
Совсем недавно на хабре уже появилась рекламная статья о борьбе с DDoS атаками на уровне приложения. У меня был аналогичный опыт поиска оптимального алгоритма противодействия нападениям, может кому пригодится — когда человек в первый раз сталкивается в DDoS-ом его сайта, это вызывает шок, поэтому полезно заранее знать, что всё не так уж страшно.
DDoS — распределенная атака на отказ — грубо говоря, бывает нескольких видов. DDoS сетевого уровня — IP-TCP-HTTP, DDoS уровня приложения — когда поток запросов сильно снижает производительность сервера или делает его работу невозможной, и я бы еще добавил DDoS уровня хостера — когда сайт работает, но нагрузка на сервер превышает установленную хостером квоту, в результате чего у владельца сайта тоже возникают проблемы.
Если вас ддосят на сетевом уровне, то вас можно поздравить, что ваш бизнес поднялся до таких высот, и вы сами наверняка знаете, что в этом случае делать. Мы рассмотрим два других вида ддоса.
Любую CMS можно наполнить, разукрасить и оттюнинговать так, что даже один запрос в секунду будет давать недопустимую нагрузку даже на Хецнеровском VDS. Поэтому в общем случае задача стоит отфильтровать по возможности все ненужные запросы к сайту. В то же время, человек должен гарантированно на сайт попадать и не испытывать неудобств от наличия DDoS защиты.
Боты бывают нескольких типов. Полезные (нужные поисковые), бесполезные (ненужные поисковые и спайдеры) и вредные (те, что вредят). Первые два типа — это добропорядочные боты, которые в своем User-Agent'e говорят о себе правду. Бесполезные боты отфильтровываются в .htaccess, полезные пропускаются на сайт, а вредных будем ловить. Случай, когда вредный бот представляется Яндекс ботом, например, мы опустим для простоты (для него тоже есть решение — Яндекс по ip дает возможность узнать, их это бот или нет, и таких можно сразу банить).
Не допустив вредных ботов к бэкэнду получим необходимое снижение нагрузки на сервер.
Вредные боты можно разделить на два типа: умные (которые понимают cookie и javascript) и глупые (которые не понимают). Есть мнение, что ддос-ботов, понимающих javascript, вообще не существует, но это для серьезных сетевых DDoS атак. В наших условиях даже чрезмерно активный анонимный спайдер формально становится ддос-ботом, которого надо нейтрализовать.
Пока займемся глупыми ботами.
Код защиты приводить не будем, он простой — несколько десятков строчек на php; намного короче и проще этой статьи. Опишем логику. Будем записывать клиенту куку (метод проверки на куки используется даже при защитах от мощных DDoS атак). С любым именем и любым содержимым, можно использовать уже устанавливаемую сайтом куку.
Для простоты считаем, что на сайт есть единая точка входа, туда встраиваем наш ddos-shield. Сразу проверяем у запроса нашу куку: если она есть — безусловно пропускаем на сайт. Если нету, то записываем пару ip и юзер-агент в виде отдельного файла в отдельную директорию /suspected. Файл имеет название ip-ua.txt, где ua — dechex(crc32($_SERVER[«HTTP_USER_AGENT»])) — просто короткий хэш юзер-агента.
В сам файл пишем разделяя переводом строки время запроса, страницу (url) запроса, User-Agent, и еще можно использовать Sypex Geo или зарегистрироваться на maxmind.com и на пять дней заиметь бесплатный доступ к их geoip базе — по ip они выдают географическое местоположение, его тоже в этот файл.
Если файл с таким именем ip-ua.txt уже существует, то добавляем всю эту информацию нового запроса в конец файла.
Еще один момент — AJAX запросы нашего сайта. Если они есть, то их тоже нужно безусловно пропускать, определяя по своим меткам. Вероятность того, что боты тоже будут бить именно по ним — минимальна.
