
Random numbers should not be generated with a method chosen at random.
— Donald Knuth
Копаясь как-то в исходниках одного сервиса в поисках уязвимостей, я наткнулся на генерацию одноразового кода для аутентификации через SMS. Обработчик запросов на отправку кода упрощённо выглядел так:
class AuthenticateByPhoneHandler
{
/* ... */
static string GenerateCode() => rnd.Next(100000, 1000000).ToString();
readonly static Random rnd = new Random();
}Проблема видна невооруженным глазом: для генерации 6-тизначного кода используется класс Random — простой некриптографический генератор псевдослучайных чисел (ГПСЧ). Займёмся им вплотную: научимся предсказывать последовательность случайных чисел и прикинем возможный сценарий атаки на сервис.
Потокобезопасность
Кстати, заметим, что в приведённом фрагменте кода доступ к статическому экземпляру rnd класса Random из нескольких потоков не синхронизирован. Это может привести к неприятному казусу, который можно часто встретить в вопросах и ответах на StackOverflow:
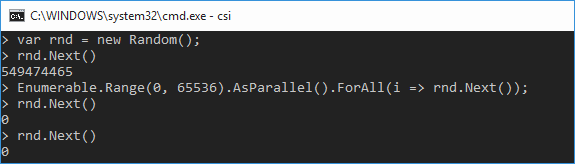
То есть первый сценарий атаки прост — шлём на сервер множество параллельных запросов на отправку SMS, в результате экземпляр класса Random оказывается в весьма плачевном состоянии.
Однако, эта атака слишком грубая. Кроме того, нарушать работоспособность сервиса в планы не входило. Поэтому перейдём к предсказанию кодов, отправляемых в SMS.
Потрошим Random.cs
В документации написано, что класс Random реализует алгоритм генерации случайных чисел методом вычитания, предложенный Дональдом Кнутом во втором томе «Искусства программирования», это вариация запаздывающего генератора Фибоначчи.
Забавно, что алгоритм реализован с опечаткой. Генератор инициализируется значениями, которые отличаются от описанных Кнутом, поэтому свойства и период генерируемых чисел могут быть хуже ожидаемых. Microsoft решила не исправлять реализацию, чтобы не ломать обратную совместимость. Вместо этого в документации появилась оговорка про «модифицированную» версию алгоритма.
Так выглядит метод для генерации следующего псевдослучайного числа.
private int InternalSample()
{
int locINext = inext;
int locINextp = inextp;
if(++locINext >= 56) locINext = 1;
if(++locINextp >= 56) locINextp = 1;
var retVal = SeedArray[locINext] - SeedArray[locINextp];
if(retVal == int.MaxValue) retVal--;
if(retVal < 0) retVal += int.MaxValue;
SeedArray[locINext] = retVal;
inext = locINext;
inextp = locINextp;
return retVal;
}
private int inext = 0;
private int inextp = 21;
private readonly int[] SeedArray = new int[56];У генератора есть внутреннее состояние SeedArray из 56 int-ов (нулевой элемент не используется, поэтому на самом деле их 55). Новое псевдослучайное число получается путем вычитания двух чисел, расположенных во внутреннем состоянии c индексами inext и inextp. Это же число заменяет элемент внутреннего состояния с индексом inext.
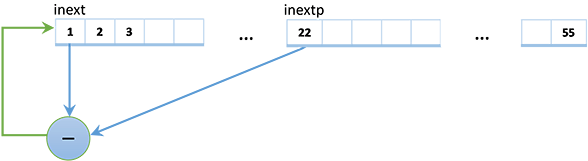
Это означает, что для предсказания следующего псевдослучайного числа не нужно знать теорию аддитивных случайных генераторов, а достаточно лишь узнать текущее внутреннее состояние генератора. И это можно сделать на основе его выходных значений.
