

Это продолжение первой части статьи
В первой части статьи автор рассказал об условиях конкурса по игре Агарио на mail.ru, структуре игрового мира и частично об устройстве бота. Частично, потому что затронули только устройство входных сенсоров и команд на выходе из нейронной сети (далее в картинках и тексте будет сокращение NN). Так попробуем приоткрыть черный ящик и понять как же там все устроено.
А вот и первая картинка:
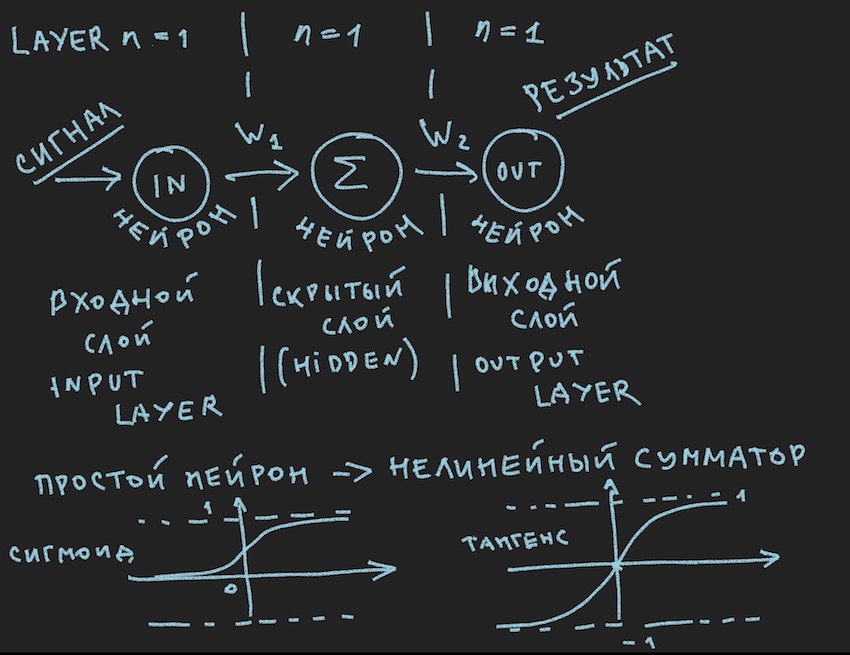
На ней схематично изображено то, что должно вызвать скучающую улыбку у моего читателя, мол опять в первый класс, видели много раз в различных источниках. Но мы ведь хотим практически применить эту картинку к управлению ботом, поэтому после Важного замечания приглядимся к ней повнимательнее.
Важное замечание: существует большое количество готовых решений(фреймворков) для работы с нейронными сетями:

Все эти пакеты решают главные задачи для разработчика нейронных сетей: построение и обучение NN или поиск "оптимальных" весовых коэффициентов. И основной метод этого поиска Метод обратного распространения ошибки (англ. backpropagation) . Изобрели его в 70-х годах прошлого века, на что указывает статья по вышеуказанной ссылке, за это время, как дно корабля, он оброс различными усовершенствованиями, но суть прежняя: нахождение весовых коэффициентов при наличии базы примеров для обучения и крайне желательно, чтобы каждый из этих примеров содержал уже готовый ответ в форме выходного сигнала нейронной сети. Мне может возразить читатель. что уже придуманы самообучающиеся сети различных классов и принципов, но там не все гладко, насколько понимаю. Конечно есть в планах изучить этот зоопарк подробнее, но думаю найду единомышленников в том, что сделанный своими руками без особых чертежей велосипед, даже самый кривой ближе сердцу создателя, чем конвейерный клон идеального велосипеда.
Понимая, что на игровом сервере скорее всего не будет этих библиотек и вычислительной мощности выделенной организаторами в виде 1 процессорного ядра явно не хватит для тяжелого фрейворка, автор пошел путем создания своего велосипеда. Важное замечание на этом закончилось.
Вернемся к картинке изображающей наверное простейшую из возможных нейронных сетей со скрытым слоем(он же скрытый лейер или hidden layer). Сейчас автор сам пристально всмотрелся в картинку с идей на этом простом примере приоткрыть читателю глубины искусственных нейросетей. Когда все упрощается до примитива, легче понять суть. Суть в том, что нейрону скрытого слоя нечего суммировать. И скорее всего это даже не нейронная сеть, в учебниках простейшая NN это сеть с двумя входами. Так что мы здесь как-бы первооткрыватели простейшей из простейших сетей.
