
Привет! Меня зовут Кирилл и я алкоголик более 10 лет был менеджером в сфере ИТ. Я не всегда был таким: во время учебы в МФТИ писал код, иногда за вознаграждение. Но столкнувшись с суровой реальностью (в которой необходимо зарабатывать деньги, желательно побольше) пошел по наклонной — в менеджеры.

Но не все так плохо! С недавнего времени мы с партнерами целиком и полностью ушли в развитие своего стартапа: системы учета клиентов и клиентских заявок Okdesk. С одной стороны — больше свободы в выборе направления движения. Но с другой — нельзя просто так взять и заложить в бюджет "3-х разработчиков на 6 месяцев для проведение исследований и разработки прототипа для…". Много приходится делать самим. В том числе — непрофильные эксперименты, связанные с разработкой (т.е. те эксперименты, что не относятся к основной функциональности продукта).
Одним из таких экспериментов стала разработка алгоритма классификации клиентских заявок по текстам для дальнейшей маршрутизации на группу исполнителей. В этой статье я хочу рассказать, как "не программист" может за 1,5 месяца в фоновом режиме освоить python и написать незамысловатый ML-алгоритм, имеющий прикладную пользу.
Как учиться?
В моём случае — дистанционное обучение на Coursera. Там довольно много курсов по машинному обучению и другим дисциплинам, связанным с искусственным интеллектом. Классикой считается курс основателя Coursera Эндрю Ына (Andrew Ng). Но минус этого курса (помимо того, что курс на английском языке: это не всем по силам) — редкостный инструментарий Octave (бесплатный аналог MATLAB-а). Для понимания алгоритмов это не главное, но лучше учиться на более популярных инструментах.
Я выбрал специализацию "Машинное обучение и анализ данных" от МФТИ и Яндекса (в ней 6 курсов; для того что написано в статье, достаточно первых 2-х). Главное преимущество специализации — это живое сообщество студентов и менторов в Slack-е, где почти в любое время суток есть кто-то, к кому можно обратиться с вопросом.
Что такое "Машинное обучение"?
В рамках статьи не будем погружаться в терминологические споры, поэтому желающих придраться к недостаточной математической точности прошу воздержаться (обещаю, что не буду выходить за рамки приличия :).
Итак, что же такое машинное обучение? Это набор методов для решения задач, требующих каких-либо интеллектуальных затрат человека, но при помощи вычислительных машин. Характерной чертой методов машинного обучения является то, что они "обучаются" на прецедентах (т.е. на примерах с заранее известными правильными ответами).
Более математизированное определение выглядит так:
- Имеется множество объектов с набором характеристик. Обозначим это множество буквой X;
- Есть множество ответов. Обозначим это множество буквой Y;
- Существует (неизвестная) зависимость между множеством объектов и множеством ответов. Т.е. такая функция, которая ставит в соответствие объекту множества X объект множества Y. Назовем её функцией y;
- Имеется конечное подмножество объектов из X (обучающая выборка), для которой известны ответы из Y;
- По обучающей выборке необходимо максимально хорошо приблизить функцию y какой-то функцией a. При помощи функции a мы хотим для любого объекта из X получить с хорошей вероятностью (или точностью — если речь о числовых ответах) верный ответ из Y. Поиск функции a — задача машинного обучения.
Вот пример из жизни. Банк выдает кредиты. У банка накопилось множество анкет заёмщиков, для которых уже известен исход: вернули кредит, не вернули, вернули с просрочкой и т.д. Объектом в этом примере является заемщик с заполненной анкетой. Данные из анкеты — параметры объекта. Факт возврата или невозврата кредита — это "ответ" на объекте (анкете заёмщика). Совокупность анкет с известными исходами является обучающей выборкой.
Возникает естественное желание уметь предсказывать возврат или невозврат кредита потенциальным заемщиком по его анкете. Поиск алгоритма предсказания — задача машинного обучения.
Примеров задач машинного обучения множество. В этой статье подробнее поговорим о задаче классификации текстов.
Постановка задачи
Напомним о том, что мы разрабатываем Okdesk — облачный сервис для обслуживания клиентов. Компании, которые используют Okdesk в своей работе, принимают клиентские заявки по разным каналам: клиентский портал, электронная почта, web-формы с сайта, мессенджеры и так далее. Заявка может относиться к той или иной категории. В зависимости от категории у заявки может быть тот или иной исполнитель. Например, заявки по 1С должны отправляться на решение к специалистам 1С, а заявки связанные с работой офисной сети — группе системных администраторов.
Для классификации потока заявок можно выделить диспетчера. Но, во-первых, это стоит денег (зарплата, налоги, аренда офиса). А во-вторых, на классификацию и маршрутизацию заявки будет потрачено время и заявка будет решена позже. Если бы можно было классифицировать заявку по её содержанию автоматически — было бы здорово! Попробуем решить эту задачу силами машинного обучения (и одного ИТ-менеджера).
Для проведения эксперимента была взята выборка из 1200 заявок с проставленными категориями. В выборке заявки распределены по 14-ти категориям. Цель эксперимента: разработать механизм автоматической классификации заявок по их содержанию, который даст в разы лучшее качество, по сравнению с random-ом. По результатам эксперимента необходимо принять решение о развитии алгоритма и разработке на его базе промышленного сервиса для классификации заявок.
