
Этот пост — перевод трех частей серии Data acquisition in R из моего англоязычного блога. Исходная серия задумана в четырех частях, три из которых легли в основу данного поста: Использование подготовленных наборов данных; Доступ к популярным статистическим БД; Демографические данные; Демографические данные. В еще не написанной заключительной части речь пойдет об использовании пространственных данных.

R заточен под воспроизводимость результатов. Существует множество прекрасных решений, обеспечивающих сопоставимость версий системы и пакетов, помогающих применять принципы literate programming… Я же хочу показать, как можно легко и эффективно находить/скачивать/добывать данные, используя собственно R и документируя каждый шаг, что обеспечивает полную воспроизводимость всего процесса. Разумеется, я не ставлю перед собой задачи перечислить все возможные источники данных и фокусирую внимание в основном на демографических данных. Если ваши интересы лежат вне сферы статистики населения, стоит посмотреть в сторону великолепного проекта Open Data Task View.
Для иллюстрации использования каждого из источников информации я привожу пример визуализации полученных данных. Каждый пример кода задуман как самостоятельная единица — копируйте и воспроизводите. Разумеется, сперва необходимо установить требуемые пакеты. Весь код целиком лежит тут.
Встроенные наборы данных
Во многие пакеты включены небольшие удобные наборы данных для иллюстрации методов. Собственно в ядро R входит пакет datasets, в котором содержится большое количество небольших, разнообразных, иногда очень знаменитых, датасетов. Подробный список встроенных в различные пакеты иллюстрационных датасетов ведет на своем сайте Vincent Arel-Bundock.
Приятная черта встроенных датасетов в том, что они "всегда с тобой". Уникальные имена тренировочных датасетов можно использовать так же легко, как и любые объекты из Global Environment. Давайте взглянем на очаровательный крохотный набор данных swiss — Swiss Fertility and Socioeconomic Indicators (1888) Data. Ниже я отображу различия в рождаемости между кантонами Швейцарии в зависимости от доли сельского населения и распространенности католической веры.
library(tidyverse)
swiss %>%
ggplot(aes(x = Agriculture, y = Fertility,
color = Catholic > 50))+
geom_point()+
stat_ellipse()+
theme_minimal(base_family = "mono")
Gapminder
Некоторые пакеты специально созданы для того, чтобы сделать определенные наборы данных легко доступными пользователям R. Хороший пример подобного пакета — gapminder, который содержит иллюстративный сэмпл данных проекта Gapminder Ханса Рослинга.
