

В этой статье я хотел бы рассказать о том, какой жизненный путь проходят процессы в семействе ОС Linux. В теории и на примерах я рассмотрю как процессы рождаются и умирают, немного расскажу о механике системных вызовов и сигналов.
Данная статья в большей мере рассчитана на новичков в системном программировании и тех, кто просто хочет узнать немного больше о том, как работают процессы в Linux.
Всё написанное ниже справедливо к Debian Linux с ядром 4.15.0.
Содержание
Введение
Системное программное обеспечение взаимодействует с ядром системы посредством специальных функций — системных вызовов. В редких случаях существует альтернативный API, например, procfs или sysfs, выполненные в виде виртуальных файловых систем.
Атрибуты процесса
Процесс в ядре представляется просто как структура с множеством полей (определение структуры можно прочитать здесь).
Но так как статья посвящена системному программированию, а не разработке ядра, то несколько абстрагируемся и просто акцентируем внимание на важных для нас полях процесса:
- Идентификатор процесса (pid)
- Открытые файловые дескрипторы (fd)
- Обработчики сигналов (signal handler)
- Текущий рабочий каталог (cwd)
- Переменные окружения (environ)
- Код возврата
Жизненный цикл процесса
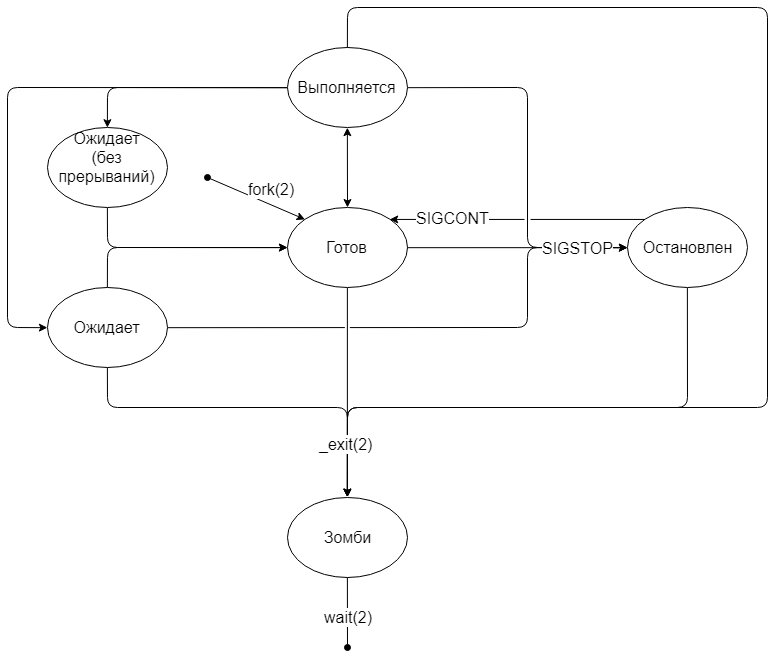
Рождение процесса
Только один процесс в системе рождается особенным способом —
init — он порождается непосредственно ядром. Все остальные процессы появляются путём дублирования текущего процесса с помощью системного вызова fork(2). После выполнения fork(2) получаем два практически идентичных процесса за исключением следующих пунктов:-
fork(2)возвращает родителю PID ребёнка, ребёнку возвращается 0; - У ребёнка меняется PPID (Parent Process Id) на PID родителя.
После выполнения
fork(2) все ресурсы дочернего процесса — это копия ресурсов родителя. Копировать процесс со всеми выделенными страницами памяти — дело дорогое, поэтому в ядре Linux используется технология Copy-On-Write. Все страницы памяти родителя помечаются как read-only и становятся доступны и родителю, и ребёнку. Как только один из процессов изменяет данные на определённой странице, эта страница не изменяется, а копируется и изменяется уже копия. Оригинал при этом «отвязывается» от данного процесса. Как только read-only оригинал остаётся «привязанным» к одному процессу, странице вновь назначается статус read-write.
