

Фото: Jesse Darland с Unsplash
В этой статье речь пойдёт о том, как перенести процесс предварительной обработки изображений с сервера приложений на абсолютно бессерверную архитектуру платформы AWS.
Суть проблемы
Если веб-приложение позволяет загрузить изображение, скорее всего его необходимо обработать перед тем, как показать пользователю.
В статье будет рассказано о бессерверной архитектуре на основе платформы AWS, которая предоставляет широкие возможности для масштабирования.
В одном из моих последних проектов (веб-приложение для торговли, при работе с которым пользователю необходимо загружать изображение товара) исходное изображение сначала обрезается по соотношению сторон 4:3. Затем оно преобразуется в три разных формата, используемых в различных элементах пользовательского интерфейса: 800x600, 400x300 и 200x150.
Будучи разработчиком фреймворка Ruby on Rails, я в первую очередь решил попробовать пакеты RubyGem, а именно Paperclip или Dragonfly, которые используют для обработки изображений набор ImageMagick.
Это довольно простой подход, но у него есть свои недостатки:
- Изображения обрабатываются на сервере приложений. Это может привести к увеличению общего времени отклика из-за повышенной нагрузки на процессор.
- Сервер приложений имеет ограниченную производительность и не подходит для скачкообразной обработки запросов. Если требуется одновременно обработать множество изображений, он может оказаться полностью загружен на долгое время. Повышение производительности сервера, в свою очередь, приведёт к увеличению затрат.
- Изображения обрабатываются последовательно. Опять же, если требуется сразу обработать много изображений, это будет долго.
- Если вышеописанные пакеты настроены неправильно, обработанные изображения будут сохраняться на диске, что может быстро привести к нехватке свободного места на сервере.
В общем, если в приложении обрабатывается достаточно большое количество изображений, это решение не масштабируется.
Решение
Если присмотреться к процессу предварительной обработки изображений, можно понять, что в большинстве случаев нет необходимости в его выполнении непосредственно на сервере приложений. Это особенно актуально, если всегда осуществляются одни и те же преобразования, которые не требуют других данных, кроме самого изображения. Так было и в моём случае: я всегда только и делал, что создавал несколько изображений разного размера, оптимизируя их уровень качества.
Как только стало понятно, что эту задачу можно легко отделить от остальной логики приложения, на ум сразу же пришла мысль о бессерверном решении, которое будет просто брать исходное изображение в качестве входных данных и выполнять все необходимые преобразования.
Оказалось, сервис AWS Lambda идеально подходит для этой цели. Он способен обрабатывать тысячи запросов в секунду, при этом платить надо только за фактическое время вычислений. Если же код не выполняется, то и денег с вас требовать не будут.
Сервис AWS S3 предлагает неограниченное хранилище по низкой цене, а служба AWS SNS обеспечивает простой обмен сообщениями по модели «издатель-подписчик» для микросервисов, распределённых систем и бессерверных приложений. Наконец, AWS Cloudfront используется в качестве сети доставки контента для изображений, хранящихся в S3.
Сочетание этих четырёх услуг AWS даёт нам мощное решение для обработки изображений при минимальных затратах.
Высокоуровневая архитектура
Создание различных версий изображения из одного исходного начинается с загрузки оригинала в AWS S3. Затем с помощью AWS SNS запускается функция AWS Lambda, которая отвечает за создание новых версий и их повторную загрузку в AWS S3. Более подробно процесс выглядит так:
- Изображения загружаются в определённую папку внутри бакета AWS S3.
- Каждый раз, когда в эту папку загружается новое изображение, сервис отправляет сообщение с S3-ключом созданного объекта в топике AWS SNS.
- AWS Lambda, настроенная как пользователь в том же топике SNS, считывает сообщение и использует этот ключ для извлечения нового изображения.
- AWS Lambda обрабатывает изображение, выполняя необходимые преобразования, и затем загружает его обратно в S3.
- Обработанные изображения демонстрируются пользователям. В целях оптимизации скорости загрузки для этого используется сеть доставки контента AWS Cloudfront.
