
Вам нужно вести разработку с использованием микросервисной архитектуры. Все советуют Spring Cloud, но почему? Достаточно ли он обкатан? Как он устроен внутри, какой логикой руководствовались разработчики, насколько удобно всё это применять?
На эти и другие вопросы ответили в интервью редакции JUG.ru Group спикеры конференции Joker 2017 — Евгений Борисов и Кирилл Толкачёв.
 Евгений Борисов работает в Naya Technologies. Он разрабатывает на Java с 2001 года, и принял участие в большом количестве Enterprise-проектов. Пройдя путь от простого программиста до архитектора и устав от рутины, он стал свободным художником. Сегодня Женя пишет и проводит курсы, семинары и мастер-классы для различной аудитории: live-курсы по J2EE для офицеров израильской армии, Spring — по WebEx для румын, Hibernate через GoToMeeting для канадцев, Troubleshooting и Design Patterns для украинцев.
Евгений Борисов работает в Naya Technologies. Он разрабатывает на Java с 2001 года, и принял участие в большом количестве Enterprise-проектов. Пройдя путь от простого программиста до архитектора и устав от рутины, он стал свободным художником. Сегодня Женя пишет и проводит курсы, семинары и мастер-классы для различной аудитории: live-курсы по J2EE для офицеров израильской армии, Spring — по WebEx для румын, Hibernate через GoToMeeting для канадцев, Troubleshooting и Design Patterns для украинцев.
 Кирилл Толкачёв работает в Альфа-Лаборатории. Он разрабатывает различные банковские API. Формирует принципы и наборы инструментов для работы с микросервисной архитектурой. Большой поклонник Groovy, Gradle, Spring и стека технологий Netflix-а. Постоянный резидент подкаста «Разбор Полётов». Методологию DevOps знает не понаслышке и имеет почти двухлетний опыт её применения.
Кирилл Толкачёв работает в Альфа-Лаборатории. Он разрабатывает различные банковские API. Формирует принципы и наборы инструментов для работы с микросервисной архитектурой. Большой поклонник Groovy, Gradle, Spring и стека технологий Netflix-а. Постоянный резидент подкаста «Разбор Полётов». Методологию DevOps знает не понаслышке и имеет почти двухлетний опыт её применения.
— Spring Cloud — довольно новая вещь, можешь рассказать, для чего она предназначена? Насколько я понимаю, это доп. архитектура, позволяющая проще деплоить микросервисы в облака.
Евгений: Да, действительно. Spring Cloud — вещь новая. Года два назад он только начал входить в обиход, но уже очень быстро распространяется. Для чего он предназначен? Spring Cloud — это модуль Spring, в котором есть много всего разного для разработки микросервисной архитектуры. Там есть куски инфраструктуры и другие полезные плюшки. Одна из основных вещей, которые там есть — это Service Discovery. Одна из насущных задач, существующих в мире микросервисов — это максимально автоматизировать механизм обнаружения друг другом таких микросервисов, которые не знают о местонахождении друг друга. Они знают, что в принципе существуют какие-то другие микросервисы, к которым можно обращаться и что-то от них получать, но они не знают, куда обращаться, потому что сегодня мы это запускаем на одном кластере, завтра — на другом, послезавтра мы это запускаем на Amazon, потом ещё где-то. Примером модуля, входящего в мир Spring Cloud, является Service Discovery, через который все микросервисы могут узнать о местонахождении друг друга.
То есть, существуют какие-то имена, про которые они знают, и могут узнать настоящие url-ы. Например, один микросервис знает всё про юзеров системы, а другой — всё про сериалы. Вы обращаетесь к первому микросервису и спрашиваете, есть ли юзер с таким-то id, понравится или нет ему «Игра Престолов»? Соответственно, первый микросервис, который отвечает за юзеров, лезет в свою базу данных, вытаскивает информацию конкретно об этом юзере, смотрит, какие у него есть вкусы, и теперь ему нужно будет уточнить информацию про «Игру Престолов», сравнить и понять, подходит это или нет. Соответственно, он должен пойти в другой микросервис. Он знает, что есть микросервис, который называется «Игра Престолов», но не знает, где именно тот находится. Наш микросервис, при помощи Service Discovery, говорит: «Дай мне, пожалуйста, URL, по которому я смогу обратиться к нужному мне микросервису». И после этого он может обращаться к нему по REST после того, как он этот URL получит. Это если совсем в двух словах. Кстати, модуль Spring Cloud не подразумевает обязательную работу в облаке. Он именно служит помощником для разработчиков микросервисной архитектуры в своём проекте. А то, что чаще всего, вся построенная система запускается именно в облаке, и породило название Spring Cloud. Но на самом деле нет никакой проблемы иметь весь кластер микросервисов на одной локальной машине. От этого смысл не изменится. Ведь микросервис и так не знает, где он запустится.
