
Недавно мы открыли для внешних пользователей Яндекс.Трекер – нашу систему управления задачами и процессами. В Яндексе его используют не только для создания сервисов, но даже для закупки печенья на кухни.
Как известно, чем меньше компания, тем более простые инструменты она может использовать. Если с утра вы можете поздороваться с каждым сотрудником лично, то вам хватит для работы даже чата в Telegram. Когда появляются отдельные команды, не только поприветствовать каждого лично не получится, но и в статусах задач можно запутаться.

Облако из слов в заголовках тикетов во внутреннем Яндекс.Трекере
На таком этапе важно сохранять прозрачность процессов: все стороны должны иметь возможность в любой момент узнать о ходе работы над задачей или, например, оставить свой комментарий, который не пропадёт в потоке рабочего чата. Для небольших команд трекер – это и вовсе своего рода новостная лента с последними новостями из жизни их компании.
Сегодня мы расскажем читателям Хабрахабра, почему Яндекс решил создать свой трекер, как он устроен внутри, и с какими сложностями нам пришлось столкнуться, открывая его наружу.
В Яндексе сейчас работает больше шести тысяч человек. Несмотря на то, что многие его части устроены как независимые стартапы со своими командами разного размера, необходимость понимать, что происходит у людей на соседнем этаже всегда есть – их работа может пересекаться с вашей, их улучшения могут помочь вам, а какие-то процессы наоборот могут негативно повлиять на ваши. В такой ситуации сложно, например, призывать коллегу из другого рабочего пространства в Slack. Особенно, когда прозрачность задачи важна для множества людей из разных направлений.
В какой-то момент мы начали использовать известную всем Джиру. Это хороший инструмент, функциональность которого в принципе всех устраивала, но его было сложно интегрировать с нашими внутренними сервисами. Кроме того, на масштабе в тысячи человек, которым нужно единое пространство, где каждый сможет сориентироваться без фонарика, Джиры переставало хватать. Случалось и такое, что она ложилась под нагрузкой, даже при том, что работала на наших серверах. Яндекс рос, количество тикетов также увеличивалось, а обновления на новые версии занимали всё больше времени (последний апгрейд занял полгода). Нужно было что-то менять.
В конце 2011 года у нас было несколько вариантов решения проблемы:
- Увеличить производительность старого трекера. Отбросили идею, т.к. переделывать архитектуру чужого продукта самим – плохо. Это значило бы как минимум поставить крест на обновлениях.
- Распилить трекер на несколько независимых копий (инстансов), чтобы снизить нагрузку на каждую. Идея не новая, её используют большие компании в аналогичных случаях. В итоге не работали бы сквозные отчеты, фильтрация, линковка и перенос задач между копиями. Всё это было критично для компании.
- Приобрести другой инструмент. Рассмотрели возможные варианты трекеров. Большинство из них не позволяют легко масштабироваться, то есть стоимость инфраструктурных доработок и последующих изменений под наши нужды получилась бы выше, чем стоимость собственной разработки..
- Написать свой трекер. Рискованный вариант. Дает больше всего свободы и возможностей в случае успеха. В случае неуспеха имеем проблемы с одним из ключевых инструментов разработки и планирования. Как вы уже догадались, мы рискнули и выбрали именно этот вариант. Ожидаемые плюсы перевесили минусы и риски.
Разработка собственного трекера началась в январе 2012 года. Первой свои задачи в новый сервис перевезла сама команда трекера через несколько месяцев после начала работы над проектом. Дальше начался процесс переезда остальных команд. Каждая команда выдвигала свои требования к функциональности, их прорабатывали, трекер обрастал новыми фичами, затем перевозили команду. На полный переезд всех команд и закрытие Джиры понадобилось два года.
Но давайте вернемся немного назад и посмотрим на список требований, который был составлен для нового сервиса:
- Отказоустойчивость. Как вы возможно слышали, в компании регулярно проводятся учения с отключением одного из ДЦ. Сервис должен переживать их незаметно как для пользователя, так и для команды, без необходимости выполнять ручные действия при начале учений.
- Масштабируемость. У задач в трекере нет срока давности. Разработчику или менеджеру может понадобиться как посмотреть на сегодняшнюю задачу, так и на ту, которая была закрыта ещё 7 лет назад. А это значит, что удалять или архивировать старые данные мы не можем.
- Интеграция с внутренними сервисами компании. Тесная провязка с нашими многочисленными сервисами требовалась большинству команд Яндекса: интеграции с сервисами по долгосрочному планированию, системами контроля версий, каталогом сотрудников и т.д.
А ещё в момент сбора требований мы определились с теми технологиями, которые будем использовать для создания трекера:
- Java 8 для бекенда.
- Node.js + BEMHTML + i-bem для фронтенда.
- MongoDB как основное хранилище данных: автоматический failover, неплохая скорость работы и возможность легко включить шардирование, schemaless (удобно для пользовательских полей в задачах).
- Elasticsearch для быстрого поиска и агрегации по произвольному полю. Гибкие возможности настройки анализаторов для саджестов, перколатор и прочие плюшки эластика также сыграли свою роль при выборе.
