

Без формул никуда, ну и краткая теория
Байесовский классификатор относится к разряду машинного обучения. Суть такова: система, перед которой стоит задача определить, является ли следующее письмо спамом, заранее обучена каким-то количеством писем точно известных где «спам», а где «не спам». Уже стало понятно, что это обучение с учителем, где в роли учителя выступаем мы. Байесовский классификатор представляет документ (в нашем случае письмо) в виде набора слов, которые якобы не зависят друг от друга (вот от сюда и вытекает та самая наивность).
Необходимо рассчитать оценку для каждого класса (спам/не спам) и выбрать ту, которая получилась максимальной. Для этого используем следующую формулу:
— вхождение слова в документ класса (со сглаживанием)*
— количество слов входящих в документ класса
М — количество слов из обучающей выборки
— количество вхождений слова в документ класса
— параметр для сглаживания
Когда объем текста очень большой, приходится работать с очень маленькими числами. Для того чтобы этого избежать, можно преобразовать формулу по свойству логарифма**:
Подставляем и получаем:
*Во время выполнения подсчетов вам может встретиться слово, которого не было на этапе обучения системы. Это может привести к тому, что оценка будет равна нулю и документ нельзя будет отнести ни в одну из категорий (спам/не спам). Как бы вы не хотели, вы не обучите свою систему всем возможным словам. Для этого необходимо применить сглаживание, а точнее – сделать небольшие поправки во все вероятности вхождения слов в документ. Выбирается параметр 0<??1 (если ?=1, то это сглаживание Лапласа)
**Логарифм – монотонно возрастающая функция. Как видно из первой формулы – мы ищем максимум. Логарифм от функции достигнет максимума в той же точке (по оси абсцисс), что и сама функция. Это упрощает вычисление, ибо меняется только численное значение.
От теории к практике
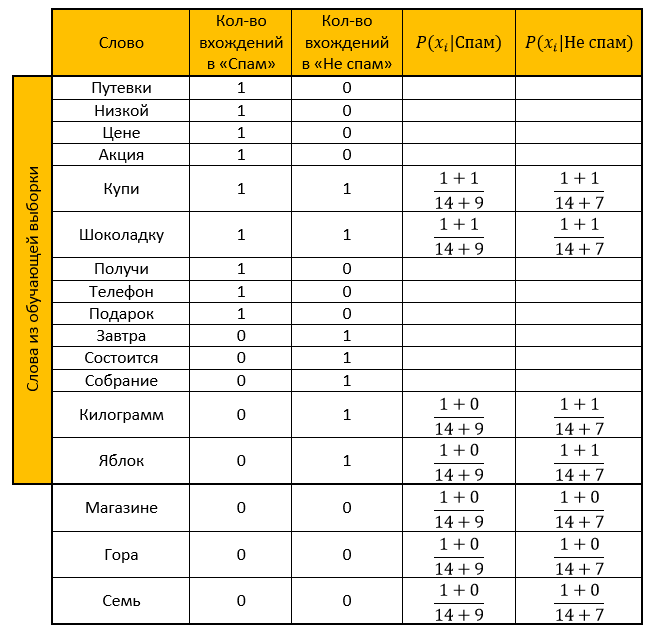
Пусть наша система обучалась на следующих письмам, заранее известных где «спам», а где «не спам» (обучающая выборка):
Спам:
- «Путевки по низкой цене»
- «Акция! Купи шоколадку и получи телефон в подарок»
Не спам:
- «Завтра состоится собрание»
- «Купи килограмм яблок и шоколадку»
Задание: определить, к какой категории отнести следующее письмо:
- «В магазине гора яблок. Купи семь килограмм и шоколадку»
Решение:
Составляем таблицу. Убираем все «стоп-слова», рассчитываем вероятности, параметр для сглаживания принимаем за единицу.
Оценка для категории «Спам»:
Оценка для категории «Не спам»:
Ответ: оценка «Не спам» больше оценки «Спам». Значит проверочное письмо — не спам!
То же самое рассчитаем и с помощью функции, преобразованной по свойству логарифма:
Оценка для категории «Спам»:
Оценка для категории «Не спам»:
Ответ: аналогично предыдущему ответу. Проверочное письмо – не спам!