Инструментарий
Для проведение эксперимента использовался ноутбук Lenovo (core i7, 8гб RAM), язык программирования Python 2.7 с библиотеками NumPy, Pandas, Scikit-learn, re и оболочкой IPython. Подробнее напишу об используемых библиотеках:
- NumPy — библиотека, содержащая множество полезных методов и классов для проведения арифметических операций с большими многомерными числовыми массивами;
- Pandas — библиотека, позволяющая легко и непринужденно анализировать и визуализировать данные и проводить операции над ними. Основные структуры данных (типы объектов) — Series (одномерная структура) и DataFrame (двумерная структура; по сути — набор Series одинаковой длины).
- Scikit-learn — библиотека, в которой реализовано большинство методов машинного обучения;
- Re — библиотека регулярных выражений. Регулярные выражения — незаменимый инструмент в задачах, связанных с анализом текстов.
Из библиотеки Scikit-learn нам понадобятся некоторые модули, о предназначение которых я напишу по ходу изложения материала. Итак, импортируем все необходимые библиотеки и модули:
import pandas as pd
import numpy as np
import re
from sklearn import neighbors, model_selection, ensemble
from sklearn.grid_search import GridSearchCV
from sklearn.metrics import accuracy_scoreИ переходим к подготовке данных.
(конструкция import xxx as yy означает, что мы подключаем библиотеку xxx, но в коде будем обращаться к ней через yy)
Подготовка данных
При решении первых реальных (а не лабораторных) задач, связанных с машинным обучением, вы откроете для себя, что основная часть времени уходит не на обучение алгоритма (выбор алгоритма, подбор параметров, сравнение качества разных алгоритмов и т.д.). Львиная доля ресурсов уйдет на сбор, анализ и подготовку данных.
Есть различные приемы, методы и рекомендации по подготовке данных для разных классов задач машинного обучения. Но большинство экспертов называют подготовку данных скорее искусством, чем наукой. Есть даже такое выражение — feature engineering (т.е. конструирование параметров, описывающих объекты).
В задаче классификации текстов "фича" у объекта одна — текст. Скормить его алгоритму машинного обучения нельзя (допускаю, что мне не все известно :). Текст необходимо как-то оцифровать и формализовать.
В рамках эксперимента использовались примитивные методы формализации текстов (но даже они показали неплохой результат). Об этом поговорим далее.
Загрузка данных
Напомним, что в качестве исходных данных у нас есть выгрузка 1200 заявок (распределенных неравномерно по 14 категориям). Для каждой заявки есть поле "Тема", поле "Описание" и поле "Категория". Поле "Тема" — сокращенное содержание заявки и оно обязательно, поле "Описание" — расширенное описание и оно может быть пустым.
Данные загружаем из .xlsx файла в DataFrame. В .xlsx файле много столбцов (параметров реальных заявок), но нам нужны только "Тема", "Описание" и "Категория".
После загрузки данных объединяем поля "Тема" и "Описание" в одно поле для удобства дальнейшей обработки. Для этого предварительно необходимо заполнить чем-нибудь все пустые поля "Описание" (пустой строкой, например).
# Объявляем переменную issues типа DataFrame
issues = pd.DataFrame()
# Добавляем в issues столбцы Theme, Description и Cat, присваивая им значения полей Тема, Описание и Категория из .xlsx файла. u’...’ — потому что ‘…’ есть utf
issues[['Theme', 'Description','Cat']] = pd.read_excel('issues.xlsx')[[u'Тема', u'Описание', u'Категория']]
# Заполняем пустые ячейки столбца Description пустой строкой
issues.Description.fillna('', inplace = True)
# Объединяем столбцы Theme и Description (пробел используем в качестве разделителя) в столбец Content
issues['Content'] = issues.Theme + ' ' + issues.DescriptionИтак, у нас есть переменная issues типа DataFrame, в которой мы будем работать со столбцами Content (объединенное поле для полей "Тема" и "Описание") и Cat (категория заявки). Перейдем к формализации содержания заявки (т.е. столбца Content).
Формализация содержания заявок
Описание подхода к формализации
Как было сказано выше, первым делом необходимо формализовать текст заявки. Формализацию будем проводить следующим образом:
- Разобьем содержание заявки на слова. Под словом понимаем последовательность из 2 или более символов, разделенную символами-разделителями (тире, дефис, точка, пробел, переход на новую строку и т.д.). В итоге для каждой заявки получим массив входящих в её содержание слов.
- Из каждой заявки исключим "слова-паразиты", не несущие смысловую нагрузку (например, слова, входящие во фразы-приветствия: "здравствуйте", "добрый", "день" и т.д.);
- Из полученных массивов составим словарь: набор слов, используемых для написания содержания всех заявок;
- Далее составляем матрицу размером (количество заявок) x (количество слов в словаре), в которой i-я ячейка в j-м столбце соответствует количеству вхождений в i-ю заявку j-го слова из словаря.
