

Александр Коротков, Дмитрий Иванов (Postgres Professional)
Ведущий: Тяжелая артиллерия в лице Александра и Дмитрия будет рассказывать про важную фичу Postgres. И не то, чтобы фичу, а проблему, с которой сталкиваются люди, работающие с Postgres – это то, как правильно секционировать или партиционировать, как вам более удобно произносить, таблицы. И Александр с Дмитрием уже довольно длительное время трудятся над расширением, которое позволяет это делать гибко, хорошо, удобно и быстро.
Александр Коротков: Как правильно уже сказали, наш доклад будет посвящен расширению pg_pathman, которое реализует продвинутое секционирование в Postgres. Основную часть доклада будет рассказывать мой коллега Дмитрий Иванов, который сейчас очень активно включился в работу над расширением pg_pathman, а я буду время от времени что-то добавлять.
Дмитрий Иванов: Давайте сначала рассмотрим, зачем нужно секционировать таблицы.

Так случилось, что до того, как появился pg_pathman, уже существовал extension pg_pathman, который нужен для секционирования, но лично у меня сложилось впечатление, что, судя по тому, какую он производительность выдает, и не только по pg_pathman, а по тому, что говорят в Хакерс, что говорит Том Лейн (Thomas G. (Tom) Lane), что у партицирования, в принципе, достаточно ограниченное применение. Зачем нужно партиционировать?
Во-первых, это управление большими объемами данных, т.е. у вас может быть какой-то невероятно большой объем данных, который нужно как-то обслуживать, нужно периодически подчищать, этим всем заниматься. У вас есть возможность сложить все в одну таблицу. Начиная с какого-то момента, у вас будет индекс блоутиться… Таблица получается реально большая, ее будет дорого вставлять, дорого UPDATE’ить, дорого ее обходить вакуумом. Поэтому, начиная с какого-то момента, можно использовать механизм наследования в Postgres, который мы через несколько слайдов подробно рассмотрим. Но базовая идея заключается в том, что когда мы добавляем партицирование, мы можем менеджить каждую партицию отдельно. Т.е. мы можем по ней отдельной делать вакуум, отдельно, зная, что ничего больше не будем INSERT’ить, мы можем вообще отключить вакуум, отключить всякие подобные вещи…
Александр Коротков: Можем вынести ее на отдельный физический сервер, сейчас FDW это позволяет.
Дмитрий Иванов: Мы можем использовать более гибкий подход, когда для каждой партиции, в зависимости от количества INSERT’ов, от разной нагрузки, мы можем совершенно по-разному с ними работать, что единая таблица не позволяет делать.
Александр Коротков: Самый простой пример. Есть у вас таблица большая, куда вы пишете логи, и вы решили, что логи за январь прошлого года вам стали уже не нужны. Если у вас все это лежит в одной таблице, и записи за это время каким-то случайным образом перемешались, то у вас пойдет какой-то IndexScan, он начнет перемалывать весь хип. Гилит у вас зависнет надолго, и вам надоест его ждать, вы его консильнете и будете не знать, что делать. А если у вас все распартицированно по месяцам, то вы просто дропнете одну таблицу, и все произойдет очень быстро. Т.е. локальность данных есть по тому атрибуту, который вам нужен.
Дмитрий Иванов: Это, в принципе, закономерный итог того, что наши коллеги рассказывали и про авто-вакуум, и про остальные такие вещи. Эти все эффекты можно в какой-то степени нивелировать по кусочкам. Далее можно придумать такие случаи, когда возможны быстрые запросы к наиболее часто используемым секциям. Т.е. если у нас есть какой-то закон, которому подчинятся данные, например, мы постоянно добавляем что-то за каждый следующий день, т.е. у нас есть блоги, у нас есть новостная лента ВК, ну все, что касается соц.сетей, когда появляются данные с каждым новым днем и, понятное дело, что они только задним числом могут попасть за предыдущее время, т.е. у нас есть возможность создавать секции во временном диапазоне, туда добавлять данные, и тогда получится, что для самых последних актуальных данных мы можем сделать партиции с IndexScan’ом. Вообще, забегая вперед, скажу, что было бы очень неплохо, если бы была возможность как-то обмануть Postgres и заставить его по нашим условиям не смотреть те партиции, которые уже не актуальны, и смотреть только из тех, которые последние, которые актуальны на сегодняшний момент, чтобы запросы наши обрабатывались быстрее. Это очень сильно перекликается с тем, что мы имеем проблемы с OFFSET’ом и, вообще, чаще всего пользователю нужны несколько последних строчек, какой-то небольшой объем данных за последнее время.
В общем, подведя итоги, когда нужно секционировать?

Если таблица содержит архивные данные, и в последнюю секцию добавляются новые данные – это раз. Два – содержимое таблицы должно быть распределено между дисками или серверами. Это шардинг. Думаю, тут нетрудно догадаться, что производительность при этом упадет, но мы будем иметь возможность разбивать все по разным серверам, и pg_pathman в какой-то мере позволяет это сделать. И еще хочется ускорить запросы к определенным срезам данных.
Александр Коротков: Т.е. вы можете взять и по последней партиции только построить индексы, а по остальным не строить.
Дмитрий Иванов: Потому что реально – зачем?

Старый добрый метод, который используется испокон веков в Postgres – это то, что мы создаем таблицу. Скажем, она будет называться partitioned. После чего мы добавляем partitioned_1, который будет играть роль партиции. Для тех, кто не знает, LIKE Including ALL позволяет нам создать партицию с таким же лейаутом, как у нашего родителя, причем отнаследуются индексы, отнаследуются чек констрейнты, отнаследуются некоторые другие свойства. В принципе, вы это можете посмотреть по документации.
Александр Коротков: Потому что если просто INHERITS сказать, то оно, по-моему, только колонки скопирует.
Дмитрий Иванов: Да, оно возьмет только колонки, причем даже not null не будет учитывать, а это не то, что нам нужно, если мы хотим создать прозрачное партицирование, где каждая партиция фактически полностью соответствует нашему родителю. И под конец мы добавляем чек констрейнт, который для данной партиции описывает диапазон, в котором лежат данные.
Но, к сожалению, у этого подхода есть определенные минусы.

Во-первых, очень много ручной работы для управления партициями. Вы сами вдумайтесь, если вы не напишете каких-то скриптов на PL/pgSQL или даже PL/Python – по вкусу. Если вы всего этого не сделаете, то просто представьте, с какой болью столкнется ваш администратор, который будет постоянно вынужден под каждый временной сегмент не забыть добавить новую секцию, которая будет содержать эти данные.
Во-вторых, партиции из итогового плана выкинутся, который под чек констрейтом не проходят для данного WHERE, но не стоит забывать о том, что будет использован executive (?) search, т.е. будет полностью перебираться для каждой партиции. А теперь представьте, что у нас их 10 тыс., 20 тыс. и еще больше. И? понятное дело, что это будет довольно грустно, и у нас вполне возможны ситуации, когда в таком случае у нас перебор и планирование будет занимать больше времени, чем достать какую-то несчастную строчку, 1 байт. И, ясное дело, что нас это не устроило.
Кроме того, отсутствуют оптимизации во время исполнения. Т.е. если вы используете какой-то джойн, и слева у вас непартицированная таблица, справа – партицированная таблица, вы хотите их заджойнить. Если не вдаваться в тематику баз данных, когда вы берете строку из таблиц, которые непартицированы, то вполне логично и понятно, что можно не перебирать вообще все секции, можно выбрать только ту секцию, которая приходится на то число, которое мы выхватили.
Александр Коротков: Очень сложно говоришь. Короче говоря, суть в том, что механизм constraint_exclusion позволяет выбрать нужные секции, когда у нас константа прямо в запросе зашита. Но она у вас может, например, быть не зашита в запросе, а приходить из условия джойна или приходить из prepared statement’а. И в этом случае нам нужно секцию, которая нам нужна, выбирать на этапе выполнения. constraint_exclusion такого не умеет, но в то же время, это очень нужно.
Дмитрий Иванов: constraint_exclusion этого не умеет по той причине, что во время планирования эти данные просто не доступны, у нас их нет, запрос еще не начал выполняться.
Дальше. Нет встроенной поддержи HASH-партицирования. То, что говорит сам Том Лейн по этому поводу, что, в общем, не нужно, потому что мы лишаемся всех тех замечательных свойств, которые стоят на первом месте. Неудобно работать с такими партициями совсем.
Александр Коротков: Но, тем не менее, все просят.
Дмитрий Иванов: Тем не менее, постоянно просят, поэтому у нас оно есть.
Не копируются foreign keys родителя. Это не самая очевидная вещь, но довольно неприятная, потому что если у вас на родителе как-то присутствует referential integrity с другими таблицами, то оно внезапно возьмет и для партиции исчезнет. Т.е. не забудьте к вашей реализации на коленке добавить еще и эту вещь.
Дальше еще более неочевидное – это то, что возможны проблемы с привилегиями. Т.е. когда вы сами создаете партиции, точнее таблицы, то вы же и создатель этих таблиц, вы же и задаете им привилегии на INSERT’ы, delete’ы, UPDATE’ы и все, что только можно, а для партиции это неочевидно для людей. Мы же хотим прозрачное партицирование, где абсолютно понятно, что партиции обладают такими же привилегиями.
Александр Коротков: Если простым языком сказать, то у вас есть таблица, вы на нее повесили триггер, чтоб на нее партиции добавлялись и, если вы не скажете, что оно security definer, то новые секции будут создаваться уже от имени того, кто данные туда вставляет, а это совершенно не обязательно тот же самый пользователь.
Дмитрий Иванов: Это достаточно большая проблема, а еще, учитывая тот факт, что тот, кто не владелец, через родителей все равно сможет их читать. Это немного нелогично, но тем не менее.
Возможные решения хотя бы для части этих проблем.