У тебя может быть локальная система в локальной сетке, или даже на одной машине. Ты поднял 10 разных микросервисов, которые хотят иногда обращаться друг к другу. Они не знают, на каком IP или URL сидит каждый микросервис, потому что это всегда может измениться. Мы ещё чуть позже поговорим о том, что у каждого микросервиса может быть много копий для перформанса. На секунду это оставим. Допустим, есть одна копия у каждого отдельного микросервиса, но всё равно — это же неправильно — хардкодить, прописывать URL в какой-нибудь property-файл, чтобы они там через RestTemplate или ещё что-то обращались друг к другу, потому что завтра ты возьмешь свою систему микросервисов из тестовой среды и перенесёшь это в прокадшн: там у тебя другие URL, другие IP — и там у тебя ничего не работает. Ты это опять всё задеплоил, наладил, потратил кучу времени, у тебя это в продакшене заработало. Потом ты это отдал другому клиенту или вы подняли это в Amazon, там опять всё другое — другие порты, URL, и опять ничего не работает. А Service Discovery в Spring Cloud предоставляет это из коробки. Всё очень просто: ты инжектишь определённый сервис, в который все зарегистрированы, и через него ты можешь сказать «дай мне URL микросервиса, который называется вот так». И всё. Делается это очень просто: ставится на каждом микросервисе в главном Main-е в главной конфигурации аннотация Spring Cloud, которая говорит о том, что я хочу зарегистрироваться, и тогда он поднимается, сам находит один единственный центральный сервис, который должны знать все, говорит: «Меня зовут так-то, вот мой URL, вот мой IP, я сижу вот здесь». И есть кто-то один, кто знает всё про всех. Переодически он их пингует, чтобы знать кто сейчас available. С другой стороны, каждый может проинжектить себе некий сервис, у которого потом можно спрашивать, кто зарегистрирован под таким-то именем, какой у него URL, и когда у тебя уже есть эти данные, ты можешь по REST к этим микросервисам обращаться. Это конкретно та фишка, которую я лично юзал в Spring Cloud. Как видишь, это не обязательно связано с облаком. Это просто называется так — Spring Cloud, но он представляет собой много всяких разных штук. Я рассказал про сервис Discovery, Кирилл может добавит ещё что-нибудь или поправит меня.
Кирилл: Spring Cloud — это целый набор модулей, живущий по своим законам и порой даже «подламывающий» механизмы Spring Boot.
Евгений: Как я и сказал, Spring Cloud предоставляет целый инструментарий, связанный с миром облаков, микросервисов и т.д.
Кирилл: Сам по себе Spring Cloud, как называют это сами разработчики, — это Release Train, содержащий набор зависимостей/модулей, версии которых согласованы между собой и рассчитаны на конкретную версию Spring Boot. Про один из модулей ты уже сказал — это Spring Cloud Discovery. Service Discovery обычно бесполезен отдельно от Load Balancer, и в Spring Cloud для этого есть Spring Cloud Netflix — проект с имплементацией Discovery для Eureka Server и клиентским балансировщиком — Ribbon и Feign. Spring Cloud Starter Ribbon — интеграция клиентского балансировщика Ribbon в привычный стек Spring MVC (RestTemplate) и связка его с Service Discovery. Spring Cloud Starter OpenFeign — декларативный клиент для того, чтобы делать клиенты в стиле RPC, для удобного общения сервисов через HTTP. Само собой, он имеет интеграцию с упомянутыми ранее решениями (Ribbon/Discovery).
Как и сказал Женя, для использования Spring Cloud «облако» (о Господи, да всё разное понимают под этим словом) вам в общем-то и не нужно. Мой позыв простой: Зачем вы делите своё решение на разные сервисы? Если есть возможность не делить и спокойно работать с одним, то лучше так и делать, потому что это проще. Как только вы разделили «монолит» на кучку «микросервисов» — вы получили сложную распределённую систему, вместо предсказуемой и понятной монолитной. У вас появились проблемы, о которых вы до этого даже не думали, а некоторые проблемы всплыли на уровень инфраструктуры. Приходится манипулировать совсем другим списком ошибок, и это при том, что старые никуда не делись.
Но всё ли так плохо? Действительно, часть трудностей берёт на себя Spring Cloud (например, реализация балансировки и клиентское обнаружение). Так, целую пачку новых вызовов привносят совершенно обычные, с точки зрения разработки, вещи. Приходится смотреть на типичные вещи под углом функционирования системы в целом (а я напомню, в случае монолитного приложения это было просто супер). Например, теперь недостаточно написать сообщение об ошибке в лог, нужно позаботиться о прозрачности его нахождения, добавляя к нему метаинформацию для сквозного поиска вызовов, участвующих в ошибочном запросе. Для этого есть решения типа Spring Cloud Sleuth, которые добавляют различную метаинформацию в логи, позволяют получать «сквозные» логи по ошибкам, производят семплинг запросов и отправляют их на Zipkin-сервер. С помощью интерфейса Zipkin уже можно удобно искать «топ самых медленных запросов», вычислять «грязных утят» — конкретные тормозящие сервисы, быстро оценивать ситуацию и локализовывать проблему.
