
Публикуем расшифровку видеозаписи выступления Станислава Лукьянова на митапе Apache Ignite сообщества в Петербурге 20 июня. Загрузить слайды можно по ссылке.
Есть целый класс проблем, с которыми сталкиваются начинающие пользователи. Они только что скачали себе Apache Ignite, запускают первые два-три-десять раз, и приходят к нам с вопросами, которые решаются схожим образом. Поэтому предлагаю создать чек-лист, который сэкономит вам много времени и нервов, когда вы делаете свои первые приложения на Apache Ignite. Мы поговорим о подготовке к запуску; как сделать так, чтобы кластер собрался; как запустить какие-нибудь вычисления в Compute Grid; как подготовить модель данных и код, чтобы можно было записать в Ignite свои данные и потом их успешно прочитать. И главное: как ничего не сломать с самого начала.
Подготовка к запуску — настраиваем логирование
Нам понадобятся логи. Если вы когда-нибудь задавали в почтовой рассылке Apache Ignite или на StackOverflow какой-нибудь вопрос, вроде «почему у меня всё зависло», скорее всего, первым делом вас попросили прислать все логи со всех нод.
Естественно, у Apache Ignite журналирование включено по умолчанию. Но есть нюансы. Во-первых, в stdout Apache Ignite пишет не так много. По умолчанию он запускается в так называемом тихом режиме (quiet mode). В stdout вы увидите только самые страшные ошибки, а всё остальное будет сохраняться в файле, путь к которому Apache Ignite выводит в самом начале (по умолчанию — ${IGNITE_HOME}/work/log). Вы его не стирайте и храните логи подольше, может очень пригодиться.
stdout Ignite при запуске по умолчанию
Чтобы проще было узнавать о проблемах, не залезая в отдельные файлы и не настраивая отдельный мониторинг для Apache Ignite, можно запустить его в verbose-режиме командой
ignite.sh -vи тогда система начнёт обо всех событиях писать в stdout вместе с остальным журналированием приложения.
Проверяйте логи! Очень часто в них можно найти решения возникающих у вас проблем. Если развалился кластер, то очень часто в логе можно увидеть сообщения типа «Увеличьте такой-то timeout в такой-то конфигурации. Мы отвалились из-за него. Он слишком маленький. Сеть недостаточно хорошая».
Сборка кластера
Незваные гости
Первая проблема, с которой сталкиваются многие, — это незваные гости в вашем кластере. Или вы сами оказываетесь незваным гостем: запускаете свеженький кластер и вдруг видите, что в первом же topology snapshot вместо одной ноды у вас с самого начала два сервера. Как так? Вы же запустили только один.
Сообщение, говорящее о том, что в кластере два узла

Дело в том, что по умолчанию Apache Ignite использует Multicast, и при запуске будет искать все другие Apache Ignite, которые находятся в той же подсети, в той же Multicast-группе. И если найдёт, то попробует подключиться. А в случае неудачного подключения — вообще не запустится. Поэтому в кластере на моём рабочем ноутбуке регулярно появляются лишние ноды из кластера на ноутбуке коллеги, что конечно, не очень удобно.
Как себя от этого обезопасить? Проще всего настроить статические IP. Вместо TcpDiscoveryMulticastIpFinder, который используется по умолчанию, есть TcpDiscoveryVmIpFinder. Там пропишите все IP и порты, к которым подключаетесь. Это намного удобнее и обезопасит вас от большого количества проблем, особенно в окружениях для разработки и тестирования.
Слишком много адресов
Следующая проблема. Вы отключили Multicast, запускаете кластер, в одном конфиге прописали приличное количество IP из разных окружений. И бывает так, что первую ноду запускаете в свежем кластере 5—10 минут, хотя все последующие подключаются к ней за 5—10 секунд.
