

Тензорный процессор третьего поколения
Тензорный процессор Google — интегральная схема специального назначения (ASIC), разработанная с нуля компанией Google для выполнения задач по машинному обучению. Он работает в нескольких основных продуктах Google, включая Translate, Photos, Search Assistant и Gmail. Облачный TPU обеспечивает преимущества, связанные с масштабируемостью и лёгкостью использования, всем разработчикам и специалистам по изучению данных, запускающим передовые модели машинного обучения в облаке Google. На конференции Google Next ‘18 мы объявили о том, что Cloud TPU v2 теперь доступен для всех пользователей, включая бесплатные пробные учётные записи, а Cloud TPU v3 доступен для альфа-тестирования.

Но многие спрашивают – какая разница между CPU, GPU и TPU? Мы сделали демонстрационный сайт, где расположена презентация и анимация, отвечающая на этот вопрос. В этом посте я хотел бы подробнее остановиться на определённых особенностях содержимого этого сайта.
Как работают нейросети
Перед тем, как начать сравнивать CPU, GPU и TPU, посмотрим, какого рода вычисления требуются для машинного обучения – а конкретно, для нейросетей.
Представьте, к примеру, что мы используем однослойную нейросеть для распознавания рукописных цифр, как показано на следующей диаграмме:
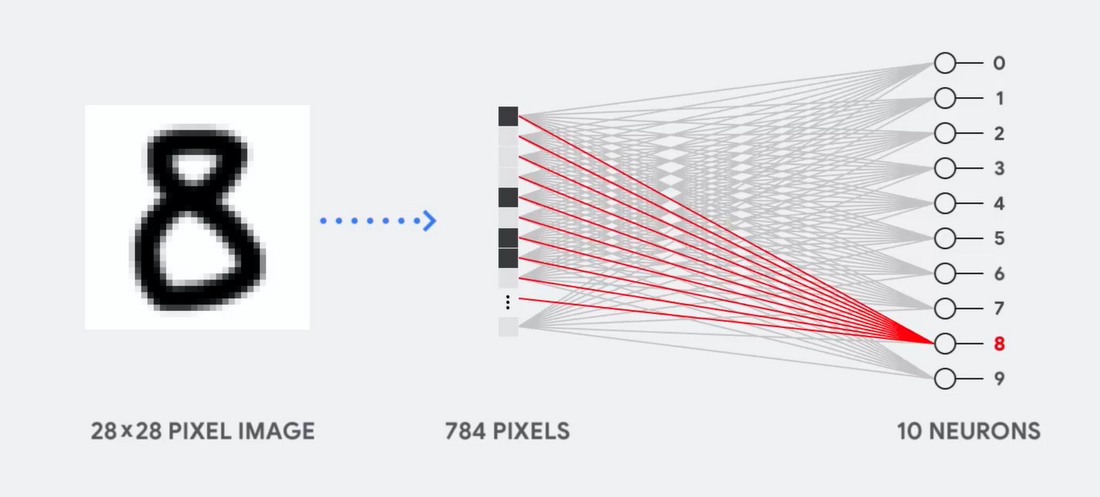
Если картинка будет сеткой размером 28х28 пикселей серой шкалы, её можно преобразовать в вектор из 784 значений (измерений). Нейрон, распознающий цифру 8, принимает эти значения и перемножает их со значениями параметра (красные линии на диаграмме).
Параметр работает как фильтр, извлекая особенности данных, говорящих о схожести изображения и формы 8:

Это наиболее простое объяснение классификации данных нейросетями. Перемножение данных с соответствующими им параметрами (окраска точек) и их сложение (сумма точек справа). Наивысший результат обозначает наилучшее совпадение введённых данных и соответствующего параметра, которое, скорее всего, и будет правильным ответом.
Проще говоря, нейросетям требуется делать огромное количество перемножений и сложений данных и параметров. Часто мы организовываем их в виде матричного перемножения, c которым вы могли столкнуться в школе на алгебре. Поэтому проблема состоит в том, чтобы выполнить большое количество матричных перемножений как можно быстрее, потратив как можно меньше энергии.