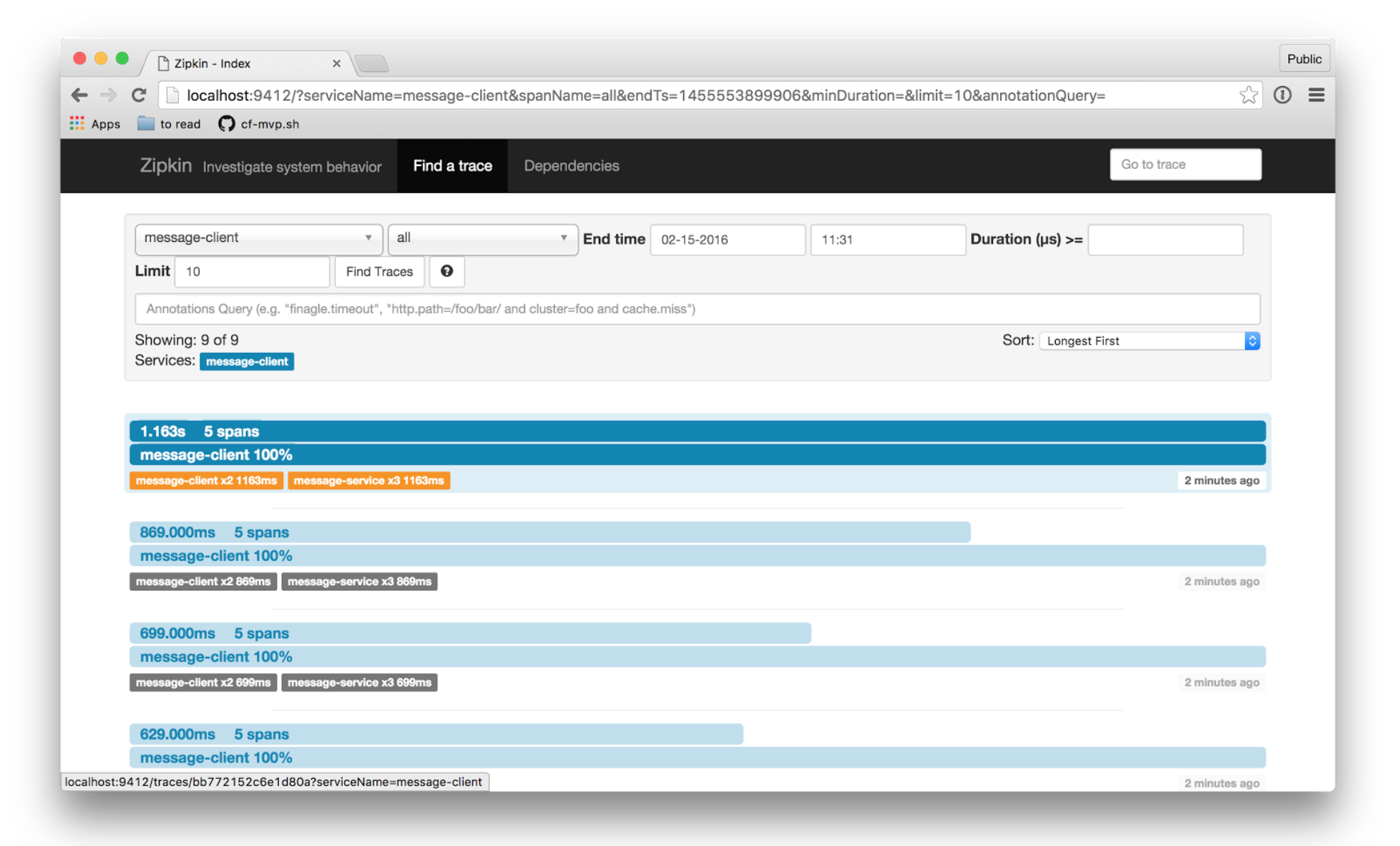
И как многое в распределённых системах, всё вышесказанное — это лишь вершина айсберга. Огромная вариативность стека заставляет непрерывно выбирать подходы, принимать решения. Например, тот же Zipkin может получать сэмплы (информация о внутренних процессах приложения – в основном различные замеры времени) для формирования TOP N медленных запросов, через очереди или по HTTP API. Обозреваемые приложения так же настраиваются на сброс информации либо в очередь (kafka/rabbitmq) либо в HTTP API Zipkin.
Сам «сэмпл» запроса, состоящий, по сути, из времён ответов разных систем, поучаствовавших в каком-то запросе, после получения также может храниться по-разному:
- In-memory
- Сassandra
Каждое решение приемлемо в разных условиях, и хорошо, если ваши условия совпали с существующим решением, иначе приходится делать своё.
