
На основе курса по администрированию EMC Data Domain Кузьма Пашков сделал внушительный обзор о видах дедупликации, архитектуре систем копирования и восстановления на примере продуктов ЕМС, сделал обзор продуктов ЕМС, подробно остановился на Data Domain, а также сделал обзор курса по администрированию Data Domain.
Почему Data Domain такой дорогой? Почему это не СХД? Что нужно знать о проектировании/пуско-наладке/настройке/техдокументации этих систем? На что обращать внимание? — на эти и другие вопросы даны исчерпывающие ответы.

Под катом обзор и видеозапись.
Семья технологий и продуктов Backup Recovery Solutions
Мне, как инженеру, не стыдно говорить о том, что этот продукт хороший, так как из всех перечисленных аналогов — Data Domain появился на рынке первый, насколько я помню. По результатам испытаний и конкурсов выбирают именно это решение. Применить к этим комплексам даже самой низшей линейки понятие «старый» можно очень условно, так как срок жизни у этих решений составляет 5-7 лет, что очень немало.
Наш учебный курс построен в формате тренинга – 50% теории и 50% практики, понятное дело, в начале я буду больше говорить. Сама лаборатория физически находится в США, там на каждого из вас, участника тренинга, стоит полноценный Data Domain.
Начнем с нужных вводных по системам хранения ЕМС. Как я понимаю, вы уже не первый раз сталкиваетесь с продукцией компании ЕМС, и помните что ЕМС, VMware, RSASecruity – это один конгломерат. Поэтому продукцию всех этих корпораций можно рассматривать в рамках единой номенклатуры, не в смысле управления компаний, а в том смысле, что все эти продукты интегрируются друг с другом. В этом достигнута очень глубокая степень интеграции. Мы будем рассматривать только продукты компании ЕМС. Нас интересует та ее часть, которая называется Backup Recovery Solutions. Часть этих решений она, как бы заимствованная, за счет поглощенных компаний. Например, головной продукт, который называется Networker – полноценное средство резервного копирования корпоративного класса, который бьется со своими конкурентами на этом рынке – откуда он? – из компании Legata, которая с конца 80-х годов этот продукт разрабатывала, сейчас это уже ЕМС.
Дальше, тот продукт, который мы с вами собираемся изучить – Data Domain – была одноименная компания, которая первая на рынке выпустила подобный программно-аппаратный комплекс для хранение резервных архивных копий, ЕМС ее поглотила. Следующий – Avamar. Я специально перечислю главные продукты, потому что они все друг с другом взаимосвязаны. Avamar – так раньше называлась компания из Калифорнии, которая опять же выпускала средства резервного копирования корпоративного класса с дедупликацией на источнике, очень специфическое решение, которое революционизировало стратегию резервного копирования, продукт раньше назывался Axion, если я правильно помню. И еще есть Data Protection Adviser, насчет этого продукта я не помню было ли это разработкой ЕМС, или это было поглощение компании.
На самом деле это не полный список, почему я перечислил все эти продукты? Для того чтобы сказать вам о том, что это все части единого целого – уже сейчас, на дворе 2015 год, ЕМС в прайс-листах, в работе своих присейлов, позиционирует все эти продукты как части единого пакета продуктов в рамках Backup Recovery Solutions – единый продукт, который позволяет унифицировать защиту любых данных, которые могут встретится в любой корпорации. Объединив эти продукты уже на протяжении долгого времени, ЕМС научило эти продукты очень глубоко интегрироваться. Networker может работать как сам, так и часть функций делегировать на Data Domain или Avamar, Avamar может напрямую интегрироваться с Data Domain без Networker, а могут все вместе работать в одной «шайке-лейке». Про Data Protection Advisor– вообще отдельный разговор.

В связи с этим, на курсах по этим продуктам нельзя об этом не говорить, потому как значительная часть функционала завязана на вот эту интеграцию. Если говорить про наш Data Domain, то в нем значительная часть функций уже годами не меняется – потому что там все уже давно хорошо, еще до поглощения. Но после, большая часть усовершенствований связанна с тем, что Data Domain должен уметь «дружить» со своими «братьями», чтобы это стало единым целым. Если рассматривать каждый продукт по отдельности – то это набор функций, или услуг. Но когда эти продукты интегрируются, то это не математическое сложение функций, появляются некие уникальный сверхсвойства, о которых нельзя не говорить. Даже на нашем курсе, который первый в списке авторизованного обучения, мы об этих функциях будем достаточно много говорить. Поэтому эти вещи нужно позиционировать: что есть что и какую роль занимает. Продукты буду перечислять и описывать в определенном, не случайном, порядке.
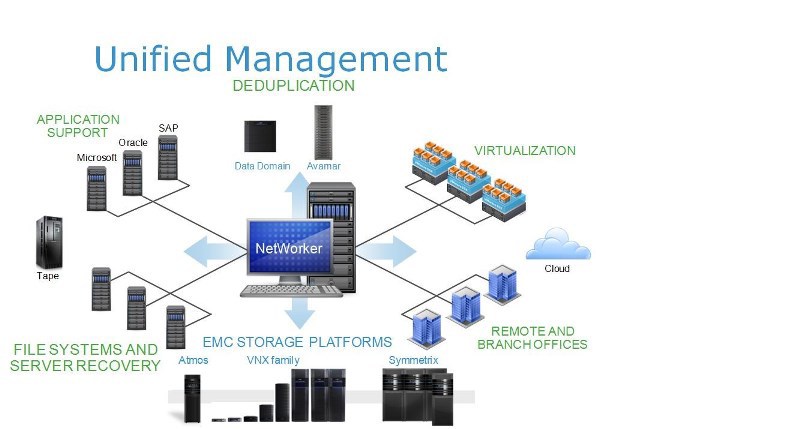
Сначала поговорю о Networker. Это головной продукт – ядро, системы защиты данных в части системного копирования и архивирования. По сути – это классическое многозвенное клиентсерверное средство резервного копирования, программный комплекс. Дистрибутив, элементы, звенья которого раскладываются на: резервные копии в виде клиентов, сервера резервного копирования в виде узлов хранения, к которым подключены какие-то хранилища, которые связаны с клиентами какой-то средой передачи данных. Пуская это будет LAN или SAN, что-то в этом духе. И есть мастер-сервер, который мы называем бэкап-каталогом. Есть централизованные средства, где есть сервер, ведущий единый учет резервных копий, носителей информации, на которых они попали, где хранятся политики резервного копирования, правила, автоматизирующее весь этот процесс. Фактически, на этом звене, которое называется – Networker сервер, самих тел резервных копий не хранится, только их учет и контроль. Сюда «тыркаются» разнообразные админские консоли и т.п. Связь всех звеньев осуществляется, естественно по протоколу ТСР/IP через локальную сеть, через глобальную сеть – не важно. Нас естественно, интересует вопросы движения трафика резервного копирования.
Вот у нас источник резервных копий – чтобы это ни было, и у нас destination. Как уже было сказано, средства резервного копирования Networker – корпоративного класса, это значит, что оно умеет отделять одно от другого. Трафик резервного копирования может передаваться по выделенным сегментам – интеллектуально и осознанно. Обычная локальная ethernet-сеть или какой сторедж эриа нетворк, работающий по fiberchannel — любой способ связи. Это значит, что Networker знает, что такое LAN Free Backup, слышали о таком, да? Что еще может делать Networker? Например, бекапить источник резервных копий не нагружая его. Особо распространяться не буду, это называется serverless или proxy backup. То, что я перечисляю эти функции, это не значит, что их только Networker может делать, это значит, что он ими владеет как и его конкуренты. Networker может бекапить NASы, за счет того, что знает, что такое NDMP, протокол NDMP freeware backup – кто не знает что это такое? Это реализация lanfree serverless для выделенных файловых «помоек». Networker породившись в 1989 году, имеет долгую историю и его матрица совместимого ПО и оборудования – очень большая. Он рассчитан на гетерогенную сеть, у него в источниках может быть что угодно, очень большая матрица совместимости: различных ОС и бизнес-приложений, которую он может бекапить без остановки, то что называется онлайн-бекап, у него огромное количество различных интеграций, включая различные Microsoft и другие.
Традиционно, Networker, в качестве резервных копий использовал роботизированные ленточные библиотеки в первую очередь – в этом он достаточно хорош, у него матрица совместимых библиотек очень большая. Никто не говорит, что он не может бекапить на диски – конечно может! Но мы знаем, что на дисках хранить бекапы – дороговато, особенно при текущих объемах. Я это говорю к тому, что изначально Networker был рассчитан на работу с ленточными библиотеками и до сих пор с ними лучше всего работает. И для традиционного подхода к защите датацентров – это вполне нормально. Экономически легко доказать целесообразность использования Networker для защиты боевых серверов, которые сидят в ЦОДе: всякие Ораклы, Сиквела, сервера приложений, огромные данные, которые в пределах ЦОДа, по высокоскоростной, выделенной какой-то сети, мы гоняем на какие хранилища резервных копий. Все хорошо, но Networker, так уж получилось, знает, что такое дедупликация, но не умеет ее самостоятельно выполнять. Не потому, что об это не подумали разработчики, а потому, что к тому моменту кто-то уже умел эту дедупликацию делать. Поэтому, если вы хотите для какой-то части источников резервных копий организовать эффективное потоковое сжатие, то в качестве одного из множества хранилищ, с которым может работать Networker, вы можете использовать Data Domain, потому что это фактически, дисковая полка с винчестерами, с какой-то, будем считать, аппаратной дедупликацией, которая позволяет очень эффективно сжимать потоки резервных архивных копий, которые валятся на эту полку.
Соответственно, у этого ящика есть масса интерфейсов, о которых мы будем говорить подробно. Мысль остается прежней – единый хозяин, единый учет резервных копий, часть из них падает на какие-то традиционные хранилища, а часть падает на хранилище с дедупликацией, дисковой дедупликацией. Нужно понимать, что дедупликация – это не панацея и экономически целесообразно использовать ее в целом, и вот такие продукты в частности. Если мы используем традиционный поход – ленты, отчуждаемые носители с последовательным доступом, то там скорость восстановления, как ты не изгаляйся, будет измеряться часами. Если этот показатель Recovery Time Objective нужно свести к какому-то приемлемому минимуму – то нужно хранить резервные копии на дисках – но это дорого, поэтому давайте применять дедупликацию, если она применима, конечно же – источник резервных копий может быть с противопоказаниями к сжатию – не жмется, и все, и хоть убейся. Тут сразу же приходит в голову резонная мысль: когда говорят об использовании чего-либо с дедупликацией, требуется обследование автоматизированной системы заказчика в рамках какой-то методики и обоснование – оценка этого достижимого коэффициента. Если обследования нет – что вы можете ожидать? Кто-то говорит, что он может «гарантировать» какой-то коэффициент сжатия – удивительно это слышать! Конечно же чистый маркетинг. А в реальной жизни не так все просто.

Data Domain может выполнять дедупликацию самостоятельно, своими силами, тратя свои процессорные тики, свою процессорную силу, оперативную память — не напрягая источник. Это очень хорошо. DD может принимать потоки резервных копий через LAN, через ethernet – 10 гигабит, 40 гигабит заявлено. А может при необходимости, делегировать часть функций, связанных с сжатием, на сам источник – если это допустимо. Интерфейсов у Data Domain много — для принятия одновременного потока множества резервных архивных копий, но самый эффективный – это лицензируемый интерфейс DD Boost, этот протокол и Data Domain неотделимы. DD может использоваться без DD Boost, но этот сам интерфейс может использовать только в DD.
Data Domain экономически целесообразен, это легко доказать, использовать для защиты, все-таки серверов, которые сидя в ЦОДе, которые связанны с DD какой-то общей, высокоскоростной средой передачи данных, это не VAN, это LAN или SAN. Опять же, речь идет только о серверах, для которых допустима дедупликация, а если нет, тогда нужны диски. Вот такая проза жизни, в общем-то.
Боевые сервера, для которых дедупликация не применима, для которых показатель RTO не такой жестокий, их вполне нормально бекапить на роботизированные ленточные библиотеки и т.д. Есть источники резервных копий, для которых показатель RTO критичен, их нужно иметь возможность быстро восстанавливать, этого требует политика безопасности и для них нет противопоказаний дедупликации – купили Data Domain и сказали Networkerу часть потоков резервных копий из этих источников направлять на такие хранилища
А что делать с третьей категорией источников резервных копий и самой многочисленной? – с рабочими местами? И если их связывают с хранилищем ненадежные каналы связи? То работают с перебоями, то пропускная способность слабая и т.д. Бекапить их традиционным способом и с дедупликацией на хранилища – бесполезно, очень неудобно. Здесь ЕМС говорит, ок, у нас есть вот такой продукт — Avamar, который конечно же может быть использован автономно – и для защиты и серверов он подходит, и для защиты чего угодно. Но его особенность в том, что он всегда выполняет сжатие на источнике. Сначала, напрягая источник, ужимая, насколько это возможно, данные подлежащие резервному копированию, а потом только уже в сжатом виде передает уникальную дельту, копию в какое-то хранилище. Avamar, в части интеграции, может работать со всеми продуктами семейства, может также очень эффективно работать под управлением Networker.
