

11 августа компания Mail.Ru Объявила об очередном конкурсе HighloadCup для системных программистов backend-разработчиков.
Вкратце задача стояла следующим образом: докер, 4 ядра, 4Гб памяти, 10Гб HDD, набор api, и нужно ответить на запросы за наименьшее количество времени. Язык и стек технологий неограничен. В качестве тестирующей системы выступал яндекс-танк с движком phantom.
О том, как в таких условиях добраться до 13 места в финале, и будет эта статья.
Постановка задачи
Подробно с описанием задачи можно ознакомиться в публикации одного из участников на хабре, или на официальной странице конкурса. О том, как происходило тестирование, написано здесь.
Api представляло из себя 3 get-запроса на просто вернуть записи из базы, 2 get-запроса на агрегирование данных, 3 post-запроса на модификацию данных, и 3 post-запроса на добавление данных.
Сразу были оговорены следующие условия, которые существенно облегчили жизнь:
- нет сетевых потерь (данные идут через loopback)
- данные гарантированно помещаются в память
- нет конкурирующих post-запросов (т.е. не будет одновременной попытки изменить одну и ту же запись)
- post- и get-запросы никогда не идут одновременно (либо только get-запросы, либо только post-запросы)
- данные никогда не удаляются, а только модифицируются или добавляются
Запросы были поделены на 3 части: сначала get-запросы по исходным данным, потом серия post-запросов на добавление/изменение данных, и последняя самая мощная серия get-запросов по модифицированным данным. Вторая фаза была очень важна, т.к. неправильно добавив или поменяв данные, можно было получить много ошибок в третьей фазе, и как результат — большой штраф. На данном этапе последняя стадия содержала линейное увеличение числа запросов от 100 до 2000rps.
Еще одним условием было то, что один запрос — одно соединение, т.е. никаких keep-alive, но в какой-то момент от этого отказались, и все get-запросы шли с keep-alive, post-запросы были каждый на новое соединение.
Моей мечтой всегда были и есть Linux, C++ и системное программирование (хотя реальность ужасна), и я решил ни в чем себе не отказывать и нырнуть в это удовольствие с головой.
Поехали
Т.к. о highload'e я знал чуть менее, чем ничего, и я до последнего надеялся, что писать свой web-сервер не придется, то первым шагом к решению задачи стал поиск подходящего web-сервера. Мой взгляд ухватился за proxygen. В целом, сервер должен был быть хорошим — кто еще знает о хайлоаде столько, сколько facebook?
Исходный код содержит несколько примеров, как использовать этот сервер.
HTTPServerOptions options;
options.threads = static_cast<size_t>(FLAGS_threads);
options.idleTimeout = std::chrono::milliseconds(60000);
options.shutdownOn = {SIGINT, SIGTERM};
options.enableContentCompression = false;
options.handlerFactories = RequestHandlerChain()
.addThen<EchoHandlerFactory>()
.build();
HTTPServer server(std::move(options));
server.bind(IPs);
// Start HTTPServer mainloop in a separate thread
std::thread t([&] () {
server.start();
});И на каждое принятое соединение вызывается метод фабрики
class EchoHandlerFactory : public RequestHandlerFactory {
public:
// ...
RequestHandler* onRequest(RequestHandler*, HTTPMessage*) noexcept override {
return new EchoHandler(stats_.get());
}
// ...
private:
folly::ThreadLocalPtr<EchoStats> stats_;
};От new EchoHandler() на каждый запрос у меня по спине вдруг пробежал холодок, но я не придал этому значения.
Сам EchoHandler должен реализовать интерфейс proxygen::RequestHandler:
class EchoHandler : public proxygen::RequestHandler {
public:
void onRequest(std::unique_ptr<proxygen::HTTPMessage> headers)
noexcept override;
void onBody(std::unique_ptr<folly::IOBuf> body) noexcept override;
void onEOM() noexcept override;
void onUpgrade(proxygen::UpgradeProtocol proto) noexcept override;
void requestComplete() noexcept override;
void onError(proxygen::ProxygenError err) noexcept override;
};Все выглядит хорошо и красиво, только успевай обрабатывать приходящие данные.
Роутинг я реализовал с помощью std::regex, благо набор апи простой и небольшой. Ответы формировал на лету с помощью std::stringstream. В данный момент я не заморачивался с производительностью, целью было получить работающий прототип.
Так как данные помещаются в память, то значит и хранить их нужно в памяти!