Предсказываем будущее
В качестве предсказателя будем использовать экземпляр того же класса Random, в котором через рефлексию заменим внутреннее состояние SeedArray. Для заполнения внутреннего состояния потребуется функция, обратная к преобразованию произвольного Int32-числа из внутреннего состояния к диапазону [min;max):
public static int GetInternalStateValue(int minValue, int maxValue, int value)
{
var range = maxValue - minValue; // Не учитываем случай range > int.MaxValue
return (int) ((double) (value - minValue) / range * int.MaxValue);
}В этом методе используются операции с вещественными числами, поэтому мы получим лишь приближённое значение внутреннего состояния. Напишем тест, чтобы узнать, насколько велика погрешность на нашем диапазоне [100000; 1000000):
var rnd = new Random(31337);
var seedArray = new[] {0}.Concat( // Нулевой элемент SeedArray не используется
Enumerable.Range(0, 55)
.Select(i => rnd.Next(Min, Max))
.Select(val => GetInternalStateValue(Min, Max, val)))
.ToArray();
var predictor = new Random();
typeof(Random)
.GetField("SeedArray", BindingFlags.Instance | BindingFlags.NonPublic)
.SetValue(predictor, seedArray); // Инициализируем предсказатель
for(int i = 0; i < 10; i++)
Console.WriteLine($"{rnd.Next(Min, Max)} vs {predictor.Next(Min, Max)}");Получим:
103753 vs 103754 // (+1)
617169 vs 617169
523211 vs 523211
382862 vs 382862
516139 vs 516140 // (+1)
555187 vs 555187
384855 vs 384856 // (+1)
543554 vs 543553 // (-1)
327867 vs 327867
745153 vs 745153Вуаля! Теперь можно, зная последовательность из 55 чисел, почти точно предсказывать следующие псевдослучайные числа из нужного диапазона.
После предсказания (55 – 21 = 34) чисел ошибка нарастает, и лучше заново инициализировать предсказатель.
Сценарий атаки
Для осуществления атаки нужно учесть ещё один нюанс. У уязвимого сервиса было несколько реплик, запросы на которые балансировались случайным образом. Можно было бы проверить еще и случайность балансировки, но этого не потребовалось — ответ сервера содержал HTTP-заголовок с именем реплики сервиса.
Кроме того, в сервисе было ограничение — не более 3 SMS на один номер. Однако это легко обойти через любой бесплатный сервис для приёма SMS, который предоставляет пул телефонных номеров.
Теперь вся мозаика в сборе. Сценарий атаки будет такой:
- Выбираем время, когда поток запросов на сервис минимален, чтобы избежать генерации псевдослучайных чисел другими пользователями.
- Используя номера телефонов из пула, получаем N ? 55 SMS с кодами для входа, где N — число реплик сервиса.
- Используя метод
GetInternalStateValueдля обратного преобразования чисел из диапазона, заполняем внутренние состояния N экземпляров генератора случайных чисел. - Отправляем SMS на интересующий телефонный номер, предсказываем отправленный код, входим в сервис под чужой учетной записью.
- Если код не подходит (предполагаем, что из-за погрешности при работе с вещественными числами), пробуем (+1) и (-1).
- Берем следующий интересующий телефон...
Вывод
Предсказание будущего для экземпляра Random — дело нехитрое.
Предсказание прошлого тоже не проблема. Для этого нужно точно так же инициализировать внутреннее состояние генератора, а затем «обратить» метод InternalSample и отмотать назад 55 уже известных значений.При использовании Random нужно не забывать о синхронизации доступа либо использовать ThreadStatic-экземпляры. При создании нескольких экземпляров, необходимо позаботиться о seed, чтобы не получить множество одинаково инициализированных объектов.
В критичных для безопасности местах нужно использовать криптографически стойкий и потокобезопасный RNGCryptoServiceProvider и не раскрывать лишнюю информацию об окружении.