- ZooKeeper для дискавери бекендов сервиса. Бекенды взаимодействуют между собой для инвалидации кешей, распределения задач, сбора собственных метрик. С помощью ZooKeeper и клиента к нему дискавери можно организовать очень легко.
- Хранилище файлов как сервис, что снимает с нас головную боль репликации и бекапов при хранении пользовательских аттачей.
- Hystrix для общения с внешними сервисами. Чтобы предотвратить каскадные отключения, не нагружать смежные сервисы, если они испытывают проблемы.
- Nginx для терминирования https и rate limits. Как показала практика, терминировать https внутри java – не лучшая идея с точки зрения производительности, поэтому переложили эту задачу на nginx. Рейт лимитер также надежней организовывать на его стороне.
Как и для любых других публичных и внутренних сервисов Яндекса, нам пришлось также задуматься о требованиях к запасу производительности и масштабируемости сервиса. Пример для понимания ситуации. На момент начала проектирования системы у нас было порядка 1 млн задач и 3 тыс. пользователей. На сегодняшний день в сервисе почти 9 млн задач и более 6 тыс. пользователей.
Кстати, несмотря на довольно приличное количество пользователей во внутреннем Трекере, бОльшая часть запросов приходит в трекер, через API от сервисов Яндекса, интегрированных с ним. Именно они и создают основную нагрузку:
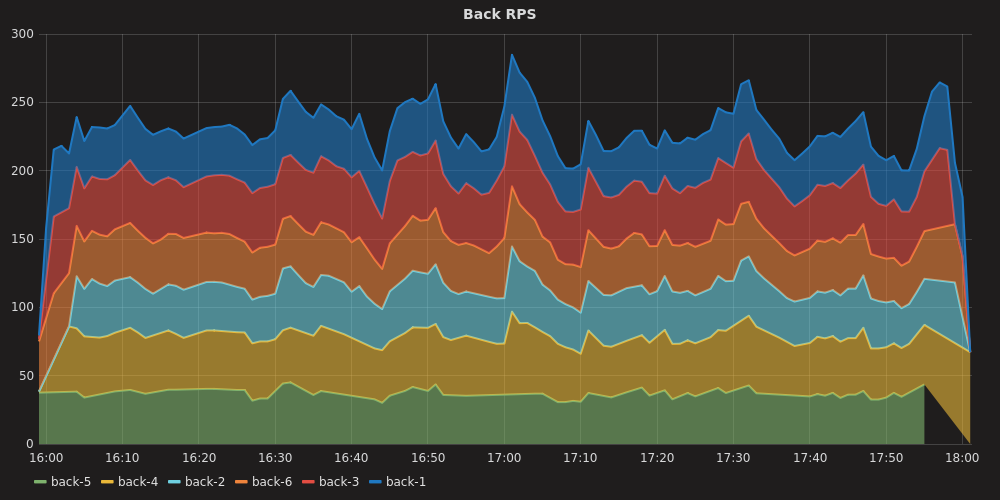
Ниже можно увидеть перцентили ответов в середине рабочего дня:

Мы стараемся регулярно оценивать будущую нагрузку на сервис. Строим прогноз на 1-2 года, затем с помощью Лунапарка проверяем, что сервис ее выдержит:

На этом графике видно, что API поиска задач начинает отдавать заметное число ошибок лишь после 500-600 rps. Это позволило оценить, что с учетом роста нагрузки от внутренних клиентов и роста количества данных мы выдержим нагрузку через 2 года.
Кроме высокой нагрузки с сервисом могут случаться и другие неприятные истории, с которыми надо уметь обращаться так, чтобы пользователи этого не замечали. Перечислим некоторые из них.
Отказ датацентра.
Весьма неприятная ситуация, которая тем не менее регулярно происходит благодаря учениям. Что происходит при этом? Худший случай, это когда мастер монги был в отключенном ДЦ. Но даже в этом случае не требуется вмешательство разработчика или админа благодаря автоматическому failover. В эластике ситуация немного иная: часть данных оказалась в единственном экземпляре т.к. фактор репликации у нас 1. Поэтому он создает новые шарды на уцелевших нодах, чтобы у всех шардов снова была резервная копия. Тем временем балансер над бекендом получает таймаут соединений в тех запросах, которые выполнялись на инстансах в отключенном ДЦ, либо ошибку от работающего бекенда, чей запрос ушел в пропавший ДЦ и не вернулся. В зависимости от обстоятельств, балансер может попытаться повторить запрос или вернуть ошибку пользователю. Но в итоге балансер поймет, что инстансы из отключенного ДЦ ему недоступны и перестанет отправлять туда запросы, проверяя в фоне, не заработал ли все-таки ДЦ и не пора ли возвращать туда нагрузку.
Потеря связности между бекендом и базой/индексом из-за проблем с сетью.
Чуть более простая ситуация на первый взгляд. Так как балансер над бекендом регулярно проверяет его состояние, то ситуация, когда бекенд не может достучаться до базы всплывает весьма быстро. И балансер опять уводит нагрузку с этого бекенда. Есть опасность, что если все бекенды потеряют связь с базой, то их всех же закроют, что в итоге повлияет на 100% запросов.
- Высокая нагрузка запросов в поиск трекера.