Структуры данных выглядели так:
struct Location {
std::string place;
std::string country;
std::string city;
uint32_t distance = 0;
std::string Serialize(uint32_t id) const {
std::stringstream data;
data <<
"{" <<
"\"id\":" << id << "," <<
"\"place\":\"" << place << "\"," <<
"\"country\":\"" << country << "\"," <<
"\"city\":\"" << city << "\"," <<
"\"distance\":" << distance <<
"}";
return std::move(data.str());
}
};Первоначальный вариант "базы данных" был такой:
template <class T>
class InMemoryStorage {
public:
typedef std::unordered_map<uint32_t, T*> Map;
InMemoryStorage();
bool Add(uint32_t id, T&& data, T** pointer);
T* Get(uint32_t id);
private:
std::vector<std::forward_list<T>> buckets_;
std::vector<Map> bucket_indexes_;
std::vector<std::mutex> bucket_mutexes_;
};
template <class T>
InMemoryStorage<T>::InMemoryStorage()
: buckets_(BUCKETS_COUNT), bucket_indexes_(BUCKETS_COUNT),
bucket_mutexes_(BUCKETS_COUNT) {
}
template <class T>
bool InMemoryStorage<T>::Add(uint32_t id, T&& data, T** pointer) {
int bucket_id = id % BUCKETS_COUNT;
std::lock_guard<std::mutex> lock(bucket_mutexes_[bucket_id]);
Map& bucket_index = bucket_indexes_[bucket_id];
auto it = bucket_index.find(id);
if (it != bucket_index.end()) {
return false;
}
buckets_[bucket_id].emplace_front(data);
bucket_index.emplace(id, &buckets_[bucket_id].front());
if (pointer)
*pointer = &buckets_[bucket_id].front();
return true;
}
template <class T>
T* InMemoryStorage<T>::Get(uint32_t id) {
int bucket_id = id % BUCKETS_COUNT;
std::lock_guard<std::mutex> lock(bucket_mutexes_[bucket_id]);
Map& bucket = bucket_indexes_[bucket_id];
auto it = bucket.find(id);
if (it != bucket.end()) {
return it->second;
}
return nullptr;
}Идея была следущей: индексы, по условию, целое 32-битное число, а значит никто не мешает добавлять данные с произвольными индексами внутри этого диапазона (о, как же я ошибался!). Поэтому у меня было BUCKETS_COUNT (=10) хранилищ, чтобы уменьшить время ожидания на мутексе для потоков.
Т.к. были запросы на выборку данных, и нужно было быстро искать все места, в которых бывал пользователь, и все отзывы, оставленные для мест, то нужны были индексы users -> visits и locations -> visits.
Для индекса был написан следующий код, с той же идеологией:
template<class T>
class MultiIndex {
public:
MultiIndex() : buckets_(BUCKETS_COUNT), bucket_mutexes_(BUCKETS_COUNT) {
}
void Add(uint32_t id, T* pointer) {
int bucket_id = id % BUCKETS_COUNT;
std::lock_guard<std::mutex> lock(bucket_mutexes_[bucket_id]);
buckets_[bucket_id].insert(std::make_pair(id, pointer));
}
void Replace(uint32_t old_id, uint32_t new_id, T* val) {
int bucket_id = old_id % BUCKETS_COUNT;
{
std::lock_guard<std::mutex> lock(bucket_mutexes_[bucket_id]);
auto range = buckets_[bucket_id].equal_range(old_id);
auto it = range.first;
while (it != range.second) {
if (it->second == val) {
buckets_[bucket_id].erase(it);
break;
}
++it;
}
}
bucket_id = new_id % BUCKETS_COUNT;
std::lock_guard<std::mutex> lock(bucket_mutexes_[bucket_id]);
buckets_[bucket_id].insert(std::make_pair(new_id, val));
}
std::vector<T*> GetValues(uint32_t id) {
int bucket_id = id % BUCKETS_COUNT;
std::lock_guard<std::mutex> lock(bucket_mutexes_[bucket_id]);
auto range = buckets_[bucket_id].equal_range(id);
auto it = range.first;
std::vector<T*> result;
while (it != range.second) {
result.push_back(it->second);
++it;
}
return std::move(result);
}
private:
std::vector<std::unordered_multimap<uint32_t, T*>> buckets_;
std::vector<std::mutex> bucket_mutexes_;
};Первоначально организаторами были выложены только тестовые данные, которыми инициализировалась база данных, а примеров запросов не было, поэтому я начинал тестировать свой код с помощью Insomnia, которая позволяла легко отправлять и модифицировать запросы и смотреть ответ.