Попробуем описать эту нейронную сеть(псевдокод):
Введем топологию сети в виде массива, где каждый элемент соответствует слою и количеству нейроном в нем:
int array Topology= { 1, 1, 1}
Еще нам понадобится float массив весов нейросети W, считая нашу сеть "нейронной сетью прямого распространения (feed forward neural networks, FF или FFNN)", где каждый нейрон текущего слоя связан с каждым нейроном последующего слоя, получаем размерность массива W[кол-во слоев, число нейроном в слое, число нейроном в слое]. Не совсем оптимальная кодировка, но учитывая горячее дыхание GPU где-то совсем рядом по тексту, вполне объяснимая.
Короткая процедура CalculateSize подсчета количества нейронов neuroncountи количества их связей в нейросети dendritecount, думаю объяснит лучше автора природу этих связей:
void CalculateSize(array int Topology, int neuroncount, int dendritecount)
{
for (int i : Topology) // i идет по лейерам и суммирует нейроны всех слоев
neuroncount += i;
for (int layer = 0, layer <Topology.Length - 1, layer++) //идет по лейерам
for (int i = 0, i < Topology[layer] + 1, i++) //идет по нейронам
for (int j = 0, j < Topology[layer + 1], j++) //идет по нейронам
dendritecount++;
}Мой читатель, тот кто все это уже знает, к такому мнению пришел автор в первой статье, конечно же не спросит: почему в третьем вложенном цикле Topology[layer1 + 1] вместо Topology[layer1], что дает на нейрон больше чем в топологии сети. А я не отвечу. Бывает полезно и читателю задавать задания на дом.
Мы почти в шаге от построения работающей нейронной сети. Осталось добавить функцию суммирования сигналов на входе нейрона и его активации. Функций активаций много, но наиболее близкие к природе нейрона это Сигмоид и Тангенсоид (наверное так лучше назвать хотя в литературе особо не используется это название, максимум тангенсоида, но это название графика, хотя что такое график если не отражение функции?)
Итак перед нами функции активации нейрона (на картинке они присутствуют, в ее нижней части)
float Sigmoid(float x)
{
if (x < -10.0f) return 0.0f;
else if (x > 10.0f) return 1.0f;
return (float)(1.0f / (1.0f + expf(-x)));
}Сигмоид возвращает значения от 0 до 1.
float Tanh(float x)
{
if (x < -10.0f) return -1.0f;
else if (x > 10.0f) return 1.0f;
return (float)(tanhf(x));
}Тангенсоид возвращает значения от -1 до 1.
Основная идея прохождения сигнала по нейронной сети это волна: подается сигнал на входные нейроны-> через нейронные связи сигнал переходит на второй слой->нейроны второго слоя суммируют дошедшие до них сигналы измененные межнейронными весами-> добавляется через дополнительный вес биас(bias)->применяем функцию активации-> и ву-аля переходим на след слой (читай крутим первый цикл из примера по слоям), то есть это повторение цепочки с самого начала только входными нейронами станут нейроны последующего слоя. В упрощении даже не нужно хранить значения нейронов всей сети, вам достаточна хранить только веса NN и значения нейронов активного слоя.
Еще раз, подаем сигнал на вход NN, побежала волна по слоям и на выходном слое снимаем полученное значение.
Здесь от вкуса читателя возможно программно решить с помощью рекурсии или просто тройного цикла как у автора, для ускорения расчетов не нужно городить объекты в виде нейронов и их связей и прочее ООП. Опять же это связано и с ощущением близких GPU расчетов, а на графических процессорах в силу их природы массового параллелизма ООП немного буксует, это относительно языков c# и с++.
Дальше читателю предлагаю самостоятельно пройти путь построения в коде нейронной сети, при его читателя добровольном желании, отсутствие которого вполне понятно и знакомо автору, что касается примеров построения NN с нуля, то примеров в сети большое количество, поэтому сбиться с пути будет сложно, он так же прямолинеен, как нейросеть прямого распространения на вышерассмотренной картинке.