library(tidyverse)
library(gapminder)
gapminder %>%
ggplot(aes(x = year, y = lifeExp,
color = continent))+
geom_jitter(size = 1, alpha = .2, width = .75)+
stat_summary(geom = "path", fun.y = mean, size = 1)+
theme_minimal(base_family = "mono")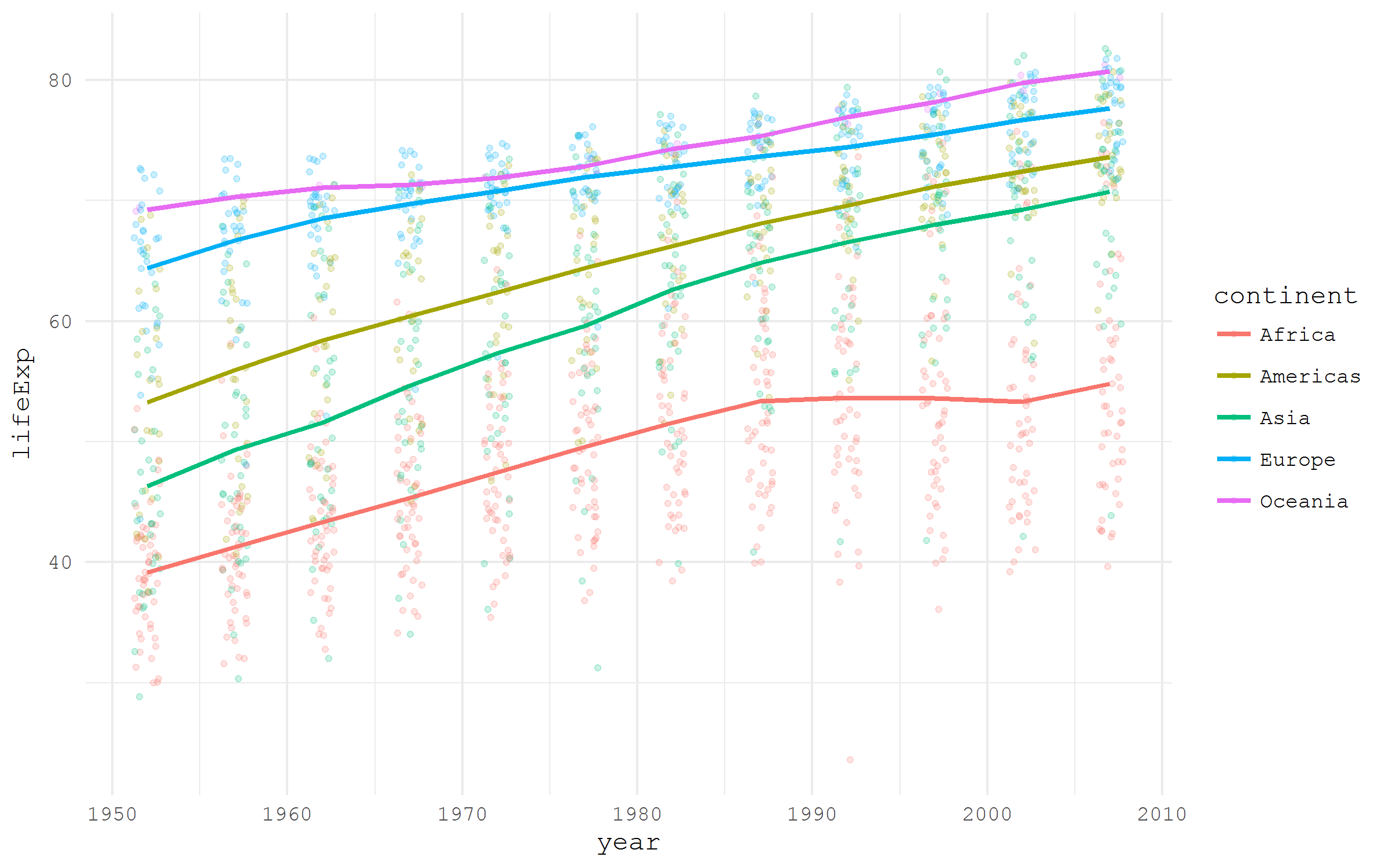
Добываем датасет по URL
Если набор данных хранится где-то онлайн и обладает прямой ссылкой на скачивание, его можно элементарно прочитать в R, всего лишь указав ссылочку. Для примера давайте возьмем знаменитый набор данных Galton о росте отцов и детей из пакета HistData. Только возьмем мы данные по прямой ссылки из списка Vincent Arel-Bundock's
library(tidyverse)
galton <- read_csv("https://raw.githubusercontent.com/vincentarelbundock/Rdatasets/master/csv/HistData/Galton.csv")
galton %>%
ggplot(aes(x = father, y = height))+
geom_point(alpha = .2)+
stat_smooth(method = "lm")+
theme_minimal(base_family = "mono")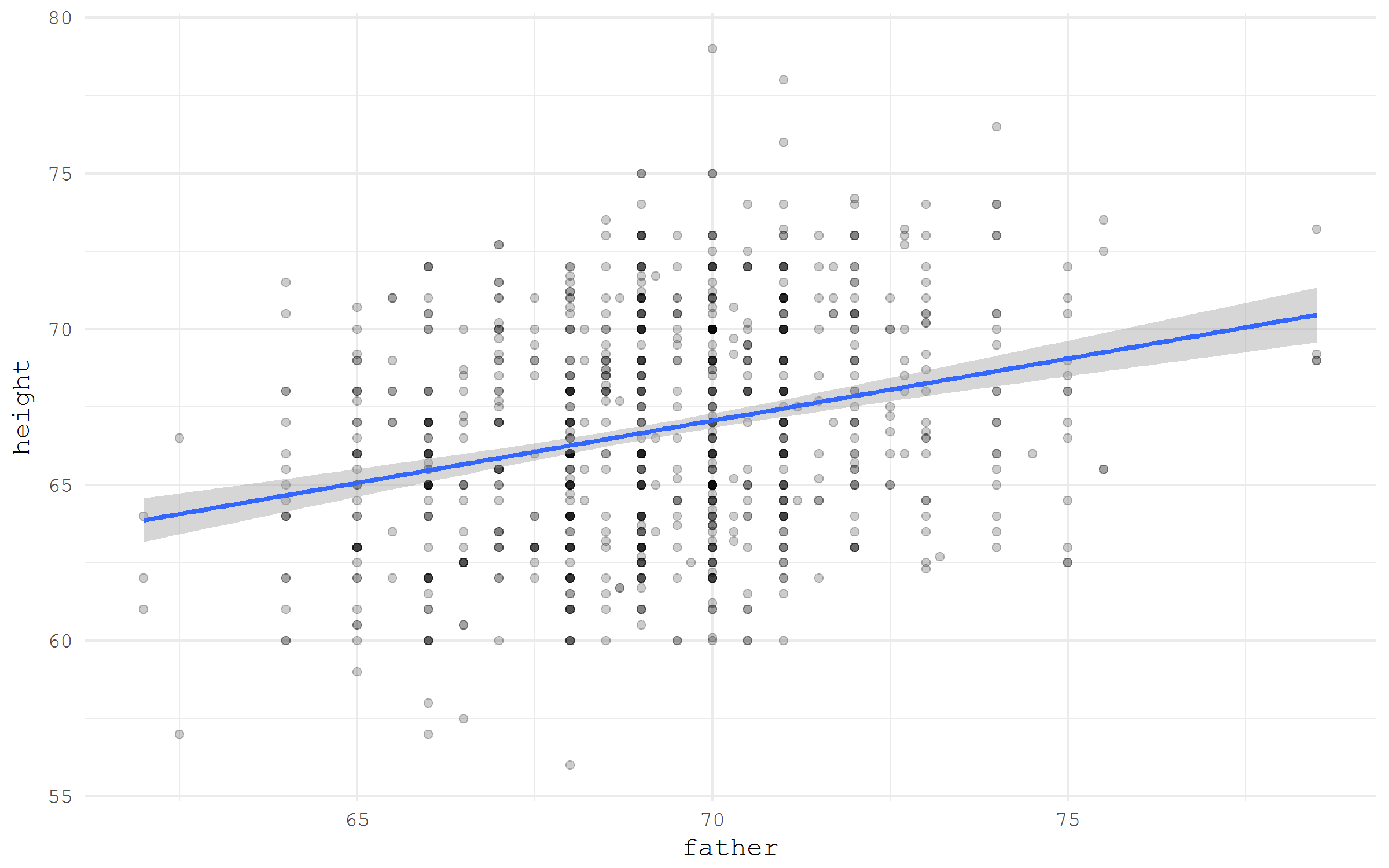
Скачиваем и распаковываем архив
Очень часто наборы данных архивируют, прежде чем отпустить в интернет. Прочитать архив сразу не получится, но решение в R достаточно простое. Логика процесса очень простая: сперва создаем директорию, куда распакуем данные; затем скачиваем архив во временный файл; наконец распаковываем архив в предварительно созданную директорию. Для примера я скачаю Historical New York City Crime Data, набор данных о преступлениях, совершенных в Нью Йорке, который любезно предоставлен правительством штата Нью Йорк и хранится в открытом репозитории данных data.gov.
library(tidyverse)
library(readxl)
# create a directory for the unzipped data
ifelse(!dir.exists("unzipped"), dir.create("unzipped"), "Directory already exists")
# specify the URL of the archive
url_zip <- "http://www.nyc.gov/html/nypd/downloads/zip/analysis_and_planning/citywide_historical_crime_data_archive.zip"
# storing the archive in a temporary file
f <- tempfile()
download.file(url_zip, destfile = f)
unzip(f, exdir = "unzipped/.")Иногда скачиваемый архив достаточно увесист, и мы бы не хотели скачивать его заново каждый раз, воспроизводя код. В таком случае имеет смысл сохранить исходный архив, а не использовать временный файл.
# if we want to keep the .zip file
path_unzip <- "unzipped/data_archive.zip"
ifelse(!file.exists(path_unzip),
download.file(url_zip, path_unzip, mode="wb"),
'file alredy exists')
unzip(path_unzip, exdir = "unzipped/.")
