
— Сегодня я расскажу об открытых проблемах в области речевых технологий. Но прежде всего давайте поймем, что речевые технологии стали неотъемлемой частью нашей жизни. Идем ли мы по улице или едем в автомобиле — когда хочется нам задать тот или иной запрос в поисковую систему, естественно сделать это голосом, а не печатать или еще что-либо.
Сегодня я поговорю в основном о распознавании речи, хотя есть множество других интересных задач. Рассказ мой будет состоять из трех частей. Для начала напомню в целом, как работает распознавание речи. Дальше расскажу, как люди стараются его улучшить и о том, какие в Яндексе стоят задачи, с которыми обычно не сталкиваются в научных статьях.
Общая схема распознавания речи. Изначально на вход нам поступает звуковая волна.

Ее мы дробим на маленькие кусочки, фреймы. Длина фрейма — обычно 25 мс, шаг — 10 мс. Они идут с некоторым захлестом.
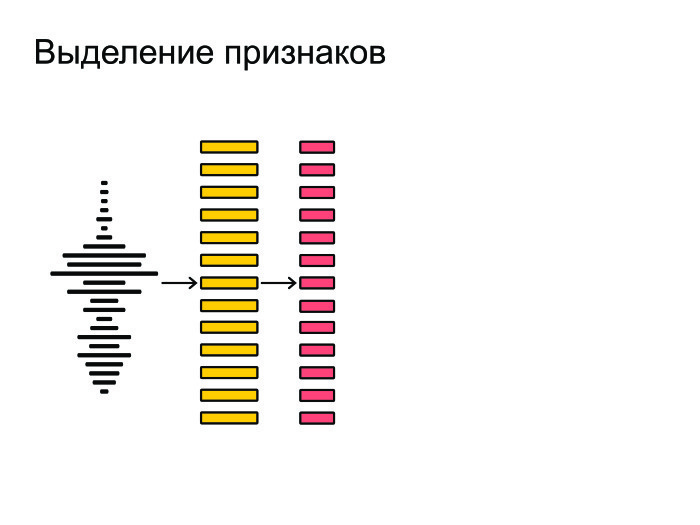
После этого из фреймов мы извлекаем наиболее важные признаки. Допустим, нам не важен тембр голоса или пол человека. Мы хотим распознавать речь вне зависимости от этих факторов, так что мы извлекаем самые важные признаки.
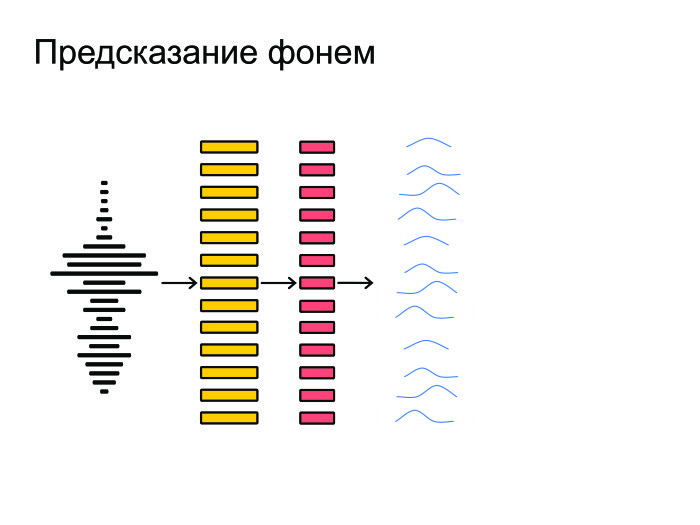
Затем нейронная сеть натравливается на все это и выдает на каждом фрейме предсказание, распределение вероятностей по фонемам. Нейронка старается угадать, какая именно фонема была сказана на том или ином фрейме.