Поиск по задачам, их фильтрация, сортировка и агрегация – весьма трудозатратные операции. Поэтому именно эта часть API имеет самые строгие лимиты по нагрузке. Раньше мы находили вручную тех, кто заваливал нас запросами и просили их сбавить нагрузку. Сейчас такое происходит всё чаще, поэтому включение rate limits позволило не замечать излишне активного клиента API.
Яндекс.Трекер – для всех
Нашими сервисом не раз интересовались другие компании – они узнавали о нашем внутреннем инструменте от тех, кто покидал Яндекс, но не мог забыть Трекер. И вот в прошлом году внутри мы решили готовить Трекер к выходу в мир – делать из него продукт для других компаний.
Мы сразу начали прорабатывать архитектуру. Перед нами встала большая задача по масштабированию сервиса до сотен тысяч организаций. До этого сервис годами разрабатывался для одной нашей компании, учитывал только её потребности и нюансы. Стало ясно, что текущая архитектура потребует сильных доработок.
В итоге у нас было два варианта решения.
| Отдельные инстансы под каждую организацию | Инстанс, который сможет принять в себя тысячи организаций |
Плюсы:
Минусы:
|
Плюсы:
Минусы:
|
Очевидно, что стабильность сервиса для внешних пользователей не менее важна, чем для внутренних, поэтому необходимо дублировать базы, поиск, бэкенд и фронтенд в нескольких датацентрах. Это делало первый вариант гораздо более сложным в обслуживании – получалось много точек отказа. Поэтому конечным вариантом мы выбрали второй.
Переписывание основной части проекта у нас заняло два месяца, для такой задачи это были рекордные сроки. Тем не менее, чтобы не ждать, мы подняли несколько копий трекера на выделенном железе, чтобы было на чём тестировать фронтенд и взаимодействие со смежными сервисами.
Отдельно стоит отметить, что еще на этапе проектирования, мы приняли принципиальное решение сохранить одну кодовую базу для обоих Трекеров: внутреннего и внешнего. Это позволяет не заниматься копированием кода из одного проекта в другой, не снижать скорость релизов и выпускать возможности наружу почти сразу после их появления в нашем внутреннем Трекере.
Но как выяснилось, мало было добавить ещё один параметр во все методы приложения, мы также столкнулись со следующими проблемами:
- Нерезиновость монги и эластика. Нельзя было сложить данные в один инстанс, эластик плохо относится к большому количеству индексов, монга также не могла бы вместить все организации. Поэтому бекенд разделили на несколько больших инстансов, каждый из которых может обслуживать закрепленные за ним организации. Каждый инстанс отказоустойчив. При этом есть возможность перетащить организацию между ними.
- Необходимость выполнять cron задачи для каждой организации. Тут нам пришлось решать вопрос с каждой задачей индивидуально. Где-то заменили pull данных на push. Где-то одна cron задача генерировала по отдельной задаче на каждую организацию.
- Разный набор полей задач в каждой организации. Из-за наличия оптимизаций работы с ними нам пришлось написать отдельный кеш для них.
- Обновление маппинга индекса. Достаточно распространенная операция, случающаяся при апдейте трекера на новую версию. Добавили механизм поэтапного обновления маппинга.
- Открытие API на внешних пользователей. Пришлось добавить рейт лимитер, закрыть доступ к служебному API.
- Наличие службы поддержки для редких действий. Наши саппорты и разработчики не имеют право заглядывать в пользовательские данные организаций, а значит все действия должны производить администраторы компаний. Добавили для них ряд админок в интерфейсе.
Отдельный момент – оценка производительности. Из-за множества переделок необходимо было оценить скорость работы, количество организаций, которое бы вместилось в инстанс, а также поддерживаемый rps. Поэтому мы провели очередные стрельбы, предварительно заселив в наш тестовый трекер большое количество организаций. По итогам определили границу нагрузки, после которой новые организации надо будет размещать в новом инстансе.
Еще один специальный выделенный инстанс Трекера мы сделали, чтобы разместить в нем демоверсию. Чтобы попасть в нее достаточно иметь просто аккаунт на Яндексе. В ней заблокированы некоторые возможности (например, загрузка файлов), но зато можно познакомиться с настоящим интерфейсом Трекера.
Комментарии (56)

Radmin
21.12.2017 16:15Судя по последней части статьи, хостить всё это вы планируете исключительно у себя? Вариантов локальной установки сервиса в ДЦ другой компании не предусмотрено?
lotrek Автор
21.12.2017 16:27+1Да, это все живет в нашем облаке, вся эксплуатация — наша забота, обновления, в том числе критичные накатываются быстро и одинаково для всех и т.п. За сохранность своих данных можете не беспокоиться: резервные копии хранятся в нескольких дата-центрах. Если есть желание/необходимость как-то сохранять свою информацию к себе внутрь, можете воспользоваться нашим API, tech.yandex.ru/connect/tracker

Mendel
22.12.2017 14:31Ну обычно люди хотят хостить чувствительные данные у себя или по незнанию или ради ограничения доступа к ним посторонних лиц, а не из соображений отказоустойчивости.
lotrek Автор
22.12.2017 14:58-1Тут есть несколько причин, с одной стороны мы не хотим делать коробку, это требует немало ресурсов. С другой стороны мы верим, что весь мир движется в сторону облаков. Люди рано или поздно начнут доверять им, поймут, что облака могут ограничить доступ к их данным лучше, чем их собственные админы.