Первый вариант – это то, что мы можем выбрать какое-нибудь расширение для автоматизации рутины, как минимум. Pg_pathman, в принципе, подходит для этого дела, но, как уже сказано, планы он не особо оптимизирует.
Александр Коротков: Т.е. pg_pathman — это расширение, написанное на PL/pgSQL, насколько я помню.
Дмитрий Иванов: На 80%.
Александр Коротков: И оно работает в рамках тех вещей, которые там доступны, т.е. на процесс планирования он никак не может повлиять.
Дмитрий Иванов: В положительную сторону.
Александр Коротков: И на самом деле, он был разработан еще тогда, когда этих механизмов в Postgres, расширяемости такой не существовало. Хуков, планировщиков определенных, плюс кастомных нод. Поэтому он и не поддерживает. А мы уже используем все эти новые механизмы, которые появились, начиная с Postgres 9.5, и поэтому у нас уже возможностей гораздо больше.
Дмитрий Иванов: Именно поэтому мы пришли ко 2-му варианту – мы решили создать партицирование таким, каким мы его видим, хотя бы на основе тех механизмов, которые появились в 9.5, и в 9.6.
Pg_pathman, что он предлагает.

Во-первых, поддержка HASH- и RANGE-партицирования.
Во-вторых, автоматическое управление секциями. Что это значит? Это значит, что, во-первых, если вы вставляете данные, для которых нет все еще секций, то вы можете включить фичу такую, чтобы автоматически создавались секции, т.е. вставляйте, не задумывайтесь. У вас запрос, конечно, работает медленнее, потому что под капотом он вынужден эти таблицы создать, но зато INSERT отлично отрабатывает, и ваши данные на новом месте.
Дальше. Улучшенное планирование запросов. Это как раз то, о чем мы сейчас говорили, поэтому потом.
Дальше. Теперь фишечки наши. Мы создали несколько специализированных узлов планировщика. Понятно, что те из вас, кто смотрели EXPLAIN ANALYZE, они видели там Nested Loop, Seq Scan, все такое. Ну вот, RuntimeAppend и PartitionFilter – это специальные узлы на основе функциональности, добавленной в 9.5, которые позволяют нам как-то вклиниваться в этот процесс и менять стандартное поведение к лучшему. Так вот, RuntimeAppend – это выбор секции во время исполнения, как раз применим в Nested Loop, когда вы должны из партицированной таблицы на основе параметра отсечь все ненужные партиции, которые заведомо не могут содержать это значение. Понятное дело, если у вас параметр вычислился в 5, то секции от миллиона до 2-х млн. искать бесполезно.
PartitionFilter – это INSERT без триггеров. Это довольно интересный момент, потому что, как мы увидим из бенчмарков, это одна из самых чуть ли не крутых фич.
Александр Коротков: Да, и еще одна проблема INSERT – это то, что INSERT RETURNING ничего не возвращается.
Дмитрий Иванов: Т.е. это INSERT без триггеров, а триггеры…
Александр Коротков: Вот с ноды возвращает и без триггеров.
Дмитрий Иванов: Сейчас мы все это расскажем. Неприятное свойство триггеров заключается в том, что когда вы делаете INSERT’ы, мало того, что вы не можете сделать RETURNING*, потому что триггер подменяет, возвращает наверх null, этого кортежа нет, я его куда-то туда вставил.
Александр Коротков: Т.е. у вас INSERT пытается вставить в родителя, вы из триггера вынуждены эту вставку отменить и сделать отдельную вставку в секцию. Но из-за этого получается то, что ничего не возвращается, потому что в родителя ничего не вставилось.
Дмитрий Иванов: И, как результат, вы не можете увидеть, какое количество строк вы вставили. У вас будет просто INSERT 0 0. Это определенно не то, чего люди ждут, когда ожидают прозрачного партицирования.
Далее у нас был feature request COPY FROM/TO, который, в принципе, использует ту же самую функциональность, что PartitionFilter. Он точно также берет и для всех данных, которые вы подаете из stdin, из файла, он расфасовывает это по партициям, причем, он точно также может создавать эти секции.
Неблокирующее конкурентное секционирование. Что это такое? Понятное дело, что если вы партицируете, у вас есть 2 стратегии. 1-ая – это разрешить INSERT’ы, разрешить модификации, тогда нужно перемещать по кускам. И 2-ой вариант, гораздо более простой – давайте заблокируем всю таблицу, пусть в нее никто не сможет INSERT’ить, т.е. это соответствует exclusive lock, возможны только селекты, потому что они ничего не меняют. И далеко не всех это устраивает, потому что, если у вас в продакшне какая-то база большая, если вы возьмете и просто заблокируете, то никто в нее не сможет INSERT’ить, никто не сможет UPDATE’ить, delete’ить и это довольно плохо. Поэтому, когда мы создавали неблокирующее партицирование, мы блокировали кусок строк, какой-то небольшой батч, с помощью for UPDATE, после этого мы его перемещаем и, наконец, мы его удаляем. Т.е. так по кускам, background worker берет и перемещает строки по партициям. Это позволяет нам сохранять доступ на INSERT’ы, delete’ы и UPDATE’ы.
Александр Коротков: И еще хотел сказать про создание секций конкурентное. Про то, что, например, если у вас есть автосоздание секций, то вы вставили строчку, при этом автоматически создалась секция. Но фишка в том, что если это происходит в той же транзакции, то эта секция пока никаким другим транзакциям не видна, т.е. если еще кто-то параллельно захочет туда за-INSERT’ить, то он будет ждать, пока ваша транзакция не завершится. Это не очень хорошо, поэтому у нас есть специальный механизм, что когда вам нужно создать секцию, порождается background worker, который ее создает, коммитит эту свою транзакцию, и она сразу видима всем, и все могут в эту секцию INSERT’ить, не блокируя друг друга.
Дмитрий Иванов: Фишка заключается в том, что если вы насоздавали секций, а потом делаете ROLLBACK, то иногда бывает закономерно, что вы хотите эти секции сохранить. Кроме всего прочего, это может быть не совсем то, что вы хотели, но хотя бы это позволяет, как только транзакция закоммитится, отпустить все блокировки. Т.е. все, что было создано background worker‘ом, мгновенно может быть увидено теми другими, конкурентными INSERT’ами, которые тут же его увидят, и они будут вынуждены ждать часами, пока вы там свой INSERT гигантский закончите в одной транзакции.
Ну и, вишенка на торте – это поддержка FDW. В какой-то мере можно сказать, что она экспериментальная, но мы имели возможность потестить ее на Postgresql FDW. Это, собственно, целевая аудитория, потому что если мы хотим сделать шардинг, то не имеет смысла на чем-то другом тестить. Фишка работает, но опять же на INSERT, т.е. UPDATE не будет нормально обработан, но зато INSERT точно так же будет выбирать нужную партицию, в нее вставлять. Сделано это тем, что он там все функции, которые под ковриком лежат, будет подменять таблицу и будет использовать для нее.