Матрица из п.4 есть формализованное описание содержания заявок. Говоря математизированным языком, каждая строка матрицы — координаты вектора соответствующей заявки в пространстве словаря. Для обучения алгоритма будем использовать полученную матрицу.
Важный момент: п.3 осуществляем после того, как выделим из обучающей выборки случайную подвыборку для контроля качества алгоритма (тестовую выборку). Это необходимо для того, чтобы лучше понимать, какое качество алгоритм покажет "в бою" на новых данных (например, не сложно реализовать алгоритм, который на обучающей выборке будет давать идеально верные ответы, но на любых новых данных будет работать не лучше random-а: такая ситуация называется переобучением). Отделение тестовой выборки именно до составления словаря важно потому, что если бы мы составляли словарь в том числе и на тестовых данных, то обученный на выборке алгоритм получился бы уже знакомым с неизвестными объектами. Выводы о его качестве на неизвестных данных будут некорректными.
Теперь покажем, как п.п. 1-4 выглядят в коде.
Разбиваем содержание на слова и убираем слова-паразиты
Первым делом приведем все тексты к нижнему регистру (“принтер” и “Принтер” — одинаковые слова только для человека, но не для машины):
#объявляем функцию приведения строки к нижнему регистру
def lower(str):
return str.lower()
#применяем функцию к каждой ячейке столбца Content
issues['Content'] = issues.Content.apply(lower)Далее определим вспомогательный словарь “слов-паразитов” (его наполнение производилось опытным итерационным путем для конкретной выборки заявок):
garbagelist = [u'спасибо', u'пожалуйста', u'добрый', u'день', u'вечер',u'заявка', u'прошу', u'доброе', u'утро']Объявим функцию, которая разбивает текст каждой заявки на слова длиной 2 и более символов, а затем включает полученные слова, за исключением “слов-паразитов”, в массив:
def splitstring(str):
words = []
#разбиваем строку по символам из []
for i in re.split('[;,.,\n,\s,:,-,+,(,),=,/,«,»,@,\d,!,?,"]',str):
#берём только "слова" длиной 2 и более символов
if len(i) > 1:
#не берем слова-паразиты
if i in garbagelist:
None
else:
words.append(i)
return wordsДля разбиения текста на слова по символам-разделителям используется библиотека регулярных выражений re и её метод split. В метод split передается массив символов-разделителей (набор символов-разделителей пополнялся итерационно-опытным путем) и строка, подлежащая разбиению.
Применяем объявленную функцию к каждой заявке. На выходе получаем исходный DataFrame, в котором появился новый столбец Words с массивом слов (за исключением “слов-паразитов”), из которых состоит каждая заявка.
issues['Words'] = issues.Content.apply(splitstring)Составляем словарь
Теперь приступим к составлению словаря входящих в содержание всех заявок слов. Но перед этим, как писали выше, разделим обучающую выборку на контрольную (так же известную как "тестовая", "отложенная") и ту, на которой будем обучать алгоритм.
Разделение выборки осуществляем методом train_test_split модуля model_selection библиотеки Scikit-learn. В метод передаем массив с данными (тексты заявок), массив с метками (категории заявок) и размер тестовой выборки (обычно выбирают 30% от всей). На выходе получаем 4 объекта: данные для обучения, метки для обучения, данные для контроля и метки для контроля:
issues_train, issues_test, labels_train, labels_test = model_selection.train_test_split(issues.Words, issues.Cat, test_size = 0.3)Теперь объявим функцию, которая составит словарь по данным, оставленным на обучение (issues_train), и применим функцию в этим данным:
def WordsDic(dataset):
WD = []
for i in dataset.index:
for j in xrange(len(dataset[i])):
if dataset[i][j] in WD:
None
else:
WD.append(dataset[i][j])
return WD
#применяем функцию к данным
words = WordsDic(issues_train)Итак, мы составили словарь из слов, составляющих тексты всех заявок из обучающей выборки (за исключением заявок, оставленных на контроль). Словарь записали в переменную words. Размер массива words получился равным 12015-м элементов (т.е. слов).
Переводим содержание заявок в пространство словаря
Перейдем к заключительному шагу подготовки данных для обучения. А именно: составим матрицу размера (количество заявок в выборке) x (количество слов в словаре), где в i-й строке j-го столбца находится количество вхождений j-го слова из словаря в i-ю заявку из выборки.
#объявляем матрицу размером len(issues_train) на len(words), заполняем её нулями
train_matrix = np.zeros((len(issues_train),len(words)))
#заполняем матрицу, проставляя в [i][j] количество вхождений j-го слова из words в i-й объект обучающей выборки
for i in xrange(train_matrix.shape[0]):
for j in issues_train[issues_train.index[i]]:
if j in words:
train_matrix[i][words.index(j)]+=1Теперь у нас есть всё необходимое для обучения: матрица train_matrix (формализованное содержание заявок в виде координат векторов, соответствующих заявкам, в пространстве словаря, составленного по всем заявкам) и метки labels_train (категории заявок из оставленной на обучение выборки).