Mendel
22.12.2017 15:06Есть тысяча и одна причина почему вам выгоднее делать в облаке. Есть стопятьсот причин почему большинству клиентов это будет лучше. Я не об этом. Я о том, что вы сказали о надежности но не о безопасности.
Верить облаку это неизбежность, тут сомнений нет, но когда что-то берешь исключительно на веру — становишься зависим от того кому веришь.
Было бы интересно услышать есть ли у Яндекса мысли о том как сделать что-то, чтобы дать повод не просто верить а знать что из данные в безопасности?lotrek Автор
25.12.2017 17:57Ну смотрите, безопасность — совокупность мер, которые можно принять по защите данных и процессов, и передачи данных и т.п.
И тут опять же получится, что у Яндекса возможность обеспечить безопасность своего облака на порядок выше, чем у (среднего) клиента в своей инфраструктуре.
Это касается и шифрования данных, и безопасной разработки кода, и проверки на уязвимости, и контроля доступа, и прочее… То есть — безопасность для Яндекса — это не продукт, не какая-то standalone система, а обязательный компонент любого процесса и сервиса, т.к. самое важное, что есть в сервисе — это сохранность и конфиденциальность клиентских данных, и от того, как мы
об этом заботимся — зависит репутация и коммерческий успех Яндекса, поэтому мы и вкладываемся в процессы и инструменты обеспечения безопасности как никто другой, а также держим в штате высококлассных специалистов по ИБ, которых на рынке «днем с огнем» не найдешь.
Да, всегда будет мнение, что данные на своей инфраструктуре в сохранности и безопасности, но в большинстве случаев это всего лишь иллюзия, случаев взлома данных в частной инфраструктуре — на порядок больше.
TheKnight
25.12.2017 20:42Навскидку могу сказать, что организации типа LSE, которые пользуются Jira и могли бы захотеть попробовать Трекер — вряд ли рискнут хранить данные на серверах Яндекса.
Это хороший пример организации которая заботится о безопасности, умеет это делать(наверное :)) и при этом является потенциальным клиентом Трекера из-за объема своих данных.
AntiPravdorub
21.12.2017 17:36До чего же не удобный интерфейс трекера…
lotrek Автор
21.12.2017 17:36+2О, а расскажите, что не понравилось?
AntiPravdorub
21.12.2017 18:56+1Ну начну по порядку почему не удобно:
1. Во первых когда смотришь на задачу, то описание явно уходит на второй план а сильно бросается в глаза title, кнопки, правая сторона, сложно переключить внимание на само содержание задачи.
2. Не понятно зачем кнопка проголосовать, приоритеты можно и цветами выделить что довольно удобно.
3. Не хватает тёмной темы, глазам тяжело смотреть, это вообще проблема многих трекеров.
4. Уведомлений нет никаких, довольно хорошо по ним видеть что кто то отписался в задачи/добавил комментарий/поменял статус
Я так понимаю по интерфейсу это redmine
ну и чего мне вообще не хватает в трекерах, это адекватного поиска задачи при активной разработке теряются, боюсь при большом количестве задач у вас есть такая же проблема.
Ну и пару предложений по продукту:
1. Тёмная схема.
2. Максимально упрощенное представление задачи, мне допустим не удобно отвлекаться на разные красивые кнопочки, мне охота открыть задачу и сразу увидеть то что от меня хотят.
3. Тело задачи я бы всё таки централизовал по центру экрану, и левше и правше всегда хорошо видно контент в центре.
4. Ну и то что бы я хотел вообще увидеть хоть в одном трекере, это вывод в левой колонке похожие задачи (т.е. найденные по смыслу ключевым словам в той или иной очереди) так сразу можно видеть что да вот эта задача похожа на эту потому что, потому что, и таким образом можно понять что сделав одну задачу ты тем самым решил и какую то похожую задачу. В больших компаниях где большой поток задач, задачи часто ставят то тех поддержка то заказчики, клиентский отдел, в итоге ты решаешь одну задачу а эти дубликаты висят так как ты их просто не увидел/пропустил, ибо кто то поставил не тот трекер/очередь/статус/исполнителя и т.д…
p.s. Не говорю про почту просто туда сюда из почты в трекер из трекера в почту тоже не дело.lotrek Автор
21.12.2017 19:56Спасибо за такой подробный ответ, отвечу по пунктам:
Во первых когда смотришь на задачу, то описание явно уходит на второй план а сильно бросается в глаза title, кнопки, правая сторона, сложно переключить внимание на само содержание задачи.
Мы стараемся излагать суть задачи в ее заголовке, описание обычно вторично. В мелких задачах зачастую только заголовок и нужен.
Не понятно зачем кнопка проголосовать, приоритеты можно и цветами выделить что довольно удобно.
Кнопка голосования в задаче нужна чтобы любой проходящий мимо мог сказать, что эта задача ему интересна. Процессы на нее обычно не завязывают. Зато приятно потом выкатывать в продакшн задачу с кучей лайков.
Не хватает тёмной темы, глазам тяжело смотреть, это вообще проблема многих трекеров.