Учитывая, что оно все друг с другом интегрируется, все категории источников резервных копий защитить – можно технологиями от единого поставщика. Осталось только что? – корреляция событий, которые происходят в этих сложных программно-аппаратных комплексах, с событиями, которые происходят на сетевом оборудовании, хранилищах, системах хранения данных и т.д. Для того, чтобы соответствовать тому, что называется SLA, во-вторых для того, чтобы можно было организовать billing. Идея очень простая – все вышеперечисленные продукты, по отдельности, и в совокупности, они то, что называется cloud ready. Это значит, что из них можно построить облачный сервис резервного копирования и сдавать его в аренду. Я – оператор, построил свои сервер-ЦОДы, поставил туда этих продуктов и сдаю вам, как юрлицам в аренду. Чтобы вам гарантировать уровень качества обслуживания и каждому выставлять счета, по мере использования моей инфраструктуры нужен биллинг. Для организации этой части нам нужен такой продукт – Data Protection Adviser (DPA), советчик. Это отдельный программный комплекс, клиенты которого ставятся на все источники информации, у которого есть централизованная БД, куда собирается вся информация, где она семантически укрупняется, сверяется с некой БД сигнатур каких-то событий. Ну и дальше сидит кто-то, смотрит на монитор, и ему показывается красным цветом – все плохо, или ему указывается, даются советы – что делать? И он либо пишет отчеты, либо счета выставляет начальству — отличная вещь.
Из чего состоит Data Domain
Я перечислил не все модули единого модульного продукта, так как времени у нас не так много. Но если есть те, кто хочет себе показать RTO свести к нулю. Есть продукт Recover Point, который опять же со всеми интегрируется, в частности с Networker, которые реализуют концепцию непрерывной защиты.
В нашем курсе акцент будет сделан на малую часть этого программно-аппаратного комплекса – только Data Domain. Но всегда мы будем говорить о нем в свете интеграции с другими продуктами из семейства, или от сторонних производителей, что тоже не проблема.
Среди вас много опытных ребят, кто уже работал с конкурентами Data Domain. Если попытаться определить, что такое Data Domain, то возможно получится так: дисковое хранилище дедупликаций для хранения резервных, архивных копий. Не больше и не меньше. Это очень важный момент. Это не СХД, сравнивать ее с чем-то таким нет никакого смысла. Потому что то — хранилище для хранения рабочих данных, для которых профиль нагрузки, в общем то, как бы универсальный: там возможно и последовательное чтение, записи, и произвольные чтение, записи. Там эти серьезные показатели iops, те, кто работает с СХД об этом знает. У СХД, какие бы они ни были: слабого, среднего, высокого класса – при всех прочих равных, есть какая-то общая архитектура. Фронт-енд, есть какой-то кеш, бекэнд, есть отказоустойчивость, мультипафинг и тому подобное. Data Domain – это не СХД, никогда его так не называйте – это грех:)
Data Domain – это сервер. Если я беру это железо, то я вижу программно-аппаратный комплекс, есть аппаратная часть, в виде средств вычислительной техники, программная часть в виде системного ПО, это ОС, есть какое-то там прикладное ПО.
Аппаратная часть это что? Интеловский чипсет, памяти как можно больше, пару блоков питания, там есть шина PCI express, сколько-то слотов, в материнскую плату встроено 4 сетевых карты с гигабитными интерфейсами и 2 медных с 10 гигабитами. По умолчанию уже есть больше чем 1 избыточных сетевых интерфейса для подключения к внешней среде, чтобы принимать управляющий трафик, чтобы принимать потоки резервных копий и выдавать потоки восстановления. Уже хорошо. В слоты мы можем воткнуть еще сетевых карт, в зависимости от моделей, мощность тоже может быть ограниченна чипсетом. Можно воткнуть fibre channel host bace adapter, правда за отдельные деньги, я видел такой адаптер 4х и 8ми гигабитный, 16гигабитный кто-то видел? Я видел, что их заявляли, как и 40гигабитные ethernetы, но пока еще их нет, их можно ожидать.
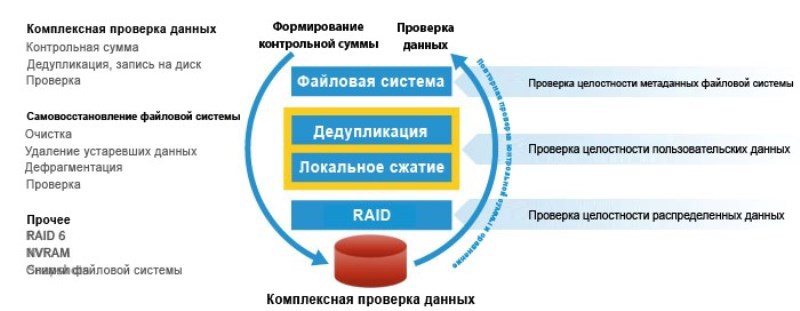
Что еще на шине есть? Там по умолчанию там уже стоит дисковый контроллер, SAS и не один, их должно быть 2. На шине которых висят какие-то диски, дисковый массив. В младших Data Domain моделях это прямо в корпусе самого сервера, который монтируется в стойку. Сколько там винчестеров? Минимум – 7, максимум – 15. Если у вас модель Data Domain более серьезная, вы можете на шину SAS-контроллеров, еще добавить одну или несколько дисковых полок. В дисковых полках крутятся, раньше это был убогие sata-винчестеры, сейчас это NL SAS-винчестеры. Чем NL SAS от SAS отличается? NL SAS – это как дешевый SAS (саташный винт, сделанный через SAS шину, скорость обмена увеличили, но саму архитектуру винта оставили как и было). SAS, грубо говоря, это старое доброе scsi. NL SAS – это сасовские винчи, которые по результатам производства не прошли каких-то жестоких испытаний на производительность, надежность, но имеют какой-то приемлемый уровень, поэтому они идут дешевле. Грубо говоря, у сасовских винчей время наработки на отказ в разы больше чем у NL SAS. Я говорю не о производительности, а о надежности. Эти винчестеры, которых много, десятки или сотни, они, естественно в какие-то рейд массивы собраны. (Каждая полка собирается в отдельный рейд массив) это еще называют дисковый группы (железных контроллеров там нету, фактически это софтовый рейд, это ни плохо и не хорошо, просто это так работает, и в каждой полке еще дополнительный диск hot spare). Я видел, что в head парочка дисков выделена под ОС. (Раньше такого не было, сейчас в более старших моделях Data Domain используется 4 диска для этой Data Domain ОС. Они вынесены отдельно, там смешанные рейды). Там полезные данные не хранятся, там только служебные.
Если вспомнить логику построение рейд 6 масивов. Какие там накладные расходы? Одна логическая операция записи какого-то блока данных – это сколько физический операций (я говорю про iops)? 3 чтения + 3 записи. То есть накладные расходы – дикие! У 6-го рейда накладные расходы самые большие, у 5-го меньше: 2 чтения + 2 записи. Дисковая система в этом сервере – очень медленная, поэтому мы вспоминаем о том, что мы говорили, что это – не СХД.
ОС – это какая-то линукс-подобная операционка, называется DD OS (Data Domain Operating System). В общем случае, для обычного кастомера, потребителя она доведена до неузнаваемого вида – традиционных шелов вы там нет. Там простецкий командный интерпретатор, с какой-то системой комманд с простым синтаксисом. И если ты не инженер, а служба техподдержки, и инженерного доступа не имеешь – то забудь о большинстве известных тебе юниксовых команд и утилит. В качестве приложения будет терминал разнообразных демонов: Daemon VTL, Deamon DDBoost, Deamon NTP, Deamon NFS и так далее. Комплект которых встроен в этот дистрибутив линукса, чтобы через разнообразные эти протоколы уровня приложения принимать/отдавать потоки резервных копий.

Почему Data Domain такой дорогой?
Хорошо, тогда спрашивается почему Data Domain такой дорогой? Что здесь такого особенного в частях, из чего я не могу сам собрать? Не берем в расчет маркетинг и т.д., если взять в расчет техническую часть – в одном из слотов PCI стоит одна или несколько специальных плат, которые называются NVRAM платы. Специализированная плата, с каким-то объемом оперативной памяти в чипе, 1 гигабайт, 2, 4 гига, с каким-то, будем считать специализированным микропроцессором. Это та самая плата, с помощью которой вот эти потоки входящих резервных архивных копий, с помощью центрального процессора – ужимаются. Та самая плата, где проходится та самая дедупликация. Это то, что позволяет старшим моделям DD «ужирать» в час десятки терабайт каких-то данных. Представьте себе 10 терабайт в час входящий поток, и какая должна быть производительность дисковой подсистемы, собранной из NL SASов в рейде 6? Да их там должно быть безумное количество!
Но как в старших так и в младших моделях Data Domain дисковая подсистема по производительности не отличается. Суммарное количество иопсов, которое оно может выдавать – оно остается маленьким. Абсолютно неадекватным тому набору функций, которые требуются для такого объема данных. Все эти «адские» терабайты сжимаются на входе до приемлемого уровня, и до дисковой подсистемы доходит лишь приемлемая нагрузка. Технология дедупликации, точнее ее реализация в Data Domain, запатентована.
Если слетать в Калифорнию, в Санта-Клару, где это подразделение, сейчас это называется Data Protection and Availability Division, бывший BRS, то там в холле, есть «зал славы», где висят все эти патенты, их копии. А это дорогое удовольствие, вы, покупая Data Domain, оплачиваете все эти патенты, владельцу патента, за его суперразработку, которая в определенной части держится в секрете, мы об этом тоже поговорим позже. Не хочу сказать, что у других вендоров аналогичных технологий нет, но порядок цен такой же как и на Data Domain. Все они бьются изо всех сил за потребителя. Основной конкурент – HP Storeonce и IBM Protectier.
То есть Data Domain будет выглядеть так: сервер, с полками или без полок, подключенный через ethernet только, или и через ethernet и через fiberchannel, принимающий потоки резервных копий через множество разнообразных протоколов. Получается, что основным конкурентным преимуществом этого продукта, по сути является дедупликация.

Дедупликация
С этим нужно разобраться чтобы идти дальше. Примерно говоря – это сжатие. В чем суть сжатия – уменьшить объем данных. Только когда говорят «сжатие» в общем случае, то подразумевают что, мы ищем повторяющееся наборы данных и заменяем их на какие-то ссылки, в каком-то локальном наборе данных. Когда мы говорим «дедупликация» — то речь идет о глобальном сжатии, я ищу не только повторяющие данных на этом источнике резервных копий, а вообще везде, на всех вообще источниках резервных копий.
Соответственно у нас дедупликация может выполняться на разных уровнях абстракции. То, что я рассказываю не ново, но это нужно чтобы говорить в одном и том же словаре.
1) Filebased. На уровне файлов. Вы все бекапите на меня какие-то данные, а я ищу какие-то повторяющиеся файлы. Пришел какой-то файл от кого-то, выяснилось, что он мне никогда не встречался, он уникальный – я положил его в хранилище. Потратил какие-то ресурсы, место в хранилище, чтобы тело этого файла там разместить. От кого-то пришел еще один экземпляр этого же файла, я каким-то образом в этом убедился. И вместо того чтобы тратить ресурсы, я сохраняю метаинформацию что такой файлик встречается там-то и там-то. И накладные расходы будут на 2 порядке меньше, вместо того чтобы сохранять тело файла в хранилище.
А как сверять файлы? Самый простой – это побитовая сверка, ее нельзя сбрасывать со счетов, в определенных случаях она эффективней чем расчет эталонной характеристики, хеши и т.д. Поэтому никогда это не упускайте, я об этом расскажу немного позже. В большинстве систем резервного копирования используется такой подход: давайте мы вот этот набор данных прогоним через какую-то функцию, и независимо от того, какой размер исходного набора данных, мы получим какой-то хеш, эталонную характеристику фиксированного размера. И в рамках вот этой математической зависимости у нас будет определённая гарантия того, что если в исходном наборе поменяется один бит, результат хеширования будет совершенно иной. Я специально поднимаю этот вопрос, в учебных материалах курса вы этого не увидите, чтобы вам сказать следующее: да, функция хеширования имеет прямое отношение к симметричной криптографии, это отдельный класс математических функций. И для них актуальна проблема коллизий. Вероятность того, что у разных наборов данных будет один и тот хеш – не нулевая. Но ее можно свести к приемлемому минимуму. И для тех случаев, когда эти коллизии случаются какими-то компенсирующими мерами гарантировать, что целостность данных не будет нарушена. Я специально это озвучиваю, потому что, в частности, в Data Domain, разработчики этому вопросу уделили внимание, и дают математическую гарантию, доказательство того, что эти коллизии не проблема, и с ними справляются с помощью компенсирующих средств.
В этом случае все уникальные наборы данных имеют уникальны хеши. Если происходят коллизии – этим можно пренебречь. Это доказано, речь идет о запатентованной технологии, не с потолка это взято. Какой алгоритм, что проверять или не проверять – мы не знаем. Я специально повторюсь, алгоритм дедупликации (он большой, если нарисовать схему – комнаты не хватит) это учитывает. И об этом говорят разработчики.
Эта технология, так сказать «тупая», но дай бог если можно получить коэффициент сжатия в 1,5-2 раза. Это средний показатель, но ожидать здесь хоть чего-то – крайне сложно. Даже если у вас в качестве источника резервных копий какая-то файловая «помойка», много повторяющихся файликов.
2) Если у меня во главе стоит коэффициент сжатия, то давайте искать не файлы, а блоки данных фиксированной длины. Давайте все данные, что нам падают крошить на фиксированный кусочки, обычно в килобайтах. Для каждого кусочка рассчитываем хеш, и сверяем с хешами тех кусочков, чьи тела лежат в нашем хранилище. Есть попадание – ок, он сохранился, не будем его сохранять, нет попадания – это кусочек уникальный, пора его поместить в хранилище.