Очередь тоже можно выбрать разную, в Spring Cloud есть поддержка Kafka и RabbitMQ.
И выбор любого решения — это огромная ответственность, так как чем «круче» и сложнее, тем больше потом кому-то придётся поддерживать, обновлять и развивать. Так что задумайтесь, когда вместо ConcurrentLinkedQueue в своём аккуратном и монолитном приложении вы захотите сделать микросервисы и Kafka.
Для работы с Kafka/RabbitMQ и создания «message-driven» микросервисов, в Spring Cloud также есть модуль — Spring Cloud Stream (основанный на других модулях Spring Boot).
Из-за такого обилия возможностей часто страдает качество конечных решений. Не всё хорошо стыкуется при необходимости использования разные версии (например Kafka 0.9 плохо дружит с новыми Spring Cloud Stream из-за встроенной версии драйвера для 0.11). Частично это нивелируется «готовым стеком». То есть берём Release Train Spring Cloud Dalston.SR4 + Kafka 0.11 + …, действуем по документации, в сторону не шагаем – работает. Но граблей всё же хватает, хотя это уже совсем другая история.
— Как вообще Spring Cloud встраивается в инфраструктуру Spring/Spring Boot? Насколько просто на всё это переехать, если ты уже плотно сидишь на Boot?
Кирилл: Как я и говорил до этого — если есть возможность не переезжать, не переезжайте. Spring Cloud — это сабсет различных модулей уже, скорее, над Spring Boot, потому что абстракция немного другого уровня, она затрагивает инфраструктурный уровень ещё больше. Получается, что в Spring — это уровень фреймворка, различные MVС/JPA/Data/ES-модули и так далее. Spring Boot — это уже связка между инфраструктурой и библиотеками, где различные модули склеиваются между собой, начинают дружить с вашей инфраструктурой (embedded Tomcat/настройки/env property sources/etc), и всё это в экстазе может запуститься в виде systemd-сервиса на Linux-сервере буквально с полпинка. Spring Cloud — это уже клей между различными сервисами, которые запускаются отдельно: например, два Spring Boot-приложения, которые интегрируются между собой. Всё на этом основано и построено.
При этом Spring Cloud X может и не являться простой библиотекой, как, например, Spring Cloud Eureka Server и Spring Cloud Config Server, которые по сути своей могут быть полноценными Spring Boot-приложениями, реализующими функциональность сервера обнаружения (Discovery Server) и сервера конфигураций (Config Server).
— Зачем это всё делается? В чём идея микросервисов?
Евгений: Идея микросервисов — в том, что мы пишем маленькие кусочки приложения, которые разговаривают друг с другом, вместо того, чтобы писать один огромный монолит. Соответственно, возникает вопрос – а как они будут разговаривать друг с другом? Можно прописать связку между ними хардкодом, но тогда это, по большому счёту, не так уж сильно отличается от монолитного приложения, которое просто состоит из многих разных модулей, в которых «всё гвоздями прибито». Мы ведь хотим более гибкую связь между ними. И это ещё до того, как мы говорим о шардировании внутри каждого микросервиса. В какой-то момент мы хотим перформанса, и у нас появляется Load Balancer.
Тогда мы говорим, что вот этот микросервис не справляется, потому что к нему очень многие обращаются. Соответственно, нам нужно пять его копий. Всё это перформанс, современный вид архитектуры, горизонтальное шардирование.
— Какие преимущества есть у решений Spring Cloud? Есть ли какие-то альтернативы?
Кирилл: Это изначально набор различных решений, стеков других компаний, например, многое взято из стека Netflix. spring-cloud-netflix — довольно важная часть Spring Cloud.
Но в тоже время, Spring Cloud не привязывает вас жёстко к стеку Netflix, нет, он говорит, хочешь — используй Consul от Hashicorp в роли Discovery Server, и даже предлагает имплементацию, хочешь — что-то другое (но везде есть нюансы, кхе-кхе).
Думаю, Spring Boot многое черпал из Dropwizard, сейчас же у него даже с ним есть какие-то интеграции. Есть, по-моему, фреймворк Axon, у которого тоже есть различные подвязки для того, чтобы делать CQRS-сервисы с интеграцией, там есть какая-то Discovery. В общем, фреймворки есть, называть их особо смысла нет, потому что Spring Boot уже засосал в себя более-менее популярные. Особняком стоит разве что Bootique, тоже приятный фреймворк, но не такой масштабный, конечно. Исповедует концепцию статической конфигурации, в отличие от подхода Spring. Про него можно даже доклад с Joker/Jpoint послушать.
— Про минусы мы, я так понимаю, уже сказали: если можно не делать микросервисы, то лучше их не делать.
Кирилл: Это действительно сложно. Микросервисы — это усложнение, усложнение как самой инфраструктуры бизнес-приложений, так и усложнение систем поддержки (мониторинг/логирование). Делать их нужно, только если есть весомые аргументы, которые перевешивают все минусы.