Основные элементы API. Что мы умеем? Во-первых, мы можем создавать секции – add, attach, append, prepend. Что это значит?
Add – это добавить новую партицию с заданным диапазоном, т.е. вы можете задать его вручную. Кстати, по поводу этого, чем мне слету не понравился pathman – это то, что если ты берешь диапазон не для чисел, а для дат, то автор посчитал, что самое удобное – это взять и создать от какой-то даты, когда-то там давно до сегодняшнего дня и плюс еще сложить, сколько вы хотите, в общем, далеко не всегда то, чего вы ждете, особенно, когда пишете ваши тесты, поэтому у нас такого нет. У нас можно создавать любые партиции с любыми диапазонами, но при условии, что они не должны пересекаться, потому что это бы усложнило планирование, а еще это не очень логично.
Аttach – это взять готовую таблицу, в которой у вас уже есть данные, модифицировать ее слегка, чтобы она стала партицией, т.е. накинуть на нее констрейнтов, прописать ее куда надо и закэшировать. У нас есть кэш для того, чтобы все это дело быстро работало.
Append, prepend – это по существующему диапазону слева/справа накинуть партицию стандартного размера, потому что когда вы партицируете вы можете сказать: «Я хочу, чтобы все новые партиции создавались с шириной 1000, в интах».
Дальше. Управление созданными партициями. Вы можете их мержить, сплейтить, разделять, т.е. склеивать диапазоны и дропать, куда же без этого. Причем, дроп мы сделали такой удобный, что теоретически вы по вьюхе, которая имеет перечень партиций, можете задать условно: «я хочу, например, дропнуть все партиции с такого-то числа по такое-то», и все, что вам нужно будет сделать – это SELECT DROP_PARTITION WHERE нижняя граница такая-то, верхняя граница такая-то, и он возьмет и по этой вьюхе пройдется и дропнет все партиции, т.е. это намного удобнее, чем когда вы будете писать свой скрипт, я уж не знаю на чем, на Python, например.
Дальше. Генерация check constraints и триггеров для UPDATE. На самом деле совсем от триггеров нам пока не удалось избавиться, потому что это более сложная задача – сделать их для UPDATE с учетом всяких хот и прочего.
Во-первых, по поводу триггеров. У нас есть функция для того, чтобы сгенерировать автоматически триггеры, которые позволят перемещать данные между партициями, т.е. если вы не просто обновляете какой-то там ключ, который не является ключом партицирования какой-то части строки. Понятное дело, что она останется в той же самой партиции, ну, значение у нее какое-то изменится. Но возможно, что вы хотите взять, и если вы партицировали по ID, за-UPDATE’ить, чтобы ID изменился. Это позволит перенести кортеж в другую партицию.
Дальше. Установка обработчиков создания секций. Нам поступил future request, который заключался примерно в следующем: «Давайте мы предоставим возможность на каждое создание секции вызывать некий пользовательский callback, который внутри сможет выполнять любую логику». Простейший пример, зачем это может быть нужно – допустим, вы хотите, чтобы все партиции, созданные в пятницу 13-го перемещались в особый tablespace. У вас партиция создаcтся, после этого все, что вам нужно будет сделать в этой функции – вы берете, делаете ALTER TABLE, изменить tablespace. И поскольку она все еще пустая, она сразу же переедет, куда надо, без особых проблем.
Дальше. Несколько вьюшек, т.е. информация о секциях, которую я уже упомянул. И вьюха, которая содержит перечень background worker‘ов, которые трудятся над вашим конкурентным партицированием. Естественно, узнав информацию об этом worker‘е, вы тут же можете его хлопнуть, т.е. вы скажете: «Для данной таблицы, пожалуйста, остановите эту задачу, потому что мне сейчас это не нужно». Это уже ваше решение будет.
И, наконец, для отключения всяких вещей, типа «давайте мы возьмем и запретим создание партиций на INSERT». У нас есть отдельная таблица, в которой мы храним эти флажки, которая позволяет некоторые фичи отключать. И дополнительно хочу отметить, что мы добавили возможность отключать определенные подсистемы pathman, аналогично тому, как это сделано в Postgres. Т.е. вы можете сделать в Postgres SET enable_indexscan, enable Nested Loop. И точно так же для pathman вы можете основные подсистемы включать/отключать, как вам нужно, для бенчмарков, для тестов, если что-то там сломалось, но вы не хотите от него полностью отказываться.
Дальше, начнем с того, для чего создавался pathman.
Дело в том, что pathman’ом он называется не просто так, т.е. path – это путь, и смысл заключается в оптимизации пути исполнения. Т.е. не просто партиция, а партиция на стероидах. Так вот, для того, чтобы проделывать такие операции, нам нужно вклиниться на 2-х стадиях – на стадии планирования и на стадии исполнения. Т.е. после того, как запрос обработался, распарсился и рерайтнулся, мы включаемся в дело, срабатывают наши хуки, и они вносят некоторые конструктивные изменения в пути исполнения.
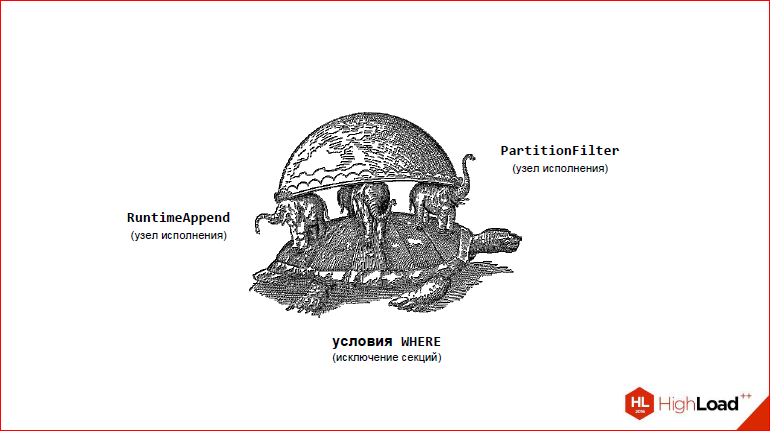
Тут я нарисовал картинку, которая обозначает ключевые фичи pathman. Ключевые фичи следующие. На чем держится? На 3-х слонах:
- RuntimeAppend – специальная нода, чтобы оптимизировать по сути Nested Loop’ы или что-то на это хотя бы как-то похожее с параметрами, чтобы отсеивать ненужные секции;
- PartitionFilter – для того, чтобы можно было делать быстрые INSERT’ы
- Обработка условия WHERE, которое лежит в основании всего, потому что именно с помощью WHERE мы создаем срез? отсеиваем те партиции, которые нам не нужны.
Давайте рассмотрим, как pathman обрабатывает условия.

Во-первых, механизм сheck constraint’ов в Postgres не может упрощать where.
Александр Коротков: Т.е. просто условие where, какое у вас было в запросе, во все партиции спускает «как есть», даже если там какие-то проверки, например, тождественную истину возвращают или тождественную ложь. А в pg_pathman мы сделали механизм, который это условие where может упрощать и те проверки, которые тождественно истинные и тождественно ложные для этой партиции просто не будут выполняться. Там механизм не очень очевидный для понимания, поэтому на простом примере его рассмотрим. Пусть у нас есть 6 секций – с января по июнь 2016 года.
Дмитрий Иванов: И давайте попробуем по ним выполнить примерно такой запрос.