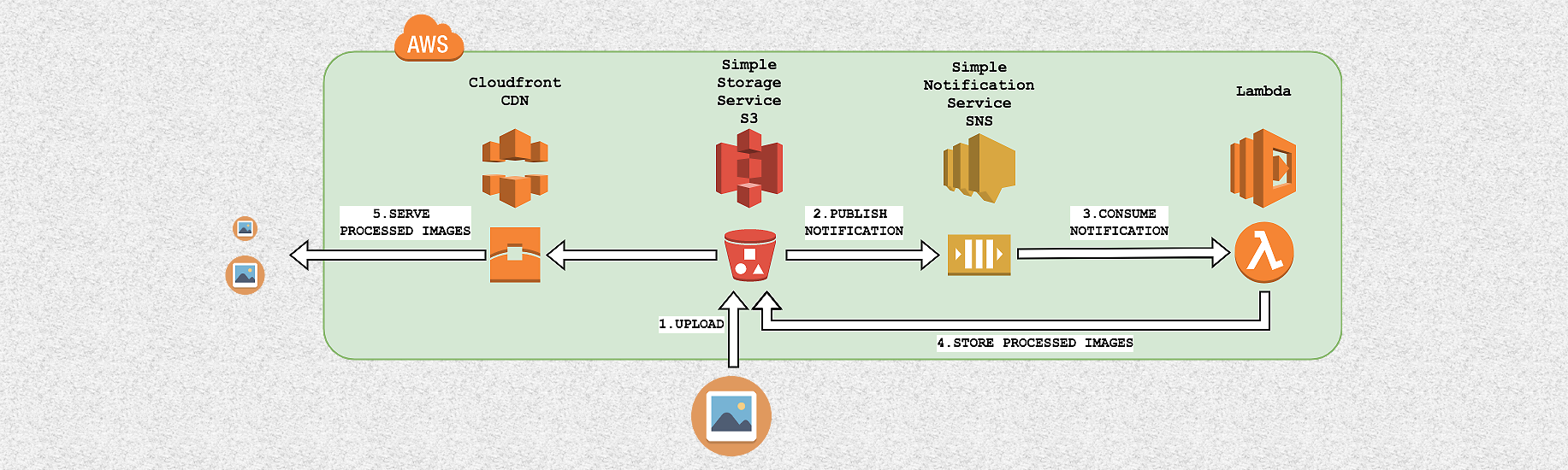
Эта архитектура легко масштабируется, так как каждое загруженное изображение инициирует новое выполнение кода Lambda для обработки конкретного запроса. Таким образом, множественное выполнение кода позволяет обрабатывать тысячи изображений одновременно.
Дисковое пространство и вычислительные ресурсы сервера приложений не используются, так как все данные хранятся в S3 и обрабатываются службой Lambda.
И наконец, настройка сети доставки контента для S3 очень проста и позволяет поддерживать высокую скорость загрузки в любой точке мира.
Пошаговая инструкция
Реализация этого решения не очень сложная, поскольку в основном (за исключением кода Lambda, который выполняет предварительную обработку изображений) включает в себя лишь настройку. Далее в статье подробно описывается, как настроить архитектуру AWS. А чтобы вы могли в полной мере оценить её работу, также приводится код AWS Lambda для изменения размера загруженного изображения.
Чтобы опробовать его самостоятельно, вам понадобится учётная запись AWS. Вы можете создать её и воспользоваться бесплатным стартовым пакетом AWS здесь.
Шаг 1: создание топика в AWS SNS
Прежде всего необходимо настроить новый топик SNS (Simple Notification Service), куда AWS будет публиковать сообщения каждый раз, когда в S3 загружается новое изображение. Такое сообщение содержит S3-ключ объекта, используемый впоследствии функцией Lambda для извлечения и обработки изображения.
Из консоли AWS зайдите на страницу SNS, нажмите Create topic и введите название топика, например, image-preprocessing.

Затем нужно изменить политику топика, чтобы позволить бакету S3 публиковать сообщения.
На странице топика нажмите Actions -> Edit Topic Policy, выберите Advanced view, добавьте следующий блок JSON (с указанием собственных имён ресурсов Amazon (arn) в строках Resource и SourceArn) в массив Statement и обновите политику:
{
"Sid": "ALLOW_S3_BUCKET_AS_PUBLISHER",
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": [
"SNS:Publish",
],
"Resource": "arn:aws:sns:us-east-1:AWS-OWNER-ID:image-preprocessing",
"Condition": {
"StringLike": {
"aws:SourceArn": "arn:aws:s3:*:*:YOUR-BUCKET-NAME"
}
}
}Пример полного JSON-текста политики здесь.
Шаг 2: создание структуры папок AWS S3
Теперь нужно подготовить структуру папок в S3, в которых будут храниться исходные и обработанные изображения. В данном примере мы будем создавать версии изображения в двух размерах: 800x600 и 400x300.
Из консоли AWS откройте страницу S3 и создайте новый бакет. Я назову его image-preprocessing-example. Далее нужно создать в бакете папки с названиями originals, 800x600 и 400x300.
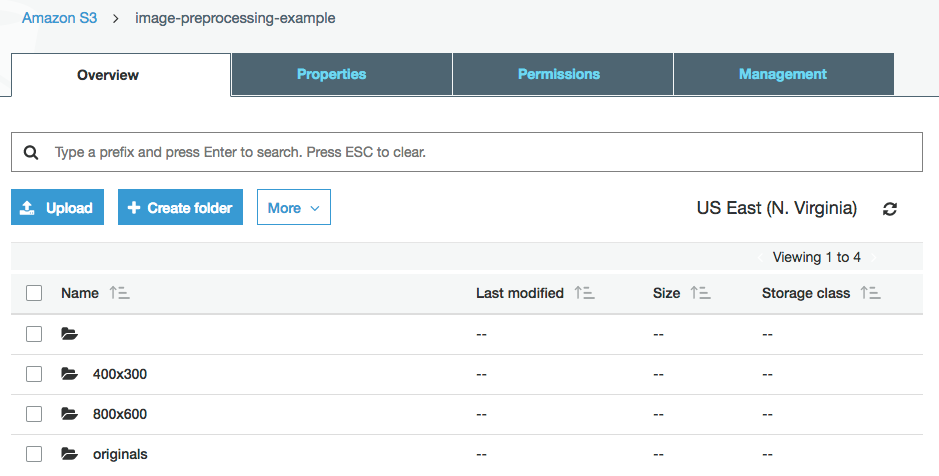
Шаг 3: настройка событий AWS S3
Каждый раз при загрузке нового изображения в папку originals S3 должен публиковать сообщение в топике image-preprocessing, чтобы это изображение можно было обработать.