Но где же новые картинки воскликнет читатель, еще не отошедший от предыдущего пассажа, и будет прав, в детстве ценность книги автор определял по иллюстрациям к ней. Вот пожалуйста:
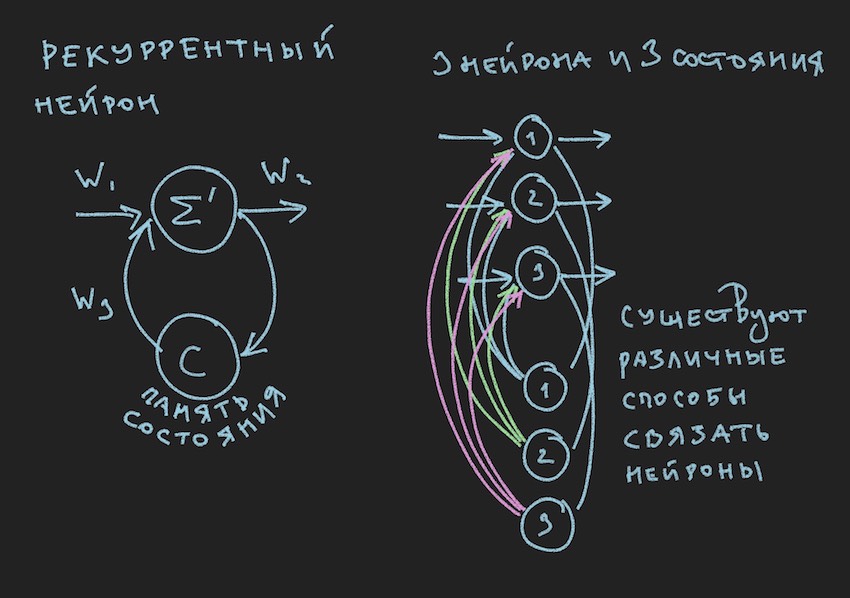
На картинке мы видим рекуррентный нейрон и NN построенная из таких нейронов называется рекуррентной или RNN. Указанная нейросеть обладает краткосрочной памятью и выбрана автором для бота, как наиболее перспективная с точки зрения адаптации к игровому процессу. Конечно же автор строил нейросеть прямого распространения, но в процессе поиска "эффективного" решения перешел на RNN.
Рекуррентный нейрон обладает дополнительным состоянием С, которое формируется после первого прохождения сигнала через нейрон, Тик+0 на временной шкале. Простыми словами это копия выходного сигнала нейрона. На втором шаге, читайте Тик+1 (так как сеть работает на частоте игрового бота и сервера), значение С возвращается на вход нейронного слоя через дополнительные веса и таким образом участвует в формировании сигнала, но уже на Тик+1 времени.
Замечание: в работах исследовательских групп в части управления NN игровыми ботами, намечается тенденция использовать два ритма для нейронной сети, один ритм это частота игрового Тика, второй ритм например в два раза медленнее первого. Разные части NN работают на разных частотах, что дает разное видение игровой ситуации внутри NN, тем самым повышая ее гибкость.
Для построения RNN в коде бота, введем в топологию дополнительный массив, где каждый элемент соответствует слою и количеству нейронных состояний в нем:
int array TopologyNN= { numberofSensors, 16, 8, 4}
int array TopologyRNN= { 0, 16, 0, 0 }
Из вышеуказанной топологии видно, что второй слой является рекуррентным, так как содержит нейронные состояния. Также введем дополнительные веса в виде float массива WRR, той же размерности что и массив W.
Подсчет соединений в нашей нейронной сети немного изменится:
for (int layer = 0, layer < TopologyNN.Length - 1, layer++)
for (int i = 0, i < TopologyNN[layer] + 1, i++)
for (int j = 0, j < TopologyNN[layer + 1] , j++)
dendritecount++;
for (int layer = 0, layer < TopologyRNN.Length - 1, layer++)
for (int i = 0, i< TopologyRNN[layer] + 1 , i++)
for (int j = 0, j< TopologyRNN[layer], j++)
dendritecount++;Общий код рекуррентной нейронной сети автор приложит в конце данной статьи, но здесь главное понять принцип: прохождение волны по слоям в случае с рекуррентной NN принципиально ничего не меняет, добавляется только еще одно слагаемое в функции активации нейрона. Это слагаемое состояние нейронов на предыдущем Тике умноженное на вес нейросвязи.
