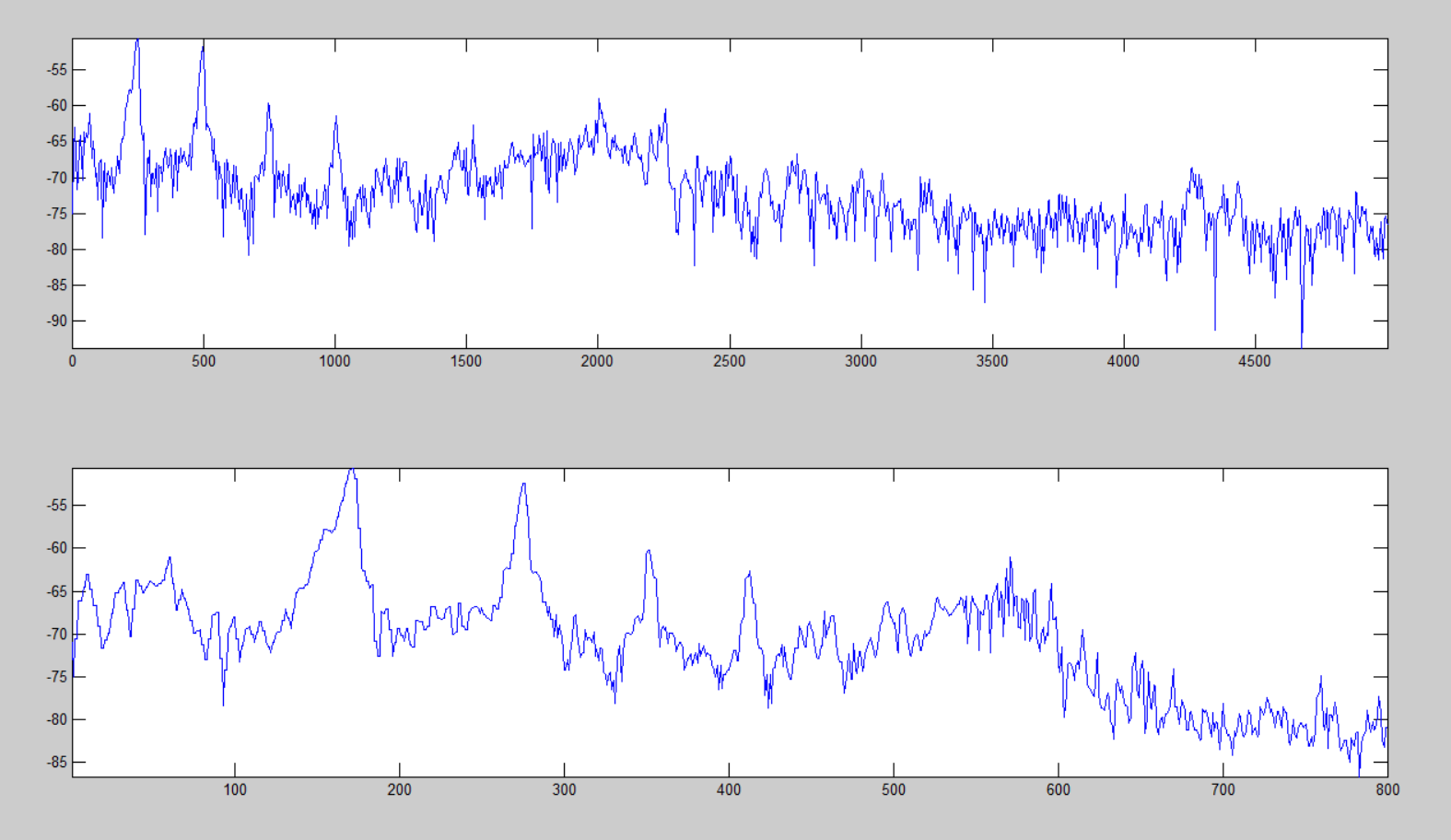
Построение LogLog спектрограммы
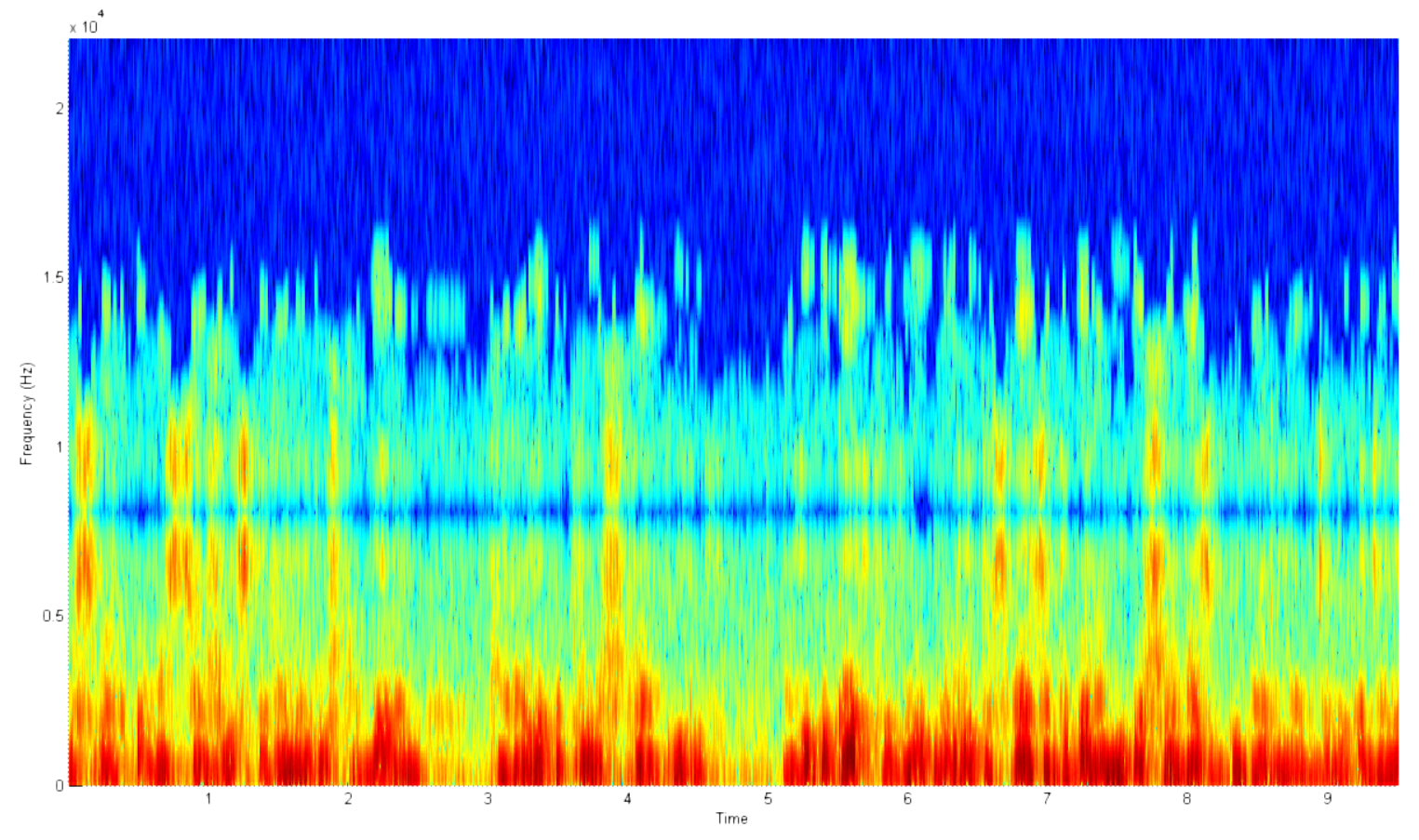
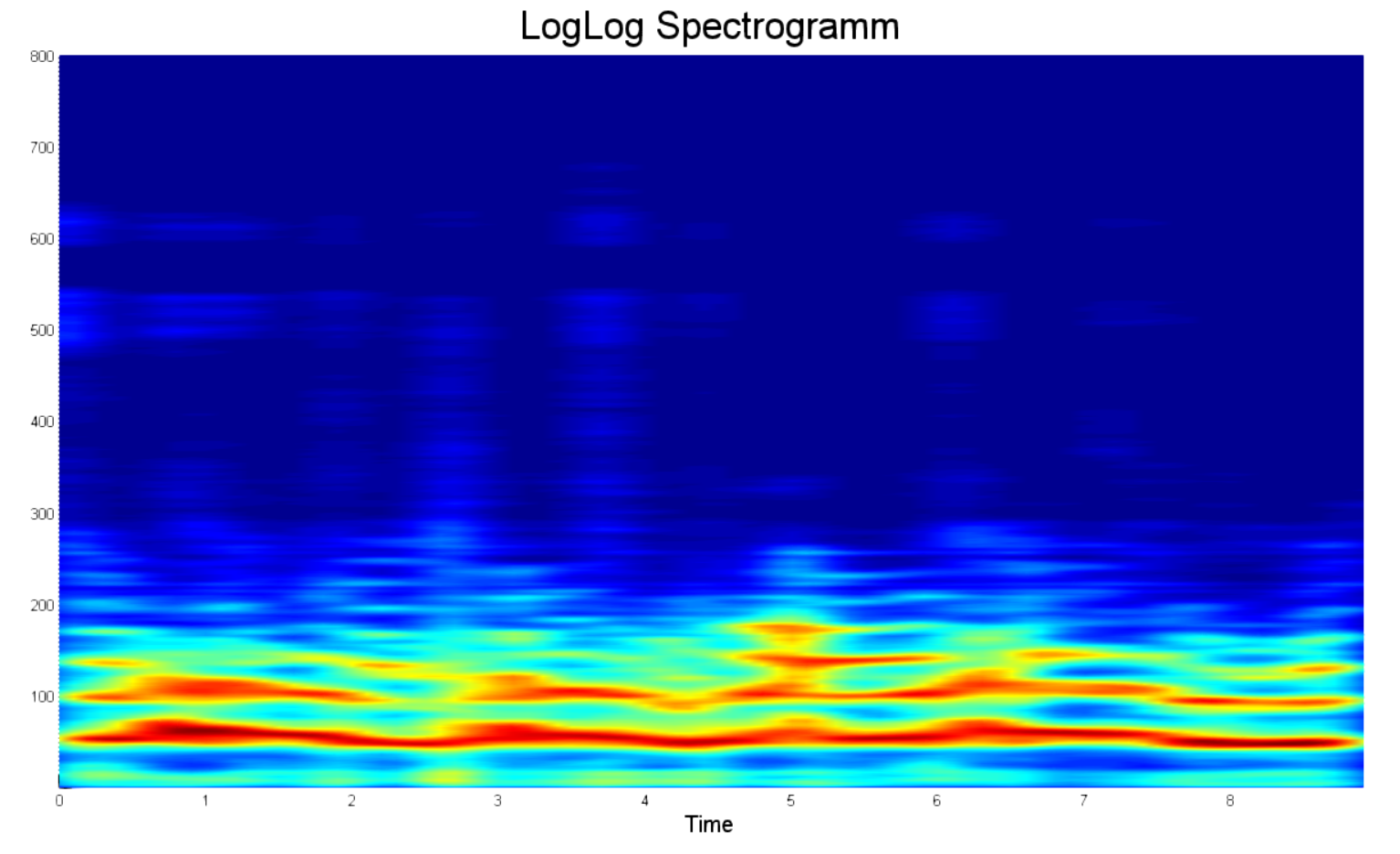
О чём речь? Для чего все эти старания? Почему нельзя построить обычную спектрограмму средствами матлаба в одну строчку и не париться со всем, что было сказано ранее? Но нельзя, и вот почему. На примере ниже показана типовая спектрограмма голоса. Какие в ней недочеты?
