

Список технологий и инструкций, поддержка которых реализована в AMD CPU семейства 17h. Фрагмент документа Software Optimization Guide for AMD Family 17h Processors.
Сложнейшие устройства, какими являются современные CPU, можно рассматривать с различных точек зрения, приходя к диаметрально противоположным выводам и результатам сравнения. Тем не менее, большинство технологий, рассмотренных ниже, ранее были реализованы в процессорах Intel, за исключением эксклюзивной для AMD инструкции CLZERO.
SMAP, Supervisor Mode Access Prevention
- Intel и AMD

Опция SMAP оказывает влияние на механизм трансляции страниц и подсистему виртуальной памяти. Позволяет блокировать доступ привилегированного кода операционной системы (Kernel Mode) к страницам уровня пользователя (User Mode).
Такое ограничение, несколько противоречащее классической иерархии защиты памяти (при которой статус супервизора допускает любые виды доступа) в некоторых случаях помогает противостоять действиям злонамеренного кода, несанкционированно использующего режим супервизора, а также упростить выявление некоторых ошибок, приводящих к искажению содержимого памяти.
RDSEED, Read Random Number (Re-Seed)
- Intel и AMD

Инструкция RDSEED, также как и ранее существующая инструкция RDRAND, генерирует случайное число. Отличие в том, что RDSEED для каждого сгенерированного числа использует аналоговый источник энтропии (Enhanced non-deterministic random bit generator, NRBG). RDRAND использует цифровой генератор (Deterministic random bit generator, DRBG), периодически перезагружаемый из аналогового источника энтропии. Такая перезагрузка называется re-seed. Недостаток инструкции RDRAND в том, что в паузах между такими перезагрузками может быть сгенерировано несколько случайных чисел, и в этом случае генерация каждого следующего числа в данной группе чисел является результатом работы цифрового автомата (DRBG), а не аналогового источника энтропии (NRBG), что теоретически снижает криптостойкость.
Данная официальная трактовка различий RDRAND и RDSEED приводится в документации Intel. Возможно, существуют некоторые Implementation-Specific различия у Intel и AMD. Упрощенно говоря, можно дать такую рекомендацию: если в приоритете производительность генератора случайных чисел, следует использовать инструкцию RDRAND, если криптографическая стойкость — RDSEED.
XSAVEC, Extended Save with Compaction
- Intel и AMD

Инструкция XSAVEC является одной из оптимизированных форм инструкции сохранения контекста XSAVE, применяемой для обеспечения работы многозадачных ОС. Инструкция XSAVEC в отличие от XSAVE не выполняет сохранение компонентов контекста процессора, состояние которых не изменялось с момента инициализации (init optimization).
XSAVES, Extended Save for Supervisor
- Intel и AMD

Инструкция XSAVES является одной из оптимизированных форм инструкции сохранения контекста XSAVE, применяемой для обеспечения работы многозадачных ОС. Инструкция XSAVES в отличие от XSAVE не выполняет сохранение компонентов контекста процессора, состояние которых не изменялось с момента предшествующего восстановления их состояния (modified optimization). Данная форма оптимизации характерна для привилегированных процедур операционной системы.
CLFLUSHOPT, Cache Line Flush Optimized
- Intel и AMD