Будем считать что освежили теорию и практику нейросетей, но автор ясно осознает что не приблизил читателя к пониманию как же обучить эту несложную структуру нейронных связей к принятию каких-либо решений в игровом процессе. Библиотеки с примерами для обучения NN у нас нет. В интернет группах разработчиков ботов, звучало мнение: дайте нам log файл в виде координат ботов и другой игровой информации для формирования библиотеки примеров. Но автор к сожалению так и не смог догадаться, как этот log файл использовать для обучения NN. Буду рад обсудить это в комментариях к статье. Поэтому единственным доступным для авторского понимая методом обучения, а точнее нахождения "эффективных" нейровесов(нейросвязей) стал генетический алгоритм.
Подготовлена картинка о принципах работы генетического алгоритма:
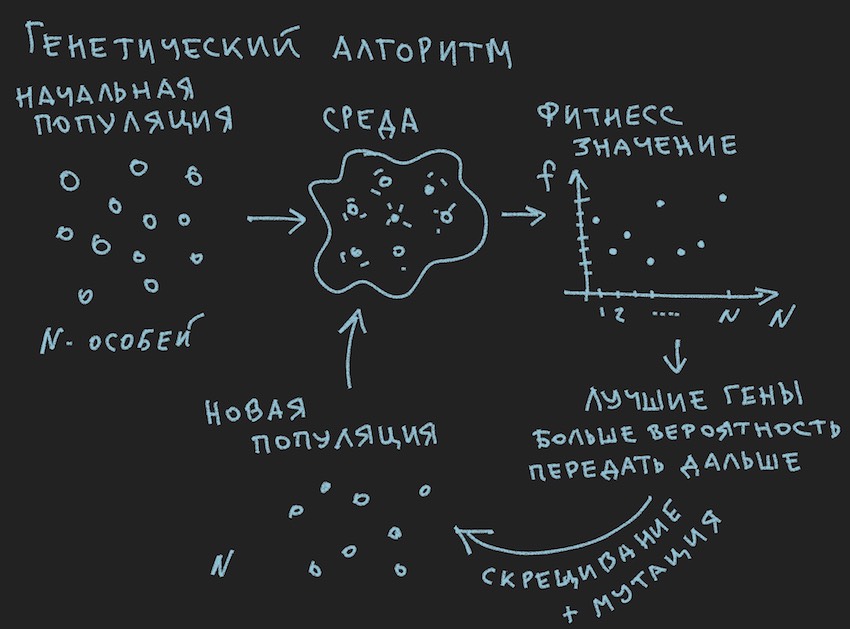
Итак Генетический алгоритм.
Автор постарается не углубляться в теорию этого процесса, а напомнить лишь тот минимум необходимый для продолжения полноценного чтения статьи.
В генетическом алгоритме основным рабочим телом является геном(ДНК это название молекулы). Геном в нашем случае это последовательный набор генов или одномерный массив float длинной...
На начальном этапе работы с только построенной нейронной сетью, необходимо ее инициализировать. Под инициализацией понимается присваивание нейровесам случайных значений от -1 до 1. Автор встречал упоминания, что отрезок значений от -1 до 1 слишком экстремален и обученные сети обладают весами в меньшем диапазоне, например от -0.5 до 0.5 и что следует принимать начальный диапазон значений отличный от -1 до 1. Но мы пойдем классическим путем сбора всех трудностей в одни ворота и возьмем максимально широкий отрезок начальных случайных величин за основу инициализации нейронной сети.
Сейчас произойдет биекция. Мы примем, что длина(размер) генома бота будет равна суммарной длине массивов нейронной сети TopologyNN.Length+TopologyRNN.Length не зря же автор тратил время читателя на процедуру подсчета нейронных связей.
Замечание: Как уже для себя отметил читатель, в генотип мы передаем только веса нейронной сети, структура связей, функции активации, состояния нейронов не передаются. Для генетического алгоритма достаточно только нейронных связей, что говорит о том что именно они являются носителями информации. Есть разработки, где генетический алгоритм меняет так же структуру связей в нейронной сети и реализовать его довольно несложно. Здесь автор оставляет пространство для творчества читателю, хотя и сам с интересом подумает над этим: нужно понять использовать два независимых генома и две фитнесс функции(упрощенно два независимых генетических алгоритма) или можно все под один геном и алгоритм.