Классная идея, обсудим в команде.
Уведомлений нет никаких, довольно хорошо по ним видеть что кто-то отписался в задачи/добавил комментарий/поменял статус
Уведомлений нет в демоверсии, потому что демо — это посмотреть на 5 минут интерфейс и возможности, не больше. Система подписок у нас получилась довольно обширной: можно подписаться на различные типы событий, на компоненты, очереди, настраивать подписки для разных ролей. Также уведомления приходят в открытые вкладки, если кто-то изменил задачу, которая у вас открыта в браузере.
ну и чего мне вообще не хватает в трекерах, это адекватного поиска задачи
У нас два механизма поиска. Структурированный поиск по полям: можно составить фильтр или написать на языке запросов, я, например, использую для поиска задач в очереди смежников такой запрос:
Queue: DIR ("Comment Author": me() OR Followers: me())"Второй механизм более гибкий в плане словоформ, им удобно искать, когда надо найти по каким-то словам, но не помнишь точной формулировки. Этот поиск чуть более глобальный, умеет искать не только по трекеру, но и по остальным сервисам внутри организации. Так что если есть хоть немного косвенных критериев для поиска, задача находится.
Максимально упрощенное представление задачи, мне допустим не удобно отвлекаться на разные красивые кнопочки, мне охота открыть задачу и сразу увидеть то что от меня хотят.
Можно подумать о таком, кстати один коллега написал к нашему трекеру command-line interface. Получилось очень минималистично!
Тело задачи я бы всё таки централизовал по центру экрану, и левше и правше всегда хорошо видно контент в центре.
Интересное замечание, особенно актуально на больших мониторах, закину идею во фронтенд.
Ну и то что бы я хотел вообще увидеть хоть в одном трекере, это вывод в левой колонке похожие задачи
Да, у нас тоже бывает такая проблема, мы в какой-то момент специально упростили в интерфейсе закрытие задачи "как дубликат". Автоматически их искать было бы классно. Вы бы какие критерии предложили для такого поиска?
AntiPravdorub
22.12.2017 10:41Я вижу это как отдельный настраиваемый виджет, и так человек заходит в настройки такого виджета, и:
1. Прописывает ключевые слова(к примеру я работаю с ssl, acme, hosting, «рога и копыта», ip, vds, vps и т.д.)
2. Процентный порог соответствия (чуть ниже дам объяснение)
3. Синонимы (простой список словоформ, для более гибкого поиска)
4. Исключения (слова и их формы которые не учитывать при поиске)
4. Временной интервал(от и до относительно созданной задачи)
И так сам алгоритм виджета я описал бы так, при открытие просмотра задачи:
1. Смотрим на временной интервал который был указан в настройках (допустим +-1 час) и выбираем все задачи за этот интервал.
2. Берём название и текст задачи и исключаем из него все слова которые есть в исключениях и их формы, а так же и синонимы.
3. преобразуем получившийся текст в индекс для поиска, т.е. некую форму (ssl|ссл|ip|letsencrypt|«рога и копыта») и т.д.
4. Ищем по запросу который мы собрали в текстах задач которые мы выбрали за интервал времени в 1 пункте.
5. Вычисляем процент совпадения названия и тела задачи, к примеру в похожей задаче мы нашли 50% слов из индекса построенного в пункте 3.
6. После вычисления процентного соотношения фильтруем соответственно п.2 порога.
7. Ранжируем в соответствие процентного соотношения
Таким образом мы получаем примерный список задач, которые косвенно могут быть дубликатами, той задачи над которой работаем. В принципе алгоритм довольно простой.
Но этот алгоритм подойдёт только для задач которые дубликаты. Для поиска задач которые могли бы быть задеты фиксом текущей, думаю подойдёт простой виджет который выводит, совпадения по тегам, потокам и т.д.
p.s. По поводу тайтлов для задач мелких фиксов более ничего не надо, но для более крупной задачи, для того что бы понимать для чего Я эту задачу делаю, даже если она разбита на подзадачи, уже важен текст.
guai
22.12.2017 15:49+1Не хватает тёмной темы, глазам тяжело смотреть, это вообще проблема многих трекеров.
Это проблема многих людей, ни разу не озаботившихся настроить моник, в которых обычно по умолчанию яркость выкручена на максимум :)

Aingis
21.12.2017 19:25Разработка собственного трекера началась в январе 2012 года… На полный переезд всех команд и закрытие трекера Х понадобилось два года.
Как получилось два года при старте в 2012 и продолжавшимся процессом переезда с Джиры ещё в 2015? (Не уверен насчёт 2016, не помню точно.)lotrek Автор
21.12.2017 20:032 года — это на переезд остальных команд. Остальных начали перевозить все же не на самом старте.

dernasherbrezon
21.12.2017 19:42Молодцы! Я не работал в Яндексе, но много слышал про трекер. Уход от реляционный базы данных — это прям очень хорошо для такого типа продукта.
Я правильно понимаю, что этот продукт скорее эксперимент? Или планируется какое то дальнейшее развитие? Есть планы?
lotrek Автор
21.12.2017 20:09Спасибо!