Возьмём список из трёх IP-адресов. Для каждого прописываем диапазоны по 10 портов. Всего получается 30 TCP-адресов. Поскольку Apache Ignite перед созданием нового кластера должен попытаться подключиться к уже имеющемуся, он будет по очереди проверять каждый IP. На вашем ноутбуке это, может быть, не помешает, но в каком-нибудь облачном окружении часто включена защита от сканирования портов. То есть при обращении на закрытый порт на каком-то IP адресе вы не получите никакого ответа, пока не пройдёт тайм-аут. По умолчанию он равен 10 секунд. И если у вас 3 адреса по 200 портов, то получается 600 секунд ожидания — те самые 5 минут на подключение.
Решение очевидное: не прописывать лишние порты. Если у вас три IP, то вряд ли вам действительно нужен диапазон по умолчанию в 10 портов. Это удобно, когда что-то тестируешь на локальной машине и запускаешь 10 нод. Но в реальных системах обычно достаточно одного порта. Либо отключите защиту от сканирования портов во внутренней сети, если у вас есть такая возможность.
Третья частая проблема связана с IPv6. Вы можете увидеть странные сообщения о сетевых ошибках: не смог подключиться, не смог отправить сообщение, node segmented. Это означает, что вы отвалились от кластера. Очень часто такие проблемы вызваны смешанным окружением из IPv4 и IPv6. Нельзя сказать, что Apache Ignite не поддерживает IPv6, но на данный момент есть определенные проблемы.
Самое простое решение — передать Java-машине опцию
-Djava.net.preferIPv4Stack=trueТогда Java и Apache Ignite не будут использовать IPv6. Это решает значительную часть проблем с разваливающимися кластерами.
Подготовка кодовой базы — сериализуем правильно
Кластер собрался, надо в нём что-нибудь запустить. Один из важнейших элементов взаимодействия вашего кода с кодом Apache Ignite является Marshaller, или сериализация. Чтобы что-то записать в память, в persistence, послать по сети, Apache Ignite сначала сериализует ваши объекты. Вы можете увидеть сообщения, которые начинаются со слов: “cannot be written in binary format” или “cannot be serialized using BinaryMarshaller”. В логе будет всего одно такое предупреждение, но заметное. Это означает, что вам нужно еще чуть-чуть настроить ваш код, чтобы подружить его с Apache Ignite.
Apache Ignite использует три механизма для сериализации:
JdkMarshaller— обычная Java-сериализация;OptimizedMarshaller— немного оптимизированная Java-сериализация, но механизмы те же;BinaryMarshaller— сериализация, написанная специально для Apache Ignite, используемая везде под его капотом. У нее целый ряд преимуществ. Где-то мы можем избежать дополнительной сериализации и десериализации, а где-то даже можем получить в API не десериализованный объект, работать с ним прямо в binary-формате как с чем-то вроде JSON.
BinaryMarshaller сможет сериализовать и десереализовать ваши POJO, у которых нет ничего кроме полей и простых методов. Но если у вас кастомная сериализация через readObject() и writeObject(), если у вас применяется Externalizable, то BinaryMarshaller не справится. Он увидит, что ваш объект нельзя сериализовать обычной записью не-transient полей и сдастся — откатится на OptimizedMarshaller.
Чтобы подружить такие объекты с Apache Ignite, нужно реализовать интерфейс Binarylizable. Он очень простой.
Например, есть стандартный TreeMap из Java. У него есть кастомная сериализация и десериализация через read and write object. Она сначала описывает какие-то поля, а потом записывает в OutputStream длину и сами данные.
Реализация TreeMap.writeObject()
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out the Comparator and any hidden stuff
s.defaultWriteObject();
// Write out size (number of Mappings)
s.writeInt(size);
// Write out keys and values (alternating)
for (Iterator<Map.Entry<K,V>> i = entrySet().iterator(); i.hasNext(); ) {
Map.Entry<K,V> e = i.next();
s.writeObject(e.getKey());
s.writeObject(e.getValue());
}
}writeBinary() и readBinary() из Binarylizable работают абсолютно так же: BinaryTreeMap обёртывает себя в обычный TreeMap и пишет его в OutputStream. Такой метод легко написать, и это довольно сильно увеличит производительность.
