
Введение
Есть несколько статей об антипаттернах разработки ПО. Но большинство из них говорят о деталях на уровне кода и фокусируются на конкретной технологии или языке программирования.
В этой статье я хочу сделать шаг назад и перечислить высокоуровневые антипаттерны тестирования, общие для всех. Надеюсь, вы узнаете некоторые из них независимо от языка программирования.
Терминология
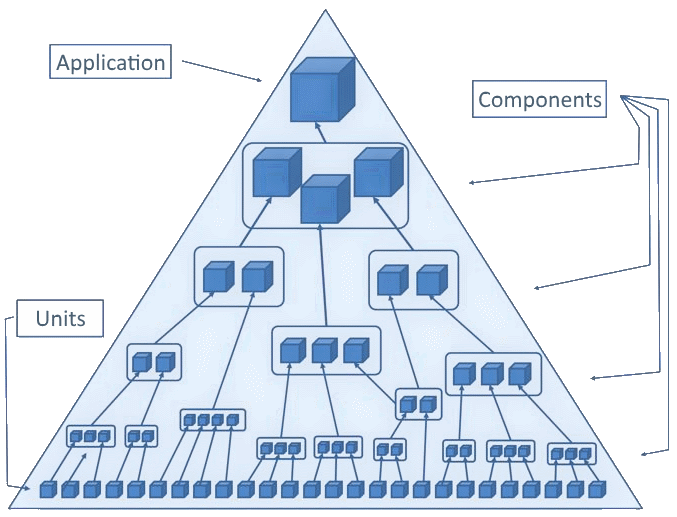
К сожалению, в тестировании пока не выработали общую терминологию. Если спросить сотню разработчиков, в чём разница между интеграционным, сквозным и компонентным тестом, то получите сто разных ответов. Для этой статьи ограничимся такой пирамидой тестирования:
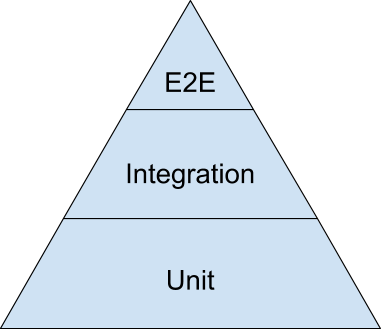
Если не видели пирамиду тестирования, настоятельно рекомендую ознакомиться с ней. Вот некоторые хорошие статьи для начала:
- Забытый слой пирамиды автоматических тестов (Майк Кон, 2009)
- «Пирамида тестирования» (Мартин Фаулер, 2012)
- «Блог отдела тестирования Google» (Google, 2015)
- «Пирамида тестирования на практике» (Хэм Вокк, 2018)
Пирамида тестирования сама заслуживает отдельного обсуждения, особенно по количеству тестов, необходимых для каждой категории. Здесь я просто ссылаюсь на неё, чтобы определить две низшие категории тестов. Обратите внимание, что в этой статье не упоминаются тесты пользовательского интерфейса (верхняя часть пирамиды) — в основном, для краткости и потому что у них собственные специфические антипаттерны.
Поэтому определим две основные категории тестов: модульные (юнит-тесты) и интеграционные.
| Тесты | Цель | Требует | Скорость | Сложность | Нужна настройка |
|---|---|---|---|---|---|
| Юнит-тесты | класс/метод | исходный код | очень быстро | низкая | нет |
| Интеграционные тесты | компонент/сервис | часть работающей системы | медленно | средняя | да |
Юнит-тесты более широко известны как по названию, так и по своему значению. Эти тесты сопровождают исходный код и обладают прямым доступ к нему. Обычно они выполняются с помощью фреймворка xUnit или аналогичной библиотеки. Юнит-тесты работают непосредственно на исходнике и имеют полное представление обо всём. Тестируется один класс/метод/функция (или наименьшая рабочая единицей для этой конкретной функциональности), а всё остальное имитируется/заменяется.
Интеграционные тесты (также именуемые сервисными тестами или даже компонентными тестами) фокусируются на целом компоненте. Это может быть набор классов/методов/функций, модуль, подсистема или даже само приложение. Они проверяют компонент путём передачи ему входных данных и изучения выдачи. Обычно требуется какое-то предварительное развёртывание или настройка. Внешние системы можно полностью имитировать или заменить (например, используя СУБД в памяти вместо реальной), а реальные внешние зависимости используются по ситуации. В сравнении с юнит-тестами требуются более специализированные инструменты либо для подготовки тестовой среды, либо для взаимодействия с ней.
Вторая категория страдает от размытого определения. Именно здесь больше всего споров о названиях. «Область» интеграционных тестов также весьма противоречива, особенно по характеру доступа к приложению (тестирование в чёрном или белом ящике; разрешены mock-объекты или нет).
Основное практическое правило таково: если тест…
- использует базу данных,
- использует сеть для вызова другого компонента/приложения,
- использует внешнюю систему (например, очередь или почтовый сервер),
- читает/записывает файлы или выполняет другие операции ввода-вывода,
- полагается не на исходный код, а на бинарник приложения,
… то это интеграционный, а не модульный тест.
Разобравшись с терминами, можно погрузиться в список антипаттернов. Их порядок примерно соответствует их распространённости. Самые частые проблемы перечислены в начале.
Список антипаттернов тестирования ПО
- Модульные тесты без интеграционных
- Интеграционные тесты без модульных
- Неправильный тип тестов
- Тестирование не той функциональности
- Тестирование внутренней реализации
- Чрезмерное внимание покрытию тестами
- Ненадёжные или медленные тесты
- Запуск тестов вручную
- Недостаточное внимание коду теста
- Отказ писать тесты для новых багов из продакшна
- Отношение к TDD как к религии
- Написание тестов без предварительного чтения документации
- Плохое отношение к тестированию по незнанию
Антипаттерн 1. Модульные тесты без интеграционных
Эта классическая проблема для малых и средних компаний. Для приложения создаются только юнит-тесты (основание пирамиды) — и больше ничего. Обычно отсутствие интеграционных тестов вызвано одной из следующих проблем:
- У компании нет разработчиков-сеньоров. Есть только джуниоры, только что окончившие колледж. Они встречали лишь модульные тесты.
- В какой-то момент интеграционные тесты существовали, но от них отказались, потому что они вызывали больше проблем, чем приносили пользы. Юнит-тесты гораздо проще в обслуживании, поэтому оставили только их.
- Рабочая среда приложения слишком «сложна» для настройки. Характеристики «испытаны» в продакшне.
Не могу ничего сказать о первом пункте. В каждой эффективной команде должен быть своего рода наставник/лидер, который показывает хорошие практики другим разработчикам. Вторая проблема подробно освещена в антипаттернах 5, 7 и 8.
Это подводит нас к последнему вопросу — сложной настройке тестовой среды. Не поймите меня неправильно, некоторые приложения действительно сложно тестировать. Однажды мне пришлось работать с набором приложений REST, которому требовалось специальное оборудование на хосте. Это оборудование существовало только в продакшне, что очень осложняло интеграционные тесты. Но это крайний случай.
Для заурядного веб- или серверного приложения, создаваемого типичной компанией, настройка тестовой среды не должна стать проблемой. С появлением виртуальных машин, а в последнее время контейнеров, сейчас это проще чем когда-либо. В основном, если вы пытаетесь протестировать приложение, которое трудно настроить, то сначала нужно исправить процесс настройки, прежде чем заниматься самими тестами.
Но почему вообще интеграционные тесты так важны?
Дело в том, что некоторые типы проблем могут обнаружить только интеграционные тесты. Канонический пример — всё, что связано с операциями СУБД. Транзакции, триггеры и любые хранимые процедуры БД можно проверить только с помощью интеграционных тестов, которые их затрагивают. Любые подключения к другим модулям, разработанным вами или внешними командами, требуют интеграционных тестов (они же контрактные тесты). Любые тесты для проверки производительности, являются интеграционными тестами по определению. Вот краткий обзор того, почему нам нужны интеграционные тесты:
| Тип проблемы | Определяется юнит-тестами | Определяется интеграционными тестами |
|---|---|---|
| Основная бизнес-логика | да | да |
| Проблемы интеграции компонентов | нет | да |
| Транзакции | нет | да |
| Триггеры/процедуры БД | нет | да |
| Неправильные контракты с другими модулями/API | нет | да |
| Неправильные контракты с другими системами | нет | да |
| Производительность/таймауты | нет | да |
| Взаимные/самоустраняемые блокировки | возможно | да |
| Перекрёстные проблемы безопасности | нет | да |
Обычно любая перекрёстная проблема приложения требует интеграционных тестов. С учётом нынешнего помешательства на микросервисах интеграционные тесты становятся ещё более важными, поскольку теперь у вас появляются контракты между собственными службами. Если эти службы разрабатываются другими группами, необходимо автоматически проверить, не нарушены ли интерфейсные контракты. Это можно покрыть только интеграционными тестами.
Подводя итог, если вы не создаёте что-то чрезвычайно изолированное (например, утилиту командной строки Linux), то вам реально нужны интеграционные тесты, чтобы найти проблемы, не найденные юнит-тестами.
Антипаттерн 2. Интеграционные тесты без модульных
Это противоположность предыдущему антипаттерну. Она чаще встречается в крупных компаниях и больших корпоративных проектах. Почти всегда такая ситуация связана с разработчиками, которые считают, что юнит-тесты не имеют реальной ценности, а отловить регрессии способны лишь интеграционные тесты. Многие опытные разработчики считают модульные тесты пустой тратой времени. Обычно если их порасспрашивать, то обнаружится, что когда-то в прошлом менеджеры потребовали увеличить покрытие кода тестами (см. антипаттерн 6) и заставили их писать тривиальные юнит-тесты.