Для настройки публикации таких сообщений откройте бакет S3 через консоль AWS, нажмите Properties -> Events -> Add notification и заполните следующие поля:
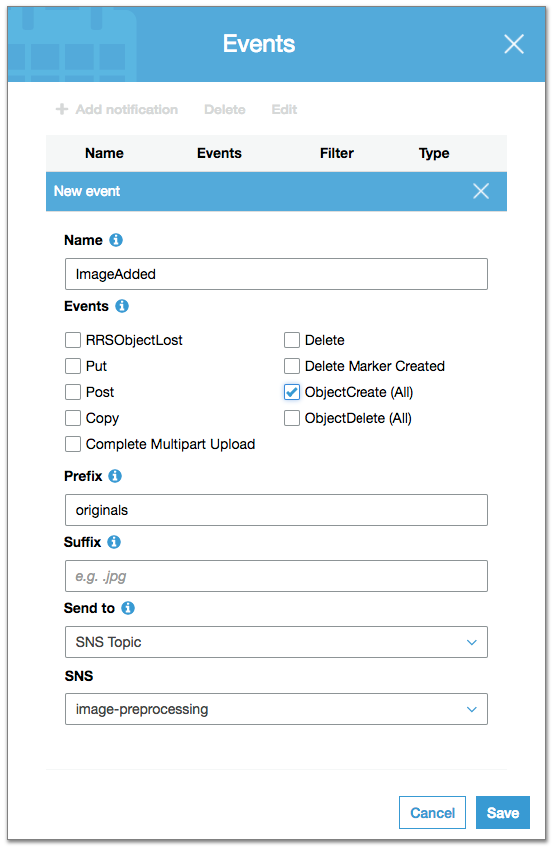
Здесь мы задаём правило для генерации события каждый раз, когда создаётся новый объект (чекбокс ObjectCreate) внутри папки originals (поле Prefix), и публикации этого события в SNS-топике image-preprocessing.
Шаг 4: настройка роли IAM для предоставления Lambda доступа к папке S3
Требуется создать функцию Lambda, которая будет скачивать изображения из папки S3, обрабатывать их и загружать обработанные версии обратно в S3. Но сначала необходимо настроить роль IAM, чтобы функция Lambda могла получить доступ к необходимой папке S3.
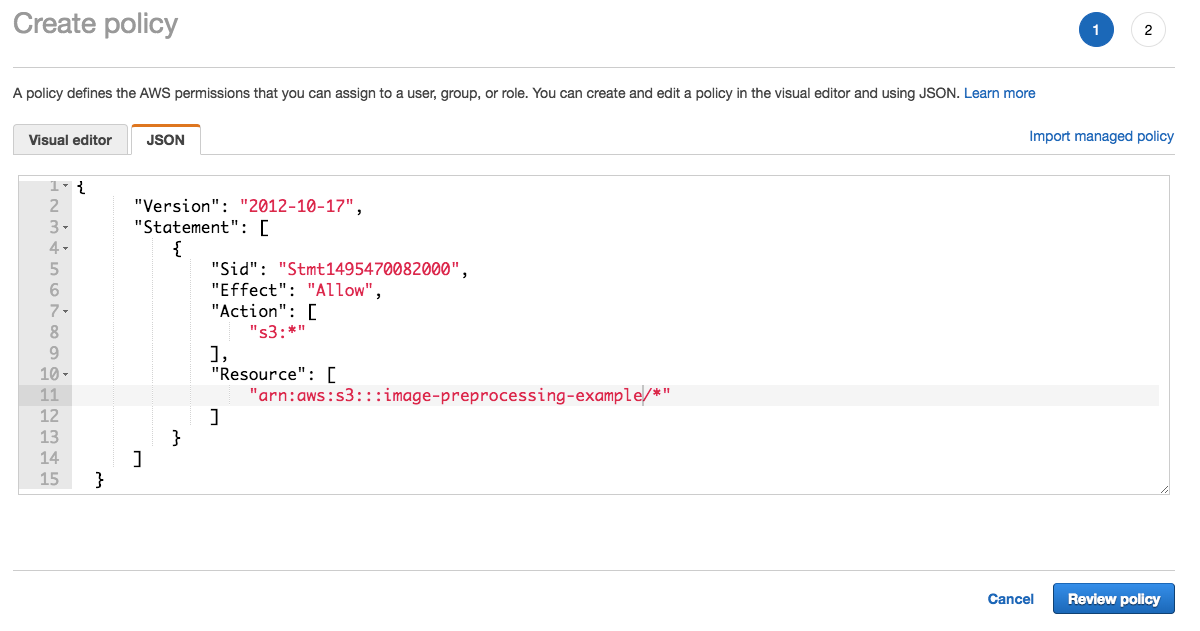
Из консоли AWS перейдите на страницу IAM:
- Нажмите Create Policy.
