
Введение
В последние годы инструментарий современного интернет-маркетолога расширяется все более и более быстрыми темпами. Сегодня помимо поисковой оптимизации () и контекстной рекламы Яндекс Директ и в практический обиход вошли каналы, социальные сети, , ремаркетинг/ретаргетинг и т. д. Поэтому перед маркетологом встает задача выбора тех рекламных каналов, которые будут наиболее эффективны для конкретного проекта. Calltouch решил поговорить о том, что помимо сложности выбора оптимальных рекламных каналов, достаточно сложным становится вопрос комплексной оценки эффективности того или иного канала для последующего распределения рекламного бюджета между ними. Колонка старшего менеджера по продукту Calltouch Федора Иванова mthmtcn.
По оценке Calltouch cложность эта связана в первую очередь с тем, что пользователь со своей стороны обладает по сути тем же самым инструментарием, что и маркетолог: он может прийти на сайт как по прямой ссылке, так и по переходу из соцсетей, из рекламной выдачи Яндекса и. т. д. Более того, прежде чем совершить на сайте целевое действие (конверсию) пользователь может неоднократно посещать сайт из разных «точек входа»: первый раз он перешел на сайт, кликнув по рекламному объявлению (), которое Яндекс выдал по его поисковому запросу, второе посещение было по прямому переходу (), ну а третье (приведшее к конверсии — ) было из социальной сети () в этом случае мы наблюдаем цепочку (многоканальную последовательность):
Таким образом, при оценке эффективности рекламных каналов маркетологу прежде всего необходимо ответить на вопрос: как оценить вклад того или иного источника на формирование конверсии на сайте? По-другому этот вопрос можно сформировать так: что случится с конверсией на сайте, если исключить тот или иной маркетинговый канал? Для ответа на данный вопрос существует ряд методологий, которые называются моделями атрибуции. Рассмотрим эти модели более подробно.
Модели атрибуции
Модель атрибуции – это способ распределения «веса» конверсии между каналами. В зависимости от выбора модели атрибуции будет рассчитан вес канала (источника), который условно можно считать тем вкладом, который данный источник внес в формирование конверсии. С данными моделями сталкивался практически каждый пользователь Яндекс Метрики или Google Analytics (раздел «многоканальные последовательности»). В настоящее время выделяют следующие основные модели атрибуции:
- По последнему взаимодействию (последнее непрямое взаимодействие, последний клик в AdWords, последний значимый переход) –
- Первое взаимодействие –
- Линейная модель –
- Временной спад –
- На основе позиции –
Как уже было отмечено, основное отличие моделей атрибуции между собой – это способ расчета веса канала в последовательности. Рассмотрим каждую модель более подробно. Для наглядности предположим, что мы имеем следующую многоканальную последовательность:
Last Click Model
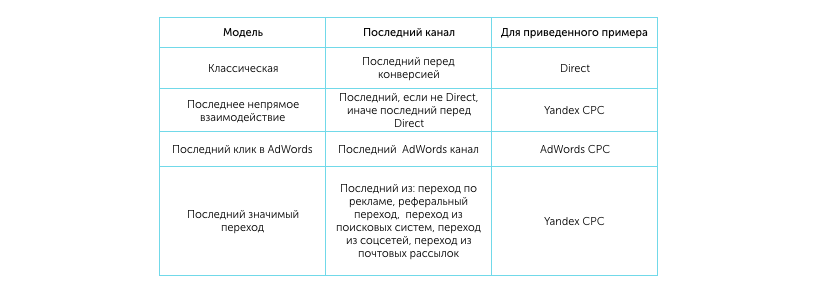
Данная модель ввиду своей простоты и интуитивной «корректности» получила наибольшее распространение на практике. В самом общем случае в рамках модели все веса конверсии отдаются последнему каналу в многоканальной последовательности, который предшествовал факту наступления целевого действия. В нашем случае классическая модель даст вес каналу и всем остальным каналам.
На практике встречаются различные разновидности модели, все они отличаются друг от друга тем, как выбирают «последний» канал. Приведем таблицу, которая демонстрирует метод выбора канала в зависимости от разновидности модели:
First Click Model
В данной модели вес отдается первому источнику в последовательности и всем остальным. В нашем случае максимальный вес получит источник Если модель “максимизирует” вес последнего канала, который «побуждает к действию», то модель отдает предпочтение каналу, который начинает цепочку, т. е. «пробуждает интерес» пользователя к сайту. Данная модель также используется на практике, хотя и значительно реже, чем
Linear Model
Линейную модель (), а также ее обобщения и улучшения (модель временного спада и на основе позиции) объединяет прежде всего то, что в ее рамках все каналы получают свой ненулевой вес. Различие между моделями заключается только в способе распределения веса между всеми каналами. В случае все каналы получают одинаковый вес (то есть их вклады в формирование конверсии) считаются равнозначными. В нашем случае каналы будут иметь вес %.