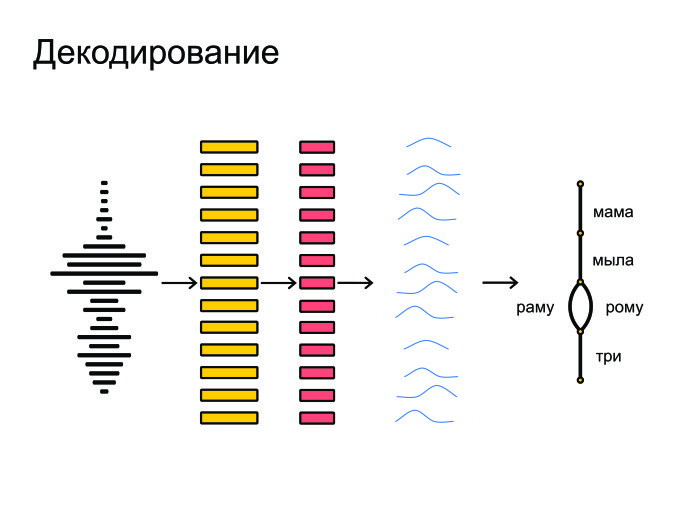
Под конец все это запихивается в граф-декодирование, которое получает распределение вероятностей и учитывает языковую модель. Допустим, «Мама мыла раму» — более популярная фраза в русском языке, чем «Мама мыла Рому». Также учитывается произношение слов и выдаются итоговые гипотезы.
В целом, именно так и происходит распознавание речи.
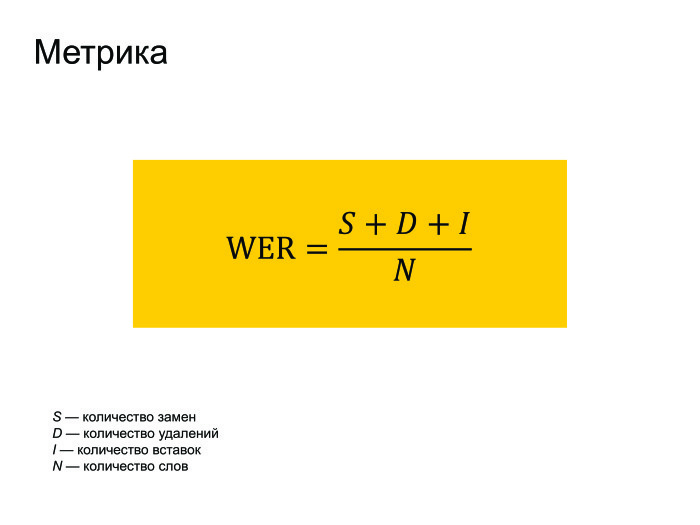
Естественно, о метрике нужно пару слов сказать. Все используют метрику WER в распознавании речи. Она переводится как World Error Rate. Это просто расстояние по Левенштейну от того, что мы распознали, до того, что реально было сказано в фразе, поделить на количество слов, реально сказанных во фразе.
Можно заметить, что если у нас было много вставок, то ошибка WER может получиться больше единицы. Но никто на это не обращает внимания, и все работают с такой метрикой.

Как мы будем это улучшать? Я выделил четыре основных подхода, которые пересекаются друг с другом, но на это не стоит обращать внимания. Основные подходы следующие: улучшим архитектуру нейронных сетей, попробуем изменить Loss-функцию, почему бы не использовать подходы End to end, модные в последнее время. И в заключение расскажу про другие задачи, для которых, допустим, не нужно декодирование.
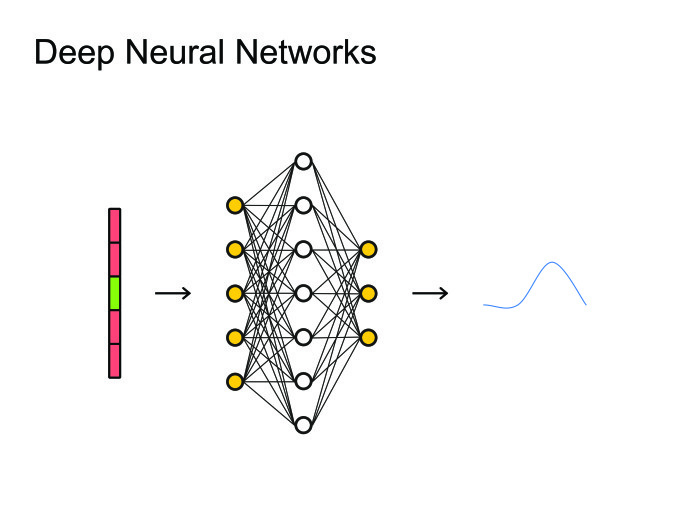
Когда люди придумали использовать нейронные сети, естественным решением было использовать самое простое: нейронные сетки feed forward. Берем фрейм, контекст, сколько-то фреймов слева, сколько-то справа, и предсказываем, какая фонема была сказана на данном фрейме. После чего можно посмотреть на все это как на картинку и применить всю артиллерию, уже использованную для обработки изображений, всевозможные сверточные нейронные сети.