Как работает CPU
Как подходит к такой задаче CPU? CPU – процессор общего назначения, основанный на архитектуре фон Неймана. Это значит, что CPU работает с ПО и памятью как-то так:
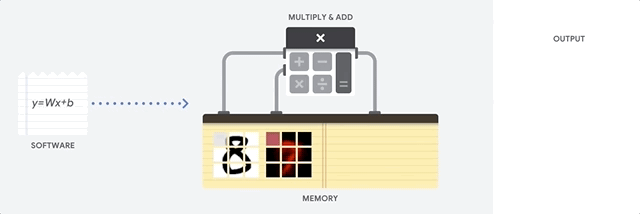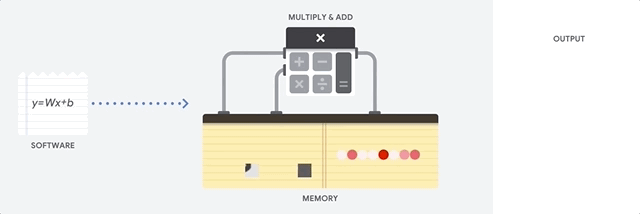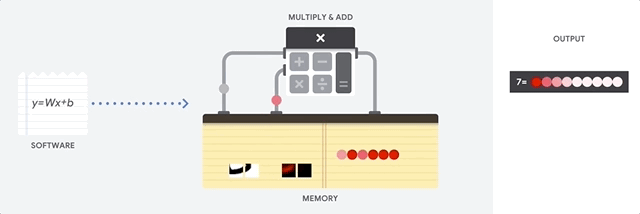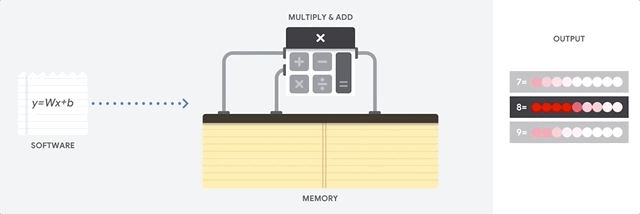
Главное преимущество CPU – гибкость. Благодаря архитектуре фон Неймана, вы можете загружать совершенно разное ПО для миллионов различных целей. CPU можно использовать для обработки текстов, управления ракетными двигателями, выполнения банковских транзакций, классификации изображений при помощи нейросети.
Но поскольку CPU такой гибкий, оборудование не всегда знает заранее, какой будет следующая операция, пока не прочтёт следующую инструкцию от ПО. CPU нужно хранить результаты каждого вычисления в памяти, расположенной внутри CPU (так называемые регистры, или L1-кэш). Доступ к этой памяти становится минусом архитектуры CPU, известным как узкое место архитектуры фон Неймана. И хотя огромное количество вычислений для нейросетей делает предсказуемым будущие шаги, каждое арифметико-логическое устройство CPU (ALU, компонент, хранящий и управляющий множителями и сумматорами) выполняет операции последовательно, каждый раз обращаясь к памяти, что ограничивает общую пропускную способность и потребляет значительное количество энергии.
Как работает GPU
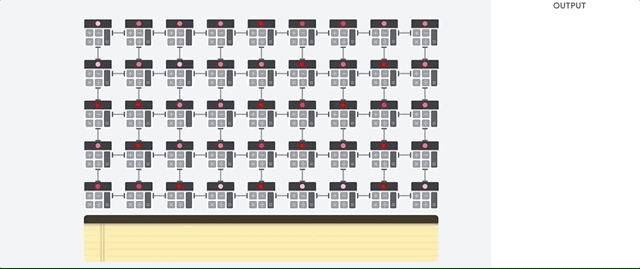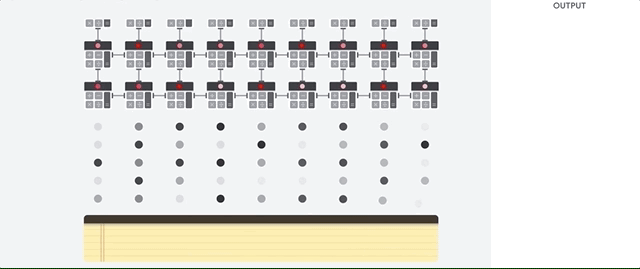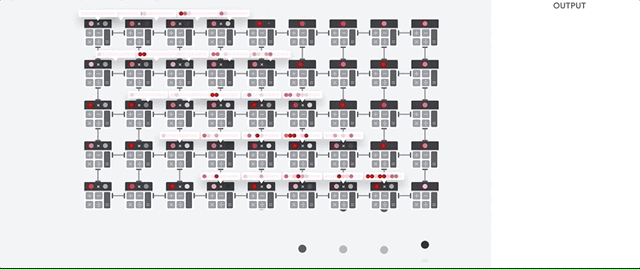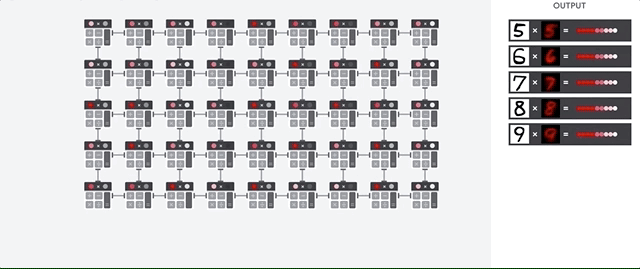
Для увеличения пропускной способности по сравнению с CPU, GPU использует простую стратегию: почему бы не встроить в процессор тысячи ALU? В современном GPU содержится порядка 2500 – 5000 ALU на процессоре, что делает возможным выполнение тысяч умножений и сложений одновременно.