Реализация BinaryTreeMap.writeBinary()
public void writeBinary(BinaryWriter writer) throws BinaryObjectException {
BinaryRawWriter rewriter = writer. rewrite ();
rawWriter.writeObject(map.comparator());
int size = map.size();
rawWriter.writeInt(size);
for (Map.Entry<Object, Object> entry : ((TreeMap<Object, Object>)map).entrySet()) {
rawWriter.writeObject(entry.getKey());
rawWriter.writeObject(entry.getValue());
}
}Запуск в Compute Grid
Ignite позволяет не только хранить данные, но и запускать распределенные вычисления. Как нам запустить какую-нибудь лямбду, чтобы она разлетелась по всем серверам и исполнилась?
Для начала, в чём проблема этих примеров кода?
В чём проблема?
Foo foo = …;
Bar bar = ...;
ignite.compute().broadcast(
() -> doStuffWithFooAndBar(foo, bar)
);А если так?
Foo foo = …;
Bar bar = ...;
ignite.compute().broadcast(new IgniteRunnable() {
@Override public void run() {
doStuffWithFooAndBar(foo, bar);
}
});Как догадаются многие, знакомые с подводными камнями лямбд и анонимных классов, проблема в захвате переменных извне. Например, мы отправляем лямбду. Она использует пару переменных, которые объявлены вне лямбды. Значит, эти переменные будут путешествовать вместе с ней и полетят по всей сети на все серверы. И тогда возникают всё те же вопросы: эти объекты дружат с BinaryMarshaller? Какого они размера? Мы вообще хотим, чтобы они куда-то передавались, или эти объекты так велики, что лучше передавать какой-то ID и воссоздавать объекты внутри лямбды уже на другой стороне?
С анонимным классом еще хуже. Если лямбда может не взять с собой this, выкинуть его, если он не используется, то анонимный класс заберет его обязательно, и ни к чему хорошему это, обычно, не приводит.
Следующий пример. Опять лямбда, но которая немного использует Apache Ignite API.
Используем Ignite внутри compute closure неправильно
ignite.compute().broadcast(() -> {
IgniteCache foo = ignite.cache("foo");
String sql = "where id = 42";
SqlQuery qry = new SqlQuery("Foo", sql).setLocal(true);
return foo.query(qry);
});В исходном варианте она берет кэш и локально делает в нем какой-то SQL-запрос. Это такой паттерн, когда нужно отправить задачу, работающую только с локальными данными на удалённых нодах.
В чём тут проблема? Лямбда опять захватывает ссылку, но теперь не на объект, а на локальный Ignite на той ноде, с которой мы её отправляем. И это даже работает, потому что у объекта Ignite есть метод readResolve(), который позволяет при десериализации подменить тот Ignite, который пришёл по сети, на локальный на той ноде, куда мы его прислали. Но это тоже иногда приводит к нежелательным последствиям.
В принципе, вы просто передаете по сети больше данных, чем хотели бы. Если вам нужно достучаться из какого-то кода, запуск которого вы не контролируете, до Apache Ignite или каких-то его интерфейсов, то самое простое — использовать метод Ignintion.localIgnite(). Можно вызвать его из любого потока, который был создан Apache Ignite, и получить ссылку на локальный объект. Если у вас есть лямбды, сервисы, что угодно, и вы понимаете, что здесь вам нужен Ignite, то рекомендую этот способ.
Используем Ignite внутри compute closure правильно — через localIgnite()
ignite.compute().broadcast(() -> {
IgniteCache foo = Ignition.localIgnite().cache("foo");
String sql = "where id = 42";
SqlQuery qry = new SqlQuery("Foo", sql).setLocal(true);
return foo.query(qry);
});
И последний пример в этой части. В Apache Ignite есть Service Grid, с помощью которого можно развёртывать микросервисы прямо в кластере, и Apache Ignite поможет постоянно держать онлайн нужное количество экземпляров. Допустим, в этом сервисе нам тоже нужна ссылка на Apache Ignite. Как её получить? Мы могли бы использовать localIgnite(), но тогда эту ссылку придётся вручную сохранить в поле.