Обучение
Перейдем к обучению алгоритмов на размеченных данных (т.е. таких данных, для которых известны правильные ответы: матрица train_matrix с метками labels_train). В этом разделе будет мало кода, так как большинство методов машинного обучения реализовано в библиотеке Scikit-learn. Разработка своих методов может быть полезной для усвоения материала, но с практической точки зрения в этом нет потребности.
Ниже постараюсь простым языком изложить принципы конкретных методов машинного обучения.
О принципах выбора лучшего алгоритма
Никогда не знаешь, какой алгоритм машинного обучения будет давать лучший результат на конкретных данных. Но, понимая задачу, можно определить набор наиболее подходящих алгоритмов, чтобы не перебирать все существующие. Выбор алгоритма машинного обучения, который будет использоваться для решения задачи, осуществляется через сравнение качества работы алгоритмов на обучающей выборке.
Что считать качеством алгоритма, зависит от задачи, которую вы решаете. Выбор метрики качества — отдельная большая тема. В рамках классификации заявок была выбрана простая метрика: точность (accuracy). Точность определяется как доля объектов в выборке, для которых алгоритм дал верный ответ (поставил верную категорию заявки). Таким образом, мы выберем тот алгоритм, который будет давать бОльшую точность в предсказании категорий заявок.
Важно сказать о таком понятии, как гиперпараметр алгоритма. Алгоритмы машинного обучения имеют внешние (т.е. такие, которые не могут быть выведены аналитически из обучающей выборки) параметры, определяющие качество их работы. Например в алгоритмах, где требуется рассчитать расстояние между объектами, под расстоянием можно понимать разные вещи: манхэттенское расстояние, классическую евклидову метрику и т.д.
У каждого алгоритма машинного обучения свой набор гиперпараметров. Выбор лучших значений гиперпараметров осуществляется, как ни странно, перебором: для каждой комбинации значений параметров вычисляется качество алгоритма и далее для данного алгоритма используется лучшая комбинация значений. Процесс затратный с точки зрения вычислений, но куда деваться.
Для определения качества алгоритма на каждой комбинации гиперпараметров используется кросс-валидация. Поясню, что это такое. Обучающая выборка разбивается на N равных частей. Алгоритм последовательно обучается на подвыборке из N-1 частей, а качество считается на одной отложенной. В итоге каждая из N частей 1 раз используется для подсчета качества и N-1 раз для обучения алгоритма. Качество алгоритма на комбинации параметров считается как среднее между значениями качества, полученными при кросс-валидации. Кросс-валидация необходима для того, чтобы мы могли больше доверять полученному значению качества (при усреднении мы нивелируем возможные “перекосы” конкретного разбиения выборки). Чуть подробнее сами знаете где.
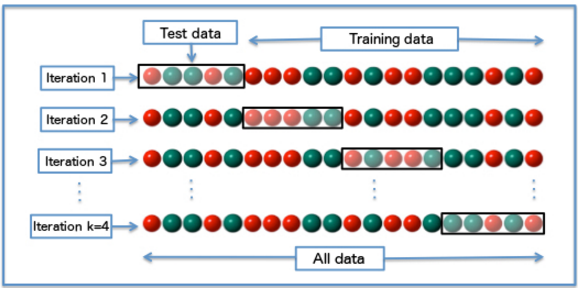
Итак, для выбора наилучшего алгоритма для каждого алгоритма:
- Перебираются все возможные комбинации значений гиперпараметров (у каждого алгоритма свой набор гиперпараметров и их значений);
- Для каждой комбинации значений гиперпараметров с использование кросс-валидации вычисляется качество алгоритма;
- Выбирается тот алгоритм и с той комбинацией значений гиперпараметров, что показывает наилучшее качество.
С точки зрения программирования описанного выше алгоритма нет ничего сложного. Но и в этом нет потребности. В библиотеке Scikit-learn есть готовый метод подбора параметров по сетке (метод GridSearchCV модуля grid_search). Все что нужно — передать в метод алгоритм, сетку параметров и число N (количество частей, на которые разбиваем выборку для кросс-валидации; их ещё называют "folds").
В рамках решения задачи было выбрано 2 алгоритма: k ближайших соседей и композиция случайных деревьев. О каждом из них рассказ далее.
k ближайших соседей (kNN)
Метод k ближайших соседей наиболее прост в понимании. Заключается он в следующем.
Есть обучающая выборка, данные в которой уже формализованы (подготовлены к обучению). Т.е объекты представлены в виде векторов какого-либо пространства. В нашем случае заявки представлены в виде векторов пространства словаря. Для каждого вектора обучающей выборки известен правильный ответ.
Для каждого нового объекта вычисляются попарные расстояния между этим объектом и объектами обучающей выборки. Затем берутся k ближайших объектов из обучающей выборки и для нового объекта возвращается ответ, который преобладает в подвыборке из k ближайших объектов (для задач, где нужно предсказать число, можно брать среднее значение из k ближайших).
