
Модель конечного автомата (finite-state machine, FSM) находит применение в написании кода для самых разных платформ, включая Android. Она позволяет сделать код менее громоздким, неплохо укладывается в парадигму Model-View-Presenter (MVP) и поддаётся несложному тестированию. Разработчик Владислав Кузнецов рассказал на Droid Party, как эта модель помогает в развитии приложения Яндекс.Диск.
— Вначале поговорим по теорию. Думаю, каждый из вас слышал и про MVP, и про стейт-машину, но повторим.

Поговорим о мотивации, о том, зачем это все нужно и как это нам может помочь. Перейдем к тому, что у нас получилось, на реальном примере покажу кусочки кода. И в конце поговорим о тестировании, о том, как этот подход помог удобно все тестировать.
Стейт-машину и MVP или что-то похожее — наверное, MVI — использовали все.
Стейт-машин существует очень много. Вот простейшее определение, которое можно им дать: это некая математическая абстракция, представленная в виде конечного набора состояний, событий и переходов из текущего состояния в новое в зависимости от наступившего события.
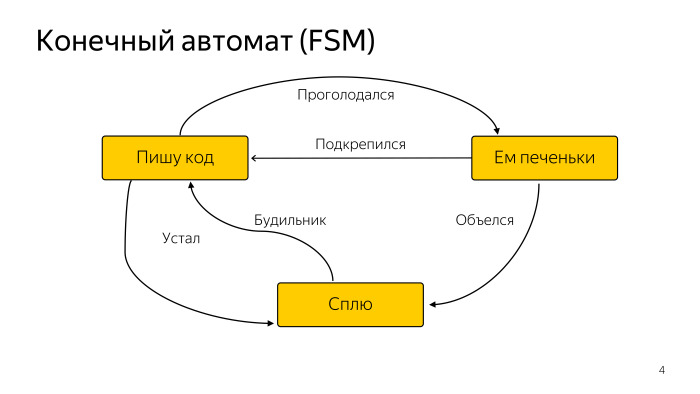
Вот простая диаграмма некоего абстрактного программиста, который иногда спит, иногда ест, но в основном пишет код. Нам этого достаточно. Существует большое количество разновидностей конечного автомата, но этого нам хватит.

Область применения стейт-машины довольно большая. По каждому пункту они используются и успешно применяются.
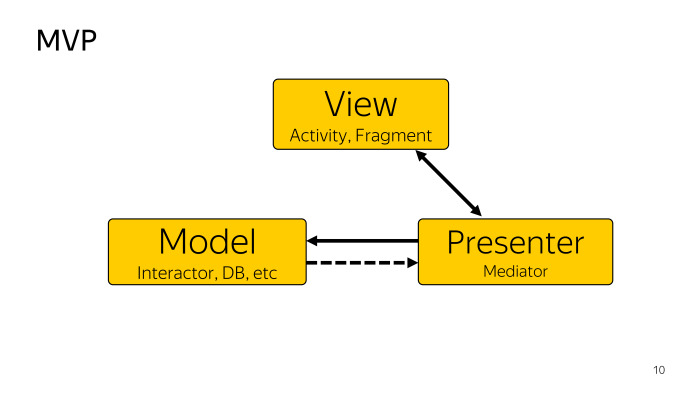
Как любой подход, MVP разделяет наше приложение на несколько слоев. View — чаще всего Activity или Fragment, задача которой пробросить какое-то действие пользователю, идентифицировать Presenter о том, что пользователь что-то сделал. Model мы рассматриваем как поставщик данных. Это может быть как БД, если мы говорим про clean architecture, или Interactor, что угодно может быть. И Presenter — посредник, который связывает View и модель, при этом может у модели что-то забрать и обновить View. Этого нам достаточно.
Кто может в одном предложении сказать, что такое программа? Исполняемый код? Слишком общо, нужно детальнее. Алгоритм? Алгоритм — это последовательность действий.
Это набор данных и какие-то потоки управления. Неважно, кто этими данными манипулирует: пользователь или нет. Из этого следует мысль, что в любой момент состояние приложение определяется совокупностью всех его данных. И чем данных в приложении больше, тем сложнее ими управлять, тем непредсказуемее может возникнуть ситуация, когда что-то пойдет не так.

Представьте простой класс, у которого три каких-то булевых флага. Чтобы гарантировать, что вы покрыли все сценарии сочетания этих флагов, вам надо 2? сценариев. Надо гарантированно покрыть восемь сценариев, чтобы сказать, что я точно все сочетания флагов обрабатываю. Если вы добавляете еще один флаг, это пропорционально увеличивается.
Мы столкнулись с похожей проблемой. Вроде была простая задача, но по мере разработки и работы над ней мы стали понимать, что что-то идет не так. Я буду рассказывать на примере фичи, которую мы запустили. Она называется удаление локальных фото. Смысл в том, что пользователь отгружает какие-то данные в облако в автоматическом режиме. Скорее всего, это фото и видео, которые он снял на свой телефон. Получается, что файлы вроде есть в облаке. Зачем занимать драгоценное место на телефоне, когда можно эти фоточки удалить?

Дизайнеры нарисовали такой концепт. Вроде просто диалог, у него заголовок, где рисуется количество места, которое мы можем освободить, текст сообщения и галочка о том, что есть два режима очистки: удалять все фото, которые загрузил пользователь, или только те, которые старше одного месяца.