А так как мы инициализировали NN случайными величинами, то тем самым и инициализировали геном. Возможен и обратный процесс: инициализации генотипа случайными величинами и последующее его копирования в нейронные веса. Обычным является второй вариант. Так как в программе генетический алгоритм часто существует обособленно от самой сущности и связан с ней только данными генома и значением фитнесс функции… Стоп, стоп, скажет читатель, на картинке ясно показана популяция и ни слова про отдельный геном.
Хорошо, добавим картинок в печь разума читателя:
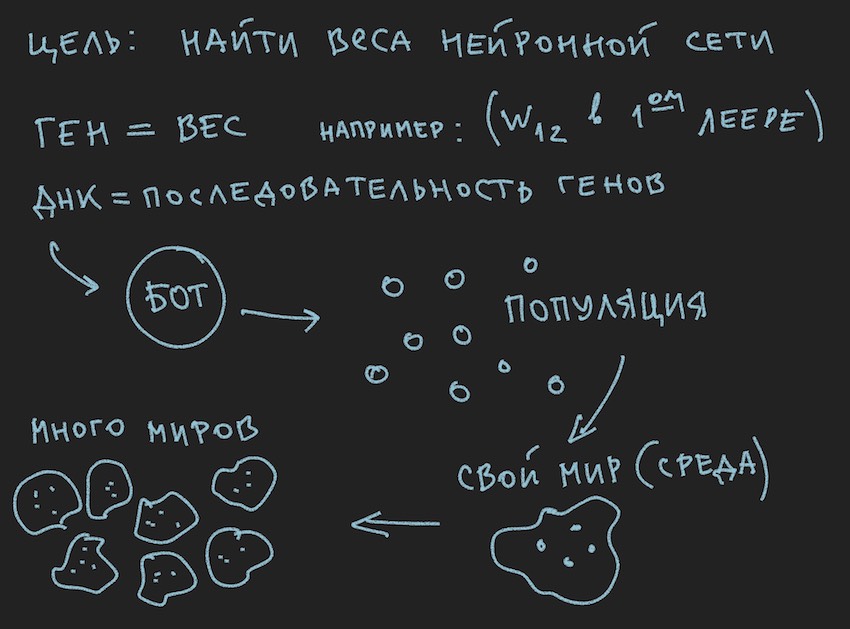
Так как картинки автор рисовал до написания текста статьи, то они поддерживают текст, но не следуют буква к букве текущему повествованию.
Из нарисованной информации следуют, что основным рабочим телом генетического алгоритма является популяция геномов. Это немного противоречит ранее сказанному автором, но как в реальном мире обойтись без небольших противоречий. Еще вчера солнце вращалось вокруг земли, а сегодня автор рассказывает о нейронной сети внутри программного бота. Не зря он печь разума вспоминал.
Доверяю читателю самому разобраться в вопросе про противоречия мира. Мир бота вполне самодостаточен для статьи.
Но что автор уже успел сделать, к этой части статьи, так это сформировать популяцию ботов.
Посмотрим на нее с программной стороны:
Есть Бот (он может быть объектом в ООП, структурой, хотя это наверное тоже объект или просто массивом данных). Внутри себя Бот содержит информацию о своих координатах, скорости, массе и другой полезной в игровом процессе информации, но основное для нас сейчас, то что он содержит ссылку на свой генотип или сам генотип в зависимости от варианта реализации. Далее можно пойти разными путями, ограничиться массивами весов нейросети или ввести дополнительный массив генотипов, как читателю будет удобно это представить у себя в воображении. На первых этапах автор в программе выделял массивы нейровесов и генотипов. Потом он отказался от дублирования информации и ограничился только весами нейронной сети.