Ссылки по теме
- Исходный код теста предсказателя
- Разбор реализаций ГПСЧ в стандартных библиотеках C, Java, .NET и PHP
- Обсуждение ошибки в реализации Random
- Статья о влиянии опечатки в реализации Random на качество псевдослучайных чисел
- Статья про влияние ошибок округления операций с вещественными числами в реализации Random на распределение псевдослучайных чисел
Комментарии (31)


Tsvetik
30.01.2018 15:16+1Объясните пожалуйста тупому, почему в первом примере rnd.Next() всегда возвращает 0

xi-tauw
30.01.2018 15:34The System.Random class and thread safety
Instead of instantiating individual Random objects, we recommend that you create a single Random instance to generate all the random numbers needed by your app. However, Random objects are not thread safe. If your app calls Random methods from multiple threads, you must use a synchronization object to ensure that only one thread can access the random number generator at a time. If you don't ensure that the Random object is accessed in a thread-safe way, calls to methods that return random numbers return 0.mayorovp
30.01.2018 15:38Но каков механизм появления этих нолей?
xi-tauw
30.01.2018 16:32+3В конструкторе Random устанавливаются значения inext в 0, inextp в 21. При безопасном использовании это расстояние сохраняется.
Смотрим на InternalSample (есть в статье).
Вангую, что из-за доступа из разных потоков к переменным inext и inextp может происходить рассинхронизация и расстояние между ними не всегда будет постоянным. Если так вдруг случилось, что inext и inextp совпали, то за 55 вызовов массив SeedArray весь обнулится. Далее все «случайные» числа будут высчитываться как 0 — 0.
dmih
30.01.2018 16:56+2Про забавную совместимость забавно, у меня использовался как-то string.GetHash() и между версиями 1.1 и 2 в .NET они его поменяли.
Поскольку функция была не особо часто используемой, но нужной для инфраструктурной совместимости, родилось public static int GetHashCode11 (string str), и чтобы особо не париться, сделано это было через вызов StringGetHashCode11.exe.
И на всех серверах стоит .NET 1 для этого :)
Ужосы какие, наверное про изменение хеша в общем тоже кто-то где-то статью написал. А с рандомом вот решили не делать.DistortNeo
30.01.2018 18:35+1> Про забавную совместимость забавно, у меня использовался как-то string.GetHash() и между версиями 1.1 и 2 в .NET они его поменяли.
Что увидительно, и про GetHashCode, и про Random написано одинаково, что их реализация от платформы к платформе может отличаться.
Note that the example may produce different sequences of random numbers if run on different versions of the .NET Framework.dmih
30.01.2018 18:44Я особо и не против, у меня много такой мякоты, но вся она находится в namespace Darwin от слова премия :)
dmih
30.01.2018 18:59… в ту же степь там всякие переходники ремоутинга, сериализации, биндеры какие-то,
я просто с уважением отношусь к legacy коду, его к сожалению очень много накапливается за года, но если он хорошо работает, то часто лучше адаптироватьсяDistortNeo
30.01.2018 19:15я просто с уважением отношусь к legacy коду, его к сожалению очень много накапливается за года, но если он хорошо работает, то часто лучше адаптироваться
То есть если код нарушает спецификации, его все равно можно считать хорошо работающим? Просто интересно, как вы использовали GetHashCode, что смена его реализации для вас оказалась критичной.
dmih
30.01.2018 19:19У меня результатом работы этого когда динамически создаваемые базы данных названы. И с ними по крайней мере какое-то время должны были работать и старый, и новый код, находя их.
Ну это очень странный случай поперек всех современных гайдлайнов, да, но когда это писалось, программирование так в целом по индустрии было несколько в другом состоянии, и у меня в частности тоже.
Вообще много таких примеров на самом деле. Зависит от того, дорог ли вам как память код 20-летней давности. Я не сторонник рефакторинга раз в 5 лет, если он и так отлично работает. До определенного предела конечно.