Инструкция CLFLUSHOPT объявляет недостоверной строку кэш-памяти. Если перед выполнением инструкции, строка содержала данные, ожидающие отложенной записи в ОЗУ, такая запись выполняется перед очисткой строки. CLFLUSHOPT является оптимизированной версией ранее существующей инструкции CLFLUSH. К сожалению, четкая формализация списка различий между CLFLUSH и CLFLUSHOPT отсутствует в документации Intel и AMD.
ADCX, Add with Carry Flag for Multi-Precision
- Intel и AMD
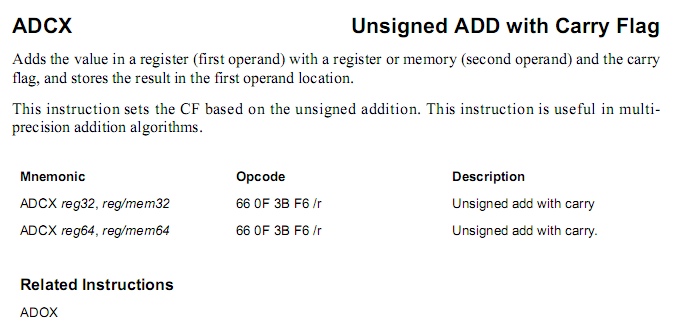
Инструкции ADCX и ADOX выполняют беззнаковое сложение двух операндов и предназначены для обработки чисел, разрядность которых превышает разрядность одной операции сложения за несколько таких операций. Признак арифметического переноса учитывается при сложении и устанавливается в соответствии с его результатами.
Имеют место следующие отличия от классической инструкции ADC, также выполняющей сложение с использованием флага переноса:
- Инструкция ADCX не модифицирует флаг переполнения OF.
- Инструкция ADOX в качестве признака арифметического переноса использует флаг переполнения (OF) и не модифицирует флаг переноса CF.
Описанный нетипичный формат использования флагов позволяет оптимизировать параллельное выполнение двух операций многоразрядного сложения, чередуя инструкции, относящиеся к двум ветвям. При использовании классической инструкции ADC, такое чередование инструкций взаимно-независимых ветвей в одном потоке было бы невозможно, в силу применения общего флага переноса (CF).
CLZERO, Cache Line Zero
- Только AMD

Инструкция CLZERO выполняет обнуление содержимого заданной строки кэш-памяти. Может использоваться для быстрого обнуления кэшируемых областей памяти а также исключения дополнительных пересылок между кэш-памятью и DRAM, имеющих место в случаях, когда содержимое кэш-строки модифицируется частично. Таким образом, оптимизируется взаимодействие Cache и DRAM.
Чтобы оценить эффект эксклюзивной для AMD инструкции CLZERO, потребуется основательно вспомнить теорию: информация, которую обрабатывает процессор, может быть классифицирована как temporal и non-temporal.
- К типу temporal можно отнести данные, которые процессор интенсивно и многократно использует в текущий момент времени, при этом их суммарный размер меньше размера кэш. Размещение таких данных в кэш повышает производительность, снимая необходимость доступа к ОЗУ.
- К типу non-temporal относятся данные, размещать которые в кэш бесполезно, а зачастую вредно. Если размер обрабатываемого блока превышает размер кэш, либо следующий доступ к данным планируется через продолжительное время, такие данные с высокой вероятностью будут вытеснены из кэш до следующего обращения к ним, а значит снова потребуется чтение ОЗУ. В таком примере, кэширование непроизводительно занимает такты CPU и объем кэш-памяти.
По умолчанию, большинство процессорных инструкций обращения к памяти работают в режиме temporal, для non-temporal доступа применяются специальные инструкции, например movntps и/или movntpd.
С учетом сказанного, процессор по-разному выполняет операцию записи:
- Запись в режиме temporal store подразумевает предварительное заполнение строки кэш-памяти, для этого считывается и кэшируется 64-байтная область ОЗУ, которую затрагивает целевая операция записи. Собственно, обновление данных, предписанное инструкцией записи, выполняется уже в кэш-памяти.
- Запись в режиме non-temporal store (streaming store) подразумевает только запись в ОЗУ, без предварительного «спекулятивного» чтения, хотя и допускает объединение серии нескольких циклов записи малой разрядности в общий цикл суммарной разрядности (write combining).
Инструкция CLZERO, атомарно выполняющая полное обнуление кэш-строки, устраняет необходимость дополнительной загрузки информации из ОЗУ при формировании достоверного содержимого строки. Этим она отличается от типовых операций записи меньшей разрядности, модифицирующих кэш-строку частично. Кроме того, явно заданная размерность данных 64 байта или 512 бит упрощает write-combining оптимизацию.
Примечание.
Для удобства изложения, размер строки кэш-памяти принят равным 64 байта. Это типовое значение для современных процессоров Intel и AMD. В общем случае, программист должен детектировать значение этого параметра с помощью инструкции CPUID, избегая использования предопределенных констант.
Вместо послесловия
Анализируя рассмотренный список функциональных расширений, можно заключить, что в фокусе внимания разработчиков оказались защита пользовательских данных, сокращение затрат процессорных тактов на переключение контекста в многозадачной среде, оптимизация взаимодействия кэш-памяти и ОЗУ, а также базовые арифметические операции с целыми числами высокой разрядности.
Информация собиралась из разных источников, процесс уточнения и верификации не завершен на данный момент, поэтому замечания и дополнения приветствуются, особенно относительно инструкций CLFLUSHOPT и CLZERO и не нормируемых официальной документацией Implementation-Specific особенностей различных процессоров.
Комментарии (71)
Karpion
13.10.2017 02:07Все эти постоянные расширения набора команд как бы намекают, что система изначально спроектирована предельно плохо и непродуманно. И давно пора уже заняться рефакторингом — засадить за работу теоретиков, чтобы те придумали нормальный набор команд; и потом реализовать его, не соблюдая требований совместимости.
Отдельная команда для получения случайного числа — это бред. Случайное число можно и нужно извлекать командой IN или через обращение к адресу памяти. Вообще, маса вещей м.б. реализована без расширения набора инструкций.
А ещё лучше — пересмотреть архитектуру компьютера. Если народу интересно — попробую написать статью, как это должно выглядеть.

