
Итак, сложив свой собственный опыт и наблюдения за другими ребятами, я решил подготовить для вас коллекцию того, «как писать тесты не стоит». Каждый пример я подкрепил подробным описанием, примерами кода и скриншотами.
Статья будет интересна начинающим авторам UI-тестов, но и старожилы в этой теме наверняка узнают что-то новое, либо просто улыбнутся, вспомнив себя «в молодости». :)
Поехали!

Содержание
- Локаторы без атрибутов
- Проверка отсутствия элемента
- Проверка появления элемента
- Случайные данные
- Атомарность тестов (часть 1)
- Атомарность тестов (часть 2)
- Ошибка клика по существующему элементу
- Текст ошибки
- Итог
Локаторы без атрибутов
Начнём с простого примера. Так как мы говорим о UI-тестах не последнюю роль в них играют локаторы. Локатор — это строка, составленная по определённому правилу и описывающая один или несколько XML- (в частности HTML-) элементов.
Существует несколько видов локаторов. Например, css-локаторы используются для каскадных таблиц стилей. XPath-локаторы используются для работы с XML-документами. И так далее.
Полный список типов локаторов, которые используются в Selenium, можно найти на seleniumhq.github.io.
В UI-тестах локаторы используются для описания элементов, с которыми драйвер должен взаимодействовать.
Практически в любом инспекторе браузера есть возможность выбрать интересующий нас элемент и скопировать его XPath. Выглядит это примерно так:
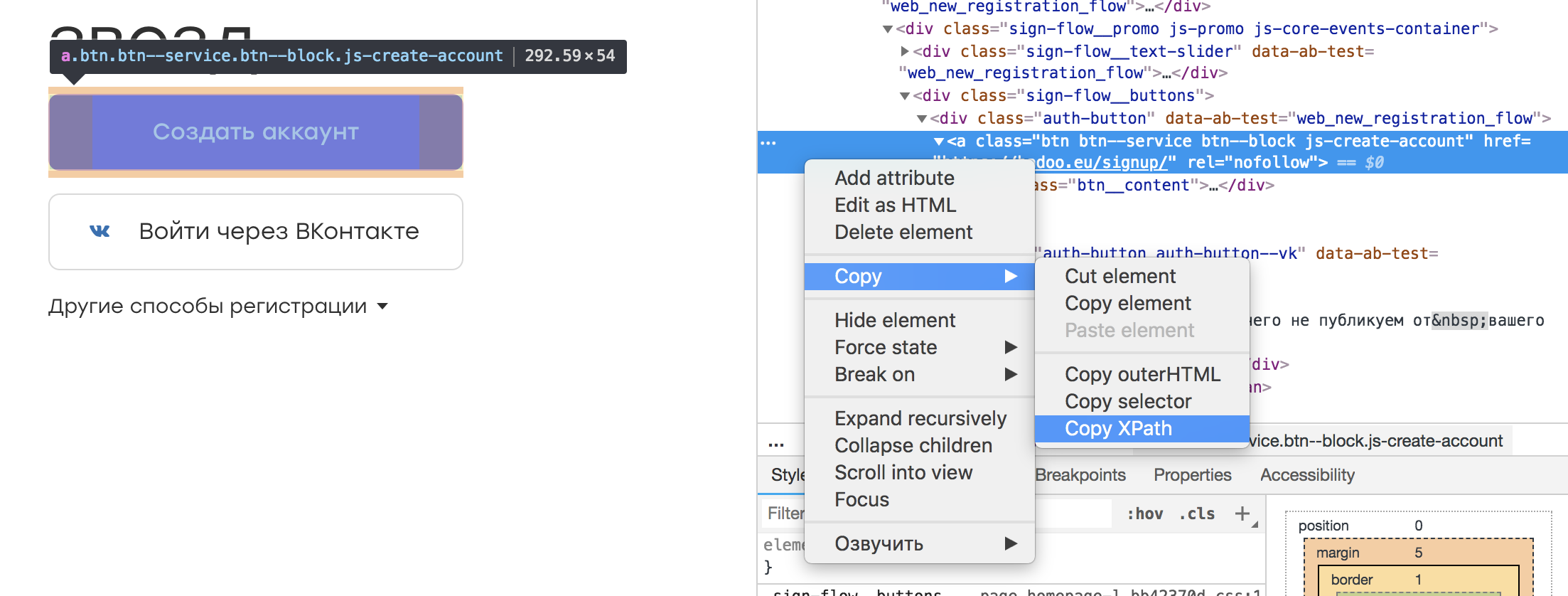
Получается такой вот локатор:
/html/body/div[3]/div[1]/div[2]/div/div/div[2]/div[1]/a
Кажется, что ничего плохого в таком локаторе нет. Ведь мы его можем сохранить в какую-то константу или поле класса, которые своим названием будут передавать суть элемента:
@FindBy(xpath = "/html/body/div[3]/div[1]/div[2]/div/div/div[2]/div[1]/a")
public WebElement createAccountButton;
И обернуть соответствующим текстом ошибки на случай, если элемент не найдётся:
public void waitForCreateAccountButton()
{
By by = By.xpath(this.createAccountButton);
WebDriverWait wait = new WebDriverWait(driver, timeoutInSeconds);
wait
.withMessage(“Cannot find Create Account button.”)
.until(
ExpectedConditions.presenceOfElementLocated(by)
);
}
У такого подхода есть плюс: отпадает необходимость изучать XPath.
Однако есть и ряд минусов. Во-первых, при изменении вёрстки нет гарантии, что элемент по такому локатору останется прежним. Вполне возможно, что на его место встанет другой, что приведёт к непредвиденным обстоятельствам. Во-вторых, задача автотестов — баги искать, а не следить за изменениями вёрстки. Следовательно, добавление какого-нибудь враппера или ещё каких-то элементов выше по дереву не должно затрагивать наши тесты. В противном случаем у нас будет уходить довольно много времени на актуализацию локаторов.
Вывод: следует составлять локаторы, которые корректно описывают элемент и при этом устойчивы к изменению вёрстки вне тестируемой части нашего приложения. Например, можно привязываться к одному или нескольким атрибутам элемента:
//a[@rel=”createAccount”]
Такой локатор и воспринимать в коде проще, и сломается он только в том случае, если пропадёт «rel».
Ещё один плюс такого локатора — возможность поиска в репозитории шаблона с указанным атрибутом. А что искать, если локатор выглядит как в первоначальном примере? :)
Если изначально в приложении у элементов нет никаких атрибутов или они выставляются автоматически (например, из-за обфускации классов), это стоит обсудить с разработчиками. Они должны быть не менее заинтересованы в автоматизации тестирования продукта и наверняка пойдут вам навстречу и предложат решение.
Проверка отсутствия элемента
У каждого пользователя Badoo есть свой профиль. На нём расположена информация о пользователе: (имя, возраст, фотографии) и информацию о том, с кем пользователь хочет общаться. Помимо этого, есть возможность указать свои интересы.
Предположим, однажды у нас был баг ( хотя, конечно, это не так :) ). Пользователь в своём профиле выбирал интересы. Не найдя подходящего интереса из списка, он решил кликнуть «Ещё», чтобы обновить список.
Ожидаемое поведение: старые интересы должны пропасть, новые — появиться. Но вместо этого выскочила «Непредвиденная ошибка»:
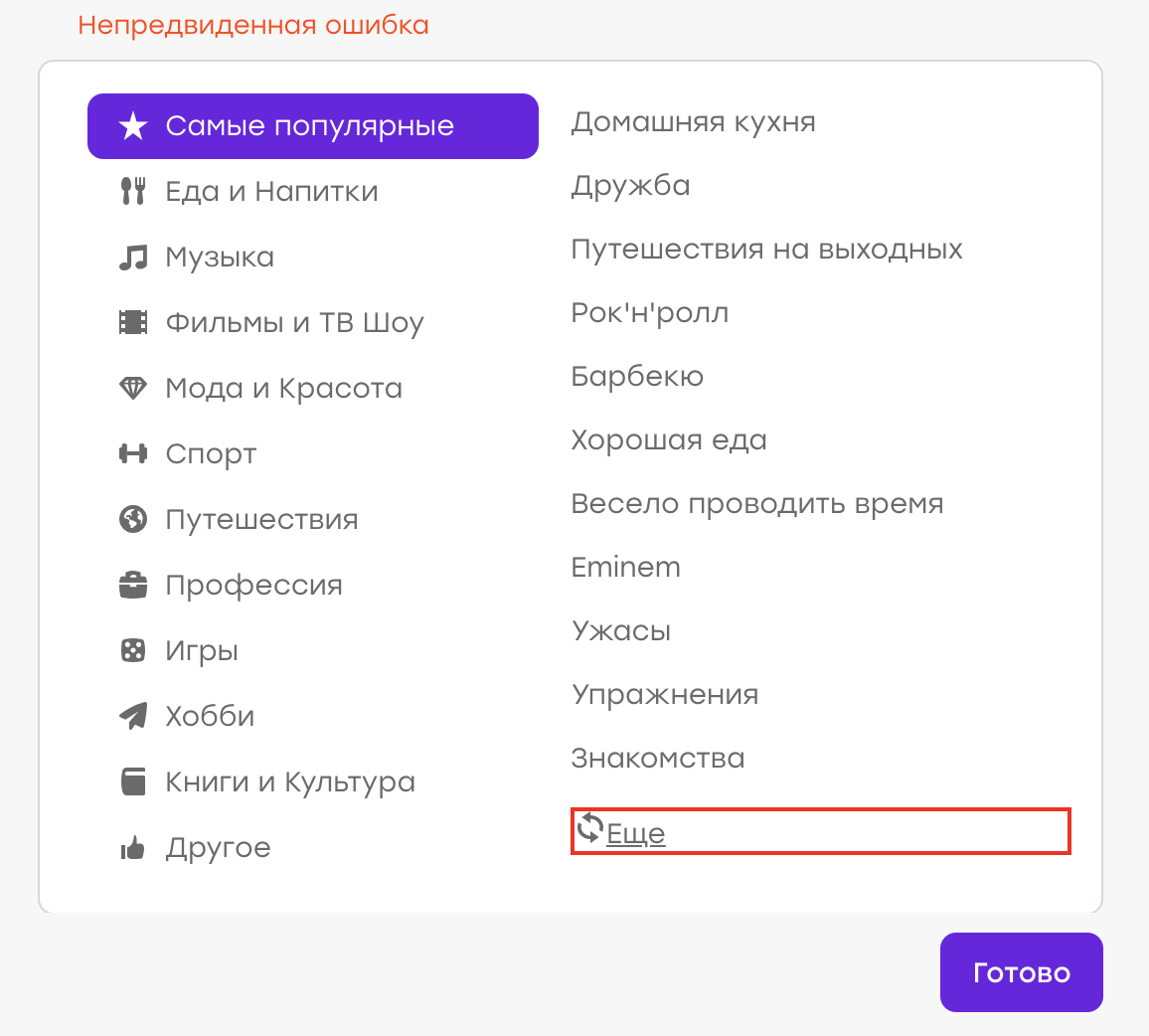
Оказалось, на стороне сервера возникла проблема, ответ пришёл не тот, и клиент это дело обработал, показав соответствующее уведомление.