Чуть позже организаторы сжалилсь над участниками и выложили патроны от танка и полные данные рейтинговых и тестовых обстрелов, и я написал простенький скрипт, который позволял тестировать локально корректность моего решения и очень помог в дальнейшем.
Highload, начало
И вот наконец-то прототип был закончен, локально тестировщик говорил, что все ОК, и настало время отправлять свое решение. Первый запуск был очень волнительным, и он показал, что что-то не так...
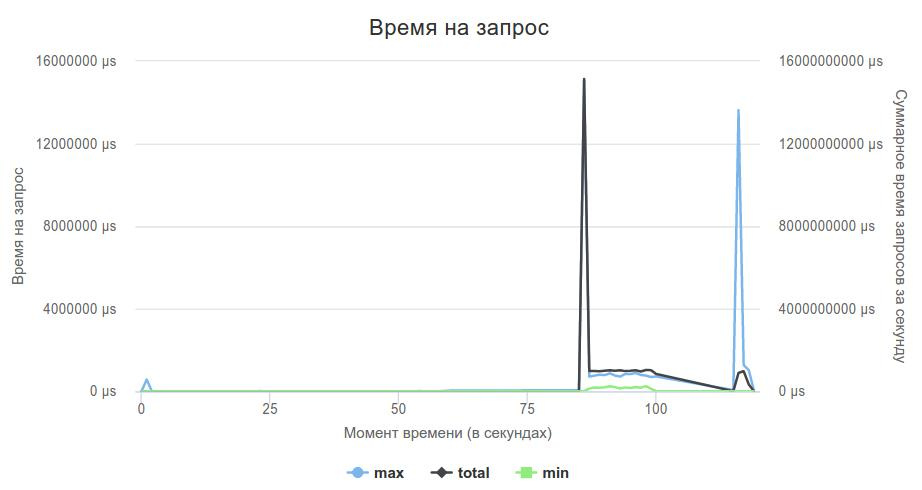
Мой сервер не держал нагрузку в 2000rps. У лидеров в этот момент, насколько я помню, времена были порядка сотен секунд.
Дальше я решил проверить, справляется ли вообще сервер с нагрузкой, или это проблемы с моей реализацией. Написал код, который на все запросы просто отдавал пустой json, запустил рейтинговый обстрел, и увидел, что сам proxygen не справляется с нагрузкой.
void onEOM() noexcept override {
proxygen::ResponseBuilder(downstream_)
.status(200, "OK")
.header("Content-Type", "application/json")
.body("{}")
.sendWithEOM();
}Вот так выглядел график 3-ей фазы.
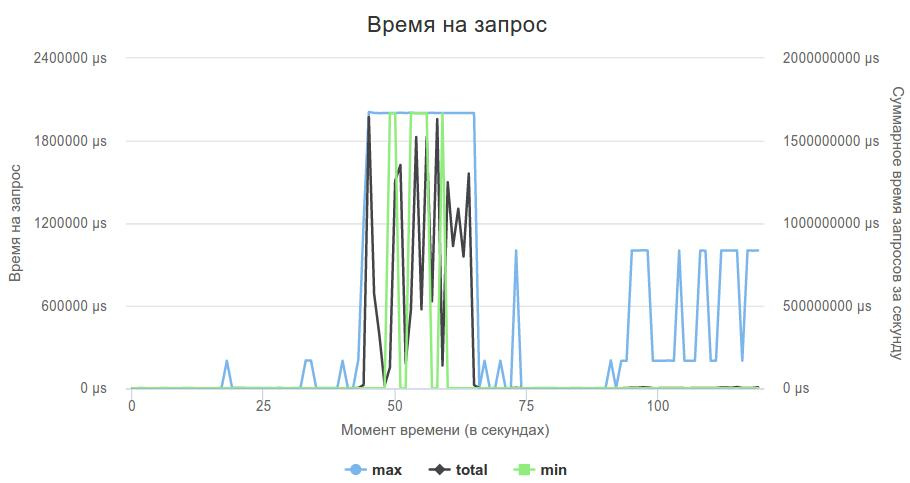
С одной стороны было приятно, что это пока еще проблема не в моем коде, с другой встал вопрос: что делать с сервером? Я все еще надеялся избежать написания своего, и решил попробовать что-нибудь другое.