Александр Коротков: Он, правда, немного мелкий, но в общем, там 4 условия, 2 рэнжа, склеенные через where.
Дмитрий Иванов: И давайте посмотрим. Собственно, что мы здесь выделяем? Мы выделяем дерево наших условий.
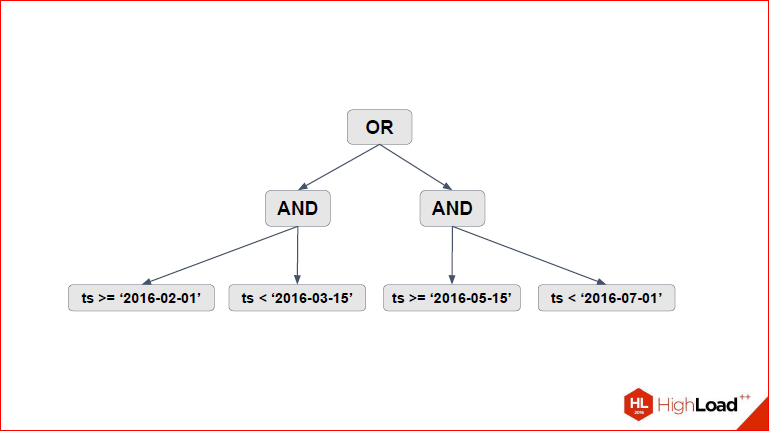
Т.е. представляем все эти условия с «or», «and», «<=», «>=» в виде дерева. Во главе у нас «or», дальше отклеиваются 2 «and».
Александр Коротков: А внутри неравенства, которые нужны для рэнжей.
Дмитрий Иванов: Теперь давайте посмотрим.
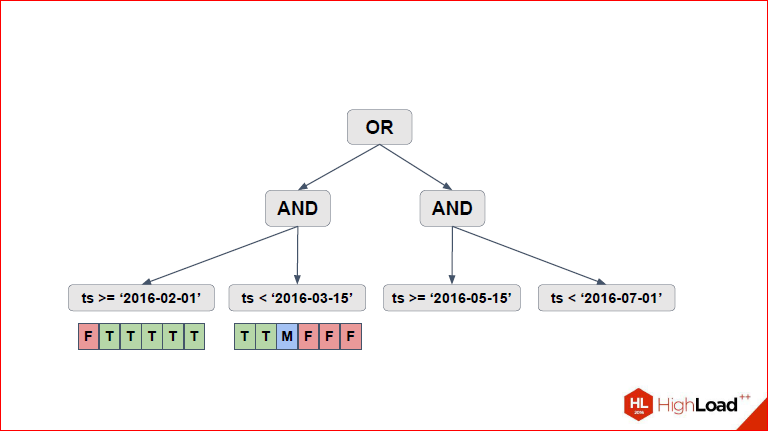
Вот, у нас первое, что появляется на слайде – это по каждому из условий самых нижних мы выделяем эти 6 партиций, которые у нас есть, и для каждого условия смотрим, какие партиции подходят, какие партиции не подходят. Если в ранних версиях pathman использовалась обычная двоичная логика (true – это подходит, false – это не подходит), и условия применялись все, то после того, как Саша внес некоторые изменения, у нас появилась троичная логика, когда становится понятно, что…
Александр Коротков: Т.е. для каждого условия есть 3 варианта – оно тождественно истинно для данной партиции, тождественно ложно или его нужно проверять. Здесь на картинке показано, T, F – тождественно истинно, тождественно ложно, а M – maybe, это значит, надо проверять. Мы здесь на картинке показали в виде массива, на самом деле учитывая, что секций может быть много, у нас там лист рэнжей хранится.
Дмитрий Иванов: Т.е. это просто удобное представление, чтобы объяснять, было, потому что false мы не храним.
Александр Коротков: Вот мы сделали для левой части выражение, потом следующий слайд –
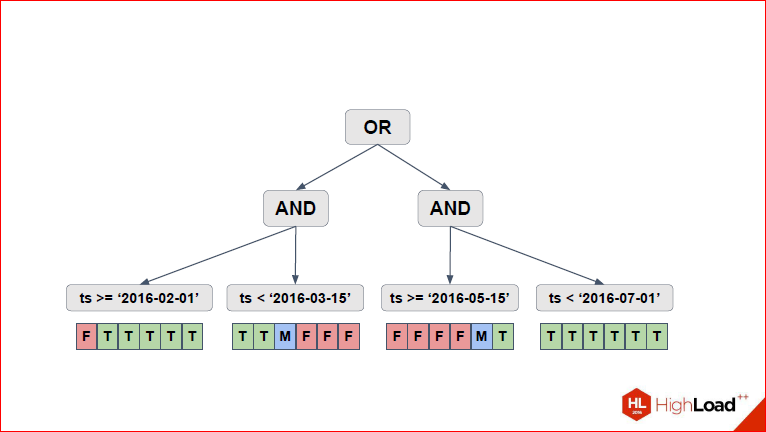
То же самое для правой части сделал, и нам остается агрегировать все значения вверх до тех пор, пока для «or» не посчитаем. Просто через трехзначную логику.
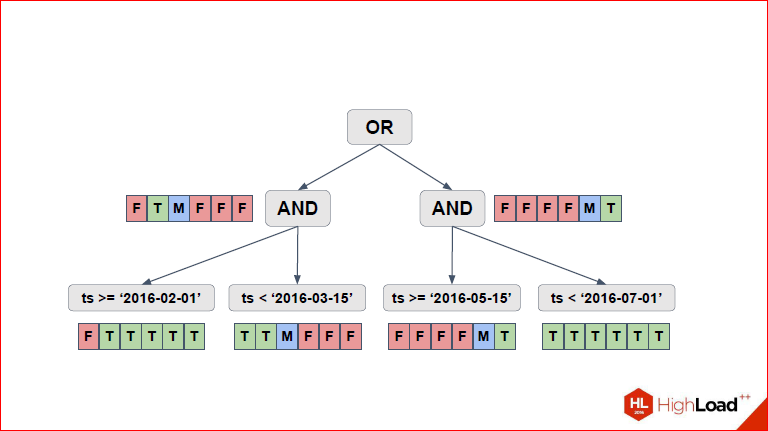
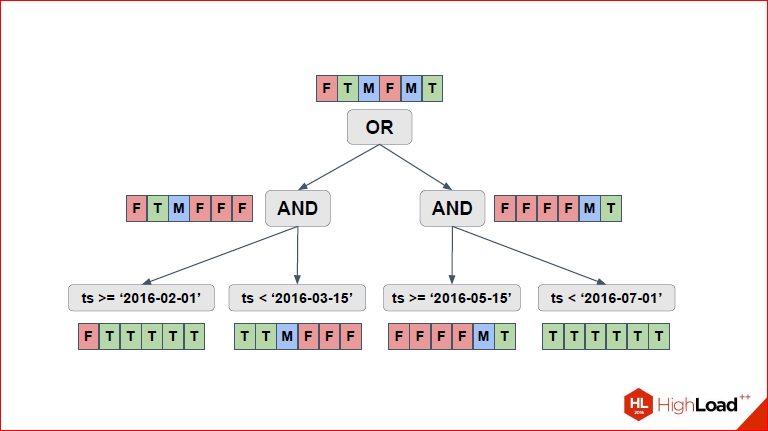
И за счет трехзначной логики решение может быть в некоторых случаях не совсем точное, но зато мы его получаем очень быстро, потому что в целом, это NP-полная задача, а тут такой алгоритм, который работает быстро и позволяет 99 реальных случаев обработать.
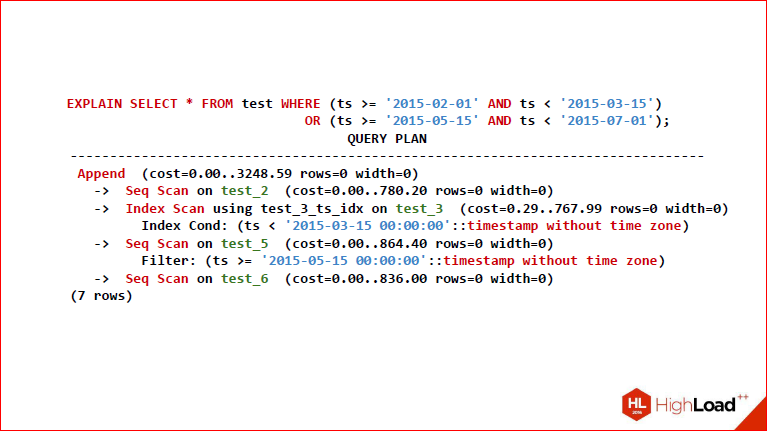
Итак, вы видите EXPLAIN ANALYZE, который получился.
Дмитрий Иванов: Давайте вернемся на секунду назад и увидим, что в итоге здесь были выбраны 4 партиции сверху.
Александр Коротков: Да, т.е. две, для которых F красненькое – это значит, мы их вообще не проверяем, потому что для них условие в целом всегда ложное, соответственно, T – это значит, что мы полностью партицию Seq Scan’ом, а M, соответственно – мы проверяем часть условия и ту, какую часть условия нам надо проверять, мы просто вниз спускаемся и смотрим, что там.
Дмитрий Иванов: Итого, у нас выбрались 2-ая, 3-я, 5-ая и 6-я. Мы здесь их и видим. Причем, заметьте, что далеко не у всех таблиц одинаковый тип скана используется, т.е. если для некоторых был выбран Seq Scan, потому что они заведомо истинные, для них нужно будет выделить все строки.
Александр Коротков: Ну, если целиком нужны все данные из таблицы, видно, что Seq Scan самый быстрый.
Дмитрий Иванов: А этот maybe как раз создает индекс Only Scan в данном случае, который выбирает те самые строки, что нужны.
Этот слайд просто для того, чтобы объяснить, что там показано дерево, реальные данные потом будут.
Теперь давайте рассмотрим 2-ой механизм. Обратимся к обычному Append, который существует в Postgres.
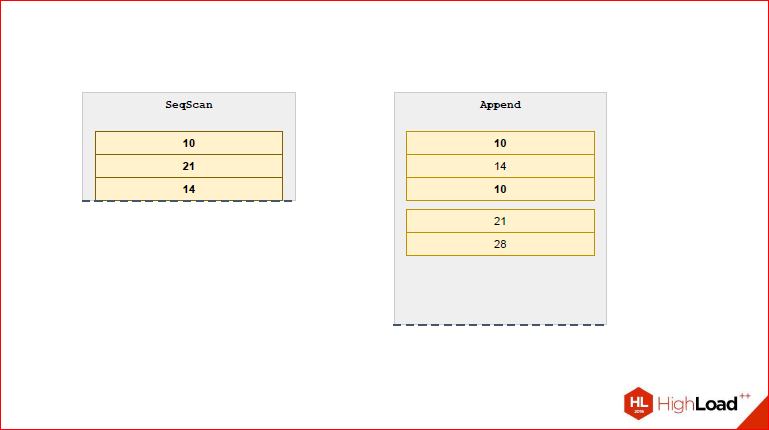
Допустим, нам нужно подждойнить 2 таблицы, у нас есть 3 вида джойна. Давайте рассмотрим на примере Nested Loop, когда мы должны для каждой строки левой таблицы попробовать каждую строку правой таблицы.
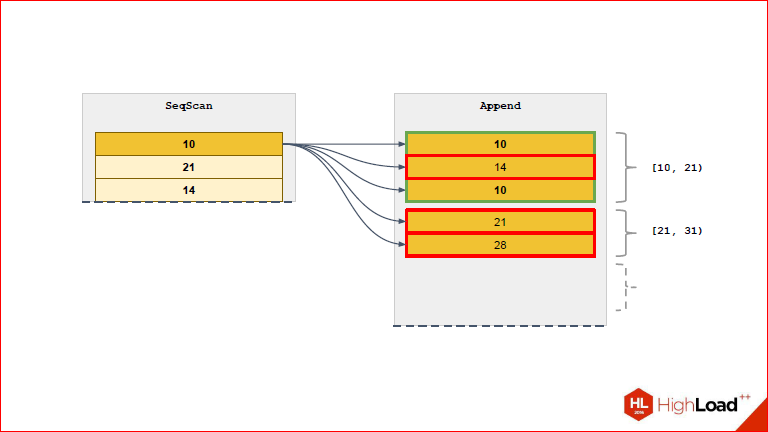
Нетрудно заметить, что для каждой левой проверяется каждая правая, теперь представьте, что у вас там 10 тыс. партиций, в каждой партиции еще очень много-много данных и выясняется, что для левой нужно перепробовать все из правой и так для каждой строки.
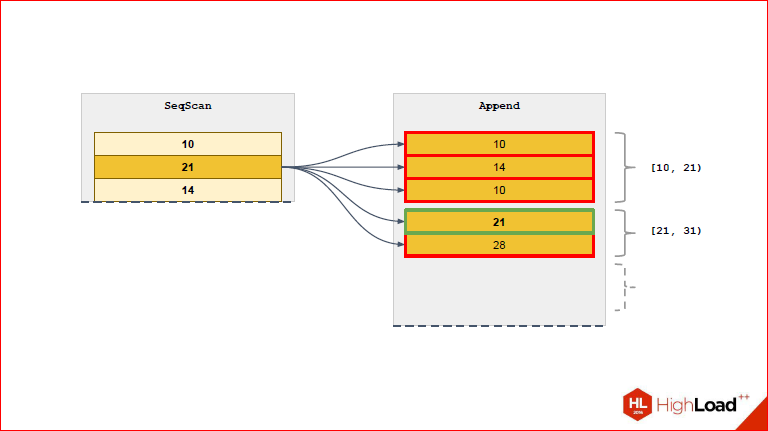
Это неудобоваримо совсем, поэтому мы придумали свое решение и назвали его RuntimeAppend с намеком на то, что все эти волшебные проверки в runtime происходят.

