

Мы начали обновлять в нашем сервисе мониторинг для PgBouncer и решили все немного причесать. Чтобы сделать всё годно, мы притянули самые известные методологии перформанс мониторинга: USE (Utilization, Saturation, Errors) Брендана Грегга и RED (Requests, Errors, Durations) от Тома Уилки.
Под катом рассказ с графиками про то, как устроен pgbouncer, какие у него есть конфигурационные ручки и как используя USE/RED выбрать правильные метрики для его мониторинга.
Сначала про сами методы
Хотя эти методы довольно известные (про них уже было и на Хабре, хоть и не очень подробно), но не то чтобы они на практике широко распространены.
USE
Для каждого ресурса следите за утилизацией, насыщением и ошибками.
Brendan Gregg
Тут ресурс это любой отдельный физический компонент — ЦПУ, диск, шина и т.п. Но не только — производительность некоторых программных ресурсов также может быть рассмотрена таким методом, в частности виртуальные ресурсы, типа контейнеров / cgroups с лимитами, тоже удобно так рассматривать.
U — Утилизация: либо процент времени (от интервала наблюдения), когда ресурс был занят полезной работой. Как, например, загрузка ЦПУ или disk utilization 90% означает, что 90% времени было занято чем-то полезным) либо, для таких ресурсов как память, это процент использованной памяти.
В любом случае 100% утилизация означает, что ресурс не может быть использован больше, чем сейчас. И либо работа будет застревать ожидая освобождения / отправляться в очередь, либо будут ошибки. Эти два сценария покрываются соответствующими двумя оставшимися метриками USE:
S — Сатурация, оно же насыщение: мера количества "отложенной" / поставленной в очередь работы.
E — Ошибки: просто считаем количество отказов. Ошибки/отказы влияют на производительность, но могут не быть заметны сразу из-за ретраев зафейленых операций или механизмов отказоустойчивости с резервными девайсами и т.п.
RED
Том Уилки (сейчас работает в Grafana Labs) был фрустрирован методологией USE, а точнее ее плохой применимостью в каких-то случаях и несоответствием практике. Как, например, измерить сатурацию памяти? Или как на практике измерить ошибки системной шины?
Линукс, оказывается, реально фигово репортит счетчики ошибок.
Т. Уилки
Короче, для мониторинга перформанса и поведения микросервисов он предложил другой, годный метод: измерять, опять-таки, три показателя:
R — Rate: количество запросов в секунду.
E — Errors: сколько запросов вернули ошибку.
D — Duration: время, затраченное на обработку запроса. Оно же latency, "латенция" (© Света Смирнова:), response time и т.д.
В целом USE больше подходит для мониторинга ресурсов, а RED — сервисов и их ворклоада / полезной нагрузки.
PgBouncer
будучи сервисом, он в тоже время имеет всякие внутренние лимиты и ресурсы. Тоже самое можно сказать и про Postgres, к которому через этот PgBouncer обращаются клиенты. Поэтому для полноценного мониторинга в такой ситуации нужны оба метода.
Чтобы разобраться с тем, как эти методы приложить к баунсеру, необходимо понимать детали его устройства. Недостаточно мониторить его как black-box — "жив ли процесс pgbouncer" или "открыт ли порт", т.к. в случае проблем это не даст понимания, что именно и как сломалось и что делать.