Следующим подопытным стал Crow. Сразу скажу, мне он очень понравился, и если вдруг в будущем мне потребуется плюсовый http-сервер, то это будет именно он. header-based сервер, я его просто добавил в свой проект вместо proxygen, и немного переписал обработчики запросов, чтобы они начали работать с новым сервером.
Использовать его очень просто:
crow::SimpleApp app;
CROW_ROUTE(app, "/users/<uint>").methods("GET"_method, "POST"_method) (
[](const crow::request& req, crow::response& res, uint32_t id) {
if (req.method == crow::HTTPMethod::GET) {
get_handlers::GetUsers(req, res, id);
} else {
post_handlers::UpdateUsers(req, res, id);
}
});
app.bindaddr("0.0.0.0").port(80).multithreaded().run();В случае, если нет подходящего описания для api, сервер сам отправляет 404, если же есть нужный обработчик, то в данном случае он достает из запроса uint-параметр и передает его как параметр в обработчик.
Но перед тем, как использовать новый сервер, наученный горьким опытом, я решил проверить, справляется ли он с нагрузкой. Также как и в предыдущем случае, написал обработчик, который возвращал пустой json на любой запрос, и отправил его на рейтинговый обстрел.
Crow справился, он держал нагрузку, и теперь нужно было добавить мою логику.
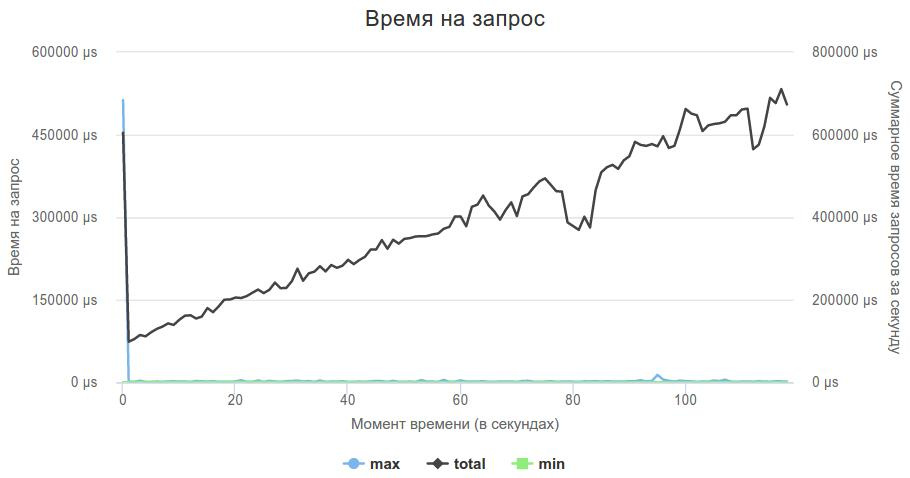
Т.к. логика была уже написана, то адаптировать код к новому серверу было достаточно просто. Все получилось!

100 секунд — уже что-то, и можно начинать заниматься оптимизацией логики, а не поисками сервера.
Т.к. мой сервер все еще формировал ответы с помощью std::stringstream, я решил избавиться от этого в первую очередь. В момент добавления записи в базу данных тут же формировалась строка, содержащая полный ответ с хедером, и в момент запроса отдавал ее.
На данном этапе я решил добавить хедер полностью в ответ по двум причинам:
- убирается лишний
write() - данных всего 200мб, памяти хватает с запасом
Еще одной проблемой, о которую было сломано много копий в чатике в телеграмме и мной лично, это фильтр пользователей по возрасту. По условию задачи, возраст пользователей хранился в unix timestamp, а в запросах он приходил в виде полных лет: fromAge=30&toAge=70. Как года привести к секундам? Учитывать високосный год или нет? А если пользователь родился 29 февраля?
Итогом стал код, который решал все эти проблемы одним махом:
static time_t t = g_generate_time; // get time now
static struct tm now = (*localtime(&t));
if (search_flags & QueryFlags::FROM_AGE) {
tm from_age_tm = now;
from_age_tm.tm_year -= from_age;
time_t from_age_t = mktime(&from_age_tm);
if (user->birth_date > from_age_t) {
continue;
}
}Результатом стало двухкратное увеличение производительности, со 100 до 50 секунд.