Но такие вот особо одаренные случаи как результат тоже неизбежны.DistortNeo
30.01.2018 22:49Вполне верю. Взять тот же C/C++ — до распространения 64-битных архитектур никто не заморачивался над размером указателя, да и не было гайдлайнов на эту тему.
dmih
30.01.2018 19:24Некоторые фрагменты кода из прошлого века сейчас нормально так работают, преимущественно C/CPP конечно, некоторые конечно выкинуты. Некоторые вообще на умерших языках типа managed extensions для CLR первой версии, которую зарубили.
Переписывать это — трудозатраты часто совершенно не оправданы.
Это всё только взгляд с перспективы десятков лет, конечно. Так вот сев подумав, «да я всё перепишу», но когда кода реально много, иногда переписывать — это просто полная дурь.
w1ld
30.01.2018 20:16Спасибо, интересно видеть, как на практике это можно взломать.
При использовании Random нужно не забывать о синхронизации доступа либо использовать ThreadStatic-экземпляры. При создании нескольких экземпляров, необходимо позаботиться о seed, чтобы не получить множество одинаково инициализированных объектов.
Не понимаю. Т.е. рекомендация такая. Делай один уникальный Random для каждого потока (ThreadStatic). Т.к. если один Random для многих потоков, то его легче предсказать. А как о seed заботиться? Количество тиков из DateTime по какому-нибудь модулю брать или как?
mayorovp
30.01.2018 20:34Можно брать seed из другого рандома или из RNGCryptoServiceProvider.

dscheg Автор
30.01.2018 21:01w1ld Количество тиков (Environment.TickCount) и так используется в конструкторе Random по умолчанию, его нежелательно использовать в сценарии ThreadStatic экземпляров, потому что тогда seed может оказаться одинаковым для всех экземпляров (потоков), если конструктор будет вызван одновременно. Обычно используют один статический экземпляр Random, как предложилmayorovp, для получения случайных seed (под локом), которыми, в свою очередь, инициализируют ThreadStatic экземпляры.

PsyHaSTe
30.01.2018 21:55У меня например в однострочник реализовано:
private static readonly ThreadLocal<Random> Random = new ThreadLocal<Random>( () => new Random(Environment.TickCount ^ Thread.CurrentThread.ManagedThreadId) );
Просто и удобно
Hixon10
30.01.2018 21:28не раскрывать лишнюю информацию об окружении.
Плохой совет, на мой вкус. Security through obscurity же.lorc
30.01.2018 21:37Сложный вопрос. Компьютер же — детерминированная штука. Так что либо нужно генерировать случайные числа с помощью квантового генератора, либо не подпускать атакующего на такое расстояние, где он может знать полное окружение.
lorc
30.01.2018 21:42К тому же, я сомневаюсь что этот принцип вообще применим в данном случае. Ведь сокрытие ключа шифрования — это не «Security through obscurity», не так ли? То же самое относится и к внутреннему состоянию ГПСЧ.
Hixon10
30.01.2018 21:45Если я правильно понял автора статьи, то этой фразой он хотел сказать: «ответ сервера, который содержит HTTP-заголовок с именем реплики сервиса — это зло».
Хотя, как мне кажется, это вполне нормальная информация, которая может быть частью Public-api, и использоваться например для клиентской балансировки.dscheg Автор
30.01.2018 22:25+1Да, под раскрытием информации я имел в виду имя реплики. Действительно спорный совет, безопасность зачастую противоречит удобству (отладки в данном случае). И всё же эта информация помогла в данном сценарии атаки. Другой пример раскрытия информаци — стэктрейсы, тоже помогают в отладке, но показывать их потенциальному злоумышленнику не кажется хорошей идеей.
green_hippo
30.01.2018 23:22Секундочу, но ведь security through obscurity — не про то! Принцип не говорит, что нужно дать атакующему всю информацию об устройстве [криптографической] системы, кроме условного «закрытого ключа». Он говорит, что не нужно полагаться на неосведомлённость атакующего как на главную защитную меру. А как на дополнительную — конечно же, можно и нужно полагаться.