zaq1xsw2cde3vfr4
13.10.2017 05:36На 100% согласен с тем, что нужно проектировать новый процессор и обнулением такой гири на ногах как совместимость ибо за почти 40 летнюю историю х86 набралось изрядно.
А вот со случайным числом есть варианты. Но тоже согласен что это не должна быть отдельная команда.
MockBeard
13.10.2017 11:41без совместимости с существующим ПО, его судьба будет как у Itanium
Tallefer
13.10.2017 11:49Это только если усилие портировать гцц или любой другой компилятор не будет перевешивать бешеный отрыв в производительности, а главное — экономии (в любом виде, бизнесс сам посчитает выгоду для себя)
Chudsaviet
13.10.2017 06:21Поздравляю, вы придумали RISC.
Причины появления все новых и новых команд — устаревшая CISC-архитектура и обратная совместимость.
Рынок десктопов и серверов просто не примет что-либо, отличное от x86.
icbook Автор
13.10.2017 06:59Мало кто заметил, что в новом семействе процессоров Intel благополучно почили в бозе ММХ-команды, а заодно и операции с портами ввода-вывода.

BiosUefi
13.10.2017 15:12>благополучно почили в бозе операции с портами ввода-вывода.
не потому ли из 80h порта уже нельзя прочитать записанное туда значение?
Cплошной FF возвращается. А ведь было удлобно пользоваться им для отладки.icbook Автор
13.10.2017 21:13- Согласно Intel Xeon Phi System Software Developer Guide, если на новом процессоре, не поддерживающем инструкции IN/OUT, попробовать их выполнить, произойдет исключение General Protection Fault (exception 0Dh, прерывание с вектором 0Dh=13). Дальнейшие действия зависят от того, как написана процедура обработки исключения: зависание, аварийное завершение, программная эмуляция порта и т. д.
- Возможность прочитать из порта 80h значение, которое ранее было туда записано, была связана с наличием по этому адресу одного из незадействованных страничных регистров Legacy DMA (i8237). В ряде платформ блок страничных регистров Legacy DMA занимает 16 байт по адресам 80h-8Fh, несмотря на то, что DMA-каналов только 7 (8 если считать канал, используемый для каскадирования). Именно в силу наличия доступных для чтения DMA Page Registers порт 80h был читаемым, ведь сама POST-карта не поддерживает чтение порта, только запись. Legacy DMA не стало немного раньше, чем IN/OUT.
Extravert34
13.10.2017 18:32+1Так в статье речь идёт о Xeon Phi, который вроде как не предлагается использовать в качестве основного
icbook Автор
13.10.2017 21:05Речь также о Bootable Xeon Phi, который может использоваться в статусе CPU.
iehrlich
13.10.2017 06:50+1И давно пора уже заняться рефакторингом — засадить за работу теоретиков, чтобы те придумали нормальный набор команд; и потом реализовать его, не соблюдая требований совместимости.
А ещё лучше — пересмотреть архитектуру компьютера.
Предыдущие попытки закончились достаточно печально :)
С другой стороны, попробовать ещё раз никто не мешает — с удовольствием почитаем и прокомментируем ваш взгляд на предмет.InChaos
13.10.2017 08:01Классика жанра — давайте придумаем еще один, но самый лучший стандарт.
iehrlich
14.10.2017 00:03У этой шутки есть свои границы применимости. Начиная с определенного уровня сложности, пробы и ошибки, в совокупности с пользовательским опытом — единственный способ улучшать результат :)
Tallefer
13.10.2017 11:59Да почему сразу печально-то, у многих камней был свой звездный час, вспомните Моторолу 64К (последний камень, «выточенный»
глубоко под землейвручную инженерами), вспомните даже ламповый Z80, который вообще кое-как дотянул до наших дней, ну и вся концепция RISC/ARM, ведь казалось, что они не переживут рубеж тысячелетий, а вона как вышло. :)
Просто камень это еще не все, нужна обвязка, а главное — софт. Ах да, и еще нужна жизнеспособная бизнес модель, что совершенно не коррелирует с качеством железа, к слову. Вот это-то и печально.
Akon32
13.10.2017 11:12засадить за работу теоретиков, чтобы те придумали нормальный набор команд; и потом реализовать его, не соблюдая требований совместимости.
Что скажете об ARM?
Присоединяюсь к тем, кто ждёт статью.

