
Логи, журналы, события – всё это довольно легко собирается, мапится и отображается в едином инструментарии. Logstash мапит данные, Elasticsearch хранит их, а Kibana отображает в виде графиков.
При всей мощи этой связки, естественно, есть задачи, которые невозможно реализовать через встроенные возможности.
Например, Kibana прекрасно показывает данные в рамках одной таблицы (индекса), но как только дело доходит до объединения разных индексов в одну выборку, она беспомощно разводит руки.
И единственный способ решить задачу в этом случае – выгрузить данные из Kibana и объединить их в любом другом средстве, например, в Excel.
Простой пример. Представьте, что Ваша Ёлка (ELK) собирает и хранит события Jira – по любому изменению любой из задач таск-трекера.
В этом случае в индексе Elasticsearch по одной задаче будет храниться несколько записей:
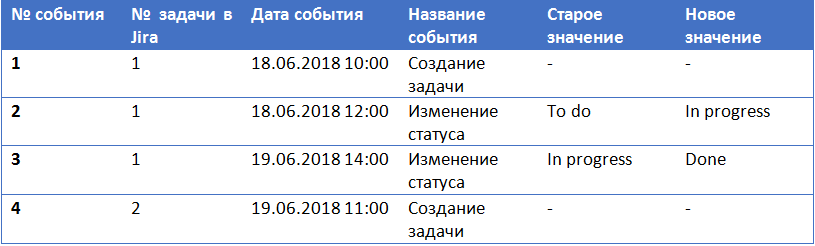
Если Вы захотите построить график событий Jira, показывающий конверсию задач по состояниям, то с помощью Kibana Вы вряд ли сможете это сделать. Из-за особенностей noSQL Вам понадобится все события по одной задаче «загнать» в одну запись Elasticsearch.
Сделать это довольно затруднительно без привлечения разрабов и переписывания конфигов Logstash.
Первое, что придёт Вам на ум – выгрузить данные из Kibana, чтобы вручную покрутить их в обычном Excel.
Но поиски кнопки выгрузки, к Вашему большому удивлению, закончатся неудачей, особенно в том случае, если Kibana корпоративная и имеет ограничения на модуль Reporting:

Что же получается, данные есть, а воспользоваться ими нельзя?
На самом деле есть один тайный способ. Через стандартный табличный отчёт Data Table.
На закладке «Visualize» можно создать множество разных отчётов, но только в Data Table есть кнопка выгрузки данных в формате csv.
Если Вы работаете с Kibana, то, вероятно, воспринимаете Data Table как агрегат, т.е. таблицу, в которой можно посчитать суммарное количество чего-нибудь, а вывести список всех записей невозможно. Однако это не совсем так.
У таблицы есть замечательная функция – Unique Count (подсчитать количество уникальных элементов), которым и можно воспользоваться, чтобы вывести весь список записей в таблицу.
Нажмите «+» в закладке Visualize, выберите «Data Table» и укажите индекс, из которого нужно сделать выгрузку. В параметрах таблицы укажите агрегат – «Unique Count» и чуть ниже поле с уникальным ID.