Действительно, теоретически в проекте могут быть только интеграционные тесты. Но на практике такое тестирование очень дорого обойдётся (по времени как разработки, так и сборки). В таблице из предыдущего раздела мы видели, что интеграционные тесты тоже могут находить ошибки бизнес-логики и поэтому способны «заменять» модульные тесты. Но жизнеспособна ли такая стратегия в долгосрочной перспективе?
Интеграционные тесты сложны
Рассмотрим пример. Предположим, что у нас сервис с четырьмя такими методами/классами/функциями.
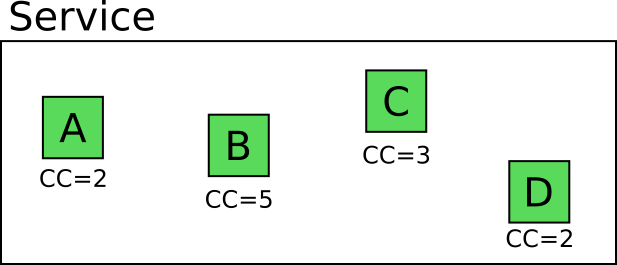
Число на каждом модуле обозначает его цикломатическую сложность то есть количество линейно независимых маршрутов через эту часть программного кода.
Разработчик Мэри действует по учебнику и хочет написать юнит-тесты для этого сервиса (потому что она понимает важность юнит-тестов). Сколько тестов нужно написать, чтобы полностью охватить все возможные сценарии?
Очевидно, можно написать 2+5+3+2 = 12 изолированных юнит-тестов, которые полностью охватывают бизнес-логику этих модулей. Помните, что это количество только для одного сервиса, а у приложения, над которым работает Мэри, несколько сервисов.
Разработчик Джо «Ворчун» не верит в ценность юнит-тестов. Он считает, что это пустая трата времени, и решает писать только интеграционные тесты для данного модуля. Сколько? Он начинает смотреть на все возможные маршруты через все части сервиса.

Опять же, должно быть очевидно, что возможно 2*5*3*2 = 60 маршрутов кода. Значит ли это, что Джо на самом деле напишет 60 интеграционных тестов? Конечно нет! Он будет хитрить. Сначала попробует выбрать подмножество интеграционных тестов, которые кажутся «репрезентативными». Это «репрезентативное» подмножество обеспечит достаточное покрытие с минимальным количеством усилий.
В теории всё просто, но на практике быстро возникнет проблема. В реальности эти 60 сценариев создаются не одинаково. Некоторые из них — пограничные случаи. Например, через модуль C проходит три маршрута кода. Один из них — очень частный случай. Его можно воссоздать только если C получит специфические входные данные из компонента B, который сам по себе является пограничным случаем и может быть получен только специальными входными данными из компонента A. Значит, этот конкретный сценарий может потребовать очень сложной настройки для выбора входных данных, которые вызовут специальное условие на компоненте C.
С другой стороны, Мэри просто воссоздаст пограничный случай с помощью простого модульного теста без дополнительной сложности.
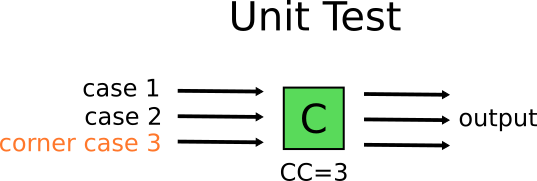
Значит, Мэри будет писать только юнит-тесты? В конце концов, это приведет ее к антипаттерну 1. Чтобы избежать этого, она напишет и модульные, и интеграционные тесты. Сохранит все модульные тесты для реальной бизнес-логики, а затем напишет один-два интеграционных теста для проверки, что остальная часть системы работает должным образом (т. е. части, которые помогают этим модулям выполнять свою работу).
Интеграционные тесты должны сосредоточиться на остальных компонентах. Саму бизнес-логику могут обрабатывать юнит-тесты. Интеграционные тесты Мэри сфокусируются на сериализации/десериализации, коммуникациях с очередью и БД системы.
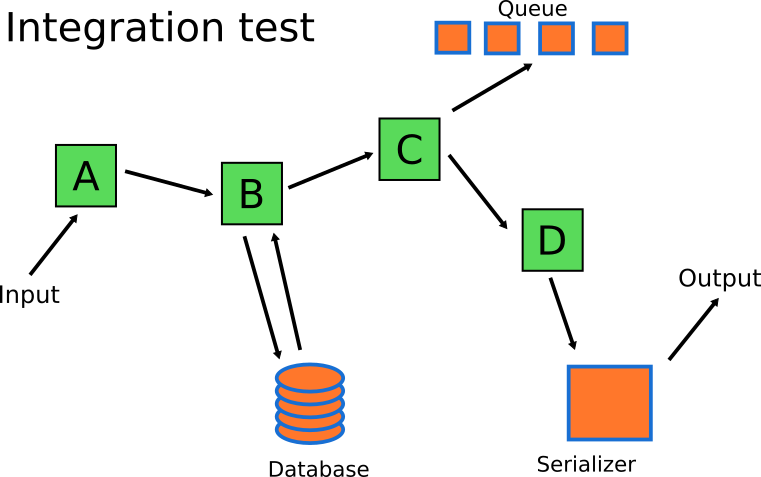
В итоге количество интеграционных тестов значительно меньше, чем количество юнит-тестов, что соответствует форме пирамиды тестирования из первого раздела этой статьи.
Интеграционные тесты медленные
Вторая большая проблема интеграционных тестов — их скорость. Как правило, интеграционный тест выполняется на порядок медленнее юнит-теста. Модульному тесту нужен только исходный код приложения и больше ничего. Они почти всегда ограничен по нагрузке на CPU. С другой стороны, интеграционные тесты могут производить операции ввода-вывода с внешними системами, так что их гораздо труднее оптимизировать.
Чтобы получить представление о разнице по времени, предположим следующие цифры.
- Каждый юнит-тест занимает 60 мс (в среднем).
- Каждый интеграционный тест занимает 800 мс (в среднем).
- В приложении 40 сервисов, как показано в предыдущем разделе.
- Мэри пишет 10 модульных тестов и 2 интеграционных теста для каждого сервиса.
- Джо пишет 12 интеграционных тестов для каждого сервиса.
Теперь посчитаем. Обратите внимание, что Джо якобы нашёл идеальное подмножество интеграционных тестов, которые дают то же покрытие кода, что у Мэри (в реальности будет не так).
| Время выполнения | Имея только интеграционные тесты (Джо) | Имея юнит-тесты и интеграционные тесты (Мэри) |
|---|---|---|
| Только юнит-тесты | N/A | 24 секунды |
| Только интеграционные тесты | 6,4 минуты | 64 секунды |
| Все тесты | 6,4 минуты | 1,4 минуты |
Разница в общем времени работы огромна. Ожидание одной минуты после каждого изменения кода значительно отличается от ожидания целых шести минут. И предположение в 800 мс для каждого интеграционного теста чрезвычайно консервативно. Я видел наборы интеграционных тестов, где один тест занимает несколько минут.
Подводя итог, попытка использовать только интеграционные тесты для покрытия бизнес-логики — огромная потеря времени. Даже если автоматизировать тесты с помощью CI, цикл обратной связи (от коммита до получения результата теста) всё равно очень долгий.
Интеграционные тесты сложнее отладить, чем модульные тесты
Последняя причина, почему не рекомендуется ограничиваться только интеграционными тестами (без модульных) — это количество времени на отладку неудачного теста. Поскольку интеграционный тест по определению тестирует несколько программных компонентов, сбой может быть вызван любым из протестированных компонентов. Выявить проблему тем сложнее, чем больше задействовано компонентов.
При сбое интеграционного теста необходимо понимать причину сбоя и как её исправить. Сложность и охват интеграционных тестов делают их чрезвычайно трудными для отладки. Опять же в качестве примера предположим, что для вашего приложения сделаны только интеграционные тесты. Скажем, это типичный интернет-магазин.
Ваш коллега (или вы) присылает новый коммит, который инициирует запуск интеграционных тестов со следующим результатом:

Как разработчик вы смотрите на результат и видите, что интеграционный тест с названием «Клиент покупает товар» не проходит. В контексте приложения интернет-магазина это не очень хорошо. Есть много причин, по которым этот тест может не проходить.
Никак невозможно узнать причину сбоя теста, не погрузившись в логи и метрики тестовой среды (предполагая, что они помогут точно определить проблему). В некоторых случаях (и более сложных приложениях) единственный способ подлинной отладки интеграционного теста — извлечение кода, воссоздание тестовой среды на локальной машине, а затем запуск интеграционных тестов и попытка воспроизвести сбой в локальной среде разработки.