Time Decay
Модель атрибуции () базируется на предположении, что вклад канала тем больше, чем “ближе” к конверсии он находится, таким образом, вес канала является монотонно возрастающей функцией от его позиции в цепочке. По ссылке можно ознакомиться с формулой расчета веса канала.
Position Type Model
Модель атрибуции является комбинацией из трех моделей: и В ее рамках по максимальную долю (как правило по ) получают первое и последнее взаимодействия в цепочке, а остальные (как правило ) равномерно (как в линейной модели) распределяются между промежуточными каналами. В нашем примере каналы и получат по веса, а по
Как выбрать модель атрибуции?
Выбор модели атрибуции – важнейший этап в оценке эффективности рекламы. В зависимости от модели аналитик может получать абсолютно противоположные выводы о рентабельности того или иного канала. Особенно явно это наблюдается в тематиках, где процесс принятия решения занимает достаточно много времени (например, в сфере недвижимости или в автомобильной тематике). Возникает естественный вопрос: какую модель атрибуции следует принимать за эталон? К сожалению, однозначного ответа на этот вопрос не существует. Только глубокий анализ поведения пользователей на сайте (пользовательских сессий) позволит принять взвешенное решение о выборе той или иной методике привязки конверсий к источнику трафика.
Как правило выбор останавливается на модели однако на практике мы сталкивались с ситуациями, когда замена на c последующим распределением средств между каналами позволяла существенно увеличить эффективность маркетинговых мероприятий.
Отдельно стоит отметить, что модель атрибуции является важнейшим фактором, который стоит учитывать при оптимизации контекстной рекламы. Выбор модели напрямую влияет на статистику, которая используется для расчета ставок. Если же считать, что каждая ключевая фраза – это отдельный рекламный канал, то можно существенно обогатить статистику, которая поступает на вход оптимизатора, кроме того, анализ последовательных переходов пользователя между ключевыми словами позволит увеличить эффективность оптимизации. Обсуждению этой темы будет посвящена отдельная глава данной работы.
Прежде чем перейти к описанию подхода, используемого нами для анализа многоканальных последовательностей, приведем «шуточный» пример, который с одной стороны покажет ограниченность классических моделей атрибуции, а с другой стороны позволит сформировать те основные вопросы, на которые следует найти ответ.
Допустим, целью является C=«увезти девушку к себе домой, чтобы посмотреть кино» .
Предположим, что мы имеем следующую цепочку действий (по сути каналов), которые привели к желаемой цели:
Познакомиться с девушкой > Пригласить в кино > Подарить цветы > Гулять вместе в парке > Проводить до дома > Пригласить на свидание в ресторан > Подарить цветы > Угостить ужином > Угостить коктейлем > Угостить еще одним коктейлем >… и еще одним > рассказать анекдот > C
Если мы имеем дело с моделью то считаем, что для достижения поставленной цели нам в принципе было достаточно обойтись анекдотом. Если считать в рамках модели то успех гарантирован, как только мы познакомились (что более похоже на правду в сравнении с тем же анекдотом). Модель предполагает, что все действия внесли равный вклад. Модель постулирует, что наибольший вклад имеют факт знакомства и анекдот (причем в равных долях), а влияние остальных факторов незначительно. Наконец, считает, что каждое наше следующее действие «подогревало» интерес девушки, тем самым увеличивая вероятность достижения конечной цели, но все же анекдот был решающим фактором.
Как мы видим, ни одна из классических моделей не может адекватно описать рассмотренную выше ситуацию и тем более не позволит правильно ответить на вопрос, какой же канал (действие) оказалось наиболее важным на самом деле.
Теперь сформулируем основные вопросы, на которые бы хотелось получить ответы от модели атрибуции:
- Достаточно ли просто рассказать анекдот? И если да, то как часто?
- Насколько в принципе типична практика рассказывания анекдотов для достижения цели?
- Что будет если не рассказывать анекдот?
- Можно ли заменить анекдот на какое-либо другое действие? Если да, то на какое следует заменить?