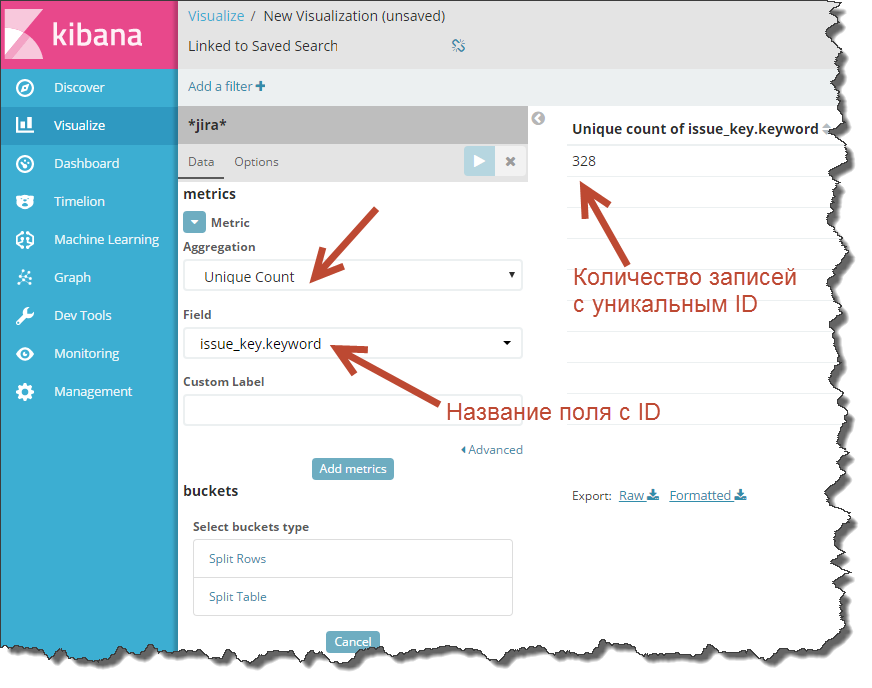
Если запустить пересчет, то Kibana выдаст количество уникальных записей в индексе.
Как же превратить одно число в список записей? Очень просто — с помощь кнопки «Split Rows»
Нажмите на неё и в качестве агрегата выберите «Terms» (разбивка по значениям поля).
Это ключевой момент: в «Field» укажите поле с уникальным ID записей.
И, о чудо, одно число при пересчете таблицы магическим образом превращается в таблицу!
Вот он, момент истины.
Что же Вы сделали? Если в двух словах, то Вы сказали Kibana, что хотите посчитать количество уникальных записей и также указали группировку записей по признаку, а именно по уникальным значениям указанного Вами поля.
Теперь Kibana отдельно подсчитывает количество элементов в каждой группе, а т.к. в качестве значений Вы указали уникальный ID записей, то Kibana стала подсчитывать количество уникальных записей, сгруппированных по уникальному ID, т.е. по сути, рядом с каждой строкой таблицы метрика «Unique Count» будет равна «1».
Вы получили нужный результат – вывели все записи и дополнительно посчитали сколько у Вас в индексе строк с одинаковым ID.
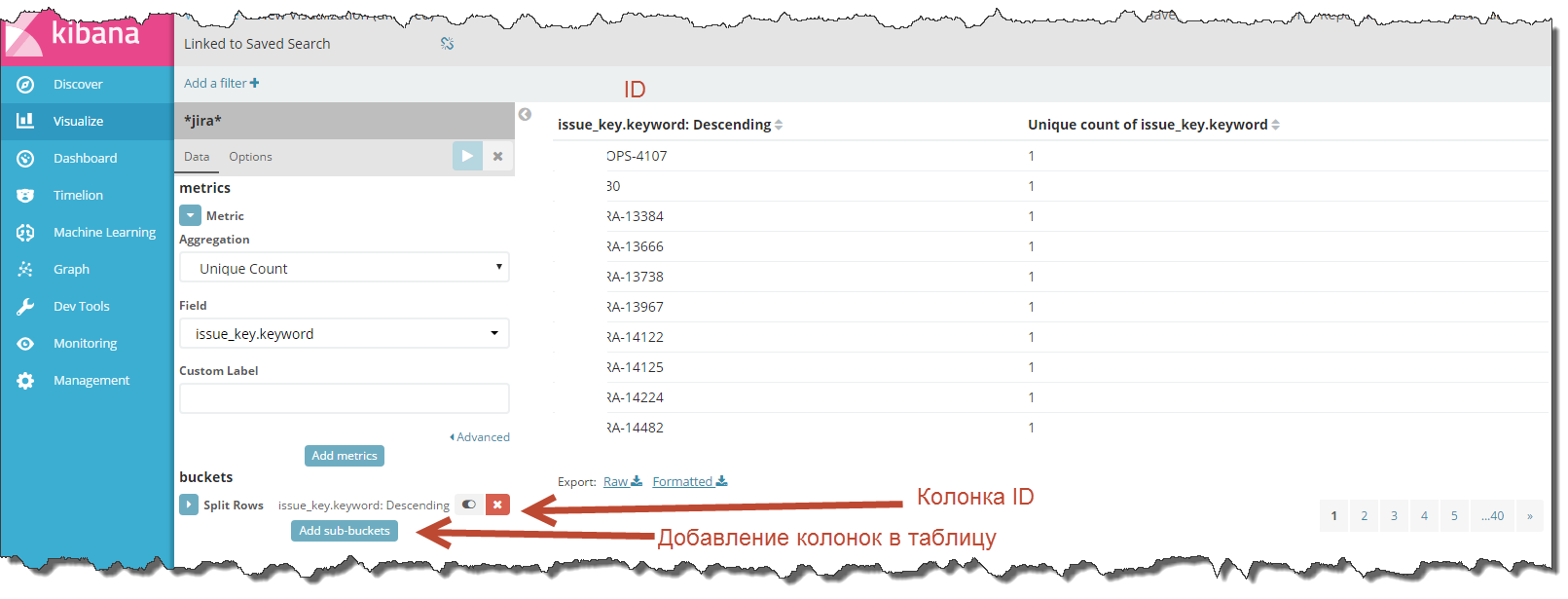
Теперь, если колонки в таблице недостаточно, добавьте дополнительные поля с помощью кнопки «Add sub-buckets» и далее «Split Rows».
Везде выбирайте «Terms» в качестве агрегата и указывайте названия полей, которые хотите добавить в таблицу.