Что вообще делает, как выглядит PgBouncer с точки зрения клиента:
- клиент коннектится
- [ клиент делает запрос — получает ответ ] x сколько ему нужно раз
Вот я тут изобразиль диаграмму соответствующих стейтов клиента с точки зрения PgBoucer'а:

В процессе login'а авторизация может происходить как локально (файлы, сертификаты, и даже PAM и hba с новых версий), так и удаленно — т.е. в самой базе данных, к которой происходит попытка подключения. Таким образом состояние логина имеет дополнительное подсостояние. Назовем его Executing чтобы обозначить, что в это время выполняется auth_query в базе данных:
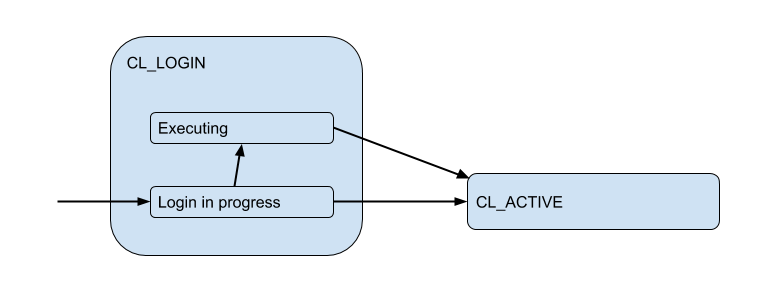
Но эти клиентские соединения на самом деле матчатся с соединеними к бекенд/апстрим базе, которые PgBouncer открывает в рамках пула и держит ограниченное количество. И выдают клиенту такое соединение только на время — на время сессии, транзакции или запроса, в зависимости от вида пулинга (определяется настройкой pool_mode). Чаще всего используется transaction pooling (его мы и будем в основном дальше обсуждать) — когда соединение выдается клиенту на одну транзакцию, а в остальное время клиент по факту к серверу не подключен. Таким образом "active" стейт клиента мало о чем нам говорит, и мы его разобьем на подстейты:
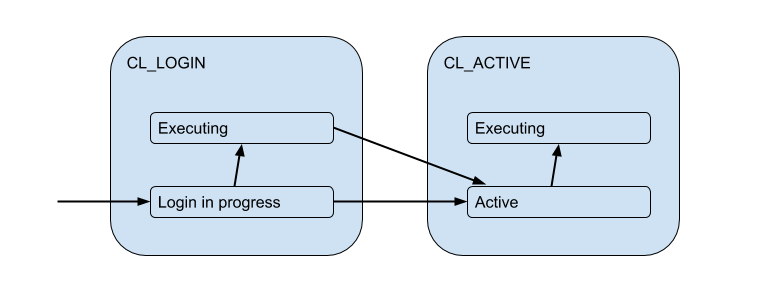
Каждый такой клиент попадает в свой пул соединений, которым будут выдаваться для использования настоящие соединения до Postgres. Это и есть основная задача PgBouncer'а — ограничивать количество соединений до Postgres.
Из-за ограниченности серверных соединений может возникнуть ситуация, когда клиенту вот прям надо выполнять запрос, а свободного соединения сейчас нет. Тогда клиента ставят в очередь и его соединение переходит в состояние CL_WAITING. Таким образом диаграмму состояний надо дополнить:
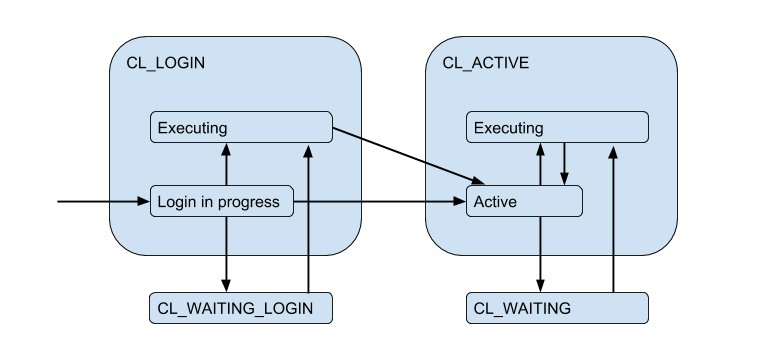
Так как это может произойти и в случае, когда клиент только логинится и ему надо выполнить запрос для авторизации, то возникает еще и состояние CL_WAITING_LOGIN.
Если теперь посмотреть с обратной стороны — со стороны серверных коннекшенов, то они, соответственно, бывают в таких состояниях: когда происходит авторизация непосредственно после коннекта — SV_LOGIN, выдан и (возможно) используется клиентом — SV_ACTIVE, или свободно — SV_IDLE.