Для правильного ответа на большинство поставленных вопросов нам недостаточно рассмотреть только одну последовательность. Требуется собрать некоторую статистику, которая бы с одной стороны позволяла прогнозировать поведение пользователей, а с другой – позволяла бы оценить вероятность конверсии на сайте для каждой из точек взаимодействия.
Рассматриваемая нами модель изначально разрабатывалась для совокупной оценки многоканальных последовательностей, предполагая, что каналы являются взаимо-зависимыми. Она позволяет ответить на большинство из сформулированных выше вопросов. Кроме того, мы покажем, как описанные нами методы позволят прогнозировать коэффициент конверсии по каждой ключевой фразе, что является необходимым элементом в оптимизации ставок в контекстной рекламе.
Прежде всего опишем тот формат данных, с которым работает наша модель.
Пользовательские сессии
Предположим, что за некоторый анализируемый нами промежуток времени , на сайт было совершено переходов, то есть мы располагаем данными об пользовательских сессиях. Каждая сессия обладает фиксированным набором параметров (атрибутов сессии) . Для нашего анализа нам потребуется, чтобы следующее множество атрибутов входило во множество всех атрибутов сессии:
где:
- – канал, по которому был совершен переход на сайт
- – время начала сессии
- — время окончания сессии
- — адрес страницы, на которую попал пользователь при переходе на сайт
- – уникальный идентификатор пользователя
- – была ли совершена конверсия в результате сессии ( – да, – нет)
Далее для простоты мы будем полагать, что промежуток времени находится внутри анализируемого периода , поэтому мы уберем атрибуты из рассматриваемого множества параметров. Также следует отметить, что параметр требуется только для того, чтобы осуществить переход от уровня каналов до уровня ключевых фраз (при условии наличия разметки в ), что пригодится для оптимизации ставок, но не обязательно для оценки влияния каналов на конверсию. Под каналом мы понимает источник трафика, к которым можно отнести:
- Yandex CPC
- Google CPC
- Vkontakte
- Direct
- Referal
- и т. д.
Для простоты изложения будем кодировать рекламные каналы следующим образом: , считая, что их количество ограничено величиной .
Теперь предположим, что сессий были инициированы пользователями. При помощи уникального идентификатора пользователя можно разбить множество на непересекающихся подмножеств:
где множество сессий (отсортированных по возрастанию даты окончания) с одинаковым , т. е. множество упорядоченных в хронологическом порядке сессий, инициированных одним и тем же пользователем. Учитывая наше предположение о том, что , то на основании данных в мы можем сопоставить с каждым пользователем следующую цепочку каналов:
где — количество элементов (по сути количество переходов пользователя на сайт) во множестве . Представленная выше цепочка переходов представляет из себя последовательность источников трафика, которые использовал пользователь в процессе взаимодействия с сайтом.
Введем два дополнительных «псевдоканала» и по правилу:
- Если во время сессии пользователя с источником произошла конверсия, то после добавим , получив
- Если в результате последней текущей сессии с источником конверсии не произошло, то после добавим , получив
Кроме того, дополнительно обратим внимание на ситуацию, когда мы имеем дело с цепочками вида:
Последовательности с такой структурой не могут возникнуть согласно сформулированным выше правилам, но тем не менее могут иметь место в ряде случаев, например в звонящих тематиках, когда помимо указанных выше параметров сессии мы имеем уникальную связку:
В этом случае первый звонок в указанной выше цепочки будет уникальным звонком, а все последующие – повторными звонками абонента с заданным . Такие цепочки будут учитываться в нашей модели в том случае, если помимо информации о переходах на сайт, ведется «журнал» взаимодействий пользователя с сайтом в том числе в офлайн режиме (например, журнал звонков).
Отметим ключевую особенность рассмотренной выше методики формирования цепочек взаимодействия пользователя с сайтом. Она заключается в том, что любая цепочка взаимодействия (многоканальная последовательность) всегда оканчивается одним из двух «событий»: или . При этом событие может встретиться только в конце последовательности, в то время как может появиться на произвольном месте.
Приведем типичные примеры последовательностей, сформированных по описанным правилам. Для простоты ограничимся 3 различными каналами , к которым добавим и
Cледующий шаг, необходимый для построения мультиканальной модели атрибуции заключается в том, чтобы преобразовать последовательности таким образом, чтобы событие , как и , могло встречаться только строго в конце последовательности (такие последовательности будем называть элементарными). Для этого будем «расщеплять» исходные цепочки так, чтобы в их конце всегда стояли или .