stanislavshwartsman
13.10.2017 22:24Уже есть группа теоретиков которая ваяет новую идеальную систему комманд: RISC-V
https://riscv.org/
RISC-V: The Free and Open RISC Instruction Set Architecture
может в конце у них чего и получиться ...
Karpion
15.10.2017 01:20Для времени своего появления это был потрясающий процессор. Однако, к сожалению, он начал эволюционировать, подобно большинству других процессоров — а в ходе любой эволюции накапливаются разные атавизмы.
Пожалуй, правильнее было бы иметь не 16 регистров, а больше. И в момент перехода в режим SWI/IRQ/FIQ надо было прятать не 2/2/7 регистров, а больше — например, 7/14/14 (в режимах IRQ и FIQ вообще не нужны регистры прежнего режима, все в тень).
А сейчас 32-битный процессор уже не тянет множества задач, нужно делать 64-битный. И команду процессора надо бы делать такой же. А значит, и систему команд надо переделывать.
Главной проблемой процессора ARM было то, что Acorn вела крайне глупую политику:
- Надо было лицензировать архитектуру, разрешив всем желающим за небольшие деньги создавать собственные клоны — и завоёвывать рынок с дешёвой стороны.
- Надо было рекламировать свои компьютеры как устойчивые к вирусам (операционка в ПЗУ закруывет основные направления вирусных атак).
- Надо было активнее продвигать сети, упирая на совместное использование HDD — это реально удобнее локальных дисков.
- Надо было не заморачиваться кооперативной многозадачностью, а портировать Unux — ну, хотя бы в виде совместимости с форматом пути к файлу (DOS/Windowsиспользуют в качестве разделителя "\"; Unix — "/"; а Acorn — ".").
И наконец, я полагаю, что сейчас надо сосредоточиться не на архитектуре процессора, а на архитектуре компьютера. Надо сделать так, чтобы в компьютере можно было поменять процессор или установить несколько разных процессоров. Короче, эту тему я сейчас как раз обдумываю.
icbook Автор
13.10.2017 12:03Подход с чтением случайного числа из порта ввода-вывода (инструкцией IN), вернее Memory-Mapped IO (инструкцией MOV), применяется в тех случаях, когда для его генерации используется некое внешнее устройство, например генератор случайных чисел в составе микросхемы BIOS ROM Intel 82802 (это день вчерашний).

Этому решению почти 20 лет, оно медленное, поскольку некэшируемое чтение занимает много процессорных тактов, а кэшировать его нельзя по очевидным причинам — вместо новых чисел будут считываться кэш-копии первого сгенерированного числа. Приведем аргумент из другой области: в рамках спецификации x2APIC для доступа к регистрам локального контроллера прерываний вместо привычного диапазона MMIO (Local APIC base = FEE00000h) сейчас применяется доступ посредством регистров MSR (Model-Specific Registers).