USE для PgBouncer
Таким образом мы приходим к (наивному варианту) Utilization конкретного пула:
Pool utiliz = использованные клиентами соединения / размер пулаУ PgBouncer есть специальная служебная база данных pgbouncer, в которой есть команда SHOW POOLS, показывающая текущие состояния коннекшенов каждого пула:

Тут открыто 4 клиентских соединения и все они cl_active. Из 5 серверных соединений — 4 sv_active и одно в новом состоянии sv_used.
Так вот sv_used означает не "соединение используется", как вы могли подумать, а "соединение было когда-то использовано и давно не использовалось". Дело в том что PgBouncer по умолчанию использует серверные соединения в режиме LIFO — т.е. сначала используются только что освобожденные соединения, потом недавно использованные и т.д. постепенно переходя к давно использованным соединениям. Соответственно серверные соединения со дна такого стека могут "протухнуть". И их перед использованием надо бы проверить на живость, что делается с помощью server_check_query, пока они проверяются состояние будет sv_tested.
Документация гласит, что LIFO включено по умолчанию, т.к. тогда "малое количество коннекшенов получает наибольшую нагрузку. И это дает наилучшую производительность в случае, когда за pgbouncer находится один сервер обслуживающий базу данных", т.е. как бы в самом типичном случае. Я полагаю, что потенциальный буст перформанса происходит из-за экономии на переключении исполнения между несколькими backend процессами посгреса. Но достоверно это выяснить не получилось, т.к. эта деталь имплементации существует уже > 12 лет и выходит за пределы commit history на гитхабе и глубины моего интереса =)
Так вот, мне показалось странным и не соответствующим текущим реалиям, что дефолтовое значение настройки server_check_delay, которая определяет что сервер слишком давно не использовался и его надо бы проверить прежде чем отдавать клиенту, — 30 секунд. Это при том, что по дефолту одновременно включен tcp_keepalive с настройками по-умолчанию — начать проверять соединение keep alive пробами через 2 часа после его idle'инга.
Получается, что в ситуации burst'а / всплеска клиентских соединений, которые хотят что-то выполнять на сервере, вносится дополнительная задержка на server_check_query, который хоть и "SELECT 1; все равно может занимать ~100 микросекунд, а если вместо него поставить просто server_check_query = ';' то можно ~30 микросекунд сэкономить =)
Но и предположение, что выполнять работу всего в нескольких коннекшенах = на нескольких "основных" бекенд процессах постгреса будет эффективнее, мне кажется сомнительным. Постгрес воркер процесс кэширует (мета)информацию про каждую таблицу, к которой было обращение в этом соединении. Если у вас большое количество таблиц, то этот relcache может сильно вырасти и занять много памяти, вплоть до своппинга страниц процесса 0_о. Для обхода этого подойдет настройка server_lifetime (по умолчанию — 1 час), по которой серверное соединение будет закрыто для ротации. Но с другой стороны есть настройка server_round_robin, которая переключит режим использования соединений с LIFO на FIFO, размазав клиентские запросы по серверным соединениям более равномерно.
Наивно снимая метрики из SHOW POOLS (каким-нибудь prometheus exporter'ом) мы можем построить график этих состояний:
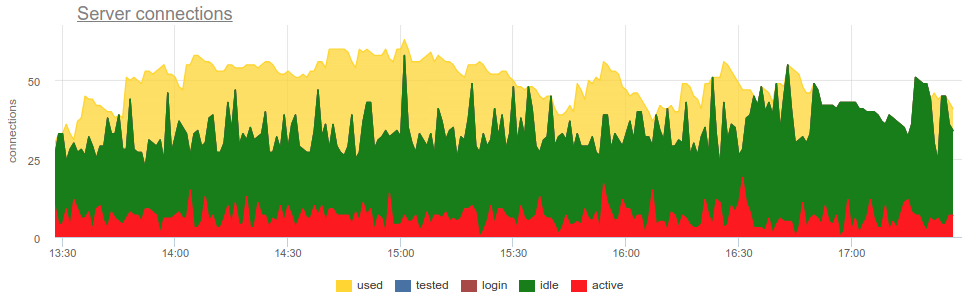
Но чтобы дойти до утилизации надо ответить на несколько вопросов:
- Какой размер пула?