Мы посмотрели — вроде ничего сложного нет. Диалог, две TextView, чек-бокс, кнопки. Но когда мы начали детально работать над этой проблемой — поняли, что получить данные о том, сколько файлов мы можем удалить, это задача достаточно долговременная. Поэтому пользователю мы должны показать некую заглушку. Это псевдокод, в реальной жизни он выглядит по-другому, но смысл такой же.
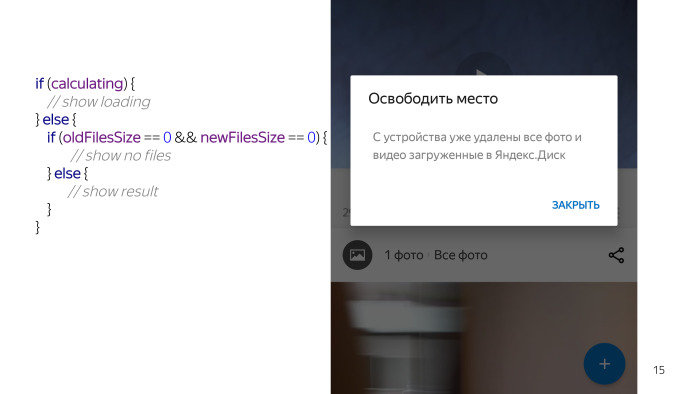
Мы проверяем какое-то состояние, проверяем, что у нас идут вычисления, и рисуем заглушечку «Подождите».

Когда вычисления закончились, у нас есть несколько вариантов, что отобразить пользователю. Например, количество файлов, которые мы можем удалить, — ноль. В этом случае мы рисуем пользователю сообщение о том, что нечего удалять, поэтому приди в следующий раз. К нам потом приходят дизайнеры и говорят, что мы должны различать ситуации, когда у нас пользователь уже очистил файлы или ничего не очищал, ничего не загрузилось. Поэтому появляется еще одно условие, что мы ждем автозагрузки и рисуем ему другое сообщение.
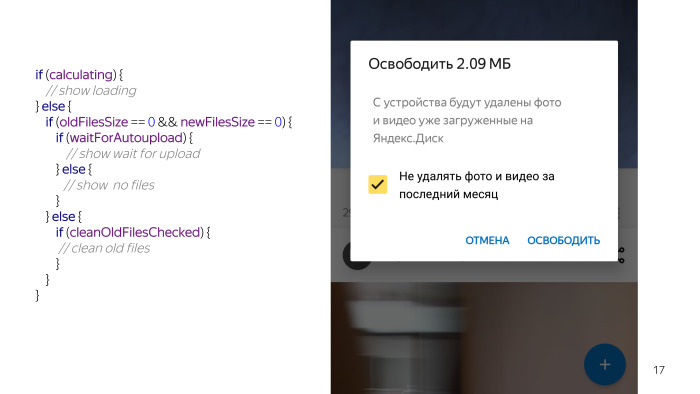
Потом есть ситуации, когда все-таки что-то отработало, и например, у пользователя стоит галочка не удалять свежие файлы. В этом случае тоже есть два варианта. Либо файлы можно очистить, либо файлы очистить нельзя, то есть он уже очищал все файлы, поэтому мы предупреждаем, что все свежие файлы ты уже удалил.
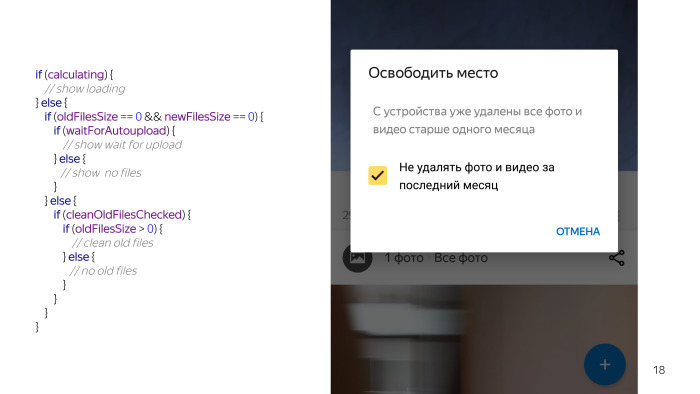
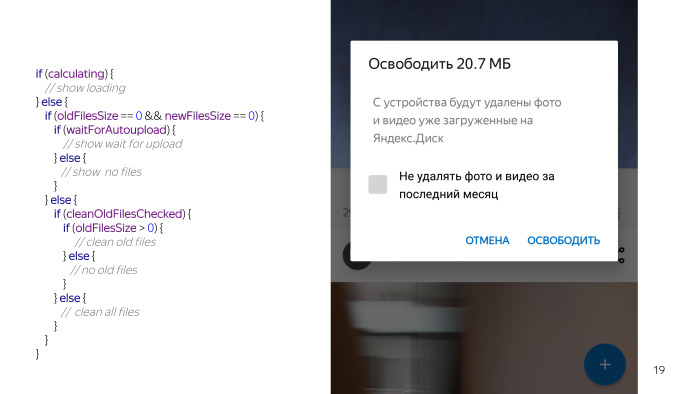
Есть еще одно условие, когда действительно что-то можем удалить. Сняли галочку, и есть вариант, что можешь что-то удалить. Смотришь на этот код, и кажется, что что-то не так. Я еще не все перечислил, у нас есть проверка пермишинов, потому что без них ничего не работает, мы не можем трогать файлы на карточке, плюс должны проверять, что у пользователя в принципе включена автозагрузка, потому что фичи бесполезны без автозагрузки, что мы будем чистить. И еще несколько условий. И блин, вроде такая простая вещь, а столько проблем из-за нее возникло.
И очевидно, сразу возникает несколько проблем. В первую очередь этот код нечитаемый. Тут некий псевдокод изображен, но в реальном проекте это размазано по разным функциям, кускам кода, это уже не так легко воспринять на глаз. Поддержка такого кода тоже достаточно сложная. Особенно когда вы приходите в новый проект, вам говорят, что надо сделать такую фичу, вы добавляете какое-то условие, проверяете позитивный сценарий, все работает, но потом приходят тестировщики и говорят, что при определенных условиях все поломалось. Так бывает, потому что вы просто не учли каких-то сценариев.
Плюс он избыточен в том плане, что так как у нас есть большая ветка условий, мы должны проверять все условия, которые заранее нам не подходят. Они заранее отрицательные, но так как написаны такими веточками, мы обязаны их проверить. Дело в том, что в примере у меня какие-то флажочки булевые, а на практике у вас могут быть вызовы функций, которые куда-то вглубь уходят, в БД роются. Всякое может быть, из-за избыточности будут дополнительные тормоза.
И самое печальное — какое-то непредвиденное поведение, которое на этапе тестирования пропустили, там ничего не случилось, а где-то в продакшене у пользователя в лучшем случае ничего не случилось, какой-то кривой UI, а в худшем — упало или данные потеряли. Просто приложение повело себя не консистентно.
Как же решать эту проблему? При помощи силы стейт-машины.