Этот подход хорош чем, что мозгов не нужно много включать. Но он лучше всего работает для источников резервных копий, где данные уже структурированные. Если тот набор данных, где мы ищем измененные блоки, он уже изначально в него вносятся изменения фиксированными транзакциями, фиксированного размера, то это очень удобно. В понедельник были одни блоки, то вторник блок такой-то и такой-то поменялся. Когда во вторник средство резервного копирования покрошит этот файлик на кусочки фиксированного размера, он строго локализует изменения.
Коэффициенты сжатия, которые можно достичь при этом подходе уже больше. В среднем это может быть 2-5 раз. Но тут важно чтобы источник удовлетворял определённым требованиям, где данные уже структурированы и изменения делаются фиксированными трансакциями определенного размера. Чаще всего это СУБД. Для таких данных выдаются хорошие показатели. А если неструктурированный виннигрет? Алгоритм не сможет локализовать эти изменения, потому что там все сдвигается.
3) Поэтому есть алгоритм дедупликации на блоки данных варьирующегося размера. Суть этого алгоритма — локализовать изменения. Даже если вначале или середине файлик поменялся, система поймет, что это только эти блоки поменялись, а остальные остались прежними. Обычно такие алгоритмы используют данные, блоки которых варьируются 4к-32к. Есть гарантия того, что если исходный набор данных не поменялся, то результат его «крошилова» будет одним и тем же. И он сможет локализовать только изменённую часть данных. Все эти алгоритмы подобного рода – запатентованы. Они все держаться в секрете. По сути, это все вариации того, что называется фильтр Блума – если захотите свой математический аппарат напрячь. Поэтому часть патентов в Санта-Кларе, они про это. О запатентованной реализации системы теорем. Кто-то реально напряг свой мозг.
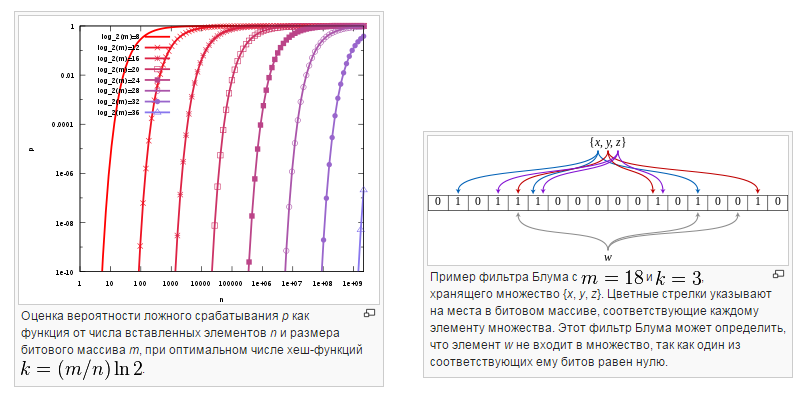
Теперь, если говорить вообще о дедупликации, на каком уровне абстракции ее лучше выполнять? 1-й, 2-й, 3-й способ… нет, неверно, нет «правильного» ответа. Примерный правильный ответ звучит так: идеальное средство резервного копирования должно уметь выполнять дедупликацию на всех уровнях абстракции, подстраиваясь под особенности источников резервных копий.
По простому: у меня файловая «помойка», неструктурированная информация бекапится? Давайте я сначала быстро, никого не напрягая: найду повторяющиеся файлики и их выброшу, те которые уникальные – ладно, начну крошить. Если это файлик – тело БД, то я его буду на структурированные файлики крошить определенного размера, если неструктурированные блоки – то на блоки данных варьирующегося размера. Потому что всегда приходится искать компромисс между коэффициентом сжатия и накладными расходами, нагрузкой на это сжатие.
Нужно рассчитывать эти хеши, нужно их сверять, а это кого-то напрягает кого-то, мы пока не уточняем кого. И чем больше нагрузка, тем больше показатель окна резервного копирования. Приходится искать какой-то компромисс. Чем лучше сжалось, тем медленнее будет какой-то RTO и т.д. Поэтому компании ищут какой-то компромисс между этими параметрами. И очень хотелось бы, чтобы средство резервного копирования, с одной стороны, ему можно было сказать: ты сам интеллектуально разбирайся какую дедупликацию, на каком уровне абстракции, для какого источника выполнять. А с другой стороны говорить ему: вот тебе такие рамки.
Например, для этих данных – мне их нужно максимально сжать, я для этого важно чтобы при сжатии это укладывалось в окно резервного копирования, а для этого важно время восстановления. Так вот, Networker в сочетании с Data Domain и Avamar и представляет такую интеллектуальную систему резервного копирования.
Был вопрос насчет Мicrosoft
В Microsoft, в ОС, 2012 версии в случае установки роли файлового сервера есть опция, которая реализует дедупликацию блоков данных варьирующейся длинны на уровне тома. И там коэффициенты 1,5-2%. Если мы говорим про Avamar, то он выполняет дедупликацию на всех 3 уровнях абстракции, если про Data Domain, то он выполняет дедупликацию всегда на 3м уровне — блоков данных варьирующейся длинны. Алгоритм хеширования, который используется – промышленный – Secure Hash Algoritm, и размер эталонной характеристики 160 бит.
Идем дальше. У нас уже была визуализирована архитектура классического современного средства резервного копирования корпоративного класса – клиентсерерное, многозвенное. Есть множество источников – клиентов, есть какая-то среда передачи данных, связывающая эти источники с тем, что называется медиасервера, узлы хранения, которые подключены к хранилищам. И есть какой-то бекап каталог, который всем этим дирижирует.
Так вот, в части касающейся дедупликации. Она может выполняться кем? Кто этот герой? Есть вариант postbased. Вот есть терабайт данных, он передался через какую-то среду на хранилище, в отведенное бекап окно, оно съело терабайты данных, для этого ему нужно много шпинделей, потратилось место терабайт, а потом уже наверное вне окна резервного копирования начинается это ужимание: на уровне файлов, блоков данных фиксированных и т.д. – но этим напряженно само хранилище. И вот оно ужалось в 10 раз, 100 гигов есть. Хорошо это или плохо – я не говорю. Например Windows Server 2012 именно так и работает. VNX работает похоже, но последние модели могут делать дедупликацию, не только на уровне файловых блоков, но и на уровне лунов – и он по своему расписанию это делает, и мы экономим наше дорогое место.
Есть дедупликация «на ходу». Терабайт прочитали, передали через среду передачи, никакой экономии нет, но перед тем как попасть в дисковую подсистему хранилища, этот терабайт, с помощью процессора, оперативки, ужимается, и мы убираем это безумное количество иопсов, и получаем какое-то их адекватное количество, которое можно писать на дисковую подсистему. Не нужно много шпинделей, не нужно куча места. Вот это у нас – Data Domain. Он это может делать через любые программные интерфейсы.
Третий вариант. Дедупликация на источнике. Терабайт я прочитал и тут же напряг источник. Он и так напряжен чтением большого массива данных, передачи их куда-то, а тут их еще нужно сжимать. Вот дожал он это до 100 гигов и уже несчастные 100 гигов передал по системе передачи данных в хранилище. Это умеет делать Avamar и Data Domain в случае использования интерфейса DDboost с включенным функционалом DCP. То есть Data Domain знает, что такое дедупликация на источнике. Самое интересное, что он знает и что такое постдедупликация, первый тип, о котором мы говорили. У Data Domain есть время, когда он сам с собой разбирается, и вот это также предполагает postbased дедупликацию.
То множество потоков, которые валятся на Data Domain, он их крошит, на кусочки варьирующегося размера, рассчитывает их на хеши, сверяет их массивы. Но есть математическая гарантия того, что для 99% этих кусочков, он сможет понят уникальны они или нет. А для 1% он этого не сможет сделать вовремя. Считайте, что он эти кусочки куда-то положит, чтобы успеть, а потом их еще постфактум дожмет. Как и почему это случается я объясню потом. В этом нет ничего плохого, это никто не декларирует, но никто от этого и не отказывается. Те показания производительности для каждой модели Data Domain, которые выложены на сайте ЕМС – это не чистой воды маркетинг. Они сделали лабораторию, программу методики испытаний, живой Data Domain поставили, и стали на него что-то бекапить и достигли этих результатов, строго их измерили. Понятно, что при соблюдении определённых условий, возможно даже идеальных, но никто не обещает манну небесную. Все говорят: проводите исследования, обосновывайте, докажите заказчику, что именно такой коэффициент будет получен, такая скорость поглощения будет получена в его ситуации – и вот это продавайте.

То, что я рассказывал – это какой-никакой ликбез по средствам резервного копирования. education.emc.com – портал обучения, вы наверняка о нем знаете, хорошо туда заходить почаще. Есть отличный курс Backup Recovery Systems and Architecture, занимает 40 часов. Курс по основам резервного копирования и архивирования, там про вот эту многозвенность, про serverless прокси бекапы, дедупликацию, там много чего написанно. Курс на самом деле университетский, читается на старших курсах технических ВУЗов, партнеров академической программы ЕМС, магистрам преподается, в рамках второго высшего. В питерском политехе, в московских вузах я такой курс читал. Курс сам по себе очень интересный, я специально о нем говорю, потому что было бы желательно, чтобы каждый из вас хотя бы его пролистал и посмотрел. Потому что белые пятна в образовании есть у всех. Занимаясь больше 10 лет системами защиты, я думал, что на этом собаку съел, что меня уже ничем не удивить – ан нет. 5 дней – 40 часов, только про вот эти основы.
Идем дальше. На сайте ЕМС в разделе защиты данных я смотрю номенклатуру продуктов. Под защитой данных подразумевается их целостность и доступность в первую очередь. Не конфиденциальность! Когда говорится о всяких секретах это уходим в RSASecurity. У меня тут есть дюжина продуктов и в разделе backup recovery у меня есть ЕМС Data Protection Suite – это и есть единый программно-аппаратный комплекс для защиты всех категорий данных.

Я хочу посмотреть на модели Data Domain и посмотреть на их характеристики. Моделей очень много, на любой вкус и кошелек. Хочу посмотреть самую слабую модель — Data Domain DD160. В ней есть 7 дисков по умолчанию, либо можно расширить до 12. Архитектура у всех моделей Data Domain одинакова, но у тех, что подешевле есть определённые ограничения. Например, полку не добавишь – ограниченна возможность масштабирования, много сетевых интерфейсов там не поставишь, hostbased адаптеров. И вот configuration maximum – 160 модель готова суммарно поглощать потоки резервных копий со скоростью до 1терабайт/час. Как интерпретировать этот показатель? При условии? что поток идет через ethernet и DDboost, DCP включен, с дедупликацией на источнике. Если нет DDboost, то можете смело делить на 2: входящий и исходящий. DDboost уже работает много с кем, даже HP Data Protector умеет с ним работать, Netbackup давно знает, Backup Exec давно знает – это промышленный стандарт, потому что других альтернатив не придумали.
Что такое 195 тб Logical capacity? Как это интерпретировать? То есть до сжатия почти 200 тб, а емкость у него 1,7. Какой нужен коэффициент сжатия? Если грубо округлить – в 20 раз? У меня есть заказчики, у которых: в 3 раза пожалось – круто!

Противопоказания
Почему я на это обращаю внимание – еще раз говорю – все зависит от данных. Когда говорили про дедупликацию я специально не упомянул о противопоказаниях. Если, например, у меня данные зашифрованы, изначально представлены в виде криптограммы, а я их бекаплю. Какие мы получим коэффициенты сжатия? Алгоритмы шифрования и алгоритмы компрессии – из одной категории математических функций. Они делают примерно одно и тоже, но цели у них разные. У одних обеспечить конфиденциальность, а у других уменьшить их объем. Все что зашифровано – противопоказано для сжатия, так как после него данные займут еще больше места.
Хорошо, если данные сжаты уже. Медиаданные, все что угодно. Каких коэффициентов можно ожидать? Можно ожидать, но тут все зависит от схемы резервного копирования. Если у меня есть медиа архив, объемом 10 тб, который не жмется, но я каждый день делаю фулл-беэкап, это не вариант – этого никто не делает.
Поэтому нужно выявлять противопоказания, там где их нет – проводить обследования. И вычислять вот этот достижимый коэффициент сжатия. В какой-то мере его можно вычислить эмпирическим путем, посмотреть на данные, у ЕМС есть статистика и сказать: в 5 раз пожмется. От этого можно отталкиваться. У вас там SQL и Exchange, столько-то почтовых ящиков такого-то размера? Есть формула, куда это вбиваешь и получаешь результат.
Все трогали Backup System Sizer? Он дает приблизительную прикидку. Мои заказчики делятся на 2 категории, одни говорят: напиши нам подробно на документах, обоснуй, техническое обоснование и т.д. А другие говорят: нам ничего не нужно из документов, но ты лично отвечаешь за то, что пообещал? В идеале, конечно, чтобы отвечать за свои слова, нужно точно самому убедится, что получится именно тот коэффициент сжатия.
Тогда лучше сделать то, что не очень любят делать интеграторы: дайте заказчику в опытную эксплуатацию хоть слабенький, хоть б/у, Data Domain. Пусть он там покрутится какое-то время, и мы по факту посмотрим какой получился коэффициент. И уже этого будем отталкиваться, разрабатывать технико-коммерческое предложение.