Такая архитектура хорошо работает с приложениями, требующими массивного распараллеливания, такими, например, как умножение матриц в нейросети. При типичной тренировочной нагрузке глубинного обучения (ГО) пропускная способность в этом случае увеличивается на порядок по сравнению с CPU. Поэтому на сегодняшний день GPU является наиболее популярной архитектурой процессоров для ГО.
Но GPU всё равно остаётся процессором общего назначения, который должен поддерживать миллион различных приложений и ПО. А это возвращает нас к фундаментальной проблеме узкого места архитектуры фон Неймана. Для каждого вычисления в тысячах ALU, GPU необходимо обратиться к регистрам или разделяемой памяти, чтобы прочесть и сохранить промежуточные результаты вычислений. Поскольку GPU выполняет больше параллельных вычислений на тысячах своих ALU, он также тратит пропорционально больше энергии на доступ к памяти и занимает большую площадь.
Как работает TPU
Когда мы в Google разрабатывали TPU, мы построили архитектуру, предназначенную для определённой задачи. Вместо разработки процессора общего назначения, мы разработали матричный процессор, специализированный для работы с нейросетями. TPU не сможет работать с текстовым процессором, управлять ракетными двигателями или выполнять банковские транзакции, но он может обрабатывать огромное количество умножений и сложений для нейросетей с невероятной скоростью, потребляя при этом гораздо меньше энергии и умещаясь в меньшем физическом объёме.
Главное, что позволяет ему это делать – радикальное устранение узкого места архитектуры фон Неймана. Поскольку основной задачей TPU является обработка матриц, разработчикам схемы были знакомы все необходимые шаги вычислений. Поэтому они смогли разместит тысячи множителей и сумматоров, и соединить их физически, сформировав большую физическую матрицу. Это называется архитектурой конвейерного массива. В случае с Cloud TPU v2 используются два конвейерных массива по 128 х 128, что в сумме даёт 32 768 ALU для 16-битных значений с плавающей точкой на одном процессоре.
Посмотрим, как конвейерный массив выполняет подсчёты для нейросети. Сначала TPU загружает параметры из памяти в матрицу множителей и сумматоров.

Затем TPU загружает данные из памяти. По выполнению каждого умножения результат передаётся следующим множителям, при одновременном выполнении сложений. Поэтому на выходе будет сумма всех умножений данных и параметров. В течение всего процесса объёмных вычислений и передачи данных доступ к памяти совершенно не нужен.
Поэтому TPU демонстрирует большую пропускную способность при подсчётах для нейросетей, потребляя гораздо меньше энергии и занимая меньше места.