Теперь представьте, что над этим приложением вы работаете вместе с Мэри, поэтому у вас есть как интеграционные, так и модульные тесты. Ваши коллеги присылают коммиты, вы запускаете все тесты и получаете следующее:
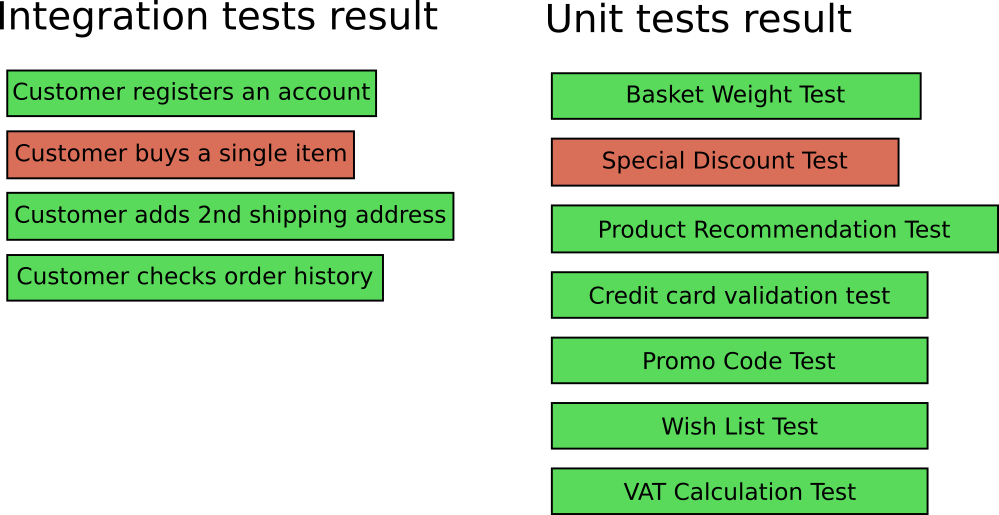
Теперь не прошли два теста:
- «Клиент покупает товар» не проходит как раньше (интеграционный тест).
- «Тест специальной скидки» тоже не проходит (юнит-тест).
Теперь очень легко понять, где искать проблему. Можно перейти непосредственно к исходному коду функциональности скидки, найти ошибку и исправить её — и в 99% случаев интеграционный тест тоже будет отлажен.
Сбой юнит-теста до или вместе с интеграционным — гораздо более безболезненный процесс, когда нужно найти ошибку.
Краткий вывод, зачем нужны юнит-тесты
Это был самый длинный раздел этой статьи, но я считаю его очень важным. Подведём итог: хотя теоретически можно использовать только интеграционные тесты, на практике
- Юнит-тесты легче поддерживать.
- Юнит-тесты легко воспроизводят пограничные случаи и редкие ситуации.
- Юнит-тесты выполняются гораздо быстрее интеграционных тестов.
- Сбойные юнит-тесты легче исправить, чем интеграционные.
Если у вас есть только интеграционные тесты, то вы впустую тратите и время разработки, и деньги компании. Нужны как модульные, так и интеграционные тесты одновременно. Они не взаимоисключающие. В сети есть несколько статей, которые пропагандируют использование только одного типа тестов. Все эти статьи распространяют дезинформацию. Печально, но это так.
Антипаттерн 3. Неправильный тип тестов
Теперь мы поняли, почему нужны оба вида тестов (модульные и интеграционные). Нужно определиться, сколько тестов нужно в каждой категории.
Здесь нет твёрдого и чёткого правила. Всё зависит от вашего приложения. Важно понять, что придётся потратить некоторое время, чтобы понять, какой тип тестов более ценный для вашего приложения. Тестовая пирамида — лишь предположение о количестве тестов. Она предполагает, что вы пишете коммерческое веб-приложение, но это не всегда так. Рассмотрим несколько примеров:
Пример: утилита командной строки Linux
Ваше приложение — утилита командной строки. Он берёт файлы одного формата (например, CSV), выполняет некоторые преобразования и экспортирует в другой формат (например, JSON). Приложение автономное, не общается ни с какими другими системами и не использует сеть. Преобразования представляют собой сложные математические процессы, которые имеют решающее значение для правильной работы приложения (они всегда должны выполняться правильно, независимо от скорости работы).
Что нужно для такого примера:
- Множество юнит-тестов для математических вычислений.
- Некоторые интеграционные тесты для чтения CSV и записи JSON.
- Никаких тестов GUI, потому что графический интерфейс отсутствует.
Вот как выглядит «пирамида» тестирования для такого проекта:
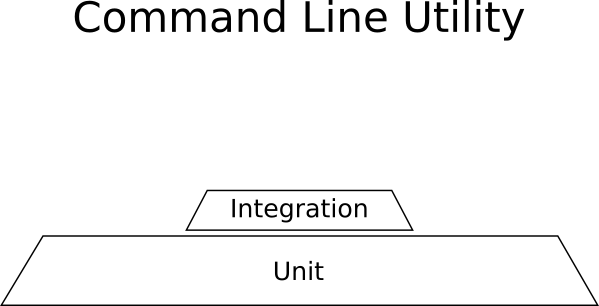
Тут доминируют юнит-тесты, а получившаяся форма не является пирамидой.
Пример: управление платежами
Вы добавляете новое приложение, которое внедрится в большую коллекцию существующих корпоративных систем. Приложение представляет собой платёжный шлюз, который обрабатывает платёжную информацию для внешней системы. Это новое приложение должно вести журнал всех транзакций во внешней БД, оно должно общаться с внешними платёжными провайдерами (Paypal, Stripe, WorldPay и др.), а также отправлять платёжные данные в ещё одну систему, которая выписывает счета.
Что нужно для такого примера:
- Почти никаких юнит-тестов, потому что нет бизнес-логики.
- Много интеграционных тестов для внешних коммуникаций, хранилища БД, системы выставления счетов.
- Никаких тестов GUI, потому что графический интерфейс отсутствует.
Вот как выглядит «пирамида» тестирования для такого проекта:
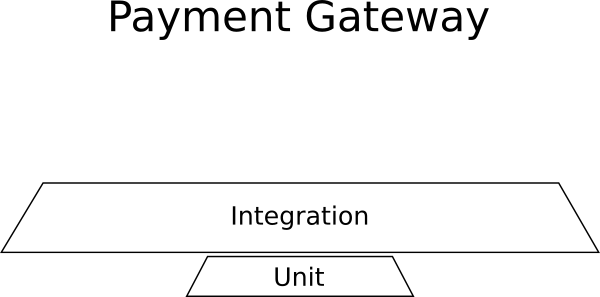
Интеграционные тесты тут доминируют, а получившаяся форма опять не является пирамидой.
Пример: конструктор сайтов
Вы работаете над совершенно новым стартапом, который разработал революционный способ создания сайтов: единственный в своем роде конструктор веб-приложений в браузере.
Приложение представляет собой графический конструктор с набором всех возможных элементов HTML, которые можно добавить на веб-страницу, и библиотеку готовых шаблонов. Есть возможность покупки новых шаблонов на рынке. Конструктор очень дружественный, позволяет перетаскивать компоненты на страницу, изменять их размер, редактировать свойства, изменять цвета и внешний вид.
Что нужно для этого надуманного примера:
- Почти никаких юнит-тестов, потому что нет бизнес-логики.
- Несколько интеграционных тестов для взаимодействия с рынком.
- Очень много тестов GUI, чтобы удостовериться в надлежащей работе графического интерфейса.
Вот как выглядит «пирамида» тестирования для такого проекта:
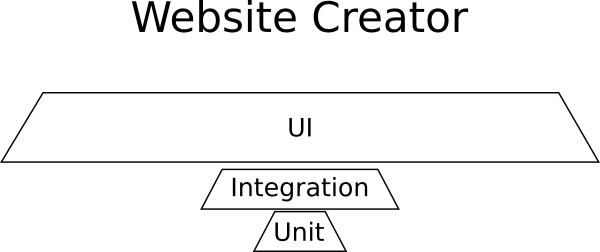
Здесь доминируют тесты UI, а получившаяся форма опять не является пирамидой.
Эти крайние ситуации показывают, что разным приложениям требуется разное сочетание тестов. Я лично видел приложения для управления платежами без интеграционных тестов, а также конструкторы веб-сайтов без тестов UI.
В интернете можно найти статьи (я не собираюсь на них ссылаться), которые называют конкретное соотношение интеграционных тестов, юнит-тестов и тестов UI. Все эти статьи основаны на предположениях, которые могут не подойти вашему проекту.
Антипаттерн 4. Тестирование не той функциональности
В предыдущих разделах мы описали типы и количество тестов, необходимых для вашего приложения. Следующий логический шаг — объяснить, какую именно функциональность нужно протестировать.
Теоретически, конечной целью является покрыть 100% кода. На практике эту цель трудно достичь и она не гарантирует отсутствие багов.
В некоторых случаях действительно реально проверить всю функциональность приложения. Если вы начинаете проект с нуля и работаете в небольшой команде, которая правильно действует и учитывает усилия, необходимые для тестов, то совершенно нормально покрыть тестами всю добавляемую функциональность (потому что для существующего кода уже есть тесты).
Но не всем разработчикам так повезло. В большинстве случаев вы наследуете существующее приложение с минимальным количеством тестов (или вообще без них!). Если вы работает в большой и устоявшейся компании, то работа с legacy-кодом — скорее правило, чем исключение.
В идеале вам дадут достаточно времени для написания тестов как для нового, так и для существующего кода legacy-приложения. Эту романтическую идею, вероятно, отвергнет менеджер проекта, более заинтересованный в добавлении новых функций, чем в тестировании/рефакторинге. Придётся расставить приоритеты и найти баланс между добавлением новой функциональности (по просьбе начальства) и расширением существующего набора тестов.
Так что именно будем тестировать? На чём сосредоточить усилия? Несколько раз я видел, как разработчики тратят драгоценное время на написание юнит-тестов, не имеющих практически никакого значения для общей стабильности приложения. Канонический пример бесполезного тестирования — тривиальные тесты, которые проверяют модель данных приложения.
Покрытие кода подробно анализируется в отдельном антипаттерне. В этом же разделе поговорим о «важности» кода и как она связана с тестами.
Если попросить любого разработчика показать исходники любого приложения, то он, вероятно, откроет IDE или репозиторий кода в браузере и покажет отдельные папки.
Это физическая модель кода. Она показывает папки в файловой системе, содержащие исходный код. Хотя эта иерархия отлично подходит для работы с самим кодом, к сожалению, она не показывает важность. Плоский список папок подразумевает, что все содержащиеся в них компоненты кода имеют одинаковое значение.