Наконец, давайте импортируем и визуализируем скачанные и разархивированные данные.
murder <- read_xls("unzipped/Web Data 2010-2011/Seven Major Felony Offenses 2000 - 2011.xls",
sheet = 1, range = "A5:M13") %>%
filter(OFFENSE %>% substr(1, 6) == "MURDER") %>%
gather("year", "value", 2:13) %>%
mutate(year = year %>% as.numeric())
murder %>%
ggplot(aes(year, value))+
geom_point()+
stat_smooth(method = "lm")+
theme_minimal(base_family = "mono")+
labs(title = "Murders in New York")
Figshare
В академическом мире все острее встает вопрос воспроизводимости результатов. Поэтому все чаще открыто публикуемые наборы данных становятся верными спутниками научных статей. Существует немало специализированных репозиториев для подобных наборов данных. Один из самых широко используемых — Figshare. Для него существует обертка для R — rfigshare. Для примера я скачаю свой же набор данных о росте хоккеистов, который я собрал для написания одного из предыдущих постов на Хабре. Обратите внимание, что при первом использовании пакета rfigshare, вас попросят ввести логин и пароль от Figshare для доступа к API — откроется специальная веб страничка в браузере.
Есть специальная функция fs_search, но, по моему опыту, проще найти в браузере интересующий нас датасет и скопировать уникальный идентификатор, по которому мы и скачаем его в R. Функция fs_download превращает id в прямую ссылку на скачивание файла.
library(tidyverse)
library(rfigshare)
url <- fs_download(article_id = "3394735")
hockey <- read_csv(url)
hockey %>%
ggplot(aes(x = year, y = height))+
geom_jitter(size = 2, color = "#35978f", alpha = .1, width = .25)+
stat_smooth(method = "lm", size = 1)+
ylab("height, cm")+
xlab("year of competition")+
scale_x_continuous(breaks = seq(2005, 2015, 5), labels = seq(2005, 2015, 5))+
theme_minimal(base_family = "mono")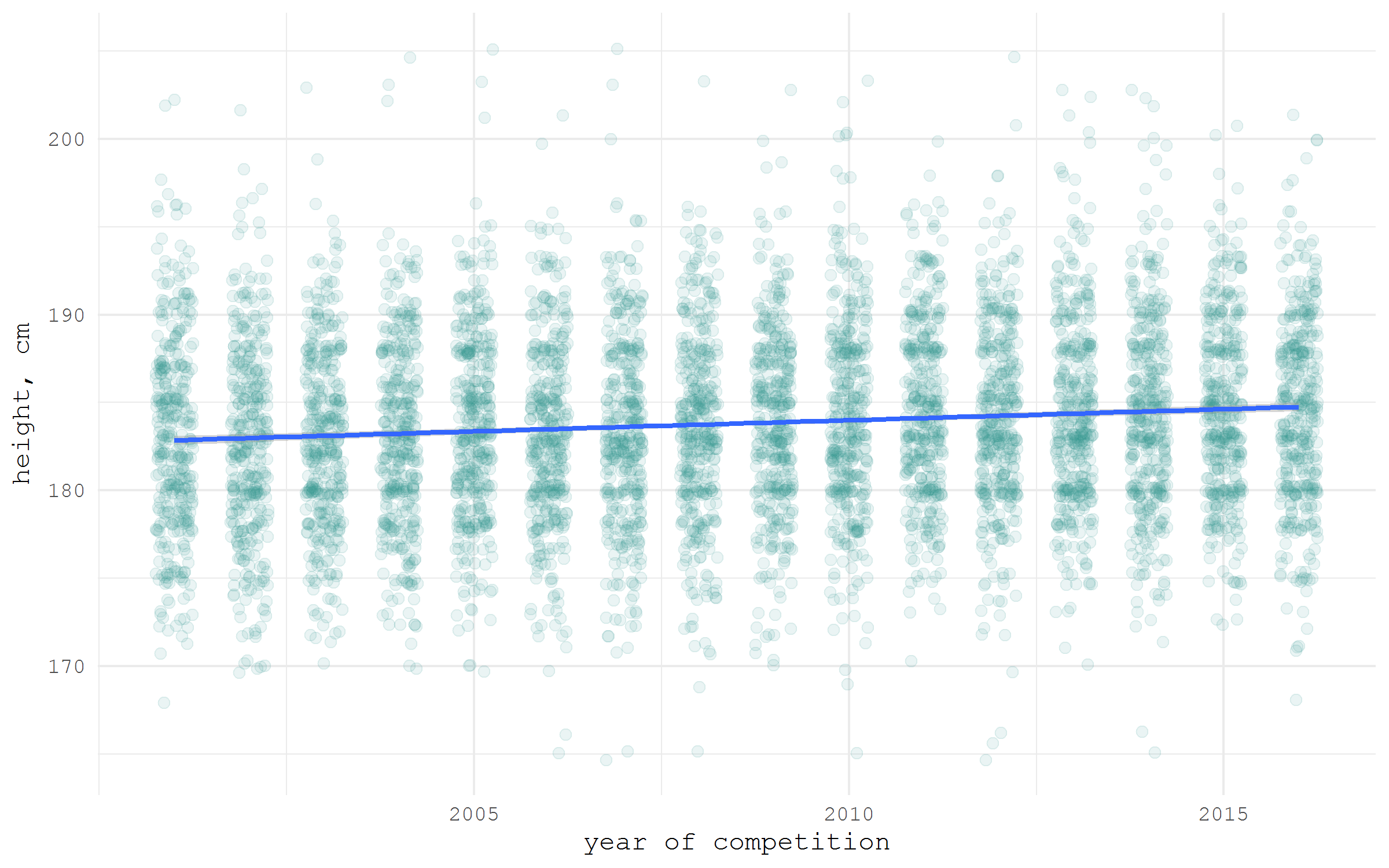
Eurostat
Евростат публикует в открытом доступе невероятное количество статистики по странам Европы и их регионам. Разумеется, есть специальный пакет eurostat для получения всего этого богатства. К сожалению, встроенная функция search_eurostat плохо справляется с задачей поиска релевантных датасетов. Например, по запросу life expectancy получаем всего лишь два варианта, в то время как в реальности должно быть несколько десятков датасетов. Поэтому наиболее удобное решение выглядит так: отправляемся на сайт Евростата, находим интересующий нас датасет, копируем только его код и, наконец, скачиваем его с помощью пакета eurostat. Обратите внимание, что вся региональная статистика Евростата находится в отдельной БД.
Я сейчас скачаю данные об ожидаемой продолжительности жизни в странах Европы, код датасета — demo_mlexpec.
library(tidyverse)
library(lubridate)
library(eurostat)
# download the selected dataset
e0 <- get_eurostat("demo_mlexpec")Скачивание может занять некоторое время, в зависимости от объема датасета. В нашем случае имеем среднего размера набор данным в 400К наблюдений. Если по какой-то причине автоматически скачать датасет не получается (у меня такого ни разу не было), вручную можно скачать с отдельного сайта Евростата Bulk Download Service.