Наша задача — написать автотест, который будет проверять этот кейс.
Мы пишем примерно следующий сценарий:
- Открыть профиль
- Открыть список интересов
- Кликнуть кнопку «Ещё»
- Убедиться, что ошибка не появилась (например, нет элемента «div.error»)
Такой тест мы и запускаем. Однако происходит следующее: через несколько дней/месяцев/лет баг снова появляется, хотя тест ничего не ловит. Почему?
Всё довольно просто: за время успешного прохождения теста локатор элемента, по которому мы искали текст ошибки, изменился. Был рефакторинг темплейтов и вместо класса «error» у нас появился класс «error_new».
Во время рефакторинга тест ожидаемо продолжал работать. Элемент “div.error” не появлялся, причины для падения не было. Но теперь элемента “div.error” вообще не существует — следовательно, тест не упадёт никогда, чтобы ни происходило в приложении.
Вывод: лучше тестировать работоспособность интерфейса позитивными проверками. В нашем примере стоило ожидать, что список интересов изменился.
Бывают ситуации, когда негативную проверку нельзя заменить позитивной. Например, при взаимодействии с каким-то элементом в «хорошей» ситуации ничего не происходит, а в «плохой» — появляется ошибка. В этом случае стоит придумать способ симулировать «плохой» сценарий и на него тоже написать автотест. Таким образом мы проверим, что в негативном кейсе элемент ошибки появляется, и тем самым будем следить за актуальностью локатора.
Проверка появления элемента
Как убедиться, что взаимодействие теста с интерфейсом прошло удачно и всё работает? Чаще всего это видно по изменениям, которые в этом интерфейсе произошли.
Рассмотрим пример. Необходимо убедиться, что при отправке сообщения оно появляется в чате:
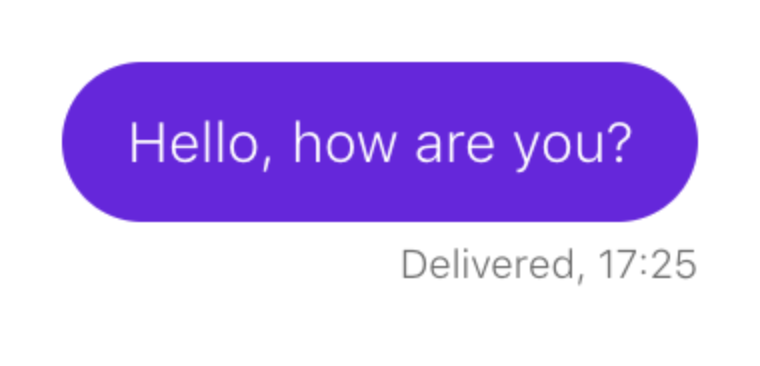
Сценарий выглядит примерно так:
- Открыть профиль пользователя
- Открыть чат с ним
- Написать сообщение
- Отправить
- Дождаться появления сообщения
Такой сценарий мы и описываем в нашем тесте. Предположим, что сообщению в чате соответствует локатор:
p.message_text
Вот так мы проверяем, что элемент появился:
this.waitForPresence(By.css(‘p.message_text’), "Cannot find sent message.");
Если наш wait работает, то всё в порядке: сообщения в чате отрисовываются.
Как вы уже догадались, через какое-то время отправка сообщений в чате ломается, но наш тест продолжает работать без перебоев. Давайте разбираться.
Оказывается, накануне в чате появился новый элемент: некий текст, который предлагает пользователю подсветить сообщение, если оно вдруг осталось незамеченным:
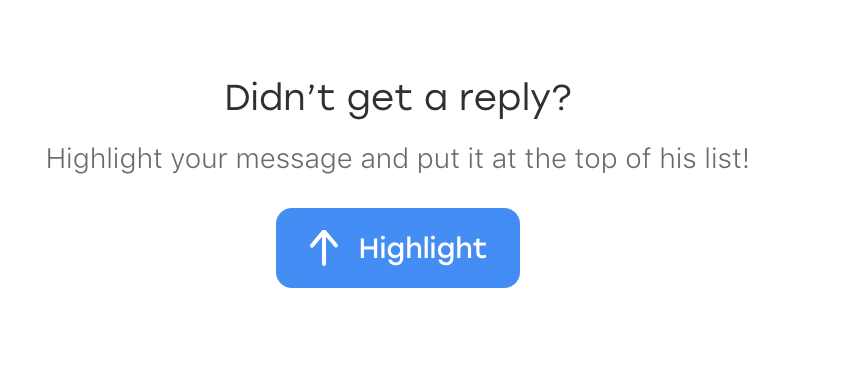
И, что самое забавное, он тоже попадает под наш локатор. Только у него есть дополнительный класс, который отличает его от отправленных сообщений:
p.message_text.highlight
Наш тест при появлении этого блока не сломался, но проверка «дождаться появления сообщения» перестала быть актуальной. Элемент, который был индикатором удачного события, теперь есть всегда.
Вывод: если логика теста строится на проверке появления какого-то элемента, обязательно надо проверять, чтобы такого элемента до нашего взаимодействия с UI не было.
- Открыть профиль пользователя
- Открыть чат с ним
- Убедиться, что отправленных сообщений нет
- Написать сообщение
- Отправить
- Дождаться появления сообщения
Случайные данные
Довольно часто UI-тесты работают с формами, в которые они вносят те или иные данные. Например, у нас есть форма регистрации:
Данные для таких тестов можно хранить в конфигах либо захардкодить в тесте. Но иногда приходит в голову мысль: а почему бы данные не рандомизировать? Это же хорошо, мы будем покрывать больше кейсов!
Мой совет: не надо. И сейчас я расскажу почему.
Предположим, наш тест регистрируется на Badoo. Мы решаем, что пол пользователя мы будем выбирать случайно. На момент написания теста флоу регистрации для девочки и для мальчика ничем не отличается, так что наш тест успешно проходит.
Теперь представим, что через некоторое время флоу регистрации становится разным. Например, девочке мы даём бесплатные бонусы сразу после регистрации, о чём уведомляем её специальным оверлеем.
В тесте нет логики закрытия оверлея, а он, в свою очередь, мешает каким-то дальнейшим действиям, прописанным в тесте. Мы получаем тест, который в 50% случаев падает. Любой автоматизатор подтвердит, что UI-тесты по своей природе и так не отличаются стабильностью. И это нормально, с этим приходится жить, постоянно лавируя между избыточной логикой «на все случаи жизни» (что заметно портит читабельность кода и усложняет его поддержку) и этой самой нестабильностью.
В следующий раз при падении теста у нас может не быть времени на то, чтобы с ним разбираться. Мы его просто перезапустим и увидим, что он прошёл. Решим, что в нашем приложении всё работает как надо и дело в нестабильном тесте. И успокоимся.
Теперь пойдём дальше. Что, если этот оверлей сломается? Тест продолжит проходить в 50% случаев, что существенно отдаляет нахождение проблемы.
И это хорошо, когда из-за рандомизации данных мы создаем ситуацию «50 на 50». Но бывает и по-другому. Например, раньше при регистрации приемлемым считался пароль не короче трёх символов. Мы пишем код, который придумывает нам случайный пароль не короче трёх символов ( иногда символов три, а иногда и больше). А потом правило меняется — и пароль должен содержать уже не менее четырёх символов. Какую вероятность падения мы получим в этом случае? И, если наш тест будет ловить настоящий баг, как быстро мы в этом разберёмся?
Особенно сложно работать с тестами где случайных данных вводится много: имя, пол, пароль и так далее… В этом случае различных комбинаций тоже много, и, если в какой-то из них происходит ошибка, обычно заметить это непросто.
Вывод. Как я писал выше, рандомизировать данные — плохо. Лучше покрыть больше кейсов за счёт дата-провайдеров, не забывая про классы эквивалентности, само собой. Прохождение тестов станет занимать больше времени, но с этим можно бороться. Зато мы будем уверены, что, если проблема есть, она будет обнаружена.
Атомарность тестов (часть 1)
Давайте разберём следующий пример. Мы пишем тест, который проверяет счётчик пользователей в футере.