Как правило, эти аргументы про масштабирование, высокие нагрузки, реже про «процессное масштабирование» для сегрегации технологий/команд. Когда у тебя много команд, и тебе нужно эти команды как-то друг от друга изолировать, придумать формат их общения. Если хотите подробнее посмотреть то, про что говорил Евгений (и про хардкод, и про различные паттерны, представленные Spring Cloud) — на одном из первых JUG-ов я и Александр Тарасов выступали с докладом «WILD microSERVICES». В докладе есть часть с демкой как раз про то, о чём мы сейчас говорили, но есть и теоретическая часть со слайдами и картинками, на которых, отчасти, мы попытались пояснить, как и зачем по этому пути шли мы :)
— Я правильно понимаю, что у Spring Cloud нет применения для монолитной архитектуры?
Евгений: Он даёт инструменты, которые помогают микросервисам. Всё. Соответственно, монолитная архитектура тут ни при чём.
— Spring Boot — это про «магию». В Spring Cloud тоже «магия» есть, в Spring вообще много «магии». Появляются такие инструменты, которые создают много высокоуровневой инфраструктуры для разработчика. Это хорошо или плохо, на ваш взгляд?
Евгений: Это хорошо, потому что это позволяет людям намного быстрее выйти в продакшн. Тебе не надо пилить свой велосипед, тебе не нужна своя инфраструктура с нуля, ты можешь взять уже готовую платформу и начинать заниматься своей бизнес-логикой, вместо того, чтобы продумывать, а как технически это всё реализовать. Вам всё дают из коробки.
Кирилл: В данный момент это всё же больше весьма увесистый фреймворк, позволяющий сделать ряд решений и встроить полученное решение у себя, но я бы не назвал его коробкой.
Евгений: Это коробка, в которой есть набор сервисов и готовых инструментов, которые можно юзать. И это очень удобно. Это стандартные вещи, которые нужны всем. Это всё равно, что спорить о том, ORM — это хорошо или плохо? Хочешь, запускай и клади в базу данных, потом начинай перегонять из ResultSet результат в объекты и так далее, но это нужно всем, поэтому придумали ORM, чтобы это у всех одинаково происходило по каким-то определённым конвенциям. Конвенции дают бенефит. Всё просто. Так же и здесь. Так, в принципе, развивается мир программирования: в любом направлении появляются популярные вещи, появляется фреймворк, который передаёт из коробки стандартный набор вещей, которые нужны всем, кто в эту область залез.
— Допустим, есть некая компания, в которой все работают на Spring Cloud или на Spring Boot, и тут приходит кто-то и говорит: «Я не хочу писать на Spring Boot, сам буду пилить велосипеды на Java 7. И стримы мне не нравятся, ничего мне не нравится». Таких сотрудников обычно переучивают или выпинывают? Или же им дают работать, как они хотят?
Евгений: Я таких ретроградов просто на работу не беру. В свою компанию я сам набираю работников и очень внимательно проверяю, чтобы они либо были готовы учиться, либо уже знали о современных технологиях. А те, кто знает только то, что было когда-то, и не хочет учиться новому — мне такие просто не нужны. Я с ними просто не успею вовремя сдать проект. Тут цена вопроса. Представь себе человека, который только знает ассемблер. И он говорит: «Я очень круто знаю ассемблер, я не готов учить Java, потому что на ассемблере можно сделать всё. Да, там немножко долго, но зато всё, и у меня полностью есть контроль». Сколько таких людей нужно?
Кирилл: У нас люди приходят, всем не нравятся разные вещи, это нормально. Главное, что у людей есть возможность всё это поменять и делать как-то по-другому, привести остальных в светлое будущее. К нам вообще не стоит идти, если не готов отстаивать свои идеи и корпеть над трансформацией процесса в лучшую сторону. В конечном итоге, любое решение — это некоторый компромисс между одним, вторым и третьим.
— В анонсе вашего тренинга вы говорите, что начнёте писать микросервисный проектик. «Для тех, кто хочет понимать, какие проблемы будут при переходе на микросервисную архитектуру, так пропагандируемую Spring Cloud, уметь бороться с ними, а также просто быть в курсе этого динамично развивающегося стека». Где возникают основные проблемы, в каких моментах?
Кирилл: Проблемы, кхм, обычно как только ты начинаешь масштабно использовать какое-то решение, внедрять её в свою инфраструктуру, в свои процессы, то сразу натыкаешься на огромное количество багов и проблем. Например, для упрощения процессов доставки нам нужно было упаковывать приложения в Docker (после, правда, мы нашли компромисс!). Docker частично инкапсулирует сеть от приложения. Приложение, в свою очередь, радостно регистрируется на Discovery Сервере под внутренним адресом Docker, и делает вид, что так и должно быть. Само собой, другие приложения работать по этому адресу с ним не могут, приходится делать различные манипуляции для определения правильного адреса, ещё хуже, когда приложения вынуждены работать через reverse proxy. Проблема, в основном, в тех местах, в которых остались белые пятна для фреймворков. Они все хорошо работают на простых примерах или заготовленных PaaS типа PCF (хотя и тут есть нюансы), в более сложных условиях сразу начинаются нестыковки, что логично, ведь нельзя сделать ПО на все случаи жизни, ещё и удобное для всех команд.