- Нажмите JSON и введите название своего бакета:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1495470082000",
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws:s3:::YOUR-BUCKET-NAME/*"
]
}
]
}Строка Resource относится к нашему бакету в S3. Нажмите Review, введите имя политики, например, AllowAccessOnYourBucketName, и создайте политику.
- Нажмите Roles -> Create role.
- Выберите AWS Service -> Lambda (служба, которая будет использовать политику).
- Выберите созданную ранее политику (AllowAccessOnYourBucketName).
- Теперь нажмите review, введите имя (LambdaS3YourBucketName) и нажмите Сreate role.
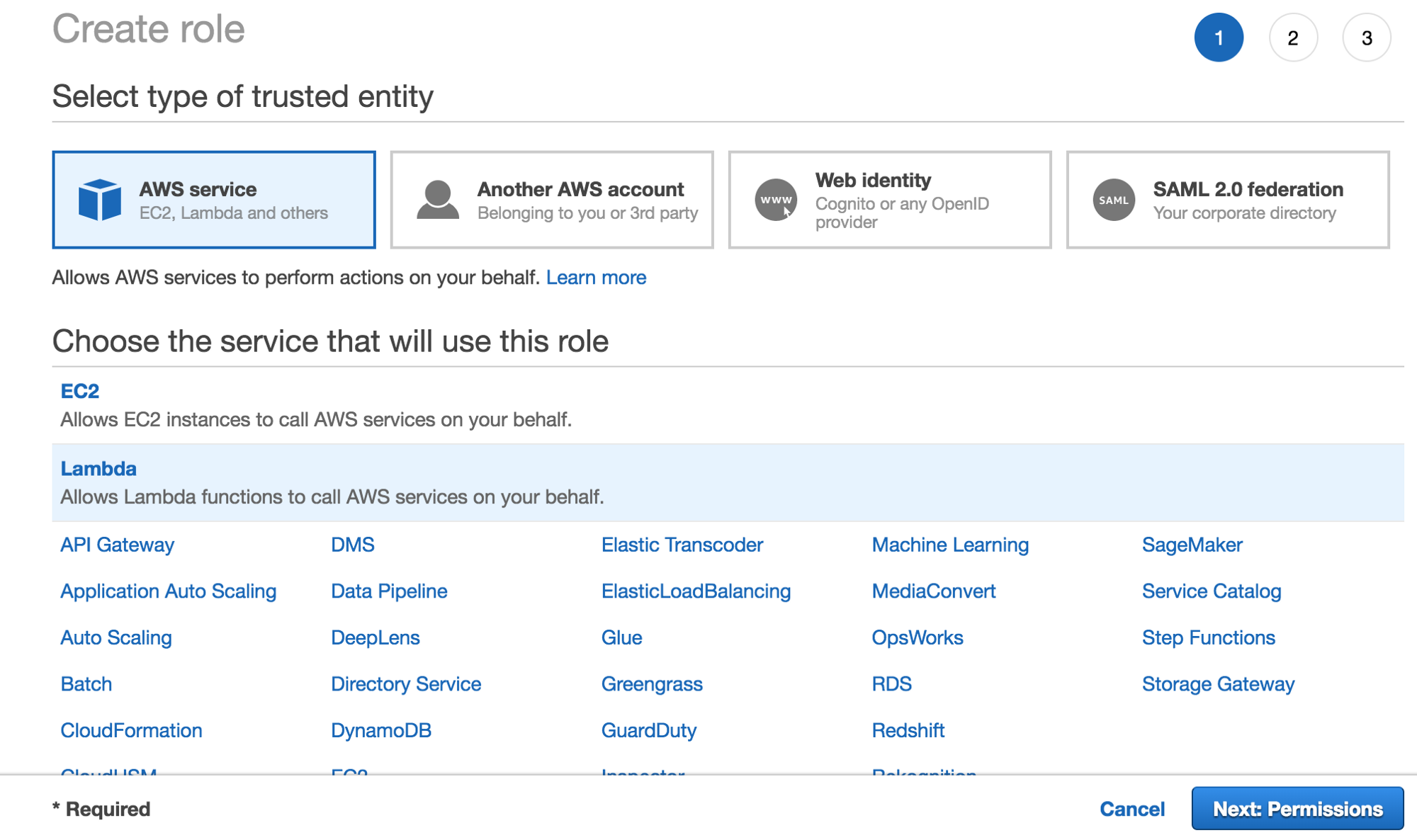
Создание роли
Lambda
Прикрепление политики к роли
Lambda
Сохранение роли
Шаг 5: создание функции AWS Lambda
Далее необходимо настроить функцию Lambda, чтобы она считывала сообщения из топика image-preprocessing и генерировала изменённые версии изображений.
Начнём с создания новой функции Lambda.