Теперь пропущенный шаг — до того, как мы записываем или дописываем ip-ua.txt, мы проверяем, что запрос с этого ip уже приходил, причем, не обращаем внимания на User-Agent:
Смысл в том, что мы даем каждому ip один шанс на получение куки. Если он приходит второй раз без нее, то срабатывает это неравенство, и мы перенаправляем клиента на отдельную страницу check-human.php, где он с помощью гугловской рекапчи будет проходить тест Тьюринга с витринами и транспортными средствами. Если не прошел — до свидания (опять рекапча), если прошел — создаем в еще одной специальной директории /whitelist файл ip-ua.txt. И в самом начале вместе с проверкой куки проверяем и на попадание пары ip-ua в наш /whitelist — этих тоже безусловно пропускаем. При такой тактике мы сможем дать возможность работать на сайте тем людям, у которых в браузере отключена поддержка куки и включен javascript, либо наоборот — отключен javascript но работают куки.
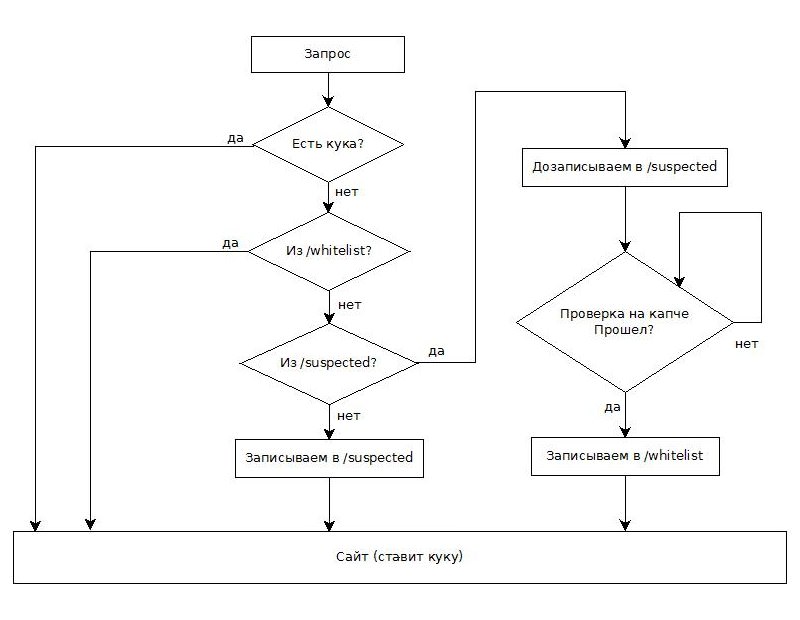
В принципе и всё. Глупых ботов отфильтровали, теперь умные. Для умных и подход уже интеллектуальный — открываем директорию /suspected, сортируем файлы по размеру. Вверху самые большие — десятки и сотни килобайт настойчивых попыток к нам пролезть. Открываем и смотрим, убеждаемся, что это действительно бот — по ip, по местоположению, по времени запроса, по периодам запросов, по страницам запросов, по сменам юзер-агента — обычно это хорошо видно, всё перед глазами. В принципе, можно выбрать все файлы с, к примеру, 10+ безуспешных попыток, и отправить их ip в бан через .htaccess. Но это нехорошо, лучше отправлять их на капчу — все-таки бывает, что несколько человек выходят в инет через один ip.
Это очень неплохо решает и вопрос умных ботов. Почему? Потому что если вас заказали, то, скорей всего, одному ддосеру. А они тоже бывают умные и глупые. И глупые обычно используют для умных и глупых своих ботов один ботнет, с одними ip. Таким образом, вы заблокируете и тех ботов, которые принимают куки и исполняют javascript. Кроме того, умных ботов намного меньше, стоят они дороже и работают медленней, поэтому данный метод эффективен для борьбы с абсолютным большинством рассматриваемых атак.
По моим наблюдениям, по данной схеме через капчу пришлось пройти порядка 1%-2% реальных пользователей сайта, остальные вообще ничего не заметили — что вполне юзер френдли. Кроме того, даже зашедшие в первый раз люди не видят никаких «заглушек» (в отличие от способа по ссылке в начале поста), а спокойно работают с сайтом.
Определенные неудобства возможны у людей, использующих специальный брузерный софт для анонимизации — динамически меняющий ip и юзер-агент клиента, стирающий куки, но мы этот вариант не рассматриваем.