Продемонстрируем эту методику на примере типичных последовательностей:
- цепочки 1-4 уже приведены к «элементарному» виду
- цепочку 5 «расщепим» на: и
- цепочку 6 «расщепим» на: и
- цепочку 7 «расщепим» на: и
- цепочку 8 «расщепим» на: , и
В результате расщепления все цепочки стали «элементарными», и теперь мы можем приступить к описанию модели. Однако прежде чем перейти к этому шагу, мы уже на данном этапе можем ответить на вопрос: как оценить влияние канала на конверсию на сайте.
Расчет влияния каналов на конверсию
Рассмотрим множество из последовательностей (будем считать, что все они уже являются элементарными, то есть оканчиваются на или . Предположим, что из последовательностей оканчиваются на и — на . Обозначим влияние канала на конверсию на сайте за промежуток времени через , а элементарную цепочку через . Величину влияния канала на конверсию будем считать как количество «недополученных» конверсий в случае удаления канала из всех конверсионных цепочек, где он присутствует, отнесенное к общему количеству конверсий :
Очевидно, что для любого величина удовлетворяет следующему неравенству:причем тогда и только тогда, когда канал не входит ни в одну «конверсионную» последовательность, и в том и только том случае, если удаление приведет к потере всех конверсий на сайте. Таким образом, легко оценить новое число конверсий, которое получится после удаления канала :
Рассчитаем влияния каналов , , для нашего примера. Всего мы наблюдаем конверсий (конверсионных цепочек) из элементарных цепочек . Канал участвует во всех конверсионных цепочках, а значит его влияние на конверсию равно : . Далее, канал присутствует в конверсионных цепочках, а значит Наконец, входит в состав одной конверсионной цепочки, тогда
Легко заменить, что сумма влияний каналов не равна единице. Для удобства можно ввести нормировку и считать нормализованное влияние каналов на конверсию:
В этом случае, очевидно
Формула для расчета влияния канала на конверсию может быть легко модифицирована на случай, когда требуется оценить влияние одного канала на другой. В частности, если стоит задача выяснить, как влияет канал на , то можно воспользоваться следующим рассуждением: сессия пользователя, инициированная каналом приводит к сессии с каналом столько раз, сколько существует цепочек , таких что в них предшествует . Тогда если обозначить через величину такого влияния, то:
В общем случае функция не является симметричной: Последовательности , такие что в них одновременно предшествует и предшествует (т. е. образуются циклы) также можно учитывать в знаменателе формулы. Введенная ранее нормировка естественным образом обобщается и на только что описанный более общий случай:
Оценка изменения базовых метрик при отключении канала
Ответив на вопрос, как изменится количество конверсий при удалении из всех цепочек того или иного канала возникает вполне естественный вопрос о том, как изменится значение таких базовых метрик, используемых при анализе эффективности рекламы, как:
- расход
- стоимость конверсии (CPA)
Ответить на данные вопросы, не привлекая дополнительные допущения, достаточно сложно. Наша базовая аксиома состоит в том, что при удалении канала из некоторой цепочки , данная цепочка прерывается. Более точно формулировка выглядит так: если цепочка до удаления канала имела вид:
то после удаления канала цепочка будет модифицирована в:
Данное допущение означает, что если убрать канал, который был использован пользователем для взаимодействия с сайтом, то дальнейшего взаимодействия пользователя с данным сайтом не будет.
Для оценки базовых метрик нам также необходимо добавить в параметры сессий пользователей такой показатель как «стоимость перехода». Eго можно интерпретировать как стоимость, которую платит рекламодатель, за клик пользователя по данному каналу, если канал бесплатен (как например прямой переход), то будем считать, что стоимость перехода равна Если возможно установить только общую стоимость затрат на канал (как например для ), то будем полагать, что стоимость перехода в конкретной сессии равна отношению общих затрат на канал к количеству использований этого канала по всем сессиям. Будем обозначать стоимость перехода для канала в цепочке через . Таким образом, мы можем оценить стоимость одной цепочки следующим образом:
При этом общие расходы на канал равны:
Oбщие расходы на привлечение пользователей на сайт при использовании каналов равны:
Двойственность формулы объясняется разными способами вычисления общих расходов: в первом случае мы суммируем расходы на каждую из цепочек по всем цепочкам, а во втором – суммируем расходы на канал по всем каналам.