Преимущество: уменьшение стоимости в 5 раз
Какие же преимущества даёт архитектура TPU? Стоимость. Вот стоимость работы Cloud TPU v2 на август 2018 года, на время написания статьи:
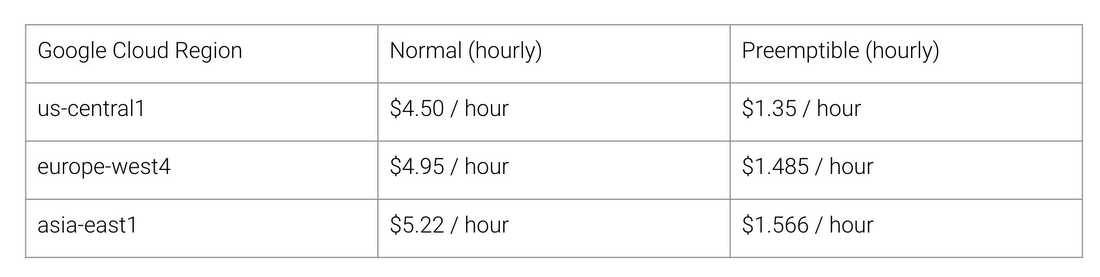
Обычная и TPU-шная стоимость работы для разных регионов Google Cloud
Стэнфордский университет раздаёт набор тестов DAWNBench, измеряющих быстродействие систем с глубинным обучением. Там можно посмотреть на различные комбинации задач, моделей и вычислительных платформ, а также на соответствующие результаты тестов.
На момент завершения соревнования в апреле 2018 минимальная стоимость тренировки на процессорах с архитектурой, отличной от TPU, равнялась $72,40 (для тренировки ResNet-50 с 93% точностью на ImageNet на спотовых инстансах). При помощи Cloud TPU v2 такую тренировку можно провести за $12,87. Это меньше 1/5 стоимости. Такова сила архитектуры, предназначенной специально для нейросетей.
Комментарии (28)

netricks
05.09.2018 16:18Любопытная система охлаждения. Это же теплоотводы на картинке?

a5b
05.09.2018 17:22
Google’s chief executive didn’t reveal much detail about the latest-generation TPUs or how the cooling systems for them are designed, but judging by the photo of TPU 3.0 he displayed during the keynote, the system brings chilled liquid directly to the chip via thin tubes.
https://www.nextplatform.com/2018/05/10/tearing-apart-googles-tpu-3-0-ai-coprocessor/
The TPUv3 chip runs so hot that for first time Google has introduced liquid cooling in its datacenters
algotrader2013
05.09.2018 18:28На момент завершения соревнования в апреле 2018 минимальная стоимость тренировки на процессорах с архитектурой, отличной от TPU, равнялась $72,40 (для тренировки ResNet-50 с 93% точностью на ImageNet на спотовых инстансах). При помощи Cloud TPU v2 такую тренировку можно провести за $12,87. Это меньше 1/5 стоимости. Такова сила архитектуры, предназначенной специально для нейросетей.
Весьма некорректное сравнение. TPU можно взять только в GCP (поэтому 1 конец сравнения корректен). А вот брать в облаке видеокарту, мягко говоря, неразумно. Ведь, какой бы ни была бизнес модель владельца облака, но по факту это будет проксирование Nvidia Tesla, которая абсолютно невыгодна (5-10 кратная переплата) в сравнении с Titan/1080 кроме 64 битных вычислений (которые замедлены на консьюмерских моделях ради прибыли). И понятно, что сверхприбыли Нвидии будут перевыставлены на конечного покупателя, и более корректно будет сравнивать либо с провайдерами, которые дают дедики с консьюмерскими картами, либо с владением консьюмерской картой.Tsimur_S
06.09.2018 13:20провайдерами, которые дают дедики с консьюмерскими картами
а такие разве остались после фокусов nvidia?
KvanTTT
06.09.2018 10:39Можно ли просто купить TPU и поставить его на обычный комп?
Tsimur_S
06.09.2018 13:13нет, гугл их не продаёт
WinPooh73
06.09.2018 15:20Тогда почему аналогичные по характеристикам устройства не начали делать другие производители? Дело в каком-то хитром ноу-хау, в патентной защите, или ещё в чём-то?
Tsimur_S
06.09.2018 21:15Все просто — у гугла есть потребности(в основном внутренние), есть возможности — финансовые и кадровые и есть понимание важности на высших эшелонах управления. Как ни странно те у кого это есть они интегрируют подобные вещи внутрь своих продуктов, qualcom snapdragon 845 интегрирует в процессоры «ядра» для матричных вычислений. Apple встроил в a11 подобное что бы ускорить работу сканера распознавателя лиц(Neural Engine). Tesla тоже пилит свой «AI процессор» для автопилота.
Единственные кто делают что-то на продажу это nvidia и IBM со своим TrueNorth, о котором правда уже два года новостей не было.