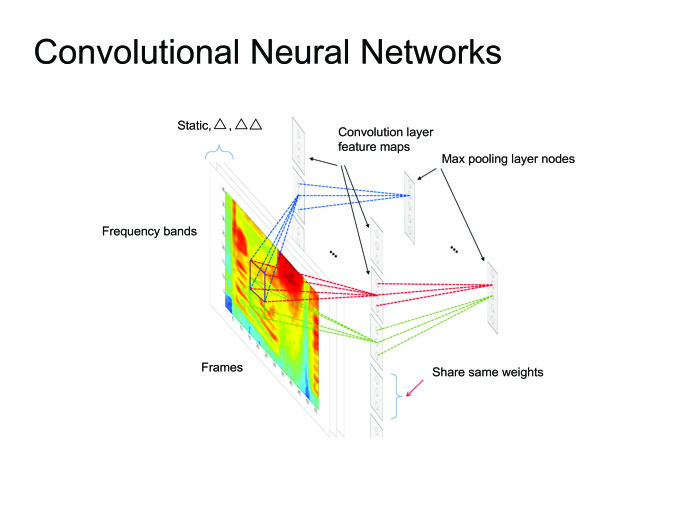
Вообще многие статьи state of the art получены именно с помощью сверточных нейронных сетей, но сегодня я расскажу больше о рекуррентных нейронных сетях.
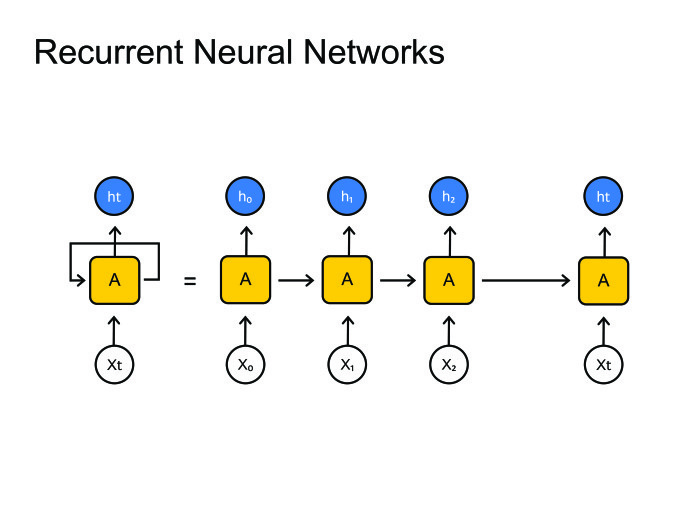
Рекуррентные нейронные сети. Все знают, как они работают. Но возникает большая проблема: обычно фреймов намного больше, чем фонем. На одну фонему приходится 10, а то и 20 фреймов. С этим нужно как-то бороться. Обычно это зашивается в граф-декодирование, где мы остаемся в одном состоянии много шагов. В принципе, с этим можно как-то бороться, есть парадигма encoder-decoder. Давайте сделаем две рекуррентных нейронных сетки: одна будет кодировать всю информацию и выдавать скрытое состояние, а декодер будет брать это состояние и выдавать последовательность фонем, букв или, может быть, слов — это как вы натренируете нейронную сеть.
Обычно в распознавании речи мы работаем с очень большими последовательностями. Там спокойно бывает 1000 фреймов, которые нужно закодировать одним скрытым состоянием. Это нереально, ни одна нейронная сеть с этим не справится. Давайте использовать другие методы.
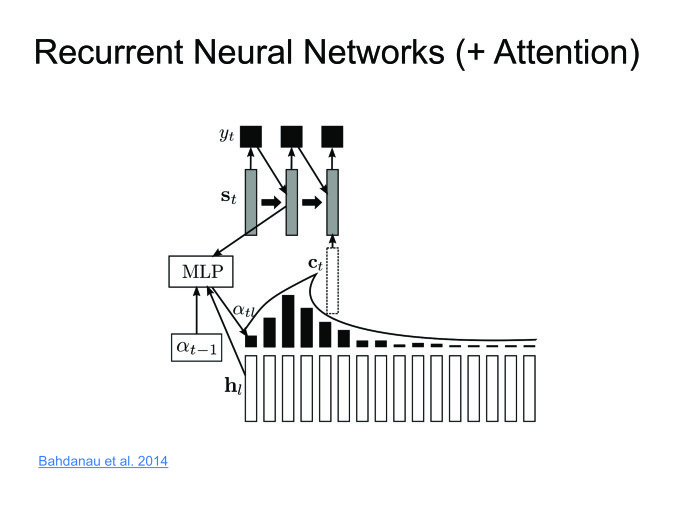
Димой Богдановым, выпускником ШАД, был придуман метод Attention. Давайте encoder будет выдавать скрытые состояния, и мы их не будем выкидывать, а оставим только последнее. Возьмем взвешенную сумму на каждом шаге. Декодер будет брать взвешенную сумму скрытых состояний. Таким образом, мы будем сохранять контекст, то, на что мы в конкретном случае смотрим.