Неплохо на первый взгляд, но в этот момент у лидеров было уже меньше 20 секунд, а я был где-то на 20-40 месте со своим результатом.
В этот момент были сделаны еще два наблюдения:
- индексы данных всегда шли по-порядку от 1 без пропусков
- размеры индексов были примерно по 1М для Users и Locations, и 10М для Visits.
Стало понятно, что хэши, мутексы и бакеты для хранения данных не нужны, и данные можно прекрасно хранить по индексу в векторе, что и было сделано. Финальную версию можно увидеть здесь (к финалу дополнительно была добавлена часть кода для обработки индексов, если вдруг они превысят лимит).
Каких-то очевидных моментов, которые бы сильно влияли на производительность в моей логике, казалось, не было. Скорей всего с помощью оптимизаций можно было бы скинуть еще несколько секунд, но нужно было скидывать половину.
Я опять начал упираться в работу с сетью/сервером. Пробежавшись по исходникам сервера, я пришел к неутешительному выводу — при отправке происходило 2 ненужных копирования данных: сначала во внутренний буфер сервера, а потом еще раз в буфер для отправки.
I want to ride my bicycle...
В мире нет ничего более беспомощного, безответственного и безнравственного, чем начинать писать свой web-сервер. И я знал, что довольно скоро я в это окунусь.
И вот этот момент настал.
При написании своего сервера было сделано несколько допущений:
- танк стреляет через loopback, и значит потери отсутствуют
- пакеты от танка очень маленькие, значит их можно вычитать за один read()
- мои ответы тоже небольшие, поэтому они будут записаны за один вызов write(), и вызов на запись не будет заблокирован
- от танка идут только корректные get- и post-запросы
Вообще, можно было по-честному поддержать read() и write() в несколько кусков, но текущий вариант работал, поэтому это осталось "на потом".
После серии экспериментов я остановился на следующей архитектуре: блокирующий аccept() в главном потоке, добавление нового сокета в epoll, и std::thread::hardware_concurrency() потоков слушают один epollfd и обрабатывают данные.
unsigned int thread_nums = std::thread::hardware_concurrency();
for (unsigned int i = 0; i < thread_nums; ++i) {
threads.push_back(std::thread([epollfd, max_events]() {
epoll_event events[max_events];
int nfds = 0;
while (true) {
nfds = epoll_wait(epollfd, events, max_events, 0);
// ...
for (int n = 0; n < nfds; ++n) {
// ...
}
}
}));
}
while (true) {
int sock = accept(listener, NULL, NULL);
// ...
struct epoll_event ev;
ev.events = EPOLLIN | EPOLLET | EPOLLONESHOT;
ev.data.fd = sock;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, sock, &ev) == -1) {
perror("epoll_ctl: conn_sock");
exit(EXIT_FAILURE);
}
}EPOLLET гарантирует, что будет разбужен только какой-то один поток, а также что если в сокете останутся недочитанные данные, то epoll на сокет не сработает до тех пор, пока они все не будут вычитаны до EAGAIN. Поэтому следующей рекомендацией по использованию этого флага является делать сокет неблокирующим и читать, пока не вернется ошибка. Но как было обозначено в допущениях, запросы маленькие и читаются за один вызов read(), данных в сокете не остается, и epoll нормально срабатывал на приход новых данных.
Тут я сделал одну ошибку: я использовал std::thread::hardware_concurrency() для определения количества доступных потоков, но это было плохой идеей, потому что этот вызов возвращал 10 (количество ядер на сервере), а в докере было доступно только 4 ядра. Впрочем, на результат это мало повлияло.
Для парсинга http я использовал http-parser (Crow также использует его), для разбора урла — libyuarel, и для декодирования параметров в query-запросе — qs_parse. qs_parse также используется в Crow, он умеет разбирать урл, но так получилось, что я его использовал только для декодирования параметров.
Переписав таким образом свою реализацию, я сумел скинуть еще 10 секунд, и теперь мой результат составлял 40 секунд.
MOAR HIGHLOAD
До конца соревнования оставалось полторы недели, и организаторы решили, что 200Мб данных и 2000rps — это мало, и увеличили размер данных и нагрузки в 5 раз: данные стали занимать 1Гб в распакованном виде, а интенсивность обстрела выросла до 10000rps на 3-ей фазе.