- Огромное количество точек. Нет, их правда много. Настолько, что у моего компьютера заканчивалась оперативная память при попытке построить спектрограмму 15 секундной записи.
- Большая часть информации посвящена шуму. Зачем мне спектр на 20кГц, если ни один нормальный человек никогда не говорит с такой частотой?
- С 2.5 по 3 секунду и с 4.5 по 5 секунду нет активности голоса. Это шум. Вдобавок он в целевой частотной зоне, а потому может катастрофически сказаться на систему классификации в дальнейшем.
- Нет четкой абсолютной шкалы мощности. Так как аудиозаписи могут быть различной громкости, то и итоговая мощность в спектре может сильно отличатся даже у одного и того же человека в разное время.
- Не логарифмическая магнитуда. Громкость человеческого голоса, как и разрешающая способность нашего слуха по мощности логарифмические.
- Не логарифмическая шкала частот. В связи с этим действительно полезная информация сосредоточена лишь в малой части спектра.
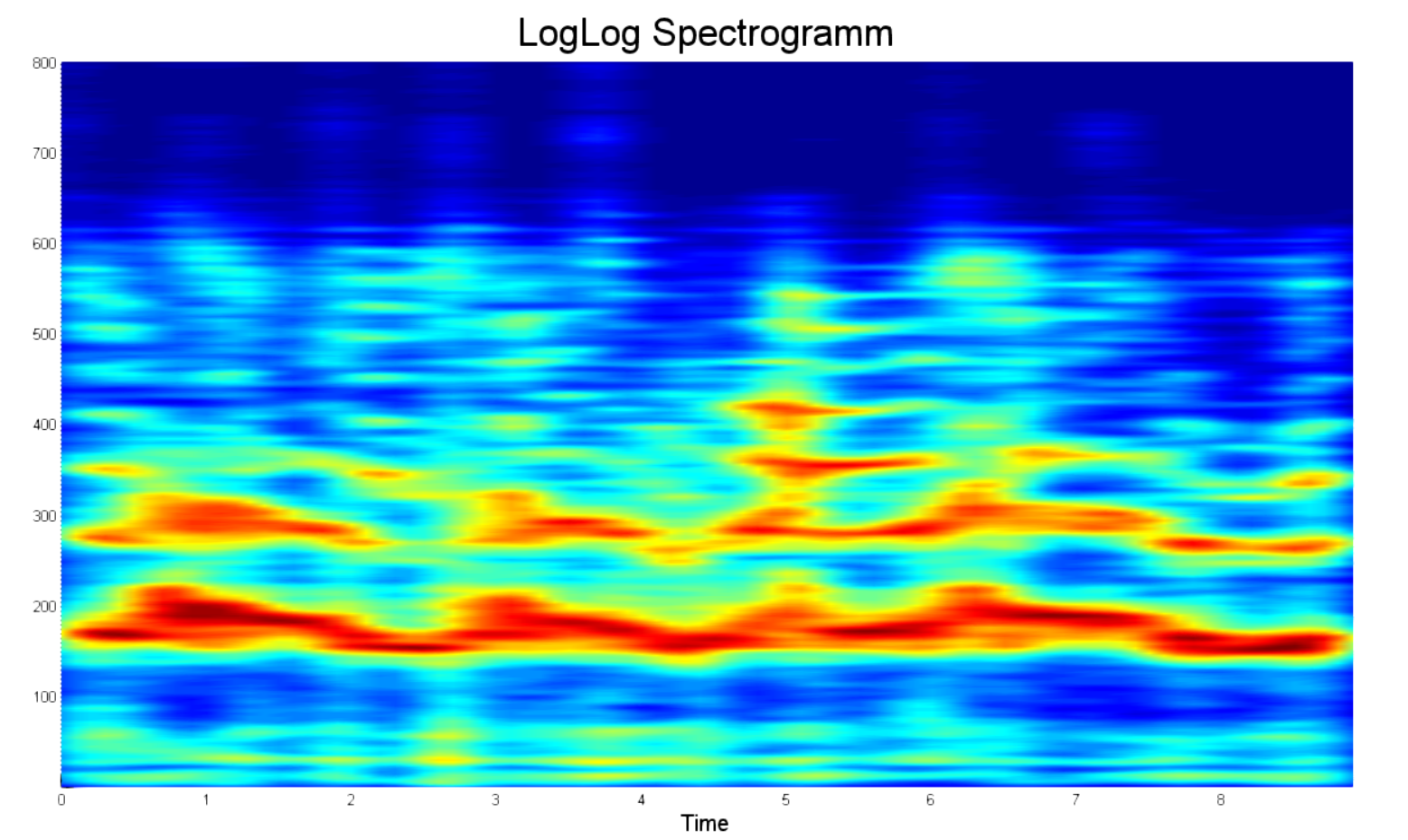
Для более наглядного сравнения между двумя спектрограммами ниже приведён пример обработанной LogLog спектрограммы в том же диапазоне частот, что и представленная выше. Что в первую очередь бросается в глаза?