Подход прекрасный, работает хорошо, на некоторых датасетах дает результаты state of the art, но есть один большой минус. Мы хотим распознавать речь в онлайне: человек сказал 10-секундную фразу, и мы сразу ему выдали результат. Но Attention требует знать фразу целиком, в этом его большая проблема. Человек скажет 10-секундную фразу, 10 секунд мы ее будем распознавать. За это время он удалит приложение и никогда больше не установит. Нужно с этим бороться. Совсем недавно с этим поборолись в одной из статей. Я назвал это online attention.
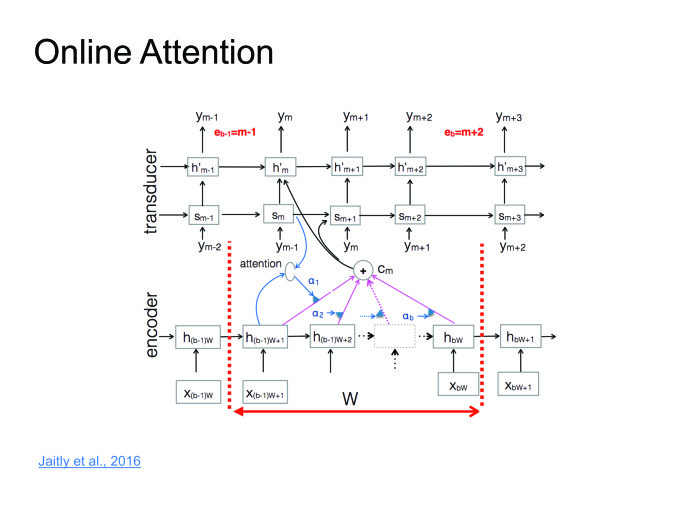
Давайте поделим входную последовательность на блоки какой-то небольшой фиксированной длины, внутри каждого блока устроим Attention, затем будет декодер, который выдает на каждом блоке соответствующие символы, после чего в какой-то момент выдает символ end of block, перемещается к следующему блоку, поскольку мы тут исчерпали всю информацию.
Тут можно серию лекций прочитать, я постараюсь просто сформулировать идею.

Когда начали тренировать нейронные сети для распознавания речи, старались угадывать фонему. Для этого использовали обычную кросс-энтропийную функцию потерь. Проблема в том, что даже если мы соптимизируем кросс-энтропию, это еще не будет значить, что мы хорошо соптимизировали WER, потому что у этих метрик корреляция не 100%.
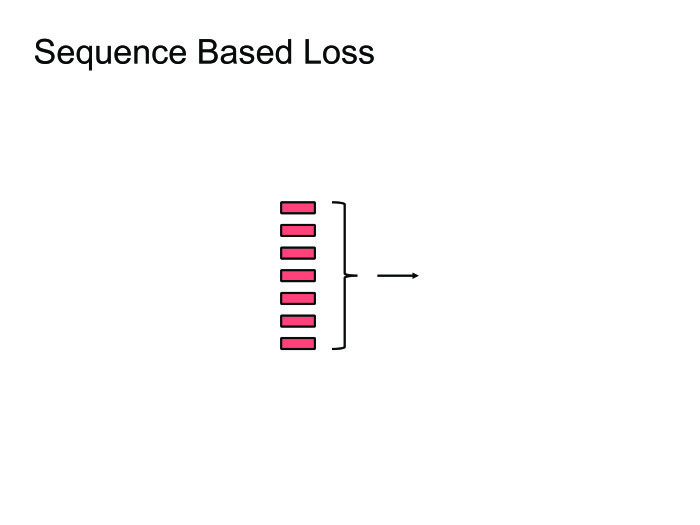
Чтобы с этим побороться, были придуманы функции Sequence Based Loss: давайте саккумулируем всю информацию на всех фреймах, посчитаем один общий Loss и пропустим градиент обратно. Не буду вдаваться в детали, можете прочитать про CTC или SNBR Loss, это очень специфичная тема для распознавания речи.