Давайте посмотрим на остаточную ожидаемую продолжительность жизни в возрасте 65 лет в некоторых выбранный странах Европы, раздельно для мужчин и женщин. Возраст 65 лет — наиболее распространенный традиционный возраст выхода на пенсию. Посмотерть на остаточную ожидаемую продолжительность жизни для этого возраста в динамике очень любопытно в свете разговоров о реформах возраста выхода на пенсию. Из скачанных данных мы отбираем только оценки остаточной ожидаемой продолжительности жизни в возрасте 65, затем отфильтровываем только оценки раздельно для мужчин и женщин, наконец, оставляем только несколько стран: Германию, Францию, Италию, Россию, Испанию и Великобританию.
e0 %>%
filter(! sex == "T",
age == "Y65",
geo %in% c("DE", "FR", "IT", "RU", "ES", "UK")) %>%
ggplot(aes(x = time %>% year(), y = values, color = sex))+
geom_path()+
facet_wrap(~ geo, ncol = 3)+
labs(y = "Life expectancy at age 65", x = NULL)+
theme_minimal(base_family = "mono")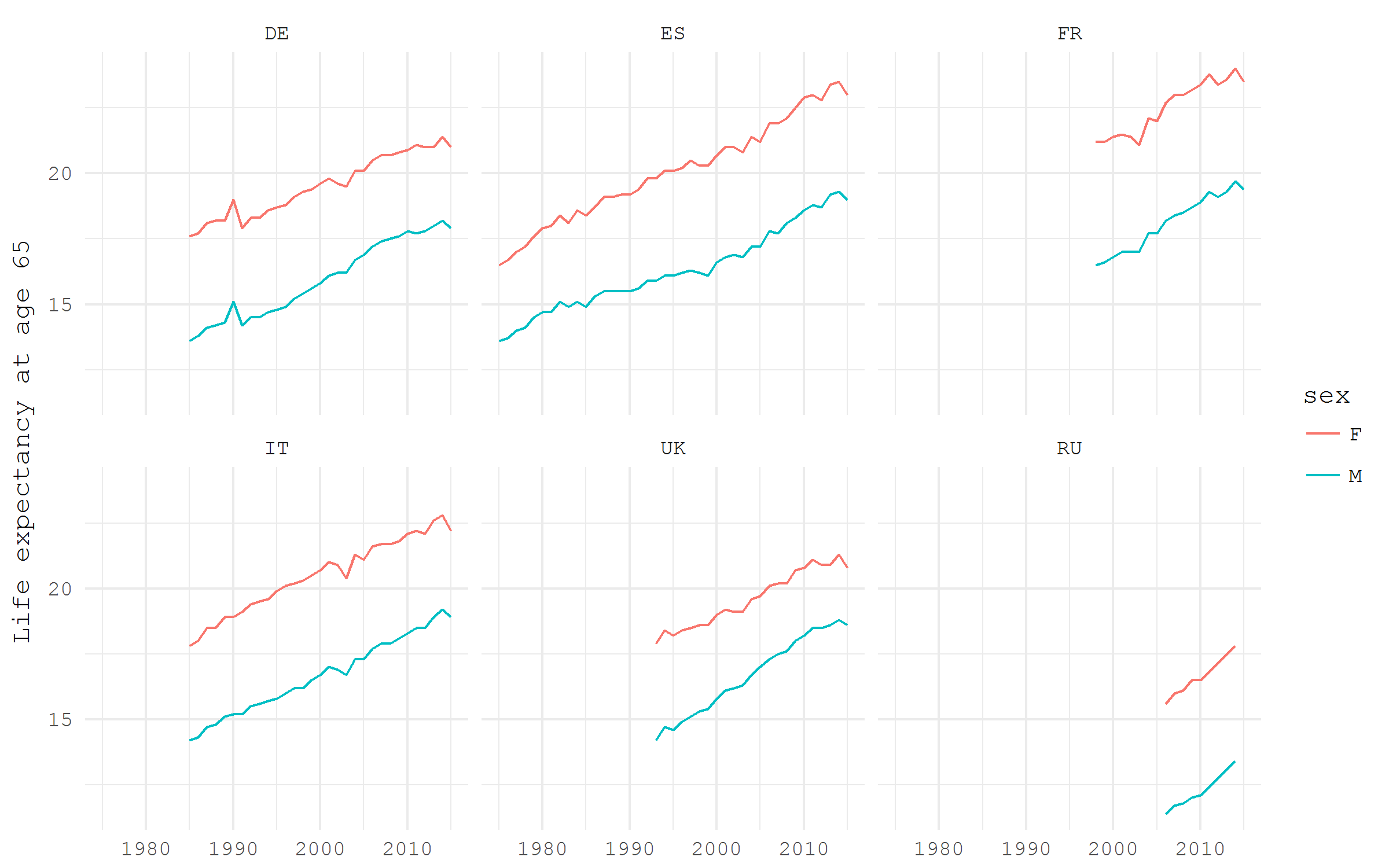
World Bank
Существует несколько пакетов, которые предоставляют доступ к данным Всемирного Банка из R. Вероятно, наиболее допиленный из них — довольно свежий wbstats. Его функция wbsearch действительно прекрасно справляется с задачей поиска релевантных датасетов. Для примера, wbsearch("fertility") выдает толковый список из 339 показателей в виде удобной таблички.
library(tidyverse)
library(wbstats)
# search for a dataset of interest
wbsearch("fertility") %>% head| indicatorID | indicator | |
|---|---|---|
| 2479 | SP.DYN.WFRT.Q5 | Total wanted fertility rate (births per woman): Q5 (highest) |
| 2480 | SP.DYN.WFRT.Q4 | Total wanted fertility rate (births per woman): Q4 |
| 2481 | SP.DYN.WFRT.Q3 | Total wanted fertility rate (births per woman): Q3 |
| 2482 | SP.DYN.WFRT.Q2 | Total wanted fertility rate (births per woman): Q2 |
| 2483 | SP.DYN.WFRT.Q1 | Total wanted fertility rate (births per woman): Q1 (lowest) |
| 2484 | SP.DYN.WFRT | Wanted fertility rate (births per woman) |
Давайте посмотрим на показатель Lifetime risk of maternal death (%) (код SH.MMR.RISK.ZS) — риск смерти для женщины на протяжении жизни, связанный с рождением детей. Всемирный Банк приводит данные по странам, а также несколько различных вариантов группировки стран. Один из примечательных вариантов группировки — разделение по принципу завершенности Демографического Перехода. Ниже я отображаю выбранный показатель для (1) стран уже завершивших ДП, (2) стран еще не завершивших ДП и (3) всего мира в целом.