Управление рисками, в том числе безопасности, подчиняется экономическим законам. Если затраты на атаку превышают выгоду от неё, нарушитель трижды подумает. Особенно если за ним не стоит большое государство или корпорация с, условно, неограниченными ресурсами. Именно поэтому раскрытие лишней информации о системе вредно — снижаются затраты на атаку, возрастает её вероятность.
Но что же я такое говорю! Конечно же, нужно передавать в HTTP-заголовках все названия и версии используемых языков программирования, фреймворков, middleware и операционных систем, сделать доступной из браузера папку .git, закоммитить node_modules, опубликовать Dockerfile-ы, а лучше сразу выкладывать списки уязвимостей с cve.mitre.org, которые ещё не закрыты, чтобы атакующие не подумали, что от них что-то скрывают (:
Hixon10
30.01.2018 23:50А как на дополнительную — конечно же, можно и нужно полагаться.
1)
Меня, если честно, очень эта фраза цепляет. Давайте рассмотрим криптографическую систему с закрытым ключом. Эта система устойчива до тех пор, пока:
1) Не доказано, что P == NP — en.wikipedia.org/wiki/P_versus_NP_problem
2) Закрытый ключ не скомпрометирован.
3) Вычислительные мощности находятся на примерно таком же уровне. Например, никто не построил себе кластер из миллиарда машин, либо квантовые компьютеры не стали стабильными, или ещё что-то.
Вы гововрите: «можно скрывать информацию о системе, для того чтобы использовать это, как дополнительный уровень зищиты». Я не очень понимаю, что бы это могло значить. Ваша система уже секьюрна, пока выполняются эти 3 условия. Либо мы пытаемся играть в: «наша система не секьюрна, но сломать её экономически дорого, так как ни у кого нет доступа до кода из вне, и т.д.».
2)
Честно, я немного не понял про версии софта в заголовках, и публичные Dockerfile.
a) Если ваш сервис работает на Некотором Софте, и в этой версии Софта нашли уязвимость, ваша система может быть взломана, вопрос лишь времени (ну да, если наша позиция — не сделать секьюрную систему, а сделать дорого взламываемую систему — это ок).
b) Что секретного в ваших Dockerfile? Вы храните там Secrets? Ну, в этом случае вы не следуете общепринятым практикам, и вина на вас. Это как хранить пароли в базке.green_hippo
31.01.2018 00:46Мы разошлись во мнениях потому, что говорим о разных «системах». Про security through obscurity уместно вспоминать в разговоре об абстрактных моделях (в частности, криптографических систем).
В разговоре про системы из реального мира, которые реализуют эти модели, — неуместно. Потому что в реальном мире любое условие может быть нарушено и будет нарушено, если это экономически выгодно. Например, любой закрытый ключ, имеющий физическое представление (в виде байт на диске или клеток в мозге), может быть скомпрометирован, если имеющие к ключу доступ приобретут должную мотивацию.
Поэтому писать на сайте компании «наш сисадмин Вася живёт по такому-то адресу, у него больные родители, заурядная зарплата и грабительский процент по ипотеке» — можно, но неосмотрительно. Это упростит реализацию атаки по некоторым из возможных векторов.

VladimirKochetkov
31.01.2018 15:58+1Утилитка, автоматизирующая атаку синхронизации с PRNG для нескольких языков/платформ (включая дотнетовский System.Random): Untwister
Scratch
Это в самом Контуре такие сервисы пишут?
dscheg Автор
Ну что вы, как вы могли такое подумать? ;)
На самом деле, да, это код 2014 года, примерно тогда же проблема была исправлена. Однако задачка показалась мне интересной, чтобы немного покопаться в теме.