Сервис хранит Ignite в поле неправильно — принимает его как аргумент конструктора
MyService s = new MyService(ignite)
ignite.services().deployClusterSingleton("svc", s);
...
public class MyService implements Service {
private Ignite ignite;
public MyService(Ignite ignite) {
this.ignite = ignite;
}
...
}Есть способ проще. У нас всё равно уже полноценные классы, а не лямбда, поэтому мы можем аннотировать поле как @IgniteInstanceResource. Когда сервис будет создан, Apache Ignite сам себя туда положит, и можно будет им спокойно пользоваться. Очень советую делать именно так, а не пытаться передавать в конструктор сам Apache Ignite и его дочерние объекты.
Сервис использует @IgniteInstanceResource
public class MyService implements Service {
@IgniteInstanceResource
private Ignite ignite;
public MyService() { }
...
}Запись и чтение данных
Следим за baseline
Теперь у нас есть кластер Apache Ignite и подготовленный код.
Давайте представим такой сценарий:
- Один
REPLICATEDcache — копии данных имеются на всех узлах; - Native persistence включен — пишем на диск.
Запускаем один узел. Так как включен native persistence, нам нужно активировать кластер, прежде чем с ним работать. Активируем. Потом запускаем ещё несколько узлов.
Всё, вроде бы, работает: запись и чтение проходят нормально. На всех узлах есть копии данных, можно спокойно остановить один узел. Но если остановить самый первый узел, с которого начинали запуск, то всё ломается: данные пропадают, а операции перестают проходить.
Причина в baseline topology — множестве узлов, которые хранят на себе persistence-данные. Во всех остальных узлах persistent-данных не будет.
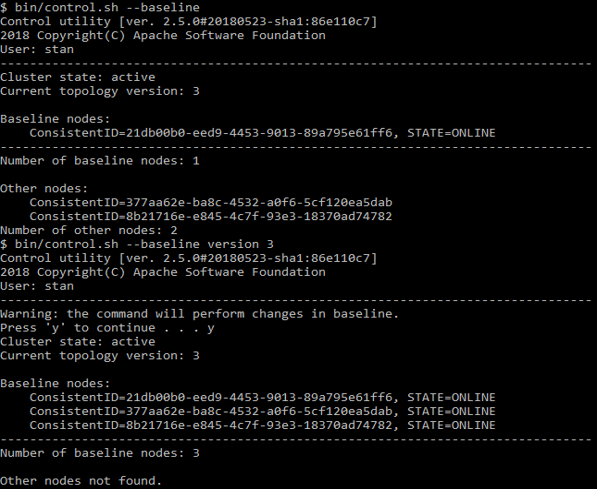
Это множество узлов в первый раз определяется в момент активации. И те узлы, что вы добавили впоследствии, в число baseline-узлов уже не включаются. То есть множество baseline topology состоит всего из одного, самого первого узла, при остановке которого всё ломается. Чтобы этого не происходило, сначала запускайте все узлы, а потом активируйте кластер. Если нужно добавить или убрать узел, с помощью команды
control.sh --baselineможете посмотреть, какие узлы там перечислены. Этот же скрипт может обновить baseline до текущего состояния.
Пример использования control.sh
Колокация данных
Теперь мы знаем, что данные сохраняются, попробуем их прочитать. У нас есть поддержка SQL, можно делать SELECT — практически как в Oracle. Но при этом мы умеем масштабироваться и запускать на любом количестве узлов, данные хранятся распределённо. Посмотрим на такую модель:
public class Person {
@QuerySqlField
public Long id;
@QuerySqlField
public Long orgId;
}
public class Organization {
@QuerySqlField
private Long id;
}Запрос
SELECT *
FROM Person as p
JOIN Organization as o ON p.orgId = o.idвернёт не все данные. Что не так?
Человек (Person) ссылается на организацию (Organization) по ID. Это классический внешний ключ. Но если мы попробуем объединить две таблицы и отправим такой SQL-запрос, то при нескольких нодах в кластере получим не все данные.