# fetch the selected dataset
df_wb <- wb(indicator = "SH.MMR.RISK.ZS", startdate = 2000, enddate = 2015)
# have look at the data for one year
df_wb %>% filter(date == 2015) %>% View
df_wb %>%
filter(iso2c %in% c("V4", "V1", "1W")) %>%
ggplot(aes(x = date %>% as.numeric(), y = value, color = country))+
geom_path(size = 1)+
scale_color_brewer(NULL, palette = "Dark2")+
labs(x = NULL, y = NULL, title = "Lifetime risk of maternal death (%)")+
theme_minimal(base_family = "mono")+
theme(panel.grid.minor = element_blank(),
legend.position = c(.8, .9))

OECD
Организация экономического сотрудничества и развития (OECD) публикует немало данных об экономическом и демографическом развитии стран-членов. Пакет OECD сильно упрощает использование этих данных в R. Функция search_dataset неплохо справляется с поиском необходимых данных по ключевым словам, а get_dataset загружает выбранный датасет. В следующем примере я скачаю данные о продолжительности периодов безработицы и отображу эти данные для мужского населения EU16, EU28 и США, используя метод визуализации heatmap.
library(tidyverse)
library(viridis)
library(OECD)
# search by keyword
search_dataset("unemployment") %>% View
# download the selected dataset
df_oecd <- get_dataset("AVD_DUR")
# turn variable names to lowercase
names(df_oecd) <- names(df_oecd) %>% tolower()
df_oecd %>%
filter(country %in% c("EU16", "EU28", "USA"), sex == "MEN", ! age == "1524") %>%
ggplot(aes(obstime, age, fill = obsvalue))+
geom_tile()+
scale_fill_viridis("Months", option = "B")+
scale_x_discrete(breaks = seq(1970, 2015, 5) %>% paste)+
facet_wrap(~ country, ncol = 1)+
labs(x = NULL, y = "Age groups",
title = "Average duration of unemployment in months, males")+
theme_minimal(base_family = "mono")
WID
World Wealth and Income Database представляет собой гармонизированные временные ряды данных о неравенстве в доходах и богатстве. Разработчики базы данных позаботились о создании специального пакета R, который пока доступен лишь на github.
library(tidyverse)
#install.packages("devtools")
devtools::install_github("WIDworld/wid-r-tool")
library(wid)Функция для скачивания данных — download_wid(). Чтобы корректно указать аргументы для скачивания данных придется немного покопаться в документации пакета и разобраться в достаточно сложной системе кодировки переменных.
?wid_series_type
?wid_conceptsПриведенный пример адаптирован из виньетки пакета. Он отображает долю богатства, которой владеет богатейшие 1% и 10% населения во Франции и Великобритании.
df_wid <- download_wid(
indicators = "shweal", # Shares of personal wealth
areas = c("FR", "GB"), # In France an Italy
perc = c("p90p100", "p99p100") # Top 1% and top 10%
)
df_wid %>%
ggplot(aes(x = year, y = value, color = country)) +
geom_path()+
labs(title = "Top 1% and top 10% personal wealth shares in France and Great Britain",
y = "top share")+
facet_wrap(~ percentile)+
theme_minimal(base_family = "mono")

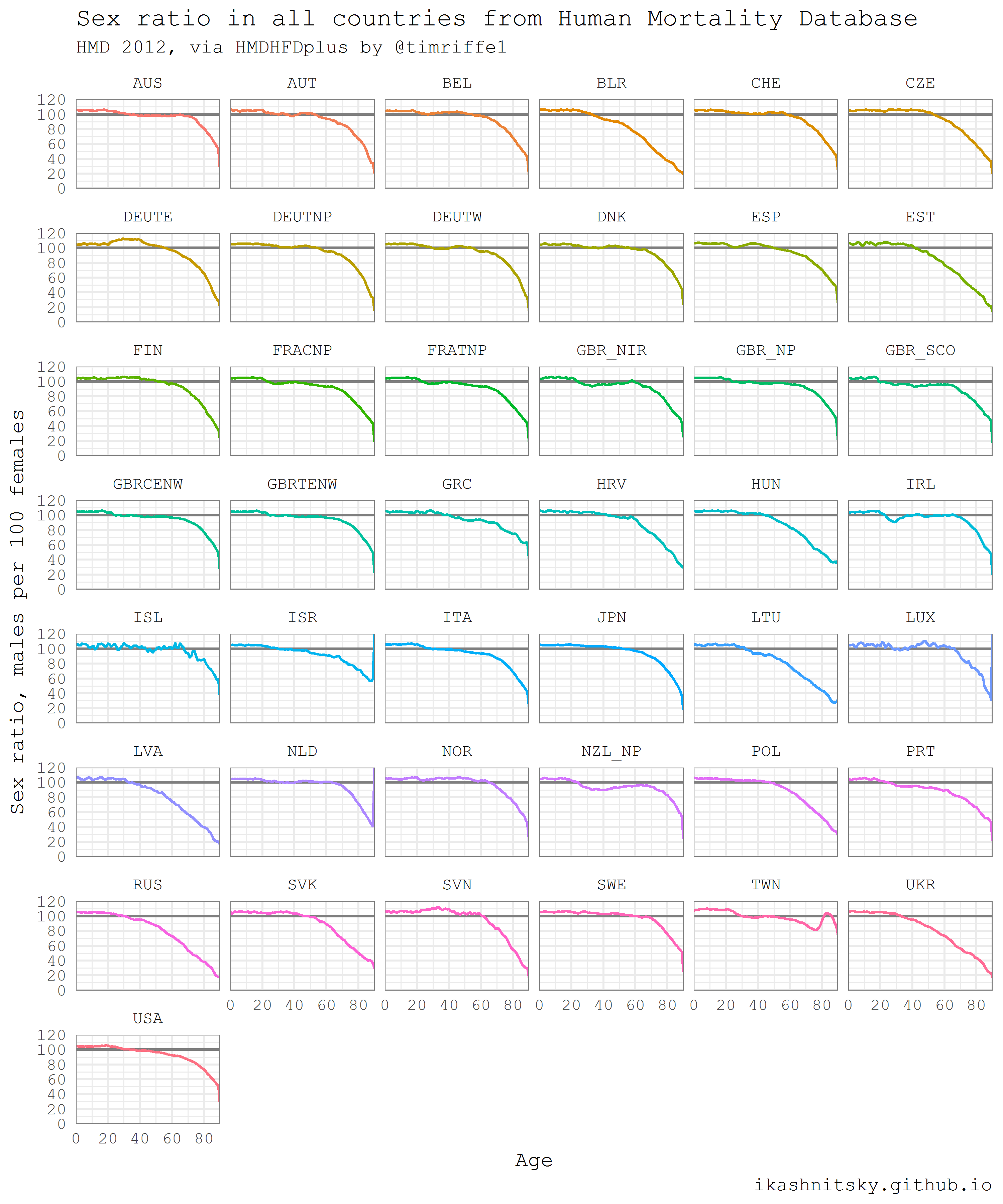
Human Mortality Database
Когда речь заходит о проверке больших вопросов о законах динамике человеческих популяций, нет более надежного источника информации, чем Human Mortality Database. Эта база данных разработана и поддерживается демографами, которые применяют state-of-the-art методологию для гармонизации исходных данных. Протокол методов HMD — это шедевр методологии работы с демографическими данными. Оборотная сторона заключается в том, что исходные данные достаточно высокого качества доступны лишь для сравнительно небольшого числа стран. Для ознакомления с доступными пользователю данными я от души рекомендую [Human Mortality Database Explorer][exp], созданный Jonas Scholey.