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
#include <sys/wait.h>
#include <sys/types.h>
int main() {
int pid = fork();
switch(pid) {
case -1:
perror("fork");
return -1;
case 0:
// Child
printf("my pid = %i, returned pid = %i\n", getpid(), pid);
break;
default:
// Parent
printf("my pid = %i, returned pid = %i\n", getpid(), pid);
break;
}
return 0;
}
$ gcc test.c && ./a.out
my pid = 15594, returned pid = 15595
my pid = 15595, returned pid = 0
Состояние «готов»
Сразу после выполнения
fork(2) переходит в состояние «готов». Фактически, процесс стоит в очереди и ждёт, когда планировщик (scheduler) в ядре даст процессу выполняться на процессоре.
Состояние «выполняется»
Как только планировщик поставил процесс на выполнение, началось состояние «выполняется». Процесс может выполняться весь предложенный промежуток (квант) времени, а может уступить место другим процессам, воспользовавшись системным вывозом
sched_yield.Перерождение в другую программу
В некоторых программах реализована логика, в которой родительский процесс создает дочерний для решения какой-либо задачи. Ребёнок в данном случае решает какую-то конкретную проблему, а родитель лишь делегирует своим детям задачи. Например, веб-сервер при входящем подключении создаёт ребёнка и передаёт обработку подключения ему.
Однако, если нужно запустить другую программу, то необходимо прибегнуть к системному вызову
execve(2):int execve(const char *filename, char *const argv[], char *const envp[]);
или библиотечным вызовам
execl(3), execlp(3), execle(3), execv(3), execvp(3), execvpe(3):int execl(const char *path, const char *arg, ... /* (char *) NULL */);
int execlp(const char *file, const char *arg, ... /* (char *) NULL */);
int execle(const char *path, const char *arg, ...
/*, (char *) NULL, char * const envp[] */);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[], char *const envp[]);
Все из перечисленных вызовов выполняют программу, путь до которой указан в первом аргументе. В случае успеха управление передаётся загруженной программе и в исходную уже не возвращается. При этом у загруженной программы остаются все поля структуры процесса, кроме файловых дескрипторов, помеченных как
O_CLOEXEC, они закроются. Как не путаться во всех этих вызовах и выбирать нужный? Достаточно постичь логику именования:
- Все вызовы начинаются с
exec - Пятая буква определяет вид передачи аргументов:
- l обозначает list, все параметры передаются как
arg1, arg2, ..., NULL - v обозначает vector, все параметры передаются в нуль-терминированном массиве;
- l обозначает list, все параметры передаются как
- Далее может следовать буква p, которая обозначает path. Если аргумент
fileначинается с символа, отличного от "/", то указанныйfileищется в каталогах, перечисленных в переменной окруженияPATH - Последней может быть буква e, обозначающая environ. В таких вызовах последним аргументом идёт нуль-терминированный массив нуль-терминированных строк вида
key=value— переменные окружения, которые будут переданы новой программе.
#define _GNU_SOURCE
#include <unistd.h>
int main() {
char* args[] = { "/bin/cat", "--help", NULL };
execve("/bin/cat", args, environ);
// Unreachable
return 1;
}
$ gcc test.c && ./a.out
Usage: /bin/cat [OPTION]... [FILE]...
Concatenate FILE(s) to standard output.
*Вывод обрезан*
Семейство вызовов
exec* позволяет запускать скрипты с правами на исполнение и начинающиеся с последовательности шебанг (#!).#define _GNU_SOURCE
#include <unistd.h>
int main() {
char* e[] = {"PATH=/habr:/rulez", NULL};
execle("/tmp/test.sh", "test.sh", NULL, e);
// Unreachable
return 1;
}
$ cat test.sh
#!/bin/bash
echo $0
echo $PATH
$ gcc test.c && ./a.out
/tmp/test.sh
/habr:/rulez
Есть соглашение, которое подразумевает, что argv[0] совпадает с нулевым аргументов для функций семейства exec*. Однако, это можно нарушить.
#define _GNU_SOURCE
#include <unistd.h>
int main() {
execlp("cat", "dog", "--help", NULL);
// Unreachable
return 1;
}
$ gcc test.c && ./a.out
Usage: dog [OPTION]... [FILE]...