Это не так, поскольку различные компоненты кода оказывают различное влияние на общую функциональность приложения. В качестве краткого примера предположим, что вы пишете приложение интернет-магазина и в продакшне возникли две ошибки:
- Клиенты не могут расплатиться по товарам из корзины, что остановило все продажи.
- Клиенты получают неправильные рекомендации при просмотре продуктов.
Хотя обе ошибки подлежат исправлению, у первой явно больший приоритет. Поэтому если вам досталось приложение интернет-магазина вообще без тестов, следует написать новые тесты, непосредственно проверяющие функциональность корзины, а не механизм рекомендаций. Несмотря на то, что механизм рекомендаций и корзина могут находиться в папках одного уровня в файловой системе, при тестировании у них разная важность.
Если обобщить, то в любом среднем/большом приложении рано или поздно у разработчика возникает иное представление кода — ментальная модель.
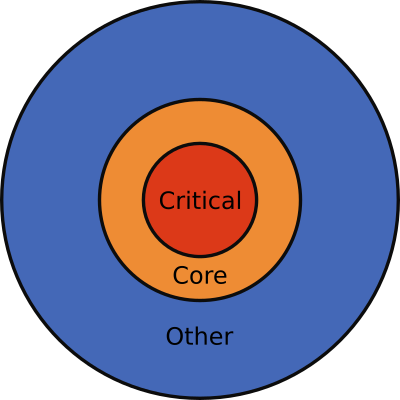
Здесь показаны три слоя кода, но в зависимости от размера приложения их может быть больше. Это:
- Критический код — код с частыми сбоями, куда вносится большинство новых функций и который важен на пользователей.
- Основной код с периодическими сбоями, небольшим количеством новых функций и средним влиянием на пользователей.
- Другой код с редкими сбоями, малым количеством новых функций и минимальным влиянием на пользователей.
Такую ментальную модель следует держать в голове всякий раз при написании нового теста ПО. Задайтесь вопросом, относится ли функциональность, для которой вы пишете тесты, к критическому или основному коду. Если да, то пишите тест. Если нет, то может есть смысл потратить время на что-нибудь другое (например, на другой баг).
Концепция степени важности кода также хорошо помогает ответить на вечный вопрос: какое покрытие кода достаточно для приложения? Для ответа нужно или самому знать уровни важности кода приложения, или спросить у того, кто знает. Когда вы обладаете этой информацией, то ответ очевиден: попробуйте написать тесты, покрывающие 100% критического кода. Если вы уже сделали это, то попробуйте написать тесты, покрывающие 100% основного кода. Однако не рекомендуется пытаться покрыть тестами 100% общего кода.
Важно отметить, что критический код — всегда лишь небольшое подмножество общего. Таким образом, если критический код составляет, скажем, 20% от общего, то покрытие тестами 20% общего кода — уже хороший первый шаг для уменьшения количества багов в продакшне.
В общем, пишите модульные и интеграционные тесты для кода, который:
- часто ломается
- часто изменяется
- критичен для бизнеса
Если есть время для дальнейшего расширения набора тестов, то убедитесь, что осознаёте уменьшение эффекта от них, прежде чем тратить время на тесты с небольшой или нулевой важностью.
Антипаттерн 5. Тестирование внутренней реализации
Больше тестов — всегда хорошо. Верно?
Неверно! Ещё нужно убедиться, что тесты на самом деле правильно структурированы. Наличие неправильно написанных тестов наносит двойной ущерб:
- Сначала они тратят драгоценное время разработчика при написании.
- Затем они тратят ещё больше времени, когда приходится их переделывать (при добавлении новой функции).
Строго говоря, тестовый код похож на любой другой код. В какой-то момент потребуется рефакторинг, чтобы постепенно его улучшать. Но если вы регулярно меняете существующие тесты при добавлении новых функций, то ваши тесты тестируют не то, что должны.
Я видел, как компании запускают новые проекты и думают, что на этот раз всё сделают правильно — они начинают писать много тестов, чтобы покрыть всю функциональность. Через некоторое время добавляют новую функцию, а для неё нужно изменить несколько существующих тестов. Затем добавляют ещё одну функцию и обновляют ещё больше тестов. Вскоре объём усилий на рефакторинг/исправление существующих тестов фактически превышает время, необходимое для реализации самой функции.
В таких ситуациях некоторые разработчики просто сдаются. Они заявляют, что тесты — пустая трата времени, и отказываются от существующего набора тестов, чтобы полностью сосредоточиться на новых функциях. В некоторых исключительных случаях даже релизы задерживаются из-за непрохождения тестов.
Конечно, здесь проблема в плохом качестве тестов. Если они постоянно нуждаются в рефакторинге, то налицо слишком тесная связь с основным кодом. К сожалению, чтобы выявить такие «неправильно» написанные тесты, требуется определённый опыт.
Изменение большого количества существующих тестов при появлении новой функции — это только симптом. Настоящая проблема в том, что тесты проверяют внутреннюю реализацию, а это всегда сценарий катастрофы. В нескольких руководствах по тестированию ПО делается попытка объяснить эту концепцию, но мало кто демонстрирует её на ясных примерах.
В начале статьи я обещал, что не буду говорить о конкретном языке программирования, и сдержу обещание. Здесь иллюстрации показывают структуру данных вашего любимого языка. Думайте о них как о структурах/объектах/классах, которые содержат поля/значения.
Допустим, объект Customer в приложении интернет-магазина выглядит следующим образом:

Тип Customer принимает только два значения, где
0 означает «гость», а 1 означает «зарегистрированный пользователь». Разработчики смотрят на объект и пишут десять юнит-тестов для проверки «гостей» и десять для «зарегистрированных пользователей». И когда я говорю «для проверки», то имею в виду, что тесты проверяют это конкретное поле в этом конкретном объекте.Проходит время, и менеджеры принимают решение, что для филиалов необходим новый тип пользователя со значением
2. Разработчики добавляют ещё десять тестов для филиалов. Наконец, добавлен ещё один тип пользователя под названием “premium customer" — и разработчики добавляют ещё десять тестов.На данный момент у нас 40 тестов в четырёх категориях, и все они проверяют эти конкретные поля. (Числа вымышленные, пример только для демонстрации. В реальном проекте может быть десять взаимосвязанных полей в шести вложенных объектах и 200 тестов).
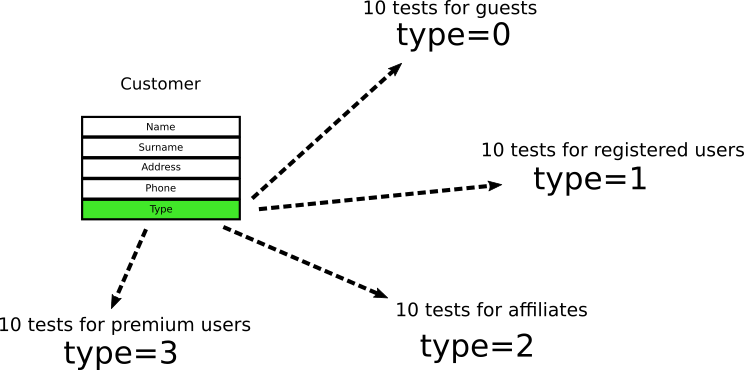
Если вы опытный разработчик, то можете представить дальнейшее развитие событий. Приходят новые требования:
- Для зарегистрированных пользователей нужно сохранять ещё электронную почту.
- Для пользователей в филиалах нужно сохранять ещё название компании.
- Премиум-пользователям теперь начисляются бонусные баллы.
Объект клиента изменяется следующим образом:
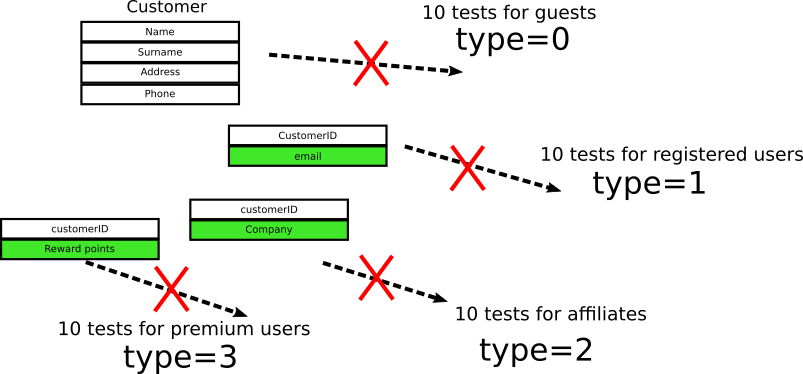
Теперь у нас четыре объекта, связанные с внешними ключами, а все 40 тестов сразу ломаются, потому что проверяемое ими поле больше не существует.
Конечно, в этом тривиальном примере можно просто сохранить существующее поле, чтобы не нарушать обратную совместимость с тестами. В реальном приложении такое не всегда возможно. Иногда обратная совместимость по сути означает, что нужно сохранить и старый, и новый код (до/после новой функции), что сильно раздует его. Также обратите внимание, что сохранение старого кода просто ради юнит-тестов — само по себе явный антипаттерн.
Когда такое происходит в реальной ситуации, разработчики просят дополнительное время на исправление тестов. Затем менеджеры проектов заявляют, что юнит-тесты — пустая трата времени, потому что они мешают внедрению нового функционала. Потом вся команда отказывается от набора тестов, быстро отключив сбойные тесты.