Благодаря Tim Riffe у нас есть пакет HMDHFDplus, который позволяет загрузить данные HMD прямо в R всего в несколько строк кода. Обратите внимание, что для доступа к данным потребуется бесплатный аккаунт на mortality.org. Как можно догадаться из названия пакета, он также позволяет скачивать данные из столь же прекрасной Human Fertility Database.
Приведенный ниже пример взят из моего предыдущего поста и немного обновлен. Мне кажется, он хорошо иллюстрирует всю мощь автоматической загрузки данных в R. Легко и непринужденно я скачаю однолетние возрастные структуры для всех стран HMD за все доступные годы, раздельно для женщин и мужчин. При воспроизведении этого кода стоит помнить, что будет скачано несколько десятков мегабайтов данных. Далее я рассчитаю и отображу соотношение полов во всех возрастах для всех стран в 2012 году. Соотношения полов отражают две ключевые демографические закономерности: 1) всегда рождается больше мальчиков; 2) мужская смертность выше женской во всех возрастах. За исключением считанных и достаточно хорошо изученных примеров соотношение полов при рождении составляет 105-106 мальчиков на 100 девочек. Таким образом, значительные различия в возрастных профилях соотношения полов отражают в первую очередь гендерные различия в смертности.
# load required packages
library(HMDHFDplus)
library(tidyverse)
library(purrr)
# help function to list the available countries
country <- getHMDcountries()
# remove optional populations
opt_pop <- c("FRACNP", "DEUTE", "DEUTW", "GBRCENW", "GBR_NP")
country <- country[!country %in% opt_pop]
# temporary function to download HMD data for a simgle county (dot = input)
tempf_get_hmd <- . %>% readHMDweb("Exposures_1x1", ik_user_hmd, ik_pass_hmd)
# download the data iteratively for all countries using purrr::map()
exposures <- country %>% map(tempf_get_hmd)
# data transformation to apply to each county dataframe
tempf_trans_data <- . %>%
select(Year, Age, Female, Male) %>%
filter(Year %in% 2012) %>%
select(-Year) %>%
transmute(age = Age, ratio = Male / Female * 100)
# perform transformation
df_hmd <- exposures %>%
map(tempf_trans_data) %>%
bind_rows(.id = "country")
# summarize all ages older than 90 (too jerky)
df_hmd_90 <- df_hmd %>%
filter(age %in% 90:110) %>%
group_by(country) %>%
summarise(ratio = ratio %>% mean(na.rm = T)) %>%
ungroup() %>%
transmute(country, age = 90, ratio)
# insert summarized 90+
df_hmd_fin <- bind_rows(df_hmd %>% filter(!age %in% 90:110), df_hmd_90)
# finaly - plot
df_hmd_fin %>%
ggplot(aes(age, ratio, color = country, group = country))+
geom_hline(yintercept = 100, color = "grey50", size = 1)+
geom_line(size = 1)+
scale_y_continuous(limits = c(0, 120),
expand = c(0, 0),
breaks = seq(0, 120, 20))+
scale_x_continuous(limits = c(0, 90),
expand = c(0, 0),
breaks = seq(0, 80, 20))+
facet_wrap(~country, ncol = 6)+