Основная задача, с которой справляется стейт-машина, это берет большую сложную задачу и разбивает на маленькие дискретные состояния, с которыми проще взаимодействовать и управлять. Посидев, подумав, так как мы стараемся делать что-то MVP, как прикрутить ко всему этому наше состояние? Мы пришли примерно к такой схеме. Кто читал книгу GOF, это классический паттерн-стейт, просто то, что там называется контекстом, я обозвал стейт-оунером, и по факту это презентер. Презентер обладает этим состоянием, умеет их переключать, и еще может предоставлять какие-то данные нашим состояниям, если они хотят что-то знать, например, размер файлов или хотят запросить асинхронный запрос, выбрать.

Ничего тут суперского нет, скорее важен следующий слайд.
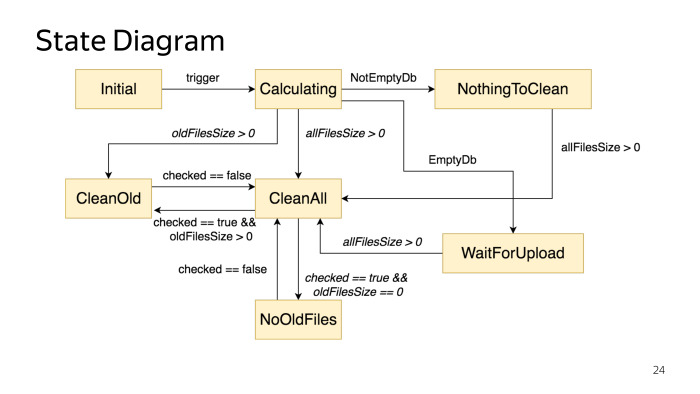
С этого надо начинать разработку, когда вы начинаете делать стейт-машину. Вы садитесь за свой компьютер или где-то за столом, и либо на бумажке, либо в специальных инструментах рисуете диаграмму состояний. Тоже ничего сложного нет, но у этого этапа очень много плюсов. Во-первых, на раннем этапе вы можете сразу задетектить какие-то неконсистентности в бизнес-логике. Ваши продакты могут прийти, изъявить свое желание, вроде все хорошо, но когда вы беретесь писать код, вы понимаете, что что-то не стыкуется. Думаю, с каждым была такая ситуация. Но когда вы делаете диаграммку, вы на раннем этапе можете увидеть, что что-то не стыкуется. Рисуется она достаточно просто, есть специальные инструменты типа PlantUML, в которых даже рисовать не надо уметь, надо уметь писать псевдокод, и она сама генерит графики.
Примерно так выглядит наша диаграммка, которая описывает состояние этого диалога. Тут несколько состояний и логика перехода между ними.

Перейдем к коду. Сам State, тут ничего важного, главное то, что у него три метода: onEnter, который при входе вызывает в первую очередь invalidateView. Для чего это сделано? Чтобы как только мы приходим в состояние, обновился UI. Плюс есть метод invalidateView, который мы перегружаем, если надо что-то с UI сделать, и метод onExit, в котором можем что-то сделать, если выходим из состояния.

StateOwner. Интерфейс, который предоставляет возможность перещелкивания состояний. Как мы выяснили, это будет будущий презентер. И это методы, которые дают дополнительный доступ к данным. Если какие-то данные шарятся между состояниями, мы можем их держать в презентере, и через этот интерфейс отдавать. В данном случае мы можем отдать размер файлов, которые мы можем очистить, и предоставляем возможность сделать какой-то запрос. Мы перешли в состояние, хотим что-то запросить и через StateOwner можем позвать метод.
Еще такая полезность, что он тоже может вернуть ссылку на вьюшку. Это сделано для того, что если у вас состояние и прилетают какие-то данные, вы не хотите переходить в новое состояние, просто это избыточно, вы можете напрямую обновить вьюшку, текст. У нас это используется для того, чтобы обновлять количество цифр, которые пользователь видит, когда смотрит на диалог. У нас в runtime идет загрузка файлов, он смотрит на диалог, и цифры обновляются. Мы не переходим в новое состояние, мы просто обновляем текущую View.

Тут стандартное MVP, все должно быть предельно простым, никакой логике, простые методы, которые что-то рисуют. Я придерживаюсь этой концепции. Не должно быть никакой логики, по минимуму каких-то действий. Чисто берем какой-то Text View, меняем его, не более.