Моя реализация, которая хранила ответы целиком, перестала влезать по памяти, делать много вызовов write(), чтобы писать ответ по частям, тоже казалось плохой идеей, и я переписал свое решение на использование writev(): не нужно было дублировать данные при хранении и запись происходила с помощью одного системного вызова (тут тоже добавлено улучшение для финала: writev может записать за раз 1024 элемента массива iovec, а моя реализация для /users/<id>/locations была очень iovec-затратной, и я добавил возможность разбить запись данных на 2 куска).
Отправив свою реализацю на запуск, я получил фантастические (в хорошем смысле) 245 секунды времени, что позволило мне оказаться на 2 месте в таблице результатов на тот момент.
Так как тестовая система подвержена большому рандому, и одно и то же решение может показывать различающееся в несколько раз время, а рейтинговые обстрелы можно было запускать лишь 2 раза в сутки, то непонятно, какие из следующих улучшений привели к конечному результату, а какие нет.
За оставшуюся неделю я сделал следующие оптимизации:
Заменил цепочки вызовов вида
DBInstance::GetDbInstance()->GetLocations()на указатель
g_location_storageПотом я подумал, что честный http-парсер для get-запросов не нужен, и для get-запроса можно сразу брать урл и больше ни о чем не заботиться. Благо, фиксированные запросы танка это позволяли. Также тут примечателен момент, что можно портить буфер (записывать \0 в конец урла, например). Таким же образом работает libyuarel.
HttpData http_data;
if (buf[0] == 'G') {
char* url_start = buf + 4;
http_data.url = url_start;
char* it = url_start;
int url_len = 0;
while (*it++ != ' ') {
++url_len;
}
http_data.url_length = url_len;
http_data.method = HTTP_GET;
} else {
http_parser_init(parser.get(), HTTP_REQUEST);
parser->data = &http_data;
int nparsed = http_parser_execute(
parser.get(), &settings, buf, readed);
if (nparsed != readed) {
close(sock);
continue;
}
http_data.method = parser->method;
}
Route(http_data);Также в чатике в телеграмме поднялся вопрос о том, что на сервере проверяется только количество полей в хедере, а не их содержимое, и хедеры были безжалостно порезаны:
const char* header = "HTTP/1.1 200 OK\r\n"
"S: b\r\n"
"C: k\r\n"
"B: a\r\n"
"Content-Length: ";Кажется, странное улучшение, но на многих запросах размер ответа существенно сокращался. К сожалению, неизвестно, дало ли это хоть какой-то прирост.
Все эти изменения привели к тому, что лучшее время в песочнице до 197 секунд, и это было 16 место на момент закрытия, а в финале — 188 секунд, и 13 место.
Код решения полностью расположен здесь: https://github.com/evgsid/highload_solution
Код решения на момент финала: https://github.com/evgsid/highload_solution/tree/final
Magic pill
А теперь давайте немного поговорим о магии.
В песочнице особенно выделялись первые 6 мест в рейтинге: у них время было ~140 сек, а у следующих ~ 190 и дальше время плавно увеличивалось.
Было очевидно, что первые 6 человек нашли какую-то волшебную пилюлю.
Я попробовал в качестве эксперимента sendfile и mmap, чтобы исключить копирование из userspace -> kernelspace, но тесты не показали никакого прироста в производительности.
И вот последние минуты перед финалом, прием решений закрывается, и лидеры делятся волшебной пилюлей: BUSY WAIT.
При прочих равных, решение, которое давало 180 секунд с epoll(x, y, z, -1) при использовании epoll(x, y, z, 0) давало сразу же 150 секунд и меньше. Конечно, это не продакшн-решение, но очень сильно уменьшало задержки.
Хорошую статью по этому поводу можно найти тут: How to achieve low latency with 10Gbps Ethernet.
Мое решение, лучший результат которого был 188 в финале, при использовании busy wait сразу же показало 136 секунд, что было бы 4-м временем в финале, и 8-ое место в песочнице на момент написания этой статьи.