Здесь основная проблема не в тестировании, а в качестве тестов. Вместо внутренней реализации следует тестировать ожидаемое поведение. В нашем простом примере вместо тестирования непосредственно внутренней структуры объекта нужно в каждом случае проверять точное бизнес-требование. Вот как следует реализовать те же тесты:
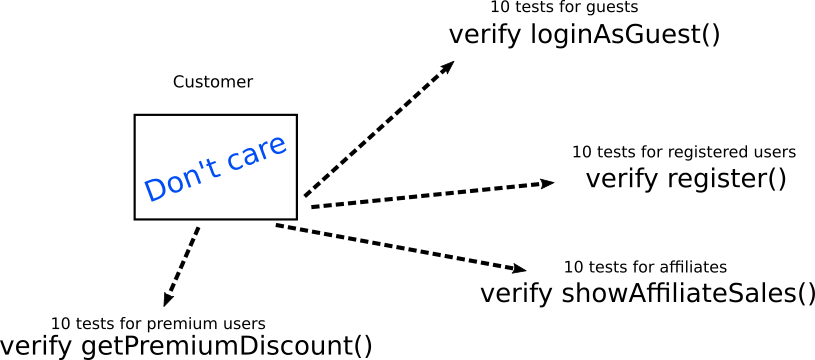
Здесь тесты вообще не проверяют внутреннюю структуру объекта. Они проверяют только его взаимодействие с другими объектами/методами/функциями. Если необходимо, другие объекты/методы/функции следует имитировать. Обратите внимание, что каждый тип теста напрямую соответствует конкретному бизнес-требованию, а не технической реализации (что всегда является хорошей практикой).
При изменении внутренней реализации объекта код верификации тестов остаётся прежним. Может измениться только код настройки для каждого теста, который должен централизованно храниться в одной вспомогательной функции
createSampleCustomer() или в чём-то подобном (подробнее см. антипаттерн 9).Конечно, теоретически сами верифицированные объекты могут измениться. На практике же нереально одновременное изменение
loginAsGuest(), register(), showAffiliateSales() и getPremiumDiscount(). В реалистичном сценарии потребуется рефакторинг десяти тестов вместо сорока.Подводя итог, если вы постоянно исправляете существующие тесты по мере добавления новых функций, это означает, что ваши тесты тесно связаны с внутренней реализацией.
Антипаттерн 6. Чрезмерное внимание покрытию тестами
Покрытие кода — любимая метрика в индустрии. Между разработчиками и менеджерами проектов идут бесконечные дискуссии по поводу необходимого покрытия кода тестами.
Все любят говорить о покрытии, потому что это понятный легко измеримый показатель. В большинстве языков программирования и фреймворков тестирования есть простые инструменты для его отображения.
Позвольте выдать маленький секрет: покрытие кода — совершенно бесполезная метрика. Не существует «правильного» показателя. Это вопрос-ловушка. У вас может быть проект со 100% покрытием кода, в котором по-прежнему остаются баги и проблемы. В реальности нужно следить за другими метриками — хорошо известными показателям CTM (Codepipes Testing Metrics).
Метрики CTM
Вот определение CTM, если вы с ними не знакомы:
| Название метрики | Описание | Идеальное значение | Обычное значение | Проблемное значение |
|---|---|---|---|---|
| PDWT | Процент разработчиков, пишущих тесты | 100% | 20%-70% | Любое меньше 100% |
| PBCNT | Процент багов, приводящих к созданию новых тестов | 100% | 0%-5% | Любое меньше 100% |
| PTVB | Процент тестов, проверящих поведение | 100% | 10% | Любое меньше 100% |
| PTD | Процент детерминированных тестов | 100% | 50%-80% | Любое меньше 100% |
PDWT (процент разработчиков, пишущих тесты) — вероятно, самый важный показатель. Нет смысла говорить об антипаттернах тестирования ПО, если у вас вообще нет тестов. Все разработчики в команде должны писать тесты. Любую новую функцию можно объявлять сделанной только если она сопровождается одним или несколькими тестами.
PBCNT (процент багов, приводящих к созданию новых тестов). Каждый баг в продакшне — отличный повод для написания нового теста, проверяющего соответствующее исправление. Любой баг должен появиться в продакшне не более одного раза. Если ваш проект страдает от появления повторных багов даже после их первоначального «исправления», то команда действительно выиграет от использования этой метрики. Более подробно об этом см. в антипаттерне 10.
PTVB (процент тестов, которые проверяют поведение, а не реализацию). Тесно связанные тесты пожирают массу времени при рефакторинге основного кода. Эта тема уже обсуждалась в антипаттерне 5.
PTD (процент детерминированных тестов от общего числа). Тесты должны завершаться ошибкой только в том случае, если что-то не так с бизнес-кодом. Если тесты периодически ломаются без видимой причины — этой огромная проблема, которая обсуждается в антипаттерне 7.
Если после прочтения о метриках вы по-прежнему настаиваете на установке жёсткого показателя для покрытия кода, я дам вам число 20%. Это число должно использоваться как эмпирическое правило, основанное на законе Парето. 20% вашего кода вызывает 80% ваших ошибок, так что если вы действительно хотите начать писать тесты, то хорошо будет начать в первую очередь с этого кода. Совет также хорошо согласуется с антипаттерном 4, где я предлагаю писать тесты в первую очередь для критического кода.
Не пытайтесь достичь 100% общего покрытия. Это хорошо звучит в теории, но почти всегда является пустой тратой времени:
- вы впустую потратите силы, потому что переход с уровня 80% на 100% гораздо сложнее, чем с 0% до 20%;
- увеличение покрытия кода приводит к уменьшению отдачи.
В любом нетривиальном приложении есть определенные сценарии, для запуска которых требуются сложные юнит-тесты. Усилия, требуемые для написания таких тестов, как правило, перевешивают риск того, что эти сценарии реализуются в продакшне (если это вообще когда-нибудь произойдёт).
Если вы работали с любым большим приложением, то должны знать: после достижения 70% или 80% покрытия становится очень трудно писать полезные тесты для остального кода.
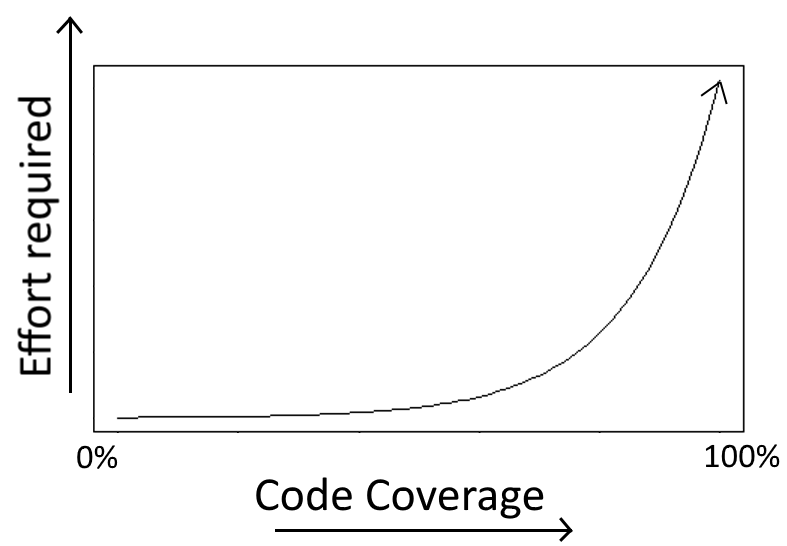
Как мы уже видели в описании антипаттерна 4, некоторые маршруты кода в реальности никогда не сбоят в продакшне, поэтому для них не рекомендуется писать тесты. Лучше потратить время на внедрение фактического функционала.
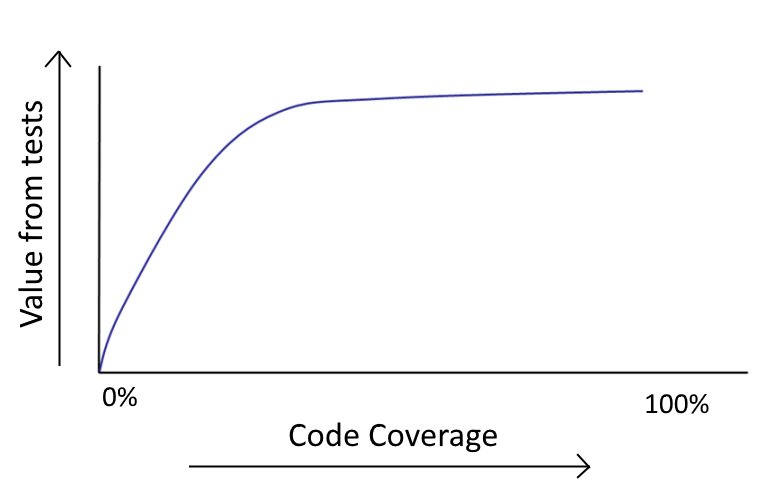
Если для проекта стоит условие определённого процента покрытия кода тестами, то разработчиков обычно заставляют тестировать тривиальный код или писать тесты, которые просто проверяют базовый язык программирования. Это огромная трата времени, и как разработчик вы обязаны пожаловаться руководству на такие необоснованные требования.
Подводя итог, покрытие кода тестами нельзя использовать как показатель качества софтверного проекта.
Антипаттерн 7. Ненадёжные или медленные тесты
Конкретно этот антипаттерн уже неоднократно подробно обсуждался, так что я только дополню.
Поскольку тесты ПО выступают ранним индикатором регрессий, они всегда должны работать надёжно. Провал теста обязан стать причиной беспокойства, а ответственные за соответствующий билд должны начать проверку, почему тест не прошёл.
Этот подход работает только с тестами, которые падают детерминированным образом. Если тест иногда сбоит, а иногда проходит (без каких-либо изменений кода между проверками), то он ненадёжен и дискредитирует всё тестирование. Это наносит двойной ущерб:
- Разработчики больше не доверяют тестам и начинают их игнорировать.