theme_minimal(base_family = "mono", base_size = 15)+
theme(legend.position = "none",
panel.border = element_rect(size = .5, fill = NA,
color = "grey50"))+
labs(x = "Age",
y = "Sex ratio, males per 100 females",
title = "Sex ratio in all countries from Human Mortality Database",
subtitle = "HMD 2012, via HMDHFDplus by @timriffe1",
caption = "ikashnitsky.github.io")
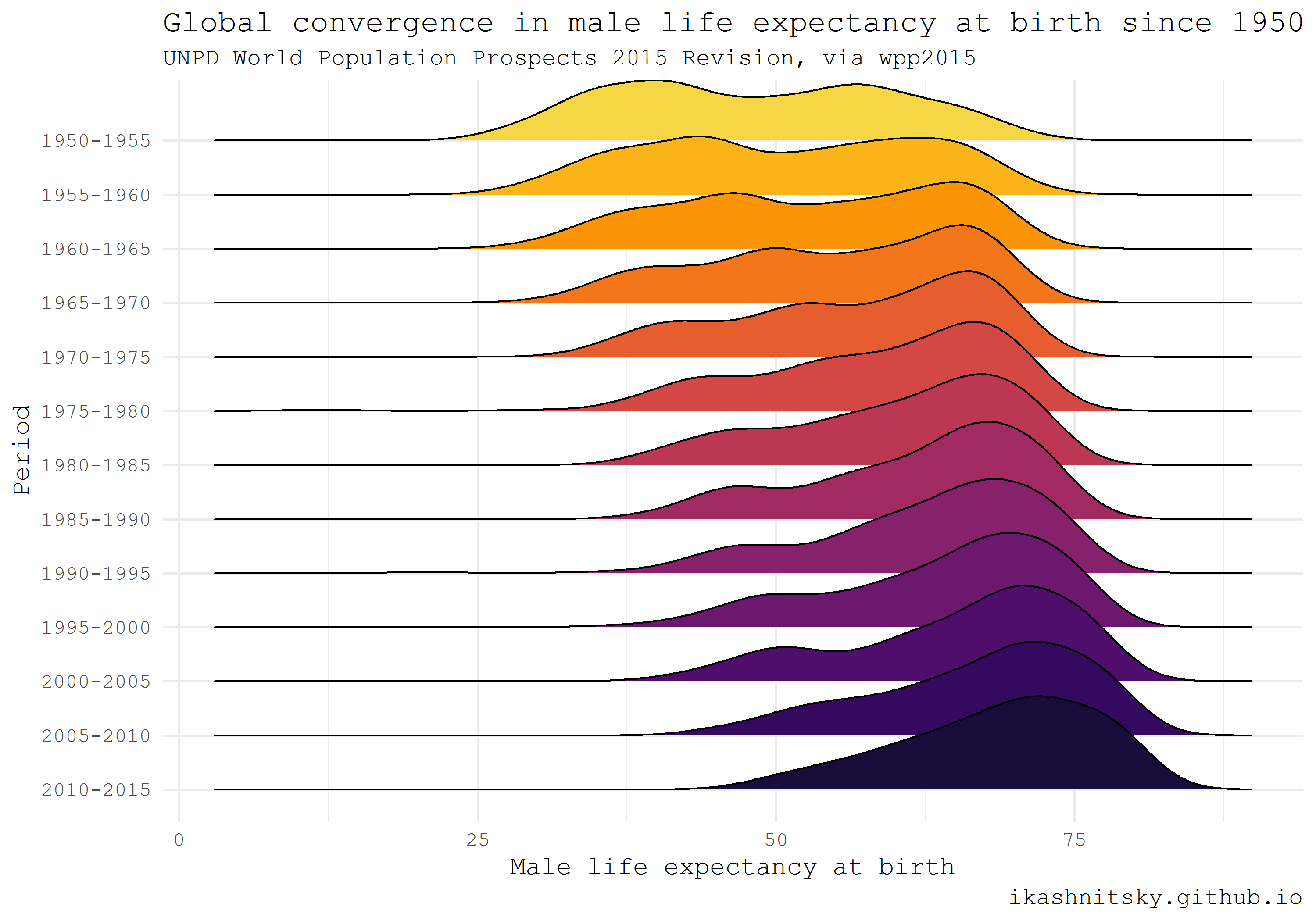
United Nations World Population Prospects
Департамент народонаселения ООН публикует высококачественные оценки и прогноз численности населения для всех стран мира. Расчеты обновляются каждые 2-3 года и публикуются в открытом доступе в виде интерактивного отчета World Population Prospects. Эти отчеты содержат очень общий дескриптивный анализ и, конечно, богатые данные. Данные доступны в R в специальных пакетах, которые имеют названия вида wpp20xx. На сегодняшний день доступны данные для релизов 2008, 2010, 2012, 2015, и 2017 годов. Здесь я приведу пример использования данных wpp2015, взятый из моего предыдущего поста.
Используя тип визуализации ridgeplot, который этим летом получил вирусную популярность (под предыдущим, ныне отвергнутом, названием ggjoy) этим летом благодаря блестящему пакету ggridges Claus Wilke, я покажу впечатляющую конвергенцию ожидаемой продолжительности жизни при рождении у мужчин в мире с 1950 года.
library(wpp2015)
library(tidyverse)
library(ggridges)
library(viridis)
# get the UN country names
data(UNlocations)
countries <- UNlocations %>% pull(name) %>% paste
# data on male life expectancy at birth
data(e0M)
e0M %>%
filter(country %in% countries) %>%
select(-last.observed) %>%
gather(period, value, 3:15) %>%
ggplot(aes(x = value, y = period %>% fct_rev()))+
geom_density_ridges(aes(fill = period))+
scale_fill_viridis(discrete = T, option = "B", direction = -1,
begin = .1, end = .9)+
labs(x = "Male life expectancy at birth",
y = "Period",
title = "Global convergence in male life expectancy at birth since 1950",
subtitle = "UNPD World Population Prospects 2015 Revision, via wpp2015",
caption = "ikashnitsky.github.io")+
theme_minimal(base_family = "mono")+
theme(legend.position = "none")
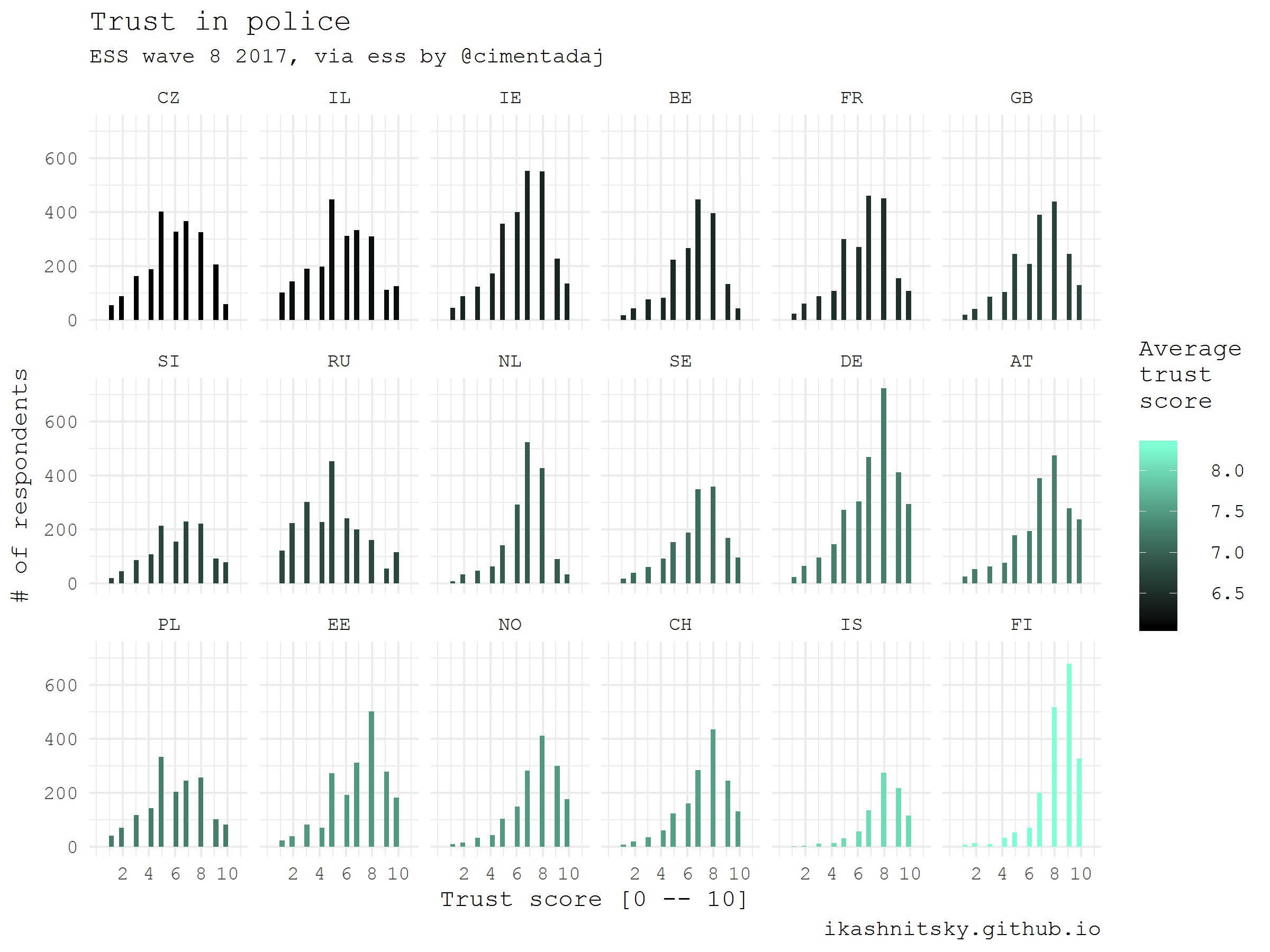
European Social Survey (ESS)
European Social Survey публикует уникально детальные данные о ценностях европейцев, репрезентативные на уровне стран и сопоставимые между странами. Каждые два года проводится очередная волна обследования в каждой из участвующих стран. Данные доступны после бесплатной регистрации. Датасеты распространяются в готовом виде для анализа с помощью SAS, SPSS, или STATA. Благодаря Jorge Cimentada мы имеем теперь возможность заполучить эти данные в готов виде и в R при помощи пакета ess. Я отображу как респонденты оценивали свой уровень доверия местной полиции во всех странах, участвовавших в последней волне опроса.