Есть много пятен, которые приходится закрывать либо собственными силами, либо идти по пути наименьшего сопротивления — например, иметь стек, очень похожий на какой-нибудь Pivotal Cloud Foundry, возможно даже покупать платную версию. В Spring Boot есть шероховатости, конечно, далеко не всегда всё задокументировано. Тот же Spring Boot куда более популярен, чем Spring Cloud, и видно, что пишут его люди разного уровня. Там есть всяких сортов говнокод. В Spring Cloud же с этим ещё хуже. Там интегрировано много различных наработок других компаний, например Netflix, и у каждой такой интеграции – своё легаси, из-за которого какая-нибудь абстракция да начинает течь (благо, модель «магических аннотаций» позволяет хоть как то дышать разработчикам).
— Мы плавно подошли к следующему вопросу: я сегодня зашёл на сайт Spring Cloud, увидел, что там целая куча всяких модулей, каких-то коннекторов, есть Netflix-модуль, есть Consul-модуль, есть модуль для RabbitMQ с Kafka, есть модуль для инфраструктуры Amazon и так далее. Допустим, под мою инфраструктуру модуля нет. Что мне лучше делать: переехать на новую инфраструктуру, запилить собственный коннектор или ждать, пока вендор моей инфраструктуры сделает коннектор под Spring? Просить Spring Cloud об этом, писать письма?
Кирилл: Писать письма точно бесполезно. Ты можешь сделать свой проект с нужной реализацией, которую потом можно легко использовать, или даже интегрировать своё поделие как официальный Spring Boot при наличии запросов от коммьюнити. Становление «частью» Spring Cloud — весьма вероятный исход для популярных решений, но в тоже время для непопулярных решений такой расклад маловероятен.
— То есть либо попытаться самому пилить, либо ждать от вендора какого-то решения, при этом непонятно, будет оно или нет.
Кирилл: Да как и во всём — либо делать самому, либо ждать. Ждать можно сколько угодно времени, и совершенно не факт, что желаемое произойдёт.
Евгений: Соглашусь с Кириллом. На этот вопрос нет однозначного ответа. Если ты давно пилишь что-то своё, и у тебя остался месяц для сдачи проекта, ты не скажешь: «А я сейчас всё брошу и перееду на существующую платформу». Или: «А подожду-ка я неизвестно сколько времени, а вдруг появится решение от вендора». Понятно, что ты будешь продолжать делать костыли, как ты и начал. А если у тебя есть время и возможность, и ты видишь, что есть классная альтернатива, то почему бы и не переехать. Это очень зависит от ситуации.
— То есть ты всё-таки за переезд?
Евгений: Я считаю, что когда ты начинаешь новый проект, то очень важно проверить, что уже существует, и очень важно поставить на правильную лошадь, потому что если ты идёшь с какой-то отмирающей технологией, то в какой-то момент ты можешь оказаться в полной жопе, и будешь продолжать клепать костыли, страдать, мучиться и ненавидеть свою работу. А весь мир будет тебя обгонять, и, пока ты допилишь свой проект, будет уже 100500 альтернативных, которые благодаря более правильному выбору технологии давно тебя обогнали, хотя, может быть, ты начинал первым.
— Расскажите про мониторинг и логирование: как я понимаю, здесь могут быть проблемы, связанные с тем, что если у нас запущены какие-то микросервисы, а они существуют в каких-то контейнерах, то с мониторингом и логированием совершенно очевидная проблема, которая заключается в том, что эти все системы крутятся в своих машинах. Например, Docker — замкнутый, к нему надо достучаться и так далее. Spring Cloud как-то помогает вообще мониторить и логировать вот эти контейнеры, виртуальные машины и так далее?
Кирилл: Как я уже говорил, одна из сложностей — иметь сквозной идентификатор, по которому можно смотреть логи в рамках внешнего запроса по всем задействованным в нём сервисам. Spring Cloud Sleuth помогает нам добавить метаинформацию в логируемые сообщения.