Вместе с тем, в будущем нас скорее всего ждет унификация — метод получения случайного числа может быть Implementation-Specific, а в качестве внешнего интерфейса используется драйвер, например EFI_RNG_PROTOCOL, инкапсулирующий метод доступа к устройству и позволяющий использовать различные методы, не нарушая совместимость (это день завтрашний). По крайней мере теоретически это так выглядит.Karpion
15.10.2017 23:52Завернуть запрос в I/O-порт (команду IN/OUT) обратно в процессор — не проблема. Благо контроллер шин адреса+данных давно уже в процессоре. И это будет не медленнее, чем отдельная команда.
Единственное преимущество специальной команды — это возможность использования этой команды в user-space.
BIOS — это программа. ROM — это микросхема, содержащая программу или данные (можно BIOS, можно что угодно другое — например, операционку с программами, Acorn подтверждает).
Фраза "генератор случайных чисел в составе микросхемы BIOS ROM" бессмысленна.
Унификация через драйвер — это стандартный путь решения задачи, когда один и тот же результат на разных платформах получают разными способами. Однако, этот способ — реально медленный; обычно лучше внедрять нужный код внутрь программы при компиляции.
SteelRat1
13.10.2017 14:34И приделать к нему отдельный модуль для обратной совместимости со всеми-всеми-всеми существующими архитектурами. И всех-всех разработчиков низкоуровнего кода отправить на многомесячную переподготовку.
Karpion
14.10.2017 08:44Я зачем нужна совместимость, особенно "со всеми-всеми-всеми существующими архитектурами"? Кто сейчас нуждается в совместимости с Z80, Motorolla 68k и прочими "героями вчерашних дней"?
SteelRat1
14.10.2017 11:39Ну не надо так буквально все понимать. По сути, вы сами ответили на свой вопрос. «Герои вчерашнего дня» в расчет не берутся. Только это никак не облегчает задачи совместимости радикально новой архитектуры. Как и многие предшественники, она займет узкую нишу и через какое-то время, с большой вероятностью, станет частью истории.
Karpion
14.10.2017 18:33Есть масса ниш, куда можно вторгнуться, не заботясь о совместимости.
Например, LAMP: Linux + Apache + MySQL + PHP (в наше время компоненты м.б. другие, но аналогичные. Для новой архитектуры портируются Linux и Си-компилятор, после чего без труда портируются все программы. Рынок достаточно востребованный.
Другой рынок — это рынок хостинга вирт.машин. Тут надо портировать ещё и вирт.машину; но основная её часть переносится простой перекомпиляцией. Скорее всего, появится ограничение на список поддерживаемых операционок — ну так для успешного старта достаточно поддерживать хотя бы одну распространённую, Linux годится.
Третий рынок — это рынок платёжных терминалов. Тут совместимость вообще вредна, ибо она — совместимость с вирусами и прочими вредоносными программами.


stanislavshwartsman
13.10.2017 06:51Почему у меня такое чувство, что автор не имеет представления о чем пишет?
Не увиделось ничего "изнутри", статья не более чем плохой перевод документации по новым инструкциям ryzen, даже без попыток вникнуть в детали :(icbook Автор
13.10.2017 07:00Расскринили Ваш коммент, чтобы избежать обвинений в предвзятости. Ваше мнение важно для нас! (С)
stanislavshwartsman
13.10.2017 17:58+1Обращайтесь с конкретными вопросами. Помогу понять чем отличаются все эти разные XSAVE* инструкции, CLFLUSH от CLFLUSHOPT и что-такое write-back/write-allocate и какое отношение они имеют к temporal/non-temporal.
icbook Автор
13.10.2017 18:34Давайте лучше своё видение перспектив использования инструкции CLZERO.
stanislavshwartsman
13.10.2017 22:12+1CLZERO как инструкция давненько напрашивается. Вы будете удивлены как часто бывает нужно проинициализировать (читай: обнулить) какой-нибуль кусочек памяти. Например при создании нового объекта в ЯВУ.
Вопрос в том какие есть альтернативные пути это сделать:
- Можно обнулять с помощью streaming stores. но не самый лучший вариант если объект не большой и сразу будет использоваться. После обнуления streaming stores в кешах процессора ничего не останется и первое использование будет дорого стоит (cache miss до самой памяти)
- Можно использовать rep stosb.
- На Intel с поддержкой AVX-512 можно тупо сделать 512-битный store, хоть WB streaming, хоть обычный.
Intel решил не добавлять новую инструкцию потому что добился того, что альтернативные пути работают не хуже, а значит она просто не нужна.
AMD не смог или не захотел докрутить rep stosb и предпочел создать новую инструкцию.
На первый взгляд она кажется нишевой (только на AMD, Intel ее не поддердивает и не собирается), но это только на первый взгляд. Run time library (тот же libc) у большинства ЯВУ уже сейчас платформенно зависимы, умеют делать CPUID и выбирать лучшую имплементацию для каждой конкретной платформы. Так что CLZERO будет использоваться или уж используется везде и всюду, каждый раз когда ваша старая программа вызывает тот же memset, malloc, calloc и т.п. Ну а на Intel они будет использовать rep stosb и оно будет не сколько не медленнее и с теми же "фичами", только за кулисами.