Из консоли AWS перейдите на страницу Lambda, нажмите Create function и введите имя новой функции, например, ImageResize. Выберите среду выполнения (в данном случае Node.js 6.10) и ранее созданную роль IAM.
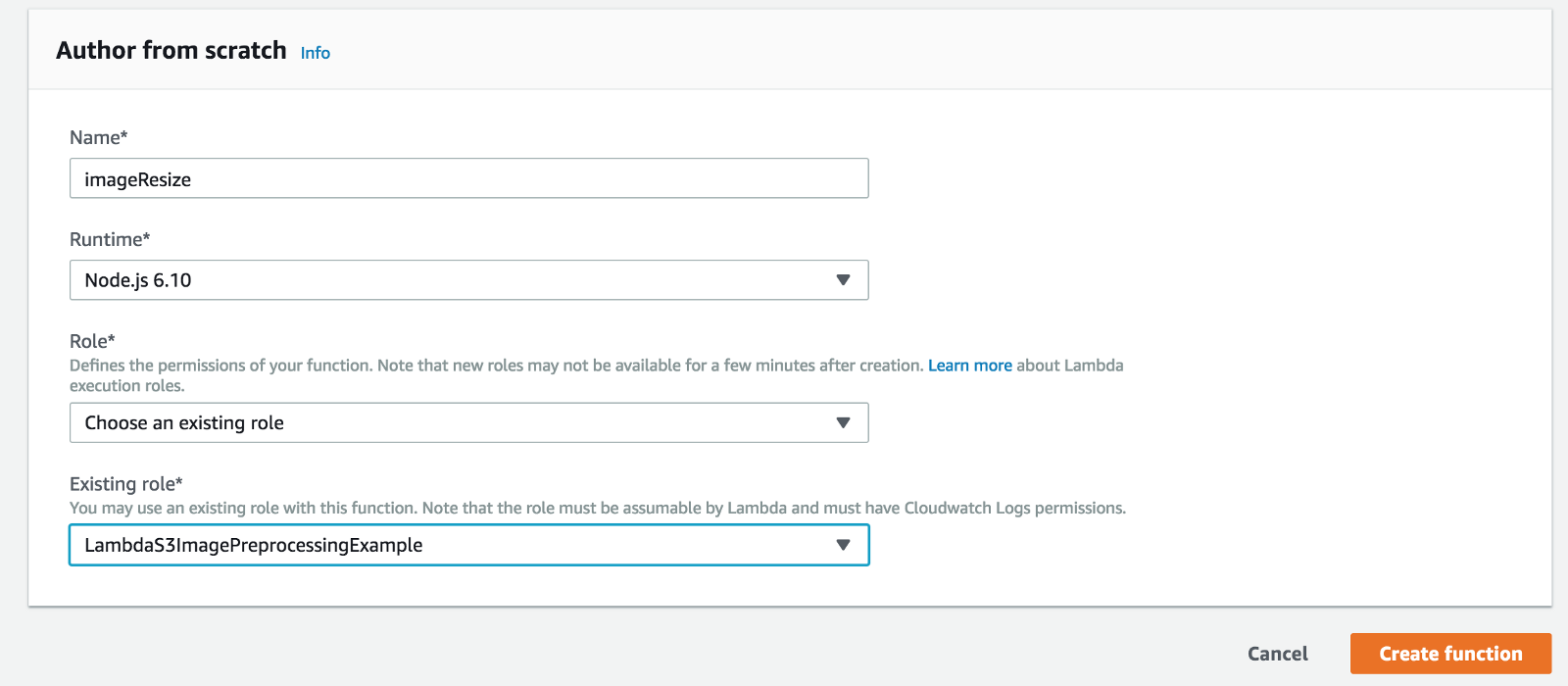
Затем нужно добавить SNS в число триггеров, чтобы функция Lambda вызывалась каждый раз, когда новое сообщение публикуется в теме image-preprocessing.
Для этого нажмите SNS в списке триггеров, выберите image-preprocessing в списке топиков SNS и нажмите Add.