Документация и обучение
К чему это все. Без этапа проектирования – не обойтись. Кто-то должен провести обследование в рамках какой-то разработанной методики, написать техническое задание на систему защиты. План защиты, положение и категорирование информационных ресурсов. План обеспечения работы, восстановления после сбоев. Все эти документы должны быть. Кто-то должен оценить, сказать, например, что вот эта категория – там дедупликация не нужна, здесь можно – но не нагружать источник, здесь можно, здесь такой коэффициент, здесь такой.
Эту работу делает интегратор, или партнер, как их называет ЕМС. У ЕМС есть специальная обучающая программа для архитекторов, для тех проектирует, для инженеров-конструкторов. Где всему этому учат: обследованию и составлению технической документации. ЕМС работает на уровне планеты – у них все стандартизировано. Инженер и в США и в Украине работает по одинаковым образцам. Ничего не нужно придумывать.
Но, не каждый заказчик это просит. Поэтому если вы заказчик вы должны у интегратора просить этот пакет документов. Не справочную инфу с сайта, а описания технологии изготовления и обслуживания этого изделия. Если вы работаете в интеграторе – все есть, только нужно спросить.
Для пуско-наладчиков, тех, кто по документации изготавливает изделие – есть свои курсы обучения, мы на одном из них находимся. Это обычно инженеры из партнеров и из самого ЕМС.
Для кастомеров, тех, кто после сдачи с этим работает и обслуживает, есть свои курсы – для админов, наш курс также можно назвать для админов.
Все это расписано на портале обучения ЕМС. Даже если вы кастомер, вам доступно там много чего. Лично я могу поделится примерами конструкторской документации, потому что с чистого листа их написать сложно. Поэтому приходится поддерживать инженерную интеллигенцию, потому что хозяева не любят за это платить деньги, но это нужно, потому что это отдельный вид деятельности.
Либо ты сидишь в интеграторе и потоково создаешь эти комплекты документов, или ты находишься в крупном заказчики и для тебя это как первый раз. Даже если ты выступаешь в роли представителя заказчика и контролируешь действия подрядчика, нужно понимать, что от него нужно требовать. Поэтому лучше знать что делать.
По всем этапам жизненного цикла автоматизированной системы в части ее системы защиты – у ЕМС есть программа обучения и сертификации по всем их продуктам. Будете ли вы другие курсы рассматривать – это уже нужно смотреть.
Администрирование ЕМС Data Domain: введение в курс
Вводные у нас относились к основам систем системного копирования и архивирования. Мы, фактически быстро пробежали содержание университетского курса, или обучающего 5дневного курса по архитектуре этих систем. Заодно посмотрели дедупликацию. Строго позиционировали Data Domain в номенклатуре продукции ЕМС. Сделали выводы – чего от него ожидать и чего от него ожидать не стоит – что самое важное.
Из названия нашего курса очевидно, о чем мы будем говорить. Если посмотрите на нашу модель жизненного цикла, то речь идет о поддержке, обслуживании, уже, фактически готового черного ящика. Который кто-то: спроектировал, как он будет встраиваться в существующую либо новую среду, расписал комплект конструкторско-эксплуатационной документации. Кто-то по этому комплекту осуществил сборку, монтаж, пуско-наладку этого изделия, хотя бы в общей части и дальше это было передано персоналу заказчика вместе с документацией. Заказчик осуществляет администрирование, в малой, узкой степени, в каком-то коридоре он осуществляет донастройку. Но основная задача этого персонала – мониторинг. Мы сверяем текущее состояние этого ящика, с эталонным, которое было зафиксировано на этапе сдачи в эксплуатацию.
Траблшутинг
Если текущее состояние не соответствует эталонному – выявляем причину, устраняем неисправность. И далее все это идет по циклу. Заново дорабатываем ТЗ — версия 2.0. Потому что-то поменялось, риски поменялись, жизнь поменялась. И по такому циклу и развивается система защиты. Нормальная, зрелая компания этот цикл проходит уже 5й или 7й раз, не делая все с нуля, а развиваясь. Это актуально для любых других изделий.
Наш курс – определенный проект, есть начало, есть результат. И поэтому мне нужно определить границы этого проекта: о чем мы будем говорить, о чем не будем говорить. О проектировании мы говорить не будем, так как про это есть другие курсы. О пуске-наладке мы будем говорить лишь в части, касающейся кастомера. Есть отдельные курсы для инженеров ЕМС и партнеров-интеграторов, где расписано: как собрать вот этот Data Domain, вмонтировать с комплектом полок в стойку, как отмаркировать, подключить все эти соединения, как создавать рейд-массивы, как залить образ ОС, как осуществлять инженерное техобслуживание, которое не бесплатно.
Мы, как кастомеры, говорим, что нам кто-то собрал, назначил IP для управляющего интерфейса, кто-то поставил пароль встроенной учетки админа и передал нам эти атрибуты доступа. И мы в рамках имеющейся документации что-то там допишем. У нас акцент на администрирование, в какой-то части на настройку.

О чем курс – понятно. Целевая аудитория – я уже озвучил, тоже понятно: и кастомеры, и партнеры, и ребята из ЕМС. Все сюда ходят, потому что нужно всем под единые стандарты образования подходить. Входные требования – я тоже уже озвучил: это университетский курс, он есть, где его найти и что с ним делать вы уже представляете.

Раз этот курс – проект, то помним, что по результатам этого маленького проекта, у вас должно быть какое-то понимание, теоретические знания, практические, совершенно конкретные, навыки, связанные с этим изделием. Это значит, что должно быть исчерпывающее понимание про дедупликацию: какая она бывает, и как она конкретно реализована в конкретном изделии. Какой комплекс запатентованных технологий есть, не обязательно имеющий отношение к дедупликации, реализованной в Data Domain, он стоит своих денег, чтобы вы видел, что это за патенты.
Как мониторить этот черный ящик, как им управлять, через какие административные интефейсы к нему можно подключится и можно начать с ним что-то делать. Здесь и командная строка и GUI. Как разграничить доступ к этому изделию. Data Domain – это многопользовательский эплайнс, там много людей должны иметь доступ к нему. Соответственно нужно разграничивать этот доступ и контролировать, нельзя допустить чтобы кто-то что-то испортил – это дорогое оборудование.
Как выполнить initial setup – это когда есть готовый черный ящик, который вы конфигурируете под свою структуру. Опираясь на конструкторскую документацию, которую кто-то для вас разработал. Пример такой документации у вас в виде учебного пособия для выполнения лаб. Тот формат что у вас для примера – он идеален для такой документации. Если вы хотите для своих пуско-наладчиков такие документы разрабатывать – делайте ее в таком виде, хороший пример у вас есть.
Identify and configure Data Domain data paths – через какие интерфейсы физические, логические, Data Domain может принимать потоки резервных архивных копий – их очень много. Давайте их все перечислим, и для каждого их них напишем процедуру настройки, проведем испытания на стенде, чтобы это описание соответствовало действительности, чтобы было какое-то доказательство. У нас для этого есть стенд.
Configure and manage Data Domain network interfaces – настроим сетевую подсистему Data Domain. У самой простой модели избыточное количество встроенных в материнскую плату сетевых интерфейсов. Это хорошо, потому что можно обеспечить как минимум – отказоустойчивость, интерфейсы ломаются, провода обрываются, а оно работает. А как максимум – агрегировать ее пропускную способность, суммировать интерфейсы для достижения каких-то результатов.

Одно дело — инициализировать Data Domain, другое дело начать бросать на него какие-то данные через разные интерфейсы. Будем следовать простой логике: от простого к сложному, от общего к частному. Вначале мы будем трогать простые интерфейсы, которые легко настраиваются и не требуют отдельных лицензий. А дальше все это будет ротивно усложнять. Например, возьмем и внутреннюю файловую систему Data Domain и начнем структурировать. Из какого-то большого куска данных сделаем структурированную систему, чтобы ей было удобно управлять.
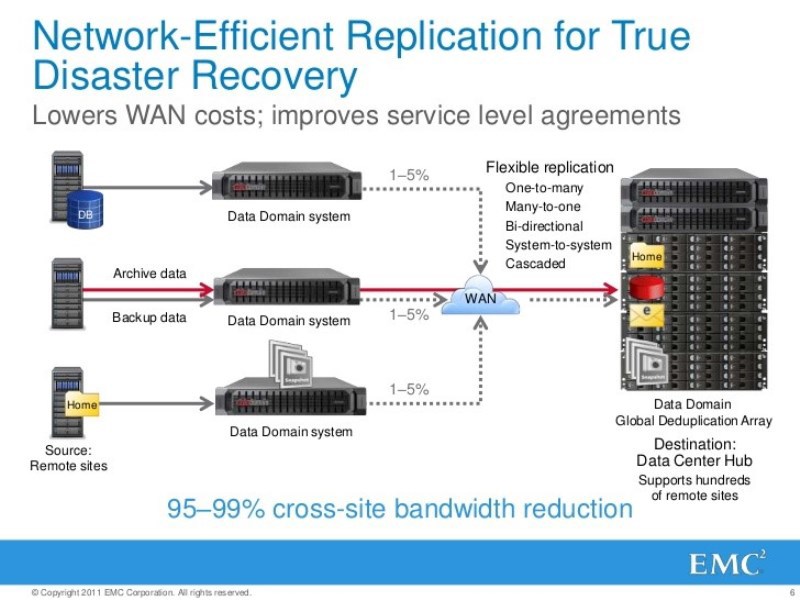
Вспомним, что Data Domain в общем случае – катастрофоустойчивое изделие. Когда писали ТЗ его разработчикам, то дали задание чтобы Data Domain мог пережить полное уничтожение. Это что значит? — вовремя сбросить реплику критичных резервных копий данных на другой Data Domain. Правда это вещь лицензируемая.
Вопросы непрерывности обеспечения бизнеса – очень актуальны, особенно после 9/11. И люди задумались: а что будет если у меня будет пожар или еще что?
Помните показатель RTO – чтобы не случилось потеряется ровно столько – не больше, и чтобы ни случилось все вернуть обратно можно за столько-то времени.
Тут был вопрос о что, одна из причин использовать дисковое хранилище для резервных копий – это улучшение показателя RTO, время восстановления. Например, мы делали все бэкапы на ленточные библиотеки, теперь требования к безопасности поменялись, теперь данные нужно восстанавливать еще быстрее, библиотеки не работают, что делать? Давайте подменим библиотеку Data Domain, который будет на фронэнде выглядеть как библиотека, но с более лучшим показателем RTO. Как сделать из одного или двух Data Domainов сделать одно или несколько виртуальных роботизированных ленточных библиотек? Как их презентовать существующим средствам резервного копирования, чтобы они минимально напрягались?
Самое важно здесь понять: как нужно донастроить средства резервного копирования, чтобы они правильно на такую виртуальную ленточную библиотеку что-то писали. Потому что писать по старинке, как они привыкли, физически, тут уже не стоит, в связи с той самой дедупликацией.

Если вы не привязаны к библиотекам, если у вас нет задачи подменить физическую библиотеку виртуальной то покупайте Data Domain с лицензируемой функцией DDboost. Так как это для Data Domain родной интерфейс, который раскрывает все его возможности. Это самый лучший вариант использования Data Domain. Это значит, что средства резервного копирования знает что такое DDboost, в худшем случае, в лучшем случае это знают боевые бизнес-приложения, которые бекапятся, это круче всего.
По-моему, самая продаваемая конфигурация: это Networker с Data Domain через DDboost, они смотрятся очень органично. Но мы понимаем, что DDboost – открытый интерфейс. ЕМС говорит: пусть у вас будет ваше средство резервного копирования, но пускай они знают, что такое DDboost, и для хранения резервных архивных копий используют наш оптимизированный интерфейс. Как его настроить – посмотрим.
В нашем курсе будет лаба как по дружбе Data Domain с Networker через DDboost, так и лаба по дружбе Симантековского нетбекапа через DDboost с Data Domainом. Чтобы продемонстрировать эту гибкость Data Domain.
Будет затравка по проектированию систем резервного копирования для архитекторов, о которых мы говорили. Какие-то элементы методики подбора подходящей модели Data Domain под требования конкретного заказчика, их модельный ряд большой. Мы поймем, что работа в этом даже присейла – не простая.
Кому будет интересно дальше углубится в вопросы проектирования – знаете у кого спрашивать.
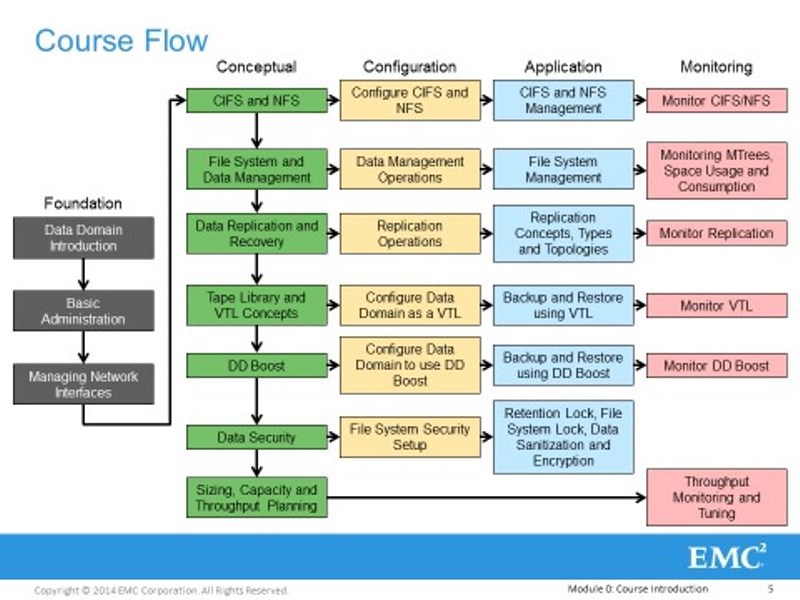
Вот наши модули. От простого к сложному, от общего к частному. У нас 10 модулей, но еще сделаем 11й опциональный модуль. Начнем со знакомства, основ администрирования, настройки сетевой подсистемы. Продолжим простыми, не требующими лицензий интерфейсами – CIFS, NFS, которым можно гонять трафик резервного копирования и архивирования. А дальше будем все это ротивно усложнять. Двигаясь к VTL и DDboost и к таким вещем защиты, которые есть в Data Domain, с помощью которых можно обеспечить приемлемый уровень информационной безопасности. В соответствии с требованиями законов и регуляторов.