*Вывод обрезан*
Любопытный читатель может заметить, что в сигнатуре функции
int main(int argc, char* argv[]) есть число — количество аргументов, но в семействе функций exec* ничего такого не передаётся. Почему? Потому что при запуске программы управление передаётся не сразу в main. Перед этим выполняются некоторые действия, определённые glibc, в том числе подсчёт argc.Состояние «ожидает»
Некоторые системные вызовы могут выполняться долго, например, ввод-вывод. В таких случаях процесс переходит в состояние «ожидает». Как только системный вызов будет выполнен, ядро переведёт процесс в состояние «готов».
В Linux так же существует состояние «ожидает», в котором процесс не реагирует на сигналы прерывания. В этом состоянии процесс становится «неубиваемым», а все пришедшие сигналы встают в очередь до тех пор, пока процесс не выйдет из этого состояния.
Ядро само выбирает, в какое из состояний перевести процесс. Чаще всего в состояние «ожидает (без прерываний)» попадают процессы, которые запрашивают ввод-вывод. Особенно заметно это при использовании удалённого диска (NFS) с не очень быстрым интернетом.
Состояние «остановлен»
В любой момент можно приостановить выполнение процесса, отправив ему сигнал SIGSTOP. Процесс перейдёт в состояние «остановлен» и будет находиться там до тех пор, пока ему не придёт сигнал продолжать работу (SIGCONT) или умереть (SIGKILL). Остальные сигналы будут поставлены в очередь.
Завершение процесса
Ни одна программа не умеет завершаться сама. Они могут лишь попросить систему об этом с помощью системного вызова
_exit или быть завершенными системой из-за ошибки. Даже когда возвращаешь число из main(), всё равно неявно вызывается _exit.Хотя аргумент системного вызова принимает значение типа int, в качестве кода возврата берется лишь младший байт числа.
Состояние «зомби»
Сразу после того, как процесс завершился (неважно, корректно или нет), ядро записывает информацию о том, как завершился процесс и переводит его состояние «зомби». Иными словами, зомби — это завершившийся процесс, но память о нём всё ещё хранится в ядре.
Более того, это второе состояние, в котором процесс может смело игнорировать сигнал SIGKILL, ведь что мертво не может умереть ещё раз.
Забытье
Код возврата и причина завершения процесса всё ещё хранится в ядре и её нужно оттуда забрать. Для этого можно воспользоваться соответствующими системными вызовами:
pid_t wait(int *wstatus); /* Аналогично waitpid(-1, wstatus, 0) */
pid_t waitpid(pid_t pid, int *wstatus, int options);
Вся информация о завершении процесса влезает в тип данных int. Для получения кода возврата и причины завершения программы используются макросы, описанные в man-странице
waitpid(2).#include <stdio.h>
#include <unistd.h>
#include <errno.h>
#include <sys/wait.h>
#include <sys/types.h>
int main() {
int pid = fork();
switch(pid) {
case -1:
perror("fork");
return -1;
case 0:
// Child
return 13;
default: {
// Parent
int status;
waitpid(pid, &status, 0);
printf("exit normally? %s\n", (WIFEXITED(status) ? "true" : "false"));
printf("child exitcode = %i\n", WEXITSTATUS(status));
break;
}
}
return 0;
}
$ gcc test.c && ./a.out
exit normally? true
child exitcode = 13
Передача argv[0] как NULL приводит к падению.
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
#include <sys/wait.h>
#include <sys/types.h>
int main() {
int pid = fork();
switch(pid) {
case -1:
perror("fork");
return -1;
case 0:
// Child
execl("/bin/cat", NULL);
return 13;
default: {
// Parent
int status;
waitpid(pid, &status, 0);
if(WIFEXITED(status)) {
printf("Exit normally with code %i\n", WEXITSTATUS(status));
}
if(WIFSIGNALED(status)) {
printf("killed with signal %i\n", WTERMSIG(status));
}
break;
}
}
return 0;
}
$ gcc test.c && ./a.out
killed with signal 6
Бывают случаи, при которых родитель завершается раньше, чем ребёнок. В таких случаях родителем ребёнка станет
init и он применит вызов wait(2), когда придёт время.После того, как родитель забрал информацию о смерти ребёнка, ядро стирает всю информацию о ребёнке, чтобы на его место вскоре пришёл другой процесс.