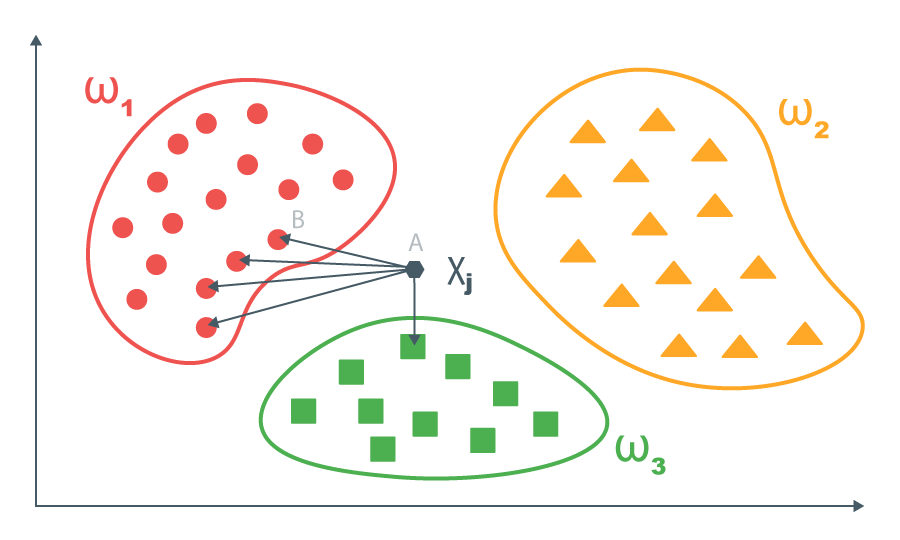
Алгоритм можно развить: давать бОльший вес значению метки на более близком объекте. Но для задачи классификации заявок делать этого не будем.
Гиперпараметрами алгоритма в рамках нашей задачи являются число k (по скольки ближайшим соседям будем делать вывод) и определение расстояния. Количество соседей перебираем в диапазоне от 1 до 7, определение расстояния выбираем из манхэттенского расстояния (сумма модулей разности координат) и евклидовой метрики (корень из суммы квадратов разности координат).
Выполняем незамысловатый код:
%%time
#задаем сетку для подбора гиперпараметров
param_grid = {'n_neighbors': np.arange(1,8), 'p': [1,2]}
#задаем количество fold-ов для кросс-валидации
cv = 3
#объявляем классификатор
estimator_kNN = neighbors.KNeighborsClassifier()
#передаем сетку, классификатор и количество fold-ов в метод подбора параметров по сетке
optimazer_kNN = GridSearchCV(estimator_kNN, param_grid, cv = cv)
#запускаем подбор параметров по сетке на обучающей выборке
optimazer_kNN.fit(train_matrix, labels_train)
#смотрим лучшие параметры и качество алгоритма на лучших параметрах
print optimazer_kNN.best_score_
print optimazer_kNN.best_params_Через 2 минуты 40 секунд узнаем, что лучшее качество в 53,23% показывает алгоритм на 3 ближайших соседях, определенных по манхэттенскому расстоянию.
Композиция случайных деревьев
Решающие деревья
Решающие деревья — ещё один алгоритм машинного обучения. Обучение алгоритма представляет собой пошаговое разбиение обучающей выборки на части (чаще всего на две, но в общем случае это не обязательно) по какому-либо признаку. Вот простой пример, иллюстрирующий работу решающего дерева:

У решающего дерева есть внутренние вершины (в которых принимаются решения о дальнейшем разбиении выборки) и финальные вершины (листы), по которым дается прогноз попавшим туда объектам.
В решающей вершине проверяется простое условие: соответствие какого-то (об этом далее) j-го признака объекта условию xj больше или равно какому-то t. Объекты, удовлетворяющие условию, отправляются в одну ветку, а не удовлетворяющие — в другую.
При обучении алгоритма можно было бы разбивать обучающую выборку до тех пор, пока во всех вершинах не останется по одному объекту. Такой подход даст отличный результат на обучающей выборке, но на неизвестных данных получится "шляпа". Поэтому важно определить так называемый "критерий останова" — условие, при котором вершина становится листом и дальнейшее ветвление этой вершины приостанавливается. Критерий останова зависит от задачи, вот некоторые типы критериев: минимальное количество объектов в вершине и ограничение на глубину дерева. В решении поставленной задачи использовался критерий минимального количества объектов в вершине. Число, равное минимальному количеству объектов, является гиперпараметром алгоритма.
Новые (требующие предсказания) объекты прогоняются по обученному дереву и попадают в соответствующий им лист. Для объектов, попавших в лист, даем следующий ответ:
- Для задач классификации возвращаем самый распространенный в этом листе класс объектов обучающей выборки;
- Для задач регрессии (т.е. таких, где ответом является число) возвращаем среднее значение на объектах обучающей выборки из этого листа.
Осталось поговорить о том, как выбирать для каждой вершины признак j (по какому признаку разбиваем выборку в конкретной вершине дерева) и соответствующий этому признаку порог t. Для этого вводят так называемый критерий ошибки Q(Xm,j,t). Как видно, критерий ошибки зависит от выборки Xm (та часть обучающей выборки, что дошла до рассматриваемой вершины), параметра j, по которому будет разбиваться выборка Xm в рассматриваемой вершине и порогового значения t. Необходимо подобрать такое j и такое t, при котором критерий ошибки будет минимальным. Так как возможный набор значений j и t для каждой обучающей выборки ограничен, задача решается перебором.