Для оценки новых расходов после удаления из всех цепочек канала кажется наиболее очевидным воспользоваться формулой: где — новый расход после удаления канала , а — прежний расход. Однако, такая простая логика не приводит к правильной оценке расходов по той причине, что в тех цепочках , где встречается , перед ним могли быть задействованы другие, не удаленные каналы. Таким образом, для более точной оценки, нам необходимо учитывать стоимость «усеченных» цепочек. Поэтому:
Очевидно, что
а значит
Последнее неравенство означает, что удаление любого канала как правило приводит к появлению новых цепочек с определенной стоимостью, которые заведомо не принесут конверсий. Таким образом, мы можем оценить потери от удаления канала (стоимость всех «усеченных» цепочек), а также экономию как стоимость всех «неосущественных» переходов, которые имели бы место в случае сохранения канала в цепочках:
Теперь, после того, как мы научились оценивать изменение расходов после удаления канала , мы можем оценить новую стоимость конверсии, которая бы имела место в случае отсутствия канала:
Если положить, что до удаления канала мы имели прежнюю стоимость конверсии: и целью удаления канала стоит снижение стоимости конверсии, то решающее правило может быть следующим:
То есть если удаление канала приводит к снижению стоимости конверсии (при разумном снижении их количества), то его можно исключить из цепочек и перестать тратить на него бюджет.
Кроме того, можно оценить стоимость «недополученных конверсий» при удалении канала: поэтому вместо правила можно воспользоваться другим: если выполняется соотношение то удаление канала приведет к снижению общей стоимости конверсии на сайте.
Теперь приступим к описанию основной модели, требуемой для расчета вероятности конверсии канала.
Описание модели
Прежде чем мы приступим к описанию многоканальной модели атрибуции, нам бы хотелось сослаться на замечательные статьи Сергея Брыля, и вторую статью, в которых автор использовал красоту и функциональность марковских цепей для описания многоканальной атрибуции. В рамках данной статьи мы более подробно описали основные моменты, связанные с расчетом вероятности конверсии в рамках марковских процессов, а также предложили эффективный метод вычисления вероятности конверсии – на основании стохастических матриц.
Мы предложим две альтернативных интерпретации многоканальной модели атрибуции: графовую и матричную. Первая позволит наглядно описать модель, в то время как вторая позволяет эффективно вычислять требуемые характеристики. Мы покажем, что оба описания на самом деле представляют один и тот же случайный процесс, который называется марковским, а соответствующая процессу модель – марковской цепью.
Графовая модель
Граф — абстрактный математический объект, представляющий собой множество вершин графа и набор рёбер, то есть соединений между парами вершин. Например, за множество вершин можно взять множество аэропортов, обслуживаемых некоторой авиакомпанией, а за множество рёбер взять регулярные рейсы этой авиакомпании между городами.
Граф называется ориентированным, если каждое из его ребер имеет направление, т. е. по сути представляет из себя вектор: для ребра точно указано, из какой вершины оно исходит, и в какой заканчивается.
Граф называется взвешенным, если каждому его ребру приписано некоторое числовое значение, называемое весом. Типичным примером взвешенного ориентированного графа является сеть автомобильных дорог между городами (вершинами графа), где под весом ребра (дороги) мы понимаем ее протяженность.
Для того, чтобы представить множество цепочек в виде графа, нам необходимо зафиксировать два множества: множество вершин и множество связей между ними. В роли вершин будут выступать маркетинговые каналы а так же два дополнительных события:
В качестве будем выбирать пары соединенных между собой элементов из . Для рассмотренных выше элементарных цепочек имеем:
Ввиду того, что во множестве могут встречаться совпадающие элементы, полученный граф может иметь кратные (дублированные) ребра.