Благодарности
Спасибо Саше «Al» за редактуру и помощь в оформлении;
Спасибо Саше «Reisse» за понятные ответы на сложные вопросы.
Они стойко перенесли напавшее на меня вдохновение и напавший на них шквал моих вопросов.
Комментарии (60)

1KoT1
17.09.2018 06:21А где бы почитать, почему fork() устроен именно так или иначе?
Мне непонятно, зачем ребёнку наследовать открытые сокеты, файлы и т. д.fishHook
17.09.2018 08:20Например, чтобы писать что-то в общий лог, или читать что-то из общего файла (который мы можем передать в stdin, т.о. программа заранее не знает, какой файл надо открыть в дочернем процессе). Допустим, у нас программа веб-сервер. Сервер слушает 80-й порт и как только он получает новый запрос на создание соединения, он запускает дочерний процесс, разумеется, мы хотим, чтобы stdout и stderr остались такими же, какие были и главного процесса.
Firemoon Автор
17.09.2018 10:11Помимо того, что написал fishHook, могу добавить, что возможно просто так исторически сложилось.
iig
17.09.2018 14:56Раз потомок получает копию адресного пространства родителя, значит, заодно получает и все открытые файлы (это же тоже структура в памяти). Делать иначе — очевидно, дороже (ядро, вместо Copy-On-Write должно будет сделать полную копию памяти и освободить некоторые ресурсы, пользовательская программа — должна проверять валидность некоторых указателей..)
khim
17.09.2018 16:10Раз потомок получает копию адресного пространства родителя, значит, заодно получает и все открытые файлы (это же тоже структура в памяти).
Это структура в другой памяти. И её нужно копировать, да.
Делать иначе — очевидно, дороже (ядро, вместо Copy-On-Write должно будет сделать полную копию памяти и освободить некоторые ресурсы, пользовательская программа — должна проверять валидность некоторых указателей..)
Какой ужас. У вас вообще представление есть о том, как файловые дескрипторы работают? Даю подсказку — это ни разу не указатель. Это число. Маленькое. От 0 до 1023 в далёком прошлом, сейчас верхний предел динамический, но принцип тот же. Дальше — рассказывать или сами догадаетесь?
Копировать файловые дескрипторы сложнее и дороже, но удобнее. Hint: Unix, в ранних версиях, сокетов не имел — но зато имел pipes. Дальше рассказывать или сами догадаетесь?iig
17.09.2018 22:01Я программист ненастоящий, man в репозитории нашел :) Если есть маленькое число, идентифицирующее файловый дескриптор, должна существовать структура, указывающая на имя файла и его атрибуты.
khim
17.09.2018 22:42Если есть маленькое число, идентифицирующее файловый дескриптор, должна существовать структура, указывающая на имя файла и его атрибуты.
Угу. Вот только самое важное вы пропустили — если число маленькое, то это, скорее всего, индекс в массиве. И массив копируется, когда вы делаете fork. И количество ссылок пересчитывается.
В общем совершается довольно много работы, которую можно было бы и не делать, если бы у «копии» процесса все файлы бы закрывались. Но так — этим было бы сложнее пользоваться…

lega
17.09.2018 10:01Не указана важная «фича», exec не запускает новый процесс, он запускает приложение в текущем процессе, в итоге для того что-бы запустить новый процесс сначала нужно сделать fork и после — exec.
Отсюда есть проблема — т.к. fork делает дублирование текущего процесса, происходит проверка есть ли свободная памяти под этот форк (в 100% размера от текщего процесса), в итоге процесс который использует много памяти (>60%) не сможет запустить другое приложение (тот же /bin/cat) по причине не хватки памяти под форк.Firemoon Автор
17.09.2018 10:12Хм. У меня появилось желание опытным путём проверить истинность этого высказывания. Как только доберусь до ПК, проверю и отпишусь.
fishHook
17.09.2018 10:24А разве copy-on-write не решает эту проблему на корню?
lega
17.09.2018 11:53Решает, но linux все равно возвращает ошибку «не достаточно памяти», т.к. идет проверка есть ли память для всего объема, т.е. проблема в проверке, как минимум у меня на серевере с linux 3.13 это воспроизводится (в свежем linux ожидаю аналогичного).
fishHook
17.09.2018 11:56В таком случае вообще непонятно, а нафига в линуксе есть swap? Может быть у вас просто раздел подкачки не подключен или у него размер крошечный?