Сценарий простой:
- Открыть приложение
- Найти счётчик на футере
- Убедиться, что он видимый
Такой тест мы называем testFooterCounter и запускаем. Потом появляется необходимость проверять, что счётчик не показывает ноль. Эту проверку мы добавляем в уже существующий тест, почему нет?
А вот потом появляется необходимость проверять, что в футере есть ссылка на описание проекта (ссылка «О нас»). Написать новый тест или добавить в уже существующий? В случае нового теста нам придётся заново поднимать приложение, готовить пользователя (если мы проверяем футер на авторизованной странице), логиниться — в общем, тратить драгоценное время. В такой ситуации переименовать тест в testFooterCounterAndLinks кажется удачной идеей.
С одной стороны, плюсы у такого подхода есть: экономия времени, хранение всех проверок какой-то части нашего приложения (в данном случае футера) в одном месте.
Но есть и заметный минус. Если тест упадёт на первой же проверке, мы не проверим оставшуюся часть компонента. Предположим, тест упал в какой-то ветке не из-за нестабильности, а из-за бага. Что делать? Возвращать задачу, описав только эту проблему? Тогда мы рискуем получить задачу с фиксом только этого бага, запустить тест и обнаружить, что дальше компонент тоже сломан, в другом месте. И таких итераций может быть много. Пинание тикета туда-сюда в этом случае займёт много времени и будет неэффективно.
Вывод: стоит по возможности атомизировать проверки. В таком случае, даже имея проблему в одном кейсе, мы проверим все остальные. И, если придётся возвращать тикет, мы сможем сразу описать все проблемные места.
Атомарность тестов (часть 2)
Рассмотрим ещё один пример. Мы пишем тест на чат, который проверяет следующую логику. Если у пользователей возникла взаимная симпатия, в чате появляется такой промоблок:

Сценарий выглядит следующим образом:
- Проголосовать юзером А за юзера Б
- Проголосовать юзером Б за юзера А
- Юзером А открыть чат с юзером Б
- Подтвердить, что блок на месте
Какое-то время тест успешно работает, но потом происходит следующее… Нет, в этот раз тест не пропускает никакой баг. :)
Через какое-то время мы узнаём, что есть другой, не связанный с нашим тестом баг: если открыть чат, тут же закрыть и открыть снова, блок пропадает. Не самый очевидный кейс, и в тесте мы, само собой, его не предвидели. Но мы решаем, что покрыть его тоже надо.
Возникает тот же вопрос: написать ещё один тест или вставить проверку в уже существующий? Писать новый кажется нецелесообразным, ведь 99% времени он будет делать то же самое, что уже существующий. И мы решаем добавить проверку в тест, который уже есть:
- Проголосовать юзером А за юзера Б
- Проголосовать юзером Б за юзера А
- Юзером А открыть чат с юзером Б
- Подтвердить, что блок на месте
- Закрыть чат
- Открыть чат
- Подтвердить, что блок на месте
Проблема может всплыть тогда, когда мы будем, например, рефакторить тест спустя много времени. Например, на проекте случится редизайн — и придётся переписывать много тестов.
Мы откроем тест и будем пытаться вспомнить, что же он проверяет. Например, тест называется testPromoAfterMutualAttraction. Поймём ли мы, зачем в конце прописано открытие и закрытие чата? Скорее всего, нет. Особенно если этот тест писали не мы. Оставим ли мы этот кусок? Может, и да, но, если с ним будут какие-то проблемы, велика вероятность, что мы его просто удалим. И проверка потеряется просто потому, что её смысл будет неочевиден.
Решения я тут вижу два. Первое: всё же сделать второй тест и назвать его testCheckBlockPresentAfterOpenAndCloseChat. С таким названием будет понятно, что мы не просто так совершаем какой-то набор действий, а делаем вполне осознанную проверку, поскольку был негативный опыт. Второе решение — написать в коде подробный комментарий о том, зачем мы делаем эту проверку именно в этом тесте. В комментарии желательно также указать номер бага.
Ошибка клика по существующему элементу
Следующий пример подкинул мне bbidox, за что ему большой плюс в карму!
Бывает очень интересная ситуация, когда код тестов становится уже… фреймворком. Предположим, у нас есть такой метод:
public void clickSomeButton()
{
WebElement button_element = this.waitForButtonToAppear();
button_element.click();
}
В какой-то момент с этим методом начинает происходить что-то странное: тест падает при попытке кликнуть по кнопке. Мы открываем скриншот, сделанный в момент падения теста, и видим, что на скриншоте кнопка есть и метод waitForButtonToAppear сработал успешно. Вопрос: что не так с кликом?
Самое сложное в этой ситуации то, что тест иногда может проходить успешно. :)
Давайте разбираться. Предположим, что рассматриваемая в примере кнопка расположена на таком оверлее:
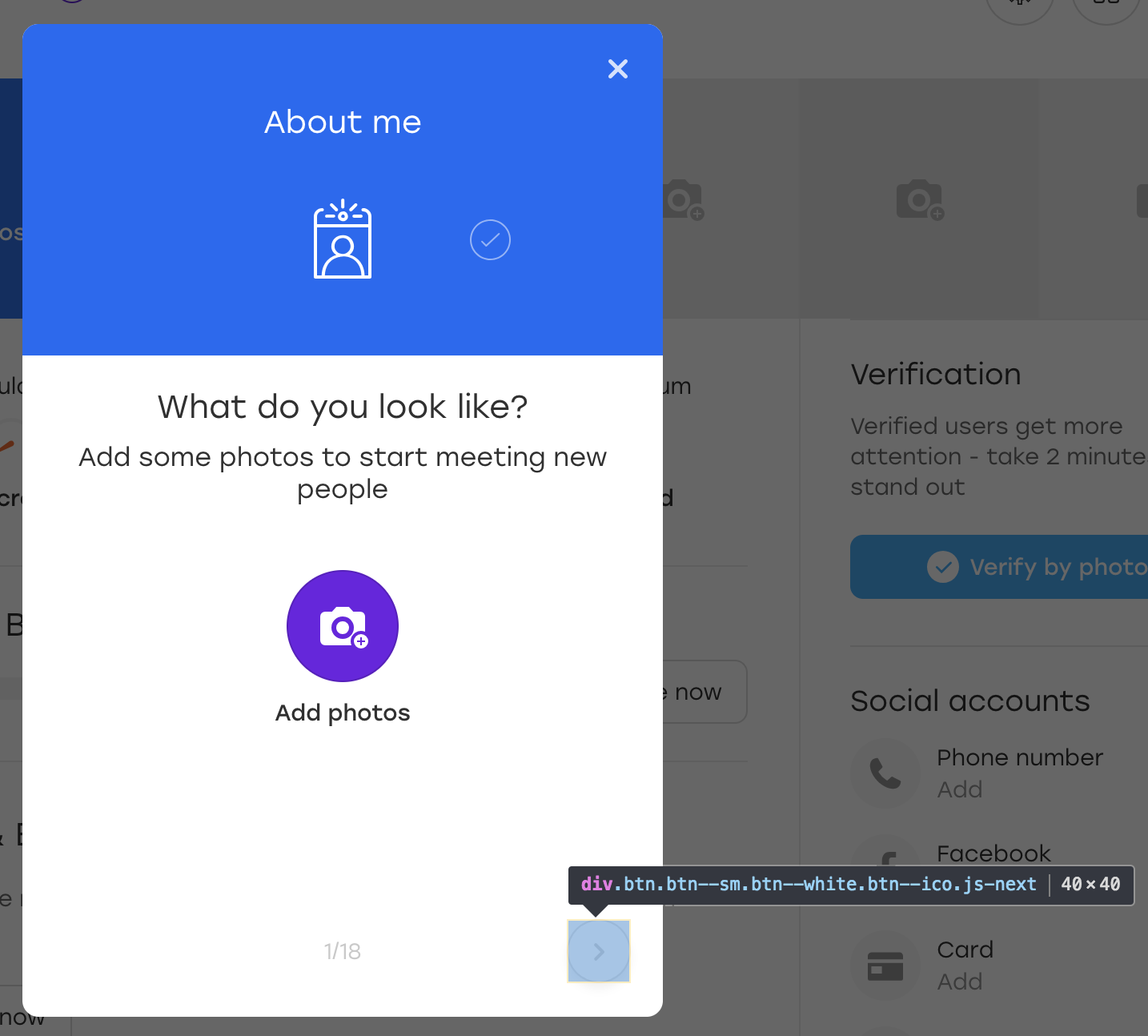
Это специальный оверлей, через который пользователь на нашем сайте может заполнять информацию о себе. При нажатии на выделенную кнопку оверлея появляется следующий блок для заполнения.