Что такое критерий ошибки? В черновой версии статьи на этом месте было много формул и сопровождающих объяснений, рассказ про критерий информативности и его частные случаи (критерий Джинни и энтропийный критерий). Но статья получилась и так раздутой. Желающие разобраться в формальностях и математике смогут почитать обо всем в интернете (например, здесь). Ограничусь "физическим смыслом" на пальцах. Критерий ошибки показывает уровень "разнообразия" объектов в получающихся после разбиения подвыборках. Под "разнообразием" в задачах классификации подразумевается разнообразие классов, а в задачах регрессии (где предсказываем числа) — дисперсия. Таким образом, при разбиении выборки мы хотим максимальным образом уменьшить "разнообразие" в получающихся подвыборках.
С деревьями разобрались. Перейдем к композиции деревьев.
Композиция решающих деревьев
Решающие деревья могут выявить очень сложные закономерности в обучающей выборке. Но чем лучший результат обучающие деревья показывают на обучении, тем худший результат они покажут на новых данных — деревья переобучаются. Для устранения этой проблемы придуман механизм объединения обучающих деревьев в композиции (леса).
Для построения композиции деревьев берется N обученных деревьев и их результат “усредняется”. Для задач регрессии (там, где предсказываем число) берется среднее значение предсказанных чисел, а для задач классификации — самый популярный (из N предсказаний) предсказанный класс.
Таким образом, для построения леса необходимо сначала обучить N решающих деревьев. Но делать это на одной и той же обучающей выборке бессмысленно: мы получим N одинаковых алгоритмов и результат усреднения будет равен результату любого из них. Поэтому для обучения базовых деревьев используется рандомизация: обучение каждого базового дерева производится по случайной подвыборке объектов исходной обучающей выборки и/или по случайному набору параметров (т.е. для обучения каждого базового алгоритма берутся не все параметры объектов, а только случайный набор определенного размера). Но и этого бывает недостаточно для построения независимых алгоритмов — применяют рандомизацию признаков для разбиения на каждой вершине (т.е. на каждой вершине каждого дерева признак выбирают не из всего набора, а из случайной подвыборки признаков определенного размера; важно, что для каждой вершины каждого дерева случайная подвыборка — своя). Поэтому алгоритм и называется композицией случайных деревьев.
Перейдем наконец-то к практике! При обучении алгоритма будем искать лучшие значения для 2-х гиперпараметров: минимального количества объектов в узле (гиперпараметр для дерева) и количества базовых алгоритмов (гиперпараметр для леса).
Запускаем код:
%%time
#задаем сетку для подбора гиперпараметров
param_grid = {'n_estimators': np.arange(20,101,10), 'min_samples_split': np.arange(4,11, 1)}
#задаем количество fold-ов для кросс-валидации
cv = 3
#объявляем классификатор
estimator_tree = ensemble.RandomForestClassifier()
#передаем сетку, классификатор и количество fold-ов в метод подбора параметров по сетке
optimazer_tree = GridSearchCV(estimator_tree, param_grid, cv = cv)
#запускаем подбор параметров по сетке на обучающей выборке
optimazer_tree.fit(train_matrix, labels_train)
#смотрим лучшие параметры и качество алгоритма на лучших параметрах
print optimazer_tree.best_score_
print optimazer_tree.best_params_Через 3 минуты 30 секунд узнаем, что лучшее качество в 65,82% показывает алгоритм из 60 деревьев, для которых минимальное количество объектов в узле равно 4.
Результат
Результаты на отложенной выборке
Теперь проверим работу двух обученных алгоритмов на отложенной (тестовой, контрольной — как её только не называют) выборке.
Для этого составим матрицу test_matrix, являющуюся проекцией объектов отложенной выборки на пространство словаря, составленного по обучающей выборке (т.е. составляем такую же матрицу, что и train_matrix, только для отложенной выборки).
#Создаем матрицу размером len(issues_test) на len(words)
test_matrix = np.zeros((len(issues_test),len(words)))
#заполняем матрицу, проставляя в [i][j] количество вхождений j-го слова из words в i-й объект тестовой выборки
for i in xrange(test_matrix.shape[0]):
for j in issues_test[issues_test.index[i]]:
if j in words:
test_matrix[i][words.index(j)]+=1Для получения качества алгоритмов используем метод accuracy_score модуля metrics библиотеки Scikit-learn. Передаем в него предсказания на отложенной выборке каждого из алгоритмов и известные для отложенной выборки значения меток:
print u'Случайный лес:', accuracy_score(optimazer_tree.best_estimator_.predict(test_matrix), labels_test)
print u'kNN:', accuracy_score(optimazer_kNN.best_estimator_.predict(test_matrix), labels_test)Получаем 51,39% на алгоритме k ближайших соседей и 73,46% на композиции случайных деревьев.
Сравнение с "глупыми" алгоритмами
Целью эксперимента было получение результата, “в разы” лучшего, чем random. На самом деле речь шла о “глупых” алгоритмах, частным случаем которых является random. В общем случае, “глупые” алгоритмы это такие алгоритмы, построить которые можно без сколь-нибудь серьезного анализа обучающей выборки.