Presenter. Тут побольше интересных вещей. В первую очередь мы можем данные шарить через него для каких-то состояний, у нас есть две переменные, помеченные аннотацией State. Кто использовал Icepick, знаком с ней. Мы не пишем руками сериализацию в Partible, используем готовую библиотеку.
Следующее — начальное состояние. Всегда полезно задать начальное состояние, даже если оно ничего не делает. Полезность в том, что не нужно делать проверки на null, а если говорить о том, что оно может что-то делать. Например, вам нужно один раз что-то сделать за жизненный цикл вашего приложения, когда мы стартуем, надо один раз процедуру выполнить, и больше никогда ее не делать. При выходе из состояния initial мы всегда можем что-то такое выполнить, и мы никогда в это состояние не возвращаемся. Типа так нарисована диаграмма состояний. Хотя кто знает, кто нарисует, может, у вас можно будет вернуться.
Я сторонник того, чтобы как можно меньше было проверок на Null и прочее, поэтому здесь держу ссылку на простую имплементацию вьюшки. Нам не надо ничего синхронизировать, просто в какой-то момент, когда случается detach, мы подменяем вьюшку на пустую, и презентер может где-то задетаченный переключаться в состояниях, думать, что вьюшка есть, он ее обновляет, но на самом деле он работает с пустой имплементацией.
Есть еще несколько методов для того, чтобы сохранить состояние, мы же хотим переживать переворот Activity, в данном случае это все сделано через конструктор. Все немного сложнее, здесь утрированный пример.

Пробросить надо saveState, если кто-то работал с подобными библиотеками, все довольно тривиально. Можете руками писать. И два метода очень важных: attach, вызываемый в onStart, и detach, вызываемый в onStop.

В чем их важность? Изначально мы планировали аттачиться и детачиться в onCreateView, onDestroyView, но этого оказалось не совсем достаточно. Если у вас View, у вас может обновляться текст, а может показаться диалог-фрагмент. И если вы не задетачитесь в onStop, и потом попытаетесь показать фрагмент, вы словите всем известное исключение про то, что нельзя коммитить транзакцию, когда у нас сохранилось состояние. Либо используйте commit state loss, либо не делайте так. Поэтому мы детачимся в onStop, при этом там презентер продолжит работать, переключать состояния, отлавливать события. И в тот момент, когда случится старт, мы вызовем событие view attached, и презентер обновит UI в соответствие текущему состоянию.


Есть метод release, вызывается обычно в onDestroy, делаете детач и дополнительно освобождаете ресурсы.

Еще важный метод setState. Так как мы в onEnter и onExit планируем изменять UI, то тут есть проверка на главный поток. Это создает нам ограничение, что мы здесь не делаем ничего тяжеловесного, все запросы должны быть либо к UI, либо должны быть асинхронными. Плюсом этого места является то, что здесь мы можем залогировать вход и выход из состояния, очень полезно бывает при отладке, например, когда что-то идет не так, вы можете посмотреть, как система перещелкивалась и понять, что же было не так.
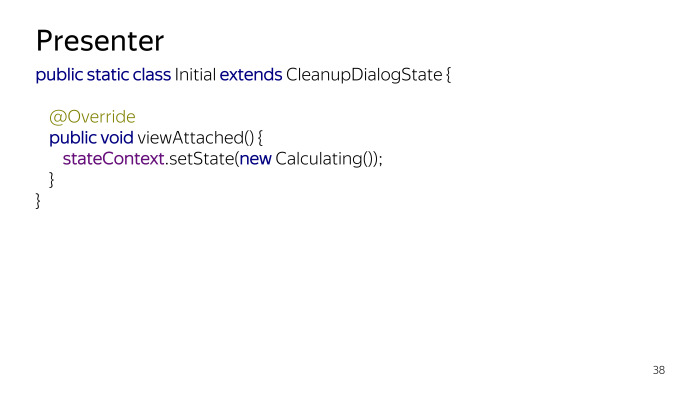
Пара примеров состояний. Есть состояние Initial, просто триггерит вычисления, сколько места нужно освободить в тот момент, когда вьюшка стала доступна. Это произойдет после onStart. Как только случается onStart, мы переходим в новое состояние, и система начинает запрашивать данные.

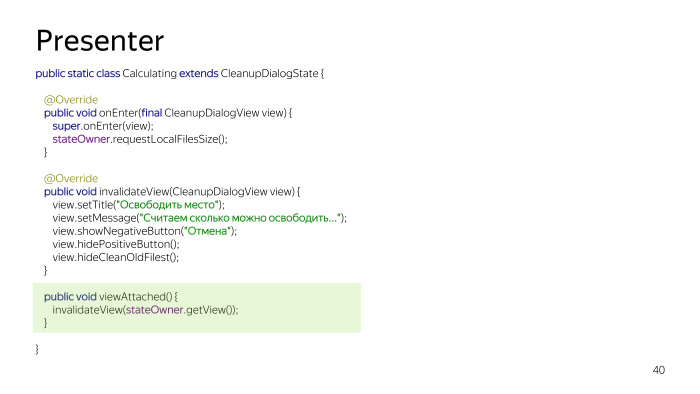
Пример состояния Calculating, мы у stateOwner реквестим размер файлов, он как-то лезет в базу, и потом еще есть inValidateView, мы обновляем текущий UI пользователя. И viewAttached вызовется в том случае, если вьюшка заново зааттачится. Если мы были в фоне, Calculating был в фоне, мы опять возвращаемся в нашу Activity, вызовется этот метод и актуализирует все данные.

Пример события, мы запросили у stateOwner сколько файлов можно освободить, и он вызывает метод filesSizeUpdated. Тут я поленился, можно было написать три отдельных метода, типа обновилось, старых файлов столько-то, как разные события разделить. Но надо понимать, когда-то у вас это сложно будет, когда-то гораздо проще. Не надо в оверинжениринг впадать, что каждое событие — отдельный метод. Можно вполне обойтись простым if, ничего страшного я в этом не вижу.