KvanTTT
06.09.2018 18:57Ну вообще да: судя по фотографиям вставить эти платы в стандартные разъемы не получится.
wormball
06.09.2018 14:09Я правильно понял, что чтобы получить аналогичное на ГПУ (или ЦПУ), достаточно добавить возможность последовательной передачи данных между АЛУ? Ежели да, то отчего это ещё не сделано? Или уже сделано?
Tsimur_S
06.09.2018 20:53Разница в количестве и сложности ALU. Грубо говоря одно ядро современного процессора — 8 АЛУ, оно очень дорогое и энергозатратное но может выполнять вычисления как с float32 так и int: целые, float32, более того оно поддерживает векторные команды и может обрабатывать несколько чисел за один такт. У видеокарты alu больше — около 2000. У TPUv1 65 536(256*256) АЛУ которые срабатывают за 1 такт. В ядро процессора они бы банально не влезли.
Tsimur_S
Интересно почему до сих пор нету рынка вычислительных мощностей с движком типа SETI. Условно — компания выставляет датасет и модель некому брокеру за определенную сумму, тот распределяет нагрузку между агентами которые установленны у обладателей коммодити видеокарт (допустим nvidia 970 и выше). Также брокер перераспределяет вознаграждение между агентами за вычетом комиссии. Можно давать один кусок работы двум агентам для контроля мошенничества.
Vlad_IT
Мне кажется, тут слабым местом будет ширина канала. Ведь датасеты обычно очень объемные, и передавать их даже кусками, будет довольно долго.
adeptoleg
— Если выгодно для заказчика невыгодно для исполнителей
— Если выгодно для исполнителей невыгодно для заказчика
— Не хочется отдавать свои данные на сторону где их (теоретически) можно украсть
— Имидж темы загажен всякими оклохайпами
Любой ответ на ваш вкус
Tsimur_S
а вы к какому из них склоняетесь?
adeptoleg
Лично я глубоко сомневаюсь что конечному исполнителю дадут конкурентную цену чтоб был смысл жечь электричество и напрягать железо. Те же которым было бы интересно даже с низкой ценой (всё равно жрёт невсебя а есть например панели солнечные) к теме будут относится с подозрением. Может это я такой параноик но первая мысля после прочтения вашего предложения это про новую вариацию хайпа с хранением данных.
DnD_designer
Я б еще добавил:
— те, у кого есть достаточные объемы данных для обсчета, не может/не хочет за это моного платить
— те, у кого сеть достаточные мощности для обсчета больших данных, не хочет/не может с эти заморачиваться за предлагаемые деньги
А так, — есть же облака AWS, Azure, GoogleCloud и т.п.
Tsimur_S
Речь же не про облака а про физ лиц. Основная идея как раз таки радикально уменьшить цену относительно облаков\хостеров и обеспечить неким притоком денег людей купивших топ\предтоп видеокарту сэкономив на завтраках. Превратить пассивный капитал в средство получения прибыли(airnb для компов)
Это решает обе указаные вами проблемы — 1 — поскольку дешевле никто не предложит, 2- как показала история с биткоином люди готовы держать видеокарту 24/7(в перерывах между использованием для других целей) ради 5-10$ в день. Тем более что EULA Nvidia уже не позволяет хостить консьюмерские gpu, хотите deep learning в облаке — арендуйте K100/k40 за сумасшедший прайс.
Hardcoin
Так явно не выгодно. Облачный провайдер, если 20% прибыли в год на вложенный капитал получил — хороший год. А домашний владелец видеокарты на такое согласится? Да и эффект масштаба. У школьника преимущество только в том, что налоги не платит.
Deerenaros
Не сказал бы, что это не выгодно. Довольно таки выгодно, потому что консьюмерские видео стоят несказанно дешевле энтерпрайз решений. А производительность на уровне или даже выше если учитывать два-три поколения за раз (а это примерное время отработки железа в облаке до замены). И вообще, политика современного обновления железа раз в 1-2 года порочна как раз тем, что очень тщетно охватывает облачные решения именно из-за того, что сама железка окупается год-два плюс год нарабатывает прибыль и никто менять работающие решения в угоду 10% не будет. Выкручиваются ожелезняя софт, но тем не менее.