- Во-первых, это явно выраженные пики мощности. Теперь можно отличить спектр двух людей просто на глаз.
- Во-вторых, нет зон затишья, они вырезаны. Поэтому и длительность меньше.
- В-третьих, здесь всего 800 точек на каждую частотную дорожку. Да 800 точек, а не 20 000, как на примере выше. Теперь не придется перезагружать комп, когда случайно напутал с длительностью.
- В-четвертых, нормализация мощности спектра. Было решено ограничиться мощностью спектра в 25 децибел. Всё, что отличалось от максимума более, чем на 25 децибел считалось равным нулю.
В то же время, по-прежнему большая часть информации посвящена шуму. Поэтому есть смысл обрезать частотную выборку на 8кГц, как показано ниже.
%% spetrogramm
buffer_duration = 0.1; % in seconds
overlap = 50; % in percent
sample_size = round(buffer_duration * fs);
buffer_size = round( ((1 + 2*(overlap / 100))*buffer_duration) * fs);
time_space = 0 : sample_size/fs : length(y)/fs - 1/(fs);
[~, log_space] = eject_spectr(buffer_size, x(1 : buffer_size), fs, band_pass);
% array of power buffer samples
db_range = 25;
spectrum_array = zeros(length(time_space), length(log_space));
for iter = 1 : length(time_space)
start_index = (iter - 1) * sample_size;
start_index = max(round(start_index - (overlap / 100)*sample_size), 1);
end_index = min(start_index + buffer_size, length(y));
phrase_space = start_index : end_index;
buffer = y(phrase_space) ./ max(y(phrase_space));
buffer = buffer .* kaiser(length(buffer), betta);
spectr = eject_spectr(buffer_size, buffer, fs, band_pass);
spectr = max(spectr - (max(spectr) - db_range), 0);
spectrum_array(iter, 1 : length(log_space)) = spectr;
end
spectrum_array = spectrum_array';
win_len = 11;
win = fspecial('gaussian',win_len,2);
win = win ./ max(win(:));
spectrum_array = filter2(win, spectrum_array) ./ (win_len*2);Статистическая обработка
Что мы имеем на данный момент? Мы имеем 800-мерный случайный процесс, реализация которого зависит от произносимого звука, настроения и интонации спикера. Однако параметры самого процесса зависят исключительно от физических параметров голосового тракта спикера и потому постоянны. Главный вопрос состоит в том, сколько таких параметров, и как их оценивать.
"Да прибудет с тобой ЦПТ"
Почему бы не представить каждый из процессов в виде суммы различных Гауссовых процессов? Таким образом получается всего различных процессов. Для такого подхода даже придумали название — GMM.