Как видно, даже для небольшого числа сессий такое графическое представление является достаточно громоздким, что затрудняет анализ. Некоторого упрощения можно добиться, если заменить дублированные ребра одним ребром, взяв за вес количество дублей. Тогда исходный граф преобразуется в ориентированный взвешенный граф:
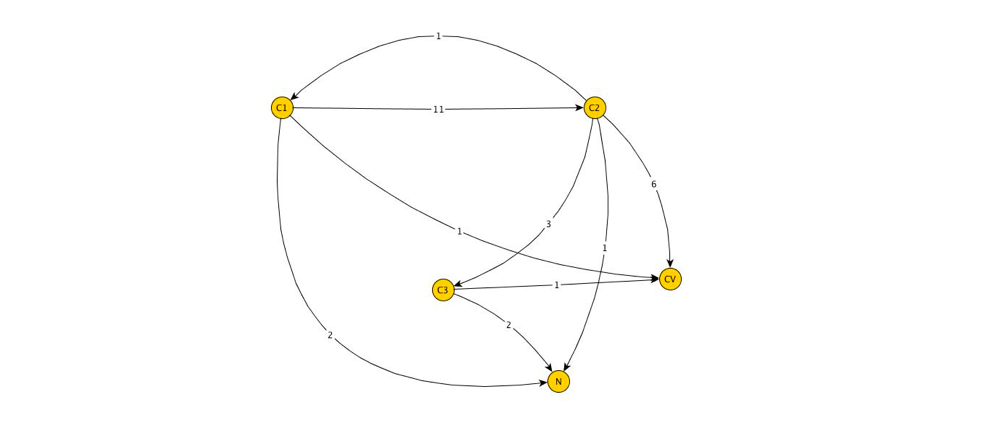
Данный граф уже более пригоден для анализа. Наша следующая цель – это преобразование веса ребра к вероятностной нотации. Заменим вес ребра, соединяющий две вершины, вероятностью перехода из одной вершины в другую.
В частности, рассмотрим вершину . Из нее достижимы следующие вершины графа: . Всего из вершины было зафиксировано переходов, причем из них было в , – в и одно в . Тогда если обозначить – вероятности перейти из в соответственно, то:
Легко заменить, что — это вероятность конверсии источника в классической модели Становится очевидно, что модель не учитывает большой объем статистических данных, которые мы можем собрать, анализируя пользовательские сессии. Если произвести расчеты для всех оставшихся вершин, то наш граф будет преобразован к виду:

На основании данной модели можно рассчитать полную вероятность конверсии для определенного канала. Для расчета используется следующая рекурсивная формула:
Смысл этой формулы в том, что для того, чтобы рассчитать полную вероятность конверсии некоторой вершины, требуется выбрать все вершины, достижимые из данной, затем рассчитать вероятности перехода в эти вершины из исходной, а затем для каждой достижимой вершины снова рассчитать полную вероятность конверсии. Данная формула тут же дает полную вероятность конверсии, если граф является однонаправленным, т. е. если есть ребро, соединяющее вершины и , но отсутствует ребро, которое соединяет c . В противном случае указанная выше формула задает систему линейных уравнений, количество неизвестных в которой равно количеству «возвратных» ребер в графе.
Например, рассчитаем полную вероятность конверсии для источника .
Так как связан с , но вероятность перейти из в равна нулю, а вероятность перейти из в равна 1, то:
В свою очередь из можно вернуться в или же перейти в , а значит:
тогда
Для удобства обозначим , тогда получим следующее линейное уравнение:
Теперь рассчитаем . Из источника можно перейти только в или . Тогда
Окончательно имеем следующее уравнение:
Откуда
.
Основным достоинством указанной выше модели является ее наглядность, в то время к очевидным недостаткам (что видно даже на простом примере) следует отнести высокую вычислительную сложность для случая большого числа источников трафика. Более того, если в качестве источников использовать различные ключевые слова, то объем вычислений увеличивается на порядки, что сделает все последующие расчеты нереализуемыми. Помимо этого, если допустить возможность переходов в графе вида: (то есть разрешить петли), то система уравнений становится нелинейной, что заметно усложняет нахождение требуемых вероятностей. В следующем разделе мы перейдем к рассмотрению матричной модели и покажем эффективные методы вычисления формул полной вероятности.
Матричная модель
В предыдущей главе мы рассмотрели графовую модель мультиканальной атрибуции. Для того, чтобы преобразовать ее к более удобному для вычислений виду, вновь рассмотрим набор из каналов и двух дополнительных «псевдоканалов» , . Напомню, что в графовой модели они играли роль вершин.
По наблюдаемым последовательностям, составленным для каждого из пользователей, мы можем без труда рассчитать вероятности перехода (иначе говоря, условные вероятности) . Как уже было отмечено ранее, будем считать, что и . Тогда можно составить квадратную матрицу размера , элементами которой будут условные вероятности
и :
В частности, для рассматриваемого выше примера мы получим:
Легко заметить, что для любой строки матрицы справедливо:
Матрица, для которой выполнено данное условие, называется стохастической. Известно, что произвольная стохастическая матрица определяет некоторый случайный процесс, называемый марковским. Дадим такому процессу более формальное (хотя и не строгое с математической точки зрения) определение.