Я не готов назвать это экспериментом. Хотя бы потому, что это сервис, которым уже пользуется большая компания. Новая инсталляция также готова к крупным клиентам.
Планов у нас много, иногда сложно расставить приоритеты, много всего хочется сделать. Прямо сейчас несколько крупных задач в разработке.
lingvo
21.12.2017 23:37А все-таки вопрос по конкурентному продукту. Вот вы написали, что Джиры с какого-то момента стало не хватать и что она не очень увязывалась с вашими внутренними сервисами. А если, допустим, есть команда из 10-100 человек со сравнительно небольшими по вашим меркам требованиями и нетребовательными сервисами — что Я.Трекер готов им предложить, лучше, чем в Джире, на Ваш взгляд?

Morj
21.12.2017 23:55Лучше всего облачный YouTrack. Интерфейс лучше и чем в ЯТ, и чем в Jira, великолепная Agile-доска с живыми обновлениями, кастомизируемые воркфлоу с редактором кода прямо в браузере. В новой версии UI будет Darcula (тёмная цветовая схема) и distraction-free mode.
Boyd_Rice
22.12.2017 03:44Интерфейс сильно уступает тому же гитлабу. Тормозной местами, перегруженный. Функциональность, вероятно, выше, но пользоваться этим не хочется примерно в той же степени, что и джирой.
Ant-VAV
22.12.2017 12:14Поддержу за YT. Что меня покорило: простой с виду и при этом хорошо так настраиваемый. Ну и достаточно быстрый (standalone).
lingvo
Вели там всякое: как обычные баги (спринты-минты) так и запилили систему хранения соискателей. Обмазались workflow по самое — половина рутинных вещей просто не успела даже появиться.
Но надо понимать, что YT — не серебряная пуля и есть всякие недостатки. Надо примерять его к своим реалиям.
lotrek Автор
22.12.2017 14:47Ну отличия есть :) и они, кажется, полезны компаниям любого размера.
Например, мы много думали о скорости и производительности.
Все задачи у нас «живые» — страницы задач обновляются в реальном времени. Если кто-то изменил или прокомментировал задачу, страница которои? открыта, вы увидите уведомление об этом во вкладке браузера, а на странице будет написано, какие поля изменились.
Есть возможность быстрого создания задач прямо из комментариев, создания связанной задачи из открытой и т.п.
Еще у нас сразу без всяких плагинов есть шаблоны задач и комментариев: личные или доступные для использования другими коллегами – тоже хорошо ускоряет и упрощает работу, если один раз настроить.
А еще Яндекс.Трекер дешевле Джиры :)
Boyd_Rice
22.12.2017 03:50Интеграции с гитом нет, я так понимаю? Т.е. для разработки этим пользоваться не получится. Глядя на демку, ещё более явственно ощутил то, что давно сидело в подсознании — то, насколько фирстиль Яндекса устарел и насколько он негоден для плотных интерфейсов.
lotrek Автор
22.12.2017 14:02Интеграция с гитом уже есть во внутреннем трекере, будем переносить наружу.
annabella0131
22.12.2017 12:15отл начинание! и отличная возможность, имея ресурсы разработки и опыт, запилить-таки вкусный трекер.
теперь ругаться буду немножко:
1) а маркдаун в комментариях? хоткеи? такое ощущение, что без руки на мышке с трекером особо не пообщаешься…
2)
Мы стараемся излагать суть задачи в ее заголовке, описание обычно вторично. В мелких задачах зачастую только заголовок и нужен.
мне как QA от этой фразы в вашем комменте подурнело =( а если задача — баг или фича? настолько задвинутое описание (а его и так плохо читают обычно) может очень негативно повлиять на процесс.lotrek Автор
22.12.2017 13:421) а маркдаун в комментариях? хоткеи? такое ощущение, что без руки на мышке с трекером особо не пообщаешься…
В комментариях и в описании поддерживается наша разметка, она похожа на маркдаун, но в ней больше разных фич. Про хоткеи замечание справедливое, хотим делать.
настолько задвинутое описание (а его и так плохо читают обычно) может очень негативно повлиять на процесс
Специально задвигать его не планировали, неужели правда таким выглядит?
Спасибо за свежий взгляд!

FuriousAngel
22.12.2017 12:15Здорово!
Интересно, об этом трекере рассказывали на ZeroNights 2016, обещая открыть к нему внешний доступ? (тогда это было в контексте сервис деска и обратной связи с сотрудниками компании)
Посмотрела демо, как вижу почти 1 в 1 джира, но существенно более быстрая и интерфейс не "прыгает". Так же проекты заменены на очереди (даже интересно, из OTRS термин взяли?), что решает джировский парадокс — проект, который закрыть (=завершить) нельзя.