Чтобы определить границы нашего курса, еще раз скажем о том, что – это программно-аппаратный комплекс. Есть аппаратная часть, есть программная. У аппаратной части есть своя система идентификации – трёхзначные модели, например, 160 – это постарее, 4значные – поновее. А программная часть определяется версией ОС – DD OS, текущая версия DD OS, которую можно скачать с сайта – 5.5, а наш курс пока еще рассчитан на 5.4. Так вот 11й модуль из 10 будет о значимых изменениях в 5.5. У каждой аппаратной части оборудования, есть свой предел обновления программной части.
В рамках этой части, пока все.
Видеозапись
Курсы ЕМС в УЦ МУК
6-9 июля в УЦ МУК будет курс по Data Domain System Administration, который будет вести этот инструктор — записаться на курс
А также:
15-17 июля — VNX Block Storage Management
21-25 июля — EMC NetWorker Microsoft Applications Implementation and Management
Дистрибуция решений ЕМС в Украине, Таджикистане, Беларуси, Молдове, странах СНГ.
Почему Data Domain такой дорогой? Почему это не СХД? Что нужно знать о проектировании/пуско-наладке/настройке/техдокументации этих систем? На что обращать внимание? — на эти и другие вопросы даны исчерпывающие ответы.
Под катом обзор и видеозапись.
Семья технологий и продуктов Backup Recovery Solutions
Мне, как инженеру, не стыдно говорить о том, что этот продукт хороший, так как из всех перечисленных аналогов — Data Domain появился на рынке первый, насколько я помню. По результатам испытаний и конкурсов выбирают именно это решение. Применить к этим комплексам даже самой низшей линейки понятие «старый» можно очень условно, так как срок жизни у этих решений составляет 5-7 лет, что очень немало.
Наш учебный курс построен в формате тренинга – 50% теории и 50% практики, понятное дело, в начале я буду больше говорить. Сама лаборатория физически находится в США, там на каждого из вас, участника тренинга, стоит полноценный Data Domain.
Начнем с нужных вводных по системам хранения ЕМС. Как я понимаю, вы уже не первый раз сталкиваетесь с продукцией компании ЕМС, и помните что ЕМС, VMware, RSASecruity – это один конгломерат. Поэтому продукцию всех этих корпораций можно рассматривать в рамках единой номенклатуры, не в смысле управления компаний, а в том смысле, что все эти продукты интегрируются друг с другом. В этом достигнута очень глубокая степень интеграции. Мы будем рассматривать только продукты компании ЕМС. Нас интересует та ее часть, которая называется Backup Recovery Solutions. Часть этих решений она, как бы заимствованная, за счет поглощенных компаний. Например, головной продукт, который называется Networker – полноценное средство резервного копирования корпоративного класса, который бьется со своими конкурентами на этом рынке – откуда он? – из компании Legata, которая с конца 80-х годов этот продукт разрабатывала, сейчас это уже ЕМС.
Дальше, тот продукт, который мы с вами собираемся изучить – Data Domain – была одноименная компания, которая первая на рынке выпустила подобный программно-аппаратный комплекс для хранение резервных архивных копий, ЕМС ее поглотила. Следующий – Avamar. Я специально перечислю главные продукты, потому что они все друг с другом взаимосвязаны. Avamar – так раньше называлась компания из Калифорнии, которая опять же выпускала средства резервного копирования корпоративного класса с дедупликацией на источнике, очень специфическое решение, которое революционизировало стратегию резервного копирования, продукт раньше назывался Axion, если я правильно помню. И еще есть Data Protection Adviser, насчет этого продукта я не помню было ли это разработкой ЕМС, или это было поглощение компании.
На самом деле это не полный список, почему я перечислил все эти продукты? Для того чтобы сказать вам о том, что это все части единого целого – уже сейчас, на дворе 2015 год, ЕМС в прайс-листах, в работе своих присейлов, позиционирует все эти продукты как части единого пакета продуктов в рамках Backup Recovery Solutions – единый продукт, который позволяет унифицировать защиту любых данных, которые могут встретится в любой корпорации. Объединив эти продукты уже на протяжении долгого времени, ЕМС научило эти продукты очень глубоко интегрироваться. Networker может работать как сам, так и часть функций делегировать на Data Domain или Avamar, Avamar может напрямую интегрироваться с Data Domain без Networker, а могут все вместе работать в одной «шайке-лейке». Про Data Protection Advisor– вообще отдельный разговор.
В связи с этим, на курсах по этим продуктам нельзя об этом не говорить, потому как значительная часть функционала завязана на вот эту интеграцию. Если говорить про наш Data Domain, то в нем значительная часть функций уже годами не меняется – потому что там все уже давно хорошо, еще до поглощения. Но после, большая часть усовершенствований связанна с тем, что Data Domain должен уметь «дружить» со своими «братьями», чтобы это стало единым целым. Если рассматривать каждый продукт по отдельности – то это набор функций, или услуг. Но когда эти продукты интегрируются, то это не математическое сложение функций, появляются некие уникальный сверхсвойства, о которых нельзя не говорить. Даже на нашем курсе, который первый в списке авторизованного обучения, мы об этих функциях будем достаточно много говорить. Поэтому эти вещи нужно позиционировать: что есть что и какую роль занимает. Продукты буду перечислять и описывать в определенном, не случайном, порядке.
Сначала поговорю о Networker. Это головной продукт – ядро, системы защиты данных в части системного копирования и архивирования. По сути – это классическое многозвенное клиентсерверное средство резервного копирования, программный комплекс. Дистрибутив, элементы, звенья которого раскладываются на: резервные копии в виде клиентов, сервера резервного копирования в виде узлов хранения, к которым подключены какие-то хранилища, которые связаны с клиентами какой-то средой передачи данных. Пуская это будет LAN или SAN, что-то в этом духе. И есть мастер-сервер, который мы называем бэкап-каталогом. Есть централизованные средства, где есть сервер, ведущий единый учет резервных копий, носителей информации, на которых они попали, где хранятся политики резервного копирования, правила, автоматизирующее весь этот процесс. Фактически, на этом звене, которое называется – Networker сервер, самих тел резервных копий не хранится, только их учет и контроль. Сюда «тыркаются» разнообразные админские консоли и т.п. Связь всех звеньев осуществляется, естественно по протоколу ТСР/IP через локальную сеть, через глобальную сеть – не важно. Нас естественно, интересует вопросы движения трафика резервного копирования.
Вот у нас источник резервных копий – чтобы это ни было, и у нас destination. Как уже было сказано, средства резервного копирования Networker – корпоративного класса, это значит, что оно умеет отделять одно от другого. Трафик резервного копирования может передаваться по выделенным сегментам – интеллектуально и осознанно. Обычная локальная ethernet-сеть или какой сторедж эриа нетворк, работающий по fiberchannel — любой способ связи. Это значит, что Networker знает, что такое LAN Free Backup, слышали о таком, да? Что еще может делать Networker? Например, бекапить источник резервных копий не нагружая его. Особо распространяться не буду, это называется serverless или proxy backup. То, что я перечисляю эти функции, это не значит, что их только Networker может делать, это значит, что он ими владеет как и его конкуренты. Networker может бекапить NASы, за счет того, что знает, что такое NDMP, протокол NDMP freeware backup – кто не знает что это такое? Это реализация lanfree serverless для выделенных файловых «помоек». Networker породившись в 1989 году, имеет долгую историю и его матрица совместимого ПО и оборудования – очень большая. Он рассчитан на гетерогенную сеть, у него в источниках может быть что угодно, очень большая матрица совместимости: различных ОС и бизнес-приложений, которую он может бекапить без остановки, то что называется онлайн-бекап, у него огромное количество различных интеграций, включая различные Microsoft и другие.
Традиционно, Networker, в качестве резервных копий использовал роботизированные ленточные библиотеки в первую очередь – в этом он достаточно хорош, у него матрица совместимых библиотек очень большая. Никто не говорит, что он не может бекапить на диски – конечно может! Но мы знаем, что на дисках хранить бекапы – дороговато, особенно при текущих объемах. Я это говорю к тому, что изначально Networker был рассчитан на работу с ленточными библиотеками и до сих пор с ними лучше всего работает. И для традиционного подхода к защите датацентров – это вполне нормально. Экономически легко доказать целесообразность использования Networker для защиты боевых серверов, которые сидят в ЦОДе: всякие Ораклы, Сиквела, сервера приложений, огромные данные, которые в пределах ЦОДа, по высокоскоростной, выделенной какой-то сети, мы гоняем на какие хранилища резервных копий. Все хорошо, но Networker, так уж получилось, знает, что такое дедупликация, но не умеет ее самостоятельно выполнять. Не потому, что об это не подумали разработчики, а потому, что к тому моменту кто-то уже умел эту дедупликацию делать. Поэтому, если вы хотите для какой-то части источников резервных копий организовать эффективное потоковое сжатие, то в качестве одного из множества хранилищ, с которым может работать Networker, вы можете использовать Data Domain, потому что это фактически, дисковая полка с винчестерами, с какой-то, будем считать, аппаратной дедупликацией, которая позволяет очень эффективно сжимать потоки резервных архивных копий, которые валятся на эту полку.
Соответственно, у этого ящика есть масса интерфейсов, о которых мы будем говорить подробно. Мысль остается прежней – единый хозяин, единый учет резервных копий, часть из них падает на какие-то традиционные хранилища, а часть падает на хранилище с дедупликацией, дисковой дедупликацией. Нужно понимать, что дедупликация – это не панацея и экономически целесообразно использовать ее в целом, и вот такие продукты в частности. Если мы используем традиционный поход – ленты, отчуждаемые носители с последовательным доступом, то там скорость восстановления, как ты не изгаляйся, будет измеряться часами. Если этот показатель Recovery Time Objective нужно свести к какому-то приемлемому минимуму – то нужно хранить резервные копии на дисках – но это дорого, поэтому давайте применять дедупликацию, если она применима, конечно же – источник резервных копий может быть с противопоказаниями к сжатию – не жмется, и все, и хоть убейся. Тут сразу же приходит в голову резонная мысль: когда говорят об использовании чего-либо с дедупликацией, требуется обследование автоматизированной системы заказчика в рамках какой-то методики и обоснование – оценка этого достижимого коэффициента. Если обследования нет – что вы можете ожидать? Кто-то говорит, что он может «гарантировать» какой-то коэффициент сжатия – удивительно это слышать! Конечно же чистый маркетинг. А в реальной жизни не так все просто.
Data Domain может выполнять дедупликацию самостоятельно, своими силами, тратя свои процессорные тики, свою процессорную силу, оперативную память — не напрягая источник. Это очень хорошо. DD может принимать потоки резервных копий через LAN, через ethernet – 10 гигабит, 40 гигабит заявлено. А может при необходимости, делегировать часть функций, связанных с сжатием, на сам источник – если это допустимо. Интерфейсов у Data Domain много — для принятия одновременного потока множества резервных архивных копий, но самый эффективный – это лицензируемый интерфейс DD Boost, этот протокол и Data Domain неотделимы. DD может использоваться без DD Boost, но этот сам интерфейс может использовать только в DD.
Data Domain экономически целесообразен, это легко доказать, использовать для защиты, все-таки серверов, которые сидя в ЦОДе, которые связанны с DD какой-то общей, высокоскоростной средой передачи данных, это не VAN, это LAN или SAN. Опять же, речь идет только о серверах, для которых допустима дедупликация, а если нет, тогда нужны диски. Вот такая проза жизни, в общем-то.
Боевые сервера, для которых дедупликация не применима, для которых показатель RTO не такой жестокий, их вполне нормально бекапить на роботизированные ленточные библиотеки и т.д. Есть источники резервных копий, для которых показатель RTO критичен, их нужно иметь возможность быстро восстанавливать, этого требует политика безопасности и для них нет противопоказаний дедупликации – купили Data Domain и сказали Networkerу часть потоков резервных копий из этих источников направлять на такие хранилища
А что делать с третьей категорией источников резервных копий и самой многочисленной? – с рабочими местами? И если их связывают с хранилищем ненадежные каналы связи? То работают с перебоями, то пропускная способность слабая и т.д. Бекапить их традиционным способом и с дедупликацией на хранилища – бесполезно, очень неудобно. Здесь ЕМС говорит, ок, у нас есть вот такой продукт — Avamar, который конечно же может быть использован автономно – и для защиты и серверов он подходит, и для защиты чего угодно. Но его особенность в том, что он всегда выполняет сжатие на источнике. Сначала, напрягая источник, ужимая, насколько это возможно, данные подлежащие резервному копированию, а потом только уже в сжатом виде передает уникальную дельту, копию в какое-то хранилище. Avamar, в части интеграции, может работать со всеми продуктами семейства, может также очень эффективно работать под управлением Networker.