Сравним полученное качество с 3-мя видами “глупых” алгоритмов:
- Равномерный random;
- Всегда выдаем самый популярный класс из обучающей выборки;
- Random, пропорциональный плотности классов в обучающей выборке.
Равномерный random на 14 классах дает примерно 100/14 * 100% = 7,14% качество. Алгоритм, который всегда выдает самый популярный класс даст качество в 14,5% (такая доля у самого популярного класса в обучающей выборке). Для получения качества на пропорциональном random-е напишем простой код. Каждому объекту отложенной выборки алгоритм будет присваивать класс объекта из обучающей выборки, выбранный равномерным random-ом:
#импортируем библиотеку random
import random
#объявляем массив, куда будем складывать random-ные предсказания
rand_ans = []
#предсказываем
for i in xrange(test_matrix.shape[0]):
rand_ans.append(labels_train[labels_train.index[random.randint(0,len(labels_train))]])
#смотрим качество
print u'Пропорциональный random:', accuracy_score(rand_ans, labels_test)Получаем 14,52%.
Итак, используя не самые сложные методы мы получили качество классификации в разы выше, чем дают “глупые” алгоритмы. Ура!
Что дальше?
Для промышленного применения машинного обучения при классификации заявок, необходимо получить качество не ниже 90% — такой ориентир дают потенциальные потребители. Результаты эксперимента показывают, что такое качество может быть достигнуто. Ведь даже при подготовке данных к обучению мы не использовали такие “классические” методы подготовки текстов как стемминг и ранжирование слов при попадании в словарь (если слово встречается пару раз в выборке, оно скорее всего мусорное и его можно исключить). К тому-же, в словаре для одного и того же слова было несколько написаний (например: "печать", "пичать", "печять" и т.д.) — с этим тоже можно бороться (желательно в школе) и повышать качество алгоритма.
Кроме того, в эксперименте использовался только один параметр: текст. Если весь текст заявки это фраза "Не работает" или "Проблема", у нас не так много вариантов определить что случилось. У всех возможных категорий заявок одинаковая вероятность быть верным ответом. Но если мы знаем, что заявка пришла из бухгалтерии, а дата регистрации совпадает с датой квартального отчета, количество возможных вариантов резко сокращается.
В общем, можно инвестировать в разработку промышленного модуля классификации заявок для Okdesk.
"Отлично! Работаем дальше!" (с)
Комментарии (21)

smazin
11.09.2017 16:09-1Поясню еще — «суржик», это когда в одном предложении могут быть и русские и украинские слова с соответствующим написанием. Такие предложения люди в Украине воспринимают и понимают без проблем. И алфавит русского и украинского языков несколько отличен :-) Так что решение совсем не простое… И я его, в этой части к сожалению, не вижу…

mefrill
11.09.2017 16:57В чем проблема, почему просто не использовать UNICODE внутри, а снаружи UTF-8? Если классификация на словах, то слова — это последовательности символов, разделенные сепаратором (есть такой класс символов в UNICODE). Будут английские, русский, украинский (по желанию и китайские) слова, выделенные из текста как признаки. В чем здесь трудность?
krubinshteyn Автор
11.09.2017 17:02По умолчанию оно так и есть — просто разные слова. Но без «сливания» смыслов получится низкое качество, о чем пишет smazin. Т.е. то, на что в конце статьи указано (слова «печать», «пичать», «пичять» — считайте что одно и тоже слово на разных языках :), но в бОльшем масштабе.
mefrill
11.09.2017 17:25Не понятно, почему низкое качество получится. Если не нужно выделять классы слов, т.е. приводить их в какую-то нормальную форму, то все опечатки и форму таки или иначе будут присутствовать в словаре, полученном на обучающей выборке. Для описанной в статье задачи никто не гарантирует, что приведение к нормальной форме повысит качество до 90%. Ну а для Вашей задачи вообще не понятно, к чем приведет такой улучшение. Качество для таких задач обычно улучшают расширением контекста. Самое простое решение — использовать словный n-граммы вместо слов (униграмм). Еще радикальнее — прогнать все тексты из обучающей выборки через word2vec и использовать вектора чисел, полученные для слов этим алгоритмом. Эти вектора учитывают синтаксическую синонимию (употребление слов в одном контексте), тогда к нормальной форме вообще не нужно ничего преобразовывать.
krubinshteyn Автор
11.09.2017 17:27Вот то о чем вы пишите — на третьем курсе специализации проходят. А я прошел только 2 :) Ну и в целом, без конкретных данных гадать о причинах сложно.
smazin
12.09.2017 10:15Я дам три отчасти синтетических, отчасти реальных примера. Мне кажется это даст представление о чем писал я. Все три примера после анализа человеком адресуются в одну группу исполнения:
1.Русский:
"… От сотрудника прямого контакта поступил запрос: «Отсутствуе возможность активации номера ХХХХХХ (л/сХХХХХХХХХХ)» Просьба помочь в данном вопросе. Спасибо!..."
2. Украинский:
"… Від працівника прямого контакту надійшов запит: «Відсутня можливість активувати номер ХХХХХХ (о/рХХХХХХХХХХ)» Прохання допомогти у цьому питанню. Дякую!..."