Несколько вопросов:
- Вы планируете убрать\переделать фрейм при закрытии задачи\изменении статуса? Это страшно мешает в джире, а тут тоже самое… Кейс: Поставлена задача с несколькими вопросами, я исполнитель — закрываю и хочу ответить с указанием цитат\вопросов и тп, скопировав из текста или комментариев. Это невозможно, так как фрейм закрывает задачу и не дает из нее копировать. =((
- То что сделали возможность ставить задачи к подзадачам — круто, но почему в родительской задаче не видно все дерево подзадач (т.е. уровни далее первой подзадачи)? в том же редмайне это довольно удобно
- В предпросмотре задачи (справа) — невозможно посмотреть наличие связей\подзадач, это грустно
- Не совсем очевидна (а может непривычна) при использовании с Гантта механика\интерфейс — при создании задачи по умолчанию не включено поле "Дата начала": получается, что создаю задачи с дедлайном, а они на диаграмме отображаются как неразобранные (брр). При этом в режиме диаграммы у задачи можно по править 2 поля: "В работе с" и "дедлайн", но при создании задачи я поля "В работе с" не вижу, есть "Дата начала". Запутано =)
- После изменения сроков задачи через правое меню приходится вручную рефрешить страницу браузера чтобы посмотреть на диаграмме результат =( Chrome Версия 63.0.3239.84
- Диаграмму можно двигать (сроки задач) — классно (+1)
- На диаграмме не отображаются связи и иерархия (родительская, дочерняя) — жаль(
- Печально, что существует только 1 тип связи, хотелось бы еще — следующая, предыдущая и блокирует.
Интеграцию с confluence (это наверное, единственное что у atlassian удобно) планируете или будете писать что-то свое?
lotrek Автор
22.12.2017 14:29Вы планируете убрать\переделать фрейм при закрытии задачи\изменении
статуса? Это страшно мешает в джире, а тут тоже самое… Кейс:
Поставлена задача с несколькими вопросами, я исполнитель — закрываю
и хочу ответить с указанием цитат\вопросов и тп, скопировав из
текста или комментариев. Это невозможно, так как фрейм закрывает
задачу и не дает из нее копировать. =((Менять прямо в этом месте не планировали, но это вообще можно
настроить в воркфлоу очереди. Например, сделать так, чтобы по кнопке
"закрыть" задача просто закрывалась, а комментарии написать в
комментариях :)
То что сделали возможность ставить задачи к подзадачам — круто, но
почему в родительской задаче не видно все дерево подзадач (т.е.
уровни далее первой подзадачи)? в том же редмайне это довольно удобноУже думаем как сделать, чтобы было удобно, самим очень хочется :)
В предпросмотре задачи (справа) — невозможно посмотреть наличие связей\подзадач, это грустно
Хотим в этом месте много улучшений, и связи в том
числе попробуем.
Не совсем очевидна (а может непривычна) при использовании с Гантта
механика\интерфейс — при создании задачи по умолчанию не включено
поле "Дата начала": получается, что создаю задачи с дедлайном, а они
на диаграмме отображаются как неразобранные (брр). При этом в режиме
диаграммы у задачи можно по править 2 поля: "В работе с" и
"дедлайн", но при создании задачи я поля "В работе с" не вижу, есть "Дата начала". Запутано =)
После изменения сроков задачи через правое меню приходится вручную
рефрешить страницу браузера чтобы посмотреть на диаграмме результат =( Chrome Версия 63.0.3239.84
На диаграмме не отображаются связи и иерархия (родительская, дочерняя) — жаль(
Печально, что существует только 1 тип связи, хотелось бы еще —
следующая, предыдущая и блокирует.У нас про Гантта есть планы – тут будут изменения.
В частности, про даты хотим вообще переделать механику в этом месте, чтобы можно было установить даты начала и окончания прямо с Гантта.
А еще сейчас вы можете сделать 1 раз настройку очереди и выбрать все нужные поля, чтобы они были сразу доступны для заполнения.
Печально, что существует только 1 тип связи, хотелось бы еще — следующая, предыдущая и блокирует.
На самом деле их несколько. А почему показалось, что только один тип?
Интеграцию с confluence (это наверное, единственное что у atlassian
удобно) планируете или будете писать что-то свое?У нас есть своя Wiki, рядом, в Коннекте, с ней Трекер интегрирован, как минимум ссылки на задачи раскрываются и
отражают статус задачи и ответственного, думаем как интегрировать плотнее.FuriousAngel
22.12.2017 16:50Спасибо за ответы)
Например, сделать так, чтобы по кнопке
«закрыть» задача просто закрывалась, а комментарии написать в
комментариях :)
Ммм, а потом помудрить со схемой нотификейшнов? т.к. по дефолту автору их влетит 2 — комментарий и смена статуса… Ну как-то все равно сомнительно — у нас на этом как раз народ и прокалывается — жмет «отменить» в расчете, что будет предложен ввод комента — а его нет( т.е. исполнителю надо помнить, что прежде чем сменить статус, нужно что-то написать, а если при изменении статуса нужно еще какие-то поля заполнить — то опять фрейм. т.е. написал коммент. нажал закрыть, опять что-то написал, опять сохранил… в общем механика сомнительная, но на вкус и цвет…
На самом деле их несколько. А почему показалось, что только один тип?
Потому что связанную задачу я создала через выпадающий список «Действия», и невозможно в этом режиме поменять тип связи в 2 клика — нужно нажать «добавить связь», указать тот же номер задачи, выбрать ее, выбрать тип связи, сохранить. И не очень очевидно почему именно так.