Однако. K80 это условные 5 1080Ti как по производительности, так и по цене. Почему условные? Потому что где-то они лучше, где-то даже хуже. Однако K80 это про GPGPU, поэтому у них очень крутой double, много сравнимой памяти, но нет графического конвейра и отсутствуют современные фишки, вроде оптимизации TensorFLOW. Собственно, взвешивая все за и против для числодробления оказывается лучше как раз K80, а для рассчёта графики/шейдеров/физики консьюмерский 1080Ti. Не смотря ни на что, этот рынок Nvidia не обламала, это скорее относится к уровню бесполезности Quadro, у которых чего-то стоили только hi-end решения, однако даже они кому-то действительно были нужны (например, из-за нормального OpenGL или лучшей поддержки), но тем не менее, не стоит сваливать в кучу профессиональные решения.
Собственно, мы и пришли к тому, что стоимость K80 относительно оправданная, а возможность запускать весь пайплайн на условной одной машине/карте, а не заниматься непонятным батчингом на много карт, довольно выгодна как для поставщиков облачных решений, так и пользователей облаков. В принципе любой может арендовать сегодня K80 даже на несколько дней и не только не обеднеть, но и минимальными усилиями провернуть полный пайплайн.
Но таки кое-где 1080Ti будет выгоднее. Вернее даже не кое-где, а в огромном пласте — 2D/3D графика. Это то, где зелёные не дают развернуться своим карточкам по… На самом деле не совсем понятным причинам. Но это относительно узкий рынок, который тем не менее использует идеи рендер-ферм, была даже пара проектов. Но они не особо взлетают по той простой причине, что особого смысла ренедерть в full-res на уровне реалтайма нет, а распределённый рендеринг относительно скуп на решения, практически все они довольно не оптимальны и имеют значительный оверхед, хотя прогресс идёт, в любом случае останутся проблемы которые не решить легко. А кто может за это платить? На самом деле мало кто. Рынок, как говорилось мал, и почти все, кому надо имеют свои рендер-фермы, причём рендер сцены возможен почти в реалтайме. А сейчас ещё пришли RT-карты. Они 146% добьют рынок почти в ноль, так как за 100к получить сабреалтайм RT на рабочей машине это довольно вкусно, хотя и не очень нужно. Что уж говорить про совсем не реалтаймовые распределённые фермы, зачем они нужны? Если сцена очень сложная она даже в память не поместится на среднем консьюмер-едишн.
Так что вот. Банальная экономика, консьюмер уже не очень натягиваются на энтерпрайз рынок, а с новыми ценами… Да не, ну бросьте, бесполезно.
Есть ещё один рынок, на который теоретически можно рассчитывать для владельцев бесполезных видеокарт. Распределённый облачный гейминг. Отдаю эту идею бесплатно, потому что это дичь и беспольза. Сначала кажется бредом, потом чем-то крутым, но после посчитать всё и получив выхлоп понимаешь, что лютый беспонт. Слишком много ограничений, тут уже любая машина с много-карт не подойдёт, потребуется готовить целые кластеры с нормальными, полными ПК, пилить крутой софт и максимально оптимизировать нет-код, а в итоге всё равно не сравнится с Nvidia GRID и прямой оптикой. А по деньгам снова жопа, 100 условных деревянных в день на один ПК это на самом деле дорого для потребителя, но довольно дёшево для поставщика. И вот этой точки равновесия просто не существует, потому что никто не гарантирует поставщику полную загрузку мощности, да и её наращивание ограничено каналом. По итогу максимум можно иметь 4 машины, а это копейки на самом деле для таких вложений. И если бы ещё весь софт с вылизанным неткодом и крутой организацией дистрибьюции существовал — это можно было бы устроить. Но этого нет и вкладываются в это гавно полторы калеки, надеясь на облачное сохранение прогресса, благонадёжность поставщиков и разворот прогресса на 180 градусов в ближайшие несколько лет.
Hardcoin
Это просто выпуск новых моделей. Никто железо раз в два года не обновляет. Та же упомянутая k80 вышла в 14-м году, вполне достаточно для окупаемости. Серверное железо 6-летней давности тоже вполне актуально.
В целом я согласен с вашими доводами, но вывод из них делаю как и в первом комментарии — распределять обучение сетей по пользователям не выгодно. Большой кластер GPU с большим количеством памяти выгоднее и удобнее. Да вы и сами об этом пишете, что K80 вполне конкурентоспособна. А специализированные устройства вообще убьют пользу от бытовых gpu для нейросетей.