Я вижу несколько потенциальных улучшений. Мне не нравится, что мы вынуждены пробрасывать руками эти методы, типа onStart, on Stop, onCreate, onSave и прочее. Можно привязаться к Lifecycle, но непонятно, как быть с saveState. Есть идея, например, сделать презентер фрагментом. Почему нет? Фрагмент без UI, который ловит жизненный цикл, и вообще нам тогда ничего не надо будет, все само будет к нам прилетать.
Еще интересный момент: этот презентер каждый раз пересоздается, и если у вас в презентере хранятся большие данные, вы в БД сходили, держите огромный курсор, то это недопустимо каждый раз запрашивать при повороте экрана. Поэтому можно кэшировать презентер, как это делает, например, ViewModule из Architecture Components, сделать какой-то фрагмент, который будет держать в себе кэш презентеров и возвращать их для каждой вьюшки.
Можно использовать табличный способ задания стейт-машин, потому что у тот паттерн стейт, который мы используем, обладает одним существенным минусом: как только вам нужно добавить один метод в новое событие, вы должны добавить имплементацию во все наследники. Хотя бы пустую. Либо сделать это в базовом состоянии. Это не очень удобно. Так что табличный способ задания стейт-машин используется во всех библиотеках — если поискать на GitHub по слову FSM, вы найдете большое количество библиотек, которые предоставляют вам некий билдер, где вы задаете начальное состояние, ивент и конечное состояние. Расширять и поддерживать такую стейт-машину гораздо проще.
Еще один интересный момент: если вы используете паттерн стейт, если у вас стейт-машина начинает разрастаться, скорее всего, вам придется какие-то ивенты хэндлить одинаково, чтобы код не копипастить, вы создаете базовое состояние. Чем больше ивентов, тем больше начинает появляться базовых состояний, иерархия разрастается, и что-то идет не так.
Как мы знаем, наследование надо заменять делегированием, и иерархические стейт-машины помогают такую проблему решить. У вас появляются состояния, которые зависят не от уровня наследования — просто строится дерево состояний, которые передают обработчик выше. Тоже можете почитать отдельно, очень полезная штука. В Android, например, иерархические стейт-машины используются в WatchDog Wi-Fi, который мониторит состояние сети, там они есть, прямо в исходниках Android.

Последний, но не менее важный момент. Как это можно тестировать? В первую очередь, можно тестировать детерминированные состояния. Есть отдельное состояние, мы создаем экземпляр, дергаем метод onEnter и смотрим, что у вьюшки вызвались соответствующие значения. Таким образом валидируем, что наше состояние правильно обновляет View. Если у вас View ничего серьезного не делает, то, скорее всего, вы покроете огромное количество сценариев.

Вы можете замокать какие-то методы функцией, которая возвращает размер, позвать после onEnter еще какое-то событие и посмотреть, как конкретное состояние реагирует на конкретные события. В данном случае при возникновении события filesSizeUpdated и когда AllFilesSize больше нуля, мы должны перейти в новое состояние CleanAllFiles. При помощи макета мы все это проверяем.

И последнее — мы можем тестировать систему целиком. Мы конструируем состояние, отправляем в него ивент и проверяем, как система себя ведет. У нас есть три этапа тестирования. Отдельно тестируем, как обновляется UI, отдельно тестируем, как происходит логика перехода, переключения между состояниями, и отдельно тестируем всю систему в целом.
Мы переписывали видеоплеер на такую концепцию, и получили покрытие больше 70%. Под 80% инструкций было покрыто такими тестами. Мне кажется, это очень крутой показатель.