Итак, осталось разобраться только с тем, чему равен этот . Берем спектрограмму, строим по ней гистограмму и вуаля:
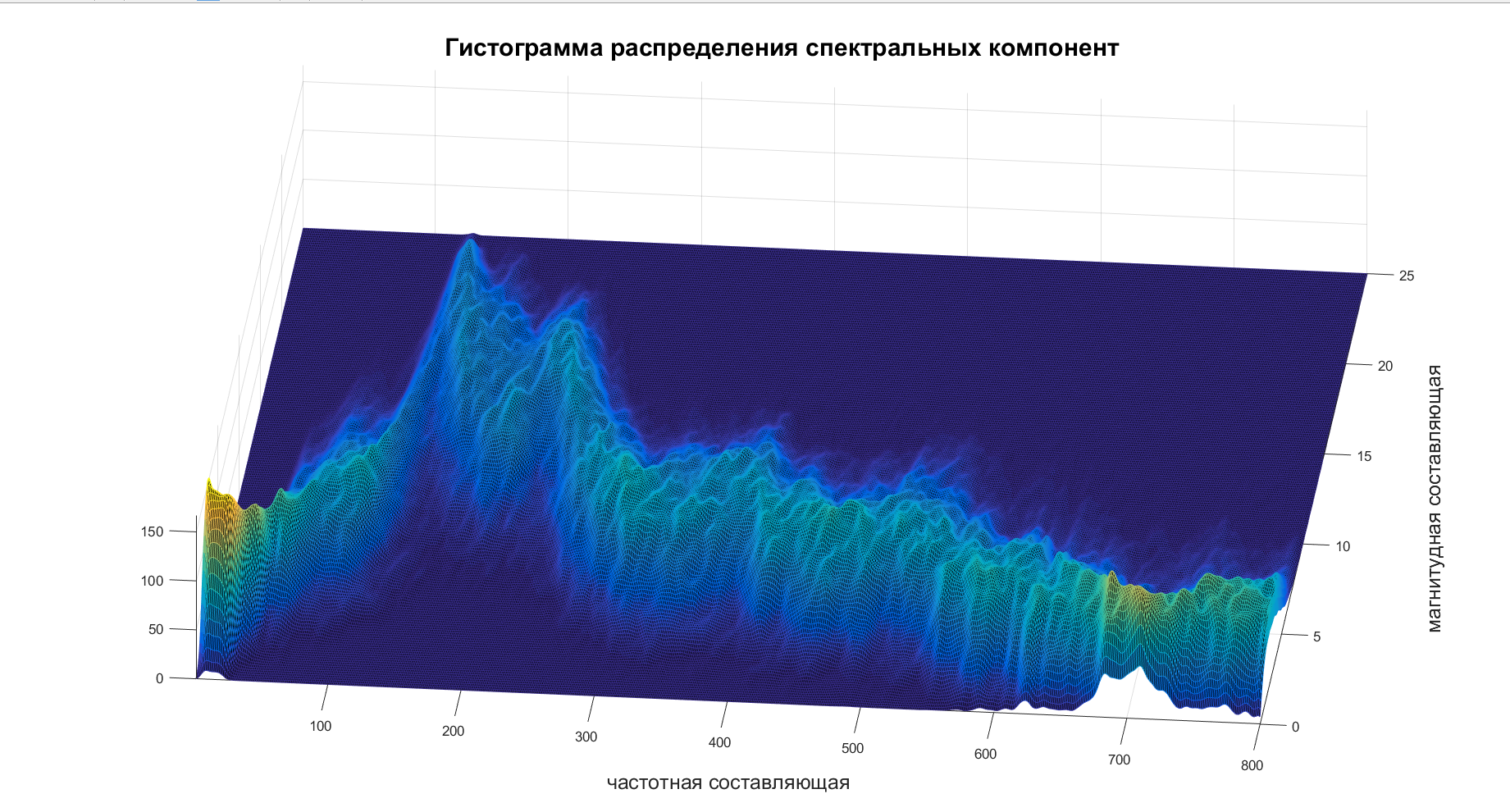
После просмотров нескольких таких гистограмм моя лень праздновала решительную победу и установила . Вдогонку она предложила забить на составление ковариационной матрицы связи различных частот и считать каждую частотную компоненту независимой, что не есть правда. Лень — она такая.