- Сбои даже нормальных тестов становится сложно обнаружить в море недетерминированных результатов.
О неудачном тесте следует чётко информировать всех членов команды, поскольку он меняет статус всей сборки. С другой стороны, при наличии ненадёжных тестов трудно понять, то ли происходят новые сбои, то ли это результат старых ненадёжных тестов.
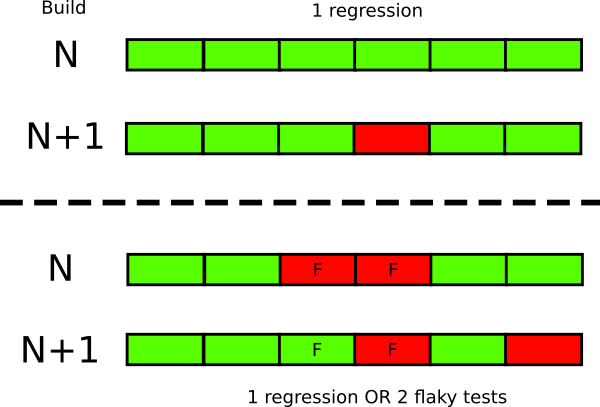
Даже небольшого количества ненадёжных тестов достаточно, чтобы разрушить доверие к остальным. Например, у вас пять ненадёжных тестов, вы прогнали новый билд через тесты и получили три сбоя. Непонятно, всё в порядке или у вас появились три регрессии.
Аналогичная проблема с очень медленными тестами. Разработчикам нужна быстрая обратная связь по результатам каждого коммита (это обсуждается также в следующем разделе), поэтому медленные тесты они в итоге будут игнорировать или вообще не станут запускать.
На практике ненадёжные и медленные тесты почти всегда являются интеграционными и/или тестами пользовательского интерфейса. По мере подъёма по пирамиде тестирования вероятность появления ненадёжных тестов значительно возрастает. Известно, что если тест обрабатывает события браузера, то его трудно сделать детерминированным. Источниками ненадёжности могут выступать многие факторы, но обычно виновата среда тестирования и её требования.
Основная защита от ненадёжных и медленных тестов — изолировать их в отдельном наборе тестов (при условии, что они неисправимы). В интернете есть много ресурсов о том, как исправить такие тесты на любом языке программирования, так что нет смысла объяснять это здесь.
Подводя итог, у вас должен быть абсолютно надёжный набор тестов, пусть это будет лишь подмножество всего набора тестов. Если тест из этого набора не проходит, то проблема однозначно с кодом. Любой сбой такого теста означает, что код нельзя пускать в продакшн.
Антипаттерн 8. Запуск тестов вручную
В разных организациях используются разные типы тестов. Юнит-тесты, нагрузочные, тесты приёма пользователей (UAT) — это типичные категории тестовых наборов, которые могут выполняться перед выпуском кода в продакшн.
В идеале все тесты выполняются автоматически без вмешательства человека. Если это невозможно, то хотя бы тесты, которые проверяют корректность кода (т.е. модульные и интеграционные тесты), должны выполняться автоматически. Таким образом, разработчики максимально оперативно получают обратную связь по коду. Функцию очень легко исправить, когда код свеж у вас в голове и вы ещё не переключили контекст на другую функцию.
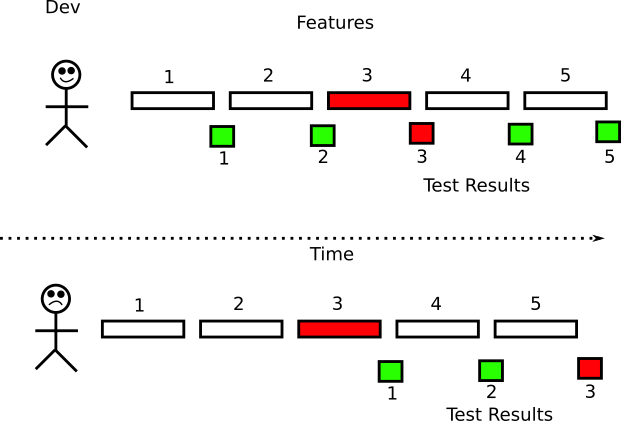
Раньше самым длительным этапом жизненного цикла ПО было развёртывание приложения. В облаке машины создаются по запросу (в виде VM или контейнеров), так что время подготовки новой машины сократилось до нескольких минут или секунд. Такой сдвиг парадигмы застал врасплох многие компании, которые оказались не готовы к столь частым циклам. Большинство существующих практик сосредоточены на длительных циклах выпуска. Ожидать определённого времени релиза с ручной «отмашкой» — одна из устаревших практик, от которых следует отказаться, если компания стремится к быстрым деплоям.
Быстрое развёртывание подразумевает доверие к каждому деплою. Доверие к автоматическому деплою требует высокой степени уверенности в коде. Хотя есть несколько способов получить эту уверенность, но первая линия защиты — ваши тесты ПО. Однако наличие набора тестов с быстрым поиском регрессий — это лишь полдела. Второе необходимое условие — автоматическое выполнение тестов (возможно, после каждого коммита).
Многие компании думают, что у них внедрена непрерывная поставка и/или развёртывание. На самом деле это не так. Практика истинной CI/CD означает, что в любой момент времени существует версия кода, готовая к развёртыванию. Это значит, что релиз-кандидат уже протестирован. Поэтому наличие «готового» пакета, который ещё не получил отмашку — это не настоящая CI/CD.
Большинство компаний поняли, что человеческое участие вызывает ошибки и задержки, но по-прежнему остались компании, где запуск тестов является полуавтоматическим процессом. Под «полуавтоматическим» подразумевается то, что сам набор тестов может быть автоматизирован, но люди выполняют некоторые задачи по обслуживанию, такие как подготовка тестовой среды или очистка тестовых данных по завершению тестов. Это антипаттерн, потому что это не настоящая автоматизация. Все аспекты тестирования должны быть автоматизированы.
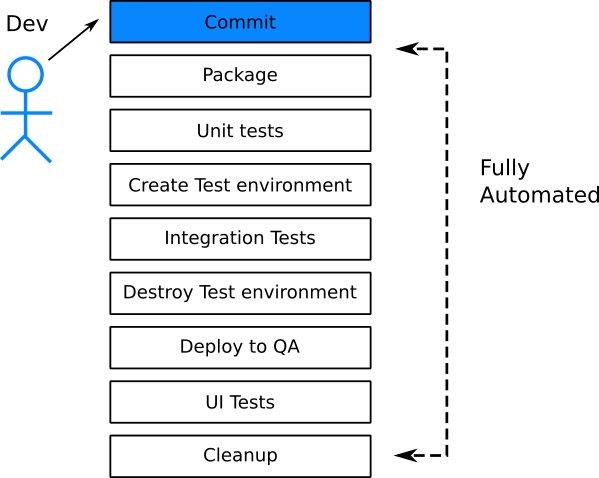
Имея доступ к виртуальным машинам или контейнерам, очень легко по запросу создавать различные тестовые среды. Создание тестовой среды на лету по каждому запросу должно стать стандартной практикой в вашей организации. Это означает, что каждая новая функция тестируется отдельно. Проблемный компонент (т.е. вызывающий сбой тестов) не должен блокировать деплой остальных.
Простой способ понять уровень автоматизации тестирования в компании — понаблюдать за рутинной работой сотрудников отделов QA/тестирования. В идеальном случае тестировщики просто создают новые тесты, которые добавляются в существующий набор. Они не запускают их вручную. Набор тестов выполняется сервером сборки.
Подводя итог, тестирование должно всё время происходить за кулисами. Разработчики узнают результат теста для своей конкретной функции через 5?15 минут после коммита. Тестеры создают новые тесты и проводят рефакторинг существующих тестов, но не запускают их вручную.
Антипаттерн 9. Недостаточное внимание коду теста
Опытный разработчик всегда сначала потратит некоторое время на упорядочивание кода в уме, прежде чем приступать к написанию. Относительно дизайна кода есть несколько принципов, а некоторые из них так важны, что им посвящены даже отдельные статьи в Википедии. Вот некоторые примеры:
Возможно, первый принцип самый важный, поскольку он заставляет установить для кода единственный источник истины, который повторно используется в нескольких функциях. В зависимости от языка программирования вы также можете использовать некоторые другие рекомендации и шаблоны проектирования. Могут быть отдельные рекомендации, принятые специально в вашей команде.
Однако по какой-то неизвестной причине некоторые разработчики не применяют те же принципы к коду тестов ПО. Я видел проекты, где код функций отлично спроектирован, но код тестов страдает от огромных объёмов дублирования, жёстко закодированных переменных, фрагментов копипаста и других ошибок, которые считались бы непростительными в основном коде.
Не имеет смысла рассматривать тестовый код как второсортный, ведь в долгосрочной перспективе весь код нужно обслуживать. В будущем тесты придётся обновлять и перерабатывать. Их переменные и структура изменятся. Если вы пишете тесты, не задумываясь об их дизайне, то создаёте дополнительный технический долг, который добавится к уже существующему в основном коде.
Попробуйте писать тесты с тем же вниманием, которое уделяете коду компонентов. Здесь нужно использовать все те же техники рефакторинга. Для начала:
- Весь код теста должен быть централизованным. Таким же образом все тесты должны выдавать тестовые данные.
- Сложные сегменты верификации следует извлечь в общую для данной области библиотеку.
- Часто используемые имитации и эмуляции не следует копировать копипастом.
- Код инициализации теста должен быть общим для аналогичных тестов.
Если вы используете инструменты статического анализа, форматирования исходного кода или качества кода, настройте их для обработки тестового кода тоже.