Т.е. когда у нас появилась такая ситуация, что constraint_exclusion не смог отсечь те партиции, которые нам не нужны, потому что «ну, параметры, а что мы сделаем, мы не знаем, чему это значение равно». RuntimeAppend может взять и со стороны executor’а и эти переменные выдрать. Затем, используя спрятанные выражение, которое мы взяли из запроса, примерить и, наконец, выделить те партиции, которые на данной итерации нам нужны. Если у вас есть Nested Loop, и слева у вас Seq Scan, а справа у вас Index Scan, то Index Scan параметризуется и каждый раз для каждой итерации принимает на вход строку из левой таблицы. Т.е. executor постоянно, когда этот скан выполнит на следующую строчку из левой таблицы, возьмет и обновит Index Scan и заменит в нем параметр. В принципе, можно привести прямую параллель между Index Scan’ом и RuntimeAppend, потому что в какой-то мере, он на основании этой переменной может отсекать те партиции, которые не нужны.
Александр Коротков: Если простым языком сказать, в чем проблема с append – в том, что если у вас значения параметра партицирования неизвестны заранее, то у вас он сгенерирует такой append, там будут все партиции и в нем Index Scan. И, как бы, довольно глупо, потому что большая часть этих Index Scan’ов вам вернет 0, и только та, которая нужна, вернет вам 1. А что делает RuntimeAppend? Он тоже спланирует, сделает планы для всех партиций, но экзекьютить он будет только ту, которая реально нужна, и он это в runtime проверяет.
Дмитрий Иванов: Ну, естественно, это не обходится нам совсем бесплатно, и побочный эффект заключается в том, что когда запрос выполняется, мы ничего не планируем, а значит запланировать все аccess’ы ко всем партициям мы должны были заранее. Т.о. мы действительно на этапе планирования сочиняем сканы ко всем партициям, а затем имеем возможность на основе сохраненных данных отсекать. Поэтому, если вы сделаете EXPLAIN без ANALYZE, он вам покажет перечень всех партиций. А если вы делаете EXPLAIN с ANALYZE, то пропадут те, из которых ни одного скана в действительности не было.
Александр Коротков: Дима правильно сказал, мы вынуждены все равно все партиции спланировать, и если вам нужно выбрать всего одну строчку, вы на ту же самую проблему натыкаетесь. Здесь суть в том, что мы уже выходим за рамки того, что мы можем сделать просто в extension’е и нам это нужно будет делать в виде патча, и этот патч будет в нашем форке.
Дмитрий Иванов: И давайте посмотрим, что в таком случае меняется, чтобы подкрепить слова.

Вот мы видим, что для 1-ой строчки выбрана только та партиция, которая для нее подходит. Мы видим также напротив этой партиции диапазон, чтобы удобней было.
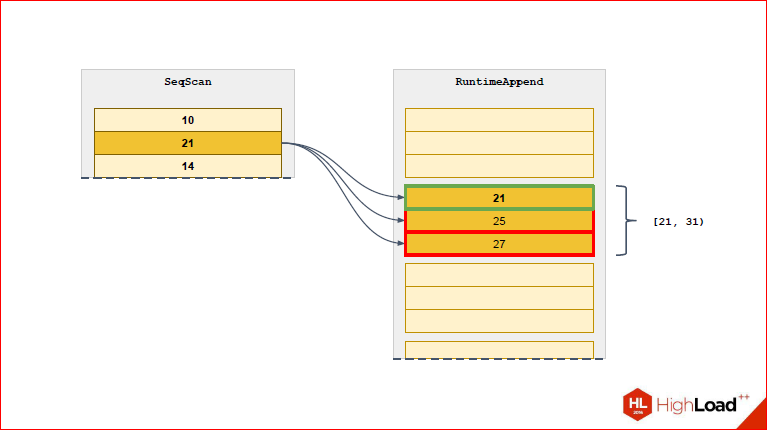
Из следующей строчки выберется новая партиция.
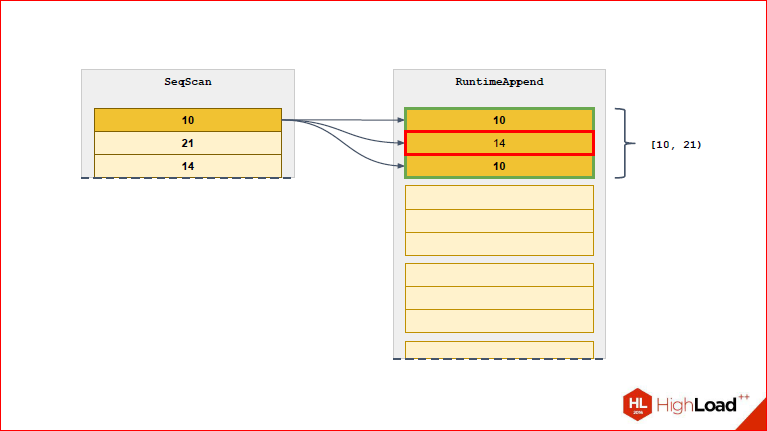
Т.о. мы постоянно будем сужать тот список партиций, который нам нужен, до действительно необходимого.

Соответственно, в каких случаях это применимо? Я решил выписать те запросы, для которых это действительно актуально, т.е. мы видим, что у нас колонка партицирования приравнивается к чему-то, что мы не в состоянии на этапе планирования узнать. Это какой-то sub-select, причем мы видим, что здесь равно sub-select с лимитом 1, потому что для равенства нужно обязательно вернуть одну строку, мы видим, что также можно делать равно any. В данном случае Postgres это трансформирует как раз в Nested Loop, в котором и будет использоваться RuntimeAppend, который и будет на основе текущего значения, полученного из этого sub-select отсеивать партиции. И мы видим еще один запрос, это напрямую джойн, который мы явно написали. Тут то же самое будет в принципе происходить, потому что это оно и есть. Т.е. последние 2 случая написаны по-разному, но на деле это практически одно и то же.