3.«Суржик»:
"… От сотрудника прямого контакта поступил запрос: «Відсутня можливість активувати номер ХХХХХХ (л/сХХХХХХХХХХ)» Просьба помочь в данном вопросе. Спасибо!..."
Это три комбинации. Причем «суржик» может иметь больше вариаций. То что делал я, переводил пословно без учета контекста на английский с задачей распознания языка слова источника. Распозначание языка слова источника не всегда срабатывает. Или срабатывает неверно, может определить источник как скажем словацкий язык, с совершенно другим значением и как следствие — переводом… Вот здесь проблема таких задач…
nikolay_karelin
11.09.2017 18:53То, что в русском (и близких языках) слова довольно сильно меняются (все эти склонения/спряжения) не мешало?
Не смотрели, насколько важно сдалать лемматизацию?
(привести все слова в нормальную форму)krubinshteyn Автор
11.09.2017 18:55Не могу сказать, на сколько это поможет — но есть предположение, что поможет. Пока никаких других методов не применял — они на 3 курсе специализации, я до него не дошел ещё :)
evvlasov
11.09.2017 18:56Я сейчас прохожу курс на Курсере от мистера Ына, там всё на Питоне 3.5
krubinshteyn Автор
11.09.2017 18:58Вы о каком из курсов? У него их теперь два. Если о первом (на который дана ссылка в публикации), то ещё полгода назад он был на Octave. Возможно, новая специализация (https://www.coursera.org/specializations/deep-learning) на Питоне (да, судя по программе — на Питоне).
Hellslayer
11.09.2017 20:49А какой смысл пользоваться отложенной выборкой если вы на этапе подбора гиперпараметров используете кросс-валидацию? Это ведь с учётом того что кросс-валидация обычно проводится на n количестве фолдов что по сути является n раз использованной разной отложенной выборкой. Просто для спокойствия?
krubinshteyn Автор
11.09.2017 20:51В примере из публикации, кросс-валидация проводится в пространстве словаря, составленного на обучающей выборке — т.е. каждый отложенный фолд уже внёс свой вклад в обучение. Что в целом — грешно, но для цели «выбрать лучший набор гиперпараметров» и сравнить алгоритмы — норм.

techus
12.09.2017 10:13Для формирования векторов слов (то, что вы называете словарем) в sklearn есть класс CountVectorizer.
И дополнительно советую попробовать использовать TF-IDF. Соответствующий класс тоже есть в этой библиотеке. Предполагаю, что качество модели серьезно возрастет.
Для классификации таких данных в наших задачах (подобных) очень хорошо подошел SGDClassifier.
Можно попробовать еще ансамбль из SGD и SVC
И уж совсем для полноты картины пробуйте подбирать параметры классификаторов методом поиска по сетке параметров.
Советую прочитать эту книгу «Python и машинное обучение» Себастьян Рашка — в ней подробно на примерах разбираются практические задачи и детально поясняется, что, зачем, как и почему.krubinshteyn Автор
12.09.2017 10:14Спасибо. Всему свое время :) Ещё 4 курса специализации впереди.
> И уж совсем для полноты картины пробуйте подбирать параметры классификаторов методом поиска по сетке параметров.
этому вопросу в публикации уделено достаточно много. Вы точно прочитали всё до конца? :)

vzhicharra
13.09.2017 22:21А заявки все строго стандартизированы?
Не было проблем с падежами, окончаниями, формами слов?krubinshteyn Автор
13.09.2017 22:22Заявки в свободном стиле, как сформулирует пользователь. Падежи, окончания и формы слов — это не проблема, это задача. Впрочем, об этом написано в последнем абзаце :)

Abyasov
14.09.2017 09:45Почему ещё ни кто не вспомнил word2vec? Это способ кодировать слова с учётом контекста их употребления. Есть готовые решения. Позволяет заметно поднять качество модели.
krubinshteyn Автор
14.09.2017 09:52Да вроде в комментариях писали об этом. Но я решил пока не использовать методы, с работой которых руки не дошли разобраться. Разберусь — напишу как они работают и на сколько улучшилась модель :)
smazin
Я прошел тот же путь. Задача была не класификация. Было обучение с учителем. Т. е. был доступен датасет с историческими данными обращений и направлениями в определенную рабочую группу (одну из 80) для решения. Определение группы. Остановился на достижении необходимого качества. Основная проблема с которой столкнулся — это подготовка данных и… «суржик». Обращения пользователей в моем случае — это обращения пользователей живущих в Украине. Тексты могут быть на украинском языке, на руссском и «суржике», т. е. смеси двух языков. Пытался решить проблему переводом на английский с определением исходного языка используя Google Cloud Translation API… Качество стало лучше, но не достаточно… Путей решения пока не вижу.
krubinshteyn Автор
Кроме как «определять в начале язык» наверное и нет простого решения :) И отдельно классифицировать на своем языке.
ps «Классификация» и «Обучение с учителем» — это две разных категории, не противоречащих друг другу. Классификация — это тип задачи, которую решаем, «обучение с учителем» — тип обучения (есть известные ответы, или нужно найти зависимости и связи между объектами по описанию объектов).