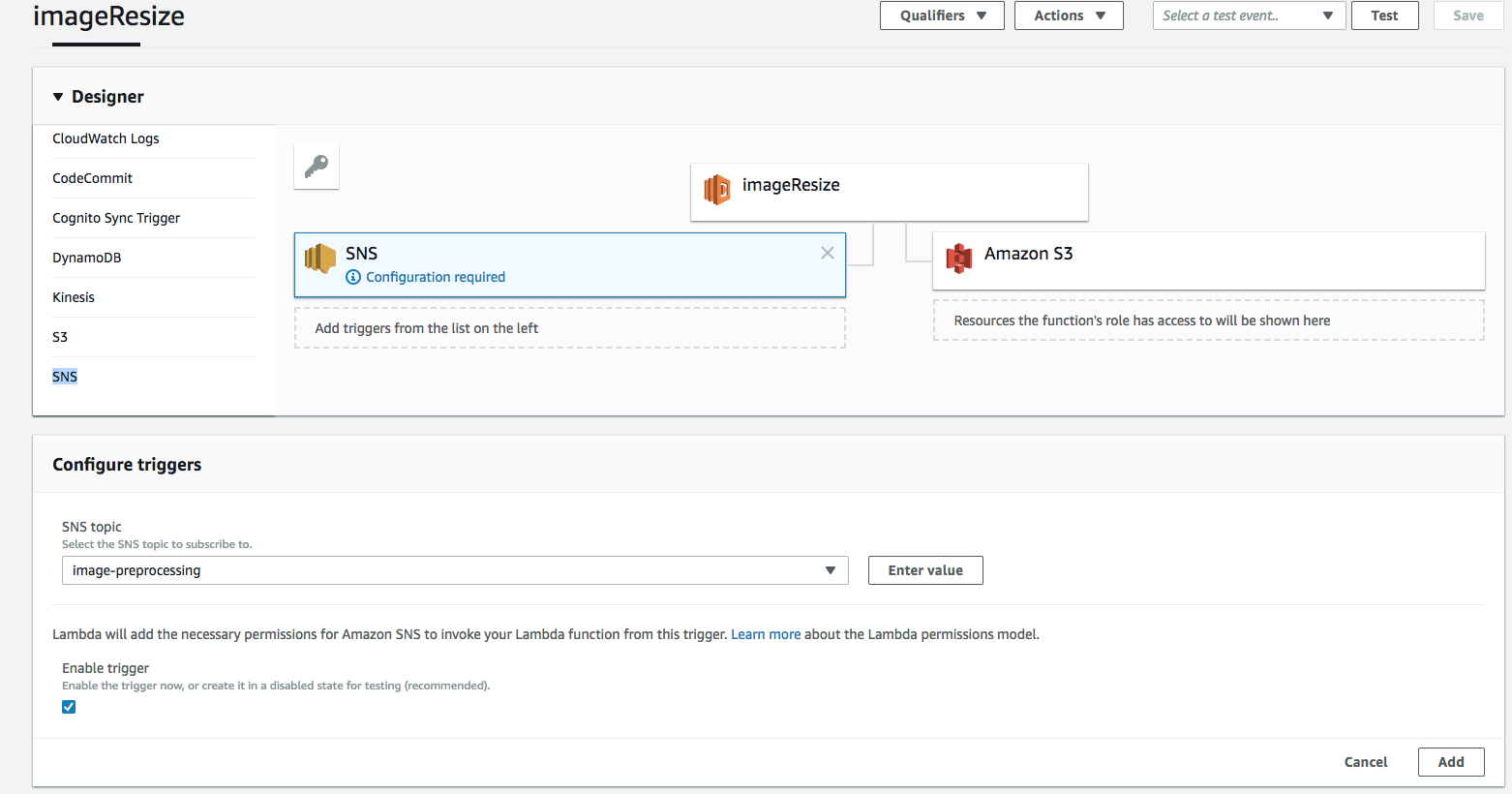
Теперь нужно загрузить код, который будет обрабатывать событие S3 ObjectCreated, что включает в себя получение загруженного изображения из папки originals, его обработку и повторную загрузку в соответствующие папки для изменённых изображений.
Код можно скачать здесь.
Единственный элемент, который необходимо загрузить в функцию Lambda, — это архив version1.1.zip, который содержит файл index.js и папку node_modules.
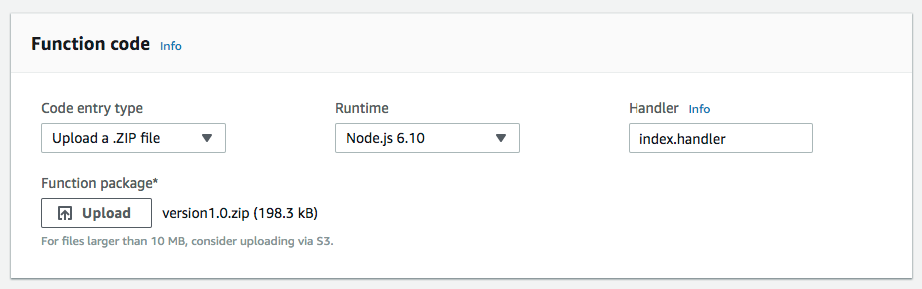
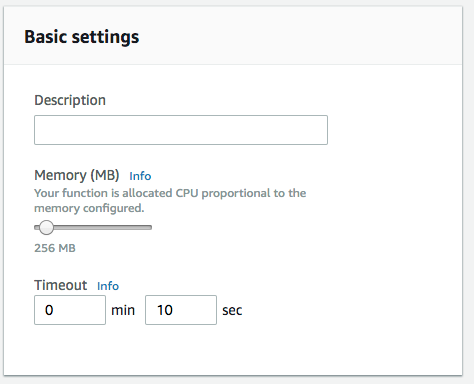
Чтобы предоставить функции Lambda достаточное количество ресурсов для обработки изображения, можно увеличить объём памяти до 256 Мб, а максимальное время выполнения (timeout) до 10 секунд. Потребность в ресурсах зависит от размера изображения и сложности преобразований.
Сам код довольно прост и предназначен для демонстрации интеграции AWS.