Следующая наша фича. Давайте теперь подробнее посмотрим, как же мы сделали так, что у нас не нужны триггеры. Назвали мы эту ноду PartitionFilter и, как следует из названия, она фильтрует те партиции, которые нам не нужны.
Давайте посмотрим, вот слева показан EXPLAIN с выключенными COSTS’ами, потому они в данном случае неинтересны, EXPLAIN в случае обычного INSERT. Мы видим, что у нас есть INSERT-нода, у которой дочерняя Result, т.е. какой-то набор данных. Фактически мы видим, что здесь я применял это на generate_series, он создает ноду Result, которые тупо вычисляет эти значения. Справа мы видим, что в план добавилась наша нода, кастомная. Кастомные ноды появились как раз в 9.5. Т.е. мы берем и на этапе планирования модифицируем план так, что между INSERT и источником данных, который он будет вставлять, мы вставляем наш прокси, которому отведена специальная роль.
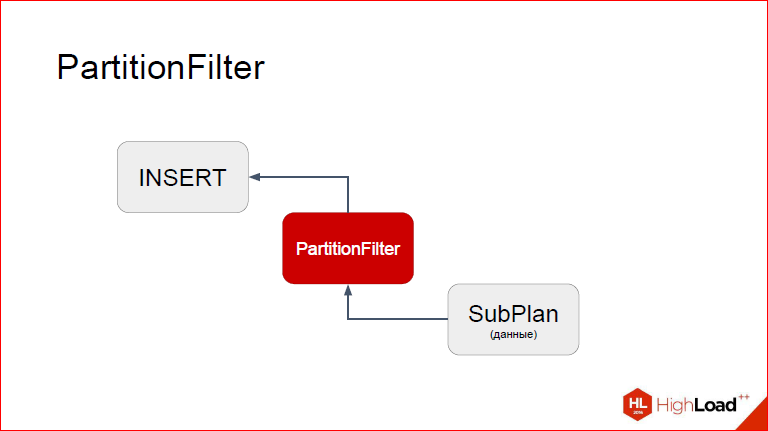
Давайте посмотрим. Так, я думаю, удобней на это все смотреть непривычным взглядом. Итак, сверху INSERT, снизу proxy-нода, а еще ниже SubPlan, из которого будут браться данные. Я сейчас покажу, как это работает поэтапно. Предположим, что INSERT у нас уже начался, дело перешло к PartitionFilter. Напомню, что у вас каждый узел, когда выполняется, в какой-то момент передает управление дочернему узлу, тот – своему дочернему узлу до тех пор, пока самый нижний не сгенерировал кортеж, который он потом будет возвращать снова родителям, т.е. у нас фактически кортеж из недр поднимается наверх. И процесс повторяется до тех пор, пока мы не скажем, что кортежей больше нет. Так вот, представим, что мы уже находимся в PartitionFilter. Что мы здесь делаем? Что нужно учесть?
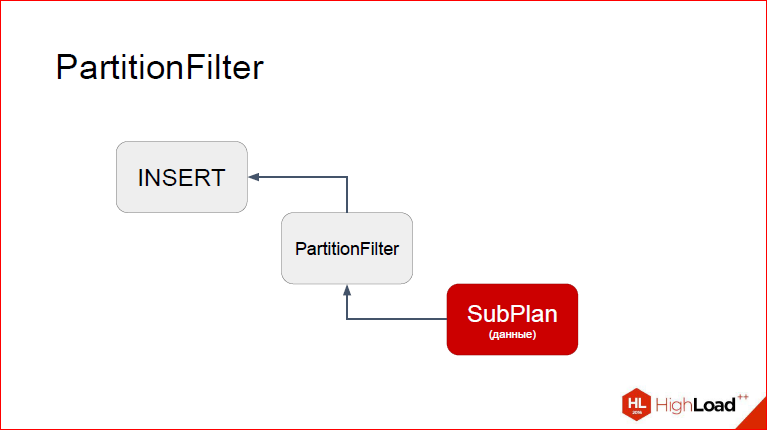
PartitionFilter запустил дочерний план, чтобы взять новый кортеж.
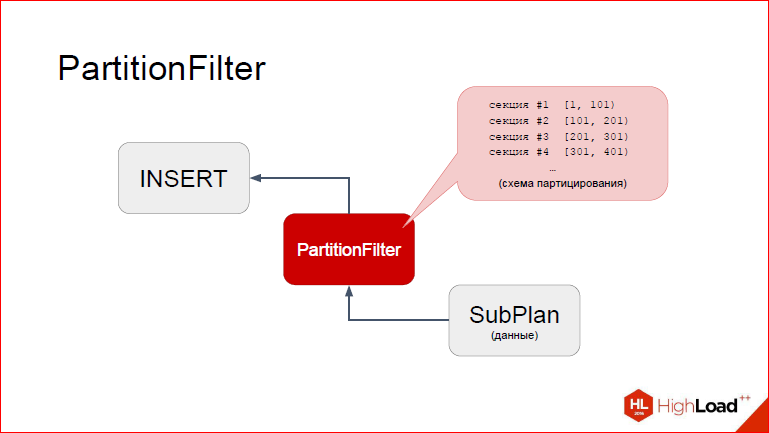
Потом, после того как кортеж взят, управление снова возвращается в PartitionFilter, и тут мы видим, что PartitionFilter имеет доступ к кэшированной информации о партицировании, т.е. он про все наши секции партицированной таблицы имеет вполне конкретное представление, он видит, какие у них диапазоны. Я схематично это изобразил в виде перечня. Что мы можем с этим сделать?
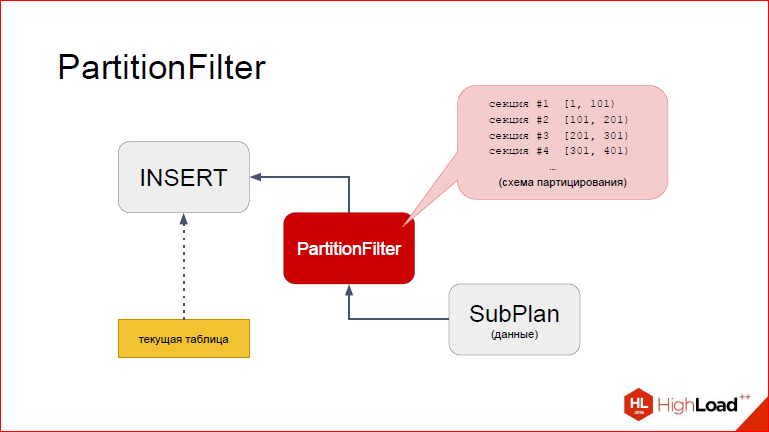
На самом деле, в Postgres есть еще один элемент, который мы сейчас добавили на слайд. Дело в том, что INSERT не просто с бухты-барахты определяет, куда вставлять. Есть определенная структура во время исполнения, которая заполняется неким дескриптором таблицы.
Дескриптор что содержит? Он содержит в себе, грубо говоря, путь к таблице, какие по ней есть индексы и другую дополнительную информацию. Например, для FDW он будет содержать список методов, которые нужны для того, чтобы с FDW что-то делать, INSERT’ить там. Именно поэтому PartitionFilter и работает с FDW, что фактически мы там еще небольшую обвязку наколдовали. Но методика остается та же самая.
Кстати, мы выложили в открытый доступ видеозаписи последних пяти лет конференции разработчиков высоконагруженных систем HighLoad++. Смотрите, изучайте, делитесь и подписывайтесь на канал YouTube.
И что PartitionFilter’у нужно сделать на основе этих перечня секций и данных из запроса. Мы используем ту же самую механику для вычисления WHERE-условия, только дерево у нас тривиальное, у нас просто константа, которую мы примеряем. Так вот, все что ему нужно сделать, это в этой структуре заменить таблицу, которую подставил Postgres в процессе планирования на ту, которая нам нужна. А именно партицию.
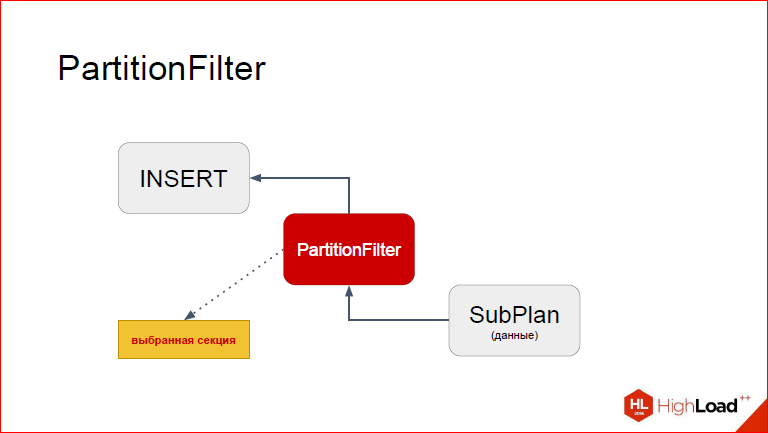
После того, как мы ее заменили, управление возвращается в INSERT, и он уже видит другую таблицу.
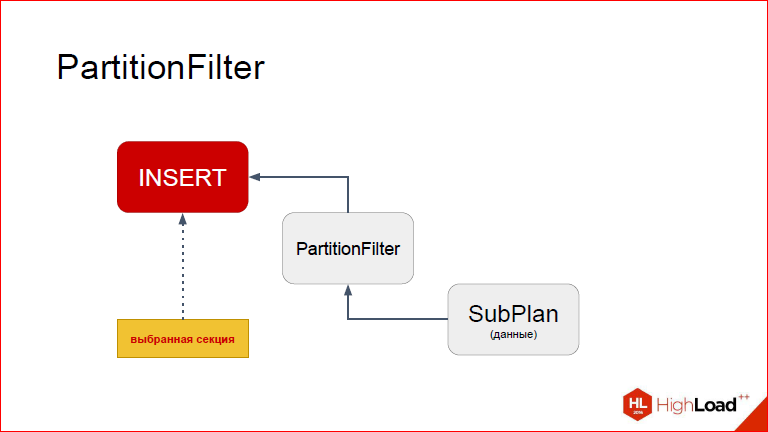
Т.е. для него на самом деле как произошло? Он впал в кому, он дождался, когда вернулись данные, после чего: «О, я вижу таблицу, я в нее инсерчу». И это получается наша партиция.

Так какие плюсы у нас? Во-первых, действительно быстрая вставка данных без триггеров, без PL/pgSQL или даже написанных на C, потому что если мы напишем какую-то функцию на C в Postgres, то там добавляются накладные расходы на особую конвенцию вызовов. В принципе, даже если мы напишем на C, так быстро не получится, как с помощью ноды. И, помимо всего прочего, как я уже сказал, работает Returning, и мы видим, сколько строк мы реально вставили. Собственно, триггеры многим людям все равно нужны, поэтому эта нода ничего не ломает в этом плане, триггеры вы по-прежнему можете использовать, и с ними все хорошо.
Александр Коротков: Т.е. можно сделать триггеры на родителе, и он будет вызываться при вставке в любую секцию.
Дмитрий Иванов: Это все по-прежнему работает, но с такой прекрасной примочкой. А теперь давайте посмотрим на это дело.
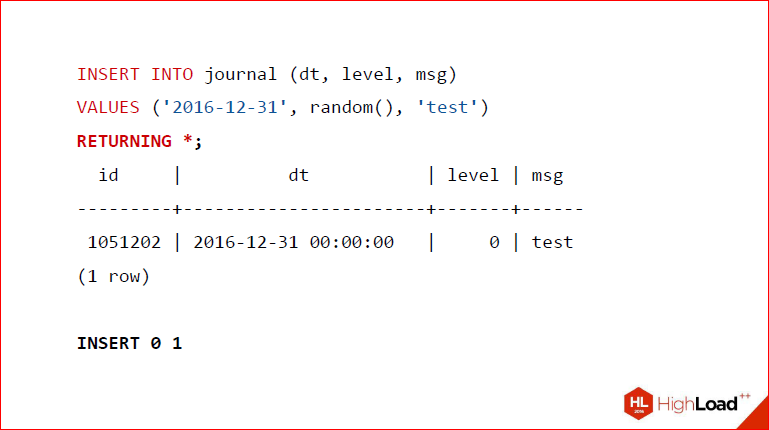
Вот мы вставляем в таблицу journal значение, потом делаем RETURNING и – вуаля – у нас возвращается то, что мы сейчас вставили, да еще и пишется сколько-то строк.
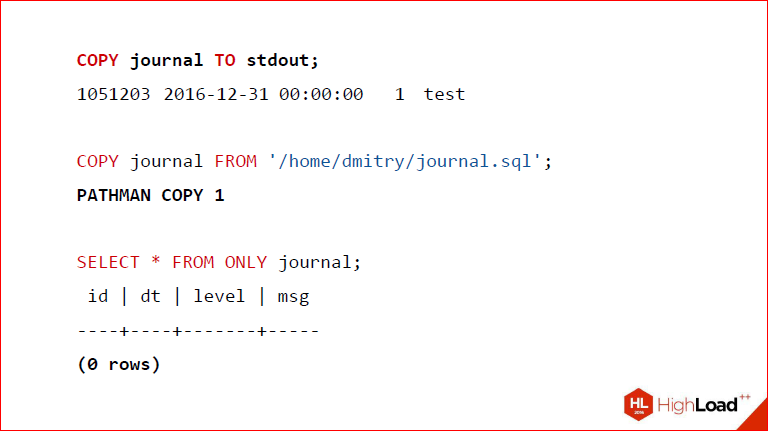
Далее, как я уже сказал, тот же самый механизм используется для COPY, только вся разница в том, что у нас не дочерний план, а мы этот кортеж получили из файла stdin или из файла, который лежит на диске, но имейте ввиду, это только суперюзеру можно делать. Собственно, я здесь это и показал, что у нас работает вывод stdout, у нас работает вставка в таблицу из файла, причем, чтобы никого не смущать и, чтобы всем было предельно понятно, мы изменяем стандартное название оператора, который возвращается, мы пишем PATHMAN COPY. Т.о. если вам, допустим, это поведение не нравится, вы можете его отключить, у вас все будет по-прежнему.
Александр Коротков: Он скопирует у родителя.
Дмитрий Иванов: Это просто convenience. И, наконец, мы видим, в качестве доказательства, что когда мы делаем SELECT * FROM ONLY, а ONLY – это значит, что мы берем только из родителя, у нас 0 строк, ничего там нет.