Подводя итог, разрабатывайте тесты настолько же тщательно, как и основной код компонента.
Антипаттерн 10. Отказ писать тесты для новых багов из продакшна
Одна из задач тестирования — найти регрессии. Как мы видели в антипаттерне 4, в большинстве приложений есть «критическая» часть кода, где появляется большинство багов. Когда вы исправляете ошибку, то нужно убедиться, что она не повторится. Один из лучших способов гарантировать это — написать тест для исправления (либо юнит-тест, либо интеграционный, либо оба).
Ошибки, которые просачиваются в продакшн — идеальные кандидаты для написания тестов:
- они показывают отсутствие тестирования в данной области, поскольку баг уже попал в продакшн;
- если вы напишете тест для этой ошибки, то он защитит и будущие релизы.
Я всегда поражаюсь, когда команды разработчиков (даже с солидной стратегией тестирования) не пишут тест на ошибку, найденную в продакшне. Они исправляют код и сразу исправляют ошибку. По какой-то странной причине многие разработчики предполагают, что написание тестов имеет значение только при добавлении новой функции.
Сложно представить что-то более далёкое от истины. Я бы даже сказал, что тесты, которые вытекают из реальных ошибок, более ценны, чем тесты, которые добавляются как часть новой разработки. В конце концов, вы никогда не знаете, как часто новая функция будет сбоить в производстве (возможно, она принадлежит некритическому коду, который никогда не будет сбоить). Соответствующий тест хорош, но его ценность сомнительна.
А вот тест, который вы пишете для реальной ошибки, очень ценный. Он не только проверяет правильность исправления, но и гарантирует, что оно всегда будет действовать, даже после рефакторинга в данной области.
Если вы присоединитесь к legacy-проекту без тестов, то это и самый очевидный способ начать внедрение полезного тестирования. Вместо того, чтобы пытаться угадать, какой код покрыть тестами, просто обратите внимание на существующие баги — и напишите тесты для них. Через некоторое время тесты охватят критическую часть кода, так как по определению все ваши тесты проверяют то, что часто сбоит. Одна из предложенных мною метрик отображает эти усилия.
Единственный случай, когда допустимо отказаться от теста — если ошибка в рабочей среде не связана с кодом и происходит из самой среды. Например, неправильную конфигурацию подсистемы балансировки нагрузки нельзя исправить с помощью юнит-теста.
Подводя итог, если вы не уверены в том, какой код тестировать, посмотрите на ошибки, которые попадают в продакшн.
Антипаттерн 11. Отношение к TDD как к религии
TDD означает разработку через тестирование. Как и все предыдущие методологии, она хороша на бумаге до тех пор, пока консультанты не начинают доказывать, что это единственно верное решение. На момент написания данной статьи такая практика постепенно прекращается, но я решил упомянуть о ней для полноты (поскольку корпоративный мир особенно страдает от этого антипаттерна).
Вообще говоря, когда дело доходит до тестирования программного обеспечения:
- тесты можно писать перед соответствующим кодом;
- тесты можно писать одновременно с соответствующим кодом;
- тесты можно писать после соответствующего кода;
- можно вообще не писать тесты для конкретного кода.
Один из основных принципов TDD — всегда следовать варианту 1 (написание тестов перед кодом реализации). В целом это хорошая практика, но не всегда лучшая.
Написание тестов перед кодом подразумевает, что вы уверены в окончательном API, а это не всегда так. Может, у вас есть чёткая спецификация и вы знаете точные сигнатуры всех методов, которые следует реализовать. Но в других случаях вы можете просто с чем-то экспериментировать или написать код в направлении решения, а не сразу окончательный вариант.
С практической точки зрения тому же стартапу рано слепо следовать TDD. Если вы работаете в стартапе, то ваш код может меняться так быстро, что TDD мало поможет. Вы можете даже отбросить код и начинать сначала, пока не напишете «правильный» вариант. Написание тестов после кода реализации — совершенно правильная стратегия в таком случае.
Отсутствие тестов вообще (вариант 4) тоже допустим. Как мы видели в антипаттерне 4, некоторый код вообще не нуждается в тестировании. Написание тестов для тривиального кода как «положено по TDD» ничего вам не даст.
Навязчивая идея апологетов TDD об обязательном написании сначала тестов нанесла огромный ущерб психическому здоровью здравомыслящих разработчиков. Об этой одержимости уже неоднократно говорили, так что надеюсь мне не нужно повторяться (поиск по ключевым словам «TDD дерьмо/глупо/мертво»).
Тут я хочу признаться, что несколько раз и сам работал по следующему сценарию:
- Сначала реализация основного компонента.
- Затем написание теста.
- Запуск теста — успешно.
- Комментирование критических частей кода компонента.
- Запуск теста — сбой.
- Удаление комментариев, возвращение кода в исходное состояние.
- Запуск теста — снова успех.
- Коммит.
Подводя итог, TDD — это хорошая идея, но не нужно постоянно следовать ей. Если вы работаете в компании из списка Fortune 500 с кучей бизнес-аналитиков и получаете чёткие спецификации, что конкретно нужно реализовать, тогда TDD может быть полезен.
С другой стороны, если вы просто играетесь дома с новым фреймворком в выходной день и пытаетесь понять, как он работает, то необязательно следовать TDD.
Антипаттерн 12. Написание тестов без предварительного чтения документации
Профессионал хорошо знает свой рабочий инструмент. Возможно, в начале проекта придётся потратить дополнительное время, чтобы детально изучить технологии, которые вы собираетесь использовать. Постоянно выходят новые веб-фреймворки, и всегда полезно знать все возможности, которые можно применить для написания эффективного и лаконичного кода. Затраченное время вернётся сторицей.
С таким же уважением надо относиться к тестам. Поскольку некоторые разработчики рассматривают тесты как нечто второстепенное (см. также антипаттерн 9), они никогда не стараются узнать в деталях, на что способен их фреймворк тестирования. Копипаст кода из других проектов и примеров на первый взгляд работает, но не так должен вести себя профессионал.
К сожалению, такая картина встречается слишком часто. Люди пишут несколько «вспомогательных функций» и «утилит» для тестов, не понимая, что во фреймворке эта функция либо встроена, либо подключается с помощью внешних модулей.
Такие утилиты затрудняют понимание тестов (особенно для джуниоров), поскольку наполнены «внутренними» знаниями, которые не распространяются на другие проекты/компании. Несколько раз я заменял «умные внутренние решения для тестирования» стандартными готовыми библиотеками, которые делают то же самое стандартизированным образом.
Следует потратить некоторое время и узнать о возможностях своего тестового фреймворка. Например, как он работает с:
- параметризованными тестами;
- имитациями и эмуляциями;
- тестовыми настройками и демонтажом (teardown);
- категоризацией текстов;
- обусловленным выполнением тестов.
Если вы работаете над типичным веб-приложением, то следует произвести минимальное исследование и изучить лучшие практики в отношении:
- генераторов тестовых данных;
- клиентских HTTP-библиотек;
- серверов для HTTP-имитации;
- мутационного тестирования и фаззинга;
- очистки/отката БД;
- нагрузочного тестирования и так далее.
Не нужно заново изобретать колесо. Это относится и к тестированию кода. Возможно, в некоторых пограничных ситуациях ваше приложение — действительно уникальная жемчужина и нуждается в некоей особой утилите для основного кода. Но могу поспорить, что модульные и интеграционные тесты у вас совершенно обычные, так что написание особых утилит тестирования — сомнительная практика.
Антипаттерн 13. Плохое отношение к тестированию по незнанию
Хотя данный антипаттерн я упоминаю последним, но именно он заставил меня написать эту статью. Меня всегда разочаровывает, когда на конференциях и митапах я встречаю людей, которые «гордо» заявляют, что все тесты — пустая трата времени и что их приложение отлично работает вообще без тестов. Ещё чаще встречаются те, кто против определённого типа тестирования (обычно против модульных или интеграционных тестов), как мы видели в антипаттернах 1 или 2.
Когда я встречаю таких людей, то люблю расспрашивать их и узнавать истинные причины, стоящие за ненавистью к тестам. И всегда это сводится к антипаттернам. Или они работали в компаниях с медленными тестами (антипаттерн 7), или тестам требовался постоянный рефакторинг (антипаттерн 5). Их «задолбали» необоснованные требования покрыть тестами 100% кода (антипаттерн 6) или фанатики TDD (антипаттерн 11), которые пытались навязать всей команде собственное искажённое понимание TDD.
Если вы один из таких людей, я действительно вам чувствую. Знаю, насколько тяжело работать в компании с неправильной организацией процесса.
Плохой опыт тестирования в прошлом не должен мешать вашей объективной оценке, когда дело доходит до тестирования следующего проекта, который начинается с нуля. Попытайтесь объективно взглянуть на свою команду, свой проект и понять, применимы ли к вам какие-либо антипаттерны. Если да, то просто тестирование проводится неправильно и никакое количество тестов не исправит ваше приложение. Печально, но это так.
Одно дело, когда ваша команда страдает от плохих практик тестирования, а другое — внушать джуниорам мысль, что «тестирование — пустая трата времени». Пожалуйста, не делайте этого. Существуют компании, которые не страдают ни от каких антипаттернов, упомянутых в статье. Попробуйте их найти!
Комментарии (17)

Duha666
10.05.2018 00:09Не статья, а целый гайдбук, почему тесты — это хорошо, и как делать их правильно.
Большое спасибо.
yogghy
10.05.2018 00:20Спасибо за перевод!