Tangeman
17.09.2018 15:12+1Это зависит от того, разрешен ли безусловный overcommit (значение 1). Если да, то ядро не будет проверять наличие памяти до того как она реально используется (т.е. в неё реально что-то запишут). По умолчанию значение параметра 0 (использовать эвристику), и в этом случае ядро будет (скорее всего) проверять память с учётом свопа.
Просто из вредности я проверил это на 4.15 (поставив vm.overcommit_memory=1), без проблем всё работает (как и ожидалось). Ядро 4.15 (Ubuntu 18.04), реальной памяти 2G, свопа нет, процесс запрашивает 1G памяти через calloc() и потом делает fork() 16 раз — без проблем.
Если посмотреть на процессы, то видно 17 процессов и каждый имеет резидентных чуть более 1G — но реально этот 1G является shared memory. Если же дети начнут писать в эту память — вот тогда начнутся проблемы.
lega
17.09.2018 16:38Просто из вредности я проверил это на 4.15 (поставив vm.overcommit_memory=1), без проблем всё работает
Да, это опционально, и vm.overcommit_memory=1 может быть не безопасно, но в дефолтном состоянии будет валится.
Так что не плохо упомянуть «особый» способ запуска новых процессов в статье про процессы.sh1kel
18.09.2018 17:47Есть приложения (например редис), которые могут занимать десятки ГБ памяти и любят форкаться (для сохранения данных на диск, в случае редиса в примере), и им необходим безусловный оверкоммит, хотя по факту там за счет cow перерасход памяти будет совсем небольшой, но вот виртуальной памяти это будет занимать х2
lega
18.09.2018 17:59В таком случае обычно форкается мастер процесс, который использует минимум памяти, а работой уже занимаются дочерние ворекры. При таком подходе этой проблемы нет.
im_stD
17.09.2018 10:25Здравствуйте. Спасибо за статью.
Обьясните пожалуйста, Вы или кто-то другой, более развернуто, что такое ядро? То есть обозначьте его рамки что-ли. Его везде описывают как некую абстракцию, а хочется чуть больше конкретики, и простым языком.
…
И ещё один вопрос:
void child_sm_kill() { wait(NULL); } void SendMessage(char *chat_id, char *send_text, int cod) { pid_t smpid; signal(SIGCHLD, child_sm_kill); smpid = fork(); if(smpid == 0) { char json_str[LENJSONSEND] = {0,}; char str[BREADSIZE] = {0,}; if(cod == 0) // strat { ...
Функция SendMessage вызывается время от времени, выполняет свою работу и завершается.
Скажите, правильно ли я убиваю зомби?
signal(SIGCHLD, child_sm_kill); ? void child_sm_kill() { wait(NULL); }
Заранее спасибо.
Firemoon Автор
17.09.2018 12:55Вряд ли я отвечу Вам как-то более подробно, что такое ядро. В моём понимании, ядро — это просто большая программа и ничего более. А рамки… Про привилегированный и непривилегированный режим знаете?
Функция SendMessage вызывается время от времени, выполняет свою работу и завершается.
Во-первых, использование signal(2) не рекомендуется, даже ман-страница об этом говорит:
The behavior of signal() varies across UNIX versions, and has also varied historically across different versions of Linux. Avoid its use: use sigaction(2) instead.
Во-вторых, мне кажется несколько избыточным устанавливать обработчик сигналов КАЖДЫЙ раз, это достаточно сделать один раз при инициализации.
К самому обработчику вопросов нет, я бы так же сделал.im_stD
17.09.2018 15:16Спасибо.
В моём понимании, ядро — это просто большая программа и ничего более.
Собственно про это и хотел спросить. Мне однажды задали вопрос — «что такое ядро»? — и я не смог дать какого-либо ответа, кроме похожего на Ваш. Углубление в режимы (привилегированный и непривилегированный) приводит к ещё большему размыванию понятия. )))
Просто хотел услышать Ваше мнение и мнение других людей в виде тезиса.