Теперь давайте перейдем к бенчмаркам. Что мы здесь сделали? Мы создали эту таблицу journal. Заполнили ее какими-то данными. Так какие же бенчмарки мы будем проводить, что будем сравнивать? Раз уж речь зашла о partman, мы сравним partman, pathman и обычную непартицированную таблицу, чтобы знать, а что мы все-таки потеряли после этих изменений.
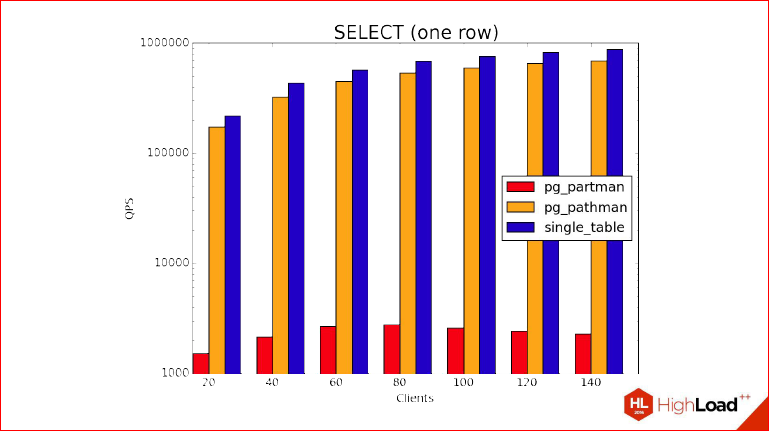
Давайте и посмотрим. Здесь показан SELECT, который возвращает нам одну строку. Сколько мы создали партиций? Мы создали 366 партиций, как дней в високосном году. И в чем дизайн этого бенчмарка, в чем идея? Мы не используем здесь prepared statement, нам интересно знать накладные расходы, которые произошли, когда мы планировали план.
Понятное дело, что учитывая тот факт, что мы создали там индексы, обложились ими по всем партициям, то, чтобы вернуть одну строку, на это уйдет очень мало времени по сравнению с тем, сколько реально будет длиться планирование. И обратите внимание, что на графике показана логарифмическая шкала, т.е. часть partman отстает на 2 порядка. Partman находится где-то на дне.
Александр Коротков: По вертикали это QPS – число запросов в секунду обрабатываются. Но тут еще нужно обратить внимание, что здесь мы тестируем худший случай для партицирования, т.е. это случай, когда мы равномерно убираем случайную партицию, потому что на самом деле, если будет локализовано – какая-нибудь чаще, какая-нибудь реже, то результаты будут лучше, и может быть партицированный вариант даже начнет выигрывать по сравнению с одной таблицей.
Дмитрий Иванов: В общем, не испытывайте ложных иллюзий каких-то, это действительно показан терминальный случай, когда съедается именно планированием, а не исполнением, за счет этой одной строки. И давайте покажем другой график.
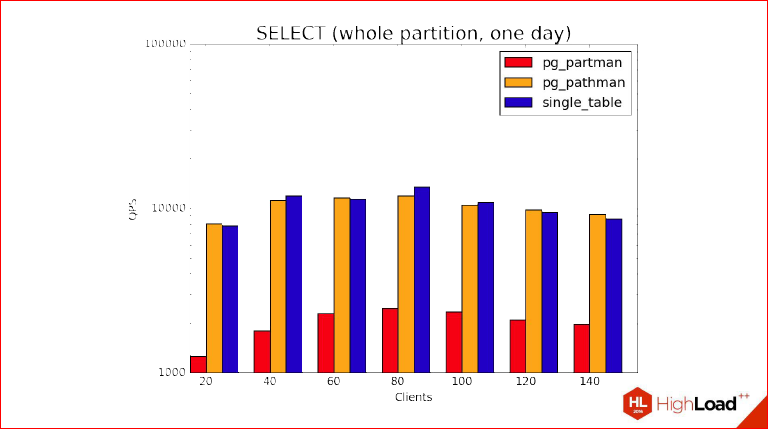
Это уже, когда мы возвращаем данные из одного дня. Т.е. мы берем одну партицию целиком, один день, и видим, что здесь действительно QPS очень хорошо просел, тем не менее, что называется ноздря в ноздрю идут обычная таблица непартицированная и pathman, но partman по-прежнему отстает, причем, как вы можете заметить, они все упираются в особенности нашего сервера, на пике они находятся там, где у нас 72 ядра где-то. Partman точно так же себя ведет, но хуже за счет его особенностей.
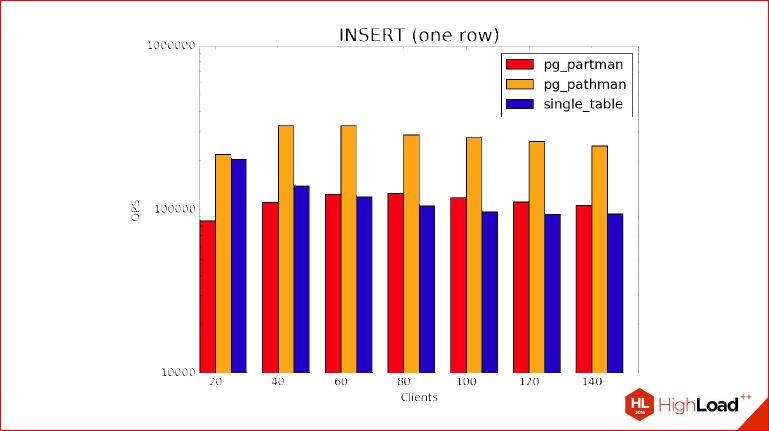
Теперь давайте за бенчмарком INSERT. И это та самая интересная часть, о которой я говорил, потому что тут мы видим, что за счет особенностей партицирования, той магии, которую мы применили в PartitionFilter, мы видим, что INSERT’ы в партицированную таблицу становятся быстрее, чем в непартицированную, потому что этому можно придумать достаточно много объяснений, начав с того, что у нас есть здоровый индекс по родителю, а на партициях он, естественно, будет на порядки меньше.
Александр Коротков: Здоровый индекс и при этом в нем есть неплохая конкуренция за его страницы, за root’овую страницу, в которую все постоянно пинят, лочат, разлочивают и т.д.
Дмитрий Иванов: И, конечно, это неединственная, т.е. если бы мы рассматривали не INSERT’ы в вакууме, где мы только их INSERT’им, а точно также использовали Free Space Map, то тут еще хуже было. И Visibility Map тоже не забывайте. Короче, видим, что pathman лидирует в этом тесте.
Я забыл добавить, что этот тест был выполнен с помощью pg_bench с опцией -M prepared, т.е. это именно prepared statement, т.е. не нужно думать, что время здесь съедается планированием. Планирование вообще не играет никакой роли, потому что INSERT очень просто планируется, там конкурентов быть не может, он очень быстро создает generic plan, который должен INSERT’ить, время на планирование на каждом запросе не тратится вообще, и этот бенчмарк позволяет оценить именно накладные расходы при выборе партиции. И, плюс ко всему, эти особенности с индексами. В реальном случае мы используем много индексов и, вообще, используем индексы, поэтому стоит иметь это в виду.
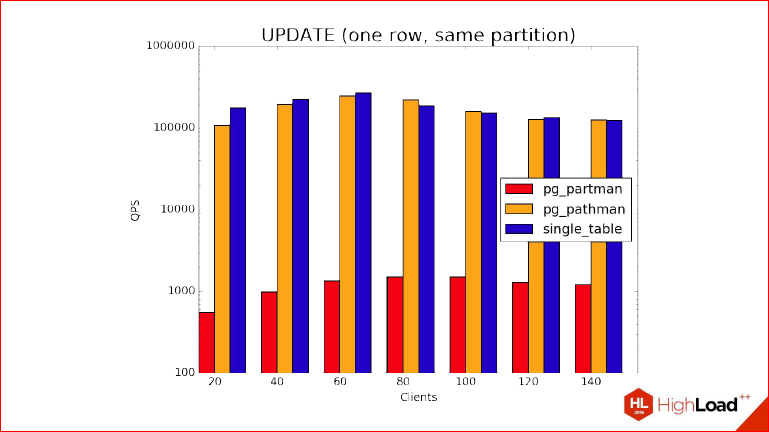
И наконец, UPDATE. Точно так же мы видим, вполне закономерно, что partman находится внизу, и в то же самое время pathman и обычная несекционированная таблица тоже идут ноздря в ноздрю. Что мы здесь делаем? Пояснение небольшое к бенчмарку – здесь мы не используем prepared statement, потому что UPDATE не работает как INSERT, UPDATE действительно планирует все для дочерних партиций, т.е. INSERT подразумевается, что он вообще в природе в Postgres может только в одну таблицу вставлять за 1 раз, то с UPDATE все не так. Вы увидите, что у вас UPDATE такой волшебный, что у него очень много таблиц, которые он одновременно UPDATE’тит. Так вот, мы не используем prepare statement, потому что тогда не получится показать преимущества pathman в этом случае.
Александр Коротков: Короче говоря, у нас UPDATE пока с preapare statement’ом не оптимизируется, но мы это в дальнейшем поправим.
Дмитрий Иванов: А сейчас, он если видит, что реально пересечение по условию перешло в одну партицию, то он автоматически заменяет родителя ею и вставляет в нее. Мы видим, что они действительно лидируют, несекционированная таблица и обычная, а partman – нет.