- Как считать сколько соединений использованы? В шутках или по времени, в среднем или в пике?
Размер пула
Тут всё сложно, как в жизни. Всего в пгбаунсере есть аж пять настроек-лимитов!
pool_sizeможно задать для каждой базы. На каждую пару DB / user создается отдельный пул, т.е. от любого дополнительного пользователя, можно создать ещеpool_sizeбекендов/воркеров Postgres. Т.к. еслиpool_sizeне задан, он фолбечится вdefault_pool_size, который по дефолту 20, то получается, что каждый пользователь имеющий права коннекта к базе (и работающий через pgbouncer) потенциально может создать 20 процессов Postgres, что вроде не много. Но если у вас много разных пользователей баз или самих баз, и пулы прописаны не с фиксированным пользователем, т.е. будут создаваться на лету (а потом поautodb_idle_timeoutудаляться), то это может быть опасно =)
Возможно стоит оставлять
default_pool_sizeмаленьким, на всякий пожарный.
max_db_connections— как раз нужен для того, чтобы ограничить суммарное количество коннектов к одной базе, т.к. иначе badly behaving клиенты могут насоздавать очень много бекендов/процессов постгреса. И по дефолту тут — unlimited ?_(?)_/?
Возможно стоит поменять default'овый
max_db_connections, например, можно ориентироваться наmax_connectionsвашего Postgres (по дефолту 100). Но если у вас много PgBouncer'ов…
reserve_pool_size— собственно, еслиpool_sizeвесь использован, то PgBouncer может открыть еще несколько коннекшенов до базы. Я так понимаю это сделано, чтобы справиться с всплеском нагрузки. Мы еще вернемся к этому.max_user_connections— Это, наоборот, лимит коннекшенов от одного юзера ко всем базам, т.е. актуально если у вас несколько баз и в них ходят под одинаковыми юзерами.max_client_conn— сколько клиентских соединений вообще суммарно PgBouncer будет принимать. Дефолт, как впрочем привычно, имеет очень странное значение — 100. Т.е. предполагается, что если вдруг ломятся больше 100 клиентов, то им надо просто практически молча на уровне TCP отдаватьresetи всё (ну в логах, надо признать, при этом будет "no more connections allowed (max_client_conn)").
Возможно стоит сделать
max_client_conn >> SUM ( pool_size'ов ), например, в 10 раз больше.
Кроме SHOW POOLS служебная псевдо-база pgbouncer предоставляет еще и команду SHOW DATABASES, показывающую реально применяемые к конкретному пулу лимиты:

Серверные соединения
Еще раз — как измерять сколько соединений использованы?
В шутках в среднем / в пике / по времени?