Что мы получили, используя такую концепцию? В первую очередь — тестирование. Стейт-машину и наш презентер несложно подружить с жизненным циклом.
Расширяемость. Такой подход позволяет вас сдерживать в определенной концепции. Вы можете что-то закостылить, но скорее всего, когда кто-то будет делать ревью вашего кода, он скажет — зачем ты так делаешь, когда просто можно добавить новое состояние и все будет работать.
Порог вхождения в понятие стейт-машины достаточно низкий, и люди, которые приходят в команду, видят отдельные детерминированные состояния. Они могут легко понять, что они делают, и вариантов ошибиться гораздо меньше. Плюс за счет того, что у нас есть единая точка переключения состояний, мы можем это все логировать. Разные библиотеки для стейт-машин позволяют не только понять, какое состояние было старым, а какое новым. Они также позволяют вам, например, отлавливать определенные переходы. Вы можете поставить триггер lock на определенный переход. Если вы что-то отлаживаете, это может быть очень важно.
В конце — документируемость. Сам подход подразумевает, что в начале разработки вы рисуете диаграмму, потом можете ее приаттачить на вики или в документ вашего проекта, использовать уже как базу знаний, шарить между командами. Предположим, у вас что-то сложное, библиотека, еще что-то, и смежные команды спрашивают, как это работает. Вы просто показываете такую диаграмму, и им сразу все становится понятно. На этом все, спасибо.
— Вначале поговорим по теорию. Думаю, каждый из вас слышал и про MVP, и про стейт-машину, но повторим.
Поговорим о мотивации, о том, зачем это все нужно и как это нам может помочь. Перейдем к тому, что у нас получилось, на реальном примере покажу кусочки кода. И в конце поговорим о тестировании, о том, как этот подход помог удобно все тестировать.
Стейт-машину и MVP или что-то похожее — наверное, MVI — использовали все.
Стейт-машин существует очень много. Вот простейшее определение, которое можно им дать: это некая математическая абстракция, представленная в виде конечного набора состояний, событий и переходов из текущего состояния в новое в зависимости от наступившего события.
Вот простая диаграмма некоего абстрактного программиста, который иногда спит, иногда ест, но в основном пишет код. Нам этого достаточно. Существует большое количество разновидностей конечного автомата, но этого нам хватит.
Область применения стейт-машины довольно большая. По каждому пункту они используются и успешно применяются.
Как любой подход, MVP разделяет наше приложение на несколько слоев. View — чаще всего Activity или Fragment, задача которой пробросить какое-то действие пользователю, идентифицировать Presenter о том, что пользователь что-то сделал. Model мы рассматриваем как поставщик данных. Это может быть как БД, если мы говорим про clean architecture, или Interactor, что угодно может быть. И Presenter — посредник, который связывает View и модель, при этом может у модели что-то забрать и обновить View. Этого нам достаточно.
Кто может в одном предложении сказать, что такое программа? Исполняемый код? Слишком общо, нужно детальнее. Алгоритм? Алгоритм — это последовательность действий.
Это набор данных и какие-то потоки управления. Неважно, кто этими данными манипулирует: пользователь или нет. Из этого следует мысль, что в любой момент состояние приложение определяется совокупностью всех его данных. И чем данных в приложении больше, тем сложнее ими управлять, тем непредсказуемее может возникнуть ситуация, когда что-то пойдет не так.
Представьте простой класс, у которого три каких-то булевых флага. Чтобы гарантировать, что вы покрыли все сценарии сочетания этих флагов, вам надо 2? сценариев. Надо гарантированно покрыть восемь сценариев, чтобы сказать, что я точно все сочетания флагов обрабатываю. Если вы добавляете еще один флаг, это пропорционально увеличивается.
Мы столкнулись с похожей проблемой. Вроде была простая задача, но по мере разработки и работы над ней мы стали понимать, что что-то идет не так. Я буду рассказывать на примере фичи, которую мы запустили. Она называется удаление локальных фото. Смысл в том, что пользователь отгружает какие-то данные в облако в автоматическом режиме. Скорее всего, это фото и видео, которые он снял на свой телефон. Получается, что файлы вроде есть в облаке. Зачем занимать драгоценное место на телефоне, когда можно эти фоточки удалить?
Дизайнеры нарисовали такой концепт. Вроде просто диалог, у него заголовок, где рисуется количество места, которое мы можем освободить, текст сообщения и галочка о том, что есть два режима очистки: удалять все фото, которые загрузил пользователь, или только те, которые старше одного месяца.
Мы посмотрели — вроде ничего сложного нет. Диалог, две TextView, чек-бокс, кнопки. Но когда мы начали детально работать над этой проблемой — поняли, что получить данные о том, сколько файлов мы можем удалить, это задача достаточно долговременная. Поэтому пользователю мы должны показать некую заглушку. Это псевдокод, в реальной жизни он выглядит по-другому, но смысл такой же.
Мы проверяем какое-то состояние, проверяем, что у нас идут вычисления, и рисуем заглушечку «Подождите».
Когда вычисления закончились, у нас есть несколько вариантов, что отобразить пользователю. Например, количество файлов, которые мы можем удалить, — ноль. В этом случае мы рисуем пользователю сообщение о том, что нечего удалять, поэтому приди в следующий раз. К нам потом приходят дизайнеры и говорят, что мы должны различать ситуации, когда у нас пользователь уже очистил файлы или ничего не очищал, ничего не загрузилось. Поэтому появляется еще одно условие, что мы ждем автозагрузки и рисуем ему другое сообщение.
Потом есть ситуации, когда все-таки что-то отработало, и например, у пользователя стоит галочка не удалять свежие файлы. В этом случае тоже есть два варианта. Либо файлы можно очистить, либо файлы очистить нельзя, то есть он уже очищал все файлы, поэтому мы предупреждаем, что все свежие файлы ты уже удалил.
Есть еще одно условие, когда действительно что-то можем удалить. Сняли галочку, и есть вариант, что можешь что-то удалить. Смотришь на этот код, и кажется, что что-то не так. Я еще не все перечислил, у нас есть проверка пермишинов, потому что без них ничего не работает, мы не можем трогать файлы на карточке, плюс должны проверять, что у пользователя в принципе включена автозагрузка, потому что фичи бесполезны без автозагрузки, что мы будем чистить. И еще несколько условий. И блин, вроде такая простая вещь, а столько проблем из-за нее возникло.
И очевидно, сразу возникает несколько проблем. В первую очередь этот код нечитаемый. Тут некий псевдокод изображен, но в реальном проекте это размазано по разным функциям, кускам кода, это уже не так легко воспринять на глаз. Поддержка такого кода тоже достаточно сложная. Особенно когда вы приходите в новый проект, вам говорят, что надо сделать такую фичу, вы добавляете какое-то условие, проверяете позитивный сценарий, все работает, но потом приходят тестировщики и говорят, что при определенных условиях все поломалось. Так бывает, потому что вы просто не учли каких-то сценариев.