Работаю на проекте, в котором явно видны большинство перечисленных антипаттернов, и хочу искренне пожать автору руку — он явно пролил не один литр своей крови в похожих местах за годы опыта!
ganqqwerty
10.05.2018 02:05Отлично, наконец-то у кого-то руки дошли это описать, я уже неделю долбаюсь над созданием похожего документа по тестированию фронтэнда.
NIKOSV
10.05.2018 05:35И все же из статьи не понятно куда относить тесты из разряда:
Тестируемый объект: SerivceA(ServiceB, ServiceC)
Тесты: мокаем ServiceB, ServiceC, тестируем публичный интерфейс SerivceA. В моках имитируем все известные поведения ServiceB, ServiceC. Отдельно таким же способом тестируем ServiceB и ServiceC.
А таких тестов подавляющее большинство.
Из личного опыта, подобные тесты + юнит тесты покрывают 99% всех возможных проблем с функционалом. Если будут какие-то зашкварные проблемы с интеграцией, конфигурацией или деплойментом они будут выявлены во время UAT так ли иначе. Можно попытаться это протестировать, но:
1. Полноценный интеграционный тест это сложно, очень сложно
2. Это медленно
3. Это false-positive срабатывания (что-то отвалилось во время тестирование, то что ты не контролируешь)
4. Это никакой гарантии что в продакшине все будет нормально
Я конечно пишу парочку интеграционных тестов чтобы удостоверится что глобально все работает и что все сервисы/компоненты поднимаются и взаимодействуют, что dependency injectction нигде не тупит. Но не более того — не стоит оно потраченного времени, поэтому у меня:
99% — юнит тесты и тесты описаны выше
1% — интеграционные тестыgasizdat
10.05.2018 08:55Интеграционный тест с блекбоксом и мокингом? Вообще говоря писать для маломальски сложного объекта что-нибудь проще интеграционного теста с мокингом — очень затратное занятие. Если сосредотачиваться на обязательных модульных тестах всех новых функций, то код, готовый к модульному тестированию, будет выглядеть просто ужасно. Это наверное самое неприятное в модульном тестировании ооп кода.
Scf
10.05.2018 10:29Обилие моков в тестах — признак плохого дизайна. Юнит-тесты должны тестировать логику, а логика по-возможности должна быть вынесена в отдельные функции, у которых нет внешних зависимостей. На эти функции и нужно писать юнит-тесты.
NIKOSV
10.05.2018 11:58Таких функций не бывает, они по-любому будут дергать вспомогательные функции, функции нижнего уровня. Вопрос только как — через интерфейсы или напрямую. Первое легко и просто тестируется, второе — 80% времени будете тесты писать.
vintage
10.05.2018 10:28-1Автор говорит много правильных вещей, но и сам же подвержен некоторым антипаттернам и заблуждениям.
Начнём с терминологии. Тесты не делятся на "юнит", "интеграционные" и "gui". Интеграционными он называет компонентные тесты, что является довольно распространённой ошибкой. Интеграционный тест проверяет взаимодействие модулей. Компонентный просто проверяет интерфейс компонента и ему плевать использует ли тот какие-либо другие компоненты код капотом или нет. На картинках у него правильно написано UI (ещё правильнее — e2e), что несколько шире, чем GUI. Например, CLI или Speech UI — тоже относятся к UI. Тестируются они по одним и тем же принциам — поднимается приложение и эмулируются действия клиента (это может быть как пользователь в случае UI так программа в случае API). В общем, из-за бардака в классификации далее он делает кучу неверных выводов. Для упорядочивания терминов рекомендую статью: Концепции автоматического тестирования. Там же можно увидеть и правильную пирамиду тестирования:
Заметьте, что тут ни слова про e2e тестирование, так как эмуляция пользовательских событий происходит в самых нижних компонентах и высокоуровневые тесты не зависят от деталей реализации низкоуровневых. Это делает тесты менее хрупкими и более простыми и быстрыми, чем e2e, при сравнимом качестве покрытия. А юнит тесты — не более чем вырожденные случаи компонентных, так что противопоставлять их нет никакого смысла.
Дальше идут глупости про то, что компонентные тесты надо настраивать, а юнит — нет. Но это не так. В юнит тестах необходимо мокать кучу объектов, эмулируя их поведение. В компонентных же как правило мокать ничего не надо ибо используются реальные зависимости. Далее про скорость. Если мы уже протистировали взаимодействие со внешним миром (несколько компонент в основании пирамиды), то для остальных тестов мы вполне можем это взаимодействие замокать, что даёт компонентные тесты не менее шустрые, чем юнит. В статье говорится, что мокание внешних зависимостей требует дополнительной настройки, но в отличие от юнит-тестов, эта настройка делается один раз. Причём она может выполняться вендором, а не самим программистом (моки автоматически регистрируются в тестовом контексте).
Теперь пройдёмся по "антипаттернам"...
Антипаттерн 1. Модульные тесты без интеграционных
Антипаттерн 2. Интеграционные тесты без модульныхМодульным действительно нужны интеграционные и наоборот. Только вот компонентным тестам не нужны ни те, ни другие. Каждый компонент вышележащего уровня тестируется исходя из того, что компоненты нижележащего уровня уже протестированы и не требуют дополнительной проверки, а значит их можно безопасно использовать, игнорируя их внутреннюю цикломатическую сложность. Подробности опять же в упомянутой мной выше статье.
Антипаттерн 3. Неправильный тип тестов
Довольно странные выводы о нужности/ненужности e2e тестов. CLI — такой же UI как любой другой и может быть протестирован e2e тестами. Я бы сказал, что многие CLI утилиты вполне можно покрывать только e2e тестами, так как они в этом случае дадут хорошее покрытие минимумом усилий. Подготовили пачку CSV и JSON, прогнали их все через утилиту и всё. Вот с GUI всё сложнее, там много входов, выходов, да ещё и динамическое состояние имеется — тут одними только e2e не обойтись, иначе будет комбинаторный взрыв. Ну а пресловутая "бизнес-логика" — это вообще не понятно что. Что это за мифическое приложение такое без "бизнесс-логики"?
Дальше у меня остались только мелкие придирки, но не осталось времени, так что всем зелёных билдов.)
nsinreal
11.05.2018 10:41Интеграционными он называет компонентные тесты, что является довольно распространённой ошибкой. Интеграционный тест проверяет взаимодействие модулей
В защиту автора хочу сказать, что есть разница между академическим определением и тем как термины понимают в жизни. То, что описывает автор ближе к людям. Хотя такие ремарки конечно стоит делать.
Ну а пресловутая «бизнес-логика» — это вообще не понятно что. Что это за мифическое приложение такое без «бизнесс-логики»?
Есть довольно широкий класс малопродуманных полуполезных говноприложений.
kababok
10.05.2018 11:17Простите, как это не выработали терминологии, если есть, например, тот же ISTQB ?
Sad_Bro
10.05.2018 12:55Тут другая проблема, с легкой руки появляются такие вот синонимы общепринятых терминов.
К сожалению habr многими потом воспринимается как первоисточник и можно услышать вопросы на собеседовании чем отличается компонентное тестирование от модульного или что такое операционное тестирование. why?
ps статья полезная.
kababok
10.05.2018 14:16Что статья полезная — это бесспорно! :)
Ну, и насчет упомянутых вами вопросов — тоже согласен.
От себя добавлю, что есть ещё и существенное различие в определении границ терминов для, скажем для начала, мобильных приложений, потом промышленных приложений для софта, предназначенного для коммуникации с промтехникой, дальше отличие в границах будет и в тестировании непосредственно программного функционала самой промтехники ( сложные embedded-системы), а у автомобилистов и авиатехников будут свои границы для терминологических множеств...
Но это не отменяет того факта, чтт всё это следует обсуждать и вычленять полезное. :)
amarao
10.05.2018 17:38Скажите, а если приложение использует full view от Tier1-карриеров (нескольких) для своей работы, то интеграционный тест подразумевает поднятие своих Tier-1 карриеров со своим интернетом, или можно обойтись меньшей кровью? Какой?
poxvuibr
11.05.2018 10:26+1Очень странно написано про TDD
Написание тестов перед кодом подразумевает, что вы уверены в окончательном API, а это не всегда так.
Это утверждение попросту ложно. API можно менять на ходу, прямо в процессе написания кода и TDD этого не запрещает.
С практической точки зрения тому же стартапу рано слепо следовать TDD. Если вы работаете в стартапе, то ваш код может меняться так быстро, что TDD мало поможет.
Почему TDD не поможет? Если добавляются новые классы, а старые удаляются — просто написать новый код по методике TDD, а старый код со старыми тестами удалить. Если речь об изменениях в старых классах — поправить тесты, а потом поправить код, тоже согласно TDD. Создаётся впечатление, что автор понимает TDD как-то по своему.
Вы можете даже отбросить код и начинать сначала, пока не напишете «правильный» вариант.
И TDD поможет это сделать.
Написание тестов после кода реализации — совершенно правильная стратегия в таком случае.
Написание тестов — вообще правильная стратегия. Но непонятно, почему не применить тут TDD.
В общем неприменимость TDD в стартапах это как раз миф, порождённый непониманием того, что такое TDD и зачем эта методика нужна.
KeyJoo
11.05.2018 23:14Третий абзац с конца: первое предложение —
… я действительно вам чувствую.
Это мелочи, в целом такого рода статьи всегда призваны популяризировать высокий тон у кодеров.
boblenin
Антипатерн X
Называют тест сценарии — юнит тестами.
Антипатерн X+1
Используют тесты в широком смысле один раз — во время создания функциональности.
Антипатерн X+2
Пытаются покрыть юнит тестами все возможные сценарии (если сценарий не существует — надо его выдумать).
и т.д.
Увы в плане адекватного использования технологии юнит и шире автоматическое тестирование осталось непаханым полем.