Вот так выглядит график лучшего решения:
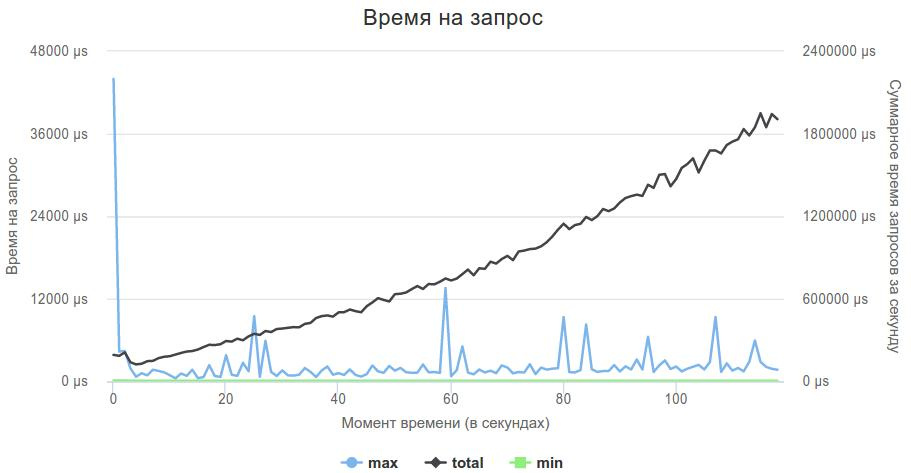
На самом деле, busy wait нужно использовать очень осторожно. Мое решение, когда главный поток принимает соединения, а 4 потока только обрабатывают данные из сокетов, при использовании busy wait стало сильно проседать на post-фазе, потому что accept'у не хватало процессорного времени, и мое решение сильно тормозило. Уменьшение количества обрабатывающих потоков до 3 полностью решило эту проблему.
Заключение
Тамада хороший, и конкурсы интересные.
Это было очень круто! Это были незабываемые 3 недели системного прогрммирования. Спасибо моей жене и детям, что они были в отпуске, а иначе семья была бы близка к разводу. Спасибо организаторам, которые не спали ночами, помогали участниками и боролись с танком. Спасибо участникам, которые дали много новых идей и подталкивали к поиску новых решений.
С нетерпением жду следующего конкурса!
Комментарии (29)

Vadem
12.09.2017 12:28+6Конечно, это не продакшн-решение, но очень сильно уменьшало задержки.
Кажется, что там почти всё не продакшн-решение.
Но за статью спасибо. Было очень интересно читать. Вы отлично пишете.x67
14.09.2017 13:16Спорткары тоже не очень предназначены для обычных дорог) Такова уж суть любого спорта. Однако надеюсь, в следующий раз все используемые сейчас уловки будут учтены, дабы максимально приблизить соревнование к реальности

reatfly Автор
14.09.2017 13:19Спорткары, в которых топлива только на один круг и все повороты левые :)
alexeykuzmin0
14.09.2017 14:27Ну, если не на круг, а на гонку (или ее часть), то как раз примерно F1 получится

YuliyF
12.09.2017 12:56а можно на этом яндекс-танке свой серверный движок поганять? может есть где описание как это сделать?
reatfly Автор
12.09.2017 12:59Я c танком не разбирался и локально не использовал, но его точно можно использовать для своего проекта. Наверно этот вопрос стоит начать изучать с оф документации на гитхабе.

reiser
12.09.2017 13:18+2Было действительно здорово, помню свои эмоции, когда в четыре утра воскресенья поднялся на десятое место (в первом раунде).

Дальше уже было понятно, что принципиально улучшить к финалу я ничего не успею и дальше буду только падать.
Ну хоть в финальную выборку вошёл, уже хорошо :)

vlreshet
12.09.2017 13:25-1А где-то есть все решения участников? Интересно узнать это стёб или нет
Вот это

AterCattus
12.09.2017 13:28+3Все известные решения собраны тут github.com/proton/highloadcup17_solutions
reatfly Автор
12.09.2017 13:44Там можно писать все, что угодно :)
У одного из участников в топ-10 было написано php + что-то, но реально там был С/С++.
morozovsk
12.09.2017 20:38>У одного из участников в топ-10 было написано php
ещё хлеще, там было кажется что-то типа «вордпресс» :)
А лучшее решение на php сейчас — это 89 место с результатом 293 секунды, Виталий Дятлов xytop со стеком "(PHP, MySQL+Memcache, Lightttpd)".

Не знаю как ему удалось добиться таких результатов с таким стеком. У меня «php + shared memory» и мне удалось получить только 404 секунды. Хотя есть ещё куда оптимизировать.
xytop
12.09.2017 21:32+1Там C+nxweb (а в первом туре еще whitedb для базы было).
Это я зашифровался так :)
yokotoka
12.09.2017 13:42+4В подобных спортивных соревнованиях есть особенность. Для достижения максимальной эффективности приходится делать много допущений и упрощений, писать код так, чтобы он был эффективным, не принимая во внимание его дальнейшую поддерживаемость.