Плюс он избыточен в том плане, что так как у нас есть большая ветка условий, мы должны проверять все условия, которые заранее нам не подходят. Они заранее отрицательные, но так как написаны такими веточками, мы обязаны их проверить. Дело в том, что в примере у меня какие-то флажочки булевые, а на практике у вас могут быть вызовы функций, которые куда-то вглубь уходят, в БД роются. Всякое может быть, из-за избыточности будут дополнительные тормоза.
И самое печальное — какое-то непредвиденное поведение, которое на этапе тестирования пропустили, там ничего не случилось, а где-то в продакшене у пользователя в лучшем случае ничего не случилось, какой-то кривой UI, а в худшем — упало или данные потеряли. Просто приложение повело себя не консистентно.
Как же решать эту проблему? При помощи силы стейт-машины.
Основная задача, с которой справляется стейт-машина, это берет большую сложную задачу и разбивает на маленькие дискретные состояния, с которыми проще взаимодействовать и управлять. Посидев, подумав, так как мы стараемся делать что-то MVP, как прикрутить ко всему этому наше состояние? Мы пришли примерно к такой схеме. Кто читал книгу GOF, это классический паттерн-стейт, просто то, что там называется контекстом, я обозвал стейт-оунером, и по факту это презентер. Презентер обладает этим состоянием, умеет их переключать, и еще может предоставлять какие-то данные нашим состояниям, если они хотят что-то знать, например, размер файлов или хотят запросить асинхронный запрос, выбрать.
Ничего тут суперского нет, скорее важен следующий слайд.
С этого надо начинать разработку, когда вы начинаете делать стейт-машину. Вы садитесь за свой компьютер или где-то за столом, и либо на бумажке, либо в специальных инструментах рисуете диаграмму состояний. Тоже ничего сложного нет, но у этого этапа очень много плюсов. Во-первых, на раннем этапе вы можете сразу задетектить какие-то неконсистентности в бизнес-логике. Ваши продакты могут прийти, изъявить свое желание, вроде все хорошо, но когда вы беретесь писать код, вы понимаете, что что-то не стыкуется. Думаю, с каждым была такая ситуация. Но когда вы делаете диаграммку, вы на раннем этапе можете увидеть, что что-то не стыкуется. Рисуется она достаточно просто, есть специальные инструменты типа PlantUML, в которых даже рисовать не надо уметь, надо уметь писать псевдокод, и она сама генерит графики.
Примерно так выглядит наша диаграммка, которая описывает состояние этого диалога. Тут несколько состояний и логика перехода между ними.
Перейдем к коду. Сам State, тут ничего важного, главное то, что у него три метода: onEnter, который при входе вызывает в первую очередь invalidateView. Для чего это сделано? Чтобы как только мы приходим в состояние, обновился UI. Плюс есть метод invalidateView, который мы перегружаем, если надо что-то с UI сделать, и метод onExit, в котором можем что-то сделать, если выходим из состояния.
StateOwner. Интерфейс, который предоставляет возможность перещелкивания состояний. Как мы выяснили, это будет будущий презентер. И это методы, которые дают дополнительный доступ к данным. Если какие-то данные шарятся между состояниями, мы можем их держать в презентере, и через этот интерфейс отдавать. В данном случае мы можем отдать размер файлов, которые мы можем очистить, и предоставляем возможность сделать какой-то запрос. Мы перешли в состояние, хотим что-то запросить и через StateOwner можем позвать метод.
Еще такая полезность, что он тоже может вернуть ссылку на вьюшку. Это сделано для того, что если у вас состояние и прилетают какие-то данные, вы не хотите переходить в новое состояние, просто это избыточно, вы можете напрямую обновить вьюшку, текст. У нас это используется для того, чтобы обновлять количество цифр, которые пользователь видит, когда смотрит на диалог. У нас в runtime идет загрузка файлов, он смотрит на диалог, и цифры обновляются. Мы не переходим в новое состояние, мы просто обновляем текущую View.
Тут стандартное MVP, все должно быть предельно простым, никакой логике, простые методы, которые что-то рисуют. Я придерживаюсь этой концепции. Не должно быть никакой логики, по минимуму каких-то действий. Чисто берем какой-то Text View, меняем его, не более.
Presenter. Тут побольше интересных вещей. В первую очередь мы можем данные шарить через него для каких-то состояний, у нас есть две переменные, помеченные аннотацией State. Кто использовал Icepick, знаком с ней. Мы не пишем руками сериализацию в Partible, используем готовую библиотеку.
Следующее — начальное состояние. Всегда полезно задать начальное состояние, даже если оно ничего не делает. Полезность в том, что не нужно делать проверки на null, а если говорить о том, что оно может что-то делать. Например, вам нужно один раз что-то сделать за жизненный цикл вашего приложения, когда мы стартуем, надо один раз процедуру выполнить, и больше никогда ее не делать. При выходе из состояния initial мы всегда можем что-то такое выполнить, и мы никогда в это состояние не возвращаемся. Типа так нарисована диаграмма состояний. Хотя кто знает, кто нарисует, может, у вас можно будет вернуться.
Я сторонник того, чтобы как можно меньше было проверок на Null и прочее, поэтому здесь держу ссылку на простую имплементацию вьюшки. Нам не надо ничего синхронизировать, просто в какой-то момент, когда случается detach, мы подменяем вьюшку на пустую, и презентер может где-то задетаченный переключаться в состояниях, думать, что вьюшка есть, он ее обновляет, но на самом деле он работает с пустой имплементацией.
Есть еще несколько методов для того, чтобы сохранить состояние, мы же хотим переживать переворот Activity, в данном случае это все сделано через конструктор. Все немного сложнее, здесь утрированный пример.
Пробросить надо saveState, если кто-то работал с подобными библиотеками, все довольно тривиально. Можете руками писать. И два метода очень важных: attach, вызываемый в onStart, и detach, вызываемый в onStop.
В чем их важность? Изначально мы планировали аттачиться и детачиться в onCreateView, onDestroyView, но этого оказалось не совсем достаточно. Если у вас View, у вас может обновляться текст, а может показаться диалог-фрагмент. И если вы не задетачитесь в onStop, и потом попытаетесь показать фрагмент, вы словите всем известное исключение про то, что нельзя коммитить транзакцию, когда у нас сохранилось состояние. Либо используйте commit state loss, либо не делайте так. Поэтому мы детачимся в onStop, при этом там презентер продолжит работать, переключать состояния, отлавливать события. И в тот момент, когда случится старт, мы вызовем событие view attached, и презентер обновит UI в соответствие текущему состоянию.