Теперь осталось только посчитать оценки МО и СКО для каждой частотной компоненты, а после объединить в один вектор главных компонент.
std_spectr = std(spectrum_array, 0, 1);
mean_spectr = mean(spectrum_array, 1);
principal_component = cat(2, mean_spectr, std_spectr);Заключение
В технике биометрической аутентификации статические методы значительно превосходят динамические по точности и скорости реакции. Однако, несмотря на это, динамические методы имеют ряд преимуществ, которые хоть являются чисто практическими и не влияют на процесс распознавания, но могут оказаться наиболее существенными для заказчика.
При реализации систем на динамических признаках такими преимуществами могут быть:
- дешевизна аппаратуры
- малая чувствительность к шумам
- простота регистрации человека и съема данных.
Комментарии (6)

BalinTomsk
28.08.2017 20:37Надо бы в выборку кастратов добавить и мальчиковые голоса до ломки — наверняка алгоритм oшибаeтся на них. Ну и выборку раcширить — например участниками конкурса Голос.

pan-alexey
29.08.2017 13:16Я думаю намного лучше будет создать еще одну группу — не определен. Т.к. существует моменты в которых и группа людей не однозначно определяет м/ж
AVI-crak
29.08.2017 01:34Имея линейную спектрограмму можно выполнить детект голосовых фреймов до слогов, а там и до фонетического разбора речи не так-уж и далеко.
Но всё-же, зачем строить спектрограмму (вычислять и хранить всё это) — если совпадение можно вычислять на лету. Да будут промахи, и множество ложных срабатываний — но это всё для системы без обратной связи.
Причём первая обратная связь на уровне голосовых фреймов, те самые сочетания гласных и согласных — их не так-уж и много. Причём использовать все возможные варианты нет нужды — потому как некоторые сочетания произнести просто невозможно.
Итак — произнесена первая «буква», в нашем случае звук похожий на согласную. Ещё до смены рисунка спектрограммы — можно выставить весовые коэффициенты для всех имеющихся сочетаний. Большая часть из них даже не будет участвовать в обработке.
После уверенного распознания нескольких букв, можно подключать второй контур — распознавание слов. Тут всё намного сложнее. В устной речи нет явных признаков пунктуации, это всё предназначено для письменного общения — для наиболее полного восстановления смысловых форм. Чтоб вас могли отличить от робота.
Самое неприятное — в сети практически нет работ по этому направлению. Теоретиков не считаем, их как грязи.
Перевести все звуки речи в буквенный массив, можно и на слабеньком мк. Но для полноценного распознавания речи необходим огромный массив мыслеформ. Но просто набор слов, а их связи. Именно связи будут влиять на смысл сказанного.
И кстати, как это в конце концов обрабатывать.
Думаю что вариант одно_битного пьяного электрика — наиболее удобная модель (образно). Ну то-есть свести все мыслеформы до вполне понятного для такого существа чувства: то как обида, гордость, страх, радость и так далее. Часть критических состояний просто не может находится сразу в двух противоположностях, и это многое упрощает.
Подобную реакцию можно масштабировать на все мыслеформы, и тогда одно_битный пьяный электрик научится думать не только про себя.
К сожалению, последнее требование не выполнимо в реальном времени даже на очень больших и мощных машинах. В усечённом варианте — вполне, но не в полном.
nad_oby
29.08.2017 21:41Всё это мило, но какое отношение это имеет к теме статьи.
Тут ставится достаточно узкая задача, ещё немного сужается и успешно решается.
При этом автор разбирает в паре узких мест, почему он сделал тот или иной, неочевидный, на первый взгляд выбор.
Это и делает статью по настоящему полезной на мой взгляд.
А пьяные однобитые электрики меня смутили и никакой ясности не добавили.
И к конструктивному диалогу не побудили.
hDrummer
Труд проделан немалый, но заплюсовал сразу за первое прочитанное предложение:
Оно шикарно.
Vasyutka
Я даже не знаю… теперь наверное цитировать в каждой своей статье это буду в самом начале :). Подписываюсь под каждым словом!