Deerenaros
Я и говорю, что выпуск новых моделей не очень хорошо ложится на обновление железа. Закупаться новым может быть полезно только входящим на рынок игрокам, и то спорно, так как старое железо обычно дешевле, а бу так и вообще едва ли не за копейки сдаётся.
K80 не просто конкуретноспособна. Она крайне конкурентноспособна. Но из этого вытекает как минимум и то, что 1080Ti так же конкурирует. И если смотреть на организацию дистрибьютед сети под числодробление условных данных, то это так же конкуретно, потому что у пользователей консьюмер железа это самое железо просто стоит. Если сделать прайс чуть выше цены за электричество, если не рассматривать амортизацию, но условные 2 года на гарантии её можно и не рассматривать, то на этом можно делать деньги, так что конкуренция в принципе имеется. Однако стоит заметить всё тот же сложный софт и конкуренцию со стороны криптовалют. Если предлагать прайс сравнимый с криптой, то мы едва ли дешевле облаков сегодня, а уж про год другой назад и подавно. При этом тенденция к числодроблению на GPU вообще говоря актуальной стала буквально последние лет 5, как раз во времена активного развития криптовалют. Так что выгода есть, просто биткойны/кефир/зкеш/монеро майнить выгодне. Это раз. Два заключатся в том, что под всё это нужен софт. Софт сложный, с возможностью приватизации и маскировки данных, очевидно (это не проблема вообще ни разу, банальная нормализация убьёт 99% данных, а восстановление как два пальца об асфальт), но ведь ещё потребуется одновременно привлечь и «майнеров» так и «монеты».
Причём не стоит забывать, что люди кому надо обрабатывать много данных в облаке это в основном мелкие (средние) компание, но с ощутимыми суммами. То есть средний чек условно несколько миллионов, это мало для закупки собственного решения, но достаточно вообще хоть для чего-то. Для супер-маленьких старатпов на коленке в гараже всегда решение №1 это консьюмерский сектор и мышление инженера, только в последнее время на этот рынок начало приходить облако, но и то, боюсь для условного AWS или Azure это вложения и инвестиции, а не работа на прибыль, которая если и есть вряд ли имеет нулей достаточно для инвесторов. Так вот, даже 5% прайса от этих самых сумм это значительная экономия, ради которой можно даже гарантиями пожертовать. Ну и для особо чувствительных данных всегда были собственные решения, тут ни супер-престижное с супер NDA супер мелкомягкое и всё из себя модно-молодёжно-корпоративное оранжевое облако, ни условный Вася в 4 подъезде 42 дома на улице Ленина не подойдут. А 5% прайса сбить условными Васями очень легко, ещё и на мороженное с вагоном нефти останется.
Как уже говорил. Сложности всё таки две. Это софт и привлечь, причём одновременно. Не получится так, чтобы там условный зелёный банк не получил географический анализ использований кредитных карт в зависимости от фазы луны, равно как не получится сказать условному Васе, вот софт стоит, ты электричество жги, а мы пойдём тебе клиентов искать. Ни банк, ни Вася на такое не подпишутся, а поэтому или надо будет докупать на старте мощности у облака (что из условий в убыток работать), либо доплачивать Васе из кармана (что по логике вещей убыток). А не проще ли тогда закупить старое оборудование и продавать его время на те же самые 5% дешевле?
Как показывает реальность, не просто проще. Так и делают. И да. Это только одна сторона вопроса. Она не оперирует реальными данными с рынка, которые не такие уж и радостные, ибо майнеры не совсем наш тип. И если чисто экономически выгоднее одно другому, то чисто политически делать что-то подобное крайне неудобно.
Это спорный момент, так как новые RT-карты как раз имеют молодёжные тензорные ядра. Пока не совсем ясно, конечно, как работает, но в общем-то сами Nvidia вроде заявляли, что API для ИИ в играх (и не только) будет.
arielf
Меня такие мысли посещали ещё в 2012 ;-)
zxweed
куча таких проектов есть уже
BelBES
Вот поэтому нет такого рынка. Никто в здравом уме не будет отдавать свою интеллектуальную собственность, причем в полном объеме, третьим лицам. Не говоря уж о том, что, например, распространение некоторых типов данных подобным образом может быть просто вне закона (например, персональные данные клиентов банка).