Есть метод release, вызывается обычно в onDestroy, делаете детач и дополнительно освобождаете ресурсы.
Еще важный метод setState. Так как мы в onEnter и onExit планируем изменять UI, то тут есть проверка на главный поток. Это создает нам ограничение, что мы здесь не делаем ничего тяжеловесного, все запросы должны быть либо к UI, либо должны быть асинхронными. Плюсом этого места является то, что здесь мы можем залогировать вход и выход из состояния, очень полезно бывает при отладке, например, когда что-то идет не так, вы можете посмотреть, как система перещелкивалась и понять, что же было не так.
Пара примеров состояний. Есть состояние Initial, просто триггерит вычисления, сколько места нужно освободить в тот момент, когда вьюшка стала доступна. Это произойдет после onStart. Как только случается onStart, мы переходим в новое состояние, и система начинает запрашивать данные.
Пример состояния Calculating, мы у stateOwner реквестим размер файлов, он как-то лезет в базу, и потом еще есть inValidateView, мы обновляем текущий UI пользователя. И viewAttached вызовется в том случае, если вьюшка заново зааттачится. Если мы были в фоне, Calculating был в фоне, мы опять возвращаемся в нашу Activity, вызовется этот метод и актуализирует все данные.
Пример события, мы запросили у stateOwner сколько файлов можно освободить, и он вызывает метод filesSizeUpdated. Тут я поленился, можно было написать три отдельных метода, типа обновилось, старых файлов столько-то, как разные события разделить. Но надо понимать, когда-то у вас это сложно будет, когда-то гораздо проще. Не надо в оверинжениринг впадать, что каждое событие — отдельный метод. Можно вполне обойтись простым if, ничего страшного я в этом не вижу.
Я вижу несколько потенциальных улучшений. Мне не нравится, что мы вынуждены пробрасывать руками эти методы, типа onStart, on Stop, onCreate, onSave и прочее. Можно привязаться к Lifecycle, но непонятно, как быть с saveState. Есть идея, например, сделать презентер фрагментом. Почему нет? Фрагмент без UI, который ловит жизненный цикл, и вообще нам тогда ничего не надо будет, все само будет к нам прилетать.
Еще интересный момент: этот презентер каждый раз пересоздается, и если у вас в презентере хранятся большие данные, вы в БД сходили, держите огромный курсор, то это недопустимо каждый раз запрашивать при повороте экрана. Поэтому можно кэшировать презентер, как это делает, например, ViewModule из Architecture Components, сделать какой-то фрагмент, который будет держать в себе кэш презентеров и возвращать их для каждой вьюшки.
Можно использовать табличный способ задания стейт-машин, потому что у тот паттерн стейт, который мы используем, обладает одним существенным минусом: как только вам нужно добавить один метод в новое событие, вы должны добавить имплементацию во все наследники. Хотя бы пустую. Либо сделать это в базовом состоянии. Это не очень удобно. Так что табличный способ задания стейт-машин используется во всех библиотеках — если поискать на GitHub по слову FSM, вы найдете большое количество библиотек, которые предоставляют вам некий билдер, где вы задаете начальное состояние, ивент и конечное состояние. Расширять и поддерживать такую стейт-машину гораздо проще.
Еще один интересный момент: если вы используете паттерн стейт, если у вас стейт-машина начинает разрастаться, скорее всего, вам придется какие-то ивенты хэндлить одинаково, чтобы код не копипастить, вы создаете базовое состояние. Чем больше ивентов, тем больше начинает появляться базовых состояний, иерархия разрастается, и что-то идет не так.
Как мы знаем, наследование надо заменять делегированием, и иерархические стейт-машины помогают такую проблему решить. У вас появляются состояния, которые зависят не от уровня наследования — просто строится дерево состояний, которые передают обработчик выше. Тоже можете почитать отдельно, очень полезная штука. В Android, например, иерархические стейт-машины используются в WatchDog Wi-Fi, который мониторит состояние сети, там они есть, прямо в исходниках Android.
Последний, но не менее важный момент. Как это можно тестировать? В первую очередь, можно тестировать детерминированные состояния. Есть отдельное состояние, мы создаем экземпляр, дергаем метод onEnter и смотрим, что у вьюшки вызвались соответствующие значения. Таким образом валидируем, что наше состояние правильно обновляет View. Если у вас View ничего серьезного не делает, то, скорее всего, вы покроете огромное количество сценариев.
Вы можете замокать какие-то методы функцией, которая возвращает размер, позвать после onEnter еще какое-то событие и посмотреть, как конкретное состояние реагирует на конкретные события. В данном случае при возникновении события filesSizeUpdated и когда AllFilesSize больше нуля, мы должны перейти в новое состояние CleanAllFiles. При помощи макета мы все это проверяем.
И последнее — мы можем тестировать систему целиком. Мы конструируем состояние, отправляем в него ивент и проверяем, как система себя ведет. У нас есть три этапа тестирования. Отдельно тестируем, как обновляется UI, отдельно тестируем, как происходит логика перехода, переключения между состояниями, и отдельно тестируем всю систему в целом.
Мы переписывали видеоплеер на такую концепцию, и получили покрытие больше 70%. Под 80% инструкций было покрыто такими тестами. Мне кажется, это очень крутой показатель.
Что мы получили, используя такую концепцию? В первую очередь — тестирование. Стейт-машину и наш презентер несложно подружить с жизненным циклом.
Расширяемость. Такой подход позволяет вас сдерживать в определенной концепции. Вы можете что-то закостылить, но скорее всего, когда кто-то будет делать ревью вашего кода, он скажет — зачем ты так делаешь, когда просто можно добавить новое состояние и все будет работать.
Порог вхождения в понятие стейт-машины достаточно низкий, и люди, которые приходят в команду, видят отдельные детерминированные состояния. Они могут легко понять, что они делают, и вариантов ошибиться гораздо меньше. Плюс за счет того, что у нас есть единая точка переключения состояний, мы можем это все логировать. Разные библиотеки для стейт-машин позволяют не только понять, какое состояние было старым, а какое новым. Они также позволяют вам, например, отлавливать определенные переходы. Вы можете поставить триггер lock на определенный переход. Если вы что-то отлаживаете, это может быть очень важно.
В конце — документируемость. Сам подход подразумевает, что в начале разработки вы рисуете диаграмму, потом можете ее приаттачить на вики или в документ вашего проекта, использовать уже как базу знаний, шарить между командами. Предположим, у вас что-то сложное, библиотека, еще что-то, и смежные команды спрашивают, как это работает. Вы просто показываете такую диаграмму, и им сразу все становится понятно. На этом все, спасибо.
Quarc
Программист с 1-ой диаграммы лопнул.