В подходах End to end два пути. Первый — делать более «сырые» фичи. У нас был момент, когда мы извлекали из фреймов фичи, и обычно они извлекаются, стараясь эмулировать ухо человека. А зачем эмулировать ухо человека? Пусть нейронка сама научится и поймет, какие фичи ей полезны, а какие бесполезны. Давайте в нейронку подавать все более сырые фичи.
Второй подход. Мы пользователям выдаем слова, буквенное представление. Так зачем нам предсказывать фонемы? Хотя их предсказывать очень естественно, человек говорит в фонемах, а не буквах, — но итоговый результат мы должны выдать именно в буквах. Поэтому давайте предсказывать буквы, слоги или пары символов.
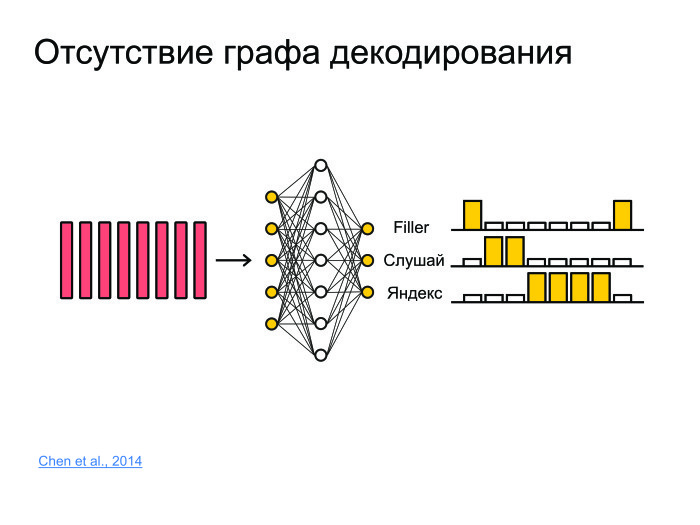
Какие еще есть задачи? Допустим, задача фреймспоттинга. Есть какой-нибудь кусок звука, откуда надо извлечь информацию о том, была ли сказана фраза «Слушай, Яндекс» или не была. Для этого можно фразу распознать и грепнуть «Слушай, Яндекс», но это очень брутфорсный подход, причем распознавание обычно работает на серверах, модели очень большие. Обычно звук отсылается на сервер, распознается, и распознанная форма высылается обратно. Грузить 100 тыс. юзеров каждую секунду, слать звук на сервер — ни одни сервера не выдержат.
Надо придумать решение, которое будет маленьким, сможет работать на телефоне и не будет жрать батарейку. И будет обладать хорошим качеством.
Для этого давайте всё запихнем в нейронную сеть. Она просто будет предсказывать, к примеру, не фонемы и не буквы, а целые слова. И сделаем просто три класса. Сеть будет предсказывать слова «слушай» и «Яндекс», а все остальные слова замапим в филлер.
Таким образом, если в какой-то момент сначала шли большие вероятности для «слушай», потом большие вероятности для «Яндекс», то с большой вероятностью тут была ключевая фраза «Слушай, Яндекс».

Задача, которая не сильно исследуется в статьях. Обычно, когда пишутся статьи, берется какой-то датасет, на нем получаются хорошие результаты, бьется state of the art — ура, печатаем статью. Проблема этого подхода в том, что многие датасеты не меняются в течение 10, а то и 20 лет. И они не сталкиваются с проблемами, с которыми сталкиваемся мы.
Иногда возникают тренды, хочется распознавать, и если этого слова нет в нашем графе декодирования в стандартном подходе, то мы никогда его не распознаем. Нужно с этим бороться. Мы можем взять и переварить граф декодирования, но это трудозатратный процесс. Может, утром одни трендовые слова, а вечером другие. Держать утренний и вечерний граф? Это очень странно.

Был придуман простой подход: давайте к большому графу декодирования добавим маленький граф декодирования, который будет пересоздаваться каждые пять минут из тысячи самых лучших и трендовых фраз. Мы просто будем параллельно декодировать по этим двум графам и выбирать наилучшую гипотезу.
Какие задачи остались? Там state of the art побили, тут задачи решили… Приведу график WER за последние несколько лет.