Во-первых, использование signal(2) не рекомендуется, даже ман-страница об этом говорит:
Приму к сведению.
Во-вторых, мне кажется несколько избыточным устанавливать обработчик сигналов КАЖДЫЙ раз, это достаточно сделать один раз при инициализации.
Достаточно будет поместить его в майн()?Firemoon Автор
17.09.2018 15:27Достаточно будет поместить его в майн()?
Зависит от того, как вы написали программу. Если инициализация программы происходит в main() — то да, самое место. Если где-то ещё — то лучше вставить его туда, где логически ему самое место.im_stD
17.09.2018 16:06Я немного недопонимаю. Если у меня несколько разных функций вызывающих форки…
void child_sm_kill() { wait(NULL); } void child_ui_kill() { wait(NULL); } void SendMessage(char *chat_id, char *send_text, int cod) { pid_t smpid; signal(SIGCHLD, child_sm_kill); smpid = fork(); if(smpid == 0) { ... void update_instag(char *chat_id) { pid_t geekfork; signal(SIGCHLD, child_ui_kill); geekfork = fork(); if(geekfork == 0) { ... int main() { ...
… то как быть? Сделать в main() один вызов сигнала для обоих функций?khim
17.09.2018 16:15+1Не очень понимаю чего вы не понимаете. Вы ж не можете на один сигнал два обработчика поставить!
А процесс может завершаться сколько угодно времени (например если NFS-сервер «выйдет погулять»).
Так что если у вас несколько обработчиков, то это всё равно надёжно работать не будет, а если один — то почему бы его в main и не проинициализировать?im_stD
17.09.2018 16:40Как бы Вы сделали? Применительно к выше указанному коду.
mayorovp
17.09.2018 16:55Применительно к указанному вами коду, у вас обработчики абсолютно одинаковые и их можно заменить одним. Который и проставлять в main.
Если же обработчики будут разные — значит, нужно сохранять значения возвращаемые fork в какой-нибудь структуре данных, а в обработчике сигнала проверять что вам вернула wait и принимать на основе этого нужное решение.im_stD
17.09.2018 17:08Спасибо.
Если обработчик будет один, будет ли он правильно работать (подчищать зомби) для обоих функций, или нужно обязательно писать два разных обработчика?khim
17.09.2018 17:31Если вы напишите два обработчика — то что вы с ними будете делать? Ещё раз: вы можете вызвать
signal(2)(или, лучше,sigaction(2)) хоть 100 раз — но работать-то будет только обрабочик, поставленный последним!
Потому обработчик должен быть один… а дальше уже всё, что писал mayorovp. Да, конечно, «чистый»wait— для «зачистки зомби» достаточен, а если вам нужно что-то большее, то писать два обработчика всё равно бессмысленно, так как использовать-то можно безопасно только один! Нужно как-то в рамках вот этого одного всё разруливать…im_stD
17.09.2018 17:48Спасибо.
Мне нужно только убийство зомби. Если я оставлю один вызов сигнала в main(), и один обработчик, то этого будет достаточно для убийства зомби обоих функций?
До этого момента я думал, что понимаю работу signal и wait, оказывается нет.khim
17.09.2018 20:04До этого момента я думал, что понимаю работу signal и wait, оказывается нет.
У меня есть ощущение, что вы всей картины не видите.
То, что вы изобразили — это то, что называется code smell — то есть код, который не то, что на 100% неверен, но, скорее, код, который скорее всего неверен — потому что вы не смотрите на всю картину с достаточно большой высоты.
То есть начнём сначала: зачем вы вообще вешаете обработчик на SIGCHLD? Если вам нужно просто запустить ребёнка и дождаться пока он отработает — то никакие сигналы вам не нужны! Просто вызываетеwaitpid(2)и ждёте, пока процесс завершится.
Если же вы устраиваете возню с сигналами — то это значит, что вы хотите, чтобы программа работала параллельно со своим ребёнком.