Т.е. выигрывает не подход, когда пишется эффективный код, который можно легко доработать в дальнейшем, а подход «сделать одноразовый сервис». Наверное, в условиях mail.ru поиск кадров, способных на такое, оправдан (из-за количества серверов разработчик «одноразовых» высокоэффективных сервисов будет дешевле — даже если их придется время от времени писать с нуля при необходимости что-то поменять). Но на массовом рынке это не такая уж важная фича.
werevolff
12.09.2017 19:10Ну, как бы для прикладной задачи решение под-ключ почти всегда плохо обслуживается, но максимально направлено на выполнение условий. Последующая оптимизация, как-правило, вызывает погрешности в решении поставленных задач. Например, если речь идёт только о скорости обработки запроса, то решение будет исключать универсальность, возможность повторного использования и обработку кастомных параметров. Когда добавляется необходимость перестроить решение под другие сервисы, добавляются настройки и интерфейсы, загрузка которых съедает ресурс и скорость обработки запроса снижается. Полагаю, что если будет стоять задача сохранения скорости при обработке сотни различных параметров, срок разработки увеличится с недели до нескольких месяцев, или даже лет. В коммерческом плане, разумеется, никто не будет платить программисту за такое решение. Будет проще написать по велосипеду на каждый юзкейс, либо, если стоит задача разработки универсального обработчика, поступиться параметрами скорости обработки.
NYM
13.09.2017 11:28В качестве библиотеки для разработки http-сервиса рассматривал несколько решений и пока не нашел для себя ничего лучше, чем libevent (ее поддержку http). Не смотря на ее C'шное а не C++ API производительность и удобство использования дают хорошее сочетание.
Не рассматривали libevent, а если да, то чем она уступила иным решениям?
Некоторое время назад так же в качестве почти «тестового задания» писал http-сервер на epoll. Производительность по сравнению с готовыми решениями, например, тем же libevent лучше, но много нюансов… Не смотря на большую собственную лояльность к «своим решениям», пришел к заключению, что писать http-сервер с помощью epoll — это крайняя мера.reatfly Автор
14.09.2017 12:08libevent не рассматривал по двум причинам:
1. Я про не знал (но теперь знаю)
2. Когда дело дошло до сокетов и epoll, время поджимало, и мне было проще сделать это все руками.
И я полностью согласен, что если делать не решение, заточенное под конкретный конкурс, то сторонние библиотеки/сервера будут лучше. Хотя бы потому, что их уже не нужно писать и тестировать.
Как известно, 20% кода занимают 80% времени.
И кажется, конкретно в этом случае выстрелило сочетание epoll + busy wait, и все остальные реализации заведомо проигрывали.

Kwisatz
14.09.2017 11:46Поздравляю 8)
Когда начал читать статью первой мыслью было «круто я тоже хочу».
Но когда дочитал честно говоря был разочарован: какой практический толк от всего этого? Высокая нагрузка мне интересна и знаю я о таких вещах не по наслышке, но в этом соревновании чистая синтетика.reatfly Автор
14.09.2017 11:50Это всегда проблема подобных соревнований: либо синтетика, либо очень сложно как для участников, так и для организаторов. Конкретно в этом случае я соглашусь: толку нет, потому что это было тестовое соревнование на попробовать, взлетит или нет, и по словам организаторов, они рассчитывали на 100 человек, а в итоге было 400+ решений в рейтинге.
Вот тут участники своими идеями делятся на будущее: github.com/sat2707/hlcupdocs/issues/94Kwisatz
14.09.2017 16:12Видимо у меня несколько иной склад ума. Я не могу себя заставить делать то, что не принесет практической пользы. Мне бы БД, да потолще, да с проблемами побольше)

DimaKurb
Спасибо что поделились. Я правильно понимаю, что «busy wait» указывается при запуске сервера и оно никак не интегрируется в код. То есть сам код не меняется просто добавляется флаг при запуске сервера?
reatfly Автор
Busy wait — это общее название техники, когда процесс/поток не блокируется, а просто в цикле проверяет наступление какого-то условия. Из плюсов — очень низкие задержки. Из минусов — потребляется 100% процессорного времени. Busy wait
Ответ на вопрос: да, никаких дополнительных изменений в коде, просто меняется последний параметр у epoll().