Ради интереса давайте добавим дополнительный класс OLOLO для этой кнопки:
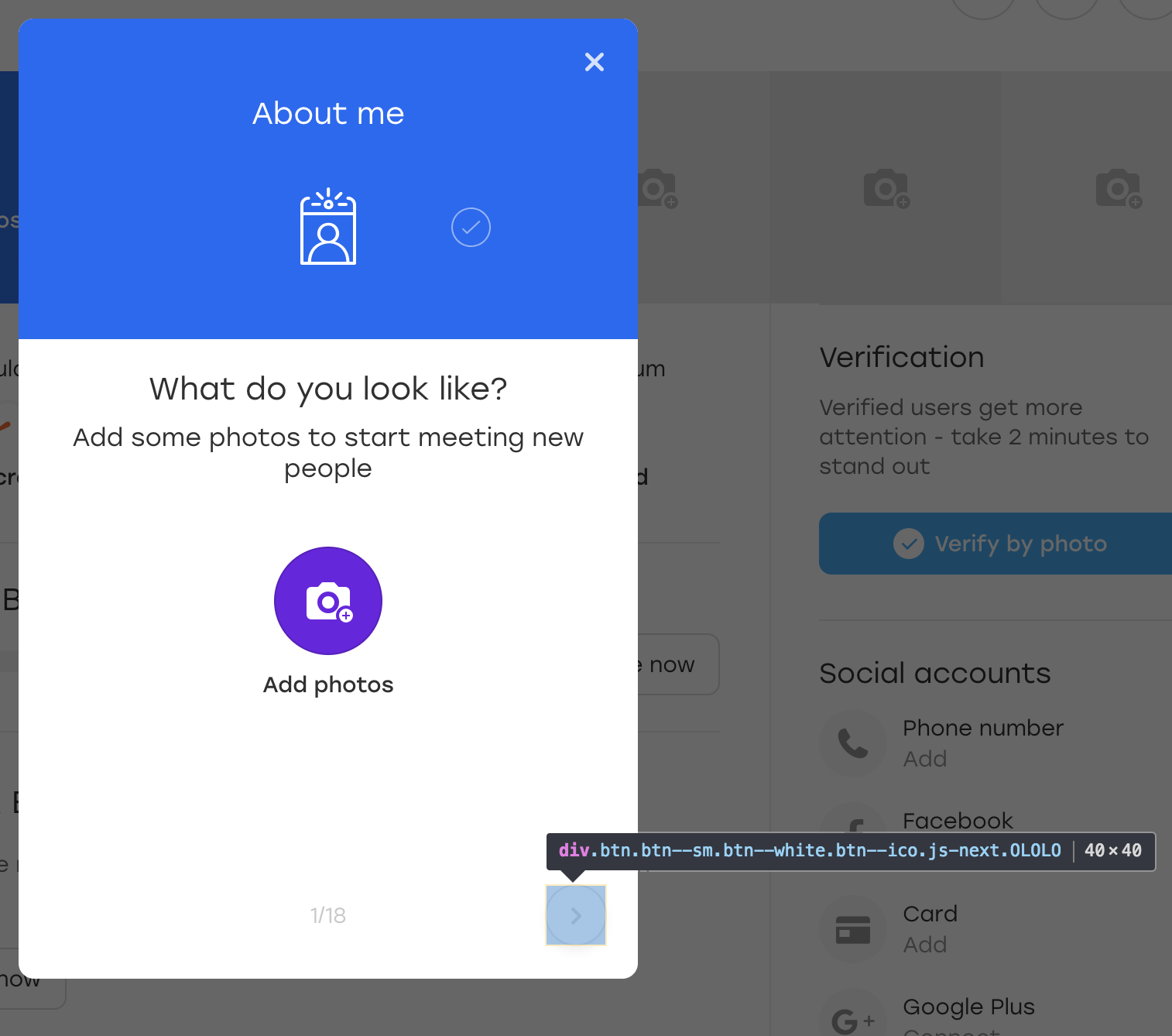
После чего мы кликаем на эту кнопку. Визуально ничего не изменилось, а сама кнопка осталась на месте:
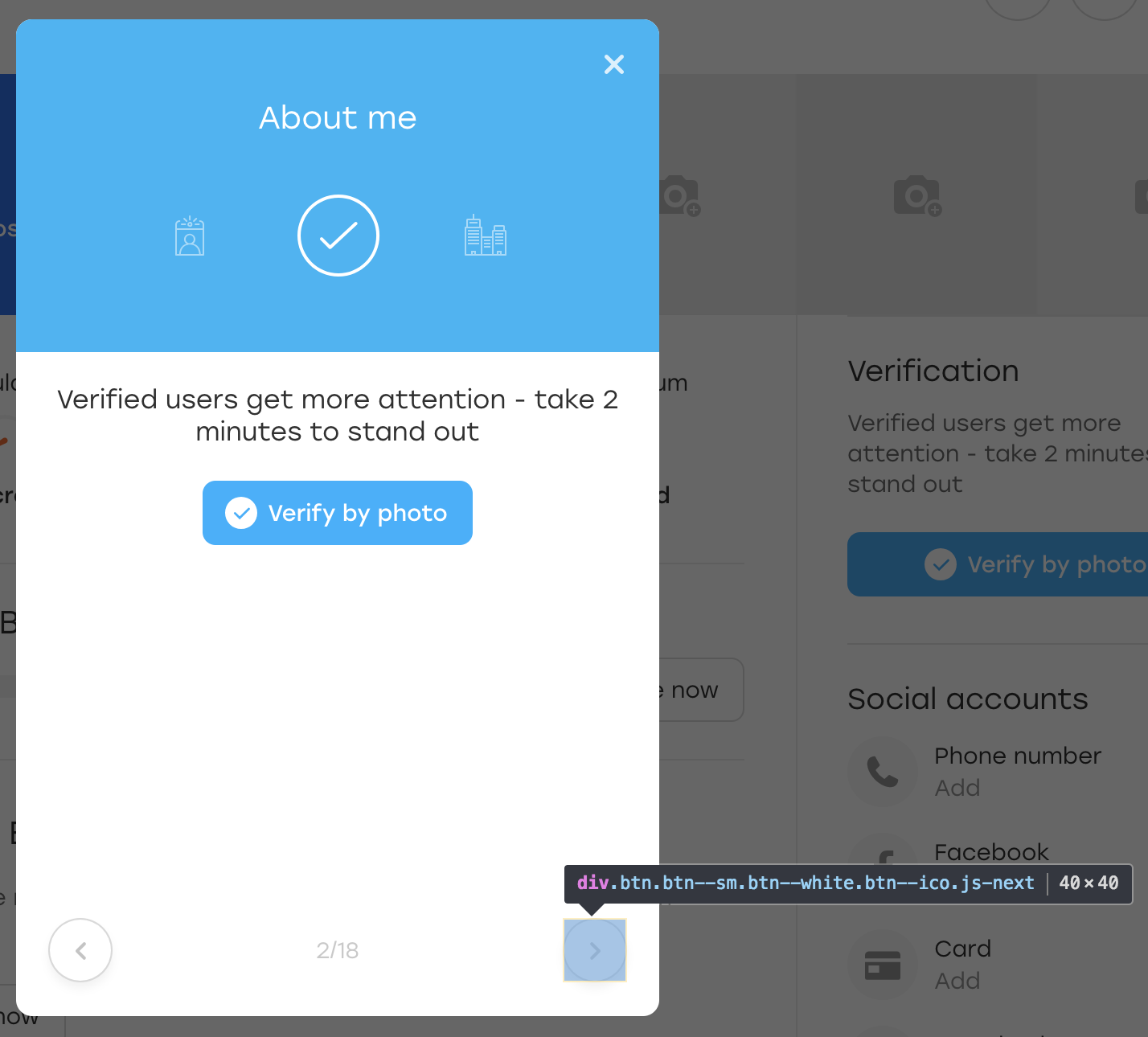
Что же произошло? По сути, когда JS перерисовывал нам блок, кнопку он перерисовал тоже. Она всё ещё доступна по тому же локатору, но это уже другая кнопка. Об этом говорит отсутствие добавленного нами класса OLOLO.
В коде выше мы сохраняем элемент в переменную $element. Если за это время элемент перегенерируется, визуально это может быть незаметно, но кликнуть по нему уже не получится — метод click() упадёт с ошибкой.
Вариантов решения несколько:
- Оборачивать click в try-блок и в catch пересобирать элемент
- Добавлять кнопке какой-то атрибут, чтобы сигнализировать, что она изменилась
Текст ошибки
Напоследок простой, но не менее важный момент.
Данный пример касается не только UI-тестов, но и в них встречается очень часто. Обычно, когда пишешь тест, находишься в контексте происходящего: описываешь проверку за проверкой и понимаешь их значение. И тексты ошибок пишешь в том же контексте:
WebElement element = this.waitForPresence(By.css("a.link"), "Cannot find button");
Что может быть непонятно в этом коде? Тест ожидает появления кнопки и, если её нет, закономерно падает.
Теперь представьте, что автор теста на больничном, а за тестами присматривает его коллега. И вот у него падает тест testQuestionsOnProfile и пишет такое сообщение: “Cannot find button”. Коллеге надо как можно быстрее разобраться в происходящем, потому что скоро релиз.

Что ему придётся делать?
Открывать страницу, на которой тест упал, и проверять локатор “a.link” бессмысленно — элемента же нет. Следовательно, придётся внимательно изучать тест и разбираться, что же он проверяет.
Куда проще было бы с более подробным текстом ошибки: “Cannot find the submit button on the questions overlay”. С такой ошибкой можно сразу открывать оверлей и смотреть, куда делась кнопка.
Вывода два. Во-первых, в любой метод вашего тестового фреймворка стоит передавать текст ошибки, причём обязательным параметром, чтобы не было соблазна про него забыть. Во-вторых, текст ошибки стоит делать подробным. Это не всегда означает, что он должен быть длинным, — достаточно, чтобы по нему было понятно, что пошло не так в тесте.
Как понять, что текст ошибки написан хорошо? Очень просто. Представьте, что ваше приложение сломалось и вам надо подойти к разработчикам и объяснить, что и где сломалось. Если вы им скажете только то, что написано в тексте ошибки, им будет понятно?