Дело в том, что по умолчанию SQL JOIN работает только в рамках одной ноды. Если бы SQL постоянно ходил по всему кластеру, чтобы собрать данные и вернуть полный результат, это было бы невероятно медленно. Мы бы потеряли все преимущества распределенной системы. Поэтому вместо этого Apache Ignite смотрит только на локальные данные.
Чтобы получить правильные результаты, нам нужно размещать данные совместно (colocation). То есть для корректного объединения Person и Organization данные обеих таблиц должны храниться на одном узле.
Как это сделать? Самое простое решение — объявить affinity-ключ. Это значение, которое определяет, на каком узле, в какой партиции, в какой группе записей будет находиться то или иное значение. Если мы объявим ID организации в Person как affinity-ключ, это будет означать, что люди с таким ID организации должны находиться на том же узле, на котором находится и организация с тем же ID.
Если по каким-то причинам вы так сделать не можете, есть другое, менее эффективное решение — включить distributed joins. Это делается через API, и процедура зависит от того, что вы используете — Java, JDBC или что-то еще. Тогда JOIN будут выполняться помедленнее, но зато станут возвращать правильные результаты.
Рассмотрим, как работать с affinity-ключами. Как нам понять, что такой-то ID, такое-то поле подходит для определения affinity? Если мы говорим, что все люди с одним и тем же orgId будут храниться вместе, значит orgId — это одна неделимая группа. Мы не можем распределять её по нескольким узлам. Если в базе хранится 10 организаций, то будет 10 неделимых групп, которые можно положить на 10 узлов. Если узлов в кластере больше, то все «лишние» узлы останутся без групп. Это очень сложно определить в runtime, поэтому думайте об этом заранее.
Если у вас есть одна большая организация и 9 маленьких, то и размер групп будет различным. Но Apache Ignite не смотрит на количество записей в affinity-группах, когда распределяет их по узлам. Поэтому он не положит одну группу на один узел, а 9 других на другой, чтобы как-то уровнять распределение. Скорее, он положит их 5 и 5, (или 6 и 4, или даже 7 и 3).
Как бы сделать так, чтобы данные распределились равномерно? Пусть у нас есть
- К ключей;
- А различных affinity-ключей;
- P партиций, то есть больших групп данных, которые Apache Ignite будет распределять между нодами;
- N узлов.
Тогда нужно, чтобы выполнялось условие
K >> A >> P >> Nгде >> — "много больше", и данные будут распределены относительно равномерно.
К слову, по умолчанию P = 1024.
Совсем равномерного распределения у вас, скорее всего, не получится. Такое было в Apache Ignite 1.x до 1.9. Это называлось FairAffinityFunction и работало не очень хорошо — приводило к слишком большому трафику между узлами. Сейчас алгоритм называется RendezvousAffinityFunction. Он не дает абсолютно честного распределения, погрешность между узлами будет плюс минус 5—10 %.
Чек-лист для новых пользователей Apache Ignite
- Настройте, читайте, храните логи
- Выключите multicast, пропишите только те адреса и порты, которые используете
- Отключите IPv6
- Подготовьте свои классы к
BinaryMarshaller - Следите за своим baseline
- Настройте affinity collocation
Комментарии (2)

devozerov
06.07.2018 11:57Apache Calcite нам не интересен, потому что все, что он делает, мы умеем делать сами — и парсинг, и JDBC, и оптимизации. Более того, распределенный SQL предполагает другие правила оптимиации запросов, поэтому полагаться на какую-то внещнюю систему для этого мы не можем.
Что касается H2, он может быть сыроват в плане стораджа, но мы его и не используем. От H2 мы используем преимущественно движок локального выполнения запросов. Он не дико навороченный конечно, но работает вполне неплохо.
Главные вызовы, которые сейчас перед нами стоят находятся вне функционала H2 и Calcite.
igor_suhorukov
Спасибо за обзор!
Скажите, почему в качестве SQL engine под капотом Ignite используется достаточно примитивный H2, вместо более функционального Apache Calcite?