library(ess)
library(tidyverse)
# help gunction to see the available countries
show_countries()
# check the available rounds for a selected country
show_country_rounds("Netherlands")
# get the full dataset of the last (8) round
df_ess <- ess_rounds(8, your_email = ik_email)
# select a variable and calculate mean value
df_ess_select <- df_ess %>%
bind_rows() %>%
select(idno, cntry, trstplc) %>%
group_by(cntry) %>%
mutate(avg = trstplc %>% mean(na.rm = T)) %>%
ungroup() %>%
mutate(cntry = cntry %>% as_factor() %>% fct_reorder(avg))
df_ess_select %>%
ggplot(aes(trstplc, fill = avg))+
geom_histogram()+
scale_x_continuous(limits = c(0, 11), breaks = seq(2, 10, 2))+
scale_fill_gradient("Average\ntrust\nscore",
low = "black", high = "aquamarine")+
facet_wrap(~cntry, ncol = 6)+
theme_minimal(base_family = "mono")+
labs(x = "Trust score [0 -- 10]",
y = "# of respondents",
title = "Trust in police",
subtitle = "ESS wave 8 2017, via ess by @cimentadaj",
caption = "ikashnitsky.github.io")
American Community Survey and Census
Сразу несколько пакетов предоставляют доступ к данным переписей США и регулярных выборочных обследований домохозяйств (American Community Survey). Вероятно, наиболее красивая реализация создана недавно Kyle Walker — tidycensus. Kill-feature этого пакета заключается в возможности скачать пространственные данные вместе со статистическими данными. Пространственные данные скачиваются в виде simple features, революционного подхода к геоданным в R, недавно представленного в паекте sf Edzer Pebesma. Этот подход ускорят обработку годанных в десятки раз, при этом упрощая до невозможности код. Но подробности — в заключительном посте серии. Обратите внимание, что для отрисовки simple features нам потребуется установить development версию пакета ggplot2.
Карта ниже отражает медианный возраст населения в переписных трактах города Чикаго по данным ACS за 2015 год. Для добычи этих данных с помощью tidycensus придется сперва получить ключ API, что легко можно сделать при регистрации тут.
library(tidycensus)
library(tidyverse)
library(viridis)
library(janitor)
library(sf)
# to use geom_sf we need the latest development version of ggplot2
devtools::install_github("tidyverse/ggplot2", "develop")
library(ggplot2)
# you need a personal API key, available free at
# https://api.census.gov/data/key_signup.html
# normally, this key is to be stored in .Renviron
# see state and county codes and names
fips_codes %>% View
# the available variables
load_variables(year = 2015, dataset = "acs5") %>% View
# data on median age of population in Chicago
df_acs <- get_acs(
geography = "tract",
county = "Cook County",
state = "IL",
variables = "B01002_001E",
year = 2015,
key = ik_api_acs,
geometry = TRUE
) %>% clean_names()
# map the data
df_acs %>%
ggplot()+
geom_sf(aes(fill = estimate %>%
cut(breaks = seq(20, 60, 10))),
color = NA)+
scale_fill_viridis_d("Median age", begin = .4)+
coord_sf(datum = NA)+
theme_void(base_family = "mono")+
theme(legend.position = c(.15, .15))+
labs(title = "Median age of population in Chicago\nby census tracts\n",
subtitle = "ACS 2015, via tidycensus by @kyle_e_walker",
caption = "ikashnitsky.github.io",
x = NULL, y = NULL)
Приятных вам путешествий в мир открытых данных с R!
Комментарии (7)

jzha
28.12.2017 10:59Илья, здравствуйте. Спасибо за статью!
У меня вопрос немного в сторону — почему в примерах для ESS и ACS вы используете невзвешенные данные? Понятно, что это просто пример, но всё таки, например, поменяется упорядочение стран на графике для ESS.
ikashnitsky Автор
28.12.2017 15:29Спасибо! Хорошее замечание. Честный ответ — потому что не подумал. Но действительно, картинки тут только как примеры использования, не в них суть. Кроме того, этот материал я готовил для студентов, которым прививаю интерес к R через визуализацию данных.
ikashnitsky Автор
28.12.2017 15:36Кстати, не понял, где та же проблема с ACS?
jzha
29.12.2017 08:29Я подумал, что используется невзвешенная медиана. Возможно, это не так.
Кстати, доступ к сайту census.gov из России запрещен (по крайней мере, для некоторых интернет-провайдеров). В браузере эта проблема решаема. Можно ли так настроить tidycensus, чтобы был доступ к данным ACS из России, может вы знаете?
jzha
28.12.2017 11:11Любопытно сравнить гистограммы Ирландии (IE) и России (RU) в примере для ESS данных. Навскидку ожидаешь видеть цвет у Ирландии немного светлее, чем у России, а не так как оно есть на самом деле. Если сравнить взвешенные медианы, то для России получается 5, для Ирландии — 7.
WizardryIB
Огромное спасибо!
Хочу ещё!!!)
ikashnitsky Автор
Спасибо! Еще будет про геоданные и карты, вероятно, под конец января, и сперва в моем блоге. Если хотите немного "забежать вперед", можете пройтись по моему коду (gist) к этому посту. Вся карта воссоздается с нуля этим кодом.