Готово. Вы получили полную выгрузку индекса.
Все, что осталось сделать – сохранить визуализацию и нажать кнопку «Export Raw» или «Export Formatted».
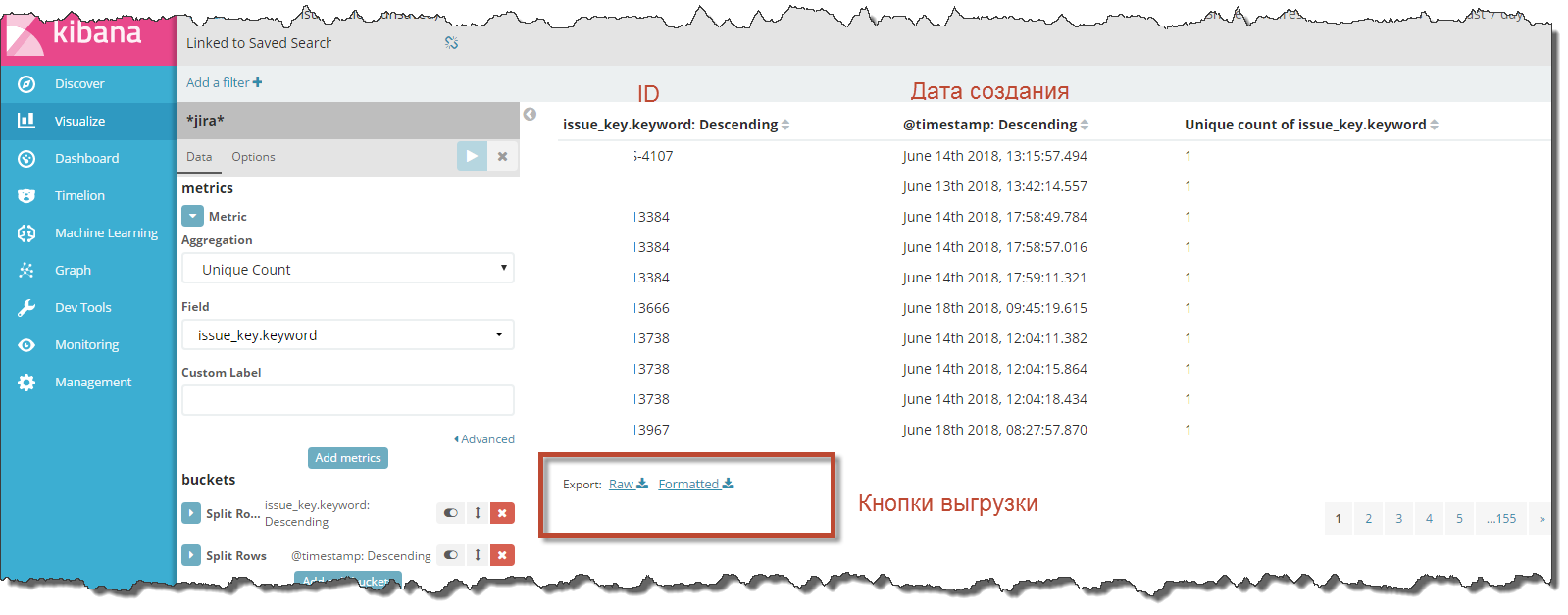
«Raw» выгрузить всё в сыром виде, а «Formatted» переформатирует данные согласно установленной в Kibana локали.
Всё.
Как видите, сделать выгрузку из Kibana простому человеку, не знакомому с программированием, все же возможно, хотя решение и не лежит на поверхности.
Надеюсь, этим маленьким трюком я облегчу кому-то жизнь и дам возможность быстро проанализировать данные не привлекая для выгрузок разработчиков.
Если мой опыт помог Вам, буду рад увидеть Ваш комментарий к этой статье.
Комментарии (8)

Hixon10
19.06.2018 23:51Тоже в последнее время думаю между делом, как достать данные из Kibana + Elasticsearch. Есть логи, которые хранятся в Elasticsearch. Через Kibana делаю разные запросы к логам, фильтруя логи. Хочется отфильтрованный поток логов куда-то заливать (база, или что-то другое) для анализа.
sloniki
20.06.2018 16:22Штатный путь — использовать родной Elastic Logstash. Не очень понятно, правда, почему не хватает анализа в Кибане, в ней можно делать почти всё.
Hixon10
20.06.2018 16:28Не уверен, что кибана позволит программировать некоторую бизнес логику над потоком логов для выявления каких-то паттернов, для того чтобы обнаружить отклонения и начать бить тревогу.
sloniki