Учитывая, что оно все друг с другом интегрируется, все категории источников резервных копий защитить – можно технологиями от единого поставщика. Осталось только что? – корреляция событий, которые происходят в этих сложных программно-аппаратных комплексах, с событиями, которые происходят на сетевом оборудовании, хранилищах, системах хранения данных и т.д. Для того, чтобы соответствовать тому, что называется SLA, во-вторых для того, чтобы можно было организовать billing. Идея очень простая – все вышеперечисленные продукты, по отдельности, и в совокупности, они то, что называется cloud ready. Это значит, что из них можно построить облачный сервис резервного копирования и сдавать его в аренду. Я – оператор, построил свои сервер-ЦОДы, поставил туда этих продуктов и сдаю вам, как юрлицам в аренду. Чтобы вам гарантировать уровень качества обслуживания и каждому выставлять счета, по мере использования моей инфраструктуры нужен биллинг. Для организации этой части нам нужен такой продукт – Data Protection Adviser (DPA), советчик. Это отдельный программный комплекс, клиенты которого ставятся на все источники информации, у которого есть централизованная БД, куда собирается вся информация, где она семантически укрупняется, сверяется с некой БД сигнатур каких-то событий. Ну и дальше сидит кто-то, смотрит на монитор, и ему показывается красным цветом – все плохо, или ему указывается, даются советы – что делать? И он либо пишет отчеты, либо счета выставляет начальству — отличная вещь.
Из чего состоит Data Domain
Я перечислил не все модули единого модульного продукта, так как времени у нас не так много. Но если есть те, кто хочет себе показать RTO свести к нулю. Есть продукт Recover Point, который опять же со всеми интегрируется, в частности с Networker, которые реализуют концепцию непрерывной защиты.
В нашем курсе акцент будет сделан на малую часть этого программно-аппаратного комплекса – только Data Domain. Но всегда мы будем говорить о нем в свете интеграции с другими продуктами из семейства, или от сторонних производителей, что тоже не проблема.
Среди вас много опытных ребят, кто уже работал с конкурентами Data Domain. Если попытаться определить, что такое Data Domain, то возможно получится так: дисковое хранилище дедупликаций для хранения резервных, архивных копий. Не больше и не меньше. Это очень важный момент. Это не СХД, сравнивать ее с чем-то таким нет никакого смысла. Потому что то — хранилище для хранения рабочих данных, для которых профиль нагрузки, в общем то, как бы универсальный: там возможно и последовательное чтение, записи, и произвольные чтение, записи. Там эти серьезные показатели iops, те, кто работает с СХД об этом знает. У СХД, какие бы они ни были: слабого, среднего, высокого класса – при всех прочих равных, есть какая-то общая архитектура. Фронт-енд, есть какой-то кеш, бекэнд, есть отказоустойчивость, мультипафинг и тому подобное. Data Domain – это не СХД, никогда его так не называйте – это грех:)
Data Domain – это сервер. Если я беру это железо, то я вижу программно-аппаратный комплекс, есть аппаратная часть, в виде средств вычислительной техники, программная часть в виде системного ПО, это ОС, есть какое-то там прикладное ПО.
Аппаратная часть это что? Интеловский чипсет, памяти как можно больше, пару блоков питания, там есть шина PCI express, сколько-то слотов, в материнскую плату встроено 4 сетевых карты с гигабитными интерфейсами и 2 медных с 10 гигабитами. По умолчанию уже есть больше чем 1 избыточных сетевых интерфейса для подключения к внешней среде, чтобы принимать управляющий трафик, чтобы принимать потоки резервных копий и выдавать потоки восстановления. Уже хорошо. В слоты мы можем воткнуть еще сетевых карт, в зависимости от моделей, мощность тоже может быть ограниченна чипсетом. Можно воткнуть fibre channel host bace adapter, правда за отдельные деньги, я видел такой адаптер 4х и 8ми гигабитный, 16гигабитный кто-то видел? Я видел, что их заявляли, как и 40гигабитные ethernetы, но пока еще их нет, их можно ожидать.
Что еще на шине есть? Там по умолчанию там уже стоит дисковый контроллер, SAS и не один, их должно быть 2. На шине которых висят какие-то диски, дисковый массив. В младших Data Domain моделях это прямо в корпусе самого сервера, который монтируется в стойку. Сколько там винчестеров? Минимум – 7, максимум – 15. Если у вас модель Data Domain более серьезная, вы можете на шину SAS-контроллеров, еще добавить одну или несколько дисковых полок. В дисковых полках крутятся, раньше это был убогие sata-винчестеры, сейчас это NL SAS-винчестеры. Чем NL SAS от SAS отличается? NL SAS – это как дешевый SAS (саташный винт, сделанный через SAS шину, скорость обмена увеличили, но саму архитектуру винта оставили как и было). SAS, грубо говоря, это старое доброе scsi. NL SAS – это сасовские винчи, которые по результатам производства не прошли каких-то жестоких испытаний на производительность, надежность, но имеют какой-то приемлемый уровень, поэтому они идут дешевле. Грубо говоря, у сасовских винчей время наработки на отказ в разы больше чем у NL SAS. Я говорю не о производительности, а о надежности. Эти винчестеры, которых много, десятки или сотни, они, естественно в какие-то рейд массивы собраны. (Каждая полка собирается в отдельный рейд массив) это еще называют дисковый группы (железных контроллеров там нету, фактически это софтовый рейд, это ни плохо и не хорошо, просто это так работает, и в каждой полке еще дополнительный диск hot spare). Я видел, что в head парочка дисков выделена под ОС. (Раньше такого не было, сейчас в более старших моделях Data Domain используется 4 диска для этой Data Domain ОС. Они вынесены отдельно, там смешанные рейды). Там полезные данные не хранятся, там только служебные.
Если вспомнить логику построение рейд 6 масивов. Какие там накладные расходы? Одна логическая операция записи какого-то блока данных – это сколько физический операций (я говорю про iops)? 3 чтения + 3 записи. То есть накладные расходы – дикие! У 6-го рейда накладные расходы самые большие, у 5-го меньше: 2 чтения + 2 записи. Дисковая система в этом сервере – очень медленная, поэтому мы вспоминаем о том, что мы говорили, что это – не СХД.
ОС – это какая-то линукс-подобная операционка, называется DD OS (Data Domain Operating System). В общем случае, для обычного кастомера, потребителя она доведена до неузнаваемого вида – традиционных шелов вы там нет. Там простецкий командный интерпретатор, с какой-то системой комманд с простым синтаксисом. И если ты не инженер, а служба техподдержки, и инженерного доступа не имеешь – то забудь о большинстве известных тебе юниксовых команд и утилит. В качестве приложения будет терминал разнообразных демонов: Daemon VTL, Deamon DDBoost, Deamon NTP, Deamon NFS и так далее. Комплект которых встроен в этот дистрибутив линукса, чтобы через разнообразные эти протоколы уровня приложения принимать/отдавать потоки резервных копий.
Почему Data Domain такой дорогой?
Хорошо, тогда спрашивается почему Data Domain такой дорогой? Что здесь такого особенного в частях, из чего я не могу сам собрать? Не берем в расчет маркетинг и т.д., если взять в расчет техническую часть – в одном из слотов PCI стоит одна или несколько специальных плат, которые называются NVRAM платы. Специализированная плата, с каким-то объемом оперативной памяти в чипе, 1 гигабайт, 2, 4 гига, с каким-то, будем считать специализированным микропроцессором. Это та самая плата, с помощью которой вот эти потоки входящих резервных архивных копий, с помощью центрального процессора – ужимаются. Та самая плата, где проходится та самая дедупликация. Это то, что позволяет старшим моделям DD «ужирать» в час десятки терабайт каких-то данных. Представьте себе 10 терабайт в час входящий поток, и какая должна быть производительность дисковой подсистемы, собранной из NL SASов в рейде 6? Да их там должно быть безумное количество!
Но как в старших так и в младших моделях Data Domain дисковая подсистема по производительности не отличается. Суммарное количество иопсов, которое оно может выдавать – оно остается маленьким. Абсолютно неадекватным тому набору функций, которые требуются для такого объема данных. Все эти «адские» терабайты сжимаются на входе до приемлемого уровня, и до дисковой подсистемы доходит лишь приемлемая нагрузка. Технология дедупликации, точнее ее реализация в Data Domain, запатентована.
Если слетать в Калифорнию, в Санта-Клару, где это подразделение, сейчас это называется Data Protection and Availability Division, бывший BRS, то там в холле, есть «зал славы», где висят все эти патенты, их копии. А это дорогое удовольствие, вы, покупая Data Domain, оплачиваете все эти патенты, владельцу патента, за его суперразработку, которая в определенной части держится в секрете, мы об этом тоже поговорим позже. Не хочу сказать, что у других вендоров аналогичных технологий нет, но порядок цен такой же как и на Data Domain. Все они бьются изо всех сил за потребителя. Основной конкурент – HP Storeonce и IBM Protectier.
То есть Data Domain будет выглядеть так: сервер, с полками или без полок, подключенный через ethernet только, или и через ethernet и через fiberchannel, принимающий потоки резервных копий через множество разнообразных протоколов. Получается, что основным конкурентным преимуществом этого продукта, по сути является дедупликация.
Дедупликация
С этим нужно разобраться чтобы идти дальше. Примерно говоря – это сжатие. В чем суть сжатия – уменьшить объем данных. Только когда говорят «сжатие» в общем случае, то подразумевают что, мы ищем повторяющееся наборы данных и заменяем их на какие-то ссылки, в каком-то локальном наборе данных. Когда мы говорим «дедупликация» — то речь идет о глобальном сжатии, я ищу не только повторяющие данных на этом источнике резервных копий, а вообще везде, на всех вообще источниках резервных копий.
Соответственно у нас дедупликация может выполняться на разных уровнях абстракции. То, что я рассказываю не ново, но это нужно чтобы говорить в одном и том же словаре.
1) Filebased. На уровне файлов. Вы все бекапите на меня какие-то данные, а я ищу какие-то повторяющиеся файлы. Пришел какой-то файл от кого-то, выяснилось, что он мне никогда не встречался, он уникальный – я положил его в хранилище. Потратил какие-то ресурсы, место в хранилище, чтобы тело этого файла там разместить. От кого-то пришел еще один экземпляр этого же файла, я каким-то образом в этом убедился. И вместо того чтобы тратить ресурсы, я сохраняю метаинформацию что такой файлик встречается там-то и там-то. И накладные расходы будут на 2 порядке меньше, вместо того чтобы сохранять тело файла в хранилище.
А как сверять файлы? Самый простой – это побитовая сверка, ее нельзя сбрасывать со счетов, в определенных случаях она эффективней чем расчет эталонной характеристики, хеши и т.д. Поэтому никогда это не упускайте, я об этом расскажу немного позже. В большинстве систем резервного копирования используется такой подход: давайте мы вот этот набор данных прогоним через какую-то функцию, и независимо от того, какой размер исходного набора данных, мы получим какой-то хеш, эталонную характеристику фиксированного размера. И в рамках вот этой математической зависимости у нас будет определённая гарантия того, что если в исходном наборе поменяется один бит, результат хеширования будет совершенно иной. Я специально поднимаю этот вопрос, в учебных материалах курса вы этого не увидите, чтобы вам сказать следующее: да, функция хеширования имеет прямое отношение к симметричной криптографии, это отдельный класс математических функций. И для них актуальна проблема коллизий. Вероятность того, что у разных наборов данных будет один и тот хеш – не нулевая. Но ее можно свести к приемлемому минимуму. И для тех случаев, когда эти коллизии случаются какими-то компенсирующими мерами гарантировать, что целостность данных не будет нарушена. Я специально это озвучиваю, потому что, в частности, в Data Domain, разработчики этому вопросу уделили внимание, и дают математическую гарантию, доказательство того, что эти коллизии не проблема, и с ними справляются с помощью компенсирующих средств.
В этом случае все уникальные наборы данных имеют уникальны хеши. Если происходят коллизии – этим можно пренебречь. Это доказано, речь идет о запатентованной технологии, не с потолка это взято. Какой алгоритм, что проверять или не проверять – мы не знаем. Я специально повторюсь, алгоритм дедупликации (он большой, если нарисовать схему – комнаты не хватит) это учитывает. И об этом говорят разработчики.
Эта технология, так сказать «тупая», но дай бог если можно получить коэффициент сжатия в 1,5-2 раза. Это средний показатель, но ожидать здесь хоть чего-то – крайне сложно. Даже если у вас в качестве источника резервных копий какая-то файловая «помойка», много повторяющихся файликов.
2) Если у меня во главе стоит коэффициент сжатия, то давайте искать не файлы, а блоки данных фиксированной длины. Давайте все данные, что нам падают крошить на фиксированный кусочки, обычно в килобайтах. Для каждого кусочка рассчитываем хеш, и сверяем с хешами тех кусочков, чьи тела лежат в нашем хранилище. Есть попадание – ок, он сохранился, не будем его сохранять, нет попадания – это кусочек уникальный, пора его поместить в хранилище.