А тогда как вы обеспечите, что ребёнок умрёт и будет «подметён» обрабочиком SIGCHLD, который вы установили до вызоваfork(2), до того, как другая функция с другим обработчиком вызовется? Даже если ребёнок сообщает родителю о том, что он завершил работу — я вам сейчас 2-3 сценария могу нарисовать, когда от завершения функцииmainдо завершения процесса будет полчаса проходить при корректно написанном коде!
Да, можно навернуть какие-то локи, семафоры и как-то «разрулить» эту ситуацию… но зачем? В 99% программ проще иметь один обработчик SIGCHLD, который будет «обслуживать» все форки. Ибо, как я уже сказал — этот обрабочик это глобальный ресурс (когда-то давно в Линуксе можно было повесить этот обработчик на поток, но потом кто-то огрел Линуса талмудом с распечаткой POSIX-стандарта по башке и это стало невозможно)!im_stD
17.09.2018 21:11У меня есть ощущение, что вы всей картины не видите.
Вы правы.
это значит, что вы хотите, чтобы программа работала параллельно со своим ребёнком.
Да, нужно чтоб программа работала независимо от «детей». Функция маин() крутится в цикле и время от времени вызывает функции с форками.
А тогда как вы обеспечите, что ребёнок умрёт и будет «подметён» обрабочиком SIGCHLD, который вы установили до вызова fork(2), до того, как другая функция с другим обработчиком вызовется?
Мыслил исходя из того, что каждый форк делает копию всей программы.
Сделал так:
void ckill_all_childl() { wait(NULL); } void SendMessage(char *chat_id, char *send_text, int cod) { pid_t smpid; smpid = fork(); if(smpid == 0) { ... void update_instag(char *chat_id) { pid_t geekfork; geekfork = fork(); if(geekfork == 0) { ... int main() { signal(SIGCHLD, kill_all_child); ...khim
17.09.2018 22:50Мыслил исходя из того, что каждый форк делает копию всей программы.
Ребёнок — да, копия… но оригинал-то не дублируется!
Сделал так:
Да — так оно разумнее будет. И кода меньше.
lorc
17.09.2018 20:09Сигналы — вообще страшная штука. Практически, как прерывания. Могут прийти тогда, когда вы их совершенно не ожидаете (и когда не ожидает рантайм), например во время работы
malloc()или во времяpthread_mutex_lock(). Поэтому и не рекомендуют использоватьsignal (2), а в особо сложных случаях — рекомендуют обрабатывать сигналы синхронно, черезsigwait (3)/sigwaitinfo(2)khim
17.09.2018 20:30С сигналами вообще много мороки если вы не всё программу пишете, а используете чужие библиотеки. Так-то удобнее всего через signalfd, но, увы, для него требуются те ещё пляски с бубном.
lorc
17.09.2018 20:00Мне однажды задали вопрос — «что такое ядро»? — и я не смог дать какого-либо ответа, кроме похожего на Ваш.
Зависит от того что хочет услышать вопрошающий. Еще круче спросить «что такое ОС»?
Особенно, принимая во внимание существование всяких baremetal OS (типа freertos или minios), микроядер и попытки запихнуть веб-сервер прямо в linux kernel.im_stD
17.09.2018 21:13Что бы Вы ответили?
lorc
17.09.2018 21:27Зависит от того кто и когда спрашивает. Незнакомому мужику на остановке я бы сказал одно, жене — другое, интервьюеру на собеседовании — третье.
Вообще наиболее полный ответ, который я могу дать звучит приблизительно так: «ОС — понятие довольно размытое. В большинстве случаев под этим словом подразумевают минимальных набор системных программ, который позволит пользователю запускать их прикладные приложения и таким образом получать какую-то пользу от использования компьютера». Можно еще ввернуть что-то про управление и разделение ресурсов (процессор, память, сеть, диск, батарея и другая периферия) и абстрагирование от железа, но все равно совершенно точное определение дать не получится потому что практически всегда можно будет привести контрпример.
mayorovp
18.09.2018 09:44и попытки запихнуть веб-сервер прямо в linux kernel.
В другой ОС эта попытка даже оказалась успешной...