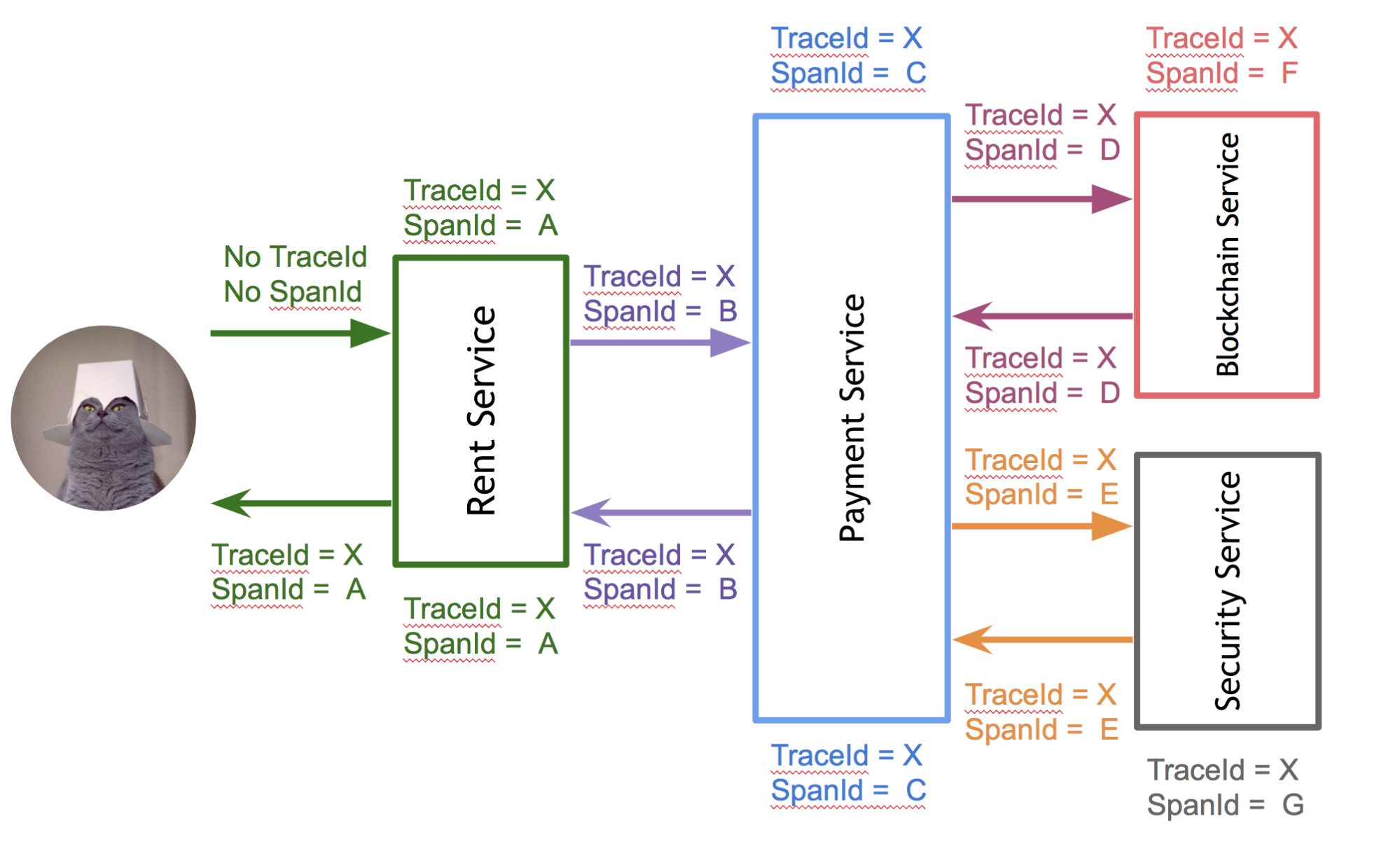
Он может действовать довольно жёстко, инструментируя какую-то часть кода, отвечающую за внешнее взаимодействие, добавляя туда необходимую метаинформацию (сквозные идентификаторы, времена ответов, и т.д.) Также из коробки можно получить интеграцию с инструментом OpenZipkin, который аккумулирует различную информацию по отправленным ему трейсам и обнаруживает самые проблемные запросы, которые длятся долго, падают, ретраятся и ещё что-нибудь такое. И уже встаёт вопрос о распространении этой информации для больших систем: есть варианты через очереди предоставлять информацию Zipkin, можно напрямую писать, можно хранить это дело в разных источниках. Тут много вариаций.
Кажется, что эти инструменты даже решают поставленные проблемы, но, как я и сказал, сейчас это скорее белое пятно в не очень продакшн-виде. Есть ещё множество различных решений, помогающих мониторить состояние системы, например, Hystrix dashboard, который отображает работоспособность отдельных компонент в системе. Turbine, который позволяет агрегировать различные маленькие дашбордики в один большой, показывает состояние всей системы в целом. Но, как правило, там тоже есть очень много нюансов. Просто так это не развернёшь и не установишь, это довольно сложно интегрируется. С тем же reverse proxy это не дружит, авторизацию необходимо делать свою, и т.д. В общем, для крупной компании использование таких инструментов — это довольно большой труд.
— Ребята, спасибо большое!