Следуя логике повествования нужно рассказать, что популяция ботов это массив вышеуказанных ботов. Что игровой цикл… Опять стоп, какой игровой цикл? разработчики вежливо предоставили место только одному Боту на борт программы симуляции игрового мира на сервере или максимум четырем ботам в локальном симуляторе. А если вспомнить топологию выбранной автором нейронной сети:
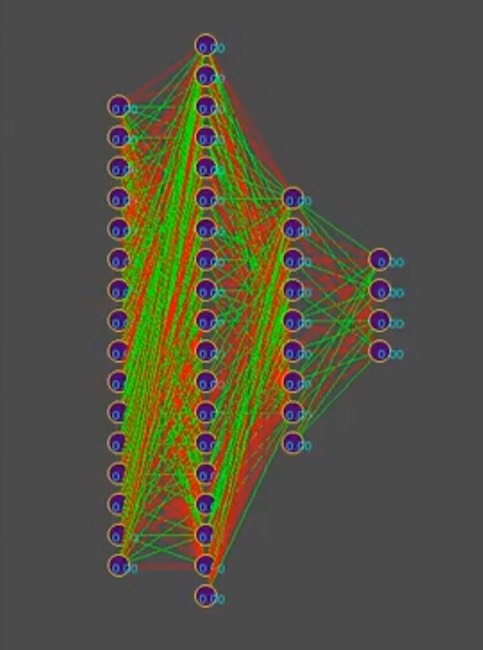
И предположить для упрощения повествования, что генотип содержит примерно 1000 нейронных связей, кстати в симуляторе генотипы выглядят так(красный цвет отрицательное значение гена, зеленый положительное значение, каждая строчка это отдельный геном):

Замечание к фото: со временем рисунок меняется в сторону доминирования одного из решений, вертикальные полосы это общие гены генотипов.
Итак, имеем 1000 генов в генотипе и максимум четыре бота в программе симуляторе игрового мира от устроителей конкурса. Сколько раз надо запустить симуляцию сражения ботов чтобы перебором, даже самым умным, приблизиться в поиске к "эффективному"
генотипу, читай "эффективной" комбинации нейронных связей, при условии что каждая нейронная связь меняется от -1 до 1 с шагом, а какой шаг? инициализация была случайными величинами float, это 15 знаков после запятой. Шаг пока нам непонятен. О количестве вариантов комбинаций нейровесов автор предполагает, что это бесконечное количество, при выборе определенного размера шага наверное конечное количество, но в любом случае эти числа гораздо больше 4 мест в симуляторе даже учитывая последовательный запуск из очереди ботов плюс одновременный параллельный запуск официальных симуляторов допустим до 10 на одном компьютере (для поклонников винтажного программирования: ЭВМ).
Надеюсь картинки помогают читателю.
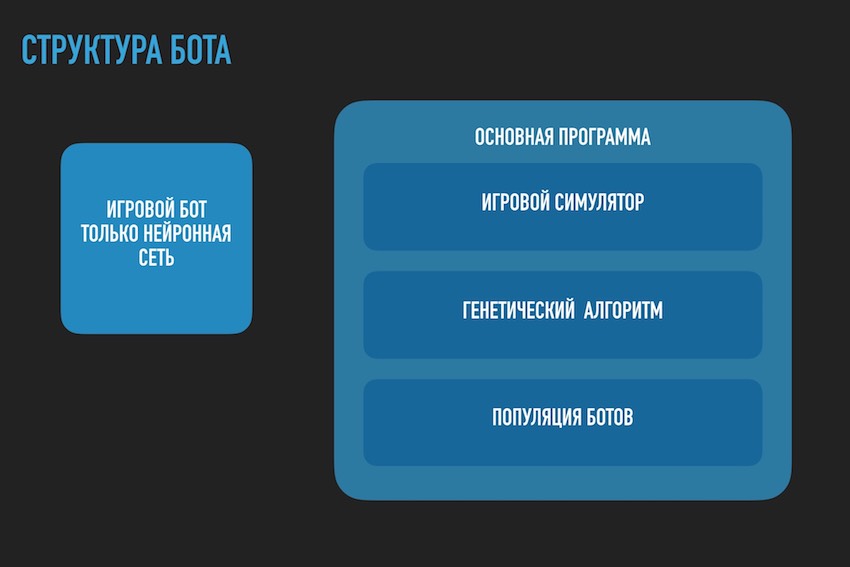
Здесь надо приостановиться и поговорить об архитектуре программного решения. Так как решение в виде отдельного программного бота загружаемого на сайт соревнований уже не подходило. Нужно было разделить бота играющего по правилам соревнований в рамках экосистемы организаторов и программы пытающейся найти конфигурацию нейронной сети для него. Нижеуказанная схема взята из презентации к конференции, но в целом отражает реальную картину.