Tangeman
17.09.2018 22:44Честно говоря, в вашем конкретном случае, раз уж неважно как завершится child, вам вообще не нужно обрабатывать сигналы. Просто делаете (в начале main()):
signal(SIGCHLD, SIG_IGN);
и забываете про зомби как страшный сон — их просто не будет. Для этого простейшего случая использование signal() вместо sigaction() вполне адекватно.
wait() нужно только если вам важен код завершения процесса или если нужно дождаться завершения оного.im_stD
18.09.2018 01:57Да, действительно этого достаточно, и даже в википедии про это написано.) Спасибо.
im_stD
18.09.2018 03:15Обращаюсь и к Вам, и к khim. Правильно ли я понимаю работу signal()?
Функция signal() вызванная единожды из main() висит где-то в памяти на протяжении всего времени жизни приложения и ожидает сигналов. То есть функция signal() это что-то вроде какого-то отдельного процесса? Или это что-то похожее на обработчик прерываний в микроконтроллерах?
И с параметрами поясните пожалуйста. Первый параметр — это ожидаемый сигнал, второй параметр — это то, что нужно сделать при поступлении сигнала.
То есть, вот это — signal(SIGCHLD, SIG_IGN) нужно понимать как — signal(при получении сигнала от ребёнка, игнорировать сигнал), что значит игнорировать? Типа пошёл ты к чёрту, плевать я на тебя хотел. ))
amarao
17.09.2018 11:25Это всё работает пока мы не начинаем рассматривать поведение процесса в состоянии TASK_UNINTERRUPTIBLE. Для однопоточного приложения всё просто — процесс застыл в IO (или чём-то подобном) и его нельзя убить.
Но!
Как только приложение становится многопоточным и один из его тредов застревает в этом состоянии, то ситуация становится creepy.
Во-первых, все потоки работают нормально (кроме залипшего). Во-вторых, попытка сделать SIG_STOP приводит к тому, что ядро не возвращает управление из обработчика сигнала (и SIG_CONT не работает). В третьих, выход из треда переводит процесс в состояние (которое я не могу толком описать).
Короче, всё хорошо, пока не случается TASK_UNINTERRUPTIBLE (D+ в ps'е).
Tangeman
17.09.2018 14:34+1Вся информация о завершении процесса влезает в тип данных int.
На самом деле это не совсем так — можно получить несколько больше информации о завершении процесса, если использовать waitid() и потом изучить данные из siginfo_t. Это тоже далеко не всё (есть ещё taskstats), хотя в большинстве случаев это мало кому нужно.
maydjin
18.09.2018 11:58Хорошая статья. Но, не раскрыта тема потоков и примитивов синхронизации.
Например — что будет если ждать в дочернем процессе на cv созданной в родительском? Какие потоки наследуются дочерним процессом? Как с этим жить, какие коллбэки для этого предусмотренны в posix?
roginvs
Можно поподробнее про то, что именно получает дочерний процесс (fork и/или exec): открытые файлы, активные соединения, ждущие входящих запросов соединения, итд.
Firemoon Автор
Проще перечислить то, чего дочерний процесс НЕ получает.
Википедия в этом плане чуть более развёрнуто объясняет:
Всё остальное наследуется. Если открыт сокет, то после fork'а он будет открыт и у родителя, и у ребёнка. Так как сокет остаётся один, то и очередь у них будет общая.
khim
Это не совсем так. Есть ещё такие вещи, как «информация о файловой системе» (что для нас корень, текущая директория и тому подобное), соединение с дебаггером (если кто-то наш процесс ptrace'ит, то он, по умолчанию, не будет ptrace'ить наших детей), semadj-лист и ещё какие-то вещи. Они по умлочанию не шарятся. Есть гораздо больше вещей (много разных namespaces, cgroup и прочее), которые по умолчанию шарятся, но можно этого не делать.
В man clone это всё описано. Собственно в Linux fork(2) — это обёртка над clone(2) (правда внутри ядра, не внутри системной библиотеки).
red75prim
Потоки (threads) тоже не наследуются.
khim
В Linux (в ядре) понятие «threads» отсутствует. С точки зрения ядра все потоки — это полноценные, отдельные, процессы (просто с общим адресным пространством).
Потому даже сложно представить как могли бы наследоваться потоки и что это могло бы значить…