Итог
Составление сценария теста зачастую бывает интересным занятием. Одновременно мы преследуем множество целей. Наши тесты должны:
- покрывать как можно больше кейсов
- работать как можно быстрее
- быть понятными
- просто расширяться
- легко поддерживаться
- заказывать пиццу
- и так далее…
Особенно интересно работать с тестами в постоянно развивающемся и меняющемся проекте, где их приходится постоянно актуализировать: что-то добавлять и что-то выпиливать. Вот почему стоит заранее продумывать некоторые моменты и не всегда спешить с решениями. :)
Надеюсь, мои советы помогут вам избежать некоторых проблем и заставят подходить к составлению кейсов более вдумчиво. Если статья понравится публике, я постараюсь собрать ещё несколько нескучных примеров. А пока — пока!
Комментарии (63)

nodonutsforyou
07.08.2018 17:58+1Вывод. Как я писал выше, рандомизировать данные — плохо.
Тут еще можно добавить, что если и нужно кровь-из-носа сделать что-то случайное — нужно делать псевдослучайные тесты. Чтобы зерно генератора случайности хранилось в логах теста и должна быть возможность перезапустить тест со старым зерном.nizkopal Автор
07.08.2018 17:59Именно так. Но только если «кровь из носа». :)
Спасибо за комментарий.dimm_ddr
09.08.2018 12:22Ну вообще в ваших же примерах рандомизатор мог бы и помочь: если появилась новая функциональность — изменилось флоу для каких-то определенных вариантов данных, а тест никто не написал, то это, конечно, в первую очередь косяк процесса, но так как мы живем не в идеальном мире, то и на такой случай полезно иметь страховку. Случайные данные как раз такую страховку могут добавить. Можно конечно просто набрать данных для всех вменяемых вариантов, но мы, снова не в идеальном мире, а значит у нас скорее всего есть некие ограничения по времени выполнения тестов. Просто нужно на самом деле хранить зерно и иметь возможность запустить с ним. А еще нужно избавляться от нестабильных тестов и обращать внимания на каждый фейл. Это не так уж и сложно на самом деле зачастую.
Melman898
07.08.2018 17:59А что на счет е2е, где есть сложная логика и кейсы могут быть длинные? Да атомарность это здорово звучит, ноне везде ее можно реализовать.
За «Проверка отсутствия элемента» плюсую.
На счет «Проверка появления элемента», не согласен, в описанном примере, проблема скорее в локаторе элемента, а не в самой проверке, плюс можно проверять что отобразилось сообщение именно с тем текстом которым мы вводили (текст рандомизировать если есть вариант наткнуться на ранее отправленные сообщения, либо брать чистого юзера всегда)nizkopal Автор
07.08.2018 18:07+1Добрый день.
А что на счет е2е, где есть сложная логика и кейсы могут быть длинные? Да атомарность это здорово звучит, ноне везде ее можно реализовать.
Суть атомарности — не городить там, где избежать можно. Если можно что-то придумать и избежать — на это стоит потратить время. Это почти наверняка окупится. Если ничего придумать нельзя, значит нельзя. Никто не спорит, что на первом месте стоит решение бизнес-задачи, а не перфекционизм.
На счет «Проверка появления элемента», не согласен, в описанном примере, проблема скорее в локаторе элемента, а не в самой проверке
Проблема и в проверке тоже. Мы не можем заранее придумать такой локатор, который никогда не перестанет быть уникальным.
плюс можно проверять что отобразилось сообщение именно с тем текстом которым мы вводили (текст рандомизировать если есть вариант наткнуться на ранее отправленные сообщения, либо брать чистого юзера всегда)
Можно придумать много решения, да. Главное — предпринять хоть что-то. А для этого надо учитывать, что такой подводный камень есть. Это из серии — первый шаг в решении проблемы, осознать, что проблема существует.
dimm_ddr
09.08.2018 12:26Для таких случаев в большинстве популярных фреймворков есть возможность создавать группы тестов, которые выполняются независимо но после другой группы. Например если нужно проверить существование разных элементов для залогиненного пользователя, то сначала пишется тест на логин, а потом по тесту на каждый элемент, которые ставятся в зависимость от первого. Да, естественно если упадет логин, то остальные не запустятся, но так и в атомарных тестах вы то же самое получите если вам залогиненный пользователь нужен, а средств получить сразу такого из базы — нет (если есть, то нужно конечно именно их и использовать и не городить цепочек). Но при этом каждая проверка независима и вы получите полную картину того что происходит. Паттерн Steps, примерно об этом же если мне память не изменяет.
dedotmoroz
07.08.2018 18:08Может нужно расставить ID-шники в полях форм и кнопок?
nizkopal Автор
07.08.2018 18:09Таким образом Вы точно решите часть проблем. Но это может быть довольно трудозатратно со стороны разработки. Все зависит от того, как устроена шаблонизация проекта.
И это все еще не убережет от остальных подводных камнях. Голову включать придется в любом случае. :)
CrownBerry
07.08.2018 18:21Не думали использовать БЭМ-методологию для именования html-элементов? Как мне кажется, это принесет пользу и разработчикам и автоматизаторам тестирования.
nizkopal Автор
07.08.2018 18:23Привет.
БЭМ мы используем (соглашения по именованию, не библиотеки). К сожалению, это спасает не от всех проблем. Я, пожалуй, даже не уверен, от какой именно проблемы из описанных это могло бы спасти наверняка.
Tab10id
07.08.2018 23:22Смотрю на ui тесты со своей колокольни (ruby web). У нас используется другой подход к проблеме локаторов (продвигаемый библиотекой capybara https://github.com/teamcapybara/capybara/blob/3.5_stable/README.md#using-capybara-with-rspec)
Если коротко, в качестве локаторов используется обычный человекочитаемый текст:
describe 'регистрация' do before do fill_in 'Имя пользователя', 'vasya_pupkin' fill_in 'Пароль', 'qwerty' fill_in 'Подтверждение', 'qwerty' click_button 'Регистрация' end it 'работает' do expect(page).to have_text('Вы зарегистрированы!') end end
Такой тест значительно проще пишется и читается. css и xpath все еще бывают нужны, но это скорее исключение из правил и обычно используются в качестве ограничения зоны видимости:
within('#comments') do click_button 'Ещё' end
Поиск таких элементов идет дольше, но для нас на текущий момент более важны читаемость и поддерживаемость тестов.
bbidox
08.08.2018 00:50+2Не бейте меня палкой, пожалуйста, но я не вижу как поиск элемента по тексту / подписи поможет с описанными проблемами.
Во-первых, у кнопки может вообще не быть осмысленного текста. У неё есть только иконка. Вот такой вот "венец" юзабилити на сайте.
Во-вторых,…
Например, на форме-опроснике есть кнопка Сontinue, по нажатию на которую показывается новый вопрос. Нам точно так же после её нажатия надо убедиться, что мы не стали заложниками stale element error и кнопка Continue — новая, а старая не пропала.
Вот если вы каждый раз переполучаете элемент заново и нигде не храните на него ссылок, то это, конечно сработает. До поры до времени, пока вы не начнёте хранить ссылки.Tab10id
08.08.2018 09:12+2Бить никого и не собирался, и вероятно это действительно наша специфика, но у нас в проекте нет обилия кнопок, ссылок без текста (если их много пользователям сложно разобраться что делает каждая из них).
Да, иногда приходится писать хелперы типа click_burger с css-селекторами, или использовать xpath чтобы найти конкретный элемент среди множество, но как и писал выше, это скорее исключение.
А в случае с формой опросником я бы проверял что после нажатия на кнопку появился новый вопрос, или завершился тест, а не то что появилась новая кнопка вместо старой.bbidox
08.08.2018 12:52+1Конечно это специфика проекта. Например, у инстаграма основные кнопки без подписей.
Вообще про то, как писать эффективные локаторы много спорят. Вот, например, на selenium conf доклад был: https://www.slideshare.net/orenrubin/statistical-element-locator-by-oren-rubin-seleniumconf-uk-2016 Там ещё в кулуарах очень много разговоров было про то, как не сделать из такой штуки бегемота, но быстрого носорога :)
А пример про формочку — да, я его не очень сильно "придумывал", поэтому там легко решается проверкой другого вопроса. Ну так придумайте не опросник, а форму, в которой может ничего не изменяться, а что-то исчезать или появляться (например, фотография с одним и тем же адресом может меняться. или вообще flash-контент).
nizkopal Автор
08.08.2018 15:01+1А в случае с формой опросником я бы проверял что после нажатия на кнопку появился новый вопрос
Вы правы — можно таким путем пойти. Или другим. Как я уже где-то выше писал, важно знать о возможной проблеме. А дальше при наличии определенного багажа опыта решить ее не составит уже труда.
у нас в проекте нет обилия кнопок, ссылок без текста
Возможна ли ситуация, когда у нескольких разных элементов управления один и тот же текст? Например текст: «дальше», чтобы пролистать какой-то информационный блок и где-то ниже текст «дальше», обозначающий что-то еще. Если да — как вы решаете такие «коллизии»?Tab10id
08.08.2018 21:31Коллизии возможны, тест при этом падает сообщая что найдено более одного элемента. В этом случае прибегаем к помощи css/xpath (обычно все же css), но используем их для обозначения области поиска, выше приводил пример:
within('#comments') do click_button 'Ещё' end
Локатор в итоге указывает на контейнер, а не на сам элемент, соответственно меньше вероятность что он изменится из-за правок верстки.
В нашем проекте, эта практика работает почти всегда.
Иногда конечно бывают исключения, но они часто говорят о проблемах юзабилити.
К примеру, тест находит 2 кнопки с текстом "Ещё", это значит что на странице действительно находится 2 такие кнопки и какую из них заметил будет нажимать пользователь — большой вопрос.
В случаях когда наличие нескольких элементов действительно оправдано (например, идентичный пагинатор сверху и снизу страницы), можно использовать уточнения:
within('.article_list') do click_link('следующая страница', match: :first) end
Tab10id
07.08.2018 23:33+1По поводу нескольких проверок в одном тесте.