Вспомнил бородатый анекдот:
Крупная организация.
Время 18.00, все сотрудники как один трудятся. Вдруг один из сотрудников выключает компьютер, одевается и уходит.
Все провожают его удивленным взглядом.
Следующий день. В 18.00 тот же сотрудник выключает компьютер и уходит. Все продолжают работать и начинают недовольно шептаться.
На следующий день. В 18.00 тот же сотрудник выключает компьютер…
К нему подходит коллега:
-Как тебе не стыдно, мы сидим работаем, конец квартала, столько отчетов, нам тоже хочется вовремя домой а ты такой единоличник…
-Ребята, да я вообще в ОТПУСКЕ!
… продолжение следует.
Да, чуть не забыл приложить код процедуры расчета RNN, он действующий и написанный самостоятельно, так что возможно в нем есть ошибки. Для усиления приведу его как есть, он на c++ применительно с CUDA(библиотека для расчета на GPU).
Замечание: многомерные массивы плохо уживаются на графических процессорах, есть конечно текстуры и матричные вычисление, но рекомендуют использовать одномерные массивы.
Пример массив [i,j] размерностью M по j превращается в массив вида [i*M+j].
__global__ void cudaRNN(Bot *bot, argumentsRNN *RNN, ConstantStruct *Const, int *Topology, int *TopologyRNN, int numElements, int gameTick)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int threadN = gridDim.x * blockDim.x;
int TopologySize = Const->TopologySize;
for (int pos = tid; pos < numElements; pos += threadN)
{
const int ii = pos;
const int iiA = pos*Const->ArrayDim;
int ArrayDim = Const->ArrayDim;
const int iiAT = ii*TopologySize*ArrayDim;
if (bot[pos].TTF != 0 && bot[pos].Mass>0)
{
RNN->outputs[iiA + Topology[0]] = 1.f; //bias
int neuroncount7 = Topology[0];
neuroncount7++;
for (int layer1 = 0; layer1 < TopologySize - 1; layer1++)
{
for (int j4 = 0; j4 < Topology[layer1 + 1]; j4++)
{
for (int i5 = 0; i5 < Topology[layer1] + 1; i5++)
{
RNN->sums[iiA + j4] = RNN->sums[iiA + j4] + RNN->outputs[iiA + i5] *
RNN->NNweights[((ii*TopologySize + layer1)*ArrayDim + i5)*ArrayDim + j4];
}
}
if (TopologyRNN[layer1] > 0)
{
for (int j14 = 0; j14 < Topology[layer1]; j14++)
{
for (int i15 = 0; i15 < Topology[layer1]; i15++)
{
RNN->sumsContext[iiA + j14] = RNN->sumsContext[iiA + j14] +
RNN->neuronContext[iiAT + ArrayDim * layer1 + i15] *
RNN->MNweights[((ii*TopologySize + layer1)*ArrayDim + i15)*ArrayDim + j14];
}
RNN->sumsContext[iiA + j14] = RNN->sumsContext[iiA + j14] + 1.0f*
RNN->MNweights[((ii*TopologySize + layer1)*ArrayDim + Topology[layer1])*ArrayDim + j14]; //bias=1
}
for (int t = 0; t < Topology[layer1 + 1]; t++)
{
RNN->outputs[iiA + t] = Tanh(RNN->sums[iiA + t] + RNN->sumsContext[iiA + t]);
RNN->neuronContext[iiAT + ArrayDim * layer1 + t] = RNN->outputs[iiA + t];
}
//SoftMax
/*
double sum = 0.0;
for (int k = 0; k <ArrayDim; ++k)
sum += exp(RNN->outputs[iiA + k]);
for (int k = 0; k < ArrayDim; ++k)
RNN->outputs[iiA + k] = exp(RNN->outputs[iiA + k]) / sum;
*/
}
else
{
for (int i1 = 0; i1 < Topology[layer1 + 1]; i1++)
{
RNN->outputs[iiA + i1] = Sigmoid(RNN->sums[iiA + i1]); //sigma
}
}
if (layer1 + 1 != TopologySize - 1)
{
RNN->outputs[iiA + Topology[layer1 + 1]] = 1.f;
}
for (int i2 = 0; i2 < ArrayDim; i2++)
{
RNN->sums[iiA + i2] = 0.f;
RNN->sumsContext[iiA + i2] = 0.f;
}
}
}
}
}Комментарии (8)

TiesP
20.07.2018 11:59Интересно, а как вы отбирали лучшие варианты весов (лучшие геномы)?