В моем случае нагрузка на сервер упала сразу. Боты долбились еще какое-то время; через пару дней я заметил, что они ушли — ддосеры тоже не любят тратить ресурсы вхолостую. Снял защиту.
Можно варьировать логику защиты — добавить проверку на javascript (он и будет ставить куку, например); можно мониторить тех, кто был перенаправлен на капчу и не прошел ее, чтобы не допускать случая «плохого» поведения по отношению к человеку; можно делать именные куки, следить за числом захода клиента и при превышении лимита так же отправлять его на капчу; можно реализовать систему токенов; можно пускать ботов по цепи редиректов с временными задержками, чтобы затормозить их; можно анализировать ip ботов и банить целыми сетками, как Роскомнадзор — но это уже по мере надобности. По закону 20-80 самые простые нужные решения решают просто всё, что нужно.
Главное — оперативно вычленив и забанив очевидно зловредные ip из /suspected, вы сразу ощутимо снизите нагрузку на сервер и получите время для подготовки дальнейших действий по отражению атаки.
Вот таким нехитрым способом можно наказать нечистоплотных конкурентов на деньги.
Disclaimer: данная статья написана только для легких DDoS атак уровня приложения, преимущественно для сайтов на shared хостинге, лимит доступных ресурсов которых ограничен.
DDoS — распределенная атака на отказ — грубо говоря, бывает нескольких видов. DDoS сетевого уровня — IP-TCP-HTTP, DDoS уровня приложения — когда поток запросов сильно снижает производительность сервера или делает его работу невозможной, и я бы еще добавил DDoS уровня хостера — когда сайт работает, но нагрузка на сервер превышает установленную хостером квоту, в результате чего у владельца сайта тоже возникают проблемы.
Если вас ддосят на сетевом уровне, то вас можно поздравить, что ваш бизнес поднялся до таких высот, и вы сами наверняка знаете, что в этом случае делать. Мы рассмотрим два других вида ддоса.
Боты
Любую CMS можно наполнить, разукрасить и оттюнинговать так, что даже один запрос в секунду будет давать недопустимую нагрузку даже на Хецнеровском VDS. Поэтому в общем случае задача стоит отфильтровать по возможности все ненужные запросы к сайту. В то же время, человек должен гарантированно на сайт попадать и не испытывать неудобств от наличия DDoS защиты.
Боты бывают нескольких типов. Полезные (нужные поисковые), бесполезные (ненужные поисковые и спайдеры) и вредные (те, что вредят). Первые два типа — это добропорядочные боты, которые в своем User-Agent'e говорят о себе правду. Бесполезные боты отфильтровываются в .htaccess, полезные пропускаются на сайт, а вредных будем ловить. Случай, когда вредный бот представляется Яндекс ботом, например, мы опустим для простоты (для него тоже есть решение — Яндекс по ip дает возможность узнать, их это бот или нет, и таких можно сразу банить).
Не допустив вредных ботов к бэкэнду получим необходимое снижение нагрузки на сервер.
Вредные боты можно разделить на два типа: умные (которые понимают cookie и javascript) и глупые (которые не понимают). Есть мнение, что ддос-ботов, понимающих javascript, вообще не существует, но это для серьезных сетевых DDoS атак. В наших условиях даже чрезмерно активный анонимный спайдер формально становится ддос-ботом, которого надо нейтрализовать.
Пока займемся глупыми ботами.
Защита
Код защиты приводить не будем, он простой — несколько десятков строчек на php; намного короче и проще этой статьи. Опишем логику. Будем записывать клиенту куку (метод проверки на куки используется даже при защитах от мощных DDoS атак). С любым именем и любым содержимым, можно использовать уже устанавливаемую сайтом куку.
Для простоты считаем, что на сайт есть единая точка входа, туда встраиваем наш ddos-shield. Сразу проверяем у запроса нашу куку: если она есть — безусловно пропускаем на сайт. Если нету, то записываем пару ip и юзер-агент в виде отдельного файла в отдельную директорию /suspected. Файл имеет название ip-ua.txt, где ua — dechex(crc32($_SERVER[«HTTP_USER_AGENT»])) — просто короткий хэш юзер-агента.