Этот подход хорош чем, что мозгов не нужно много включать. Но он лучше всего работает для источников резервных копий, где данные уже структурированные. Если тот набор данных, где мы ищем измененные блоки, он уже изначально в него вносятся изменения фиксированными транзакциями, фиксированного размера, то это очень удобно. В понедельник были одни блоки, то вторник блок такой-то и такой-то поменялся. Когда во вторник средство резервного копирования покрошит этот файлик на кусочки фиксированного размера, он строго локализует изменения.
Коэффициенты сжатия, которые можно достичь при этом подходе уже больше. В среднем это может быть 2-5 раз. Но тут важно чтобы источник удовлетворял определённым требованиям, где данные уже структурированы и изменения делаются фиксированными трансакциями определенного размера. Чаще всего это СУБД. Для таких данных выдаются хорошие показатели. А если неструктурированный виннигрет? Алгоритм не сможет локализовать эти изменения, потому что там все сдвигается.
3) Поэтому есть алгоритм дедупликации на блоки данных варьирующегося размера. Суть этого алгоритма — локализовать изменения. Даже если вначале или середине файлик поменялся, система поймет, что это только эти блоки поменялись, а остальные остались прежними. Обычно такие алгоритмы используют данные, блоки которых варьируются 4к-32к. Есть гарантия того, что если исходный набор данных не поменялся, то результат его «крошилова» будет одним и тем же. И он сможет локализовать только изменённую часть данных. Все эти алгоритмы подобного рода – запатентованы. Они все держаться в секрете. По сути, это все вариации того, что называется фильтр Блума – если захотите свой математический аппарат напрячь. Поэтому часть патентов в Санта-Кларе, они про это. О запатентованной реализации системы теорем. Кто-то реально напряг свой мозг.
Теперь, если говорить вообще о дедупликации, на каком уровне абстракции ее лучше выполнять? 1-й, 2-й, 3-й способ… нет, неверно, нет «правильного» ответа. Примерный правильный ответ звучит так: идеальное средство резервного копирования должно уметь выполнять дедупликацию на всех уровнях абстракции, подстраиваясь под особенности источников резервных копий.
По простому: у меня файловая «помойка», неструктурированная информация бекапится? Давайте я сначала быстро, никого не напрягая: найду повторяющиеся файлики и их выброшу, те которые уникальные – ладно, начну крошить. Если это файлик – тело БД, то я его буду на структурированные файлики крошить определенного размера, если неструктурированные блоки – то на блоки данных варьирующегося размера. Потому что всегда приходится искать компромисс между коэффициентом сжатия и накладными расходами, нагрузкой на это сжатие.
Нужно рассчитывать эти хеши, нужно их сверять, а это кого-то напрягает кого-то, мы пока не уточняем кого. И чем больше нагрузка, тем больше показатель окна резервного копирования. Приходится искать какой-то компромисс. Чем лучше сжалось, тем медленнее будет какой-то RTO и т.д. Поэтому компании ищут какой-то компромисс между этими параметрами. И очень хотелось бы, чтобы средство резервного копирования, с одной стороны, ему можно было сказать: ты сам интеллектуально разбирайся какую дедупликацию, на каком уровне абстракции, для какого источника выполнять. А с другой стороны говорить ему: вот тебе такие рамки.
Например, для этих данных – мне их нужно максимально сжать, я для этого важно чтобы при сжатии это укладывалось в окно резервного копирования, а для этого важно время восстановления. Так вот, Networker в сочетании с Data Domain и Avamar и представляет такую интеллектуальную систему резервного копирования.
Был вопрос насчет Мicrosoft
В Microsoft, в ОС, 2012 версии в случае установки роли файлового сервера есть опция, которая реализует дедупликацию блоков данных варьирующейся длинны на уровне тома. И там коэффициенты 1,5-2%. Если мы говорим про Avamar, то он выполняет дедупликацию на всех 3 уровнях абстракции, если про Data Domain, то он выполняет дедупликацию всегда на 3м уровне — блоков данных варьирующейся длинны. Алгоритм хеширования, который используется – промышленный – Secure Hash Algoritm, и размер эталонной характеристики 160 бит.
Идем дальше. У нас уже была визуализирована архитектура классического современного средства резервного копирования корпоративного класса – клиентсерерное, многозвенное. Есть множество источников – клиентов, есть какая-то среда передачи данных, связывающая эти источники с тем, что называется медиасервера, узлы хранения, которые подключены к хранилищам. И есть какой-то бекап каталог, который всем этим дирижирует.
Так вот, в части касающейся дедупликации. Она может выполняться кем? Кто этот герой? Есть вариант postbased. Вот есть терабайт данных, он передался через какую-то среду на хранилище, в отведенное бекап окно, оно съело терабайты данных, для этого ему нужно много шпинделей, потратилось место терабайт, а потом уже наверное вне окна резервного копирования начинается это ужимание: на уровне файлов, блоков данных фиксированных и т.д. – но этим напряженно само хранилище. И вот оно ужалось в 10 раз, 100 гигов есть. Хорошо это или плохо – я не говорю. Например Windows Server 2012 именно так и работает. VNX работает похоже, но последние модели могут делать дедупликацию, не только на уровне файловых блоков, но и на уровне лунов – и он по своему расписанию это делает, и мы экономим наше дорогое место.
Есть дедупликация «на ходу». Терабайт прочитали, передали через среду передачи, никакой экономии нет, но перед тем как попасть в дисковую подсистему хранилища, этот терабайт, с помощью процессора, оперативки, ужимается, и мы убираем это безумное количество иопсов, и получаем какое-то их адекватное количество, которое можно писать на дисковую подсистему. Не нужно много шпинделей, не нужно куча места. Вот это у нас – Data Domain. Он это может делать через любые программные интерфейсы.
Третий вариант. Дедупликация на источнике. Терабайт я прочитал и тут же напряг источник. Он и так напряжен чтением большого массива данных, передачи их куда-то, а тут их еще нужно сжимать. Вот дожал он это до 100 гигов и уже несчастные 100 гигов передал по системе передачи данных в хранилище. Это умеет делать Avamar и Data Domain в случае использования интерфейса DDboost с включенным функционалом DCP. То есть Data Domain знает, что такое дедупликация на источнике. Самое интересное, что он знает и что такое постдедупликация, первый тип, о котором мы говорили. У Data Domain есть время, когда он сам с собой разбирается, и вот это также предполагает postbased дедупликацию.
То множество потоков, которые валятся на Data Domain, он их крошит, на кусочки варьирующегося размера, рассчитывает их на хеши, сверяет их массивы. Но есть математическая гарантия того, что для 99% этих кусочков, он сможет понят уникальны они или нет. А для 1% он этого не сможет сделать вовремя. Считайте, что он эти кусочки куда-то положит, чтобы успеть, а потом их еще постфактум дожмет. Как и почему это случается я объясню потом. В этом нет ничего плохого, это никто не декларирует, но никто от этого и не отказывается. Те показания производительности для каждой модели Data Domain, которые выложены на сайте ЕМС – это не чистой воды маркетинг. Они сделали лабораторию, программу методики испытаний, живой Data Domain поставили, и стали на него что-то бекапить и достигли этих результатов, строго их измерили. Понятно, что при соблюдении определённых условий, возможно даже идеальных, но никто не обещает манну небесную. Все говорят: проводите исследования, обосновывайте, докажите заказчику, что именно такой коэффициент будет получен, такая скорость поглощения будет получена в его ситуации – и вот это продавайте.
То, что я рассказывал – это какой-никакой ликбез по средствам резервного копирования. education.emc.com – портал обучения, вы наверняка о нем знаете, хорошо туда заходить почаще. Есть отличный курс Backup Recovery Systems and Architecture, занимает 40 часов. Курс по основам резервного копирования и архивирования, там про вот эту многозвенность, про serverless прокси бекапы, дедупликацию, там много чего написанно. Курс на самом деле университетский, читается на старших курсах технических ВУЗов, партнеров академической программы ЕМС, магистрам преподается, в рамках второго высшего. В питерском политехе, в московских вузах я такой курс читал. Курс сам по себе очень интересный, я специально о нем говорю, потому что было бы желательно, чтобы каждый из вас хотя бы его пролистал и посмотрел. Потому что белые пятна в образовании есть у всех. Занимаясь больше 10 лет системами защиты, я думал, что на этом собаку съел, что меня уже ничем не удивить – ан нет. 5 дней – 40 часов, только про вот эти основы.
Идем дальше. На сайте ЕМС в разделе защиты данных я смотрю номенклатуру продуктов. Под защитой данных подразумевается их целостность и доступность в первую очередь. Не конфиденциальность! Когда говорится о всяких секретах это уходим в RSASecurity. У меня тут есть дюжина продуктов и в разделе backup recovery у меня есть ЕМС Data Protection Suite – это и есть единый программно-аппаратный комплекс для защиты всех категорий данных.
Я хочу посмотреть на модели Data Domain и посмотреть на их характеристики. Моделей очень много, на любой вкус и кошелек. Хочу посмотреть самую слабую модель — Data Domain DD160. В ней есть 7 дисков по умолчанию, либо можно расширить до 12. Архитектура у всех моделей Data Domain одинакова, но у тех, что подешевле есть определённые ограничения. Например, полку не добавишь – ограниченна возможность масштабирования, много сетевых интерфейсов там не поставишь, hostbased адаптеров. И вот configuration maximum – 160 модель готова суммарно поглощать потоки резервных копий со скоростью до 1терабайт/час. Как интерпретировать этот показатель? При условии? что поток идет через ethernet и DDboost, DCP включен, с дедупликацией на источнике. Если нет DDboost, то можете смело делить на 2: входящий и исходящий. DDboost уже работает много с кем, даже HP Data Protector умеет с ним работать, Netbackup давно знает, Backup Exec давно знает – это промышленный стандарт, потому что других альтернатив не придумали.
Что такое 195 тб Logical capacity? Как это интерпретировать? То есть до сжатия почти 200 тб, а емкость у него 1,7. Какой нужен коэффициент сжатия? Если грубо округлить – в 20 раз? У меня есть заказчики, у которых: в 3 раза пожалось – круто!
Противопоказания
Почему я на это обращаю внимание – еще раз говорю – все зависит от данных. Когда говорили про дедупликацию я специально не упомянул о противопоказаниях. Если, например, у меня данные зашифрованы, изначально представлены в виде криптограммы, а я их бекаплю. Какие мы получим коэффициенты сжатия? Алгоритмы шифрования и алгоритмы компрессии – из одной категории математических функций. Они делают примерно одно и тоже, но цели у них разные. У одних обеспечить конфиденциальность, а у других уменьшить их объем. Все что зашифровано – противопоказано для сжатия, так как после него данные займут еще больше места.
Хорошо, если данные сжаты уже. Медиаданные, все что угодно. Каких коэффициентов можно ожидать? Можно ожидать, но тут все зависит от схемы резервного копирования. Если у меня есть медиа архив, объемом 10 тб, который не жмется, но я каждый день делаю фулл-беэкап, это не вариант – этого никто не делает.
Поэтому нужно выявлять противопоказания, там где их нет – проводить обследования. И вычислять вот этот достижимый коэффициент сжатия. В какой-то мере его можно вычислить эмпирическим путем, посмотреть на данные, у ЕМС есть статистика и сказать: в 5 раз пожмется. От этого можно отталкиваться. У вас там SQL и Exchange, столько-то почтовых ящиков такого-то размера? Есть формула, куда это вбиваешь и получаешь результат.
Все трогали Backup System Sizer? Он дает приблизительную прикидку. Мои заказчики делятся на 2 категории, одни говорят: напиши нам подробно на документах, обоснуй, техническое обоснование и т.д. А другие говорят: нам ничего не нужно из документов, но ты лично отвечаешь за то, что пообещал? В идеале, конечно, чтобы отвечать за свои слова, нужно точно самому убедится, что получится именно тот коэффициент сжатия.
Тогда лучше сделать то, что не очень любят делать интеграторы: дайте заказчику в опытную эксплуатацию хоть слабенький, хоть б/у, Data Domain. Пусть он там покрутится какое-то время, и мы по факту посмотрим какой получился коэффициент. И уже этого будем отталкиваться, разрабатывать технико-коммерческое предложение.
Документация и обучение
К чему это все. Без этапа проектирования – не обойтись. Кто-то должен провести обследование в рамках какой-то разработанной методики, написать техническое задание на систему защиты. План защиты, положение и категорирование информационных ресурсов. План обеспечения работы, восстановления после сбоев. Все эти документы должны быть. Кто-то должен оценить, сказать, например, что вот эта категория – там дедупликация не нужна, здесь можно – но не нагружать источник, здесь можно, здесь такой коэффициент, здесь такой.
Эту работу делает интегратор, или партнер, как их называет ЕМС. У ЕМС есть специальная обучающая программа для архитекторов, для тех проектирует, для инженеров-конструкторов. Где всему этому учат: обследованию и составлению технической документации. ЕМС работает на уровне планеты – у них все стандартизировано. Инженер и в США и в Украине работает по одинаковым образцам. Ничего не нужно придумывать.
Но, не каждый заказчик это просит. Поэтому если вы заказчик вы должны у интегратора просить этот пакет документов. Не справочную инфу с сайта, а описания технологии изготовления и обслуживания этого изделия. Если вы работаете в интеграторе – все есть, только нужно спросить.
Для пуско-наладчиков, тех, кто по документации изготавливает изделие – есть свои курсы обучения, мы на одном из них находимся. Это обычно инженеры из партнеров и из самого ЕМС.