Если вы заходили в Сашин блог, вы могли видеть примерно такие бенчмарки, но тут был более серьезный сервер.
Александр Коротков: Тут бенчмарки на более мощном сервере, с более новым pathman, результаты улучшились.
Дмитрий Иванов: Условия ближе намного к боевым. Но? естественно, бенчмарки были бы неполными, если бы мы не попробовали RuntimeAppend в деле. Здесь использована другая таблица. Пробовали мы в 2-х случаях, я не случайно выделил 2 переменные, всего мы в таблицу вставляли 100 млн. строк, они были не шибко сложные, там всего лишь текстовое поле, там вставлялось md 5, случайное число и просто int. Но, тем не менее, мы создавали так секции, чтобы всего в таблице получалось 100 млн. строк, а секций было 500 и 1000. Я думаю, этого достаточно для того, чтобы примерно прикинуть, что получится. Т.е. вы можете судить, что в одном случае будет чуть больше кортежей в секции, в другом – чуть меньше. Тут точно так же созданы индексы по колонкам, чтобы, когда мы делаем запрос, у нас опять же использовался Index Scan, и мы могли бы посмотреть не на то, как у нас эффективно или неэффективно берутся кортежи, а действительно на то, как там выбрать. Опять же, мы получаем, что строки здесь не играют большой роли, именно все дело в том, чтобы выбрать партиции правильно.
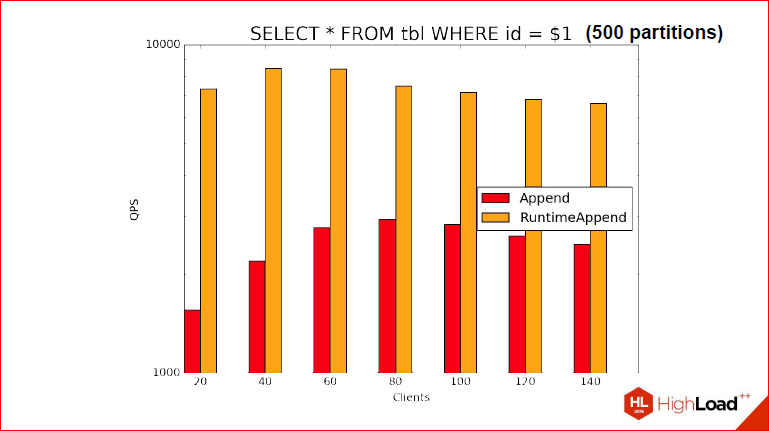
Тут уже не все так радужно, во-первых, потому что в тот раз, как вы помните, 366 секций было, здесь уже 500 и 1000, да еще и preapare statement мы использовали. Т.е. я напрямую демонстрирую то, что мы на предыдущих слайдах показали, у нас используется select. С prepared statement, т.е. на этапе планирования еще неизвестно какую секцию мы выберем. Мы не можем знать и QPS у нас не очень большой, но все равно видно, что…
Александр Коротков: … что в несколько раз быстрее, чем обычный Append, а не RuntimeAppend.
Дмитрий Иванов: Как вы можете видеть, у нас для RuntimeAppend получилось где-то 8900, а для обычного Append получилось 800, около того.
Александр Коротков: Это на самом деле такие результаты на prepared statment. У меня в блоге был тест, где Nested Loop Join там получше получается выигрыш за счет того, что мы для Nested Loop Join спланировали RuntimeAppend только один раз, а дальше его мы много раз выполнили. И тут выигрыш за счет того, что мы сразу выбрали нужную партицию только для нее исполнили запрос, он гораздо больше, оказывается.
Дмитрий Иванов: В принципе, это неплохая отправная точка, чтобы дальше смотреть.
Александр Коротков: Тут еще особенность, связанная с тем, что даже несмотря на то, что мы один раз спланировали prepared statement, нам все равно нужно каждый раз, когда мы его начинаем экзекьютить, все равно все партиции залочить. И за счет этого не на 100% удается это преимущество использовать и, опять же, мы уперлись в те механизмы расширяемости, которые мы используем, но уже с помощью патча к ядру, это можно будет зарешать.
Дмитрий Иванов: Мы хотим в нашем дистрибутиве решить эту проблему.
Александр Коротков: Также там будет на 2 порядка выигрыш по сравнению с Append.
Дмитрий Иванов: Еще раз, в стандартном планировании мы не можем использовать таблицы, если мы не знаем, что они существуют, как раз за счет конкурентности, поэтому вынужденная мера, что при начале выполнения мы должны проверить, что план валиден, все заблокировать. Когда мы действительно решим эту проблему, так что лок будет браться только, когда дело дойдет до этой партиции. Тогда можно будет с уверенностью сказать, что бенчмарки станут еще лучше.
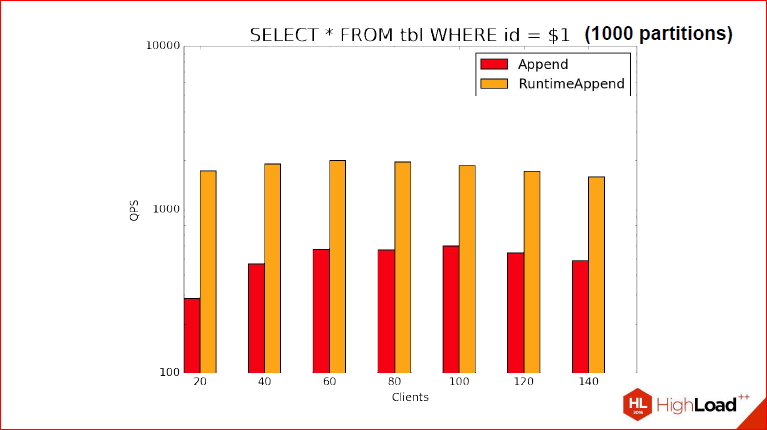
2-ой бенчмарк. Тут мы используем 1000 партиций, и видно, что QPS просел, но кардинально ситуация не изменилась, т.е. просел, что RuntimeAppend, что обычный Append, но преимущество по-прежнему сохраняется и даже в том же порядке.
Какие мы можем сделать из этого выводы?

Александр Коротков: То, что pathman у нас дает достаточно богатую функциональность, и высокую производительность по сравнению с теми решениями на базе наследования, которые до него существовали, и его уже можно брать и просто им пользоваться.
Был у нас релиз 1.0, сейчас баги потихоньку исправляем, сейчас уже 1.2 релиз. Мы поддерживаем его на GitHub и все issue, которые нам кидают, мы очень оперативно исправляем.
Отдельно хочется сказать про декларативное партицирование, патч который есть на камит фесте, мы за этим следим, но в хакерсах все продвигается достаточно медленно, поэтому мы сейчас сосредоточились на pathman. Когда декларативный партишининг базовая версия будет закоммичена мы туда потихоньку начнем свои наработки портировать, потому что наработок у нас, как вы видели, достаточно много. И когда декларативное партицирование достигнет нашей функциональности хотя бы текущего pathman, это будет год 2018 где-нибудь, потому что в десятку уже в лучшем случае войдет только базовый декларативный синтаксис.
Дмитрий Иванов: Не стоит забывать, что мы к тому моменту еще наверняка что-нибудь придумаем.
Александр Коротков: Еще что-нибудь придумаем, но мы за декларативным синтаксисом следим и думаем даже перенести его к себе в свой форк, чтобы внутри все это исполнялось pathman’ом, теми механизмами, про которые мы вам рассказали.
Дмитрий Иванов: И дело в том, что мы занимаемся вообще разработками Postgres, это не единственная фича, которую можно в синергию с pathman внести. Например, Настя Лубейникова создает read only таблицы и представьте, как можно их соединить вместе pathman, что если у вас большой сегмент read only данных, скажем, процентов 80-90, вы берете и просто помечаете эти таблицы как read only, по ним отключается вакуум, по ним отключается все, что не нужно, т.е. производительность становится еще выше и дополнительно вы защищаетесь от ненужных потенциальных INSERT’ов. Т.е. используя все эти сопряжения фич, мы можем получить еще более мощный инструмент.
Александр Коротков: У нас еще есть бинарная миграция таблиц между серверами. Таблицу можно дампом, рестором перезагрузить, но это сравнительно долго, потому что там COPY вначале сделать, потом индексы все будут строиться, а то, что Настя сделала, это можно просто бинарные файлы перенести на другой сервер, там их подцепить, и таблицы будут работать намного быстрее и т.о. можно, например, взять какую-нибудь архивную таблицу, очень быстро вынести на другой сервер и подключить через FDW.
Дмитрий Иванов: И еще одна фича, про которую я забыл упомянуть – это то, что все это дело транзакционное. У нас изначально первая топорная модель, Proof Of Concept использовала Shared Memory, но теперь у нас, во-первых, кэш по образу и подобию того, который используется в Postgres, т.е. там перед бэкендом идет кэширование, а, во-вторых, чтобы реализовать все это дело правильно, Саша предположил, что логичней всего подключаться напрямую к тому кэшу, который есть в Postgres, там есть хуки, и мы создаем свой собственный хук, который, когда у нас инвалидируется…
Александр Коротков: Если не вдаваться в детали, то просто, все транзакционно у нас. Вы можете взять, начать транзакцию, распартицировать таблицу, откатиться и у вас снова будет все, как было.
Дмитрий Иванов: И все должно работать by design.
Контакты
» Блог компании Postgres Professional
Этот доклад — расшифровка одного из лучших выступлений на профессиональной конференции разработчиков высоконагруженных систем HighLoad++ 2016.
Сейчас мы уже вовсю готовим конференцию 2017-года — приём докладов уже закрыт и Программный комитет приступает к своей работе
fingoldo
Хороший материал, жаль, в тестах нет сравнения с «родным» партицированием, появившимся в Postgresql 10.0 (беты ведь уже доступны для скачивания)
smagen
Сравнение будет. Доклад делался в прошлом году, и на тот момент declarative partitioning ещё не был закоммичен.