В сам файл пишем разделяя переводом строки время запроса, страницу (url) запроса, User-Agent, и еще можно использовать Sypex Geo или зарегистрироваться на maxmind.com и на пять дней заиметь бесплатный доступ к их geoip базе — по ip они выдают географическое местоположение, его тоже в этот файл.
Если файл с таким именем ip-ua.txt уже существует, то добавляем всю эту информацию нового запроса в конец файла.
Еще один момент — AJAX запросы нашего сайта. Если они есть, то их тоже нужно безусловно пропускать, определяя по своим меткам. Вероятность того, что боты тоже будут бить именно по ним — минимальна.
Теперь пропущенный шаг — до того, как мы записываем или дописываем ip-ua.txt, мы проверяем, что запрос с этого ip уже приходил, причем, не обращаем внимания на User-Agent:
count(glob(__DIR__ . "/suspected/$ip-*.txt")) > 0Смысл в том, что мы даем каждому ip один шанс на получение куки. Если он приходит второй раз без нее, то срабатывает это неравенство, и мы перенаправляем клиента на отдельную страницу check-human.php, где он с помощью гугловской рекапчи будет проходить тест Тьюринга с витринами и транспортными средствами. Если не прошел — до свидания (опять рекапча), если прошел — создаем в еще одной специальной директории /whitelist файл ip-ua.txt. И в самом начале вместе с проверкой куки проверяем и на попадание пары ip-ua в наш /whitelist — этих тоже безусловно пропускаем. При такой тактике мы сможем дать возможность работать на сайте тем людям, у которых в браузере отключена поддержка куки и включен javascript, либо наоборот — отключен javascript но работают куки.
Ботнет
В принципе и всё. Глупых ботов отфильтровали, теперь умные. Для умных и подход уже интеллектуальный — открываем директорию /suspected, сортируем файлы по размеру. Вверху самые большие — десятки и сотни килобайт настойчивых попыток к нам пролезть. Открываем и смотрим, убеждаемся, что это действительно бот — по ip, по местоположению, по времени запроса, по периодам запросов, по страницам запросов, по сменам юзер-агента — обычно это хорошо видно, всё перед глазами. В принципе, можно выбрать все файлы с, к примеру, 10+ безуспешных попыток, и отправить их ip в бан через .htaccess. Но это нехорошо, лучше отправлять их на капчу — все-таки бывает, что несколько человек выходят в инет через один ip.
Это очень неплохо решает и вопрос умных ботов. Почему? Потому что если вас заказали, то, скорей всего, одному ддосеру. А они тоже бывают умные и глупые. И глупые обычно используют для умных и глупых своих ботов один ботнет, с одними ip. Таким образом, вы заблокируете и тех ботов, которые принимают куки и исполняют javascript. Кроме того, умных ботов намного меньше, стоят они дороже и работают медленней, поэтому данный метод эффективен для борьбы с абсолютным большинством рассматриваемых атак.
По моим наблюдениям, по данной схеме через капчу пришлось пройти порядка 1%-2% реальных пользователей сайта, остальные вообще ничего не заметили — что вполне юзер френдли. Кроме того, даже зашедшие в первый раз люди не видят никаких «заглушек» (в отличие от способа по ссылке в начале поста), а спокойно работают с сайтом.
Определенные неудобства возможны у людей, использующих специальный брузерный софт для анонимизации — динамически меняющий ip и юзер-агент клиента, стирающий куки, но мы этот вариант не рассматриваем.
В моем случае нагрузка на сервер упала сразу. Боты долбились еще какое-то время; через пару дней я заметил, что они ушли — ддосеры тоже не любят тратить ресурсы вхолостую. Снял защиту.
Развитие логики
Можно варьировать логику защиты — добавить проверку на javascript (он и будет ставить куку, например); можно мониторить тех, кто был перенаправлен на капчу и не прошел ее, чтобы не допускать случая «плохого» поведения по отношению к человеку; можно делать именные куки, следить за числом захода клиента и при превышении лимита так же отправлять его на капчу; можно реализовать систему токенов; можно пускать ботов по цепи редиректов с временными задержками, чтобы затормозить их; можно анализировать ip ботов и банить целыми сетками, как Роскомнадзор — но это уже по мере надобности. По закону 20-80 самые простые нужные решения решают просто всё, что нужно.