Кстати, если хотите пообщаться с Евгением и Кириллом — приходите на нашу конференцию Joker 2017. Они приезжают с докладом «Boot yourself, Spring is coming» (это большой серьёзный доклад, состоящий из двух частей, каждая из которых длится один час).
Если же хочется более глубокого погружения, они проведут два специальных тренинга:
У этих тренингов разная цель, программа и ключевые темы, подробней узнать о которых можно, перейдя по ссылкам. Они проводятся раздельно, т.е. можно пропустить Boot и сходить только на Cloud.
Обращаем внимание, что каждый из них занимает весь день (с 10 до 18 часов). Желательно иметь ноутбук со следующим ПО: IntelliJ IDEA, Docker, Docker Compose, Java 8. Тренинги пройдут 1-2 ноября, то есть до Joker, таким образом, вы сможете взглянуть на доклады Евгения и Кирилла сквозь призму приобретенных знаний и навыков.
schroeder
Мы пилили один проект на Spring Cloud и все было здорово, до тех пор пока не подумали, а не взять ли нам Kubernetes?
И тогда всплыла вот такая картинка, взятая отсюда
tolkkv
Kubernetes обеспечивает сервис для ваших приложений на инфраструктурном уровне.
В остальном, это всегда компромис между тем чтобы вынести всё из приложения в инфраструктуру и завязаться на неё, или втащить побольше в приложение сделав его более самодостаточным, переносимым, устойчивым к внештатным ситуациям.
Например: Вот Distributed Tracing указан на вашей картинке и в Kubernetes и в Spring. Разница лишь в том, что самое ценное при трассировке – полная картинка. Frontend->Api1->Api2 трейс не полон. Frontend->Api1->Api2->Database например выглядит уже интереснее
Часто чтобы решать задачу оптимально нужно просто не быть паранаиком :) Решать её на нужном уровне – инфраструктура/приложение/процесс
schroeder
Я вижу это по другому.
У вас же микросервисы в докере работают, иначе сложно все становится, не так ли? А когда у вас появляется с пару десятков контейнеров, хочется этот зоопарк как то в порядок привести. Начинается поиск решений и после прочтений нескольких статей приходишь к Kubernetes. А когда начинаешь разбиратся с этой штукой, первое, что приходит в голову: а нафига мне Spring Cloud?
Мой опыт говорит, что надо рассматривать проект в контексте его полного цикла жизни, а не только разработки. Т.е. надо смотреть например, а в какой среде наш проект будет у клиента работать? Как мы его будем деплоить, как мониторить и т.д.
Ну и плюс к этой теме, все чаще появляются статьи, что все что не относится к бизнес логике, надо выносить в инфраструктуру. Т.е. такая штука, как Load Balancer не должна быть в сервисе, ее место в инфраструктуре. Тоже самое касается и например Circuit Breaker. Даже такая штука как Timeout запроса должна быть определена не в сервисе, а в инфраструкруре.
В общем и целом похоже на то, что решения Netflix( но не идеи!), устарели, будущее за такими штуками как Kubernetes.
olegchir Автор
А если я хочу так написать, чтобы мой софт работал на любой инфраструктуре?
И еще, почему микросервисы — сразу в докере? Есть ведь и rkt и lxd/lxc, и cri-o, и честная виртуализация. В конце концов, есть честное голое железо со всеми его преимуществами.
А почему именно k8s? А если я захочу заложить в систему свою собственную хитрую специфику, то всё, лапки?
tolkkv
Мне кажется вы вышеизложенных тезисов не услышали. Есть задачи, в которых необходимо связать инфраструктурные вещи с «контекстом» внутри приложения. Нет плохого или старого подхода, устаревшего или нового. Kubernetes про одно, Spring Cloud про другое, они пересекаются чтобы быть более самостоятельными, при этом продолжая предоставлять сервис на разных уровнях
Многие задачи решаются на разных уровнях, от этого есть некая синергия. Вопрос насколько сложно в итоге это реализовать, чтобы бы получить эффективную реализацию
Впрочем, сам Spring Cloud больше интегрирован с PCF нежели в Kubernetes. Хочешь затратить меньше усилий и получить максимум профита — используй готовые связки. Так везде
kkorsakoff
В какой момент discovery становится выгоднее в обслуживании, чем "static discovery" через к примеру ansible? Считает ли служба эксплуатации схему с discovery удобнее/целесообразнее/практичнее?
tolkkv
Думаю вопрос "в какой момент" зависит от множества условий
Когда в маленьком кластере 160 разных приложений, управляемых разными командами, уже не хочется отдавать конфигурацию портов на откуп человеческой голове. Это не та задача которой она справляется безошибочно и качественно, человеческий фактор будет стрелять всё чаще и чаще. Поэтому мы пошли по пути шлифования автоматизированного решения.
Служба эксплуатации разбирается в этих решениях, причем и в Consul и Eureka( если говорить про наши реализации). Конечно вегда есть что узнать нового, но в эту сторону мы тоже потихоньку движемся, развиваемся :)