20.06.2018 16:38Для алертинга лучше использовать X-Pack Watcher (дорого) или, например, Elastalert (бесплатно). Оба позволяют конфигурить алерты на определённые паттрены в документах или индексах: ключевые слова/фразы, количество определённых документов и т.д.
varenich Автор
20.06.2018 17:04Я провожу когортный анализ различных конверсий по той структуре индекса, скрин которого привел в начале статьи. Пока что не нашел способа как это сделать в Кибане. Поговорив с другими людьми я понял, что они тоже с этим сталкивались и не смогли получить результат.
Приходится сначала делать выгрузки записей по одному состоянию, а потом по другому. Далее объединять их в Excel в одну таблицу функцией ВПР.
sloniki
20.06.2018 09:56Начиная с версии Kibana 6.0 (в посте интерфейс версии 5.x) есть более прямой путь выгружать csv. Всё что нужно — установить X-Pack Base (бесплатно, но нужна регистрация) и активировать репортинг.
jehy
Да, в кибане очень нетривиально сделать какие-то сложные выгрузки. В какой-то момент я отчаялся и сделал свой дашборд для ошибок при помощи выгрузки данных из эластика через кибану в рсубд (mysql, но можно что угодно другое). Апи там выходит не сложное, только проблема в том, что ломается при апгрейдах периодически. Если вам близок node.is, то можно посмотреть, как это делается в моём проекте. То, что касается именно выгрузки — в функции getData в этом файле. Использовать код прямо as is вряд ли выйдет, но даст нужное направление.