Реализация на языке программирования R
Комментировал почти каждое свое действие, ибо знаю, насколько порой не хочется разбираться в чужом коде, поэтому надеюсь, чтение моего не вызовет у вас трудностей. (ой как надеюсь)
library("tm") #Библиотека для stopwords
library("stringr") #Библиотека для работы со строками
#Обучаюшая выборка со спам письмами:
spam <- c(
'Путевки по низкой цене',
'Акция! Купи шоколадку и получи телефон в подарок'
)
#Обучающая выборка с не спам письмами:
not_spam <- c(
'Завтра состоится собрание',
'Купи килограмм яблок и шоколадку'
)
#Письмо требующее проверки
test_letter <- "В магазине гора яблок. Купи семь килограмм и шоколадку"
#----------------Для спама--------------------
#Убираем все знаки препинания
spam <- str_replace_all(spam, "[[:punct:]]", "")
#Делаем все маленьким регистром
spam <- tolower(spam)
#Разбиваем слова по пробелу
spam_words <- unlist(strsplit(spam, " "))
#Убираем слова, которые совпадают со словами из stopwords
spam_words <- spam_words[! spam_words %in% stopwords("ru")]
#Создаем таблицу с уникальными словами и их количеством
unique_words <- table(spam_words)
#Создаем data frame
main_table <- data.frame(u_words=unique_words)
#Переименовываем столбцы
names(main_table) <- c("Слова","Спам")
#---------------Для не спама------------------
not_spam <- str_replace_all(not_spam, "[[:punct:]]", "")
not_spam <- tolower(not_spam)
not_spam_words <- unlist(strsplit(not_spam, " "))
not_spam_words <- not_spam_words[! not_spam_words %in% stopwords("ru")]
#---------------Для проверки------------------
test_letter <- str_replace_all(test_letter, "[[:punct:]]", "")
test_letter <- tolower(test_letter)
test_letter <- unlist(strsplit(test_letter, " "))
test_letter <- test_letter[! test_letter %in% stopwords("ru")]
#---------------------------------------------
#Создаем новый столбик для подсчета не спам писем
main_table$Не_спам <- 0
for(i in 1:length(not_spam_words)){
#Создаем логическую переменную
need_word <- TRUE
for(j in 1:(nrow(main_table))){
#Если "не спам" слово существует, то к счетчику уникальных слов +1
if(not_spam_words[i]==main_table[j,1])
{
main_table$Не_спам[j] <- main_table$Не_спам[j]+1
need_word <- FALSE
}
}
#Если слово не встречалось еще, то добавляем его в конец data frame и создаем счетчики
if(need_word==TRUE)
{
main_table <- rbind(main_table,data.frame(Слова=not_spam_words[i],Спам=0,Не_спам=1))
}
}
#-------------
#Создаем столбик содержащий вероятности того, что выбранное слово - спам
main_table$Вероятность_спам <- NA
#Создаем столбик содержащий вероятности того, что выбранное слово - не спам
main_table$Вероятность_не_спам <- NA
#-------------
#Создаем функцию подсчета вероятности вхождения слова Xi в документ класса Qk
formula_1 <- function(N_ik,M,N_k)
{
(1+N_ik)/(M+N_k)
}
#-------------
#Считаем количество слов из обучающей выборки
quantity <- nrow(main_table)
for(i in 1:length(test_letter))
{
#Используем ту же логическую переменную, чтобы не создавать новую
need_word <- TRUE
for(j in 1:nrow(main_table))
{
#Если слово из проверочного письма уже существует в нашей выборке то считаем вероятность каждой категории
if(test_letter[i]==main_table$Слова[j])
{
main_table$Вероятность_спам[j] <- formula_1(main_table$Спам[j],quantity,sum(main_table$Спам))
main_table$Вероятность_не_спам[j] <- formula_1(main_table$Не_спам[j],quantity,sum(main_table$Не_спам))
need_word <- FALSE
}
}
#Если слова нет, то добавляем его в конец data frame, и считаем вероятность спама/не спама