qw1
13.10.2017 22:51+1Пара вопросов.
CLZERO это макрос для контроллера памяти и далее контроллер уже сам выполняет запись нулей? Или протокол DRAM имеет возможность передать только адрес, без пакета нулей, и тем самым экономится bandwidth?
Если на Intel выполнять rep stosb, но с ненулевым заполнителем, оптимизация пропадает?icbook Автор
14.10.2017 07:14Дело не в содержании заполнителя (нули или другие данные), а в обеспечении условий, при которых процессор после записи располагает полной информацией о содержимом 64-байтной кэш-строки. Если строка перезаписана частично (записано менее 64 байт), то для получения содержимого не перезаписанной части строки требуется подгружать данные из ОЗУ, чтобы обеспечить достоверность всех 64 байт.
Если строка перезаписана полностью (записано 64 байта по адресу кратному 64), то исходное содержимое ОЗУ можно проигнорировать, так как оно полностью «перекрыто» новыми данными и содержимое кэш-строки является функцией только данных записи и не является функцией исходного содержимого ОЗУ.
Такой метод обслуживания записи без обращения к ОЗУ, экономит не только такты, но и потребляемую мощность. Да, верно подмечено, у процессоров Intel, поддерживающих AVX512, инициировать 64-байтную запись можно и без CLZERO инструкцией записи, например, VMOVAPD [rax],zmm0. Такой подход работает для 64-байтных кэш-строк (512 бит = 64 байта), но пока нет оснований полагать, что размер кэш-строк изменится в новых процессорах. Или есть?
stanislavshwartsman
13.10.2017 22:21+1Кстати, гораздо интереснее не CLZERO а вообще пропущенные в статье MONITORX/MWAITX. Вот это больше похоже на настоящий прорыв. Оригинальные MONITOR/MWAIT доступны только для OS (ring0) и не поддерживают выход по timeout. В результат у user-code нет альтернативы кроме использования busy (pause) loops. На Ryzen c MONITORX/MWAITX можно практически вырубить энергопортребление или отдать все ресурсы другому потоку вместо тупого pause loop который еще и в память будет каждую итерацию заново лазить семафор проверять!
icbook Автор
14.10.2017 07:07+1Согласны, но статья про новшества процессоров Family 17h, а MONITORX/MWAITX появились раньше.
Tallefer
13.10.2017 06:51Damn, полезная статейка, спасибо. Вот бы такие читать каждый раз, когда новые команды в железе появляются… Не посоветуете такую подписку, если такая есть где-то?
stanislavshwartsman
13.10.2017 17:59+1

yTom48
13.10.2017 06:51+1Интересно, насколько равномерно распределены числа аналогового генератора рандома?
icbook Автор
13.10.2017 07:05У нас есть наивная визуализация RDRAND для 64-битной версии UEFI.
А вот хорошая иллюстрация из независимого источника:

Temtaime
13.10.2017 10:39Лучше бы кто написал, что все ранние модели райзенов имеют физический дефект из-за которого, к примеру, gcc уходит в sigsegv, и всем, кто об этом отрепортит — амд, тадам, отправляет новый процессор.