На практике довольно проблемно нормально замониторить использование пулов баунсером широко распространенными инструментами, т.к. сам pgbouncer предоставляет только сиюминутную картину, и как часто не делай опрос, все равно есть вероятность неправильной картины из-за семплинга. Вот реальный пример, когда в зависимости от того когда экспортер отрабатывал — в начале минуты или в конце — принципиально меняется картина как открытых так и использованных соединений:
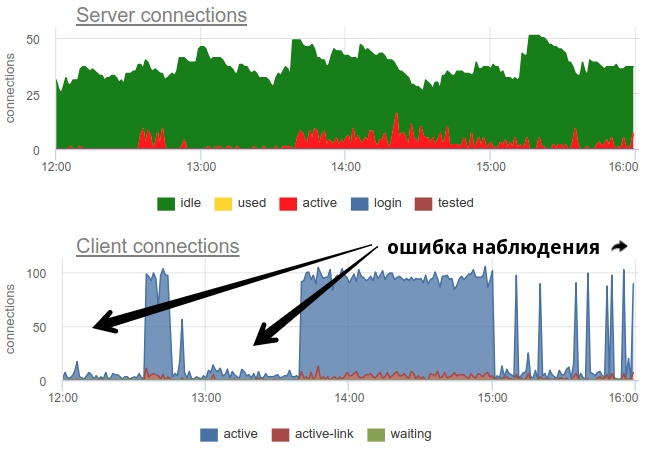
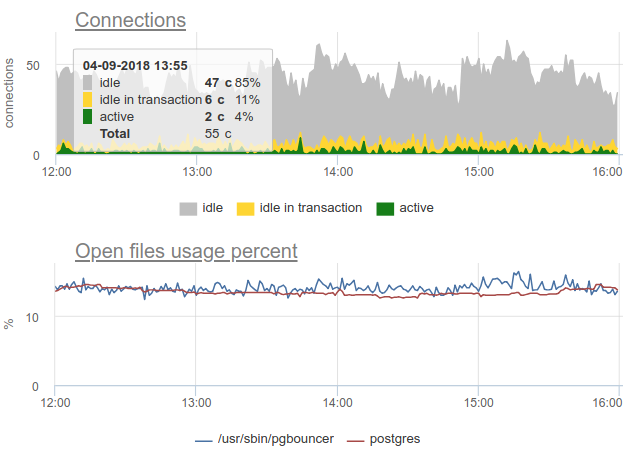
Тут все изменения в нагрузке / использовании соединений просто фикция, артефакт рестартов сборщика статистики. Вот можно посмотреть на графики соединений в Postgres'е за это время и на файловые дескрипторы баунсера и PG — никаких изменений:
Вернемся к вопросу утилизации. Мы в нашем сервисе решили использовать комбинированный подход — мы сэмплим SHOW POOLS раз в секунду, а раз в минуту рендерим и среднее и максимальное количество соединений в каждом стейте:
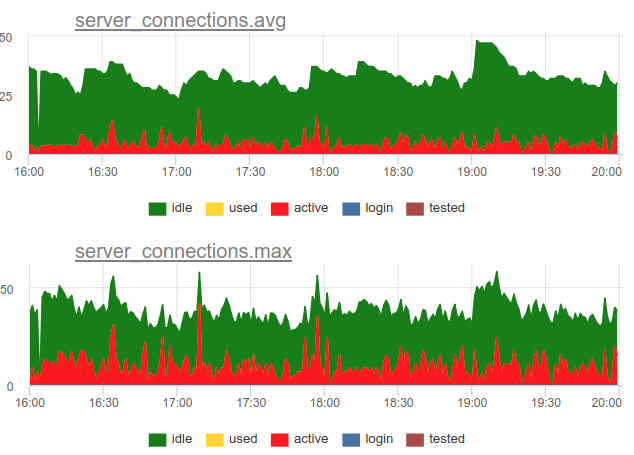
А если поделить количество этих active state соединений на размер пула, получим среднюю и пиковую утилизацию данного пула и сможем алертить, если она близка к 100%.
Кроме того у PgBouncer есть команда SHOW STATS которая покажет статистику использования для каждой проксируемой базы:

Нас тут больше всего интересует колонка total_query_time — время, проведенное всеми соединениями в процессе выполнения запросов в postgres. А с версии 1.8 есть еще и метрика total_xact_time — время проведенное в транзакциях. Исходя из этих метрик мы можем построить утилизацию времени серверных соединений, этот показатель не подвержен, в отличие от рассчитанного из стейтов соединений, проблемам семплинга, т.к. эти total_..._time счетчики являются кумулятивными и ничего не пропускают:

Сравните
Видно, что семплинг не показывает все моменты высокой ~100% утилизации, а query_time — показывает.
Saturation и PgBouncer
Зачем вообще нужно следить за Saturation, ведь по высокой утилизации уже и так понятно, что все плохо?