if(need_word==TRUE)
{
main_table <- rbind(main_table,data.frame(Слова=test_letter[i],Спам=0,Не_спам=0,Вероятность_спам=NA,Вероятность_не_спам=NA))
main_table$Вероятность_спам[nrow(main_table)] <- formula_1(main_table$Спам[nrow(main_table)],quantity,sum(main_table$Спам))
main_table$Вероятность_не_спам[nrow(main_table)] <- formula_1(main_table$Не_спам[nrow(main_table)],quantity,sum(main_table$Не_спам))
}
}
#Переменная для подсчета оценки класса "Спам"
probability_spam <- 1
#Переменная для подсчета оценки класса "Не спам"
probability_not_spam <- 1
for(i in 1:nrow(main_table))
{
if(!is.na(main_table$Вероятность_спам[i]))
{
#Шаг 1.1 Определяем оценку того, что письмо - спам
probability_spam <- probability_spam * main_table$Вероятность_спам[i]
}
if(!is.na(main_table$Вероятность_не_спам[i]))
{
#Шаг 1.2 Определяем оценку того, что письмо - не спам
probability_not_spam <- probability_not_spam * main_table$Вероятность_не_спам[i]
}
}
#Шаг 2.1 Определяем оценку того, что письмо - спам
probability_spam <- (length(spam)/(length(spam)+length(not_spam)))*probability_spam
#Шаг 2.2 Определяем оценку того, что письмо - не спам
probability_not_spam <- (length(not_spam)/(length(spam)+length(not_spam)))*probability_not_spam
#Чья оценка больше - тот и победил
ifelse(probability_spam>probability_not_spam,"Это сообщение - спам!","Это сообщение - не спам!")
Спасибо большое за потраченное время на чтение моей статьи. Надеюсь, Вы узнали для себя что-то новое, или просто пролили свет на непонятные для Вас моменты. Удачи!
Источники:
- Очень хорошая статья о наивном бейесовском классификаторе
- Черпал знания из Wiki: тут, тут, и тут
- Лекции по Data Mining Чубуковой И.А.
Комментарии (13)

vladob
03.07.2018 01:51+1Затрудняюсь дать общую оценку статьи, это длинный разговор.
А «наивный Байес» у аналитика должен от зубов отскакивать — это «хелло ворлд» классификации, ну или как в ардуино светодиодами поморгать.
Он не может устареть. Это основы.
Чуть-чуть про R код здесьПро общее качество R кода здесь не буду — здесь тоже много чего говорить.
Я только про вот этот фрагмент:
test_letter <- str_replace_all(test_letter, "[[:punct:]]", "") test_letter <- tolower(test_letter) test_letter <- unlist(strsplit(test_letter, " ")) test_letter <- test_letter[! test_letter %in% stopwords("ru")]
Не секрет, что люди со склонностью к функциональщине могли бы записать так
test_letter <- unlist(strsplit(tolower(str_replace_all(test_letter, "[[:punct:]]", "")), " ")) test_letter <- test_letter[! test_letter %in% stopwords("ru")]
И это не склонность к беспорядку. Такой код у меня получается постоянно, когда (в стиле R) программируешь с данными.
Кстати, последняя строчка не влезла в потенциальный однострочник.
Ведь, нужно две ссылки на test_letter (думаете вы).
Обойдемся.
(просто освоим команду setdiff)
test_letter <- setdiff(unlist(strsplit(tolower(str_replace_all(test_letter, "[[:punct:]]", "")), " ")), stopwords("ru")])
Мда.
Читаемость в последнем варианте, как говорится" оставляет желать.
Если вы планируете и дальше работать в R, настоятельно рекомендую освоить piping.
Не в последнюю очередь моя непреходящая любовь к R поддерживается его адаптивностью.
Я, даже, не говорю здесь о «крутых» библиотеках типа Keros, Tensflow etc. — все, ценное что есть для Python, уже есть и для R (как, впрочем, и наоборот).
На сей пространный комментарий меня подтолкнула сравнительно свежая фича — piping.
Сам освоил сравнительно недавно — до сих пор радует.