Сначала определяется функция-обработчик (export.handler). Она вызывается внешним триггером. В данном случае — сообщением, опубликованным в SNS, которое содержит S3-ключ объекта загруженного изображения.
В первую очередь, она анализирует JSON-текст сообщения о событии, чтобы извлечь имя бакета S3, S3-ключ объекта загруженного изображения, а также имя файла (последняя часть ключа).
После получения имени бакета и ключа объекта загруженное изображение извлекается с помощью операции s3.getObject, а затем передаётся в функцию для изменения размера. Переменная SIZE содержит размеры изображений, которые нужно получить. Они соответствуют именам папок S3, в которые загружаются преобразованные изображения.
var async = require('async');
var AWS = require('aws-sdk');
var gm = require('gm').subClass({ imageMagick: true });
var s3 = new AWS.S3();
var SIZES = ["800x600", "400x300"];
exports.handler = function(event, context) {
var message, srcKey, dstKey, srcBucket, dstBucket, filename;
message = JSON.parse(event.Records[0].Sns.Message).Records[0];
srcBucket = message.s3.bucket.name;
dstBucket = srcBucket;
srcKey = message.s3.object.key.replace(/\+/g, " ");
filename = srcKey.split("/")[1];
dstKey = "";
...
...
// Download the image from S3
s3.getObject({
Bucket: srcBucket,
Key: srcKey
}, function(err, response){
if (err){
var err_message = 'Cannot download image: ' + srcKey;
return console.error(err_message);
}
var contentType = response.ContentType;
// Pass in our image to ImageMagick
var original = gm(response.Body);
// Obtain the size of the image
original.size(function(err, size){
if(err){
return console.error(err);
}
// For each SIZES, call the resize function
async.each(SIZES, function (width_height, callback) {
var filename = srcKey.split("/")[1];
var thumbDstKey = width_height +"/" + filename;
resize(size, width_height, imageType, original,
srcKey, dstBucket, thumbDstKey, contentType,
callback);
},
function (err) {
if (err) {
var err_message = 'Cannot resize ' + srcKey;
console.error(err_message);
}
context.done();
});
});
});
}
Функция изменения размера преобразует исходное изображение при помощи библиотеки gm, в частности, она изменяет размер изображения, при необходимости обрезает его и снижает качество до 80%. Затем она загружает изменённое изображение в S3, используя операцию s3.putObject, и указывает ACL: public-read, чтобы новое изображение стало общедоступным.
var resize = function(size, width_height, imageType,
original, srcKey, dstBucket, dstKey,
contentType, done) {
async.waterfall([
function transform(next) {
var width_height_values = width_height.split("x");
var width = width_height_values[0];
var height = width_height_values[1];
// Transform the image buffer in memory
original.interlace("Plane")
.quality(80)
.resize(width, height, '^')
.gravity('Center')
.crop(width, height)
.toBuffer(imageType, function(err, buffer) {
if (err) {
next(err);
} else {
next(null, buffer);
}
});
},
function upload(data, next) {
console.log("Uploading data to " + dstKey);
s3.putObject({
Bucket: dstBucket,
Key: dstKey,
Body: data,
ContentType: contentType,
ACL: 'public-read'
},
next);
}
], function (err) {
if (err) {
console.error(err);
}
done(err);
}
);
};
Шаг 6: тестирование
Теперь можно проверить, всё ли работает верно, загрузив изображение в папку originals. Если всё было сделано правильно, мы получим соответствующие преобразованные версии загруженного изображения в папках 800x600 и 400x300.
В видеоролике ниже вы можете увидеть три окна: слева — папка originals, посередине — папка 800x600, а справа — папка 400x300. После загрузки файла в папку originals два других окна обновляются, чтобы проверить, были ли созданы изображения.
И вуаля, вот они ;)
(Опционально) Шаг 7: добавление сети доставки контента Cloudfront
Теперь, когда изображения созданы и загружены в S3, их необходимо доставить конечным пользователям. Чтобы повысить скорость загрузки, можно использовать сеть доставки контента Cloudfront. Для этого:
- Откройте страницу CloudFront.
- Нажмите Create Distribution.
- При запросе метода доставки выберите Web Distribution.
- В поле Origin Domain Name выберите требуемый бакет S3 и нажмите Create Distribution.
Процесс создания сети займёт какое-то время, поэтому подождите, пока статус CDN не изменится с In Progress на Deployed.
После того как сеть развёрнута, можно использовать имя домена вместо ссылки на бакет S3. Например, если имя вашего домена Cloudfront — 1234-cloudfront-id.cloudfront.net, то вы сможете получить доступ к папке обработанных изображений по ссылкам 1234-cloudfront-id.cloudfront.net/400x300/FILENAME и 1234-cloudfront-id.cloudfront.net/800х600/FILENAME
В Cloudfront есть множество других важных параметров, но в рамках этой статьи мы их рассматривать не будем. Чтобы получить более подробную инструкцию по настройке вашей сети доставки контента, обратитесь к Руководству от Amazon.