В рубишном rspec'e на этот случай есть фича aggregate_failures. При включении, в случае провала одной из проверок, тест продолжает выполнение, а потом выдает все собранные ошибки. В UI-тестах используем очень часто, в остальных случаях пригождается значительно реже.bbidox
08.08.2018 00:38+3Ещё это называется soft assert. Про них столько копий сломано, что можно отдельную (но скучную) статью писать.
Лично мне они кажутся каким-то переусложнением теста — сколько с ними не работал, они постепенно "вымывались" из проектов.
Если есть ошибка, то тест должен упасть. Если есть что-то "не совсем ошибка, но хорошо бы знать", то надо разобраться с критериями того, что считать ошибкой в данной конкретной конфигурации тестов. Например, для проверки работоспособности приложения в принципе можно игнорировать ошибки в JS-консоли браузера (если при этом всё работает), но если мы выпускаем новую версию, то эти ошибки достойны того, чтобы прервать тест.
Сугубо моё личное мнение.anonymous
08.08.2018 09:18+2Согласен насчет soft assert полностью. :)
А статью напишите, интересно было бы!
Tab10id
08.08.2018 09:29Не не не, aggregate_failures в rspec это не soft assert, тест падает, просто падает не на первой проверке, а после проведения всех проверок.
Мы используем его когда точно уверены что каждую из этих проверок нет смысла проводить в изоляции.
Например проверки наличия всех необходимых элементов на странице (нет смысла второй раз готовить окружение, чтобы проверить что помимо блока «новости» на странице присутствует блок «комментарии»).nizkopal Автор
08.08.2018 09:34+1Не не не, aggregate_failures в rspec это не soft assert, тест падает, просто падает не на первой проверке, а после проведения всех проверок.
Насколько я знаю, soft assert устроены таким же способом. Если он не проходит, тест это «запоминает» и идет дальше. Но в конце помечает запуск неудавшимся. Вроде все, как у Вас.
Например проверки наличия всех необходимых элементов на странице (нет смысла второй раз готовить окружение, чтобы проверить что помимо блока «новости» на странице присутствует блок «комментарии»).
Я понял Вас. Моя идея была больше о том, что тесты стоит разделять по смыслу. Я где-то выше писал в комментариях — главное, чтобы по названию теста было понятно, что же он проверяет. Иначе логика проверки перестанет быть понятной со временем и наверняка затеряется при каком-нибудь рефакторинге. Как и везде — стоит руководствоваться здравым смыслом.
bbidox
08.08.2018 12:44Я настолько засомневался в своей правоте, что даже в гугл обратился. И знаете, всё-таки, это — soft assert https://stackoverflow.com/questions/19091526/how-soft-assertions-work#25068591
Только в данном случае не важно, как мы это называть будем.
Тест должен падать сразу же, как только обнаружена ошибка. Вернёмся к длинным тестам и JS ошибкам (как пример). Если обнаружена JS ошибка важно знать где, когда, после какой операции с какими параметрами была ошибка. В идеале — запись скриншотов, состояния DOM (если web), видео. Короче, вообще всё.
А если вы собрали ошибочки и положили их в хранилище, то потом такие ошибки разбирать удовольствием не назовёшь.
Лично мне кажется, что soft assert — это плохой паттерн. Но иногда лучше плохой паттерн, чем полное отсутствие тестов. Если вам привычнее и вы умеете этим эффективно управлять — отлично!Tab10id
08.08.2018 12:59+1Спасибо, меня смутили ваши фразы «Если есть ошибка, то тест должен упасть» и «не совсем ошибка, но хорошо бы знать». Кроме того, одна из нагугленных страниц говорила о том, что при провале soft assert'а тест все равно будет помечен как пройденный, потому решил что мы говорим о разных вещах.
Tab10id
08.08.2018 13:03+1Я бы сказал, что использовать эту штуку можно, если по факту проверяется состояние одной сущности с помощью нескольких проверок, а написание для этого случая отдельного матчера нецелесообразно или ухудшит чтение теста.
bbidox
08.08.2018 13:37Главное из таких исключительных ситуаций не делать норму.
Мы друг друга поняли :)
saw_tooth
08.08.2018 02:19-4Вот так мы проверяем, что элемент появился:
present говорит что элемент в dom дереве есть, а не то что он visible
а почему бы данные не рандомизировать
А почему бы техники граничных условий не юзать?
Вариантов решения несколько:
Оборачивать click в try-блок и в catch пересобирать элемент
Или перестать молится на исключения, и использовать объектную модель сложных компонентов и пересчитуемые проперти c yield.
Статья на 10 экранов — 80% воды, зато теги какие..oh waitnizkopal Автор
08.08.2018 07:34+3Привет. Спасибо за интерес к статье. :)
present говорит что элемент в dom дереве есть, а не то что он visible
Так вроде нигде обратного и не утверждается. Вы это к чему?
А почему бы техники граничных условий не юзать?
Мы их юзаем, спасибо. Проблема как раз в то, что данные могут стать не эквивалентными уже после написания теста. Я как раз об этом писал:
Мы решаем, что пол пользователя мы будем выбирать случайно. На момент написания теста флоу регистрации для девочки и для мальчика ничем не отличается
Так что читайте, пожалуйста, внимательнее.
использовать объектную модель сложных компонентов и пересчитуемые проперти c yield.
Звучит, как что-то страшное. :) Можно ссылку, где такое описано? Или подробнее рассказать — чем именно это должно было нампомочь в описанных примерах? Пока звучит, как набор умных слов… Спасибо.
Статья на 10 экранов — 80% воды, зато теги какие..oh wait
Вообще, я старался воды не лить. Я просто хотел, чтобы примеры были хорошо описаны и понятны людям с разным опытом, «от мала до велика». Потому она вышла в таком объеме.
Жаль, что Вам не понравилась.
lxsmkv
08.08.2018 04:10Спасибо за статью. Особенно радует, что это не перевод, не подборка и не пересказ, а эксклюзивная статья основанная на собственном опыте. Такого материала вправду, довольно мало.
Про рандомизацию:
Я не делаю рандомизацию из другого принципа: «Если ты не можешь сказать какой пользовательский сценарий тестом покрывается — тебя занесло не в ту степь». Один тест и на мальчика и на девочку — не пойдет. В сценарии есть действующее лицо и это не Кошка Шрёдингера, а какая-то сущность (пусть это даже не человек а какой-то сервис) с вполне однозначными свойствами и аттрибутами.
Тут нужно разбить на классы эквивалентности, взять каждой «твари по паре» и так далее по учебнику. Не самое интересное занятие для увлеченных программистов, но покрытие на то и покрытие, оно должно быть пусть не полным, но целостным.
Про атомарность:
Вообще есть такое убеждение, что тесты должны быть независимы друг от друга — чтобы выполнять их можно было в любом порядке. Я считаю, что придерживаться этого можно, но не обязательно. У нас тестовые наборы по разделам приложения между собой независимы, а в одном наборе тесты выполняются в определенной последовательности. Когда ты не можешь зайти на какой-то экран — краснеет целый блок. И нужно чинить продукт, а не пилить двести тонн дополнительного тестового кода.
Хуже еще, когда пытаются искать обходные пути, чтобы обогнуть проблемное место и потестировать за ним. Нет. Так делать нельзя. Должно быть как на заводе Тойота — у одного что-то не так — он дергает аварийный шнур и останавливается вся линия. Пользователь не может зайти на страницу, какя разница ему теперь, горемыке несчастному, что там с футером. Он его не увидит. Бегом чинить продукт. Ведь ради этого мы и делаем автоматизацию. Ради того, чтобы улучшать качество продукта.
nizkopal Автор
08.08.2018 07:48+1Добрый день. Спасибо за интерес к статье. :)
Тут нужно разбить на классы эквивалентности, взять каждой «твари по паре»
Именно так. Я об этом говорил в статье, даже ссылку давал на определение. А вообще имел в виду, что данные могут перестать быть эквивалентными уже после создания теста. Как, например, выбор пола при регистрации. За этим сложно уследить, но можно подстраховаться.
Вообще есть такое убеждение, что тесты должны быть независимы друг от друга — чтобы выполнять их можно было в любом порядке. Я считаю, что придерживаться этого можно, но не обязательно.
Я старался донести мысль, что тесты должны оставаться понятными, а то, что они тестируют — предсказуемым из названия. Чтобы с ними работать было просто и быстро. Речь не про перфекционизм, а про практичность. Тесты должны решать свою бизнес-задачу, а для этого с ними должно легко работаться. К сожалению, иногда желание вставить лишнюю проверочку в уже существующий тест в итоге заводит не туда…
Должно быть как на заводе Тойота — у одного что-то не так — он дергает аварийный шнур и останавливается вся линия.
Тут нужно действовать так, как удобно вашей компании. Мы стараемся проверить как можно больше, а не остановиться на первой найденой проблеме. Так получается быстрее разбираться — если две задачи сломали две фичи (или даже одну), надо откатывать обе сразу, а не по одной. Скорость нам важна, у нас релизов много. :)
Пользователь не может зайти на страницу, какя разница ему теперь, горемыке несчастному, что там с футером. Он его не увидит. Бегом чинить продукт. Ведь ради этого мы и делаем автоматизацию. Ради того, чтобы улучшать качество продукта.
Мы делаем автоматизацию, чтобы поймать проблему заранее и не пустить ее до пользователя. Так что до пользователя проблема чаще всего не доходит (в штатной ситуации).
В любом случае спасибо за Ваш комментарий.