Rast1234
13.10.2017 12:30Правильно ли я понимаю, что когда в популярные компиляторы добавят поддержку новых AMD-only инструкций, будут отдельные бинарники для собранные для интелов и амд?

sumanai
13.10.2017 12:44Нет. Во-первых, все новые инструкции живут за флагами до того, как станут повсеместно распространёнными, а принудительно их включать будут для ограниченного набора софта. Во-вторых, все инструкции кросс-лицензируются, и можно ждать их скорого появления в Intel, так же, как и большая часть инструкций в статье перекочевала в AMD из Intel. В третьих, никто не запрещает проверить поддержку любых инструкций и выполнять вариант без них там, где они не поддерживаются.
Rast1234
13.10.2017 12:54Интересные детали, спасибо. А есть информация, как быстро новые команды начинают использоваться в gcc, clang и прочих? А то вот процессор есть, инструкции есть, что-то может быстрее работать, но надо непонятно сколько ждать пока поддержка будет.
icbook Автор
13.10.2017 13:33По нашему опыту, оперативнее всего обновляется FASM (Flat Assembler). Поэтому ранняя и тонкая оптимизация потребует ассемблерной реализации критических фрагментов кода, как бы старомодно это не звучало…
Tallefer
13.10.2017 13:42А опыт достаточно свежий и при этом охватывает большой промежуток времени? Я к тому, что фасм тогда можно, в теории, приладить и использовать как бэкенд для bleeding-edge, если кому-то приспичит. Но хочется быть уверенным.
sumanai
13.10.2017 13:41+1Так как большая часть инструкций из статьи перекочевала из Intel, то они уже есть как минимум в Intel® C++ Compiler. Но ждать ещё долго. Мало поддержки компилятора, нужны новые версии софта.
erwins22
13.10.2017 16:21Вообще судя по AVX2 процессостроение ЦП вымирает. Последние потуги.
icbook Автор
13.10.2017 18:30erwins22
13.10.2017 18:50+1Я немного о другом. AVX512 не стали внедрять в десктопные компы, а только с Фи и Хсионы. Причина малопонятна, но говорит о том, что Intel вероятно отказалась от гонки за производительность с видюхами.
Верьте делам, а не словам.icbook Автор
13.10.2017 20:10Судя по успехам криптовалюты, он не отказался, а просто проиграл гонку. Хотя окончательные итоги подводить рановато.

vvzvlad
13.10.2017 20:34+1А сколько инструкций сейчас в современных x64-процессорах?

CodeRush
14.10.2017 01:35+1Вот тут Крис Домас решил найти их все (даже недокументированные) при помощи весьма забавного трюка с помещением очередного кандидата в валидные инструкции на границу между страницами памяти.
Видео оригинального доклада, рекомендую двумя руками:icbook Автор
14.10.2017 19:05+1Идея понятна — располагаем исследуемую многобайтовую последовательность на границе страниц памяти, при этом вторая страница должна быть отмечена как отсутствующая, чтобы при попытке обращения к ней генерировался Page Fault. Пытаемся выполнить эту последовательность как инструкцию, ждем реакцию процессора и анализируем ее.
Если сгенерирован Page Fault (PF, vector 0Eh), значит исследуемая последовательность байтов является инструкцией, при этом ее часть «залезла» на вторую страницу, что позволяет сделать вывод о длине байтового представления инструкции.
Если вместо Page Fault генерируется General Protection Fault (GPF, vector 0Dh) или Invalid Opcode Exception (vector 06h), то это значит, что байтов, расположенных в первой странице, процессору достаточно, чтобы «понять» что операция недопустима, «понять» до попытки адресации второй страницы.
Когда-то делали что-то подобное под DOS для поиска недокументированных MSR. Но там все было значительно проще:
- Устанавливаем собственную процедуру обработки GPF (vector 0Dh)
- Загружаем в ECX адрес исследуемого (якобы несуществующего) MSR
- Выполняем инструкцию RDMSR
- Если не генерируется General Protection Fault, значит этот MSR существует.
Делая тот же трюк с недокументированными кодами инструкций нет уверенности в том, что на любой недопустимый код операции процессор дисциплинированно сгенерирует #UD (vector 06h) или #GPF (vector 0Dh), в ходе исследования возможны зависания и рестарты, вероятность которых можно уменьшить, проводя исследования на виртуальной машине, что автор и сделал.
melchermax
Прочитал. Лопнул мозг. Пишите ещё! ;)
Jeyko
А у меня даже не раздуло его. Просто это все в него не помещается…
icbook Автор
Поздравляем! Ваш комментарий первый. Сообщите пожалуйста свой почтовый адрес — на него мы вышлем восьмитомник процессорных инструкций и воздушный поцелуй :)
Skerrigan
Простите, это такой новый способ прибить человека или отправить его в дурку (я шуткую если чего)?
icbook Автор
Шутка принята :)