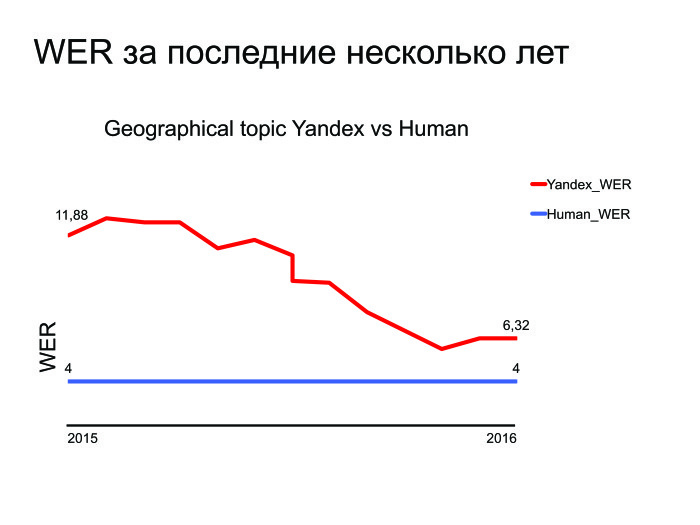
Как видите, Яндекс улучшился за последние несколько лет, и тут приводится график для лучшей тематики — геопоиска. Вы можете понять, что мы стараемся и улучшаемся, но есть тот маленький разрыв, который нужно побить. И даже если мы сделаем распознавание речи — а мы его сделаем, — которое сравнится со способностями человека, то возникнет другая задача: это сделалось на сервере, но давайте перенесем это на устройство. Речь идет об отдельной, сложной и интересной задаче.
У нас есть и множество других задач, о которых меня можно спросить. Спасибо за внимание.
Комментарии (8)

TiesP
10.09.2017 20:16Ещё такой вопрос — а обрабатывается каким-то образом при распознавании речь с акцентом?
Например, это может быть либо своеобразный говор, когда некоторые фонемы по-другому произносятся. Либо некоторые слова могут произноситься с ошибками.
erwins22
11.09.2017 08:31делать что то типа железного тензорного процессора не собрались?
Нагрузка именно на тензорное вычисление у вас получится большой…

sterling239
11.09.2017 12:29А как синтез речи в яндексе происходит? Насколько я знаю, есть два с половиной подхода: компоновать заранее записанные фонемы, генерировать спектрограмму, и работающий в 100 раз медленнее реалтайма wavenet. Минус первого — безэмоциональность, минус второго — «железность» звука. Что яндекс делает в этом направлении?

Regis
11.09.2017 20:01Какой сейчас лучший WER у open source библиотек? Просто интересно, насколько Яндекс лучше?
Regis
11.09.2017 20:01Насколько результаты распознавания через https://tech.yandex.ru/speechkit/ могут отличаться от распознования приложениями Яндекса?
TiesP
Вы говорите, что фрейм около 25мс, а фонема обычно в неск.раз длиннее. При этом получается несколько одинаковых фонем. Было бы логично как-то складывать одинаковые фреймы и получать на выходе один суммарный. Наверняка слух именно так и работает — пока длиться звук с тембром буквы "а" (например, в течении 100 мс) — раздражается какой-то "условный нейрон", который отвечает за букву "а" :). Не знаю, как это математически описать, но может такой алгоритм как-то уже используется?… и потом для такого алгоритма было бы логично делать фреймы поменьше: ведь средняя основная частота голоса у мужчины ~120Гц, а у женщин ~200Гц. Тогда один период будет примерно 5-8 мс.
Optik
Фреймы обычно делают с перекрытием, потому что нужно уловить не только звуки но и переходы между ними. Длительность всего фрейма 25мс, перекрытие со следующим 15мс.
TiesP
Да, это я понял. За счет этого, наверное, некое суммирование/усреднение происходит. Но не получается "эффекта резонанса", когда несколько одинаковых фреймов подтверждают один и тот же звук (фонему). Для примера изобразил схематично на рисунке. Внизу мы уже после одного фрейма (который между пиками составляет ~5мс) можем определить, к примеру, что это звук "у" и каждый следующий только подтверждает.
А переход на другой звук, наоборот, будет ослаблять нашу текущую фонему (уменьшать вероятность определения как "у"), но он сам по себе не несёт ценной информации… конечно, это совсем другой алгоритм и его надо сначала проверить, прежде чем что-то утверждать :)
https://imgur.com/a/fXGYM