Quilin
08.08.2018 15:19Часто встречаю у автотестеров тему про «тесты нестабильны по своей природе, поэтому что они иногда падают — это нормально». Сам в свое время писал UI тесты на Selenium под дотнет и у меня появилось впечатление, что:
1. Критическая нестабильность Selenium или условного chromedriver это какой-то миф. Они иногда ведут себя странно, но самая банальная WaitAndRetry политика устойчивости к ошибкам решает порядка 90% проблем, когда остальные проблемы — это либо некорретное использование Selenium (например клик по существующей в DOM, но закрытой чем-то при отрисовке кнопке), либо уже баги системы, которые можно и нужно репортить авторам фреймворка/драйвера.
2. Как правило, разработчики не идут в автотестеры, а скорее наоборот, так что у автотестеров просто повальный дефицит знаний паттернов как написания кода, так и тестирования и дебага (подтверждением тому наличие пунктов про вывод человекопонятных ошибок, атомарность тестов и детерминированность тестовых данных, хотя они и абсолютно корректные, но очень уж «нубские», в духе «не называйте ваш тест Test1»).
Если один и тот же набор тестов на соседних прогонах имеет шанс выдать разные результаты, то это значит, что весь набор тестов бесполезен. Это не только «ой, этот тест Х постоянно падает, не парься», это еще и кейс «тест был зеленым по той же причине, по которой тест Х постоянно падал».nizkopal Автор
08.08.2018 15:40+1Добрый день.
По поводу пункта 1. От части Вы правы, но все же с WaitAndRetry тоже можно заиграться. Иногда таким «паттерном» можно упустить баг, который после того же Retry не ловится. Да и тесты — не боевой код, здесь к отказоустойчивости требований поменьше. :)
По поводу пункта 2. Я, если честно, не понял Вашу мысль. В ней был конструктив?
они и абсолютно корректные, но очень уж «нубские», в духе «не называйте ваш тест Test1»
В начале статьи указано, что она по большей части для начинающих авторов. Это же касается и знаний паттернов: в автоматизации тестирования без них даже проще начать что-то делать, чем в разработке, хотя и там попадаются люди, не знающий дальше Синглтона и Фабрик ничего. И самое прекрасное — не просто начать, а вполне решать бизнес-задачи. С опытом и ростом проекта (в данном случае — тестового фремворка) появляется необходимость использования этих паттернов. Уверен, в разработке все точно так же.
Как правило, разработчики не идут в автотестеры, а скорее наоборот
По поводу статистики перехода — может быть, не знаю, не проводил опрос. :)
Если один и тот же набор тестов на соседних прогонах имеет шанс выдать разные результаты, то это значит, что весь набор тестов бесполезен.
Имеет. И тем не менее не бесполезен.
Я не защищаю нестабильные тесты. Я говорю, что такое случается довольно часто. Надо ли с этим бороться? Конечно, в меру необходимости. Иногда стабилизировать какие-то сложные проверки дороже, чем запускать тест дважды. Например, если речь идет о тестировании сложного функционала, который завязан на очереди, внешние сервисы и прочие непрогнозируемые вещи.Quilin
08.08.2018 16:481. Отказоустойчивость должна быть не к вашему коду, а к внешним зависимостям, которыми вы пользуетесь. Если webElement.click() не срабатывает в одном из пяти случаев, и причиной тому какая-то ошибка вебдрайвера, то лучше завернуть его в политику, чем оставлять все тесты, в которых кликается кнопка, с вероятностью 20% ложного отказа.
2. UI-тесты для веб-приложений являются по сути e2e-тестами, а значит характеризуют собой SLA данного приложения. Если в SLA прописано «вот эта кнопка может не сработать с вероятностью 10%», то тест должен именно это и проверять — запускаться условные 100 раз и проверять, что падений не больше 10. Но я честно еще не видел рандомизированного бизнеса.
3. Если тест падает из-за недоступности/ошибок внешней системы — это совершенно нормально. Если тест падает из-за ее нестабильности — это уже повод а) пересмотреть SLA, б) отказаться от внешней системы. Если мои e2e-тесты не имеют доступа к стабильному тестовому окружению, то зачем вообще они нужны?
По пункту 2. Я имел в виду не design patterns, к которым относятся упомянутые вами Singleton и Factory, я говорил о паттернах написания кода (например, SOLID, соглашений по именованиям или code review), а также тестирования (атомарность, идемпотентность, детерминированность) и дебага (логи), о которых вы здесь и писали. Напомню, что в контексте своего комментария я скорее говорил об опыте взаимодействия с автотестерами, а не о вашей статье. Просто меня триггернуло «любой автоматизатор подтвердит, что UI-тесты по своей природе и так не отличаются стабильностью. И это нормально». Вот я могу подтвердить, что многие автоматизаторы так считают, но это ненормально.
Вы подменяете конечную цель абстрактным «все тесты зеленые». Никому не нужны зеленые UI-тесты, всем нужно соблюдение SLA. Если у пользователя есть сценарий «пытаться нажать на кнопку, пока она не заработает» — чудесно, тогда ваш подход работает. Как правило, в UI-тестах еще и отваливается какой-то определенный шаг, и полный перезапуск сценария не будет соответствовать попыткам юзера совладать с плавающей ошибкой очереди или внешнего сервиса.
TLDR: Если какая-то часть вашей системы нестабильна by design, то UI-тесты должны повторять ожидаемое поведение пользователя при встрече с нестабильностью. И это должно быть частью теста, а не частью подхода к тестам.nizkopal Автор
08.08.2018 18:22+2Про нестабильность. Тесты могут падать в тех, случаях, с которыми пользователь просто не столкнется. Конкретный пример — выпадающее меню в мобильном приложении. У нас есть код — увидишь пункт “опции”, кликай в него. Appium, на котором я ловил нестабильность, поступает следующим образом. Он начинает ожидать пункт меню. Как только находит, фиксирует его локаторы и следующим запросом к драйверу кликает. За это время пункт меню (оно же у нас выпадающее) может успеть переместиться чуть ниже и клик произойдет по соседнему пункту.
К SLA это не имеет никакого отношения. К UX тоже — пользователь не настолько быстрый. Тест при этом может валиться не один раз из десяти, а один раз из двадцати. Может валиться на разных сборках (где меню чуть быстрее инициализируется, где-то медленнее). При написании такого теста можно не поймать нестабильность, она всплывет потом. За это можно написать еще 20-30 тестов. И там тоже могут быть свои проблемы.
И это я не говорю про Web (где тесты в разы шустрее гоняются, чем на мобильных девайсах) и то, что на сложном приложении Selenium успевает что-то делать раньше, чем JS повесит лисенеры или отправить и обработать фоновый запрос…
Все проблемы заранее довольно сложно учесть (но, конечно, возможно), хотя Вы правы — стремиться надо. И с опытом приходит возможность предугадывать некоторые вещи. Еще раз — статья для начинающих автоматизаторов. :)
Про SOLID и другие страшные слова (атомарность, идемпотентность, детерминированность). Я не спорю с тем, что это знать-уметь надо. А применять с умом, чтобы это было уместно (и не пихать везде) — тем более навык на вес золота. Я говорю о том, что есть люди, который (пока что) этого не знают. И стоит об этом рассказывать. Можно в виде теоретических выкладок (тут лучше дядюшки Боба никто не справится) или собственных примеров из жизни. Одно второму не мешает.
Про подмену целей — кажется, это Вы делаете. Цель — писать тесты, которые баги ищут и по которым суть бага можно легко понять. Если тесты с этой задачей справляются — хорошо. Если нет — плохо. Стабильные они при этом (или мы перезапускаем из по 10 раз), со знанием ли SOLID и других вещей они написаны (или мы пишем процедурный код) — вопрос второстепенный. Я старался рассказать о том, как не попасть в ловушку, когда тест вроде бы проверяет что-то (как Вы думаете), а на самом деле — нет. Или как не усложнить себе будущий разбор теста, если он начнет падать (а очень правильно написанный и невероятно стабильный тест, который перегружен логикой, тоже жизнь осложнить может). Как-то так.
Надеюсь, мне удалось объяснить свою точку зрения. :)Quilin
08.08.2018 18:39Про первый пример — ну если пользователь не умеет так быстро работать, то зачем тест так работает? Можно например написать приложение, в котором после ввода пароля есть только 50мс на клик «отправить», тест справится, а юзер нет. Вы же должны тестировать не интерфейс, а взаимодействие предполагаемого юзера с ним, нет?
И про веб та же история — если сайт начинает работу только после прогрузки всех скриптов, то это должно быть учтено в тестах и явно видно всем.
Про страшные слова (солид я просто приплел в качестве примера) — это мастхэв для любых тестов. Типа такие скрижали: тесты должны быть зелеными, они должны проверять только что-то одно, тестовые данные должны быть неизменными для разных прогонов одного теста, результат прогона одного теста один раз должен полностью совпадать с результатом прогона этого теста более одного раза.
Подмена целей — ну окей. По моему опыту поиск багов нестабильными тестами отнимает времени у более дорогих автотестеров и разрабов больше чем, ручное протыкивание всего регресса. Баги они находят — но, как вы сами сказали, причиной нестабильности нередко является несоответствие тестов SLA (слишком быстро кликнули, не дождались чего-то итд). Но я вас понял.nizkopal Автор
08.08.2018 19:37+1Про первый пример — ну если пользователь не умеет так быстро работать, то зачем тест так работает?
Если тест работает медленно, потребуется больше времени на проверку функционала. Это плохо. Насколько я знаю, ни Selenium, ни Appium из коробки не позволяют замедлить тесты. Собственно одна из причин нестабильности — компромисс между скоростью теста и работоспособностью сайта при такой скорости.