И да — при этом нет предыдущей и последующей которые должны влиять на даты задач
И еще… почему-то не производится проверка полей дат начала и завершения: когда я меняла на гантта дату начала и дату дедлайна — трекер не ругнулся на то, что «дата дедлайна» раньше «В работе с». Это баг или фитча?) В других трекерах, есть парные поля, по которым выполняются проверки системы (т.е. план. дата начала не может быть больше план. даты завершения)
У нас есть своя Wiki, рядом, в Коннекте,
О, посмотрим =)

Abyasov
23.12.2017 20:02Весь хелп перерыл: неужели у вас нет чек-листов?
TheKnight
25.12.2017 04:46А можно подробнее и с примерами о функциональности чек-листов в трекере?
Я правильно понимаю, что искомое есть в issue-трекере GitHub?
Пример.Abyasov
25.12.2017 12:34Кажется, вы промахнулись со ссылкой ((
TheKnight
25.12.2017 12:42Вроде бы нет. Может это вам покажет пример?
В любом случае, что для вас значат чек листы с точки зрения Issue Tracker?Abyasov
25.12.2017 13:35Да, это похоже на то, что нужно.
А я не рассматриваю трекер как Issue Tracker. Есть ведь и другие области, где нужно управлять задачами. К примеру, digital-агентства часто делают похожие задачи и надо уметь закрывать их одинаково качественно. Тут чек-листы и приходят на помощь.
sergey-b
24.12.2017 14:14Включил оповещения о действиях, которые я совершил сам.
Завел на себя задачу.
Получил по почте уведомление.
Отправил на это уведомление ответное письмо с небольшим текстом и аттачментом.
Текст ответа добавился к задаче в виде нового комментария, и аттачмент прикрепился к задаче.
Получил об этом уведомление из трекера.
В тексте уведомления четко расписано, почему оно пришло, есть ссылка, чтобы отписаться.
Именно так и должен работать хороший трекер.
Интерфейс, на мой взгляд, немного перегружен, но это не беда. Яндекс сделал хороший продукт.

jehy
25.12.2017 10:54Очень круто звучит! Давно хотелось ту же джиру, только пошустрее и более масштабируемую. Плюсую к вопросу о миграции из джиры.
Ещё я помню, что у вас был внутренний продукт для учёта сотрудников — фио, схема кто где сидит, фоточки — эта штука куда-то вовне ушла? Не знаю, как правильный поисковый запрос построить на этот счёт.
TheKnight
25.12.2017 12:24Яндекс.Коннект.
jehy
25.12.2017 13:00Обидно — именно по тому, что хочется, никакой документации нет. И всё представляется как единый проект, 90% (почта, вики, мессенджер, трекер) которого нам не нужно — эти задачи решаются имеющейся инфраструктурой, которая нас устраивает. Хотелось именно некий прогрессивный аналог keepteam.
TheKnight
25.12.2017 13:26jehy
25.12.2017 13:32Да, спасибо, на первый взгляд похоже — хотя описания до обидного мало.
На самом деле, хочется, чтобы система управления командой решала вроде бы простую задачу — чтобы можно было загрузить карту офиса, отметить там рабочие места и обозначить, где сидит каждый сотрудник. А то нас 250 человек, и порой кого-то найти это настоящий квест — в особенности для стеснительного человека.

I-ilya
25.12.2017 15:25Очень интересный трекер и действительно, в отличии от джиры нет тормозов и интерфейс не «прыгает»!!! Подскажите: 1. Планируется ли постановка регулярных (например, по понедельникам, пока не закроется задача или с указанием сроков) задач? 2. Планируются ли мобильные версии? 3. Языковые версии (меня в частности волнуют на английскоая и китайская) 4. Как устроена работа при постановке задач с разными тайм зонами?
lotrek Автор
25.12.2017 15:26Спасибо!
- Планируется ли постановка регулярных (например, по понедельникам, пока не закроется задача или с указанием сроков) задач?
Сделать автоповтор задач по расписанию планируем, но конкретных сроков на данных момент нет.
- Планируются ли мобильные версии?
Мы разрабатываем мобильное приложение под iOS и Android и планируем опубликовать их в ближайшие пару месяцев
- Языковые версии (меня в частности волнуют на английскоая и китайская)
Сейчас можно переключить на английский язык, но мы хотим, чтобы его вычитали редакторы, плюс некоторые дефолтные сущности сейчас создаются сразу на русском языке, документацию на английском тоже скоро выложим. Поддерживать китайский язык в планах пока нет. А с чем связана потребность в китайской версии, если не секрет?
- Как устроена работа при постановке задач с разными тайм зонами?
У себя мы храним все в UTC, пользователям показываем данные в их таймзоне.
kuptservol
А как вы решаете проблемы с эластиком на больших данных?
lotrek Автор
Эластик неплохо шардируется из коробки, можно заваливать его железом.
В целом у нас было несколько проблем с ним:
1. Длинные таймауты в случае ухода одной из нод и начала перешардирования. Добавили таймауты, чтобы не забивать потоки бекенда. Также в эластике начиная со второй версии есть возможность задержать релокацию шардов, на случай если нода только мигнула, но не ушла надолго.
2. Перезатирание данных в индексе одновременными апдейтами. Решили проблему версионированием и ретраями.
Возможно у нас не такие уж и большие данные (сотни гигабайт), чтобы иметь специфичные для них проблемы.