Для кастомеров, тех, кто после сдачи с этим работает и обслуживает, есть свои курсы – для админов, наш курс также можно назвать для админов.
Все это расписано на портале обучения ЕМС. Даже если вы кастомер, вам доступно там много чего. Лично я могу поделится примерами конструкторской документации, потому что с чистого листа их написать сложно. Поэтому приходится поддерживать инженерную интеллигенцию, потому что хозяева не любят за это платить деньги, но это нужно, потому что это отдельный вид деятельности.
Либо ты сидишь в интеграторе и потоково создаешь эти комплекты документов, или ты находишься в крупном заказчики и для тебя это как первый раз. Даже если ты выступаешь в роли представителя заказчика и контролируешь действия подрядчика, нужно понимать, что от него нужно требовать. Поэтому лучше знать что делать.
По всем этапам жизненного цикла автоматизированной системы в части ее системы защиты – у ЕМС есть программа обучения и сертификации по всем их продуктам. Будете ли вы другие курсы рассматривать – это уже нужно смотреть.
Администрирование ЕМС Data Domain: введение в курс
Вводные у нас относились к основам систем системного копирования и архивирования. Мы, фактически быстро пробежали содержание университетского курса, или обучающего 5дневного курса по архитектуре этих систем. Заодно посмотрели дедупликацию. Строго позиционировали Data Domain в номенклатуре продукции ЕМС. Сделали выводы – чего от него ожидать и чего от него ожидать не стоит – что самое важное.
Из названия нашего курса очевидно, о чем мы будем говорить. Если посмотрите на нашу модель жизненного цикла, то речь идет о поддержке, обслуживании, уже, фактически готового черного ящика. Который кто-то: спроектировал, как он будет встраиваться в существующую либо новую среду, расписал комплект конструкторско-эксплуатационной документации. Кто-то по этому комплекту осуществил сборку, монтаж, пуско-наладку этого изделия, хотя бы в общей части и дальше это было передано персоналу заказчика вместе с документацией. Заказчик осуществляет администрирование, в малой, узкой степени, в каком-то коридоре он осуществляет донастройку. Но основная задача этого персонала – мониторинг. Мы сверяем текущее состояние этого ящика, с эталонным, которое было зафиксировано на этапе сдачи в эксплуатацию.
Траблшутинг
Если текущее состояние не соответствует эталонному – выявляем причину, устраняем неисправность. И далее все это идет по циклу. Заново дорабатываем ТЗ — версия 2.0. Потому что-то поменялось, риски поменялись, жизнь поменялась. И по такому циклу и развивается система защиты. Нормальная, зрелая компания этот цикл проходит уже 5й или 7й раз, не делая все с нуля, а развиваясь. Это актуально для любых других изделий.
Наш курс – определенный проект, есть начало, есть результат. И поэтому мне нужно определить границы этого проекта: о чем мы будем говорить, о чем не будем говорить. О проектировании мы говорить не будем, так как про это есть другие курсы. О пуске-наладке мы будем говорить лишь в части, касающейся кастомера. Есть отдельные курсы для инженеров ЕМС и партнеров-интеграторов, где расписано: как собрать вот этот Data Domain, вмонтировать с комплектом полок в стойку, как отмаркировать, подключить все эти соединения, как создавать рейд-массивы, как залить образ ОС, как осуществлять инженерное техобслуживание, которое не бесплатно.
Мы, как кастомеры, говорим, что нам кто-то собрал, назначил IP для управляющего интерфейса, кто-то поставил пароль встроенной учетки админа и передал нам эти атрибуты доступа. И мы в рамках имеющейся документации что-то там допишем. У нас акцент на администрирование, в какой-то части на настройку.
О чем курс – понятно. Целевая аудитория – я уже озвучил, тоже понятно: и кастомеры, и партнеры, и ребята из ЕМС. Все сюда ходят, потому что нужно всем под единые стандарты образования подходить. Входные требования – я тоже уже озвучил: это университетский курс, он есть, где его найти и что с ним делать вы уже представляете.
Раз этот курс – проект, то помним, что по результатам этого маленького проекта, у вас должно быть какое-то понимание, теоретические знания, практические, совершенно конкретные, навыки, связанные с этим изделием. Это значит, что должно быть исчерпывающее понимание про дедупликацию: какая она бывает, и как она конкретно реализована в конкретном изделии. Какой комплекс запатентованных технологий есть, не обязательно имеющий отношение к дедупликации, реализованной в Data Domain, он стоит своих денег, чтобы вы видел, что это за патенты.
Как мониторить этот черный ящик, как им управлять, через какие административные интефейсы к нему можно подключится и можно начать с ним что-то делать. Здесь и командная строка и GUI. Как разграничить доступ к этому изделию. Data Domain – это многопользовательский эплайнс, там много людей должны иметь доступ к нему. Соответственно нужно разграничивать этот доступ и контролировать, нельзя допустить чтобы кто-то что-то испортил – это дорогое оборудование.
Как выполнить initial setup – это когда есть готовый черный ящик, который вы конфигурируете под свою структуру. Опираясь на конструкторскую документацию, которую кто-то для вас разработал. Пример такой документации у вас в виде учебного пособия для выполнения лаб. Тот формат что у вас для примера – он идеален для такой документации. Если вы хотите для своих пуско-наладчиков такие документы разрабатывать – делайте ее в таком виде, хороший пример у вас есть.
Identify and configure Data Domain data paths – через какие интерфейсы физические, логические, Data Domain может принимать потоки резервных архивных копий – их очень много. Давайте их все перечислим, и для каждого их них напишем процедуру настройки, проведем испытания на стенде, чтобы это описание соответствовало действительности, чтобы было какое-то доказательство. У нас для этого есть стенд.
Configure and manage Data Domain network interfaces – настроим сетевую подсистему Data Domain. У самой простой модели избыточное количество встроенных в материнскую плату сетевых интерфейсов. Это хорошо, потому что можно обеспечить как минимум – отказоустойчивость, интерфейсы ломаются, провода обрываются, а оно работает. А как максимум – агрегировать ее пропускную способность, суммировать интерфейсы для достижения каких-то результатов.
Одно дело — инициализировать Data Domain, другое дело начать бросать на него какие-то данные через разные интерфейсы. Будем следовать простой логике: от простого к сложному, от общего к частному. Вначале мы будем трогать простые интерфейсы, которые легко настраиваются и не требуют отдельных лицензий. А дальше все это будет ротивно усложнять. Например, возьмем и внутреннюю файловую систему Data Domain и начнем структурировать. Из какого-то большого куска данных сделаем структурированную систему, чтобы ей было удобно управлять.
Вспомним, что Data Domain в общем случае – катастрофоустойчивое изделие. Когда писали ТЗ его разработчикам, то дали задание чтобы Data Domain мог пережить полное уничтожение. Это что значит? — вовремя сбросить реплику критичных резервных копий данных на другой Data Domain. Правда это вещь лицензируемая.
Вопросы непрерывности обеспечения бизнеса – очень актуальны, особенно после 9/11. И люди задумались: а что будет если у меня будет пожар или еще что?
Помните показатель RTO – чтобы не случилось потеряется ровно столько – не больше, и чтобы ни случилось все вернуть обратно можно за столько-то времени.
Тут был вопрос о что, одна из причин использовать дисковое хранилище для резервных копий – это улучшение показателя RTO, время восстановления. Например, мы делали все бэкапы на ленточные библиотеки, теперь требования к безопасности поменялись, теперь данные нужно восстанавливать еще быстрее, библиотеки не работают, что делать? Давайте подменим библиотеку Data Domain, который будет на фронэнде выглядеть как библиотека, но с более лучшим показателем RTO. Как сделать из одного или двух Data Domainов сделать одно или несколько виртуальных роботизированных ленточных библиотек? Как их презентовать существующим средствам резервного копирования, чтобы они минимально напрягались?
Самое важно здесь понять: как нужно донастроить средства резервного копирования, чтобы они правильно на такую виртуальную ленточную библиотеку что-то писали. Потому что писать по старинке, как они привыкли, физически, тут уже не стоит, в связи с той самой дедупликацией.
Если вы не привязаны к библиотекам, если у вас нет задачи подменить физическую библиотеку виртуальной то покупайте Data Domain с лицензируемой функцией DDboost. Так как это для Data Domain родной интерфейс, который раскрывает все его возможности. Это самый лучший вариант использования Data Domain. Это значит, что средства резервного копирования знает что такое DDboost, в худшем случае, в лучшем случае это знают боевые бизнес-приложения, которые бекапятся, это круче всего.
По-моему, самая продаваемая конфигурация: это Networker с Data Domain через DDboost, они смотрятся очень органично. Но мы понимаем, что DDboost – открытый интерфейс. ЕМС говорит: пусть у вас будет ваше средство резервного копирования, но пускай они знают, что такое DDboost, и для хранения резервных архивных копий используют наш оптимизированный интерфейс. Как его настроить – посмотрим.
В нашем курсе будет лаба как по дружбе Data Domain с Networker через DDboost, так и лаба по дружбе Симантековского нетбекапа через DDboost с Data Domainом. Чтобы продемонстрировать эту гибкость Data Domain.
Будет затравка по проектированию систем резервного копирования для архитекторов, о которых мы говорили. Какие-то элементы методики подбора подходящей модели Data Domain под требования конкретного заказчика, их модельный ряд большой. Мы поймем, что работа в этом даже присейла – не простая.
Кому будет интересно дальше углубится в вопросы проектирования – знаете у кого спрашивать.
Вот наши модули. От простого к сложному, от общего к частному. У нас 10 модулей, но еще сделаем 11й опциональный модуль. Начнем со знакомства, основ администрирования, настройки сетевой подсистемы. Продолжим простыми, не требующими лицензий интерфейсами – CIFS, NFS, которым можно гонять трафик резервного копирования и архивирования. А дальше будем все это ротивно усложнять. Двигаясь к VTL и DDboost и к таким вещем защиты, которые есть в Data Domain, с помощью которых можно обеспечить приемлемый уровень информационной безопасности. В соответствии с требованиями законов и регуляторов.
Чтобы определить границы нашего курса, еще раз скажем о том, что – это программно-аппаратный комплекс. Есть аппаратная часть, есть программная. У аппаратной части есть своя система идентификации – трёхзначные модели, например, 160 – это постарее, 4значные – поновее. А программная часть определяется версией ОС – DD OS, текущая версия DD OS, которую можно скачать с сайта – 5.5, а наш курс пока еще рассчитан на 5.4. Так вот 11й модуль из 10 будет о значимых изменениях в 5.5. У каждой аппаратной части оборудования, есть свой предел обновления программной части.
В рамках этой части, пока все.
Видеозапись
Курсы ЕМС в УЦ МУК
6-9 июля в УЦ МУК будет курс по Data Domain System Administration, который будет вести этот инструктор — записаться на курс
А также:
15-17 июля — VNX Block Storage Management
21-25 июля — EMC NetWorker Microsoft Applications Implementation and Management
Дистрибуция решений ЕМС в Украине, Таджикистане, Беларуси, Молдове, странах СНГ.
ximik13
Все бы ничего, но обороты речи во многих местах статьи просто удручают. («сасовские винчи», «простецкий командный интерпретатор», "«ужирать» в час десятки терабайт", "«адские» терабайты" и т.д.) Я не говорю уже про написание на русском англоязычных названий с использованием достаточно «странной» транскрипции (не проще было написать на английском их?). Я понимаю, когда просторечные обороты используются при живой презентации для усиления эффекта для целевой аудитории, которая в курсе профессиональной терминологии и лексики. Или в крайнем случае может переспросить спикера сразу же после произнесенной фразы. Но для технической статьи на достаточно уважаемом портале все это выглядит мягко говоря «некрасиво». Впечатление что на лекции сидела стенографистка и записывала прямую речь лектора, которую потом без редактирования засунули в статью.
Кроме того в статье просто присутствуют технические неточности. Например подскажите мне хоть одну модель DD (старую или новую), где в головном корпусе можно разместить 15 дисков? Всегда в базе идет либо 7, либо 12. А дальше уже полки расширения устаревшие ES20 (12 дисковые) или актуальные ES30 (15-ти дисковые). Про NVRAM тоже не все верно. Например у младшего DD2200 нет отдельной карты NVRAM и схема организована как на массивах VNX. Вместо NVRAM выделяется часть оперативной памяти контроллера под кэширование. Защищается по питанию батарейкой (BBU). В случае отключения питания содержимое ОЗУ сбрасывается (за счет работы от BBU) на системные на диски в резервную «Vault» область.
Честно терпел и читал до середины статьи, потом терпение закончилось. Не могу в таком стиле дальше читать, уж извините :).
Muk Автор
В подводке есть упоминание о том, что этот текст — на основе стенограммы, и, поэтому, читатели понимают, что гладкости стиля здесь не будет. И да, просторечные обороты оставлены для живости текста. Насчет английских, и любых иностранных, названий — есть правила русского языка, поэтому вначале употреблено название на английском, а дальше это название на русском пишется так, как оно слышыться. Обычно, мы редактируем речь докладчика где-то на 10-20% процентов, до такой степени, чтобы было понятно о чем он говорит, но не переделываем устный текст полностью, чтобы не терялся авторский элемент. Чтобы убедится, что это не просто стенограмма достаточно послушать запись.
Не могу в таком стиле дальше читать, уж извините :)
Мы не спорим о стилях, мы выдаем ценную (мы уверенны) техническую информацию.
Технические неточности будут исправлены.