Только по результатам целой игры (выиграл/проиграл)?Geotyper Автор
20.07.2018 12:28Вопрос немного вперед моего повествования, там третья часть намечается. Но если коротко, то в данной статье упоминалась фитнесс функция. Вот она и влияет на селекцию.
ser-mk
20.07.2018 18:22Не покидает ощущение что читаешь перевод или пересказ, везде автор ссылается на себя в третьем лице.
В интернет группах разработчиков ботов, звучало мнение: дайте нам log файл в виде координат ботов и другой игровой информации для формирования библиотеки примеров. Но автор к сожалению так и не смог догадаться, как этот log файл использовать для обучения NN.
Если в логах есть запись действия лидера с хорошей тактикой, то наврено там планировалось использовать его для обучения методом backpropagation. Т.е. сравнивать действия сети и дейтсвие игрока и вовремя бить сеть по рукам если она делает что-то отличное. Но это мнение дилетанта.
cudaRNN — так понял просто просчитывает сеть, для входных значений и выдает некий результат. В CUDA тоже дилетант: поэтому вопрос зачем пришлось с ней так заморачиваться? чем это лучше реализации на С/С++. Если это делалось для симуляции игр, то вам получаетя требуется и саму игру тащить в GPU.Geotyper Автор
20.07.2018 19:22По поводу пересказа наверное верное слово, хотелось выбрать нестандартный стиль общения, не более того. Но местами путался сам: где автор, а где от первого лица. Одним словом Мы, я и читатель)
На третий пункт проще ответить, третья часть статьи как раз об этом. Как все пришлось переносить на GPU, нейросеть, генетический алгоритм и конечно сам алгоритм игрового процесса. Но начинал честно с c# потом с++ и CUDA, просто в c# к ней прямого доступа нет. Есть сторонние библиотеки но проще уж перейти на с++, хотя до этого ни Куду, ни плюсы не использовал.
Второй пункт, здесь поле для полемики, проще ответить: лучше один раз увидеть ) Но думаю, что в любом случае не так прямолинейно скармливать и потом корректировать. А может так и надо делать. Вопросы: корректировать каждый Тик когда сеть ошиблась? Что будет примерами для обучения, одно движение или траектория? Если кто знает как это устроить, готов услышать.TiesP
20.07.2018 21:19Как-то обдумывал похожую задачу (в другом конкурсе). У меня была идея обучать отдельным операциям (возможно это несколько сетей, которые потом объединяются). Например, в вашем случае можно отдельно натренировать: уходить от больших; есть маленьких или еду; уходить от вирусов (или наоборот не уходить) и т.д. Не думали над таким вариантом?… конечно, нужна какая-то эмуляция игрового мира, чтобы не тренировать на самой игре.
Geotyper Автор
20.07.2018 21:42Для отдельных операций на отдельных сетях нужен будет арбитраж, например рядом еда, бот который еда, стенка и два больших бота. Здесь более менее понятно, что нужна одна нейронка. Хуже дело обстоит если бот делится, непонятно становится кем нейронка управляет? там тоже арбитраж нужен в части принятия решения.
А про эмуляцию мира и другие моменты как раз третья статья.
vesper-bot
Not bad :)
Как я понимаю, последний нейрон нужен для нормировки выходного сигнала из каждого нейрона, потому как в сети «сколько вошло, столько вышло», а при адаптации требуется, чтобы вышло больше или меньше, и в последний нейрон просто сливается избыток сигнала.
PS: метки разделяются запятыми, у вас две в одну слились в результате.
Geotyper Автор
Not bad, безусловно лучше чем Not good, спасибо.
Если ответ про задачку о лишнем нейроне, то неверная интерпретация.
С форматированием текста пока тяжело получается, здесь Вы правы.