Комментарии (16)

astec
26.04.2018 14:50+4Безсерверным решение было если бы картинки обрабатывались на клиенте. А так все на сервере, только в облаке.
Статья годная, но название и акценты на «безсерверность» всё впечатление портят.
andreyverbin
26.04.2018 19:26В теории выглядит очень привлекательно. Но мне до сих пор не ясно как такой способ построения системы дружит с
* отладкой
* тестированием
* контролем версий
* dev/stage/production окружениемamakhrov
27.04.2018 01:12- oтладка/тестирование. Код лямбды — обычная функция. Чтобы протестировать, импортируем ее, вызываем с желаемыми параметрами и проверяем результат в коллбэке. Абсолютно так же, как вы бы тестировали ее, если бы это была часть традиционного приложения. Есть библиотеки, которые берут на себя часть бойлерплейта. Например, тут: https://www.npmjs.com/package/lambda-local#use-lambda-local-to-mock
- контролем версий — Лямбда — это код. Нет никаких проблем хранить его в СКВ.
- dev/stage/production окружение. Мы делали отдельную функцию для каждого окружения. Допустим
process-image-prod,process-image-dev.
hippoage
27.04.2018 08:09Кроме лямбды есть ещё ручное разворачивание, которое не под контролем версий. По мере развития может образоваться путаница. Так же может оказаться, что нужно переехать в другой регион. Смотрели на автоматизацию этой части?
amakhrov
27.04.2018 21:53А зачем разворачивать вручную? Все автоматизируется.
Можно банально написать свой скрипт, который деплоит через aws api. Можно воспользоваться готовыми утилитами наподобие https://github.com/motdotla/node-lambda.
Ну то есть опять же — ничем принципиально не отличается от деплоя на EC2 или ECS.
andreyverbin
27.04.2018 21:58Судя по описанию, в процессе настройки нужно довольно много кликать мышкой. Значит ли это, что кликать нужно три раза, для каждого окружения и следить, чтобы в процессе работы все три как-то друг другу соответствовали?
По поводу отладки — нетривиальные функции часто работают с БД, S3 и прочим. Можно ли такие вещи отлаживать локально или надо обязательно размещать функцию в облаке?amakhrov
28.04.2018 03:22кликать нужно три раза, для каждого окружения
Создание лямбд (как и любых других инфраструктурных ресурсов) можно (и нужно) описать в виде кода. Например, с Terraform.
Допустим, у вас код деплоится не в лямбду, а в EC2, ECS, CodeDeploy, etc — как вы убедитесь, что различные окружения (дев, прод) настроены одинаково? Вот точно так же это делается и с лямбдой.
Можно ли такие вещи отлаживать локально или надо обязательно размещать функцию в облаке
А как вы это делаете без лямбды, с обычным приложением? Точно так же поднимаете локальную базу, прописываете ее в конфиге для вашего локального окружения. Не вижу никакой разницы с лямбдой. Задача сводится к тому, чтобы подсунуть ей правильный конфиг.
amakhrov
27.04.2018 01:11- oтладка/тестирование. Код лямбды — обычная функция. Чтобы протестировать, импортируем ее, вызываем с желаемыми параметрами и проверяем результат в коллбэке. Абсолютно так же, как вы бы тестировали ее, если бы это была часть традиционного приложения. Есть библиотеки, которые берут на себя часть бойлерплейта. Например, тут: https://www.npmjs.com/package/lambda-local#use-lambda-local-to-mock
- контролем версий — Лямбда — это код. Нет никаких проблем хранить его в СКВ.
- dev/stage/production окружение. Мы делали отдельную функцию для каждого окружения. Допустим
process-image-prod,process-image-dev.
hippoage
27.04.2018 08:21Вопрос про обработки ошибок и стоимость.
В функции вы пишете log.error и на этом всё. Дальше это как-то мониторится/где-то видно. Есть механизм повтора преобразования (с или без исправления кода функции)?
По стоимости достаточно сложно подсчитать, но на сколько в процентах (?) вырос счёт на эту часть после введения лямбды? Я смотрел в сторону managed MySQL в AWS, и он где-то на 40 процентов дороже, чем просто такая же EC2. Наверняка что-то подобное и с лямбдами. Да, оплата идёт только за использование, но она дороже, чем для обычных виртуалок. При заметном объеме и учете того, что все равно управляете другими EC2, возможно, будет заметно дешевле поднять ASG с соответствующими обработчиками SNS.Stas911
27.04.2018 22:05Дороже он в том числе и потому, что его не нужно постоянно патчить руками (и ОС и сервер). То же самое и с лямбдами
Stas911
27.04.2018 22:03Хорошая статья, это не проблема автора, что многие читатели не понимают значения термина «serverless» и отчего-то считают, что при этом серверов вообще быть не должно.
dmitry_dvm
Бессерверные приложения — это как безрамочные телефоны. Вся статья про серверный код, но делаем вид, что сервера нет.
yusman
Не путайте выделенный сервер с сервисом Lambda и подобными. Это разные вещи. Когда вам сервер не нужен или нет нагрузки на него — он работает в холостую и ест деньги в любом случае.
Когда не работает Lambda она не ест деньги.