Проблема в том, что как ни измеряй утилизацию, даже накопленные счетчики не могут показать локальное 100% использование ресурса, если оно происходит только на очень коротких интервалах. Например, у вас есть какие-нибудь кроны или другие синхронные процессы, которые могут одновременно по команде начать делать запросы в базу. Если эти запросы будут короткие, то утилизация, измеренная на масштабах минуты и даже секунды, может быть низкой, но при этом в какой-то момент эти запросы были вынуждены ждать очереди на исполнение. Это похоже с ситуацией не 100% CPU usage и высокого Load average — вроде процессорное время еще есть, а тем не менее много процессов ждут в очереди на исполнение.
Как можно отслеживать такую ситуацию — ну опять таки, мы можем просто считать количество клиентов в состоянии cl_waiting согласно SHOW POOLS. В нормальной ситуации таких — ноль, а больше нуля означает переполнение этого пула:
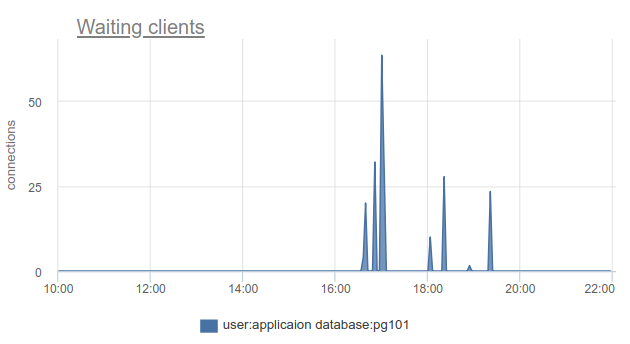
Тут остается проблема с тем, что SHOW POOLS можно только сэмплить, и в ситуации с синхронными кронами или чем-то таким, мы можем просто пропустить и не увидеть таких waiting клиентов.
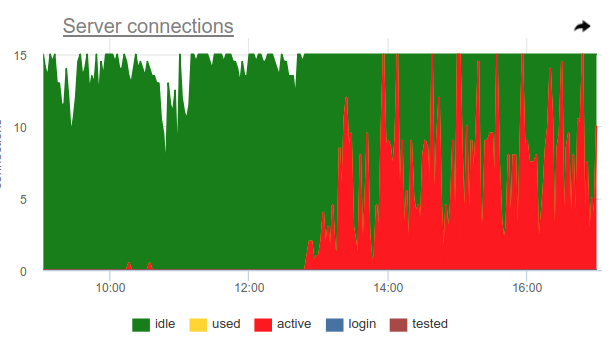
Можно использовать такое ухищрение, pgbouncer сам умеет детектить 100% использование пула и открывать резервный пул. За это отвечают две настройки: reserve_pool_size — за его размер, как я уже говорил, и reserve_pool_timeout — сколько секунд должен какой-то клиент быть waiting прежде чем использовать резервный пул. Таким образом, если мы видим на графике серверных соединений, что количество открытых до Postgres коннекшенов больше чем pool_size, значит была сатурация пула, как вот тут:

Явно что-то типа кронов раз в час делают много запросов и полностью занимают пул. И даже несмотря на то, что мы не видим сам момент, когда active соединения превышают pool_size лимит, все равно pgbouncer был вынужден открывать дополнительные соединения.
Так же на этом графике хорошо видна работа настройки server_idle_timeout — через сколько переставать держать и закрывать соединения, которые не используются. По дефолту это 10 минут, что мы и видим на графике — после пиков active ровно в 5:00, в 6:00 и т.д. (согласно cron'у 0 * * * *), соединения висят idle + used еще 10 минут и закрываются.