Главное — оперативно вычленив и забанив очевидно зловредные ip из /suspected, вы сразу ощутимо снизите нагрузку на сервер и получите время для подготовки дальнейших действий по отражению атаки.
Вот таким нехитрым способом можно наказать нечистоплотных конкурентов на деньги.
Disclaimer: данная статья написана только для легких DDoS атак уровня приложения, преимущественно для сайтов на shared хостинге, лимит доступных ресурсов которых ограничен.
Комментарии (15)

SDKiller
02.05.2018 11:14Реализовать защиту от ддоса на php и javascript, подключать базу от maxmind, писать сигнатуры в текстовый файл, потом парсить его…
Вам и ддоса не надо, вы сами свой сайт положите своими проверками.altrus Автор
02.05.2018 11:19Я просто описал свой реальный случай, как смог избавиться от подобной DDoS атаки.
Вы на что злитесь?remzalp
03.05.2018 07:33судя по простоте мер, которые сумели помочь — это была пара ленивых индусов.
DDos начинается когда трудно пробиться на ssh сервера, до этого только ленивые эксперименты досеров.
remzalp
03.05.2018 07:33Я бы сказал, что это скорей меры против спам ботов и (иногда) скачивальщиков страниц, остальные боты обычно более злые.
apapacy
Есть небольшие вопросы по реализации. У некоторых поисковых ботов нет чётко закрепленных адресов, например у googlebot. В то же время под них могут подделывать заголовок другие боты. А также по ajax запросам. запрос fetch не имеет характерного заголовка поэтому если такие запросы не имеют выделенного url например /api/… Определить что пришёл ajax невозможно.
altrus Автор
Я поисковых ботов определяю не по адресам, а по юзер-агенту. Яндекс и Гугл — проходи, остальным разворот. Если вредный бот подстраивается под них, так как и написано, можно запрашивать у поисковиков проверку — их ip или нет (у Яндекса я точно видел такой сервис).
Но с моей точки зрения, всё это второстепенно. Ддос-боты редко подделываются под поисковые, потому что так их проще отрубить. Если то решение, которое я привел в статье не спасет, тогда уже нужно копать дальше. И файлы в директории /suspected очень сильно помогут в анализе атаки и определении направления дальнейшего движения. После того, как вы забаните самые активные вредоносные ip, можно уже будет спокойно думать.
Просто логи вебсервера даже с анализаторами так наглядно источники атаки не покажут.
altrus Автор
По поводу fetch — там можно установить в HTTP запросе свой заголовок и на сервере проверять его, например. Или добавлять какой-то параметр.
Но, это абсолютно не критично — ведь fetch будет всегда (по идее) передавать куку. Случай с fetch — теоретический, когда пользователь открыл сайт, потом перешел из одной wifi, например, сети в другую, сменил ip адрес. И всё равно должно работать, по идее…
Возможно, я перестраховался по ajax. У меня SPA и такой специальной проверки (пропуск ajax) не было, и все и так работало при включенной защите.
hololoev
Поисковых роботов нужно вайтлистить так: support.google.com/webmasters/answer/80553?hl=ru
Нельзя вайтлистить ни по юзерагенту ни по адресу. Юзерагент- подделывается, адреса у ботов меняются, + с гуглосети могут ходить не только поисковые боты. Этот же способ справедлив для яндекса.
Но тут есть момент, если на каждый запрос спрашивать днску, то получаем +много времени ответа, особенно если обратной записи нет совсем. Приходится проверять ип постфактум в фоновом режиме, затем сохранять результаты в редис и после этого уже можно быстро узнать принадлежит ли адрес гуглоботу.
altrus Автор
Ну, да, у Яндекса подобная штука. Но с моей точки зрения, это перебор. Только если есть подозрения, что гугл это не гугл, а так юзер-агента достаточно.