И про веб та же история — если сайт начинает работу только после прогрузки всех скриптов, то это должно быть учтено в тестах и явно видно всем
Тут сложно. В идеальном мире такого быть не должно, согласен. Приложение должно работать адекватно на любых скоростях «тыкания» по нему.
В реальном же мире продукт делается конечным количеством разработчиков. Бросить силы на рефакторинг UI потому, что тесты местами плохо работают из-за своей скорости (но реального юзера не аффектит) или выпустить новую фичу, важную для реального пользователя и компании? Такой себе выбор. :)
Тесты намеренно sleep-ами обкладывать тоже не хочется (хотя приходится). А иного способа оценить готовность UI к работе иногда нет. Могу привести кучу примеров из жизни, но все они так или иначе сведутся либо к запросам к серверу в бэкграунде, либо к особенности работы самого UI.
Вообщем, нестабильность UI-тестов — отдельная тема. Про нее можно много рассуждать. Я наверняка бы смог даже написать статью про восемь (примерно) способов стабилизации своих UI-тестов. Написание идеального кода будет там далеко не единственным способом, даже не на первом месте. :)
Quilin
09.08.2018 11:52Если тест работает медленно, потребуется больше времени на проверку функционала. Это плохо.
Но если тест работает медленно потому что так устроен бизнес-процесс, что же в этом плохого? Если бизнес состоит из «нажать кнопку в выпадающем меню, дождаться, когда оно впадет обратно, нажать другую кнопку», то какие же проблемы подождать? Тест занимает не больше времени, чем SLA, так или иначе.
Такой себе выбор. :)
Вы так сформулировали, будто я говорил, что разработчики продукта должны тюнить его под тесты. Но это просто диаметрально противоположная моей точка зрения — я же всю дорогу распинаюсь, что тесты должны быть стабильными, а не продукт (ну типа тесты для того и нужны, чтобы находить нестабильности продукта).
Я ничего не сказал про идеальный код, обратите внимание, есть ощущение, что у вас маякнуло сначала «паттерны», а потом «SOLID», но это просто примеры. Идеальный код нужен не для стабилизации тестов, а для их поддержки, но бизнесу как правило наплевать на условия содержания автотестов, так что я даже и не собираюсь спорить с финальным тезисом.
Я наверняка бы смог даже написать статью
Вот это уже интересно, подписываюсь =)nizkopal Автор
09.08.2018 12:53Вот это уже интересно, подписываюсь =)
Обязательно подумаю о том, чтобы описать свой опыт. Мне нравится такой формат статей — свой опыт, описание проблемы, описание возможного решения.
А пока вот вам довольно крупные ребята, который тоже сталкиваются с нестабильностью тестов и делятся своим опытом:
- testing.googleblog.com/2016/05/flaky-tests-at-google-and-how-we.html
- docs.microsoft.com/en-us/azure/devops/devops-at-microsoft/eliminating-flaky-tests
- blogs.dropbox.com/tech/2018/05/how-were-winning-the-battle-against-flaky-tests
- hackernoon.com/flaky-tests-a-war-that-never-ends-9aa32fdef359
- semaphoreci.com/community/tutorials/how-to-deal-with-and-eliminate-flaky-tests
Там есть и о причинах (особенно мне понравилось у гугла описание по ссылке), и о решениях.
vintage
09.08.2018 07:58Ребята тестировщики, я вам искренне сочувствую, ибо разработчики пилят свои инструменты совершенно не думая о том, как их поделки потом будут тестировать. Основная беда в том, что элементы не имеют уникальных семантичных идентификаторов. А нет их потому, что используемый фреймворк не добавляет их автоматически, а вручную добавлять сложно и муторно.
Посыплю вам соль на рану и покажу, как это делается у нас :-) Открываем http://mol.js.org и, допустим, нам надо проверить, что ссылка на гитхаб присутствует на странице. Для неё был автоматически сформирован идентификатор "$mol_app_demo.Root(0).Placeholder().Github_link()", то есть вы можете достучаться до элемента через селектор:
[id="$mol_app_demo.Root(0).Placeholder().Github_link()"]
, либо через JS:
$mol_app_demo.Root(0).Placeholder().Github_link().dom_node()
В последнем случае вы можете проверять в том числе и на отсутствие, так как если разработчик переименует элемент, то код упадёт с ошибкой. Ну и я думаю не надо говорить, что в случае падения будет предельно ясно какую именно кнопку не удалось найти без дополнительных текстовых описаний.
Этот идентификатор не зависит от вёрстки, только от семантики, а значит его можно смело использовать в тестах, не опасаясь, что они будут ломаться при изменениях вёрстки.
Вторая ваша беда в том, что один и тот же элемент может пересоздаваться по нескольку раз. Причина опять же в выбранном инструменте. Правильный инструмент не будет заново создавать элемент, если он уже присутствует в доме.
TheKnight
У меня есть ряд вопросов:
1) Причем тут хаб «Тестирование мобильных приложений»?
2) Почему в статье нет информации о тестировании UI-приложений за пределами Web, хоть название и намекает на это?
3) HtmlElements не пробовали?
nizkopal Автор
Привет.
Спасибо за интерес :)
1) К сожалению, нет выделенного хаба «автоматизации тестирования». Потому вместо них выбрал хабы и про «веб», и про мобильные девайсы. Что касается примеров, которые я привел — они легко могут касаться мобильных UI-автотестов, например, на том же Appium. Или я не прав?
2) Думаю, я ответил в предыдущем комментарии. Примеры одинаково хорошо работают (или не работают) и для веба, и для мобильного веба, и для тестов приложений на мобильные девайсы.
3) Пока нет. Но планирую.
TheKnight
1) Уговорили. Хотя специфика мобильных не отражена, а там далеко не все работает так же как в Web.
2) Помимо мобильных и Web приложений есть еще десктоп, навскидку к нему ваши советы не применимы совсем. Хотя тут я могу ошибаться.
3) Сейчас в разработке новая версия, которая почему то называется Atlas. Хотя и HtmlElements 2.0 версии beta16 вполне себе интересны.
nizkopal Автор
Я думаю, все же не совсем. :)
Там тоже можно писать перегруженные по логике тесты. И тоже можно писать плохие тексты ошибок. Можно ждать исчезновения элемента, которого давно не существует. Разве что с локаторами там иначе обстоят дела. Но там тоже есть свои программы для автоматического подбора локаторов, и они тоже не всегда выдают разумный результат.
Спасибо за наводку. Обязательно поинтересуюсь.
vasily-v-ryabov
Привет от декстопников. Для десктопного UI точно так же полезно детальнее указывать, где именно находится кнопка, какой у неё class_name, title и так далее. Какие-то вещи вроде ControlID или обычного индекса лучше не использовать. В общем, некоторые отличия разве что в списке стабильных и не очень стабильных пропертей/локаторов.
Что касается вменяемых ошибок, то это вообще к любому коду относится, не только к тестам.
nizkopal Автор
Прекрасно, спасибо большое, что поделились опытом. Теперь я спокоен. :)
TheKnight
А чем десктоп то тестируется? И на чем написано приложение?
vasily-v-ryabov
А десктоп мало чем тестируется, и не всякий. Из юзабельных — топ-12 из рейтинга, который я обновляю раз в месяц. На каждой оси — свои технологии доступа к текстовым свойствам. На Windows большинство покрывается технологией MS UI Automation API: она сложна, поэтому есть более простые в освоении библиотеки (это pywinauto, TestStack.White, MS WinAppDriver, FlaUI и Winium.Desktop). На Линуксе это AT-SPI, но там реально простых библиотек пока нет, есть зубодробительные. На макоси есть встроенный AppleScript и pyatom — очень даже годный, хоть и Python2.7 только и в установке не очень прост. Я со своими студентами пытаюсь все эти технологии собрать в pywinauto в максимально простом виде, тут ещё 2-3 года работы, учитывая, что это хобби (на основной работе я сейчас вообще не GUI занимаюсь). Ещё есть распознавалки эталонных картинок типа Sikuli, pyautogui, lackey. Они менее надёжны и подкушивают CPU, но зато универсальней не придумаешь.
nizkopal Автор
Хм, а разве тот же Appium не умеет с десктопом работать?
Мне казалось, как минимум когда-то умел.
nizkopal Автор
Вот, нашел:
Ссылка: appium.io/docs/en/drivers/windows
С ним не сложилось?
vasily-v-ryabov
Так получилось, что pywinauto я использую с 2010 года и начал поддерживать его в опен сорсе с лета 2015-го. Поддержку UIA мы выпустили в ноябре 2016-го, а WinAppDriver появился весной 2016-го. Узнал я про WinAppDriver в июне 2017-го. В этом году гонка продолжается. Мы уже год работаем над "record-replay" фичей (планируем релизить осенью, думали, что будем первыми в опен сорсе с подобным), а Microsoft взял да и выпустил свой UI Recorder в июне этого года. Правда, я его пробовал и пока не смог получить ничего вменяемого.
vasily-v-ryabov
Вообще, умеет. Как раз майкрософтовский WinAppDriver совместим с Appium, и там есть на 14-м месте appium-for-mac. :)
nizkopal Автор
Ага, я как раз написал чуть выше :)
А почему так низко в рейтинге? По каким критериям он строится?
vasily-v-ryabov
Рейтинг тупо по звёздам на гитхабе. Ниже ещё есть по вопросам на StackOverflow, но там я про Appium забыл. В следующем месяце добавлю, он там будет лидером. :)
vasily-v-ryabov
Единственно, надо понимать, что Appium изначально был для мобилок и его рейтинг будет прихватывать более широкую целевую аудиторию.
nizkopal Автор
Понял Вас. Ещё раз спасибо за опыт. :)
TheKnight
Спасибо.