Если же вы живете на острие прогресса и обновили PgBouncer за прошедшие 9 месяцев, то сможете найти в SHOW STATS колонку total_wait_time, которая лучше всего показывает сатурацию, т.к. кумулятивно считает
время проведенное клиентами в waiting состоянии. Например, тут — стейт waiting появился в 16:30:
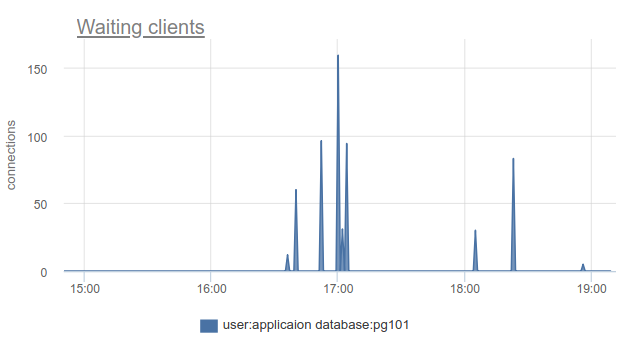
А wait_time, сравнимый и явно влияющий на average query time, можно увидеть начиная с 15:15 и почти до 19:

Тем не менее мониторинг состояний клиентских соединений все равно очень полезен, т.к. позволяет узнать не только факт, что к такой-то базе данных все соединения истрачены и клиенты вынуждены ждать, но и благодаря тому, что SHOW POOLS разбито на отдельные пулы по пользователям, а SHOW STATS — нет, позволяет выяснить какие именно клиенты использовали все коннекты до заданной базы — по колонке sv_active соответствующего пула. Или по метрике
sum_by(user, database, metric(name="pgbouncer.clients.count", state="active-link")):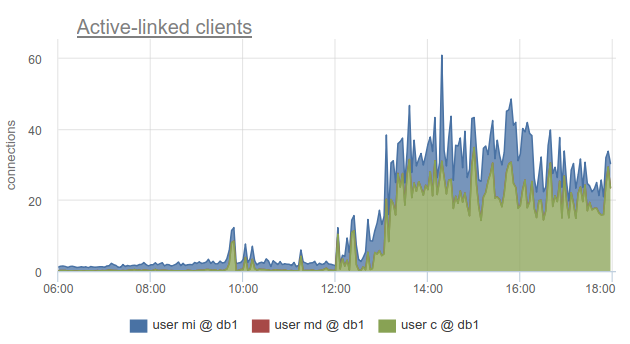
Мы в okmeter пошли даже дальше и добавили разбивку используемых соединений по IP адресам клиентов, которые их открыли и используют. Это позволяет понять, какие именно инстансы приложения ведут себя не так:

Тут мы видим айпишники конкретных kubernetes подов, с которыми нужно разбираться.
Errors
Тут ничего особо хитрого нет: pgbouncer пишет логи, в которых сообщает об ошибках, если достигнут лимит клиентских соединений, таймаут подключения к серверу и т.п. Мы пока до логов pgbouncer сами не добрались:(
RED для PgBouncer
В то время как USE больше ориентирован на перформанс, в смысле про узкие места, RED, на мой взгляд, это больше про характеристики приходящего и исходящего трафика в целом, а не про узкие места. То есть RED отвечает на вопрос — нормально ли всё работает, а если нет, то USE поможет понять из-за чего проблема.
Requests
Тут казалось бы все довольно просто для SQL базы и для прокси / connection пулера в такую базу — клиенты выполняют SQL statement'ы, которые и есть Requests. Из SHOW STATS берем total_requests и строим график его производной по времени
rate(metric(name="pgbouncer.total_requests", database: "*"))
Но на самом деле есть разные режимы пуллинга, и самый распространенный — transactions. Единица работы этого режима — транзакция, а не запрос. В соответствии с этим начиная с версии 1.8 Pgbouсner предоставляет уже две другие статистики — total_query_count, вместо total_requests, и total_xact_count — количество прошедших транзакций.
Теперь workload можно охарактеризовать не только с точки зрения количества совершенных запросов / транзакций, но можно, например, посмотреть на среднее количество запросов на одну транзакцию в разные базы, поделив одно на другое
rate(metric(name="total_requests", database="*")) / rate(metric(name="total_xact", database="*"))
Тут мы видим явные изменения профиля нагрузки, что может быть причиной изменения перформанса. А если бы смотрели только на rate транзакций или запросов, то могли бы этого не увидеть.