Марковским процессом называется такой случайный процесс с некоторым числом состояний, что вероятность перехода в следующее состояние зависит только от того текущего состояния, в котором находится система.
Таким образом, рассматриваемый нами процесс переходов между различными маркетинговыми каналами можно считать марковским процессом, определяемым матрицей переходных вероятностей . Определенная таким образом модель позволяет ответить на ряд важных вопросов, в частности:
- Какова вероятность перейти из состояния в состояние за шагов?
- Как будет выглядеть распределение вероятности нахождения в каждом из каналов через шагов?
В нашей прикладной задаче оценки вероятности конверсии каждого из каналов, нам требуется ответить на частный случай первого вопроса:
Какова полная вероятность перейти из состояния (канала) в ?
Марковская теория случайных процессов позволяет дать очень простой ответ на этот вопрос (в случае, если из состояний и невозможны переходы ни в какие другие состояния): для расчета данной вероятности необходимо возвести матрицу в бесконечную степень и взять значение, стоящее на позиции :
Можно строго доказать, что для случая, когда из состояний и невозможны переходы ни в какое другое состояние, этот предел существует. Конечно, на практике мы не можем оперировать с «бесконечной» степенью матрицы. Однако вместо «бесконечности» как правило достаточно взять достаточно большую степень двойки. Удобство возведения матрицы в степень заключается в том, что требуется произвести ровно умножений матрицы на себя.
В самом деле, пусть, например, . Тогда для вычисления достаточно вычислить:
Покажем на нашем примере скорость «сходимости» предела к нужной нам вероятности:
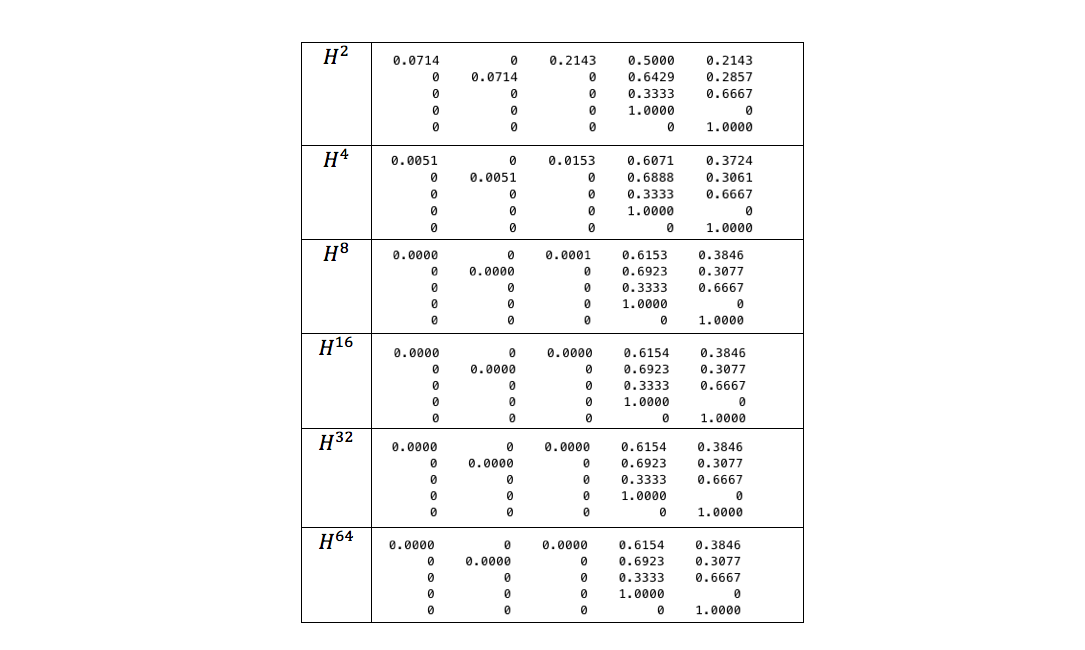
Как видно из таблицы, уже для рассчитанная вероятность отличается от точного значения, которое мы ранее получили на основе графовой модели, в 4 знаке после запятой. Значения вероятностей, посчитанные для , , и вовсе совпадают. Таким образом, в данном случае достаточно было ограничиться вычислением , что требует всего матричных умножения. Таким образом, скорость сходимости предела к требуемой вероятности достаточно высока, что делает данную модель эффективной в практических приложениях.