Аналогично X-ам теперь результат одного функции можно передавать в другую, используя вместо многократного вложения в скобочки лаконичную нотацию "%>%"
Эта нотация появилась сравнительно недавно — 5-6 лет назад в пакетах magrittr или dplyr, но очень активно используется в пакетах последних лет, например — для обработки изображений, AI, ML.
Код, выполняющий те же функции, что и выше, но теперь с использованием pipe нотации
require(dlypr) test_letter<-test_letter %>% str_replace_all("[[:punct:]]", "") %>% tolower() %>% strsplit(" ") %>% unlist() %>% setdiff(stopwords(«ru»))
Однострочник того же самого будет выглядеть так
test_letter<-test_letter %>% str_replace_all("[[:punct:]]", "") %>% tolower() %>% strsplit(" ") %>% unlist() %>% setdiff(stopwords(«ru»))
Еще, кажется, скобочки в функциях тоже можно не ставить, если передаваемый параметр единственный.
Любите R! :)WinDigo
03.07.2018 11:23Я бы ещё порекомендовал замечательный пакет {tidytext}. Имея опыт работы с {tidyverse} (https://www.tidyverse.org/), очень удобный инструмент для анализа текста.
К тому же имеется общедоступная книга от авторов пакета: www.tidytextmining.com.
Belyaev_Al Автор
03.07.2018 11:30Я согласен, что запись в одну строку и дополнительные библиотеки повысят «уровень» кода, но я старался предоставить алгоритм максимально легко, чтобы и читался он без напряга, и чтобы каждый шаг сопровождался комментарием.
vladob
03.07.2018 11:37Вот уж на то, чтобы быть примером в аккуратности кода я ни разу не претендовал.
Просто воспользовался случаем показать немножко больше R.
Одна строка возникает из удобства процесса кодирования.
Удобочитаемость, естественно, спорная.
epee
04.07.2018 16:41require(dlypr)
тут не ошибка случаем, может dplyr?
хотя честно говоря давно на R ничего не делал, то может отстал от жизни :)vladob
04.07.2018 23:35Да, конечно dplyr!
Извиняюсь за опечатку.
Просто этот пакет вместе с другими фундаментальными пакетами за авторством Hadley Wickham во многом определяют лицо современного R и его конкурентоспособность.
Его пакеты ggplot2, plyr/dplyr, reshaper, RStudio — в принципе, «подрастающе поколение» дата саентистов думают, что это и есть R.
Поэтому, кстати, получается, что явно библиотеку dplyr в своем коде почти не приходится вызывать — его подгружают другие частные библиотеки.
SinsI
03.07.2018 07:27Теперь понятно, почему спамеры рассылают кучу бессмысленных сообщений вида «Завтра состоится собрание по низкой цене» или «купи килограмм путёвок в подарок» — они нарушают работу таких фильтров.
roryorangepants
Я, конечно, не специалист, но что-то мне подсказывает, что реальный антиспам давно использует более продвинутые алгоритмы, чем Naive Bayes поверх bag-of-words.
Belyaev_Al Автор
Наивный Байес, по своей сути очень легкий и достаточно популярный алгоритм. Если его по-умному собрать (анализ по словосочетаниям, падежи и пр.), то он дает достаточно хорошие результаты. Из этого я и сделал вывод, что пусть он и устарел, но все еще остается актуальным.
immaculate
Не дает он «достаточно хорошие результаты», это выдача желаемого за действительное. В свое время я работал в паре компаний, которые занимались фильтрацией спама. Он и спам отфильтровать толком не может, но что хуже, количество ложных срабатываний тоже достаточно велико.
В теории все красиво, на практике толку от такого фильтра немного.
Для меня честно говоря, самое интересное, как работают фильтры в GMail. Лучше я не видел, и это явно не наивный байес. Хотя большую часть спама они отсеивают прямо-таки фашистскими методами: чтобы отправить письмо на gmail со своего сервера, надо очень много времени потратить на настройку всяких dkim, dmarc и т.д.
remzalp
они используют еще данные с соседних ящиков, так что массовая рассылка однотипного текста вычисляется на раз
Belyaev_Al Автор
Спорить не буду, ибо в жизненных ситуациях еще не приходилось работать с фильтрами спама. Тогда поправлю то предложение, чтобы никого не путать.