RED Errors
Понятно, что RED и USE пересекаются на мониторинге ошибок, но как мне кажется errors в USE в основном про ошибки обработки запроса из-за 100% утилизации, т.е. когда сервис отказывается принять больше работы. А errors для RED было бы лучше измерять ошибки именно с точки зрения клиента, клиентских запросов. То есть не только в ситуации когда пул в PgBouncer'е переполнен или сработал другой лимит, но так же когда сработали таймауты запросов, такие как "canceling statement due to statement timeout", cancel'ы и rollback'и транзакций самим клиентом, т.е. более высокоуровневые, более близкие к бизнес-логике типы ошибок.
Durations
Тут нам опять поможет SHOW STATS с кумулятивными счетчиками total_xact_time, total_query_time и total_wait_time, поделив которые на количество запросов и транзакций соответственно, получим среднее время запроса, среднее время транзакции, среднее время ожидания на одну транзакцию. Я уже показывал график про первое и третье:
Что тут можно еще классного получить? Известный антипаттерн в работе с базой и Postgres в частности, когда приложение открывает транзакцию, делает запрос, потом начинает (долго) обрабатывать его результаты или того хуже — ходит в какой-то другой сервис / базу и делает там запросы. Все это время транзакция "висит" в постгресе открытой, сервис потом возвращается и делает еще какие-то запросы, обновления в базе и только потом закрывает транзакцию. Для постгреса это бывает особенно неприятно, т.к. pg-воркеры — штука дорогая. Так вот мы можем мониторить, когда такое приложение пребывает idle in transaction в самом постгресе — по колонке state в pg_stat_activity, но там все те же описанные проблемы с семплингом, т.к. pg_stat_activity дает только текущую картину. В PgBouncer'е же мы можем вычесть время проведенное клиентами в запросах total_query_time из времени проведенного в транзакциях total_xact_time — это будет как раз время такого idling'а. Если результат еще поделить на total_xact_time, то оно получится отнормированным: значение 1 соответствует ситуации, когда клиенты 100% времени находятся idle in transaction. И с такой нормировкой дает возможность легко понять насколько все плохо:
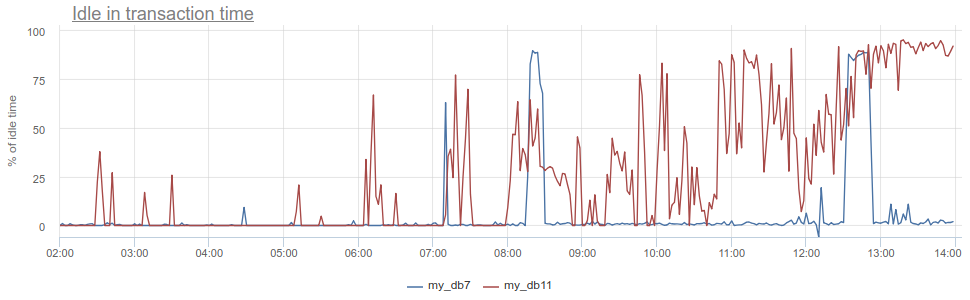
Кроме того, возвращаясь к Duration, метрику total_xact_time - total_query_time можно поделить на количество транзакция, чтобы увидеть сколько в среднем приложение idle'ится на одну транзакцию.
На мой взгляд методы USE / RED полезны больше всего для структурирования того, какие метрики вы снимаете и зачем. Так как мы занимаемся мониторингом full-time и нам приходится делать мониторинг для самых разных компонентов инфраструктуры, эти методы помогают нам снимать правильные метрики, делать правильные графики и триггеры для наших клиентов.
Хороший мониторинг нельзя сделать сразу, это итеративный процесс. У нас в okmeter.io как раз continuous monitoring (много чего есть, но завтра будет лучше и детальнее:)