От оценки каналов к оптимизации
Построенная аналитическая модель позволяет решить 3 основные задачи:
- Оценить влияние канала на конверсию на сайте
- Оценить взаимное влияние каналов друг на друга
- Оценить вероятность того, что использование канала приведет к конверсии на сайте
При проектировании оптимизатора конверсий, который позволяет управлять ставками в контекстной рекламе на основе их эффективности так, чтобы достигать требуемых (ключевых показателей эффективности), требуется оценивать коэффициент конверсии для каждой ключевой фразы. Как нами отмечалось, выбор той или иной модели атрибуции конверсий напрямую влияет на расчет коэффициента конверсии не только на уровне рекламного канала, но и на уровне ключевой фразы. Традиционно оптимизаторы работают с моделью или ее модификациями. Ранее мы показали ограниченную способность предсказывать коэффициент конверсии (как правило она занижает его, так как учитывает только прямую связь кейворд конверсия, не анализируя промежуточные переходы).
Представленная модель атрибуции конверсий избавлена от этих недостатков, хотя для вычисления вероятностей требует значительно больше вычислительных ресурсов. Гибкость описанного подхода заключается еще и в том, что в качестве «канала» мы можем использовать любой неотъемлемый атрибут сессии.
В частности, рассмотрим параметр , который не использовался нами ранее в расчетах. содержит информацию о той странице на сайте, на которую переходит пользователь в начале сессии. Если на ассоциированном с сайтом рекламном аккаунте все объявления размечены метками, то мы можем значительно углубить нашу аналитику.
метки – это параметры (переменные) содержащие дополнительные данные, которые добавляются к целевой (посадочной) страницы и позволяют передать в системы веб-аналитики дополнительную информацию о характеристиках трафика. Рассмотрим типичный пример метки, например в формате, принятом в компании :
site.ru/?utm_source=YD&utm_medium=cpc&utm_content=kvartiry_ceny&utm_campaign=YD_KVARTIRY_POISK_MSK&calltouch_tm=yd_c:{campaign_id}_gb:{gbid}_ad:{ad_id}_ph:{phrase_id}_st:{source_type}_pt:{position_type}_p:{position}_s:{source}_dt:{device_type}_reg:{region_id}_ret:{retargeting_id}_apt:{addphrasestext}
На основе динамических параметров, которые содержатся в фигурных скобках, мы можем, в частности, отследить «путь» клика на рекламное объявление с точностью до ключевой фразы, которая инициировала показ рекламного объявления, на которое кликнул пользователь. Мы можем выбрать любой «разумный» динамический параметр (или их связку) в качестве канала. В частности, если выбрать в качестве канала параметр , то мы можем отследить цепочки переходов пользователя на сайт по разным ключевым словам. Если повторить все рассуждения для такого типа каналов, то модель позволит рассчитать полную вероятность конверсии для каждой ключевой фразы.
Полученный таким образом массив коэффициентов конверсии можно использовать в качестве входных данных для оптимизатора конверсий.
Заключение
В работе дан обзор используемых в настоящий момент классических моделей атрибуции конверсий. Кроме того описана модель мультиканальной атрибуции, основанная на марковских процессах (цепях), которая позволяет комплексно оценить как вероятность конверсии для каждого рекламного канала, так и рассчитать влияние канала на конверсию на сайте. Продемонстированы подходы, позволяющие адаптировать построенную модель для оптимизации ставок в контекстной рекламе.
Комментарии (4)

PR-GOD
02.12.2017 20:13Очень и очень внушительно. Один вопрос, такие вычисления и анализ следует принимать во внимание даже маркетологам в маленьких компаниях? Или это все больше для громадных компаний?
CalltouchForever Автор
04.12.2017 09:40Доброе утро! Я бы сказал, что их следует принимать во внимание в первую очередь когда на сайт гонится трафик по многим платным рекламным каналам. Я бы не сказал, что все это очень связано с величиной компании. Просто чем больше трафика, тем больше данных для анализа.
limp79
Спасибо за статью и отдельное спасибо за ссылки на analyzecore.com. Первая ссылка ведет на статью про атрибуцию на основе воронки продаж, но, скорее всего, имелась в виду эта analyzecore.com/2016/08/03/attribution-model-r-part-1
И имя автора на русском Сергей Брыль, подкорректируйте, пожалуйста.
CalltouchForever Автор
Спасибо за комментарий! Поправим.